MeDi: диффузионные модели с метаданными для снижения предвзятости при классификации опухолей
Проблема «shortcut learning» в медицинской сфере применения ИИ обусловлена тем, что модели глубокого обучения зачастую слишком эффективно выявляют закономерности — настолько эффективно, что они фокусируются на...
История и академическая преемственность
Проблема «shortcut learning» в медицинской сфере применения ИИ обусловлена тем, что модели глубокого обучения зачастую слишком эффективно выявляют закономерности — настолько эффективно, что они фокусируются на нерелевантном «шуме» окружающей среды, а не на фактическом биологическом сигнале. В гистопатологии это означает, что модель может научиться идентифицировать опухоль на основе специфического цветового оттенка сканера или протокола окрашивания в конкретной клинике, а не на основе клеточной морфологии самого новообразования. Исторически эта проблема проявилась при переходе ИИ от контролируемых лабораторных наборов данных к реальному клиническому внедрению, где гетерогенность данных является нормой. Фундаментальная «болевая точка» заключается в том, что при смещении обучающей выборки (например, когда все образцы определенного типа рака предоставлены одной больницей) модель создает ложную корреляцию между метаданными (клиникой) и целевой переменной (типом рака). В результате при столкновении с данными из другой клиники модель демонстрирует катастрофическое снижение производительности, поскольку ее «shortcut» перестает существовать.
Интуитивные доменные термины
- Shortcut Learning: Представьте студента, который сдает экзамен по математике не путем изучения алгебры, а путем запоминания того, что ответом на каждый вопрос на первой странице является «5». Студент идеально справляется с пробным тестом, но проваливает реальный экзамен, так как вопросы в нем расположены в другом порядке.
- Diffusion Model: Рассматривайте это как работу скульптора в обратном порядке. Вы начинаете с глыбы случайного, зашумленного мрамора (random noise) и, руководствуясь набором инструкций (метаданные/метки классов), постепенно отсекаете шум, пока не проявится четкая, детализированная статуя (медицинское изображение).
- Subpopulation Shift: Это подобно обучению повара готовить только из ингредиентов с конкретного локального рынка. Если внезапно перевезти этого повара в другую страну с совершенно иными продуктами, он столкнется с трудностями при приготовлении того же блюда, поскольку не научился адаптироваться к новым, незнакомым компонентам.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| $\alpha_k$ | $k$-й атрибут метаданных (например, местоположение клиники, раса пациента). |
| $d_e$ | Фиксированная размерность обучаемого вектора эмбеддинга для категориальных метаданных. |
| $\mathbf{z}_{\text{site}(i)}$ | Вектор эмбеддинга, представляющий конкретный медицинский центр $i$. |
| $\mathbf{z}_{\text{class}}$ | Вектор эмбеддинга, представляющий подтип заболевания/рака. |
| $\mathbf{z}_{\text{meta},i}$ | Вектор эмбеддинга для $i$-го атрибута метаданных. |
| $\mathbf{z}_t$ | Вектор эмбеддинга временного шага (timestep), используемый в процессе диффузии. |
| $\mathbf{z}_{\text{cond}}$ | Итоговый конкатенированный вектор условий (conditioning vector), используемый для управления генерацией. |
| $\mathbf{z}_{\text{final}}$ | Комбинированный вектор $\mathbf{z}_t + \mathbf{z}_{\text{cond}}$, подаваемый в блоки UNet. |
Математическая интерпретация
Авторы решают проблему смещения путем явного внедрения метаданных в генеративный процесс. Вместо стандартной диффузионной модели, которая изучает только отображение $p(\text{image} \mid \text{class})$, они переопределяют целевую функцию для изучения $p(\text{image} \mid \text{class}, \text{metadata})$.
Это достигается путем создания вектора условий $\mathbf{z}_{\text{cond}}$, который объединяет информацию о классе со всеми релевантными атрибутами метаданных:
$$\mathbf{z}_{\text{cond}} = \text{concat}(\mathbf{z}_{\text{class}}, \mathbf{z}_{\text{meta},1}, \dots, \mathbf{z}_{\text{meta},k}) \in \mathbb{R}^{d_t}$$
Затем этот вектор интегрируется во внутренний процесс шумоподавления UNet путем сложения с эмбеддингом временного шага $\mathbf{z}_t$:
$$\mathbf{z}_{\text{final}} = \mathbf{z}_t + \mathbf{z}_{\text{cond}}$$
Благодаря этому модель вынуждена изучать, как конкретные метаданные (например, уникальный стиль окрашивания в клинике) взаимодействуют с биологическими характеристиками ткани. В процессе инференса пользователь может комбинировать эти условия для генерации синтетических данных для недостаточно представленных или ранее не встречавшихся сочетаний, эффективно балансируя набор данных и вынуждая последующий классификатор игнорировать «shortcuts», основанные на метаданных.
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Исходная точка (входные данные / текущее состояние):
В клинической гистопатологии модели deep learning обучаются на обширных наборах данных (таких как TCGA) для решения диагностических задач, например, субтипирования опухолей. Эти наборы данных по своей природе характеризуются смещением (skewed), поскольку они агрегируют информацию из различных медицинских центров, каждый из которых использует уникальные протоколы окрашивания, аппаратное обеспечение сканеров и обладает специфическими демографическими характеристиками пациентов.
Желаемый результат (целевое состояние):
Целью является создание робастной диагностической модели, способной к генерализации в различных клинических условиях. В частности, авторы стремятся генерировать высокоточные (high-fidelity) синтетические гистопатологические изображения, представляющие недостаточно представленные или вовсе отсутствующие субпопуляции (например, специфический тип рака из медицинского учреждения, не представленного в обучающей выборке). За счет аугментации обучающих данных такими синтетическими образцами модель должна достичь сбалансированного Distribution, эффективно «заполняя» пробелы в данных.
Отсутствующее звено:
Проблема заключается в неспособности стандартных генеративных моделей отделять биологические признаки (заболевание) от вариаций, обусловленных метаданными (эффекты «домена» или «центра»). Когда модель обучается на смещенном наборе данных, она не может провести различие между истинной морфологией опухоли и ложными корреляциями (spurious correlations), привнесенными артефактами визуализации конкретного центра.
Дилемма (компромисс):
Исследователи сталкиваются с классической ловушкой «shortcut learning». Если модель обучается классифицировать опухоли, она часто начинает полагаться на метаданные (например, «этот специфический паттерн окрашивания принадлежит Больнице А») как на прокси-переменную для метки класса. Если принудительно заставить модель игнорировать эти вариации, утрачивается способность генерировать реалистичные, специфичные для конкретного центра изображения. И наоборот, если позволить модели изучать эти вариации, она становится предвзятой и теряет способность к генерализации на новые, ранее не встречавшиеся медицинские центры.
Жесткие реалистичные ограничения:
1. Комбинаторный взрыв: Пространство метаданных огромно. При наличии 626 центров сбора тканей и 32 типов рака потенциальные комбинации ($626 \times 32 = 20,032$) представлены в реальных данных лишь частично. Это делает невозможным полагаться исключительно на сбор данных для покрытия всех сценариев.
2. Ложные корреляции (Spurious Correlations): Данные характеризуются сильным дисбалансом; определенные типы рака в обучающей выборке ассоциированы исключительно с конкретными больницами. Это создает эффект «Умного Ганса» (Clever Hans effect), при котором модель учится ассоциировать уникальный «визуальный стиль» больницы с типом рака, а не с биологическими признаками самой опухоли.
3. Недифференцируемые/дискретные метаданные: Интеграция категориальных метаданных (таких как ID больниц) в непрерывный процесс diffusion требует тщательно разработанной стратегии embedding, чтобы гарантировать, что модель сможет эффективно обусловливать процесс генерации, не допуская коллапса в единственный «модус» (mode) распределения данных.
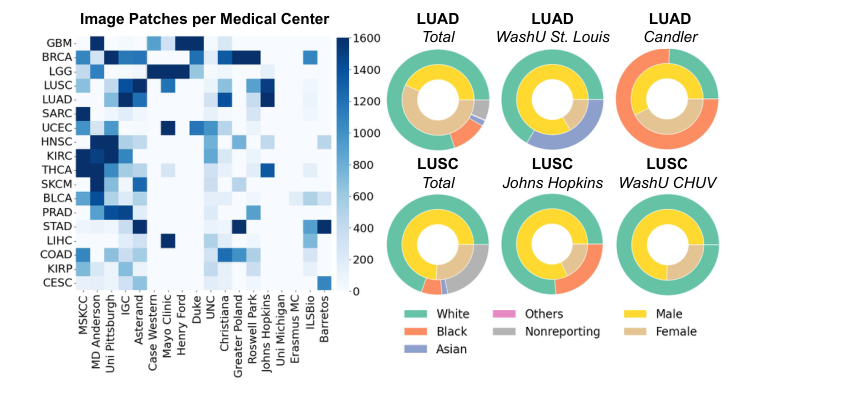 Figure 2. Dataset statistics for TCGA-UT. Left: The number of patches for the 18 largest cancer types (vertical axis) and tissue source sites (horizontal axis), capped at 1,600. Right: Race and gender distributions for the patches of selected cancer types and tissue source sites. The dataset is highly imbalanced across classes, hospitals, and demographics, with many missing or underrepresented metadata combinations
Figure 2. Dataset statistics for TCGA-UT. Left: The number of patches for the 18 largest cancer types (vertical axis) and tissue source sites (horizontal axis), capped at 1,600. Right: Race and gender distributions for the patches of selected cancer types and tissue source sites. The dataset is highly imbalanced across classes, hospitals, and demographics, with many missing or underrepresented metadata combinations
Почему именно этот подход
Основная проблема, рассматриваемая в данной работе, заключается в эффекте «Умного Ганса» (Clever Hans effect) в вычислительной патологии, при котором модели deep learning непреднамеренно начинают полагаться на небиологические метаданные — такие как специфические для конкретных клиник протоколы окрашивания, артефакты сканеров или демографические искажения — вместо анализа морфологии опухоли. Когда модель обучается на датасете, где определенные типы рака коррелируют с конкретными медицинскими учреждениями, она воспринимает эти метаданные как «короткие пути» (shortcuts), что приводит к катастрофическим ошибкам при развертывании в новой клинической среде с иным распределением данных.
Неизбежность выбора
Авторы установили, что стандартные подходы SOTA, включая крупномасштабные foundation models, обученные с помощью self-supervised learning, оказываются недостаточно эффективными, поскольку они имплицитно кодируют эти смещения метаданных в свои latent representations. Если распределение обучающей выборки искажено, модели неизбежно наследуют данное смещение. Авторы пришли к выводу, что для эффективного решения этой проблемы нельзя полагаться на пассивное обучение; необходимо explicitly model метаданные в качестве обусловливающей переменной (conditioning variable).
- Сравнительное преимущество: В отличие от традиционных методов нормализации окрашивания или техник style-transfer (например, CycleGAN), которые пытаются «исправить» изображение, приводя его к каноническому стилю, MeDi рассматривает метаданные как контролируемый параметр. Используя diffusion model, обусловленную как метками классов, так и метаданными (например, Tissue Source Site), фреймворк получает возможность выполнять целенаправленную data augmentation. Он способен осуществлять интерполяцию в пространстве метаданных для балансировки существующих комбинаций или экстраполяцию для генерации синтетических образцов для недостаточно представленных или ранее не встречавшихся субпопуляций. Это структурное преимущество позволяет модели «заполнять» пробелы в распределении обучающих данных, эффективно отделяя метку заболевания от артефактов, специфичных для конкретного медицинского учреждения.
- «Союз» требований и решений: Поставленная задача требует генеративной модели, обладающей одновременно высокой точностью (high-fidelity) и высокой степенью управляемости. Diffusion models являются единственным жизнеспособным решением в данном контексте, поскольку они обеспечивают стабильный итеративный процесс denoising, который может быть легко обусловлен на каждом шаге. Определяя вектор условия $\mathbf{z}_{\text{cond}} = \text{concat}(\mathbf{z}_{\text{class}}, \mathbf{z}_{\text{meta},1}, \dots, \mathbf{z}_{\text{meta},k})$ и внедряя его в residual blocks архитектуры UNet посредством $\mathbf{z}_{\text{final}} = \mathbf{z}_t + \mathbf{z}_{\text{cond}}$, авторы гарантируют, что процесс генерации строго направляется заданными метаданными. Это полностью соответствует необходимости синтеза изображений, которые сохраняют биологическую целостность, демонстрируя при этом специфический «стиль» недостаточно представленного клинического центра.
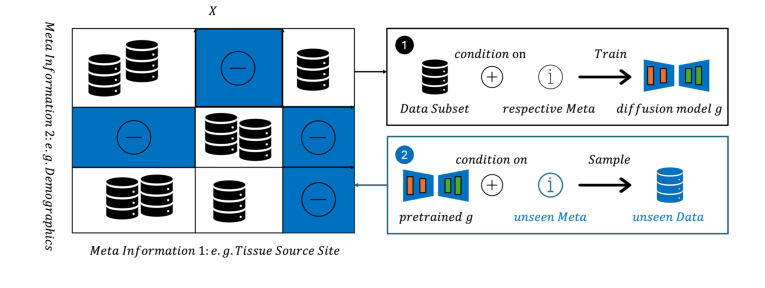 Figure 1. MeDi Training and Inference Framework. During training (1), the model receives real images along with their class labels and metadata. At inference (2), users can condition on arbitrary combinations of class and metadata, enabling the genera- tion of synthetic images for underrepresented subpopulations or unseen subpopulations altogether
Figure 1. MeDi Training and Inference Framework. During training (1), the model receives real images along with their class labels and metadata. At inference (2), users can condition on arbitrary combinations of class and metadata, enabling the genera- tion of synthetic images for underrepresented subpopulations or unseen subpopulations altogether
Математический и логический механизм
Для понимания данной работы необходимо прежде всего освоить концепцию «shortcut learning» в области медицинской AI. При обучении модели классификации опухолей она зачастую непреднамеренно начинает ассоциировать специфические артефакты, связанные с конкретным медицинским учреждением (например, цветовые оттенки окрашивания или шум сканера), с меткой заболевания, вместо того чтобы изучать истинные биологические признаки рака. Это происходит из-за того, что определенные клиники могут предоставлять данные только по специфическим типам рака, что создает ложную корреляцию. Авторы предлагают метод MeDi для устранения подобных корреляций путем явного внедрения метаданных (например, идентификатора медицинского центра) в генеративный процесс, что позволяет модели «декоплировать» (decouple) заболевание от специфического для конкретного центра шума.
Основное уравнение
Ядром фреймворка MeDi является построение вектора кондиционирования (conditioning vector), который направляет процесс шумоподавления (denoising process) диффузионной модели. Итоговый сигнал кондиционирования, подаваемый на UNet, определяется следующим образом:
$$ \mathbf{z}_{\text{final}} = \mathbf{z}_t + \mathbf{z}_{\text{cond}} $$
Где $\mathbf{z}_{\text{cond}}$ определяется как:
$$ \mathbf{z}_{\text{cond}} = \text{concat}(\mathbf{z}_{\text{class}}, \mathbf{z}_{\text{meta},1}, \dots, \mathbf{z}_{\text{meta},k}) \in \mathbb{R}^{d_t} $$
Анализ уравнения
- $\mathbf{z}_t$: Это эмбеддинг временного шага (timestep embedding). Он отражает текущий «уровень шума» в диффузионном процессе. Его роль заключается в информировании модели о том, какая степень шумоподавления необходима на текущем этапе.
- $\mathbf{z}_{\text{class}}$: Это обучаемый эмбеддинг подтипа рака (например, аденокарцинома легкого). Он обеспечивает основное семантическое руководство относительно того, какая биологическая структура должна быть сгенерирована.
- $\mathbf{z}_{\text{meta},i}$: Это обучаемые эмбеддинги для $k$ атрибутов метаданных (например, источник ткани). Их роль заключается в выполнении функции контроллера «стиля» или «домена», принуждая модель изучать специфические визуальные артефакты, ассоциированные с конкретным медицинским учреждением.
- $\text{concat}(\dots)$: Авторы используют конкатенацию для объединения этих различных источников информации в единый вектор. Данный подход предпочтительнее сложения, так как класс и метаданные представляют собой независимые категориальные измерения, которые не должны смешиваться до тех пор, пока модель не обработает их явным образом внутри слоев UNet.
- $\mathbf{z}_{\text{final}}$: Это комбинированный вектор кондиционирования. Добавляя его к $\mathbf{z}_t$, авторы гарантируют, что операция шумоподавления одновременно учитывает как «время» (уровень шума), так и «контекст» (класс + метаданные).
Результаты, ограничения и заключение
Анализ MeDi: Диффузионные модели с метаданными (Metadata-Guided Diffusion Models)
В области вычислительной патологии модели глубокого обучения часто подвержены проблеме «shortcut learning». Поскольку медицинские наборы данных, как правило, собираются в конкретных клинических центрах, они содержат внутренние смещения (biases) — такие как уникальные протоколы окрашивания, артефакты сканеров или демографические перекосы, — которые коррелируют с метками заболеваний. Модель может научиться идентифицировать опухоль не по её биологической морфологии, а по специфическому «виду» гистологических препаратов из конкретного медицинского учреждения. При развертывании в новой среде такие модели демонстрируют низкую эффективность, поскольку опираются на эти ложные корреляции, а не на фундаментальные патологические признаки.
Экспериментальная валидация
Авторы подвергли свою гипотезу строгой проверке, создав сложный сценарий out-of-distribution. Они исключили 30% комбинаций конкретных медицинских центров и расовых групп пациентов, гарантируя, что модель никогда не сталкивалась с данными подгруппами в процессе обучения.
-
Результаты:
-
Fidelity: MeDi достигла более низкого среднего значения Fréchet Inception Distance (FID), равного 37.73, по сравнению с 50.65 у базовой модели CLS, что доказывает: использование метаданных в качестве условия (metadata conditioning) обеспечивает более точный синтез изображений.
-
Downstream Utility: Авторы обучили линейные классификаторы поверх эмбеддингов, полученных с помощью фундаментальной модели (UNI). При тестировании на невидимых ранее подгруппах обучающая выборка, дополненная с помощью MeDi, стабильно превосходила набор, дополненный CLS, по показателю сбалансированной точности (balanced accuracy) в задачах классификации NSCLC и рака матки. Это служит убедительным доказательством того, что MeDi успешно устраняет ложные корреляции, которые обычно снижают эффективность подобных моделей.
-
Авторы наглядно продемонстрировали, что за счет явного моделирования «шума» (метаданных) можно принудительно переключить внимание модели на «сигнал» (патологию), что приводит к созданию более устойчивой и объективной системы.
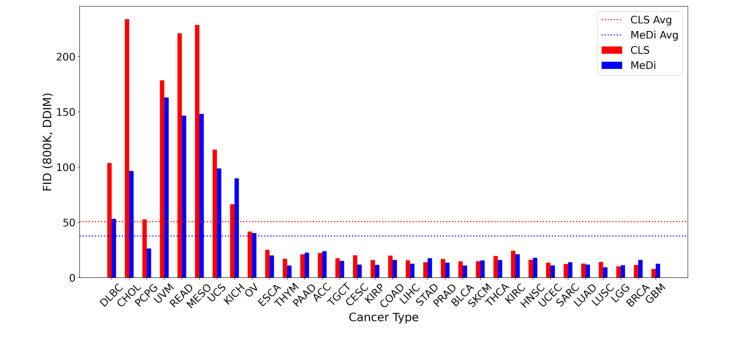 Figure 3. FID per cancer type at 800K optimization steps sampled with DDIM. Depicted are the class-only baseline (CLS, red) and the metadata-conditioned model (MeDi, blue). Cancer types are ordered in descending order based on the number of images in the dataset. Dotted horizontal lines represent the average FID per model: CLS: 50.65, MeDi: 37.73
Figure 3. FID per cancer type at 800K optimization steps sampled with DDIM. Depicted are the class-only baseline (CLS, red) and the metadata-conditioned model (MeDi, blue). Cancer types are ordered in descending order based on the number of images in the dataset. Dotted horizontal lines represent the average FID per model: CLS: 50.65, MeDi: 37.73
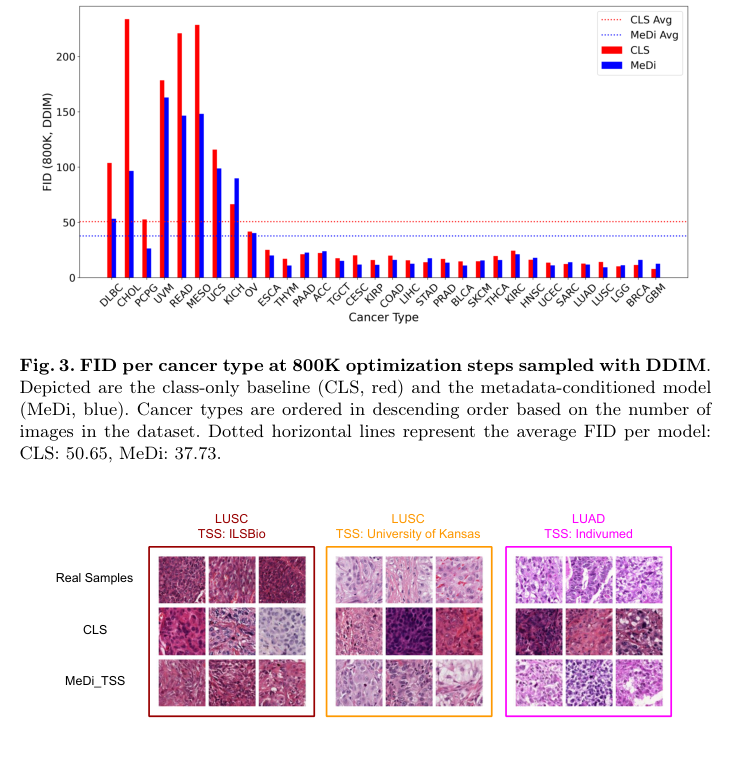 Figure 4. LUSC and LUAD samples from different tissue source sites (TSS) along with generated images. The top row shows real data, while the two other rows show generated samples. MeDi enables capturing the staining mode of the different tissue source sites, while the CLS only model can not be conditioned on a specific TSS and, therefore, is unable to match the real data sample distribution
Figure 4. LUSC and LUAD samples from different tissue source sites (TSS) along with generated images. The top row shows real data, while the two other rows show generated samples. MeDi enables capturing the staining mode of the different tissue source sites, while the CLS only model can not be conditioned on a specific TSS and, therefore, is unable to match the real data sample distribution
Изоморфизмы с другими полями
Анализ MeDi: Диффузионные модели с метаданными (Metadata-Guided Diffusion Models)
Теоретический базис
Для понимания данной работы необходимо освоить концепцию shortcut learning в глубоком обучении. При обучении модели классификации медицинских изображений (например, для идентификации типов рака) алгоритм зачастую находит «короткие пути» — ложные корреляции, — вместо того чтобы анализировать истинные биологические признаки заболевания. Например, если все изображения определенного типа рака получены из одного медицинского учреждения, модель может научиться ассоциировать уникальные артефакты сканера или протоколы окрашивания препаратов с данным диагнозом. В результате при встрече с аналогичным заболеванием из другого учреждения модель демонстрирует низкую эффективность, так как «короткий путь» (визуальный стиль конкретной клиники) отсутствует. В данной работе используются Diffusion Models — генеративные ИИ-системы, которые обучаются создавать новые данные путем обращения процесса добавления шума к изображениям.
Мотивация и ограничения
Основная мотивация заключается в обеспечении устойчивости медицинской ИИ-системы к domain shifts — падению производительности, возникающему при тестировании модели на данных, отличных от обучающей выборки. Ключевым ограничением является imbalance of data: в реальных клинических наборах данных определенные типы рака представлены избыточно, в то время как другие (или специфические комбинации типа рака и учреждения) встречаются крайне редко. Авторам требовался метод «заполнения» этих пробелов без сбора колоссальных объемов новых, дорогостоящих и потенциально конфиденциальных данных пациентов.
Математическая интерпретация
Авторы решают задачу условной генерации данных путем дополнения стандартного диффузионного процесса эмбеддингами метаданных.
В стандартной диффузионной модели алгоритм обучается предсказывать шум $\epsilon$ при заданном изображении $x_t$ и временном шаге $t$. Авторы вводят вектор условий $\mathbf{z}_{\text{cond}}$, который объединяет метку класса $\mathbf{z}_{\text{class}}$ и атрибуты метаданных $\mathbf{z}_{\text{meta},i}$.
Вектор условий определяется следующим образом:
$$\mathbf{z}_{\text{cond}} = \text{concat}(\mathbf{z}_{\text{class}}, \mathbf{z}_{\text{meta},1}, \dots, \mathbf{z}_{\text{meta},k}) \in \mathbb{R}^{d_t}$$
Затем этот вектор интегрируется в архитектуру UNet путем сложения с эмбеддингом временного шага:
$$\mathbf{z}_{\text{final}} = \mathbf{z}_t + \mathbf{z}_{\text{cond}}$$
Обучая модель генерировать изображения, обусловленные этими специфическими тегами метаданных, авторы позволяют модели изучать «стиль» конкретного учреждения или демографической группы независимо от метки заболевания. Это дает возможность синтезировать «отсутствующие» комбинации, эффективно балансируя набор данных и вынуждая последующий классификатор игнорировать «короткие пути», основанные на метаданных.
Структурный каркас
Генеративный механизм, который отделяет доменно-специфичный шум от целевых признаков путем обусловливания latent space на вспомогательных метаданных, что позволяет осуществлять интерполяцию недостаточно представленных точек данных.