組合せ的多腕バンディットに対する敵対的攻撃
New research reveals how to identify and exploit vulnerabilities in "reward poisoning" attacks on a type of AI decision-making system, showing attacks are harder than previously thought.
背景と学術的系譜
起源と学術的系譜
本稿で扱う「組合せ的多腕バンディット(CMAB)に対する敵対的攻撃」という問題は、多腕バンディットと機械学習における敵対的ロバスト性の研究という、2つの重要な研究領域の収束から生じる。 Auer (2002) によって最初に探求された多腕バンディット(MAB)の基本的な枠組みは、エージェントが累積報酬を最大化するために、新しい選択肢の探索と既知の収益性の高い選択肢の活用を戦略的にバランスさせる必要がある逐次的意思決定をモデル化する。この枠組みは、様々な分野で広範に調査され、応用されてきた。
組合せ的多腕バンディット(CMAB)として知られるMABのより一般化されたバージョンは、オンライン広告、推薦システム、影響力最大化など、幅広い現実世界の応用により、著しい注目を集めている(Liu & Zhao, 2012; Kveton et al., 2015)。CMABでは、エージェントの意思決定は、各ラウンドで単一のアームではなく、ベースアームの組合せ(「スーパーアーム」と呼ばれる)を選択することを含む。この組合せ的側面は、探索と活用のトレードオフを著しく複雑にする。なぜなら、可能なスーパーアームの数がベースアームの数とともに指数関数的に増加する可能性があるからである。
この特定の問題、すなわちCMABにおける「攻撃可能性」の概念を再定義し、再評価することの正確な起源は、MABアルゴリズムとその変種が敵対的攻撃、特に「報酬ポイズニング攻撃」に対して脆弱であるという最近の発見に由来する(Jun et al., 2018; Liu & Shroff, 2019)。このような攻撃では、敵対者は引かれたアームとその報酬フィードバックを観察し、次にこのフィードバックを微妙に変更して、敵対者の利益に資する特定のターゲットアームへと学習アルゴリズムを誤誘導する。攻撃可能性の概念は以前は標準的なMAB設定に適用されていたが(Wang et al., 2022)、この定義をCMABに直接拡張することは問題があることが判明した。先行アプローチの主な限界は、MABの攻撃可能性定義をCMABに直接適用すると、時間ホライズン$T$に対して劣線形であるが、ベースアームの数$m$に対して指数関数的なコスト境界が得られることだった。$m$に対するこの指数関数的な依存性は、実際的なシナリオでは非常に望ましくなく、攻撃コストが総時間ホライズン$T$を超えることさえあるような、しばしば無意味な結果につながる。この不備は、元の攻撃可能性の概念が不十分であることを浮き彫りにし、それゆえCMABにとって、より適切で新しい定義が必要であることを示唆しており、本稿はその提供を試みるものである。
直感的なドメイン用語
- 多腕バンディット(MAB): カジノで、それぞれ平均ペイアウトが不明な一列のスロットマシンに直面していると想像してください。あなたの目標は、多くのプレイを通じて総賞金を最大化することです。各ターンで、1台のマシンを選択し、レバーを引き、報酬を受け取ります。あなたは、どのマシンが良いか(活用)を学習しながら、より良いものを見つけるために他のマシンを試す(探索)必要があります。
- 組合せ的多腕バンディット(CMAB): これはMABシナリオに似ていますが、1ターンあたり1台のスロットマシンを選ぶ代わりに、グループまたは組合せのマシンを同時にプレイすることを選択します。例えば、マシン2、5、8を一緒にプレイすることに決めるかもしれません。この問題は、個々のマシンよりも可能な組合せがはるかに多いため、はるかに困難です。
- スーパーアーム: CMABの文脈では、「スーパーアーム」とは、特定のラウンドでプレイすることを選択する個々のスロットマシンのセットまたは組合せです。それはそのターンの完全なアクションを表します。
- ベースアーム: これらは、組合せを構成する個々の基本的なスロットマシンです。マシン2、5、8からなるスーパーアームを選択した場合、2、5、8は、選択されたスーパーアームの一部であった個々の「ベースアーム」です。
- 報酬ポイズニング攻撃: これは、悪意のある当事者がスロットマシンから受け取る報酬情報を秘密裏に変更する状況を説明します。彼らの目的は、特定の、しばしば収益性の低い組合せ(彼らの「ターゲットスーパーアーム」)のペイアウトを、実際よりも良く見せかけたり、実際に良い組合せを悪く見せかけたりすることによって、意思決定プロセスを欺き、その組合せを繰り返し選択させることです。
記法表
| 記法 | 説明 |
|---|---|
| $m$ | ベースアームの総数。 |
| $\mathcal{S}$ | すべての可能なスーパーアーム(ベースアームの組合せ)の集合。 |
| $S \in \mathcal{S}$ | 特定のスーパーアーム。 |
| $T$ | バンディット問題の総時間ホライズン(ラウンド数)。 |
| $\mu = (\mu_1, \ldots, \mu_m)$ | すべての$m$個のベースアームの真の平均報酬ベクトル。 |
| $r_S(\mu)$ | 真の平均報酬ベクトル$\mu$が与えられたときのスーパーアーム$S$の期待報酬。 |
| $O_S$ | スーパーアーム$S$が選択されたときに確率的にトリガーされる可能性のあるベースアームの集合。 |
| $\mu \odot O_S$ | $\mu$と$O_S$に含まれないベースアームの平均報酬をゼロにする、$O_S$のバイナリベクトルとの要素ごとの積。 |
| $\Delta_S$ | 定義3.5(攻撃可能性)を定量化するスーパーアーム$S$の「ギャップ」。 |
| $M$ | 敵対者がバンディットアルゴリズムに引かせたいターゲットスーパーアームの集合。 |
| $\Delta_M$ | ターゲットセット$M$の全体的な「ギャップ」、$\max_{S \in M} \Delta_S$と定義される。 |
| $C(T)$ | 時間ホライズン$T$全体で敵対者によって発生する総攻撃コスト。 |
| $o(T)$ | $T$よりもゆっくり成長する関数、すなわち$\lim_{T \to \infty} o(T)/T = 0$。 |
| $p^*$ | ベースアームの最小トリガー確率に関連するパラメータ(定義3.1)。 |
| $K$ | 問題固有のパラメータで、しばしばスーパーアームのベースアーム数や後悔バウンドに関連する。 |
| $\gamma, \gamma'$ | 後悔と攻撃コストの劣線形成長に関連する正の定数。 |
| $\hat{\mu}_i^{(t)}$ | ラウンド$t$におけるベースアーム$i$の経験的平均報酬推定値。 |
| UCB | 探索と活用のためにバンディットアルゴリズムによって使用されるUpper Confidence Bound。 |
問題定義と制約
中核的な問題定式化とジレンマ
本稿は、組合せ的多腕バンディット(CMAB)の脆弱性を敵対的攻撃に対して理解する上での重要なギャップに対処する。
入力/現在の状態:
出発点は、学習エージェントが時間ホライズン$T$にわたって「ベースアーム」から構成される「スーパーアーム」を逐次的に選択する標準的なCMAB問題である。各ラウンドで、エージェントはフィードバック(トリガーされたベースアームの結果)を観察し、報酬を受け取り、累積報酬の最大化を目指す。現在の研究状況では、多腕バンディット(MAB)とその変種が「報酬ポイズニング攻撃」に対して脆弱であることが認識されている。このような攻撃では、敵対者はエージェントのアクションとフィードバックを観察し、次に観測された報酬を微妙に変更する。敵対者の目標は、バンディットアルゴリズムを、時間ホライズン$T$全体で劣線形な攻撃コスト$o(T)$を発生させながら、特定の「ターゲットアーム」(敵対者の利益に資するアーム)を一貫して引くように誤誘導することである。
望ましい出力/目標状態:
本稿の主な目標は、「CMABの脆弱性とロバスト性を捉えるための良い概念」を確立することであり、それは実用的に意味のあるものである。この新しい定義は「多項式攻撃可能性」と名付けられ、CMABインスタンスが効率的に攻撃可能であるかを正確に定義することを目的とする。この洗練された定義の下では、成功した攻撃は、その目標(エージェントを$T - o(T)$回ターゲットアームを引くように誤誘導する)を達成するだけでなく、時間ホライズン$T$に対して劣線形であり、かつ、決定的に、ベースアームの数$m$およびその他の関連する問題要因(例:$1/p^*$、$K$)に対して多項式的な攻撃コストでそれを達成しなければならない。
欠落しているリンク/数学的ギャップ:
正確な欠落リンクは、CMABのための堅牢で実用的な「攻撃可能性」の定義である。以前の定義は、単純なMAB設定から直接借用されたものであり、CMABには不十分であることが判明している。これは、CMABの組合せ的な性質により、可能な「スーパーアーム」の数がベースアーム$m$の数に対して指数関数的に大きくなる可能性があるためである。古い定義を適用すると、攻撃コストが$m$に対して指数関数的になり、実用的には「望ましくなく」「無意味」になり、そのようなコストは総時間ホライズン$T$を容易に超える可能性がある。本稿は、「多項式攻撃可能性」を導入することでこのギャップを埋める。これは、攻撃コストを明示的に$m$に対して多項式に制限し、それによって攻撃可能性の概念をCMABにとって関連性があり実用的なものにする。数学的には、これは一般的な$C(T) = o(T)$コストから、より具体的な$C(T) = O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma'})$(ただし、$\gamma' > 0$)への移行を含む。ここで、$m$はベースアームの数、$p^*$はトリガー確率に関連し、$K$は問題固有のパラメータである。本稿はまた、各スーパーアーム$S$に対して「ギャップ」$\Delta_S$(定義3.5)を定義する。これは、期待報酬と他の任意のスーパーアームの最大期待報酬との差を定量化し、攻撃可能性の重要な数学的指標として機能する。
ジレンマ:
以前の研究者を悩ませてきた中心的なジレンマは、CMABの組合せ的複雑さと攻撃コストの実用性との間のトレードオフである。MAB攻撃の概念を直接拡張したくなるかもしれないが、そうするとベースアーム$m$の数に対して指数関数的なコストが生じ、どのような「成功した」攻撃の定義も現実世界のシナリオでは無意味になる。本稿は、驚くべき、そして痛ましいトレードオフを強調する。攻撃可能性は、単なる内在的な特性ではなく、「バンディットインスタンスが敵対者に知られているか未知かにも依存する」ということである。これは、ホワイトボックス設定(環境パラメータが既知の場合)で効果的な攻撃戦略が、ブラックボックス設定(パラメータが未知の場合)では完全に失敗する可能性があることを意味し、普遍的な攻撃戦略を捉えどころのないものにし、問題を実質的に「非常に困難」にする。
制約と失敗モード
CMABインスタンスを効率的かつ意味のある方法で攻撃するという問題は、いくつかの厳しい現実的な壁によって制約されている。
- スーパーアームの組合せ爆発: 最も重要な制約は、可能な「スーパーアーム」の数であり、これはベースアーム$m$に対して指数関数的に大きくなる可能性がある。この組合せ的複雑さは、すべてのスーパーアームを探索または操作する必要がある攻撃戦略が指数関数的なコストを発生させることを意味し、多項式攻撃可能性という実用的な要件に違反する。これにより、MAB攻撃戦略の直接的な適用が非実用的になり、「無意味な結果」につながる。
- 環境の敵対者の知識: 重要な制約は、CMABインスタンスの基盤となるパラメータ、例えば報酬分布($\mu$)やベースアームのトリガー分布に対する敵対者のアクセスである。
- 既知の環境(ホワイトボックス): 敵対者がこれらのパラメータを完全に把握している場合、高度に標的化された効率的な攻撃を設計できる。
- 未知の環境(ブラックボックス): より現実的なブラックボックス設定では、敵対者はこの事前知識を欠いている。これにより、敵対者はパラメータを推定するために探索を実行する必要があり、それ自体がコストを発生させ、攻撃をはるかに困難または不可能にする可能性がある。本稿は、「ハード例」(定理4.1)でこれを実証している。この例では、環境が既知であれば多項式攻撃可能であるが、未知であれば多項式攻撃不可能であるインスタンスを示す。これは主要な実用的な障壁を強調する。
- 攻撃コスト予算: 敵対者は厳格な予算制約の下で動作する。攻撃コストは時間ホライズン$T$に対して劣線形であり、新しい定義の下ではベースアーム$m$およびその他の要因に対して多項式でなければならない。この予算を超過すると、攻撃は「効率的」または「成功」と見なされないため、失敗モードとなる。
- セミバンディットフィードバック: CMABの学習エージェントは「セミバンディットフィードバック」を受け取る。これは、選択されたスーパーアームによってトリガーされたベースアームの結果のみを観測し、すべてのベースアームを観測するわけではないことを意味する。この部分的な観測可能性は、敵対者が利用できる情報を制限し、特に未知の環境では、報酬を正確に推定したり効果的に操作したりすることをより困難にする。
- アルゴリズムのロバスト性と後悔バウンド: 攻撃は、しばしば$O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma})$という理論的な後悔バウンドを持つ、後悔を最小化するように設計された学習アルゴリズム(CUCBなど)に対して成功しなければならない。敵対者は、過剰なコストを発生させることなく、アルゴリズムの固有の学習と探索メカニズムを克服する必要がある。
- オラクルの限界: CMAB問題は、しばしば計算オラクル(例:最適なスーパーアームを見つけるため)に依存する。これらのオラクルが正確ではなく近似的である場合(例:($\alpha$, $\beta$)近似オラクル)、アルゴリズムの動作が正確なオラクルが生成するものから逸脱する可能性があるため、敵対者に追加の複雑さを導入し、攻撃効果に影響を与える可能性がある。
なぜこのアプローチなのか
選択の必然性
著者らが組合せ的多腕バンディット(CMAB)の「多項式攻撃可能性」を定義するという選択は、単なる選択肢ではなく、この複雑な領域に従来の攻撃可能性の概念を適用することの本質的な限界から生まれた必然であった。著者らが最先端(SOTA)の標準多腕バンディット(MAB)からの方法が不十分であると認識した正確な瞬間は、導入部で明確に述べられている。彼らは、「CMABに攻撃可能性のMAB概念を直接適用することは魅力的である...しかし、それは$T$に対して劣線形であるが、$m$(ベースアームの数)に対して指数関数的なコスト境界につながる」と述べている。この$m$に対する指数関数的な依存性は、明確に「望ましくない」とされ、時間ホライズン$T$を超える可能性があり、結果を「無意味」にする(1ページ)。
この重要な観察は、CMABに固有の組合せ的爆発、すなわちスーパーアームの数が$m$に対して指数関数的に大きくなる可能性があることが、以前のMAB攻撃可能性定義の仮定を根本的に破ったことを浮き彫りにした。実用的な計算限界内で意味のある保証を提供できるソリューションが必要とされた。したがって、提案された多項式攻撃可能性の定義は、攻撃コストが時間ホライズン$T$に対して劣線形であるだけでなく、ベースアームの数$m$およびその他の要因に対して多項式であることを要求する。これは、CMABに対する敵対的攻撃を分析するための、実行可能で関連性のある枠組みを提供する唯一の実行可能な解決策となった。
比較優位性
このアプローチの質的な優位性は、CMABの組合せ的複雑さに対処できる能力に直接由来する。これは、MAB攻撃可能性の従来のゴールドスタンダードが克服できなかった課題である。単純なパフォーマンス指標を超えて、構造的な利点は、非現実的な指数関数的コストの問題を、実行可能な多項式問題に変えることにある。
具体的には、MABの「元の攻撃可能性の概念」をCMABに適用すると、「$m$に対する指数関数的なコスト」(1ページ)が生じた。これは、ベースアームの数が増加するにつれて、攻撃コストが急速に天文学的に大きくなり、理論的な保証が実質的に無意味になることを意味した。新しい「多項式攻撃可能性」(定義3.1)の定義は、攻撃コストを$m$、$1/p^*$、$K$(ただし、$p^*$はトリガー確率に関連し、$K$は後悔バウンドからの要因)の多項式関数に制限することを要求することにより、これを根本的に変える。これは、スーパーアームの数が指数関数的である高次元CMAB設定での攻撃可能性の意味のある分析を可能にする、質的な飛躍である。
さらに、本稿は「ギャップ」$\Delta_M$(定義3.5)に基づいた多項式攻撃可能性の十分条件および必要条件(定理3.6)を提供する。この理論的特徴付けは、単に攻撃がどれだけうまく機能するかを測定するのではなく、なぜ特定のCMABインスタンスが攻撃可能または攻撃不可能であるかについての深い構造的洞察を提供する。それは、経験的なパフォーマンスのみを提供する方法よりも、内在的なロバスト性の明確な境界を提供する。この方法は、メモリの複雑さを暗黙的な$O(2^m)$(指数関数的なスーパーアームのため)から$m$への多項式依存性に効果的に削減し、問題を分析可能にする。
制約との整合性
「多項式攻撃可能性」を定義するという選択された方法は、CMAB問題の核心的な制約、特にその組合せ的な性質によってもたらされる課題と完全に一致する。問題定義で強調されている主な制約は、CMABにおける候補スーパーアームの数が「$m$に対して指数関数的」(1ページ)になりうるということである。MAB攻撃可能性の定義を直接適用すると、この指数関数的な成長を考慮しないため、攻撃コストも$m$に対して指数関数的に増加するため、「無意味な結果」につながる。
定義3.1における、問題の厳しい要件とソリューションのユニークなプロパティとの「結婚」は明らかである。この定義は、成功した攻撃が、時間ホライズン$T$に対して劣線形であるだけでなく、ベースアーム$m$(および$1/p^*$、$K$などのその他の要因)の数に対して多項式なコストを持つことを明示的に義務付けている。これにより、大規模なCMABインスタンスでも、攻撃可能性の概念が意味があり実用的なままであることが保証される。
さらに、本稿は、敵対者が観測された報酬を変更する「報酬ポイズニング攻撃」(セクション2.2)に焦点を当てている。提案された攻撃アルゴリズム(アルゴリズム1)と攻撃可能性条件(定理3.6)は、この脅威モデルに特に適合しており、ソリューションが定義された敵対的機能と制約を遵守することを保証する。この方法は、「セミバンディットフィードバック」というCMABの性質も考慮している。これは、トリガーされたベースアームの結果のみが観測されるため、このフィードバック構造を攻撃戦略に統合している。
代替案の却下
本稿は、主に従来のMAB攻撃可能性定義の直接適用に焦点を当て、既存のアプローチを却下または修正した理由を明確に説明している。それらの不十分さの主な理由は、CMABに適用すると「$m$に対する指数関数的なコスト」につながることである(1ページ)。これは単なるパフォーマンスの問題ではなく、結果を実質的に「望ましくなく」「無意味」にする根本的な欠陥である。指数関数的に多数のスーパーアームを持つCMABの組合せ的な性質は、ベースアームの数に対して指数関数的にスケールする攻撃コストは、単に実行可能でも意味のあるものでもないことを意味する。したがって、著者らは、$m$に対して多項式なコストを要求する新しい定義を導入する必要があった。
さらに、本稿は、暗黙のうちに他の関連する研究ラインを、特定の特定の問題定式化に直接適用可能または十分ではないとして却下している。
- 既存のMAB攻撃可能性の概念: 上記で詳述したように、これらは$m$に対する指数関数的なコストのため、不十分と見なされた。
- 強化学習(RL)に対する敵対的攻撃: 関連しているが、本稿は「既存の研究のいずれも、特定のインスタンスの攻撃可能性を分析していなかった」(2ページ、セクション1.2)と述べている。これは、RL攻撃が広範な分野であるにもかかわらず、本稿がCMABに求めたインスタンスレベルの攻撃可能性の特性化を提供しなかったことを示唆している。
- 腐敗耐性バンディット: ポイズニング攻撃に対するロバスト性を研究するこの代替研究ラインは、言及されているが、直接的な解決策としては暗黙のうちに却下されている。なぜなら、それはしばしば「より弱い脅威モデル」を考慮するからである(2ページ、セクション1.2)。例えば、一部のモデルは、オブリービアスな敵対者を想定したり、腐敗を結果を増加させる場合に限定したりする。対照的に、本稿の脅威モデルは、敵対者が結果を増加または減少させることを許可しており、問題は、腐敗耐性バンディットアルゴリズムが通常対処するものよりも一般的で困難になっている。このより広範な敵対的機能は、より堅牢な攻撃可能性の枠組みを必要とする。
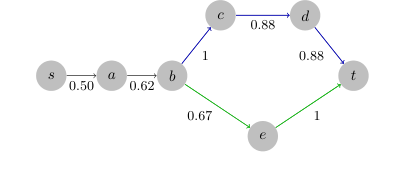 Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
数学的・論理的メカニズム
マスター方程式
本稿における組合せ的多腕バンディット(CMAB)インスタンスの攻撃可能性を定義する絶対的な中心方程式は、定義3.5に示されているスーパーアーム$S$の「ギャップ」である。このギャップは、CMABインスタンスの固有の脆弱性またはロバスト性を報酬ポイズニング攻撃に対して定量化する。
$$ \Delta_S := r_S(\mu) - \max_{S' \neq S} r_{S'}(\mu \odot O_S) $$
ターゲットスーパーアームの集合$M$に対して、全体的なギャップは$\Delta_M = \max_{S \in M} \Delta_S$と定義される。定理3.6は、$\Delta_M > 0$であればCMABインスタンスは多項式攻撃可能であり、$\Delta_M < 0$であれば多項式攻撃不可能であると確立する。
用語ごとの解剖
マスター方程式を用語ごとに分解して、その数学的定義、物理的/論理的役割、およびその演算子の背後にある理由を理解しよう。
-
$\Delta_S$:
- 数学的定義: これは、特定のターゲットスーパーアーム$S$の期待報酬と、他の任意のスーパーアーム$S'$の最大期待報酬との差を、変更された平均報酬ベクトルで評価した場合の差を定量化するスカラー値である。
- 物理的/論理的役割: 特定のターゲットスーパーアーム$S$の「脆弱性指標」として機能する。正の$\Delta_S$は、ターゲットスーパーアーム$S$が、それらの代替がそれら自体が観測するベースアームでのみ評価される場合でも、それらの代替$S'$よりも固有に「優れている」ことを示唆する。これは、敵対者がバンディットアルゴリズムを$S$へと誤誘導する可能性のある経路を示唆する。$\Delta_S$が負の場合、それは$S$がこの特定の評価の下でも最良の選択ではないことを示し、攻撃をより困難にする。
- なぜ減算と最大値なのか: 減算は、$S$のその最良の代替に対する「利点」を定量化するために使用される。$\max$演算子は、特定の評価コンテキストの下で$S$の最も強力な競合相手を特定し、ギャップが克服すべき最も困難な代替を真に反映することを保証する。
-
$r_S(\mu)$:
- 数学的定義: これは、ベースアームの真の平均報酬ベクトルが$\mu$である場合に、スーパーアーム$S$を選択することの期待報酬を表す。
- 物理的/論理的役割: これは、スーパーアーム$S$の真の、改変されていない期待パフォーマンスである。敵対者がいなかった場合にバンディットアルゴリズムが理想的に達成すべきものである。
- なぜこの形式なのか: これは、バンディット問題におけるアクション(スーパーアーム)の期待効用を、基盤となる真の報酬分布に依存して表す標準的な方法である。
-
$\mu$:
- 数学的定義: これは、$m$次元ベクトル$(\mu_1, \mu_2, \ldots, \mu_m)$であり、ここで$\mu_i = E_{X \sim D}[X_i^{(t)}]$はベースアーム$i$の真の平均報酬である。
- 物理的/論理的役割: このベクトルは、CMAB環境におけるすべての個々のベースアームの真の、基盤となる報酬分布を表す。これは、バンディットアルゴリズムが推定しようとするグラウンドトゥルースであり、敵対者が操作しようとするものである。
-
$\max_{S' \neq S}$:
- 数学的定義: この演算子は、ターゲットスーパーアーム$S$とは異なるすべてのスーパーアーム$S'$の期待報酬の中から最大値を見つける。
- 物理的/論理的役割: これは、敵対者の操作戦略の観点から、ターゲットスーパーアーム$S$の「最良の代替」を特定する。敵対者は、$S$をすべての他のオプションよりも良く見せたいので、最も強力な競合相手を考慮する必要がある。
-
$S'$:
- 数学的定義: ターゲットスーパーアーム$S$とは異なる、アクション空間$\mathcal{S}$内の任意のスーパーアームを表す。
- 物理的/論理的役割: これらは、バンディットアルゴリズムがターゲットスーパーアーム$S$の代わりに選択する可能性のある代替アクションである。敵対者の目標は、これらの代替を魅力が低いように見せることである。
-
$\mu \odot O_S$:
- 数学的定義: これは、真の平均報酬ベクトル$\mu$とバイナリベクトル$O_S$との間の要素ごとの積(アダマール積)である。ベクトル$O_S$は、スーパーアーム$S$によってトリガーされる可能性のあるベースアーム(すなわち、$i \in O_S$)に対して1、それ以外の場合は0のエントリを持つ。
- 物理的/論理的役割: この変更された平均ベクトルは、ターゲットスーパーアーム$S$によって観測されないベースアームの報酬が事実上「ゼロにされる」または無視されるという仮説的なシナリオを表す。これは、敵対者の攻撃戦略(アルゴリズム1)が、非ターゲットベースアームの観測報酬を0に設定することを含むことが多いため重要である。$S'$を$\mu \odot O_S$で評価することにより、本稿は、敵対者の操作が代替スーパーアームに与える影響をモデル化する。それは、「$S$が見ることができるベースアームのみを考慮した場合、他のスーパーアーム$S'$はどれだけうまく機能するか?」と問う。
- なぜ要素ごとの積なのか: $O_S$との要素ごとの積は、$\mu$ベクトルを効果的にフィルタリングし、$O_S$に含まれるベースアームの平均報酬のみを保持する。これは、$S$に関連するベースアームのサブセットに焦点を当てるという考えを数学的に捉える。
ステップバイステップの流れ
ギャップ定義を使用してCMABインスタンスの攻撃可能性がどのように決定されるかをトレースしてみましょう。これは、機械的な組み立てラインのように感じさせます。
-
インスタンス特性化入力: 特定のCMABインスタンスがシステムに供給される。このインスタンスは、ベースアーム$[m]$、スーパーアーム$\mathcal{S}$のアクション空間、環境のトリガー分布$D$、確率的トリガー関数$D_{trig}$、および報酬関数$R$によって定義される。決定的に、すべてのベースアームの真の平均報酬ベクトル$\mu$は、この初期評価のために既知であると仮定される。
-
ターゲットセットの特定: 敵対者は、バンディットアルゴリズムに引かせたいターゲットスーパーアームの集合$M$を指定する。
-
個々のスーパーアーム評価($S \in M$ごと): ターゲットセット$M$内の各スーパーアーム$S$について:
- 真の報酬計算: このスーパーアーム$S$の期待報酬$r_S(\mu)$は、真の平均報酬$\mu$に基づいて計算される。これはそのベースラインパフォーマンスである。
- 観測可能なベースアームの特定: 集合$O_S$が決定される。これは、スーパーアーム$S$が選択されたときに確率的にトリガーされる可能性のあるベースアームのコレクションである。これは$S$の「視野」または直接影響を与えることができるリソースと考えることができる。
- 変更された環境シミュレーション: 真の平均報酬ベクトル$\mu \odot O_S$を使用して、ターゲットスーパーアーム$S$によって観測されないベースアームの真の平均報酬が事実上ゼロに設定される仮説的な環境が構築される。これは、非$O_S$ベースアームの報酬を抑制するという敵対者の戦略をシミュレートする。
- 競合相手の評価: 他のすべてのスーパーアーム$S' \neq S$(すなわち、現在ターゲットとして検討されていない任意のスーパーアーム)について、その期待報酬$r_{S'}(\mu \odot O_S)$が、この変更された平均報酬ベクトルを使用して計算される。このステップは、代替の競合相手が$S$が見ることができるものしか見ることができない場合、または敵対者が他のアームを操作した場合に、どれだけうまく機能するかを評価する。
- 最強の競合相手の特定: これらの評価された競合相手すべての中から、期待報酬の最大値、$\max_{S' \neq S} r_{S'}(\mu \odot O_S)$が特定される。これは、$S$が克服しなければならない最も高いハードルである。
- ギャップ計算: 個々のギャップ$\Delta_S$は、最強の競合相手の報酬(変更された環境下)を$S$の真の報酬から差し引くことによって計算される。この値はその後保存される。
-
全体的な攻撃可能性の決定: すべての$S \in M$について$\Delta_S$を計算した後、これらの個々のギャップの最大値、$\Delta_M = \max_{S \in M} \Delta_S$が求められる。
-
攻撃可能性の出力:
- $\Delta_M > 0$の場合、CMABインスタンスは「多項式攻撃可能」と宣言される。これは、競合相手が敵対者の操作下で評価された場合でも、十分な利点を持つ少なくとも1つのターゲットスーパーアーム$S$が存在することを示唆する。
- $\Delta_M < 0$の場合、CMABインスタンスは「多項式攻撃不可能」と宣言される。これは、M内のターゲットスーパーアームが、敵対者の提案された操作下で明確な利点を持たないことを意味し、成功した攻撃を困難または不可能にする。
最適化ダイナミクス
本稿の「数学的・論理的メカニズム」は、ギャップ自体に対する伝統的な学習または最適化プロセスを含まない。なぜなら、$\Delta_S$はCMABインスタンスとターゲットセットの静的なプロパティだからである。代わりに、ダイナミクスは、敵対者の固定戦略(アルゴリズム1)がバンディットアルゴリズムの学習ダイナミクスをどのように悪用して目標を達成するか、そしてギャップ$\Delta_M$が成功の予測因子としてどのように機能するかを中心に展開する。
-
敵対者の目標: 敵対者の「最適化」は、時間ホライズン$T$で$T - o(T)$回ターゲットスーパーアーム$S \in M$を引かせることであり、劣線形攻撃コスト$o(T)$を発生させることである。これは目標駆動型の操作であり、反復的なパラメータ更新ではない。
-
バンディットアルゴリズムの学習(例:CUCB): 被害者バンディットアルゴリズム(例:CUCB)は、ベースアームの期待報酬を反復的に推定し、Upper Confidence Bounds(UCB)をスーパーアーム用に構築することによって動作する。各ラウンド$t$で:
- 引かれたスーパーアーム$S^{(t)}$とトリガーされたベースアームの結果$X^{(t)}$を観測する。
- ベースアームの平均報酬の経験的推定値($\hat{\mu}_i^{(t)}$)とその信頼区間を更新する。
- これらの推定値を使用して、すべてのスーパーアームのUCBを計算する。
- 次に、最も高いUCBを持つスーパーアームを次のラウンドに選択する。このプロセスは、探索(不確かなアームを試す)と活用(高い推定報酬を持つアームを引く)のバランスを取ることによって後悔を最小化することを目指す。
-
敵対者の操作(アルゴリズム1): 敵対者はこの学習ループに介入する。バンディットアルゴリズムがスーパーアーム$S^{(t)}$を引き、結果$X^{(t)}$を観測すると、敵対者はこれらの結果を$\tilde{X}^{(t)}$に変更する。具体的には、トリガーされたがターゲットスーパーアーム$S$の観測可能セット$O_S$の一部ではないベースアーム$i$(すなわち、$i \in \mathcal{T}^{(t)} \setminus O_S$)の場合、敵対者はその観測報酬を$\tilde{X}_i^{(t)} = 0$に設定する。他の結果は変更されない。
-
バンディットのUCBへの影響: この操作は、バンディットの学習に直接影響を与える。
- $O_S$に含まれないベースアームの報酬を一貫して0に設定することにより、敵対者は、それらのベースアームの経験的平均報酬推定値($\hat{\mu}_i^{(t)}$)を体系的に低下させる。
- これにより、これらの「ゼロ化された」ベースアームに大きく依存するスーパーアームのUCBが低下する。
- しかし、ターゲットスーパーアーム$S$は、その真の期待報酬$r_S(\mu)$(または敵対者が高く保ちたいUCB)に基づいて評価される。
-
ターゲットアームへの収束: ギャップ$\Delta_M > 0$の場合、ターゲットスーパーアーム$S$の真の期待報酬$r_S(\mu)$が、敵対者の操作下で評価された代替$S'$よりも十分に高いターゲットスーパーアームが存在することを示唆する。この正のギャップは、「損失ランドスケープ」がバンディットアルゴリズムによって効果的に形成されうることを示唆する。非$O_S$アームの報酬を抑制するという敵対者の戦略は、非ターゲットスーパーアームのUCBをターゲットスーパーアームのUCBを下回らせる。時間とともに、バンディットアルゴリズムの反復更新は、そのUCBが操作されたフィードバックのために優れているように見えるため、ターゲットスーパーアームから一貫して選択するように収束する。攻撃は、バンディットのUCBが十分に歪められたときに「成功」する。
-
攻撃不可能性($\Delta_M < 0$): $\Delta_M < 0$の場合、敵対者の最も有利な操作(非$O_S$アームのゼロ化)の下でも、ターゲットスーパーアーム$S \in M$がすべての代替よりも優れているように見えるものはないことを意味する。このシナリオでは、バンディットアルゴリズムのUCBはターゲットアームを一貫して支持するように収束しない。なぜなら、常に非ターゲットアームがより高い(または同等の)UCBを持つため、インスタンスは固有にこの種の攻撃に対してロバストになるからである。報酬を操作しようとするバンディットアルゴリズムの努力は無駄になるか、指数関数的なコストを必要とし、多項式攻撃可能性の定義に違反する。バンディットアルゴリズムの自然な探索と活用は、それが一貫して誤誘導されるのを防ぐだろう。
結果、限界、結論
実験設計とベースライン
実験的検証は、さまざまな組合せ的多腕バンディット(CMAB)インスタンスの多項式攻撃可能性に関する理論的主張を厳密にテストするために細心の注意を払って設計された。研究者たちは、現実世界のデータセットと一連のCMABアプリケーションを利用した多面的なアプローチを採用し、それぞれに特定のターゲット構成とベースラインアルゴリズムがあった。
確率的最大カバレッジ(PMC)、オンライン最小全域木(MST)、およびオンライン最短経路問題については、Flickrデータセット(McAuley & Leskovec, 2012)が使用された。サブグラフはダウンサンプリングされ、最大の弱連結成分を保持し、1,892ノードと7,052の有向エッジ、およびそれらの固有のエッジ活性化重みを保持した。カスケードバンディットについては、MovieLens smallデータセット(Harper & Konstan, 2015)が使用され、9,000本の映画が含まれ、実験のために5,000本の映画がランダムにサンプリングされた。d-rank SVD近似を使用して、映画の評価をユーザーのクリック確率にマッピングした。統計的ロバスト性を確保するために、すべての実験は少なくとも10回繰り返され、平均結果と分散が報告された。
「被害者」(ベースラインモデル)は標準的なCMAB学習アルゴリズムであった。PMCの場合、貪欲オラクルを備えたCUCBアルゴリズムが使用された。2種類の攻撃ターゲットが考慮された。1つは「固定ターゲット」で、平均出力エッジ重みが減少するノードで構成され、もう1つは平均出力エッジ重みが0.5を超えるランダムにサンプリングされたK個のノードで構成される「ランダムターゲット」であった。
オンラインMST問題については、Flickrデータセットが無向グラフに変換され、平均確率が期待エッジコストとして使用された。攻撃はアルゴリズム1の変更されたバージョンを使用し、目標は変更されたベースアーム結果$X_T = 1$を設定することによってコストを最小化するように変更された。ベースラインは標準的なCUCBアルゴリズムであった。ターゲットには「固定ターゲット」(2番目に良い最小全域木)と「ランダムターゲット」(ランダム化されたエッジ重みを持つ最小全域木)が含まれていた。
オンライン最短経路問題では、CUCBに対して2つの異なるターゲットタイプが評価された。「攻撃不可能なターゲット」(ターゲットパスのコストが最適パスよりも本質的に高いため、アルゴリズムを誤誘導するのが困難な、慎重に構築されたパス)と「ランダムターゲット」(ランダムにサンプリングされたソースと宛先ノード間の最短パスで、ランダム化されたエッジ重みを持つ)。この設定は、本質的にロバストなインスタンスと攻撃可能なインスタンスの両方を示すために重要であった。
カスケードバンディットについては、攻撃はCascadeKL-UCB、CascadeUCB1、およびCascadeUCB-Vアルゴリズムと対戦した。ターゲットスーパーアームは、平均クリック確率が0.1を超えるベースアームのサブセットから選択された。
さらに、オンライン影響力最大化(IM)に関する実験(付録A.2で詳述)では、問題のNP困難性のため、($\alpha$, $\beta$)近似オラクル(IMMオラクル)が使用された。攻撃戦略は、ターゲットノードと特定の距離$l$内のノードを含む「拡張ターゲットセット」$S_{ex}$の外のエッジの観測された実現を0に変更するヒューリスティックを含んでいた。これらの実験は少なくとも5回繰り返された。この包括的な実験設計は、多様なCMABアプリケーションとターゲット構成にまたがり、理論的な攻撃可能性条件の包括的な経験的検証を可能にした。
証拠が証明するもの
実験的証拠は、特に定理3.6および補題3.8に概説されている条件に関して、CMAB攻撃可能性に関する本稿の主要な数学的主張に対する説得力のある決定的な検証を提供する。
確率的最大カバレッジ(PMC)については、図2(a)および2(b)に示すように、攻撃はCUCBアルゴリズムにターゲットアームを線形に引かせ、総攻撃コストは劣線形に増加した。この劣線形コストは、ノードとエッジの数が大きいにもかかわらず、ベースアームの数に対して明らかに多項式であり、定理3.9($\Delta_M > 0$の場合、PMCは多項式攻撃可能であると述べている)を直接検証した。劣線形コストでのターゲットアームの引きの線形増加は、攻撃メカニズムがCUCBベースラインを効果的に誤誘導していることの否定できない証拠である。ランダムターゲットへの攻撃は、そのようなシナリオの固有の予測不可能性を示唆する、より高い分散を示した。
同様に、オンライン最小全域木(MST)問題(図2(c)および2(d))では、総攻撃コストは劣線形に留まり、ターゲットアームは線形に引かれた。この結果は、補題3.8(オンラインMST問題は常に攻撃可能であると仮定している、なぜならそのギャップ$\Delta_M \ge 0$だからである)に完全に一致する。CUCBベースラインに対する実験全体での一貫した劣線形コストと線形ターゲットアームの引きは、このドメインでの攻撃可能性の理論的予測に対する強力な経験的サポートを提供する。
オンライン最短経路実験(図2(e)および2(f))は、攻撃可能なインスタンスと攻撃不可能なインスタンスの両方の重要なデモンストレーションを提供した。「ランダムターゲット」の場合、攻撃は劣線形コストと線形ターゲットアームの引きを達成し、PMCおよびMSTに似ていた。しかし、「攻撃不可能なターゲット」(ロバストになるように慎重に構築されたパス)の場合、総コストは線形に増加し、決定的に、ターゲットアームの引きはほぼ一定に留まった。この明白なコントラストは、$\Delta_M$条件に基づく攻撃可能と攻撃不可能なシナリオの理論的な区別を決定的に証明し、本質的に攻撃不可能なCMABインスタンスの存在を証明する。この場合、CUCBアルゴリズムは欺かれず、攻撃可能性の限界に対するハードな証拠を提供した。
カスケードバンディット(図2(g)および2(h))では、攻撃はCascadeKL-UCB、CascadeUCB1、およびCascadeUCB-Vに対して劣線形攻撃コストでターゲットアームの線形プレイを成功裏に誘発した。この結果は補題3.8をさらに強化し、カスケードバンディットが多項式攻撃可能であることを確認した。異なるベースラインアルゴリズム全体でのターゲットアームプレイの増加の継続的な線形増加と最小限のコストは、攻撃の有効性の強力な証拠を提供する。
オンライン影響力最大化(IM)の結果(図4(a)および4(b))は、より微妙な状況を示した。攻撃コストは減少したが、ターゲットノードの割合は0で一定であり、ターゲットノード選択の増加傾向はなかった。この結果は、攻撃可能性を否定するのではなく、オンラインIMを攻撃することの難しさを強調し、近似オラクルを伴うCMABインスタンスの場合、攻撃可能性はインスタンスごとに分析する必要があるという本稿の主張を強調する。これは、現在の攻撃ヒューリスティックがIMには不十分であることを示唆しているが、その固有の攻撃可能性を排除するものではなく、さらなる研究を促す。
要約すると、実験は、$\Delta_M > 0$(PMC、MST、カスケードバンディット)のインスタンスでは、攻撃アルゴリズムがさまざまなCUCBベースラインを劣線形コストと線形ターゲットアームの引きで効果的に誤誘導することを示し、数学的主張を厳しく証明した。逆に、$\Delta_M < 0$(特定の最短経路構成)のインスタンスでは、攻撃は失敗し、線形コストと一定のターゲットアームの引きにつながり、攻撃可能性(または攻撃不可能性)の核となるメカニズムが現実で機能することの決定的な、否定できない証拠を提供する。
限界と将来の方向性
本稿はCMAB攻撃可能性の画期的な特徴付けを提示しているが、いくつかの限界も公然と認め、エキサイティングな将来の研究の方向性を提案している。
1つの重要な限界は、提案された攻撃アルゴリズム(アルゴリズム1)が攻撃コストに関して最適ではない可能性があることである。現在の結果は攻撃可能性の十分性を確立するが、可能な限り低いコストを保証するものではない。重要な将来の方向性は、より洗練された攻撃アルゴリズムを開発し、より低い攻撃コストを達成することである。これには、CMABインスタンスにおける攻撃コストの理論的な下限を確立することも必要となり、これは興味深く挑戦的な分野である。
議論のもう1つの重要な領域は、既知と未知のバンディット環境の区別を中心に展開する。本稿は驚くべき事実を明らかにする。すなわち、同じCMABインスタンスの多項式攻撃可能性は、敵対者が環境のパラメータ(例:報酬分布)を事前に知っているかどうかに応じて異なる可能性があることである。構築された「ハード例」(定理4.1)は、既知の環境では多項式攻撃可能であるが、環境が未知の場合は攻撃不可能なインスタンスを示す。これは、ブラックボックス設定における任意のCMABインスタンスに対する一般的な攻撃戦略が存在しない可能性を示唆している。将来の研究は、未知の環境におけるCMABインスタンスのロバスト性保証の特性化、特にギャップ$\Delta_M$が正または負になりうる最短経路のような問題に焦点を当てるべきである。攻撃不可能なCMAB問題をこれらのハード例に還元するための一般的なフレームワークを開発することは非常に価値があるだろう。
さらに、現在の攻撃可能性の特徴付けは、報酬ポイズニング攻撃に厳密に限定されている。著者らは、彼らの結果が、環境ポイズニング攻撃(敵対者が環境の報酬関数を直接変更できる場合)やアクションポイズニング攻撃のような、より強力な他の脅威モデルに直接一般化できないことを明確に述べている。将来の研究は、CMABの脆弱性のより包括的な理解を提供するために、これらの代替脅威モデルへの分析を拡張すべきである。これには、さまざまな種類の敵対的摂動が攻撃可能性の条件とコストにどのように影響するかを調査することが含まれるだろう。
最後に、本稿の結論は、確率的トリガーアームが攻撃可能性に与える影響をさらに調査する必要性を強調している。確率的にベースアームがトリガーされるこのメカニズムは、CMABに複雑さの別の層を追加する。その影響を攻撃可能性に理解すること、特にさまざまな拡散モデルを伴うオンライン影響力最大化のようなアプリケーションでは、新しい洞察とより堅牢なアルゴリズムにつながる可能性がある。オンライン影響力最大化に関する初期の結果は、攻撃戦略が明確に成功しなかったため、この特定の調査線の重要性を強調しており、特に近似オラクルを扱う場合には、この調査線の重要性を強調している。
これらの将来志向の議論は、攻撃コストの最適化から多様な脅威モデルと環境知識の探求まで、より堅牢なCMABアルゴリズムを開発し、現実世界のアプリケーションにおけるそれらのセキュリティへの影響をよりよく理解することを目指す研究者のための豊かな議題を提供する。