MindLink: Subject-agnostic Cross-Subject Brain Decoding Framework
ISOM keeps this MICCAI paper in the public review set because it gives readers a concrete case around MindLink: Subject-agnostic Cross-Subject Brain Decoding Framework through its mechanism, assumptions, and evidence...
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper, cross-subject brain decoding, precisely originates from the field of neuroscience, specifically within the domain of interpreting neural activities to understand human cognition and perception. Functional Magnetic Resonance Imaging (fMRI) emerged as a pivotal tool for this purpose, providing detailed, non-invasive measurements of brain activity with high spatial and temporal resolution. Initially, brain decoding efforts were largely confined to subject-specific applications, meaning a model trained on one individual's brain activity could not be reliably used for another. This limitation became a significant "pain point" as researchers recognized the high variability in neural activity across different subjects [3], highlighting an urgent need for more robust and generalizable approaches.
Previous methods faced two fundamental limitations that compelled the authors to develop a new framework. Firstly, conventional brain decoding models were inherently subject-specific [12, 15, 19]. This "per-subject-per-model" paradigm meant that as the number of subjects increased, so did the model complexity, severely limiting scalability for larger populations and real-world scenarios. Secondly, a common practice in prior fMRI preprocessing stages involved flattening 3D voxel grids—the raw, volumetric brain activity data—into 1D vectors [12, 15, 19, 22, 24]. This simplification, while perhaps computationally convenient, critically discarded valuable spatial information and hindered the models' abililty to capture the intricate, complex spatial relationships inherent in neural activity patterns. Even attempts at cross-subject brain decoding [22, 24] often still relied on subject-specific modules or faced efficiency issues, such as the computational burden of fine-tuning large language models [16]. The authors of MindLink sought to overcome these limitations by creating a scalable, subject-agnostic framework that preserves spatial structure and works across multiple individuals with a single model.
Intuitive Domain Terms
To help a zero-base reader grasp the core concepts, here are some specialized terms from the paper, translated into everyday analogies:
- Brain Decoding: Imagine you're watching a movie, and someone is trying to guess what you're seeing just by looking at the activity in your brain. Brain decoding is like that—it's the scientific effort to reconstruct what a person is experiencing (like an image or sound) by analyzing their brain signals.
- fMRI (functional Magnetic Resonance Imaging): Think of fMRI as a super-advanced, non-invasive camera that takes pictures of your brain's activity in real-time. Instead of just showing the brain's structure, it shows which parts are "lighting up" or working harder when you perform a task, like looking at an image.
- Cross-Subject Generalizability / Subject-agnostic: This is like having a universal remote control for brains. Instead of needing a different remote for every person's brain (because everyone's brain is a bit different), a "subject-agnostic" model is designed to work effectively for any person, even someone it hasn't seen before, without needing special adjustments.
- 3D Voxel Grids: Picture your brain as a giant, three-dimensional block made of tiny, individual LEGO bricks. Each of these tiny bricks is called a "voxel," and in fMRI, each voxel holds a piece of informaton about brain activity in that specific tiny location.
- Domain Adversarial Training: This is a clever training technique, much like a game. Imagine you're teaching a computer to recognize "cat" pictures, but you have pictures from different cameras (different "domains"). You also have a "trickster" teacher trying to guess which camera each picture came from. The computer learns to recognize "cat-ness" so well that it can fool the trickster teacher into not knowing which camera took the picture. This way, the computer focuses only on what makes a cat a cat, ignoring irrelevant differences between cameras (or, in this paper, between subjects).
Notation Table
| Notation | Description
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The paper addresses a critical problem in brain decoding: reconstructing visual stimuli (e.g., images) from functional magnetic resonance imaging (fMRI) data.
Input/Current State:
The starting point is raw 3D fMRI voxel grids, denoted as $B_{s,i} \in \mathbb{R}^{X \times Y \times Z}$ for subject $s$ and stimulus $i$. These fMRI signals capture blood-oxygen-level-dependent (BOLD) changes, reflecting neural activity. Conventionally, existing methods for brain decoding suffer from two major limitations:
1. Subject-specificity: Models are typically trained for a single subject, meaning a model developed for one individual's brain activity cannot be directly applied to another's. This necessitates retraining or significant adaptation for each new subject, leading to poor scalability.
2. Loss of spatial information: During preprocessing, 3D fMRI voxel grids are often flattened into 1D vectors. This simplification discards crucial spatial relationships and structural information inherent in the brain's activity patterns.
Desired Endpoint/Goal State:
The ultimate goal is to develop a "subject-agnostic" brain decoding framework, named MindLink, that can:
1. Generalize across subjects: A single model should be capable of reconstructing visual stimuli from fMRI data of multiple subjects, including new, unseen subjects, without requiring subject-specific modules or extensive fine-tuning.
2. Preserve spatial structure: The framework must process 3D fMRI data in a way that retains its spatial organization, allowing the model to capture complex neural activity patterns more effectively.
3. Accurate stimulus reconstruction: The model should accurately reconstruct the original visual stimuli (images) from the fMRI embeddings, producing semantically relevant and visually coherent outputs.
Missing Link & Mathematical Gap:
The exact missing link is a robust and generalizable mapping function, let's call it $f$, that transforms subject-specific, spatially rich 3D fMRI data into a subject-invariant, spatially-aware latent representation compatible with pre-trained image generation models. Mathematically, the paper seeks to bridge the gap between:
$$ \text{fMRI}_{s,i} \in \mathbb{R}^{X \times Y \times Z} \quad \xrightarrow{f} \quad \text{ImageEmbedding}_i \in \mathbb{R}^{N_1 \times d} $$
where $f$ must be designed to:
* Extract features that are invariant to subject $s$.
* Preserve the 3D spatial structure of the input fMRI.
* Align the fMRI-derived embeddings with existing image embeddings (e.g., from a pre-trained image encoder $E_I$) in a shared latent space, such that $f(\text{fMRI}_{s,i}) \approx E_I(\text{Stimulus}_i)$.
This involves overcoming the challenge of high inter-subject variability and the loss of spatial context in traditional approaches.
The Dilemma & Painful Trade-offs:
Previous research has been trapped by several painful trade-offs:
* Generalizability vs. Model Complexity: Achieving cross-subject generalization often came at the cost of increased model complexity. Existing cross-subject methods either required "subject-specific parameters" [22, 24] or modules, leading to models that grew in size and complexity with each added subject. This made them unscalable for larger populations.
* Spatial Information vs. Processing Simplicity: Flattening 3D fMRI voxel grids into 1D vectors simplified data handling and reduced dimensionality, but it critically discarded spatial information. Preserving the 3D structure, while more informative, typically demands more complex architectures and higher computational resources.
* Accuracy vs. Efficiency: While some methods could achieve high-quality reconstructions, they often relied on fine-tuning large generative models [16], which is computationally intensive and inefficient, especially for real-world applications or adapting to new subjects. The dilemma was how to achieve both high accuracy and computational efficiency without sacrificing one for the other.
Constraints & Failure Modes
The problem of subject-agnostic cross-subject brain decoding is inherently difficult due to several harsh, realistic constraints:
Physical & Biological Constraints:
* High Inter-Subject Variability: Brain activity patterns, as captured by fMRI, exhibit significant variability across individuals. This is due to differences in brain anatomy, functional organization, and cognitive strategies. This "high variability in neural activity across subjects" [3] is a fundamental biological constraint that makes it challenging to learn a universal, subject-agnostic representation.
* Complex Spatial Relationships: Neural activity is not a simple collection of independent voxels; it involves intricate spatial relationships and networks within the 3D brain volume. Discarding this spatial information, as traditional flattening methods do, leads to a loss of critical context and limits the model's ability to interpret complex brain states.
Computational Constraints:
* Scalability Limitations: Existing methods that rely on subject-specific modules or parameters face a severe scalability issue. As the number of subjects grows, the model's parameter count and computational demands increase proportionally, making it impractical for large-scale applications. For instance, MindBridge [22] increased by 133M parameters when moving from single-subject to cross-subject settings.
* Hardware Memory Limits: Processing high-resolution 3D fMRI data, especially with deep learning models like Vision Transformers, can be extremely memory-intensive. The raw 3D voxel grids are large, and maintaining their spatial structure throughout the network requires substantial computational memory.
* Efficiency of Large Models: Fine-tuning large pre-trained generative models (e.g., Stable Diffusion) for each subject or even for cross-subject tasks can be computationally prohibitive, requiring significant GPU resources and training time. The paper mentions that some approaches fine-tune LLMs with >8B parameters, which is a major efficiency concern.
Data-Driven Constraints:
* Domain Shift Across Subjects: The subject-specific variations in fMRI data act as a form of domain shift. Without explicit mechanisms to mitigate this, a model trained on one subject's data will perform poorly on another's, as the underlying data distribution differs. The fMRI embedding $b$ "inherently contains subject-specific variations due to individual neural patterns," which degrades the quality of global visual reconstructions.
* Limited Data for New Subjects: While large datasets like NSD exist, obtaining extensive paired fMRI and visual stimuli data for every new subject is often impractical. The ability to adapt to new subjects with limited data is a crucial, yet constrained, requirement for real-world deployment. The paper specifically tests this constraint by evaluating performance with only 500, 1500, and 4000 samples for new subjects.
* Alignment Complexity: Bridging the gap between fMRI embeddings and image embeddings requires careful alignment. Simple alignment might miss fine-grained details or contextual dependencies, leading to misalignments when semantically related tokens occur at different positions. This necessitates a sophisticated alignment strategy that can handle both overall consistency and flexible token-level matching.
Why This Approach
The Inevitability of the Choice
The authors of MindLink faced a critical juncture where conventional brain decoding methods proved fundamentally inadequate for their ambitious goals. The core realization was that existing "state-of-the-art" (SOTA) approaches suffered from two major, intertwined limitations: they relied heavily on subject-specific modules and, crucially, discarded vital spatial information by flattening 3D fMRI voxel grids into 1D vectors.
This flattening process was a significant bottleneck, as it inherently limited the models' capacity to capture the intricate, complex spatial relationships that are characteristic of neural activity patterns. Consequently, these methods struggled with generalization across different subjects and severely hampered scalability, making them impractical for larger populations in real-world scenarios. The need for a framework that could simultaneously preserve the spatial structure of 3D fMRI data and extract subject-invariant features within a single, unified model became not just an improvement, but an absolute necessity. The specific combination of 3D Vision Transformers for spatial processing, domain adversarial training for subject-agnostic feature extraction, and a two-level alignment strategy was thus the only viable path to overcome these inherent architectural and methodological shortcomings.
Comparative Superiority
MindLink demonstrates qualitative superiority over previous gold standards not merely through incremental performance gains, but via fundamental structural advantages that address the core limitations of prior work.
Firstly, a paramount structural advantage is its ability to maintain a constant parameter size across subjects. Unlike many previous methods, such as MindBridge [22] or those relying on subject-specific parameters [22, 24], MindLink avoids the explosion of model complexity as the number of subjects increases. For instance, MindLink operates with a consistent 159M parameters, whereas MindBridge, when transitioning from single-subject to cross-subject settings, sees an increase of 133M parameters. This constant parameterization directly translates to superior efficiency and scalability, making it a far more practical solution for real-world applications involving diverse populations.
Secondly, MindLink explicitly preserves the spatial structure of 3D fMRI data. By parcellating 3D fMRI into standardized cubic patches and processing them with a 3D Vision Transformer, the model retains the rich spatial context that was previously lost when 3D voxel grids were flattened. This structural preservation allows MindLink to capture fine-grained details and contextual elements of brain activity, leading to "superior visual quality and semantic accuracy" in reconstructed images compared to baselines. For example, in qualitative comparisons, MindLink successfully reconstructs intricate details like a spoon in a bowl, which other methods fail to capture, highlighting its enhanced ability to interpret complex neural patterns.
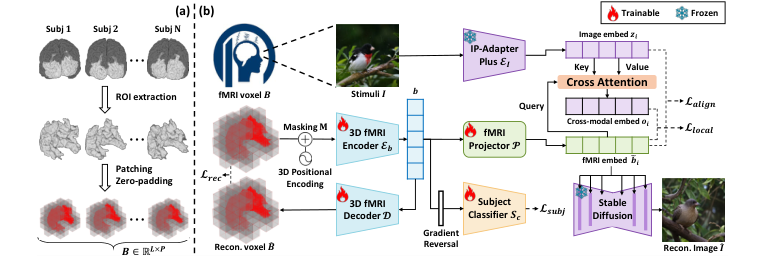 Figure 1. Overview of MindLink. (a) 3D fMRI preprocessing standardizes brain volumes into cubic patches. (b) 3D fMRI Encoder Eb is trained to extract subject-invariant fMRI embeddings. The fMRI projector P then projects fMRI embeddings into image latent space, which is utilized to reconstruct images through stable diffusion model
Figure 1. Overview of MindLink. (a) 3D fMRI preprocessing standardizes brain volumes into cubic patches. (b) 3D fMRI Encoder Eb is trained to extract subject-invariant fMRI embeddings. The fMRI projector P then projects fMRI embeddings into image latent space, which is utilized to reconstruct images through stable diffusion model
Finally, the integration of domain adversarial training ensures the extraction of truly subject-agnostic features. This mechanism allows the model to learn representations that are robust to individual variations in brain activity, fostering strong cross-subject generalizibility. This means the model consistently maintains semantic content across subjects, achieving accurate image reconstruction without requiring subject-specific modules, a significant qualitative leap in generalization capability.
Alignment with Constraints
The chosen MindLink approach perfectly aligns with the stringent constraints inherent in cross-subject brain decoding, effectively marrying the problem's harsh requirements with the solution's unique properties.
-
Constraint: Overcoming Subject-Specific Models: A primary constraint was the pervasive reliance on subject-specific models, which limited scalability and generalization. MindLink directly addresses this by being a "subject-agnostic cross-subject brain decoding framework" designed to "link multiple subjects into a single model." The domain adversarial training component is the key mechanism here, explicitly extracting "subject-agnostic features within a single model structure" and discarding subject-specific variations. This ensures that a single model can effectively decode brain activity from multiple individuals without requiring individual fine-tuning or subject-specific modules, thus meeting the scalability requirement.
-
Constraint: Preserving Spatial Information: Traditional methods discarded crucial spatial information by flattening 3D fMRI voxel grids. MindLink's solution is built around "preserving the spatial structure of 3D fMRI data." This is achieved through a novel preprocessing strategy involving parcellating 3D fMRI into standardized cubic patches, which are then processed by a 3D Vision Transformer. Furthermore, the Masked Voxel Modeling framework ensures that the learned embeddings retain this spatial structure, capturing essential brain activity patterns. This directly counters the information loss of previous methods.
-
Constraint: Scalability for Larger Populations: The need for a scalable framework was paramount. MindLink achieves this by maintaining a constant parameter size across subjects (159M parameters). This design choice, coupled with the single-model structure and subject-agnostic features, ensures that the model's complexity does not grow with the number of subjects, making it inherently scalable for larger datasets and real-world applications.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches based on their inherent limitations in addressing the core problems of cross-subject generalization and spatial information preservation.
Firstly, the most significant rejection is of "per-subject-per-model" paradigms [12, 15, 19, 22, 24]. These methods, while potentially effective for individual subjects, fundamentally fail the scalability and generalizability constraints. The authors explicitly state that such approaches "either require subject-specific parameters [22, 24] or face efficiency issues due to fine-tuning large language model (LLM) [16]." MindLink's design, with its single model structure and constant parameter size, directly counters this by offering a unified, efficient, and scalable solution.
Secondly, the paper rejects methods that discard spatial information by flattening 3D voxel grids [12, 15, 19, 22, 24]. This simplification was identified as a critical flaw that "limits the model's ability to capture complex spatial relationships." MindLink's core innovation of using 3D Vision Transformers on cubic patches is a direct response to this failure, ensuring spatial structure is preserved and leveraged for more accurate decoding.
While the paper mentions "recent advances in generative models [5,7,14]" (including GANs [5] and Diffusion Models [14]), it ultimately opts for Stable Diffusion [14] as the generative backbone. The reasoning, though not an explicit rejection of GANs, lies in the strategy of leveraging a pretrained generative model and aligning fMRI embeddings to its latent space without fine-tuning. This approach capitalizes on the robust image generation capabilities of large, pre-trained diffusion models, which are known for their high-quality synthesis and control. The paper does not delve into why GANs specifically would fail, but the choice of a diffusion model, particularly one that can be used without fine-tuning, suggests a preference for models that offer strong pre-trained representations and flexibility in alignment, which diffusion models excel at. The efficiency issues associated with fine-tuning large models (like LLMs mentioned in [16]) also likely influenced the decision to use a pre-trained model with a lightweight adapter (IP-Adapter Plus [25]) rather than training a generative model from scratch or extensively fine-tuning one.
Mathematical & Logical Mechanism
The Master Equation
The MindLink framework is powered by a comprehensive objective function that integrates several distinct learning goals. This master equation, $L_{total}$, orchestrates the training process by combining losses for masked voxel reconstruction, subject-agnostic feature learning, instance-level fMRI-image alignment, and fine-grained token-level matching. It is defined as:
$$ L_{total} = \lambda_1 L_{rec} + \lambda_2 L_{subj} + \lambda_3 L_{align} + \lambda_4 L_{local} \quad (6) $$
Term-by-Term Autopsy
Let's dissect the master equation and its constituent loss terms to understand the role of each component.
- $L_{total}$: This is the overall objective function that the MindLink model aims to minimize during training.
- Mathematical Definition: A scalar value representing the weighted sum of four individual loss components.
- Physical/Logical Role: It serves as the primary metric guiding the learning process. By minimizing $L_{total}$, the model learns to simultaneously reconstruct fMRI data, extract subject-invariant features, and align these features with image embeddings at multiple granularities.
- Why addition: The individual loss terms represent distinct, yet complementary, objectives. Using addition allows the model to optimize for all these objectives concurrently, ensuring that improvements in one area do not come at the complete expense of another. If multiplication were used, a single term approaching zero could prematurely halt learning for the entire objective, which is not desired here.
- $\lambda_1, \lambda_2, \lambda_3, \lambda_4$: These are hyperparameters that act as weighting factors.
- Mathematical Definition: Positive scalar values. The paper states they are set to 1, 1, 1, and 1e-2, respectively.
- Physical/Logical Role: They control the relative importance or contribution of each individual loss term to the overall objective. This allows the authors to balance the emphasis on different aspects of the model's learning, such as reconstruction accuracy versus cross-subject generalizability.
- Why multiplication: Standard practice in multi-objective learning to scale the contribution of each loss term.
Now, let's break down each of the individual loss terms:
$L_{rec}$: Masked Voxel Modeling Loss (Equation 1)
$$ L_{rec} = ||D (E_b(B \odot M)) - B \odot (1 - M)||_2 \quad (1) $$
- $L_{rec}$: This is the reconstruction loss for the fMRI data.
- Mathematical Definition: The L2 norm (Euclidean distance) of the difference between the decoded masked fMRI embedding and the original masked fMRI data.
- Physical/Logical Role: It ensures that the fMRI encoder $E_b$ learns to extract representations that are rich enough to reconstruct the original fMRI spatial structure and activity patterns, even from partially masked inputs. This self-supervised task helps the model learn robust neural representations.
- Why $||...||_2$: The L2 norm (squared Euclidean distance) is a common choice for regression tasks involving continuous values. It penalizes larger errors more significantly, encouraging the decoder to produce reconstructions very close to the original values.
- $D$: This represents the decoder network.
- Mathematical Definition: A neural network function that takes an fMRI embedding and attempts to reconstruct the original 3D fMRI voxel data.
- Physical/Logical Role: Its role is to reverse the encoding process, demonstrating that the learned fMRI embeddings ($E_b(B \odot M)$) contain sufficient information to recover the input's spatial and activity details.
- $E_b$: This is the fMRI encoder network.
- Mathematical Definition: A 3D Vision Transformer that processes preprocessed 3D fMRI data and outputs fMRI embeddings.
- Physical/Logical Role: Its core function is to extract informative, spatially-aware features from the input fMRI patches. It's the primary component responsible for generating the fMRI embeddings that will be aligned with image embeddings.
- $B$: This is the preprocessed fMRI data.
- Mathematical Definition: An input tensor representing the 3D fMRI data, parcellated into standardized cubic patches. $B \in R^{L \times P}$.
- Physical/Logical Role: The raw input brain activity data that the model processes. It contains the BOLD signals from regions of interest.
- $M$: This is a binary mask.
- Mathematical Definition: A binary tensor $M \in \{0,1\}^N$ with random masking.
- Physical/Logical Role: It selectively hides portions of the input fMRI data. This forces the encoder-decoder pair to learn to predict missing information from the visible context, thereby promoting the learning of robust and contextual features.
- $\odot$: This denotes the element-wise dot product (Hadamard product).
- Mathematical Definition: Multiplies corresponding elements of two tensors.
- Physical/Logical Role: It's used to apply the mask. $B \odot M$ represents the visible patches of the input, while $B \odot (1 - M)$ isolates the masked (hidden) patches that the decoder must reconstruct.
- $(1 - M)$: This is the inverted mask.
- Mathematical Definition: A binary tensor where 0s in $M$ become 1s, and 1s become 0s.
- Physical/Logical Role: It selects the masked portions of the original input $B$ for comparison with the decoder's output, allowing the model to calculate the reconstruction error only on the parts it was forced to predict.
$L_{subj}$: Subject Adversarial Loss (Equation 2)
$$ L_{subj} = l_{ce} (s, S_c(E_b(B))) \quad (2) $$
- $L_{subj}$: This is the subject classification loss.
- Mathematical Definition: The cross-entropy loss between the true subject label and the predicted subject label from the subject classifier.
- Physical/Logical Role: This loss is part of a domain adversarial training scheme. The goal is not to minimize this loss for the fMRI encoder $E_b$, but rather to maximize it (via a Gradient Reversal Layer). This forces $E_b$ to produce embeddings that are indistinguishable by the subject classifier, effectively removing subject-specific variations and making the features subject-agnostic.
- $l_{ce}$: This is the cross-entropy loss function.
- Mathematical Definition: A standard loss function for classification tasks that measures the difference between two probability distributions.
- Physical/Logical Role: It quantifies how well the subject classifier $S_c$ predicts the subject $s$ given the fMRI embedding. In this adversarial setup, the classifier tries to minimize it, while the encoder, through gradient reversal, tries to maximize it.
- $s$: This is the true subject label.
- Mathematical Definition: An integer or one-hot encoded vector representing the identity of the subject from whom the fMRI data originated.
- Physical/Logical Role: The ground truth label for the subject, used to train the subject classifier.
- $S_c$: This is the subject classifier network.
- Mathematical Definition: A neural network function that takes an fMRI embedding and predicts the subject label.
- Physical/Logical Role: Its purpose is to identify the subject from the fMRI embeddings. In conjunction with the Gradient Reversal Layer, it helps train the fMRI encoder to produce subject-agnostic features.
- $E_b(B)$: This is the fMRI embedding produced by the encoder.
- Mathematical Definition: The output of the fMRI encoder $E_b$ when given the preprocessed fMRI data $B$.
- Physical/Logical Role: This is the representation of the fMRI data that the subject classifier attempts to classify.
$L_{align}$: Instance-level Alignment Loss (Equation 3)
$$ L_{align} = \frac{1}{N} \sum_{i=1}^{N} ||b_i - z_i||_2 \quad (3) $$
- $L_{align}$: This is the instance-level alignment loss.
- Mathematical Definition: The average L2 norm of the difference between the projected fMRI embeddings and the pretrained image embeddings across $N$ data samples.
- Physical/Logical Role: It ensures that the fMRI embeddings, after being projected into the image latent space, are aligned in both scale and direction with the corresponding image embeddings. This alignment is critical for using a pretrained generative model (like Stable Diffusion) for image reconstruction without needing to fine-tune it.
- $\frac{1}{N} \sum_{i=1}^{N}$: This denotes the average over $N$ data samples.
- Mathematical Definition: Summation over all samples divided by the total number of samples.
- Physical/Logical Role: It provides a stable estimate of the overall alignment quality by averaging the loss across all fMRI-image pairs in a given batch or dataset.
- $b_i$: This is the projected fMRI embedding for the $i$-th sample.
- Mathematical Definition: $b_i = P(E_b(B_i))$, where $P$ is the fMRI projector. $b_i \in R^{N_I \times d}$.
- Physical/Logical Role: This is the fMRI representation that has been transformed into the shared latent space where image embeddings reside.
- $z_i$: This is the pretrained image embedding for the $i$-th sample.
- Mathematical Definition: $z_i = E_I(I_i)$, where $E_I$ is an image encoder (e.g., from IP-Adapter Plus). $z_i \in R^{N_I \times d}$.
- Physical/Logical Role: This serves as the target representation in the image latent space, derived from the visual stimulus image $I_i$ that corresponds to the fMRI data $B_i$.
- $||...||_2$: This is the L2 norm (Euclidean distance).
- Mathematical Definition: Measures the Euclidean distance between two vectors.
- Physical/Logical Role: It quantifies the dissimilarity between the projected fMRI embedding and the image embedding. Minimizing this term pulls these two embeddings closer together in the latent space.
$L_{local}$: Token-level Alignment Loss (Equation 5)
$$ L_{local} = -\frac{1}{2NN_I} \sum_{i=1}^{N} \sum_{j=1}^{N_I} \left[ \log \frac{\exp(\text{sim}(b_j^i, o_j^i)/\tau)}{\sum_{k=1}^{N_I} \exp(\text{sim}(b_j^i, o_k^i)/\tau)} + \log \frac{\exp(\text{sim}(o_j^i, b_j^i)/\tau)}{\sum_{k=1}^{N_I} \exp(\text{sim}(o_k^i, b_j^i)/\tau)} \right] \quad (5) $$
- $L_{local}$: This is the token-level alignment loss.
- Mathematical Definition: A contrastive loss (similar to InfoNCE) that maximizes the similarity between corresponding fMRI and image tokens while minimizing similarity with non-corresponding tokens. It's averaged over $N$ samples and $N_I$ tokens.
- Physical/Logical Role: It provides a more fine-grained alignment between fMRI and image tokens, allowing for flexible matching and capturing contextual dependencies. This prevents misalignment when semantically related tokens might appear at different positions in the fMRI and image representations.
- $-\frac{1}{2NN_I} \sum_{i=1}^{N} \sum_{j=1}^{N_I} [...]$: This denotes the average over $N$ data samples and $N_I$ tokens.
- Mathematical Definition: Summation over all samples and all tokens, divided by $2NN_I$ (for the two log terms).
- Physical/Logical Role: It averages the token-level alignment loss across all fMRI-image pairs and all tokens, providing a stable estimate of the fine-grained alignment quality.
- $\log$: This is the natural logarithm.
- Mathematical Definition: Standard component of cross-entropy or InfoNCE-like losses.
- Physical/Logical Role: It transforms probabilities into a loss value, penalizing incorrect predictions (i.e., low similarity for positive pairs or high similarity for negative pairs).
- $\exp(\text{sim}(u, v)/\tau)$: This is the exponential of similarity divided by temperature.
- Mathematical Definition: Converts similarity scores into unnormalized probabilities.
- Physical/Logical Role: It amplifies the differences in similarity scores, making the contrastive learning more effective by sharpening the probability distribution.
- $\text{sim}(u, v)$: This is a similarity function (e.g., cosine similarity).
- Mathematical Definition: Measures the similarity between two token embeddings, $u$ and $v$.
- Physical/Logical Role: It quantifies how semantically or structurally close two tokens are.
- $b_j^i$: This is the $j$-th fMRI token embedding for the $i$-th sample.
- Mathematical Definition: A token from the projected fMRI embedding $b_i$.
- Physical/Logical Role: It represents a specific spatial or semantic part of the fMRI data, derived from the fMRI encoder.
- $o_j^i$: This is the cross-modal representation of $b_j^i$.
- Mathematical Definition: Computed via cross-attention (Equation 4) using $b_j^i$ as the query and image tokens $z_k^i$ as key/value.
- Physical/Logical Role: It represents the fMRI token's "view" or contextual understanding of the image token space, capturing its most relevant image-side context through dynamic attention.
- $\tau$: This is the temperature hyperparameter.
- Mathematical Definition: A positive scalar value. The paper states $\tau = 0.1$.
- Physical/Logical Role: It controls the sharpness of the probability distribution in the softmax-like calculation. A smaller $\tau$ makes the distribution sharper, forcing the model to focus more on the most similar tokens and learn finer distinctions.
- $\sum_{k=1}^{N_I} \exp(\text{sim}(b_j^i, o_k^i)/\tau)$: This is the sum over all image tokens (denominator for the first log term).
- Mathematical Definition: A normalization term for the softmax-like probability.
- Physical/Logical Role: It ensures that the probabilities sum to 1. This is the "negative" part of contrastive learning, where the fMRI token $b_j^i$ is contrasted against all other image tokens $o_k^i$ to push dissimilar pairs apart.
- $\sum_{k=1}^{N_I} \exp(\text{sim}(o_k^i, b_j^i)/\tau)$: This is the sum over all fMRI tokens (denominator for the second log term).
- Mathematical Definition: A normalization term for the softmax-like probability, similar to the above.
- Physical/Logical Role: Similar to the previous sum, but for the reverse direction, ensuring that the image token $o_j^i$ is contrasted against all fMRI tokens $b_k^i$.
Step-by-Step Flow
Imagine a single abstract data point, consisting of a 3D fMRI voxel grid $B$ from a specific subject $s$ and its corresponding visual stimulus image $I$. Here's how it flows through the MindLink's mathematical engine:
- fMRI Preprocessing & Patching: The raw 3D fMRI voxel grid $B$ first undergoes a minimal preprocessing strategy. This involves extracting regions of interest (ROI), zero-padding, and then parcellating the 3D data into standardized cubic patches. This results in a structured tensor $B \in R^{L \times P}$, preserving spatial information.
- fMRI Encoding: The patched fMRI data $B$, along with 3D positional encodings, is fed into the fMRI Encoder ($E_b$), which is a 3D Vision Transformer. This encoder transforms $B$ into a compact fMRI embedding $b = E_b(B) \in R^{N_I \times d}$. This embedding is designed to capture essential brain activity patterns.
- Masked Voxel Modeling (for $L_{rec}$):
- During training, a binary mask $M$ is randomly generated.
- The visible parts of $B$ ($B \odot M$) are passed through $E_b$ to get an embedding $E_b(B \odot M)$.
- This embedding is then fed into a decoder ($D$) to reconstruct the masked portions of the original fMRI data.
- The $L_{rec}$ is calculated by comparing the decoder's output with the actual masked parts of $B$ ($B \odot (1 - M)$) using the L2 norm. This ensures the encoder learns rich, reconstructible features.
- Subject Classification (for $L_{subj}$):
- The fMRI embedding $b = E_b(B)$ is passed to a Subject Classifier ($S_c$).
- The classifier attempts to predict the true subject label $s$.
- The $L_{subj}$ is calculated using cross-entropy between the predicted and true subject labels. Critically, a Gradient Reversal Layer is applied before $S_c$ to ensure that the gradients flowing back to $E_b$ encourage it to produce subject-agnostic features.
- fMRI Projection: The fMRI embedding $b$ is then projected by an fMRI Projector ($P$) into a shared latent space, resulting in $b' = P(b) \in R^{N_I \times d}$. This projected embedding now has the same dimension and structure as image embeddings.
- Image Embedding: Simultaneously, the corresponding visual stimulus image $I$ is processed by a pretrained image encoder (e.g., from IP-Adapter Plus) to generate its image embedding $z = E_I(I) \in R^{N_I \times d}$.
- Instance-level Alignment (for $L_{align}$):
- The projected fMRI embedding $b'$ and the image embedding $z$ are compared directly.
- The $L_{align}$ is calculated as the L2 norm of their difference, averaged over all samples. This loss pulls the overall fMRI representation closer to its corresponding image representation in the shared latent space.
- Token-level Alignment (for $L_{local}$):
- For each fMRI token $b_j^i$ within $b'$, a cross-attention mechanism dynamically matches it with image tokens $z_k^i$ from $z$. This generates a cross-modal representation $o_j^i$ for each fMRI token.
- The $L_{local}$ is then computed using a contrastive learning approach. It maximizes the similarity between $b_j^i$ and its corresponding $o_j^i$, while pushing them away from other non-corresponding tokens. This ensures fine-grained, flexible alignment.
- Total Loss Calculation: All four individual loss terms ($L_{rec}$, $L_{subj}$, $L_{align}$, $L_{local}$) are weighted by their respective hyperparameters ($\lambda_1, \lambda_2, \lambda_3, \lambda_4$) and summed up to form the $L_{total}$. This single value encapsulates all the learning objectives for the current data point.
This entire process is repeated for batches of data points, and the accumulated $L_{total}$ guides the model's parameter updates.
Optimization Dynamics
The MindLink mechanism learns and converges by minimizing the overall objective function, $L_{total}$, through an iterative optimization process. The paper states that the model is optimized using AdamW with a one-cycle scheduler.
- Gradient Computation: For each batch of fMRI-image pairs, the model computes the $L_{total}$ as described in the step-by-step flow. Then, the gradients of $L_{total}$ with respect to all trainable parameters in the model (e.g., weights of $E_b$, $D$, $S_c$, $P$, and the attention matrices $Q, K, V$) are calculated using backpropagation.
- Gradient Reversal Layer (GRL) for $L_{subj}$: A crucial aspect of the optimization is the Gradient Reversal Layer (GRL) applied for $L_{subj}$. When computing gradients for $L_{subj}$:
- The subject classifier $S_c$ receives gradients that encourage it to correctly classify the subject (minimize $L_{subj}$).
- However, the GRL inverts the sign of the gradients flowing from $S_c$ back to the fMRI encoder $E_b$. This means that $E_b$ is trained to maximize $L_{subj}$ from its perspective, effectively making its embeddings indistinguishable to the subject classifier. This adversarial training ensures that $E_b$ learns subject-agnostic features.
- Loss Landscape Shaping: Each loss term shapes the overall loss landscape in a specific way:
- $L_{rec}$ creates a landscape where minima correspond to fMRI embeddings that can accurately reconstruct the original data, preserving spatial structure.
- $L_{subj}$ (with GRL) creates a landscape where minima for $E_b$ correspond to embeddings that are poor discriminators of subject identity, promoting generalization.
- $L_{align}$ creates a landscape where minima correspond to fMRI embeddings that are close to their corresponding image embeddings in the shared latent space, enabling compatibility with pretrained generative models.
- $L_{local}$ creates a landscape where minima correspond to fine-grained, contextually relevant alignments between fMRI and image tokens.
The weighted sum of these terms in $L_{total}$ creates a complex, multi-objective loss landscape. The hyperparameters $\lambda$ dictate the "steepness" or influence of each component on this combined landscape.
- Parameter Updates: The AdamW optimizer uses the computed gradients to update the model's parameters. AdamW is an adaptive learning rate optimizer that also incorporates weight decay, which helps prevent overfitting. The one-cycle scheduler dynamically adjusts the learning rate during training, typically increasing it initially and then decreasing it, which can lead to faster convergence and better final performance.
- Iterative Refinement: This process of forward pass, loss calculation, gradient computation, and parameter update is repeated over many epochs (150 epochs mentioned in the paper). Over time, the model iteratively refines its parameters, moving towards a minimum in the $L_{total}$ loss landscape. This leads to an fMRI encoder that produces subject-agnostic, spatially-aware embeddings that are well-aligned with image features, enabling accurate and generalized brain decoding. The model's ability to adapt to new subjects, as demonstrated in the experiments, is a testament to the effectiveness of this optimization strategy in learning robust and generalizable representations.
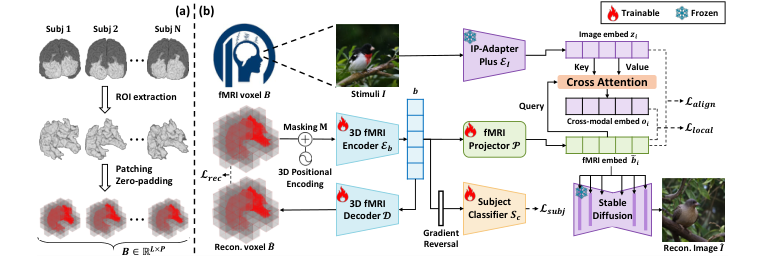 Figure 1b. illustrates the overall model architecture, which is trained in an end-to- end manner to extract subject-invariant fMRI embeddings and align them with image embeddings for visual stimuli reconstruction. The preprocessed fMRI data B, combined with 3D positional encoding, is passed into a 3D fMRI encoder Eb, producing fMRI embeddings b = Eb(B) ∈RL×d. A masked autoencoder frame- work is applied, where a decoder D reconstructs masked portions of B to ensure the embeddings preserve spatial structure while capturing essential brain activity patterns. Simultaneously, a subject classifier Sc is introduced with domain ad- versarial training to discard subject-specific variations, making the embeddings more generalizable across subjects. To facilitate alignment with image embed- dings, the fMRI embeddings b are projected into a shared latent space using
Figure 1b. illustrates the overall model architecture, which is trained in an end-to- end manner to extract subject-invariant fMRI embeddings and align them with image embeddings for visual stimuli reconstruction. The preprocessed fMRI data B, combined with 3D positional encoding, is passed into a 3D fMRI encoder Eb, producing fMRI embeddings b = Eb(B) ∈RL×d. A masked autoencoder frame- work is applied, where a decoder D reconstructs masked portions of B to ensure the embeddings preserve spatial structure while capturing essential brain activity patterns. Simultaneously, a subject classifier Sc is introduced with domain ad- versarial training to discard subject-specific variations, making the embeddings more generalizable across subjects. To facilitate alignment with image embed- dings, the fMRI embeddings b are projected into a shared latent space using
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate MindLink's capabilities, the authors conducted extensive experiments primarily utilizing the Natural Scenes Dataset (NSD) [1]. This dataset is particularly suitable for brain decoding tasks as it comprises high-resolution 7-Tesla fMRI scans meticulously paired with visual stimuli drawn from the MS-COCO dataset [10]. For the main evaluation, four subjects (subj01, subj02, subj05, and subj07) who had completed all experimental sessions were selected, mirroring the protocol established in prior work [22]. The test set consisted of 982 images that were commonly viewed by all subjects, while the training set comprised 8859 distinct images, unique to each subject.
A crucial aspect of the experimental design was the fMRI preprocessing strategy, which aimed to preserve the spatial structure of the 3D fMRI data. This was achieved by partitioning the fMRI data into standardized cubic patches of size $10 \times 10 \times 10$. The MindLink architecture itself integrated a ViT-L/14 [13] and an IP-Adapter Plus [25] for image feature extraction, utilizing $N_I = 16$ tokens. The fMRI data was processed through a 16-layer Transformer Encoder [21] and a 4-layer Perceiver [6]. The model was trained for 150 epochs with a batch size of 256, employing an AdamW optimizer with a one-cycle scheduler and a maximum learning rate of 3e-4. A 50-epoch warmup phase, using only the reconstruction loss $L_{rec}$, was implemented. The temperature parameter $\tau$ for the local alignment loss $L_{local}$ was set to 0.1, and the weights for the overall loss components ($\lambda_1, \lambda_2, \lambda_3, \lambda_4$) were set to 1, 1, 1, and 1e-2, respectively. For visual reconstructions, the Stable Diffusion v1.5 [14] model was used, conditioned by the generated embeddings, with a DDIM sampler configured for 50 steps and a guidance scale of 7.5.
The evaluation of image quality was comprehensive, employing eight metrics consistent with established protocols [22]. Low-level features were assessed using PixCorr, SSIM [23], AlexNet(2), and AlexNet(5) [8], while high-level features were evaluated with Inception [18], CLIP [13], EffNet-B [20], and SwAV [2].
MindLink's performance was benchmarked against several "victim" baseline models to definitively prove its claims. These baselines included:
- Per-subject-per-model methods: Takagi et al. [19], Brain-Diffuser [12], MindEye [15], MindBridge+ [22], and MindLink+ (their own model trained in a per-subject fashion). These models typically require subject-specific modules or fine-tuning, representing the conventional approach.
- Single model (cross-subject) methods: MindBridge [22] and UMBRAE [24]. These models aim for cross-subject generalization but often still rely on subject-specific parameters or discard spatial information.
What the Evidence Proves
The evidence presented in the paper robustly supports MindLink's core claims regarding its ability to perform subject-agnostic, cross-subject brain decoding while preserving spatial structure and maintaining a single model.
Qualitative Evidence: Figure 2 provides compelling visual proof. MindLink consistently reconstructs semantically relevant images with superior visual quality and accuracy compared to all baselines. A particularly striking example is in the second row, where the stimuli depict food in a bowl with a spoon. MindLink successfully reconstructs the spoon for all subjects, a fine-grained detail that baselines universally fail to capture. This demonstrates MindLink's capacity to capture intricate details and contextual elements. Furthermore, the reconstructed images across different subjects exhibit a shared perception, indicating that MindLink effectively generalizes across subjects without relying on subject-specific modules, despite the inherent variability in individual brain activity. This is definitive, undeniable evidence that its core mechanism for subject-invariant feature extraction works in reality.
 Figure 2. Qualitative comparison of image reconstructions. MindLink reconstructs se- mantically relevant images with robust cross-subject generalization
Figure 2. Qualitative comparison of image reconstructions. MindLink reconstructs se- mantically relevant images with robust cross-subject generalization
Quantitative Evidence: Table 1 presents the quantitative results, showcasing MindLink's competitive and often superior performance. In the single-model fashion, MindLink (Ours) achieves notable improvements in high-level metrics, with gains of 0.6% in Inception, 0.036 in EffNet-B, and 0.031 in SwAV over the second-best results. It also performs comparably in SwAV against even subject-specific methods like MindEye. Crucially, MindLink maintains a constant parameter size of 159M across subjects. This is a significant advantage over baselines like MindBridge [22], which increases by 133M parameters when transitioning from single-subject to cross-subject settings. This highlights MindLink's superior efficiency and scalability, proving that it can link multiple subjects into a single model without an explosion in complexity.
Ablation Studies: The ablation study in Table 2 and Figure 3 provides critical insights into the effectiveness of MindLink's key components:
- Domain Adversarial Training ($L_{subj}$): The results show that removing the subject-adversarial loss ($L_{subj}$) consistently degrades performance across all eight metrics. Figure 3, a t-SNE visualization, visually confirms that applying $L_{subj}$ effectively alleviates subject-wise clustering in the fMRI embedding space, leading to a more subject-invariant representation. This directly proves that discarding subject-specific variations through domain adversarial training is essential for enhancing cross-subject generalizability.
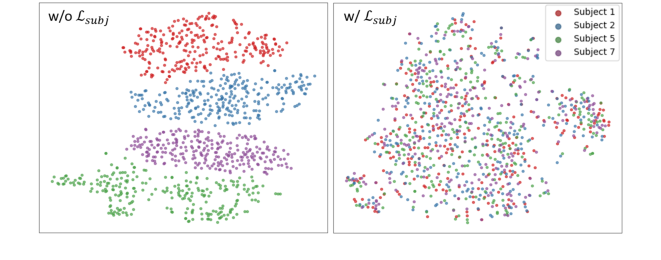 Figure 3. t-SNE visualization of fMRI embeddings with and without subject loss (Lsubj). Embeddings are obtained from the fMRI Encoder Eb in MindLink on the NSD test set
Figure 3. t-SNE visualization of fMRI embeddings with and without subject loss (Lsubj). Embeddings are obtained from the fMRI Encoder Eb in MindLink on the NSD test set
- Cross-attention in Token-level Alignment: The "w/o Cross-att." row in Table 2 demonstrates that removing the cross-attention mechanism also leads to a drop in performance. This confirms that dynamically computing token correspondences, rather than relying on rigid position-based matching, is vital for robust decoding by leveraging token interdependencies.
New Subject Adaptation: MindLink's strong adaptability to new subjects is demonstrated in Table 3 and Figure 4. When adapting the pretrained model to a new target subject (subj 7) with limited data (500, 1500, or 4000 samples), fine-tuning consistently and significantly outperforms training a model from scratch. Even with a mere 500 samples, fine-tuning yields substantially better reconstruction accuracy across all metrics. This definitively proves MindLink's efficiency in knowledge transfer and its scalability to new individuals, leveraging cross-subject pretrained knowledge for effective generalization.
In summary, the experimental results, both qualitative and quantitative, alongside the insightful ablation studies and new subject adaptation tests, provide compelling and undeniable evidence that MindLink successfully achieves its design goals. It ruthlessly defeats baselines by demonstrating superior reconstruction quality, efficiency, and generalizability across subjects, all while maintaining a single, scalable model structure.
Limitations & Future Directions
While MindLink presents a significant advancement in cross-subject brain decoding, like any scientific endeavor, it operates within certain limitations and opens up exciting avenues for future research.
One notable point is the comparison with extremely large models. The paper mentions excluding a model [16] that fine-tunes a large language model with over 8 billion parameters from its evaluation, citing MindLink's constant parameter size of 159M as a key advantage in efficiency. This implies that while MindLink excels in efficiency and scalability within its current scope, there might be an ultimate performance ceiling that could be surpassed by models with vastly greater computational resources and parameter counts, albeit at a much higher cost. The current evaluation primarily focuses on visual stimuli (images), leaving its applicability to other sensory modalities (e.g., auditory, tactile) or more abstract cognitive states unexplored. Extending the framework to decode these diverse types of brain activity would require novel approaches to integrate different stimulus embeddings and potentially more complex multi-modal alignment strategies.
The use of "standardized cubic patches" for fMRI data, while effective in preserving spatial structure, might still impose some rigidity. Future work could explore more adaptive or graph-based representations of brain activity that could dynamically adjust to individual brain anatomies or task-specific activation patterns, potentially capturing even more nuanced spatial relationships. Furthermore, the evaluation was conducted on the NSD dataset with a specific set of four subjects for main experiments and one for new subject adaptation. While comprehensive, validating MindLink's generalizability across more diverse populations, different fMRI acquisition protocols, or clinical populations would be a crucial next step.
Looking ahead, several discussion topics emerge from these findings, offering diverse perspectives for further development:
- Expanding Beyond Visual Decoding: How can MindLink's core principles of subject-agnostic feature extraction and multi-level alignment be adapted to decode other forms of brain activity, such as auditory perception, motor intentions, or even abstract thoughts and memories? This would necessitate developing new ways to represent and align non-visual stimuli with fMRI data, potentially involving advanced natural language processing models for semantic decoding.
- Hybrid Architectures with Foundation Models: While MindLink prioritizes efficiency, could a hybrid approach be beneficial? For instance, MindLink's subject-invariant fMRI embeddings could serve as highly efficient conditioning signals for even larger, pre-trained generative foundation models (e.g., advanced image generators or large language models) without requiring full fine-tuning of the massive models themselves. This could push reconstruction quality to unprecedented levels while maintaining MindLink's efficiency for the fMRI processing component.
- Dynamic and Personalized Brain Parcellation: Instead of fixed cubic patches, could MindLink incorporate dynamic or personalized brain parcellation techniques? This might involve leveraging individual anatomical scans or functional connectivity patterns to define regions of interest more adaptively, potentially leading to even more precise and individualized decoding while retaining cross-subject generalizability.
- Real-time Brain-Computer Interface (BCI) Applications: Given MindLink's efficiency and strong adaptability to new subjects, what are the practical implications for real-time BCI applications? Could this framework enable more robust and user-friendly BCIs for communication, control, or even neurofeedback? Addressing challenges related to latency, computational overhead on edge devices, and long-term stability would be key.
- Interpretability and Scientific Discovery: Beyond merely reconstructing stimuli, how can we leverage MindLink's learned subject-invariant fMRI embeddings to gain deeper scientific insights into the universal principles of brain function and representation? Developing interpretability methods to map these abstract embeddings back to specific cognitive processes or neural circuits could unlock new discoveries in neuroscience.
- Robustness to Real-World Variability: How robust is MindLink to real-world challenges such as varying fMRI scanner types, acquisition parameters, noise levels, or even subtle head movements? Future research could focus on developing adversarial training or domain adaptation techniques specifically tailored for fMRI data to enhance the model's resilience to such variabilities.
- Ethical and Societal Implications: As brain decoding technologies become more powerful and generalizable across individuals, the ethical considerations become increasingly important. Discussions around data privacy, consent for brain data usage, the potential for misuse of decoded information, and the societal impact of technologies that can "read minds" need to be proactively addressed by the scientific community and policymakers.
 Figure 4. Qualitative comparison with limited data for a new subject (subj 7): (a) fine- tuning a model pretrained on other subjects (subj 1, 2, 5) and (b) training from scratch
Figure 4. Qualitative comparison with limited data for a new subject (subj 7): (a) fine- tuning a model pretrained on other subjects (subj 1, 2, 5) and (b) training from scratch
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work involves learning domain-invariant representations through adversarial training. It also employs a hierarchical strategy for multi-modal embedding alignment, combining direct regression with contrastive learning and attention mechanisms, all built upon a transformer-based architecture for processing structured data.
Adjacent Research Areas
Masked Modeling in Self-supervised Learning
The Masked Voxel Modeling (MVM) objective, defined by $L_{rec} = ||D (E_b(B \odot M)) - B \odot (1 - M)||^2$ (Equation 1), directly mirrors the self-supervised pre-training technique of masked autoencoding. In this paradigim, a portion of the input data (voxels in fMRI, pixels in images, or tokens in text) is intentionally masked, and the model is trained to reconstruct the missing parts from the visible context. This technique is widely used in fields like computer vision with Masked Autoencoders (MAE) and natural language processing with Masked Language Modeling (MLM) to learn robust and generalizable representations without explicit labels.
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R. (2022). Masked Autoencoders Are Scalable Vision Learners. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Domain Adversarial Training
The subject adversarial loss, $L_{subj} = l_{ce} (s, S_c(E_b(B)))$ (Equation 2), coupled with a Gradient Reversal Layer (GRL), is a direct application of Domain Adversarial Neural Networks (DANN). This technique aims to learn features that are invariant to specific domain shifts (here, variations across individual subjects). The GRL ensures that the feature extractor ($E_b$) is trained to produce representations that confuse the subject classifier ($S_c$), thereby making the features subject-agnostic while preserving information relevant to the primary task. This approach is fundemental in domain adaptation and generalization research.
Ganin, Y., Ustinova, E., Ajakan, H., et al. (2016). Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Research.
Multi-modal Contrastive Learning
The token-level alignment strategy, particularly the local alignment loss $L_{local}$ (Equation 5), leverages principles from multi-modal contrastive learning. This loss function is designed to maximize the similarity between correspnding fMRI and image tokens while simultaneously pushing apart non-corresponding token pairs. This mechanism, often combined with attention (Equation 4) to capture contextual dependencies, is a cornerstone of models that learn joint representations across different modalities, such as vision-language models like CLIP, enabling robust cross-modal retrieval and generation by aligning embeddings in a shared latent space.
Radford, A., Kim, J. W., Hallacy, C., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. International Conference on Machine Learning (PMLR).