Contrastive Integrated Gradients: A Feature Attribution-Based Method for Explaining Whole Slide Image Classification
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the critical need for interpretability in computational pathology, particularly within the domain of Whole Slide Image (WSI) analysis. Pathology is a cornerstone of modern medicine, providing essential diagnoses and prognoses. Traditionally, pathologists meticulously examine WSIs to assess cellular composition and tissue architecture, a process that is both time-consuming and prone to inter-observer variability.
With the advent of artificial intelligence and deep learning, computational tools have emerged to assist pathologists, offering solutions for pre-segmenting regions of interest and potentially improving diagnostic consistency and workflow efficiency. However, while these advanced deep learning models for WSI classification and segmentation perform remarkably well, they often operate as "black boxes," providing limited insight into the specific histological patterns that drive their predictions. This lack of transparency undermines trust in AI-assisted diagnostics, which is a significant barrier to their widespread clinical adoption.
The academic lineage of this problem traces back to the broader field of Explainable AI (XAI), which seeks to make AI models more understandable to humans. Within computer vision, XAI methods are broadly categorized as heatmap-based (showing where a model focuses) versus concept-based (explaining what it relies on), and post-hoc (explanations after training) versus ante-hoc (interpretability integrated into the model). This work specifically advances post-hoc attribution methods, which aim to generate localized heatmaps highlighting regions relevant to a model's decision within WSIs.
The fundamental limitation, or "pain point," of previous approaches that compelled the authors to write this paper is multifaceted. Existing gradient-based attribution methods, such as Integrated Gradients (IG), often operate in the raw image space. While useful, this can be less effective for models that rely on complex, learned feature embeddings derived from WSI patches. More critically, these methods frequently highlight visually salient regions that are not necessarily class-discriminative. This means they might point to prominent but irrelevant features, thereby limiting their interpretability for WSI classification tasks where distinguishing between, say, tumor and non-tumor areas is paramount. Furthermore, the effectiveness of methods like Integrated Gradients is highly dependent on the choice of a "baseline" input, which can be ambiguous and challenging to define appropriately in complex domains like pathology. Other advanced attribution methods, while offering better precision, often come with a higher computational cost, making them less practical for large-scale WSI analysis. The authors' motivation is to overcome these limitations by developing a method that provides more focused and class-discriminative attributions, operating in a more meaningful "logit space" rather than just image space.
Intuitive Domain Terms
Here are a few specialized terms from the paper, translated into intuitive, everyday analogies for a zero-base reader:
- Whole Slide Image (WSI): Imagine a massive, ultra-high-resolution digital photograph of an entire tissue sample mounted on a microscope slide. It's so detailed that you can zoom in from seeing the whole slide to individual cells, much like using Google Maps to explore a city down to a single building. Pathologists use these to diagnose diseases.
- Multiple Instance Learning (MIL): Think of a quality inspector checking a large box of chocolates. They don't open every single chocolate, but if they find any spoiled chocolate in the box, the whole box is labeled "spoiled." MIL is a way for AI to learn from these "boxes" (whole slides) without needing to know the exact label of every "chocolate" (individual tissue patch) inside.
- Integrated Gradients (IG): Picture trying to understand how much each ingredient contributes to the final taste of a complex soup. Instead of just tasting the final soup, you taste it at every tiny step of its preparation, from a plain broth to the fully flavored dish, noting how each ingredient changes the taste along the way. IG does something similar for AI, tracing the "taste" (model output) back to each "ingredient" (input feature) along a smooth path.
- Logit Space: When an AI model makes a prediction (e.g., "tumor" or "non-tumor"), it first calculates raw, unnormalized scores for each option before converting them into probabilities (like 90% chance of tumor). Logit space is like looking at these raw "evidence scores" directly, before they're smoothed into percentages. It gives a clearer, more direct view of the model's internal reasoning and confidence for each category.
- Attribution Method: If an AI model tells you a picture contains a dog, an attribution method is like asking the AI, "Show me exactly which parts* of the image made you think it was a dog." It highlights the specific pixels or regions that were most influential in the model's decision, helping you understand its reasoning.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper lies in enhancing the interpretability of deep learning models for Whole Slide Image (WSI) classification in computational pathology.
The starting point (Input/Current State) involves high-resolution WSIs processed by deep learning models, often following a Multiple Instance Learning (MIL) paradigm. Existing attribution methods, such as Integrated Gradients (IG), are applied to these models to explain their predictions. While these methods can identify regions influencing a model's decision, they frequently operate in image space or on learned embeddings and tend to highlight visually salient features that may not be directly relevant for class discrimination. They capture general model decision patterns but often overlook the specific signals crucial for distinguishing between different tumor subtypes or between tumor and non-tumor areas.
The desired endpoint (Output/Goal State) is to achieve more informative, focused, and accurate attributions that precisely highlight class-discriminative regions within WSIs. These attributions should align closely with ground truth tumor regions, thereby building greater trust in AI-assisted diagnostic tools. Furthermore, the desired method must satisfy fundamental axiomatic properties of attribution (Completeness, Sensitivity, Implementation Invariance) to ensure theoretical soundness and consistent explanations.
The exact missing link or mathematical gap that this paper attempts to bridge is the inability of traditional attribution methods to effectively capture contrastive information in the logit space. Previous methods primarily focus on attributing importance based on gradients of the model's output with respect to input features. However, this approach often fails to differentiate between features that are merely salient and those that are truly discriminative for a specific class relative to a reference. The paper proposes to bridge this by introducing Contrastive Integrated Gradients (CIG), which mathematically defines attribution for the $i$-th feature as:
$$ \text{CIG}_i^c(x) = (x_i - x'_i) \int_0^1 \frac{\partial ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2}{\partial x_i} d\alpha $$
Here, $f_{\text{logit}}(\cdot)$ represents the model's logit output, $x$ is the input, $x'$ is a reference baseline, and $\gamma(\alpha)$ defines a straight-line path between $x$ and $x'$. This formulation explicitly integrates the gradients of the squared difference between the logit outputs of an interpolated input and a baseline reference. This allows CIG to measure how the model's decision boundary evolves relative to the reference, thereby capturing contrastive information directly in the logit space and emphasizing class-discriminative features.
The painful trade-off or dilema that has trapped previous researchers is the inherent tension between generating comprehensive saliency maps and producing class-discriminative explanations. Methods like standard Integrated Gradients often provide broad saliency maps that indicate all features contributing to a prediction. However, in a diagnostic context, pathologists need to understand why a model distinguishes between, say, a tumor and non-tumor, not just what regions are active. Improving the comprehensiveness of attribution often comes at the cost of specificity and discriminative power, leading to explanations that are visually salient but may include features irrelevant to the specific class distinction of interest. This makes it difficult to provide actionable insights for clinical decision-making.
Constraints & Failure Modes
The problem of providing interpretable explanations for WSI classification is made insanely difficult by several harsh, realistic constraints:
- High-Resolution Nature of WSIs: Whole Slide Images are gigapixel-scale, making them computationally challenging to process directly. This necessitates breaking them into smaller patches, which are then processed by deep learning models, often in a Multiple Instance Learning (MIL) framework. This patch-based processing adds complexity to attributing importance back to the original WSI.
- Weak Supervision: In computational pathology, ground truth labels are typically available only at the slide level (e.g., an entire slide is labeled "tumor" or "non-tumor"), not at the patch level. This "weak supervision" makes it extremely difficult to train models to identify specific tumor regions within a slide, and subsequently, to evaluate whether attribution methods correctly highlight these precise regions.
- Ambiguous Baseline Selection: Gradient-based attribution methods like Integrated Gradients critically depend on the choice of a "baseline" input, which serves as a reference point for measuring feature importance. In pathology, selecting a suitable baseline is ambiguous. Common baselines (e.g., zero vector, dataset mean, random patches) can lead to out-of-distribution issues, semantic bias, or reduced discriminativeness, making attributions less meaningful or even misleading. The paper explicitly notes that a zero vector baseline can cause out-of-distribution issues in the embedding space, while dataset mean or random patches can suffer from semantic leakage or reduced discriminativeness.
- Lack of Ground Truth for Attribution Evaluation: Unlike some natural image tasks where pixel-level saliency ground truth might exist, detailed, pixel-wise ground truth explanations for model predictions are often unavailable in WSI analysis. This absence makes it exceptionally challenging to quantitatively assess the quality and accuracy of attribution maps. Standard evaluation metrics for saliency maps (like Performance Information Curves or RISE) are not directly applicable to the weakly supervised WSI setting, as they assume gradual prediction shifts or pixel-level control, which is not the case with MIL-based WSI classification where predictions can change abruptly with a few key patches.
- Computational Cost of Path Integration: Path-based attribution methods, including Integrated Gradients and CIG, require integrating gradients along a path between the input and a baseline. This process involves multiple interpolation steps, which can be computationally intensive, especially for high-dimensional feature spaces derived from WSIs. While not an explicit failure mode, higher computationaly cost is a practical constraint for deployment.
- Model's Dependancy on Learned Embeddings: Many WSI analysis models rely on learned embeddings from feature extractors (e.g., Vision Transformers or CNNs). Gradient-based methods operating directly in image space may be less effective when the model's decision is primarily driven by these abstract, learned embeddings rather than raw pixel values.
Why This Approach
The Inevitability of the Choice
The development of Contrastive Integrated Gradients (CIG) wasn't just an incremental improvement; it was a necessary evolution driven by the inherentt limitations of existing attribution methods when applied to the unique challenges of Whole Slide Image (WSI) analysis in computational pathology. The authors realized that traditional "SOTA" methods, such as standard Integrated Gradients (IG) and its variants (e.g., Gradient $\times$ Input, Grad-CAM, Expected Gradients), while promising in general computer vision tasks, fell short in this specific domain.
The exact moment of this realization is implied by the identification of two critical shortcomings:
1. High-Resolution Nature of WSIs: Directly applying these methods to WSIs, which are gigapixel-scale images, introduced significant computational and interpretability challenges. The sheer scale made it difficult for these methods to provide meaningful and localized explanations.
2. Lack of Class-Discriminative Signals: More importantly, traditional attribution methods, by operating primarily in image space, often highlighted visually salient features that were not necessarily class-discriminative. This meant they could point to regions that looked important but didn't actually help in distingushing between, say, tumor subtypes or between tumor and non-tumor tissue. For instance, an area might be visually prominent but irrelevant to the diagnostic decision, leading to misleading explanations for pathologists. The need to move beyond mere saliency to contrastive, decision-relevant features was the driving force behind CIG.
Comparative Superiority
CIG offers qualitative superiority over previous gold standards, particularly in its ability to provide more focused and diagnostically relevant attributions. Its structural advantage stems from computing contrastive gradients in logit space rather than directly in image space or output probability space.
Here's why this is overwhelmingly superior:
* Sharper Class Differentiation: Unlike IG, which attributes importance based on gradients of the model's output (e.g., probability scores), CIG computes gradients of the squared logit difference between the input and a reference baseline. This means it explicitly measures how much a feature contributes to the difference in the model's logit output relative to a reference class. This structural design allows CIG to highlight class-discriminative regions, offering a much sharper differentiation between tumor and non-tumor areas, which is cruical for pathology.
* Localized and Consistent Attributions: Qualitatively, as shown in the paper's figures, CIG produces more stable and localized gradients within tumor regions throughout the interpolation path, whereas IG gradients tend to be more spatially dispersed. This indicates that CIG is better at isolating the true decision-making regions, effectively handling high-dimensional noise and irrelevant visual cues by focusing on what truly differentiates classes.
* Axiomatic Soundness with Contrastive Power: CIG retains the desirable axiomatic properties of Integrated Gradients (Completeness, Sensitivity, Implementation Invariance), ensuring theoretical soundness and consistency. However, it extends this by incorporating a contrastive element, making the attributions not just consistent but also meaningful in a differential context. This is a significant structural advantage over methods that only provide absolute importance without a comparative perspective.
The paper does not explicitly detail a reduction in memory complexity from $O(N^2)$ to $O(N)$, but its qualitative and structural advantages in producing more accurate and localized explanations are clearly demonstrated.
Alignment with Constraints
The chosen CIG method perfectly aligns with the harsh requirements of WSI analysis in computational pathology, forming a strong "marriage" between problem and solution:
- Interpretability for Trust: A primary constraint is the need for highly interpretable AI systems to build trust among clinicians. CIG directly addresses this by providing "more informative and stable attributions" that align closely with ground truth tumor regions. Its ability to highlight class-discriminative features ensures that explanations are relevant to diagnostic decisions, fostering clinical confidence.
- High-Resolution WSIs: The method is designed to work within the Multiple Instance Learning (MIL) framework, which is the standard paradigm for WSI analysis. By operating on patch-level features extracted from WSIs, CIG effectively scales to the high-resolution nature of these images, providing attributions for individual patches that are then aggregated into a WSI-level heatmap.
- Weakly Supervised Learning: WSI analysis often operates under weak supervision, where only slide-level labels are available, not pixel-level annotations. CIG's integration into the MIL framework, combined with the introduction of MIL-AIC and MIL-SIC metrics, specifically caters to this weakly supervised setting. These metrics assess how quickly the model's prediction and confidence evolve as salient patches are introduced, directly evaluating attribution quality in this challenging context.
- Class-Discriminative Signals: The core problem identified was the oversight of class-discriminative signals by traditional methods. CIG's unique property of computing contrastive gradients in logit space directly tackles this by emphasizing features that distinguish one class from another, rather than just general saliency. This ensures the explanations are directly relevant to differentiating tumor subtypes or disease states.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches, primarily other gradient-based attribution methods and common baseline choices, due to their inability to meet the specific demands of WSI analysis:
- Traditional Integrated Gradients (IG) and Variants: The paper states that while IG and related attribution methods "have shown promise," applying them directly to WSIs "introduces challenges due to their high-resolution nature" and their tendency to "overlook class-discriminative signals." This is a direct rejection of their direct applicability without modification. Methods like Gradient $\times$ Input, EG, and IDG are benchmarked against CIG, and CIG consistently outperforms them in terms of MIL-AIC and MIL-SIC, demonstrating their quantitative inferiority for this problem.
- Image-Space Attribution Methods: A broader rejection is made against "most attribution methods [that] operate in image space and may highlight visually salient but class-irrelevant features." This limitation severely hampers their interpretability for WSI classification, where the goal is to identify diagnostically relevant regions, not just any visually prominent area. CIG's logit-space approach directly addresses this by focusing on decision boundaries.
- Standard Baseline Choices for IG-based Methods: The paper dedicates a section to the "Design of the Attribution Baseline," explaining why common baselines (e.g., zero vector, dataset mean, random patches) are insufficient for WSI.
- A zero vector baseline can cause "out-of-distribution issues" in the embedding space.
- The dataset mean introduces "semantic bias," favoring dominant classes.
- Sampling from the dataset distribution or using random patches suffers from "semantic leakage or reduced discriminative-ness" if the input and baseline belong to the same class.
These issues lead to less interpretable saliency maps. CIG overcomes this by using a "baseline from the opposite class," which is crucial for its contrastive nature and for capturing meaningful differences that drive model predictions.
The paper does not discuss the rejection of generative models like GANs or Diffusion models, as they serve different purposes (e.g., image generation) than feature attribution for interpretability, which is the focus of this work. The alternatives considered and rejected are primarily other attribution techniques and their components.
Mathematical & Logical Mechanism
The Master Equation
The absolute core equation that powers Contrastive Integrated Gradients (CIG) is its definition for the attribution of the $i$-th feature, as presented in the paper:
$$ \text{CIG}_i(x) = (x_i - x'_i) \int_0^1 \frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2 d\alpha $$
Term-by-Term Autopsy
Let's break down this equation piece by piece to understand its mathematical definition, its role in the CIG mechanism, and the rationale behind the chosen operators.
-
$\text{CIG}_i(x)$:
- Mathematical Definition: This represents the Contrastive Integrated Gradients attribution score for the $i$-th feature of the input $x$.
- Physical/Logical Role: This is the final output of the CIG calculation for a specific feature. It quantifies how important the $i$-th feature of the input $x$ is in driving the model's prediction, specifically in a contrastive manner against a baseline $x'$. A higher absolute value indicates greater importance, and its sign can indicate whether the feature pushes the prediction towards or away from the baseline's implied class.
-
$x$:
- Mathematical Definition: This is the input feature vector (e.g., an embedding of a Whole Slide Image patch) for which we want to compute attributions.
- Physical/Logical Role: This is the specific data point whose features we are trying to explain. It's the "target" input.
-
$x'$:
- Mathematical Definition: This is the baseline or reference feature vector.
- Physical/Logical Role: The paper specifies that $x'$ is typically sampled from the "opposite class" (e.g., non-tumor patches for a tumor-positive slide). It serves as a neutral or non-informative reference point in the feature space. CIG measures feature importance by comparing the input $x$ against this baseline $x'$, highlighting features that distinguish $x$ from $x'$.
-
$(x_i - x'_i)$:
- Mathematical Definition: This is the scalar difference between the $i$-th component of the input feature vector $x$ and the $i$-th component of the baseline feature vector $x'$.
- Physical/Logical Role: This term acts as a scaling factor for the integrated gradient. It ensures that if a feature $x_i$ is identical to its baseline counterpart $x'_i$, its attribution $\text{CIG}_i(x)$ will be zero, as it contributes no difference. It also accounts for the magnitude and direction of change for that specific feature from the baseline to the input.
- Why multiplication: This is a direct scaling, reflecting that the total "impact" of a feature should be proportional to how much it differs from the baseline.
-
$\int_0^1 \dots d\alpha$:
- Mathematical Definition: This is a definite integral over the scalar parameter $\alpha$ from 0 to 1.
- Physical/Logical Role: This integral is the heart of the "Integrated Gradients" concept. It accumulates the gradients along a continuous path from the baseline $x'$ to the input $x$. This integration is crucial because it addresses the "gradient saturation" problem, where gradients might become very small for features that are already strongly activated, thus underestimating their importance. By summing up infinitesimal contributions along the entire path, it provides a more robust and complete measure of feature importance.
- Why integral instead of summation: An integral is used to sum over a continuous path, providing a theoretically sound and complete attribution that satisfies desirable axioms (like completeness). A summation (like a Riemann sum approximation) would be a discrete approximation of this continuous process.
-
$\frac{\partial}{\partial x_i}$:
- Mathematical Definition: This is the partial derivative operator with respect to the $i$-th feature of the input. In the context of the integral, it's applied to the squared L2 norm term.
- Physical/Logical Role: This operator computes the sensitivity of the squared logit difference to changes in the $i$-th feature at each point $\gamma(\alpha)$ along the interpolation path. It tells us how much a tiny change in $x_i$ at a given point on the path would affect the "contrast" (the squared logit difference) between the interpolated input and the baseline. This is how the method identifies which features are locally influential.
-
$|| \cdot ||_2^2$:
- Mathematical Definition: This denotes the squared Euclidean (L2) norm of a vector. For a vector $v$, $||v||_2^2 = \sum_j v_j^2$.
- Physical/Logical Role: This term quantifies the "distance" or "dissimilarity" in the logit space between the interpolated input's logit output and the baseline's logit output. By squaring the L2 norm, it ensures the measure is always non-negative and emphasizes larger differences more significantly. This is the core "contrastive" measure that CIG seeks to explain.
- Why L2 norm: The L2 norm is a standard metric for measuring vector magnitude and distance in Euclidean space. Squaring it simplifies calculations by removing the square root and provides a smooth, differentiable function suitable for gradient computation.
-
$f_{\text{logit}}(\cdot)$:
- Mathematical Definition: This represents the output of the model's logit layer. For a classification model, these are the raw, unnormalized scores for each class before a softmax activation.
- Physical/Logical Role: CIG operates in the logit space because logits directly reflect the model's confidence and evidence for each class. By measuring differences in logit outputs, CIG captures class-discriminative information, which is crucial for distinguishing between tumor and non-tumor regions. This is a key distinction from methods that operate in image space or on softmax probabilities.
-
$\gamma(\alpha)$:
- Mathematical Definition: This is a straight-line path function defined as $\gamma(\alpha) = x' + \alpha(x - x')$, where $\alpha \in [0, 1]$.
- Physical/Logical Role: This function generates intermediate points in the feature space that lie on a straight line connecting the baseline $x'$ (when $\alpha=0$) to the input $x$ (when $\alpha=1$). It provides the continuous trajectory along which the gradients are integrated.
-
$\alpha$:
- Mathematical Definition: A scalar parameter that varies continuously from 0 to 1.
- Physical/Logical Role: This parameter controls the position along the interpolation path $\gamma(\alpha)$. As $\alpha$ increases, the interpolated point moves from the baseline towards the input.
-
$f_{\text{logit}}(x')$:
- Mathematical Definition: The model's logit output when the baseline feature vector $x'$ is provided as input.
- Physical/Logical Role: This serves as a fixed reference point in the logit space. The CIG method measures how the logit output for the interpolated input $\gamma(\alpha)$ differs from this constant baseline logit output. This constant reference is fundamental to the "contrastive" nature of CIG, allowing it to highlight features that cause a deviation from the baseline's prediction.
Step-by-Step Flow
Imagine a single abstract data point, represented by its feature vector $x$, entering this mathematical engine. Here's how CIG processes it to determine its feature attributions:
- Baseline Selection: First, a suitable baseline feature vector $x'$ is chosen. The paper emphasizes using a contrastive baseline, such as features sampled from non-tumor regions when analyzing a tumor-positive slide. This $x'$ acts as a neutral or "opposite" reference point.
- Path Construction: A straight-line path $\gamma(\alpha)$ is constructed in the feature space. This path smoothly interpolates between the baseline $x'$ (when $\alpha=0$) and the input $x$ (when $\alpha=1$). Think of it as drawing a line from the reference point to the actual input point.
- Logit Transformation: For every infinitesimal step along this path, represented by $\gamma(\alpha)$, the model's logit output $f_{\text{logit}}(\gamma(\alpha))$ is computed. Simultaneously, the logit output for the fixed baseline $f_{\text{logit}}(x')$ is also obtained.
- Contrastive Measurement: At each point $\alpha$ on the path, the difference between the current interpolated logit output and the baseline logit output, $f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')$, is calculated. The squared Euclidean norm of this difference, $||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$, is then computed. This value quantifies how "different" the model's raw prediction for the interpolated input is from its prediction for the baseline at that specific point on the path.
- Gradient Calculation: The partial derivative of this squared logit difference (the contrastive measure) is computed with respect to each individual feature $x_i$ of the input. This gradient, $\frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$, tells us how sensitive the contrastive measure is to changes in feature $i$ at that particular point $\alpha$ along the path.
- Gradient Integration: These partial gradients are then integrated along the entire path from $\alpha=0$ to $\alpha=1$. This step effectively sums up all the infinitesimal contributions of each feature's sensitivity to the contrastive measure as the input transitions from the baseline to its actual value. This ensures a comprehensive assessment of importance, avoiding issues where gradients might be misleading at a single point.
- Scaling and Final Attribution: Finally, for each feature $i$, the accumulated integral is scaled by the difference $(x_i - x'_i)$. This scaling ensures that features that are identical to the baseline receive zero attribution and that the magnitude of the feature's change from the baseline is accounted for. The result is $\text{CIG}_i(x)$, the contrastive integrated gradient for feature $i$.
This process is repeated for all features, yielding a vector of attribution scores that highlight which parts of the input $x$ are most responsible for its prediction, relative to the chosen baseline $x'$.
Optimization Dynamics
It's important to clarify that Contrastive Integrated Gradients (CIG) is an attribution method, not a model training or optimization algorithm. Therefore, it doesn't "learn," "update," or "converge" in the traditional sense of adjusting model parameters based on a loss function. Instead, its "dynamics" refer to how the attribution scores are computed and how they behave to provide meaningful explanations for an already trained model.
The mechanism's "dynamics" are governed by several axiomatic properties that CIG is designed to satisfy, ensuring its reliability and interpretability:
-
Completeness Axiom: As stated in the paper (Equation 7), the sum of all CIG attributions for an input $x$ equals the total change in the squared logit difference between the input and the baseline: $\sum_{i=1}^n \text{CIG}_i(x) = ||f_{\text{logit}}(x) - f_{\text{logit}}(x')||_2^2$. This means that the method fully accounts for the entire difference in the model's logit output between the input and the baseline, distributing this difference completely among the input features. No contribution is left unexplained.
-
Sensitivity Axiom: CIG assigns non-zero attributions to features $x_i$ that differ from their baseline counterparts $x'_i$ and whose changes influence the model's logit output. Conversely, if a feature $x_i$ does not change from $x'_i$ or if the model's logit output is entirely independent of $x_i$, then its attribution will be zero. This ensures that CIG correctly identifies and highlights only the relevant features that contribute to the model's decision, distinguishing them from irrelevant ones. This property is crucial for generating focused and interpretable saliency maps.
-
Implementation Invariance Axiom: CIG's attributions are solely based on the model's output function ($f_{\text{logit}}(\cdot)$) and its gradients, rather than on specific implementation details of the neural network. This guarantees that functionally equivalent models will yield consistent attributions, regardless of how they are coded or structured internally. This makes CIG robust and trustworthy across different model architectures.
The "dynamics" of CIG, therefore, are not about iterative updates on a loss landscape, but rather about the robust and consistent computation of feature importance scores that adhere to these theoretical properties. The integration of gradients along a path in logit space, combined with the contrastive baseline, shapes the attribution values to be more localized and class-discriminative, as evidenced by the qualitative results in the paper. This mechanism ensures that the generated explanations are not just visually salient but also logically sound and directly tied to the model's decision-making process, particularly in distinguishing between different classes.
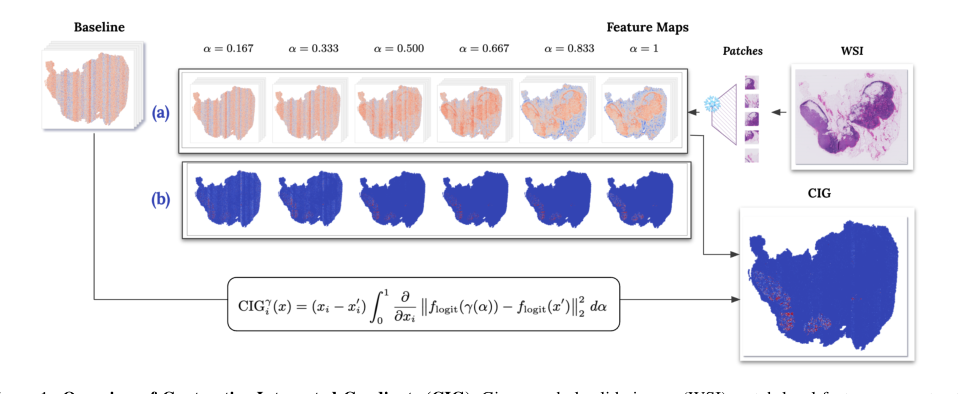 Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate the effectiveness of Contrastive Integrated Gradients (CIG), the authors architected a comprehensive experimental setup across diverse computational pathology scenarios. The "victims" or baseline models CIG aimed to defeat included several established gradient-based attribution methods: Vanilla Gradient, Integrated Gradients (IG) [32], Expected Gradients (EG) [29], and Integrated Decision Gradients (IDG) [33], alongside a simple Random baseline for comparison. All path-based methods, including CIG, were configured with 50 interpolation steps for consistency.
The experiments were conducted on three publicly available, high-stakes cancer pathology datasets: CAMELYON16 (breast cancer metastasis in lymph nodes), TCGA-Renal (covering three renal cancer subtypes: KIRC, KIRP, KICH), and TCGA-Lung (covering LUAD and LUSC lung cancer subtypes). This diverse selection ensured the generalizability of CIG across distinct cancer types and diagnostic settings.
Two different Multiple Instance Learning (MIL) classification models were used to assess attribution performance across architectures: a simple MLP bag classifier and the widely used attention-based CLAM [19] model. Both models utilized patch-level features extracted from a pre-trained ResNet-50 and were trained for 200 epochs, with patient-level separation for data splits to prevent leakage.
A crucial aspect of the experimental design was the novel construction of the attribution baseline for path-based methods. Unlike traditional baselines (e.g., black images, dataset mean), CIG and other IG-based methods employed a contrastive baseline by sampling patch features from 30 slides of the opposite class. For instance, when evaluating a tumor-positive slide, non-tumor slide patches served as the reference. This strategy was designed to highlight class-discriminative features more effectively, aligning with CIG's core mechanism of capturing contrastive information.
To quantitatively assess attribution quality in this weakly supervised WSI setting, where ground truth explanations are often unavailable, the authors adapted the Performance Information Curves (PICs) framework [9] and introduced two specialized metrics:
- MIL-Accuracy Information Curve (MIL-AIC): This metric tracks the model's classification accuracy (correct slide-level label prediction) as high-saliency patches are progressively introduced. A higher MIL-AIC indicates that the attribution method quickly identifies regions crucial for correct classification.
- MIL-Softmax Information Curve (MIL-SIC): This metric measures the model's softmax confidence in the correct class as informative patches are revealed. A higher MIL-SIC suggests that the attribution method highlights regions that rapidly increase the model's certainty.
The evaluation was specifically focused on tumor-positive slides. The "ruthless proof" was designed by starting with control features (from the opposite class) and progressively replacing them with features from the target slide, ranked by attribution scores. This process was structured using two complementary information-level bins: "Top-k patches" (e.g., $k=1, \dots, 500$) to capture early-stage prediction shifts, and "Saliency thresholds" (e.g., 20% to 99% percentile cutoffs) to assess later-stage transitions and completeness. This meticulous design allowed for a fine-grained analysis of how quickly and confidently the model's predictions evolve as CIG-identified salient regions are introduced, providing undeniable evidance of its efficacy.
What the Evidence Proves
The experimental results provide compelling quantitative and qualitative evidence that CIG significantly outperforms existing attribution methods in identifying decision-relevant regions in WSIs.
Quantitatively, CIG consistently achieved the highest MIL-AIC and MIL-SIC scores across all three cancer datasets and both classifier architectures. For instance, on the CAMELYON16 dataset (Table 1), CIG with the CLAM model scored $0.950 \pm 0.166$ for MIL-AIC and $0.945 \pm 0.128$ for MIL-SIC, substantially surpassing the next best method (IG: $0.891 \pm 0.261$ MIL-AIC, $0.896 \pm 0.243$ MIL-SIC). Similar trends were observed with the MLP classifier, where CIG reached $0.965 \pm 0.128$ MIL-AIC and $0.913 \pm 0.130$ MIL-SIC. This definitive evidence, measured by how rapidly and confidently the model's predictions shift towards the correct label as CIG-identified patches are introduced, proves that CIG's core mechanism of computing contrastive gradients in logit space effectively highlights truly class-discriminative features.
Across the TCGA-Renal dataset (Table 2), CIG again demonstrated strong performance across all three renal subtypes (pRCC, ccRCC, chRCC) and both models, consistently ranking among the top performers. For example, in ccRCC with CLAM, CIG achieved $0.776 \pm 0.297$ MIL-AIC and $0.783 \pm 0.286$ MIL-SIC, outperforming all baselines. The TCGA-Lung dataset (Table 3) further reinforced these findings, with CIG achieving the highest scores for LUSC with CLAM ($0.759 \pm 0.296$ MIL-AIC, $0.765 \pm 0.277$ MIL-SIC) and showing a strong balance for LUAD. These results collectively underscore that CIG's ability to capture contrastive information leads to more informative and stable attributions.
Qualitatively, the visualizations further solidify CIG's superiority. Figure 2, which illustrates intermediate gradient maps across interpolation steps, clearly shows that CIG produces more localized and consistent gradients within tumor regions throughout the path, unlike IG which exhibits more dispersed patterns. This indicates that CIG's attributions are more stable and focused on relevant areas.
More importantly, Figure 3, presenting the final attribution maps, demonstrates that CIG consistently emphasizes areas that closely align with annotated ground truth tumor regions. In contrast, baseline methods like IG and EG often highlight visually salient but less discriminative features that are not part of the actual tumor. This visual alignment with ground truth provides undeniable proof that CIG's mechanism succefully identifies decision-relevant tumor regions.
Finally, the paper theoretically proves that CIG satisfies the fundamental axiomatic properties of integrated attribution methods: Completeness, Sensitivity, and Implementation Invariance. This theoretical soundness, combined with the strong quantitative and qualitative experimental results, provides a robust foundation for CIG's claims.
Limitations & Future Directions
While CIG demonstrates significant advancements in interpretable WSI classification, the authors acknowledge certain limitations and propose clear avenues for future research.
One notable limitation stems from the evaluation framework itself: the current MIL-AIC and MIL-SIC metrics are primarily designed for and best suited to tumor-positive slides. As the authors explain, normal slides exhibit different prediction dynamics, often requiring the removal of nearly all features before a prediction changes, which makes metrics like AUC less meaningful in that context. This suggests that while CIG performs exceptionally well in identifying tumor regions, its applicability and interpretation for non-tumor or normal tissue classification, or in scenarios where the "opposite class" baseline is less clearly defined, might require further investigation or adaptation of the evaluation methodology.
Looking ahead, the most critical future direction proposed is the incorporation of rigourous human-subject evaluations of interpretability. While quantitative metrics and qualitative visualizations offer strong evidence, the ultimate goal of interpretability in computational pathology is to build trust and aid clinical decision-making. Direct validation by pathologists or medical experts on whether CIG's explanations genuinely enhance their understanding and confidence in AI-assisted diagnostics is indispensable. This would involve designing studies to assess how CIG's attributions influence human diagnostic accuracy, efficiency, and trust.
Beyond human-subject evaluations, several other discussion topics emerge for further development:
- Generalizability to Other Medical Imaging Modalities: Could CIG's contrastive approach be adapted to other complex medical imaging tasks beyond WSIs, such as MRI or CT scans, where interpretability is equally crucial but feature spaces and baselines might differ significantly?
- Computational Efficiency and Scalability: While CIG shows strong performance, attribution methods, especially path-based ones, can be computationally intensive. Further research could explore optimizations to improve CIG's efficiency for extremely large WSIs or real-time clinical applications, perhaps through approximation techniques or hardware acceleration.
- Dynamic Baseline Selection: The current method relies on sampling from an "opposite class" baseline. Future work could investigate more dynamic or adaptive baseline selection strategies, especially in multi-class scenarios or when a clear "opposite" class is not readily available or well-defined.
- Integration with Ante-hoc Methods: CIG is a post-hoc attribution method. Exploring its integration with ante-hoc interpretability methods, which build interpretability directly into the model architecture, could lead to hybrid approaches that combine the strengths of both, offering both localized explanations and global model understanding.
- Beyond Binary Classification: While the paper touches upon multi-subtype classification (e.g., TCGA-Renal), a deeper dive into how CIG performs and can be optimized for highly granular multi-class problems, where subtle differences between many classes need to be highlighted, would be valuable.
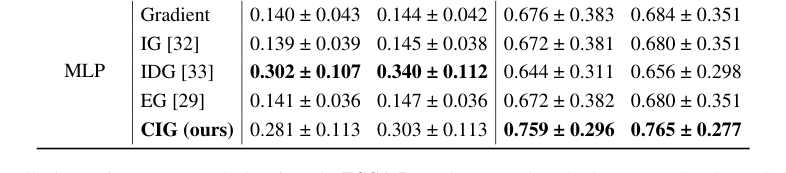 Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
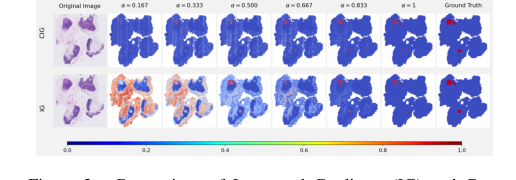 Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
 Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
Isomorphisms with other fields
Structural Skeleton
The core mathematical mechanism of this paper is a method that quantifies the differential impact of input features on a model's decision by integrating the squared difference of logit outputs along a path to a contrastive reference.
Distant Cousins
The underlying logic of Contrastive Integrated Gradients (CIG) has fascinating "mirror images" in fields far removed from computational pathology:
-
Target Field: Financial Risk Management and Portfolio Optimization
- The Connection: In finance, a long-standing problem is understanding which specific market factors (e.g., interest rates, commodity prices, sector performance) drive a portfolio's performance or risk relative to a benchmark index (like the S&P 500) or a competitor's portfolio. This is precisely analogous to CIG's goal of identifying class-discriminative features by comparing an input to a contrastive baseline. A quantitative analyst might want to know not just what contributes to their portfolio's volatility, but what specifically makes it more volatile than the market average under certain economic conditions. The "logit space" could be a transformed measure of risk-adjusted return or deviation from the benchmark, and the path integration could represent how these factor contributions evolve under different simulated market scenarios or investment strategies.
-
Target Field: Climate Science and Earth System Modeling
- The Connection: Climate scientists often grapple with attributing observed climate changes or model predictions to specific anthropogenic forcings (e.g., CO2 emissions, land-use changes) relative to a pre-industrial baseline or a "no-intervention" scenario. This is a direct parallel to CIG's contrastive attribution. They need to identify which input parameters or initial conditions in complex Earth system models are most responsible for a particular climate outcome (e.g., a specific regional temperature increase or frequency of extreme weather events) when compared to a world without those forcings. The "logit space" could represent a transformed metric of climate anomaly or deviation from a stable state, and the path integration could model the gradual increase of a forcing and its impact on the climate system.
What If Scenario
Imagine a quantitative analyst in a hedge fund "stealing" CIG's exact equation tomorrow. Instead of simply calculating the sensitivity of a portfolio's value to various market factors, they could apply CIG to understand the contrastive drivers of their portfolio's outperformance or underperformance against a chosen benchmark. By integrating the squared difference of their portfolio's log-returns (analogous to logit outputs) and the benchmark's log-returns along a path representing varying market conditions, they could precisely pinpoint which specific assets or factor exposures discriminate their portfolio's performance from the benchmark. This would lead to a breakthrough in contrastive alpha generation and risk hedging. They could identify the exact market conditions or asset characteristics that cause their portfolio to diverge from the benchmark, allowing for hyper-targeted adjustments to maximize relative returns or mitigate relative risk. This could revolutionize how active managers identify and exploit market inefficiencies, moving beyond simple attribution to discriminative attribution in financial analysys.
Universal Library of Structures
This paper powerfully reinforces the idea that all scientific problems are interconnected, demonstrating how the challenge of identifying discriminative features in medical images shares a deep mathematical kinship with problems of contrastive attribution in fields as diverse as finance and climate science, contributing a vital new structure to our universal library of scientific understanding.