कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स: होल स्लाइड इमेज क्लासिफिकेशन को समझाने के लिए एक फीचर एट्रिब्यूशन-आधारित विधि
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या कम्प्यूटेशनल पैथोलॉजी में व्याख्यात्मकता (interpretability) की महत्वपूर्ण आवश्यकता से उत्पन्न होती है, विशेष रूप से होल स्लाइड इमेज (WSI) विश्लेषण के क्षेत्र में। पैथोलॉजी आधुनिक चिकित्सा का एक आधारशिला है, जो आवश्यक निदान और पूर्वानुमान प्रदान करती है। पारंपरिक रूप से, पैथोलॉजिस्ट सेलुलर संरचना और ऊतक वास्तुकला का आकलन करने के लिए WSIs की सावधानीपूर्वक जांच करते हैं, एक ऐसी प्रक्रिया जो समय लेने वाली और अंतर-अवलोकनकर्ता परिवर्तनशीलता (inter-observer variability) के प्रति प्रवण है।
कृत्रिम बुद्धिमत्ता और डीप लर्निंग के आगमन के साथ, कम्प्यूटेशनल उपकरण पैथोलॉजिस्ट की सहायता के लिए उभरे हैं, जो रुचि के क्षेत्रों के पूर्व-विभाजन (pre-segmenting) के लिए समाधान प्रदान करते हैं और संभावित रूप से नैदानिक संगति और कार्यप्रवाह दक्षता में सुधार करते हैं। हालांकि, WSI वर्गीकरण और विभाजन के लिए ये उन्नत डीप लर्निंग मॉडल उल्लेखनीय रूप से अच्छा प्रदर्शन करते हैं, वे अक्सर "ब्लैक बॉक्स" के रूप में कार्य करते हैं, जो उन विशिष्ट हिस्टोलॉजिकल पैटर्न में सीमित अंतर्दृष्टि प्रदान करते हैं जो उनकी भविष्यवाणियों को संचालित करते हैं। इस पारदर्शिता की कमी एआई-सहायता प्राप्त निदान में विश्वास को कम करती है, जो उनके व्यापक नैदानिक अपनाने में एक महत्वपूर्ण बाधा है।
इस समस्या का अकादमिक वंश व्याख्यात्मक एआई (XAI) के व्यापक क्षेत्र में वापस जाता है, जो एआई मॉडल को मनुष्यों के लिए अधिक समझने योग्य बनाने का प्रयास करता है। कंप्यूटर विजन के भीतर, XAI विधियों को मोटे तौर पर हीटमैप-आधारित (यह दिखाते हुए कि मॉडल कहां केंद्रित है) बनाम अवधारणा-आधारित (यह समझाते हुए कि यह किस पर निर्भर करता है) और पोस्ट-हॉक (प्रशिक्षण के बाद स्पष्टीकरण) बनाम एंटी-हॉक (मॉडल में एकीकृत व्याख्यात्मकता) के रूप में वर्गीकृत किया जाता है। यह कार्य विशेष रूप से पोस्ट-हॉक एट्रिब्यूशन विधियों को आगे बढ़ाता है, जिनका उद्देश्य WSIs के भीतर मॉडल के निर्णय से संबंधित क्षेत्रों को उजागर करने वाले स्थानीयकृत हीटमैप उत्पन्न करना है।
मौजूदा दृष्टिकोणों की मौलिक सीमा, या "दर्द बिंदु," जिसने लेखकों को यह पत्र लिखने के लिए मजबूर किया, बहुआयामी है। इंटीग्रेटेड ग्रेडिएंट्स (IG) जैसी मौजूदा ग्रेडिएंट-आधारित एट्रिब्यूशन विधियां अक्सर रॉ इमेज स्पेस में काम करती हैं। जबकि उपयोगी, यह उन मॉडलों के लिए कम प्रभावी हो सकता है जो WSI पैच से प्राप्त जटिल, सीखे हुए फीचर एम्बेडिंग पर निर्भर करते हैं। अधिक महत्वपूर्ण रूप से, ये विधियां अक्सर दृश्य रूप से प्रमुख क्षेत्रों को उजागर करती हैं जो आवश्यक रूप से वर्ग-भेदभावपूर्ण (class-discriminative) नहीं हैं। इसका मतलब है कि वे प्रमुख लेकिन अप्रासंगिक विशेषताओं की ओर इशारा कर सकते हैं, जिससे WSI वर्गीकरण कार्यों के लिए उनकी व्याख्यात्मकता सीमित हो जाती है जहां, उदाहरण के लिए, ट्यूमर और गैर-ट्यूमर क्षेत्रों के बीच अंतर करना सर्वोपरि है। इसके अलावा, इंटीग्रेटेड ग्रेडिएंट्स जैसी विधियों की प्रभावशीलता "बेसलाइन" इनपुट की पसंद पर अत्यधिक निर्भर है, जो पैथोलॉजी जैसे जटिल डोमेन में अस्पष्ट और परिभाषित करने में चुनौतीपूर्ण हो सकता है। अन्य उन्नत एट्रिब्यूशन विधियां, बेहतर सटीकता प्रदान करते हुए, अक्सर उच्च कम्प्यूटेशनल लागत के साथ आती हैं, जिससे वे बड़े पैमाने पर WSI विश्लेषण के लिए कम व्यावहारिक हो जाती हैं। लेखकों की प्रेरणा एक ऐसी विधि विकसित करके इन सीमाओं को दूर करना है जो केवल इमेज स्पेस के बजाय एक अधिक सार्थक "लॉजिट स्पेस" में काम करते हुए अधिक केंद्रित और वर्ग-भेदभावपूर्ण एट्रिब्यूशन प्रदान करती है।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें शून्य-आधारित पाठक के लिए सहज, रोजमर्रा की उपमाओं में अनुवादित किया गया है:
- होल स्लाइड इमेज (WSI): एक माइक्रोस्कोप स्लाइड पर लगे पूरे ऊतक नमूने की एक विशाल, अल्ट्रा-हाई-रिज़ॉल्यूशन डिजिटल तस्वीर की कल्पना करें। यह इतनी विस्तृत है कि आप पूरी स्लाइड से लेकर व्यक्तिगत कोशिकाओं तक ज़ूम इन कर सकते हैं, ठीक वैसे ही जैसे आप Google Maps का उपयोग करके किसी शहर को एक इमारत तक एक्सप्लोर करते हैं। पैथोलॉजिस्ट बीमारियों का निदान करने के लिए इनका उपयोग करते हैं।
- मल्टीपल इंस्टेंस लर्निंग (MIL): एक गुणवत्ता निरीक्षक को चॉकलेट के एक बड़े डिब्बे की जांच करने के बारे में सोचें। वे हर चॉकलेट को नहीं खोलते हैं, लेकिन अगर उन्हें डिब्बे में कोई भी खराब चॉकलेट मिलती है, तो पूरा डिब्बा "खराब" के रूप में लेबल किया जाता है। MIL एआई के लिए इन "डिब्बों" (पूरी स्लाइड) से सीखने का एक तरीका है, बिना अंदर की हर "चॉकलेट" (व्यक्तिगत ऊतक पैच) के सटीक लेबल को जाने।
- इंटीग्रेटेड ग्रेडिएंट्स (IG): एक जटिल सूप के अंतिम स्वाद में प्रत्येक सामग्री के योगदान को समझने की कोशिश करने की कल्पना करें। अंतिम सूप का स्वाद लेने के बजाय, आप इसकी तैयारी के हर छोटे कदम पर इसका स्वाद लेते हैं, एक सादे शोरबा से लेकर पूरी तरह से सुगंधित व्यंजन तक, यह ध्यान में रखते हुए कि प्रत्येक सामग्री रास्ते में स्वाद को कैसे बदलती है। IG AI के लिए कुछ ऐसा ही करता है, "स्वाद" (मॉडल आउटपुट) को एक चिकनी पथ के साथ प्रत्येक "सामग्री" (इनपुट फीचर) तक ट्रेस करता है।
- लॉजिट स्पेस: जब कोई एआई मॉडल भविष्यवाणी करता है (जैसे, "ट्यूमर" या "गैर-ट्यूमर"), तो यह उन्हें प्रतिशत में बदलने से पहले प्रत्येक विकल्प के लिए कच्चे, अनियंत्रित स्कोर की गणना करता है। लॉजिट स्पेस इन कच्चे "साक्ष्य स्कोर" को सीधे देखने जैसा है, इससे पहले कि उन्हें प्रतिशत में सुचारू किया जाए। यह प्रत्येक श्रेणी के लिए मॉडल के आंतरिक तर्क और आत्मविश्वास का एक स्पष्ट, अधिक सीधा दृश्य देता है।
- एट्रिब्यूशन मेथड: यदि कोई एआई मॉडल आपको बताता है कि एक तस्वीर में कुत्ता है, तो एक एट्रिब्यूशन विधि एआई से पूछने जैसी है, "मुझे दिखाओ कि छवि के कौन से हिस्से ने आपको इसे कुत्ता मानने पर मजबूर किया।" यह उन विशिष्ट पिक्सेल या क्षेत्रों को उजागर करता है जो मॉडल के निर्णय में सबसे प्रभावशाली थे, जिससे आपको उसके तर्क को समझने में मदद मिलती है।
नोटेशन तालिका
| नोटेशन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या कम्प्यूटेशनल पैथोलॉजी में होल स्लाइड इमेज (WSI) वर्गीकरण के लिए डीप लर्निंग मॉडल की व्याख्यात्मकता को बढ़ाने में निहित है।
शुरुआती बिंदु (इनपुट/वर्तमान स्थिति) में उच्च-रिज़ॉल्यूशन WSIs शामिल हैं जिन्हें डीप लर्निंग मॉडल द्वारा संसाधित किया जाता है, अक्सर मल्टीपल इंस्टेंस लर्निंग (MIL) प्रतिमान का पालन करते हुए। मौजूदा एट्रिब्यूशन विधियों, जैसे इंटीग्रेटेड ग्रेडिएंट्स (IG), को उनके भविष्यवाणियों को समझाने के लिए इन मॉडलों पर लागू किया जाता है। जबकि ये विधियां उन क्षेत्रों की पहचान कर सकती हैं जो मॉडल के निर्णय को प्रभावित करते हैं, वे अक्सर इमेज स्पेस या सीखे हुए एम्बेडिंग पर काम करती हैं और दृश्य रूप से प्रमुख विशेषताओं को उजागर करती हैं जो वर्ग भेदभाव के लिए सीधे प्रासंगिक नहीं हो सकती हैं। वे सामान्य मॉडल निर्णय पैटर्न को कैप्चर करते हैं लेकिन अक्सर विशिष्ट संकेतों को नजरअंदाज करते हैं जो विभिन्न ट्यूमर उपप्रकारों या ट्यूमर और गैर-ट्यूमर क्षेत्रों के बीच अंतर करने के लिए महत्वपूर्ण होते हैं।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) अधिक जानकारीपूर्ण, केंद्रित और सटीक एट्रिब्यूशन प्राप्त करना है जो WSIs के भीतर वर्ग-भेदभावपूर्ण क्षेत्रों को सटीक रूप से उजागर करते हैं। ये एट्रिब्यूशन ग्राउंड ट्रुथ ट्यूमर क्षेत्रों के साथ निकटता से संरेखित होने चाहिए, जिससे एआई-सहायता प्राप्त नैदानिक उपकरणों में अधिक विश्वास पैदा हो। इसके अलावा, वांछित विधि को एट्रिब्यूशन के मौलिक अक्षीय गुणों (पूर्णता, संवेदनशीलता, कार्यान्वयन अपरिवर्तनीयता) को संतुष्ट करना चाहिए ताकि सैद्धांतिक सुदृढ़ता और सुसंगत स्पष्टीकरण सुनिश्चित हो सके।
सटीक लुप्त कड़ी या गणितीय अंतर जिसे यह पत्र पाटने का प्रयास करता है, वह लॉजिट स्पेस में कंट्रास्टिव जानकारी को प्रभावी ढंग से कैप्चर करने के लिए पारंपरिक एट्रिब्यूशन विधियों की अक्षमता है। पिछली विधियां मुख्य रूप से मॉडल के आउटपुट के ग्रेडिएंट के आधार पर महत्व को एट्रिब्यूट करने पर ध्यान केंद्रित करती हैं, इनपुट सुविधाओं के संबंध में। हालांकि, यह दृष्टिकोण अक्सर उन विशेषताओं के बीच अंतर करने में विफल रहता है जो केवल प्रमुख हैं और वे जो किसी विशिष्ट वर्ग के सापेक्ष वास्तव में भेदभावपूर्ण हैं। पत्र CIG का परिचय देकर इसे पाटने का प्रस्ताव करता है, जो गणितीय रूप से $i$-वें सुविधा के लिए एट्रिब्यूशन को परिभाषित करता है:
$$ \text{CIG}_i^c(x) = (x_i - x'_i) \int_0^1 \frac{\partial ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2}{\partial x_i} d\alpha $$
यहां, $f_{\text{logit}}(\cdot)$ मॉडल के लॉजिट आउटपुट का प्रतिनिधित्व करता है, $x$ इनपुट है, $x'$ एक संदर्भ बेसलाइन है, और $\gamma(\alpha)$ $x$ और $x'$ के बीच एक सीधी रेखा पथ को परिभाषित करता है। यह सूत्रीकरण स्पष्ट रूप से एक बेसलाइन संदर्भ के साथ एक इंटरपोलेटेड इनपुट के लॉजिट आउटपुट के वर्ग अंतर के ग्रेडिएंट को एकीकृत करता है। यह CIG को संदर्भ के सापेक्ष मॉडल के निर्णय सीमा के विकास को मापने की अनुमति देता है, इस प्रकार लॉजिट स्पेस में सीधे कंट्रास्टिव जानकारी को कैप्चर करता है और वर्ग-भेदभावपूर्ण सुविधाओं पर जोर देता है।
दर्दनाक ट्रेड-ऑफ या दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह व्यापक सलिन्सी मैप्स उत्पन्न करने और वर्ग-भेदभावपूर्ण स्पष्टीकरण उत्पन्न करने के बीच अंतर्निहित तनाव है। इंटीग्रेटेड ग्रेडिएंट्स जैसे तरीके अक्सर व्यापक सलिन्सी मैप प्रदान करते हैं जो किसी भविष्यवाणी में योगदान करने वाली सभी विशेषताओं को इंगित करते हैं। हालांकि, एक नैदानिक संदर्भ में, पैथोलॉजिस्ट को यह समझने की आवश्यकता होती है कि मॉडल क्यों अंतर करता है, उदाहरण के लिए, ट्यूमर और गैर-ट्यूमर के बीच, न कि केवल कौन से क्षेत्र सक्रिय हैं। एट्रिब्यूशन की व्यापकता में सुधार अक्सर विशिष्टता और भेदभावपूर्ण शक्ति की कीमत पर आता है, जिससे ऐसे स्पष्टीकरण मिलते हैं जो दृश्य रूप से प्रमुख होते हैं लेकिन रुचि की विशिष्ट वर्ग भिन्नता के लिए अप्रासंगिक विशेषताओं को शामिल कर सकते हैं। यह नैदानिक निर्णय लेने के लिए कार्रवाई योग्य अंतर्दृष्टि प्रदान करना मुश्किल बनाता है।
बाधाएँ और विफलता मोड
कम्प्यूटेशनल पैथोलॉजी में WSI वर्गीकरण के लिए व्याख्यात्मक स्पष्टीकरण प्रदान करने की समस्या को कई कठोर, यथार्थवादी बाधाओं द्वारा अविश्वसनीय रूप से कठिन बना दिया गया है:
- WSIs की उच्च-रिज़ॉल्यूशन प्रकृति: होल स्लाइड इमेज गीगापिक्सेल-स्केल की होती हैं, जिससे उन्हें सीधे संसाधित करना कम्प्यूटेशनल रूप से चुनौतीपूर्ण हो जाता है। इसके लिए उन्हें छोटे पैच में तोड़ने की आवश्यकता होती है, जिन्हें बाद में डीप लर्निंग मॉडल द्वारा संसाधित किया जाता है, अक्सर मल्टीपल इंस्टेंस लर्निंग (MIL) ढांचे में। यह पैच-आधारित प्रसंस्करण मूल WSI पर महत्व को वापस एट्रिब्यूट करने में जटिलता जोड़ता है।
- कमजोर पर्यवेक्षण: कम्प्यूटेशनल पैथोलॉजी में, ग्राउंड ट्रुथ लेबल आम तौर पर केवल स्लाइड स्तर पर उपलब्ध होते हैं (जैसे, एक पूरी स्लाइड को "ट्यूमर" या "गैर-ट्यूमर" लेबल किया जाता है), न कि पैच स्तर पर। यह "कमजोर पर्यवेक्षण" मॉडल को स्लाइड के भीतर विशिष्ट ट्यूमर क्षेत्रों की पहचान करने के लिए प्रशिक्षित करना बेहद मुश्किल बना देता है, और बाद में, यह मूल्यांकन करना कि एट्रिब्यूशन विधियां इन सटीक क्षेत्रों को सही ढंग से उजागर करती हैं या नहीं।
- अस्पष्ट बेसलाइन चयन: इंटीग्रेटेड ग्रेडिएंट्स जैसी ग्रेडिएंट-आधारित एट्रिब्यूशन विधियां "बेसलाइन" इनपुट की पसंद पर महत्वपूर्ण रूप से निर्भर करती हैं, जो सुविधा महत्व को मापने के लिए एक संदर्भ बिंदु के रूप में कार्य करती है। पैथोलॉजी में, एक उपयुक्त बेसलाइन का चयन अस्पष्ट है। सामान्य बेसलाइन (जैसे, शून्य वेक्टर, डेटासेट माध्य, यादृच्छिक पैच) आउट-ऑफ-डिस्ट्रीब्यूशन मुद्दों, सिमेंटिक पूर्वाग्रह, या कम भेदभावपूर्णता का कारण बन सकती है, जिससे एट्रिब्यूशन कम सार्थक या भ्रामक हो जाते हैं। पत्र स्पष्ट रूप से नोट करता है कि एक शून्य वेक्टर बेसलाइन एम्बेडिंग स्पेस में आउट-ऑफ-डिस्ट्रीब्यूशन मुद्दों का कारण बन सकती है, जबकि डेटासेट माध्य या यादृच्छिक पैच सिमेंटिक रिसाव या कम भेदभावपूर्णता से पीड़ित हो सकते हैं।
- एट्रिब्यूशन मूल्यांकन के लिए ग्राउंड ट्रुथ की कमी: कुछ प्राकृतिक छवि कार्यों के विपरीत जहां पिक्सेल-स्तरीय सलिन्सी ग्राउंड ट्रुथ मौजूद हो सकता है, WSI विश्लेषण में मॉडल भविष्यवाणियों के लिए विस्तृत, पिक्सेल-वार ग्राउंड ट्रुथ स्पष्टीकरण अक्सर अनुपलब्ध होते हैं। यह अनुपस्थिति एट्रिब्यूशन मैप्स की गुणवत्ता और सटीकता का मात्रात्मक रूप से आकलन करना असाधारण रूप से चुनौतीपूर्ण बनाती है। सलिन्सी मैप्स के लिए मानक मूल्यांकन मेट्रिक्स (जैसे परफॉर्मेंस इंफॉर्मेशन कर्व्स या RISE) सीधे तौर पर कमजोर पर्यवेक्षित WSI सेटिंग पर लागू नहीं होते हैं, क्योंकि वे क्रमिक भविष्यवाणी बदलाव या पिक्सेल-स्तरीय नियंत्रण मानते हैं, जो MIL-आधारित WSI वर्गीकरण के साथ मामला नहीं है जहां भविष्यवाणियां कुछ प्रमुख पैच के साथ अचानक बदल सकती हैं।
- पथ एकीकरण की कम्प्यूटेशनल लागत: पथ-आधारित एट्रिब्यूशन विधियों, जिसमें इंटीग्रेटेड ग्रेडिएंट्स और CIG शामिल हैं, को इनपुट और बेसलाइन के बीच एक पथ के साथ ग्रेडिएंट को एकीकृत करने की आवश्यकता होती है। इस प्रक्रिया में कई इंटरपोलेशन चरण शामिल होते हैं, जो WSIs से प्राप्त उच्च-आयामी फीचर स्पेस के लिए विशेष रूप से कम्प्यूटेशनल रूप से गहन हो सकते हैं। हालांकि यह एक स्पष्ट विफलता मोड नहीं है, उच्च कम्प्यूटेशनल लागत परिनियोजन के लिए एक व्यावहारिक बाधा है।
- मॉडल की सीखे हुए एम्बेडिंग पर निर्भरता: कई WSI विश्लेषण मॉडल फीचर एक्सट्रैक्टर्स (जैसे, विजन ट्रांसफॉर्मर या CNNs) से सीखे हुए एम्बेडिंग पर निर्भर करते हैं। इमेज स्पेस में सीधे काम करने वाली ग्रेडिएंट-आधारित विधियां कम प्रभावी हो सकती हैं जब मॉडल का निर्णय मुख्य रूप से इन अमूर्त, सीखे हुए एम्बेडिंग द्वारा संचालित होता है न कि रॉ पिक्सेल मानों द्वारा।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स (CIG) का विकास केवल एक वृद्धिशील सुधार नहीं था; यह कम्प्यूटेशनल पैथोलॉजी में होल स्लाइड इमेज (WSI) विश्लेषण की अनूठी चुनौतियों के लिए लागू मौजूदा एट्रिब्यूशन विधियों की अंतर्निहित सीमाओं द्वारा संचालित एक आवश्यक विकास था। लेखकों ने महसूस किया कि पारंपरिक "SOTA" विधियां, जैसे कि मानक इंटीग्रेटेड ग्रेडिएंट्स (IG) और इसके वेरिएंट (जैसे, ग्रेडिएंट $\times$ इनपुट, Grad-CAM, एक्सपेक्टेड ग्रेडिएंट्स), सामान्य कंप्यूटर विजन कार्यों में आशाजनक होने के बावजूद, इस विशिष्ट डोमेन में कम पड़ गईं।
इस अहसास का सटीक क्षण दो महत्वपूर्ण कमियों की पहचान से निहित है:
1. WSIs की उच्च-रिज़ॉल्यूशन प्रकृति: गीगापिक्सेल-स्केल की छवियों, WSIs पर सीधे इन विधियों को लागू करने से महत्वपूर्ण कम्प्यूटेशनल और व्याख्यात्मक चुनौतियां पेश हुईं। पैमाने की विशालता ने इन विधियों के लिए सार्थक और स्थानीयकृत स्पष्टीकरण प्रदान करना मुश्किल बना दिया।
2. वर्ग-भेदभावपूर्ण संकेतों की कमी: अधिक महत्वपूर्ण रूप से, पारंपरिक एट्रिब्यूशन विधियां, मुख्य रूप से इमेज स्पेस में काम करके, अक्सर दृश्य रूप से प्रमुख विशेषताओं को उजागर करती थीं जो आवश्यक रूप से वर्ग-भेदभावपूर्ण नहीं थीं। इसका मतलब था कि वे उन क्षेत्रों की ओर इशारा कर सकते थे जो महत्वपूर्ण दिखते थे लेकिन वास्तव में ट्यूमर उपप्रकारों या ट्यूमर और गैर-ट्यूमर ऊतक के बीच अंतर करने में मदद नहीं करते थे। उदाहरण के लिए, एक क्षेत्र दृश्य रूप से प्रमुख हो सकता है लेकिन नैदानिक निर्णय के लिए अप्रासंगिक हो सकता है, जिससे पैथोलॉजिस्ट के लिए भ्रामक स्पष्टीकरण मिलते हैं। केवल सलिन्सी से कंट्रास्टिव, निर्णय-प्रासंगिक सुविधाओं की ओर बढ़ने की आवश्यकता CIG के पीछे प्रेरक शक्ति थी।
तुलनात्मक श्रेष्ठता
CIG पिछले स्वर्ण मानकों पर गुणात्मक श्रेष्ठता प्रदान करता है, विशेष रूप से अधिक केंद्रित और नैदानिक रूप से प्रासंगिक एट्रिब्यूशन प्रदान करने की अपनी क्षमता में। इसका संरचनात्मक लाभ इमेज स्पेस या आउटपुट संभाव्यता स्पेस में सीधे के बजाय लॉजिट स्पेस में कंट्रास्टिव ग्रेडिएंट की गणना करने में निहित है।
यहां बताया गया है कि यह अत्यधिक श्रेष्ठ क्यों है:
* तेज वर्ग विभेदन: IG के विपरीत, जो मॉडल के आउटपुट (जैसे, संभाव्यता स्कोर) के ग्रेडिएंट के आधार पर महत्व को एट्रिब्यूट करता है, CIG इनपुट और एक संदर्भ बेसलाइन के बीच लॉजिट अंतर के वर्ग के ग्रेडिएंट की गणना करता है। इसका मतलब है कि यह स्पष्ट रूप से मापता है कि कोई सुविधा किसी संदर्भ वर्ग के सापेक्ष लॉजिट आउटपुट के अंतर में कितना योगदान करती है। यह संरचनात्मक डिजाइन CIG को वर्ग-भेदभावपूर्ण क्षेत्रों को उजागर करने की अनुमति देता है, ट्यूमर और गैर-ट्यूमर क्षेत्रों के बीच बहुत तेज विभेदन प्रदान करता है, जो पैथोलॉजी के लिए महत्वपूर्ण है।
* स्थानीयकृत और सुसंगत एट्रिब्यूशन: गुणात्मक रूप से, पेपर के आंकड़ों में दिखाए गए अनुसार, CIG इंटरपोलेशन पथ के दौरान ट्यूमर क्षेत्रों के भीतर अधिक स्थिर और स्थानीयकृत ग्रेडिएंट उत्पन्न करता है, जबकि IG ग्रेडिएंट स्थानिक रूप से अधिक बिखरे हुए होते हैं। यह इंगित करता है कि CIG वास्तविक निर्णय लेने वाले क्षेत्रों को अलग करने में बेहतर है, उच्च-आयामी शोर और अप्रासंगिक दृश्य संकेतों को प्रभावी ढंग से संभालता है जो वर्गों को अलग करने के लिए वास्तव में महत्वपूर्ण हैं।
* कंट्रास्टिव शक्ति के साथ अक्षीय सुदृढ़ता: CIG इंटीग्रेटेड ग्रेडिएंट्स (पूर्णता, संवेदनशीलता, कार्यान्वयन अपरिवर्तनीयता) के वांछनीय अक्षीय गुणों को बरकरार रखता है, जो सैद्धांतिक सुदृढ़ता और संगति सुनिश्चित करता है। हालांकि, यह एक कंट्रास्टिव तत्व को शामिल करके इसका विस्तार करता है, जिससे एट्रिब्यूशन न केवल सुसंगत बल्कि एक विभेदक संदर्भ में सार्थक भी हो जाते हैं। यह उन विधियों पर एक महत्वपूर्ण संरचनात्मक लाभ है जो तुलनात्मक परिप्रेक्ष्य के बिना केवल पूर्ण महत्व प्रदान करती हैं।
पेपर स्पष्ट रूप से $O(N^2)$ से $O(N)$ तक मेमोरी जटिलता में कमी का विवरण नहीं देता है, लेकिन अधिक सटीक और स्थानीयकृत स्पष्टीकरण उत्पन्न करने में इसके गुणात्मक और संरचनात्मक लाभ स्पष्ट रूप से प्रदर्शित होते हैं।
बाधाओं के साथ संरेखण
चुनी गई CIG विधि कम्प्यूटेशनल पैथोलॉजी में WSI विश्लेषण की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, जो समस्या और समाधान के बीच एक मजबूत "विवाह" बनाती है:
- विश्वास के लिए व्याख्यात्मकता: एक प्राथमिक बाधा नैदानिकों के बीच विश्वास बनाने के लिए अत्यधिक व्याख्यात्मक एआई सिस्टम की आवश्यकता है। CIG सीधे "अधिक जानकारीपूर्ण और स्थिर एट्रिब्यूशन" प्रदान करके इसे संबोधित करता है जो ग्राउंड ट्रुथ ट्यूमर क्षेत्रों के साथ निकटता से संरेखित होते हैं। वर्ग-भेदभावपूर्ण सुविधाओं को उजागर करने की इसकी क्षमता यह सुनिश्चित करती है कि स्पष्टीकरण नैदानिक निर्णयों के लिए प्रासंगिक हैं, जिससे नैदानिक आत्मविश्वास को बढ़ावा मिलता है।
- उच्च-रिज़ॉल्यूशन WSIs: विधि को मल्टीपल इंस्टेंस लर्निंग (MIL) ढांचे के भीतर काम करने के लिए डिज़ाइन किया गया है, जो WSI विश्लेषण के लिए मानक प्रतिमान है। WSIs से निकाले गए पैच-स्तरीय सुविधाओं पर काम करके, CIG प्रभावी ढंग से इन छवियों की उच्च-रिज़ॉल्यूशन प्रकृति के लिए स्केल करता है, व्यक्तिगत पैच के लिए एट्रिब्यूशन प्रदान करता है जिन्हें फिर WSI-स्तरीय हीटमैप में एकत्रित किया जाता है।
- कमजोर पर्यवेक्षित शिक्षण: WSI विश्लेषण अक्सर कमजोर पर्यवेक्षण के तहत संचालित होता है, जहां केवल स्लाइड-स्तरीय लेबल उपलब्ध होते हैं, पिक्सेल-स्तरीय एनोटेशन नहीं। MIL ढांचे में CIG का एकीकरण, MIL-AIC और MIL-SIC मेट्रिक्स के परिचय के साथ मिलकर, विशेष रूप से इस कमजोर पर्यवेक्षित सेटिंग के लिए तैयार किया गया है। ये मेट्रिक्स इस चुनौतीपूर्ण संदर्भ में एट्रिब्यूशन गुणवत्ता का सीधे मूल्यांकन करते हुए, प्रमुख पैच पेश किए जाने पर मॉडल की भविष्यवाणी और आत्मविश्वास कितनी जल्दी विकसित होता है, इसका आकलन करते हैं।
- वर्ग-भेदभावपूर्ण संकेत: पहचानी गई मुख्य समस्या पारंपरिक विधियों द्वारा वर्ग-भेदभावपूर्ण संकेतों की उपेक्षा थी। लॉजिट स्पेस में कंट्रास्टिव ग्रेडिएंट की गणना करने की CIG की अनूठी संपत्ति सीधे इस पर काम करती है, उन सुविधाओं पर जोर देती है जो एक वर्ग को दूसरे से अलग करती हैं, न कि केवल सामान्य सलिन्सी को। यह सुनिश्चित करता है कि स्पष्टीकरण ट्यूमर उपप्रकारों या रोग राज्यों को अलग करने के लिए सीधे प्रासंगिक हैं।
विकल्पों का अस्वीकरण
पत्र अप्रत्यक्ष रूप से और स्पष्ट रूप से कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है, मुख्य रूप से अन्य ग्रेडिएंट-आधारित एट्रिब्यूशन विधियों और सामान्य बेसलाइन विकल्पों को, WSI विश्लेषण की विशिष्ट मांगों को पूरा करने में उनकी असमर्थता के कारण:
- पारंपरिक इंटीग्रेटेड ग्रेडिएंट्स (IG) और वेरिएंट: पत्र बताता है कि जबकि IG और संबंधित एट्रिब्यूशन विधियों "ने वादा दिखाया है," उन्हें सीधे WSIs पर लागू करने से "उनकी उच्च-रिज़ॉल्यूशन प्रकृति के कारण चुनौतियां पेश होती हैं" और उनकी प्रवृत्ति "वर्ग-भेदभावपूर्ण संकेतों को नजरअंदाज करने की" होती है। यह संशोधन के बिना उनकी प्रत्यक्ष प्रयोज्यता का एक सीधा अस्वीकरण है। ग्रेडिएंट $\times$ इनपुट, EG, और IDG जैसी विधियों को CIG के मुकाबले बेंचमार्क किया जाता है, और CIG लगातार MIL-AIC और MIL-SIC के मामले में उनसे बेहतर प्रदर्शन करता है, जो इस समस्या के लिए उनकी मात्रात्मक हीनता को प्रदर्शित करता है।
- इमेज-स्पेस एट्रिब्यूशन विधियां: एक व्यापक अस्वीकरण "अधिकांश एट्रिब्यूशन विधियों [जो] इमेज स्पेस में काम करती हैं और दृश्य रूप से प्रमुख लेकिन वर्ग-अप्रासंगिक विशेषताओं को उजागर कर सकती हैं" के खिलाफ किया जाता है। यह सीमा WSI वर्गीकरण के लिए उनकी व्याख्यात्मकता को गंभीर रूप से बाधित करती है, जहां लक्ष्य किसी भी दृश्य रूप से प्रमुख क्षेत्र के बजाय नैदानिक रूप से प्रासंगिक क्षेत्रों की पहचान करना है। CIG का लॉजिट-स्पेस दृष्टिकोण निर्णय सीमाओं पर ध्यान केंद्रित करके सीधे इस पर काम करता है।
- IG-आधारित विधियों के लिए मानक बेसलाइन विकल्प: पत्र "एट्रिब्यूशन बेसलाइन के डिजाइन" को समर्पित एक अनुभाग है, जिसमें बताया गया है कि सामान्य बेसलाइन (जैसे, शून्य वेक्टर, डेटासेट माध्य, यादृच्छिक पैच) WSI के लिए अपर्याप्त क्यों हैं।
- एक शून्य वेक्टर बेसलाइन एम्बेडिंग स्पेस में "आउट-ऑफ-डिस्ट्रीब्यूशन मुद्दों" का कारण बन सकती है।
- डेटासेट माध्य "सिमेंटिक पूर्वाग्रह" पेश करता है, प्रमुख वर्गों का पक्ष लेता है।
- डेटासेट वितरण से नमूनाकरण या यादृच्छिक पैच का उपयोग करना "सिमेंटिक रिसाव या कम भेदभावपूर्णता" से ग्रस्त है यदि इनपुट और बेसलाइन एक ही वर्ग से संबंधित हैं।
ये मुद्दे कम व्याख्यात्मक सलिन्सी मैप्स की ओर ले जाते हैं। CIG एक "विपरीत वर्ग से बेसलाइन" का उपयोग करके इसे दूर करता है, जो इसके कंट्रास्टिव प्रकृति और मॉडल भविष्यवाणियों को संचालित करने वाले सार्थक अंतरों को कैप्चर करने के लिए महत्वपूर्ण है।
पत्र GANs या डिफ्यूजन मॉडल जैसे जनरेटिव मॉडल के अस्वीकरण पर चर्चा नहीं करता है, क्योंकि वे व्याख्यात्मकता के लिए फीचर एट्रिब्यूशन के फोकस के विपरीत, विभिन्न उद्देश्यों (जैसे, छवि निर्माण) की सेवा करते हैं। विचार किए गए और अस्वीकृत विकल्प मुख्य रूप से अन्य एट्रिब्यूशन तकनीकें और उनके घटक हैं।
गणितीय और तार्किक तंत्र
मास्टर समीकरण
कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स (CIG) को शक्ति प्रदान करने वाला पूर्ण मुख्य समीकरण इनपुट के $i$-वें सुविधा के लिए एट्रिब्यूशन की इसकी परिभाषा है, जैसा कि पत्र में प्रस्तुत किया गया है:
$$ \text{CIG}_i(x) = (x_i - x'_i) \int_0^1 \frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2 d\alpha $$
पद-दर-पद विच्छेदन
इसके गणितीय परिभाषा, CIG तंत्र में इसकी भूमिका और चुने गए ऑपरेटरों के पीछे के तर्क को समझने के लिए आइए इस समीकरण को टुकड़े-टुकड़े करके तोड़ें।
-
$\text{CIG}_i(x)$:
- गणितीय परिभाषा: यह इनपुट $x$ की $i$-वीं सुविधा के लिए कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स एट्रिब्यूशन स्कोर का प्रतिनिधित्व करता है।
- भौतिक/तार्किक भूमिका: यह CIG गणना का अंतिम आउटपुट है जो एक विशिष्ट सुविधा के लिए है। यह मापता है कि इनपुट $x$ की $i$-वीं सुविधा बेसलाइन $x'$ के मुकाबले कंट्रास्टिव तरीके से मॉडल की भविष्यवाणी को चलाने के लिए कितनी महत्वपूर्ण है। एक उच्च निरपेक्ष मान अधिक महत्व को इंगित करता है, और इसका संकेत यह इंगित कर सकता है कि सुविधा भविष्यवाणी को बेसलाइन के निहित वर्ग की ओर धकेलती है या उससे दूर ले जाती है।
-
$x$:
- गणितीय परिभाषा: यह इनपुट फीचर वेक्टर है (जैसे, होल स्लाइड इमेज पैच का एक एम्बेडिंग) जिसके लिए हम एट्रिब्यूशन की गणना करना चाहते हैं।
- भौतिक/तार्किक भूमिका: यह विशिष्ट डेटा बिंदु है जिसकी सुविधाओं को हम समझाना चाह रहे हैं। यह "लक्ष्य" इनपुट है।
-
$x'$:
- गणितीय परिभाषा: यह बेसलाइन या संदर्भ फीचर वेक्टर है।
- भौतिक/तार्किक भूमिका: पत्र निर्दिष्ट करता है कि $x'$ आम तौर पर "विपरीत वर्ग" से नमूना लिया जाता है (जैसे, ट्यूमर-पॉजिटिव स्लाइड के लिए गैर-ट्यूमर पैच)। यह फीचर स्पेस में एक तटस्थ या गैर-सूचनात्मक संदर्भ बिंदु के रूप में कार्य करता है। CIG बेसलाइन $x'$ के मुकाबले इनपुट $x$ की तुलना करके फीचर महत्व को मापता है, उन सुविधाओं को उजागर करता है जो $x$ को $x'$ से अलग करती हैं।
-
$(x_i - x'_i)$:
- गणितीय परिभाषा: यह इनपुट फीचर वेक्टर $x$ के $i$-वें घटक और बेसलाइन फीचर वेक्टर $x'$ के $i$-वें घटक के बीच स्केलर अंतर है।
- भौतिक/तार्किक भूमिका: यह पद एकीकृत ग्रेडिएंट के लिए एक स्केलिंग कारक के रूप में कार्य करता है। यह सुनिश्चित करता है कि यदि कोई सुविधा $x_i$ अपने बेसलाइन समकक्ष $x'_i$ के समान है, तो उसका एट्रिब्यूशन $\text{CIG}_i(x)$ शून्य होगा, क्योंकि यह कोई अंतर योगदान नहीं करता है। यह बेसलाइन से इनपुट तक उस विशिष्ट सुविधा के परिवर्तन के परिमाण और दिशा को भी ध्यान में रखता है।
- गुणा क्यों: यह एक सीधा स्केलिंग है, जो दर्शाता है कि किसी सुविधा का कुल "प्रभाव" बेसलाइन से कितना भिन्न होता है, उसके अनुपात में होना चाहिए।
-
$\int_0^1 \dots d\alpha$:
- गणितीय परिभाषा: यह 0 से 1 तक स्केलर पैरामीटर $\alpha$ पर एक निश्चित समाकलन है।
- भौतिक/तार्किक भूमिका: यह समाकलन "इंटीग्रेटेड ग्रेडिएंट्स" की अवधारणा का हृदय है। यह बेसलाइन $x'$ से इनपुट $x$ तक एक सतत पथ के साथ ग्रेडिएंट्स को जमा करता है। यह एकीकरण महत्वपूर्ण है क्योंकि यह "ग्रेडिएंट संतृप्ति" समस्या को संबोधित करता है, जहां उन सुविधाओं के लिए ग्रेडिएंट बहुत छोटे हो सकते हैं जो पहले से ही दृढ़ता से सक्रिय हैं, इस प्रकार उनके महत्व को कम आंकते हैं। पूरे पथ के साथ सूक्ष्म योगदानों को जोड़कर, यह सुविधा महत्व का अधिक मजबूत और पूर्ण माप प्रदान करता है।
- योग के बजाय समाकलन क्यों: एक सतत पथ के साथ योग करने के लिए एक समाकलन का उपयोग किया जाता है, जो वांछनीय अक्षों (जैसे पूर्णता) को संतुष्ट करने वाला एक सैद्धांतिक रूप से सुदृढ़ और पूर्ण एट्रिब्यूशन प्रदान करता है। एक योग (जैसे रीमैन योग सन्निकटन) इस निरंतर प्रक्रिया का एक असतत सन्निकटन होगा।
-
$\frac{\partial}{\partial x_i}$:
- गणितीय परिभाषा: यह इनपुट की $i$-वीं सुविधा के संबंध में आंशिक व्युत्पन्न ऑपरेटर है। समाकलन के संदर्भ में, इसे वर्ग L2 मानदंड पद पर लागू किया जाता है।
- भौतिक/तार्किक भूमिका: यह ऑपरेटर पथ के प्रत्येक बिंदु $\gamma(\alpha)$ पर वर्ग लॉजिट अंतर की $i$-वीं सुविधा में परिवर्तनों के प्रति वर्ग लॉजिट अंतर की संवेदनशीलता की गणना करता है। यह बताता है कि पथ पर एक दिए गए बिंदु पर $x_i$ में एक छोटा सा परिवर्तन कंट्रास्ट (वर्ग लॉजिट अंतर) को बेसलाइन से कितना प्रभावित करेगा। इस तरह विधि यह पहचानती है कि कौन सी सुविधाएं स्थानीय रूप से प्रभावशाली हैं।
-
$|| \cdot ||_2^2$:
- गणितीय परिभाषा: यह एक वेक्टर के वर्ग यूक्लिडियन (L2) मानदंड को दर्शाता है। एक वेक्टर $v$ के लिए, $||v||_2^2 = \sum_j v_j^2$।
- भौतिक/तार्किक भूमिका: यह पद इंटरपोलेटेड इनपुट के लॉजिट आउटपुट और बेसलाइन के लॉजिट आउटपुट के बीच लॉजिट स्पेस में "दूरी" या "भिन्नता" को मापता है। L2 मानदंड को वर्ग करके, यह सुनिश्चित करता है कि माप हमेशा गैर-नकारात्मक हो और बड़े अंतरों पर अधिक महत्वपूर्ण रूप से जोर देता है। यह मूल "कंट्रास्टिव" माप है जिसे CIG समझाना चाहता है।
- L2 मानदंड क्यों: L2 मानदंड यूक्लिडियन स्पेस में वेक्टर परिमाण और दूरी को मापने के लिए एक मानक मीट्रिक है। इसे वर्ग करने से वर्गमूल को हटाकर गणना सरल हो जाती है और एक चिकना, अवकलनीय फ़ंक्शन प्रदान करता है जो ग्रेडिएंट गणना के लिए उपयुक्त है।
-
$f_{\text{logit}}(\cdot)$:
- गणितीय परिभाषा: यह मॉडल की लॉजिट परत के आउटपुट का प्रतिनिधित्व करता है। एक वर्गीकरण मॉडल के लिए, ये सॉफ्टमैक्स सक्रियण से पहले प्रत्येक वर्ग के लिए कच्चे, अनियंत्रित स्कोर होते हैं।
- भौतिक/तार्किक भूमिका: CIG लॉजिट स्पेस में काम करता है क्योंकि लॉजिट सीधे प्रत्येक वर्ग के लिए मॉडल के आत्मविश्वास और साक्ष्य को दर्शाते हैं। लॉजिट आउटपुट में अंतर को मापकर, CIG वर्ग-भेदभावपूर्ण जानकारी को कैप्चर करता है, जो ट्यूमर और गैर-ट्यूमर क्षेत्रों के बीच अंतर करने के लिए महत्वपूर्ण है। यह उन विधियों से एक प्रमुख अंतर है जो इमेज स्पेस या सॉफ्टमैक्स संभावनाओं पर काम करती हैं।
-
$\gamma(\alpha)$:
- गणितीय परिभाषा: यह एक सीधी रेखा पथ फ़ंक्शन है जिसे $\gamma(\alpha) = x' + \alpha(x - x')$ के रूप में परिभाषित किया गया है, जहां $\alpha \in [0, 1]$।
- भौतिक/तार्किक भूमिका: यह फ़ंक्शन फीचर स्पेस में मध्यवर्ती बिंदु उत्पन्न करता है जो बेसलाइन $x'$ (जब $\alpha=0$) से इनपुट $x$ (जब $\alpha=1$) तक एक सीधी रेखा पर स्थित होते हैं। यह वह निरंतर प्रक्षेपवक्र प्रदान करता है जिस पर ग्रेडिएंट्स को एकीकृत किया जाता है।
-
$\alpha$:
- गणितीय परिभाषा: 0 से 1 तक निरंतर भिन्न होने वाला एक स्केलर पैरामीटर।
- भौतिक/तार्किक भूमिका: यह पैरामीटर $\gamma(\alpha)$ पर इंटरपोलेशन पथ के साथ स्थिति को नियंत्रित करता है। जैसे-जैसे $\alpha$ बढ़ता है, इंटरपोलेटेड बिंदु बेसलाइन से इनपुट की ओर बढ़ता है।
-
$f_{\text{logit}}(x')$:
- गणितीय परिभाषा: बेसलाइन फीचर वेक्टर $x'$ को इनपुट के रूप में प्रदान किए जाने पर मॉडल का लॉजिट आउटपुट।
- भौतिक/तार्किक भूमिका: यह लॉजिट स्पेस में एक निश्चित संदर्भ बिंदु के रूप में कार्य करता है। CIG विधि मापती है कि इंटरपोलेटेड इनपुट $\gamma(\alpha)$ के लिए लॉजिट आउटपुट इस स्थिर बेसलाइन लॉजिट आउटपुट से कैसे भिन्न होता है। यह स्थिर संदर्भ CIG की "कंट्रास्टिव" प्रकृति का मूल है, जिससे यह उन सुविधाओं को उजागर करने की अनुमति देता है जो बेसलाइन की भविष्यवाणी से विचलन का कारण बनती हैं।
चरण-दर-चरण प्रवाह
एक एकल अमूर्त डेटा बिंदु की कल्पना करें, जिसे उसके फीचर वेक्टर $x$ द्वारा दर्शाया गया है, जो इस गणितीय इंजन में प्रवेश कर रहा है। यहां बताया गया है कि CIG इसे उसके फीचर एट्रिब्यूशन निर्धारित करने के लिए कैसे संसाधित करता है:
- बेसलाइन चयन: सबसे पहले, एक उपयुक्त बेसलाइन फीचर वेक्टर $x'$ चुना जाता है। पत्र एक कंट्रास्टिव बेसलाइन का उपयोग करने पर जोर देता है, जैसे कि ट्यूमर-पॉजिटिव स्लाइड का विश्लेषण करते समय गैर-ट्यूमर क्षेत्रों से नमूना किए गए फीचर्स। यह $x'$ एक तटस्थ या "विपरीत" संदर्भ बिंदु के रूप में कार्य करता है।
- पथ निर्माण: फीचर स्पेस में एक सीधी रेखा पथ $\gamma(\alpha)$ का निर्माण किया जाता है। यह पथ बेसलाइन $x'$ (जब $\alpha=0$) और इनपुट $x$ (जब $\alpha=1$) को जोड़ने वाले एक चिकने इंटरपोलेशन का निर्माण करता है। इसे संदर्भ बिंदु से वास्तविक इनपुट बिंदु तक एक रेखा खींचने के रूप में सोचें।
- लॉजिट परिवर्तन: इस पथ के साथ हर सूक्ष्म कदम, $\gamma(\alpha)$ द्वारा दर्शाया गया, मॉडल का लॉजिट आउटपुट $f_{\text{logit}}(\gamma(\alpha))$ की गणना की जाती है। साथ ही, निश्चित बेसलाइन $f_{\text{logit}}(x')$ के लिए लॉजिट आउटपुट भी प्राप्त किया जाता है।
- कंट्रास्टिव माप: पथ पर प्रत्येक बिंदु $\alpha$ पर, वर्तमान इंटरपोलेटेड लॉजिट आउटपुट और बेसलाइन लॉजिट आउटपुट, $f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')$ के बीच अंतर की गणना की जाती है। इस अंतर के वर्ग यूक्लिडियन मानदंड, $||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$, की गणना की जाती है। यह मान मापता है कि बेसलाइन से इसके अंतर की तुलना में इंटरपोलेटेड इनपुट के लिए मॉडल की कच्ची भविष्यवाणी कितनी "भिन्न" है।
- ग्रेडिएंट गणना: इस वर्ग लॉजिट अंतर (कंट्रास्टिव माप) के आंशिक व्युत्पन्न की गणना इनपुट की प्रत्येक व्यक्तिगत सुविधा $x_i$ के संबंध में की जाती है। यह ग्रेडिएंट, $\frac{\partial}{\partial x_i} ||f_{\text{logit}}(\gamma(\alpha)) - f_{\text{logit}}(x')||_2^2$, बताता है कि पथ पर उस विशेष बिंदु $\alpha$ पर सुविधा $i$ में परिवर्तनों के प्रति कंट्रास्टिव माप कितना संवेदनशील है।
- ग्रेडिएंट एकीकरण: इन आंशिक ग्रेडिएंट्स को फिर $\alpha=0$ से $\alpha=1$ तक पूरे पथ के साथ एकीकृत किया जाता है। यह कदम प्रभावी रूप से प्रत्येक सुविधा की संवेदनशीलता के सभी सूक्ष्म योगदानों को कंट्रास्टिव माप में जोड़ता है क्योंकि इनपुट बेसलाइन से उसके वास्तविक मान में परिवर्तित होता है। यह महत्व का एक व्यापक मूल्यांकन सुनिश्चित करता है, उन मुद्दों से बचता है जहां ग्रेडिएंट एक बिंदु पर भ्रामक हो सकते हैं।
- स्केलिंग और अंतिम एट्रिब्यूशन: अंत में, प्रत्येक सुविधा $i$ के लिए, संचित समाकलन को अंतर $(x_i - x'_i)$ से स्केल किया जाता है। यह स्केलिंग सुनिश्चित करती है कि बेसलाइन के समान सुविधाओं को शून्य एट्रिब्यूशन मिले और बेसलाइन से सुविधा के परिवर्तन के परिमाण को ध्यान में रखा जाए। परिणाम $\text{CIG}_i(x)$ है, जो सुविधा $i$ के लिए कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट है।
यह प्रक्रिया सभी सुविधाओं के लिए दोहराई जाती है, जिससे एट्रिब्यूशन स्कोर का एक वेक्टर प्राप्त होता है जो उजागर करता है कि इनपुट $x$ के कौन से हिस्से इसकी भविष्यवाणी के लिए सबसे अधिक जिम्मेदार हैं, चुने गए बेसलाइन $x'$ के सापेक्ष।
अनुकूलन गतिशीलता
यह स्पष्ट करना महत्वपूर्ण है कि कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स (CIG) एक एट्रिब्यूशन विधि है, न कि मॉडल प्रशिक्षण या अनुकूलन एल्गोरिथम। इसलिए, यह पारंपरिक अर्थों में मॉडल मापदंडों को एक हानि फ़ंक्शन के आधार पर समायोजित करने के आधार पर "सीखता," "अपडेट" या "अभिसरण" नहीं करता है। इसके बजाय, इसके "गतिशीलता" इस बात से नियंत्रित होती है कि एट्रिब्यूशन स्कोर की गणना कैसे की जाती है और वे विश्वसनीय स्पष्टीकरण प्रदान करने के लिए कैसे व्यवहार करते हैं, जो पहले से प्रशिक्षित मॉडल के लिए होते हैं।
तंत्र की "गतिशीलता" कई अक्षीय गुणों द्वारा शासित होती है जिन्हें CIG को संतुष्ट करने के लिए डिज़ाइन किया गया है, जो इसकी विश्वसनीयता और व्याख्यात्मकता सुनिश्चित करते हैं:
-
पूर्णता अक्ष (Completeness Axiom): जैसा कि पत्र में (समीकरण 7) बताया गया है, एक इनपुट $x$ के लिए सभी CIG एट्रिब्यूशन का योग इनपुट और बेसलाइन के बीच वर्ग लॉजिट अंतर के कुल परिवर्तन के बराबर होता है: $\sum_{i=1}^n \text{CIG}_i(x) = ||f_{\text{logit}}(x) - f_{\text{logit}}(x')||_2^2$ । इसका मतलब है कि विधि इनपुट और बेसलाइन के बीच मॉडल के लॉजिट आउटपुट के पूरे अंतर को पूरी तरह से खातों में लेती है, इस अंतर को इनपुट सुविधाओं में पूरी तरह से वितरित करती है। कोई भी योगदान अस्पष्ट नहीं रहता है।
-
संवेदनशीलता अक्ष (Sensitivity Axiom): CIG उन सुविधाओं $x_i$ को गैर-शून्य एट्रिब्यूशन प्रदान करता है जो उनके बेसलाइन समकक्षों $x'_i$ से भिन्न होते हैं और जिनके परिवर्तन मॉडल के लॉजिट आउटपुट को प्रभावित करते हैं। इसके विपरीत, यदि कोई सुविधा $x_i$ $x'_i$ से नहीं बदलती है या यदि मॉडल का लॉजिट आउटपुट $x_i$ से पूरी तरह से स्वतंत्र है, तो उसका एट्रिब्यूशन शून्य होगा। यह सुनिश्चित करता है कि CIG केवल उन प्रासंगिक सुविधाओं की सही पहचान और हाइलाइट करता है जो मॉडल के निर्णय में योगदान करती हैं, उन्हें अप्रासंगिक लोगों से अलग करती हैं। यह संपत्ति केंद्रित और व्याख्यात्मक सलिन्सी मैप उत्पन्न करने के लिए महत्वपूर्ण है।
-
कार्यान्वयन अपरिवर्तनीयता अक्ष (Implementation Invariance Axiom): CIG के एट्रिब्यूशन केवल मॉडल आउटपुट फ़ंक्शन ($f_{\text{logit}}(\cdot)$) और इसके ग्रेडिएंट्स पर आधारित होते हैं, न कि न्यूरल नेटवर्क के विशिष्ट कार्यान्वयन विवरणों पर। यह गारंटी देता है कि कार्यात्मक रूप से समतुल्य मॉडल आंतरिक रूप से कैसे कोडित या संरचित किए जाते हैं, इसके बावजूद सुसंगत एट्रिब्यूशन उत्पन्न करेंगे। यह CIG को विभिन्न मॉडल आर्किटेक्चर में मजबूत और भरोसेमंद बनाता है।
इसलिए, CIG की "गतिशीलता" हानि परिदृश्य पर पुनरावृत्त अपडेट के बारे में नहीं है, बल्कि इन सैद्धांतिक गुणों का पालन करने वाले फीचर महत्व स्कोर की मजबूत और सुसंगत गणना के बारे में है। लॉजिट स्पेस में एक पथ के साथ ग्रेडिएंट्स का एकीकरण, कंट्रास्टिव बेसलाइन के साथ मिलकर, एट्रिब्यूशन मानों को अधिक स्थानीयकृत और वर्ग-भेदभावपूर्ण बनाने के लिए आकार देता है, जैसा कि पत्र में गुणात्मक परिणामों से पता चलता है। यह तंत्र सुनिश्चित करता है कि उत्पन्न स्पष्टीकरण केवल दृश्य रूप से प्रमुख नहीं हैं, बल्कि तार्किक रूप से सुदृढ़ भी हैं और सीधे मॉडल की निर्णय लेने की प्रक्रिया से जुड़े हैं, विशेष रूप से विभिन्न वर्गों के बीच अंतर करने में।
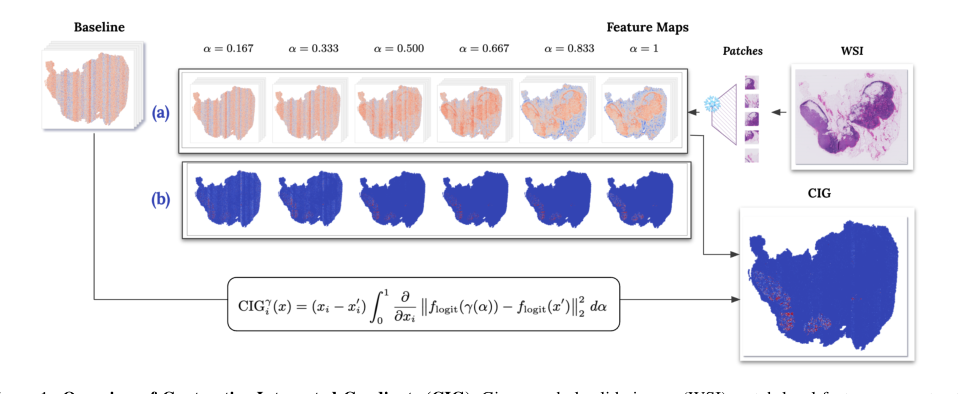 Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
Figure 1. Overview of Contrastive Integrated Gradients (CIG). Given a whole-slide image (WSI), patch-level features are extracted and compared to a baseline sampled from non-tumor regions. An interpolated path \ga m ma (\a lpha ) = x + \alpha (x' - x) is constructed between the input x and the baseline x' . CIG computes attributions by integrating the gradients of the squared logit difference along this path, where f_{\text {logit}}(\cdot ) denotes the model’s logit output and \ | \cdot \|_2 is the Euclidean norm. Row (a) shows interpolated features at different \alpha values ( \ alpha = 0.167 to 1 ). Row (b) illustrates how contrastive gradients evolve with increasing \alpha , indicating the sensitivity of each feature at each interpolation step. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x - x' . The final heatmap (bottom right) shows the CIG attribution result, indicating which regions most strongly influence the model’s decision relative to the baseline
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स (CIG) की प्रभावशीलता को कठोरता से मान्य करने के लिए, लेखकों ने विविध कम्प्यूटेशनल पैथोलॉजी परिदृश्यों में एक व्यापक प्रयोगात्मक सेटअप तैयार किया। CIG के लक्ष्य के रूप में स्थापित ग्रेडिएंट-आधारित एट्रिब्यूशन विधियों में से कई शामिल थे: वैनिला ग्रेडिएंट, इंटीग्रेटेड ग्रेडिएंट्स (IG) [32], एक्सपेक्टेड ग्रेडिएंट्स (EG) [29], और इंटीग्रेटेड डिसीजन ग्रेडिएंट्स (IDG) [33], साथ ही तुलना के लिए एक सरल रैंडम बेसलाइन। स्थिरता के लिए सभी पथ-आधारित विधियों, CIG सहित, को 50 इंटरपोलेशन चरणों के साथ कॉन्फ़िगर किया गया था।
प्रयोग तीन सार्वजनिक रूप से उपलब्ध, उच्च-दांव वाले कैंसर पैथोलॉजी डेटासेट पर आयोजित किए गए थे: CAMELYON16 (लिम्फ नोड्स में स्तन कैंसर मेटास्टेसिस), TCGA-Renal (तीन गुर्दे के कैंसर उपप्रकारों को कवर करता है: KIRC, KIRP, KICH), और TCGA-Lung (LUAD और LUSC फेफड़ों के कैंसर उपप्रकारों को कवर करता है)। यह विविध चयन सुनिश्चित करता है कि CIG की सामान्यता विभिन्न कैंसर प्रकारों और नैदानिक सेटिंग्स में हो।
आर्किटेक्चर में एट्रिब्यूशन प्रदर्शन का आकलन करने के लिए दो अलग-अलग मल्टीपल इंस्टेंस लर्निंग (MIL) वर्गीकरण मॉडल का उपयोग किया गया था: एक साधारण MLP बैग क्लासिफायर और व्यापक रूप से इस्तेमाल किया जाने वाला ध्यान-आधारित CLAM [19] मॉडल। दोनों मॉडल प्री-ट्रेंड ResNet-50 से निकाले गए पैच-स्तरीय फीचर्स का उपयोग करते थे और 200 युगों के लिए प्रशिक्षित किए गए थे, जिसमें रिसाव को रोकने के लिए रोगी-स्तरीय अलगाव डेटा स्प्लिट के लिए उपयोग किया गया था।
प्रयोगात्मक डिजाइन का एक महत्वपूर्ण पहलू एट्रिब्यूशन बेसलाइन का उपन्यास निर्माण था, विशेष रूप से पथ-आधारित विधियों के लिए। पारंपरिक बेसलाइन (जैसे, काली छवियां, डेटासेट माध्य) के विपरीत, CIG और अन्य IG-आधारित विधियों ने विपरीत वर्ग के 30 स्लाइडों से पैच फीचर्स का नमूना करके एक कंट्रास्टिव बेसलाइन का उपयोग किया। उदाहरण के लिए, ट्यूमर-पॉजिटिव स्लाइड का मूल्यांकन करते समय, गैर-ट्यूमर स्लाइड पैच संदर्भ के रूप में कार्य करते थे। इस रणनीति को वर्ग-भेदभावपूर्ण सुविधाओं को अधिक प्रभावी ढंग से उजागर करने के लिए डिज़ाइन किया गया था, जो CIG के कंट्रास्टिव जानकारी को कैप्चर करने के मूल तंत्र के साथ संरेखित था।
इस कमजोर पर्यवेक्षित WSI सेटिंग में एट्रिब्यूशन गुणवत्ता का मात्रात्मक रूप से आकलन करने के लिए, जहां ग्राउंड ट्रुथ स्पष्टीकरण अक्सर अनुपलब्ध होते हैं, लेखकों ने परफॉर्मेंस इंफॉर्मेशन कर्व्स (PICs) फ्रेमवर्क [9] को अनुकूलित किया और दो विशेष मेट्रिक्स पेश किए:
- MIL-एकीकरण सूचना वक्र (MIL-AIC): यह मीट्रिक मॉडल की वर्गीकरण सटीकता (सही स्लाइड-स्तरीय लेबल भविष्यवाणी) को ट्रैक करता है क्योंकि उच्च-सलिन्सी पैच को उत्तरोत्तर पेश किया जाता है। एक उच्च MIL-AIC इंगित करता है कि एट्रिब्यूशन विधि सही वर्गीकरण के लिए महत्वपूर्ण क्षेत्रों की शीघ्र पहचान करती है।
- MIL-सॉफ्टमैक्स सूचना वक्र (MIL-SIC): यह मीट्रिक सही वर्ग में मॉडल के सॉफ्टमैक्स आत्मविश्वास को मापता है क्योंकि सूचनात्मक पैच प्रकट होते हैं। एक उच्च MIL-SIC बताता है कि एट्रिब्यूशन विधि उन क्षेत्रों को उजागर करती है जो मॉडल की निश्चितता को तेजी से बढ़ाते हैं।
मूल्यांकन विशेष रूप से ट्यूमर-पॉजिटिव स्लाइड पर केंद्रित था। "क्रूर प्रमाण" को नियंत्रण सुविधाओं (विपरीत वर्ग से) के साथ शुरू करके और धीरे-धीरे लक्ष्य स्लाइड से सुविधाओं को बदलकर संरचित किया गया था, जो एट्रिब्यूशन स्कोर द्वारा रैंक किए गए थे। इस प्रक्रिया को दो पूरक सूचना-स्तर के डिब्बे का उपयोग करके संरचित किया गया था: "टॉप-के पैच" (जैसे, $k=1, \dots, 500$) भविष्यवाणी बदलावों के शुरुआती चरण को कैप्चर करने के लिए, और "सलिन्सी थ्रेशोल्ड" (जैसे, 20% से 99% प्रतिशत कटऑफ) बाद के चरण संक्रमणों और पूर्णता का आकलन करने के लिए। इस सावधानीपूर्वक डिजाइन ने इस बात का बारीक विश्लेषण करने की अनुमति दी कि CIG-पहचाने गए सलिन्सी क्षेत्रों को पेश किए जाने पर मॉडल की भविष्यवाणियां कितनी जल्दी और आत्मविश्वास से विकसित होती हैं, इसकी प्रभावशीलता का निर्विवाद प्रमाण प्रदान करती हैं।
साक्ष्य क्या साबित करते हैं
प्रायोगिक परिणाम WSIs में निर्णय-प्रासंगिक क्षेत्रों की पहचान करने में मौजूदा एट्रिब्यूशन विधियों को CIG महत्वपूर्ण रूप से पार करने का सम्मोहक मात्रात्मक और गुणात्मक प्रमाण प्रदान करते हैं।
मात्रात्मक रूप से, CIG ने लगातार सभी तीन कैंसर डेटासेट और दोनों क्लासिफायर आर्किटेक्चर में उच्चतम MIL-AIC और MIL-SIC स्कोर प्राप्त किए। उदाहरण के लिए, CAMELYON16 डेटासेट (तालिका 1) पर, CLAM मॉडल के साथ CIG ने MIL-AIC के लिए $0.950 \pm 0.166$ और MIL-SIC के लिए $0.945 \pm 0.128$ स्कोर किया, जो अगले सर्वश्रेष्ठ विधि (IG: $0.891 \pm 0.261$ MIL-AIC, $0.896 \pm 0.243$ MIL-SIC) से काफी बेहतर है। MLP क्लासिफायर के साथ समान रुझान देखे गए, जहां CIG $0.965 \pm 0.128$ MIL-AIC और $0.913 \pm 0.130$ MIL-SIC तक पहुंच गया। यह निर्णायक साक्ष्य, जो मापता है कि CIG-पहचाने गए पैच पेश किए जाने पर मॉडल की भविष्यवाणियां कितनी जल्दी और आत्मविश्वास से सही लेबल की ओर बढ़ती हैं, साबित करता है कि CIG का मूल तंत्र लॉजिट स्पेस में कंट्रास्टिव ग्रेडिएंट की गणना करता है, जो वास्तव में वर्ग-भेदभावपूर्ण सुविधाओं को प्रभावी ढंग से उजागर करता है।
TCGA-Renal डेटासेट (तालिका 2) में, CIG ने सभी तीन गुर्दे के उपप्रकारों (pRCC, ccRCC, chRCC) और दोनों मॉडलों में मजबूत प्रदर्शन का प्रदर्शन किया, लगातार शीर्ष प्रदर्शन करने वालों में से एक रहा। उदाहरण के लिए, CLAM के साथ ccRCC में, CIG ने $0.776 \pm 0.297$ MIL-AIC और $0.783 \pm 0.286$ MIL-SIC प्राप्त किया, जो सभी बेसलाइन से बेहतर प्रदर्शन कर रहा है। TCGA-Lung डेटासेट (तालिका 3) ने इन निष्कर्षों को और मजबूत किया, जिसमें CIG ने CLAM के साथ LUSC ($0.759 \pm 0.296$ MIL-AIC, $0.765 \pm 0.277$ MIL-SIC) के लिए उच्चतम स्कोर प्राप्त किया और LUAD के लिए एक मजबूत संतुलन दिखाया। ये परिणाम सामूहिक रूप से इस बात को पुष्ट करते हैं कि कंट्रास्टिव जानकारी को कैप्चर करने की CIG की क्षमता अधिक जानकारीपूर्ण और स्थिर एट्रिब्यूशन की ओर ले जाती है।
गुणात्मक रूप से, विज़ुअलाइज़ेशन CIG की श्रेष्ठता को और मजबूत करते हैं। चित्र 2, जो इंटरपोलेशन चरणों में मध्यवर्ती ग्रेडिएंट मैप्स को दर्शाता है, स्पष्ट रूप से दिखाता है कि CIG पथ के दौरान ट्यूमर क्षेत्रों के भीतर अधिक स्थानीयकृत और सुसंगत ग्रेडिएंट उत्पन्न करता है, इसके विपरीत IG जो अधिक बिखरे हुए पैटर्न प्रदर्शित करता है। यह इंगित करता है कि CIG के एट्रिब्यूशन अधिक स्थिर और प्रासंगिक क्षेत्रों पर केंद्रित हैं।
अधिक महत्वपूर्ण बात, चित्र 3, अंतिम एट्रिब्यूशन मैप्स प्रस्तुत करता है, यह दर्शाता है कि CIG लगातार उन क्षेत्रों पर जोर देता है जो एनोटेट किए गए ग्राउंड ट्रुथ ट्यूमर क्षेत्रों के साथ निकटता से संरेखित होते हैं। इसके विपरीत, IG और EG जैसी बेसलाइन विधियां अक्सर दृश्य रूप से प्रमुख लेकिन कम भेदभावपूर्ण विशेषताओं को उजागर करती हैं जो वास्तविक ट्यूमर का हिस्सा नहीं हैं। ग्राउंड ट्रुथ के साथ यह दृश्य संरेखण निर्विवाद प्रमाण प्रदान करता है कि CIG का तंत्र निर्णय-प्रासंगिक ट्यूमर क्षेत्रों की पहचान करने में सफल रहा है।
अंत में, पत्र सैद्धांतिक रूप से साबित करता है कि CIG इंटीग्रेटेड एट्रिब्यूशन विधियों के मौलिक अक्षीय गुणों को संतुष्ट करता है: पूर्णता, संवेदनशीलता और कार्यान्वयन अपरिवर्तनीयता। यह सैद्धांतिक सुदृढ़ता, मजबूत मात्रात्मक और गुणात्मक प्रायोगिक परिणामों के साथ मिलकर, CIG के दावों के लिए एक मजबूत आधार प्रदान करती है।
सीमाएँ और भविष्य की दिशाएँ
जबकि CIG व्याख्यात्मक WSI वर्गीकरण में महत्वपूर्ण प्रगति प्रदर्शित करता है, लेखक कुछ सीमाओं को स्वीकार करते हैं और भविष्य के शोध के लिए स्पष्ट रास्ते प्रस्तावित करते हैं।
एक उल्लेखनीय सीमा स्वयं मूल्यांकन ढांचे से उत्पन्न होती है: वर्तमान MIL-AIC और MIL-SIC मेट्रिक्स मुख्य रूप से ट्यूमर-पॉजिटिव स्लाइड के लिए डिज़ाइन किए गए हैं और उनके लिए सबसे उपयुक्त हैं। जैसा कि लेखक बताते हैं, सामान्य स्लाइड अलग भविष्यवाणी गतिशीलता प्रदर्शित करती हैं, अक्सर भविष्यवाणी बदलने से पहले लगभग सभी सुविधाओं को हटाने की आवश्यकता होती है, जो उस संदर्भ में AUC जैसे मेट्रिक्स को कम सार्थक बनाती है। यह बताता है कि जबकि CIG ट्यूमर क्षेत्रों की पहचान करने में असाधारण रूप से अच्छा प्रदर्शन करता है, गैर-ट्यूमर या सामान्य ऊतक वर्गीकरण के लिए इसकी प्रयोज्यता और व्याख्या, या उन परिदृश्यों में जहां "विपरीत वर्ग" बेसलाइन स्पष्ट रूप से परिभाषित नहीं है, आगे की जांच या मूल्यांकन पद्धति के अनुकूलन की आवश्यकता हो सकती है।
आगे देखते हुए, सबसे महत्वपूर्ण भविष्य की दिशा व्याख्यात्मकता के कठोर मानव-विषय मूल्यांकन का समावेश है। जबकि मात्रात्मक मेट्रिक्स और गुणात्मक विज़ुअलाइज़ेशन मजबूत प्रमाण प्रदान करते हैं, कम्प्यूटेशनल पैथोलॉजी में व्याख्यात्मकता का अंतिम लक्ष्य विश्वास बनाना और नैदानिक निर्णय लेने में सहायता करना है। क्या CIG के स्पष्टीकरण वास्तव में उनकी समझ और एआई-सहायता प्राप्त निदान में विश्वास को बढ़ाते हैं, इस पर सीधे सत्यापन अपरिहार्य है। इसमें यह आकलन करने के लिए अध्ययन डिजाइन करना शामिल होगा कि CIG के एट्रिब्यूशन मानव नैदानिक सटीकता, दक्षता और विश्वास को कैसे प्रभावित करते हैं।
मानव-विषय मूल्यांकन से परे, आगे के विकास के लिए कई अन्य चर्चा विषय उभरते हैं:
- अन्य चिकित्सा इमेजिंग तौर-तरीकों के लिए सामान्यीकरण: क्या CIG के कंट्रास्टिव दृष्टिकोण को अन्य जटिल चिकित्सा इमेजिंग कार्यों के लिए अनुकूलित किया जा सकता है, जैसे MRI या CT स्कैन, जहां व्याख्यात्मकता समान रूप से महत्वपूर्ण है लेकिन फीचर स्पेस और बेसलाइन काफी भिन्न हो सकते हैं?
- कम्प्यूटेशनल दक्षता और स्केलेबिलिटी: जबकि CIG मजबूत प्रदर्शन दिखाता है, एट्रिब्यूशन विधियां, विशेष रूप से पथ-आधारित, कम्प्यूटेशनल रूप से गहन हो सकती हैं। भविष्य के शोध अत्यंत बड़े WSIs या वास्तविक समय नैदानिक अनुप्रयोगों के लिए CIG की दक्षता में सुधार के लिए अनुकूलन का पता लगा सकते हैं, शायद सन्निकटन तकनीकों या हार्डवेयर त्वरण के माध्यम से।
- गतिशील बेसलाइन चयन: वर्तमान विधि "विपरीत वर्ग" बेसलाइन से नमूनाकरण पर निर्भर करती है। भविष्य के काम विशेष रूप से बहु-वर्ग परिदृश्यों में या जब एक स्पष्ट "विपरीत" वर्ग आसानी से उपलब्ध या अच्छी तरह से परिभाषित नहीं होता है, तो अधिक गतिशील या अनुकूली बेसलाइन चयन रणनीतियों की जांच कर सकते हैं।
- एंटी-हॉक विधियों के साथ एकीकरण: CIG एक पोस्ट-हॉक एट्रिब्यूशन विधि है। एंटी-हॉक व्याख्यात्मकता विधियों के साथ इसके एकीकरण की खोज, जो मॉडल आर्किटेक्चर में सीधे व्याख्यात्मकता का निर्माण करती हैं, हाइब्रिड दृष्टिकोणों को जन्म दे सकती हैं जो दोनों की शक्तियों को जोड़ती हैं, जो स्थानीयकृत स्पष्टीकरण और वैश्विक मॉडल समझ दोनों प्रदान करती हैं।
- बाइनरी वर्गीकरण से परे: जबकि पत्र बहु-उपप्रकार वर्गीकरण (जैसे, TCGA-Renal) को छूता है, CIG कैसे प्रदर्शन करता है और इसे कई वर्गों के बीच सूक्ष्म अंतरों को उजागर करने की आवश्यकता वाले अत्यधिक दानेदार बहु-वर्ग समस्याओं के लिए कैसे अनुकूलित किया जा सकता है, इसका एक गहरा गोता मूल्यवान होगा।
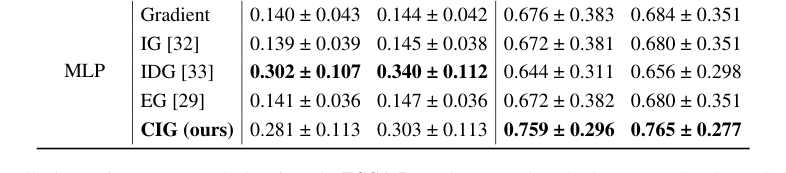 Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 3. Attribution performance on each class from the TCGA-Lung dataset, evaluated using MIL-AIC and MIL-SIC metrics
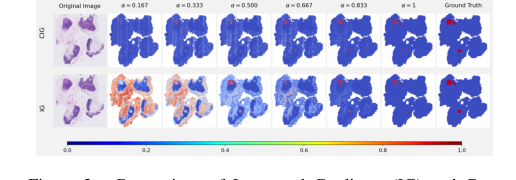 Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
Figure 2. Comparison of Integrated Gradients (IG) and Con- trastive Integrated Gradients (CIG) across interpolation steps ( \alpha ), each row shows intermediate gradient maps at increasing \alpha val- ues, from 0.167 to 1.0, illustrating how gradients evolve along the interpolation path. Note that the final heatmap ( \ alpha = 1 ) shows only the gradient at the last step and is not the complete attribution result. The full attribution is computed by summing the gradients across all \alpha values and multiplying by the input difference x ' - x . CIG produces more stable and localized gradients in tumor regions throughout the path, while IG exhibits more dispersed patterns
 Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
Table 1. Attribution performance on tumor-positive slides from the Camelyon16 dataset, evaluated using MIL-AIC and MIL-SIC metrics
अन्य क्षेत्रों के साथ समरूपता
संरचनात्मक कंकाल
इस पत्र का मुख्य गणितीय तंत्र एक ऐसी विधि है जो एक कंट्रास्टिव संदर्भ के लिए एक पथ के साथ लॉजिट आउटपुट के वर्ग अंतर को एकीकृत करके मॉडल के निर्णय पर इनपुट सुविधाओं के विभेदक प्रभाव को मापती है।
दूर के चचेरे भाई
कंट्रास्टिव इंटीग्रेटेड ग्रेडिएंट्स (CIG) के अंतर्निहित तर्क के कम्प्यूटेशनल पैथोलॉजी से बहुत दूर के क्षेत्रों में आकर्षक "दर्पण चित्र" हैं:
-
लक्ष्य क्षेत्र: वित्तीय जोखिम प्रबंधन और पोर्टफोलियो अनुकूलन
- संबंध: वित्त में, एक लंबे समय से चली आ रही समस्या यह समझना है कि कौन से विशिष्ट बाजार कारक (जैसे, ब्याज दरें, कमोडिटी की कीमतें, क्षेत्र का प्रदर्शन) एक पोर्टफोलियो के प्रदर्शन या जोखिम को एक बेंचमार्क इंडेक्स (जैसे S&P 500) या प्रतिस्पर्धी पोर्टफोलियो के सापेक्ष संचालित करते हैं। यह CIG के लक्ष्य के समान है, जो एक कंट्रास्टिव बेसलाइन की तुलना करके वर्ग-भेदभावपूर्ण सुविधाओं की पहचान करता है। एक मात्रात्मक विश्लेषक यह जानना चाह सकता है कि केवल यह नहीं कि उनके पोर्टफोलियो की अस्थिरता में क्या योगदान देता है, बल्कि विशेष रूप से क्या इसे औसत बाजार से अधिक अस्थिर बनाता है कुछ आर्थिक परिस्थितियों में। "लॉजिट स्पेस" जोखिम-समायोजित रिटर्न या बेंचमार्क से विचलन का एक परिवर्तित माप हो सकता है, और पथ एकीकरण विभिन्न सिम्युलेटेड बाजार परिदृश्यों या निवेश रणनीतियों के तहत इन कारक योगदानों के विकास को मॉडल कर सकता है।
-
लक्ष्य क्षेत्र: जलवायु विज्ञान और पृथ्वी प्रणाली मॉडलिंग
- संबंध: जलवायु वैज्ञानिक अक्सर देखे गए जलवायु परिवर्तनों या मॉडल भविष्यवाणियों को विशिष्ट मानवजनित फोर्सेस (जैसे, CO2 उत्सर्जन, भूमि-उपयोग परिवर्तन) पूर्व-औद्योगिक बेसलाइन या "कोई हस्तक्षेप नहीं" परिदृश्य के सापेक्ष को एट्रिब्यूट करने से जूझते हैं। यह CIG के कंट्रास्टिव एट्रिब्यूशन के समान है। उन्हें यह पहचानने की आवश्यकता है कि जटिल पृथ्वी प्रणाली मॉडल में कौन से इनपुट पैरामीटर या प्रारंभिक स्थितियां किसी विशेष जलवायु परिणाम (जैसे, एक विशिष्ट क्षेत्रीय तापमान वृद्धि या चरम मौसम की घटनाओं की आवृत्ति) के लिए सबसे अधिक जिम्मेदार हैं, उन फोर्सेस के बिना दुनिया की तुलना में। "लॉजिट स्पेस" जलवायु विसंगति या स्थिर अवस्था से विचलन के एक परिवर्तित मीट्रिक का प्रतिनिधित्व कर सकता है, और पथ एकीकरण एक बल की वृद्धि और जलवायु प्रणाली पर इसके प्रभाव को क्रमिक रूप से मॉडल कर सकता है।
क्या होगा यदि परिदृश्य
एक हेज फंड में एक मात्रात्मक विश्लेषक की कल्पना करें जो कल CIG के सटीक समीकरण को "चोरी" कर रहा है। विभिन्न बाजार कारकों के लिए पोर्टफोलियो के मूल्य की संवेदनशीलता की गणना करने के बजाय, वे अपने पोर्टफोलियो के आउटपरफॉर्मेंस या अंडरपरफॉर्मेंस के कंट्रास्टिव ड्राइवरों को समझने के लिए CIG लागू कर सकते हैं, जो एक चुने हुए बेंचमार्क के मुकाबले है। इंटरपोलेटिंग लॉगरिथम रिटर्न (लॉजिट आउटपुट के समान) और बेंचमार्क के लॉगरिथम रिटर्न के वर्ग अंतर को विभिन्न बाजार स्थितियों का प्रतिनिधित्व करने वाले पथ के साथ एकीकृत करके, वे सटीक रूप से पहचान सकते हैं कि कौन सी विशिष्ट संपत्तियां या कारक एक्सपोज़र उनके पोर्टफोलियो के प्रदर्शन को बेंचमार्क से अलग करते हैं। इससे कंट्रास्टिव अल्फा जनरेशन और जोखिम हेजिंग में एक सफलता मिलेगी। वे उन सटीक बाजार स्थितियों या परिसंपत्ति विशेषताओं की पहचान कर सकते हैं जो उनके पोर्टफोलियो को बेंचमार्क से अलग करती हैं, जिससे सापेक्ष रिटर्न को अधिकतम करने या सापेक्ष जोखिम को कम करने के लिए हाइपर-लक्षित समायोजन की अनुमति मिलती है। यह सक्रिय प्रबंधकों द्वारा बाजार की अक्षमताओं की पहचान और शोषण के तरीके में क्रांति ला सकता है, जो साधारण एट्रिब्यूशन से भेदभावपूर्ण एट्रिब्यूशन की ओर बढ़ रहा है।
संरचनाओं की सार्वभौमिक लाइब्रेरी
यह पत्र इस विचार को शक्तिशाली रूप से पुष्ट करता है कि सभी वैज्ञानिक समस्याएं आपस में जुड़ी हुई हैं, यह प्रदर्शित करते हुए कि चिकित्सा छवियों में भेदभावपूर्ण सुविधाओं की पहचान करने की चुनौती वित्त और जलवायु विज्ञान जैसे विविध क्षेत्रों में कंट्रास्टिव एट्रिब्यूशन की समस्याओं के साथ एक गहरा गणितीय संबंध साझा करती है, जो वैज्ञानिक समझ की हमारी सार्वभौमिक लाइब्रेरी में एक महत्वपूर्ण नई संरचना का योगदान करती है।