Pre-to-Post Operative MRI Generation with Retrieval-based Visual In-Context Learning
New AI generates realistic post-op MRIs from pre-op scans, aiding brain tumor surgery.
Background & Academic Lineage
The problem of generating realistic and clinically useful post-operative Magnetic Resonance Imaging (MRI) from pre-operative MRI scans, particularly for aggressive brain tumors like glioblastoma, has emerged as a critical challenge in the field of medical image synthesis and neuro-oncology. Historically, neurosurgeons have relied on analyzing vast databases of past pre- and post-operative MRI pairs to predict surgical outcomes and plan treatments for new patients. This manual, experience-based approach, while valuable, is inherently time-consuming, subjective, and limited by the availability of perfectly matching historical cases. The precise origin of this problem stems from the clinical necessity for more accurate, patient-specific pre-surgical planning and prognosis prediction, especially given the complex and variable nature of tumor resection and its physiological consequences.
The fundamental limitation, or "pain point," of previous approaches in image translation and synthesis is their inability to adequately capture and reflect the intricate structural and visual changes that occur post-surgery in the brain. Prior generative models, often focusing on general image-to-image translation or style transfer, primarily aimed to preserve the source image's structure while adapting its style. However, post-operative MRI generation demands more than just style translation; it requires modeling significant anatomical alterations. These include the actual resection cavity (where the tumor was removed), brain tissue shift, edema (swelling), and hemorrhage (bleeding). Crucially, these changes are highly dependent on the tumor's specific location and shape, as well as the extent of resection, which is carefully determined to minimize complications. Previous models largely failed to account for these tumor-specific post-operative outcomes, leading to generated images that were often generic, lacked precise anatomical fidelity, or did not accurately represent the complex, patient-specific structural modifications resulting from surgery. This made their real-time clinical application for precise surgical outcome estimation impossible.
Intuitive Domain Terms
- Glioblastoma: Imagine a particularly aggressive and fast-spreading weed in a garden. It's a type of brain cancer that grows quickly and infiltrates surrounding healthy brain tissue, making it very difficult to remove completely without damaging vital areas.
- Magnetic Resonance Imaging (MRI): Think of it as a super-advanced, non-invasive camera that uses powerful magnets and radio waves to take incredibly detailed "photos" of the inside of your body, especially soft tissues like the brain, without any cutting.
- Visual In-context Learning: This is like showing a chef a few pictures of dishes you want, along with some examples of similar dishes they've made before. The chef then understands your request and cooks the new dish by picking up on the visual cues and patterns from the examples, rather than needing a full, explicit recipe.
- Tumor-guided Retrieval: Picture a doctor searching through a massive digital library of thousands of past patient brain scans. They're looking for cases where the tumor was almost identical to yours in terms of its exact location and shape, so they can see what the post-surgery MRI looked like for those specific, similar patients.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem this paper addresses is the accurate generation of post-operative Magnetic Resonance Imaging (MRI) scans from pre-operative MRI scans for glioblastoma patients.
The starting point (Input/Current State) is a pre-operative MRI of a patient diagnosed with glioblastoma, along with its corresponding tumor segmentation mask. This input provides information about the tumor's initial location, shape, and the surrounding anatomical structures before any surgical intervention.
The desired endpoint (Output/Goal State) is a synthetic post-operative MRI that accurately reflects the visual and structural changes resulting from surgical resection. This includes the precise tumor resection region, potential tissue shift, edema, and hemorrhage, all while maintaining anatomical consistency and realism. The ultimate goal is for this generated image to assist neurosurgeons in predicting surgical outcomes and guiding treatment planning.
The exact missing link or mathematical gap is the ability to robustly and accurately model the complex, non-linear, and patient-specific transformations that occur in the brain due to tumor resection. Previous image translation methods primarily focused on "style translation" (e.g., converting a CT scan to an MRI) while largely preserving the underlying anatomical structure. However, post-operative MRI generation demands significant structural modifications – the removal of a tumor, the resulting cavity, and secondary effects like tissue displacement and fluid accumulation. This is a much harder problem than simple style transfer, as it requires a deep understanding of surgical outcomes tied to specific tumor characteristics.
The painful trade-off or dilemma that has trapped previous researchers is precisely this conflict between preserving the source image structure (as in typical image-to-image translation) and introducing drastic, yet medically accurate, structural changes. If a model focuses too much on preserving the pre-operative structure, it fails to depict the resection and its consequences. Conversely, if it attempts to introduce large changes without sufficient guidance, it risks generating unrealistic or anatomically incorrect images. Furthermore, the extent of resection and the resulting post-operative appearance are highly dependent on the tumor's specific location and shape, especially if it's in a critical brain region. This means a generic image translation approach often produces blurred or indistinct structures that do not accurately reflect tumor-specific surgical outcomes, making them clinically unhelpful.
Constraints & Failure Modes
This problem is insanely difficult to solve due to several harsh, realistic walls the authors hit:
-
Physical/Biological Complexity of Post-operative Changes: Post-operative MRI scans exhibit highly complex and variable structural changes. These include:
- Resection Region: The actual cavity left after tumor removal, which varies significantly in size and shape based on the original tumor.
- Tissue Shift: The brain tissue around the resected area can shift, deforming the surrounding anatomy.
- Edema: Swelling of brain tissue, which can appear as bright signals on MRI.
- Hemorrhage: Bleeding, which also has distinct appearances on MRI.
These changes are not simple pixel manipulations but involve intricate anatomical deformations and signal alterations that are difficult to predict and synthesize accurately.
-
Tumor-Specific Outcomes: The extent of surgical resection and the resulting post-operative appearance are highly dependent on the individual tumor's location and infiltration characteristics. A model must consider these tumor-specific outcomes, which means a generalized approach that doesn't account for these nuances will fail to produce clinically relevant results. This necessitates a mechanism to incorporate detailed tumor information into the generation process.
-
Data-Driven Constraints (Limited Paired Data): While the paper mentions using a publicly available dataset (LUMIERE) with 71 paired pre- and post-operative MRI scans, this number is relatively small for training complex deep generative models, especially considering the vast variability in tumor types, locations, and surgical outcomes. This limited data makes it challenging for models to learn the full spectrum of possible post-operative transformations robustly.
-
Lack of Explicit Guidance in Previous Methods: Prior image editing or translation methods often lack explicit mechanisms to guide the generation process with specific instructions about what structural changes should occur. Without such guidance, models tend to produce images that are either too similar to the input (failing to show resection) or too generic and unrealistic. The paper notes that previous methods often "fail to reflect the post-operative tumor resection region, often generating blurred and indistinct structures instead," highlighting this failure mode.
-
Requirement for High Fidelity and Medical Plausibility: The generated images are intended to assist neurosurgeons. This imposes a strict requirement for high fidelity, anatomical correctness, and medical plausibility. Any significant artifacts or inaccuracies could mislead clinicians, making the problem not just about image generation but about reliable medical image synthesis.
Why This Approach
The Inevitability of the Choice
The authors' choice of a novel approach integrating tumor-guided retrieval and tumor-aware visual in-context learning with a diffusion model was not merely an incremental improvement but a necessity driven by the unique complexities of generating post-operative MRI from pre-operative scans. Traditional state-of-the-art (SOTA) methods, such as standard CNNs, basic diffusion models, or general image-to-image transformers, were deemed insufficient becuase they primarily focus on preserving the source image's structure while adapting its style to the target domain. This problem, however, demands a fundamental structural transformation that reflects complex biological changes.
The exact moment the authors realized the inadequacy of existing methods stems from two core challenges identified in the problem definition:
1. Tumor-specific Post-operative Outcomes: Generating post-operative MRI requires considering the specific location and shape of the tumor, as the extent of surgical resection is highly dependent on these factors. This is critcal for minimizing complications, especially when tumors are in sensitive brain regions or have infiltrated surrounding tissues. Standard generative models lack the inherent mechanism to account for such highly localized, patient-specific surgical planning outcomes.
2. Capturing Complex Structural Changes: Post-operative MRI significantly differs from pre-operative scans due to various structural and visual alterations, including the actual resection region, brain tissue shift, edema, and hemorrhage. Generic image translation models are not designed to simulate these profound, anatomically specific transformations accurately. They might preserve overall brain anatomy but fail to depict the precise, localized changes resulting from surgery.
Therefore, a solution was needed that could not only generate images but also reason about and incorporate tumor-specific anatomical and surgical information, which existing SOTA methods could not inherently provide without significant modification.
Comparative Superiority
Beyond simple quantitative performance metrics, the proposed method demonstrates overwhelming qualitative superiority due to its structural advantages in handling the specific nuances of post-operative MRI generation. While the paper does not explicitly discuss memory complexity reductions from $O(N^2)$ to $O(N)$, its core strength lies in its ability to produce anatomically plausible and clinically relevant structural changes.
The key structural advantages are:
* Tumor-Guided Retrieval: This mechanism allows the model to retrieve instruction pairs (pre- and post-operative MRI) from a database that closely match the query's tumor location and shape. This provides highly relevant, real-world examples of how similar tumors were resected and how the brain responded, offering invaluable context that general image translation models simply cannot access. This "case-based reasoning" directly addresses the need for tumor-specific outcomes.
* Tumor-Aware Prompt Adapter: This component explicitly integrates information about the pre-operative tumor location and anatomical structure, as well as the post-operative resection region. By composing the retrieved post-operative MRI with the query's pre-operative MRI and using bounding box masks, the adapter creates a rich, tumor-specific prompt embedding ($P_{tumor}$). This embedding then guides the diffusion process through cross-attention, ensuring that the generated image accurately reflects the expected surgical changes.
* Visual In-Context Learning: By providing explicit visual instructions from retrieved similar cases, the method significantly improves the capture of stuctural changes between paired pre- and post-operative MRI. This is crucial for depicting the resection cavity, tissue shifts, and other post-surgical alterations with high fidelity.
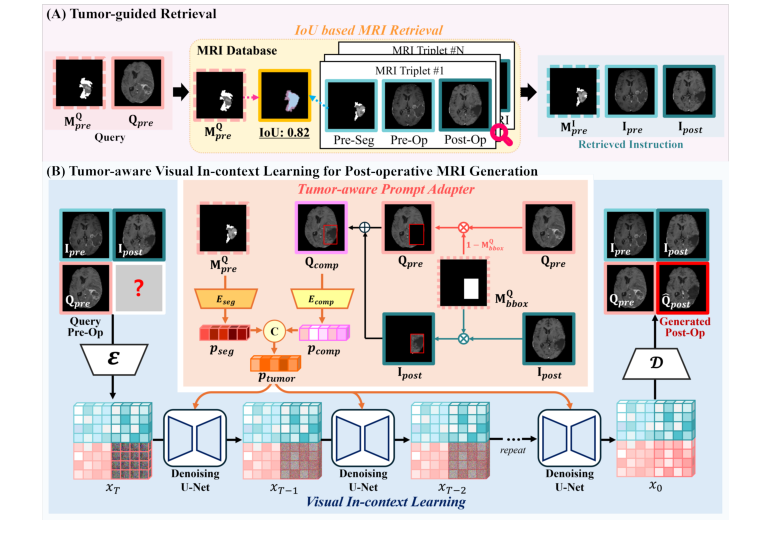 Figure 1. Overview of the proposed method for post-operative MRI generation, which accurately reflects the tumor resection region and post-operative structural changes through two key components: (A) tumor-guided retrieval, (B) tumor-aware visual in- context learning for post-operative MRI generation
Figure 1. Overview of the proposed method for post-operative MRI generation, which accurately reflects the tumor resection region and post-operative structural changes through two key components: (A) tumor-guided retrieval, (B) tumor-aware visual in- context learning for post-operative MRI generation
Qualitatively, as shown in Fig. 2, competing diffusion-based image editing methods like DDPM, PBE, InstructPix2Pix, and VISII often "fail to reflect the post-operative tumor resection region, often generating blurred and indistinct structures instead." In contrast, the proposed method generates images that are "the most similar to real post-operative MRI," demonstrating its unique capability to produce sharp, distinct, and medically accurate representations of post-surgical anatomy. This ability to tailor instructions based on tumor characteristics and integrate specific resection information is the overwhelming structural advantage.
Alignment with Constraints
The chosen method perfectly aligns with the inherent constraints of generating post-operative MRI, which can be inferred from the problem definition:
-
Constraint: Accurately reflect tumor-specific post-operative outcomes.
- Marriage: The "tumor-guided retrieval" component directly addresses this by identifying and leveraging historical cases with similar tumor characteristics (location and shape). This ensures that the generated post-operative MRI is informed by real-world surgical outcomes relevant to the specific tumor being analyzed. Furthermore, the "tumor-aware prompt adapter" integrates the tumor resection region from the retrieved post-operative MRI with the anatomical structure of the query pre-operative MRI, explicitly guiding the generation towards tumor-specific surgical results.
-
Constraint: Capture visual and structural changes resulting from resection (e.g., tissue shift, edema, hemorrhage, resection region).
- Marriage: The "visual in-context learning" component is designed precisely for this. By providing explicit visual instructions derived from the retrieved pre- and post-operative MRI pairs, the model learns to capture the complex structural transformations that occur post-surgery. The prompt adapter, by incorporating the pre-operative segmentation mask and the composite image ($Q_{comp}$), provides spatial guidance for the tumor's location and shape, ensuring that the generated image accurately depicts the resection region and surrounding anatomical changes. The iterative denoising process of the underlying Stable Diffusion model, conditioned by these specific prompts, allows for the gradual reconstruction of an image that embodies these intricate structural modifications.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches or simpler applications of existing methods based on their inability to meet the unique demands of post-operative MRI generation:
- General Image-to-Image Translation Methods (e.g., basic GANs or Diffusion models without specific guidance): The authors state that previous methods "primarily focused on preserving the structure of the source image while reflecting the style of the target image" (page 2). This is insufficient because the problem requires structural changes (resection, tissue shift) rather than mere style transfer or structure preservation. Such methods would fail to accurately depict the complex anatomical transformations.
- Established Diffusion-Based Image Editing Methods (e.g., DDPM, PBE, InstructPix2Pix, VISII, ImageBrush): The comparative study (Table 1, Fig. 2) clearly shows that these methods "fail to reflect the post-operative tumor resection region, often generating blurred and indistinct structures instead" (page 7). While they are powerful generative models, their general-purpose nature means they lack the specialized mechanisms to incorporate tumor-specific anatomical context and surgical outcomes, leading to less accurate and less distinct representations of the resection area.
- Simpler Retrieval Strategies (e.g., Random Selection, Image-Retrieval based on overall anatomical similarity): The ablation study (Table 2, Fig. 3) provides strong evidence for rejecting these alternatives.
- Random Selection: This strategy "selects the instruction that differ entirely in anatomical structure, as well as in tumor location and shape" (page 7). Such irrelevant instructions would obviously lead to poor generation quality, as they provide no meaningful guidance for the specific query.
- Image-Retrieval (cosine similarity in embedding space): This approach, while better than random, still "performs comparably to random selection, indicating its limited effectiveness for post-operative MRI generation" (page 7). The critical flaw is that it "primarily relies on overall anatomical similarity and does not consider the tumor location and shape." Since the tumor region plays a crucial role in post-operative MRI generation, ignoring these specific characteristics renders this retrieval method inadequate for the task.
In essence, the paper argues that while diffusion models provide a strong generative backbone, their application to this domain requires highly specialized conditioning and retrieval mechanisms to overcome the limitations of general-purpose image generation and editing techniques.
Mathematical & Logical Mechanism
The Master Equation
The absolute core equation that powers this paper, driving the generation of post-operative MRI, is the training objective for the Latent Diffusion Model (LDM). This loss function guides the model to accurately predict the noise component within a noisy latent representation of an image. It is formulated as follows:
$$L_{LDM} = E_{x_0, \epsilon, t} [||\epsilon - \epsilon_\theta(x_t, t, c)||_2^2]$$
Term-by-Term Autopsy
Let's tear this equation apart to understand each component's role and mathematical definition.
-
$L_{LDM}$
- Mathematical Definition: This symbol represents the overall loss function for the Latent Diffusion Model.
- Physical/Logical Role: Its purpose is to quantify the discrepancy between the actual noise added to a latent image and the noise predicted by our model. Minimizing this loss during training teaches the model how to reverse the noise-adding proces, effectively learning to generate images.
- Why it's here: This is the objective that the optimization algorithm (AdamW) will strive to minimize, thereby training the neural network.
-
$E_{x_0, \epsilon, t}$
- Mathematical Definition: This is the expectation operator, indicating an average over the distributions of $x_0$, $\epsilon$, and $t$.
- Physical/Logical Role: It ensures that the model learns to predict noise accurately across a wide range of scenarios: different initial clean latent images ($x_0$), various instances of random noise ($\epsilon$), and all possible time steps ($t$) in the diffusion process. Averaging over these stochastic elements makes the model robust and generalizable.
- Why expectation: Diffusion models are inherently probabilistic. We cannot train on a single fixed $x_0$, $\epsilon$, or $t$. Instead, we sample these variables from their respective distributions, and the expectation ensures that the model learns from the overall statistical properties of the data and noise.
-
$||\cdot||_2^2$
- Mathematical Definition: This denotes the squared L2 norm, also known as the squared Euclidean distance. For a vector $v$, $||v||_2^2 = \sum v_i^2$.
- Physical/Logical Role: It measures the magnitude of the difference between the true noise and the predicted noise. Squaring this difference serves two main purposes: it penalizes larger errors more heavily than smaller ones, and it provides a smooth, differentiable loss surface, which is crucial for gradient-based optimization.
- Why squared L2 norm: It's a standard choice for regression tasks in machine learning. It encourages the model to predict the mean of the noise distribution and is computationally efficient for gradient calculation.
-
$\epsilon$
- Mathematical Definition: A random variable representing noise, typically sampled from a standard normal distribution, $N(0, I)$, where $I$ is the identity matrix.
- Physical/Logical Role: This is the actual, true noise that was added to the clean latent representation $x_0$ at a specific time step $t$ to produce the noisy latent $x_t$. It serves as the ground truth target that the model aims to predict.
- Why it's here: The entire diffusion process is built upon the iterative addition of Gaussian noise. The model learns by trying to "undo" this exact noise.
-
$\epsilon_\theta(x_t, t, c)$
- Mathematical Definition: This represents the output of the noise prediction network, which is parameterized by $\theta$. It's a function that takes the noisy latent $x_t$, the current time step $t$, and the conditioning input $c$ as inputs.
- Physical/Logical Role: This is the model's prediction of the noise component present in $x_t$. The network $\epsilon_\theta$ is the core learning component; it's a U-Net architecture designed to estimate the noise that needs to be removed to denoise the image.
- Why it's here: This is the "brain" of the diffusion model. It's what we are training to learn the complex mapping from a noisy image to the noise itself, guided by time and context.
-
$\theta$
- Mathematical Definition: A set of learnable paramters (weights and biases) that define the noise prediction network $\epsilon_\theta$.
- Physical/Logical Role: These parameters are iteratively adjusted during the training proces to minimize the loss function. They encapsulate all the knowledge the model acquires about how to predict noise and, consequently, how to generate images.
- Why it's here: Without learnable parameters, the network would be static and unable to adapt or learn from data.
-
$x_t$
- Mathematical Definition: The noisy latent representation of an image at time step $t$. It is derived from the initial clean latent $x_0$ by applying a series of noise additions up to time $t$.
- Physical/Logical Role: This is the primary input to the noise prediction network. It represents the current state of the image in the forward diffusion process, containing a mixture of the original image signal and accumulated noise. The network must infer the noise from this corrupted input.
- Why it's here: It's the observation from which the model must deduce the noise. The level of noise in $x_t$ depends on $t$.
-
$t$
- Mathematical Definition: A discrete time step, typically an integer ranging from 1 to $T$, where $T$ is the total number of diffusion steps.
- Physical/Logical Role: This input provides crucial information to the noise prediction network about the current stage of the diffusion process. The amount of noise in $x_t$ is directly related to $t$. Knowing $t$ helps the network understand how much noise to expect and how to scale its prediction.
- Why it's here: Diffusion models are inherently time-dependent. The noise distribution changes at each step, so the model needs to be aware of the current "time" to make an accurate prediction.
-
$c$
- Mathematical Definition: The conditioning input, which in this paper is the
Ptumorembedding.Ptumoris formed by concatenatingpsegandpcomp.psegis a 1024-dimensional latent representation derived from the query pre-operative segmentation mask $M_{pre}^Q$.pcompis a 1024-dimensional latent representation derived from the composite image $Q_{comp}$.- $Q_{comp}$ itself is constructed via a compositing operation: $Q_{comp} = M_{bbox}^{I_{post}} \cdot I_{post} + (1 - M_{bbox}^{I_{post}}) \cdot Q_{pre}$.
- $I_{post}$: The post-operative MRI retrieved from a similar case.
- $Q_{pre}$: The query pre-operative MRI.
- $M_{bbox}^{I_{post}}$: A bounding box mask derived from the segmentation mask of the retrieved post-operative MRI, highlighting the tumor resection region.
- Physical/Logical Role: This is the "tumor-aware" guidance that steers the generation process.
psegprovides information about the pre-operative tumor's location and shape from the query.pcompintegrates the resection pattern from a similar retrieved post-operative MRI ($I_{post}$) onto the anatomical context of the query pre-operative MRI ($Q_{pre}$). Together,Ptumorexplicitly instructs the model on tumor-specific characteristics and desired post-operative changes. - Why it's here: This is the key mechanism for achieving "tumor-aware visual in-context learning." It allows the model to generate highly specific and accurate post-operative MRIs that reflect realistic surgical outcomes based on the input pre-operative scan and similar historical cases.
- Mathematical Definition: The conditioning input, which in this paper is the
Step-by-Step Flow
Imagine a single abstract data point, representing a clean pre-operative MRI, embarking on a journey through this mathematical engine to become a generated post-operative MRI.
-
Initial Encoding: First, a clean pre-operative MRI image, $Q_{pre}$, is fed into a Variational Autoencoder (VAE) encoder. This transforms the high-dimensional pixel data into a compact, lower-dimensional latent representation, $x_0$. This $x_0$ is the "ground truth" latent post-operative MRI we aim to generate.
-
Forward Diffusion (Training): To train the system, $x_0$ is subjected to a forward diffusion proces. Over a series of discrete time steps, $t$ (from 1 to $T$), progressively more Gaussian noise $\epsilon$ is added to $x_0$. This creates a sequence of increasingly noisy latents, $x_1, x_2, \dots, x_T$, where $x_T$ is essentially pure noise. For any given training iteration, a random time step $t$ is chosen, and the corresponding noisy latent $x_t$ is prepared.
-
Conditioning Input Assembly: Simultaneously, the "tumor-aware prompt adapter" is at work.
- The query pre-operative segmentation mask, $M_{pre}^Q$, is processed by an encoder ($E_{seg}$) to produce a latent representation
pseg. This captures the pre-operative tumor's location and shape. - A "composite image" $Q_{comp}$ is created. This involves taking the retrieved post-operative MRI ($I_{post}$) and using its bounding box mask ($M_{bbox}^{I_{post}}$) to "paste" the resection region onto the query pre-operative MRI ($Q_{pre}$). This $Q_{comp}$ is then fed into another encoder ($E_{comp}$) to produce
pcomp, which represents the integrated tumor resection information. - Finally,
psegandpcompare concatenated to form the comprehensive conditioning input, $c = P_{tumor}$. This $P_{tumor}$ is a rich embedding containing both pre-operative tumor context and retrieved post-operative resection patterns.
- The query pre-operative segmentation mask, $M_{pre}^Q$, is processed by an encoder ($E_{seg}$) to produce a latent representation
-
Noise Prediction: Now, the noisy latent $x_t$, the current time step $t$, and the conditioning input $c$ are all fed into the noise prediction network, $\epsilon_\theta$. This network, typically a U-Net, analyzes $x_t$ in light of $t$ (how noisy it should be) and $c$ (what kind of post-operative changes are expected) to predict the noise component, $\epsilon_{pred} = \epsilon_\theta(x_t, t, c)$.
-
Loss Calculation: The predicted noise $\epsilon_{pred}$ is then compared to the actual noise $\epsilon$ that was added to $x_0$ to create $x_t$. The squared L2 norm of their difference, $||\epsilon - \epsilon_{pred}||_2^2$, is computed. This value represents how "wrong" the model's noise prediction was for this specific sample.
-
Model Update: This calculated loss is then averaged over many such samples (as indicated by the expectation $E_{x_0, \epsilon, t}$). This average loss is used to compute gradients with respect to the network's paramters $\theta$. An optimizer (AdamW) uses these gradients to adjust $\theta$, nudging the network to make more accurate noise predictions in future iterations. This iterative process continues until the model converges.
-
Reverse Diffusion (Inference): During inference, the process reverses. We start with a pure noise latent $x_T$ (or a noisy version of a blank image). The conditioning input $c = P_{tumor}$ is generated from the query $Q_{pre}$ and retrieved instructions, just as in training. The noise prediction network $\epsilon_\theta$ iteratively predicts the noise at each step $t$ (from $T$ down to 1), and this predicted noise is subtracted from $x_t$ to gradually denoise it into $x_{t-1}$. This iterative denoising, guided by $c$, reconstructs the latent representation of the desired post-operative MRI.
-
Final Decoding: Once the denoising process yields the clean latent $x_0$, it is passed through the VAE decoder to transform it back into the pixel space, resulting in the final generated post-operative MRI, $Q_{post}$.
Optimization Dynamics
The mechanism learns and updates its internal state through a standard gradient-based optimization process, specifically designed for diffusion models.
-
Loss Landscape and Gradients: The core of the learning is the $L_{LDM}$ loss function, which measures the squared L2 distance between the true noise $\epsilon$ and the model's predicted noise $\epsilon_\theta(x_t, t, c)$. This squared L2 norm creates a smooth, differentiable loss landscape. While the overall landscape for a deep neural network is highly non-convex with many local minima and saddle points, the smoothness of the L2 loss allows for effective navigation using gradient descent. The gradients of $L_{LDM}$ with respect to the network's learnable parameters $\theta$ are computed via backpropagation. These gradients indicate the direction and magnitude by which each parameter should be adjusted to reduce the prediction error.
-
Iterative Parameter Updates: The model's parameters $\theta$ are updated iteratively. In each training step, a mini-batch of data is sampled, consisting of clean latent images $x_0$, random noise $\epsilon$, and time steps $t$. For each sample, the forward diffusion proces generates $x_t$, the noise prediction network $\epsilon_\theta$ makes its prediction, and the loss is calculated. The gradients are then accumulated across the mini-batch, and the AdamW optimizer uses these aggregated gradients to update $\theta$.
-
AdamW Optimizer: The paper employs the AdamW optimizer. AdamW is an adaptive learning rate optimization algorithm that builds upon Adam by decoupling weight decay from the L2 regularization term in the loss. It maintains per-parameter learning rates and uses estimates of first and second moments of the gradients (momentum-like terms). This allows it to adaptively adjust the step size for each parameter, accelerating convergence in relevant directions and dampening oscillations. Its robustness makes it well-suited for complex, high-dimensional models like diffusion U-Nets.
-
Cosine Learning Rate Scheduler: To further refine the optimization, a cosine learning rate scheduler is used. This scheduler gradually decreases the learning rate following a cosine curve over the course of training. Initially, the learning rate is high to allow for rapid exploration of the loss landscape. As training progresses, the learning rate slowly decays, enabling finer adjustments to the parameters and helping the model settle into a good minimum without overshooting or oscillating excessively, which often leads to better final performance and stability.
-
Classifier-Free Guidance (Inference Enhancement): While not directly part of the training loss, Classifier-Free Guidance (CFG) significantly impacts the model's behavior during inference. CFG enhances the influence of the conditioning input $c$ (our
Ptumor). During inference, the model performs two noise predictions for each step: one with the conditioning $c$ and one without (unconditional). The final noise prediction used for denoising is a weighted interpolation of these two predictions. By increasing the weight of the conditional prediction, the model can generate images that adhere more strongly to the specific instructions provided byPtumor, ensuring the generated post-operative MRI accurately reflects the tumor-specific resection and anatomical changes. This technique allows for a trade-off between adherence to the prompt and diversity of generated images.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate their novel approach for pre-to-post operative MRI generation, the authors architected a comprehensive experimental setup. They leveraged the publicly available LUMIERE [28] dataset, which comprises 71 paired pre- and post-operative T1-weighted MRI scans of glioblastoma patients, all normalized to MNI space. From these 3D scans, 2D axial slices containing tumors with corresponding segmentation masks were extracted, resulting in a dataset split into 2,530 training slices and 205 testing slices.
The core of their method, which integrates tumor-guided retrieval and a tumor-aware prompt adapter within a Stable Diffusion [24] framework, was trained using the AdamW [14] optimizer with a learning rate of $10^{-5}$ and a cosine scheduler. For feature extraction from composite images, they employed the MedSAM [17] image encoder. The tumor-guided retrieval mechanism was configured to select the top-15 most similar triplets during training (from which one was randomly chosen per batch as instruction) and the single most similar triplet ($k=1$) for inference, ensuring that the model received highly relevant visual context.
The "victims" (baseline models) against which their method was ruthlessly tested were several established diffusion-based image editing techniques, each adapted to the task:
- DDPM [12]: A foundational denoising diffusion probabilistic model, trained by simply concatenating pre- and post-operative MRI.
- PBE [30] (Paint by Example): This method was provided with randomly selected resection regions from post-operative MRI in the training dataset as exemplar images.
- InstructPix2Pix [3] and VISII [21]: These models followed DDPM's concatenation approach but were additionally guided by the text instruction "Post-operative glioblastoma MRI".
- ImageBrush [31]: Another visual in-context learning method, which received random instructions during its process.
The performance of all models was quantitatively assessed using a suite of standard image quality metrics: Structural Similarity Index Measure (SSIM) and Multi-Scale SSIM (MS-SSIM), where higher values indicate better similarity; Peak Signal-to-Noise Ratio (PSNR), also favoring higher values; and Learned Perceptual Image Patch Similarity (LPIPS), where lower values denote greater perceptual similarity.
What the Evidence Proves
The evidence presented in this paper definitively proves the superiority and efficacy of the proposed tumor-aware visual in-context learning approach for generating post-operative MRI. The authors' method consistently outperformed all baseline models across every quantitative metric, providing undeniable hard evidence that their core mechanisms—tumor-guided retrieval and the tumor-aware prompt adapter—actually work in reality.
In the comparative study (Table 1), "Ours" achieved the highest SSIM (0.7001), MS-SSIM (0.7814), and PSNR (31.67), while also securing the lowest LPIPS (0.1845). These results are not marginal improvements; for instance, the SSIM score of 0.7001 for "Ours" is a substantial leap compared to DDPM's 0.5744, PBE's 0.6695, InstructPix2Pix's 0.6649, VISII's 0.6682, and ImageBrush's 0.6718. This quantitative dominance underscores that the model is generating images that are both structurally and perceptually closer to real post-operative MRIs.
Qualitatively, as illustrated in Fig. 2, the generated images from "Ours" are visibly the most similar to the real post-operative MRIs. Crucially, the baseline models like DDPM, PBE, InstructPix2Pix, and VISII often failed to accurately reflect the tumor resection region, frequently producing blurred or indistinct structures. Even ImageBrush, which also uses visual in-context learning, showed visibly inferior performance. This visual evidence is a powerful testament to the proposed method's ability to capture the complex structural changes resulting from surgical resection, a critical aspect that generic image editing methods struggle with. The definitive proof lies in the model's capacity to generate a clear, anatomically plausible resection cavity, which is paramount for clinical utility.
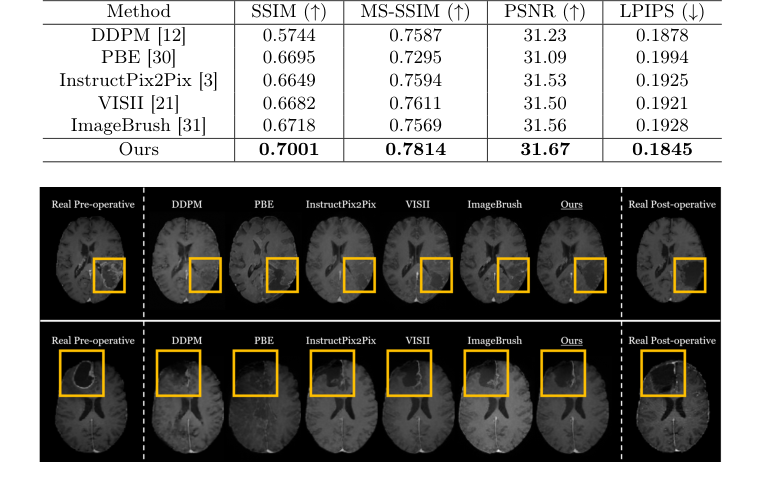 Figure 2. Qualitative comparison of post-operative MRI generation with state-of-the-art image editing methods
Figure 2. Qualitative comparison of post-operative MRI generation with state-of-the-art image editing methods
The ablation study further solidified these claims by dissecting the contribution of each novel component. The "Effectiveness of tumor-guided retrieval" analysis (Table 2, Fig. 3) showed that "Ours" (tumor-guided retrieval) significantly outperformed "Random" selection and "Image-retrieval" strategies. The image-retrieval, based on general image embedding similarity, performed only marginally better than random selection, highlighting its limitation in not considering the crucial tumor location and shape. This ruthlessly proves that explicitly guiding retrieval by tumor-specific characteristics is essential for generating accurate post-operative MRIs.
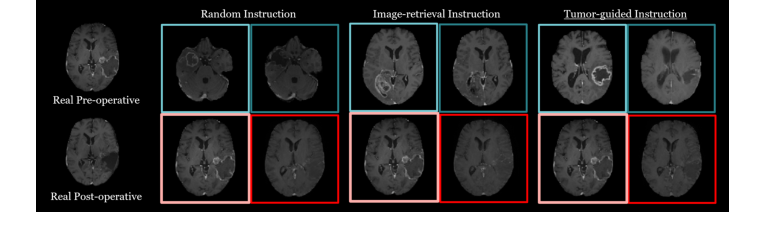 Figure 3. Qualitative results from the ablation study comparing retrieval strategies for visual in-context learning in post-operative MRI generation
Figure 3. Qualitative results from the ablation study comparing retrieval strategies for visual in-context learning in post-operative MRI generation
Similarly, the "Effectiveness of tumor-aware prompt adapter" ablation demonstrated the critical role of both the composite image ($P_{comp}$) and the segmentation mask ($P_{seg}$) components. Removing either ($P_{seg}$ or $P_{comp}$) led to a noticeable degradation in performance (Table 2), with the absence of $P_{comp}$ causing an even more significant drop. This confirms that the prompt adapter, by integrating both the tumor resection region and anatomical structure information, is indispensable for capturing tumor-specific surgical outcomes and enabling precise post-operative MRI generation. The evidence is clear: the combination of tumor-guided retrieval and the tumor-aware prompt adapter is what enables this method to overcome the inherent challenges of medical image translation involving significant structural alterations.
Limitations & Future Directions
While the proposed method demonstrates outstanding performance in generating post-operative MRI, it's important to acknowledge certain limitations and consider avenues for future development. The paper, to be honest, doesn't explicitly list a "Limitations" section, but we can infer some from the methodology and results.
One clear limitation is the reliance on the LUMIERE dataset, which, while publicly available, consists of 71 paired scans. While this is a good start, the diversity and size of medical imaging datasets are often critical for robustness. The model's performance might be sensitive to the quality and representativeness of the retrieved cases, especially if a query MRI presents a highly unusual tumor morphology or surgical outcome not well-represented in the database. Furthermore, the current approach processes 2D axial slices. While effective, a full 3D volumetric generation could offer a more comprehensive and clinically relevant output, though it would introduce significant computational challenges.
Looking ahead, the findings in this paper open up several exciting and diverse discussion topics for further development and evolution:
-
Expanding Clinical Scope and Generalizability: How can this method be adapted and validated for other types of brain tumors (e.g., meningiomas, metastases) or even different anatomical regions requiring surgical intervention? What modifications would be necessary to handle diverse MRI sequences (e.g., T2, FLAIR) or multi-modal inputs? A crucial next step would be to test the model's robustness across different patient populations, scanner manufacturers, and image acquisition protocols to ensure its broad applicability in real-world clinical settings.
-
Dynamic Prediction and Longitudinal Modeling: Currently, the model generates a single post-operative MRI. Could this be extended to predict a sequence of post-operative MRIs over time? This would involve modeling the dynamic evolution of post-surgical changes, such as the resolution of edema, potential tumor recurrence, or long-term treatment effects. Such a capability could provide invaluable insights for longitudinal patient monitoring and adaptive treatment planning.
-
Uncertainty Quantification and Explainable AI: In medical applications, knowing when a model is uncertain is as important as its prediction. How can we integrate robust uncertainty quantification into the generative process, perhaps by highlighting regions of the generated MRI where the model's confidence is low? Moreover, developing explainable AI techniques to show why a particular post-operative MRI was generated (e.g., which retrieved cases or features were most influential) would significantly increase clinician trust and adoption.
-
Interactive Surgical Planning and "What-If" Scenarios: Imagine a neurosurgeon being able to interactively define a hypothetical resection margin on a pre-operative MRI and immediately visualize the predicted post-operative outcome. This could transform surgical planning by allowing for "what-if" scenario testing, optimizing resection extent to balance tumor removal with preservation of critical brain functions. This would require real-time generation capabilities and intuitive user interfaces.
-
Integration with Functional and Connectomic Data: Beyond anatomical changes, surgical resections can impact brain function and connectivity. Could the generative model be extended to predict changes in functional MRI (fMRI) or diffusion tensor imaging (DTI) data post-operatively? This would provide a more holistic view of surgical impact, aiding in predicting neurological deficits and guiding rehabilitation strategies.
-
Ethical Implications and Bias Mitigation: As synthetic medical images become more sophisticated, the ethical considerations grow. How do we ensure that the training data is diverse enough to prevent biases that could lead to suboptimal predictions for underrepresented patient groups? What are the regulatory pathways for deploying such generative models in clinical practice, and how do we establish clear guidelines for their responsible use to avoid misinterpretation or over-reliance?
These discussions highlight the immense potential of this research, pushing beyond mere image generation towards a future where AI-driven predictive modeling can profoundly impact personalized medicine and surgical outcomes.
 Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
Table 2. An ablation study on different retrieval strategies and the effectiveness of the two prompts in our tumor-aware prompt adapter. We evaluate three retrieval strategies: Random (random selection), Image-retrieval (retrieval based on cosine similarity in the image embedding space), and Ours (tumor-guided retrieval). Additionally, we assess the impact of two prompts: pseg (segmentation mask of the input pre-operative MRI) and pcomp (composite image)
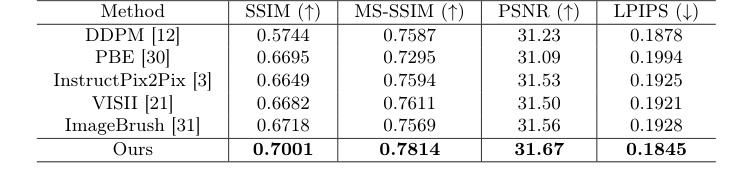 Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Table 1. Comparison of post-operative MRI generation results with state-of-the-art image editing methods
Connections to Other Fields
Mathematical Skeleton
The pure mathematical core of this work lies in the conditional generation of images using a latent diffusion model, where the conditioning signal is constructed through a similarity-based retreival process utilizing the Intersection over Union metric and a novel image blending operation to form a comprehensive prompt embedding.
Adjacent Research Areas
Latent Diffusion Models for Image Synthesis
This work directly leverages the mathematical framework of Latent Diffusion Models (LDMs) for its core generatve process. The paper employs a Stable Diffusion model, which operates by iteratively denoising data in a latent space. The underlying mathematical mechanism, including the forward process of adding Gaussian noise and the reverse process of learning to predict and remove this noise, is identical to established LDM theory. The training objective, formulated as $L_{LDM} = E_{x_0, \epsilon, t} [||\epsilon - \epsilon_\theta(x_t, t, c)||^2]$, is a standard L2 loss for noise prediction, where $c$ represents the conditioning input derived from the tumor-aware prompt adapter. This direct application of LDM principles for complex image-to-image translation tasks, specifially in medical imaging, highlights its connection to the broader field of generative AI.
(Rombach et al., 2022, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition)
Content-Based Medical Image Retrieval
The "tumor-guided retrieval" component of the proposed method is a specialized application of Content-Based Image Retrieval (CBIR). The system identifies similar pre-operative MRI cases by computing the Intersection over Union (IoU) between the segmentation mask of the query tumor and those in a database. IoU, a fundamental metric for assessing the overlap between two sets, serves as the primary mathematical object for quantifying similarity in this context. This approach allows for the retrieval of images based on specific visual features (tumor location and shape), which is a hallmark of CBIR systems, particularly those tailored for medical diagnostics and planning where precise anatomical or pathological similarity is crucial.
Visual In-Context Learning for Generative Models
The paper's "tumor-aware visual in-context learning" and "tumor-aware prompt adapter" draw a clear connection to the emerging field of visual in-context learning, inspired by advancements in large language models. The method constructs a grid-like visual instruction from retrieved pre- and post-operative MRI pairs and the query pre-operative MRI. This visual input, combined with a structured prompt embedding ($P_{tumor}$) derived from image composition and segmentation masks, conditions the generative model. This strategy mirrors the concept of providing task-relevant examples and explicit instructions within the input to guide a model's output without requiring extensive fine-tuning, thereby enabling more flexible and context-aware image generation.
(Bar et al., 2022, Advances in Neural Information Processing Systems 35)