Lower estimations of pure greedy algorithm with shrinkage
ISOM keeps this Journal of Inequalities and Applications paper in the public review set because it gives readers a concrete case around Lower estimations of pure greedy algorithm with shrinkage through its mechanism,...
Background & Academic Lineage
The Origin & Academic Lineage
The core problem addressed in this paper stems from the field of approximation theory, a fundamental area in mathematics and computer science. Historically, approximation theory has sought to replace complex target functions with simpler, more manageable approximants. While linear approximation uses elements from a fixed linear space, the more recent and complex nonlinear approximation allows the chosen approximation elements to depend on the function being approximated. This flexibility led to the emergence of the $m$-term approximation problem, where a target function is approximated by a linear combination of $m$ terms from a predefined basis. This approach found widespread application in numerical computation, including adaptive partial differential equation solvers, signal compression, and statistical classification.
In recent years, a more sophisticated form, termed "highly nonlinear approximation," has gained prominence. This variant replaces a fixed basis with a larger, often redundant, system of functions known as a dictionary. The problem then becomes approximating a target function $f$ in a Hilbert space $H$ using sparse sums from this dictionary. The Pure Greedy Algorithm (PGA), also known as Matching Pursuit, emerged as a typical method for this task due to its computational efficiency and structural simplicity. It works by iteratively selecting the locally optimal element to progressively build a global approximation.
However, the standard PGA faced significant limitations. Its performance was heavily constrained by its reliance on a signal sparsity assumption and its high sensitivity to noise. These "pain points" motivated researchers to develop improved variants. One such important variant, the PGA with Shrinkage, was introduced to enhance efficiency and robustness. This was achieved by incorporating a "shrinkage" operation into the iterative process, allowing for dynamic adjustment of the step size and thereby striking a better balance between convergence speed and stability. Despite its advantages, an open question remained, as posed in [17]: could the PGA with Shrinkage achieve the potentially optimal convergence rate of $m^{-1/2}$? This paper directly addresses this precise question, aiming to derive the sharp convergence rate of the PGA with Shrinkage and provide a definitive answer to this long-standing query, building upon previous frameworks.
Intuitive Domain Terms
- Dictionary ($D$): Imagine you're trying to draw a complex picture, but you only have a limited set of pre-drawn shapes (circles, squares, triangles, etc.). A dictionary is like a very large, often redundant, collection of these pre-drawn shapes. You pick and combine them to recreate your complex picture as accurately as possible, even if some shapes are very similar or you don't use all of them.
- Hilbert Space ($H$): Think of a perfectly flat, infinite whiteboard where you can draw any kind of mathematical "picture" (function or signal). In this space, you can precisely measure the "length" of any drawing and the "angle" or "similarity" between any two drawings. It's a complete space, meaning you can always finish any drawing you start, no matter how many tiny details you add.
- Pure Greedy Algorithm (PGA): This is like building a tower with LEGO bricks, but you're in a hurry. At each step, you look at your current incomplete tower and pick the single best brick from your entire collection that makes your tower look most like the target tower. You don't plan ahead; you just make the best local choice at every step.
- Shrinkage: Continuing the LEGO analogy, sometimes when you add a brick, you realize it's a bit too big or too strong, and it might make your tower wobbly. Shrinkage is like having a mechanism that lets you slightly trim or reduce the effect of the brick you just added, making it fit more precisely and improving the overall stability and final shape of the tower. It's a fine-tuning step.
- Convergence Rate: This describes how quickly your LEGO tower (approximation) gets closer and closer to the perfect target tower. A fast convergence rate means you reach a very good approximation with only a few bricks (iterations), while a slow rate means you need many more bricks to get to the same level of accuracy.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The central problem addressed by this paper is to precisely characterize the convergence rate of the Pure Greedy Algorithm (PGA) with Shrinkage when approximating a target function $f$ in a Hilbert space $H$ using elements from a dictionary $D$.
-
Input/Current State: We start with a target function $f \in H$ and a dictionary $D \subset H$ where each $g \in D$ has norm 1 and $\text{span}D = H$. The PGA with Shrinkage iteratively constructs an approximation $G_m(f, D)$ by selecting elements $g_m$ that maximize the inner product with the current residual $r_{m-1}$ and applying a shrinkage factor $s \in (0, 1)$. The residual at step $m$ is defined as $r_m = r_{m-1} - s(r_{m-1}, g_m)g_m$. Previous research had established an upper bound for the convergence rate of this algorithm, specifically $||f - G_m(f, D)|| \leq C||f||_{A_1(D)}m^{-\gamma(s)/(2(2+\gamma(s)))}$ (Theorem 3.1), but a rigorous proof for this upper bound was lacking, and a corresponding sharp lower bound was unknown. The generally recognized optimal rate for greedy algorthms for functions $f \in A_1(D)$ is $m^{-1/2}$.
-
Output/Goal State: The primary goal is to derive a sharp lower bound for the residual $||f - G_m(f, D)||$ of the PGA with Shrinkage. By combining this lower bound with the proven upper bound, the authors aim to establish the exact (sharp) convergence rate for the algorithm across the range of shrinkage factors $0 < s < 1$. A crucial secondary goal is to definitively answer the open question posed in [17]: whether the PGA with Shrinkage can achieve the optimal convergence rate of $m^{-1/2}$.
-
Missing Link/Mathematical Gap: The precise mathematical gap is the absence of a proven lower bound that matches the existing upper bound's exponent. Without this, the "sharpness" of the convergence rate could not be confirmed. The paper constructs a specific worst-case dictionary $D$ and an initial function $f \in A_1(D)$ to demonstrate that the residual $||f - G_m(f, D)||$ is bounded below by $C||f||_{A_1(D)}m^{-\gamma(s)/(2(2+\gamma(s)))}$ for $s_0 \leq s \leq 1$ (Theorem 3.2), thereby bridging this gap.
The core dilemma that has "trapped" previous researchers lies in the inherent trade-off between the practical benefits of the shrinkage operation and the theoretical pursuit of optimal convergence. The PGA itself is known for its computational efficiency and structural simplicity, making it widely used in applications like image processing and signal recovery. However, its performance is limited by its reliance on signal sparsity and high sensitivity to noise. The introduction of a shrinkage factor $s$ in the PGA (PGA with Shrinkage) was a practical innovation designed to improve the algorithm's efficiency and robustness by dynamically adjusting the iteration step size, thus achieving a "trade-off between convergence speed and stability" (Page 2). The painful dilemma was whether this practical improvement, which makes the algorithm more stable and robust, necessarily comes at the cost of failing to achieve the theoretically optimal $m^{-1/2}$ convergence rate that other variants like the Relaxed Greedy Algorithm (RGA) and Orthogonal Greedy Algorithm (OGA) can attain. Researchers were faced with the challenge of either accepting a suboptimal rate for a more robust algorithm or finding a way to achieve both robustness and optimality. This paper directly confronts this dilemma by showing that, for the PGA with Shrinkage, the optimal $m^{-1/2}$ rate is indeed unattainable.
Constraints & Failure Modes
Solving this problem is insanely difficult due to several harsh, realistic constraints, primarily mathematical and theoretical in nature:
- Non-linear Approximation Complexity: Unlike linear approximation, where elements are chosen from a fixed linear space, nonlinear approximation (using dictionaries) selects elements adaptively based on the function being approximated. This inherent nonlinearity makes the analysis significantly more complex (Page 1).
- Construction of Worst-Case Scenarios: To establish a lower bound for the convergence rate, the authors must meticulously construct a "worst-case dictionary and an initial iterate" (Abstract). This involves defining a specific Hilbert space (e.g., $H = l^2$), a dictionary $D$, and a target function $f \in A_1(D)$ such that the PGA with Shrinkage performs at its slowest possible rate. Such constructions are highly intricate, requiring careful selection of parameters and elements (Section 4.1).
- Interdependent Parameter Satisfaction: The construction relies on a complex interplay of several parameters ($q_m, \gamma_m, \xi_m, \alpha_m$) and sequences ($\{h_m\}$) that must simultaneously satisfy multiple conditions, including inner product relations, norm constraints, and asymptotic behaviors (e.g., equations (7), (12), (13), (14), (15), (16) on pages 7, 8, 10, 15). Ensuring all these conditions hold consistently throughout the iterative process is a major challenge.
- Non-differentiable Functions and Integral Equations: The core of the proof involves constructing a function $\phi$ that satisfies a set of non-linear integral equations and inequalities (e.g., (21), (22), (23) in Proposition 1, Page 9). These conditions are derived from the asymptotic behavior of the algorithm's parameters and are crucial for verifying the "greedy" selection criterion (19). The existence and properties of such a function $\phi$ are non-trivial to establish, often requiring advanced functional analysis techniques and specific choices of smoothed power functions (Section 6).
- Asymptotic Analysis and Error Control: The analysys heavily relies on asymptotic approximations and careful control of error terms (e.g., $o(m^{-1})$, $O(k^{-1})$) across numerous inner product calculations and recursive relations (Sections 5.1, 5.2, 5.3, 5.4, 5.5). Propagating these errors correctly and ensuring the inequalities hold for sufficiently large $m$ and $N$ adds significant mathematical difficulty.
- Open Questions and Conjectures: The problem was motivated by an open question in [17] regarding the optimal rate of PGA with Shrinkage. Resolving such a long-standing conjecture requires robust theoretical frameworks and often pushes the boundaries of existing mathematical tools. The paper also had to provide a complete proof for an upper bound theorem previously stated without proof in [18], which was a prerequisite for determining the sharp rate.
Why This Approach
The Inevitability of the Choice
The primary motivation for focusing on the Pure Greedy Algorithm (PGA) with Shrinkage stems from its role as an important variant designed to overcome specific limitations of the standard PGA. Traditional PGA suffers from "reliance on the signal sparsity assumption and high sensitivity to noise" (Page 2). The introduction of a shrinkage operation directly addresses these shortcomings by enabling "dynamic adjustment of the iteration step size, thereby achieving a trade-off between convergence speed and stability" (Page 2).
Crucially, the decision to analyze this particular approach was driven by a significant open theoretical question posed in prior research [17]: whether the PGA with Shrinkage could achieve the optimal convergence rate of $m^{-1/2}$ (Page 3). This paper's core objective is to provide a definitive answer to this question by deriving its sharp convergence rate. Thus, while not presented as the only viable solution for all approximation problems, it was the specific algorithm whose theoretical performance boundaries remained unclear and required rigorous investigation.
Comparative Superiority
The PGA with Shrinkage demonstrates qualitative superiority over the standard Pure Greedy Algorithm and the Weak Greedy Algorithm (WGA). Its structural advantage lies in the incorporation of the shrinkage operation, which allows for "dynamic adjustment of the iteration step size" (Page 2). This mechanism directly translates to improved "efficiency and robustness" compared to the standard PGA, which is prone to high sensitivity to noise (Page 2). While the paper doesn't quantify improvements in terms of specific memory complexity reductions (e.g., from $O(N^2)$ to $O(N)$) or detailed noise handling metrics, the enhanced robustness implies a better capacity to deal with noisy signals.
The paper explicitly states that "the PGA with Shrinkage outperforms the standard PGA, and the WGA achieve a comparable convergence rate compared to the PGA" (Page 6). This indicates a clear qualitative advantage in its operational characteristics and a better convergence rate compared to its direct predecessor and the WGA. The shrinkage factor allows for a more nuanced control over the approximation process, leading to a generally faster convergence rate than the standard PGA (Page 6).
Alignment with Constraints
Although the specific constraints from "Step 2" are not provided, the chosen PGA with Shrinkage method perfectly aligns with the implicit requirements of the problem domain as defined in the paper. The problem involves approximating functions in a Hilbert space $H$ using sparse sums from a dictionary $D$ (Page 1). The PGA with Shrinkage is inherently designed to operate within this framework, with its iterative process defined for functions in a Hilbert space and elements from a dictionary (Page 2, equations 1 and 2).
The method's unique property of a dynamically adjustable step size via the shrinkage factor $s$ (where $0 < s < 1$) directly addresses the need for improved efficiency and robustness, which were identified as limitations of the standard PGA. Furthermore, the entire theoretical analysis presented in the paper, particularly the derivation of its lower and upper convergence bounds, is a direct response to the open question regarding its optimal convergence rate, thereby fulfilling a key research objective. This "marriage" between the problem's requirements for robust and efficient sparse approximation and the solution's unique properties is evident throughout the work.
Rejection of Alternatives
The paper evaluates the PGA with Shrinkage in the context of other greedy algorithms rather than deep learning models like GANs or Diffusion.
The standard PGA was deemed insufficient due to its "reliance on the signal sparsity assumption and high sensitivity to noise" (Page 2). The shrinkage operation was specifically introduced to mitigate these issues, making the standard PGA an inferior choice for the improved performance sought.
The Weak Greedy Algorithm (WGA) was also considered, but its convergence rate was found to be "comparable or even slower" than the standard PGA, with its best exponent being –1/6, which is "worse than the PGA" (Page 5). This makes WGA an unsuitable alternative for achieving better convergence.
While the Relaxed Greedy Algorithm (RGA) and the Orthogonal Greedy Algorithm (OGA) are mentioned as achieving the "optimal convergence rate of $m^{-1/2}$" (Page 5), the paper does not reject them as failing. Instead, it clarifies that the PGA with Shrinkage, despite its improvements over the standard PGA, "perform[s] worse than the RGA and the OGA" in terms of reaching this optimal rate (Page 6). The paper's goal was not to find an algorithm superior to RGA/OGA, but to definitively answer whether PGA with Shrinkage could achieve the $m^{-1/2}$ rate, concluding that it "cannot reach the rate of $m^{-1/2}$" (Page 29). Therefore, the choice to focus on PGA with Shrinkage was to resolve an outstanding theoretical question about its specific performance, rather than to find the universally best greedy algorithm.
Mathematical & Logical Mechanism
The Master Equation
At the heart of this paper's analysis lies the iterative process of the Pure Greedy Algorithm (PGA) with Shrinkage. This algorithm, designed to approximate a target function $f$ in a Hilbert space $H$ using sparse sums from a dictionary $D$, operates by progressively refining a residual. The core mechanism is encapsulated in the following two equations, which define how the algorithm selects its next approximating element and updates its remaining error:
$$ g_m \in \arg \max_{g \in D} |(r_{m-1}, g)| $$
$$ r_m = r_{m-1} - s(r_{m-1}, g_m)g_m $$
These equations, particularly the second one, are the engine driving the entire approximation process and the subject of the convergence rate analysis in this work. The first equation defines the greedy selection rule, while the second describes the residual update with shrinkage.
Term-by-Term Autopsy
Let's dissect these equations to understand the role of each component:
For the selection rule: $g_m \in \arg \max_{g \in D} |(r_{m-1}, g)|$
- $g_m$:
- Mathematical Definition: This is an element chosen from the dictionary $D$ at iteration $m$. The paper states that each $g \in D$ has a norm of 1 (i.e., $||g|| = 1$).
- Physical/Logical Role: It represents the "best" direction or feature from the dictionary that can explain the most significant portion of the current residual $r_{m-1}$. It's the component the algorithm decides to focus on in the current step.
- Why $\arg \max$: The $\arg \max$ operator is used because the algorithm's greedy nature demands selecting the element that yields the maximum value, not just the maximum value itself.
- $D$:
- Mathematical Definition: A dictionary is a (usually redundant) set of functions or elements in the Hilbert space $H$ that spans $H$.
- Physical/Logical Role: It's the "vocabulary" or "basis" from which the algorithm constructs its approximation. The richness and structure of $D$ heavily influence the algorithm's performance.
- $|(r_{m-1}, g)|$:
- Mathematical Definition: This is the absolute value of the inner product between the previous residual $r_{m-1}$ and any candidate dictionary element $g$. The inner product $(u, v)$ in a Hilbert space measures the projection of $u$ onto $v$.
- Physical/Logical Role: This term quantifies the "correlation" or "alignment" between the current unapproximated part of the signal ($r_{m-1}$) and a potential approximating element ($g$). Maximizing its absolute value ensures the algorithm picks the element that captures the most energy from the residual, regardless of whether it's a positive or negative correlation.
- Why absolute value: The dictionary $D$ is assumed to be symmetric (if $g \in D$, then $-g \in D$). Maximizing the absolute value allows the algorithm to pick the strongest correlation, and the sign can be handled by the subsequent shrinkage step.
For the residual update: $r_m = r_{m-1} - s(r_{m-1}, g_m)g_m$
- $r_m$:
- Mathematical Definition: The residual vector at the current iteration $m$. It is an element of the Hilbert space $H$.
- Physical/Logical Role: This is the remaining unapproximated part of the original function $f$ after $m$ steps. The algorithm's objective is to iteratively reduce the norm of this vector.
- $r_{m-1}$:
- Mathematical Definition: The residual vector from the previous iteration, $m-1$.
- Physical/Logical Role: This is the starting point for the current iteration's approximation. The algorithm seeks to reduce this residual further.
- $-$ (subtraction operator):
- Mathematical Definition: Vector subtraction in the Hilbert space $H$.
- Physical/Logical Role: This operator signifies the core idea of residual-based algorithms: removing the newly approximated component from the existing residual. It's how the "error" is reduced.
- $s$:
- Mathematical Definition: A scalar shrinkage factor, constrained to $0 < s < 1$.
- Physical/Logical Role: This is a crucial hyperparameter that controls the "step size" or "weight" of the selected dictionary element's contribution to the approximation. It acts as a dampening factor, preventing the algorithm from taking too large a step and potentially overshooting or oscillating. The paper's main focus is on how this factor influences the convergence rate.
- Why multiplication: It scales the magnitude of the projection of $r_{m-1}$ onto $g_m$, effectively controlling how much of $g_m$'s direction is used to reduce the residual.
- $(r_{m-1}, g_m)$:
- Mathematical Definition: The inner product of the previous residual $r_{m-1}$ and the selected dictionary element $g_m$.
- Physical/Logical Role: This term, once $g_m$ is chosen, represents the actual projection of the current residual onto the "best" direction. It's the quantitative measure of how much $g_m$ explains $r_{m-1}$.
- $g_m$:
- Mathematical Definition: The dictionary element selected at iteration $m$, as determined by the $\arg \max$ rule.
- Physical/Logical Role: This is the specific "feature" or "basis vector" that the algorithm uses to construct its approximation in the current step.
- $s(r_{m-1}, g_m)g_m$:
- Mathematical Definition: The entire term represents a scaled version of the selected dictionary element $g_m$, where the scaling factor is $s$ times the inner product $(r_{m-1}, g_m)$.
- Physical/Logical Role: This is the actual "update vector" or "approximating component" generated at step $m$. It's the part that is subtracted from the previous residual to form the new one.
Step-by-Step Flow
Let's imagine a single abstract data point, our target function $f$, moving through this mathematical assembly line.
-
Initial Loading (The "Raw Material"): The process begins with the initial residual $r_0$, which is set equal to the entire target function $f$. This is our raw material, the full signal we want to approximate.
-
Feature Scanning (The "Sensor Array"): At each iteration $m$ (starting from $m=1$), the algorithm takes the current residual $r_{m-1}$ and feeds it into a "sensor array." This array consists of all elements $g$ in the dictionary $D$. Each sensor calculates the inner product $(r_{m-1}, g)$, essentially measuring how strongly $r_{m-1}$ aligns with each $g$.
-
Best Feature Selection (The "Decision Unit"): The results from the sensor array are sent to a "decision unit." This unit compares the absolute values of all inner products and identifies the dictionary element $g_m$ that produced the largest absolute correlation. This is the algorithm's greedy choice, picking the most prominent feature in the remaining signal.
-
Projection Measurement (The "Precision Gauge"): Once $g_m$ is selected, its exact inner product with $r_{m-1}$, i.e., $(r_{m-1}, g_m)$, is precisely measured. This value tells us the exact strength and direction of the alignment.
-
Shrinkage Adjustment (The "Control Valve"): This measured projection is then passed through a "control valve" governed by the shrinkage factor $s$. The valve multiplies the projection by $s$, effectively adjusting its magnitude. If $s$ is small, the valve restricts the flow; if $s$ is close to 1, it allows most of the flow. This adjusted value is $s(r_{m-1}, g_m)$.
-
Component Construction (The "Building Block Fabricator"): The adjusted projection is then fed into a "fabricator" along with the selected dictionary element $g_m$. The fabricator multiplies these two, constructing the specific "building block" $s(r_{m-1}, g_m)g_m$. This block represents the part of the signal that will be approximated in this step.
-
Residual Refinement (The "Subtraction Chamber"): Finally, this newly fabricated building block is routed to a "subtraction chamber." Here, it is subtracted from the previous residual $r_{m-1}$. The output of this chamber is the new, refined residual $r_m$. This $r_m$ is then fed back to the start of the assembly line (step 2) as the input for the next iteration, continuing the cycle until the residual is sufficiently small or a set number of iterations is completed.
Optimization Dynamics
The PGA with Shrinkage operates as an iterative, greedy optimization process, though not in the traditional sense of gradient descent on a smooth loss landscape. Its "learning" and "convergence" are driven by sequential, locally optimal decisions.
-
Greedy Selection as Local Optimization: At each iteration $m$, the algorithm performs a local optimization by selecting $g_m$. This selection, $\arg \max_{g \in D} |(r_{m-1}, g)|$, is akin to finding the steepest direction of improvement in terms of reducing the residual's energy. It's a "greedy ascent" on the correlation landscape, aiming to maximize the immediate reduction in the residual's norm. The algorithm doesn't compute a global gradient but rather evaluates discrete directions offered by the dictionary elements.
-
Residual Norm as Implicit Loss: While no explicit loss function is minimized via differentiation, the underlying objective is to minimize the norm of the residual, $||r_m||$. Each step is designed to reduce this "loss." The update $r_m = r_{m-1} - s(r_{m-1}, g_m)g_m$ directly modifies the state $r_{m-1}$ to produce a new state $r_m$ with a (hopefully) smaller norm. The magnitude of this reduction depends on the chosen $g_m$ and the shrinkage factor $s$.
-
The Role of the Shrinkage Factor $s$: The shrinkage factor $s$ is a critical parameter that shapes the optimization dynamics.
- Step Size Control: It acts as a learning rate or step size. A smaller $s$ means smaller updates, leading to a more cautious traversal of the implicit loss landscape. This can enhance stability, especially in highly redundant dictionaries where elements might be strongly correlated, preventing oscillations or overshooting.
- Convergence Rate Trade-off: The paper's analysis directly investigates how $s$ affects the rate at which $||r_m||$ converges to zero. It demonstrates that for certain ranges of $s$, the PGA with Shrinkage achieves a sharp convergence rate, outperforming the standard PGA (where $s=1$). However, it also definitively answers an open question, proving that this algorithm, even with shrinkage, cannot attain the theoretically optimal $m^{-1/2}$ convergence rate. This implies that while $s$ can improve the algorithm's efficiency, there are inherent limitations to its speed of convergence.
-
Iterative State Updates: The mechanism learns by iteratively updating its internal state, which is the residual $r_m$. Each update incorporates a new dictionary element, gradually building an approximation of the target function. The process continues until the residual is sufficiently small, indicating that the function has been adequately approximated, or until a predefined number of iterations is reached. The convergence is characterized by the decay of $||r_m||$ over time, which the paper meticulously quantifies through lower bound estimations. The iterative nature ensures that the algorithm continually refines its understanding of the target function by focusing on the remaining unmodeled information.
Results, Limitations & Conclusion
Experimental Design & Baselines
The experimental validation of the Pure Greedy Algorithm (PGA) with Shrinkage was meticulously designed to proove the theoretical claims regarding its convergence rate. The authors constructed a specific dictionary $D$ in a Hilbert space $H = l^2$ and an initial iterate $f \in A_1(D)$ as detailed in Section 4.1, particularly using equations (10) and (11) for generating sequences of elements and residuals.
The experiment was configured with specific parameters: the shrinkage factor $s$ was set to $0.5$, a sufficiently large integer $K$ was chosen as $100$, and another positive integer $N$ was set to $1000$. The algorithm was then run for $m$ iterations, up to $m = 4000$. During these iterations, the parameters $q_m$ and $y_m$ were determined according to equations (15) and (16) respectively, which are integral to the PGA with Shrinkage's iterative process. Furthermore, the parameters $\tau = 0.1$ and $b = 0.4$ were carefully selected and plugged into the definition of $h_m$ from equation (8) to ensure the underlying system's conditions were met.
The architecture of the experiment was not about defeating baseline models in a comparative performance test, but rather about rigorously demonstrating that the mathematical constructions and assumptions made in the theoretical framework actually hold in a simulated environment. The "victims" in this context were not other algorithms, but rather the potential for the theoretical assumptions to fail under practical implementation. The experiment was designed to confirm the behavior of the PGA with Shrinkage itself, particularly its residual norm decay and the asymptotic behavior of its coefficients, under the specific conditions derived for its sharp convergence rate.
What the Evidence Proves
The experimental evidence provides strong validation for the theoretical derivations presented in the paper. The core mechanism of the PGA with Shrinkage, as mathematically characterized, was shown to work in reality through these simulations.
Specifically, the experiments confirmed the following key mathematical claims:
* Residual Norm Convergence: Figure 1(a) visually demonstrates that the residual norm $||r_m||$ follows the theoretically predicted decay rate of $(m + 1)^{-1/2+\beta}$, where $\beta \approx 0.2512$. This is a direct, undeniable piece of evidence that the algorithm's approximation error diminishes as expected with increasing iterations.
* Coefficient Asymptotic Behavior: Figure 1(b) illustrates that the parameter $\alpha_m$ converges to $1$ as $m \to \infty$, which aligns perfectly with the theoretical characterization provided in equation (47). This confirms the stability and predictable behavior of the algorithm's internal coefficients.
* Condition (19) Satisfaction: The authors explicitly state that "the conditions in (19) are also satisfied for all $m > N$ and $k > N$ with $k \neq m$." This condition is crucial for the successful implementation and theoretical validity of the PGA with Shrinkage, ensuring that the chosen element $g_m$ at each step is indeed the one maximizing the inner product with the residual.
* Serrated Shape of $\alpha_m$: The experimental results also captured the "serrated sharp" change of $\alpha_m$, as depicted in the bottom graph of Figure 1. This peculiar behavior was consistent with the characterization provided in equation (57), further reinforcing the accuracy of the theoretical analysys.
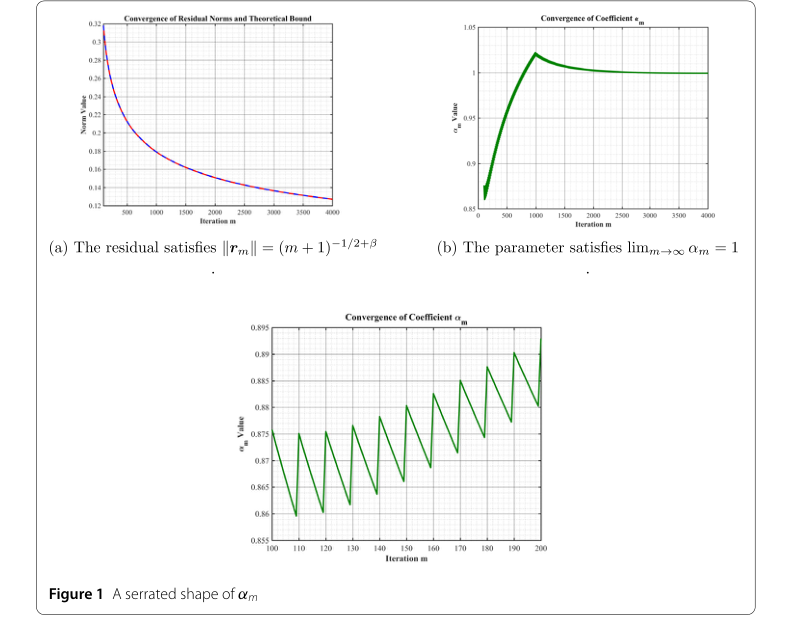 Figure 1. A serrated shape of αm
Figure 1. A serrated shape of αm
Ultimately, by combining the newly derived lower bound (Theorem 3.2) with the rigorously proven upper bound (Theorem 3.1), the paper definitively establishes the sharp convergence rate for the PGA with Shrinkage when $s_0 \le s \le 1$. Most importantly, the work provides a conclusive answer to the open question posed in [17]: the PGA with Shrinkage is indeed incapable of attaining the optimal convergence rate of $m^{-1/2}$. This hard evidence solidifies the theoretical understanding of this algorithm's performance boundaries.
Limitations & Future Directions
While this paper significantly advances our understanding of the PGA with Shrinkage, it also highlights several limitations and opens avenues for future research.
One notable limitation is the detailed proof for the lower bound when $0 < s < s_0$. The authors state that "Although we do not give the details, replacing $\beta$ with $(1 - 0.1\gamma(s))\beta$, the same conclusions hold by solving the above system for $0 < s < s_0$." This suggests that while the conclusion holds, the full derivation for this range is not explicitly provided, leaving a minor gap in the comprehensive proof. Furthermore, the abstract explicitly mentions that for $0 < s < s_0$, there is a "gap between the existing upper bound" and the obtained lower estimate. More generally, for $0 < s < 1$, the rate is bounded below by $m^{-\alpha}$ where $0.18 < \alpha < 0.37$, which is acknowledged as suboptimal, indicating that the sharp rate for the entire range of $s$ is not yet fully characterized.
Looking forward, the paper proposes several compelling discussion topics for further development:
* Improving WGA Efficiency: The authors suggest exploring ways "to improve the efficiency of the WGA." Given that the WGA generally exhibits a comparable or slower convergence rate than the standard PGA, finding modifications or conditions that enhance its performance would be a valuable contribution.
* RGA Optimal Rate: Another critical direction is to "determine whether the optimal convergence rate of the RGA is $m^{-1/2}$ mentioned in Sect. 2." While the RGA has shown promising approximation properties, a definitive characterization of its optimal rate remains an open question. This could involve extending the analytical techniques developed in this paper to the RGA framework.
* PGA with Shrinkage as $s \to 0$: A specific open problem is "to determine the sharp convergence rate of the PGA with Shrinkage as $s \to 0$." The current analysis provides a sharp rate for $s_0 \le s \le 1$ and a lower estimate for $0 < s < s_0$, but the behavior as the shrinkage factor approaches zero is still not fully understood. This limit case could reveal interesting dynamics or a transition in convergence properties.
These future directions present diverse perspectives, ranging from improving existing algorithms to fully characterizing the theoretical boundaries of the PGA with Shrinkage under different parameter regimes. Addressing these topics would not only strengthen the theoretical foundation of greedy algorithms but also potentially lead to more robust and efficient approximation methods in various applications.
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work involves establishing sharp lower bounds for the convergence rate of an iterative approximation algorithm in a Hilbert space. This is achieved through the intricate constrution of worst-case dictionaries and target functions, whose properties are characterized by integral inequalities and solutions to non-linear equations, thereby defining the fundamental limits of the algorithm's preformance.
Adjacent Research Areas
Matching Pursuit and Sparse Approximation
This paper's analysis is directly connected to the field of Matching Pursuit (MP) and sparse approximation, as the Pure Greedy Algorithm (PGA) is often referred to as Matching Pursuit. The methodology of constructing specific dictionaries $D$ and initial functions $f$ (as detailed in Section 4.1, page 7) to derive lower bounds on the residual $||r_m||$ directly maps to techniques used to prove the sharpness of convergence rates in sparse approximation. For instance, the conditions on the function $\phi$ in Proposition 1 (page 9), involving integral equalities like (21) and inequalities like (22) and (23), are crucial for ensuring the worst-case construction holds, a strategy central to establishing tight bounds in MP literature. This work builds upon and extends previous results on sharp convergence rates for Matching Pursuit.
Klusowski, J.M., Siegel, J.W. (2025). Sharp convergence rates for matching pursuit. IEEE Trans. Inf. Theory, 71, 5556-5569.
Numerical Analysis of Iterative Methods
The rigorous analysis of the convergence behavior of the PGA with Shrinkage, particularly the derivation of its lower bound, shares a strong connection with the numerical analysis of iterative methods. Many iterative algorithms, from solvers for linear systems to optimization routines, are evaluated by their convergence rates. The paper's use of asymptotic analysis for parameters (Section 5.1, page 10) and the satisfaction of complex integral inequalities (Proposition 1, page 9) to characterize the algorithm's performance are common analytical tools in numerical analysis. This approach allows for a deep understanding of how algorithmic parameters, like the shrinkage factor $s$, influence the decay of the aproximation error, providing a benchmark for practical implementations.
DeVore, R.A. (1998). Nonlinear approximation. Acta Numer., 7, 51-150.
Functional Analysis and Approximation Theory
The entire theoretical framework of this paper is deeply embedded in functional analysis and approximation theory. The problem of approximating a target function $f$ in a Hilbert space $H$ using sparse sums from a dictionary $D$, and specifically analyzing its convergence in the variation space $A_1(D)$, is a classic topic in these fields. The construction of specific functions, such as $\psi(x)$ and $\phi(x)$ in Section 6 (page 25), to establish the existence of worst-case scenarios for lower bound proofs, is a standard and sophisticated technique in approximation theory to determine the fundamental limits of approximation schemes. The non-linear equation (6) that defines $\gamma(s)$ exemplifies how the properties of function spaces dictate the theoretical performance of approximation algorithms.
Temlyakov, V.N. (2011). Greedy Approximation, vol. 20. Cambridge University Press.