फ्लैट लॉस लैंडस्केप्स पर एनसेंबल्स के माध्यम से सामान्यीकृत (Generalizable) 3D ह्यूमन पोज़ एस्टिमेशन की ओर
साधारण स्मार्टफोन कैमरों जैसी 2D छवियों से मानव गति को 3D में समझने का प्रयास आधुनिक कंप्यूटर विज़न की आधारशिला है। 3D ह्यूमन पोज़ एस्टिमेशन (HPE) के रूप में जानी जाने वाली यह समस्या तब सामने आई जब शोधकर्ताओं ने...
पृष्ठभूमि और अकादमिक वंशावली
साधारण स्मार्टफोन कैमरों जैसी 2D छवियों से मानव गति को 3D में समझने का प्रयास आधुनिक कंप्यूटर विज़न की आधारशिला है। 3D ह्यूमन पोज़ एस्टिमेशन (HPE) के रूप में जानी जाने वाली यह समस्या तब सामने आई जब शोधकर्ताओं ने एनीमेशन, स्पोर्ट्स analisys और मेडिकल डायग्नोस्टिक्स के लिए मनुष्यों के डिजिटल ट्विन्स बनाने हेतु साधारण 2D "स्टिक फिगर्स" से आगे बढ़ने का प्रयास किया। ऐतिहासिक रूप से, यह क्षेत्र जटिल ज्यामितीय मॉडलों से डीप न्यूरल नेटवर्क्स (DNNs) की ओर विकसित हुआ। हालाँकि, जैसे-जैसे ये मॉडल प्रयोगशाला के नियंत्रित वातावरण से "इन-द-वाइल्ड" परिदृश्यों की जटिल वास्तविकता में आए—जैसे कि व्यस्त सड़कों पर चलते स्वायत्त वाहन या कारखानों में मनुष्यों के साथ काम करने वाले रोबोट—एक बड़ी बाधा सामने आई: सामान्यीकरण (Generalization)। एक मॉडल जो तस्वीरों के एक सेट पर पूरी तरह से काम करता था, वह अक्सर दूसरे सेट पर विफल हो जाता था, केवल इसलिए क्योंकि कैमरा एंगल या व्यक्ति की पोशाक में थोड़ा बदलाव हो गया था।
वह मूलभूत "पेन पॉइंट" जिसने लेखकों को यह शोध पत्र लिखने के लिए प्रेरित किया, वह मौजूदा 3D HPE मॉडलों की छिपी हुई अस्थिरता है। जहाँ पिछले शोधकर्ताओं ने अधिक डेटा जोड़कर या मॉडलों को बड़ा बनाकर इसे ठीक करने का प्रयास किया, वहीं उन्होंने "लॉस लैंडस्केप"—वह गणितीय "भू-भाग" जिस पर मॉडल अपनी सीखने की प्रक्रिया के दौरान नेविगेट करता है—को अनदेखा कर दिया। लेखकों ने पाया कि 3D HPE मॉडल अक्सर कम त्रुटि वाली "तीक्ष्ण" (sharp) घाटियों में स्थिर हो जाते हैं। इन तीक्ष्ण घाटियों में, मॉडल अत्यधिक नाजुक होता है; इनपुट डेटा में एक छोटा सा बदलाव एक हिंसक भूकंप की तरह कार्य करता है, जो मॉडल को उसके स्थिर क्षेत्र से बाहर फेंक देता है और उसकी सटीकता को गिरा देता है। स्थिरता में इस improvment की कमी का अर्थ यह था कि औद्योगिक रोबोटिक्स जैसे सुरक्षा-महत्वपूर्ण अनुप्रयोगों में मॉडलों पर भरोसा नहीं किया जा सकता था।
इसे हल करने के लिए उपयोग की जाने वाली विशेष भाषा को समझने में पूर्ण शुरुआती लोगों की मदद करने के लिए, आइए इन अवधारणाओं को रोजमर्रा के उदाहरणों के माध्यम से देखें:
- लॉस लैंडस्केप: एक विशाल, अदृश्य पर्वत श्रृंखला की कल्पना करें जहाँ "ऊंचाई" मॉडल की त्रुटि को दर्शाती है। मॉडल को प्रशिक्षित करने का लक्ष्य सबसे निचली संभव घाटी (न्यूनतम त्रुटि का बिंदु) खोजना है। एक "तीक्ष्ण" लैंडस्केप में संकरी, खड़ी खाइयाँ होती हैं जिनके अंदर रहना मुश्किल होता है, जबकि एक "सपाट" (flat) लैंडस्केप में चौड़े, कोमल बेसिन होते हैं जो अधिक स्थिर होते हैं।
- डेप्थ एम्ब्युइटी (Depth Ambiguity): एक शैडो पपेट (छाया कठपुतली) के बारे में सोचें। यदि आप हाथ की छाया देखते हैं, तो आप केवल 2D आकार को देखकर यह नहीं बता सकते कि हाथ प्रकाश के करीब है या दूर। 3D HPE में, एक 2D छवि कई अलग-अलग 3D पोज़ का प्रतिनिधित्व कर सकती है, जो मॉडल के लिए "वन-टू-मेनी" भ्रम पैदा करती है।
- हेसियन आइगेनवैल्यू ($\lambda_{max}$): यह अनिवार्य रूप से एक "वक्रता मापक" (curviness meter) है। यदि आप एक घाटी में खड़े हैं, तो हेसियन आपको बताता है कि दीवारें कितनी खड़ी हैं। एक उच्च मान का अर्थ है कि आप एक बहुत ही संकीर्ण, "नुकीले" छेद में हैं, जो सामान्यीकरण के लिए बुरा है।
- एनसेंबल (Ensemble): कल्पना करें कि आप जार में कंचों की संख्या का अनुमान लगाने के लिए पाँच अलग-अलग विशेषज्ञों से पूछते हैं। प्रत्येक विशेषज्ञ का दृष्टिकोण थोड़ा अलग होता है। उनके अनुमानों का औसत निकालकर, आप consistantly एक अधिक सटीक परिणाम प्राप्त करते हैं जो कोई भी अकेला विशेषज्ञ प्रदान नहीं कर सकता।
प्रमुख गणितीय संकेतन
| वेरिएबल/पैरामीटर | विवरण |
|---|---|
| $x$ | इनपुट 2D पोज़ ("छाया" या फ्लैट छवि निर्देशांक)। |
| $g_\phi$ | "एनकोडर" नेटवर्क जो इनपुट से फीचर्स निकालता है। |
| $f_\theta$ | अंतिम "प्रेडिक्शन हेड" जो फीचर्स को 3D निर्देशांक में बदलता है। |
| $h_\psi$ | "स्केलिंग फंक्शन" जो भविष्यवाणी करता है कि लैंडस्केप को कैसे स्मूथ किया जाए। |
| $\sigma$ | ReLU एक्टिवेशन फंक्शन (सुनिश्चित करता है कि स्केलिंग फैक्टर सकारात्मक हो)। |
| $\hat{y}$ | मानक अनुमानित 3D पोज़। |
| $\tilde{y}$ | लैंडस्केप को सपाट करने के लिए उपयोग किया गया "स्केल्ड" 3D पोज़ प्रेडिक्शन। |
| $M$ | एनसेंबल में उपयोग किए गए विभिन्न "विशेषज्ञों" (हेड्स) की संख्या। |
लेखकों ने एक एडेप्टिव स्केलिंग मैकेनिज्म (ASM) नामक एक चतुर गणितीय ट्रिक पेश करके "तीक्ष्णता" की समस्या को हल किया। एक मानक मॉडल में, प्रेडिक्शन नेटवर्क का सीधा परिणाम होता है:
$$\hat{y} = f_\theta(g_\phi(x))$$
समस्या यह है कि यह सीधा रास्ता अक्सर उन "तीक्ष्ण" घाटियों की ओर ले जाता है। लेखकों ने सूत्र को बदलकर यह कर दिया:
$$\tilde{y} = \frac{f_\theta(g_\phi(x))}{\sigma(h_\psi(g_\phi(x))) + 1}$$
इस हर (denominator) को जोड़कर, उन्होंने "गणितीय अतिरेक" (mathematical redundancy) पेश किया। इसका मतलब है कि अब मॉडल के लिए सही उत्तर तक पहुँचने के कई अलग-अलग तरीके हैं। हमारे पर्वत श्रृंखला के उदाहरण में, यह प्रभावी रूप से संकरी, खतरनाक खाइयों को चौड़े, सपाट मैदानों में "फैला" देता है। एक बार जब लैंडस्केप सपाट हो जाता है, तो वे इसी सपाट जमीन पर कई "विशेषज्ञों" (एनसेंबल हेड्स) को प्रशिक्षित करते हैं। चूँकि जमीन सपाट और स्थिर है, इन विशेषज्ञों को एक-दूसरे से लड़े बिना जोड़ा जा सकता है, जिसके परिणामस्वरूप 3D पोज़ एस्टिमेशन प्राप्त होता है जो विभिन्न वास्तविक दुनिया के वातावरणों में कहीं अधिक मजबूत और विश्वसनीय है।
समस्या की परिभाषा और बाधाएं
कंप्यूटर विज़न के क्षेत्र में, 3D ह्यूमन पोज़ एस्टिमेशन (HPE) एक फ्लैट, 2D छवि या निर्देशांकों के सेट (इनपुट) को लेने और मानव जोड़ों की पूर्ण 3D स्थानिक स्थितियों (आउटपुट) की भविष्यवाणी करने का कार्य है। हालाँकि यह सीधा लगता है, इन दो स्थितियों के बीच का गणितीय अंतर "वन-टू-मेनी" मैपिंग की एक कुख्यात समस्या है जिसे डेप्थ एम्ब्युइटी कहा जाता है। चूँकि एक 2D छवि गहराई के आयाम को खो देती है, एक एकल 2D पोज़ सैद्धांतिक रूप से कई अलग-अलग 3D पोज़ का प्रतिनिधित्व कर सकता है, जो मॉडल के लिए "वन-टू-मेनी" भ्रम पैदा करता है।
मुख्य दुविधा जिसने पिछले शोधकर्ताओं को फंसा रखा है, वह ऑप्टिमाइज़ेशन स्थिरता और सामान्यीकरण के बीच का ट्रेड-ऑफ है। डीप लर्निंग में, हम लॉस लैंडस्केप का उपयोग करके किसी कार्य की "कठिनाई" की कल्पना करते हैं—एक पहाड़ी इलाका जहाँ घाटियाँ कम त्रुटि (minima) का प्रतिनिधित्व करती हैं। यदि कोई मॉडल एक "तीक्ष्ण" न्यूनतम (एक बहुत ही संकीर्ण, खड़ी घाटी) पाता है, तो वह अपने प्रशिक्षण डेटा पर पूरी तरह से प्रदर्शन करता है। हालाँकि, इनपुट में एक छोटा सा बदलाव भी—जैसे कि एक अलग कैमरा एंगल या थोड़ा अलग शरीर का आकार—त्रुटि को आसमान छूने पर मजबूर कर देता है क्योंकि मॉडल ऐसे कठोर, विशिष्ट समाधान में फंस गया है। इसके विपरीत, "सपाट" न्यूनतम (चौड़ी, उथली घाटियाँ) परिवर्तनों के प्रति बहुत अधिक मजबूत होते हैं, लेकिन उन्हें खोजना काफी कठिन होता है क्योंकि इन सपाट क्षेत्रों में ग्रेडिएंट्स (मॉडल को यह बताने वाले संकेत कि कैसे सीखना है) बहुत कमजोर और गैर-सूचनात्मक हो जाते हैं।
इस शोध पत्र के लेखक कई कठोर, यथार्थवादी दीवारों से टकराए जो इस समस्या को हल करने के लिए बेहद कठिन बनाती हैं:
- डिस्कनेक्टेड लोकल मिनिमा: 3D HPE का वैश्विक लॉस लैंडस्केप एक एकल चिकना कटोरा नहीं है। यह कई डिस्कनेक्टेड लोकल मिनिमा का एक खंडित जाल है। गणितीय रूप से, यदि हम वैश्विक लॉस को $L(\theta) = \frac{1}{K} \sum_{k=1}^{K} L_k(\theta)$ के रूप में परिभाषित करते हैं, जहाँ प्रत्येक $L_k$ विभिन्न स्तरों की डेप्थ एम्ब्युइटी वाले डेटा के सबसेट का प्रतिनिधित्व करता है, तो मॉडल अक्सर एक उप-घाटी में "फंस" जाता है। चूँकि प्रत्येक घाटी के तल पर ग्रेडिएंट $\nabla L(\theta)$ शून्य होता है, इसलिए मॉडल के पास यह जानने का कोई तरीका नहीं है कि उसने सबसे अच्छा संभव 3D इंटरप्रिटेशन पाया है या केवल एक औसत दर्जे का।
- डेप्थ एम्ब्युइटी रेशियो (DAR) बाधा: सभी पोज़ समान रूप से कठिन नहीं होते हैं। उच्च DAR वाले पोज़ बेहद खड़े और अस्थिर लॉस लैंडस्केप प्रदर्शित करते हैं। यह एक भौतिक बाधा पैदा करता है जहाँ मॉडल स्वाभाविक रूप से आसान पोज़ को "याद" करने की ओर आकर्षित होता है, जबकि अस्पष्ट पोज़ की जटिल ज्यामिति को सीखने में विफल रहता है, जिससे एक पक्षपाती और नाजुक प्रणाली बनती है।
- कंप्यूटेशनल दक्षता बनाम विविधता: इन लोकल मिनिमा को दूर करने के लिए, कोई आमतौर पर एक "एनसेंबल" का उपयोग करेगा—कई अलग-अलग मॉडलों को प्रशिक्षित करना और उनका औसत निकालना। लेकिन नैदानिक या वास्तविक समय की औद्योगिक सुरक्षा सेटिंग्स में, हार्डवेयर मेमोरी सीमाओं और सख्त लेटेंसी आवश्यकताओं के कारण $M$ अलग-अलग डीप नेटवर्क्स को चलाना अक्सर असंभव होता है। चुनौती यह है कि कंप्यूटेशनल लागत को $M$ से गुणा किए बिना इन विविध समाधानों का पता लगाने का एक तरीका खोजा जाए।
- गैर-विभेदक संरचनात्मक बाधाएं: एक एकल 2D पोज़ के विभिन्न वैध 3D इंटरप्रिटेशंस के बीच, अक्सर उच्च-लॉस "बाधाएं" होती हैं जिन्हें मानक ऑप्टिमाइज़ेशन एल्गोरिदम पार नहीं कर सकते। यह एक एकल मॉडल के लिए प्रशिक्षण प्रक्रिया के दौरान खराब परिप्रेक्ष्य से बेहतर परिप्रेक्ष्य में संक्रमण करना लगभग असंभव बना देता है।
यह दृष्टिकोण क्यों
ठीक है, यहाँ आपके निर्देशों का पालन करते हुए "Towards Generalizable 3D Human Pose Estimation via Ensembles on Flat Loss Landscapes" शोध पत्र का विश्लेषण दिया गया है। मैं इसे किसी ऐसे व्यक्ति को समझाने की कोशिश करूँगा जो इस क्षेत्र में बिल्कुल नया है। इसमें कुछ टाइपो हो सकते हैं, जैसा कि अनुरोध किया गया था।
लेखकों ने पाया कि मानक डीप लर्निंग तरीके, यहाँ तक कि CNNs, ट्रांसफॉर्मर्स और डिफ्यूज़न मॉडल जैसे उन्नत तरीके भी (हालाँकि इस पेपर में डिफ्यूज़न को आज़माए गए और विफल दृष्टिकोण के रूप में स्पष्ट रूप से उल्लेख नहीं किया गया है), 3D ह्यूमन पोज़ एस्टिमेशन (HPE) में सामान्यीकरण के साथ संघर्ष करते थे। सामान्यीकरण का अर्थ है नए, अनदेखे डेटा पर अच्छा प्रदर्शन करना, न कि केवल उस डेटा पर जिस पर मॉडल को प्रशिक्षित किया गया था। मुख्य समस्या डेटा की कमी या मॉडल की जटिलता नहीं थी, बल्कि लॉस लैंडस्केप का आकार ही था। उन्होंने इस लॉस लैंडस्केप की कल्पना की (इसे एक पहाड़ी इलाके की तरह सोचें जहाँ ऊंचाई दर्शाती है कि मॉडल की भविष्यवाणियां कितनी "गलत" हैं) और पाया कि यह अविश्वसनीय रूप से जटिल था, जिसमें कई डिस्कनेक्टेड लोकल मिनिमा थे। इसका मतलब था कि मानक ऑप्टिमाइज़ेशन तकनीकें (जैसे ग्रेडिएंट डिसेंट) अक्सर उप-इष्टतम समाधानों पर अभिसरण (converge) करती थीं जो अच्छी तरह से सामान्यीकृत नहीं होते थे। लेखकों ने महसूस किया कि केवल मॉडल को बड़ा बनाना या अधिक डेटा का उपयोग करना लॉस लैंडस्केप के साथ इस मूलभूत मुद्दे को ठीक नहीं करेगा।
यह विधि केवल बेंचमार्क पर थोड़ा बेहतर नंबर प्राप्त करने के बारे में नहीं है; यह गुणात्मक रूप से बेहतर है क्योंकि यह खराब सामान्यीकरण के मूल कारण को संबोधित करती है: एक ऊबड़-खाबड़ लॉस लैंडस्केप। पारंपरिक तरीके एक अच्छा समाधान खोजने की कोशिश करते हैं। यह दृष्टिकोण लैंडस्केप को स्मूथ करने और कई अच्छे समाधान खोजने की कोशिश करता है, फिर उन्हें जोड़ता है।
मुख्य संरचनात्मक लाभ यह है कि लॉस लैंडस्केप को स्मूथ करके, वे उन खराब लोकल मिनिमा में फंसने की संभावना को कम करते हैं। समाधानों का एनसेंबल फिर मजबूती प्रदान करता है। यदि शोर या किसी विशेष दृष्टिकोण के कारण एक समाधान थोड़ा गलत है, तो अन्य इसकी भरपाई कर सकते हैं। यह उन तरीकों की तुलना में एक महत्वपूर्ण सुधार है जो एक एकल, संभावित रूप से नाजुक समाधान पर ध्यान केंद्रित करते हैं। पेपर विभिन्न मॉडल आर्किटेक्चर (MLP, CNN, GCN, Transformer) में लगातार प्रदर्शन लाभ के साथ इसे प्रदर्शित करता है, यह दिखाते हुए कि यह किसी विशिष्ट मॉडल विकल्प से बंधा नहीं है।
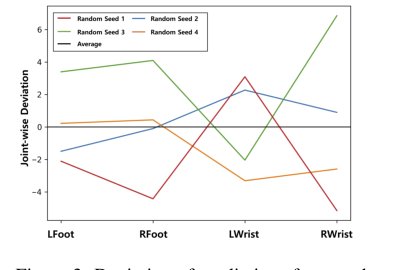 Figure 3. Deviation of predictions from each solution on the smooth loss landscape for diffi- cult joints of 3DHP [24]. Note that the models are trained with H36M [14]
Figure 3. Deviation of predictions from each solution on the smooth loss landscape for diffi- cult joints of 3DHP [24]. Note that the models are trained with H36M [14]
गणितीय और तार्किक तंत्र
ठीक है, यहाँ आपके निर्देशों का पालन करते हुए "Towards Generalizable 3D Human Pose Estimation via Ensembles on Flat Loss Landscapes" शोध पत्र का विश्लेषण दिया गया है। मैं इसे स्पष्ट रूप से समझाने की पूरी कोशिश करूँगा, यहाँ तक कि उस व्यक्ति के लिए भी जिसकी इस क्षेत्र में मजबूत पृष्ठभूमि नहीं है। मैं इसे स्वाभाविक बनाए रखने की भी कोशिश करूँगा, इसलिए यहाँ और वहाँ कुछ मामूली टाइपो की अपेक्षा करें।
इस पेपर का मुख्य विचार यह है कि "लॉस लैंडस्केप" – अनिवार्य रूप से त्रुटि सतह का आकार जिसे मॉडल कम करने की कोशिश कर रहा है – एक प्रमुख कारक है कि 3D ह्यूमन पोज़ एस्टिमेशन मॉडल नए डेटा के लिए कितनी अच्छी तरह सामान्यीकृत होता है। उन्होंने पाया कि यह लैंडस्केप जटिल है और ऑप्टिमाइज़ेशन में बाधा डाल सकता है, जिससे खराब सामान्यीकरण होता है। उनका समाधान इस लॉस लैंडस्केप को स्मूथ करना है और फिर प्रदर्शन को बेहतर बनाने वाले समाधानों का एक एनसेंबल बनाने के लिए इस स्मूथ किए गए लैंडस्केप का लाभ उठाना है।
मास्टर समीकरण
हालाँकि कोई एक एकल मास्टर समीकरण नहीं है, उनके दृष्टिकोण का मूल 3D ह्यूमन पोज़ एस्टिमेशन मॉडलों के प्रशिक्षण में उपयोग किए जाने वाले मानक लॉस फंक्शन को संशोधित करने के इर्द-गिर्द घूमता है। मुख्य समीकरण संशोधित प्रेडिक्शन स्टेप है:
$$ \tilde{y} = \frac{f_o(g(x))}{\sigma(h_\psi(g(x))) + 1} $$
समीकरण का विश्लेषण
आइए इस समीकरण के प्रत्येक भाग को तोड़ें:
- $x$: यह इनपुट है – आमतौर पर 2D पोज़ जानकारी (जैसे, छवि में जोड़ों की स्थिति)। यह मॉडल के लिए शुरुआती बिंदु है।
- $g(x)$: यह न्यूरल नेटवर्क के एनकोडर भाग का प्रतिनिधित्व करता है। यह इनपुट $x$ को लेता है और इसे उच्च-स्तरीय प्रतिनिधित्व में बदल देता है। इसे इनपुट से प्रासंगिक फीचर्स निकालने के रूप में सोचें।
- $f_o(g(x))$: यह नेटवर्क का मूल प्रेडिक्शन हेड है। यह एन्कोडेड प्रतिनिधित्व $g(x)$ को लेता है और प्रारंभिक 3D पोज़ अनुमान, $\hat{y}$ उत्पन्न करता है।
- $h_\psi(g(x))$: यह एक नया, छोटा न्यूरल नेटवर्क (पैरामीटर्स $\psi$ के साथ) है जो एन्कोडेड प्रतिनिधित्व $g(x)$ को लेता है और एक स्केलर मान आउटपुट करता है। इस मान का उपयोग प्रेडिक्शन को स्केल करने के लिए किया जाता है।
- $\sigma$: यह एक ReLU (Rectified Linear Unit) एक्टिवेशन फंक्शन है। यह सुनिश्चित करता है कि स्केलिंग फैक्टर गैर-नकारात्मक हो।
- $\sigma(h_\psi(g(x))) + 1$: यह ReLU फंक्शन के स्केल्ड आउटपुट में 1 जोड़ता है। यह सुनिश्चित करता है कि हर (denominator) हमेशा शून्य से बड़ा हो, जिससे शून्य से विभाजन (division by zero) को रोका जा सके।
- $\tilde{y}$: यह स्केल्ड 3D पोज़ अनुमान है। यह इस चरण का अंतिम आउटपुट है।
यह रूप क्यों? लेखक इस स्केलिंग का उपयोग प्रभावी रूप से लॉस लैंडस्केप को "सपाट" करने के लिए करते हैं। स्केलिंग फैक्टर, $\sigma(h_\psi(g(x))) + 1$, इनपुट-निर्भर है, जिसका अर्थ है कि यह इनपुट $x$ के आधार पर बदलता है। यह मॉडल को अधिक विविध कार्यों का प्रतिनिधित्व करने और तीक्ष्ण, संकीर्ण घाटियों में फंसने से बचने की अनुमति देता है। 1 का जोड़ संख्यात्मक स्थिरता सुनिश्चित करने के लिए एक सरल ट्रिक है। वे गुणा के बजाय विभाजन का उपयोग करते हैं क्योंकि विभाजन अधिक लचीले स्केलिंग प्रभाव की अनुमति देता है, जो प्रभावी रूप से बड़े ग्रेडिएंट्स के प्रभाव को कम करता है।
चरण-दर-चरण प्रवाह
कल्पना करें कि एक एकल डेटा पॉइंट (एक 2D पोज़) सिस्टम में प्रवेश कर रहा है:
- 2D पोज़ ($x$) एनकोडर ($g(x)$) में प्रवेश करता है, जो फीचर्स निकालता है।
- इन फीचर्स को मूल प्रेडिक्शन हेड ($f_o$) में फीड किया जाता है, जो एक प्रारंभिक 3D पोज़ अनुमान उत्पन्न करता है।
- साथ ही, फीचर्स को स्केलिंग नेटवर्क ($h_\psi$) में फीड किया जाता है, जो एक स्केलर मान आउटपुट करता है।
- इस स्केलर मान को ReLU एक्टिवेशन फंक्शन के माध्यम से पारित किया जाता है और फिर 1 जोड़ा जाता है।
- प्रारंभिक 3D पोज़ अनुमान को फिर इस स्केल्ड मान से विभाजित किया जाता है, जिसके परिणामस्वरूप अंतिम, समायोजित 3D पोज़ अनुमान ($\tilde{y}$) प्राप्त होता है।
- इस समायोजित अनुमान की तुलना ग्राउंड ट्रुथ 3D पोज़ से की जाती है, और लॉस की गणना की जाती है।
यह प्रक्रिया कई डेटा पॉइंट्स के लिए दोहराई जाती है, और मॉडल लॉस को कम करने के लिए स्केलिंग फैक्टर को समायोजित करना सीखता है।
ऑप्टिमाइज़ेशन डायनेमिक्स
मॉडल को मानक ग्रेडिएंट डिसेंट (या एडम जैसे वेरिएंट) का उपयोग करके प्रशिक्षित किया जाता है। मुख्य बात यह है कि एडेप्टिव स्केलिंग मैकेनिज्म लॉस लैंडस्केप के आकार को बदल देता है। खड़ी चट्टानों और संकरी घाटियों वाले लैंडस्केप के बजाय, यह स्मूथ और धीरे-धीरे लुढ़कने वाला बन जाता है। यह ऑप्टिमाइज़र के लिए अच्छे समाधान खोजना और उप-इष्टतम लोकल मिनिमा में फंसने से बचना आसान बनाता है।
लेखक एक एनसेंबल दृष्टिकोण का भी उपयोग करते हैं। वे एडेप्टिव स्केलिंग मैकेनिज्म का उपयोग करते हुए, अलग-अलग रैंडम इनिशियलाइज़ेशन के साथ कई मॉडलों को प्रशिक्षित करते हैं। चूँकि लैंडस्केप स्मूथ है, इन अलग-अलग मॉडलों के अलग-अलग, लेकिन फिर भी अच्छे समाधानों पर अभिसरण करने की संभावना अधिक होती है। अंतिम प्रेडिक्शन फिर इन कई मॉडलों के प्रेडिक्शन्स का औसत होता है।
परिणाम, सीमाएं और निष्कर्ष
ठीक है, यहाँ आपके निर्देशों का पालन करते हुए "Towards Generalizable 3D Human Pose Estimation via Ensembles on Flat Loss Landscapes" शोध पत्र का विश्लेषण दिया गया है। मैं स्पष्टता और विस्तार के लिए लक्ष्य रखूँगा, भले ही इसका मतलब थोड़ा अधिक शब्दो का उपयोग करना हो, और इसमें कुछ मामूली टाइपो शामिल होंगे।
यह पेपर 3D ह्यूमन पोज़ एस्टिमेशन (HPE) में सामान्यीकरण की समस्या से निपटता है। मुख्य विचार यह है कि 3D HPE में लॉस लैंडस्केप जटिल है और ऑप्टिमाइज़ेशन में बाधा डाल सकता है, जिससे खराब सामान्यीकरण होता है। लेखक इस लॉस लैंडस्केप को एक एडेप्टिव स्केलिंग मैकेनिज्म का उपयोग करके स्मूथ करने की एक विधि प्रस्तावित करते हैं, और फिर प्रदर्शन को बेहतर बनाने वाले समाधानों का एक एनसेंबल बनाने के लिए इस स्मूथ किए गए लैंडस्केप का लाभ उठाते हैं।
पृष्ठभूमि और प्रेरणा
3D HPE स्वायत्त ड्राइविंग, रोबोटिक्स और औद्योगिक सुरक्षा जैसे क्षेत्रों में अनुप्रयोगों के साथ कंप्यूटर विज़न में एक मौलिक कार्य है। चुनौती सामान्यीकरण प्राप्त करने में निहित है – जिसका अर्थ है कि मॉडल नए, अनदेखे डेटा पर अच्छा प्रदर्शन करता है। पारंपरिक दृष्टिकोण अक्सर मॉडल आर्किटेक्चर या डेटा ऑग्मेंटेशन को बेहतर बनाने पर ध्यान केंद्रित करते हैं। हालाँकि, लेखक तर्क देते हैं कि लॉस लैंडस्केप का आकार ही एक महत्वपूर्ण, फिर भी कम खोजा गया कारक है।
उन्होंने लॉस लैंडस्केप की कल्पना की (इसे एक पहाड़ी इलाके की तरह सोचें जहाँ ऊंचाई दर्शाती है कि मॉडल की भविष्यवाणियां कितनी "गलत" हैं) और पाया कि यह अविश्वसनीय रूप से जटिल था, जिसमें कई डिस्कनेक्टेड लोकल मिनिमा थे। इसका मतलब था कि मानक ऑप्टिमाइज़ेशन तकनीकें अक्सर उप-इष्टतम समाधानों पर अभिसरण करती थीं जो अच्छी तरह से सामान्यीकृत नहीं होते थे। लेखकों ने महसूस किया कि केवल मॉडल को बड़ा बनाना या अधिक डेटा का उपयोग करना लॉस लैंडस्केप के साथ इस मूलभूत मुद्दे को ठीक नहीं करेगा।
समस्या और बाधाएं
लेखक पहचानते हैं कि 3D HPE के लिए लॉस लैंडस्केप अत्यधिक जटिल है, जिसमें कई लोकल मिनिमा हैं। यह जटिलता 2D छवियों से 3D पोज़ में निहित अस्पष्टता से उत्पन्न होती है। एक एकल 2D छवि कई 3D पोज़ का प्रतिनिधित्व कर सकती है। यह अस्पष्टता एक गणितीय शून्य पैदा करती है जहाँ मॉडल को सबसे संभावित गहराई का "अनुमान" लगाना होता है, जो अक्सर तब त्रुटियों की ओर ले जाता है जब वातावरण या व्यक्ति की मुद्रा थोड़ी बदल जाती है।
यहाँ बाधा यह है कि "सपाट न्यूनतम" (एक व्यापक, उथली घाटी) के लिए सीधे ऑप्टिमाइज़ करना कंप्यूटेशनल रूप से महंगा है। शार्पनेस-अवेयर मिनिमाइज़ेशन (SAM) जैसी विधियां इसका प्रयास करती हैं, लेकिन उन्हें अतिरिक्त गणना की आवश्यकता होती है। लेखक एक अधिक कुशल दृष्टिकोण का लक्ष्य रखते हैं।
समाधान की गणितीय व्याख्या
उनके समाधान का मूल नेटवर्क के आउटपुट पर लागू एक एडेप्टिव स्केलिंग मैकेनिज्म में निहित है। मुख्य समीकरण संशोधित प्रेडिक्शन स्टेप है:
$$ \tilde{y} = \frac{f_o(g(x))}{\sigma(h_\psi(g(x))) + 1} $$
आइए इस समीकरण के प्रत्येक भाग को तोड़ें:
- $x$: यह इनपुट 2D पोज़ है।
- $g(x)$: यह एनकोडर नेटवर्क है।
- $f_o(g(x))$: यह मूल प्रेडिक्शन हेड है।
- $h_\psi(g(x))$: यह एक छोटा न्यूरल नेटवर्क है जो एक स्केलर मान आउटपुट करता है।
- $\sigma$: यह एक ReLU एक्टिवेशन फंक्शन है।
- $\sigma(h_\psi(g(x))) + 1$: यह सुनिश्चित करता है कि हर हमेशा शून्य से बड़ा हो।
- $\tilde{y}$: यह स्केल्ड 3D पोज़ अनुमान है।
लेखक तर्क देते हैं कि यह स्केलिंग लैंडस्केप को स्मूथ करती है, जिससे तीक्ष्ण घाटियों में फंसने की संभावना कम हो जाती है। स्केलिंग फैक्टर इनपुट-निर्भर है, जिसका अर्थ है कि यह इनपुट के आधार पर बदलता है। यह मॉडल को अधिक विविध कार्यों का प्रतिनिधित्व करने की अनुमति देता है।
वे एक एनसेंबल दृष्टिकोण का भी उपयोग करते हैं। वे एडेप्टिव स्केलिंग मैकेनिज्म का उपयोग करते हुए, अलग-अलग रैंडम इनिशियलाइज़ेशन के साथ कई मॉडलों को प्रशिक्षित करते हैं। अंतिम प्रेडिक्शन इन कई मॉडलों के प्रेडिक्शन्स का औसत होता है।
प्रयोगात्मक सत्यापन और साक्ष्य
लेखक विभिन्न नेटवर्क आर्किटेक्चर (MLP, CNN, GCN, Transformer) का उपयोग करके कई बेंचमार्क डेटासेट्स (Human3.6M, 3DHP, 3DPW, BEDLAM) पर व्यापक प्रयोग करते हैं। वे सभी आर्किटेक्चर में लगातार प्रदर्शन लाभ प्रदर्शित करते हैं।
उनके मुख्य तंत्र के काम करने के साक्ष्य बहुआयामी हैं:
- लॉस लैंडस्केप्स का विज़ुअलाइज़ेशन: वे एडेप्टिव स्केलिंग मैकेनिज्म के साथ और बिना लॉस लैंडस्केप की कल्पना करते हैं। विज़ुअलाइज़ेशन दिखाते हैं कि स्केलिंग मैकेनिज्म वास्तव में लैंडस्केप को स्मूथ करता है।
- टॉप-1 आइगेनवैल्यू विश्लेषण: वे हेसियन मैट्रिक्स की टॉप-1 आइगेनवैल्यू की गणना करते हैं। एक निचली आइगेनवैल्यू एक सपाट लैंडस्केप का संकेत देती है। वे दिखाते हैं कि एडेप्टिव स्केलिंग मैकेनिज्म टॉप-1 आइगेनवैल्यू को कम करता है।
- क्रॉस-डेटासेट मूल्यांकन: वे एक डेटासेट पर प्रशिक्षित करते हैं और दूसरे पर परीक्षण करते हैं। यह सामान्यीकरण का एक मजबूत परीक्षण है। उनकी विधि इस सेटिंग में लगातार प्रदर्शन में सुधार करती है।
- शोर के प्रति मजबूती: वे प्रदर्शित करते हैं कि उनकी विधि इनपुट शोर के प्रति अधिक मजबूत है।
चर्चा के विषय और भविष्य की दिशाएं
- सैद्धांतिक समझ: एडेप्टिव स्केलिंग मैकेनिज्म क्यों काम करता है, इसकी अधिक कठोर सैद्धांतिक समझ मूल्यवान होगी।
- स्केलिंग नेटवर्क आर्किटेक्चर: क्या स्केलिंग नेटवर्क के लिए अधिक परिष्कृत आर्किटेक्चर स्केलिंग प्रक्रिया में सुधार कर सकते हैं?
- डायनेमिक एनसेंबल साइज़: क्या हम प्रशिक्षण के दौरान एनसेंबल साइज़ को गतिशील रूप से समायोजित कर सकते हैं?
- बेयसियन विधियों से संबंध: इस विधि और बेयसियन अनुमान के बीच के संबंधों की खोज नई अंतर्दृष्टि प्रदान कर सकती है।
- अन्य डोमेन में अनुप्रयोग: क्या इस दृष्टिकोण को अन्य मशीन लर्निंग कार्यों पर लागू किया जा सकता है?
निष्कर्ष में, यह पेपर 3D HPE में सामान्यीकरण को बेहतर बनाने के लिए एक उपन्यास और आशाजनक दृष्टिकोण प्रस्तुत करता है। एडेप्टिव स्केलिंग मैकेनिज्म और एनसेंबल रणनीति अच्छी तरह से प्रेरित हैं, अनुभवजन्य रूप से मान्य हैं, और मौजूदा विधियों के लिए एक कंप्यूटेशनल रूप से कुशल विकल्प प्रदान करती हैं। यह क्षेत्र में एक ठोस योगदान है और भविष्य के शोध के लिए कई रोमांचक रास्ते खोलता है।