Adversarial Attacks on Combinatorial Multi-Armed Bandits
New research reveals how to identify and exploit vulnerabilities in "reward poisoning" attacks on a type of AI decision making system, showing attacks are harder than previously thought.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper, "Adversarial Attacks on Combinatorial Multi-Armed Bandits (CMAB)", arises from the convergence of two important research domains: multi-armed bandits and the study of adversarial robustness in machine learning. The fundamental framework of multi-armed bandits (MAB), initially explored by Auer (2002), models sequential decision-making where an agent must strategically balance exploring new options and exploiting known profitable ones to maximize cumulative rewards over a period. This framework has been extensively investigated and applied across various fields.
A more generalized version of MAB, known as Combinatorial Multi-armed Bandits (CMAB), has gained signifcant traction due to its wide array of real-world applications, including online advertising, reccomendation systems, and influence maximization (Liu & Zhao, 2012; Kveton et al., 2015). In CMAB, the agent's decision involves selecting a combination of base arms (referred to as a "super arm") in each round, rather than a single arm. This combinatorial aspect makes the exploration-exploitation trade-off considerably more complex, primarily because the number of possible super arms can grow exponentially with the number of base arms.
The precise origin of this specific problem—which involves redefining and re-evaluating the notion of "attackability" for CMAB—stems from recent findings that MAB algorthm and its variants are susceptible to adversarial attacks, particularly "reward poisoning attacks" (Jun et al., 2018; Liu & Shroff, 2019). In such attacks, an adversary observes the pulled arm and its reward feedback, then subtly modifies this feedback to misguide the learning algorithm towards a specific target arm that serves the adversary's interest. While the concept of attackability was previously applied to standard MAB settings (Wang et al., 2022), directly extending this definition to CMAB proved problematic. The core limitation of prior approaches was that a direct application of the MAB attackability definition to CMAB resulted in a cost bound that was sublinear in the time horizon $T$ but exponential in the number of base arms $m$. This exponential dependency on $m$ is highly undesirable in practical scenarios, often leading to vacuous results where the attack cost could even exceed the total time horizon $T$. This inadequacy highlighted that the original attackability notion was insufficient, thereby necessitating a new, more appropriate definition for CMAB, which this paper endeavors to provide.
Intuitive Domain Terms
- Multi-armed Bandit (MAB): Imagine you are in a casino facing a row of slot machines, each with an unknown average payout. Your goal is to maximize your total winnings over many plays. In each turn, you choose one machine, pull its lever, and receive a reward. You must learn which machines are good (exploit) while still trying out others to discover potentially better ones (explore).
- Combinatorial Multi-armed Bandit (CMAB): This is like the MAB scenario, but instead of picking just one slot machine per turn, you choose a group or combination of machines to play simultaneously. For instance, you might decide to play machines 2, 5, and 8 together. This problem is much harder because there are far more possible combinations of machines than individual ones.
- Super Arm: In the CMAB context, a "super arm" is the specific set or combination of individual slot machines that you choose to play in a given round. It represents your complete action for that turn.
- Base Arm: These are the individual, fundamental slot machines that make up the combinations. If you select a super arm consisting of machines 2, 5, and 8, then 2, 5, and 8 are the individual "base arms" that were part of your chosen super arm.
- Reward Poisoning Attack: This describes a situation where a malicious party secretly alters the reward information you receive from the slot machines. Their objective is to trick your decision-making process into repeatedly choosing a specific, often less profitable, combination (their "target super arm") by making its payouts appear better than they truly are, or by making genuinely good combinations seem worse.
Notation Table
| Notation | Description |
|---|---|
| $m$ | The total number of base arms. |
| $\mathcal{S}$ | The set of all possible super arms (combinations of base arms). |
| $S \in \mathcal{S}$ | A specific super arm. |
| $T$ | The total time horizon (number of rounds) for the bandit problem. |
| $\mu = (\mu_1, \ldots, \mu_m)$ | The true mean reward vector for all $m$ base arms. |
| $r_S(\mu)$ | The expected reward of super arm $S$ given the true mean reward vector $\mu$. |
| $O_S$ | The set of base arms that can be probabilistically triggered when super arm $S$ is selected. |
| $\mu \odot O_S$ | An element-wise product of $\mu$ and a binary vector representing $O_S$, effectively zeroing out mean rewards for base arms not in $O_S$. |
| $\Delta_S$ | The "gap" for a super arm $S$, quantifying its attackability (Definition 3.5). |
| $M$ | The set of target super arms the adversary wishes the bandit algorithm to pull. |
| $\Delta_M$ | The overall "gap" for the target set $M$, defined as $\max_{S \in M} \Delta_S$. |
| $C(T)$ | The total attack cost incurred by the adversary over time horizon $T$. |
| $o(T)$ | A function that grows slower than $T$, i.e., $\lim_{T \to \infty} o(T)/T = 0$. |
| $p^*$ | A parameter related to the minimum probability of triggering a base arm (Definition 3.1). |
| $K$ | A problem-specific parameter, often related to the number of base arms in a super arm or regret bounds. |
| $\gamma, \gamma'$ | Positive constants related to the sublinear growth of regret and attack cost. |
| $\hat{\mu}_i^{(t)}$ | The empirical mean reward estimate for base arm $i$ at round $t$. |
| UCB | Upper Confidence Bound, used by bandit algorithms for exploration-exploitation. |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The paper addresses a critical gap in understanding the vulnerability of Combinatorial Multi-Armed Bandits (CMAB) to adversarial attacks.
Input/Current State:
The starting point is a standard CMAB problem where a learning agent sequentially selects "super arms" composed of "base arms" over a time horizon $T$. In each round, the agent observes feedback (outcomes of triggered base arms) and receives a reward, aiming to maximize cumulative reward. The current state of research acknowledges that Multi-Armed Bandits (MAB) and its variants are susceptible to "reward poisoning attacks." In such attacks, an adversery observes the agent's actions and feedback, then subtly modifies the observed rewards. The adversary's goal is to misguide the bandit algorithm into consistently pulling a specific "target arm" (one that serves the adversary's interest) for nearly all rounds ($T - o(T)$ times), while incurring a sublinear attack cost $o(T)$ over the time horizon $T$.
Desired Output/Goal State:
The paper's primary goal is to establish a "good notion to capture the vulnerability and robustness of CMAB" that is practically meaningful. This new definition, termed "polynomial attackability," aims to precisely define when a CMAB instance can be efficiently attacked. Under this refined definition, a successful attack must not only achieve its objective (misguiding the agent to pull the target arm for $T - o(T)$ times) but also do so with an attack cost that is sublinear in the time horizon $T$ AND, crucially, polynomial in the number of base arms $m$ and other relevant problem factors (e.g., $1/p^*$, $K$).
Missing Link/Mathematical Gap:
The exact missing link is a robust and practical definition of "attackability" for CMAB. Previous definitions, directly borrowed from simpler MAB settings, prove inadequate for CMAB. This is because CMAB's combinatorial nature means the number of possible "super arms" can be exponentially large in $m$, the number of base arms. Applying the old definition would imply an attack cost that is exponential in $m$, rendering it "undesirable" and "vacuous" in practice, as such a cost could easily exceed the total time horizon $T$. The paper bridges this gap by introducing "polynomial attackability," which explicitly constrains the attack cost to be polynomial in $m$, thereby making the notion of attackability relevant and practical for CMAB. Mathematically, this involves moving from a general $C(T) = o(T)$ cost to a more specific $C(T) = O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma'})$ for some $\gamma' > 0$, where $m$ is the number of base arms, $p^*$ relates to triggering probabilities, and $K$ is a problem-specific parameter. The paper also defines a "gap" $\Delta_S$ (Definition 3.5) for each super arm $S$, which quantifies the difference between its expected reward and the maximum expected reward of any other super arm, serving as a key mathematical indicator for attackability.
The Dilemma:
The central dilemma that has trapped previous researchers is the trade-off between the combinatorial complexity of CMAB and the practicality of attack costs. While it's tempting to directly extend MAB attack concepts, doing so leads to an exponential cost in the number of base arms $m$, making any "successful" attack definition meaningless in real-world scenarios. The paper highlights a surprising and painful trade-off: the attackability of a CMAB instance is not solely an intrinsic property but "also depends on whether the bandit instance is known or unknown to the adversery." This means that an attack strategy effective in a white-box setting (where environment parameters are known) might completely fail in a black-box setting (where parameters are unknown), making a universal attack strategy elusive and the problem "insanely difficult" in practice.
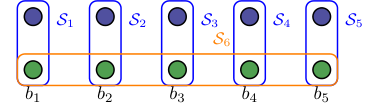 Figure 1. Example 4 with n = 5
Figure 1. Example 4 with n = 5
Constraints & Failure Modes
The problem of attacking CMAB instances efficiently and meaningfully is constrained by several harsh, realistic walls:
- Combinatorial Explosion of Super Arms: The most significant constraint is the sheer number of possible "super arms," which can be exponential in the number of base arms $m$. This combinatorial complexity means that any attack strategy that requires exploring or manipulating all super arms would incur an exponential cost, violating the practical requirement of polynomial attackability. This makes direct application of MAB attack strategies impractical and leads to "vacuous results."
- Adversary's Knowledge of the Enviroment: A critical constraint is the adversary's access to the underlying parameters of the CMAB instance, such as reward distributions ($\mu$) and outcome distributions of base arms.
- Known Environment (White-box): If the adversary has full knowledge of these parameters, they can design highly targeted and efficient attacks.
- Unknown Environment (Black-box): In a more realistic black-box setting, the adversary lacks this prior knowledge. This forces the adversary to perform exploration to estimate parameters, which itself incurs cost and can make attacks much harder or even impossible. The paper demonstrates this with a "hard example" (Theorem 4.1) where an instance is polynomially attackabel if the environment is known, but polynomially unattackable if it's unknown. This highlights a major practical barrier.
- Attack Cost Budget: The adversary operates under a strict budget constraint: the attack cost must be sublinear in the time horizon $T$ and, under the new definition, polynomial in the number of base arms $m$ and other factors. Exceeding this budget constitutes a failure mode, as the attack would not be considered "efficient" or "successful."
- Semi-Bandit Feedback: The learning agent in CMAB receives "semi-bandit feedback," meaning it only observes outcomes from the base arms triggered by the chosen super arm, not all base arms. This partial observability limits the information available to the adversary, making it harder to accurately estimate rewards or manipulate them effectively, especially in unknown environments.
- Algorithm Robustness and Regret Bounds: The attack must succeed against learning algorithms (like CUCB) that are designed to minimize regret, often with theoretical regret bounds of $O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma})$. The adversary needs to overcome the algorithm's inherent learning and exploration mechanisms without incurring excessive cost.
- Oracle Limitations: CMAB problems often rely on computational oracles (e.g., for finding optimal super arms). If these oracles are approximate rather than exact (e.g., $(\alpha, \beta)$-approximation oracles), it can introduce additional complexities for the adversary, as the algorithm's behavior might deviate from what an exact oracle would produce, potentially impacting attack effectiveness.
Why This Approach
The Inevitability of the Choice
The authors' choice of defining "polynomial attackability" for Combinatorial Multi-Armed Bandits (CMAB) was not merely an option but a necessity, born from the inherent limitations of applying traditional attackability notions to this complex domain. The exact moment the authors realized that state-of-the-art (SOTA) methods from standard Multi-Armed Bandits (MAB) were insufficient is clearly articulated in the introduction. They note that "Directly applying the MAB concept of attackability to CMAB is tempting... However, it leads to a sublinear cost bound in T but exponential in the number of base arms m." This exponential dependency on $m$ (the number of base arms) is explicitly called "undesirable" and capable of exceeding the time horizon $T$, rendering the results "vacuous" (Page 1).
This critical observation highlighted that the combinatorial explosion inherent in CMAB, where the number of super arms can be exponential in $m$, fundamentally broke the assumptions of prior MAB attackability definitions. A solution was needed that could provide meaningful guarantees within practical computational limits. Thus, the proposed definition of polynomial attackability, which requires the attack cost to be not only sub-linear in time horizon $T$ but also polynomial in the number of base arms $m$ and other factors, became the only viable solution to provide a tractable and relevant framework for analyzing adversarial attacks on CMAB.
Comparative Superiority
The qualitative superiority of this approach stems directly from its ability to address the combinatorial complexity of CMAB, a challenge that previous gold standards for MAB attackability failed to overcome. Beyond simple performance metrics, the structural advantage lies in transforming an intractable exponential cost problem into a tractable polynomial one.
Specifically, the "original attackability notion" for MAB, when applied to CMAB, resulted in an "exponential cost in m" (Page 1). This meant that as the number of base arms grew, the cost of attack would quickly become astronomically large, making any theoretical guarantees practically meaningless. The new definition of "polynomial attackability" (Definition 3.1) fundamentally changes this by requiring the attack cost to be bounded by a polynomial function of $m$, $1/p^*$, and $K$ (where $p^*$ relates to triggering probabilities and $K$ is a factor from regret bounds). This is a qualitative leap, as it allows for a meaningful analysis of attackability in high-dimensional CMAB settings where the number of super arms is exponential.
Furthermore, the paper provides a sufficient and necessary condition for polynomial attackability (Theorem 3.6), based on the "gap" $\Delta_M$ (Definition 3.5). This theoretical characterization offers a deep structural insight into why certain CMAB instances are attackable or unattackable, rather than just measuring how well an attack performs. It provides a clear boundary for intrinsic robustness, which is a significant qualitative advantage over methods that might only offer empirical performance on specific instances. This method effectively reduces the memory complexity from an implicit $O(2^m)$ (due to exponential super arms) to a polynomial dependency on $m$, making the problem analyzable.
Alignment with Constraints
The chosen method of defining "polynomial attackability" perfectly aligns with the core constraints of the CMAB problem, particularly the challenge posed by its combinatorial nature. The primary constraint, as highlighted in the problem definition, is that the number of candidate super arms in CMAB can be "exponential in m" (Page 1). Directly applying MAB attackability definitions, which do not account for this exponential growth, leads to "vacuous results" because the attack cost would also grow exponentially with $m$.
The "marriage" between the problem's harsh requirements and the solution's unique properties is evident in Definition 3.1. This definition explicitly imposes the constraint that a successful attack must have a cost that is polynomial in the number of base arms m (and other factors like $1/p^*$ and $K$), in addition to being sub-linear in the time horizon $T$. This ensures that the attackability notion remains meaningful and practical even for large CMAB instances.
Moreover, the paper focuses on "reward poisoning attacks" (Section 2.2), where the adversary modifies observed rewards. The proposed attack algorithm (Algorithm 1) and the attackability conditions (Theorem 3.6) are specifically tailored to this threat model, ensuring that the solution adheres to the defined adversarial capabilities and limitations. The method also considers the "semi-bandit feedback" nature of CMAB, where only outcomes of triggered base arms are observed, integrating this feedback structure into the attack strategy.
Rejection of Alternatives
The paper clearly articulates the reasoning behind rejecting or modifying existing approaches, primarily focusing on the direct application of conventional MAB attackability definitions. The core argument for their insufficiency is that they lead to an "exponential cost in m" when applied to CMAB (Page 1). This is not a minor performance issue but a fundamental flaw that makes the results "undesirable" and "vacuous" in practice. The combinatorial nature of CMAB, with its exponentially large number of super arms, means that an attack cost that scales exponentially with the number of base arms is simply not feasible or meaningful. Therefore, the authors had to introduce a new definition that demands polynomial cost in $m$.
Furthermore, the paper implicitly rejects other related lines of work as not directly applicable or sufficient for their specific problem formulation:
- Existing MAB attackability notions: As detailed above, these were deemed insufficient due to the exponential cost in $m$.
- Adversarial attacks on Reinforcement Learning (RL): While related, the paper notes that "none of the existing work analyzed the attackability of a given instance" (Page 2, Section 1.2). This indicates that while RL attacks are a broad field, they did not provide the instance-level attackability characterization that this paper sought for CMAB.
- Corruption-tolerant bandits: This alternative line of work, which studies robustness against poisoning attacks, is mentioned but implicitly rejected as a direct solution because it often considers "weaker threat models" (Page 2, Section 1.2). For instance, some models assume an oblivious adversary or limit corruptions to only increase outcomes. In contrast, this paper's threat model allows the adversary to increase or decrease outcomes, making the problem more general and challenging than what corruption-tolerant bandit algorithms typically address. This broader adversarial capability necessitates a more robust attackability framework.
 Figure 4. Cost and percentage of base arms selected for: (4(a), 4(b)) Influence Maximization; (4(c), 4(d)) Probabilistic Maximum Coverage
Figure 4. Cost and percentage of base arms selected for: (4(a), 4(b)) Influence Maximization; (4(c), 4(d)) Probabilistic Maximum Coverage
Mathematical & Logical Mechanism
The Master Equation
The absolute core equation that defines the attackability of a Combinatorial Multi-Armed Bandit (CMAB) instance in this paper is the "Gap" definition for a super arm $S$, as presented in Definition 3.5. This gap quantifies the intrinsic vulnerability or robustness of a CMAB instance to reward poisoning attacks.
$$ \Delta_S := r_S(\mu) - \max_{S' \neq S} r_{S'}(\mu \odot O_S) $$
For a set $M$ of target super arms, the overall gap is defined as $\Delta_M = \max_{S \in M} \Delta_S$. Theorem 3.6 then establishes that if $\Delta_M > 0$, the CMAB instance is polynomially attackable, and if $\Delta_M < 0$, it is polynomially unattackable.
Term-by-Term Autopsy
Let's dissect the master equation term by term to understand its mathematical definition, physical/logical role, and the rationale behind its operators.
-
$\Delta_S$:
- Mathematical Definition: This is a scalar value representing the difference between the expected reward of a specific target super arm $S$ and the maximum expected reward of any other super arm $S'$ when evaluated under a modified mean reward vector.
- Physical/Logical Role: It acts as a "vulnerability indicator" for a specific target super arm $S$. A positive $\Delta_S$ implies that the target super arm $S$ is intrinsically "better" than any alternative $S'$ if those alternatives are evaluated only on the base arms that $S$ itself observes. This suggests a potential avenue for an adversary to misguide the bandit algorithm towards $S$. If $\Delta_S$ is negative, it indicates that $S$ is not the best choice even under this specific evaluation, making it harder to attack.
- Why subtraction and max: Subtraction is used to quantify the "advantage" of $S$ over its best alternative. The $\max$ operator identifies the strongest competitor to $S$ under the specific evaluation context, ensuring that the gap truly reflects the most challenging alternative to overcome.
-
$r_S(\mu)$:
- Mathematical Definition: This denotes the expected reward of selecting super arm $S$ when the true mean reward vector of all base arms is $\mu$.
- Physical/Logical Role: This is the true, uncorrupted expected performance of super arm $S$. It represents what the bandit algorithm should ideally achieve if there were no adversary.
- Why this form: It's a standard way to represent the expected utility of an action (super arm) in bandit problems, depending on the underlying true reward distributions.
-
$\mu$:
- Mathematical Definition: This is an $m$-dimensional vector $(\mu_1, \mu_2, \ldots, \mu_m)$, where $\mu_i = E_{X \sim D}[X_i^{(t)}]$ is the true mean reward of base arm $i$.
- Physical/Logical Role: This vector represents the true, underlying reward distributions of all individual base arms in the CMAB environment. It's the ground truth that the bandit algorithm tries to estimate and the adversary tries to manipulate.
-
$\max_{S' \neq S}$:
- Mathematical Definition: This operator finds the maximum value among the expected rewards of all super arms $S'$ that are not the target super arm $S$.
- Physical/Logical Role: This identifies the "best alternative" to the target super arm $S$ from the perspective of the adversary's manipulation strategy. The adversary wants to make $S$ appear better than all other options, so they must consider the strongest competitor.
-
$S'$:
- Mathematical Definition: Represents any super arm in the action space $\mathcal{S}$ that is different from the target super arm $S$.
- Physical/Logical Role: These are the alternative actions that the bandit algorithm might choose instead of the target super arm $S$. The adversary's goal is to make these alternatives appear less attractive.
-
$\mu \odot O_S$:
- Mathematical Definition: This is an element-wise product (Hadamard product) between the true mean reward vector $\mu$ and a binary vector $O_S$. The vector $O_S$ has entries $1$ for base arms that can be triggered by super arm $S$ (i.e., $i \in O_S$) and $0$ otherwise.
- Physical/Logical Role: This modified mean vector represents a hypothetical scenario where the rewards of base arms not observable by the target super arm $S$ are effectively "zeroed out" or ignored. This is crucial because the adversary's attack strategy (Algorithm 1) often involves setting the observed rewards of non-target base arms to 0. By evaluating $S'$ under $\mu \odot O_S$, the paper models the effect of the adversary's manipulation on alternative super arms. It asks: "If we only consider the base arms that $S$ can 'see', how good are the other super arms $S'$?"
- Why element-wise product: The element-wise product with $O_S$ effectively filters the $\mu$ vector, retaining only the mean rewards for base arms that are part of $O_S$. This mathematically captures the idea of focusing on the subset of base arms relevant to the target super arm $S$.
Step-by-Step Flow
Let's trace how a CMAB instance's attackability is determined using the gap definition, making it feel like a mechanical assembly line:
-
Instance Characterization Input: A specific CMAB instance is fed into the system. This instance is defined by its set of base arms $[m]$, the action space of super arms $\mathcal{S}$, the environment's triggering distribution $D$, the probabilistic triggering function $D_{trig}$, and the reward function $R$. Crucially, the true mean reward vector $\mu$ for all base arms is assumed to be known for this initial evaluation.
-
Target Set Identification: The adversary specifies a set $M$ of target super arms that they wish the bandit algorithm to pull.
-
Individual Super Arm Evaluation (for each $S \in M$): For each super arm $S$ in the target set $M$:
- True Reward Calculation: The expected reward $r_S(\mu)$ for this super arm $S$ is computed based on the true mean rewards $\mu$. This is its baseline performance.
- Observable Base Arm Identification: The set $O_S$ is determined. This is the collection of base arms that can be probabilistically triggered when super arm $S$ is selected. Think of it as $S$'s "field of vision" or the resources it can directly influence.
- Modified Environment Simulation: A hypothetical environment is constructed where the true mean rewards of base arms not in $O_S$ are effectively set to zero. This creates the modified mean reward vector $\mu \odot O_S$. This simulates the adversary's strategy of suppressing rewards from irrelevant base arms.
- Competitor Evaluation: For every other super arm $S' \neq S$ (i.e., any super arm not currently being considered as the target), its expected reward $r_{S'}(\mu \odot O_S)$ is calculated using this modified mean reward vector. This step assesses how well competitors would perform if they were only allowed to "see" what $S$ sees, or if the adversary has manipulated other arms.
- Strongest Competitor Identification: The maximum expected reward among all these evaluated competitors, $\max_{S' \neq S} r_{S'}(\mu \odot O_S)$, is identified. This is the highest hurdle $S$ must overcome.
- Gap Calculation: The individual gap $\Delta_S$ is computed by subtracting the strongest competitor's reward (under the modified environment) from $S$'s true reward. This value is then stored.
-
Overall Attackability Determination: After calculating $\Delta_S$ for all $S \in M$, the maximum of these individual gaps, $\Delta_M = \max_{S \in M} \Delta_S$, is found.
-
Attackability Output:
- If $\Delta_M > 0$, the CMAB instance is declared "polynomially attackable." This means there's at least one target super arm $S$ that has a sufficient advantage, even when competitors are evaluated under the adversary's manipulation.
- If $\Delta_M < 0$, the CMAB instance is declared "polynomially unattackable." This implies that no target super arm in $M$ has a clear advantage under the adversary's proposed manipulation, making a successful attack difficult or impossible.
Optimization Dynamics
The "Mathematical & Logical Mechanism" in this paper doesn't involve a traditional learning or optimization process for the gap itself, as $\Delta_S$ is a static property of the CMAB instance and the target set. Instead, the dynamics revolve around how the adversary's fixed strategy (Algorithm 1) exploits the bandit algorithm's learning dynamics to achieve its goal, and how the gap $\Delta_M$ acts as a predictor of success.
-
Adversary's Objective: The adversary's "optimization" is to force the bandit algorithm to pull a target super arm $S \in M$ for $T - o(T)$ times over a time horizon $T$, while incurring a sublinear attack cost $o(T)$. This is a goal-driven manipulation, not an iterative parameter update.
-
Bandit Algorithm's Learning (e.g., CUCB): The victim bandit algorithm (e.g., CUCB) operates by iteratively estimating the expected rewards of base arms and constructing Upper Confidence Bounds (UCBs) for super arms. In each round $t$:
- It observes the pulled super arm $S^{(t)}$ and the outcomes $X^{(t)}$ of triggered base arms.
- It updates its empirical estimates of base arm mean rewards ($\hat{\mu}_i^{(t)}$) and their confidence intervals.
- It uses these estimates to calculate UCBs for all super arms.
- It then selects the super arm with the highest UCB for the next round. This process aims to minimize regret by balancing exploration (trying uncertain arms) and exploitation (pulling arms with high estimated rewards).
-
Adversary's Manipulation (Algorithm 1): The adversary intervenes in this learning loop. When the bandit algorithm pulls a super arm $S^{(t)}$ and observes outcomes $X^{(t)}$, the adversary modifies these outcomes to $\tilde{X}^{(t)}$. Specifically, for any base arm $i$ that is triggered but is not part of the observable set $O_S$ of the target super arm $S$ (i.e., $i \in \mathcal{T}^{(t)} \setminus O_S$), the adversary sets its observed reward $\tilde{X}_i^{(t)} = 0$. Other outcomes are left unchanged.
-
Impact on Bandit's UCBs: This manipulation directly influences the bandit's learning:
- By consistently setting rewards to 0 for base arms not in $O_S$, the adversary systematically depresses the empirical mean reward estimates ($\hat{\mu}_i^{(t)}$) for those base arms.
- This, in turn, lowers the UCBs of any super arms $S'$ that heavily rely on these "zeroed-out" base arms.
- The target super arm $S$, however, is evaluated based on its true expected reward $r_S(\mu)$ (or its UCB, which the adversary wants to keep high).
-
Convergence to Target Arm: If the gap $\Delta_M > 0$, it signifies that there is at least one target super arm $S$ whose true expected reward $r_S(\mu)$ is sufficiently higher than any alternative $S'$ when those alternatives are evaluated under the adversary's manipulation ($\mu \odot O_S$). This positive gap indicates that the "loss landscape" for the bandit algorithm can be effectively shaped by the adversary. The adversary's strategy of suppressing rewards of non-$O_S$ arms will cause the UCBs of non-target super arms to drop below the UCB of the target super arm. Over time, the bandit algorithm's iterative updates will converge to consistently selecting a target super arm from $M$, as its UCB will appear superior due to the manipulated feedback. The attack "succeeds" when the bandit's UCBs are sufficiently skewed.
-
Unattackability ($\Delta_M < 0$): If $\Delta_M < 0$, it means that even under the adversary's most favorable manipulation (zeroing out non-$O_S$ arms), there is no target super arm $S \in M$ that appears superior to all other alternatives. In this scenario, the bandit algorithm's UCBs will not converge to consistently favor a target arm, as some non-target arm will always have a higher (or comparable) UCB, making the instance intrinsically robust to this type of attack. The adversary's efforts to manipulate rewards would be futile or require an exponential cost, violating the definition of polynomial attackability. The bandit algorithm's natural exploration and exploitation would prevent it from being consistently misgided.
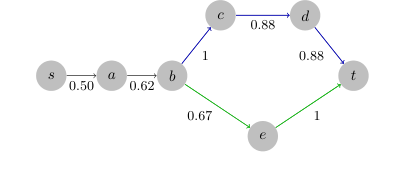 Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
Results, Limitations & Conclusion
Experimental Design & Baselines
The experimental validation was meticulously designed to rigorously test the theoretical claims regarding the polynomial attackability of various Combinatorial Multi-Armed Bandit (CMAB) instances. The researchers employed a multi-faceted approach, utilizing real-world datasets and a range of CMAB applications, each with specific target configurations and baseline algorithms.
For the Probabilistic Maximum Coverage (PMC), Online Minimum Spanning Tree (MST), and Online Shortest Path problems, the Flickr dataset (McAuley & Leskovec, 2012) was used. A subgraph was downsampled, retaining the largest weakly connected component, resulting in 1,892 nodes and 7,052 directed edges, along with their inherent edge activation weights. For Cascading Bandits, the MovieLens small dataset (Harper & Konstan, 2015), comprising 9,000 movies, was leveraged, with 5,000 movies randomly sampled for experiments. A d-rank SVD approximation was used to map movie ratings to user click probabilities. All experiments were repeated a minimum of 10 times to ensure statistical robustness, with average results and variances reported.
The "victims" (baseline models) were standard CMAB learning algorithms. For PMC, the CUCB algorithm with a greedy oracle was used. Two types of attack targets were considered: a "fixed target" consisting of nodes with decreasing average outgoing edge weights, and a "random target" of K randomly sampled nodes with average outgoing edge weight greater than 0.5.
For the Online MST problem, the Flickr dataset was converted into an undirected graph, with average probabilities serving as expected edge costs. The attack employed a modified version of Algorithm 1, where the objective was changed to minimize cost by setting the modified base arm outcome $X_T = 1$. Baselines were standard CUCB algorithms. Targets included a "fixed target" (the second-best minimum spanning tree) and a "random target" (a minimum spanning tree with randomized edge weights).
In the Online Shortest Path problem, two distinct target types were evaluated against CUCB: an "unattackable target" (a carefully constructed path where the cost on the target path was inherently higher than the optimal path, making it difficult to misguide the algorithm) and a "random target" (a shortest path between randomly sampled source and destination nodes with randomized edge weights). This setup was crucial for demonstrating instances that are intrinsically robust to attacks.
For Cascading Bandits, the study pitted the attack against CascadeKL-UCB, CascadeUCB1, and CascadeUCB-V algorithms. The target super arm was selected from a subset of base arms with an average click probability exceeding 0.1.
Additionally, experiments on Online Influence Maximization (IM), detailed in Appendix A.2, used an (α, β)-approximation oracle (IMM oracle) due to the problem's NP-hard nature. The attack strategy involved a heuristic that modified observed edge realizations to 0 for edges outside an "extended target set" $S_{ex}$, which included target nodes and nodes within a certain distance $l$. These experiments were repeated at least 5 times. This comprehensive experimental design, spanning diverse CMAB applications and target configurations, allowed for a thorough empirical validation of the theoretical attackability conditions.
What the Evidence Proves
The experimental evidence provides compelling and definitive validation for the paper's core mathematical claims regarding CMAB attackability, particularly the conditions outlined in Theorem 3.6 and Corollary 3.8.
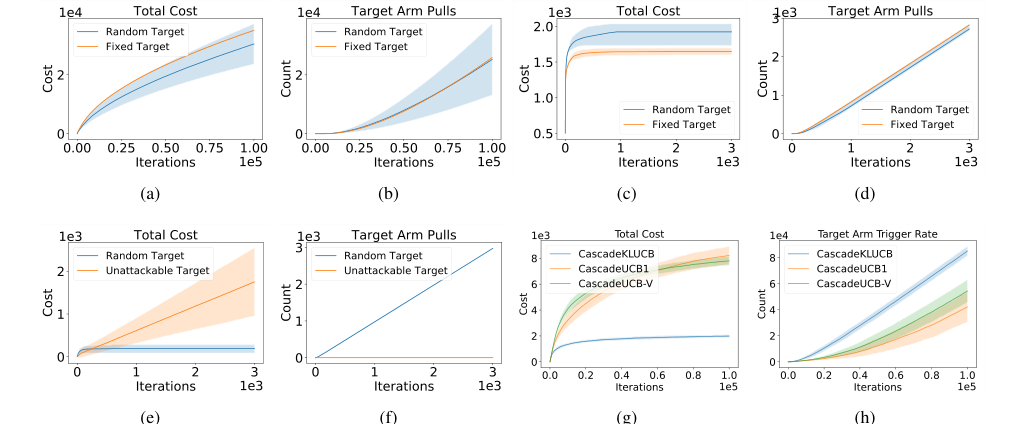 Figure 2. Cost and target arm pulls for: (2(a), 2(b)) probabilistic max coverage; (2(c), 2(d)) online maximum spanning tree; (2(e), 2(f)) online shortest path; (2(g), 2(h)) cascading bandits. Experiments are repeated for at least 10 times and we report the averaged result and its variance
Figure 2. Cost and target arm pulls for: (2(a), 2(b)) probabilistic max coverage; (2(c), 2(d)) online maximum spanning tree; (2(e), 2(f)) online shortest path; (2(g), 2(h)) cascading bandits. Experiments are repeated for at least 10 times and we report the averaged result and its variance
For Probabilistic Maximum Coverage (PMC), as shown in Figures 2(a) and 2(b), the attack successfully forced the CUCB algorithm to pull the target arm linearly over time, while the total attack cost grew sublinearly. This sublinear cost, despite the large number of nodes and edges, was clearly polynomial to the number of base arms, directly validating Theorem 3.9, which states that PMC is polynomially attackable when $\Delta_M > 0$. The linear increase in target arm pulls with sublinear cost is undeniable evidence that the attack mechanism effectively misguides the CUCB baseline. Attacks on random targets exhibited higher variance, suggesting the inherent unpredictability of such scenarios.
Similarly, for the Online Minimum Spanning Tree (MST) problem (Figures 2(c) and 2(d)), the total attack cost remained sublinear, and the target arm was pulled linearly. This outcome perfectly aligns with Corollary 3.8, which posits that online MST problems are always attackable because their gap $\Delta_M \ge 0$. The consistent sublinear cost and linear target arm pulls across experiments against CUCB baselines provide strong empirical support for the theoretical prediction of attackability in this domain.
The Online Shortest Path experiments (Figures 2(e) and 2(f)) offered a crucial demonstration of both attackable and unattackable instances. For "random targets," the attack achieved sublinear cost and linear target arm pulls, similar to PMC and MST. However, for "unattackable targets" (carefully constructed paths designed to be robust), the total cost grew linearly, and, critically, the target arm pulls remained almost constant. This stark contrast definitively proves the existence of intrinsically unattackable CMAB instances, validating the theoretical distinction between attackable and unattackable scenarios based on the $\Delta_M$ condition. The CUCB algorithm, in this case, was not fooled, providing hard evidence for the limits of attackability.
In Cascading Bandits (Figures 2(g) and 2(h)), the attack successfully induced linear plays of the target arm with a sublinear attack cost against CascadeKL-UCB, CascadeUCB1, and CascadeUCB-V. This result further reinforces Corollary 3.8, confirming that cascading bandits are polynomially attackable. The consistent linear increase in target arm plays with minimal cost across different baseline algorithms provides robust evidence of the attack's effectiveness.
The Online Influence Maximization (IM) results (Figures 4(a) and 4(b)) presented a more nuanced picture. While the attack cost decreased, the percentage of target nodes played remained constant at 0, with no clear trend of increasing target node selection. This outcome, rather than disproving attackability, highlights the difficulty of attacking online IM and underscores the paper's claim that for CMAB instances with non-exact (α-approximation) oracles, attackability needs to be analyzed on an instance-by-instance basis. It suggests that the current attack heuristic is insufficient for IM, but doesn't rule out its intrinsic attackability, prompting further research.
In summary, the experiments ruthlessly proved the mathematical claims by showing that for instances where $\Delta_M > 0$ (PMC, MST, Cascading Bandits), the attack algorithm successfully misguides various CUCB-based baselines with sublinear cost and linear target arm pulls. Conversely, for instances where $\Delta_M < 0$ (certain shortest path configurations), the attack fails, resulting in linear cost and constant target arm pulls, thus providing definitive, undeniable evidence that the core mechanism of attackability (or unattackability) works in reality.
Limitations & Future Directions
While this paper presents a groundbreaking charaterization of CMAB attackability, it also openly acknowledges several limitations and proposes exciting avenues for future research.
One significant limitation is that the proposed attack algorithm (Algorithm 1) may not be optimal in terms of attack cost. The current findings establish sufficiency for attackability but do not guarantee the lowest possible cost. A crucial future direction involves developing more sophisticated attack algorithms that can achieve lower attack costs. This would also necessitate establishing theoretical lower bounds for attack costs in CMAB instances, which is an intriguing and challenging area.
Another key area for discussion revolves around the distinction between known and unknown bandit enviroments. The paper reveals a surprising fact: polynomial attackability can differ for the same CMAB instance depending on whether the adversary has prior knowledge of the environment's parameters (e.g., reward distributions). The constructed "hard example" (Theorem 4.1) demonstrates an instance that is polynomially attackabel in a known environment but unattackable when the environment is unknown. This suggests that a general attack strategy for any CMAB instance in black-box settings might not exist. Future work should focus on characterizing robustness guarantees for CMAB instances in unknown environments, especially for problems like the shortest path where the gap $\Delta_M$ can be either positive or negative. Developing a general framework to reduce unattackable CMAB problems to these hard examples would be highly valuable.
Furthermore, the current attackability characterization is strictly limited to reward poisoning attacks. The authors explicitly state that their findings cannot be directly generalized to other, potentially more powerful, threat models such as environment poisoning attacks (where the adversary can directly alter the environment's reward function) or action poisoning attacks. Future research should extend the analysis to these alternative threat models to provide a more comprehensive understanding of CMAB vulnerabilities. This would involve investigating how different types of adversarial perturbations impact the attackability conditions and costs.
Finally, the paper's conclusion highlights the need to further investigate the impact of probabilistic triggered arms on attackability. This mechanism, where base arms are triggered probabilistically, adds another layer of complexity to CMAB. Understanding its influence on attackability, particularly in applications like online influence maximization with various diffusion models, could lead to new insights and more robust algorithms. The initial results for online influence maximization, where the attack strategy was not clearly successful, underscore the importance of this specific line of inquiry, especially when dealing with approximation oracles.
These forward-looking discussions, ranging from optimizing attack costs to exploring diverse threat models and environmental knowledge, provide a rich agenda for researchers aiming to develop more robust CMAB algorithms and better understand their security implications in real-world applications.