Hybrid Graph Mamba: раскрытие неевклидова потенциала для точной сегментации полипов
Сегментация колоректальных полипов является критически важной задачей в медицинской визуализации, направленной прежде всего на поддержку врачей при проведении колоноскопии.
Общие сведения и академический контекст
Сегментация колоректальных полипов является критически важной задачей в медицинской визуализации, направленной прежде всего на поддержку врачей при проведении колоноскопии. Конечная цель заключается в профилактике колоректального рака (CRC), который является одной из ведущих причин смертности от онкологических заболеваний во всем мире. Полипы представляют собой небольшие новообразования в толстой кишке, способные перерождаться в злокачественные опухоли, поэтому их раннее и точное обнаружение имеет первостепенное значение.
Исторически процесс идентификации и оконтуривания полипов на изображениях колоноскопии выполнялся врачами вручную. Этот подход, несмотря на свою стандартность, обладает рядом существенных недостатков. Он крайне трудоемок, требует значительных временных затрат и характеризуется высокой степенью субъективности, вследствие чего разные специалисты могут интерпретировать одно и то же изображение по-разному. Подобная субъективность и огромный объем данных часто приводят к пропускам патологий, что может иметь серьезные последствия для пациентов.
Для преодоления этих ограничений были разработаны методы автоматизированной сегментации полипов. Ранние попытки опирались на «ручные признаки» (handcrafted features), где инженеры вручную проектировали алгоритмы для распознавания специфических паттернов, форм или текстур, ассоциированных с полипами. Однако эти методы были весьма ограничены в своей способности улавливать сложный и вариативный внешний вид полипов, что часто приводило к высокому уровню ложноположительных результатов или пропуску новообразований.
Появление deep learning ознаменовало значительный качественный скачок, позволив моделям обучаться более комплексным и точным признакам непосредственно на данных. Несмотря на эти достижения, сохранился ряд фундаментальных ограничений, или «болевых точек», которые непосредственно рассматриваются в данной работе:
- Игнорирование неевклидовых признаков: Большинство существующих методов deep learning фокусируются преимущественно на «евклидовых признаках», таких как простая форма, размер и текстура полипа. При этом они в значительной степени игнорируют «неевклидовы признаки», описывающие более сложные геометрические и топологические взаимосвязи между полипом и окружающими тканями. Речь идет не только о самом полипе, но и о его связи со стенкой кишки, его неровной поверхности и взаимодействии с близлежащими складками. Эти реляционные признаки критически важны для точной сегментации, но зачастую остаются без внимания.
- Неэффективная агрегация признаков для неевклидовых структур: Неевклидовы признаки неоднородны; они существенно варьируются в разных областях изображения (например, внутренняя часть полипа, его границы или фон). Предыдущие методы объединения признаков часто обрабатывали все области унифицированно, не учитывая региональные различия и уникальные топологические структуры, присутствующие в неевклидовых данных. Это приводило к потере или некачественной интеграции ценной контекстной информации.
- Недостаточное использование низкоуровневых признаков и разрыв в представлении данных: Модели deep learning обычно извлекают признаки на нескольких уровнях: «низкоуровневые» признаки фиксируют мелкие детали, такие как края и текстуры, в то время как «высокоуровневые» признаки фиксируют более широкую семантическую информацию (например, «это определенно полип»). Существующие методы часто не в полной мере используют эти низкоуровневые детали или испытывают трудности с их эффективным объединением с высокоуровневой семантикой, что приводит к менее точному выделению границ и сегментации в целом.
Эти три проблемы в совокупности представляют собой основную мотивацию для разработки авторами модели Hybrid Graph Mamba (HGM), направленной на раскрытие потенциала неевклидовых признаков для более точной сегментации полипов.
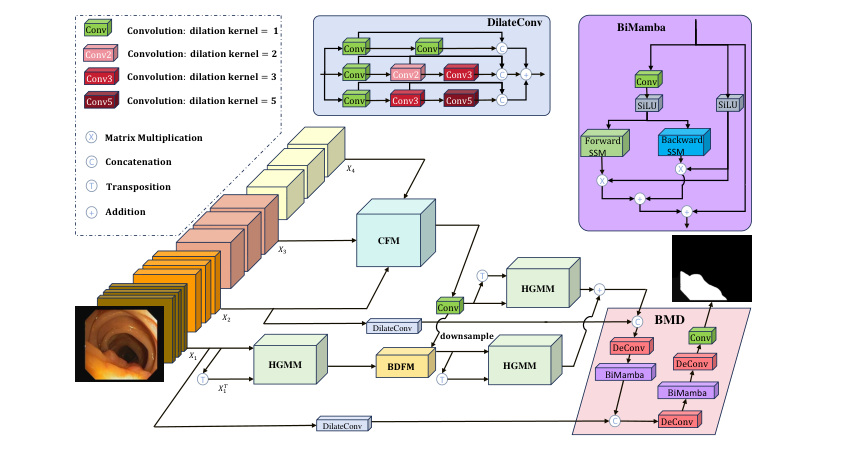 Figure 1. Overall architecture of HGM. Our model consists of a pyramid vision trans- former, a CFM, three HGMMs, a BDFM, and a BMD
Figure 1. Overall architecture of HGM. Our model consists of a pyramid vision trans- former, a CFM, three HGMMs, a BDFM, and a BMD
Постановка задачи и ограничения
Формулировка основной проблемы и дилемма
Исходные данные (Input): Модель получает необработанные изображения колоноскопии, содержащие полипы различных размеров, форм и текстур, часто скрытые из-за неоднозначных границ на фоне окружающих тканей толстой кишки.
Желаемый результат (Output): Точная бинарная маска сегментации, которая четко отделяет область полипа от фона, фиксируя как глобальный семантический контекст, так и мелкозернистые детали границ.
Отсутствующее звено: Фундаментальный разрыв заключается в неспособности традиционных архитектур deep learning одновременно фиксировать евклидовы признаки (локальная текстура и форма) и неевклидовы признаки (сложные топологические и геометрические взаимосвязи между полипом и окружающими тканями). Хотя стандартные CNN или Transformers превосходно справляются с локальными или глобальными паттернами, они часто не способны моделировать нерегулярные, графоподобные структурные зависимости, присущие биологическим тканям.
Дилемма (Компромисс): Исследователи сталкиваются с «узким местом репрезентации» (representation bottleneck). Увеличение способности модели фиксировать глобальную семантическую информацию (высокоуровневые признаки) обычно приводит к потере пространственного разрешения и точности границ (низкоуровневые признаки). И наоборот, фокусировка исключительно на деталях высокого разрешения часто приводит к отсутствию глобального контекста, заставляя модель ошибочно принимать фоновый шум за полипы.
Жесткие ограничения:
1. Топологическая сложность: Полипы не следуют простым сеточным структурам; их границы крайне нерегулярны, что делает стандартные сверточные ядра недостаточными для фиксации «неевклидовых» геометрических взаимосвязей.
2. Однородность признаков: Большинство существующих методов слияния придают всем уровням признаков (низкоуровневые детали против высокоуровневой семантики) одинаковый математический вес, не учитывая различные роли внутренних, граничных и фоновых областей.
3. Вычислительная эффективность: Реализация графовых операций или сложных механизмов внимания часто вносит непомерные накладные расходы по памяти, что затрудняет поддержание производительности в реальном или близком к реальному времени, необходимой для клинических условий. Авторы разработали разреженную матрицу смежности, чтобы сделать вычисления GCN управляемыми, так как полносвязный граф был бы вычислительно невозможен для медицинских изображений высокого разрешения.
Математическая интерпретация решения
Авторы преодолевают этот разрыв, предлагая Hybrid Graph Mamba (HGM), которая интегрирует Mamba (модель пространства состояний) с графовыми сверточными сетями (GCN).
-
Четырехнаправленная Mamba (QM): Чтобы устранить ограничение стандартной последовательной обработки, авторы используют четырехнаправленный подход для извлечения признаков. Это позволяет модели фиксировать долгосрочные зависимости в изображении при сохранении линейной сложности, в отличие от квадратичной сложности стандартных Transformers. Основная операция определяется как:
$$ \text{BiMamba}(x) = \text{RS}(x + x' \text{SSM}_F(x'') + x' \text{SSM}_B(x'')) $$
где $x'$ и $x''$ — нелинейные преобразования входных данных, а $\text{SSM}_F$ и $\text{SSM}_B$ представляют собой прямое и обратное модели пространства состояний. -
Извлечение неевклидовых признаков: Для явного моделирования неевклидовой топологии авторы подают конкатенированные направленные признаки в GCN. Выход модуля Hybrid Graph Mamba Module (HGMM) определяется как:
$$\text{HGMM}(X) = \text{GCN}([X_F, X_B, X_F^\top, X_B^\top], A) + X_M + X_M^\top + X$$
Здесь $A$ — разреженная матрица смежности, в которой только определенные позиции (каждые 32 единицы) установлены в единицу для снижения вычислительной нагрузки при сохранении структурных взаимосвязей. -
Boundary Discrimination Fusion (BDFM): Для решения дилеммы слияния авторы обрабатывают высокоуровневые признаки для генерации начальной карты сегментации, которая затем используется для получения отдельных карт признаков для внутренних, граничных и фоновых областей. Они преобразуются в тензор $U$ и объединяются с низкоуровневыми признаками $X'$ посредством серии сверток:
$$X_{\text{BDFM}} = \text{Conv}([\text{RS}(\text{Conv}(UX'))(\text{Conv}(UX')\text{Conv}(X')), \text{RS}(X')])$$
Почему этот подход
Авторы пришли к выводу, что существующие SOTA-методы, основанные преимущественно на стандартных сверточных нейронных сетях (CNN) и даже некоторых ранних подходах на базе Transformer, были недостаточны из-за трех ключевых ограничений:
- Игнорирование неевклидовых признаков: Большинство методов фокусировались исключительно на «евклидовых признаках», таких как форма и текстура полипов. Однако геометрические и топологические взаимосвязи между полипом и окружающими тканями — «неевклидовы признаки» — в значительной степени игнорировались.
- Неэффективное слияние признаков для региональных различий: Неевклидовы признаки неоднородны; они существенно варьируются в разных областях изображения. Существующие методы слияния часто обрабатывали все признаки унифицированно, не учитывая эти важные региональные различия.
- Недостаточное использование низкоуровневых признаков и разрыв между уровнями: Традиционные методы часто не в полной мере использовали низкоуровневые детали или испытывали трудности с эффективным преодолением информационного разрыва между низко- и высокоуровневыми признаками в процессе слияния, что приводило к размытым границам или пропуску мелких полипов.
Сравнительное преимущество (Логика бенчмаркинга)
Метод Hybrid Graph Mamba (HGM) предлагает качественное превосходство за счет прямого устранения выявленных недостатков:
- Явное извлечение неевклидовых признаков: В отличие от стандартных CNN, работающих с сеточными (евклидовыми) данными, HGM включает графовые сверточные сети (GCN) в состав своего модуля Hybrid Graph Mamba Module (HGMM). GCN специально разработаны для обработки графоструктурированных данных, что позволяет HGM явно моделировать и извлекать неевклидовы геометрические и топологические взаимосвязи.
- Регионально-ориентированное многомасштабное слияние: HGM внедряет модуль Boundary Discrimination Fusion Module (BDFM), который не обрабатывает все признаки унифицированно. Вместо этого он использует начальную карту сегментации для получения отдельных карт признаков для внутренних, граничных и фоновых областей.
- Эффективная многомасштабная агрегация признаков с помощью Mamba: Интеграция Mamba (в частности, блоков BiMamba) предоставляет мощный механизм для моделирования последовательностей. Архитектура State Space Model (SSM) в Mamba обеспечивает линейную сложность относительно длины последовательности, что является значительным преимуществом по сравнению с квадратичной сложностью self-attention в стандартных Transformers.
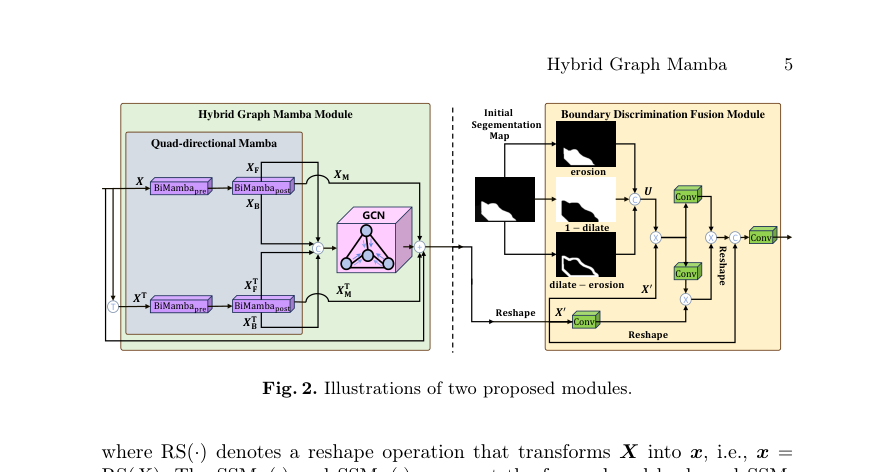 Figure 2. Illustrations of two proposed modules
Figure 2. Illustrations of two proposed modules
Математический и логический механизм
Модель Hybrid Graph Mamba (HGM) решает ограничения традиционного deep learning в медицинской визуализации путем явного моделирования неевклидовых топологических структур наряду со стандартными евклидовыми признаками.
Основное уравнение
Основная логика модуля Hybrid Graph Mamba Module (HGMM), который служит первичным механизмом для извлечения неевклидовых признаков, определяется как:
$$\text{HGMM}(\mathbf{X}) = \text{GCN}([\mathbf{X}_F, \mathbf{X}_B, \mathbf{X}_F^\top, \mathbf{X}_B^\top], \mathbf{A}) + \mathbf{X}_M + \mathbf{X}_M^\top + \mathbf{X}$$
Разбор уравнения
- $[\mathbf{X}_F, \mathbf{X}_B, \mathbf{X}_F^\top, \mathbf{X}_B^\top]$: Конкатенация четырех направленных карт признаков.
- $\mathbf{A}$: Матрица смежности, определяющая структуру графа. Авторы устанавливают определенные значения в 1 (каждые 32 единицы) для обеспечения разреженной, но значимой связности.
- $\text{GCN}(\cdot, \mathbf{A})$: Оператор графовой свертки, агрегирующий информацию от соседних узлов, определенных матрицей $\mathbf{A}$.
- $\mathbf{X}_M + \mathbf{X}_M^\top$: Остаточные выходы из блоков post-BiMamba, сохраняющие последовательную информацию.
- $+\mathbf{X}$: Финальное остаточное соединение (residual connection), предотвращающее проблему затухания градиента.
Результаты, ограничения и заключение
Авторы провели всестороннее тестирование своей архитектуры на восьми SOTA-моделях с использованием пяти эталонных наборов данных (CVC-300, ClinicDB, Kvasir, ColonDB и ETIS).
Убедительным доказательством превосходства HGM является стабильная производительность на всех наборах данных. HGM достигает наилучшего среднего показателя (Dice: 0.887, IoU: 0.825). Абляционное исследование, представленное в Таблице 2, служит «решающим аргументом», доказывающим, что добавление каждого компонента — BMD, QM, GCN и BDFM — инкрементально улучшает метрики Dice и IoU, подтверждая, что архитектурные решения являются не случайными, а математически обоснованными.
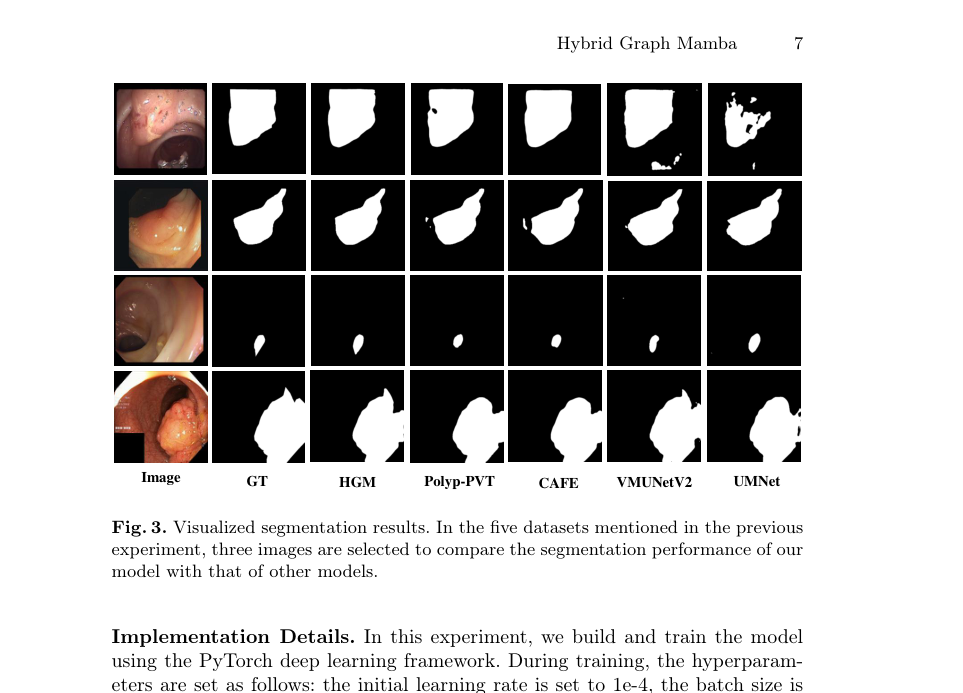 Figure 3. Visualized segmentation results. In the five datasets mentioned in the previous experiment, three images are selected to compare the segmentation performance of our model with that of other models
Figure 3. Visualized segmentation results. In the five datasets mentioned in the previous experiment, three images are selected to compare the segmentation performance of our model with that of other models