Generative Video Propagation
The problem of generative video propagation, as addressed in this paper, is rooted in the broader field of computer vision, specifically within the domain of video generation and editing.
Background & Academic Lineage
The Origin & Academic Lineage
The problem of video editing, particularly propagating changes across frames, has a long history in computer vision. Traditionally, methods for "video propagation" relied on techniques like optical flow [9, 44], depth maps [6, 55], radiance fields [33], or atlases [20, 24]. These approaches aimed to transfer modifications made in a sparse set of frames (often just the first frame) to the rest of the video sequence.
However, the precise origin of the problem addressed by this paper, "generative video propagation," stems from the recent explosion in the capabilities of large-scale generative models. Over the past few years, models capable of generating highly realistic videos from text (Text-to-Video, T2V) [7, 17, 18, 32, 35, 42, 46, 57] or images (Image-to-Video, I2V) [2, 5, 32, 53, 60] have emerged. This new era of generative power has opened up possibilities for more sophisticated video editing tasks, including inpainting [65], appearance editing [34, 43], and object insertion [31]. The authors observe that many of these distinct video editing applications can be unified under a single, more general "generative video propagation" framework, leveraging the power of these advanced generative models. This shift from explicit motion or depth cues to implicit generation is the core historical context.
The fundamental limitation or "pain point" of previous approaches that forced the authors to write this paper can be summarized as follows:
- Limited Robustness and Generalization: Traditional methods, often relying on explicit cues like optical flow, are prone to error accumulation over time, leading to inconsistencies and limited ability to generalize to diverse scenarios.
- Task-Specific and Retraining Requirements: Many prior methods were designed for a single, specific video editing task (e.g., object removal or background replacement) and often required extensive re-training or fine-tuning for each new task or even for different videos [28, 31, 34, 61]. This made them inflexible and computationally expensive for broad application.
- Inability to Handle Significant Changes: Diffusion-based video editing models, while powerful for appearance changes, often struggled with substantial modifications to object shapes or complex background alterations. They also frequently required dense mask labeling for every frame, which is a tedious and time-consuming process.
- Auxiliary Inputs and Computational Complexity: Existing first-frame propagation methods often demanded additional inputs like optical flow or depth maps to maintain motion continuity [13, 40, 55, 56]. Others, like I2VEdit [34], introduced computational complexity by requiring learning motion LoRAs for each video clip. Some methods also restricted edits by masking parts of the input video with black squares, losing valuable information [31].
GenProp aims to overcome these limitations by providing a unified, generative framework that can handle a wide range of video editing tasks from a single first-frame edit, without needing auxiliary inputs, task-specific retraining, or dense mask annotations.
Intuitive Domain Terms
- Generative Video Propagation: Imagine you're a movie director, and you've just decided to change the color of a character's shirt in the very first scene. "Generative Video Propagation" is like having a magical film studio that, after you make that one change, automatically and perfectly updates the shirt color in every single subsequent frame of the movie, making sure it looks natural, moves correctly with the character, and seamlessly integrates into the entire film. It "generates" the future based on your initial edit and "propagates" that change throughout.
- Selective Content Encoder (SCE): Think of the SCE as a highly attentive personal assistant. When you're making an edit to a video, this assistant carefully observes the original video and makes a mental note of everything that you haven't touched. If you're changing a car in the foreground, the assistant ensures that the background buildings, the sky, and other elements remain exactly as they were, so the new car can be inserted without accidentally altering the rest of the scene. It "selectively" focuses on and "encodes" (remembers) the unchanged "content."
- Image-to-Video (I2V) Generation Model: This is like a brilliant animator who can take a single still picture (an "image") and a simple instruction (like "make the person in this picture walk across the park") and then create an entire animated movie clip (a "video") from that one image, complete with realistic motion and details. In this paper, it's the core engine that takes your edited first frame and generates the rest of the video, propagating your changes.
- Region-Aware Loss: Picture a teacher grading a project where students had to both fix a specific "region" (like a broken part of a drawing) and also preserve the rest of the drawing perfectly. A "Region-Aware Loss" is like a fair grading system that gives separate, balanced attention to both tasks. It ensures students are rewarded for making the required fixes well and for keeping the untouched parts pristine, even if the fixed area was tiny. It's "aware" of different "regions" and applies a specific "loss" (a penalty for mistakes) to each to ensure both goals are met.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is generative video propagation. This involves taking an existing video, applying an arbitrary edit to its very first frame, and then seamlessly propagating that edit throughout the entire video sequence, ensuring both realism and temporal consistency, while preserving the unedited parts of the original video.
Input/Current State: The system receives an original video, denoted as $V = \{V_1, V_2, \dots, V_T\}$, consisting of $T$ frames. Additionally, a single modified first frame, $v_1'$, is provided. This $v_1'$ represents the desired edit (e.g., object removal, insertion, replacement, or complex shape alteration) applied to the original first frame $V_1$.
Output/Goal State: The desired output is a new, modified video $V' = \{v_1', v_2', \dots, v_T'\}$. For each subsequent frame $v_t'$ (where $t = 2, \dots, T$), the goal is to ensure that it accurately reflects the modification introduced in $v_1'$ while maintaining perfect consistency in appearance and motion with the original video's unedited regions. The propagated changes must be physically plausible and temporally coherent, without introducing artifacts or inconsistencies.
Missing Link & Mathematical Gap: The exact missing link is a robust and generalizable mechanism to bridge the static, single-frame edit ($v_1'$) with the dynamic, multi-frame video sequence ($V_2, \dots, V_T$). Mathematically, the paper aims to learn a generative function $G$ that, given the original video's content (encoded as $E(V)$), the edited first frame $v_1'$, and the current time step $t$, can produce the corresponding modified frame $v_t'$. The challenge lies in ensuring that $G$ can:
1. Propagate any first-frame edit, not just specific types.
2. Maintain consistency in both appearance and motion for the edited regions.
3. Strictly preserve the content of the unedited regions from the original video.
4. Achieve this without requiring additional per-frame inputs (like dense masks or optical flow) or task-specific retraining.
The formal problem statement is to generate $v_t'$ for $t \in \{2, \dots, T\}$ such that:
$$v_t' = G(E(V), v_1', t)$$
where $E(V)$ represents the encoded information of the original video $V$, and $G$ is the image-to-video generation model guided by a selective content encoder.
The Dilemma: Previous researchers have been trapped by a painful trade-off between generality, realism, and consistency.
* Generality vs. Specificity: Traditional methods often excel at specific tasks (e.g., inpainting, tracking) but require task-specific models or retraining, limiting their general applicability. Achieving a unified framework for diverse tasks (removal, insertion, replacement, tracking, outpainting, complex shape changes) without task-specific data or auxiliary inputs has been a significant hurdle.
* Realism/Plausibility vs. Consistency/Stability: While large generative models can produce realistic content, ensuring that propagated edits remain temporally consistent (no flickering, ghosting, or sudden changes) and physically plausible throughout a video, especially for complex motions or large shape changes, is extremely difficult. Often, improving the "generative" aspect (allowing for novel content) can lead to inconsistencies or artifacts in unedited regions or over time. Conversely, enforcing strict consistency (e.g., via optical flow) can limit the flexibility and realism of the generated content, especially for substantial edits.
* Computational Cost vs. Usability: Many existing approaches require dense mask labeling for all frames, per-case fine-tuning, or complex intermediate representations (like motion LoRAs), which are computationally expensive and hinder real-time application or ease of use. The dilemma is to achieve high-quality, generalizable video editing without these prohibitive costs and manual efforts.
Constraints & Failure Modes
The problem of generative video propagation is insanely difficult due to several harsh, realistic constraints:
-
Data-Driven Constraints:
- Lack of Paired Training Data: Obtaining large-scale, diverse paired video datasets (original video + edited video) that cover a wide range of editing tasks (object removal, insertion, complex shape changes, background replacement, tracking with effects) is prohibitively expensive and challenging. This necessitates the use of synthetic data generation, which itself introduces challenges in ensuring realism and diversity.
- Supervision for Disentanglement: It's difficult to design loss functions that effectively disentangle the edited regions from the unedited regions. The model needs to learn to propagate changes only in the modified area while strictly preserving the original content elsewhere. This requires careful region-aware loss design, especially when edited areas are proportionally small.
-
Computational & Algorithmic Constraints:
- Error Accumulation: Traditional propagation methods relying on optical flow or depth maps are prone to accumulating errors over time, leading to degraded quality and inconsistencies in later frames. This makes long video propagation particularly challenging.
- Computational Complexity: Generating high-resolution, long video sequences with consistent edits is computationally intensive. Many methods require dense mask inputs for every frame or per-video fine-tuning, which is not scalable.
- Non-Differentiable Functions/Complex Interactions: The interplay between preserving original content and generating new, plausible content in edited regions involves complex, often non-linear and potentially non-differentiable, interactions within the model. Ensuring that a selective content encoder only encodes unchanged regions while an image-to-video model only propagates changes in edited regions is a delicate balancing act.
- Hardware Memory Limits: Processing and generating high-resolution video frames, especially for longer sequences, can quickly hit hardware memory limits, requiring efficient model architectures and data handling.
-
Physical & Visual Plausibility Constraints:
- Complex Motion & Dynamics: Inserted objects must exhibit physically plausible motion that interacts realistically with the scene (e.g., gravity, collisions). This is far more complex than simple appearance changes.
- Effect Propagation: Edits are not just about objects; they involve associated effects like shadows, reflections, and lighting. Removing an object means removing its shadow and reflection, and inserting one means generating plausible effects. Previous models often struggle with these subtle but crucial details.
- Significant Shape Changes: Many existing methods are limited to altering object appearance or small shape changes. Handling substantial shape modifications (e.g., transforming a girl into a cat with different proportions) while maintaining temporal consistency is a major hurdle.
- Background Coherence: When objects are removed or backgrounds are replaced, the newly generated content must be visually coherent and realistic, seamlessly filling occluded areas or integrating new environments without obvious seams or distortions. This is especially hard in complex scenes.
- Real-time Latency (Implicit): While not explicitly stated as a strict real-time requirement, the desire for a "single inference run" and broader applications implies a need for efficient processing, avoiding the high latency associated with per-clip fine-tuning or extensive manual intervention.
Why This Approach
The Inevitability of the Choice
The authors of GenProp arrived at their specific generative video propagation framework by first identifying critical shortcomings in existing video editing and propagation methods. Traditional approaches, often relying on techniques like optical flow, depth maps, radiance fields, or atlases, were found to be severely limited. These methods were prone to error accumulation, which meant that small inaccuracies in early frames would compound, leading to noticeable inconsistencies and artifacts later in the video. Furthermore, they typically lacked robustness and generalization ability, often requiring specific retraining for each new task or being confined to a single type of edit. For instance, a model designed for object removal might not handle background replacement or complex object insertion effectively.
The exact moment of realization that traditional "SOTA" methods were insufficient appears to be when the authors observed that these methods struggled with the core requirements of a truly versatile video editing system: handling substantial shape modifications, independent motion of inserted objects, comprehensive removal of object effects (like shadows and reflections), and accurate tracking without dense, frame-by-frame mask inputs. The paper explicitly states, "In contrast, we extend the first-frame editing and design a more general framework for generative video propagation encompassing various editing scenarios by leveraging video generation models' power in modeling real-world scenes." This marked a pivot from task-specific, propagation-centric methods to a more holistic, generative approach. The inherent ability of large-scale video generation models to realistically model natural scenes and generate coherent video sequences from an initial image (I2V models) was recognized as the only viable foundation for a unified framework that could overcome the limitations of prior methods and address a broad spectrum of video editing tasks.
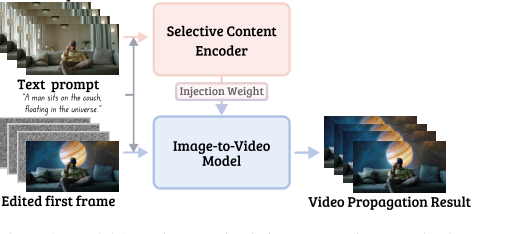 Figure 2. Model Overview. During inference, our framework takes in the original video as input through a selective content encoder (SCE) to retain content in unchanged regions. Changes applied to the first frame are propagated throughout the video using an I2V model while other regions remain intact
Figure 2. Model Overview. During inference, our framework takes in the original video as input through a selective content encoder (SCE) to retain content in unchanged regions. Changes applied to the first frame are propagated throughout the video using an I2V model while other regions remain intact
Comparative Superiority
GenProp demonstrates qualitative superiority over previous gold standards not just through improved performance metrics, but via fundamental structural advantages. One of its most significant benefits is the elimination of the need for explicit motion predictions, such as optical flow. Traditional methods often relied on these intermediate representations, which added complexity and were a primary source of error accumulation, especially with large shape changes or complex backgrounds. GenProp, by leveraging an Image-to-Video (I2V) generation model, inherently understands and propagates motion and appearance, making it robust to these challenges.
Furthermore, GenProp drastically simplifies the editing process by not requiring dense mask labeling for all individual frames. Existing video editing models frequently demand such detailed input, which is time-consuming and labor-intensive. GenProp's propagation-based approach means that edits applied to the first frame are intelligently extended throughout the video, significantly reducing user effort and computational overhead. This is a clear structural advantage, moving from an $O(N)$ (where $N$ is the number of frames) manual annotation process to a single-frame edit.
The framework's ability to handle a wide range of applications—including object removal with associated effects (shadows, reflections), background replacement, object insertion with physically plausible motion, and tracking—within a single unified model is another qualitative leap. Previous methods were often specialized, requiring different models or retraining for each task. GenProp's generative nature, combined with its Selective Content Encoder (SCE) and Mask Prediction Decoder (MPD), allows it to consistently preserve unchanged content while dynamically propagating modifications, even those involving substantial shape changes or complex background alterations. This versatility and robustness to diverse and challenging edits make it overwhelmingly superior.
 Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Figure 1. GenProp. We propose a generative video propagation framework (GenProp), which can seamlessly propagate any first frame edit through the video. GenProp supports a wide range of video applications, including (a) complete object removal with effects such as shadows and reflections, (b) background replacement with realistic effects, (c) object insertion where inserted objects have physically plausible motion (i.e., blueberries falling while spoon goes up), (d) tracking of objects and their associated effects, and (e) multiple edits (outpainting, insertion, removal) at a single inference run
Alignment with Constraints
The chosen generative video propagation method, GenProp, perfectly aligns with the core problems harsh requirements, creating a harmonious "marriage" between the problem's demands and the solution's unique properties. The paper outlines three key challenges (constraints) that GenProp was designed to address:
- Realism: The requirement that "changes in the first frame should be naturally propagated to the following frames" is met by leveraging an I2V generation model. These models are pretrained on vast datasets and possess an inherent capability to generate highly realistic and temporally coherent video content, ensuring that propagated edits look natural and consistent with the original video's style and motion.
- Consistency: The demand that "all other regions should remain consistent to the original video" is addressed through the careful design of the Selective Content Encoder (SCE) and a Mask Prediction Decoder (MPD), coupled with a region-aware loss. The SCE is specifically engineered to encode information from the unchanged parts of the original video, preventing unintended alterations. The MPD helps the model disentangle the modified and unmodified regions, while the region-aware loss (RA Loss) penalizes changes in the unedited areas and ensures stability, even when edited regions are proportionally small. This ensures that only the intended modifications are propagated, preserving the integrity of the rest of the video.
- Generality: The need for the model to be "general enough to be applicable to multiple video tasks" is satisfied by GenProp's versatile I2V model backbone and a novel synthetic data generation scheme. The synthetic data, derived from video instance segmentation datasets and augmented with techniques like Copy-and-Paste, Mask-and-Fill, and Color Fill, explicitly trains the model to handle diverse tasks such as object insertion, removal, replacement, and tracking. This comprehensive training, combined with the inherent flexibility of generative I2V models, allows GenProp to perform a wide array of video editing tasks without task-specific retraining.
Rejection of Alternatives
The authors implicitly and explicitly reject several alternative approaches based on their inherent limitations for the problem of general video propagation.
Traditional Video Propagation Methods (e.g., optical flow, depth maps, radiance fields): These methods were deemed insufficient primarily due to their susceptibility to error accumulation, limited robustness, and poor generalization. They often required retraining for each specific task and struggled with significant shape changes or complex backgrounds. GenProp avoids these issues by not relying on such explicit intermediate representations, instead letting the generative model handle motion and appearance implicitly.
Diffusion-based Video Editing (text-guided or image-guided): While powerful, many existing diffusion-based video editing methods were found to be "generally limited to altering the appearance rather than making significant changes to object shapes." They often lacked precision for background changes and struggled with controlling motion. For example, InsV2V [8] and EVE [43] were limited to appearance changes, and methods relying on text prompts for motion editing often resulted in a difficult balance between text guidance and original video motion. GenProp, in contrast, focuses on propagating first-frame edits directly, allowing for substantial shape modifications and independent object motion.
Image-to-Video (I2V) Editing Methods (requiring auxiliary inputs or specific training): Several I2V-based methods were also found wanting. Some, like VideoSwap [15], relied on sparse key points, limiting their flexibility. Others, such as AnyV2V [27] and VideoShop [12], were training-free but suffered from limited generalization. I2VEdit [34] required learning motion LoRAs [19] for each video clip, adding computational complexity. ReVideo [31], while enabling control, involved masking parts of the input video with black squares, which removed significant information and restricted its ability to handle complex background edits and large shape alterations. GenProp's design, with its SCE and RA Loss, specifically addresses the challenge of preserving unedited regions while propagating changes, a weakness in methods that simply mask out areas.
Traditional Inpainting Pipelines (e.g., SAM + Propainter): For object removal, cascading models like SAM-V2 [39] for mask tracking and Propainter [64] for inpainting were rejected because they require dense mask annotations for all frames. This is a labor-intensive process that GenProp bypasses. Furthermore, these pipelines often struggled with removing object effects like shadows and reflections, and with realistically filling large occluded areas, which GenProp handles effectively due to its generative capabilities and understanding of physical rules. SAM-V2 itself, while good at tracking, often struggles with object effects due to its limited and biased training data.
Mathematical & Logical Mechanism
The Master Equation
The GenProp framework operates on two core mathematical principles: the inference mechanism, which generates the modified video, and the training objective, which guides the model's learning process. While the inference equation describes the forward pass, the overall training loss function is arguably the "master equation" as it dictates how the model learns to achieve its sophisticated video propagation capabilities.
The primary inference mechanism for generating each frame $v'_t$ of the modified video is given by:
$$
v'_t = G(E(V), v'_1, t), \quad \forall t \in \{2, \dots, T\}
$$
This equation describes how the Image-to-Video (I2V) generation model $G$ produces subsequent frames $v'_t$ by taking the original video's content encoded by $E(V)$, the modified first frame $v'_1$, and the current time step $t$ as inputs.
However, the true "engine" that enables the model to learn and perform this propagation is the comprehensive Region-Aware Loss (RA Loss) function, which is minimized during training:
$$
\mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}}
$$
This master equation combines several loss components, each designed to ensure realism, consistency, and generality in the video propagation task. The model is trained to minimize this total loss across all frames $i \in \{2, \dots, T\}$ of synthetic video sequences.
Term-by-Term Autopsy
Let's dissect the components of the master training loss function and the inference equation:
From the Inference Equation: $v'_t = G(E(V), v'_1, t)$
-
$v'_t$:
- Mathematical Definition: The $t$-th frame of the modified video sequence, represented in the latent space.
- Physical/Logical Role: This is the desired output of the GenProp model for a given time step $t$. It represents the original video frame $V_t$ with the edits from $v'_1$ propagated consistently.
- Why this form: It's the output of a generative model, indicating that each frame is produced sequentially or in parallel based on the initial state and context.
-
$G(\cdot)$:
- Mathematical Definition: The Image-to-Video (I2V) generation model. This is typically a diffusion model or a similar generative architecture.
- Physical/Logical Role: This is the core generative engine. Its role is to synthesize new video frames, taking an image (the modified first frame $v'_1$) and additional context (from $E(V)$ and $t$) to generate a video sequence that extends the initial edit.
- Why a function: It represents a complex neural network that learns to map inputs to a desired video output.
-
$E(\cdot)$:
- Mathematical Definition: The Selective Content Encoder (SCE). It's a neural network component designed to extract features from the original video.
- Physical/Logical Role: The SCE's critical role is to preserve the unchanged content of the original video $V$. It acts as a "memory" or "context provider" for the I2V model $G$, ensuring that regions not affected by the first-frame edit remain consistent with the original video. It's "selective" because it's designed to ignore the modified regions.
- Why a function: It's a neural network that encodes high-dimensional pixel information into a more compact, meaningful latent representation.
-
$V$:
- Mathematical Definition: The original, unedited video sequence, represented as a set of frames $\{V_1, V_2, \dots, V_T\}$. In the context of the latent diffusion model, this refers to its latent representation.
- Physical/Logical Role: This is the source material. The SCE processes this to understand the underlying scene, motion, and appearance of the unedited parts, which is then used to guide the generation of $v'_t$.
- Why an input: It provides the ground truth for what should not change.
-
$v'_1$:
- Mathematical Definition: The first frame of the video, after it has been modified by the user. This is also in the latent space.
- Physical/Logical Role: This is the "seed" or "instruction" for the propagation. All subsequent frames $v'_t$ are generated to consistently extend the edits introduced in this first frame.
- Why an input: It defines the desired initial state and the specific changes to be propagated.
-
$t$:
- Mathematical Definition: The time index of the frame being generated, ranging from $2$ to $T$.
- Physical/Logical Role: This provides temporal context to the I2V model, allowing it to understand which frame in the sequence it is currently generating. This is crucial for maintaining temporal coherence and motion.
- Why an input: Time is a fundamental dimension in video, and generative models often use it as a conditional input to produce frames in sequence.
From the Master Training Loss: $\mathcal{L} = \mathcal{L}_{\text{non-mask}} + \lambda \cdot \mathcal{L}_{\text{mask}} + \beta \cdot \mathcal{L}_{\text{grad}} + \gamma \cdot \mathcal{L}_{\text{MPD}}$
-
$\mathcal{L}$:
- Mathematical Definition: The total Region-Aware Loss (RA Loss).
- Physical/Logical Role: This is the overall objective function that the model aims to minimize during training. It's a weighted sum of individual loss components, each addressing a specific aspect of the video propagation problem (consistency, edit propagation, encoder disentanglement, mask prediction). Minimizing this loss trains the model to generate high-quality, consistent, and correctly edited videos.
- Why summation: Summing the losses allows the model to optimize for multiple, sometimes competing, objectives simultaneously. Each term contributes to the overall "badness" of the model's output, and reducing the sum means improving across all desired criteria.
-
$\mathcal{L}_{\text{non-mask}}$:
- Mathematical Definition: The diffusion Mean Squared Error (MSE) loss computed for the non-masked (unchanged) regions. It's defined as $E_{t \sim U(1,T)} [\mathcal{L}_d((1 - m_t) \cdot v'_{\text{out}}, (1 - m_t) \cdot \hat{v}_t)]$.
- Physical/Logical Role: This term acts as a "consistency enforcer." It penalizes discrepancies between the generated frame $v'_{\text{out}}$ and the ground truth frame $\hat{v}_t$ only in the areas that were not edited. Its purpose is to ensure that the model faithfully preserves the original content in regions where no changes were intended.
- Why addition: It's one of the primary objectives, added to the total loss to ensure that preserving unedited content is a key training goal.
-
$\lambda$:
- Mathematical Definition: A scalar weighting coefficient (set to 2.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the importance of the $\mathcal{L}_{\text{mask}}$ term relative to other loss components. A higher $\lambda$ means the model will prioritize accurately propagating the edits in the masked region more strongly.
- Why multiplication: It scales the contribution of $\mathcal{L}_{\text{mask}}$ to the total loss, allowing for flexible balancing of objectives.
-
$\mathcal{L}_{\text{mask}}$:
- Mathematical Definition: The diffusion MSE loss computed for the masked (edited) regions. It's defined as $E_{t \sim U(1,T)} [\mathcal{L}_d(m_t \cdot v'_{\text{out}}, m_t \cdot \hat{v}_t)]$.
- Physical/Logical Role: This term is the "edit propagator." It ensures that the generated content in the edited regions ($m_t$) matches the desired modified content from the synthetic ground truth $\hat{v}_t$. This is where the model learns to generate the new, edited content.
- Why addition: Similar to $\mathcal{L}_{\text{non-mask}}$, it's a core objective, ensuring that the model learns to correctly apply and propagate the edits.
-
$\beta$:
- Mathematical Definition: A scalar weighting coefficient (set to 1.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the importance of the $\mathcal{L}_{\text{grad}}$ term. It balances the need for SCE to ignore edited regions against other objectives.
- Why multiplication: It scales the contribution of $\mathcal{L}_{\text{grad}}$ to the total loss.
-
$\mathcal{L}_{\text{grad}}$:
- Mathematical Definition: A gradient loss that minimizes the effect of the masked area in the encoder's input, defined as $E_{t \sim U(1,T)} [m_t \cdot ||\Delta f||_2]$. Here, $\Delta f = \frac{f(E(\hat{V} + \delta)) - f(E(\hat{V}))}{\delta}$ is a finite difference approximation of the gradient of the encoder's feature $f(E(\hat{V}))$ with respect to a small perturbation $\delta$ in the input.
- Physical/Logical Role: This is the "disentanglement enforcer" for the Selective Content Encoder (SCE). It encourages the SCE to be "blind" to changes within the masked region. By minimizing the gradient of the SCE's output with respect to perturbations in the masked area, the model learns that the SCE should not encode information from the edited parts, thus preventing it from trying to reconstruct the original content in areas that are supposed to be changed. This helps the I2V model focus on generating new content in those regions.
- Why addition: It's a crucial regularization term that helps the SCE specialize in its role of preserving unedited content.
- Why L2 norm ($||\cdot||_2$): The L2 norm measures the magnitude of the gradient. Minimizing it pushes the gradient towards zero, effectively making the encoder's output less sensitive to changes in the masked input region.
- Why finite difference: It's an approximation of the gradient, used here to simplify computation instead of second-order gradients.
-
$\gamma$:
- Mathematical Definition: A scalar weighting coefficient (set to 1.0 in the paper).
- Physical/Logical Role: This hyperparameter controls the importance of the $\mathcal{L}_{\text{MPD}}$ term.
- Why multiplication: It scales the contribution of $\mathcal{L}_{\text{MPD}}$ to the total loss.
-
$\mathcal{L}_{\text{MPD}}$:
- Mathematical Definition: An MSE loss (Mean Squared Error) between the output of the Mask Prediction Decoder (MPD) and the ground truth instance mask of the video.
- Physical/Logical Role: This term serves as an "attention guide." The MPD is an auxiliary head that predicts the modified region. By training it to accurately predict the mask, it helps the overall model, particularly the I2V model, to explicitly understand where the edits are located. This guides the generative process to focus its efforts on those specific regions, improving the accuracy of the attention maps and ensuring changes are applied precisely.
- Why addition: It's an auxiliary loss that provides explicit supervision for a sub-task (mask prediction) that indirectly benefits the main video propagation task by improving disentanglement and focus.
-
$m_t$:
- Mathematical Definition: A binary mask (values 0 or 1) indicating the edited regions in frame $\hat{v}_t$. It's downsampled and repeated to match latent representation dimensions.
- Physical/Logical Role: This mask is the key to the "region-aware" aspect of the loss. It explicitly delineates which parts of the frame are edited and which are not, allowing the loss function to apply different supervision strategies to each region.
- Why multiplication (e.g., $m_t \cdot v'_{\text{out}}$): It acts as a filter, isolating the pixels or latent features within the masked region (where $m_t=1$) or outside it (where $m_t=0$).
-
$\mathcal{L}_d(\cdot, \cdot)$:
- Mathematical Definition: The diffusion MSE loss. This is the standard loss function used in diffusion models to measure the difference between the denoised output and the ground truth.
- Physical/Logical Role: In the context of diffusion models, this loss guides the model to accurately reverse the noise process, effectively generating realistic images/frames. Here, it's applied to specific regions (masked or non-masked) to ensure fidelity to the ground truth in those areas.
- Why MSE: MSE is a common and effective metric for pixel-wise or latent-feature-wise similarity, penalizing larger errors more significantly.
-
$E_{t \sim U(1,T)}$:
- Mathematical Definition: Expectation over time steps $t$ sampled uniformly from $1$ to $T$.
- Physical/Logical Role: This indicates that the loss is computed not just for a single frame, but averaged over all frames in the video sequence. This ensures temporal consistency and that the model learns to propagate edits throughout the entire duration.
- Why expectation/summation: It ensures that the model learns to perform well across the entire video, not just isolated frames, promoting temporal coherence.
Step-by-Step Flow
Let's trace the journey of an abstract data point during inference through the GenProp framework, specifically focusing on how a single modified first frame is propagated to generate subsequent frames. Imagine we have an original video $V = \{V_1, V_2, \dots, V_T\}$ and a user has edited the first frame $V_1$ to create $v'_1$. The goal is to produce $v'_t$ for $t \in \{2, \dots, T\}$.
-
Original Video Encoding (SCE): First, the entire original video $V$ is fed into the Selective Content Encoder (SCE), denoted as $E(V)$. The SCE's job is to analyze the original video and extract features that represent the unchanged content and motion. It's designed to ignore any modifications that might be present in the first frame (though during inference, it sees the original $V_1$). Think of it as creating a "background context" or "motion blueprint" of the original scene.
-
Modified First Frame Input: Simultaneously, the user-modified first frame, $v'_1$, is prepared. This frame contains the specific edits (e.g., object removed, background changed, new object inserted) that need to be propagated.
-
I2V Model Initialization: The Image-to-Video (I2V) generation model, $G$, is now ready to work. It takes the modified first frame $v'_1$ as its initial visual input.
-
Contextual Guidance Injection: The features extracted by the SCE from the original video, $E(V)$, are injected into the I2V model $G$. This injection happens hierarchically, allowing the I2V model to access information about the original scene's structure, appearance, and motion at various levels of abstraction. This is crucial for guiding the generation process to maintain consistency in the unedited regions.
-
Temporal Conditioning: For each subsequent frame $t$ (from $2$ to $T$), the time index $t$ is also fed into the I2V model. This tells the model which frame in the sequence it is currently generating, helping it to produce temporally coherent motion and changes.
-
Generative Propagation: With $v'_1$, $E(V)$, and $t$ as inputs, the I2V model $G$ then performs its generative magic. It synthesizes the $t$-th frame, $v'_t$. During this process, the model leverages its learned understanding of video dynamics (from its pre-training) and the specific guidance from $E(V)$ to:
- Propagate Edits: Extend the modifications introduced in $v'_1$ to $v'_t$, ensuring they evolve naturally and consistently with the scene's motion. For example, if an object was removed, it remains removed; if a new object was inserted, it moves plausibly.
- Preserve Unchanged Content: Keep the parts of the scene that were not edited in $v'_1$ consistent with the original video $V_t$, thanks to the strong guidance from $E(V)$.
-
Iterative Frame Generation: This process repeats for each time step $t$ until all frames up to $T$ have been generated, resulting in the complete modified video $V' = \{v'_1, v'_2, \dots, v'_T\}$. The output is a seamless video where the first-frame edit has been naturally propagated throughout the entire sequence, while unedited regions remain faithful to the original.
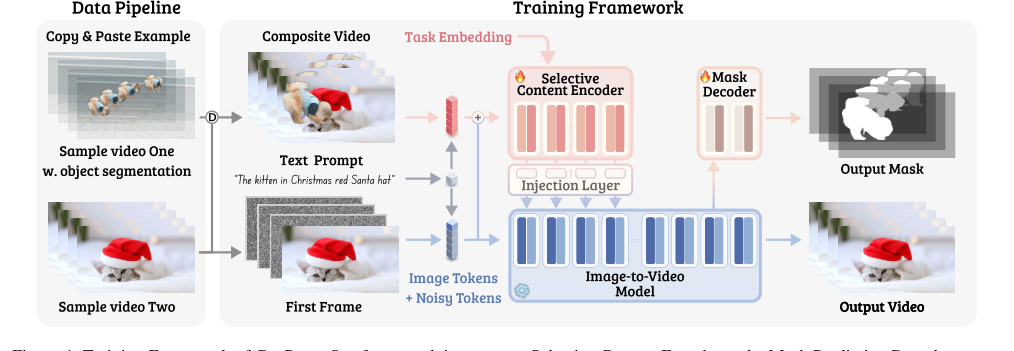 Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Figure 4. Training Framework of GenProp. Our framework integrates a Selective Content Encoder and a Mask Prediction Decoder on top of the I2V generation model, enforcing the model to propagate the edited region while preserving the content in the original video for all other regions. With synthetic data augmentations and task embeddings, our model is trained to propagate various changes in the first frame
Optimization Dynamics
The GenProp model learns and updates its parameters through an iterative optimization process, primarily driven by minimizing the Region-Aware Loss ($\mathcal{L}$) using gradient descent. Here's how the mechanism learns and converges:
-
Synthetic Data Generation: The training begins with a unique data generation scheme. Instead of real-world edited videos (which are hard to obtain in large quantities), synthetic data pairs $(\hat{V}, \hat{v}_1)$ are created from existing video instance segmentation datasets. This involves operations like "Copy-and-Paste" (for object insertion), "Mask-and-Fill" (for inpainting/removal), and "Color Fill" (for tracking). This synthetic data provides the necessary ground truth for both edited and unedited regions across the video.
-
Forward Pass and Loss Calculation:
- For each training iteration, a batch of original video sequences $\hat{V}$ and their corresponding modified first frames $\hat{v}_1$ (derived from synthetic data) are fed into the model.
- The Selective Content Encoder (SCE), $E$, processes the original synthetic video $\hat{V}$ to extract features representing its unchanged content.
- The Image-to-Video (I2V) generation model, $G$, takes the modified first frame $\hat{v}_1$, the encoded features from $E(\hat{V})$, and the time step $i$ to generate a predicted frame $v'_{\text{out}}$.
- An auxiliary Mask Prediction Decoder (MPD) also predicts the modified region mask.
- The overall Region-Aware Loss $\mathcal{L}$ is then calculated for each frame $i \in \{2, \dots, T\}$ by summing its four components:
- $\mathcal{L}_{\text{non-mask}}$: Compares the generated frame $v'_{\text{out}}$ with the ground truth $\hat{v}_i$ only in the unedited regions (defined by $1-m_i$). This term pulls the model towards preserving original content.
- $\mathcal{L}_{\text{mask}}$: Compares $v'_{\text{out}}$ with $\hat{v}_i$ only in the edited regions (defined by $m_i$). This term pulls the model towards accurately propagating the edits.
- $\mathcal{L}_{\text{grad}}$: Penalizes the gradients of the SCE's output with respect to perturbations in the masked region. This term encourages the SCE to ignore the edited parts, ensuring it focuses solely on preserving the original, unedited content. This is key for disentanglement.
- $\mathcal{L}_{\text{MPD}}$: Compares the MPD's predicted mask with the ground truth mask $m_i$. This auxiliary loss helps the model explicitly learn where the edits are, further aiding the I2V model's focus.
- These individual losses are weighted by hyperparameters $\lambda, \beta, \gamma$ (set to 2.0, 1.0, and 1.0 respectively) and summed to form the total loss $\mathcal{L}$.
-
Gradient Calculation and Parameter Update:
- The gradients of the total loss $\mathcal{L}$ with respect to all trainable parameters in the SCE, I2V model, and MPD are computed using backpropagation.
- An optimizer (e.g., Adam) then uses these gradients to update the model's parameters, iteratively adjusting them to minimize $\mathcal{L}$.
- The learning rate is managed with a cosine-decay scheduler and a linear warmup, which helps stabilize training and achieve better convergence.
- A gradient norm threshold (0.001) is applied to prevent training instability, clipping gradients if their norm exceeds this value.
- An exponential moving average (EMA) is applied to the model parameters, which often leads to more stable and better-performing models, especially in generative tasks.
-
Loss Landscape Shaping: The combination of these loss terms shapes a complex loss landscape.
- $\mathcal{L}_{\text{non-mask}}$ and $\mathcal{L}_{\text{mask}}$ create "valleys" where the generated content matches the ground truth in their respective regions.
- $\mathcal{L}_{\text{grad}}$ creates a landscape that encourages the SCE to have a "flat" response (zero gradient) in edited regions, effectively making it insensitive to changes there. This helps disentangle the roles of the SCE (preserve original) and the I2V model (propagate edits).
- $\mathcal{L}_{\text{MPD}}$ adds another guiding force, making the model explicitly aware of the edit boundaries.
- The weights $\lambda, \beta, \gamma$ control the "steepness" and "depth" of these valleys, balancing the model's priorities.
-
Convergence: Through many iterations of this process, the model's parameters are refined. The SCE learns to selectively encode only unedited content, the I2V model learns to propagate edits realistically while preserving consistency, and the MPD learns to accurately identify edited regions. This iterative refinement allows the GenProp framework to converge to a state where it can generate high-quality, consistent, and plausibly edited videos from a single modified first frame. The model's ability to generalize to diverse tasks is a direct result of this carefully designed loss landscape and synthetic data strategy.
Results, Limitations & Conclusion
Experimental Design & Baselines
The authors meticulously designed their experiments to rigorously validate GenProp's core mechanism: propagating first-frame edits throughout a video while preserving unedited content. The framework integrates a Selective Content Encoder (SCE) to retain original video information, an Image-to-Video (I2V) generation model for propagating changes, and a Mask Prediction Decoder (MPD) to guide the model's focus.
To train this complex system, a novel synthetic data generation pipeline was developed. This pipeline constructs paired training samples from existing video instance segmentation datasets like Youtube-VOS and SAM-V2. It employs various augmentation techniques tailored to specific propagation sub-tasks: "Copy-and-Paste" for object insertion, "Mask-and-Fill" for inpainting/removal, and "Color Fill" for basic object tracking. Task embeddings corresponding to these augmentations were injected into the model to guide its adaptation. A crucial component of the training objective was the Region-Aware Loss (RA Loss), which disentangles modified and unmodified regions, ensuring stability in unchanged areas and accurate propagation in edited ones. This loss function, along with a gradient loss, was designed to prevent the SCE from encoding content in the edited area, thereby preserving the I2V model's generative capabilities for the altered parts.
GenProp was implemented using two base video generation models: a DiT architecture (similar to Sora) and a U-Net architecture (based on Stable Video Diffusion, SVD). The primary results were derived from the DiT variant, which showed superior video generation quality. Training involved processing videos at 32, 64, and 128 frames, at 12 and 24 FPS, with a base resolution of 360p, later upscaled to 720p. Standard deep learning practices were followed, including a learning rate of 5e-5 with a cosine-decay scheduler, linear warmup, exponential moving average, and a gradient norm threshold of 0.001 to ensure stability. Classifier-free guidance (CFG) was set to 20, and specific weights ($\lambda=2.0$, $\beta=1.0$, $\gamma=1.0$) were applied to the RA Loss components. Experiments were conducted on NVIDIA A100 GPUs.
The "victims" (baseline models) GenProp was pitted against varied by task:
- Video Editing: InsV2V [8], AnyV2V [27], Pika [2], and ReVideo [31]. These models represent different approaches to video editing, including text-guided and image-guided methods, some relying on auxiliary inputs like optical flow or motion LoRAs.
- Object Removal: A traditional inpainting pipeline combining SAM-V2 [39] for mask tracking and Propainter [64] for inpainting, as well as ReVideo [31].
- Object Tracking: SAM-V2 [39].
The definitive evidence of GenProp's mechanism working in reality was gathered through quantitative metrics and qualitative user studies. Quantitative metrics included PSNRm (Peak Signal-to-Noise Ratio in the unmodified region, measuring consistency), CLIP-T (cosine similarity between edited frame and text prompt, measuring text alignment), and CLIP-I (distance between CLIP features across frames, measuring frame consistency). A user study on Amazon MTurk with 121 participants provided subjective evaluations of alignment with instructions and visual quality, offering a human-centric perspective on the generated results. Ablation studies were also conducted to isolate the impact of the MPD, RA Loss, and Color Fill augmentation.
What the Evidence Proves
The experimental validation provides compelling evidence that GenProp's core mechanism—propagating first-frame edits using a generative I2V model while preserving unchanged content via a selective encoder and region-aware loss—is highly effective.
Superior Performance Across Video Editing Tasks:
GenProp consistently outperformed all baselines on both the "Classic Test Set" and the more challenging "Challenging Test Set" for general video editing (Table 1). On the Challenging Test Set, GenProp achieved the highest PSNRm (32.163), CLIP-T (0.3336), and CLIP-I (0.9904), demonstrating superior consistency in unedited regions, better alignment with text prompts, and higher frame-to-frame consistency. The user study further solidified these findings, with participants overwhelmingly preferring GenProp over competing methods for both alignment and quality, especially on the Challenging Test Set. For instance, GenProp was preferred over AnyV2V by 97.78% for alignment and 95.56% for quality on this set.
Effective Object Removal and Effect Handling:
For object removal, GenProp significantly surpassed the SAM + Propainter pipeline and ReVideo (Table 2). It achieved a CLIP-I of 0.9879, indicating excellent consistency. Visually, as shown in Figure 6 (c) and (d), GenProp demonstrated a remarkable ability to not only remove objects but also their associated effects like shadows and reflections, and to naturally fill large occluded areas without requiring dense mask annotations. This is a crucial advantage over traditional methods that often struggle with these complexities.
Robust Object Tracking:
While SAM-V2 is a faster, real-time tracking method, GenProp proved its capability to consistently track objects and their associated effects (Figure 6e). This highlights GenProp's deeper understanding of physical rules, a direct benefit of its video generation pretraining, which allows it to handle effects that SAM-V2, with its limited and biased training data, often misses. This demonstrates the potential of generation-based models to tackle classic vision tasks with enhanced realism.
Validation of Core Architectural Components:
The ablation studies provided undeniable evidence for the necessity of GenProp's key components:
- Mask Prediction Decoder (MPD): Without the MPD, the model's ability to disentangle modified and unmodified regions suffered, leading to degraded output masks and partially removed objects reappearing in subsequent frames (Figure 7, rows 1-2). Quantitatively, removing MPD caused a drop in both CLIP-T (from 0.3316 to 0.3252) and CLIP-I (from 0.9872 to 0.9834), proving its critical role in accurate removal and consistency.
- Region-Aware Loss (RA Loss): The absence of RA Loss resulted in the original object gradually reappearing (Figure 7, rows 3-5), indicating a failure to stably propagate first-frame edits. This was reflected in lower CLIP-T (0.3261) and CLIP-I (0.9825) scores, confirming the RA Loss's effectiveness in maintaining stable and consistent propagation.
- Color Fill Augmentation: This augmentation was shown to be a crucial factor for addressing propagation failures, particularly for tracking and propagating large shape modifications (Figure 7, rows 6-8). It explicitly trains the model for tracking, ensuring modifications are maintained throughout the sequence.
In essence, the evidence proves that GenProp's careful design, leveraging generative I2V models with a selective content encoder, mask prediction decoder, and region-aware loss, enables it to perform a wide array of video editing tasks with unprecedented realism, consistency, and generality, outperforming existing specialized methods.
Limitations & Future Directions
While GenProp presents a significant leap forward in generative video propagation, the paper acknowledges certain limitations and opens several avenues for future research and development.
Current Limitations:
One notable limitation is that GenProp, despite its superior quality and ability to handle complex effects, is slower than real-time tracking methods like SAM-V2. This trade-off between quality/generality and speed is common in advanced generative models. Furthermore, the current framework primarily focuses on propagating edits made to the first frame of a video. While powerful, this restricts the complexity of temporal edits that can be achieved, as all changes must originate from a single initial state. The reliance on synthetic data, while enabling broad task coverage, might still present generalization challenges when encountering highly unusual or out-of-distribution real-world video scenarios not adequately represented in the synthetic datasets. Finally, although the DiT backbone showed better generation quality, the ablation studies were conducted with the SVD-based architecture, suggesting potential differences in performance characteristics between the two variants that were not fully explored.
Future Directions and Discussion Topics:
-
Multi-Key Frame Editing and Temporal Control:
- Discussion: How can we extend GenProp to incorporate edits from multiple key frames throughout a video, rather than just the first? This would allow for more dynamic and evolving edits, such as an object changing its appearance or motion at different points in time. What architectural modifications would be needed to handle non-linear temporal dependencies and ensure smooth transitions between different edited keyframes? Could a hierarchical approach, where edits are propagated locally and then globally, be beneficial?
- Perspective: This could unlock more sophisticated storytelling and interactive video editing applications, moving beyond simple propagation to complex temporal manipulation.
-
Real-time Performance and Efficiency:
- Discussion: Given GenProp's current speed, what strategies can be employed to accelerate inference without sacrificing its high-quality output? Could techniques like model distillation, quantization, or more efficient network architectures (e.g., pruning, sparse attention) be integrated? Are there hardware-specific optimizations or parallel processing paradigms that could be leveraged to achieve near real-time performance, especially for applications like live video editing or augmented reality?
- Perspective: Improving speed would broaden GenProp's applicability to time-sensitive tasks and make it more accessible for everyday users and professional workflows.
-
Expanding the Scope of Video Tasks and Generality:
- Discussion: The paper mentions uncovering additional video tasks. What are these tasks, and how can GenProp's framework be adapted to support them? Could it be extended to tasks like video style transfer, motion retargeting, or even generating entirely new video segments based on semantic descriptions? How can the synthetic data generation pipeline be further enhanced to cover an even wider array of complex real-world scenarios and edge cases, reducing the sim-to-real gap?
- Perspective: Pushing the boundaries of generality could establish GenProp as a foundational model for a truly unified video manipulation platform, reducing the need for task-specific models.
-
Enhanced User Control and Interpretability:
- Discussion: While GenProp simplifies editing by not requiring dense mask inputs, how can users be given more granular control over the propagation process? Could a more intuitive interface allow users to specify motion trajectories, stylistic preferences, or semantic constraints for inserted or modified objects? How can the model's internal workings, such as attention maps (Figure 3), be made more interpretable to users, allowing them to understand and debug propagation failures?
- Perspective: Greater control and transparency would empower creators, making GenProp a more versatile and user-friendly tool for artistic and professional applications.
-
Longer Video Sequence Handling and Memory Management:
- Discussion: Current video generation models often have limitations on the length of videos they can process efficiently. How can GenProp be scaled to handle significantly longer video sequences (e.g., minutes instead of seconds) while maintaining temporal consistency and managing computational resources effectively? This might involve novel memory-efficient architectures or chunk-based processing with consistent propagation across chunks.
- Perspective: Addressing this would be crucial for editing feature-length content or long-form video productions, opening up new commercial applications.
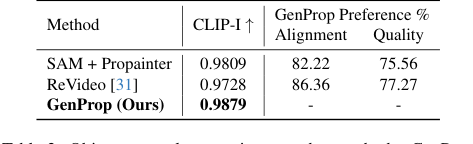 Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
Table 2. Object removal comparison to other methods. GenProp outperforms baselines on consistency, alignment, and quality
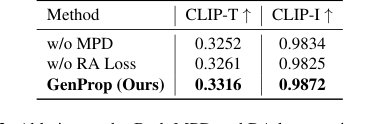 Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
Table 3. Ablation study. Both MPD and RA loss can improve the success rate of editing and the quality of the output video
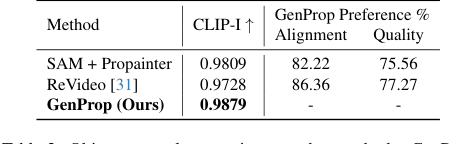 Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Table 1. Video editing benchmark compared to existing models. PSNRm measures the consistency outside the edited region. CLIP-T and CLIP-I measure text alignment and frame consistency. User study shows the percentage of users who preferred Ours over the compared method on alignment (left) and quality (right). GenProp significantly outperforms the other methods on the Challenging Set
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work is a conditional latent diffusion process for video sequence generation, where a selective encoder guides content preservation in specific regions, and a mask prediction decoder aids in disentangling modified areas, all optimized by a region-aware loss that applies differential penalties to altered and unaltered parts, including a finite-difference-based gradient regularization.
Adjacent Research Areas
Conditional Diffusion Models for Image and Video Synthesis
The Selective Content Encoder (SCE) in GenProp serves as a direct analouge to conditional control mechanisms found in diffusion models, most notably ControlNet [59]. The SCE's architecture, which replicates initial blocks of the main generation model and injects extracted features into corresponding layers of the I2V model, directly maps to ControlNet's method of adding task-specific conditions to guide generation. This allows GenProp to preserve original video content in unedited regions by conditioning the generative process on these features, a technique central to controllable image and video synthesis.
Masked and Region-Weighted Loss Functions in Image/Video Inpainting
The Region-Aware Loss ($\mathcal{L}$) employed in GenProp exhibits a strong connection to masked and region-weighted loss functions prevelant in image and video inpainting. Specifically, the paper's use of $\mathcal{L}_{mask}$ and $\mathcal{L}_{non-mask}$ (Equation 4) to apply distinct diffusion MSE losses to modified and unmodified regions, respectively, is a common strategy to ensure high fidelity in known areas while allowing creative freedom in edited parts. Furthermore, the gradient loss $\mathcal{L}_{grad}$ (Equation 6), which approximates second-order gradients via finite differences to minimize the encoder's influence on masked regions, functions as a regularization term, similar to gradient penalties used in generative adversarial networks (GANs) or other generative models to enforce smoothness or disentanglement across different image regions. This ensures a clean separation of responsiblities between the encoder and the I2V model. A representative example of such masked loss application can be found in video inpainting works like Ke et al. (2021, ICCV) [25].