SOO-Bench: オフライン・ブラックボックス最適化の安定性評価のためのベンチマーク
The problem of Offline Black-Box Optimization (BBO) emerged from the practical necessity of optimizing complex systems where direct, real-time evaluation of the objective function is either too dangerous,...
背景と学術的系譜
起源と学術的系譜
オフライン・ブラックボックス最適化(Offline Black-Box Optimization: BBO)という課題は、目的関数の直接的かつリアルタイムな評価が、危険を伴う、コストが過大である、あるいは物理的に不可能であるような複雑なシステムを最適化する必要性から生じた。歴史的に、BBO手法は「アクティブ・サンプリング」、すなわちシステムの挙動を学習するために反復的にクエリを行う手法に依存してきた。しかし、創薬(分子構造の設計など)やハードウェア工学(機械構造のパラメータ設計など)といった領域では、新しい設計をその場で「テスト」することはできない。そのため、研究者は過去の実験データからなる静的で既存の「オフライン」データセットに依存せざるを得ない。
本論文の動機となった根本的な「ペインポイント」は、これらのオフライン・データセットが持つ狭い分布(narrow distribution)である。過去のデータは、実験者の主観的なバイアスや特定の限定的な戦略に基づいて収集されることが多いため、解空間全体を網羅できていない。従来のアルゴリズムは、このような狭いデータで学習すると、しばしば「分布外(Out-of-Distribution: OOD)」問題に直面する。すなわち、データが存在しない領域で過信に陥り、最適化中に性能が低下してしまうのである。さらに、Design-Bench のような既存のベンチマークは、主にタスクやデータセットを提供することを目的としており、アルゴリズムの安定性(stability)、つまり狭いデータ分布に惑わされることなく、オフライン・データセットに対して一貫して改善を続ける能力を評価する機能が欠如していた。
直感的なドメイン用語
- ブラックボックス最適化(BBO): ケーキの完璧なレシピを見つけようとしているが、生地を味見することも、材料リストを見ることも許されない状況を想像してほしい。できるのはケーキを焼いて審査員からスコアをもらうことだけである。BBOとは、ケーキの背後にある「化学(関数)」を知ることなく、これらのスコアのみに基づいて最適な「レシピ(入力)」を見つける数学的プロセスである。
- サロゲートモデル(Surrogate Model): 実際の「ブラックボックス」を評価するのはコストがかかるため、その「デジタルツイン」や簡略化された数学的近似モデルを構築する。このモデルを過去のデータで学習させることで、コストのかかる実際のシステムではなく、モデル上で数百万通りの潜在的な解を「テスト」することが可能になる。
- 狭い分布(Narrow Distribution): これは、教科書の第1章の問題しか勉強したことのない学生のようなものである。もし本全体を網羅するテストを受けさせれば、他の章の内容に経験がないため、おそらく失敗するだろう。最適化において、過去のデータが狭く特定の領域しかカバーしていない場合、モデルは「未知」の領域に踏み込んだときにどのように振る舞うべきかを知ることができない。
- 分布外(OOD): これは前述の「未知の領域」を指す。解空間のうち、過去のデータには存在しない領域である。アルゴリズムは、予測の根拠となるデータがないため、これらの領域における解の良さについて「幻覚」を見たり、極端に誤った推測をしたりすることが多い。
表記一覧
| 表記 | 説明 |
|---|---|
| $f: \mathcal{X} \to \mathbb{R}$ | 未知のブラックボックス目的関数。 |
| $\mathcal{X} \subseteq \mathbb{R}^d$ | $d$次元の解空間。 |
| $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$ | $N$個の解とその値を含む静的なオフライン・データセット。 |
| $\hat{f}_\theta(x)$ | $\mathcal{D}$で学習されたパラメータ $\theta$ を持つサロゲートモデル。 |
| $x^{(t)}$ | 最適化ステップ $t$ における解。 |
| $\eta$ | 最適化プロセスの学習率(ステップサイズ)。 |
| $T$ | 最適化ステップの総数。 |
| $x_{\text{app}} = x^{(T)}$ | オンライン適用に向けた最終的な出力解。 |
| $SO$ | 安定性・最適性指標(Stability-Optimality indicator)。 |
| $OI(t)$ | ステップ $t$ における最適性指標(Optimality Indicator)。 |
| $SI(t)$ | ステップ $t$ における安定性指標(Stability Indicator)。 |
数学的解釈
著者らは、直接的な相互作用なしに $f(x)$ を最大化することで最適解 $x^*$ を見つける問題に取り組んでいる。核心的な課題は、サロゲートモデル $\hat{f}_{\theta^*}(x)$ が $\mathcal{D}$ 内のデータ付近でしか信頼できないという点である。最適化プロセスは通常、勾配上昇法に従う:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}$$
「ペインポイント」は、$t$ が増加するにつれて $x^{(t)}$ が $\hat{f}_{\theta^*}(x)$ が不正確なOOD領域へドリフトし、性能が崩壊する可能性があることである。
これを解決するため、著者らはアルゴリズムがグローバルな最適解を見つけること(最適性)と、信頼できる領域内に留まること(安定性)をどの程度両立させているかを定量化する安定性・最適性(SO)指標を提案する。SOは以下のように定義される:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
ここで $OI(t) = \frac{S}{S_1}$、$SI(t) = \frac{S}{S_2}$ である。$S$ はアルゴリズムの性能の累積和、$S_1$ はオフライン・データセットの最良解に基づく「理想的な」性能、$S_2$ はアルゴリズムがこれまでに発見した最良の解に対する相対的な性能を表す。$SO$ を最大化することで、アルゴリズムは単に良い解を見つけるだけでなく、それを維持することを強制され、従来のモデルを悩ませていた性能低下を防ぐことができる。また、ユーザーが特定のニーズに応じて安定性と最適性のどちらを優先できるかを選択できるよう、重み付け版である $SO_\omega$ も導入されている。
問題定義と制約
核心的な問題定式化とジレンマ
標準的なブラックボックス最適化(BBO)では、アルゴリズムは能動的に解をサンプリングし、目的関数値を評価して最適値を見つける。しかし、創薬や機械設計といった多くの重要な実世界ドメインでは、新しい解を評価することは危険であったり、コストが過大であったり、物理的に不可能であったりすることが多い。これが、アルゴリズムが静的で既存のデータセット $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$ のみに依存してサロゲートモデル $\hat{f}_\theta(x)$ を学習し、その後最適解 $x_{app}$ を特定しなければならないオフライン・ブラックボックス最適化の必要性を生じさせている。
ジレンマ:
根本的な課題は、オフライン・データセットの狭い分布である。データ収集はしばしば人間の専門知識や特定の実験的制約によってバイアスがかかるため、データセットが解空間全体を網羅することは稀である。その結果、サロゲートモデル $\hat{f}_\theta(x)$ は「分布外(OOD)」領域において極めて不正確になる。アルゴリズムが既知のデータから遠く離れた場所で最適値を見つけようとすると、サロゲートモデルは目的関数値を過大評価することが多く、最適化プロセス中に深刻な性能低下を招く。
制約:
研究者は「安定性対最適性」のトレードオフに直面している。グローバルな最適解を積極的に追求するアルゴリズムは容易にOODの罠に陥る可能性があり、逆に保守的すぎるアルゴリズムはデータセット内に既に存在する最良の解を改善できない可能性がある。著者らは、いくつかの過酷で現実的な壁を特定している:
1. Ground Truthの欠如: 多くの実世界タスクでは真のグローバル最適解が不明であり、アルゴリズムの性能を測定することが困難である。
2. データの疎性: 過去のデータのサイズが限定的であり、分布が不均一であるため、信頼性の高いサロゲートモデルを学習することが困難である。
3. 安定性の評価: アルゴリズムが未知の領域を探索する際に、性能を崩壊させることなく、オフライン・データセットを一貫して上回ることができるかを評価するための標準化された定量的な指標が存在しなかった。
解法の数学的解釈
著者らは、現在の状態(限定的なオフライン・データ)と目標状態(安定した高品質なオンライン解)の間のギャップを、SOO-Bench と新規の 安定性・最適性(SO)指標 を導入することで埋めている。
問題は、反復的な勾配上昇法を通じてサロゲートモデル $\hat{f}_\theta(x)$ を最大化することにより $x_{app}$ を見つけることとして定式化される:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}, \quad t = 1, 2, \dots, T$$
ここで $x_{app} = x^{(T)}$ である。
安定性を定量化するため、著者らは2つのコンポーネントをバランスさせる 安定性・最適性(SO)指標 を定義する:
1. 最適性指標(OI): アルゴリズムの評価曲線の面積と、オフラインの最適解曲線の面積の比率を測定する。
$$OI(t) = \frac{S}{S_1}, \quad S = \sum_{t=1}^T f(x_t), \quad S_1 = T \cdot f(x^*_{OFF})$$
2. 安定性指標(SI): アルゴリズムの性能が、これまでに発見した最良の解とどの程度一致しているかを測定し、変動を効果的にペナルティ化する。
$$SI(t) = \frac{S}{S_2}, \quad S_2 = T \cdot \max_t f(x_t)$$
最終的な SO スコアは、これら2つの調和平均であり、高いスコアを得るためには高い性能(最適性)と一貫した挙動(安定性)の両方が必要となる:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
カスタマイズ可能なデータセット(上位/下位の解の除去を調整可能)とこのSO指標を提供することで、著者らは研究者がアルゴリズムがOOD領域をどのように扱うかを体系的にテストできるようにし、実質的に「狭い分布」の罠に対する堅牢性を証明することを強制している。
なぜこのアプローチなのか
オフライン・ブラックボックス最適化(BBO)における核心的な課題は、過去のデータの「狭い分布」である。標準的なCNNや基本的なTransformerのような従来の手法は、広範で代表的なデータセットから学習するように設計されている。しかし、創薬や衛星軌道設計のような実世界のシナリオでは、利用可能なデータはしばしばバイアスのかかった、あるいは限定的な戦略を通じて収集されており、解空間全体を網羅していない。
なぜこのアプローチなのか?
著者らは、従来の手法がこの狭いデータに「惑わされる」ために失敗することを見出した。サロゲートモデルが狭いデータセットで学習されると、データが存在しない領域(OOD領域)における解の質を過大評価することが多い。これが、最適化プロセス中の壊滅的な性能低下につながる。
- 比較優位性: 固定された人工的な狭い分布を使用する Design-Bench のような以前のベンチマークとは異なり、SOO-Bench はこれらの分布のカスタマイズを可能にする。この構造的な利点は、研究者が「狭さ」のレベルを変えてアルゴリズムをストレス・テストし、実世界のデータ収集の予測不可能性を効果的にシミュレートできるため、極めて重要である。
- 要件の「融合」: 本論文では 安定性・最適性(SO)指標 を導入している。これは、オフライン・データセットを上回る必要があるという厳しい要件と、OOD領域に惑わされてはならないという制約との「融合」である。最適性指標(OI)と安定性指標(SI)を数学的に組み合わせることで、モデルは良い解を見つけるだけでなく、最適化ステップ全体を通じてその性能を維持できることを証明するよう強制される。
- なぜ他の手法は失敗するのか: 著者らは、高リスクなOOD領域を探索することに対してモデルをペナルティ化するメカニズムを欠いているため、単純で保守的でないアプローチを否定する。ARCOO のような手法は、勾配上昇中のステップサイズを制御するために「リスク抑制因子」を明示的に組み込み、モデルが危険で検証されていない領域へ迷い込むことを防ぐため、高く評価されている。
数学的解釈
問題は、静的なデータセット $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$ で学習されたサロゲートモデル $\hat{f}_\theta(x)$ によって近似されるブラックボックス関数 $f(x)$ を最大化する最適解 $x^*$ を見つけることとして定義される。最適化プロセスは通常以下に従う:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}$$
著者らは、$T$(ステップ数)が大きすぎると、アルゴリズムがOOD領域へドリフトすることに気づいた。これを解決するために、彼らはSO指標を提案した:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
ここで $OI(t) = \frac{S}{S_1}$、$SI(t) = \frac{S}{S_2}$ である。ここで $S$ は評価曲線の累積和、$S_1$ はオフライン最適値と総ステップ数の積、$S_2$ はアルゴリズムが発見した最良値と総ステップ数の積を表す。このモデルは、高い分散や「不安定な」性能を示すアルゴリズムを効果的にペナルティ化し、サロゲートモデルが不完全であってもアルゴリズムの軌跡が堅牢であることを保証する。
このアプローチは、「最良の点を見つける」ことから「安全を維持しながら最良の点を見つける」ことへとフィールドを移行させるため、根本的に優れている。これは純粋な性能から信頼できる性能への転換であり、誤った推測が危険を招きかねないハイステークスな工学タスクにおいて、唯一実行可能な道である。
数学的・論理的メカニズム
マスター方程式
本論文の核心的なメカニズムは、オフライン最適化アルゴリズムがオフライン・データセットの最良解に対してどの程度機能し、かつ最適化プロセス全体を通じて安定性を維持しているかを評価する 安定性・最適性(SO)指標 である。主要な方程式は以下の通りである:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
各コンポーネントは以下のように定義される:
$$OI(t) = \frac{S}{S_1}, \quad SI(t) = \frac{S}{S_2}$$
方程式の分解
- $S = \sum_{t=1}^{T} f(x_t)$: これは、全最適化ステップ $T$ にわたる目的関数値の累積和である。アルゴリズムの全体的な「性能フットプリント」を表す。
- $S_1 = T \cdot f(x^*_{\text{OFF}})$: これはベースライン参照である。アルゴリズムが全ステップ $T$ にわたってオフライン・データセットで見つかった最良値 ($f(x^*_{\text{OFF}})$) を一貫して達成していた場合の性能を表す。
- $S_2 = T \cdot \max_t f(x_t)$: これはピーク性能参照である。アルゴリズムが全ステップにわたって、自身が発見した最良値 ($\max_t f(x_t)$) を一貫して達成していた場合の性能を表す。
- $OI(t)$(最適性指標): この比率は、オフライン・データセットの最良値に対するアルゴリズムの性能を測定する。$OI > 1$ であれば、アルゴリズムはオフライン・データを上回ることに成功している。
- $SI(t)$(安定性指標): この比率は、アルゴリズムの性能が自身のピークとどの程度一致しているかを測定する。1に近い値は高い安定性(最小限の変動)を示し、低い値はアルゴリズムが「ジタバタしている」か、性能低下を起こしやすいことを示唆する。
- 調和平均 ($2 \cdot \frac{OI \cdot SI}{SI + OI}$): 著者らは、SO指標が両方のコンポーネントに対して敏感であることを保証するために、単純な算術平均ではなく調和平均を使用している。$OI$ または $SI$ のいずれかが非常に低い場合、調和平均は合計スコアを大幅に引き下げ、不安定であるか、オフライン・データセットを上回ることに失敗したアルゴリズムを効果的にペナルティ化する。
ステップバイステップのフロー
このシステムにおける抽象データポイントのライフサイクルは、以下の組立ラインに従う:
- 初期化: アルゴリズムはオフライン・データセット $\mathcal{D}$ から開始する。ブラックボックス関数を近似するためにサロゲートモデル $\hat{f}_\theta(x)$ を学習する。
- 最適化: アルゴリズムは新しい解 $x_{\text{app}}$ を見つけるために $T$ ステップの勾配上昇法を実行する。
- 評価: 各ステップ $t$ で、アルゴリズムは解 $x_t$ を生成する。システムは目的関数値 $f(x_t)$ を計算する。
- 集計: これらの値は $S$ に合計される。同時に、システムはオフライン最良値 ($f(x^*_{\text{OFF}})$) とアルゴリズム自身の最良値 ($\max_t f(x_t)$) を追跡する。
- 指標計算: システムは $OI(t)$ と $SI(t)$ を計算し、アルゴリズムがオフライン・データよりどれだけ優れているか、またその軌跡がどれだけ安定しているかを定量化する。
- 最終スコア: SO指標はこれらを単一の指標に統合し、アルゴリズムの安定性と最適性に対する定量的な「成績」を提供する。
最適化のダイナミクス
このメカニズムは、オフライン・データセット $\mathcal{D}$ 上の教師あり学習を用いてサロゲートモデル $\hat{f}_\theta(x)$ を反復的に更新することで学習する。損失関数は以下の通りである:
$$\theta^* \leftarrow \arg \min_\theta \sum_{i=1}^N (\hat{f}_\theta(x_i) - y_i)^2$$
その後、最適化プロセスは勾配上昇法を用いてサロゲートモデルのランドスケープをナビゲートする:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^t}$$
ここでの「学習」は、本質的にオフライン・データの狭い分布からより広い解空間へと汎化するサロゲートモデルの能力である。安定性は、(ARCOOアルゴリズムのように)勾配上昇に対する「ガバナー(調速機)」として機能し、データが不足しているOOD領域でモデルが値を過大評価することを防ぐリスク抑制因子によって維持される。これにより、オフラインBBOにおける一般的な失敗モードである、モデルが自身の過信によって「惑わされる」ことが防がれる。
結果、限界、および結論
SOO-Benchの分析:オフライン・ブラックボックス最適化の安定性評価のためのベンチマーク
背景知識
ブラックボックス最適化(BBO)は、$f(x)$ の明示的な数学的形式を知ることなく、目的関数 $f(x)$ を最大化する最適入力 $x^*$ を見つけるための手法である。従来のBBOでは、アルゴリズムは能動的に点をサンプリングし、評価することができる。しかし、多くの実世界のシナリオ(創薬、機械設計など)では、$f(x)$ の評価はコストがかかりすぎるか、危険である。これが、静的で事前に収集されたデータセット $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$ のみを使用してサロゲートモデル $\hat{f}_\theta(x)$ を学習しなければならない オフラインBBO につながる。
ここでの核心的な課題は、オフライン・データセットの 狭い分布 である。データはしばしば人間のバイアスや特定の実験的制約に基づいて収集されるため、解空間全体を網羅していない。このデータで学習されたサロゲートモデルは、学習データから遠く離れた領域(分布外、すなわちOOD領域)の値を予測しようとすると、しばしば「惑わされ」、最適化性能が低下する。
動機と問題提起
著者らは、既存のベンチマーク(Design-Benchなど)は主に 最適性、すなわち可能な限り最良の解を見つけることに焦点を当てていると主張する。しかし、ハイステークスな工学において、安定性 も同様に重要である。安定性とは、狭いデータ分布に惑わされることなく、オフライン・データセットにおける既知の最良の解を上回る解を一貫して見つけるアルゴリズムの能力として定義される。著者らは、現在のベンチマークにはこの安定性を測定するための定量的な方法が欠如していることを特定した。
数学的解釈
本論文では、最適化プロセス全体を通じてアルゴリズムがどの程度機能するかを定量化するために 安定性・最適性(SO)指標 を導入している。合計 $T$ 回の最適化ステップについて、ステップ $t$ における解の評価を $f(x_t)$ とすると、指標は以下のように定義される:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
ここで:
* 最適性指標(OI): $OI(t) = \frac{S}{S_1}$。ここで $S = \sum_{t=1}^T f(x_t)$、$S_1 = T \cdot f(x^*_{OFF})$。これは、アルゴリズムの性能曲線の面積とベースライン(オフライン・データセットの最良解)の面積の比率を測定する。
* 安定性指標(SI): $SI(t) = \frac{S}{S_2}$。ここで $S_2 = T \cdot \max_t f(x_t)$。これは、アルゴリズムの性能がこれまでに発見した最良の解とどの程度一致しているかを測定する。
著者らはまた、最適化プロセスの異なるフェーズで最適性または安定性のいずれかを優先できるようにする重み付け版 $SO_\omega$ も提案している。
実験的証明
著者らは、以下のようにアルゴリズムを「容赦なく」テストするためにSOO-Benchを設計した:
1. データの難易度のカスタマイズ: 上位 $n\%$(高品質な解を見つけるのを難しくする)および下位 $m\%$(疎性を高める)のデータを除去することでデータセットを作成した。
2. 多様なタスク: 衛星軌道最適化(GTOPX)、工業設計(CEC)、DNA配列設計(PROTEIN)からの実世界タスクを含めた。
3. ベースライン比較: ARCOO、Tri-mentoring、TTDDEAを含む最先端(SOTA)アルゴリズムを、BO-qEIやCMA-ESのような古典的なベースラインと比較した。
「犠牲者」(ベースラインモデル)は、OOD領域に対して非常に敏感であることが示されることが多かった。提供された決定的な証拠は、一部のアルゴリズム(ARCOOなど)はエネルギーベースモデルを使用してリスクを抑制することで安定した性能を維持する一方で、他のアルゴリズム(DE-PFやDE-SPFなど)は低いSO値を示し、頻繁に実行不可能な領域に陥ったり停滞したりすることを示している。
今後の開発に向けた議論のトピック
- 動的重み付け: 著者らは $SO_\omega$ に対して線形減少する重み関数 $\omega(t)$ を使用している。サロゲートモデルの不確実性を感知し、最適化の最中に最適性と安定性の間の優先順位をリアルタイムでシフトさせる適応型重み付けメカニズムを開発できるか?
- OODを超えて: 問題の背後にある物理法則や制約が時間とともに変化する可能性があるオフライン・データセットにおける「コンセプトドリフト」を扱うために、SOO-Benchをどのように拡張できるか?
- 制約の扱い: 本論文は、現在の手法が厳しい制約に苦労していることを指摘している。今後の研究では、アルゴリズムが保守的になりすぎて停滞することを防ぐために、サロゲートモデルの学習に「ソフト」な制約充足をどのように組み込むかを探求できるだろう。
全体として、本論文は、評価指標においてある種「西部開拓時代」であった分野に対して、切望されていた厳密なフレームワークを提供している。
 Table 2. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at t = 50 during the optimization process, which consists of a total of T = 150 optimization steps. In this case, 25% of the values are missing near the worst value and another 25% near the optimal value
Table 2. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at t = 50 during the optimization process, which consists of a total of T = 150 optimization steps. In this case, 25% of the values are missing near the worst value and another 25% near the optimal value
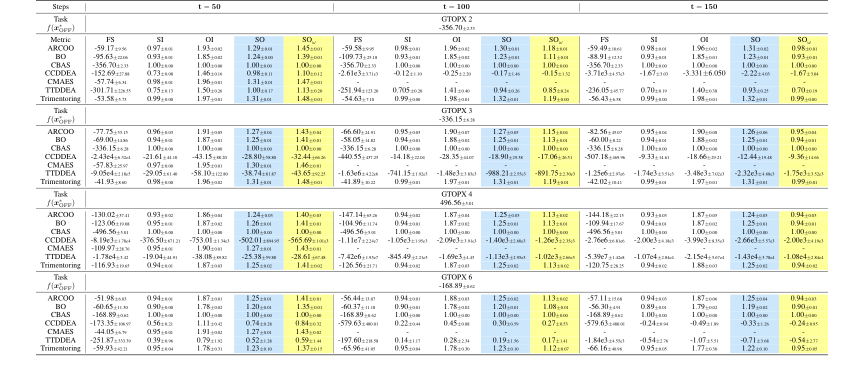 Table 5. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at the final step of specific optimization steps (i.e., t = 50, 100, 150). The symbol "-“ means that the algorithm cannot complete the corresponding task within 24 hours. In this case, 0% of the values are missing near the worst value and another 50% near the optimal value
Table 5. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at the final step of specific optimization steps (i.e., t = 50, 100, 150). The symbol "-“ means that the algorithm cannot complete the corresponding task within 24 hours. In this case, 0% of the values are missing near the worst value and another 50% near the optimal value
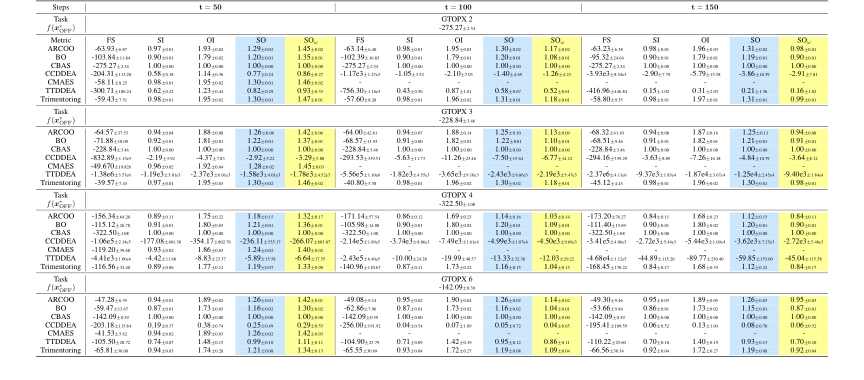 Table 6. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations. In this case, 0% of the values are missing near the worst value and another 40% near the optimal value. Details are the same as Table 5
Table 6. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations. In this case, 0% of the values are missing near the worst value and another 40% near the optimal value. Details are the same as Table 5
他分野との同型性(Isomorphisms)
構造的骨格
本論文は、制限された非代表的な過去のデータセット上で動作する際に、ブラックボックス最適化アルゴリズムの安定性と最適性を定量化する標準化された評価フレームワークを導入している。