SOO-Bench: 오프라인 블랙박스 최적화의 안정성 평가를 위한 벤치마크
The problem of Offline Black-Box Optimization (BBO) emerged from the practical necessity of optimizing complex systems where direct, real-time evaluation of the objective function is either too dangerous,...
배경 및 학문적 계보
기원 및 학문적 계보
오프라인 블랙박스 최적화(Offline Black-Box Optimization, BBO) 문제는 목적 함수(objective function)에 대한 실시간 평가가 위험하거나, 비용이 과도하게 발생하거나, 물리적으로 불가능한 복잡한 시스템을 최적화해야 하는 실무적 필요성에서 대두되었다. 역사적으로 BBO 방법론은 시스템의 동작을 학습하기 위해 반복적으로 쿼리를 수행하는 '능동적 샘플링(active sampling)'에 의존해 왔다. 그러나 신약 개발(예: 분자 구조 설계)이나 하드웨어 공학(예: 기계 구조 파라미터 최적화)과 같은 도메인에서는 새로운 설계를 즉석에서 '테스트'하는 것이 불가능하다. 따라서 연구자들은 과거 실험 데이터로 구성된 정적이고 기성품인 '오프라인' 데이터셋에 의존할 수밖에 없다.
본 논문을 관통하는 핵심적인 '페인 포인트(pain point)'는 이러한 오프라인 데이터셋의 좁은 분포(narrow distribution) 문제이다. 과거 데이터는 종종 실험자의 주관적 편향이나 특정된 제한적 전략에 기반하여 수집되기 때문에, 전체 솔루션 공간을 포괄하지 못한다. 기존 알고리즘들은 이러한 편향된 데이터로 학습될 경우, 데이터가 존재하지 않는 영역에서 과도한 확신을 갖게 되는 '분포 외(Out-of-Distribution, OOD)' 문제에 직면하며, 이로 인해 최적화 과정에서 성능이 급격히 저하된다. 더욱이 Design-Bench와 같은 기존 벤치마크들은 태스크와 데이터셋을 제공하는 데는 충실했으나, 알고리즘이 좁은 데이터 분포에 현혹되지 않고 오프라인 데이터셋의 성능을 일관되게 개선할 수 있는 능력, 즉 안정성(stability)을 평가하는 기능은 결여되어 있었다.
직관적 도메인 용어
- 블랙박스 최적화(BBO): 케이크 반죽을 맛보거나 재료 목록을 볼 수 없는 상태에서 완벽한 레시피를 찾는 상황을 가정해 보자. 오직 케이크를 구워 심사위원에게 점수를 받는 것만 가능하다. BBO는 케이크의 '화학적 원리(함수)'를 모르는 상태에서 오직 점수만을 바탕으로 최적의 '레시피(입력값)'를 찾는 수학적 과정이다.
- 대리 모델(Surrogate Model): 실제 '블랙박스'를 평가하는 것은 비용이 많이 들기 때문에, 이를 모사하는 '디지털 트윈'이나 단순화된 수학적 근사 모델을 구축한다. 이 모델을 과거 데이터로 학습시켜, 비용이 많이 드는 실제 시스템 대신 수백만 개의 잠재적 솔루션을 모델 상에서 '테스트'한다.
- 좁은 분포(Narrow Distribution): 교과서의 1장 문제만 공부한 학생을 생각해보자. 전체 내용을 다루는 시험을 치르면, 다른 장의 내용을 전혀 경험하지 못했기 때문에 실패할 가능성이 높다. 최적화에서 과거 데이터가 좁고 특정된 영역만 다룬다면, 모델은 '보지 못한' 영역으로 진입했을 때 어떻게 행동해야 할지 알지 못한다.
- 분포 외(Out-of-Distribution, OOD): 앞서 언급한 '보지 못한 영역'을 의미한다. 이는 과거 데이터에 표현되지 않은 솔루션 공간의 영역이다. 알고리즘은 이 영역에서 예측을 뒷받침할 데이터가 없기 때문에, 솔루션의 품질에 대해 종종 '환각(hallucination)'을 일으키거나 잘못된 추측을 하게 된다.
표기법 테이블
| 표기 | 설명 |
|---|---|
| $f: \mathcal{X} \to \mathbb{R}$ | 미지의 블랙박스 목적 함수 |
| $\mathcal{X} \subseteq \mathbb{R}^d$ | $d$차원 솔루션 공간 |
| $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$ | $N$개의 솔루션과 그 값을 포함하는 정적 오프라인 데이터셋 |
| $\hat{f}_\theta(x)$ | $\mathcal{D}$로 학습된 파라미터 $\theta$를 가진 대리 모델 |
| $x^{(t)}$ | 최적화 단계 $t$에서의 솔루션 |
| $\eta$ | 최적화 과정의 학습률(step size) |
| $T$ | 총 최적화 단계 수 |
| $x_{\text{app}} = x^{(T)}$ | 온라인 적용을 위한 최종 솔루션 출력 |
| $SO$ | 안정성-최적성(Stability-Optimality) 지표 |
| $OI(t)$ | 단계 $t$에서의 최적성 지표(Optimality Indicator) |
| $SI(t)$ | 단계 $t$에서의 안정성 지표(Stability Indicator) |
수학적 해석
저자들은 직접적인 상호작용 없이 $f(x)$를 최대화하여 최적 솔루션 $x^*$를 찾는 문제를 다룬다. 핵심적인 난제는 대리 모델 $\hat{f}_{\theta^*}(x)$가 $\mathcal{D}$ 내의 데이터 근처에서만 신뢰할 수 있다는 점이다. 최적화 과정은 일반적으로 경사 상승법(gradient ascent)을 따른다:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}$$
'페인 포인트'는 $t$가 증가함에 따라 $x^{(t)}$가 $\hat{f}_{\theta^*}(x)$의 정확도가 떨어지는 OOD 영역으로 표류할 수 있으며, 이로 인해 성능이 붕괴된다는 점이다.
이를 해결하기 위해 저자들은 알고리즘이 전역 최적값 탐색(최적성)과 신뢰 가능한 영역 내 유지(안정성) 사이의 균형을 얼마나 잘 맞추는지 정량화하는 안정성-최적성(SO) 지표를 제안한다. SO는 다음과 같이 정의된다:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
여기서 $OI(t) = \frac{S}{S_1}$이고 $SI(t) = \frac{S}{S_2}$이다. $S$는 알고리즘 성능의 누적 합이며, $S_1$은 오프라인 데이터셋의 최적 솔루션에 기반한 '이상적인' 성능, $S_2$는 알고리즘이 지금까지 찾은 최적 솔루션 대비 성능을 나타낸다. $SO$를 최대화함으로써 알고리즘은 단순히 좋은 솔루션을 찾는 것을 넘어, 이를 유지하도록 강제되어 기존 모델들을 괴롭히던 성능 저하를 방지한다. 또한 저자들은 사용자가 필요에 따라 안정성이나 최적성 중 하나를 우선시할 수 있도록 가중치가 적용된 버전인 $SO_\omega$를 도입하였다.
문제 정의 및 제약 조건
핵심 문제 정식화 및 딜레마
표준 블랙박스 최적화(BBO)에서 알고리즘은 능동적으로 솔루션을 샘플링하고 목적 함수 값을 평가하여 최적값을 찾는다. 그러나 신약 개발이나 하드웨어 기계 설계와 같은 많은 중요한 실제 도메인에서는 새로운 솔루션을 평가하는 것이 위험하거나, 비용이 과도하거나, 물리적으로 불가능한 경우가 많다. 이는 알고리즘이 오직 정적이고 기성품인 데이터셋 $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$에만 의존하여 대리 모델 $\hat{f}_\theta(x)$를 학습하고 최적 솔루션 $x_{app}$을 식별해야 하는 오프라인 블랙박스 최적화의 필요성을 야기한다.
딜레마:
근본적인 도전 과제는 오프라인 데이터셋의 좁은 분포이다. 데이터 수집은 종종 인간의 전문 지식이나 특정 실험적 제약에 의해 편향되므로, 데이터셋이 전체 솔루션 공간을 포괄하는 경우는 드물다. 결과적으로 대리 모델 $\hat{f}_\theta(x)$는 '분포 외(OOD)' 영역에서 매우 부정확해진다. 알고리즘이 알려진 데이터에서 멀리 떨어진 최적값을 찾으려 시도하면, 대리 모델은 종종 목적 값을 과대평가하여 최적화 과정 중에 심각한 성능 저하를 초래한다.
제약 조건:
연구자들은 '안정성 대 최적성'의 트레이드오프에 직면한다. 전역 최적값을 공격적으로 추구하는 알고리즘은 쉽게 OOD 함정에 빠질 수 있는 반면, 지나치게 보수적인 알고리즘은 데이터셋에 이미 존재하는 최적 솔루션을 개선하지 못할 수 있다. 저자들은 다음과 같은 가혹하고 현실적인 장벽들을 식별한다:
1. Ground Truth의 부재: 많은 실제 태스크에서 진정한 전역 최적값은 알려져 있지 않아, 알고리즘의 성능을 측정하기 어렵다.
2. 데이터 희소성: 과거 데이터의 제한된 크기와 불균일한 분포는 신뢰할 수 있는 대리 모델을 학습하기 어렵게 만든다.
3. 안정성 평가: 알고리즘이 미지의 영역을 탐색할 때 성능 붕괴를 겪지 않고 오프라인 데이터셋을 일관되게 능가할 수 있는지 평가할 표준화된 정량적 지표가 부재했다.
솔루션의 수학적 해석
저자들은 SOO-Bench와 새로운 안정성-최적성(SO) 지표를 도입하여 현재 상태(제한된 오프라인 데이터)와 목표 상태(안정적이고 고품질인 온라인 솔루션) 사이의 간극을 메운다.
문제는 반복적인 경사 상승법을 통해 대리 모델 $\hat{f}_\theta(x)$를 최대화함으로써 $x_{app}$을 찾는 것으로 정식화된다:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}, \quad t = 1, 2, \dots, T$$
여기서 $x_{app} = x^{(T)}$이다.
안정성을 정량화하기 위해 저자들은 두 가지 요소를 균형 있게 고려하는 안정성-최적성(SO) 지표를 정의한다:
1. 최적성 지표(OI): 알고리즘의 평가 곡선 아래 면적과 오프라인 최적 솔루션 곡선 아래 면적의 비율을 측정한다.
$$OI(t) = \frac{S}{S_1}, \quad S = \sum_{t=1}^T f(x_t), \quad S_1 = T \cdot f(x^*_{OFF})$$
2. 안정성 지표(SI): 알고리즘의 성능이 지금까지 찾은 최적 솔루션과 얼마나 밀접하게 일치하는지를 측정하여, 변동성을 효과적으로 페널티 처리한다.
$$SI(t) = \frac{S}{S_2}, \quad S_2 = T \cdot \max_t f(x_t)$$
최종 SO 점수는 이 둘의 조화 평균으로, 높은 점수를 얻기 위해서는 높은 성능(최적성)과 일관된 행동(안정성)이 모두 요구됨을 보장한다:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
저자들은 맞춤형 데이터셋(상위/하위 솔루션 제거 조정)과 이 SO 지표를 제공함으로써, 연구자들이 알고리즘이 OOD 영역을 어떻게 처리하는지 체계적으로 테스트할 수 있게 하며, '좁은 분포'의 함정에 대한 견고함을 증명하도록 강제한다.
왜 이 접근 방식인가
오프라인 블랙박스 최적화(BBO)의 핵심 과제는 과거 데이터의 '좁은 분포'이다. 표준 CNN이나 기본적인 Transformer와 같은 전통적인 방법들은 광범위하고 대표성 있는 데이터셋에서 학습하도록 설계되었다. 그러나 신약 개발이나 위성 궤도 설계와 같은 실제 시나리오에서 가용한 데이터는 종종 편향되거나 제한된 전략을 통해 수집되므로, 전체 솔루션 공간을 포괄하지 못한다.
왜 이 접근 방식인가?
저자들은 전통적인 방법들이 이 좁은 데이터에 의해 '현혹'되기 때문에 실패한다는 점을 파악했다. 대리 모델이 좁은 데이터셋으로 학습되면, 데이터가 없는 영역(분포 외 또는 OOD 영역)의 솔루션 품질을 종종 과대평가하게 된다. 이는 최적화 과정에서 치명적인 성능 저하로 이어진다.
- 비교 우위: 고정되고 인위적으로 구축된 좁은 분포를 사용했던 Design-Bench와 같은 이전 벤치마크와 달리, SOO-Bench는 이러한 분포의 커스터마이징을 허용한다. 이 구조적 이점은 연구자들이 다양한 수준의 '좁음'에 대해 알고리즘을 스트레스 테스트할 수 있게 하여, 실제 데이터 수집의 예측 불가능한 성격을 효과적으로 시뮬레이션할 수 있게 하므로 매우 중요하다.
- 요구사항의 '결합': 본 논문은 안정성-최적성(SO) 지표를 도입한다. 이는 오프라인 데이터셋을 능가해야 한다는 가혹한 요구사항과 OOD 영역에 현혹되지 않아야 한다는 제약 사이의 '결합'이다. 최적성 지표(OI)와 안정성 지표(SI)를 수학적으로 결합함으로써, 모델은 알고리즘이 좋은 솔루션을 찾을 뿐만 아니라 최적화 단계 전반에 걸쳐 그 성능을 유지할 수 있음을 증명하도록 강제한다.
- 다른 방법들이 실패하는 이유: 저자들은 모델이 고위험 OOD 영역을 탐색하는 것에 대해 페널티를 줄 메커니즘이 없기 때문에 단순하고 비보수적인 접근 방식을 거부한다. ARCOO와 같은 방법들은 경사 상승법 동안 스텝 사이즈를 제어하기 위해 '위험 억제 계수(risk suppression factor)'를 명시적으로 포함하여 모델이 위험하고 검증되지 않은 영역으로 방황하는 것을 방지하기 때문에 강조된다.
수학적 해석
문제는 정적 데이터셋 $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$으로 학습된 대리 모델 $\hat{f}_\theta(x)$에 의해 근사되는 블랙박스 함수 $f(x)$를 최대화하는 최적 솔루션 $x^*$를 찾는 것으로 정의된다. 최적화 과정은 일반적으로 다음을 따른다:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^{(t)}}$$
저자들은 $T$(단계 수)가 너무 크면 알고리즘이 OOD 영역으로 표류한다는 것을 깨달았다. 이를 해결하기 위해 그들은 SO 지표를 제안했다:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
여기서 $OI(t) = \frac{S}{S_1}$이고 $SI(t) = \frac{S}{S_2}$이다. 여기서 $S$는 평가 곡선의 누적 합, $S_1$은 오프라인 최적값과 총 단계의 곱, $S_2$는 알고리즘이 찾은 최적값과 총 단계의 곱을 나타낸다. 이 모델은 높은 분산이나 '불안정한' 성능을 보이는 알고리즘에 효과적으로 페널티를 주어, 대리 모델이 불완전할 때조차 알고리즘의 궤적이 견고하게 유지되도록 보장한다.
이 접근 방식은 필드를 '최고의 지점을 찾는 것'에서 '안전하게 유지하면서 최고의 지점을 찾는 것'으로 전환하기 때문에 근본적으로 우월하다. 이는 순수한 성능에서 신뢰할 수 있는 성능으로의 전환이며, 잘못된 추측이 위험할 수 있는 고위험 공학 태스크를 위한 유일한 실행 가능한 경로이다.
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 핵심 메커니즘은 오프라인 최적화 알고리즘이 최적화 과정 전반에 걸쳐 안정성을 유지하면서 오프라인 데이터셋의 최적 솔루션 대비 얼마나 잘 수행하는지를 평가하는 안정성-최적성(SO) 지표이다. 기본 방정식은 다음과 같다:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
각 구성 요소는 다음과 같이 정의된다:
$$OI(t) = \frac{S}{S_1}, \quad SI(t) = \frac{S}{S_2}$$
방정식의 분해
- $S = \sum_{t=1}^{T} f(x_t)$: 이는 모든 최적화 단계 $T$에 걸친 목적 함수 값의 누적 합이다. 이는 알고리즘의 총 '성능 발자취(performance footprint)'를 나타낸다.
- $S_1 = T \cdot f(x^*_{\text{OFF}})$: 이는 기준 참조값이다. 알고리즘이 모든 단계 $T$에 대해 오프라인 데이터셋에서 발견된 최적값($f(x^*_{\text{OFF}})$)을 일관되게 달성했을 경우의 성능을 나타낸다.
- $S_2 = T \cdot \max_t f(x_t)$: 이는 최고 성능 참조값이다. 알고리즘이 모든 단계에 대해 자신이 지금까지 찾은 최적값($\max_t f(x_t)$)을 일관되게 달성했을 경우의 성능을 나타낸다.
- $OI(t)$ (최적성 지표): 이 비율은 오프라인 데이터셋의 최적값 대비 알고리즘의 성능을 측정한다. $OI > 1$이면 알고리즘이 오프라인 데이터를 성공적으로 능가하고 있는 것이다.
- $SI(t)$ (안정성 지표): 이 비율은 알고리즘의 성능이 자신의 최고 성능과 얼마나 밀접하게 일치하는지를 측정한다. 1에 가까운 값은 높은 안정성(최소한의 변동)을 나타내며, 낮은 값은 알고리즘이 '불안정'하거나 성능 저하가 발생하기 쉬움을 시사한다.
- 조화 평균 ($2 \cdot \frac{OI \cdot SI}{SI + OI}$): 저자들은 SO 지표가 두 구성 요소 모두에 민감하도록 단순 산술 평균 대신 조화 평균을 사용한다. $OI$나 $SI$ 중 하나라도 매우 낮으면 조화 평균은 전체 점수를 크게 낮추어, 불안정하거나 오프라인 데이터셋을 능가하지 못하는 알고리즘에 효과적으로 페널티를 준다.
단계별 흐름
이 시스템에서 추상 데이터 포인트의 수명 주기는 다음과 같은 조립 라인을 따른다:
- 초기화: 알고리즘은 오프라인 데이터셋 $\mathcal{D}$로 시작한다. 블랙박스 함수를 근사하기 위해 대리 모델 $\hat{f}_\theta(x)$를 학습시킨다.
- 최적화: 알고리즘은 새로운 솔루션 $x_{\text{app}}$을 찾기 위해 $T$ 단계 동안 경사 상승법을 수행한다.
- 평가: 각 단계 $t$에서 알고리즘은 솔루션 $x_t$를 생성한다. 시스템은 목적 값 $f(x_t)$를 계산한다.
- 집계: 이 값들은 $S$로 합산된다. 동시에 시스템은 오프라인 최적값($f(x^*_{\text{OFF}})$)과 알고리즘 자체의 최적값($\max_t f(x_t)$)을 추적한다.
- 지표 계산: 시스템은 $OI(t)$와 $SI(t)$를 계산하여 알고리즘이 오프라인 데이터보다 얼마나 더 나은지, 그리고 그 궤적이 얼마나 안정적인지 정량화한다.
- 최종 점수: SO 지표는 이를 단일 메트릭으로 결합하여 알고리즘의 안정성과 최적성에 대한 정량적 '등급'을 제공한다.
최적화 역학
이 메커니즘은 오프라인 데이터셋 $\mathcal{D}$에 대한 지도 학습을 사용하여 대리 모델 $\hat{f}_\theta(x)$를 반복적으로 업데이트함으로써 학습한다. 손실 함수는 다음과 같다:
$$\theta^* \leftarrow \arg \min_\theta \sum_{i=1}^N (\hat{f}_\theta(x_i) - y_i)^2$$
그런 다음 최적화 과정은 대리 모델의 지형을 탐색하기 위해 경사 상승법을 사용한다:
$$x^{(t+1)} \leftarrow x^{(t)} + \eta \nabla_x \hat{f}_{\theta^*}(x)|_{x=x^t}$$
여기서 '학습'은 본질적으로 오프라인 데이터의 좁은 분포에서 더 넓은 솔루션 공간으로 일반화하는 대리 모델의 능력이다. 안정성은 경사 상승법에 대한 '조속기(governor)' 역할을 하여 모델이 데이터가 부족한 OOD 영역에서 값을 과대평가하는 것을 방지하는 위험 억제 계수(ARCOO 알고리즘에서와 같은)에 의해 유지된다. 이는 모델이 오프라인 BBO에서 흔한 실패 모드인 자신의 과도한 확신에 의해 '현혹'되는 것을 방지한다.
결과, 한계 및 결론
SOO-Bench 분석: 오프라인 블랙박스 최적화의 안정성 평가를 위한 벤치마크
배경 지식
블랙박스 최적화(BBO)는 $f$의 명시적인 수학적 형태를 알지 못한 채 목적 함수 $f(x)$를 최대화하는 최적 입력 $x^*$를 찾는 방법이다. 전통적인 BBO에서 알고리즘은 능동적으로 포인트를 샘플링하고 평가할 수 있다. 그러나 많은 실제 시나리오(예: 신약 개발, 기계 설계)에서 $f(x)$를 평가하는 것은 너무 비용이 많이 들거나 위험하다. 이는 알고리즘이 정적이고 미리 수집된 데이터셋 $\mathcal{D} = \{x_i, y_i\}_{i=1}^N$만을 사용하여 대리 모델 $\hat{f}_\theta(x)$를 학습해야 하는 오프라인 BBO로 이어진다.
여기서 핵심 과제는 오프라인 데이터셋의 좁은 분포이다. 데이터는 종종 인간의 편향이나 특정 실험적 제약에 기반하여 수집되기 때문에 전체 솔루션 공간을 포괄하지 못한다. 이 데이터로 학습된 대리 모델은 학습 데이터에서 멀리 떨어진 영역(분포 외 또는 OOD 영역)의 값을 예측하려고 할 때 종종 '현혹'되어 최적화 성능이 저하된다.
동기 및 문제 제기
저자들은 기존 벤치마크(Design-Bench 등)가 주로 최적성—가능한 최고의 솔루션을 찾는 것—에 초점을 맞추고 있다고 주장한다. 그러나 고위험 공학에서 안정성은 그만큼 중요하다. 안정성은 알고리즘이 좁은 데이터 분포에 현혹되지 않고 오프라인 데이터셋에서 알려진 최적 솔루션을 능가하는 솔루션을 일관되게 찾는 능력으로 정의된다. 저자들은 현재 벤치마크에 이러한 안정성을 측정할 정량적 방법이 결여되어 있음을 식별한다.
수학적 해석
본 논문은 최적화 과정 전반에 걸쳐 알고리즘이 얼마나 잘 수행되는지 정량화하기 위해 안정성-최적성(SO) 지표를 도입한다. 총 $T$번의 최적화 단계에 대해, 단계 $t$에서의 솔루션 평가를 $f(x_t)$라고 할 때, 지표는 다음과 같이 정의된다:
$$SO = \frac{2 \cdot OI(t) \cdot SI(t)}{SI(t) + OI(t)}$$
여기서:
* 최적성 지표(OI): $OI(t) = \frac{S}{S_1}$, 여기서 $S = \sum_{t=1}^T f(x_t)$이고 $S_1 = T \cdot f(x^*_{OFF})$이다. 이는 알고리즘의 성능 곡선 아래 면적과 기준선(오프라인 데이터셋의 최적 솔루션) 아래 면적의 비율을 측정한다.
* 안정성 지표(SI): $SI(t) = \frac{S}{S_2}$, 여기서 $S_2 = T \cdot \max_t f(x_t)$이다. 이는 알고리즘의 성능이 지금까지 찾은 최적 솔루션과 얼마나 밀접하게 일치하는지를 측정한다.
저자들은 또한 사용자가 최적화 과정의 다른 단계에서 최적성이나 안정성 중 하나를 우선시할 수 있도록 하는 가중치 버전 $SO_\omega$를 제안한다.
실험적 증명
저자들은 SOO-Bench를 설계하여 다음과 같이 알고리즘을 '가차 없이' 테스트했다:
1. 데이터 난이도 커스터마이징: 상위 $n\%$(고품질 솔루션 찾기를 더 어렵게 만듦)와 하위 $m\%$(희소성을 증가시킴) 데이터를 제거하여 데이터셋을 생성했다.
2. 다양한 태스크: 위성 궤도 최적화(GTOPX), 산업 설계(CEC), DNA 서열 설계(PROTEIN)와 같은 실제 태스크를 포함했다.
3. 베이스라인 비교: BO-qEI 및 CMA-ES와 같은 고전적 베이스라인에 대해 ARCOO, Tri-mentoring, TTDDEA를 포함한 최신(SOTA) 알고리즘을 테스트했다.
'희생양'(베이스라인 모델)들은 종종 OOD 영역에 매우 민감한 것으로 나타났다. 제공된 결정적인 증거는 일부 알고리즘(ARCOO 등)은 에너지 기반 모델을 사용하여 위험을 억제함으로써 안정적인 성능을 유지하는 반면, 다른 알고리즘(DE-PF, DE-SPF 등)은 낮은 SO 값을 보여 실행 불가능한 영역에 자주 빠지거나 정체됨을 나타낸다.
향후 개발을 위한 토론 주제
- 동적 가중치: 저자들은 $SO_\omega$에 대해 선형적으로 감소하는 가중치 함수 $\omega(t)$를 사용한다. 대리 모델의 불확실성을 감지하고 실시간으로 최적성과 안정성 사이의 우선순위를 전환하는 적응형 가중치 메커니즘을 개발할 수 있을까?
- OOD를 넘어서: 문제의 근본적인 물리적 법칙이나 제약 조건이 시간이 지남에 따라 변할 수 있는 오프라인 데이터셋의 '개념 드리프트(concept drift)'를 처리하도록 SOO-Bench를 어떻게 확장할 수 있을까?
- 제약 조건 처리: 본 논문은 현재 방법들이 엄격한 제약 조건으로 어려움을 겪고 있다고 지적한다. 향후 연구에서는 알고리즘이 지나치게 보수적이 되어 정체되는 것을 방지하기 위해 '소프트' 제약 조건 만족을 대리 모델 학습에 통합하는 방법을 탐구할 수 있다.
전반적으로, 이 논문은 평가 메트릭 측면에서 다소 '무법지대'였던 분야에 꼭 필요한 엄격한 프레임워크를 제공한다.
 Table 2. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at t = 50 during the optimization process, which consists of a total of T = 150 optimization steps. In this case, 25% of the values are missing near the worst value and another 25% near the optimal value
Table 2. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at t = 50 during the optimization process, which consists of a total of T = 150 optimization steps. In this case, 25% of the values are missing near the worst value and another 25% near the optimal value
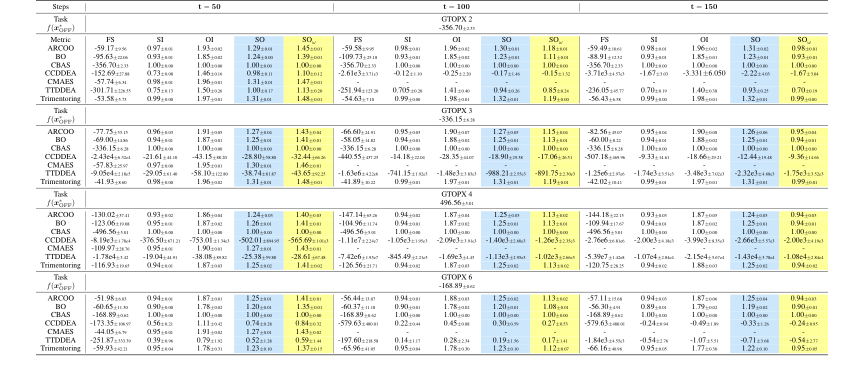 Table 5. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at the final step of specific optimization steps (i.e., t = 50, 100, 150). The symbol "-“ means that the algorithm cannot complete the corresponding task within 24 hours. In this case, 0% of the values are missing near the worst value and another 50% near the optimal value
Table 5. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations are averaged over eight runs. f(x∗ OFF) represents the optimal objective function value in the offline dataset. FS (i.e., final score) refers to the function value found by an offline optimization algorithm at the final step of specific optimization steps (i.e., t = 50, 100, 150). The symbol "-“ means that the algorithm cannot complete the corresponding task within 24 hours. In this case, 0% of the values are missing near the worst value and another 50% near the optimal value
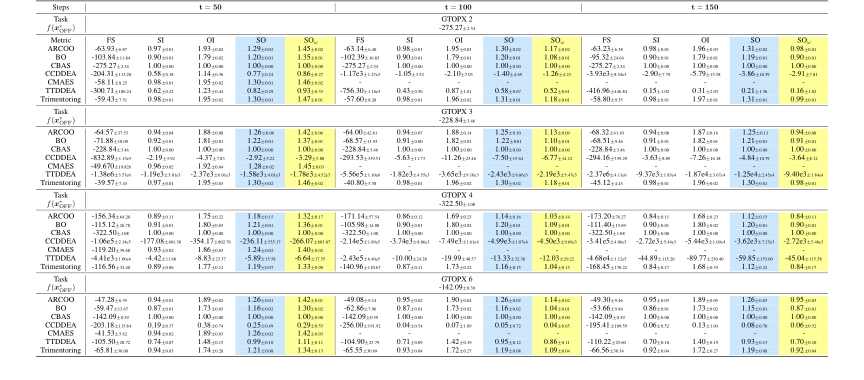 Table 6. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations. In this case, 0% of the values are missing near the worst value and another 40% near the optimal value. Details are the same as Table 5
Table 6. Overall results for GTOPX unconstrained tasks with 128 solutions and 100th percentile evaluations. In this case, 0% of the values are missing near the worst value and another 40% near the optimal value. Details are the same as Table 5
다른 분야와의 동형성(Isomorphisms)
구조적 골격
본 논문은 제한적이고 비대표적인 과거 데이터셋에서 작동할 때 블랙박스 최적화 알고리즘의 안정성과 최적성을 정량화하는 표준화된 평가 프레임워크를 도입한다.