Контрастные Интегрированные Градиенты: Метод Атрибуции Признаков для Объяснения Классификации Целых Гистологических Изображений
Предыстория и Академическая Преемственность
Истоки и Академическая Преемственность
Проблема, рассматриваемая в данной статье, проистекает из критической потребности в интерпретируемости вычислительной патологии, особенно в области анализа целых гистологических изображений (Whole Slide Image, WSI). Патология является краеугольным камнем современной медицины, предоставляя основные диагнозы и прогнозы. Традиционно патологи тщательно исследуют WSI для оценки клеточного состава и архитектуры тканей, что является трудоемким процессом, подверженным межоператорской вариабельности.
С появлением искусственного интеллекта и глубокого обучения появились вычислительные инструменты для помощи патологам, предлагающие решения для предварительной сегментации интересующих областей и потенциального повышения согласованности диагностики и эффективности рабочего процесса. Однако, несмотря на впечатляющую производительность этих передовых моделей глубокого обучения для классификации и сегментации WSI, они часто функционируют как «черные ящики», предоставляя ограниченное представление о специфических гистологических закономерностях, которые определяют их предсказания. Этот недостаток прозрачности подрывает доверие к диагностике с помощью ИИ, что является значительным препятствием для их широкого клинического внедрения.
Академическая преемственность данной проблемы прослеживается в более широкой области объяснимого ИИ (Explainable AI, XAI), которая стремится сделать модели ИИ более понятными для человека. В компьютерном зрении методы XAI широко классифицируются как основанные на тепловых картах (показывающие, куда фокусируется модель) и основанные на концепциях (объясняющие, на чем она основывается), а также как пост-хок (объяснения после обучения) и анте-хок (интерпретируемость, интегрированная в модель). Данная работа конкретно развивает пост-хок методы атрибуции, которые направлены на создание локализованных тепловых карт, выделяющих области, релевантные для принятия решения моделью в WSI.
Фундаментальным ограничением или «болевой точкой» предыдущих подходов, побудивших авторов написать эту статью, является многогранность. Существующие методы атрибуции на основе градиентов, такие как Интегрированные Градиенты (Integrated Gradients, IG), часто работают в пространстве необработанных изображений. Хотя это полезно, это может быть менее эффективно для моделей, которые полагаются на сложные, обученные эмбеддинги признаков, полученные из патчей WSI. Более критично то, что эти методы часто выделяют визуально заметные области, которые не обязательно являются классово-дискриминативными. Это означает, что они могут указывать на заметные, но нерелевантные признаки, тем самым ограничивая их интерпретируемость для задач классификации WSI, где различие между, скажем, опухолевыми и неопухолевыми областями имеет первостепенное значение. Кроме того, эффективность таких методов, как Интегрированные Градиенты, сильно зависит от выбора «базового» входного сигнала, который может быть неоднозначным и сложным для адекватного определения в таких сложных областях, как патология. Другие передовые методы атрибуции, предлагая лучшую точность, часто сопряжены с более высокими вычислительными затратами, что делает их менее практичными для крупномасштабного анализа WSI. Мотивация авторов заключается в преодолении этих ограничений путем разработки метода, который обеспечивает более сфокусированные и классово-дискриминативные атрибуции, работая в более осмысленном «пространстве логитов», а не просто в пространстве изображений.
Интуитивные Термины из Области
Вот несколько специализированных терминов из статьи, переведенных в интуитивные, повседневные аналогии для читателя без предварительной подготовки:
- Целое гистологическое изображение (Whole Slide Image, WSI): Представьте себе массивную цифровую фотографию сверхвысокого разрешения всего образца ткани, помещенного на предметное стекло микроскопа. Она настолько детализирована, что вы можете увеличить изображение от всего стекла до отдельных клеток, подобно тому, как вы используете Google Maps для исследования города вплоть до одного здания. Патологи используют их для диагностики заболеваний.
- Обучение на множестве экземпляров (Multiple Instance Learning, MIL): Представьте себе инспектора качества, проверяющего большую коробку шоколадных конфет. Он не открывает каждую конфету, но если он найдет хоть одну испорченную конфету в коробке, вся коробка будет помечена как «испорченная». MIL — это способ для ИИ учиться на этих «коробках» (целых изображениях) без необходимости знать точную метку каждой «конфеты» (отдельного патча ткани) внутри.
- Интегрированные Градиенты (Integrated Gradients, IG): Попробуйте представить, как понять, какой вклад каждый ингредиент вносит в конечный вкус сложного супа. Вместо того чтобы просто пробовать готовый суп, вы пробуете его на каждом крошечном этапе приготовления, от простого бульона до полностью приправленного блюда, отмечая, как каждый ингредиент меняет вкус по пути. IG делает нечто подобное для ИИ, отслеживая «вкус» (выход модели) до каждого «ингредиента» (входного признака) по плавному пути.
- Пространство логитов (Logit Space): Когда модель ИИ делает предсказание (например, «опухоль» или «не опухоль»), она сначала вычисляет необработанные, нормализованные оценки для каждого варианта, прежде чем преобразовать их в вероятности (например, 90% вероятность опухоли). Пространство логитов похоже на прямой просмотр этих необработанных «оценок доказательств» перед их сглаживанием в проценты. Оно дает более четкое, прямое представление о внутреннем рассуждении модели и ее уверенности для каждой категории.
- Метод атрибуции (Attribution Method): Если модель ИИ сообщает вам, что на изображении есть собака, метод атрибуции подобен вопросу к ИИ: «Покажи мне точно, какие части изображения заставили тебя подумать, что это собака». Он выделяет конкретные пиксели или области, которые оказали наибольшее влияние на решение модели, помогая понять ее рассуждения.
Таблица Обозначений
| Обозначение | Описание |
|---|---|
Определение Проблемы и Ограничения
Основная Формулировка Проблемы и Дилемма
Основная проблема, решаемая в данной статье, заключается в повышении интерпретируемости моделей глубокого обучения для классификации целых гистологических изображений (WSI) в вычислительной патологии.
Исходная точка (Вход/Текущее Состояние) включает WSI высокого разрешения, обрабатываемые моделями глубокого обучения, часто по парадигме обучения на множестве экземпляров (MIL). Существующие методы атрибуции, такие как Интегрированные Градиенты (IG), применяются к этим моделям для объяснения их предсказаний. Хотя эти методы могут идентифицировать области, влияющие на решение модели, они часто работают в пространстве изображений или на обученных эмбеддингах и имеют тенденцию выделять визуально заметные признаки, которые могут быть не напрямую релевантны для дискриминации классов. Они улавливают общие закономерности принятия решений моделью, но часто упускают из виду специфические сигналы, критически важные для различения между различными подтипами опухолей или между опухолевой и неопухолевой тканью.
Желаемая конечная точка (Выход/Целевое Состояние) — достижение более информативных, сфокусированных и точных атрибуций, которые точно выделяют классово-дискриминативные области в пределах WSI. Эти атрибуции должны тесно соответствовать истинным (ground truth) опухолевым областям, тем самым укрепляя доверие к диагностическим инструментам с поддержкой ИИ. Кроме того, желаемый метод должен удовлетворять фундаментальным аксиоматическим свойствам атрибуции (полнота, чувствительность, инвариантность реализации) для обеспечения теоретической обоснованности и последовательных объяснений.
Точное недостающее звено или математический пробел, который данная статья пытается преодолеть, — это неспособность традиционных методов атрибуции эффективно улавливать контрастную информацию в пространстве логитов. Предыдущие методы в основном фокусируются на атрибуции важности на основе градиентов выхода модели по отношению к входным признакам. Однако этот подход часто не может отличить признаки, которые просто заметны, от тех, которые действительно дискриминативны для определенного класса относительно эталона. Статья предлагает преодолеть это путем введения Контрастных Интегрированных Градиентов (Contrastive Integrated Gradients, CIG), которые математически определяют атрибуцию для $i$-го признака как:
$$ \text{CIG}_i^c(x) = (x_i - x'_i) \int_0^1 \frac{\partial ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2}{\partial x_i} d\alpha $$
Здесь $f_{\text{logit}}(\cdot)$ представляет выход логитов модели, $x$ — входные данные, $x'$ — эталонный базовый уровень, а $\gamma(\alpha)$ определяет прямолинейный путь между $x$ и $x'$. Эта формулировка явно интегрирует градиенты квадрата разности между выходами логитов интерполированного входа и базового эталона. Это позволяет CIG измерять, как граница принятия решений моделью эволюционирует относительно эталона, тем самым улавливая контрастную информацию непосредственно в пространстве логитов и подчеркивая классово-дискриминативные признаки.
Болезненный компромисс или дилемма, в ловушке которой оказались предыдущие исследователи, — это присущее напряжение между созданием исчерпывающих карт заметности и получением классово-дискриминативных объяснений. Методы, такие как стандартные Интегрированные Градиенты, часто предоставляют широкие карты заметности, указывающие на все признаки, способствующие предсказанию. Однако в диагностическом контексте патологам необходимо понимать, почему модель различает, скажем, опухоль и неопухолевую ткань, а не просто какие области активны. Улучшение исчерпываемости атрибуции часто достигается за счет специфичности и дискриминативной силы, что приводит к объяснениям, которые визуально заметны, но могут включать признаки, нерелевантные для интересующего конкретного различия классов. Это затрудняет предоставление действенных выводов для принятия клинических решений.
Ограничения и Режимы Сбоя
Проблема предоставления интерпретируемых объяснений для классификации WSI делает ее чрезвычайно сложной из-за нескольких суровых, реалистичных ограничений:
- Высокое Разрешение WSI: Целые гистологические изображения имеют масштаб гигапикселей, что делает их вычислительно сложными для прямой обработки. Это требует разбиения их на более мелкие патчи, которые затем обрабатываются моделями глубокого обучения, часто в рамках фреймворка обучения на множестве экземпляров (MIL). Эта патч-ориентированная обработка добавляет сложности при атрибуции важности обратно к исходному WSI.
- Слабое Надзором: В вычислительной патологии истинные метки (ground truth) обычно доступны только на уровне всего изображения (например, все изображение помечено как «опухоль» или «не опухоль»), а не на уровне патча. Этот «слабый надзор» делает чрезвычайно трудным обучение моделей для идентификации специфических опухолевых областей внутри изображения, а затем и оценку того, правильно ли методы атрибуции выделяют эти точные области.
- Неоднозначный Выбор Базового Уровня: Методы атрибуции на основе градиентов, такие как Интегрированные Градиенты, критически зависят от выбора «базового» входного сигнала, который служит эталонной точкой для измерения важности признаков. В патологии выбор подходящего базового уровня неоднозначен. Распространенные базовые уровни (например, нулевой вектор, среднее по набору данных, случайные патчи) могут приводить к проблемам вне распределения, семантическому смещению или снижению дискриминативности, делая атрибуции менее осмысленными или даже вводящими в заблуждение. В статье явно отмечается, что базовый уровень нулевого вектора может вызывать проблемы вне распределения в пространстве эмбеддингов, в то время как среднее по набору данных или случайные патчи могут страдать от семантической утечки или снижения дискриминативности.
- Отсутствие Истинных Данных для Оценки Атрибуции: В отличие от некоторых задач обработки естественных изображений, где могут существовать истинные данные для оценки заметности на уровне пикселей, подробные объяснения модели на уровне пикселей часто недоступны при анализе WSI. Это отсутствие делает чрезвычайно сложной количественную оценку качества и точности карт атрибуции. Стандартные метрики оценки карт заметности (такие как кривые информации о производительности или RISE) не применимы напрямую к слабо контролируемой среде WSI, поскольку они предполагают постепенные сдвиги предсказаний или контроль на уровне пикселей, чего нет при классификации WSI на основе MIL, где предсказания могут резко меняться при появлении нескольких ключевых патчей.
- Вычислительная Стоимость Интегрирования по Пути: Методы атрибуции на основе путей, включая Интегрированные Градиенты и CIG, требуют интегрирования градиентов вдоль пути между входом и базовым уровнем. Этот процесс включает в себя несколько шагов интерполяции, что может быть вычислительно затратным, особенно для высокоразмерных пространств признаков, полученных из WSI. Хотя это не является явным режимом сбоя, более высокая вычислительная стоимость является практическим ограничением для развертывания.
- Зависимость Модели от Обученных Эмбеддингов: Многие модели анализа WSI полагаются на обученные эмбеддинги от экстракторов признаков (например, Vision Transformers или CNN). Методы на основе градиентов, работающие непосредственно в пространстве изображений, могут быть менее эффективными, когда решение модели в основном определяется этими абстрактными, обученными эмбеддингами, а не необработанными значениями пикселей.
Почему Этот Подход
Неизбежность Выбора
Разработка Контрастных Интегрированных Градиентов (CIG) была не просто инкрементальным улучшением; это была необходимая эволюция, обусловленная присущими ограничениями существующих методов атрибуции при их применении к уникальным задачам анализа целых гистологических изображений (WSI) в вычислительной патологии. Авторы осознали, что традиционные «SOTA» методы, такие как стандартные Интегрированные Градиенты (IG) и их варианты (например, Gradient $\times$ Input, Grad-CAM, Expected Gradients), хотя и перспективны в общих задачах компьютерного зрения, оказались недостаточными в этой конкретной области.
Точный момент этого осознания подразумевается выявлением двух критических недостатков:
1. Высокое Разрешение WSI: Прямое применение этих методов к WSI, которые являются изображениями масштаба гигапикселей, создало значительные вычислительные проблемы и проблемы с интерпретируемостью. Огромный масштаб затруднил получение осмысленных и локализованных объяснений этими методами.
2. Отсутствие Классово-Дискриминативных Сигналов: Что более важно, традиционные методы атрибуции, работая в основном в пространстве изображений, часто выделяли визуально заметные признаки, которые не обязательно были классово-дискриминативными. Это означало, что они могли указывать на области, которые выглядели важными, но на самом деле не помогали различать, скажем, подтипы опухолей или опухолевую и неопухолевую ткань. Например, область могла быть визуально заметной, но нерелевантной для диагностического решения, что приводило к вводящим в заблуждение объяснениям для патологов. Необходимость выйти за рамки простой заметности к контрастным, релевантным для принятия решений признакам была движущей силой CIG.
Сравнительное Превосходство
CIG предлагает качественное превосходство над предыдущими золотыми стандартами, особенно в его способности предоставлять более сфокусированные и диагностически релевантные атрибуции. Его структурное преимущество заключается в вычислении контрастных градиентов в пространстве логитов, а не непосредственно в пространстве изображений или пространстве вероятностей выхода.
Вот почему это подавляющее превосходство:
* Более Четкое Различение Классов: В отличие от IG, который атрибутирует важность на основе градиентов выхода модели (например, оценок вероятности), CIG вычисляет градиенты квадрата разности логитов между входом и эталонным базовым уровнем. Это означает, что он явно измеряет, насколько признак способствует различию в выходе логитов модели относительно эталонного класса. Эта структурная конструкция позволяет CIG выделять классово-дискриминативные области, предлагая гораздо более четкое различие между опухолевыми и неопухолевыми областями, что критически важно для патологии.
* Локализованные и Последовательные Атрибуции: Качественно, как показано на рисунках статьи, CIG производит более стабильные и локализованные градиенты в пределах опухолевых областей на протяжении всего пути интерполяции, в то время как градиенты IG имеют тенденцию быть более пространственно распределенными. Это указывает на то, что CIG лучше изолирует истинные области принятия решений, эффективно обрабатывая высокоразмерный шум и нерелевантные визуальные сигналы, фокусируясь на том, что действительно различает классы.
* Аксиоматическая Обоснованность с Контрастной Силой: CIG сохраняет желаемые аксиоматические свойства Интегрированных Градиентов (полнота, чувствительность, инвариантность реализации), обеспечивая теоретическую обоснованность и последовательность. Однако он расширяет это, включая контрастный элемент, делая атрибуции не просто последовательными, но и осмысленными в дифференциальном контексте. Это значительное структурное преимущество перед методами, которые предоставляют только абсолютную важность без сравнительной перспективы.
Статья не детализирует сокращение сложности памяти с $O(N^2)$ до $O(N)$, но ее качественные и структурные преимущества в получении более точных и локализованных объяснений явно продемонстрированы.
Соответствие Ограничениям
Выбранный метод CIG идеально соответствует суровым требованиям анализа WSI в вычислительной патологии, образуя прочный «брак» между проблемой и решением:
- Интерпретируемость для Доверия: Основным ограничением является необходимость высокоинтерпретируемых систем ИИ для укрепления доверия среди клиницистов. CIG напрямую решает эту проблему, предоставляя «более информативные и стабильные атрибуции», которые тесно соответствуют истинным опухолевым областям. Его способность выделять классово-дискриминативные признаки гарантирует, что объяснения релевантны диагностическим решениям, способствуя клинической уверенности.
- WSI Высокого Разрешения: Метод разработан для работы в рамках обучения на множестве экземпляров (MIL), которое является стандартной парадигмой для анализа WSI. Работая с признаками на уровне патчей, извлеченными из WSI, CIG эффективно масштабируется до высокого разрешения этих изображений, предоставляя атрибуции для отдельных патчей, которые затем агрегируются в тепловую карту на уровне WSI.
- Слабо Контролируемое Обучение: Анализ WSI часто проводится в условиях слабого надзора, когда доступны только метки на уровне всего изображения, а не аннотации на уровне пикселей. Интеграция CIG в фреймворк MIL, в сочетании с введением метрик MIL-AIC и MIL-SIC, специально предназначена для этой слабо контролируемой среды. Эти метрики оценивают, насколько быстро предсказание и уверенность модели изменяются при введении заметных патчей, напрямую оценивая качество атрибуции в этом сложном контексте.
- Классово-Дискриминативные Сигналы: Основная выявленная проблема заключалась в упущении классово-дискриминативных сигналов традиционными методами. Уникальное свойство CIG вычислять контрастные градиенты в пространстве логитов напрямую решает эту проблему, подчеркивая признаки, которые различают один класс от другого, а не просто общую заметность. Это гарантирует, что объяснения напрямую релевантны для различения подтипов опухолей или стадий заболевания.
Отклонение Альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов, в основном другие методы атрибуции на основе градиентов и распространенные варианты выбора базового уровня, из-за их неспособности удовлетворить специфические требования анализа WSI:
- Традиционные Интегрированные Градиенты (IG) и Варианты: В статье говорится, что, хотя IG и связанные с ним методы атрибуции «показали многообещающие результаты», их прямое применение к WSI «создает проблемы из-за их высокого разрешения» и их тенденции «упускать из виду классово-дискриминативные сигналы». Это прямое отклонение их прямой применимости без модификации. Методы, такие как Gradient $\times$ Input, EG и IDG, сравниваются с CIG, и CIG последовательно превосходит их по MIL-AIC и MIL-SIC, демонстрируя их количественную неполноценность для данной проблемы.
- Методы Атрибуции в Пространстве Изображений: Более широкое отклонение делается против «большинства методов атрибуции [которые] работают в пространстве изображений и могут выделять визуально заметные, но классово-нерелевантные признаки». Это ограничение серьезно затрудняет их интерпретируемость для классификации WSI, где цель состоит в идентификации диагностически релевантных областей, а не просто любых визуально заметных областей. Подход CIG в пространстве логитов напрямую решает эту проблему, фокусируясь на границах принятия решений.
- Стандартные Выборы Базового Уровня для Методов на Основе IG: Статья посвящает раздел «Разработке Базового Уровня Атрибуции», объясняя, почему распространенные базовые уровни (например, нулевой вектор, среднее по набору данных, случайные патчи) недостаточны для WSI.
- Базовый уровень нулевого вектора может вызывать «проблемы вне распределения» в пространстве эмбеддингов.
- Среднее по набору данных вводит «семантическое смещение», отдавая предпочтение доминирующим классам.
- Выборка из распределения набора данных или использование случайных патчей страдает от «семантической утечки или снижения дискриминативности», если вход и базовый уровень принадлежат к одному классу.
Эти проблемы приводят к менее интерпретируемым картам заметности. CIG преодолевает это, используя «базовый уровень из противоположного класса», что имеет решающее значение для его контрастной природы и для улавливания осмысленных различий, которые определяют предсказания модели.
Статья не обсуждает отклонение генеративных моделей, таких как GANs или диффузионные модели, поскольку они служат другим целям (например, генерация изображений), чем атрибуция признаков для интерпретируемости, которая является фокусом данной работы. Рассматриваемые и отклоненные альтернативы — это в первую очередь другие методы атрибуции и их компоненты.
Математический и Логический Механизм
Мастер-Уравнение
Абсолютно ключевое уравнение, лежащее в основе Контрастных Интегрированных Градиентов (CIG), — это его определение атрибуции $i$-го признака, представленное в статье:
$$ \text{CIG}_i(x) = (x_i - x'_i) \int_0^1 \frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2 d\alpha $$
Покомпонентный Анализ
Разберем это уравнение по частям, чтобы понять его математическое определение, роль в механизме CIG и обоснование выбранных операторов.
-
$\text{CIG}_i(x)$:
- Математическое Определение: Это оценка контрастных интегрированных градиентов для $i$-го признака входных данных $x$.
- Физическая/Логическая Роль: Это конечный результат вычисления CIG для конкретного признака. Он количественно определяет, насколько важен $i$-й признак входных данных $x$ для принятия решения моделью, в контрастном смысле по отношению к базовому уровню $x'$. Более высокое абсолютное значение указывает на большую важность, а его знак может указывать, толкает ли признак предсказание к классу базового уровня или от него.
-
$x$:
- Математическое Определение: Это вектор входных признаков (например, эмбеддинг патча целого гистологического изображения), для которого мы хотим вычислить атрибуции.
- Физическая/Логическая Роль: Это конкретная точка данных, признаки которой мы пытаемся объяснить. Это «целевой» вход.
-
$x'$:
- Математическое Определение: Это базовый или эталонный вектор признаков.
- Физическая/Логическая Роль: Статья указывает, что $x'$ обычно выбирается из «противоположного класса» (например, неопухолевые патчи для опухолево-позитивного изображения). Он служит нейтральной или неинформативной эталонной точкой в пространстве признаков. CIG измеряет важность признаков, сравнивая вход $x$ с этим базовым уровнем $x'$, выделяя признаки, которые отличают $x$ от $x'$.
-
$(x_i - x'_i)$:
- Математическое Определение: Это скалярная разность между $i$-й компонентой вектора входных признаков $x$ и $i$-й компонентой вектора базового уровня $x'$.
- Физическая/Логическая Роль: Этот член действует как масштабирующий множитель для интегрированного градиента. Он гарантирует, что если признак $x_i$ идентичен своему аналогу базового уровня $x'_i$, его атрибуция $\text{CIG}_i(x)$ будет равна нулю, поскольку он не вносит никакого различия. Он также учитывает величину и направление изменения этого конкретного признака от базового уровня к входу.
- Почему умножение: Это прямое масштабирование, отражающее, что общее «влияние» признака должно быть пропорционально тому, насколько он отличается от базового уровня.
-
$\int_0^1 \dots d\alpha$:
- Математическое Определение: Это определенный интеграл по скалярному параметру $\alpha$ от 0 до 1.
- Физическая/Логическая Роль: Этот интеграл является сердцем концепции «Интегрированных Градиентов». Он накапливает градиенты вдоль непрерывного пути от базового уровня $x'$ к входу $x$. Эта интеграция имеет решающее значение, поскольку она решает проблему «насыщения градиента», когда градиенты могут становиться очень малыми для признаков, которые уже сильно активированы, тем самым недооценивая их важность. Суммируя бесконечно малые вклады вдоль всего пути, он обеспечивает более надежную и полную меру важности признаков.
- Почему интеграл вместо суммирования: Интеграл используется для суммирования по непрерывному пути, обеспечивая теоретически обоснованную и полную атрибуцию, которая удовлетворяет желаемым аксиомам (например, полноте). Суммирование (например, аппроксимация суммой Римана) было бы дискретным приближением этого непрерывного процесса.
-
$\frac{\partial}{\partial x_i}$:
- Математическое Определение: Это оператор частной производной по $i$-му признаку входа. В контексте интеграла он применяется к члену квадрата нормы L2.
- Физическая/Логическая Роль: Этот оператор вычисляет чувствительность квадрата разности логитов к изменениям $i$-го признака в каждой точке $\gamma(\alpha)$ вдоль пути интерполяции. Он показывает, насколько небольшое изменение $x_i$ в данной точке пути повлияет на «контраст» (квадрат разности логитов) между интерполированным входом и базовым уровнем. Именно так метод определяет, какие признаки локально влиятельны.
-
$|| \cdot ||_2^2$:
- Математическое Определение: Обозначает квадрат евклидовой (L2) нормы вектора. Для вектора $v$, $||v||_2^2 = \sum_j v_j^2$.
- Физическая/Логическая Роль: Этот член количественно определяет «расстояние» или «различие» в пространстве логитов между выходом логитов интерполированного входа и выходом логитов базового уровня. Квадратируя норму L2, он гарантирует, что мера всегда неотрицательна и более значительно подчеркивает большие различия. Это основная «контрастная» мера, которую CIG стремится объяснить.
- Почему норма L2: Норма L2 является стандартной метрикой для измерения величины вектора и расстояния в евклидовом пространстве. Ее квадратирование упрощает вычисления, устраняя квадратный корень, и обеспечивает гладкую, дифференцируемую функцию, подходящую для вычисления градиентов.
-
$f_{\text{logit}}(\cdot)$:
- Математическое Определение: Представляет выход слоя логитов модели. Для модели классификации это необработанные, ненормализованные оценки для каждого класса перед применением функции softmax.
- Физическая/Логическая Роль: CIG работает в пространстве логитов, поскольку логиты напрямую отражают уверенность модели и доказательства для каждого класса. Измеряя различия в выходах логитов, CIG улавливает классово-дискриминативную информацию, которая имеет решающее значение для различения опухолевых и неопухолевых областей. Это ключевое отличие от методов, работающих в пространстве изображений или на вероятностях softmax.
-
$\gamma(\alpha)$:
- Математическое Определение: Это функция прямолинейного пути, определенная как $\gamma(\alpha) = x' + \alpha(x - x')$, где $\alpha \in [0, 1]$.
- Физическая/Логическая Роль: Эта функция генерирует промежуточные точки в пространстве признаков, лежащие на прямой линии, соединяющей базовый уровень $x'$ (при $\alpha=0$) с входом $x$ (при $\alpha=1$). Она обеспечивает непрерывную траекторию, вдоль которой интегрируются градиенты.
-
$\alpha$:
- Математическое Определение: Скалярный параметр, непрерывно изменяющийся от 0 до 1.
- Физическая/Логическая Роль: Этот параметр контролирует положение вдоль пути интерполяции $\gamma(\alpha)$. По мере увеличения $\alpha$ интерполированная точка движется от базового уровня к входу.
-
$f_{\text{logit}}(x')$:
- Математическое Определение: Выход логитов модели при подаче вектора базового уровня $x'$ в качестве входа.
- Физическая/Логическая Роль: Это служит фиксированной эталонной точкой в пространстве логитов. Метод CIG измеряет, как выход логитов для интерполированного входа $\gamma(\alpha)$ отличается от этого постоянного выхода логитов базового уровня. Этот постоянный эталон является фундаментальным для «контрастной» природы CIG, позволяя ему выделять признаки, вызывающие отклонение от предсказания базового уровня.
Пошаговый Поток
Представьте себе одну абстрактную точку данных, представленную ее вектором признаков $x$, входящую в этот математический механизм. Вот как CIG обрабатывает ее для определения атрибуций признаков:
- Выбор Базового Уровня: Сначала выбирается подходящий вектор признаков базового уровня $x'$. Статья подчеркивает использование контрастного базового уровня, такого как патчи, выбранные из неопухолевых областей при анализе опухолево-позитивного изображения. Этот $x'$ служит нейтральной или «противоположной» эталонной точкой.
- Построение Пути: В пространстве признаков строится прямолинейный путь $\gamma(\alpha)$. Этот путь плавно интерполирует между базовым уровнем $x'$ (при $\alpha=0$) и входом $x$ (при $\alpha=1$). Представьте, что вы рисуете линию от эталонной точки к фактической входной точке.
- Логитное Преобразование: Для каждого бесконечно малого шага вдоль этого пути, представленного $\gamma(\alpha)$, вычисляется выход логитов модели $f_{\text{logit}}(\gamma(\alpha))$. Одновременно также получается выход логитов для фиксированного базового уровня $f_{\text{logit}}(x')$.
- Контрастное Измерение: В каждой точке $\alpha$ на пути вычисляется разница между текущим интерполированным выходом логитов и выходом логитов базового уровня, $f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')$. Затем вычисляется квадрат евклидовой нормы этой разности, $||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$. Это значение количественно определяет, насколько «отличается» сырое предсказание модели для интерполированного входа от ее предсказания для базового уровня в этой конкретной точке пути.
- Вычисление Градиента: Частная производная этой квадратичной разности логитов (контрастной меры) вычисляется по отношению к каждому отдельному признаку $x_i$ входа. Этот градиент, $\frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$, показывает, насколько чувствительна контрастная мера к изменениям признака $i$ в данной точке $\alpha$ на пути.
- Интегрирование Градиента: Эти частные градиенты затем интегрируются вдоль всего пути от $\alpha=0$ до $\alpha=1$. Этот шаг эффективно суммирует все бесконечно малые вклады чувствительности каждого признака к контрастной мере по мере перехода входа от базового уровня к его фактическому значению. Это обеспечивает исчерпывающую оценку важности, избегая проблем, когда градиенты могут быть вводящими в заблуждение в одной точке.
- Масштабирование и Финальная Атрибуция: Наконец, для каждого признака $i$ накопленный интеграл масштабируется разностью $(x_i - x'_i)$. Это масштабирование гарантирует, что признаки, идентичные базовому уровню, получают нулевую атрибуцию, и учитывает величину изменения признака от базового уровня. Результатом является $\text{CIG}_i(x)$, контрастный интегрированный градиент для признака $i$.
Этот процесс повторяется для всех признаков, давая вектор оценок атрибуции, которые выделяют, какие части входа $x$ наиболее ответственны за его предсказание, относительно выбранного базового уровня $x'$.
Динамика Оптимизации
Важно уточнить, что Контрастные Интегрированные Градиенты (CIG) являются методом атрибуции, а не алгоритмом обучения или оптимизации модели. Поэтому он не «обучается», «обновляется» или «сходится» в традиционном смысле корректировки параметров модели на основе функции потерь. Вместо этого его «динамика» относится к тому, как вычисляются оценки атрибуции и как они ведут себя, чтобы предоставить осмысленные объяснения для уже обученной модели.
Динамика механизма определяется несколькими аксиоматическими свойствами, которые CIG призван удовлетворять, обеспечивая его надежность и интерпретируемость:
-
Аксиома Полноты: Как указано в статье (Уравнение 7), сумма всех атрибуций CIG для входа $x$ равна полному изменению квадрата разности логитов между входом и базовым уровнем: $\sum_{i=1}^n \text{CIG}_i(x) = ||f_{\text{logit}}(x) - f_{\text{logit}}(x')||_2^2$. Это означает, что метод полностью учитывает все изменение выхода логитов модели между входом и базовым уровнем, полностью распределяя это изменение между входными признаками. Никакой вклад не остается необъясненным.
-
Аксиома Чувствительности: CIG присваивает ненулевые атрибуции признакам $x_i$, которые отличаются от их аналогов базового уровня $x'_i$ и чьи изменения влияют на выход логитов модели. И наоборот, если признак $x_i$ не изменяется от $x'_i$, или если выход логитов модели полностью независим от $x_i$, то его атрибуция будет равна нулю. Это гарантирует, что CIG правильно идентифицирует и выделяет только релевантные признаки, которые способствуют принятию решений моделью, отличая их от нерелевантных. Это свойство имеет решающее значение для создания сфокусированных и интерпретируемых карт заметности.
-
Аксиома Инвариантности Реализации: Атрибуции CIG основаны исключительно на выходной функции модели ($f_{\text{logit}}(\cdot)$) и ее градиентах, а не на конкретных деталях реализации нейронной сети. Это гарантирует, что функционально эквивалентные модели будут давать последовательные атрибуции, независимо от того, как они закодированы или структурированы внутри. Это делает CIG надежным и заслуживающим доверия для различных архитектур моделей.
Таким образом, «динамика» CIG заключается не в итеративных обновлениях на ландшафте потерь, а в надежном и последовательном вычислении оценок важности признаков, которые соответствуют этим теоретическим свойствам. Интеграция градиентов вдоль пути в пространстве логитов в сочетании с контрастным базовым уровнем формирует значения атрибуции таким образом, чтобы они были более локализованными и классово-дискриминативными, как показано в качественных результатах статьи. Этот механизм гарантирует, что создаваемые объяснения не просто визуально заметны, но и логически обоснованы и напрямую связаны с процессом принятия решений моделью, особенно при различениях между различными классами.
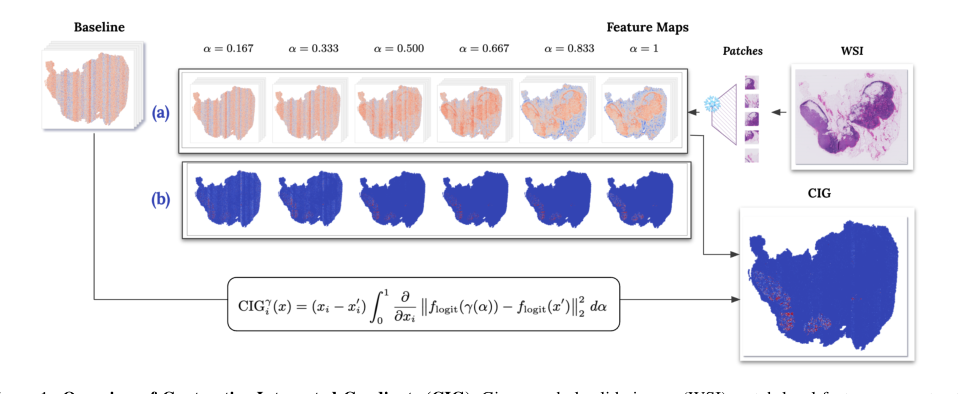 Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
Результаты, Ограничения и Заключение
Экспериментальный Дизайн и Базовые Уровни
Для строгого подтверждения эффективности Контрастных Интегрированных Градиентов (CIG) авторы разработали комплексную экспериментальную установку для различных сценариев вычислительной патологии. «Жертвами» или базовыми моделями, которые CIG стремился превзойти, были несколько устоявшихся методов атрибуции на основе градиентов: Vanilla Gradient, Integrated Gradients (IG) [32], Expected Gradients (EG) [29] и Integrated Decision Gradients (IDG) [33], а также простой Random baseline для сравнения. Все методы, основанные на путях, включая CIG, были настроены на 50 шагов интерполяции для согласованности.
Эксперименты проводились на трех общедоступных, высокозначимых наборах данных по онкологической патологии: CAMELYON16 (метастазы рака молочной железы в лимфатических узлах), TCGA-Renal (охватывающий три подтипа рака почек: KIRC, KIRP, KICH) и TCGA-Lung (охватывающий подтипы рака легких LUAD и LUSC). Этот разнообразный выбор обеспечил обобщаемость CIG для различных типов рака и диагностических сценариев.
Для оценки производительности атрибуции на различных архитектурах использовались две различные модели классификации на основе обучения на множестве экземпляров (MIL): простой MLP-классификатор мешков и широко используемая модель CLAM [19] на основе внимания. Обе модели использовали признаки на уровне патчей, извлеченные из предварительно обученной ResNet-50, и обучались в течение 200 эпох с разделением данных на уровне пациентов для предотвращения утечки.
Ключевым аспектом экспериментального дизайна было новое построение базового уровня атрибуции для методов, основанных на путях. В отличие от традиционных базовых уровней (например, черные изображения, среднее по набору данных), CIG и другие методы на основе IG использовали контрастный базовый уровень, выбирая патчи признаков из 30 изображений противоположного класса. Например, при оценке опухолево-позитивного изображения в качестве эталона использовались патчи с неопухолевых изображений. Эта стратегия была разработана для более эффективного выделения классово-дискриминативных признаков, что соответствует основной механике CIG по улавливанию контрастной информации.
Для количественной оценки качества атрибуции в этой слабо контролируемой среде WSI, где истинные объяснения часто недоступны, авторы адаптировали фреймворк кривых информации о производительности (Performance Information Curves, PICs) [9] и ввели две специализированные метрики:
- MIL-Accuracy Information Curve (MIL-AIC): Эта метрика отслеживает точность классификации модели (правильное предсказание метки на уровне изображения) по мере постепенного введения патчей с высокой заметностью. Более высокий MIL-AIC указывает на то, что метод атрибуции быстро идентифицирует области, критически важные для правильной классификации.
- MIL-Softmax Information Curve (MIL-SIC): Эта метрика измеряет уверенность модели в правильном классе (softmax confidence) по мере раскрытия информативных патчей. Более высокий MIL-SIC предполагает, что метод атрибуции выделяет области, которые быстро повышают уверенность модели.
Оценка была специально сосредоточена на опухолево-позитивных изображениях. «Жестокое доказательство» было разработано путем начала с контрольных признаков (из противоположного класса) и постепенной замены их признаками из целевого изображения, ранжированными по оценкам атрибуции. Этот процесс был структурирован с использованием двух взаимодополняющих бинов информационного уровня: «Top-k патчей» (например, $k=1, \dots, 500$) для улавливания сдвигов предсказаний на ранних стадиях и «Пороги заметности» (например, отсечки 20% до 99% перцентилей) для оценки переходов на более поздних стадиях и полноты. Этот тщательный дизайн позволил провести детальный анализ того, насколько быстро и уверенно развиваются предсказания модели по мере введения патчей, идентифицированных CIG, предоставляя неоспоримые доказательства его эффективности.
Что Доказывают Свидетельства
Экспериментальные результаты предоставляют убедительные количественные и качественные доказательства того, что CIG значительно превосходит существующие методы атрибуции в идентификации областей, релевантных для принятия решений в WSI.
Количественно, CIG последовательно достигал самых высоких оценок MIL-AIC и MIL-SIC по всем трем наборам данных рака и обеим архитектурам классификаторов. Например, на наборе данных CAMELYON16 (Таблица 1) CIG с моделью CLAM показал $0.950 \pm 0.166$ для MIL-AIC и $0.945 \pm 0.128$ для MIL-SIC, значительно превзойдя следующий лучший метод (IG: $0.891 \pm 0.261$ MIL-AIC, $0.896 \pm 0.243$ MIL-SIC). Аналогичные тенденции наблюдались и с MLP-классификатором, где CIG достиг $0.965 \pm 0.128$ MIL-AIC и $0.913 \pm 0.130$ MIL-SIC. Эти окончательные доказательства, измеренные тем, насколько быстро и уверенно предсказания модели смещаются к правильной метке по мере введения патчей, идентифицированных CIG, доказывают, что основной механизм CIG по вычислению контрастных градиентов в пространстве логитов эффективно выделяет истинно классово-дискриминативные признаки.
На наборе данных TCGA-Renal (Таблица 2) CIG снова продемонстрировал высокую производительность по всем трем подтипам рака почек (pRCC, ccRCC, chRCC) и обеим моделям, последовательно занимая лидирующие позиции. Например, в ccRCC с CLAM CIG достиг $0.776 \pm 0.297$ MIL-AIC и $0.783 \pm 0.286$ MIL-SIC, превзойдя все базовые уровни. Набор данных TCGA-Lung (Таблица 3) далее укрепил эти выводы, где CIG достиг самых высоких оценок для LUSC с CLAM ($0.759 \pm 0.296$ MIL-AIC, $0.765 \pm 0.277$ MIL-SIC) и показал хороший баланс для LUAD. Эти результаты в совокупности подчеркивают, что способность CIG улавливать контрастную информацию приводит к более информативным и стабильным атрибуциям.
Качественно, визуализации еще больше укрепляют превосходство CIG. Рисунок 2, иллюстрирующий промежуточные карты градиентов на шагах интерполяции, ясно показывает, что CIG производит более локализованные и последовательные градиенты в пределах опухолевых областей на протяжении всего пути, в отличие от IG, который демонстрирует более распределенные закономерности. Это указывает на то, что атрибуции CIG более стабильны и сфокусированы на релевантных областях.
Что более важно, Рисунок 3, представляющий финальные карты атрибуции, демонстрирует, что CIG последовательно выделяет области, которые тесно соответствуют аннотированным истинным опухолевым областям. В отличие от этого, базовые методы, такие как IG и EG, часто выделяют визуально заметные, но менее дискриминативные признаки, которые не являются частью фактической опухоли. Это визуальное соответствие истинным данным предоставляет неоспоримое доказательство того, что механизм CIG успешно идентифицирует релевантные для принятия решений опухолевые области.
Наконец, статья теоретически доказывает, что CIG удовлетворяет фундаментальным аксиоматическим свойствам интегрированных методов атрибуции: полноте, чувствительности и инвариантности реализации. Эта теоретическая обоснованность в сочетании с сильными количественными и качественными экспериментальными результатами обеспечивает надежную основу для утверждений CIG.
Ограничения и Будущие Направления
Хотя CIG демонстрирует значительные достижения в интерпретируемой классификации WSI, авторы признают определенные ограничения и предлагают четкие направления для будущих исследований.
Одно заметное ограничение проистекает из самой системы оценки: текущие метрики MIL-AIC и MIL-SIC в основном разработаны и лучше всего подходят для опухолево-позитивных изображений. Как объясняют авторы, нормальные изображения демонстрируют иную динамику предсказаний, часто требуя удаления почти всех признаков перед изменением предсказания, что делает метрики, такие как AUC, менее значимыми в этом контексте. Это предполагает, что, хотя CIG демонстрирует исключительную производительность в идентификации опухолевых областей, его применимость и интерпретация для классификации нормальной ткани или в сценариях, где «противоположный класс» базового уровня менее четко определен, могут потребовать дальнейшего изучения или адаптации методологии оценки.
Заглядывая вперед, наиболее критическим будущим направлением является включение строгих оценок интерпретируемости с участием человека. Хотя количественные метрики и качественные визуализации дают сильные доказательства, конечная цель интерпретируемости в вычислительной патологии — укрепить доверие и помочь в принятии клинических решений. Прямая проверка патологами или медицинскими экспертами того, действительно ли объяснения CIG повышают их понимание и уверенность в диагностических инструментах с поддержкой ИИ, является обязательной. Это потребует разработки исследований для оценки того, как атрибуции CIG влияют на точность человеческой диагностики, эффективность и доверие.
Помимо оценок с участием человека, возникают и другие темы для дальнейшей разработки:
- Обобщаемость на Другие Модальности Медицинской Визуализации: Может ли контрастный подход CIG быть адаптирован для других сложных задач медицинской визуализации, помимо WSI, таких как МРТ или КТ-сканирование, где интерпретируемость одинаково важна, но пространства признаков и базовые уровни могут значительно отличаться?
- Вычислительная Эффективность и Масштабируемость: Хотя CIG показывает высокую производительность, методы атрибуции, особенно основанные на путях, могут быть вычислительно затратными. Дальнейшие исследования могут изучить оптимизации для повышения эффективности CIG для чрезвычайно больших WSI или для клинических приложений в реальном времени, возможно, посредством методов аппроксимации или аппаратного ускорения.
- Динамический Выбор Базового Уровня: Текущий метод полагается на выборку из базового уровня «противоположного класса». Будущая работа может исследовать более динамичные или адаптивные стратегии выбора базового уровня, особенно в многоклассовых сценариях или когда четкий «противоположный» класс легко доступен или хорошо определен.
- Интеграция с Методами Анте-Хок: CIG является пост-хок методом атрибуции. Исследование его интеграции с методами анте-хок интерпретируемости, которые встраивают интерпретируемость непосредственно в архитектуру модели, может привести к гибридным подходам, сочетающим сильные стороны обоих, предлагая как локализованные объяснения, так и глобальное понимание модели.
- За Пределами Бинарной Классификации: Хотя статья затрагивает многоклассовую классификацию (например, TCGA-Renal), более глубокое изучение того, как CIG работает и может быть оптимизирован для многоклассовых задач с высокой детализацией, где необходимо выделять тонкие различия между многими классами, было бы ценным.
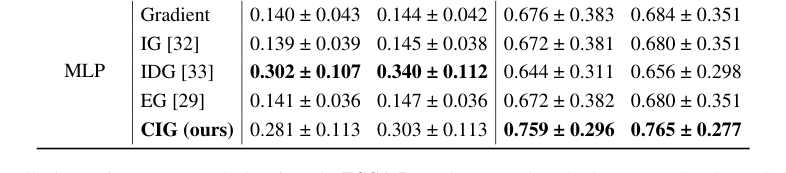 Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
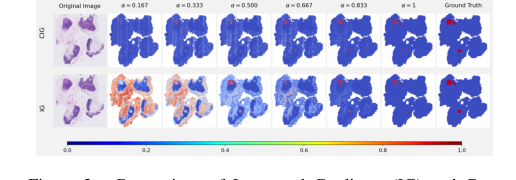 Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
 Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
Изоморфизмы с другими областями
Структурный Каркас
Основной математический механизм данной статьи — это метод, который количественно определяет дифференциальное влияние входных признаков на решение модели путем интегрирования квадрата разности выходов логитов вдоль пути к контрастному эталону.
Дальние Родственники
Основная логика Контрастных Интегрированных Градиентов (CIG) имеет захватывающие «зеркальные отражения» в областях, далеких от вычислительной патологии:
-
Целевая Область: Управление Финансовыми Рисками и Оптимизация Портфеля
- Связь: В финансах давняя проблема заключается в понимании того, какие конкретные рыночные факторы (например, процентные ставки, цены на сырьевые товары, отраслевая доходность) определяют доходность или риск портфеля относительно эталонного индекса (например, S&P 500) или портфеля конкурента. Это точно аналогично цели CIG — идентификации классово-дискриминативных признаков путем сравнения входа с контрастным базовым уровнем. Количественный аналитик может захотеть знать не только что способствует волатильности его портфеля, но и что конкретно делает его более волатильным, чем средний рынок при определенных экономических условиях. «Пространство логитов» может быть преобразованной мерой доходности с поправкой на риск или отклонения от эталона, а интегрирование по пути может представлять, как эти вклады факторов развиваются при различных смоделированных рыночных сценариях или инвестиционных стратегиях.
-
Целевая Область: Климатология и Моделирование Системы Земли
- Связь: Климатологи часто сталкиваются с задачей атрибуции наблюдаемых изменений климата или предсказаний моделей к конкретным антропогенным факторам (например, выбросы CO2, землепользование) относительно доиндустриального базового уровня или сценария «без вмешательства». Это прямое параллель с контрастной атрибуцией CIG. Им необходимо определить, какие входные параметры или начальные условия в сложных моделях системы Земли наиболее ответственны за конкретный климатический результат (например, определенное региональное повышение температуры или частоту экстремальных погодных явлений) по сравнению с миром без этих факторов. «Пространство логитов» может представлять собой преобразованную метрику климатической аномалии или отклонения от стабильного состояния, а интегрирование по пути может моделировать постепенное увеличение фактора и его влияние на климатическую систему.
Сценарий «Что Если»
Представьте, что количественный аналитик из хедж-фонда «крадет» точное уравнение CIG завтра. Вместо простого вычисления чувствительности стоимости портфеля к различным рыночным факторам, он мог бы применить CIG для понимания контрастных драйверов превосходства или отставания своего портфеля по сравнению с выбранным эталоном. Интегрируя квадрат разности логарифмических доходностей своего портфеля (аналогично выходам логитов) и логарифмических доходностей эталона вдоль пути, представляющего изменяющиеся рыночные условия, он мог бы точно определить, какие конкретные активы или факторные экспозиции различают доходность его портфеля от эталона. Это привело бы к прорыву в контрастной генерации альфы и хеджировании рисков. Он мог бы идентифицировать точные рыночные условия или характеристики активов, которые вызывают отклонение его портфеля от эталона, позволяя гиперцелевые корректировки для максимизации относительной доходности или минимизации относительного риска. Это могло бы революционизировать то, как активные управляющие идентифицируют и используют рыночные неэффективности, выходя за рамки простой атрибуции к дискриминативной атрибуции в финансовом анализе.
Универсальная Библиотека Структур
Данная статья мощно подкрепляет идею о том, что все научные проблемы взаимосвязаны, демонстрируя, как задача идентификации дискриминативных признаков в медицинских изображениях разделяет глубокое математическое родство с задачами контрастной атрибуции в таких разнообразных областях, как финансы и климатология, внося жизненно важную новую структуру в нашу универсальную библиотеку научного понимания.