Hybrid Graph Mamba: 非ユークリッド的潜在能力の解放による高精度ポリープセグメンテーション
Colorectal polyp segmentation can assist doctors in screening colonoscopy images, which is crucial for the prevention of colorectal cancer.
背景と学術的系譜
大腸ポリープのセグメンテーションは、大腸内視鏡検査における医師の診断支援を主目的とした、医療画像解析における極めて重要なタスクである。その究極的な目標は、世界的にがん関連死の主要な原因となっている大腸がん(CRC)の予防にある。ポリープは、がんへと進行する可能性のある大腸内の小さな隆起であり、その早期かつ正確な検出は極めて重要である。
歴史的に、内視鏡画像におけるポリープの特定および輪郭抽出は、医師による手動作業に依存してきた。このアプローチは標準的ではあるものの、いくつかの重大な欠点を抱えていた。極めて時間を要し、労働集約的であるだけでなく、主観性が強く、同一画像であっても医師によって解釈が異なる可能性があった。このような主観性と膨大な画像枚数は、しばしば見落としを招き、患者にとって深刻な結果をもたらす要因となっていた。
こうした人間による限界を克服するため、自動ポリープセグメンテーション技術が登場した。初期の試みは「ハンドクラフト特徴量」に依存しており、エンジニアがポリープに関連する特定のパターン、形状、テクスチャを認識するためのアルゴリズムを手動で設計していた。しかし、これらの手法はポリープの複雑かつ多様な外観を捉える能力に限界があり、しばしば高い偽陽性率や見落としを引き起こしていた。
ディープラーニングの出現は飛躍的な進歩をもたらし、モデルがデータから直接、より包括的かつ正確な特徴量を学習することを可能にした。しかし、こうした進歩にもかかわらず、本論文が直接的に取り組むいくつかの根本的な限界、すなわち「ペインポイント」が依然として存在している。
- 非ユークリッド的特徴量の軽視: 既存のディープラーニング手法の多くは、ポリープの単純な形状、サイズ、テクスチャといった「ユークリッド的特徴量」に焦点を当ててきた。しかし、ポリープと周囲組織との間のより複雑な幾何学的・位相的関係を記述する「非ユークリッド的特徴量」は、大部分が無視されてきた。ポリープそのものだけでなく、それがどのように大腸壁と接続されているか、その不規則な表面、あるいは周囲のひだとの相互作用を想像されたい。これらの関係的特徴量は正確なセグメンテーションに不可欠であるが、これまで見過ごされがちであった。
- 非ユークリッド構造に対する特徴量融合の非効率性: 非ユークリッド的特徴量は一様ではなく、画像内の領域(ポリープ内部、エッジ、背景など)によって大きく異なる。従来の特徴量結合手法はすべての領域を一様に扱う傾向があり、非ユークリッドデータに存在する地域的な差異や特有の位相構造を考慮できていなかった。その結果、貴重なコンテキスト情報が失われるか、不適切に統合されることとなった。
- 低次特徴量の過小評価と特徴量ギャップの解消: ディープラーニングモデルは通常、複数のレベルで特徴量を抽出する。「低次」特徴量はエッジやテクスチャといった微細な詳細を捉え、「高次」特徴量はより広範な意味情報(例:「これは確実にポリープである」)を捉える。既存の手法は、これらの低次詳細を十分に活用できていないか、高次の意味情報との効果的な結合に苦慮しており、境界線の描出精度や全体的なセグメンテーション精度の低下を招いていた。
これら3つの課題は、著者らがHybrid Graph Mamba (HGM) モデルを開発する核心的な動機であり、より正確なポリープセグメンテーションのために非ユークリッド的特徴量の潜在能力を解放することを目指している。
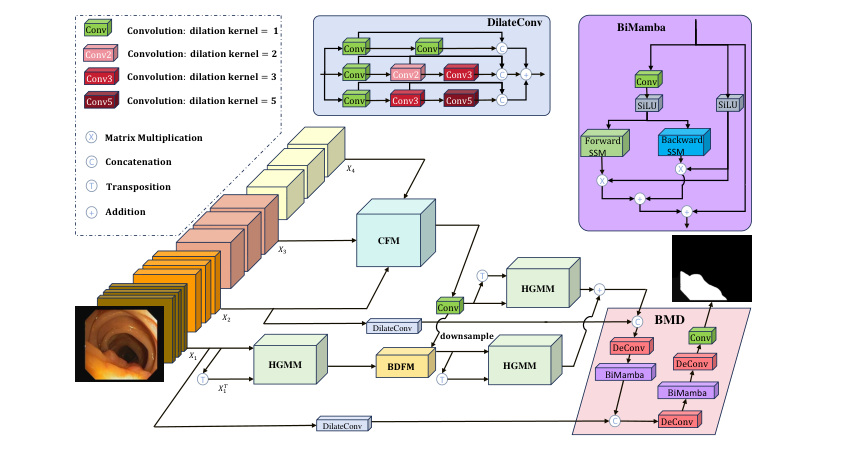 Figure 1. Overall architecture of HGM. Our model consists of a pyramid vision trans- former, a CFM, three HGMMs, a BDFM, and a BMD
Figure 1. Overall architecture of HGM. Our model consists of a pyramid vision trans- former, a CFM, three HGMMs, a BDFM, and a BMD
問題定義と制約
核心的な問題定式化とジレンマ
出発点(入力): モデルは、サイズ、形状、テクスチャが多様で、周囲の大腸組織に対して境界が曖昧なポリープを含む生の内視鏡画像を受け取る。
望ましい終着点(出力): 背景からポリープ領域を正確に分離し、グローバルな意味的コンテキストと微細な境界詳細の両方を捉えた、精密なバイナリセグメンテーションマスク。
欠落したリンク: 根本的なギャップは、従来のディープラーニングアーキテクチャが「ユークリッド的特徴量」(局所的なテクスチャと形状)と「非ユークリッド的特徴量」(ポリープと周囲組織の間の複雑な位相的・幾何学的関係)を同時に捉える能力の欠如にある。標準的なCNNやTransformerは局所的またはグローバルなパターンには優れているが、生物学的組織に固有の不規則なグラフ状の構造的依存関係をモデル化することにはしばしば失敗する。
ジレンマ(トレードオフ): 研究者は「表現のボトルネック」に直面している。グローバルな意味情報(高次特徴量)を捉えるモデルの容量を増やすと、通常、空間解像度と境界精度(低次特徴量)が失われる。逆に、高解像度の詳細のみに焦点を当てると、グローバルなコンテキストが欠如し、背景ノイズをポリープと誤認する原因となる。
厳しい制約:
1. 位相的複雑性: ポリープは単純なグリッド構造に従わず、その境界は極めて不規則であるため、標準的な畳み込みカーネルでは「非ユークリッド的」な幾何学的関係を捉えるには不十分である。
2. 特徴量の一様性: 既存の融合手法の多くは、すべての特徴量レベル(低次詳細対高次意味情報)を同一の数学的重みで扱い、内部、エッジ、背景領域の異なる役割を考慮できていない。
3. 計算効率: グラフベースの演算や複雑なアテンションメカニズムの実装は、しばしば法外なメモリオーバーヘッドを招き、臨床現場で求められるリアルタイムまたは準リアルタイムのパフォーマンス維持を困難にする。著者らは、高解像度の医療画像において完全結合グラフは計算上実行不可能であるため、GCNの計算を扱いやすくするための疎な隣接行列を設計する必要があった。
解法の数学的解釈
著者らは、Mamba(状態空間モデル)とグラフ畳み込みネットワーク(GCN)を統合したHybrid Graph Mamba (HGM)を提案することで、このギャップを埋めている。
-
Quad-directional Mamba (QM): 標準的な逐次処理の限界に対処するため、著者らは4方向から特徴量を抽出するクアッドディレクショナル・アプローチを採用している。これにより、標準的なTransformerの二次的な計算量とは対照的に、線形計算量を維持しつつ画像内の長距離依存関係を捉えることが可能となる。核心的な演算は以下のように定義される。
$$ \text{BiMamba}(x) = \text{RS}(x + x' \text{SSM}_F(x'') + x' \text{SSM}_B(x'')) $$
ここで、$x'$ および $x''$ は入力の非線形変換であり、$\text{SSM}_F$ および $\text{SSM}_B$ は順方向および逆方向の状態空間モデルを表す。 -
非ユークリッド的特徴量抽出: 非ユークリッド的トポロジーを明示的にモデル化するため、著者らは連結された方向性特徴量をGCNに入力する。Hybrid Graph Mamba Module (HGMM) の出力は以下のように定義される。
$$\text{HGMM}(X) = \text{GCN}([X_F, X_B, X_F^\top, X_B^\top], A) + X_M + X_M^\top + X$$
ここで、$A$ は計算負荷を軽減しつつ構造的関係を捉えるために、特定の箇所(32単位ごと)のみを1に設定した疎な隣接行列である。 -
Boundary Discrimination Fusion (BDFM): 融合のジレンマを解決するため、著者らは高次特徴量を処理して初期セグメンテーションマップを生成し、それを用いて内部、エッジ、背景領域のそれぞれに対して個別の特徴量マップを導出する。これらはテンソル $U$ に平坦化され、一連の畳み込みを通じて低次特徴量 $X'$ と融合される。
$$X_{\text{BDFM}} = \text{Conv}([\text{RS}(\text{Conv}(UX'))(\text{Conv}(UX')\text{Conv}(X')), \text{RS}(X')])$$
なぜこのアプローチか
著者らは、主に標準的な畳み込みニューラルネットワーク(CNN)や初期のTransformerベースの手法に基づく既存のSOTA手法が、以下の3つの主要な限界により不十分であると認識した。
- 非ユークリッド的特徴量の軽視: 多くの手法はポリープの形状やテクスチャといった「ユークリッド的特徴量」のみに焦点を当てていた。しかし、ポリープと周囲組織との間の幾何学的・位相的関係である「非ユークリッド的特徴量」は大部分が無視されていた。
- 領域的差異に対する特徴量融合の非効率性: 非ユークリッド的特徴量は一様ではなく、画像内の領域(ポリープ内部、エッジ、背景など)によって大きく異なる。既存の特徴量融合技術はすべての特徴量を一様に扱うことが多く、これらの重要な領域的差異を考慮できていなかった。
- 低次特徴量の過小評価とレベル間のギャップ: 従来の手法は、低次の詳細を十分に活用できていないか、融合過程において低次と高次の特徴量間の情報ギャップを効果的に埋めることに苦慮しており、境界のぼやけや小さなポリープの見落としを招いていた。
比較優位性(ベンチマークの論理)
Hybrid Graph Mamba (HGM) 手法は、特定された欠点に直接対処することで定性的な優位性を提供する。
- 明示的な非ユークリッド的特徴量抽出: グリッド状(ユークリッド的)データ上で動作する標準的なCNNとは異なり、HGMはHybrid Graph Mamba Module (HGMM) 内にグラフ畳み込みネットワーク(GCN)を組み込んでいる。GCNはグラフ構造化データを処理するために特別に設計されており、HGMが非ユークリッド的な幾何学的・位相的関係を明示的にモデル化し抽出することを可能にする。
- 領域を意識したマルチスケール融合: HGMは、すべての特徴量を一様に扱わないBoundary Discrimination Fusion Module (BDFM) を導入している。その代わり、初期セグメンテーションマップを処理して、内部、エッジ、背景領域のそれぞれに対して個別の特徴量マップを導出する。
- Mambaによる効率的なマルチスケール特徴量集約: Mamba(具体的にはBiMambaブロック)の統合は、シーケンスモデリングのための強力なメカニズムを提供する。Mambaの状態空間モデル(SSM)アーキテクチャは、シーケンス長に対して線形計算量を提供し、標準的なTransformerにおける自己注意機構の二次的な計算量と比較して大きな利点となる。
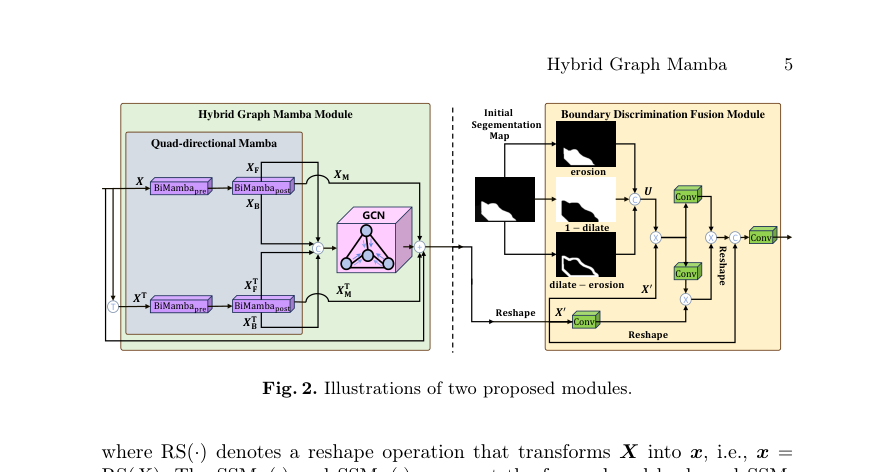 Figure 2. Illustrations of two proposed modules
Figure 2. Illustrations of two proposed modules
数学的・論理的メカニズム
Hybrid Graph Mamba (HGM) モデルは、非ユークリッド的位相構造を標準的なユークリッド的特徴量とともに明示的にモデル化することで、医療画像解析における従来のディープラーニングの限界に対処している。
マスター方程式
非ユークリッド的特徴量抽出の主要エンジンとして機能するHybrid Graph Mamba Module (HGMM) の核心的な論理は、以下のように定義される。
$$\text{HGMM}(\mathbf{X}) = \text{GCN}([\mathbf{X}_F, \mathbf{X}_B, \mathbf{X}_F^\top, \mathbf{X}_B^\top], \mathbf{A}) + \mathbf{X}_M + \mathbf{X}_M^\top + \mathbf{X}$$
方程式の分解
- $[\mathbf{X}_F, \mathbf{X}_B, \mathbf{X}_F^\top, \mathbf{X}_B^\top]$: これは4つの方向性特徴量マップの連結である。
- $\mathbf{A}$: 隣接行列であり、グラフ構造を定義する。著者らは、疎でありながら意味のある接続性を強制するために、特定の値を1(32単位ごと)に設定している。
- $\text{GCN}(\cdot, \mathbf{A})$: この演算子はグラフ畳み込みを実行し、$\mathbf{A}$ によって定義された隣接ノードから情報を集約する。
- $\mathbf{X}_M + \mathbf{X}_M^\top$: これらはポストBiMambaブロックからの残差出力であり、逐次情報を保持する。
- $+\mathbf{X}$: これは最終的な残差接続であり、勾配消失問題を防止する。
結果、限界、および結論
著者らは、8つの最先端(SOTA)モデルに対し、5つのベンチマークデータセット(CVC-300, ClinicDB, Kvasir, ColonDB, ETIS)を用いて、自らのアーキテクチャを「容赦なく」テストした。
HGMの優位性の決定的な証拠は、すべてのデータセットにわたる一貫したパフォーマンスに見られる。HGMは全体的な平均(Dice: 0.887, IoU: 0.825)で最高の結果を達成した。表2のアビレーションスタディは「決定的な証拠(smoking gun)」として機能し、BMD、QM、GCN、BDFMの各コンポーネントを追加することでDiceおよびIoU指標が段階的に向上することを証明しており、アーキテクチャの選択が単なる偶然ではなく数学的に妥当であることを裏付けている。
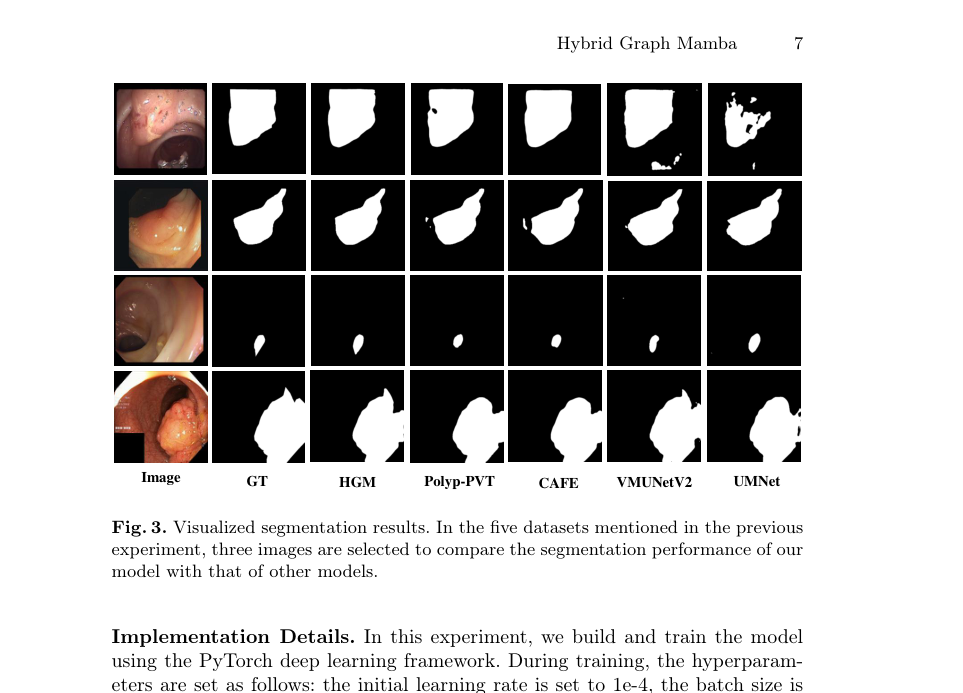 Figure 3. Visualized segmentation results. In the five datasets mentioned in the previous experiment, three images are selected to compare the segmentation performance of our model with that of other models
Figure 3. Visualized segmentation results. In the five datasets mentioned in the previous experiment, three images are selected to compare the segmentation performance of our model with that of other models
他分野との同型性(Isomorphisms)
構造的骨格
本論文は、多方向状態空間シーケンスモデリングとグラフベースの位相的関係マッピングを統合し、局所的な幾何学的特徴量とグローバルな意味的コンテキストを統一された高忠実度表現へと合成するメカニズムを提示している。