조합적 다중 팔 도적에 대한 적대적 공격
New research reveals how to identify and exploit vulnerabilities in "reward poisoning" attacks on a type of AI decision-making system, showing attacks are harder than previously thought.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 "조합적 다중 팔 도적(Combinatorial Multi-Armed Bandits, CMAB)에 대한 적대적 공격" 문제는 다중 팔 도적과 기계 학습에서의 적대적 강건성 연구라는 두 가지 중요한 연구 영역의 융합에서 비롯된다. Auer (2002)에 의해 초기에 탐구된 다중 팔 도적(MAB)의 근본적인 프레임워크는 에이전트가 기간 동안 누적 보상을 최대화하기 위해 새로운 옵션을 탐색하는 것과 알려진 수익성 있는 옵션을 활용하는 것을 전략적으로 균형 잡아야 하는 순차적 의사 결정 모델을 제시한다. 이 프레임워크는 다양한 분야에서 광범위하게 연구되고 적용되었다.
조합적 다중 팔 도적(CMAB)으로 알려진 MAB의 보다 일반화된 버전은 온라인 광고, 추천 시스템, 영향력 극대화 등 광범위한 실제 응용 분야로 인해 상당한 주목을 받고 있다 (Liu & Zhao, 2012; Kveton et al., 2015). CMAB에서 에이전트의 결정은 단일 팔이 아닌, 기본 팔의 조합("슈퍼 팔"이라고 함)을 각 라운드에서 선택하는 것을 포함한다. 이러한 조합적 측면은 탐색-활용 트레이드오프를 상당히 더 복잡하게 만드는데, 이는 주로 가능한 슈퍼 팔의 수가 기본 팔의 수에 따라 기하급수적으로 증가할 수 있기 때문이다.
이 특정 문제의 정확한 기원, 즉 CMAB에 대한 "공격 가능성"의 개념을 재정의하고 재평가하는 것은 MAB 알고리즘 및 그 변형이 적대적 공격, 특히 "보상 중독 공격"에 취약하다는 최근 연구 결과에서 비롯된다 (Jun et al., 2018; Liu & Shroff, 2019). 이러한 공격에서 공격자는 풀린 팔과 그 보상 피드백을 관찰한 다음, 이 피드백을 미묘하게 수정하여 공격자의 이익에 부합하는 특정 대상 팔로 학습 알고리즘을 잘못 유도한다. 공격 가능성이라는 개념은 이전에 표준 MAB 설정에 적용되었지만 (Wang et al., 2022), 이 정의를 CMAB에 직접 확장하는 것은 문제가 있음이 입증되었다. 이전 접근 방식의 핵심적인 한계는 MAB 공격 가능성 정의를 CMAB에 직접 적용했을 때 시간 지평 $T$에서는 부분선형이지만 기본 팔의 수 $m$에 대해서는 기하급수적인 비용 경계가 발생한다는 것이었다. $m$에 대한 이러한 기하급수적 의존성은 실제 시나리오에서 매우 바람직하지 않으며, 공격 비용이 총 시간 지평 $T$를 초과할 수도 있는 공허한 결과를 초래하는 경우가 많다. 이러한 부적절함은 원래의 공격 가능성 개념이 불충분했음을 강조하며, 따라서 본 논문이 제공하고자 하는 CMAB에 대한 새롭고 더 적절한 정의가 필요함을 시사한다.
직관적인 도메인 용어
- 다중 팔 도적 (MAB): 각기 알려지지 않은 평균 지급률을 가진 일련의 슬롯 머신 앞에 서 있는 카지노에 있다고 상상해 보라. 당신의 목표는 여러 번의 플레이를 통해 총 상금을 최대화하는 것이다. 매 턴마다 하나의 머신을 선택하고, 레버를 당기고, 보상을 받는다. 어떤 머신이 좋은지 (활용) 학습하는 동시에, 잠재적으로 더 나은 머신을 발견하기 위해 다른 머신을 계속 시도해야 한다 (탐색).
- 조합적 다중 팔 도적 (CMAB): 이는 MAB 시나리오와 유사하지만, 매 턴마다 하나의 슬롯 머신만 선택하는 대신, 여러 머신을 그룹 또는 조합으로 선택하여 동시에 플레이한다. 예를 들어, 2번, 5번, 8번 머신을 함께 플레이하기로 결정할 수 있다. 이 문제는 개별 머신보다 가능한 조합이 훨씬 많기 때문에 훨씬 더 어렵다.
- 슈퍼 팔: CMAB 맥락에서 "슈퍼 팔"은 주어진 라운드에서 플레이하기로 선택하는 특정 세트 또는 조합의 개별 슬롯 머신이다. 이는 해당 턴의 전체 행동을 나타낸다.
- 기본 팔: 이는 조합을 구성하는 개별적이고 기본적인 슬롯 머신이다. 머신 2, 5, 8로 구성된 슈퍼 팔을 선택하면, 2, 5, 8은 선택된 슈퍼 팔의 일부였던 개별 "기본 팔"이다.
- 보상 중독 공격: 이는 악의적인 당사자가 슬롯 머신에서 받는 보상 정보를 비밀리에 변경하는 상황을 설명한다. 그들의 목표는 특정, 종종 수익성이 떨어지는 조합(그들의 "대상 슈퍼 팔")의 지급률을 실제보다 더 좋게 보이게 하거나, 실제로 좋은 조합을 더 나쁘게 보이게 함으로써 의사 결정 과정을 속여 해당 조합을 반복적으로 선택하게 하는 것이다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $m$ | 기본 팔의 총 개수. |
| $\mathcal{S}$ | 모든 가능한 슈퍼 팔(기본 팔의 조합)의 집합. |
| $S \in \mathcal{S}$ | 특정 슈퍼 팔. |
| $T$ | 도적 문제의 총 시간 지평(라운드 수). |
| $\mu = (\mu_1, \ldots, \mu_m)$ | 모든 $m$개 기본 팔의 실제 평균 보상 벡터. |
| $r_S(\mu)$ | 실제 평균 보상 벡터 $\mu$가 주어졌을 때 슈퍼 팔 $S$의 기대 보상. |
| $O_S$ | 슈퍼 팔 $S$가 선택될 때 확률적으로 트리거될 수 있는 기본 팔의 집합. |
| $\mu \odot O_S$ | $\mu$와 $O_S$에 없는 기본 팔의 평균 보상을 0으로 만드는 $O_S$의 이진 벡터를 나타내는 벡터의 요소별 곱. |
| $\Delta_S$ | 슈퍼 팔 $S$의 "갭", 공격 가능성을 정량화함 (정의 3.5). |
| $M$ | 공격자가 도적 알고리즘이 풀기를 원하는 대상 슈퍼 팔의 집합. |
| $\Delta_M$ | 대상 집합 $M$에 대한 전체 "갭", $\max_{S \in M} \Delta_S$로 정의됨. |
| $C(T)$ | 시간 지평 $T$ 동안 공격자가 발생시키는 총 공격 비용. |
| $o(T)$ | $T$보다 느리게 성장하는 함수, 즉 $\lim_{T \to \infty} o(T)/T = 0$. |
| $p^*$ | 기본 팔 트리거의 최소 확률과 관련된 매개변수 (정의 3.1). |
| $K$ | 슈퍼 팔의 기본 팔 수 또는 후회 경계와 관련된 문제별 매개변수. |
| $\gamma, \gamma'$ | 후회 및 공격 비용의 부분선형 성장에 관련된 양의 상수. |
| $\hat{\mu}_i^{(t)}$ | 라운드 $t$에서 기본 팔 $i$의 경험적 평균 보상 추정치. |
| UCB | 탐색-활용을 위해 도적 알고리즘에서 사용되는 상한 신뢰 구간. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문은 조합적 다중 팔 도적(CMAB)의 취약성을 적대적 공격에 대한 이해에 있어 중요한 격차를 다룬다.
입력/현재 상태:
시작점은 학습 에이전트가 시간 지평 $T$ 동안 "기본 팔"로 구성된 "슈퍼 팔"을 순차적으로 선택하는 표준 CMAB 문제이다. 각 라운드에서 에이전트는 피드백(트리거된 기본 팔의 결과)을 관찰하고 보상을 받으며 누적 보상을 최대화하는 것을 목표로 한다. 현재 연구 상태는 다중 팔 도적(MAB) 및 그 변형이 "보상 중독 공격"에 취약하다는 것을 인정한다. 이러한 공격에서 공격자는 에이전트의 행동과 피드백을 관찰한 다음, 관찰된 보상을 미묘하게 수정한다. 공격자의 목표는 도적 알고리즘을 일관되게 특정 "대상 팔"(공격자의 이익에 부합하는 팔)을 거의 모든 라운드($T - o(T)$ 회) 동안 풀도록 잘못 유도하는 동시에 시간 지평 $T$ 동안 부분선형 공격 비용 $o(T)$를 발생시키는 것이다.
원하는 출력/목표 상태:
본 논문의 주요 목표는 CMAB의 취약성과 강건성을 포착하는 "좋은 개념"을 실질적으로 의미 있게 확립하는 것이다. "다항식 공격 가능성"이라고 명명된 이 새로운 정의는 CMAB 인스턴스가 효율적으로 공격될 수 있는 시점을 정확하게 정의하는 것을 목표로 한다. 이 개선된 정의 하에서 성공적인 공격은 목표를 달성할 뿐만 아니라(에이전트를 $T - o(T)$ 회 동안 대상 팔을 풀도록 잘못 유도), 시간 지평 $T$에 대해 부분선형이고, 결정적으로 기본 팔 $m$ 및 기타 관련 문제 요인(예: $1/p^*$, $K$)에 대해 다항식인 공격 비용으로 이를 수행해야 한다.
누락된 연결/수학적 격차:
정확한 누락된 연결은 CMAB에 대한 강력하고 실용적인 "공격 가능성" 정의이다. 이전 정의는 더 간단한 MAB 설정에서 직접 빌려왔지만 CMAB에는 부적절함이 입증되었다. 이는 CMAB의 조합적 특성으로 인해 가능한 "슈퍼 팔"의 수가 기본 팔 $m$에 대해 기하급수적으로 클 수 있기 때문이다. 이전 정의를 적용하면 $m$에 대해 기하급수적인 공격 비용이 발생하여, 그러한 비용이 총 시간 지평 $T$를 쉽게 초과할 수 있으므로 실제로는 "바람직하지 않고" "공허한" 결과가 된다. 본 논문은 "다항식 공격 가능성"을 도입하여 이 격차를 해소하며, 이는 공격 가능성 개념을 CMAB에 대해 관련성 있고 실용적으로 만들기 위해 공격 비용을 $m$에 대해 다항식으로 명시적으로 제약한다. 수학적으로 이는 일반적인 $C(T) = o(T)$ 비용에서 $C(T) = O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma'})$로 이동하는 것을 포함하며, 여기서 $\gamma' > 0$이고, $m$은 기본 팔의 수, $p^*$는 트리거 확률과 관련되며, $K$는 문제별 매개변수이다. 본 논문은 또한 각 슈퍼 팔 $S$에 대해 "갭" $\Delta_S$ (정의 3.5)를 정의하며, 이는 기대 보상과 다른 모든 슈퍼 팔의 최대 기대 보상 간의 차이를 정량화하여 공격 가능성에 대한 핵심 수학적 지표 역할을 한다.
딜레마:
이전 연구자들을 가두었던 중심 딜레마는 CMAB의 조합적 복잡성과 공격 비용의 실용성 사이의 트레이드오프이다. MAB 공격 개념을 직접 확장하는 것이 매력적이지만, 그렇게 하면 기본 팔 $m$의 수에 대해 기하급수적인 비용이 발생하여 모든 "성공적인" 공격 정의가 실제 시나리오에서 무의미해진다. 본 논문은 놀랍고 고통스러운 트레이드오프를 강조한다. CMAB 인스턴스의 공격 가능성은 단순히 내재적 속성이 아니라 "도적이 도적 알고리즘 인스턴스를 알고 있는지 여부에 따라 달라진다." 이는 화이트박스 설정(환경 매개변수를 아는 경우)에서 효과적인 공격 전략이 블랙박스 설정(매개변수를 모르는 경우)에서는 완전히 실패할 수 있음을 의미하며, 보편적인 공격 전략을 파악하기 어렵게 만들고 실제로는 "미친 듯이 어렵다"는 문제를 야기한다.
제약 조건 및 실패 모드
CMAB 인스턴스를 효율적이고 의미 있게 공격하는 문제는 몇 가지 가혹하고 현실적인 장벽에 의해 제약된다.
- 슈퍼 팔의 조합 폭발: 가장 중요한 제약 조건은 가능한 "슈퍼 팔"의 엄청난 수이며, 이는 기본 팔 $m$에 대해 기하급수적으로 증가할 수 있다. 이러한 조합적 복잡성은 모든 슈퍼 팔을 탐색하거나 조작해야 하는 모든 공격 전략이 기하급수적인 비용을 발생시켜, 실용적인 다항식 공격 가능성 요구 사항을 위반한다는 것을 의미한다. 이는 MAB 공격 전략의 직접적인 적용을 비실용적으로 만들고 "공허한 결과"를 초래한다.
- 환경에 대한 공격자의 지식: 중요한 제약 조건은 공격자가 CMAB 인스턴스의 기본 매개변수, 즉 보상 분포($\mu$) 및 기본 팔의 결과 분포에 대한 접근 권한이다.
- 알려진 환경 (화이트박스): 공격자가 이러한 매개변수에 대한 완전한 지식을 가지고 있다면, 고도로 표적화되고 효율적인 공격을 설계할 수 있다.
- 알려지지 않은 환경 (블랙박스): 보다 현실적인 블랙박스 설정에서 공격자는 이러한 사전 지식이 부족하다. 이는 공격자가 매개변수를 추정하기 위한 탐색을 수행하도록 강제하며, 이는 자체적으로 비용을 발생시키고 공격을 훨씬 더 어렵거나 불가능하게 만들 수 있다. 본 논문은 환경이 알려진 경우 다항식으로 공격 가능하지만, 알려지지 않은 경우 다항식으로 공격 불가능한 인스턴스(정리 4.1)를 통해 이를 입증한다. 이는 주요 실질적인 장벽을 강조한다.
- 공격 비용 예산: 공격자는 엄격한 예산 제약 하에서 운영된다. 공격 비용은 시간 지평 $T$에 대해 부분선형이어야 하며, 새로운 정의 하에서는 기본 팔 $m$ 및 기타 요인에 대해 다항식이어야 한다. 이 예산을 초과하면 공격이 "효율적이거나" "성공적인" 것으로 간주되지 않으므로 실패 모드가 된다.
- 반도적 피드백: CMAB의 학습 에이전트는 "반도적 피드백"을 받는다. 즉, 선택된 슈퍼 팔에 의해 트리거된 기본 팔의 결과만 관찰하고 모든 기본 팔의 결과는 관찰하지 않는다. 이러한 부분적 관찰 가능성은 공격자가 사용할 수 있는 정보를 제한하여, 특히 알려지지 않은 환경에서 보상을 정확하게 추정하거나 효과적으로 조작하기 어렵게 만든다.
- 알고리즘 강건성 및 후회 경계: 공격은 종종 이론적 후회 경계 $O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma})$를 갖는 후회를 최소화하도록 설계된 알고리즘(예: CUCB)에 대해 성공해야 한다. 공격자는 과도한 비용을 발생시키지 않고 알고리즘의 고유한 학습 및 탐색 메커니즘을 극복해야 한다.
- 오라클 제한: CMAB 문제는 종종 계산 오라클(예: 최적 슈퍼 팔 찾기)에 의존한다. 이러한 오라클이 정확한 오라클이 아닌 근사치인 경우(예: $(\alpha, \beta)$-근사 오라클), 알고리즘의 동작이 정확한 오라클이 생성하는 것과 다를 수 있어 공격 효과에 영향을 미칠 수 있으므로 공격자에게 추가적인 복잡성을 야기할 수 있다.
왜 이 접근 방식인가
선택의 불가피성
저자들이 조합적 다중 팔 도적(CMAB)에 대한 "다항식 공격 가능성"을 정의하기로 선택한 것은 단순히 선택 사항이 아니라, 이 복잡한 영역에 전통적인 공격 가능성 개념을 적용하는 데 내재된 한계에서 비롯된 필수 사항이었다. 저자들이 표준 다중 팔 도적(MAB)의 최신 기술(SOTA) 방법이 불충분하다는 것을 깨달은 정확한 순간은 서론에서 명확하게 설명된다. 그들은 "CMAB에 MAB 공격 가능성 개념을 직접 적용하는 것은 매력적이지만... $T$에 대한 부분선형 비용 경계는 발생시키지만 기본 팔 $m$에 대해서는 기하급수적인 비용 경계를 발생시킨다"고 언급한다. $m$(기본 팔의 수)에 대한 이러한 기하급수적 의존성은 명시적으로 "바람직하지 않다"고 불리며 시간 지평 $T$를 초과할 수 있어 결과를 "공허하게" 만든다 (1페이지).
이러한 결정적인 관찰은 CMAB에 내재된 조합적 폭발, 즉 슈퍼 팔의 수가 $m$에 대해 기하급수적으로 증가할 수 있다는 사실이 이전 MAB 공격 가능성 정의의 가정을 근본적으로 깨뜨렸다는 것을 강조했다. 실용적인 계산 한계 내에서 의미 있는 보장을 제공할 수 있는 해결책이 필요했다. 따라서 제안된 다항식 공격 가능성 정의는 공격 비용이 시간 지평 $T$에 대해 부분선형일 뿐만 아니라 기본 팔 $m$ 및 기타 요인에 대해 다항식이어야 함을 요구하며, 이는 CMAB에 대한 적대적 공격을 분석하기 위한 실행 가능하고 관련성 있는 프레임워크를 제공하는 유일하게 실행 가능한 해결책이 되었다.
비교 우위
이 접근 방식의 질적 우수성은 이전 MAB 공격 가능성의 황금 표준이 극복하지 못한 CMAB의 조합적 복잡성을 해결할 수 있다는 능력에서 직접적으로 비롯된다. 단순한 성능 지표를 넘어, 구조적 이점은 불가능한 기하급수적 비용 문제를 다항식으로 가능한 문제로 변환하는 데 있다.
구체적으로, MAB에 대한 "원래 공격 가능성 개념"은 CMAB에 적용될 때 "m에 대한 기하급수적 비용"을 발생시켰다 (1페이지). 이는 기본 팔의 수가 증가함에 따라 공격 비용이 빠르게 천문학적으로 커져 이론적 보장이 실질적으로 무의미해진다는 것을 의미했다. "다항식 공격 가능성"의 새로운 정의(정의 3.1)는 공격 비용이 $m$, $1/p^*$, $K$(여기서 $p^*$는 트리거 확률과 관련되고 $K$는 후회 경계의 요인임)의 다항식 함수로 제한되어야 함을 요구함으로써 이를 근본적으로 변화시킨다. 이는 슈퍼 팔의 수가 기하급수적인 고차원 CMAB 설정에서 공격 가능성을 의미 있게 분석할 수 있게 해주므로 질적인 도약이다.
또한, 본 논문은 "갭" $\Delta_M$(정의 3.5)을 기반으로 다항식 공격 가능성에 대한 충분하고 필요한 조건을 제공한다 (정리 3.6). 이 이론적 특성화는 특정 CMAB 인스턴스가 왜 공격 가능하거나 공격 불가능한지에 대한 깊은 구조적 통찰력을 제공하며, 단순히 공격이 얼마나 잘 수행되는지를 측정하는 것을 넘어선다. 이는 내재적 강건성에 대한 명확한 경계를 제공하며, 특정 인스턴스에 대한 경험적 성능만 제공하는 방법보다 중요한 질적 이점이다. 이 방법은 메모리 복잡성을 암묵적인 $O(2^m)$(기하급수적 슈퍼 팔 때문에)에서 $m$에 대한 다항식 의존성으로 효과적으로 줄여 문제를 분석 가능하게 만든다.
제약 조건과의 정렬
"다항식 공격 가능성"을 정의하는 선택된 방법은 CMAB 문제의 핵심 제약 조건, 특히 조합적 특성으로 인해 발생하는 문제와 완벽하게 일치한다. 문제 정의에서 강조된 주요 제약 조건은 CMAB의 후보 슈퍼 팔 수가 "m에 대해 기하급수적"일 수 있다는 것이다 (1페이지). 이러한 기하급수적 성장을 고려하지 않는 MAB 공격 가능성 정의를 직접 적용하면 공격 비용도 $m$에 대해 기하급수적으로 증가하기 때문에 "공허한 결과"를 초래한다.
정의 3.1은 문제의 가혹한 요구 사항과 해결책의 고유한 속성 간의 "결혼"을 보여준다. 이 정의는 성공적인 공격이 시간 지평 $T$에 대해 부분선형일 뿐만 아니라 기본 팔 $m$ 및 기타 요인에 대해 다항식이어야 한다는 제약 조건을 명시적으로 부과한다. 이는 공격 가능성 개념이 대규모 CMAB 인스턴스에서도 의미 있고 실용적으로 유지되도록 보장한다.
또한, 본 논문은 공격자가 관찰된 보상을 수정하는 "보상 중독 공격"(섹션 2.2)에 초점을 맞춘다. 제안된 공격 알고리즘(알고리즘 1)과 공격 가능성 조건(정리 3.6)은 이 위협 모델에 맞춰 특별히 설계되어 해결책이 정의된 적대적 능력 및 제약 조건을 준수하도록 보장한다. 이 방법은 또한 기본 팔의 트리거된 결과만 관찰되는 CMAB의 "반도적 피드백" 특성을 고려하여 이 피드백 구조를 공격 전략에 통합한다.
대안의 거부
본 논문은 주로 기존 MAB 공격 가능성 정의의 직접적인 적용에 초점을 맞춰 기존 접근 방식을 거부하거나 수정하는 이유를 명확하게 설명한다. 그들의 불충분성에 대한 핵심 주장은 CMAB에 적용될 때 "m에 대한 기하급수적 비용"을 초래한다는 것이다 (1페이지). 이는 사소한 성능 문제가 아니라 결과를 실제적으로 "바람직하지 않고" "공허하게" 만드는 근본적인 결함이다. 기하급수적으로 큰 슈퍼 팔의 수를 가진 CMAB의 조합적 특성은 기본 팔의 수에 대해 기하급수적으로 확장되는 공격 비용은 단순히 실행 가능하거나 의미가 없다는 것을 의미한다. 따라서 저자들은 $m$에 대해 다항식 비용을 요구하는 새로운 정의를 도입해야 했다.
또한, 본 논문은 암묵적으로 다른 관련 작업들을 특정 문제 공식화에 직접 적용하거나 충분하지 않다고 거부한다.
- 기존 MAB 공격 가능성 정의: 위에서 자세히 설명한 바와 같이, $m$에 대한 기하급수적 비용 때문에 불충분한 것으로 간주되었다.
- 강화 학습(RL)에 대한 적대적 공격: 관련이 있지만, 본 논문은 "기존 작업 중 어느 것도 주어진 인스턴스의 공격 가능성을 분석하지 않았다" (2페이지, 섹션 1.2)고 언급한다. 이는 RL 공격이 광범위한 분야이지만, 본 논문이 CMAB에 대해 추구했던 인스턴스 수준의 공격 가능성 특성화를 제공하지 않았음을 시사한다.
- 손상 방지 도적: 이 대안적인 작업 라인은 중독 공격에 대한 강건성을 연구하지만, 종종 "약한 위협 모델"을 고려하기 때문에 직접적인 해결책으로 암묵적으로 거부된다 (2페이지, 섹션 1.2). 예를 들어, 일부 모델은 무관심한 공격자를 고려하거나 손상을 보상 증가로만 제한한다. 대조적으로, 본 논문의 위협 모델은 공격자가 보상을 증가시키거나 감소시킬 수 있도록 허용하여, 이 문제가 일반적으로 더 어렵고 손상 방지 도적 알고리즘이 일반적으로 다루는 것보다 더 도전적이다. 이러한 더 넓은 적대적 능력은 더 강력한 공격 가능성 프레임워크를 필요로 한다.
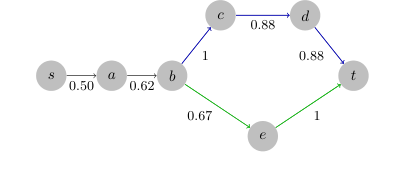 Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
수학적 및 논리적 메커니즘
마스터 방정식
본 논문에서 조합적 다중 팔 도적(CMAB) 인스턴스의 공격 가능성을 정의하는 절대적인 핵심 방정식은 정의 3.5에 제시된 슈퍼 팔 $S$에 대한 "갭" 정의이다. 이 갭은 CMAB 인스턴스의 내재적 취약성 또는 보상 중독 공격에 대한 강건성을 정량화한다.
$$ \Delta_S := r_S(\mu) - \max_{S' \neq S} r_{S'}(\mu \odot O_S) $$
대상 슈퍼 팔 집합 $M$에 대해 전체 갭은 $\Delta_M = \max_{S \in M} \Delta_S$로 정의된다. 정리 3.6은 $\Delta_M > 0$이면 CMAB 인스턴스가 다항식으로 공격 가능하고, $\Delta_M < 0$이면 다항식으로 공격 불가능하다고 명시한다.
용어별 분석
마스터 방정식의 각 용어를 자세히 분석하여 수학적 정의, 물리적/논리적 역할 및 연산자 사용 이유를 이해해 보자.
-
$\Delta_S$:
- 수학적 정의: 특정 대상 슈퍼 팔 $S$의 기대 보상과 수정된 평균 보상 벡터 하에서 평가될 때 다른 모든 슈퍼 팔 $S'$의 최대 기대 보상 간의 차이를 나타내는 스칼라 값이다.
- 물리적/논리적 역할: 특정 대상 슈퍼 팔 $S$에 대한 "취약성 지표" 역할을 한다. 양수 $\Delta_S$는 대상 슈퍼 팔 $S$가 해당 기본 팔만 관찰하는 대안을 평가할 때 본질적으로 다른 $S'$보다 "더 낫다"는 것을 시사한다. 이는 공격자가 도적 알고리즘을 $S$로 잘못 유도할 수 있는 잠재적인 경로를 시사한다. $\Delta_S$가 음수이면 $S$가 이러한 특정 평가 하에서도 최선의 선택이 아님을 나타내어 공격을 더 어렵게 만든다.
- 왜 빼기와 최대값인가: 빼기는 $S$가 가장 강력한 대안에 비해 갖는 "이점"을 정량화하는 데 사용된다. 최대값 연산자는 특정 평가 맥락에서 $S$의 가장 강력한 경쟁자를 식별하여 갭이 극복해야 할 가장 어려운 대안을 진정으로 반영하도록 보장한다.
-
$r_S(\mu)$:
- 수학적 정의: 모든 기본 팔의 실제 평균 보상 벡터가 $\mu$일 때 슈퍼 팔 $S$를 선택하는 기대 보상을 나타낸다.
- 물리적/논리적 역할: 이는 슈퍼 팔 $S$의 실제, 손상되지 않은 기대 성능이다. 이는 공격자가 없다면 도적 알고리즘이 이상적으로 달성해야 하는 것을 나타낸다.
- 왜 이 형태인가: 이는 도적 문제에서 행동(슈퍼 팔)의 기대 효용을 나타내는 표준적인 방법으로, 기본 보상 분포에 따라 달라진다.
-
$\mu$:
- 수학적 정의: 이는 $m$차원 벡터 $(\mu_1, \mu_2, \ldots, \mu_m)$이며, 여기서 $\mu_i = E_{X \sim D}[X_i^{(t)}]$는 기본 팔 $i$의 실제 평균 보상이다.
- 물리적/논리적 역할: 이 벡터는 CMAB 환경의 모든 개별 기본 팔의 실제, 근본적인 보상 분포를 나타낸다. 이는 도적 알고리즘이 추정하려고 하는 실제이며, 공격자가 조작하려고 하는 것이다.
-
$\max_{S' \neq S}$:
- 수학적 정의: 대상 슈퍼 팔 $S$가 아닌 모든 슈퍼 팔 $S'$의 기대 보상 중 최대값을 찾는 연산자이다.
- 물리적/논리적 역할: 이는 공격자의 조작 전략 관점에서 대상 슈퍼 팔 $S$의 "최상의 대안"을 식별한다. 공격자는 $S$를 다른 모든 옵션보다 더 좋게 보이게 하고 싶어하므로 가장 강력한 경쟁자를 고려해야 한다.
-
$S'$:
- 수학적 정의: 대상 슈퍼 팔 $S$와 다른 액션 공간 $\mathcal{S}$의 모든 슈퍼 팔을 나타낸다.
- 물리적/논리적 역할: 이는 도적 알고리즘이 대상 슈퍼 팔 $S$ 대신 선택할 수 있는 대안 행동이다. 공격자의 목표는 이러한 대안을 덜 매력적으로 보이게 하는 것이다.
-
$\mu \odot O_S$:
- 수학적 정의: 이는 실제 평균 보상 벡터 $\mu$와 슈퍼 팔 $S$에 의해 트리거될 수 있는 기본 팔에 대해 1이고 그렇지 않으면 0인 이진 벡터 $O_S$ 간의 요소별 곱(Hadamard 곱)이다.
- 물리적/논리적 역할: 이 수정된 평균 벡터는 대상 슈퍼 팔 $S$가 관찰할 수 없는 기본 팔의 보상이 효과적으로 "0으로 설정"되거나 무시되는 가상 시나리오를 나타낸다. 이는 공격자의 공격 전략(알고리즘 1)이 대상 슈퍼 팔 $S$의 관찰 가능한 집합 $O_S$에 속하지 않는 기본 팔의 보상을 0으로 설정하는 경우가 많다는 점을 고려할 때 중요하다. $S'$를 $\mu \odot O_S$ 하에서 평가함으로써, 본 논문은 대안 슈퍼 팔에 대한 공격자의 조작 효과를 모델링한다. 이는 "만약 우리가 $S$가 볼 수 있는 기본 팔만 고려한다면, 다른 슈퍼 팔 $S'$는 얼마나 좋을까?"라고 묻는다.
- 왜 요소별 곱인가: $O_S$와의 요소별 곱은 $\mu$ 벡터를 효과적으로 필터링하여 $O_S$에 속하는 기본 팔의 평균 보상만 유지한다. 이는 $S$와 관련된 기본 팔의 하위 집합에 초점을 맞추는 아이디어를 수학적으로 포착한다.
단계별 흐름
갭 정의를 사용하여 CMAB 인스턴스의 공격 가능성이 어떻게 결정되는지 단계별로 추적하여 기계 조립 라인처럼 느껴지도록 하자.
-
인스턴스 특성화 입력: 특정 CMAB 인스턴스가 시스템에 공급된다. 이 인스턴스는 기본 팔 $[m]$, 슈퍼 팔 $\mathcal{S}$의 액션 공간, 환경의 트리거 분포 $D$, 확률적 트리거 함수 $D_{trig}$, 보상 함수 $R$로 정의된다. 결정적으로, 모든 기본 팔의 실제 평균 보상 벡터 $\mu$는 이 초기 평가를 위해 알려져 있다고 가정된다.
-
대상 집합 식별: 공격자는 도적 알고리즘이 풀기를 원하는 대상 슈퍼 팔 집합 $M$을 지정한다.
-
개별 슈퍼 팔 평가 (각 $S \in M$에 대해): 대상 집합 $M$의 각 슈퍼 팔 $S$에 대해:
- 실제 보상 계산: 이 슈퍼 팔 $S$의 기대 보상 $r_S(\mu)$는 실제 평균 보상 $\mu$를 기반으로 계산된다. 이것이 기본 성능이다.
- 관찰 가능한 기본 팔 식별: 집합 $O_S$가 결정된다. 이는 슈퍼 팔 $S$가 선택될 때 확률적으로 트리거될 수 있는 기본 팔의 집합이다. 이는 $S$의 "시야" 또는 직접 영향을 미칠 수 있는 리소스로 생각할 수 있다.
- 수정된 환경 시뮬레이션: $O_S$에 속하지 않는 기본 팔의 실제 평균 보상이 효과적으로 0으로 설정된 가상 환경이 구성된다. 이는 관련 없는 기본 팔의 보상을 억제하는 공격자의 전략을 시뮬레이션한다.
- 경쟁자 평가: 이러한 평가된 모든 경쟁자 $S' \neq S$(즉, 현재 대상이 아닌 슈퍼 팔) 각각에 대해, 이 수정된 평균 보상 벡터를 사용하여 기대 보상 $r_{S'}(\mu \odot O_S)$가 계산된다. 이 단계는 $S$가 보는 것을 $S'$만 볼 수 있다고 가정하거나 공격자가 다른 팔을 조작한 경우 경쟁자가 얼마나 잘 수행하는지 평가한다.
- 가장 강력한 경쟁자 식별: 이러한 모든 평가된 경쟁자의 기대 보상 중 최대값, $\max_{S' \neq S} r_{S'}(\mu \odot O_S)$가 식별된다. 이것이 $S$가 극복해야 할 가장 높은 장애물이다.
- 갭 계산: 가장 강력한 경쟁자의 보상(수정된 환경 하에서)에서 $S$의 실제 보상을 빼서 개별 갭 $\Delta_S$를 계산한다. 이 값은 저장된다.
-
전체 공격 가능성 결정: $M$의 모든 $S$에 대해 $\Delta_S$를 계산한 후, 이러한 개별 갭의 최대값인 $\Delta_M = \max_{S \in M} \Delta_S$를 찾는다.
-
공격 가능성 출력:
- $\Delta_M > 0$이면 CMAB 인스턴스는 "다항식으로 공격 가능"하다고 선언된다. 이는 경쟁자가 공격자의 조작 하에서 평가될 때에도 충분한 이점을 갖는 대상 슈퍼 팔 $S$가 적어도 하나 있다는 것을 의미한다.
- $\Delta_M < 0$이면 CMAB 인스턴스는 "다항식으로 공격 불가능"하다고 선언된다. 이는 $M$의 대상 슈퍼 팔 중 어느 것도 공격자의 제안된 조작 하에서 명확한 이점을 갖지 않음을 시사하며, 성공적인 공격을 어렵거나 불가능하게 만든다.
최적화 역학
이 논문의 "수학적 및 논리적 메커니즘"은 $\Delta_S$가 CMAB 인스턴스와 대상 집합의 정적 속성이므로 갭 자체에 대한 전통적인 학습 또는 최적화 프로세스를 포함하지 않는다. 대신, 역학은 공격자의 고정 전략(알고리즘 1)이 도적 알고리즘의 학습 역학을 이용하여 목표를 달성하는 방법과 갭 $\Delta_M$이 성공을 예측하는 지표 역할을 하는 방법에 집중된다.
-
공격자의 목표: 공격자의 "최적화"는 시간 지평 $T$ 동안 $T - o(T)$ 회 동안 대상 슈퍼 팔 $S \in M$을 풀도록 도적 알고리즘을 강제하는 것이며, 부분선형 공격 비용 $o(T)$를 발생시킨다. 이는 반복적인 매개변수 업데이트가 아니라 목표 중심의 조작이다.
-
도적 알고리즘의 학습 (예: CUCB): 희생자 도적 알고리즘(예: CUCB)은 기본 팔의 기대 보상을 반복적으로 추정하고 상한 신뢰 구간(UCB)을 구성하여 작동한다. 각 라운드 $t$에서:
- 풀린 슈퍼 팔 $S^{(t)}$와 트리거된 기본 팔의 결과 $X^{(t)}$를 관찰한다.
- 기본 팔 평균 보상($\hat{\mu}_i^{(t)}$) 및 신뢰 구간의 경험적 추정치를 업데이트한다.
- 이러한 추정치를 사용하여 모든 슈퍼 팔의 UCB를 계산한다.
- 그런 다음 가장 높은 UCB를 가진 슈퍼 팔을 다음 라운드에 선택한다. 이 프로세스는 후회를 최소화하는 것을 목표로 하며, 탐색(불확실한 팔 시도)과 활용(높은 추정 보상을 가진 팔 풀기)을 균형 잡는다.
-
공격자의 조작 (알고리즘 1): 공격자는 이 학습 루프에 개입한다. 도적 알고리즘이 슈퍼 팔 $S^{(t)}$를 풀고 결과 $X^{(t)}$를 관찰할 때, 공격자는 이러한 결과를 $\tilde{X}^{(t)}$로 수정한다. 구체적으로, 트리거되었지만 대상 슈퍼 팔 $S$의 관찰 가능한 집합 $O_S$의 일부가 아닌 기본 팔 $i$에 대해 (즉, $i \in \mathcal{T}^{(t)} \setminus O_S$), 공격자는 관찰된 보상 $\tilde{X}_i^{(t)} = 0$으로 설정한다. 다른 결과는 변경되지 않는다.
-
도적의 UCB에 대한 영향: 이 조작은 도적의 학습에 직접적인 영향을 미친다.
- $O_S$에 속하지 않는 기본 팔의 보상을 일관되게 0으로 설정함으로써, 공격자는 해당 기본 팔의 경험적 평균 보상 추정치($\hat{\mu}_i^{(t)}$)를 체계적으로 낮춘다.
- 이는 결과적으로 이러한 "0으로 설정된" 기본 팔에 크게 의존하는 슈퍼 팔 $S'$의 UCB를 낮춘다.
- 그러나 대상 슈퍼 팔 $S$는 실제 기대 보상 $r_S(\mu)$(또는 공격자가 높게 유지하기를 원하는 UCB)를 기반으로 평가된다.
-
대상 팔로의 수렴: 갭 $\Delta_M > 0$이면, 대상 슈퍼 팔 $S$의 실제 기대 보상 $r_S(\mu)$가 공격자의 조작 하에서 평가된 모든 대안 $S'$보다 충분히 높은 대상 슈퍼 팔 $S$가 적어도 하나 있다는 것을 의미한다. 이 양수 갭은 도적 알고리즘의 "손실 지형"이 공격자에 의해 효과적으로 형성될 수 있음을 시사한다. $O_S$가 아닌 팔의 보상을 억제하는 공격자의 전략은 대상 슈퍼 팔의 UCB보다 낮은 비대상 슈퍼 팔의 UCB를 유발할 것이다. 시간이 지남에 따라 도적 알고리즘의 반복적인 업데이트는 조작된 피드백으로 인해 UCB가 더 우수하게 보이기 때문에 $M$의 대상 슈퍼 팔을 일관되게 선택하는 것으로 수렴될 것이다. 공격은 도적의 UCB가 충분히 왜곡될 때 "성공"한다.
-
공격 불가능성 ($\Delta_M < 0$): $\Delta_M < 0$이면, 공격자의 가장 유리한 조작(비-$O_S$ 팔을 0으로 설정) 하에서도 대상 슈퍼 팔 $S \in M$이 모든 다른 대안보다 우수해 보이지 않는다는 것을 의미한다. 이 시나리오에서 도적 알고리즘의 UCB는 일부 비대상 팔이 항상 더 높거나(또는 유사한) UCB를 가질 것이므로 대상 팔을 일관되게 선호하도록 수렴되지 않아 인스턴스가 이러한 유형의 공격에 본질적으로 강건해진다. 보상을 조작하려는 공격자의 노력은 쓸모가 없거나 기하급수적인 비용이 필요하여 다항식 공격 가능성 정의를 위반한다. 도적 알고리즘의 자연스러운 탐색 및 활용은 지속적으로 잘못 유도되는 것을 방지할 것이다.
결과, 한계 및 결론
실험 설계 및 기준선
실험적 검증은 다양한 조합적 다중 팔 도적(CMAB) 인스턴스의 다항식 공격 가능성에 대한 이론적 주장을 엄격하게 테스트하도록 세심하게 설계되었다. 연구자들은 실제 데이터셋과 다양한 CMAB 응용 프로그램을 활용하는 다면적인 접근 방식을 채택했으며, 각 응용 프로그램은 특정 대상 구성 및 기준선 알고리즘을 가지고 있었다.
확률적 최대 커버리지(Probabilistic Maximum Coverage, PMC), 온라인 최소 신장 트리(Online Minimum Spanning Tree, MST), 온라인 최단 경로(Online Shortest Path) 문제에 대해 Flickr 데이터셋(McAuley & Leskovec, 2012)이 사용되었다. 부분 그래프를 다운샘플링하여 가장 큰 약한 연결 구성 요소를 유지했으며, 이는 1,892개의 노드와 7,052개의 방향 간선 및 고유한 간선 활성화 가중치를 포함했다. 연쇄 도적(Cascading Bandits)의 경우, MovieLens 소규모 데이터셋(Harper & Konstan, 2015) 9,000개의 영화로 구성된 데이터셋이 활용되었으며, 실험을 위해 5,000개의 영화가 무작위로 샘플링되었다. 사용자 클릭 확률을 영화 등급에 매핑하기 위해 d-랭크 SVD 근사가 사용되었다. 모든 실험은 통계적 강건성을 보장하기 위해 최소 10회 반복되었으며, 평균 결과와 분산이 보고되었다.
"희생자"(기준선 모델)는 표준 CMAB 학습 알고리즘이었다. PMC의 경우, 탐욕적 오라클을 갖춘 CUCB 알고리즘이 사용되었다. 두 가지 유형의 공격 대상이 고려되었다. 평균 외향 간선 가중치가 감소하는 노드로 구성된 "고정 대상"과 평균 외향 간선 가중치가 0.5보다 큰 K개의 무작위로 샘플링된 노드로 구성된 "무작위 대상"이었다.
온라인 MST 문제의 경우, Flickr 데이터셋이 무방향 그래프로 변환되었으며, 평균 확률이 기대 간선 비용으로 사용되었다. 공격은 알고리즘 1의 수정된 버전을 사용했으며, 여기서 목표는 수정된 기본 팔 결과 $X_T = 1$로 설정하여 비용을 최소화하도록 변경되었다. 기준선은 표준 CUCB 알고리즘이었다. 대상에는 "고정 대상"(두 번째로 좋은 최소 신장 트리)과 "무작위 대상"(무작위 간선 가중치를 가진 최소 신장 트리)이 포함되었다.
온라인 최단 경로 문제에서는 두 가지 구별되는 대상 유형이 CUCB에 대해 평가되었다. "공격 불가능한 대상"(비용이 최적 경로보다 본질적으로 높은 대상 경로에 대해 신중하게 구성된 경로로 알고리즘을 잘못 유도하기 어렵게 만듦)과 "무작위 대상"(무작위로 샘플링된 소스 및 대상 노드 간의 최단 경로와 무작위 간선 가중치)이었다. 이 설정은 본질적으로 이 문제에 대해 강건한 인스턴스의 존재를 입증하는 데 중요했다.
연쇄 도적의 경우, 연구는 CascadeKL-UCB, CascadeUCB1, CascadeUCB-V 알고리즘에 대해 공격을 수행했다. 대상 슈퍼 팔은 평균 클릭 확률이 0.1을 초과하는 기본 팔의 하위 집합에서 선택되었다.
또한, 온라인 영향력 극대화(Online Influence Maximization, IM)에 대한 실험(부록 A.2에 자세히 설명됨)은 문제의 NP-난해성으로 인해 (α, β)-근사 오라클(IMM 오라클)을 사용했다. 공격 전략은 대상 노드와 특정 거리 $l$ 내의 노드를 포함하는 "확장된 대상 집합" $S_{ex}$ 외부의 간선 실현을 0으로 수정하는 휴리스틱을 포함했다. 이러한 실험은 최소 5회 반복되었다. 다양한 CMAB 응용 프로그램 및 대상 구성에 걸친 이러한 포괄적인 실험 설계는 이론적 공격 가능성 조건에 대한 철저한 경험적 검증을 가능하게 했다.
증거가 증명하는 것
실험 증거는 CMAB 공격 가능성, 특히 정리 3.6 및 따름 정리 3.8에 설명된 조건에 대한 논문의 핵심 수학적 주장에 대한 강력하고 결정적인 검증을 제공한다.
확률적 최대 커버리지(PMC)의 경우, 그림 2(a) 및 2(b)에서 볼 수 있듯이, 공격은 CUCB 알고리즘이 대상 팔을 선형적으로 풀도록 성공적으로 강제했으며, 총 공격 비용은 부분선형으로 증가했다. 노드와 간선의 수가 많음에도 불구하고 이러한 부분선형 비용은 기본 팔의 수에 대해 명백히 다항식이었으며, 이는 $\Delta_M > 0$일 때 PMC가 다항식으로 공격 가능하다고 명시하는 정리 3.9를 직접적으로 검증했다. 부분선형 비용으로 인한 대상 팔 풀림의 선형 증가는 공격 메커니즘이 CUCB 기준선을 효과적으로 잘못 유도했음을 부인할 수 없는 증거이다. 무작위 대상에 대한 공격은 이러한 시나리오의 고유한 예측 불가능성을 시사하며 더 높은 분산을 보였다.
마찬가지로, 온라인 최소 신장 트리(MST) 문제(그림 2(c) 및 2(d))의 경우, 총 공격 비용은 부분선형으로 유지되었고, 대상 팔은 선형적으로 풀렸다. 이 결과는 온라인 MST 문제가 항상 공격 가능하다고 가정하는 따름 정리 3.8과 완벽하게 일치하며, 이는 갭 $\Delta_M \ge 0$이기 때문이다. CUCB 기준선에 대한 실험 전반에 걸쳐 일관된 부분선형 비용과 선형 대상 팔 풀림은 이 영역에서 공격 가능성에 대한 이론적 예측에 대한 강력한 경험적 지원을 제공한다.
온라인 최단 경로 실험(그림 2(e) 및 2(f))은 공격 가능 및 공격 불가능 인스턴스 모두에 대한 중요한 시연을 제공했다. "무작위 대상"의 경우, 공격은 부분선형 비용과 선형 대상 팔 풀림을 달성했으며, 이는 PMC 및 MST와 유사했다. 그러나 "공격 불가능한 대상"(본질적으로 강건하도록 신중하게 구성된 경로)의 경우, 총 비용은 선형으로 증가했으며, 결정적으로 대상 팔 풀림은 거의 일정하게 유지되었다. 이러한 극명한 대조는 공격 가능성 조건에 기반한 공격 가능 및 공격 불가능 시나리오 간의 이론적 구분을 결정적으로 입증하는, 본질적으로 공격 불가능한 CMAB 인스턴스의 존재를 증명한다. 이 경우 CUCB 알고리즘은 속지 않았으며, 공격 가능성의 한계에 대한 강력한 증거를 제공했다.
연쇄 도적(그림 2(g) 및 2(h))에서 공격은 CascadeKL-UCB, CascadeUCB1 및 CascadeUCB-V에 대해 부분선형 공격 비용으로 대상 팔의 선형 플레이를 성공적으로 유도했다. 이 결과는 연쇄 도적이 다항식으로 공격 가능함을 확인하는 따름 정리 3.8을 더욱 강화한다. 다양한 기준선 알고리즘에 걸쳐 최소 비용으로 대상 팔 플레이의 일관된 선형 증가는 공격의 효과에 대한 강력한 증거를 제공한다.
온라인 영향력 극대화(IM) 결과(그림 4(a) 및 4(b))는 더 미묘한 그림을 제시했다. 공격 비용은 감소했지만, 풀린 대상 노드의 비율은 0으로 일정했으며, 대상 노드 선택 증가 추세는 없었다. 이 결과는 공격 가능성을 반증하기보다는 IM 공격의 어려움을 강조하고, 근사 오라클이 있는 경우와 같이 비정확한 (α-근사) 오라클이 있는 CMAB 인스턴스의 경우 공격 가능성을 인스턴스별로 분석해야 한다는 논문의 주장을 강조한다. 이는 현재 공격 휴리스틱이 IM에 충분하지 않음을 시사하지만, 본질적인 공격 가능성을 배제하지는 않으며, 추가 연구를 촉구한다.
요약하면, 실험은 $\Delta_M > 0$(PMC, MST, 연쇄 도적)인 인스턴스의 경우 공격 알고리즘이 다양한 CUCB 기반 기준선을 부분선형 비용과 선형 대상 팔 풀림으로 성공적으로 잘못 유도했음을 보여줌으로써 수학적 주장을 혹독하게 증명했다. 반대로, $\Delta_M < 0$(특정 최단 경로 구성)인 인스턴스의 경우 공격이 실패하여 선형 비용과 상수 대상 팔 풀림을 초래하여, 핵심 공격 가능성(또는 공격 불가능성) 메커니즘이 현실에서 작동한다는 결정적이고 부인할 수 없는 증거를 제공했다.
한계 및 향후 방향
본 논문은 CMAB 공격 가능성에 대한 획기적인 특성화를 제시하지만, 여러 한계를 공개적으로 인정하고 흥미로운 미래 연구 방향을 제안한다.
한 가지 중요한 한계는 제안된 공격 알고리즘(알고리즘 1)이 공격 비용 측면에서 최적이 아닐 수 있다는 것이다. 현재 결과는 공격 가능성에 대한 충분성을 확립하지만, 가장 낮은 가능한 비용을 보장하지는 않는다. 중요한 향후 방향은 더 낮은 공격 비용을 달성할 수 있는 더 정교한 공격 알고리즘을 개발하는 것을 포함한다. 이는 또한 CMAB 인스턴스에 대한 공격 비용의 이론적 하한을 확립해야 할 필요성을 야기할 것이며, 이는 흥미롭고 도전적인 영역이다.
논의해야 할 또 다른 핵심 영역은 알려진 것과 알려지지 않은 도적 환경의 구분을 둘러싼다. 본 논문은 놀라운 사실을 밝힌다. 즉, CMAB 인스턴스의 다항식 공격 가능성은 공격자가 환경 매개변수(예: 보상 분포)에 대한 사전 지식을 가지고 있는지 여부에 따라 동일한 인스턴스에 대해 다를 수 있다. 구성된 "어려운 예제"(정리 4.1)는 알려진 환경에서 다항식으로 공격 가능하지만 환경이 알려지지 않은 경우 공격 불가능한 인스턴스를 보여준다. 이는 블랙박스 설정에서 모든 CMAB 인스턴스에 대한 일반적인 공격 전략이 존재하지 않을 수 있음을 시사한다. 향후 연구는 특히 최단 경로와 같이 갭 $\Delta_M$이 양수 또는 음수일 수 있는 문제에 대해 알려지지 않은 환경에서 CMAB 인스턴스의 강건성 보장을 특성화하는 데 초점을 맞춰야 한다. 이러한 어려운 예제로의 공격 불가능한 CMAB 문제 축소를 위한 일반적인 프레임워크를 개발하는 것은 매우 가치가 있을 것이다.
또한, 현재 공격 가능성 특성화는 엄격하게 보상 중독 공격으로 제한된다. 저자들은 그들의 결과가 환경 중독 공격(공격자가 환경의 보상 함수를 직접 변경할 수 있는 경우) 또는 행동 중독 공격과 같은 다른, 잠재적으로 더 강력한 위협 모델로 직접 일반화될 수 없다고 명시적으로 명시한다. 향후 연구는 CMAB 취약성에 대한 보다 포괄적인 이해를 제공하기 위해 이러한 대안적인 위협 모델로 분석을 확장해야 한다. 이는 다양한 유형의 적대적 섭동이 공격 가능성 조건 및 비용에 미치는 영향을 조사하는 것을 포함할 것이다.
마지막으로, 논문의 결론은 확률적 트리거 팔이 공격 가능성에 미치는 영향을 더 조사해야 할 필요성을 강조한다. 확률적으로 기본 팔이 트리거되는 이 메커니즘은 CMAB에 또 다른 복잡성 계층을 추가한다. 이것이 공격 가능성에 미치는 영향을 이해하는 것, 특히 다양한 확산 모델을 사용하는 온라인 영향력 극대화와 같은 응용 프로그램에서는 새로운 통찰력과 더 강력한 알고리즘으로 이어질 수 있다. 온라인 영향력 극대화에 대한 초기 결과, 즉 공격 전략이 명확하게 성공하지 못한 결과는, 특히 근사 오라클을 다룰 때 이 특정 연구 분야의 중요성을 강조한다.
이러한 미래 지향적인 논의는 공격 비용 최적화부터 다양한 위협 모델 및 환경 지식 탐색에 이르기까지, 강력한 CMAB 알고리즘을 개발하고 실제 응용 프로그램에서의 보안 영향을 더 잘 이해하려는 연구자들에게 풍부한 의제를 제공한다.