収縮ユニタリと古典シャドウ・トモグラフィ
Here's a breakdown of the abstract, designed for a zero-base reader:
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題は、急速に進展する量子情報および量子計算の分野における量子状態の特性評価という根本的な課題に端を発する。量子デバイスが数百、あるいはそれ以上の量子ビットを含む規模にまで成長するにつれて、従来の「完全量子状態トモグラフィ」は非現実的になる。これは、システムサイズに対して指数関数的な数の測定を必要とし、大規模応用においてはリソース集約的かつ計算上実行不可能になるためである。
この問題に対処する上で重要なブレークスルーは、2018年にAaronsonらによって最初に提案された「古典シャドウ・トモグラフィ」の登場であった[12]。このアプローチは、「サンプル複雑性」—すなわち、必要な測定回数—を劇的に削減し、完全な再構築を必要とせずに量子状態の多くの性質を予測することを可能にした。古典シャドウ・トモグラフィは通常、量子状態にランダムなユニタリ操作を適用し、それを測定し、これらの「古典的スナップショット」を使用して性質を推測することを含む。
古典シャドウ・トモグラフィによってかなりの進歩がなされたにもかかわらず、重要な限界が残存していた。それは、サイズ $k$ の局所演算子の性質を抽出するために、サンプル複雑性を $2^k$ のスケーリング以下に低減することである。特にランダム・クリフォード回転に依存する従来のメソッドは、一般的にサンプル複雑性が $2^k$(または、未知の演算子位置を考慮すると $k \times 2^k$)でスケーリングする。この $2^k$ のスケーリングは、依然として大きな「ペインポイント」であり、より大きな $k$ に対しては依然として相当なリソースを必要とし、複雑な量子多体系の効率的な特性評価を妨げている。したがって、本論文の著者らは、この $2^k$ の障壁を克服し、より効率的なスケーリングを達成するために、古典シャドウ・トモグラフィの枠組み内で新しい戦略を探求する動機を得た。
直感的な領域用語
ゼロベースの読者が核心的な概念を把握できるように、論文中の専門用語を日常的なアナロジーに翻訳して以下に示す。
- 量子状態トモグラフィ (QST): 神秘的で複雑な物体があり、その物体のすべて—正確な形状、内部構造、そしてあらゆる微細な詳細—を知りたいと想像してほしい。QSTは、その物体の完全で高解像度の3Dスキャンを取るようなものである。それは完璧な設計図を与えるが、非常に大きかったり複雑な物体にとっては、信じられないほど時間と費用がかかる。
- 古典シャドウ・トモグラフィ: 完全な3Dスキャンではなく、神秘的な物体について、その重さ、対称性があるかどうか、あるいは浮くかどうかなど、いくつかの特定の事柄だけを知る必要があると想像してほしい。古典シャドウ・トモグラフィは、異なる角度からいくつかの慎重に選ばれた「影」や2D写真を撮るようなものである。これらから物体全体を再構築することはできないが、完全なスキャンよりもはるかに少ない労力で、その性質の多くを正確に予測できる。
- サンプル複雑性: これは、信頼できる答えを得るために、実験を何回繰り返すか、あるいは測定を何回行う必要があるかを指す。都市の人々の平均身長を調べようとしている場合、サンプル複雑性は測定する必要のある人数である。サンプル複雑性が低いということは、良い推定値を得るために少ない測定で済むことを意味する。
- パウリ文字列演算子: これは、量子システムに投げかけることができる非常に具体的な「質問」と考えてほしい。例えば、「1番目の量子ビットは特定の方向にスピンアップし、かつ3番目の量子ビットはスピンダウンしているか?」というような質問である。パウリ文字列は、これらの単純な質問をシステムの異なる部分に適用したシーケンスである。文字列の「サイズ」は、質問に関与する量子ビットの数を示す。
- 収縮ユニタリ: これは、まるで「データ圧縮機」や「単純化器」のような、特別な種類の量子操作である。その仕事は、複雑なパウリ文字列演算子を取り込み、それらを「小さく」あるいはより単純にする。これらの演算子を単純化することによって、収縮ユニタリは量子システムの性質を測定することをはるかに容易かつ迅速にし、それによって全体のサンプル複雑性を低減する。
記法表
| 記法 | 説明 |
|---|---|
| $\hat{O}$ | 期待値の推定対象となるパウリ文字列演算子(オブザーバブル)。 |
| $\rho$ | システムの量子状態。 |
| $k$ | 局所演算子のサイズ / $\hat{O}$ が作用するサブシステム内の量子ビット数。 |
| $N$ | 量子システム内の総量子ビット数。 |
| $\hat{U}$ | 量子状態に適用される一般的なグローバルユニタリ操作。 |
| $\hat{U}_{ct}$ | 2量子ビット収縮ユニタリから構築された、$k$ 量子ビット用の完全な収縮ユニタリ。 |
| $\hat{U}_{ij}$ | 量子ビット $i$ および $j$ に作用する2量子ビット収縮ユニタリ。$\exp(i\frac{\pi}{4} \hat{Z}_i\hat{Z}_j)$ と定義される。 |
| $\mathcal{E}_U$ | $\hat{U}$ がサンプリングまたは構築されるユニタリアンサンブル(例:ランダム・クリフォード、収縮ユニタリ)。 |
| $||\hat{O}||^2_{\mathcal{E}_U}$ | アンサンブル $\mathcal{E}_U$ で平均されたオブザーバブル $\hat{O}$ のシャドウノルム二乗。サンプル複雑性を直接定量化する。 |
| $w(\hat{O}_U)_{\mathcal{E}_U}$ | 進化演算子 $\hat{O}_U = \hat{U}\hat{O}\hat{U}^\dagger$ のパウリ重み。アンサンブル $\mathcal{E}_U$ で平均される。 |
| $\pi(m)_{\mathcal{E}_U}$ | 進化演算子 $\hat{O}_U$ のサイズ分布。$\hat{O}_U$ がサイズ $m$ を持つ確率を表す。 |
| $m$ | 演算子サイズ。パウリ文字列内の非恒等パウリ演算子の数として定義される。 |
| $N_{xy}$ | パウリ文字列 $\hat{O}$ における $\hat{X}$ および $\hat{Y}$ 演算子の総数。 |
| $\sigma_U(z)$ | 単一の測定結果 $z$ から再構築された密度行列の古典的スナップショット。 |
| $M$ | 期待値の推定のために収集された古典的スナップショット(測定)の数。 |
| $D[\langle \hat{O} \rangle]$ | $\hat{O}$ の期待値の分散。 |
問題定義と制約
コア問題の定式化とジレンマ
入力/現在の状態: 量子状態特性評価の現在の状況は、複雑な量子多体系の状態を効率的に記述するという課題に支配されている。完全な量子状態トモグラフィは、システムサイズとともに指数関数的に増加する測定回数を必要とし、大規模量子デバイスには非現実的であるため、古典シャドウ・トモグラフィのような代替手法が重要となる。この技術は、測定前にランダム・クリフォード回転を用いることで、状態の性質を推定するために必要な測定回数であるサンプル複雑性を低減する。しかし、これらの進歩にもかかわらず、依然として重要な課題が残っている。それは、サイズ $k$ の非連続な局所演算子の抽出のために、サンプル複雑性を $2^k$ 以下に低減することである。この $2^k$ のスケーリングは、実用的な応用には依然として高すぎる。
出力/目標状態: 本論文の主な目的は、量子状態の性質、特にサイズ $k$ の局所演算子の推定のためのサンプル複雑性を大幅に小さくすることである。著者らは、この複雑性を現在の $2^k$ のスケーリングから、改善された $\sim 1.8^k$ に低減することを目指している。この低減は、局所的にランダムでグローバルに決定論的なユニタリ操作を戦略的に組み合わせた新しいプロトコルを通じて達成される。
正確に欠けているリンク / 数学的ギャップ: 本論文が取り組むコアとなる数学的ギャップは、進化パウリ文字列演算子 $\hat{O}_U = \hat{U}\hat{O}\hat{U}^\dagger$ のサイズ分布をより効率的に「収縮」できる最適なグローバルユニタリ操作 $\hat{U}$ の不在である。既存の古典シャドウ・トモグラフィプロトコルは、しばしば最大スクランブルランダムユニタリ(ランダム・クリフォードゲートなど)に依存しており、これはシャドウノルムのスケーリングが $2^k$ になる。本論文は、ランダム・クリフォードユニタリよりも演算子サイズを効果的に低減できる決定論的グローバルユニタリ、「収縮ユニタリ」の発見を欠けているリンクとして特定している。数学的には、シャドウノルム $||\hat{O}||_{\mathcal{E}_U}^2$ を最小化する $\hat{U}$ を見つけることが課題である。これは、進化演算子 $\hat{O}_U$ の演算子サイズ分布 $\pi(m)$ に直接関連しており、方程式 (1) で表現される。
$$||\hat{O}||_{\mathcal{E}_U}^2 = w(\hat{O}_U)_{\mathcal{E}_U}, \quad w(\hat{O}_U)_{\mathcal{E}_U} = \sum_m \frac{\pi(m)_{\mathcal{E}_U}}{3^m}$$
本論文の貢献は、サイズ分布 $\pi(m)$ をより小さな $m$ の値に優先的にピークさせる $\hat{U}$ を見つけることであり、それによってシャドウノルム、ひいては必要なサンプル複雑性を低減することである。
痛みを伴うトレードオフ / ジレンマ: 古典シャドウ・トモグラフィの研究者を歴史的に制約してきた中心的なジレンマは、一般的で偏りのない測定スキームの達成とサンプル複雑性の最小化との間の固有のトレードオフである。最大スクランブルランダムユニタリは、すべての演算子が同等に測定されることを保証するために使用され、局所基底依存性を効果的に排除する。このアプローチは一般性と堅牢性を提供するが、演算子サイズの二項分布と $2^k$ のシャドウノルムにつながる。痛みを伴うトレードオフは、この「最大スクランブル」が広範な適用性を保証する一方で、特に局所パウリ文字列など、すべての種類の演算子のサンプル複雑性を低減するための最も効率的な戦略ではない可能性があるということである。著者らの重要な洞察は、「収縮ユニタリ」を組み込んだハイブリッドランダム・ディターミニスティックプロトコルが、このトレードオフを回避できるということである。このアプローチは、純粋にランダムな方法よりも効率的に演算子サイズを選択的に収縮させ、それによって一般性と測定効率との間のより良いバランスを達成する。
制約と失敗モード
量子状態を効率的に特性評価する問題、特に提案された収縮ユニタリアプローチを用いた場合、いくつかの厳しく現実的な制約によって制限される。
物理的制約:
* 指数関数的なリソーススケーリング: 根本的な物理的制約は、完全量子状態トモグラフィがシステムサイズとともに指数関数的に増加する測定回数を必要とすることである。これは、数百量子ビットを超える量子デバイスには非現実的であり、古典シャドウ・トモグラフィのような代替手法を必要とする。
* ハードウェア実装可能性: 提案された収縮ユニタリは、現在および近い将来の量子計算プラットフォームで実用的に実装可能でなければならない。著者らは、彼らの収縮ユニタリが「原子アレイ量子計算プラットフォームの利点と完全に一致し、原子アレイ量子プロセッサで容易に実現される」と強調している。これは、既存のハードウェアで効率的に実行できるゲートと操作のタイプに厳密な制約があることを示唆している。
* 回路複雑性と深さ: 実用的な展開のために、収縮ユニタリ $\hat{U}_{ct}$ は低い回路複雑性を持たなければならない。$k$ 量子ビットシステムに対して $\sim k^2$ ゲートを含むように見えるかもしれないが、論文では「決定論的で相互可換な2量子ビットゲートのみに依存」し、原子アレイプラットフォームではその並列ゲート能力により「最大 $k-1$ ステップの物理操作」で実装できると述べている。接続性が制限されたプラットフォーム(超伝導量子ビットなど)の場合、著者らは単一の補助量子ビットを追加することで $k$ ステップの局所ゲートに分解できることを示しており、回路の深さが $k$ に対して線形に保たれることを保証している。これらは、プロトコルの実現可能性にとって重要な制約である。
計算的制約:
* サンプル複雑性目標: 主要な計算的制約は、サンプル複雑性を $2^k$ からより管理しやすいスケーリング、具体的には $\sim 1.8^k$ に低減するという至上命令である。より大きなシャドウノルムは、予測分散を低減するために直接的に高い数の古典的スナップショットを必要とし、それによってデータ取得と処理に関連する計算コストが増加する。
* 古典シミュレーション限界: 現在の量子プラットフォームで達成可能な $k \sim 100$ 量子ビットの量子システムの場合、古典シミュレーションは「従来の方法ではシミュレーションが不可能」になる。これは、提案された量子ソリューションが、古典的な検証や完全なシミュレーションが実行可能なオプションではないため、実際の量子ハードウェアで有用であるのに十分効率的でなければならないことを意味する。
データ駆動型制約と失敗モード:
* 演算子位置の事前知識: 収縮ユニタリプロトコルの初期定式化は、演算子が作用する正確な位置の事前知識を仮定している。これは、多くの実世界のアプリケーション(例:エネルギー推定)では、この情報がしばしば未知であるため、重大なデータ駆動型制約である。
* 単純な拡張の失敗: 演算子位置の事前知識がないシナリオへの収縮ユニタリの単純な拡張(システム全体に適用することによって)は、逆説的に、ランダム・クリフォードプロトコルよりもさらに大きなシャドウノルム(総量子ビット $N$ に対して $\sim 2^N$)につながる。これは、著者らが演算子位置が未知の場合に効率を維持するために「スライディングトリック」で対処する重大な失敗モードを表す。このトリックなしでは、収縮ユニタリの利点は広範な問題クラスに対して失われるだろう。
* 非連続な局所演算子: 問題は、特に「サイズ $k$ の非連続な局所演算子の特性評価」に焦点を当てている。これは、ソリューションが、連続的または単純な構造ではない演算子に対しても堅牢かつ効果的であることを意味する。
なぜこのアプローチなのか
選択の必然性
本論文の著者らは、量子情報における根本的な障害に直面していた。複雑な量子状態を完全に特性評価するプロセス、すなわち完全量子状態トモグラフィは、システムサイズに対して指数関数的な数の測定を必要とする。この指数関数的なスケーリングは、現在構築されているより大きな量子デバイスには非現実的である。古典シャドウ・トモグラフィ(CST)は、測定前にランダム・クリフォード回転を用いることでサンプル複雑性を劇的に削減し、重要なブレークスルーとなった。しかし、この進歩にもかかわらず、重要な課題が残っていた。それは、サイズ $k$ の非連続な局所演算子の性質を推定するために、サンプル複雑性を $2^k$ 以下に低減することであった。
著者らが従来の「最先端」(SOTA)手法、例えば標準的なランダム・クリフォードプロトコルが不十分であると認識した正確な瞬間は、この持続的な $2^k$ スケーリングを特定したときであった。ランダム・クリフォードユニタリのスクランブル効果は、演算子重みを多くのパウリ文字列に分散させるにもかかわらず、結果として生じるシャドウノルム(サンプル複雑性の尺度)は依然として $2^k$ でスケーリングした。これは、より大きな $k$ に対して、必要な測定回数が依然として法外に高いことを意味した。著者らは明確に次のような問いを提起した。「グローバルユニタリの他の選択肢が存在し、最大スクランブルランダムユニタリを上回り、 $\sim 2^k$ よりも小さいシャドウノルムをもたらすことができるか?」この問い自体が、既存手法の不十分さと、新しいアプローチの必要性を浮き彫りにしている。「収縮ユニタリ」は、演算子サイズをより効率的に低減し、それによってより低いシャドウノルムを達成するように特別に設計された、この問いに対する直接的な答えとして考案された。
比較優位性
収縮ユニタリアプローチは、単なる数値的改善を超えて、古典シャドウ・トモグラフィにおける以前のゴールドスタンダードに対する質的な優位性を提供する。その主な構造的利点は、演算子サイズを決定論的に収縮させる能力にある。演算子を最大スクランブルするランダム・クリフォードユニタリとは異なり、これは広範な二項サイズ分布を生成し、ピークを $3k/4$ 付近に持ち、シャドウノルムは $2^k$ になる。一方、収縮ユニタリは、特定のパウリ文字列演算子のサイズを積極的に低減するように設計されている。例えば、サイズ2のパウリ演算子4つをサイズ1の演算子に変換できる。この標的化された収縮は、より小さな演算子サイズにピークを持つサイズ分布(例えば、奇数 $N_{XY}$ に対して $m/k \approx 2/3$、偶数 $N_{XY}$ に対して $k$ でのデルタピーク)をもたらし、シャドウノルム理論によれば、直接的にサンプル複雑性の低減につながる。
この構造的利点は非常に大きい。サンプル複雑性を $\sim 2^k$(ランダム・クリフォードの場合)から $\sim 1.8^k$(または演算子位置が未知の場合、$k \times 1.8^k$)に低減する。$k \sim 100$ 量子ビットのシステムでは、これは必要なサンプルリソースにおいて「10^4倍以上の改善」に相当する。さらに、本論文は、この方法が「量子ノイズに対する堅牢性を示す」と強調しており、ノイズの多い環境でもそのスケーリング利点を維持している。これは、実際の量子デバイスにとって重要な質的利点である。もう一つの重要な構造的利点は、その低い回路複雑性である。決定論的で相互可換な2量子ビットゲートのみに依存しており、現在の量子ハードウェアに非常に適している。
制約との整合性
選択された収縮ユニタリ法は、効率的な量子状態特性評価の厳格な要件と完全に整合している。コアとなる問題の制約は、完全量子状態トモグラフィの指数関数的な測定コストと、多体系量子状態の性質を推定するためのサンプル複雑性を低減する必要性である。収縮ユニタリは、 $\sim 1.8^k$(またはスライディングトリックで $k \times 1.8^k$)のサンプル複雑性スケーリングを達成することで、これを直接的に解決する。これは、以前の手法である $\sim 2^k$ のスケーリングからの大幅な改善である。この「問題の厳しい要件と解決策のユニークな特性との結婚」は、「トモグラフィ効率を向上させるために演算子サイズを低減する上でより効率的である」という設計目標に明らかである。
理論的な効率を超えて、この方法は実用的なハードウェア制約とも整合している。本論文は、収縮ユニタリが「原子アレイ量子計算プラットフォームの利点と完全に一致し、原子アレイ量子プロセッサで容易に実現される」と明確に述べている。これは、決定論的で相互可換な2量子ビットゲートを使用できるためであり、原子アレイで利用可能な全接続性と並列ゲート操作に適している。接続性が制限されたプラットフォームであっても、著者らは、単一の補助量子ビットを追加することで、収縮ユニタリを $k$ ステップの局所ゲートに分解できると述べており、異なる量子コンピューティングアーキテクチャ全体での広範な適用性を保証している。
代替案の却下
本論文は、望ましいサンプル複雑性を達成する上での定量的な劣位性のため、古典シャドウ・トモグラフィ内の他の一般的なアプローチを暗黙的かつ強力に却下している。議論されている主な代替案は、以前のSOTAであった完全ランダム・クリフォードプロトコルである。ランダム・クリフォードユニタリはトモグラフィコストを削減する上でブレークスルーであったが、シャドウノルムが $2^k$ でスケーリングするという結果になった。著者らの動機全体は、この $2^k$ スケーリングが、サイズ $k$ の非連続な局所演算子の抽出という問題に対して、この境界を下回るのに「不十分」であったという事実から生じている。収縮ユニタリは、演算子サイズをより効果的に収縮させるようにユニタリの決定論的コンポーネントを最適化することによって、この $2^k$ スケーリングを上回るように特別に設計された。
同様に、本論文は「浅い回路プロトコル」を別の代替案として言及している。しかし、表Iは、浅い回路プロトコルが、既知の演算子位置に対して $> 2^k$、未知の位置に対して $k \times 2^k$ のサンプル複雑性をもたらすことを明確に示している。これは、ランダム・クリフォードおよび、決定的に、収縮ユニタリプロトコルよりも効率が低い。したがって、これらの代替案は、収縮ユニタリが首尾よく提供するサンプル複雑性に対するサブ-$2^k$ スケーリングを達成するという重要な要件を満たせなかったため、選択されなかった。本論文は、古典シャドウの文脈で直接適用できないため、GANや拡散モデルのような他の機械学習パラダイムについては議論していない。
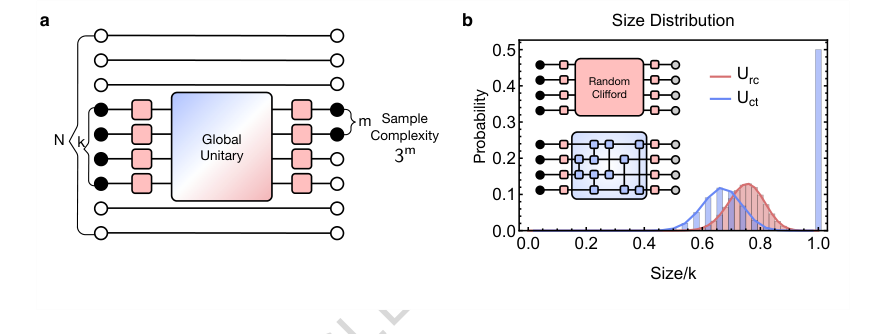 FIG. 1.
FIG. 1.
数学的および論理的メカニズム
マスター方程式
本論文の効率向上を支える絶対的なコア方程式は、古典シャドウ・トモグラフィのサンプル複雑性を直接定量化するシャドウノルムの定義である。著者らはこの量を最小化することを目指している。それは次のように提示されている。
$$ ||\hat{O}||^2_{\mathcal{E}_U} = w(\hat{O}_U)_{\mathcal{E}_U} = \sum_m \frac{\pi(m)_{\mathcal{E}_U}}{3^m} $$
この方程式は目標を定義するが、このノルムの低減を達成するメカニズムは、主に「収縮ユニタリ」とその演算子サイズへの影響によって駆動される。特定の2量子ビット収縮ユニタリは次のように与えられる。
$$ \hat{U}_{12} = \exp\left(i\frac{\pi}{4} \hat{Z}_1\hat{Z}_2\right) $$
そして、完全収縮ユニタリ $\hat{U}_{ct}$ の下での $k$ 量子ビットパウリ文字列 $\hat{O}$ に対する演算子サイズへの影響は次のように記述される。
$$ m = \text{Size}(\hat{U}_{ct} \hat{O} \hat{U}_{ct}^\dagger) = \begin{cases} N_{xy} & \text{if } N_{xy} \in \text{odd}, \\ k & \text{if } N_{xy} \in \text{even}. \end{cases} $$
最後に、シャドウノルムに直接関連する収縮ユニタリの結果としてのパウリ重みは次のように与えられる。
$$ w(\hat{O})_{ct} = \frac{1}{2 \cdot 3^k} \left[ \frac{(-1)^k + 1}{9^k} + \left(\frac{5}{9}\right)^k \right] $$
用語ごとの解剖
これらの式を分解して、その構成要素を理解しよう。
マスター方程式(シャドウノルム)について:
$$
||\hat{O}||^2_{\mathcal{E}_U} = w(\hat{O}_U)_{\mathcal{E}_U} = \sum_m \frac{\pi(m)_{\mathcal{E}_U}}{3^m}
$$
-
$||\hat{O}||^2_{\mathcal{E}_U}$: これは、ユニタリアンサンブル $\mathcal{E}_U$ で平均されたオブザーバブル $\hat{O}$ のシャドウノルム二乗を表す。
- 数学的定義: これは本質的に、$\hat{O}$ の期待値の推定に使用される推定量の分散である。シャドウノルムが小さいほど、予測の分散が小さくなることを意味する。
- 物理的/論理的役割: これは古典シャドウ・トモグラフィプロトコルの評価指標である。これはサンプル複雑性を直接特徴づける—すなわち、$\hat{O}$ を特定の精度で推定するために必要な測定スナップショットの数である。本論文の主な目標はこの値を低減することである。
- なぜ二乗か? 分散は本質的に二乗された量であり、可能な結果の広がりを反映している。
-
$w(\hat{O}_U)_{\mathcal{E}_U}$: これは、ユニタリアンサンブル $\mathcal{E}_U$ で平均された、進化演算子 $\hat{O}_U$ のパウリ重みである。
- 数学的定義: これは、演算子 $\hat{O}$ がアンサンブル $\mathcal{E}_U$ のユニタリによって変換された後に、どれだけ「広がっている」または「スクランブルされている」かの平均的な尺度である。
- 物理的/論理的役割: この項はシャドウノルムに直接比例する。パウリ重みを低減することが、サンプル複雑性が低減されるメカニズムである。著者らは、この重みを以前の手法よりも小さくする方法を見つけた。
-
$\sum_m$: これは、すべての可能な演算子サイズ $m$ に対する総和である。
- 数学的定義: 離散的な総和。
- 物理的/論理的役割: 初期パウリ文字列演算子 $\hat{O}$ がユニタリ $\hat{U}$ によって進化すると、それは様々なサイズのパウリ文字列の重ね合わせに変換される可能性がある。この総和は、これらの可能な進化サイズすべてからの寄与を考慮している。
- なぜ総和で積分ではないのか? 演算子サイズ $m$(非恒等パウリ演算子の数)は離散的な整数量であるため、総和が自然な数学的演算である。
-
$\pi(m)_{\mathcal{E}_U}$: これは、ユニタリアンサンブル $\mathcal{E}_U$ で平均された、進化演算子 $\hat{O}_U$ のサイズ分布である。
- 数学的定義: これは、進化演算子 $\hat{O}_U$ がサイズ $m$ を持つ確率を表す。演算子 $\hat{O}_U = \sum_P c_P P$ (ここで $P$ はパウリ文字列)の場合、$\pi(m) = \sum_{\text{Size}(P)=m} |c_P|^2$ である。
- 物理的/論理的役割: この分布は、ユニタリ変換が演算子の「複雑さ」にどのように影響するかを示す。ユニタリがこの分布をより小さな $m$ の値にシフトできる場合、それは直接的にシャドウノルムを低減する。これが「収縮ユニタリ」の背後にある中心的な考え方である。
-
$3^m$: この項は分母に現れる。
- 数学的定義: 指数関数的な因子。
- 物理的/論理的役割: この因子は、パウリ測定の性質から生じる。サイズ $m$ のパウリ文字列の場合、それらの $m$ 個の量子ビットに作用する非恒等パウリ演算子(X, Y, Z)は $3^m$ 通り存在する。この項は、演算子サイズが大きい場合にペナルティを与える。大きな $m$ は $1/3^m$ を小さくするが、大きな $m$ に対して $\pi(m)$ が有意であれば、シャドウノルムへの全体的な寄与は依然として大きくなる可能性がある。目標は、$\pi(m)$ を小さな $m$ の値に集中させることである。
収縮ユニタリ $\hat{U}_{12}$(式2)について:
$$
\hat{U}_{12} = \exp\left(i\frac{\pi}{4} \hat{Z}_1\hat{Z}_2\right)
$$
-
$\hat{U}_{12}$: これは2量子ビット収縮ユニタリである。
- 数学的定義: 量子ビット1と2に作用するユニタリ演算子。
- 物理的/論理的役割: この特定のゲートは、著者らの決定論的ユニタリの基本的な構成要素である。パウリ演算子との特定の交換関係により、演算子サイズを「収縮」できるため、選択されている。これは、局所回転を除いて、制御Z(CZ)ゲートに相当する。
-
$\exp(\dots)$: 行列指数関数。
- 数学的定義: 随伴生成子からユニタリ演算子を定義する。随伴演算子 $H$ に対して、$U = \exp(iH)$ はユニタリである。
- 物理的/論理的役割: 量子力学における相互作用ハミルトニアンまたは生成子から量子ゲートを構築する標準的な方法である。
-
$i$: 虚数単位。
- 数学的定義: $\sqrt{-1}$。
- 物理的/論理的役割: 量子演算子のユニタリ性と量子状態の複素性を保証するために不可欠である。
-
$\frac{\pi}{4}$: 定数位相因子。
- 数学的定義: 特定の角度。
- 物理的/論理的役割: この特定の値は、2量子ビット相互作用の強度と種類を決定する。$\hat{Z}_1\hat{Z}_2$ に対して、$\pi/4$ はエンタングルメントゲートの一般的な選択肢である。
-
$\hat{Z}_1$: 量子ビット1に作用するパウリZ演算子。
- 数学的定義: $2 \times 2$ 行列。計算基底では通常 $\begin{pmatrix} 1 & 0 \\ 0 & -1 \end{pmatrix}$。
- 物理的/論理的役割: 基本的な単一量子ビットパウリ演算子であり、Z基底での測定を表す。
-
$\hat{Z}_2$: 量子ビット2に作用するパウリZ演算子。
- 数学的定義: $\hat{Z}_1$ と同じだが、2番目の量子ビットに作用する。
- 物理的/論理的役割: $\hat{Z}_1$ と同じだが、異なる量子ビット上。
-
$\hat{Z}_1\hat{Z}_2$: 量子ビット1と2上のパウリZ演算子のテンソル積。
- 数学的定義: $\hat{Z}_1 \otimes \hat{Z}_2$。
- 物理的/論理的役割: 2量子ビット相互作用または相関を表す。この特定の相互作用は、他のパウリ演算子がそれを通過して進化する際に、演算子サイズを「収縮」させることを可能にする。
演算子サイズ収縮(式3)について:
$$
m = \text{Size}(\hat{U}_{ct} \hat{O} \hat{U}_{ct}^\dagger) = \begin{cases} N_{xy} & \text{if } N_{xy} \in \text{odd}, \\ k & \text{if } N_{xy} \in \text{even}. \end{cases}
$$
-
$m$: 進化演算子の新しいサイズ。
- 数学的定義: 非恒等パウリ演算子の数を数える整数。
- 物理的/論理的役割: これは収縮ユニタリを適用した直接的な結果である。目標はこの $m$ を可能な限り小さくすることである。
-
$\text{Size}(\dots)$: 演算子サイズ関数。
- 数学的定義: パウリ文字列内の非恒等パウリ演算子の数を数える関数。
- 物理的/論理的役割: これは演算子の「広がり」または「複雑さ」を定量化するために使用される尺度である。
-
$\hat{U}_{ct}$: $k$ 量子ビット用の完全収縮ユニタリ。
- 数学的定義: サブシステム内のすべての量子ビットペア $i, j$ に対して作用する2量子ビット収縮ユニタリ $\hat{U}_{ij}$(式2)の積として定義される。$\hat{U}_{ct} = \prod_{i
- 物理的/論理的役割: これは $k$ 量子ビットサブシステムに適用される完全な決定論的ユニタリ操作である。可換な2量子ビットゲートからのその特定の構成が、その効率の鍵となる。
- 数学的定義: サブシステム内のすべての量子ビットペア $i, j$ に対して作用する2量子ビット収縮ユニタリ $\hat{U}_{ij}$(式2)の積として定義される。$\hat{U}_{ct} = \prod_{i
-
$\hat{O}$: 初期パウリ文字列演算子。
- 数学的定義: $k$ 個のパウリ演算子(X, Y, Z, I)のテンソル積。
- 物理的/論理的役割: これは、その期待値の推定を望むオブザーバブルである。これはユニタリ進化への入力である。
-
$\hat{U}_{ct}^\dagger$: $\hat{U}_{ct}$ のエルミート共役。
- 数学的定義: ユニタリ演算子の逆。
- 物理的/論理的役割: 演算子 $\hat{O}$ のユニタリ進化は $\hat{U}\hat{O}\hat{U}^\dagger$ によって与えられる。
-
$N_{xy}$: 初期パウリ文字列 $\hat{O}$ におけるXおよびY演算子の総数。
- 数学的定義: 整数カウント。
- 物理的/論理的役割: これは、収縮ユニタリがどのように作用するかを決定する初期演算子の重要な特性である。$N_{xy}$ のパリティ(奇数または偶数)が、演算子サイズが収縮されるか、あるいは変更されないかを決定する。
-
$k$: サブシステム内の量子ビット数。
- 数学的定義: 整数。
- 物理的/論理的役割: これは演算子の初期サイズであり、それがサイズ-$k$ のパウリ文字列(すなわち、恒等演算子がない)であると仮定する。
-
if $N_{xy} \in \text{odd}$: これは条件文であり、収縮を記述する。- 物理的/論理的役割: 初期演算子にXまたはY成分が奇数個含まれている場合、収縮ユニタリは効果的にすべてのZ演算子を恒等演算子に変換し、演算子サイズを $k$ から $N_{xy}$ に低減する。これは、シャドウノルムを低減する主要なメカニズムである。
-
if $N_{xy} \in \text{even}$: これは条件文であり、収縮がないことを記述する。- 物理的/論理的役割: 初期演算子にXまたはY成分が偶数個含まれている場合、Z演算子はZのままであり、演算子サイズは $k$ のままである。この特定のケースでは、収縮ユニタリはZ演算子に関しては役立たないが、サイズを増加させることもない。
収縮ユニタリのパウリ重み(式4)について:
$$
w(\hat{O})_{ct} = \frac{1}{2 \cdot 3^k} \left[ \frac{(-1)^k + 1}{9^k} + \left(\frac{5}{9}\right)^k \right]
$$
-
$w(\hat{O})_{ct}$: サイズ $k$ のパウリ演算子のアンサンブルで平均された、進化演算子 $\hat{O}_{ct}$ のパウリ重み。
- 数学的定義: これは、収縮ユニタリを使用したときに計算される平均パウリ重みである。これは、マスター方程式の $w(\hat{O}_U)_{\mathcal{E}_U}$ の特定のインスタンスである。
- 物理的/論理的役割: この値は、シャドウノルムのスケーリングを直接決定する。著者らは、この値が $\sim 1.8^k$ でスケーリングすることを示しており、これはランダム・クリフォードユニタリの $\sim 2^k$ のスケーリングよりも優れている。
-
$\frac{1}{2 \cdot 3^k}$: 全体的なスケーリング因子。
- 数学的定義: 逆指数関数。
- 物理的/論理的役割: これは、$k$ 量子ビット上のパウリ文字列の総数に関連する正規化因子である。
-
$\frac{(-1)^k + 1}{9^k}$: これは、$N_{xy}$ が偶数の場合に寄与する項である。
- 数学的定義: $k$ に依存する項。
- 物理的/論理的役割: この式の部分は、XおよびY成分の数($N_{xy}$)が偶数である初期演算子からのパウリ重みへの寄与を説明している。このシナリオでは、Z演算子は収縮されず、演算子サイズは $k$ のままである。
-
$\left(\frac{5}{9}\right)^k$: これは、$N_{xy}$ が奇数の場合に寄与する項である。
- 数学的定義: $k$ に依存する項。
- 物理的/論理的役割: これは、改善されたスケーリングを提供する重要な項である。これは、$N_{xy}$ が奇数であり、Z演算子の収縮につながり、より小さな実効的な演算子サイズをもたらす初期パウリ演算子の集合からの寄与を説明している。この項の指数基数 $5/9 \approx 0.55$ は、ランダム・クリフォードユニタリからの $2^k$ のスケーリングとは対照的に、$1.8^k$ のスケーリングを駆動するものである。
- なぜ加算なのか? これらの2つの項は、初期パウリ演算子の2つの互いに素な集合($N_{xy}$ が偶数のものと奇数のもの)からの寄与を表しており、それらの平均重みは加算される。
ステップバイステップフロー
単一の抽象的なデータポイント、この文脈では $N$ 量子ビット上の量子状態 $\rho$ を想像し、 $k$ 量子ビットサブシステムに作用する特定のパウリ文字列オブザーバブル $\hat{O}$ の期待値を推定したいとする。以下は、「数学エンジン」がこれを処理する方法である。
-
初期状態とオブザーバブル: 量子状態 $\rho$ と、 $k$ 量子ビットサブシステム上のパウリ文字列オブザーバブル $\hat{O}$(例: $\hat{X}_1\hat{Z}_3\hat{Y}_5$)をターゲットとして開始する。目標は $\text{Tr}(\hat{O}\rho)$ を推定することである。
-
ランダム単量子ビット回転: コアユニタリを適用する前に、$k$ 量子ビットサブシステムはランダム単量子ビット回転の層、$\prod_i \hat{u}_{1,i}$ を受ける。これらの回転はクリフォード群から独立にサンプリングされ、局所基底依存性を排除する役割を果たし、すべての演算子が同等に測定されることを保証する。
-
収縮ユニタリの適用: ここで論文の革新が始まる。グローバルな決定論的ユニタリ $\hat{U}_{ct}$ が $k$ 量子ビットサブシステムに適用される。この $\hat{U}_{ct}$ は、サブシステム内のすべての量子ビットペア $i, j$ に対する2量子ビット収縮ユニタリ $\hat{U}_{ij} = \exp(i\frac{\pi}{4} \hat{Z}_i\hat{Z}_j)$ の積として構築される。このステップの目的は、オブザーバブル $\hat{O}$ を「進化した」演算子 $\hat{O}_{ct} = \hat{U}_{ct} \hat{O} \hat{U}_{ct}^\dagger$ に変換することである。ここでの魔法は、$\hat{U}_{ct}$ が、演算子のかなりの部分に対して $\hat{O}$ の「サイズ」を収縮するように設計されていることである。具体的には、初期 $\hat{O}$ が奇数個の $\hat{X}$ または $\hat{Y}$ 成分($N_{xy}$ が奇数)を持つ場合、$\hat{U}_{ct}$ は $\hat{O}$ のすべての $\hat{Z}$ 演算子を恒等演算子に変換し、演算子サイズを効果的に $k$ から $N_{xy}$ に低減する。$N_{xy}$ が偶数の場合、サイズは $k$ のままである。このプロトコルの全体的なアーキテクチャ(ランダム単量子ビット回転とグローバルユニタリを含む)は、図1aに模式的に示されている。図1bは、この収縮ユニタリがランダム・クリフォードユニタリと比較して演算子サイズ分布をどのように再形成するかをさらに示している。
-
ランダム単量子ビット回転の別の層: 収縮ユニタリの後、ランダム単量子ビット回転の別の層、$\prod_i \hat{u}_{2,i}$ が適用される。これにより、完全な複合ユニタリ操作 $\hat{U}_{\text{eff}} = (\prod_i \hat{u}_{2,i}) \hat{U}_{ct} (\prod_j \hat{u}_{1,j})$ が完了する。
-
計算基底での測定: 複合ユニタリ $\hat{U}_{\text{eff}}$ が状態 $\rho$ に適用された後、$k$ 量子ビットサブシステムは計算基底で測定される。これにより、例えば $|z\rangle = |z_1, \dots, z_k\rangle$ のような古典的な測定結果が得られる。
-
古典的スナップショット再構築: 各測定結果 $|z\rangle$ から、密度行列の「古典的スナップショット」が再構築される。このスナップショットは $\sigma_U(z) = \hat{U}_{\text{eff}}^\dagger |z\rangle\langle z| \hat{U}_{\text{eff}}$ として与えられる。これは測定結果の「逆進化」である。
-
オブザーバブルの予測: 再構築された各スナップショット $\sigma_U(z)$ に対して、$\hat{O}$ の期待値の予測が行われる。これは $\text{Tr}(\hat{O} \sigma_U(z))$ として計算される。ここでの鍵は、実効的な演算子 $\hat{O}_{\text{eff}} = \hat{U}_{\text{eff}}^\dagger \hat{O} \hat{U}_{\text{eff}}$ が、収縮ユニタリのおかげで、より小さな $m$ の値にシフトされたサイズ分布 $\pi(m)$ を持つことである。これにより、$\text{Tr}(\hat{O} \sigma_U(z))$ の計算がより効率的になる。
-
スナップショットの平均化: ステップ2〜7が多数回(例えば $M$ 回)繰り返され、十分な数の古典的スナップショットが収集される。$\text{Tr}(\hat{O}\rho)$ の最終的な推定値は、これらの個々の予測を平均することによって得られる: $\frac{1}{M} \sum_{\alpha=1}^M \text{Tr}(\hat{O} \sigma_U(z^\alpha))$。
-
サンプル複雑性の低減: プロセス全体は、この推定量の分散、すなわちシャドウノルム $||\hat{O}||^2_{\mathcal{E}_U}$ が大幅に低減されるように設計されている。演算子サイズ分布 $\pi(m)$ をより小さな $m$ の値にピークさせること(収縮ユニタリのおかげ)により、$\sum_m \frac{\pi(m)_{\mathcal{E}_U}}{3^m}$ の項が小さくなり、シャドウノルムが低減され、したがって所定の精度に必要な測定回数が少なくなる。本論文は、この低減を $2^k$ のスケーリング(ランダム・クリフォード)から $1.8^k$ のスケーリング(収縮ユニタリ)で実証している。
最適化ダイナミクス
本論文における「最適化」は、典型的な機械学習における反復学習プロセスではなく、量子演算子とユニタリの構造に関する理論的洞察に基づいた意図的な設計選択である。勾配が計算されたり、アルゴリズムによって損失関数が反復的に最小化されたりすることはない。代わりに、著者らはより優れたメカニズムを設計した。
-
「損失地形」: 概念的には、シャドウノルム $||\hat{O}||^2_{\mathcal{E}_U}$ が「損失」であり、ユニタリアンサンブル $\mathcal{E}_U$ の選択が「パラメータ」である「損失地形」を想像できる。ランダム・クリフォードユニタリを使用した以前の研究では、特定の地点が見つかり、サンプル複雑性スケーリングが $2^k$ になった。
-
設計による「学習」: 著者らは、異なるユニタリ操作が演算子サイズ分布 $\pi(m)$ にどのように影響するかを分析することによって「学習」した。彼らは、「収縮ユニタリ」($\hat{U}_{ct}$)と呼ばれる特定の決定論的ユニタリが、パウリ文字列演算子のサイズを選択的に低減するという独自の特性を持っていることを発見した。これはアルゴリズム的なものではなく、理論的なブレークスルーである。
-
収縮のメカニズム: この「最適化」の核心は、$\hat{Z}_i\hat{Z}_j$ 相互作用の特定の代数的特性にある。パウリ演算子 $\hat{X}_i$ や $\hat{Y}_i$ が $\hat{U}_{ij} = \exp(i\frac{\pi}{4} \hat{Z}_i\hat{Z}_j)$ によって進化すると、他の $\hat{Z}$ 演算子に変換される可能性がある。例えば、演算子 $\hat{O}$ が奇数個の $\hat{X}$ または $\hat{Y}$ 成分($N_{xy}$ が奇数)を持つ場合、$\hat{U}_{ct}$ は効果的に $\hat{O}$ の $\hat{Z}$ 演算子を恒等演算子($\hat{I}$)に変換する。これは交換関係の直接的な結果である: $\hat{U}_{ij} \hat{Z}_i \hat{U}_{ij}^\dagger = \hat{Z}_i$ および $\hat{U}_{ij} \hat{X}_i \hat{U}_{ij}^\dagger = \hat{X}_i \hat{Z}_j$。重要なのは、これらの相互作用が複数の量子ビットにどのように伝播するかである。$N_{xy}$ が奇数の場合、$\hat{Z}_i\hat{Z}_j$ ゲートの集合的な作用により、$\hat{Z}$ 演算子は効果的に「キャンセルアウト」するか $\hat{I}$ になる。これにより、演算子サイズは $k$ から $N_{xy}$ に低減される。
-
分布の形成: 初期パウリ文字列の相当な割合の演算子サイズを収縮させることによって、収縮ユニタリはサイズ分布 $\pi(m)$ を再形成する。$\pi(m)$ は、(ランダム・クリフォードユニタリの場合のように)$m \approx 3k/4$ 付近に広く分布するのではなく、より小さな $m$ の値(具体的には、奇数 $N_{xy}$ に対して $N_{xy}$、偶数 $N_{xy}$ に対して $k$)にピークを持つようになる。この小さな演算子サイズへのシフトは、$\sum_m \frac{\pi(m)_{\mathcal{E}_U}}{3^m}$ の値を直接低減し、それによってシャドウノルムを低減する。
-
より良いスケーリングへの収束: 「収束」は反復的なものではなく、優れたスケーリング法則の実証である。著者らは理論的に(そして数値的に検証して)、この慎重に構築された収縮ユニタリが、ランダム・クリフォードユニタリの $2^k$ スケーリングよりも大幅に優れた $\sim 1.8^k$ のシャドウノルムスケーリング(スライディングトリックで $k \times 1.8^k$)につながることを導出している。これは、反復最適化ではなく、知的な設計によって達成された、概念的な損失地形における「ジャンプ」を表す。メカニズムは、ユニタリが選択された後は本質的に決定論的である。ランダム性は、単量子ビット回転と測定結果にのみ由来し、コアユニタリ自体には由来しない。
 Figure 3. The sliding trick for situations in which the location of the Pauli string operator is un- known. a, Schematics of the sliding trick. Each box represents an independent composite unitary applied to a subsystem with k qubits, as shown in Fig. 1a
Figure 3. The sliding trick for situations in which the location of the Pauli string operator is un- known. a, Schematics of the sliding trick. Each box represents an independent composite unitary applied to a subsystem with k qubits, as shown in Fig. 1a
結果、限界、および結論
実験設計とベースライン
数学的主張を厳密に検証するために、著者らは主に2種類のN量子ビット長距離エンタングル状態:Greenberger-Horne-Zeilinger(GHZ)状態と周期境界条件を持つ一次元クラスター(ZXZ)状態に焦点を当てた一連の数値実験を設計した。これらの実験では、$k$ 個の連続した量子ビットのサブシステムが選択され、特定のパウリ文字列演算子に対する予測が行われた。GHZ状態の場合、ターゲット演算子は $\hat{O} = Z_1Z_2...Z_{k-1}Z_k$ であり、ZXZ状態の場合、それは $\hat{O} = Z_1Y_2X_3X_4...X_{k-2}Y_{k-1}Z_k$ であった。決定的なことに、これらの状態は安定化子形式の下で効率的な表現を許容し、GHZ状態に対して $\langle \hat{O} \rangle = ((-1)^{k+1})/2$、ZXZ状態に対して $\langle \hat{O} \rangle = (-1)^k$ のような正確な期待値の解析的導出を可能にした。これらの解析値は、「厳密なベンチマーク」として機能し、実験的予測はそれらと比較された。
実験手順は、各サンプリングプロセスについていくつかのステップを含んだ。まず、単量子ビット回転は、24個の単量子ビットクリフォードゲートのセットから独立に生成された。次に、図1aに示す複合ユニタリ操作が適用され、その後、計算基底での測定結果 $z^\alpha$ がサンプリングされた。各スナップショットの予測は、式(1)の正確なシャドウノルムを $O^\alpha = ||\hat{O}||^{-2} \text{Tr}(\hat{O}\sigma_U(z^\alpha))$ として使用して計算された。多数のスナップショット、具体的には $N = 10^5$ 個を収集した後、期待値の最終的な予測は、これらのスナップショットを平均することによって得られた: $E[\langle \hat{O} \rangle] = \sum_{\alpha=1}^N O^\alpha / N$。この期待値の標準偏差は、分散 $D[\langle \hat{O} \rangle] = \sum_{\alpha=1}^N (O^\alpha - E[\langle \hat{O} \rangle])^2 / N$ から推定された。
この比較における「犠牲者」(ベースラインモデル)は、古典シャドウ・トモグラフィにおける最先端技術を表すランダム・クリフォードユニタリを用いたプロトコルであった。主な結果は、$N = 20$ のシステムサイズで提示され、 $k \sim 20$ のより大きなシステムに拡張された補足情報も含まれていた。
演算子パウリ文字列の正確な位置が未知であるシナリオに対処するために、さらに一連の実験が行われた。このために、「スライディングトリック」が導入された。システムは $N = n_0 k$ 量子ビットに分割され、各サブシステムには $k$ 個の量子ビットが含まれる。次に、ユニタリは1量子ビットずつスライドされ、$k$ 個の異なるユニタリセットが生成された。回路構造は $1/k$ の確率でランダムに選択された。例えば、ZXZ状態の演算子 $\hat{O} = Z_{n_r+1}Y_{n_r+2}X_{n_r+3}X_{n_r+4}...X_{n_r+k-2}Y_{n_r+k-1}Z_{n_r+k}$ が使用され、ここで $n_r \in [0, N)$ はランダムな整数である。これらのテストのシステムサイズは $N = 3k$ であった。このシナリオのベースラインは、スライディングトリックで強化されたランダム・クリフォードプロトコルであった。このスライディングトリックの模式図は図3aに示されている。
証拠が証明すること
本論文で提示された証拠は、提案された収縮ユニタリプロトコルが、標準的なランダム・クリフォードアプローチと比較して、古典シャドウ・トモグラフィのサンプル複雑性を大幅に低減することを決定的に証明している。作用するコアメカニズムは、進化パウリ文字列の実効的な「演算子サイズ」をより効率的に低減する収縮ユニタリの能力であり、これは直接的により小さなシャドウノルム、したがってより少ない測定回数につながる。
演算子位置が既知の場合、図2aおよび2bは、収縮ユニタリとランダム・クリフォードプロトコルの両方が、パウリ文字列演算子の期待値に対して偏りのない予測をもたらすという確固たる証拠を提供する。黒い破線(解析的に導出された正確な期待値)と非常によく一致する数値結果を表す実線は、GHZ状態とZXZ状態の両方に対して、両アプローチの妥当性を確認している。
しかし、収縮ユニタリの決定的な利点は、演算子期待値の分散 $D[\langle \hat{O} \rangle]$ をプロットする図2cおよび2dにおいて、驚くほど明確になる。ここでは、収縮ユニタリプロトコルは、特に $k$ が増加するにつれて、ランダム・クリフォードプロトコルと比較して一貫してより小さな標準偏差(したがって、より低い分散)を示す。これらの図の破線は、理論的なスケーリング法則を直接確認している。収縮ユニタリは約 $2 \times 1.8^k$ のサンプル複雑性スケーリングを達成する一方、ランダム・クリフォードプロトコルは $2^k$ でスケーリングする。これは、彼らのコアメカニズムが現実世界で機能することを示す、強力な証拠である。 $2^k$ から $1.8^k$ への低減は実質的であり、$k \sim 100$(現在の量子計算プラットフォームで達成可能なサイズ)の場合、これはサンプルリソースにおいて10^4倍以上の改善に相当する。本論文はまた、収縮ユニタリプロトコルが量子ノイズに対する堅牢性を示すと述べている(補足情報、図S4参照)。
この改善されたスケーリングの根本的な理由は、図1bによって視覚的に裏付けられている。これは演算子サイズ分布 $\pi(m)$ を示している。ランダム・クリフォードユニタリ(赤線)は演算子を最大スクランブルし、ピークを $m/k \approx 3/4$ 付近に持つ広範な二項分布をもたらす。対照的に、収縮ユニタリ(青線)は、より小さな演算子サイズにピークを持つ分布をもたらし、具体的には $m/k \approx 2/3$ 付近にピークを持ち、さらに $k$ にデルタピークを持つ。この小さな演算子サイズへのより集中した分布は、収縮ユニタリが演算子サイズを低減する能力の直接的な結果であり、より小さなシャドウノルム、したがってより低いサンプル複雑性につながる。
演算子の正確な位置が未知の場合でさえ、「スライディングトリック」と収縮ユニタリの組み合わせは、その利点を維持している。図3bおよび3cは、スライディングトリックを備えた両方のプロトコルが偏りのない予測を提供することを示している。決定的に、スライディングトリックを備えた収縮ユニタリの分散は $(32/19)k \times 1.8^k$ でスケーリングし、ランダム・クリフォードプロトコルの $k \times 2^k$ スケーリングを上回っている。表Iは、収縮ユニタリが既知($1.8^k$)および未知($k \times 1.8^k$)の演算子位置シナリオの両方で、ランダム・クリフォード($2^k$ および $k \times 2^k$)および浅い回路プロトコル($>2^k$)と比較して、優れたサンプル複雑性を持つことを簡潔に要約している。
限界と将来の方向性
収縮ユニタリプロトコルは重要な進歩を示す一方で、現在の限界を認識し、将来の開発の方向性を検討することが重要である。
演算子位置の事前知識がない状況へのアプローチの拡張には、顕著な課題がある。「スライディングトリック」はこれを対処するために導入されているが、サンプル複雑性に $k$ の因子を追加し、結果として $k \times 1.8^k$ のスケーリングになる。これはランダム・クリフォードの $k \times 2^k$ よりも依然として優れているが、この $k$ 因子を軽減するためにさらなる最適化が可能であることを示唆している。収縮ユニタリをシステム全体(サブシステムではなく)に単純に適用すると、ランダム・クリフォードプロトコルのシャドウノルムの増加につながる可能性があり、収縮ユニタリの場合は、一般的に望ましくない恒等演算子をZに戻す可能性がある。これは、スケーリングアップ時の慎重な設計の必要性を強調している。さらに、論文は、スライディングトリックを備えたランダム・クリフォードプロトコルが「十分大きな $k$ に対して浅い回路プロトコルをほとんど上回ることができない」と述べており、これは収縮ユニタリとスライディングトリックの組み合わせは優れているが、ランダム・クリフォードのものはこの特定のシナリオでは強力な候補ではないことを示唆している。
将来に向けて、これらの発見はいくつかのエキサイティングな議論のトピックと研究の方向性を開いている。
-
ハードウェア固有の最適化と実装: 本論文は、収縮ユニタリが、再構成可能な性質、全接続性、および並列ゲート操作能力により、原子アレイ量子計算プラットフォームの利点と完全に一致することを強調している。これらのプラットフォームでの高忠実度CZゲートおよびグローバルCZゲートにおける最近の実験的成功により、収縮ユニタリは容易に実装可能になっている。さらに、著者らは、単一の補助量子ビットを追加することで、収縮ユニタリを $k$ ステップの局所ゲートに分解できることを示しており、これは接続性が制限されたプラットフォーム(超伝導量子ビットなど)との互換性を保証している。これは、収縮ユニタリのハードウェア認識設計と最適化を探求するための豊かな未来を示唆しており、特定の量子アーキテクチャに合わせたさらなる効率的な実装につながる可能性がある。
-
「収縮ユニタリ」概念の一般化: コアの洞察は、複雑なシステムの効率的な特性評価という探求が、量子または古典のいずれであっても、最適化された変換によるターゲット化された次元または複雑性の低減という共通の数学的パターンに収束することを示していることである。
-
ハイブリッドランダム・ディターミニスティックプロトコルを新しいパラダイムとして: 本研究は、明確に「ランダムと決定論的要素をハイブリッドしたプロトコルは、完全にランダムな測定よりも効率的である可能性がある」ことを実証している。これは、シャドウ・トモグラフィに完全にランダムな測定に依存するという従来の考え方に挑戦し、測定効率、堅牢性、および実装複雑性との間の最適なトレードオフを探求する量子測定プロトコルを設計するための新しいパラダイムを開いている。将来の研究では、測定効率、堅牢性、および実装複雑性との間の最適なトレードオフを探求するために、ランダムと決定論的要素の他の組み合わせを探索できる。
-
理論的限界と最適なユニタリ設計: 本論文は特定の収縮ユニタリを提示しているが、演算子サイズ収縮に対してそれが全体的に最適であるかどうかという問題は、未解決の理論的問題のままである。さらなる研究は、シャドウノルムとサンプル複雑性に対するよりタイトな理論的限界を確立し、それからこれらの限界を使用して、さらに最適な決定論的ユニタリ設計の探索を導くことに焦点を当てるべきである。これには、異なる数学的構造を探求したり、高度な最適化技術を活用したりすることが含まれる可能性がある。
-
堅牢性とエラー緩和: 本論文は、量子ノイズに対するプロトコルの堅牢性に簡単に言及している。現在の量子デバイスの固有のノイズを考慮すると、さまざまな現実的なノイズモデル(例:デポーラライジングノイズ、デコヒーレンス、ゲートエラー)の下での収縮ユニタリのノイズ耐性に関する詳細な調査は非常に価値があるだろう。これらのハイブリッドプロトコルに特別に合わせたエラー緩和戦略を開発することは、それらの実用的な有用性をさらに高める可能性がある。
本質的に、この研究は、量子状態特性評価のための強力な新しいツールを提供するだけでなく、測定と情報抽出のための量子回路のインテリジェント設計に関するより広範な議論を刺激している。古典シャドウ・トモグラフィ、そして最終的には量子情報処理の未来は、決定論的要素とランダム的要素のこの思慮深い統合にあるかもしれない。
 Table 1. A comparison of the sample complexity for 34 the contractive unitary protocol, the random Clifford 35 protocol, and the shallow circuits protocol for situations 36 with or without the information of the precise location 37 of the Pauli string operators ˆO. 38 Table 2. Two-qubit Pauli operators with size-2. 39
Table 1. A comparison of the sample complexity for 34 the contractive unitary protocol, the random Clifford 35 protocol, and the shallow circuits protocol for situations 36 with or without the information of the precise location 37 of the Pauli string operators ˆO. 38 Table 2. Two-qubit Pauli operators with size-2. 39