通过平坦损失平面上的集成学习实现可泛化 3D 人体姿态估计
The quest to understand human movement in three dimensions from simple two-dimensional images—like those from a standard smartphone camera—is a cornerstone of modern computer vision.
背景与学术渊源
从智能手机摄像头拍摄的普通二维图像中理解三维人体运动,是现代计算机视觉研究的基石。这一问题被称为 3D 人体姿态估计(3D Human Pose Estimation, HPE)。该领域最初的研究旨在超越简单的二维“火柴人”模型,为动画制作、体育分析(analysis)以及医学诊断构建数字孪生体。从历史演进来看,该领域已从复杂的几何模型转向深度神经网络(DNN)。然而,当这些模型从受控的实验室环境走向“野外(in-the-wild)”场景——例如自动驾驶汽车在繁忙街道行驶,或机器人在工厂中与人类协作——一个巨大的障碍便显现出来:泛化性(generalization)。一个在某组照片上表现完美的模型,往往因为摄像机角度或人物着装的微小变化而在另一组数据上表现惨淡。
促使作者撰写本文的根本“痛点”在于现有 3D HPE 模型中隐藏的不稳定性。尽管先前的研究者试图通过增加数据量或扩大模型规模来解决这一问题,但他们忽略了“损失平面(loss landscape)”——即模型在学习过程中所处的数学“地形”。作者发现,3D HPE 模型往往会陷入误差极小的“尖锐(sharp)”谷底。在这些尖锐的谷底中,模型极其脆弱;输入数据的微小变化如同剧烈地震,将模型从稳定区震出,导致其精度骤降。这种在稳定性方面缺乏改进(improvement)的现状,意味着这些模型无法在工业机器人等安全关键型应用中被信任。
为了帮助初学者理解解决该问题所使用的专业术语,我们可以通过日常类比来阐释这些概念:
- 损失平面(Loss Landscape): 想象一片巨大的、不可见的连绵山脉,其中“海拔”代表模型的误差。训练模型的目标是找到尽可能低的谷底(误差最小点)。“尖锐”的地形具有狭窄且陡峭的坑洞,难以保持在其中;而“平坦”的地形则拥有宽阔、平缓的盆地,稳定性更高。
- 深度歧义(Depth Ambiguity): 想象皮影戏。如果你看到一个手影,仅凭二维形状无法判断手是靠近光源还是远离光源。在 3D HPE 中,一张二维图像可能对应多种不同的三维姿态,从而为模型制造了“一对多”的困惑。
- Hessian 特征值($\lambda_{max}$): 这本质上是一个“弯曲度计”。如果你站在山谷中,Hessian 矩阵会告诉你谷壁有多陡。高值意味着你处于一个非常狭窄、“尖锐”的坑洞中,这对泛化性是不利的。
- 集成(Ensemble): 想象让五位不同的专家猜测罐子里有多少颗弹珠。每位专家都有略微不同的视角。通过对他们的猜测取平均值,你能够持续(consistently)获得比任何单一专家更准确的结果。
关键数学符号
| 变量/参数 | 描述 |
|---|---|
| $x$ | 输入的 2D 姿态(“影子”或平面图像坐标)。 |
| $g_\phi$ | 从输入中提取特征的“编码器(encoder)”网络。 |
| $f_\theta$ | 将特征转化为 3D 坐标的最终“预测头(prediction head)”。 |
| $h_\psi$ | 预测如何平滑损失平面的“缩放函数(scaling function)”。 |
| $\sigma$ | ReLU 激活函数(确保缩放因子为正)。 |
| $\hat{y}$ | 标准预测的 3D 姿态。 |
| $\tilde{y}$ | 用于平坦化损失平面的“缩放后”3D 姿态预测。 |
| $M$ | 集成中使用的不同“专家(heads)”数量。 |
作者通过引入一种巧妙的数学技巧——自适应缩放机制(Adaptive Scaling Mechanism, ASM)——解决了“尖锐度”问题。在标准模型中,预测结果直接由网络得出:
$$\hat{y} = f_\theta(g_\phi(x))$$
问题在于,这种直接路径往往会导致模型陷入那些“尖锐”的谷底。作者将公式修改为:
$$\tilde{y} = \frac{f_\theta(g_\phi(x))}{\sigma(h_\psi(g_\phi(x))) + 1}$$
通过增加这个分母,他们引入了“数学冗余”。这意味着模型现在有多种途径可以达到正确答案。在我们的山脉类比中,这有效地将狭窄、危险的坑洞“拉伸”成了宽阔、平坦的平原。一旦地形变得平坦,他们便在这片平坦的地面上训练多个“专家”(集成头)。由于地面平坦且稳定,这些专家可以在不相互冲突的情况下进行组合,从而产生在不同现实环境中更加稳健、可靠的 3D 姿态估计结果。
问题定义与约束
在计算机视觉领域,3D 人体姿态估计(HPE)的任务是将平面的 2D 图像或坐标集(输入)转化为人体关节的全 3D 空间位置(输出)。虽然听起来简单,但这两个状态之间的数学鸿沟是一个众所周知的“一对多”映射问题,即深度歧义。由于 2D 图像丢失了深度维度,单一的 2D 姿态在理论上可以代表多种不同的 3D 姿态,从而为模型制造了“一对多”的困惑。
困扰前人的核心困境在于优化稳定性与泛化性之间的权衡。在深度学习中,我们使用损失平面来可视化任务的“难度”——即一个丘陵地形,其中谷底代表低误差(极小值)。如果模型找到了一个“尖锐”的极小值(一个非常狭窄、陡峭的山谷),它在训练数据上表现完美。然而,输入端的微小变化——如不同的摄像机角度或略有不同的体型——都会导致误差飙升,因为模型被困在如此僵化、特定的解中。相反,“平坦”的极小值(宽阔、浅显的山谷)对变化更具鲁棒性,但由于在这些平坦区域梯度(告诉模型如何学习的信号)变得非常微弱且无信息量,因此极难找到。
本文作者遇到了几个使该问题变得极其难以解决的严峻现实障碍:
- 断开的局部极小值:3D HPE 的全局损失平面并非一个平滑的碗状结构,而是一个由多个断开的局部极小值组成的破碎集合。从数学上讲,如果我们定义全局损失为 $L(\theta) = \frac{1}{K} \sum_{k=1}^{K} L_k(\theta)$,其中每个 $L_k$ 代表具有不同深度歧义程度的数据子集,模型往往会“困”在某一个子谷中。由于每个谷底的梯度 $\nabla L(\theta)$ 均为零,模型无法判断自己找到的是最佳的 3D 解读,还是仅仅是一个平庸的解。
- 深度歧义比(DAR)约束:并非所有姿态的难度都相同。具有高 DAR 的姿态表现出极其陡峭且不稳定的损失平面。这产生了一个物理约束,即模型倾向于“记忆”简单姿态,而无法学习歧义姿态的复杂几何结构,从而导致系统产生偏差且脆弱。
- 计算效率与多样性:为了克服这些局部极小值,通常会使用“集成”——训练多个不同的模型并取平均值。但在临床或实时工业安全场景中,由于硬件内存限制和严格的延迟要求,运行 $M$ 个不同的深度网络往往是不可能的。挑战在于如何在不将计算成本乘以 $M$ 的情况下探索这些多样化的解。
- 不可微的结构壁垒:在单一 2D 姿态的多个有效 3D 解读之间,往往存在高损失的“壁垒”,标准优化算法无法跨越。这使得单一模型在训练过程中几乎不可能从一个较差的视角转换到一个更好的视角。
为何选择此方法
本文分析了“通过平坦损失平面上的集成学习实现可泛化 3D 人体姿态估计”一文。作者发现,标准的深度学习方法,即使是 CNN、Transformer 和扩散模型等先进技术,在 3D HPE 的泛化性方面也存在困难。泛化性是指在新的、未见过的数据上表现良好,而不仅仅是在训练数据上。核心问题不在于数据匮乏或模型复杂度,而在于损失平面本身的形状。他们可视化了损失平面(将其想象为高度代表模型预测“错误程度”的丘陵地形),发现其极其复杂,存在许多断开的局部极小值。这意味着标准的优化技术(如梯度下降)往往收敛到泛化性较差的次优解。作者意识到,仅仅增加模型规模或使用更多数据无法解决损失平面的这一根本问题。
这种方法不仅仅是为了在基准测试中获得更好的数值,它在质量上更胜一筹,因为它解决了泛化性差的根本原因:崎岖的损失平面。传统方法试图找到一个好的解,而该方法试图平滑损失平面并找到多个好的解,然后将它们结合起来。
其核心结构优势在于,通过平滑损失平面,降低了陷入那些糟糕局部极小值的可能性。随后,解的集成提供了鲁棒性。如果一个解因噪声或特定视角而产生偏差,其他解可以进行补偿。这比那些专注于单一、可能脆弱的解的方法有了显著改进。论文通过在不同模型架构(MLP、CNN、GCN、Transformer)上的表现证明了其一致的性能提升,表明该方法并不局限于特定的模型选择。
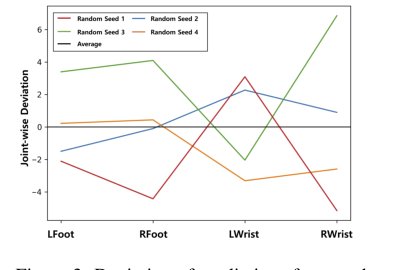 Figure 3. Deviation of predictions from each solution on the smooth loss landscape for diffi- cult joints of 3DHP [24]. Note that the models are trained with H36M [14]
Figure 3. Deviation of predictions from each solution on the smooth loss landscape for diffi- cult joints of 3DHP [24]. Note that the models are trained with H36M [14]
数学与逻辑机制
本文的核心思想是,“损失平面”——即模型试图最小化的误差曲面形状——是 3D 人体姿态估计模型泛化到新数据能力的主要决定因素。他们发现该平面结构复杂,阻碍了优化过程,导致泛化性不佳。他们的解决方案是平滑损失平面,并利用这一平滑后的平面构建集成解,从而提升性能。
主方程
虽然没有唯一的主方程,但其方法的核心在于修改训练 3D 人体姿态估计模型时使用的标准损失函数。关键方程是修改后的预测步骤:
$$ \tilde{y} = \frac{f_o(g(x))}{\sigma(h_\psi(g(x))) + 1} $$
方程解析
让我们拆解该方程的每一部分:
- $x$:这是输入——通常是 2D 姿态信息(例如图像中的关节位置)。它是模型的起点。
- $g(x)$:代表神经网络的编码器部分。它将输入 $x$ 转换为高层表示,即从输入中提取相关特征。
- $f_o(g(x))$:这是网络的原始预测头。它接收编码后的表示 $g(x)$ 并产生初始 3D 姿态估计 $\hat{y}$。
- $h_\psi(g(x))$:这是一个新的小型神经网络(参数为 $\psi$),它接收编码后的表示 $g(x)$ 并输出一个标量值。该值用于缩放预测结果。
- $\sigma$:这是 ReLU(修正线性单元)激活函数,确保缩放因子为非负数。
- $\sigma(h_\psi(g(x))) + 1$:在 ReLU 的输出上加 1,确保分母始终大于零,防止除以零。
- $\tilde{y}$:这是缩放后的 3D 姿态估计,即该步骤的最终输出。
为何采用这种形式? 作者使用这种缩放来有效地“平坦化”损失平面。缩放因子 $\sigma(h_\psi(g(x))) + 1$ 是输入相关的,意味着它随输入 $x$ 的变化而变化。这使得模型能够表示更多样化的函数,并避免陷入尖锐、狭窄的谷底。加 1 是确保数值稳定性的简单技巧。他们使用除法而非乘法,因为除法提供了更灵活的缩放效应,有效地降低了大梯度的影响。
流程步骤
想象一个数据点(2D 姿态)进入系统:
- 2D 姿态 ($x$) 进入编码器 ($g(x)$),提取特征。
- 这些特征被送入原始预测头 ($f_o$),产生初始 3D 姿态估计。
- 同时,特征被送入缩放网络 ($h_\psi$),输出一个标量值。
- 该标量值通过 ReLU 激活函数并加 1。
- 初始 3D 姿态估计被该缩放值除,得到最终的调整后 3D 姿态估计 ($\tilde{y}$)。
- 将该调整后的估计与真实 3D 姿态进行比较,计算损失。
此过程对多个数据点重复进行,模型学习调整缩放因子以最小化损失。
优化动力学
模型使用标准梯度下降(或 Adam 等变体)进行训练。关键在于自适应缩放机制改变了损失平面的形状。它不再是陡峭悬崖和狭窄山谷的地形,而是变得更加平滑、起伏更加平缓。这使得优化器更容易找到好的解,并避免陷入次优的局部极小值。
作者还使用了集成方法。他们使用不同的随机初始化训练多个模型,所有模型均采用自适应缩放机制。由于平面更平滑,这些不同的模型更有可能收敛到不同但同样优秀的解。最终预测结果是这些多个模型预测的平均值。
结果、局限性与结论
本文探讨了 3D 人体姿态估计(HPE)中的泛化问题。核心观点是 3D HPE 的损失平面复杂且阻碍优化,导致泛化性差。作者提出了一种通过自适应缩放机制平滑损失平面的方法,并利用这一平滑后的平面构建集成解以提升性能。
背景与动机
3D HPE 是计算机视觉中的基础任务,在自动驾驶、机器人和工业安全等领域有广泛应用。挑战在于实现泛化性——即模型在新的、未见过的数据上表现良好。传统方法往往侧重于改进模型架构或数据增强,但作者认为损失平面的形状是一个关键且未被充分探索的因素。
他们可视化了损失平面,发现其极其复杂,存在许多断开的局部极小值。这意味着标准优化技术往往收敛到泛化性较差的次优解。作者意识到,仅仅增加模型规模或使用更多数据无法解决损失平面的这一根本问题。
问题与约束
作者指出,3D HPE 的损失平面高度复杂,存在许多局部极小值。这种复杂性源于 2D 图像中 3D 姿态固有的歧义性。单一 2D 图像可代表多种 3D 姿态。这种歧义性创造了一个数学空洞,模型必须“猜测”最可能的深度,当环境或人体姿态发生微小变化时,往往导致错误。
这里的约束在于,直接针对“平坦极小值”(宽阔、浅显的山谷)进行优化在计算上是昂贵的。诸如锐度感知最小化(SAM)等方法尝试解决此问题,但需要额外的计算。作者旨在寻找一种更高效的方法。
解决方案的数学解读
其解决方案的核心在于应用于网络输出的自适应缩放机制。关键方程是修改后的预测步骤:
$$ \tilde{y} = \frac{f_o(g(x))}{\sigma(h_\psi(g(x))) + 1} $$
作者认为,这种缩放平滑了平面,降低了陷入尖锐谷底的可能性。缩放因子是输入相关的,允许模型表示更多样化的函数。他们还采用了集成方法,通过对多个模型取平均值,进一步提升了性能。
实验验证与证据
作者在多个基准数据集(Human3.6M, 3DHP, 3DPW, BEDLAM)上使用多种网络架构(MLP, CNN, GCN, Transformer)进行了广泛实验,证明了在所有架构上的一致性能提升。
核心机制有效的证据是多方面的:
- 损失平面可视化:他们可视化了有和无自适应缩放机制的损失平面,显示缩放机制确实平滑了平面。
- Top-1 特征值分析:他们计算了 Hessian 矩阵的 Top-1 特征值。较低的特征值表示更平坦的平面,他们证明了自适应缩放机制降低了该值。
- 跨数据集评估:他们在训练集外进行测试,这是对泛化性的强力考验。该方法在此设置下持续提升了性能。
- 对噪声的鲁棒性:他们证明了该方法对输入噪声更具鲁棒性。
讨论与未来方向
- 理论理解:对自适应缩放机制为何有效的更严谨的理论理解将极具价值。
- 缩放网络架构:更复杂的缩放网络架构是否能改进缩放过程?
- 动态集成规模:能否在训练过程中动态调整集成规模?
- 与贝叶斯方法的关系:探索该方法与贝叶斯推断之间的联系可能提供新见解。
- 其他领域的应用:该方法能否应用于其他机器学习任务?
总之,本文提出了一种新颖且有前景的改进 3D HPE 泛化性的方法。自适应缩放机制和集成策略动机明确、经验证有效,并提供了一种计算高效的替代方案。这是对该领域的扎实贡献,并为未来研究开启了多个令人兴奋的方向。