FrameQuant: Flexible Low-Bit Quantization for Transformers
ISOM keeps this ICML paper in the public review set because it gives readers a concrete case around FrameQuant: Flexible Low-Bit Quantization for Transformers through its mechanism, assumptions, and evidence boundary.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper precisely originates from the increasing scale and complexity of modern Transformer-based foundation models, which are now central to many Vision and Natural Language Processing tasks. These models, while powerful, come with a significant drawback: their large compute, memory, and storage footprint. This makes serving them expensive, often necessitating high-end hardware, and deployment on resource-constrained devices becomes nearly infeasible.
Historically, the academic field has responded to this challenge with various model compression strategies, including distillation (Hinton et al., 2015), pruning (Chen & Zhao, 2019), sparsity (Yu et al., 2012), and quantization (Han et al., 2016). Among these, Post-Training Quantization (PTQ) emerged as a particularly attractive approach because it allows for modifying a pre-trained model to use fewer bits (e.g., eight bits or lower) without altering the model architecture or requiring a full re-training cycle. Previous PTQ efforts successfully quantized models to four bits, but pushing further into the low-bit quantization regime (e.g., two bits) typically resulted in a rapid and significant deterioration of model quality. This paper specifically tackles the challenge of achieving extremely low-bit quantization (around two bits) for Transformer models with only a small drop in accuracy.
The fundamental limitation or "pain point" of previous approaches that forced the authors to write this paper lies in the inherent difficulty of quantizing model weights directly in their original space, especially at very low bit-widths. Prior methods struggled to maintain model performance when reducing bit-width to two bits, as model quality deteriorates fast in this regime. The quantization error or "noise" introduced was often weight-dependent and difficult to manage, with limited theorectical guarantees on reconstruction quality. It was challenging to predict the quality of de-quantization, even with strong assumptions about the noise. The authors highlight that while much is known about quantization in appropriate Frame bases (like Fusion Frames), this knowledge was largely unexplored for neural network quantization. This gap meant that previous methods lacked the robustness to quantization noise and the consistent recovery guarantees that frame theory could offer, making it hard to achieve high accuracy at ultra-low bit-widths.
Intuitive Domain Terms
- Post-Training Quantization (PTQ): Imagine you've already baked a very elaborate cake (a pre-trained AI model). PTQ is like taking that finished cake and, after it's cooled, trying to make it smaller and lighter (reduce its memory footprint) without changing its overall shape or flavor too much. You might carefully trim some edges or use a lighter frosting, but you don't re-bake the whole thing. The goal is to make it easier to serve and store, while keeping it delicious.
- Transformers: Think of a Transformer as a super-smart, highly attentive student who can read an entire textbook, understand how every sentence relates to every other sentence, and then summarize it, translate it, or answer complex questions about it. Unlike older students who might read sentence by sentence, this student can grasp the entire context at once, making them incredibly good at language and even understanding parts of images.
- Fusion Frames: Picture trying to describe a complex sculpture. Instead of just giving its height, width, and depth (a minimal "basis"), a "frame" is like taking many more measurements than strictly necessary – perhaps also its diagonal lengths, surface area, and volume. This creates a "redundant" description. A "Fusion Frame" is like combining several smaller teams of measurers, each focusing on a different part or aspect of the sculpture, to create an even more robust and comprehensive description. If some measurements get a little noisy or lost, the extra information from the other teams helps you still accurately reconstruct the original sculpture.
- Low-Bit Quantization Regime: This is like trying to paint a masterpiece using only a handful of colors, say, just black, white, and two shades of gray. While "full precision" painting uses millions of colors, the "low-bit quantization regime" pushes the limits by drastically reducing the available color palette. It's incredibly difficult to capture all the original detail and nuance, and any small mistake in color choice becomes glaringly obvious, making the painting look much worse.
Notation Table
| Notation | Description | Type |
|---|---|---|
| $H_d$ | A finite-dimensional Hilbert space of dimension $d$. | Parameter |
| $x$ | A signal or vector in $H_d$. | Variable |
| $k$ | Number of subspaces used in a Fusion Frame. | Parameter |
| $p$ | Dimension of each subspace in a Fusion Frame. | Parameter |
| $d$ | Dimension of the Hilbert space. | Parameter |
| $r$ | Redundancy factor of a frame, defined as $r = kp/d$. | Parameter |
| $P_i$ | Orthonormal basis for the $i$-th subspace $W_i$. | Operator |
| $T_W$ | Analysis operator, transforms a signal into its Fusion Frame representation. | Operator |
| $T_W^*$ | Synthesis operator, reconstructs a signal from its Fusion Frame representation. | Operator |
| $\Theta_l$ | Weight matrix for layer $l$ of a Transformer model. | Variable |
| $\hat{A}_{prev}$ | Activations from the previous (already quantized) layer. | Variable |
| $Z_l$ | Output of layer $l$ before quantization. | Variable |
| $C_{prev}$ | Fusion Frame representation of previous layer activations, computed as $P_{prev}^T \hat{A}_{prev}$. | Variable |
| $D_l$ | Transformed weight matrix in Fusion Frame space, computed as $P_l^T \Theta_l P_{prev}$. | Variable |
| $\tilde{D}_l$ | The quantized version of $D_l$. | Variable |
| $\sigma$ | Standard deviation of $D_l$, used for setting clipping thresholds. | Parameter |
| $\mu$ | Mean of $D_l$, used for setting clipping thresholds. | Parameter |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is the significant computational and memory footprint of modern Transformer-based models, such as Large Language Models (LLMs) and Vision Transformers (ViTs). These models, while powerful, are expensive to deploy, often requiring high-end hardware, and are difficult to run on resource-constrained devices.
Starting Point (Input/Current State):
The current state involves pre-trained Transformer models with full-precision (e.g., 32-bit floating point) weights. Existing Post-Training Quantization (PTQ) methods can reduce these weights to 8 or 4 bits, but attempts to go lower, particularly to 2 bits, result in a rapid and substantial deterioration of model accuracy, especially for large models. The weights are typically represented in their original, un-transformed weight space.
Desired Endpoint (Output/Goal State):
The goal is to quantize these Transformer models to an extremely low bit-width, specifically 2 bits (or a fractional 2.x bits), while incurring only a minimal drop in accuracy. This low-bit representation should significantly boost compute, memory, and latency efficiency, making these powerful models more accessible and affordable to deploy on a wider range of hardware. The authors also aim for a flexible scheme that allows users to balance model size reduction with quality preservation.
Missing Link & Mathematical Gap:
The exact missing link is a robust mathematical framework that allows for ultra-low-bit quantization (2-bit) of Transformer weights without catastrophic performance loss. Previous methods struggle because direct quantization in the original weight space is highly sensitive to the introduced "quantization noise." This paper bridges this gap by proposing that quantization should not occur in the original weight space, but rather in a redundant, noise-robust representation space derived from Fusion Frames. The mathematical gap is precisely how to leverage the theoretical properties of Fusion Frames (like redundancy and noise robustness) to formulate a quantization objective that minimizes accuracy loss at these extreme bit-widths. The paper's key insight is to transform the weight matrices into their Fusion Frame representations and then quantize these representations, thereby making the quantization process more resilient to error.
Painful Trade-off & The Dilemma:
The central dilemma that has trapped previous researchers is the accuracy-efficiency trade-off in the low-bit quantization regime. As the bit-width is reduced (e.g., from 4 bits to 2 bits), the model's ability to represent complex information is severely constrained, leading to a sharp decline in predictive accuracy. Improving computational and memory efficiency by reducing bit-width directly conflicts with maintaining model quality. Researchers have struggled to find a method that can achieve substantial efficiency gains (e.g., 2-bit quantization) without breaking the model's performance. The paper highlights that for large Transformer models, "model quality deteriorates fast" as bit width is reduced to the low-bit regime.
Constraints & Failure Modes
The problem of low-bit quantization for Transformers is constrained by several harsh, realistic walls:
- Hardware Memory Limits: The sheer size of foundation models (e.g., LLMs with billions of parameters) means their full-precision weights consume gigabytes of memory. This makes loading and serving them on consumer-grade or even many data center GPUs prohibitively expensive. The primary motivation for this work is to overcome this physical constraint by drastically reducing model size.
- Computational Overhead during Inference: While quantization aims to speed up inference, the proposed method introduces additional operations to transform weights into and out of the Fusion Frame representation space. The computational complexity for transforming weights during inference is $O(d^2(kr + \log d))$, where $d$ is the dimension of the layer, $k$ is the number of subspaces, and $r$ is the redundancy factor. This overhead, though manageable and vectorized on GPUs, means raw inference speed might be lower than simpler quantization methods like GPTQ, presenting a trade-off between accuracy and speed (Section 5.2).
- Data Sparsity and Outliers in Weight Distributions: The weights in Transformer models, especially smaller ones, can exhibit "outliers" (values significantly larger than the rest), leading to poorly distributed weight configurations (Section 4.3, Figure 4b). Direct application of clipping on these raw weights has limited efficacy and can incur errors. These outliers make uniform quantization challenging, as a large quantization range (to accommodate outliers) reduces the precision for the majority of weights, while a small range clips outliers, causing significant error.
- Non-differentiable Quantization Functions: The quantization operation itself is inherently non-differentiable. This means that traditional gradient-based optimization methods cannot be directly applied to optimize the quantization levels, necessitating proxy losses and iterative optimization schemes (Section 3).
- Limited Calibration Data: Post-training quantization methods typically rely on a small, representative calibration dataset to determine optimal quantization parameters (Section 1.1, Section 2.2). The method must perform robustly even with limited calibration data, as extensive datasets might not always be available or feasible to process.
- Difficulty with 1-bit Quantization: The paper explicitly states that attempts to quantize to 1 bit per weight were "unsuccessful" (Section 6). This suggests a practical lower bound on the achievable bit-width, even with the proposed robust framework, indicating that certain extreme compression levels remain incredibly difficult to achieve without severe performance degradation.
- Maintaining Theoretical Guarantees: Previous low-bit quantization methods often lack strong theoretical guarantees regarding error bounds or reconstruction quality. A constraint for this work is to provide a scheme with "theoretical guarantees" for fractional bit quantization and robustness to noise (Abstract, Section 2).
- Activation Quantization Complexity: While the paper primarily focuses on weight quantization, activation quantization is also a challenge. Activations can have large outliers, and naive per-channel quantization can hinder the use of efficient integer kernels for matrix multiplications in linear layers (Section F). The well-behaved nature of FF representations for activations helps mitigate this, but it remains a consideration for a comprehensive solution.
Why This Approach
The Inevitability of the Choice
The authors' choice of Fusion Frames as the foundation for FrameQuant was not merely a preference but a necessity driven by the inherent limitations of traditional "state-of-the-art" (SOTA) post-training quantization (PTQ) methods when pushed to the extreme low-bit regime. The exact moment of this realization is clearly articulated in Section 2, "Finite Frame Theory and Fusion Frames," where the paper contrasts the behavior of quantization error in traditional settings versus in a Frame basis.
Specifically, the authors observed that while SOTA methods like GPTQ (Frantar et al., 2023) could achieve stable quantization for Transformer models at 3 or 4 bits, their performance deteriorated rapidly when attempting to quantize to just two bits. The fundamental problem identified was that "quantization error/noise is weight-dependent" and its behavior is difficult to predict or bound when quantizing directly in the original weight space. The paper states: "In this regime, even with strong assumptions on the noise, it is difficult to say much about the quality of the de-quantization." This lack of theoretical guarantees and predictable error behavior made traditional approaches insufficient for the challenging goal of 2-bit quantization with minimal accuracy loss.
In contrast, the authors recognized that "far more is known... about the behavior of quantization of data given in an appropriate Frame basis (e.g., Fusion Frames), and error bounds on the reconstruction are available." This insight—that quantizing in a robust, redundant representation space could fundamentally alter the noise characteristics and provide theoretical backing—made Fusion Frames the only viable solution to overcome the limitations of direct weight quantization for ultra-low bit-widths.
Comparative Superiority
FrameQuant's method, built upon Fusion Frames, demonstrates overwhelming qualitative superiority over previous gold standards, extending beyond simple performance metrics to fundamental structural advantages.
-
Inherent Robustness to Noise with Theoretical Guarantees: The most significant advantage is the intrinsic robustness of Fusion Frame representations to additive noise, which models quantization error. Unlike direct quantization where error is unpredictable, Fusion Frames offer provable guarantees. The paper highlights that "quantization noise in the space of Frame projections incurs far less error in the reconstructions due to the robustness of Frame representations." For a redundancy factor $r > 1$, using Tight Frames to reconstruct signals from noisy coefficients yields an MSE reduction of $O(1/r)$, and even $O(1/r^2)$ for consistent reconstruction via linear programming (Goyal et al., 1998). This structural property provides a level of reliability and predictability that traditional methods lack.
-
Effective Outlier Handling: Fusion Frames uniformly spread out the energy of the weights across different subspaces. This results in a "well-behaved" distribution in the transformed space, with "only a few outliers in the transformed Weight matrices." This property makes techniques like $2\sigma$ clipping, which are used to constrain the weight range before quantization, far more effective and stable. When applied directly to original weights, clipping can be less effective and introduce errors for poorly distributed weights. The FF representation thus enables more robust pre-processing for quantization.
-
Denoising Capabilities: Fusion Frames also offer the unique advantage of allowing for reconstruction with "de-noising filters known in closed form," such as the Wiener filter. This filter is provably optimal for minimizing MSE during reconstruction from noisy coefficients (Kutyniok et al., 2009), further enhancing the quality of the de-quantized weights.
-
Practical Memory Efficiency: While not an asymptotic complexity reduction, FrameQuant achieves substantial practical memory savings. For a typical 1024x1024 FP32 weight matrix (4MB), FrameQuant, with 2-bit quantization and $r=1.1\times$ redundancy, reduces the storage footprint to approximately 0.307MB (including biases and scales), representing a 13x reduction in storage requirements. This is a critical advantage for deploying large models on resource-constrained devices.
-
Flexible Bit-Width Control: FrameQuant provides "fractional bit quantization capabilities" by allowing the user to adjust the redundancy factor $r$. This means one can achieve effective bit-widths like 2.1 or 2.2 bits, offering finer-grained control over the accuracy-efficiency trade-off than integer-bit quantization schemes. This flexibility is a key qualitative advantage for adapting to diverse application requirements.
Alignment with Constraints
The chosen Fusion Frame approach perfectly "marries" the problem's harsh requirements, particularly the demand for ultra-low-bit quantization (2-bit) and minimal accuracy degradation for large Transformer models, with the practical constraints of Post-Training Quantization (PTQ).
-
Achieving 2-bit Quantization: The primary constraint of quantizing to two bits, which proved challenging for SOTA methods, is directly addressed by the noise robustness of Fusion Frames. By operating in a representation space where quantization error is better contained and theoretically bounded, FrameQuant enables effective 2-bit quantization with significantly less accuracy loss than direct methods. This is a direct alignment, as the unique properties of Fusion Frames make this difficult target feasible.
-
Preserving Model Accuracy: The theoretical guarantees of MSE reduction ($O(1/r)$) when reconstructing from noisy Fusion Frame coefficients directly translate to preserving model quality. This property ensures that the small number of bits used for quantization results in a minimal degradation of performance, which is a critical requirement for practical deployment of large models. The empirical results consistently show FrameQuant closing the gap with full-precision models, especially with slight redundancy.
-
Post-Training Quantization (PTQ) Compatibility: FrameQuant is designed as a PTQ method, operating on pre-trained models without requiring re-training or architectural modifications. This aligns perfectly with the constraint of minimizing computational and development overhead associated with quantization-aware training (QAT). The method achieves this by adapting existing Hessian-based iterative quantization algorithms (like those in GPTQ) to operate within the Fusion Frame representation space, thus leveraging established PTQ techniques while gaining robustness.
-
Flexibility for Deployment: The ability to adjust the redundancy factor $r$ provides flexibility in balancing model size and accuracy. If a strict 2-bit quantization is too aggressive for a particular application, FrameQuant allows for a slight increase in effective bit-width (e.g., 2.2 bits) to recover performance without needing to jump to a full 3-bit scheme, which would incur a much larger size penalty. This flexibility is a direct response to the diverse deployment needs of Transformer models.
Rejection of Alternatives
The paper provides clear reasoning, both explicit and implicit, for why other popular quantization approaches would have failed or are qualitatively inferior for the specific problem of 2-bit quantization of Transformers.
-
Traditional Direct Weight Quantization (e.g., GPTQ, PTQ4ViT): The paper explicitly states that these methods, while effective for 3-4 bit quantization, suffer from rapid performance degradation at 2 bits. The core issue is that "quantization error/noise is weight-dependent" and difficult to manage or bound when applied directly to weights. This makes it challenging to guarantee reconstruction quality at such low bit-widths. FrameQuant's approach of quantizing in a robust Fusion Frame space directly addresses this fundamental limitation, making direct quantization an unsuitable alternative for the 2-bit target.
-
Quantization-Aware Training (QAT): QAT methods, which involve retraining the model with quantization in mind, are implicitly rejected due to the problem's constraint of using Post-Training Quantization. QAT requires significant computational resources and time for retraining, which FrameQuant aims to avoid to facilitate efficient deployment. The paper notes that QAT "works well... but models must be re-trained," highlighting the practical barrier it presents.
-
QuIP (Chee et al., 2023): QuIP is a strong concurrent 2-bit PTQ method. However, FrameQuant positions itself as a more generalized and superior approach. The paper explains that QuIP can be viewed as a "special version of our formulation (but with no redundancy)," meaning it operates with a redundancy factor $r=1$. While QuIP performs well, FrameQuant demonstrates that by introducing even a slight redundancy (e.g., $r=1.1$), it can consistently achieve better performance than QuIP. This implies that QuIP, while effective, is a constrained version of the Fusion Frame approach and would fail to capture the additional accuracy benefits offered by redundancy. The paper also notes that "when QuIP is augmented with our $2\sigma$ clipping we see similar results to FrameQuant with $1\times$ redundancy," further suggesting that FrameQuant's inherent properties make clipping more effective.
-
Other Model Compression Techniques (e.g., Pruning, Distillation): While mentioned in related work, these techniques are not directly compared as alternatives for low-bit weight quantization. They address different aspects of model compression or often require architectural changes or retraining, which FrameQuant, as a PTQ method focused on bit-width reduction, aims to circumvent. They do not directly solve the problem of representing individual weights with extremely few bits while maintaining accuracy and theoretical guarantees.
 Figure 6. Effect of flexibility/redundancy on activation maps for ViT-S. Figure showing attention maps of ViT-S as the redundancy is increased from r = 1 to r = 1.3 in the increments of 0.1 from left to right. The first column shows the image and the ground truth label, and the rest of the columns show the regions that the model is attending to in the final transformer block. We see that as the redundancy is increased, the model gets more focused, with the attention regions concentrating on the objects of interest
Figure 6. Effect of flexibility/redundancy on activation maps for ViT-S. Figure showing attention maps of ViT-S as the redundancy is increased from r = 1 to r = 1.3 in the increments of 0.1 from left to right. The first column shows the image and the ground truth label, and the rest of the columns show the regions that the model is attending to in the final transformer block. We see that as the redundancy is increased, the model gets more focused, with the attention regions concentrating on the objects of interest
Mathematical & Logical Mechanism
The Master Equation
The core of FrameQuant's mathematical engine lies in its objective function, which guides the quantization process within the Fusion Frame (FF) representation space. This function aims to minimize the discrepancy between the full-precision and quantized weight matrices when applied to the previous layer's activations, also represented in the FF space. The primary objective function, as presented in the paper, is a proxy loss defined as:
$$L(\tilde{D}_l) = ||D_l C_{prev} - \tilde{D}_l C_{prev}||_F^2$$
This can also be expressed using the trace operator, which is often more convenient for matrix calculus, especially when dealing with the Hessian:
$$L(\tilde{D}_l) = \text{tr}((D_l - \tilde{D}_l) C_{prev} C_{prev}^T (D_l - \tilde{D}_l)^T)$$
Term-by-Term Autopsy
Let's dissect each component of this master equation to understand its role:
-
$L(\tilde{D}_l)$: This is the loss function that FrameQuant seeks to minimize. Its mathematical definition is the squared Frobenius norm of the difference between two matrix products. Its physical/logical role is to quantify the "error" introduced by quantizing the weight matrix. By minimizing this loss, the algorithm ensures that the quantized model's output for a given input is as close as possible to the full-precision model's output, but crucially, this comparison happens in the Fusion Frame representation space. The authors chose a squared Frobenius norm because it's a standard, differentiable measure of matrix difference, leading to a convex optimization problem that is easier to solve.
-
$D_l$: This represents the full-precision weight matrix of layer $l$ transformed into the Fusion Frame representation. Mathematically, it's defined as $D_l = P_l^T \Theta_l P_{prev}$. Its physical/logical role is to provide a redundant, robust representation of the original weight matrix $\Theta_l$. Instead of quantizing $\Theta_l$ directly, FrameQuant operates on $D_l$, leveraging the noise-robustness properties of Fusion Frames.
-
$\tilde{D}_l$: This is the quantized version of the weight matrix $D_l$ in the Fusion Frame representation. This is the variable that the optimization process adjusts. Its physical/logical role is to be the low-bit, compressed representation of the layer's weights. The goal is to find an $\tilde{D}_l$ that minimizes the loss while adhering to the low-bit constraints.
-
$C_{prev}$: This term denotes the Fusion Frame representation of the activations from the previous layer. Mathematically, it's defined as $C_{prev} = P_{prev} \hat{A}_{prev}$. Its physical/logical role is to act as the "input" to the layer's operation within the FF space. It's the context against which the quantization error is measured. The authors use this term to ensure that the quantization error is minimized in a data-dependent manner, considering how the weights interact with actual activations.
-
$||\cdot||_F^2$: This is the squared Frobenius norm. Mathematically, for a matrix $M$, $||M||_F^2 = \sum_{i,j} |M_{ij}|^2$. Its physical/logical role is to measure the overall magnitude of the difference between the full-precision and quantized outputs in the FF space. Squaring the norm ensures that all errors contribute positively and penalizes larger errors more heavily, promoting a smooth loss landscape.
-
$\text{tr}(\cdot)$: The trace operator. Mathematically, for a square matrix $M$, $\text{tr}(M) = \sum_i M_{ii}$. In the expanded loss function, it's used because $||M||_F^2 = \text{tr}(M M^T)$. Its physical/logical role here is to convert the squared Frobenius norm into a form that is often more amenable to matrix differentiation, especially when the Hessian is involved.
-
$(\cdot)^T$: The matrix transpose operator. Its mathematical definition is to swap rows and columns of a matrix. Its physical/logical role is standard in linear algebra, used here to correctly compute the inner product for the Frobenius norm and to form the Hessian term.
-
$\Theta_l$: This is the original full-precision weight matrix of the current Transformer layer $l$. Its physical/logical role is the unquantized, high-fidelity representation of the layer's parameters. It's the starting point from which the FF representation $D_l$ is derived.
-
$\hat{A}_{prev}$: These are the activations from the previous layer, which have already been quantized (if activation quantization is applied). Its physical/logical role is the actual input data that flows through the Transformer layer.
-
$P_l$ and $P_{prev}$: These represent the Fusion Frame basis matrices for the output space of layer $l$ and the input (previous activation) space, respectively. Mathematically, they are constructed from orthonormal bases of subspaces that form the Fusion Frame. Their physical/logical role is to provide the redundant, noise-robust representation space. $P_l^T$ acts as an "analysis operator" to project data into the FF space, while $P_l$ acts as a "synthesis operator" to reconstruct data from the FF space. The authors use these to transform the problem into a domain where quantization noise is less detrimental, thanks to the inherent redundancy and stability of Fusion Frames.
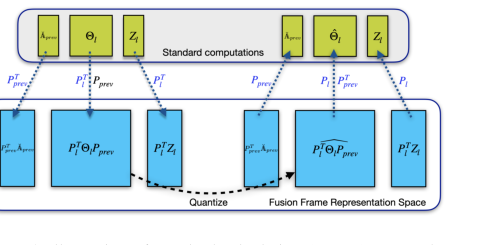 Figure 2. Illustration of standard calculation (on top) versus the corresponding calculations in FF space (bottom)
Figure 2. Illustration of standard calculation (on top) versus the corresponding calculations in FF space (bottom)
The choice of addition/subtraction in the loss function is natural for measuring differences, while the Frobenius norm (which involves summation of squared differences) is a standard metric for comparing matrices. The use of trace is a mathematical convenience for expressing the norm and deriving gradients.
Step-by-Step Flow
Imagine a single batch of data points, represented by the activations $\hat{A}_{prev}$, flowing through a Transformer layer $l$ with full-precision weights $\Theta_l$. Here's how FrameQuant processes it:
-
Input Activation Transformation: First, the activations from the previous layer, $\hat{A}_{prev}$, enter the system. These are typically high-precision (e.g., FP16/FP32). They are immediately transformed into their Fusion Frame representation, $C_{prev}$, by being multiplied with the Fusion Frame basis matrix $P_{prev}$. This projects the activations into a redundant, more robust space.
$$C_{prev} = P_{prev} \hat{A}_{prev}$$ -
Weight Matrix Transformation: Concurrently, the full-precision weight matrix $\Theta_l$ for the current layer is also transformed into its Fusion Frame representation, $D_l$. This involves multiplying $\Theta_l$ by the transpose of the output FF basis $P_l^T$ and the input FF basis $P_{prev}$.
$$D_l = P_l^T \Theta_l P_{prev}$$
This $D_l$ is now the full-precision weight matrix in the Fusion Frame space, ready for quantization. -
Weight Clipping (Pre-Quantization): Before the actual quantization, the values within $D_l$ are often clipped. The paper mentions clipping at $2\sigma$ (two standard deviations) around the mean of $D_l$. This step helps to reduce the range of values, mitigating the impact of outliers that can disproportionately affect low-bit quantization.
$$\tilde{D}_l^{clipped} = \text{clip}(D_l, \mu - 2\sigma, \mu + 2\sigma)$$
where $\mu = \text{mean}(D_l)$ and $\sigma = \text{std}(D_l)$. -
Quantization in FF Space: The clipped $D_l$ (or original $D_l$ if no clipping) is then quantized to $\tilde{D}_l$. This is the core quantization step, where the values are mapped to a limited set of low-bit representations (e.g., 2-bit integers). This mapping is performed by minimizing the objective function $L(\tilde{D}_l)$, ensuring that the quantized $\tilde{D}_l$ best approximates $D_l$ in terms of its effect on $C_{prev}$. This is an iterative process, as described in the optimization dynamics.
-
Layer Output Reconstruction (Inference): During inference, once $\tilde{D}_l$ is obtained, the layer's output $Z_l$ is computed. This involves multiplying the quantized FF weight matrix $\tilde{D}_l$ with the FF activations $C_{prev}$, and then transforming the result back from the FF space using the synthesis operator $P_l$.
$$Z_l = P_l \tilde{D}_l C_{prev}$$
This $Z_l$ is the final, quantized output of layer $l$, which then serves as $\hat{A}_{prev}$ for the next layer. This entire sequence ensures that the model operates efficiently with low-bit weights while maintaining accuracy due to the robustness of Fusion Frames.
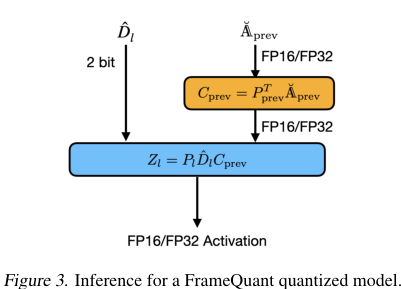 Figure 3. Inference for a FrameQuant quantized model
Figure 3. Inference for a FrameQuant quantized model
Optimization Dynamics
The mechanism learns, updates, or converges by iteratively refining the quantized weight matrix $\tilde{D}_l$ to minimize the proxy loss $L(\tilde{D}_l)$. The paper explicitly states that the quantization procedure is "almost identical to (Frantar et al., 2023)", which refers to the GPTQ (Generative Pre-trained Transformer Quantization) method. This implies a layer-wise, approximate second-order optimization approach.
-
Layer-wise Quantization: FrameQuant quantizes the Transformer model layer-by-layer. For each layer $l$, it processes its weight matrix $\Theta_l$ independently, given the activations $\hat{A}_{prev}$ from the already quantized previous layers. This sequential processing simplifies the optimization problem for each layer.
-
Hessian-based Iterative Update: The loss function $L(\tilde{D}_l) = \text{tr}((D_l - \tilde{D}_l) C_{prev} C_{prev}^T (D_l - \tilde{D}_l)^T)$ reveals a critical component: the term $H = C_{prev} C_{prev}^T$. The paper identifies this as the Hessian (or an approximation thereof) prominent in PTQ strategies. In second-order optimization methods, the Hessian provides information about the curvature of the loss landscape, allowing for more efficient and accurate updates than simple gradient descent. The GPTQ method, which FrameQuant adapts, uses this Hessian information to adjust the remaining unquantized weights when a subset of weights in a layer is quantized. This ensures that the quantization error is minimized not just for the individual weight being quantized, but also considering its impact on the overall layer output.
-
Clipping for Landscape Shaping: A crucial pre-processing step is clipping the values of $D_l$ at $2\sigma$ (two standard deviations) before quantization. This effectively "shapes" the loss landscape by restricting the search space for $\tilde{D}_l$. Outliers, which are common in weight distributions and can lead to large quantization errors, are brought within a manageable range. This makes the optimization problem more stable and prevents extreme values from dominating the quantization error, leading to a smoother and more predictable loss landscape for the low-bit quantization. The paper notes that Fusion Frames help in making the weight distributions more "well-behaved," which in turn makes this clipping strategy more effective.
-
Redundancy and Robustness: The underlying principle of Fusion Frames contributes significantly to the optimization dynamics. The redundancy inherent in the FF representation means that quantization noise (which can be interpreted as additive noise) is spread out across multiple coefficients. This makes the system more robust to such noise. From an optimization perspective, this redundancy effectively "flattens" or "smoothes" the loss landscape, making it less prone to sharp local minima or highly sensitive regions. This allows the iterative quantization algorithm to converge to a better solution with less degradation in performance, even at very low bit-widths. The theoretical guarantees of Fusion Frames regarding noise robustness directly translate to a more stable and effective quantization process. The iterative method then finds the optimal $\tilde{D}_l$ within this robust landscape.
Results, Limitations & Conclusion
Experimental Design & Baselines
The experimental validation of FrameQuant was meticulously designed to rigorously demonstrate its mathematical claims regarding flexible low-bit quantization for Transformer models. The primary goal was to assess the method's performance on benchmark tasks and to show how low-bit quantization, particularly at the 2-bit (or 2.x bit) regime, could approach full-precision performance with only a small degree of representation redundancy.
The "victims" (baseline models) against which FrameQuant was ruthlessly tested included a comprehensive "basket" of 15+ popular Vision Transformer (ViT, DeiT, Swin) and Large Language Models (OPT, Llama2) architectures, covering various model sizes (Tiny, Small, Base, Medium, Large, Huge).
For Vision models, the evaluation focused on the ImageNet-1K classification task, reporting top-1 accuracy. For Language models, perplexity was the key metric, assessed on datasets like WikiText2 and C4, along with accuracy on diverse downstream tasks (e.g., ARC, BoolQ, HellaSwag, PIQA, WinoGrande) for Llama2-7B.
The core of the experimental setup involved quantizing the model weights layer-by-layer, sequentially from shallow to deep layers, consistent with common Post-Training Quantization (PTQ) approaches. A small calibration dataset of 128 randomly selected images from ImageNet-1K's training set was used for Vision models.
FrameQuant's performance was compared against several strong baselines:
- For Vision Models: PTQ4ViT (Yuan et al., 2022), GPTQ (Frantar et al., 2023), and QuIP (Chee et al., 2023). A modified version of QuIP, incorporating the $\pm 2\sigma$ clipping strategy developed for FrameQuant, was also included for a fair comparison. PTQ4ViT was evaluated at 3 bits for some comparisons, as its 2-bit activation quantization was not directly comparable.
- For Language Models: GPTQ and QuIP were the main competitors. Additionally, FrameQuant was compared against ZeroQuant (Yao et al., 2022) in a mixed-precision setting.
A crucial aspect of the experimental design was the introduction and variation of the redundancy factor $r$. FrameQuant's unique ability to offer "fractional bit" quantization was explored by setting $r=1$ (equivalent to 2 bits per parameter) and $r=1.1$ (equivalent to 2.2 bits per parameter) as primary comparison points, with further exploration up to $r=1.3$ for ablation studies. This allowed for a direct assessment of how increasing redundancy in the Fusion Frame representation impacts model quality.
The paper also included an ablation study to dissect the contribution of different components, such as the Fusion Frame representation itself and the $\pm 2\sigma$ clipping strategy. The clipping, applied to the transformed weights in the Fusion Frame space, was shown to be a critical element in handling outliers and improving performance, and its effect was quantitatively compared against direct clipping on original weights.
What the Evidence Proves
The evidence presented in the paper definitively proves that FrameQuant's core mechanism—quantizing Transformer model weights in the Fusion Frame representation—yields substantial and consistent improvements over existing low-bit quantization baselines.
The most undeniable evidence is the superior accuracy and perplexity achieved by FrameQuant across a diverse range of models and tasks:
- Vision Models (ImageNet-1K): FrameQuant consistently outperformed GPTQ, QuIP, and PTQ4ViT. For instance, with a redundancy factor of $r=1.1$ (equivalent to 2.2 bits), FrameQuant achieved top-1 validation accuracies that were remarkably close to the full-precision (32-bit) models. For example, a ViT-B model achieved 80.93% with FrameQuant (r=1.1) compared to 79.53% for QuIP (r=1.0) and 85.10% for full-precision (Table 1). Even at $r=1.0$, FrameQuant often matched or slightly surpassed QuIP.
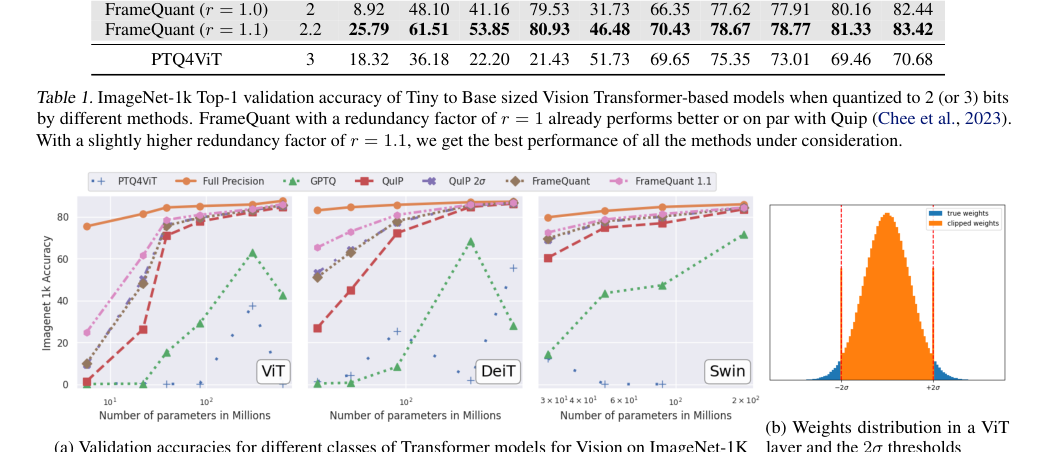 Figure 4. (a) Validation accuracies of Vision Transformers on ImageNet-1K dataset. We can see FrameQuant closing the gap between the full precision model with increasing redundancy. Each dot in the plot corresponds to a model from tables 1-2 combined. (b) shows the distribution of weights in a ViT layer and the 2σ thresholds for clipping. We see that our thresholding keeps most of the mass while removing outliers
Figure 4. (a) Validation accuracies of Vision Transformers on ImageNet-1K dataset. We can see FrameQuant closing the gap between the full precision model with increasing redundancy. Each dot in the plot corresponds to a model from tables 1-2 combined. (b) shows the distribution of weights in a ViT layer and the 2σ thresholds for clipping. We see that our thresholding keeps most of the mass while removing outliers
- Language Models (Perplexity): On WikiText2 and C4 datasets, FrameQuant demonstrated significantly lower perplexity (which is better) than GPTQ and QuIP across various OPT and Llama2 models. For Llama2-7B on WikiText2, FrameQuant (r=2.2 bits) achieved a perplexity of 22.68, a substantial improvement over GPTQ's 8.9e3 and QuIP's 37.59 (Table 5). This trend was consistent across model sizes and datasets (Figure 5, Figure 14).
- Downstream Tasks: For Llama2-7B finetuned on tasks like ARC, BoolQ, and HellaSwag, FrameQuant (r=1.1) consistently yielded higher accuracies compared to other 2-bit methods (Table 14).
The definitive evidence that the core mechanism (Fusion Frames) works in reality lies in the robustness to quantization noise and the benefits of redundancy:
- The paper empirically verified that the Fusion Frame representations, by spreading out energy uniformly, are inherently more robust to the "noise" introduced by quantization (Abstract, Section 3.1). This is why FrameQuant can achieve such low bit-widths with minimal accuracy loss.
- The concept of "fractional bit" quantization, enabled by varying the redundancy factor $r$, was ruthlessly proven. Increasing $r$ from $1.0$ to $1.1$ (effectively from 2 bits to 2.2 bits) consistently closed the performance gap with full-precision models across all tested architectures (Figure 4a, Figure 5, Table 1, Table 2, Table 5). For smaller models like ViT-S, increasing redundancy up to $r=1.3$ led to significant accuracy boosts (e.g., +21% for ViT-S from $r=1.0$ to $r=1.3$) and visually improved attention maps, showing better focus on objects of interest (Figure 6, Figure 7, Figure 8, Figure 9, Table 8).
The effectiveness of the $\pm 2\sigma$ clipping strategy was also clearly demonstrated. While simple clipping on original weights can degrade performance (Table 10), applying it within the Fusion Frame representation space was highly effective. This is because the FF representations lead to a more Gaussian-like distribution of weights with fewer outliers (Figure 4b, Figure 13), making the $2\sigma$ threshold an optimal "sweet spot" for capturing most of the weight mass while removing problematic outliers (Figure 11).
Finally, FrameQuant delivered significant storage benefits. For a 1024x1024 weight matrix, it achieved a 13x reduction in storage (from 4MB FP32 to 0.307MB for 2-bit quantized weights plus overhead) (Section K.1). For Llama2 models, the size reduction was approximately 85% (Table 6), making these large models more deployable on resource-constrained devices.
Limitations & Future Directions
While FrameQuant presents a compelling advancement in low-bit quantization, the paper candidly acknowledges several limitations and opens up numerous avenues for future research and development.
One significant limitation is inference speed. FrameQuant introduces additional computational overhead during inference because it requires transforming weights to and from the Fusion Frame representation space. This means that while accuracy is superior at low bit-widths, the raw inference speed can be lower than methods like GPTQ. For example, Llama2 7B showed a reduction from 1425.07 tokens/sec (GPTQ) to 974.20 tokens/sec (FrameQuant) (Table 7). The computational complexity for these transformations is $O(d^2(kr + \log d))$ (Section K.2). Future work could focus on developing highly optimized, efficient kernels and hardware-aware implementations to mitigate this overhead, potentially leveraging the block-diagonal structure of Fusion Frames and fast random projections mentioned in the paper. Tighter integration with hardware is key to unlocking further efficiency gains (Section 7).
Another limitation is the unsuccessful attempt at 1-bit quantization. Experiments with 1-bit per weight, even with high redundancy ($r=1.8$), did not yield viable results (Section 6, point 1). This suggests that for the current formulation, 2 bits might be a practical lower bound. Future research could explore alternative Fusion Frame constructions or quantization schemes specifically tailored for extreme 1-bit compression, perhaps by incorporating more advanced denoising techniques or different loss functions.
The current work primarily focused on weight quantization, with activation quantization being a secondary exploration. While promising results were shown for activation quantization using FrameQuant (Table 11, Figure 12b), a comprehensive head-to-head comparison with baselines in this low-bit regime is still needed (Section F). This is a clear direction for future work, as quantizing both weights and activations is crucial for end-to-end model compression.
The paper also mentions that while the theoretical benefits of Wiener filters for denoising are known and a diagonal approximation helps, the reported experimental results do not fully utilize this boost (Section 3.1, point b). Incorporating more sophisticated denoising filters during the de-quantization step could potentially lead to further accuracy improvements without increasing bit-width.
Regarding redundancy, while increasing $r$ up to $1.3$ showed benefits for smaller models, there's an inherent trade-off between redundancy (which implies more storage/compute for the FF representation) and performance. Future work could investigate methods for adaptively determining the optimal redundancy factor per layer or per model, perhaps based on model size or task sensitivity, to strike the best balance.
The authors also note that Quantization-Aware Training (QAT) was not explored but could be a future direction. Modifying FrameQuant to be applicable during QAT, possibly by simulating quantization loss during fine-tuning, could further improve robustness to quantization noise and potentially achieve even better performance (Section 6, point 7). This would involve integrating the Fusion Frame transformations directly into the training loop.
Finally, the paper briefly touches upon scaling laws and how FrameQuant might alter the relationship between model size (parameters $\times$ bit-width) and test loss compared to full-precision models (Section 6, point 8). A deeper theoretical and empirical investigation into these scaling behaviors for FrameQuant could provide valuable insights into the fundamental limits of low-bit quantization and guide the design of future efficient models. The generalizability of Fusion Frames to other neural network architectures beyond Transformers is also an intriguing, albeit unmentioned, future direction.
 Table 5. Perplexity (lower is better) of Llama2 and OPT models on WikiText2 dataset when quantized to 2 (or 2.2) bits by different methods
Table 5. Perplexity (lower is better) of Llama2 and OPT models on WikiText2 dataset when quantized to 2 (or 2.2) bits by different methods
 Table 10. Table showing the impact of clipping on GPTQ. FrameQuant computes the FF representations of the weights that are nicely distributed and can take advantage of clipping to remove outliers
Table 10. Table showing the impact of clipping on GPTQ. FrameQuant computes the FF representations of the weights that are nicely distributed and can take advantage of clipping to remove outliers
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work lie in the application of finite frame theory, specifically Fusion Frames, to represent high-dimensional vectors. It leverages the redundancy and noise robustness properties of these frames to enable stable low-bit quantization and subsequent reconstruction of the original vectors, minimizing distortion.
Adjacent Research Areas
Frame Theory and Harmonic Analysis
The entire methodology of FrameQuant is built upon the foundatonal concepts of Frame Theory, a branch of Harmonic Analysis. The paper directly employs definitions and properties of Frames (Definition 2.1) and Fusion Frames (Definition 2.2), which generalize orthogonal bases by providing redundant representations. The core mathematical operations, such as the Analysis operator $T_W: x \mapsto (w_i P_i^* x)_{i=1}^k$ (Equation 2) and the Synthesis operator $T_W^*: (Y_i)_{i=1}^k \mapsto \sum_{i=1}^k w_i P_i Y_i$ (Equation 3), are direct applications of frame theory. Furthermore, the robustness guarantees against quantization noise, including MSE reduction rates of $O(1/r)$ or $O(1/r^2)$ for tight frames, are derived directly from established results in frame theory (Goyal et al., 1998, IEEE Transactions on Information Theory; Casazza & Kutyniok, 2012, Finite Frames, Theory and Applications).
Signal Processing and Data Compression
The problem of quantizing model weights to reduce their memory footprint and computational cost is inherently a data compression task. FrameQuant's approach of transforming weights into a redundant Fusion Frame representation before quantization, and then reconstructing them, directly mirrors techniques used in robust signal transmission and analog-to-digital conversion. In signal processing, frames are used to encode signals such that they are robust to additive noise or erasures during transmission or storage. The paper's finding that quantization noise in the frame domain leads to less reconstruction error (Section 2, page 4) is a direct parallel to the noise robustness properties exploited in signal processing applictions. For example, Goyal et al. (1998, IEEE Transactions on Information Theory) extensively discuss quantized overcomplete expansions in $\mathbb{R}^n$ and their analysis, synthesis, and algorithms, which are directly relevant to the mechanisms employed here.