MTSAM: Multi-Task Fine-Tuning for Segment Anything Model
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has the potential to be a foundation model for multi-task learning.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the recent advancements in large foundation models, particularly in computer vision. The Segment Anything Model (SAM) (Kirillov et al., 2023) emerged as a powerful foundation model for image segmentation, showcasing remarkable zero-shot capabilities. Its success led researchers to explore its application across various downstream tasks, such as 3D reconstruction, medical image processing, and remote sensing. However, these initial efforts primarily focused on adapting SAM for single-task applications.
The specific problem that this paper aims to solve, therefore, is the challenge of effectively leveraging SAM's rich knowledge for multi-task learning. In many real-world computer vision scenarios, multiple tasks, like depth estimation and surface normal estimation, often need to be considered simultanously. Previous research in multi-task learning (MTL) has demonstrated that tasks can benefit from being learned together, as they often share underlying information. This insight motivated the authors to explore SAM's potential as a foundation model for multi-tasking, moving beyond its single-task adaptations.
The fundamental limitations or "pain points" of previous approaches that necessitated this work are twofold:
- Inflexibility in Output Dimensions: The original SAM architecture is designed to produce segmentation masks with a fixed number of channels. This poses a significant challenge for multi-task learning, where different tasks inherently require outputs with varying dimensions (e.g., a 1-channel depth map versus a 3-channel surface normal map). Previous SAM adaptations did not adequately address this architectural constraint for diverse multi-task outputs.
- Inefficient Multi-Task Fine-Tuning: Existing methods for fine-tuning large pre-trained models, such as Low-Rank Adaptation (LoRA), were primarily developed for single-task adaptation. When applied directly to multi-task settings, these methods either suffer from performance imbalances due to hard parameter sharing across tasks (LoRA-HPS) or fail to leverage the crucial inter-task shared information when using task-specific adaptations (LoRA-STL). This meant there was no efficient and effective way to fine-tune SAM to adapt to multiple downstream tasks concurrently while benefiting from shared knowledge. The paper highlights that these methods are not suitable for multi-task learning settings because they do not consider shared information between multiple tasks.
Intuitive Domain Terms
- Segment Anything Model (SAM): Imagine you have a super-smart digital assistant that can perfectly draw an outline around any object in any picture you show it, no matter how unusual or new the object is. You just point, and it "segments" or separates the object from its background with incredible precice.
- Zero-shot capability: This is like a brilliant student who, after learning general principles in a field, can solve a brand-new problem they've never encountered before, without needing specific instructions for that exact problem. They can apply their broad understanding to "zero" prior examples of that specific task.
- Multi-task learning (MTL): Think of a highly efficient personal assistant who can simultaneously manage your calendar, draft emails, and organize your files. Instead of having separate assistants for each job, this one person handles everything, and often gets better at each task because they learn from the overall experience and how the tasks relate.
- Parameter-Efficient Fine-Tuning (PEFT): Imagine you have a giant, incredibly powerful supercomputer that's already trained to do a vast array of general computations. If you want it to perform a slightly new, specialized calculation, PEFT is like adding a few small, clever software patches or plugins rather than reprogramming the entire supercomputer from scratch. It makes the massive machine adaptable with minimal extra effort or resources.
- Tensorized low-Rank Adaptation (ToRA): Building on the PEFT analogy, if PEFT is adding small software patches, ToRA is a particularly clever way to design those patches for multiple new calculations. Instead of creating a completely separate patch for each new calculation, ToRA uses a smart, modular system (like a universal adapter kit) that can generate many different specialized patches from a few core, reusable components. This allows it to share common knowledge across different calculations while still tailoring to each specific one, making it incredibly efficient in terms of the new paramter needed.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is how to effectively transform the Segment Anything Model (SAM), a powerful foundation model primarily designed for single-task, prompt-guided image segmentation, into a versatile foundation model capable of performing multi-task learning (MTL) across diverse computer vision tasks.
The starting point (Input/Current State) is the original SAM, which takes an image and prompts (points, boxes, masks, text) as input and outputs segmentation masks. While SAM exhibits remarkable zero-shot generalization for segmentation, its architecture is rigid regarding output dimensions and its fine-tuning mechanism is not designed for simultaneous adaptation to multiple, distinct downstream tasks.
The desired endpoint (Output/Goal State) is a Multi-Task SAM (MTSAM) that can take an image as input and simultaneously produce task-specific outputs for various computer vision tasks, such as semantic segmentation, depth estimation, and surface normal prediction. Crucially, these outputs must be able to have varying channel numbers (e.g., 1 channel for depth, 3 for surface normals, N for semantic classes), and the model should be fine-tuned efficiently to adapt to all these tasks concurrently.
The exact missing links or mathematical gaps that this paper attempts to bridge are twofold:
- Architectural Mismatch for Diverse Outputs: The original SAM's mask decoder is designed to produce segmentation masks with a fixed number of channels (e.g., $1 \times H \times W$ or $3 \times H \times W$ for different mask levels, as shown in Figure 1a). This architecture makes it difficult to generate outputs with different channel numbers required by various tasks (e.g., $1 \times H \times W$ for depth, $3 \times H \times W$ for surface normals, $13 \times H \times W$ for semantic segmentation, as shown in Figure 1b). The paper needs to modify SAM's architecture to enable this flexibility.
- Inefficient and Ineffective Multi-Task Fine-Tuning: Existing methods for fine-tuning large pre-trained models, particularly Parameter-Efficient Fine-Tuning (PEFT) techniques like Low-Rank Adaptation (LoRA), are typically designed for single-task adaptation. When applied to multi-task settings, they face challenges:
- LoRA-HPS (Hard Parameter Sharing): Using a single shared LoRA matrix for all tasks is parameter-efficient but can lead to "imbalanced performance on all the tasks due to the competition among tasks for the shared LoRA" (page 4), as it fails to capture task-specific nuances.
- LoRA-STL (Task-Specific LoRA): Training a separate LoRA for each task allows for task-specific adaptation but results in a linear increase in trainable parameters with the number of tasks, which can become computationally expensive for many tasks. More importantly, it cannot "harness the inter-task shared information necessary for fine-tuning across multiple tasks" (page 4).
The painful trade-off or dilemma that has trapped previous researchers is balancing parameter efficiency with expressive power and multi-task performance. Achieving high performance across multiple diverse tasks often requires significant model capacity and task-specific adaptations, which traditionally means a large number of trainable parameters or even full fine-tuning. However, for large foundation models like SAM, full fine-tuning is computationally prohibitive. Existing PEFT methods either sacrifice task-specific performance for efficiency (LoRA-HPS) or scale poorly in terms of parameters with the number of tasks (LoRA-STL), failing to effectively leverage the inherent relatedness between tasks while also allowing for task-specific learning. The dilemma is how to enable SAM to learn shared knowledge across tasks and task-specific adaptations simultaneously and efficiently, without a linear explosion in parameters or performance degradation due to task competition.
Constraints & Failure Modes
The problem of adapting SAM for multi-task learning is insanely difficult due to several harsh, realistic walls:
- Architectural Rigidity of SAM's Output Head: The original SAM's mask decoder is hardwired to produce outputs with a fixed channel count, primarily for segmentation. This makes it fundamentally incompatible with tasks requiring different output dimensions (e.g., 1-channel depth maps, 3-channel surface normals, or multi-class semantic segmentation maps). Modifying this requires significant architectural changes to ensure flexibility without compromising SAM's pre-trained knowledge.
- Computational and Memory Limits for Fine-Tuning: SAM is a "heavyweight image encoder" (page 3). Fine-tuning such a large model for multiple tasks simultaneously, especially with full fine-tuning, would demand immense computational resources (GPUs, memory) and time, making it impractical. Parameter-efficient methods are a necessity, but they must be carefully designed to avoid performance compromises.
- Inter-Task Interference and Negative Transfer: In multi-task learning, tasks can conflict, leading to one task's optimization negatively impacting another's performance. This is a known failure mode for simple parameter sharing strategies, such as LoRA-HPS, where tasks "compete" for shared parameters, resulting in "imbalanced performance" (page 4). A robust solution must mitigate this competition while still benefiting from shared knowledge.
- Lack of Explicit Mechanism for Task-Shared and Task-Specific Information: Previous PEFT methods, like standard LoRA, do not inherently distinguish or leverage task-shared and task-specific information in a multi-task context. This limits their ability to efficiently learn from multiple related tasks, as they either over-share (LoRA-HPS) or completely separate (LoRA-STL) parameters, missing the opportunity for synergistic learning.
- Inference Latency Requirements: For real-world applications, especially in clinical settings or real-time systems (though not explicitly mentioned as a strict constraint in this paper, it's a general constraint for such models), any fine-tuning method must not introduce significant additional latency during inference. The paper explicitly states that ToRA introduces "no additional latency introduced during inference" (page 6), indicating this was a design consideration.
- Maintaining Pre-trained Knowledge: SAM's "rich semantic knowledge acquired during pre-training" (page 4) is its core strength. Any fine-tuning approach must effectively leverage this knowledge without causing catastrophic forgetting or significantly degrading its zero-shot capabilities on its original task. This is a common challenge when adapting powerful pre-trained models.
Why This Approach
The Inevitability of the Choice
The adoption of the Multi-Task SAM (MTSAM) framework, particularly its Tensorized low-Rank Adaptation (ToRA) component, was not merely a choice but an inevitable necessity driven by the inherent limitations of the original Segment Anything Model (SAM) and existing parameter-efficient fine-tuning (PEFT) methods when applied to multi-task learning. The authors explicitly identified two critical challenges that rendered traditional "SOTA" approaches insufficient for their specific problem:
- Varying Output Dimensions: The original SAM is designed primarily for segmentation, producing outputs with a fixed number of channels (e.g., three distinct mask levels, each $1 \times H \times W$). However, real-world multi-task learning often requires diverse output formats, such as depth estimation (typically $1 \times H \times W$) or surface normal prediction ($3 \times H \times W$). Standard SAM, with its prompt encoder and fixed mask decoder architecture, simply cannot natively generate task-specific outputs with different channel numbers. This architectural rigidity meant that a direct application of SAM to tasks like depth or surface normal prediction was impossible without significant modification.
- Simultaneous Multi-Task Fine-Tuning: While SAM exhibits remarkable zero-shot capabilities, the challenge of efficiently fine-tuning it to adapt to multiple downstream tasks simultaneously remained largely unexplored. Existing PEFT methods, such as standard LoRA, were primarily developed for single-task adaptation. Applying separate LoRA instances for each task (LoRA-STL) would lead to a linear increase in parameters with the number of tasks and fail to leverage inter-task shared information. Conversely, a hard parameter-sharing LoRA (LoRA-HPS) would suffer from performance imbalances due to task competition. The sheer scale and complexity of SAM as a foundation model necessitated a fine-tuning strategy that could handle multiple tasks concurrently while remaining parameter-efficient and capturing both shared and specific task knowledge.
These two fundamental issues highlighted the insufficiency of simply using SAM as-is or applying existing PEFT techniques without significant architectural and methodological innovation. The authors' realization stemmed from these clear architectural and fine-tuning gaps.
Comparative Superiority
MTSAM, with its ToRA method, demonstrates qualitative superiority over previous gold standards, particularly in the realm of multi-task parameter-efficient fine-tuning, due to several structural advantages:
- Unified Task-Shared and Task-Specific Information Capture: Unlike traditional LoRA approaches, which either share parameters rigidly (LoRA-HPS, leading to task competition) or learn them entirely separately (LoRA-STL, neglecting inter-task relationships), ToRA leverages a low-rank tensor decomposition. By aggregating the update parameter matrices of all tasks into a single three-mode tensor $\Delta W \in R^{d \times k \times T}$, ToRA can decompose it into a core tensor $G$ and three factor matrices $U_1, U_2, U_3$. This structure inherently allows the method to capture both task-shared information (reflected in $U_1$ and $U_2$) and task-specific information (reflected in $U_3$). This holistic approach to information sharing is a significant structural advantage, leading to more balanced and effective multi-task learning.
- Superior Parameter Efficiency: ToRA exhibits overwhelmingly superior parameter efficiency compared to LoRA-based methods when scaling to multiple tasks. For $T$ tasks, LoRA's parameter complexity grows linearly, approximately $O(Trd + Trk)$. In contrast, ToRA's parameter complexity is sublinear with respect to the number of tasks, roughly $O(dp + kq)$, where $p, q, v \ll \min(d, k)$. This means that as the number of tasks $T$ increases, ToRA's memory footprint and computational overhead grow much slower than LoRA's. This is a critical advantage for adapting large foundation models like SAM to a growing number of downstream tasks without incurring prohibitive costs. The theoretical analysis in Theorem 1 formally proves this expressive power and parameter efficiency.
- Architectural Flexibility for Diverse Outputs: Beyond fine-tuning, MTSAM's architectural modifications, such as removing the prompt encoder and introducing task-specific no-mask embeddings and mask decoders, provide the necessary flexibility to generate outputs with varying channel numbers. This is a fundamental structural change that enables SAM to truly function as a multi-task foundation model, adapting to the unique output requirements of each task (e.g., $1 \times H \times W$ for depth, $3 \times H \times W$ for surface normals, $N_t \times H \times W$ for segmentation with $N_t$ classes).
Alignment with Constraints
The chosen MTSAM framework, particularly its architectural modifications and the ToRA method, perfectly aligns with the problem's harsh requirements, forming a "marriage" between the challenges and the solution's unique properties:
- Constraint: Generating Task-Specific Outputs with Varying Dimensions: The original SAM's fixed output structure was a major hurdle. MTSAM addresses this by removing the prompt encoder and implementing task-specific no-mask embeddings and mask decoders. Each task $t$ now has its own mask decoder $D_t$ capable of producing outputs with $N_t$ channels, where $N_t$ is tailored to the specific task (e.g., 1 for depth, 3 for surface normals, 13 for semantic segmentation). This direct architectural modification ensures that the model can generate outputs with dimensions precisely matching the requirements of each individual task, as illustrated in Figure 1 and Figure 3.
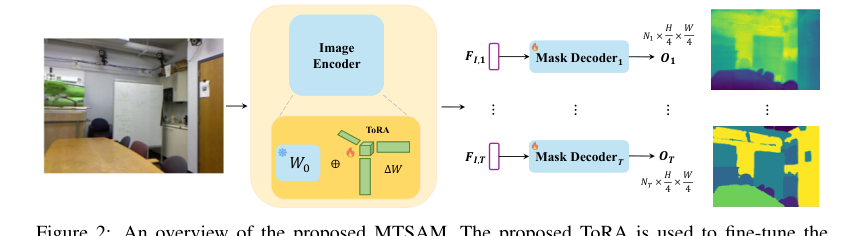 Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
Figure 2. An overview of the proposed MTSAM. The proposed ToRA is used to fine-tune the heavyweight image encoder and generate task-specific image embeddings for each task. MTSAM does not utilize the prompt encoder of the original SAM and modifies the mask decoder of SAM to generate outputs with varying numbers of output channels (denoted by Ni for task i)
- Constraint: Simultaneous Multi-Task Fine-Tuning of SAM: Fine-tuning a massive model like SAM for multiple tasks simultaneously and efficiently is a complex endeavor. ToRA is the perfect fit because it's designed specifically for multi-task parameter-efficient fine-tuning. By using low-rank tensor decomposition on an aggregated update parameter tensor $\Delta W$, ToRA simultaneously learns both task-shared and task-specific information. This allows the model to benefit from the commonalities between tasks while also adapting to their unique characteristics, all within a parameter-efficient framework that avoids the linear parameter growth of task-specific LoRA instances. The sublinear parameter complexity of ToRA directly addresses the need for efficiency when adapting a large foundation model to many tasks.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches by highlighting their shortcomings in the context of multi-task fine-tuning for foundation models like SAM:
- Standard LoRA for Multi-Task Learning: The authors discuss two direct applications of LoRA to multi-task settings:
- LoRA-HPS (Hard Parameter Sharing): This approach uses one shared LoRA matrix $\Delta W$ for all tasks. The paper states this "may lead to imbalanced performance on all the tasks due to the competition among tasks for the shared LoRA." This is a clear rejection because it fails to adequately capture task-specific nuances and can degrade performance on individual tasks.
- LoRA-STL (Task-Specific LoRA): This approach trains a separate $\Delta W_t$ for each task $t$. While it allows for task-specific adaptation, the paper argues that "this approach cannot harness the inter-task shared information necessary for fine-tuning across multiple tasks." Furthermore, it leads to a linear increase in trainable parameters with the number of tasks, which is inefficient for a large number of tasks and a large foundation model. ToRA's tensor decomposition directly overcomes both these limitations by learning shared and specific information simultaneously with sublinear parameter growth.
- Other PEFT Methods (e.g., Adapter-based, Prompt Tuning): While the "Related Works" section lists various PEFT methods, the paper's focus on LoRA-based methods for comparison implies that these other categories were deemed less suitable or less directly comparable for the specific problem of fine-tuning SAM's encoder for multi-task learning. The core issue for many of these methods, similar to LoRA-STL, is their inability to effectively leverage shared information across multiple tasks in a parameter-efficient manner, which is a central tenet of ToRA.
- Traditional Multi-Task Learning (MTL) Methods: The paper notes that previous MTL works often focus on manual design for decoupling task-shared/specific information, automatic architecture learning, loss/gradient balancing, or task grouping. However, the authors state, "Different from the previous works on multi-task learning, we leverage the powerful SAM and propose the MTSAM framework which uses a novel method TORA to fine-tune the encoder." This implies that existing MTL methods were not designed to specifically adapt a pre-trained foundation model like SAM, with its unique architecture and zero-shot capabilities, in a parameter-efficient way for diverse multi-task outputs. The challenge was not just MTL, but MTL for SAM, which required a tailored solution.
Mathematical & Logical Mechanism
The Master Equation
The core of the MTSAM framework, particularly its Tensorized low-Rank Adaptation (ToRA) mechanism, is encapsulated in two primary equations: the overall objective function that guides the learning process, and the tensor decomposition that defines the parameter updates.
The overall objective function for Multi-Task SAM (MTSAM) is given by:
$$
L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)
$$
This equation dictates how the model learns by balancing the performance across multiple tasks with a regularization term that promotes efficient and stable parameter updates.
Within this total loss, the multi-task learning objective $L_{MTL}$ is defined as:
$$
L_{MTL} = \frac{1}{T} \sum_{i=1}^{T} w_i L_i, \quad \text{where} \quad L_i = \frac{1}{N_i} \sum_{j=1}^{N_i} l_i(y_j^i, f(x_j^i))
$$
And the regularization term $R(U_1, U_2, G)$ is:
$$
R(U_1, U_2, G) = ||U_1^T U_1 - I||_F^2 + ||U_2^T U_2 - I||_F^2 + \sum_{l=1}^{v} ||G(:, :, l)^T G(:, :, l) - I||_F^2
$$
The fundamental mechanism for updating the Segment Anything Model (SAM) encoder's weights, $\Delta W$, for multi-task learning is achieved through Tucker tensor decomposition, which is expressed as:
$$
\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3
$$
Term-by-Term Autopsy
Let's dissect these equations to understand each component's role:
For the Total Objective Function ($L_{total}$):
* $L_{total}$: This is the overall objective function that the MTSAM framework aims to minimize during training. Its mathematical definition is the sum of the multi-task loss and a regularizer. Its physical/logical role is to quantify the model's performance across all tasks while ensuring the learned parameters remain well-behaved and efficient.
* $L_{MTL}$: This term represents the Multi-Task Learning (MTL) objective function. Mathematically, it's the weighted average of individual task losses. Its role is to drive the model to perform well on all specified downstream tasks simultaneously. The authors use addition here to combine the multi-task performance with the regularization, as both are aspects to be optimized.
* $\lambda$: This is a hyper-parameter that controls the impact of the orthogonal regularization. Mathematically, it's a scalar multiplier. Its role is to balance the trade-off between minimizing the task-specific errors and enforcing the desired structural properties (orthogonality) on the ToRA factor matrices. A larger $\lambda$ means stronger regularization.
* $R(U_1, U_2, G)$: This is the regularization term. Mathematically, it's a sum of squared Frobenius norms measuring deviation from orthogonality. Its role is to enforce orthogonality on the factor matrices $U_1, U_2$ and the slices of the core tensor $G$, which helps reduce redundancy and improve the stability and generalization of the learned low-rank updates.
For the Multi-Task Learning Objective ($L_{MTL}$):
* $\frac{1}{T} \sum_{i=1}^{T}$: This represents an average over the total number of tasks. $T$ is the total number of tasks. The summation aggregates the weighted losses from all tasks. The authors use summation to ensure that all tasks contribute to the overall learning signal, and the division by $T$ normalizes this contribution.
* $w_i$: This is the loss weight for task $i$. Mathematically, it's a scalar coefficient. Its role is to allow for differential importance or balancing of losses across tasks, which can be crucial in multi-task learning to prevent one task from dominating the training.
* $L_i$: This is the loss for task $i$. Mathematically, it's the average loss over samples for a single task. Its role is to quantify how well the model performs on task $i$.
* $\frac{1}{N_i} \sum_{j=1}^{N_i}$: This represents an average over the training samples for task $i$. $N_i$ is the number of training samples for task $i$. The summation aggregates losses from individual samples. Similar to the task summation, this averages the loss over all samples for a given task.
* $l_i(y_j^i, f(x_j^i))$: This is the loss function specific to task $i$ for a single sample. Mathematically, it's a function that compares the model's prediction to the ground truth. Its role is to measure the discrepancy between the model's output $f(x_j^i)$ and the true label $y_j^i$ for a specific sample $x_j^i$ and task $i$. Different tasks (e.g., segmentation, depth estimation) will use different loss functions (e.g., cross-entropy, L1 loss).
For the Regularization Term ($R(U_1, U_2, G)$):
* $||\cdot||_F^2$: This denotes the squared Frobenius norm. Mathematically, for a matrix $A$, $||A||_F^2 = \sum_{m,n} |A_{mn}|^2$. Its role is to quantify the "size" or magnitude of the deviation from orthogonality. Squaring ensures the value is non-negative and penalizes larger deviations more strongly.
* $U_1^T U_1 - I$: This term measures the deviation from orthogonality for factor matrix $U_1$. If $U_1$ were orthogonal, $U_1^T U_1$ would be the identity matrix $I$. Its role is to encourage $U_1$ to be an orthogonal matrix, which helps ensure that the components captured by $U_1$ are independent and non-redundant.
* $U_2^T U_2 - I$: Similar to $U_1$, this measures the deviation from orthogonality for factor matrix $U_2$. Its role is to enforce orthogonality on $U_2$ for the same reasons as $U_1$.
* $\sum_{l=1}^{v} ||G(:, :, l)^T G(:, :, l) - I||_F^2$: This term measures the deviation from orthogonality for each slice of the core tensor $G$ along its third mode. $G(:, :, l)$ refers to the $l$-th slice of $G$ (a matrix). The summation aggregates these deviations. Its role is to ensure that the task-specific components within the core tensor are also orthogonal, further reducing redundancy and improving the interpretability and efficiency of the decomposition. The authors use summation to apply this constraint uniformly across all task-related slices.
* $I$: This is the identity matrix of appropriate size. Its role is the target for orthogonal matrices ($U^T U = I$).
* $+$ (addition): The addition operator combines these individual regularization penalties. Its role is to enforce all orthogonality constraints simultaneously, contributing to the overall stability and efficiency of the ToRA decomposition.
For the Tensor Decomposition ($\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$):
* $\Delta W$: This is the three-mode update parameter tensor. Mathematically, it's a tensor of dimensions $d \times k \times T$. Its role is to represent the aggregated low-rank updates for the pre-trained weight matrices across all $T$ tasks. Each slice $\Delta W(:, :, t)$ corresponds to the update matrix for task $t$.
* $G$: This is the core tensor. Mathematically, it's a tensor of dimensions $p \times q \times v$. Its role is to capture the interactions between the principal components identified by the factor matrices. It can be thought of as a compressed representation of the tensor's "essence."
* $U_1$: This is the factor matrix for the first mode (output feature dimension). Mathematically, it's a matrix of dimensions $d \times p$. Its role is to capture the principal components or basis vectors along the output feature dimension, representing task-shared information.
* $U_2$: This is the factor matrix for the second mode (input feature dimension). Mathematically, it's a matrix of dimensions $k \times q$. Its role is to capture the principal components or basis vectors along the input feature dimension, also representing task-shared information.
* $U_3$: This is the factor matrix for the third mode (task dimension). Mathematically, it's a matrix of dimensions $T \times v$. Its role is to capture the principal components or basis vectors along the task dimension, specifically encoding task-specific information and how tasks relate to each other.
* $\times_n$: This denotes the n-mode product. Mathematically, it's a tensor-matrix multiplication along a specific mode. For example, $G \times_1 U_1$ multiplies $G$ by $U_1$ along its first mode. Its role is to reconstruct the full $\Delta W$ tensor from the core tensor and factor matrices, effectively "uncompressing" the low-rank representation. This operator is fundamental to Tucker decomposition, allowing for the separation of different modes' variations.
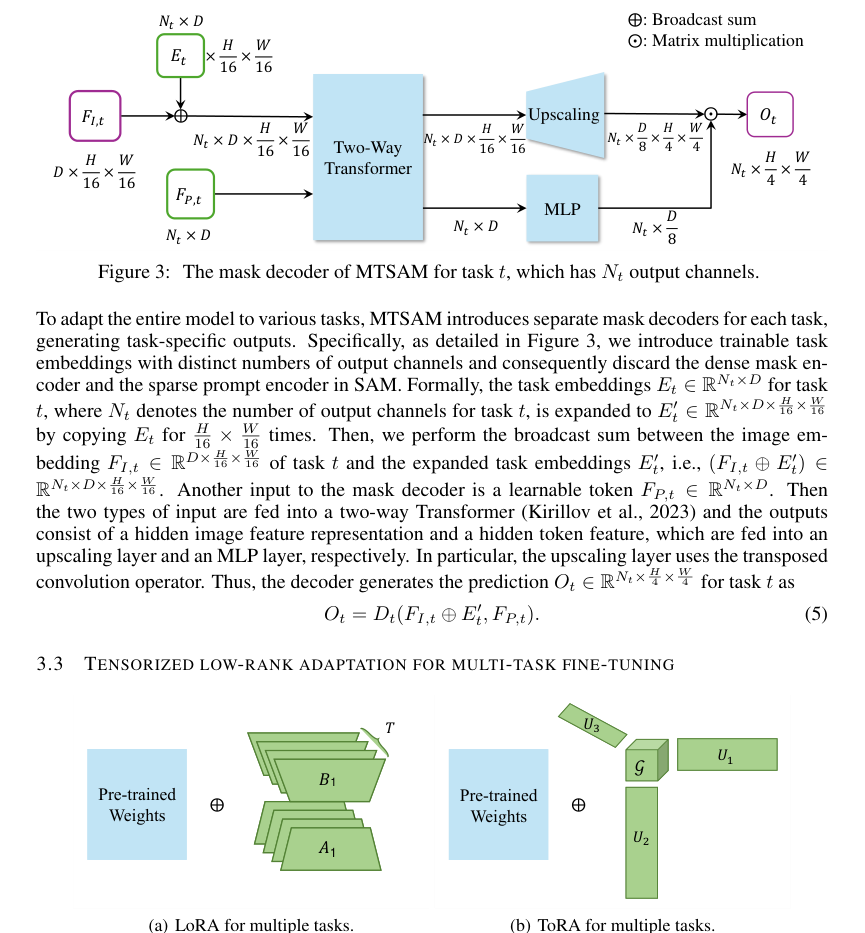 Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Figure 4. Comparison between (a) LoRA and (b) ToRA. LoRA uses separate low-rank matrices for the update parameter matrix of each task, while ToRA aggregates the update parameter matrices of all the tasks into an update parameter tensor and applies low-rank tensor decomposition
Step-by-Step Flow
Imagine a single input image $I$ entering the MTSAM pipeline for a specific task $t$. Here's how it flows through the mathematical engine:
-
Image Encoding (Frozen Foundation): The journey begins with the input image $I \in \mathbb{R}^{3 \times H \times W}$ (3 channels, height $H$, width $W$) being fed into the heavyweight, pre-trained SAM image encoder $E_1$. This encoder is largely frozen, meaning its original weights $W_0$ are not directly updated. It extracts a rich, high-dimensional image feature map $F_1 \in \mathbb{R}^{D \times \frac{H}{16} \times \frac{W}{16}}$, where $D$ is the hidden state dimension. This is the foundation of SAM's knowledge.
-
Task-Specific Feature Adaptation: For our particular task $t$, a trainable task embedding $E_t \in \mathbb{R}^{N_t \times D}$ is introduced. This embedding is expanded to match the spatial dimensions of $F_1$, resulting in $E'_t \in \mathbb{R}^{N_t \times D \times \frac{H}{16} \times \frac{W}{16}}$. The image features $F_1$ are then broadcast-summed with $E'_t$ to create task-adapted image features $(F_{1,t} \oplus E'_t) \in \mathbb{R}^{N_t \times D \times \frac{H}{16} \times \frac{W}{16}}$. This step injects task-specific context directly into the image features.
-
Prompt Integration (Learnable Token): Alongside the task-adapted image features, a learnable token $F_{P,t} \in \mathbb{R}^{N_t \times D}$ is introduced. Unlike original SAM, MTSAM removes the prompt encoder, replacing it with these direct learnable tokens for each task.
-
Mask Decoding (Task-Specific Output): Both the task-adapted image features $(F_{1,t} \oplus E'_t)$ and the learnable token $F_{P,t}$ are fed into a task-specific mask decoder $D_t$. This decoder first processes them through a two-way Transformer, then an upscaling layer (using transposed convolution) to restore spatial resolution, and finally an MLP layer. The output is the task-specific prediction $O_t \in \mathbb{R}^{N_t \times H \times W}$, where $N_t$ is the number of output channels required for task $t$ (e.g., 1 for depth, 3 for surface normals, 13 for semantic segmentation).
-
Parameter Update (ToRA Injection): While the image encoder $E_1$ is mostly frozen, its internal self-attention modules and layer normalization layers are fine-tuned using ToRA.
- The core of ToRA is the update parameter tensor $\Delta W \in \mathbb{R}^{d \times k \times T}$, which is dynamically constructed via Tucker decomposition: $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$. Here, $G$ is the core tensor, and $U_1, U_2, U_3$ are factor matrices.
- For the current task $t$, a specific slice of this tensor, $\Delta W_t = \Delta W(:, :, t)$, is extracted. This $\Delta W_t$ acts as a low-rank update matrix.
- This $\Delta W_t$ is then added to the original pre-trained weight matrix $W_0$ of a specific layer in the image encoder (e.g., a query, key, or value projection matrix in a self-attention block). So, the effective weight matrix becomes $W'_t = W_0 + \Delta W_t$. This means that for an input $x$ to that layer, the output is $h = W'_t x = W_0 x + \Delta W_t x$.
-
Loss Calculation (Task-Specific): The generated output $O_t$ is compared against the ground truth label $y_j^i$ for the current sample $x_j^i$ using the task-specific loss function $l_i(y_j^i, f(x_j^i))$. This yields the individual sample loss. These are then averaged over all samples for task $i$ to get $L_i$.
-
Multi-Task Loss Aggregation: The individual task losses $L_i$ from all $T$ tasks are combined, weighted by $w_i$, and averaged to form the multi-task learning objective $L_{MTL} = \frac{1}{T} \sum_{i=1}^{T} w_i L_i$.
-
Regularization Calculation: The regularization term $R(U_1, U_2, G)$ is computed based on the current states of the factor matrices $U_1, U_2$ and the core tensor $G$, penalizing deviations from orthogonality.
-
Total Loss Computation: Finally, the total loss $L_{total} = L_{MTL} + \lambda R(U_1, U_2, G)$ is calculated. This single scalar value represents the overall performance and structural integrity of the model for the current batch of data.
Optimization Dynamics
The MTSAM framework learns and converges by iteratively minimizing the total objective function $L_{total}$ through gradient-based optimization. Here's how the dynamics unfold:
-
Frozen Base, Tunable Adapters: The vast majority of parameters in the pre-trained SAM image encoder ($W_0$) are kept frozen. This is a crucial aspect of parameter-efficient fine-tuning. Instead, the learning focuses on a much smaller set of parameters:
- The core tensor $G$ and factor matrices $U_1, U_2, U_3$ of the ToRA decomposition.
- The parameters of the task-specific mask decoders $D_t$, including the task embeddings $E_t$ and learnable tokens $F_{P,t}$.
-
Gradient Flow and Backpropagation: After computing $L_{total}$ for a batch of data, backpropagation is performed. Gradients are calculated with respect to all the tunable parameters ($G, U_1, U_2, U_3$, and the mask decoder parameters). The gradients indicate the direction and magnitude by which each parameter should be adjusted to reduce the total loss.
-
Optimizer (Adam): The paper specifies using the Adam optimizer. Adam adaptively adjusts the learning rate for each parameter based on estimates of first and second moments of the gradients. This helps in navigating complex loss landscapes more efficiently than simpler optimizers like SGD. The initial learning rate is set to $10^{-3}$, with a linear learning rate scheduler and warmup, and a weight decay of $10^{-6}$.
-
Loss Landscape Shaping (Regularization): The regularization term $R(U_1, U_2, G)$ plays a vital role in shaping the loss landscape. By penalizing non-orthogonal factor matrices and core tensor slices, it encourages the optimization process to explore regions of the parameter space where $U_1, U_2$, and $G$ are orthogonal. This effectively "smoothes" or "constrains" the loss landscape, making it easier for the optimizer to find stable and generalizable solutions. Orthogonality helps prevent redundancy in the learned components, leading to more robust and interpretable representations. Without this regularization, the optimization might wander into less optimal or unstable regions.
-
Iterative Updates: In each training step (iteration), the optimizer uses the calculated gradients to update the tunable parameters. For instance, $G \leftarrow G - \eta \nabla_G L_{total}$, where $\eta$ is the learning rate. These updates are performed iteratively over many epochs.
-
Convergence: The process continues until the model converges, meaning the total loss $L_{total}$ reaches a minimum or stops significantly decreasing. The low-rank nature of ToRA, combined with the orthogonality regularization, contributes to efficient convergence by reducing the number of parameters to optimize and guiding the optimization towards a well-structured solution space. The ability of ToRA to capture both task-shared (via $U_1, U_2$) and task-specific (via $U_3$) information allows the model to learn effectively across diverse tasks without significant negative interference, leading to improved overall performance and faster convergence compared to methods that don't leverage this structure. The parameter efficiency of ToRA, with sublinear growth in learnable parameters with respect to the number of tasks, makes the optimization problem tractable even for many tasks.
Results, Limitations & Conclusion
Experimental Design & Baselines
The authors meticulously designed their experiments to validate the Multi-Task SAM (MTSAM) framework, focusing on its architectural modifications and the Tensorized low-Rank Adaptation (ToRA) method. They rigorously tested MTSAM on three well-established benchmark datasets: NYUv2 (Silberman et al., 2012), CityScapes (Cordts et al., 2016), and PASCAL-Context (Everingham et al., 2010).
For NYUv2, the model was evaluated on three distinct tasks: 13-class semantic segmentation, depth estimation, and surface normal prediction. On CityScapes, the focus was on 7-class semantic segmentation and depth estimation. PASCAL-Context presented a more diverse challenge with four tasks: 21-class semantic segmentation, 7-class human parts segmentation, saliency estimation, and surface normal estimation.
To establish a comprehensive comparison, MTSAM was pitted against a broad spectrum of "victim" baseline models:
- CNN-based Multi-Task Learning (MTL) methods: Single-Task Learning (STL), Hard-Parameter Sharing (HPS), Cross-Stitch (Misra et al., 2016), Multi-Task Attention Network (MTAN) (Liu et al., 2019), and NDDR-CNN (Gao et al., 2019). These represent traditional approaches to MTL.
- Transformer-based MTL methods: VTAGML (Bhattacharjee et al., 2023), SwinMTL (Taghavi et al., 2024), and DenseMTL (Lopes et al., 2023). These baselines reflect more recent advancements in vision models.
- Parameter-Efficient Fine-Tuning (PEFT) methods: Specifically, LoRA-based variants adapted for multi-task settings: LoRA-STL (task-specific LoRA for each task), LoRA-HPS (a single shared LoRA matrix for all tasks), and MultiLoRA (Wang et al., 2023). Additionally, Terra (Zhuang et al., 2024) and HydraLoRA (Tian et al., 2024) were included for a more direct comparison with ToRA.
- Full Fine-Tuning: The most parameter-intensive baseline, where the entire model is fine-tuned.
The evaluation was quantitative, employing multiple metrics tailored to each task (detailed in Appendix B.1):
- Semantic Segmentation: mean Intersection over Union (mIoU) and Pixel Accuracy (Pix Acc), both higher values indicating better performance.
- Depth Prediction: Absolute Error (Abs Err) and Relative Error (Rel Err), where lower values are better.
- Surface Normal Estimation: Mean and Median of angular error (lower is better), and the percentage of pixels whose angular error is within 11.25, 22.5, and 30 degrees (higher is better).
- Overall Performance: A composite metric, $\Delta_b$, representing the average relative improvement of each task over the HPS architecture, with higher values indicating superior performance. This metric was crucial for demonstrating MTSAM's holistic advantage.
Implementation details were carefully controlled, including batch sizes (4 for NYUv2, 8 for CityScapes and PASCAL-Context), specific loss functions (cross-entropy, L1, cosine similarity), Adam optimizer settings (initial learning rate of $10^{-3}$, linear learning rate scheduler with warmup, weight decay of $10^{-6}$, dropout rate of 0.1), and ToRA's rank parameters ($p, q, v$) and regularization hyper-parameter $\lambda$.
What the Evidence Proves
The experimental evidence overwhelmingly supports the efficacy of the proposed MTSAM framework and its core mechanism, ToRA. The results definitively prove that MTSAM not only achieves superior performance across diverse multi-task learning scenarios but also does so with remarkable parameter efficiency.
Definitive Evidence of MTSAM's Superiority:
Across all three benchmark datasets (NYUv2, CityScapes, and PASCAL-Context), MTSAM consistently achieved the best average performance, as quantified by the $\Delta_b$ metric, compared to all baselines. This is the undeniable evidence that the core mechanism—the combination of SAM's architectural adaptation and ToRA's tensorized low-rank fine-tuning—actually works in reality.
-
Overall Performance & Parameter Efficiency:
- On NYUv2 (Table 1), MTSAM achieved a $\Delta_b$ of +23.93% with only 59.59 MB of trainable parameters. This significantly outperformed MultiLoRA (+20.11%, 65.12 MB), LoRA-STL (r=16) (+20.25%, 64.83 MB), and SwinMTL (+19.55%, 333.91 MB).
- For CityScapes (Table 2), MTSAM again led with a $\Delta_b$ of +20.99% and 37.44 MB parameters, surpassing MultiLoRA (+19.51%, 46.81 MB) and LoRA-STL (r=8) (+20.07%, 37.35 MB).
- On PASCAL-Context (Table 3), MTSAM's $\Delta_b$ of +8.95% was superior, especially when considering its parameter count (74.71 MB) against MultiLoRA (-0.16%, 92.80 MB) and LoRA-STL (r=32) (+6.42%, 110.33 MB).
- A direct comparison with full fine-tuning (Table 7) on NYUv2 showed MTSAM's $\Delta_b$ of +23.93% far exceeding full fine-tuning's +14.57%, while using a mere 59.59 MB parameters compared to the massive 1222.47 MB of full fine-tuning. This highlights MTSAM's exceptional parameter efficiency.
-
ToRA's Effectiveness in Leveraging Shared and Specific Information:
- The comparison between LoRA-STL (task-specific LoRA) and LoRA-HPS (hard parameter sharing LoRA) was crucial. LoRA-STL consistently outperformed LoRA-HPS, demonstrating the importance of task-specific components.
- Crucially, MTSAM with ToRA then outperformed both LoRA-STL and LoRA-HPS. This is definitive evidence that ToRA effectively leverages both task-shared and task-specific information through its tensor decomposition approach, leading to improved overall performance. The theoretical analysis in Theorem 1, which proves ToRA's superior expressive power and fewer parameters compared to multiple LoRAs, is empirically validated by these results.
-
Ablation Studies Reinforcing Design Choices:
- Impact of Orthogonal Regularization: Table 5 clearly showed that applying orthogonal regularization on $U_1, U_2,$ and the core tensor $G$ significantly improved performance. MTSAM with full regularization achieved a $\Delta_b$ of +23.93%, compared to +22.30% without $G$ regularization and +17.01% without $U_1, U_2, G$ regularization. This proves the effectiveness of this regularization in reducing redundancy and enhancing performance.
- Impact of Task Embeddings: Table 8 demonstrated that the proposed task embeddings, which facilitate cross-attention between task embeddings and image features, yielded better results ($\Delta_b$ of +23.93%) than simply modifying MLP output dimensions ($\Delta_b$ of +17.35%). This confirms the architectural modification's contribution to learning task-specific knowledge.
- Robustness to Hyper-parameters: Sensitivity analyses (Table 4 for ranks $p, q, v$ and Table 6 for $\lambda$) showed that MTSAM's performance remained consistently strong across different settings, indicating the robustness and ease of tuning for the ToRA method.
-
Qualitative Evidence:
- Visual comparisons in Figures 5-11 provided compelling qualitative evidence. The white boxes in these figures highlight areas where MTSAM, fine-tuned with ToRA, generated visibly more accurate segmentation, depth, and surface normal predictions compared to LoRA-HPS, LoRA-STL, and MultiLoRA, especially for "vague and slender objects." This visual proof complements the quantitative metrics, showing the practical benefits of the proposed method.
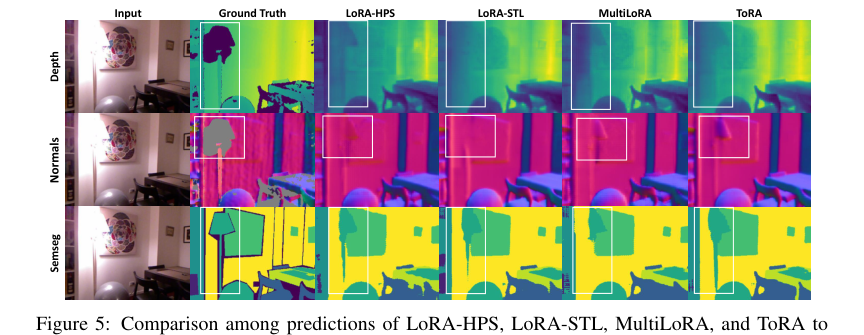 Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 5. Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Limitations & Future Directions
While MTSAM demonstrates impressive capabilities, the paper also acknowledges certain limitations and opens avenues for future research.
Limitations:
- Zero-Shot Generalization Across Disparate Domains: The paper highlights a limitation in MTSAM's zero-shot depth estimation when trained on an indoor dataset (NYUv2) and evaluated on an outdoor dataset (CityScapes) (Section E, Figure 12). Despite some capability to handle unseen data distributions, significant inaccuracies arise, particularly for distant objects. This is attributed to fundamental domain shifts, including differences in depth distribution, object types, image resolution, and ground-truth acquisition hardware between indoor and outdoor scenes. This suggests that while ToRA effectively adapts SAM for multi-task learning within a domain, bridging vastly different domains in a zero-shot manner remains a challenge.
Future Directions & Discussion Topics:
The findings of this paper lay a strong foundation, and I believe several exciting directions can be explored to further develop and evolve these results:
-
Enhanced Domain Adaptation for Zero-Shot Multi-Tasking: Given the observed limitations in cross-domain zero-shot performance, a critical future direction is to integrate more sophisticated domain adaptation techniques directly into the MTSAM framework. Could we develop a "domain embedding" alongside task embeddings, allowing ToRA to learn domain-shared and domain-specific adaptations? Or perhaps, a hierarchical ToRA structure where higher-level tensors capture cross-domain commonalities, and lower-level tensors handle task-specific and domain-specific nuances.
-
Dynamic Rank Adaptation for ToRA: Currently, the ranks $p, q, v$ for ToRA's tensor decomposition are fixed hyper-parameters. Inspired by dynamic LoRA variants like DyLoRA or SORA, could ToRA be extended to dynamically adjust these ranks during training or inference? This could lead to even greater parameter efficiency and adaptability, allowing the model to allocate representational capacity more intelligently based on the complexity and relatedness of tasks and features.
-
Scalability to a Vast Number of Tasks: The current experiments involve a handful of tasks per dataset. How would ToRA scale to scenarios with hundreds or even thousands of tasks, which are increasingly common in real-world applications? The parameter complexity of ToRA is sublinear with respect to the number of tasks, which is promising, but practical considerations like memory management for the core tensor $G$ and factor matrices $U_3$ might become important. Exploring hierarchical task grouping or meta-learning strategies to learn optimal tensor decompositions for task clusters could be a fruitful path.
-
Application to Broader Multi-Modal and Generative Tasks: The paper focuses on dense prediction tasks in computer vision. SAM itself is a powerful foundation model for segmentation. Could MTSAM and ToRA be extended to multi-modal tasks, such as vision-language understanding (e.g., image captioning, visual question answering) or even generative tasks (e.g., image generation conditioned on multiple attributes)? Adapting the tensor decomposition to handle the intricacies of different modalities and output types would be a fascinating challenge.
-
Theoretical Deep Dive into Optimal Tensor Ranks and Structures: While Theorem 1 provides a theoretical basis for ToRA's parameter efficiency, further theoretical work could explore the optimal choice of tensor ranks ($p, q, v$) based on the inherent relationships and complexities of the multi-task problem. Can we derive bounds or heuristics for these ranks that are more principled than empirical tuning? Additionally, investigating alternative tensor decomposition methods (e.g., CP decomposition, or even novel hybrid approaches) within the ToRA framework could yield further insights into capturing task-shared and task-specific information more effectively.
-
Computational Efficiency of ToRA Training: While ToRA is parameter-efficient, the tensor decomposition itself can be computationally intensive during training, especially for very high-dimensional tensors. Future work could investigate methods to accelerate the training process, perhaps through approximate tensor decomposition techniques, sparse tensor methods, or specialized hardware acceleration for tensor operations. This would make MTSAM even more practical for large-scale deployment.
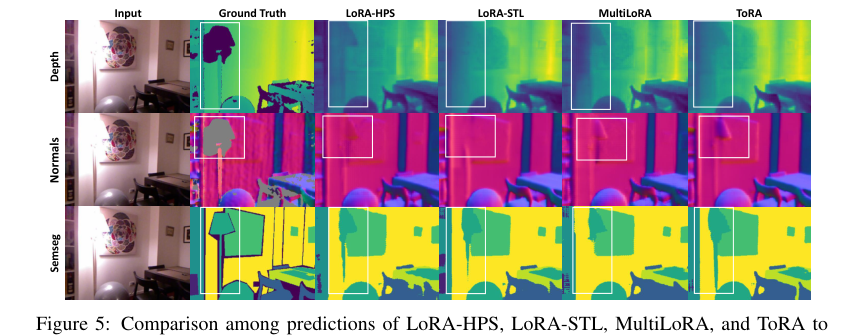 Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
Figure 5. shows the predictions of the MTSAM fine-tuned with LoRA-STL, LoRA-HPS, Multi- LoRA, and ToRA on the NYUv2 dataset, respectively. More qualitative results are shown in Figures 6-11 in Appendix D. As can be seen, the prediction results of ToRA are better than the baselines for different tasks. As shown in the white boxes, the proposed ToRA method generates more accu- rate results than the baseline methods given the ground truth when dealing with vague and slender objects. Therefore, the proposed MTSAM fine-tuned with ToRA achieves the best performance in both qualitative and quantitative evaluations
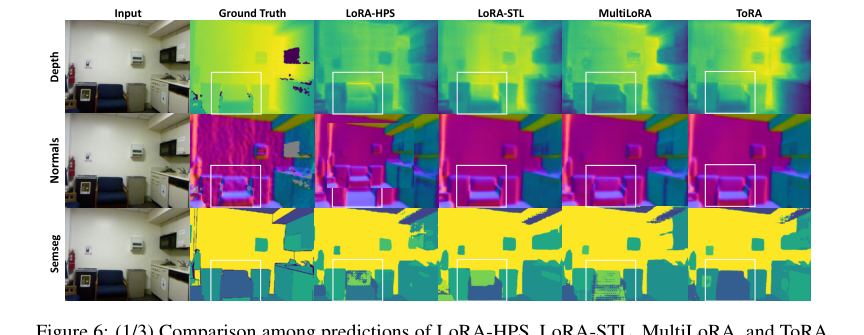 Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Figure 6. (1/3) Comparison among predictions of LoRA-HPS, LoRA-STL, MultiLoRA, and ToRA to fine-tune MTSAM on the NYUv2 dataset
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work lies in the application of low-rank tensor decomposition, specifically Tucker decomposition, to efficiently parameterize and update a multi-mode tensor representing weight adjustments across various tasks and feature dimensions. This framework enables the disentanglement of shared and task-specific information within the update parameters.
Adjacent Research Areas
Tensor Decomposition in Machine Learning and Signal Processing
The paper's Tensorized low-Rank Adaptation (ToRA) method directly employs Tucker decomposition, a foundational technique in tensor analysis, to factorize the update parameter tensor $\Delta W \in \mathbb{R}^{d \times k \times T}$ into a core tensor $G$ and factor matrices $U_1, U_2, U_3$. This mathematical operation is a direct analouge to how tensor decomposition is used in broader machine learning and signal processing to extract latent components from multi-way data. For instance, in fields like chemometrics or psychometrics, multi-way arrays (tensors) are decomposed to identify underlying factors that explain observed variations, much like ToRA identifies shared and specific update components. The equation $\Delta W = G \times_1 U_1 \times_2 U_2 \times_3 U_3$ is a standard form of Tucker decomposition, which is widely used for dimensionality reduction and feature extraction in high-dimensional, multi-modal datasets.
Papalexakis et al., 2016, ACM Transactions on Intelligent Systems and Technology
Parameter-Efficient Fine-Tuning (PEFT) for Large Models
ToRA is presented as a novel parameter-efficient fine-tuning method, building upon the principles of Low-Rank Adaptation (LoRA). The core idea of injecting low-rank updates into pre-trained model layers to adapt them to new tasks with minimal additional parameters is a central theme in PEFT. While LoRA uses a low-rank matrix product $\Delta W_t = B_t A_t$ for each task, ToRA extends this to a tensor decomposition for multiple tasks, effectively reducing the parameter count for multi-task adaptation. The paper's analysis of parameter complexity, showing ToRA's sublinear growth compared to LoRA's linear growth with respect to the number of tasks, directly addresses a key concern in PEFT research: how to scale adaptation to many tasks without prohibative memory or computational costs.
Hu et al., 2021, International Conference on Learning Representations
Multi-Task Learning (MTL) Architectures
The design of ToRA to capture both task-shared and task-specific information within its tensor decomposition framework is a direct connection to the fundamental challenges in multi-task learning. MTL aims to improve overall performance by leveraging commonalities among tasks while allowing for indivdual task specialization. ToRA's decomposition of $\Delta W$ into a core tensor $G$ and factor matrices $U_1, U_2, U_3$ can be interpreted as explicitly modeling these shared and specific components. $U_1$ and $U_2$ can be seen as capturing general feature transformations relevant across tasks, while $U_3$ specifically modulates these transformations for each individual task. This aligns with architectural patterns in MTL that use shared backbones and task-specific heads, or more sophisticated mechanisms like cross-stitch networks that learn to combine task-specific representations.