संयोजी बहु-भुजा वाले डाकू पर प्रतिकूल हमले
इस पत्र में संबोधित समस्या, "संयोजी बहु भुजा वाले डाकू (CMAB) पर प्रतिकूल हमले", दो महत्वपूर्ण अनुसंधान डोमेन के अभिसरण से उत्पन्न होती है: बहु भुजा वाले डाकू और मशीन लर्निंग में प्रतिकूल मजबूती का अध्ययन। बहु भुजा...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या, "संयोजी बहु-भुजा वाले डाकू (CMAB) पर प्रतिकूल हमले", दो महत्वपूर्ण अनुसंधान डोमेन के अभिसरण से उत्पन्न होती है: बहु-भुजा वाले डाकू और मशीन लर्निंग में प्रतिकूल मजबूती का अध्ययन। बहु-भुजा वाले डाकू (MAB) का मौलिक ढांचा, जिसे शुरू में Auer (2002) द्वारा खोजा गया था, अनुक्रमिक निर्णय लेने का मॉडल करता है जहाँ एक एजेंट को एक अवधि में संचयी पुरस्कारों को अधिकतम करने के लिए नए विकल्पों का पता लगाने और ज्ञात लाभदायक लोगों का फायदा उठाने के बीच रणनीतिक रूप से संतुलन बनाना होता है। इस ढांचे की विभिन्न क्षेत्रों में व्यापक रूप से जांच और अनुप्रयोग किया गया है।
संयोजी बहु-भुजा वाले डाकू (CMAB) के रूप में जाना जाने वाला MAB का एक अधिक सामान्यीकृत संस्करण, ऑनलाइन विज्ञापन, अनुशंसा प्रणाली और प्रभाव अधिकतमकरण (Liu & Zhao, 2012; Kveton et al., 2015) सहित वास्तविक दुनिया के अनुप्रयोगों की एक विस्तृत श्रृंखला के कारण महत्वपूर्ण कर्षण प्राप्त कर चुका है। CMAB में, एजेंट का निर्णय प्रत्येक दौर में एक एकल भुजा के बजाय आधार भुजाओं के एक संयोजन (जिसे "सुपर आर्म" कहा जाता है) का चयन करना शामिल है। यह संयोजी पहलू अन्वेषण-शोषण व्यापार को काफी अधिक जटिल बनाता है, मुख्य रूप से क्योंकि संभव सुपर आर्म की संख्या आधार भुजाओं की संख्या के साथ घातीय रूप से बढ़ सकती है।
इस विशिष्ट समस्या की सटीक उत्पत्ति - जिसमें CMAB के लिए "हमले की क्षमता" की धारणा को फिर से परिभाषित करना और पुनर्मूल्यांकन करना शामिल है - हाल के निष्कर्षों से उत्पन्न होती है कि MAB एल्गोरिथम और इसके वेरिएंट प्रतिकूल हमलों, विशेष रूप से "पुरस्कार विषाक्तता हमलों" (Jun et al., 2018; Liu & Shroff, 2019) के प्रति संवेदनशील हैं। ऐसे हमलों में, एक प्रतिकूलता खींची गई भुजा और उसके पुरस्कार प्रतिक्रिया का अवलोकन करती है, फिर सीखने के एल्गोरिथम को एक विशिष्ट लक्ष्य भुजा की ओर गलत मार्गदर्शन करने के लिए इस प्रतिक्रिया को सूक्ष्मता से संशोधित करती है जो प्रतिकूलता के हित में कार्य करती है। जबकि हमले की क्षमता की अवधारणा को पहले मानक MAB सेटिंग्स (Wang et al., 2022) पर लागू किया गया था, इस परिभाषा को सीधे CMAB तक विस्तारित करना समस्याग्रस्त साबित हुआ। पिछले दृष्टिकोणों की मुख्य सीमा यह थी कि CMAB पर MAB हमले की क्षमता की परिभाषा का सीधा अनुप्रयोग एक लागत सीमा में परिणत हुआ जो समय क्षितिज $T$ में उप-रैखिक थी लेकिन आधार भुजाओं $m$ की संख्या में घातीय थी। $m$ पर यह घातीय निर्भरता व्यावहारिक परिदृश्यों में अत्यधिक अवांछनीय है, अक्सर खाली परिणाम होते हैं जहाँ हमले की लागत कुल समय क्षितिज $T$ से अधिक हो सकती है। इस अपर्याप्तता ने उजागर किया कि मूल हमले की क्षमता की धारणा अपर्याप्त थी, जिससे CMAB के लिए एक नई, अधिक उपयुक्त परिभाषा की आवश्यकता हुई, जिसे यह पत्र प्रदान करने का प्रयास करता है।
सहज डोमेन शब्द
- बहु-भुजा वाला डाकू (MAB): कल्पना कीजिए कि आप एक कैसीनो में स्लॉट मशीनों की एक पंक्ति का सामना कर रहे हैं, प्रत्येक का एक अज्ञात औसत भुगतान है। आपका लक्ष्य कई नाटकों पर अपने कुल जीत को अधिकतम करना है। प्रत्येक मोड़ में, आप एक मशीन चुनते हैं, उसका लीवर खींचते हैं, और एक पुरस्कार प्राप्त करते हैं। आपको यह सीखना होगा कि कौन सी मशीनें अच्छी हैं (शोषण) जबकि अभी भी संभावित रूप से बेहतर खोजने के लिए दूसरों को आज़मा रहे हैं (अन्वेषण)।
- संयोजी बहु-भुजा वाला डाकू (CMAB): यह MAB परिदृश्य की तरह है, लेकिन प्रति मोड़ केवल एक स्लॉट मशीन चुनने के बजाय, आप एक समूह या संयोजन मशीनों को एक साथ खेलने के लिए चुनते हैं। उदाहरण के लिए, आप मशीन 2, 5, और 8 को एक साथ खेलने का निर्णय ले सकते हैं। यह समस्या बहुत कठिन है क्योंकि व्यक्तिगत मशीनों की तुलना में मशीनों के संभावित संयोजनों की संख्या बहुत अधिक है।
- सुपर आर्म: CMAB संदर्भ में, एक "सुपर आर्म" व्यक्तिगत स्लॉट मशीनों का विशिष्ट सेट या संयोजन है जिसे आप किसी दिए गए दौर में खेलने के लिए चुनते हैं। यह उस मोड़ के लिए आपकी पूरी कार्रवाई का प्रतिनिधित्व करता है।
- आधार भुजा: ये व्यक्तिगत, मौलिक स्लॉट मशीनें हैं जो संयोजनों का निर्माण करती हैं। यदि आप मशीनों 2, 5, और 8 से मिलकर एक सुपर आर्म का चयन करते हैं, तो 2, 5, और 8 व्यक्तिगत "आधार भुजाएं" हैं जो आपके चुने हुए सुपर आर्म का हिस्सा थीं।
- पुरस्कार विषाक्तता हमला: यह एक ऐसी स्थिति का वर्णन करता है जहाँ एक दुर्भावनापूर्ण पक्ष गुप्त रूप से स्लॉट मशीनों से प्राप्त पुरस्कार जानकारी को बदल देता है। उनका उद्देश्य आपके निर्णय लेने की प्रक्रिया को बार-बार एक विशिष्ट, अक्सर कम लाभदायक, संयोजन (उनके "लक्ष्य सुपर आर्म") को चुनने के लिए धोखा देना है, जिससे इसके भुगतान वास्तव में होने से बेहतर दिखाई देते हैं, या वास्तव में अच्छे संयोजनों को खराब दिखाते हैं।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
| $m$ | आधार भुजाओं की कुल संख्या। |
| $\mathcal{S}$ | सभी संभव सुपर आर्म (आधार भुजाओं के संयोजन) का सेट। |
| $S \in \mathcal{S}$ | एक विशिष्ट सुपर आर्म। |
| $T$ | डाकू समस्या के लिए कुल समय क्षितिज (दौरों की संख्या)। |
| $\mu = (\mu_1, \ldots, \mu_m)$ | सभी $m$ आधार भुजाओं के लिए वास्तविक माध्य पुरस्कार वेक्टर। |
| $r_S(\mu)$ | वास्तविक माध्य पुरस्कार वेक्टर $\mu$ दिए जाने पर सुपर आर्म $S$ का अपेक्षित पुरस्कार। |
| $O_S$ | आधार भुजाओं का सेट जिसे सुपर आर्म $S$ का चयन करने पर संभाव्य रूप से ट्रिगर किया जा सकता है। |
| $\mu \odot O_S$ | $\mu$ और $O_S$ में नहीं होने वाली आधार भुजाओं के लिए माध्य पुरस्कारों को प्रभावी ढंग से शून्य करने वाले $O_S$ का प्रतिनिधित्व करने वाले एक बाइनरी वेक्टर का तत्व-वार उत्पाद। |
| $\Delta_S$ | सुपर आर्म $S$ के लिए "गैप", इसकी हमले की क्षमता को मापता है (परिभाषा 3.5)। |
| $M$ | लक्ष्य सुपर आर्म का सेट जिसे प्रतिकूलता डाकू एल्गोरिथम को खींचना चाहती है। |
| $\Delta_M$ | लक्ष्य सेट $M$ के लिए समग्र "गैप", जिसे $\max_{S \in M} \Delta_S$ के रूप में परिभाषित किया गया है। |
| $C(T)$ | समय क्षितिज $T$ पर प्रतिकूलता द्वारा अर्जित कुल हमले की लागत। |
| $o(T)$ | एक फ़ंक्शन जो $T$ से धीमा बढ़ता है, अर्थात, $\lim_{T \to \infty} o(T)/T = 0$। |
| $p^*$ | आधार भुजा को ट्रिगर करने की न्यूनतम संभावना से संबंधित एक पैरामीटर (परिभाषा 3.1)। |
| $K$ | एक समस्या-विशिष्ट पैरामीटर, अक्सर एक सुपर आर्म में आधार भुजाओं की संख्या या पश्चता सीमाओं से संबंधित होता है। |
| $\gamma, \gamma'$ | पश्चता और हमले की लागत की उप-रैखिक वृद्धि से संबंधित सकारात्मक स्थिरांक। |
| $\hat{\mu}_i^{(t)}$ | दौर $t$ पर आधार भुजा $i$ के लिए अनुभवजन्य माध्य पुरस्कार अनुमान। |
| UCB | ऊपरी विश्वास सीमा, डाकू एल्गोरिदम द्वारा अन्वेषण-शोषण के लिए उपयोग की जाती है। |
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
यह पत्र संयोजी बहु-भुजा वाले डाकू (CMAB) की प्रतिकूल हमलों के प्रति भेद्यता को समझने में एक महत्वपूर्ण अंतर को संबोधित करता है।
इनपुट/वर्तमान स्थिति:
शुरुआती बिंदु एक मानक CMAB समस्या है जहाँ एक सीखने वाला एजेंट समय क्षितिज $T$ पर "आधार भुजाओं" से बनी "सुपर भुजाओं" का चयन करता है। प्रत्येक दौर में, एजेंट प्रतिक्रिया (ट्रिगर की गई आधार भुजाओं के परिणाम) का अवलोकन करता है और संचयी पुरस्कार को अधिकतम करने के उद्देश्य से एक पुरस्कार प्राप्त करता है। अनुसंधान की वर्तमान स्थिति स्वीकार करती है कि बहु-भुजा वाले डाकू (MAB) और इसके वेरिएंट "पुरस्कार विषाक्तता हमलों" के प्रति संवेदनशील हैं। ऐसे हमलों में, एक प्रतिकूलता एजेंट की क्रियाओं और प्रतिक्रिया का अवलोकन करती है, फिर देखी गई पुरस्कारों को सूक्ष्मता से संशोधित करती है। प्रतिकूलता का लक्ष्य डाकू एल्गोरिथम को एक विशिष्ट "लक्ष्य भुजा" (एक जो प्रतिकूलता के हित में कार्य करती है) को लगभग सभी दौरों ($T - o(T)$ बार) के लिए लगातार खींचने के लिए धोखा देना है, जबकि समय क्षितिज $T$ पर एक उप-रैखिक हमले की लागत $o(T)$ का वहन करना है।
वांछित आउटपुट/लक्ष्य स्थिति:
इस पत्र का प्राथमिक लक्ष्य "CMAB की भेद्यता और मजबूती को पकड़ने के लिए एक अच्छा विचार स्थापित करना" है जो व्यावहारिक रूप से सार्थक है। इस नई परिभाषा, जिसे "बहुपद हमले की क्षमता" कहा जाता है, का उद्देश्य सटीक रूप से परिभाषित करना है कि CMAB उदाहरण को कुशलतापूर्वक कैसे हमला किया जा सकता है। इस परिष्कृत परिभाषा के तहत, एक सफल हमले को न केवल अपने उद्देश्य को प्राप्त करना चाहिए (एजेंट को $T - o(T)$ बार लक्ष्य भुजा खींचने के लिए गलत मार्गदर्शन करना) बल्कि ऐसा हमला लागत के साथ भी करना चाहिए जो समय क्षितिज $T$ में उप-रैखिक हो और, महत्वपूर्ण रूप से, आधार भुजाओं $m$ की संख्या और अन्य प्रासंगिक समस्या कारकों (जैसे, $1/p^*$, $K$) में बहुपद हो।
लुप्त कड़ी/गणितीय अंतर:
सटीक लुप्त कड़ी CMAB के लिए "हमले की क्षमता" की एक मजबूत और व्यावहारिक परिभाषा है। पिछली परिभाषाएँ, जो सीधे सरल MAB सेटिंग्स से उधार ली गई हैं, CMAB के लिए अपर्याप्त साबित होती हैं। ऐसा इसलिए है क्योंकि CMAB की संयोजी प्रकृति का मतलब है कि संभव "सुपर आर्म" की संख्या $m$, आधार भुजाओं की संख्या में घातीय रूप से बड़ी हो सकती है। पुरानी परिभाषा लागू करने से एक हमला लागत का पता चलेगा जो $m$ में घातीय है, जिससे यह व्यवहार में "अवांछनीय" और "खाली" हो जाएगा, क्योंकि ऐसी लागत कुल समय क्षितिज $T$ से आसानी से अधिक हो सकती है। यह पत्र "बहुपद हमले की क्षमता" पेश करके इस अंतर को पाटता है, जो स्पष्ट रूप से हमला लागत को $m$ में बहुपद तक सीमित करता है, जिससे हमले की क्षमता की धारणा CMAB के लिए प्रासंगिक और व्यावहारिक हो जाती है। गणितीय रूप से, इसमें $C(T) = o(T)$ लागत से अधिक विशिष्ट $C(T) = O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma'})$ तक जाना शामिल है, जो कुछ $\gamma' > 0$ के लिए है, जहाँ $m$ आधार भुजाओं की संख्या है, $p^*$ ट्रिगरिंग संभावनाओं से संबंधित है, और $K$ एक समस्या-विशिष्ट पैरामीटर है। पत्र प्रत्येक सुपर आर्म $S$ के लिए एक "गैप" $\Delta_S$ (परिभाषा 3.5) भी परिभाषित करता है, जो किसी अन्य सुपर आर्म के अधिकतम अपेक्षित पुरस्कार और उसके बीच के अंतर को मापता है, जो हमले की क्षमता के लिए एक प्रमुख गणितीय संकेतक के रूप में कार्य करता है।
दुविधा:
केंद्रीय दुविधा जिसने पिछले शोधकर्ताओं को फंसाया है, वह CMAB की संयोजी जटिलता और हमले की लागतों की व्यावहारिकता के बीच व्यापार-बंद है। जबकि MAB हमले की अवधारणाओं को सीधे विस्तारित करना आकर्षक है, ऐसा करने से आधार भुजाओं $m$ की संख्या में घातीय लागत आती है, जिससे कोई भी "सफल" हमला परिभाषा वास्तविक दुनिया के परिदृश्यों में अर्थहीन हो जाती है। यह पत्र एक आश्चर्यजनक और दर्दनाक व्यापार-बंद को उजागर करता है: एक CMAB उदाहरण की हमले की क्षमता न केवल एक आंतरिक संपत्ति है, बल्कि "इस बात पर भी निर्भर करती है कि क्या डाकू को डाकू उदाहरण ज्ञात है या अज्ञात है।" इसका मतलब है कि एक सफेद-बॉक्स सेटिंग (जहां पर्यावरण पैरामीटर ज्ञात हैं) में प्रभावी एक हमला रणनीति एक काले-बॉक्स सेटिंग (जहां पैरामीटर अज्ञात हैं) में पूरी तरह से विफल हो सकती है, जिससे एक सार्वभौमिक हमला रणनीति मायावी हो जाती है और समस्या व्यवहार में "अविश्वसनीय रूप से कठिन" हो जाती है।
बाधाएँ और विफलता मोड
CMAB उदाहरणों पर कुशलतापूर्वक और सार्थक रूप से हमला करने की समस्या कई कठोर, यथार्थवादी दीवारों द्वारा बाधित है:
- सुपर आर्म का संयोजी विस्फोट: सबसे महत्वपूर्ण बाधा "सुपर आर्म" की विशाल संख्या है, जो आधार भुजाओं $m$ की संख्या में घातीय हो सकती है। यह संयोजी जटिलता का मतलब है कि किसी भी हमला रणनीति को जिसमें सभी सुपर आर्म का अन्वेषण या हेरफेर करने की आवश्यकता होती है, एक घातीय लागत का वहन करना होगा, जो बहुपद हमले की क्षमता की व्यावहारिक आवश्यकता का उल्लंघन करता है। यह MAB हमले की रणनीतियों के प्रत्यक्ष अनुप्रयोग को अव्यावहारिक बनाता है और "खाली परिणाम" की ओर ले जाता है।
- पर्यावरण के बारे में प्रतिकूलता का ज्ञान: एक महत्वपूर्ण बाधा CMAB उदाहरण के अंतर्निहित मापदंडों तक प्रतिकूलता की पहुंच है, जैसे पुरस्कार वितरण ($\mu$) और आधार भुजाओं के परिणाम वितरण।
- ज्ञात पर्यावरण (व्हाइट-बॉक्स): यदि प्रतिकूलता के पास इन मापदंडों का पूरा ज्ञान है, तो वे अत्यधिक लक्षित और कुशल हमले डिजाइन कर सकते हैं।
- अज्ञात पर्यावरण (ब्लैक-बॉक्स): अधिक यथार्थवादी ब्लैक-बॉक्स सेटिंग में, प्रतिकूलता के पास यह पूर्व ज्ञान नहीं होता है। यह प्रतिकूलता को पैरामीटर का अनुमान लगाने के लिए अन्वेषण करने के लिए मजबूर करता है, जो स्वयं लागत वहन करता है और हमलों को बहुत कठिन या असंभव भी बना सकता है। पत्र इसे एक "कठिन उदाहरण" (प्रमेय 4.1) के साथ प्रदर्शित करता है जहाँ एक उदाहरण बहुपद रूप से हमला करने योग्य है यदि पर्यावरण ज्ञात है, लेकिन बहुपद रूप से अयोग्य है यदि यह अज्ञात है। यह एक प्रमुख व्यावहारिक बाधा को उजागर करता है।
- हमले की लागत बजट: प्रतिकूलता एक सख्त बजट बाधा के तहत काम करती है: हमले की लागत समय क्षितिज $T$ में उप-रैखिक होनी चाहिए और, नई परिभाषा के तहत, आधार भुजाओं $m$ और अन्य कारकों की संख्या में बहुपद होनी चाहिए। इस बजट को पार करने से विफलता मोड होता है, क्योंकि हमले को "कुशल" या "सफल" नहीं माना जाएगा।
- अर्ध-डाकू प्रतिक्रिया: CMAB में सीखने वाला एजेंट "अर्ध-डाकू प्रतिक्रिया" प्राप्त करता है, जिसका अर्थ है कि यह केवल चुनी गई सुपर आर्म द्वारा ट्रिगर की गई आधार भुजाओं के परिणामों का अवलोकन करता है, न कि सभी आधार भुजाओं का। यह आंशिक अवलोकन प्रतिकूलता के लिए उपलब्ध जानकारी को सीमित करता है, जिससे पुरस्कारों का सटीक अनुमान लगाना या उन्हें प्रभावी ढंग से हेरफेर करना कठिन हो जाता है, खासकर अज्ञात वातावरण में।
- एल्गोरिथम मजबूती और पश्चता सीमाएँ: हमले को सीखने वाले एल्गोरिदम (जैसे CUCB) के खिलाफ सफल होना चाहिए जो पश्चता को कम करने के लिए डिज़ाइन किए गए हैं, अक्सर $O(\text{poly}(m, 1/p^*, K) \cdot T^{1-\gamma})$ की सैद्धांतिक पश्चता सीमाओं के साथ। प्रतिकूलता को अत्यधिक लागत वहन किए बिना एल्गोरिथम के अंतर्निहित सीखने और अन्वेषण तंत्र पर काबू पाने की आवश्यकता है।
- ओरेकल सीमाएँ: CMAB समस्याओं में अक्सर कम्प्यूटेशनल ओरेकल (जैसे, इष्टतम सुपर आर्म खोजने के लिए) पर निर्भरता होती है। यदि ये ओरेकल सटीक के बजाय अनुमानित हैं (जैसे, $(\alpha, \beta)$-अनुमान ओरेकल), तो यह प्रतिकूलता के लिए अतिरिक्त जटिलताएँ पेश कर सकता है, क्योंकि एल्गोरिथम का व्यवहार एक सटीक ओरेकल द्वारा उत्पन्न होने वाले से विचलित हो सकता है, जिससे हमले की प्रभावशीलता प्रभावित हो सकती है।
यह दृष्टिकोण क्यों
चुनाव की अनिवार्यता
संयोजी बहु-भुजा वाले डाकू (CMAB) के लिए "बहुपद हमले की क्षमता" को परिभाषित करने के लेखकों की पसंद केवल एक विकल्प नहीं बल्कि एक आवश्यकता थी, जो इस जटिल डोमेन पर पारंपरिक हमले की क्षमता की धारणाओं को लागू करने की अंतर्निहित सीमाओं से पैदा हुई थी। जिस क्षण लेखकों को एहसास हुआ कि मानक बहु-भुजा वाले डाकू (MAB) से अत्याधुनिक (SOTA) तरीके अपर्याप्त थे, वह स्पष्ट रूप से परिचय में बताया गया है। वे नोट करते हैं कि "हमले की क्षमता की MAB अवधारणा को सीधे CMAB पर लागू करना आकर्षक है... हालांकि, यह T में एक उप-रैखिक लागत सीमा की ओर ले जाता है लेकिन आधार भुजाओं m की संख्या में घातीय है।" $m$ (आधार भुजाओं की संख्या) पर यह घातीय निर्भरता को स्पष्ट रूप से "अवांछनीय" कहा गया है और समय क्षितिज $T$ से अधिक होने में सक्षम है, जिससे परिणाम "खाली" हो जाते हैं (पृष्ठ 1)।
इस महत्वपूर्ण अवलोकन ने उजागर किया कि CMAB में अंतर्निहित संयोजी विस्फोट, जहां सुपर आर्म की संख्या $m$ में घातीय हो सकती है, ने पूर्व MAB हमले की क्षमता परिभाषाओं की मान्यताओं को मौलिक रूप से तोड़ दिया। एक ऐसे समाधान की आवश्यकता थी जो व्यावहारिक कम्प्यूटेशनल सीमाओं के भीतर सार्थक गारंटी प्रदान कर सके। इस प्रकार, बहुपद हमले की क्षमता की प्रस्तावित परिभाषा, जो हमले की लागत को न केवल समय क्षितिज $T$ में उप-रैखिक होने की आवश्यकता है, बल्कि आधार भुजाओं $m$ और अन्य कारकों की संख्या में बहुपद होने की भी आवश्यकता है, CMAB पर प्रतिकूल हमलों का विश्लेषण करने के लिए एक सुलभ और प्रासंगिक ढांचा प्रदान करने के लिए एकमात्र व्यवहार्य समाधान बन गया।
तुलनात्मक श्रेष्ठता
इस दृष्टिकोण की गुणात्मक श्रेष्ठता सीधे CMAB की संयोजी जटिलता को संबोधित करने की इसकी क्षमता से उत्पन्न होती है, एक ऐसी चुनौती जिसे MAB हमले की क्षमता के लिए पिछले स्वर्ण मानकों ने दूर करने में विफल रहे। सरल प्रदर्शन मेट्रिक्स से परे, संरचनात्मक लाभ एक असाध्य घातीय लागत समस्या को एक सुलभ बहुपद समस्या में बदलने में निहित है।
विशेष रूप से, MAB के लिए "मूल हमले की क्षमता की धारणा", जब CMAB पर लागू होती है, तो "m में घातीय लागत" (पृष्ठ 1) में परिणत होती है। इसका मतलब था कि जैसे-जैसे आधार भुजाओं की संख्या बढ़ी, हमले की लागत तेजी से खगोलीय रूप से बड़ी हो जाएगी, जिससे कोई भी सैद्धांतिक गारंटी व्यावहारिक रूप से अर्थहीन हो जाएगी। "बहुपद हमले की क्षमता" (परिभाषा 3.1) की नई परिभाषा मौलिक रूप से इसे बदल देती है, जिससे हमले की लागत को $m$, $1/p^*$, और $K$ (जहां $p^*$ ट्रिगरिंग संभावनाओं से संबंधित है और $K$ पश्चता सीमाओं से एक कारक है) के बहुपद फलन द्वारा सीमित करने की आवश्यकता होती है। यह एक गुणात्मक छलांग है, क्योंकि यह उच्च-आयामी CMAB सेटिंग्स में हमले की क्षमता के सार्थक विश्लेषण की अनुमति देता है जहाँ सुपर आर्म की संख्या घातीय है।
इसके अलावा, पत्र "गैप" $\Delta_M$ (परिभाषा 3.5) पर आधारित बहुपद हमले की क्षमता के लिए एक पर्याप्त और आवश्यक शर्त (प्रमेय 3.6) प्रदान करता है। यह सैद्धांतिक लक्षण वर्णन इस बात में गहरी संरचनात्मक अंतर्दृष्टि प्रदान करता है कि क्यों कुछ CMAB उदाहरण हमला करने योग्य या अयोग्य हैं, बजाय केवल यह मापने के कि हमला कितना अच्छा प्रदर्शन करता है। यह आंतरिक मजबूती के लिए एक स्पष्ट सीमा प्रदान करता है, जो उन तरीकों की तुलना में एक महत्वपूर्ण गुणात्मक लाभ है जो केवल विशिष्ट उदाहरणों पर अनुभवजन्य प्रदर्शन की पेशकश कर सकते हैं। यह विधि प्रभावी रूप से स्मृति जटिलता को एक अंतर्निहित $O(2^m)$ (घातीय सुपर आर्म के कारण) से $m$ पर एक बहुपद निर्भरता तक कम कर देती है, जिससे समस्या का विश्लेषण किया जा सकता है।
बाधाओं के साथ संरेखण
"बहुपद हमले की क्षमता" को परिभाषित करने की चुनी हुई विधि CMAB समस्या की मुख्य बाधाओं के साथ पूरी तरह से संरेखित होती है, विशेष रूप से इसकी संयोजी प्रकृति द्वारा प्रस्तुत चुनौती। समस्या परिभाषा में उजागर की गई प्राथमिक बाधा यह है कि CMAB में उम्मीदवार सुपर आर्म की संख्या "m में घातीय" (पृष्ठ 1) हो सकती है। MAB हमले की क्षमता परिभाषाओं को सीधे लागू करना, जो इस घातीय वृद्धि को ध्यान में नहीं रखते हैं, "खाली परिणाम" की ओर ले जाता है क्योंकि हमले की लागत भी $m$ के साथ घातीय रूप से बढ़ेगी।
परिभाषा 3.1 में समस्या की कठोर आवश्यकताओं और समाधान के अद्वितीय गुणों के बीच "विवाह" स्पष्ट है। यह परिभाषा स्पष्ट रूप से यह बाधा लगाती है कि एक सफल हमले की लागत समय क्षितिज $T$ में उप-रैखिक होने के अतिरिक्त, आधार भुजाओं $m$ (और $1/p^*$ और $K$ जैसे अन्य कारकों) की संख्या में बहुपद होनी चाहिए। यह सुनिश्चित करता है कि हमले की क्षमता की धारणा बड़े CMAB उदाहरणों के लिए भी सार्थक और व्यावहारिक बनी रहे।
इसके अलावा, पत्र "पुरस्कार विषाक्तता हमलों" (धारा 2.2) पर केंद्रित है, जहां प्रतिकूलता देखी गई पुरस्कारों को संशोधित करती है। प्रस्तावित हमला एल्गोरिथम (एल्गोरिथम 1) और हमले की क्षमता की शर्तें (प्रमेय 3.6) विशेष रूप से इस खतरे मॉडल के अनुरूप हैं, यह सुनिश्चित करते हुए कि समाधान परिभाषित प्रतिकूल क्षमताओं और सीमाओं का पालन करता है। विधि "अर्ध-डाकू प्रतिक्रिया" की CMAB प्रकृति पर भी विचार करती है, जहां केवल ट्रिगर की गई आधार भुजाओं के परिणाम देखे जाते हैं, इस प्रतिक्रिया संरचना को हमला रणनीति में एकीकृत करती है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से मौजूदा दृष्टिकोणों को अस्वीकार करने या संशोधित करने के कारणों को बताता है, मुख्य रूप से पारंपरिक MAB हमले की क्षमता परिभाषाओं के प्रत्यक्ष अनुप्रयोग पर ध्यान केंद्रित करता है। उनकी अपर्याप्तता के लिए मुख्य तर्क यह है कि वे CMAB (पृष्ठ 1) पर लागू होने पर "m में घातीय लागत" की ओर ले जाते हैं। यह एक मामूली प्रदर्शन मुद्दा नहीं है, बल्कि एक मौलिक दोष है जो परिणामों को व्यवहार में "अवांछनीय" और "खाली" बनाता है। CMAB की संयोजी प्रकृति, जिसमें घातीय रूप से बड़ी संख्या में सुपर आर्म हैं, का मतलब है कि आधार भुजाओं की संख्या के साथ घातीय रूप से स्केल करने वाली हमले की लागत बस संभव या सार्थक नहीं है। इसलिए, लेखकों को एक नई परिभाषा पेश करनी पड़ी जिसमें $m$ में बहुपद लागत की आवश्यकता होती है।
इसके अलावा, पत्र अप्रत्यक्ष रूप से अन्य संबंधित कार्य रेखाओं को उनके विशिष्ट समस्या सूत्रीकरण के लिए प्रत्यक्ष रूप से लागू या पर्याप्त के रूप में अस्वीकार करता है:
- मौजूदा MAB हमले की क्षमता की धारणाएँ: जैसा कि ऊपर विस्तृत है, इन्हें $m$ में घातीय लागत के कारण अपर्याप्त माना गया था।
- सुदृढीकरण सीखने (RL) पर प्रतिकूल हमले: जबकि संबंधित है, पत्र नोट करता है कि "किसी भी मौजूदा काम ने किसी दिए गए उदाहरण की हमले की क्षमता का विश्लेषण नहीं किया है" (पृष्ठ 2, धारा 1.2)। यह इंगित करता है कि जबकि RL हमले एक व्यापक क्षेत्र हैं, उन्होंने CMAB के लिए इस पत्र द्वारा मांगी गई उदाहरण-स्तरीय हमले की क्षमता का लक्षण वर्णन प्रदान नहीं किया।
- भ्रष्टाचार-सहिष्णु डाकू: यह वैकल्पिक कार्य रेखा, जो विषाक्तता हमलों के खिलाफ मजबूती का अध्ययन करती है, का उल्लेख किया गया है लेकिन प्रत्यक्ष समाधान के रूप में अप्रत्यक्ष रूप से अस्वीकार कर दिया गया है क्योंकि यह अक्सर "कमजोर खतरे के मॉडल" (पृष्ठ 2, धारा 1.2) पर विचार करता है। उदाहरण के लिए, कुछ मॉडल एक उदासीन प्रतिकूलता मानते हैं या केवल बढ़ाने के लिए भ्रष्टाचार को सीमित करते हैं। इसके विपरीत, इस पत्र का खतरा मॉडल प्रतिकूलता को परिणामों को बढ़ाने या घटाने की अनुमति देता है, जिससे समस्या अधिक सामान्य और भ्रष्टाचार-सहिष्णु डाकू एल्गोरिदम द्वारा आमतौर पर संबोधित की जाने वाली समस्या से अधिक चुनौतीपूर्ण हो जाती है। यह व्यापक प्रतिकूल क्षमता एक अधिक मजबूत हमले की क्षमता ढांचे की आवश्यकता है।
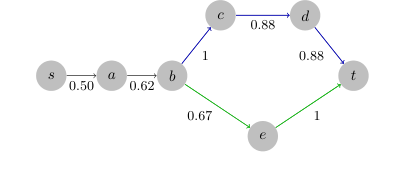 Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
Figure 3. An unattackable shortest path from s to t in the Flickr dataset. Optimal path: (s, a, b, e, t). Target path: (s, a, v, c, d, t). The cost on (b, c, d, t) is larger than the number of edges on (b, e, t), and the attacker cannot fool the algorithm to play the target path
गणितीय और तार्किक तंत्र
मास्टर समीकरण
इस पत्र में एक संयोजी बहु-भुजा वाले डाकू (CMAB) उदाहरण की हमले की क्षमता को परिभाषित करने वाला पूर्ण मुख्य समीकरण, परिभाषा 3.5 के अनुसार, एक सुपर आर्म $S$ के लिए "गैप" है। यह गैप एक CMAB उदाहरण की अंतर्निहित भेद्यता या प्रतिकूल पुरस्कार विषाक्तता हमलों के प्रति मजबूती को मापता है।
$$ \Delta_S := r_S(\mu) - \max_{S' \neq S} r_{S'}(\mu \odot O_S) $$
लक्ष्य सुपर आर्म के एक सेट $M$ के लिए, समग्र गैप को $\Delta_M = \max_{S \in M} \Delta_S$ के रूप में परिभाषित किया गया है। प्रमेय 3.6 तब स्थापित करता है कि यदि $\Delta_M > 0$, तो CMAB उदाहरण बहुपद रूप से हमला करने योग्य है, और यदि $\Delta_M < 0$, तो यह बहुपद रूप से अयोग्य है।
पद-दर-पद विच्छेदन
आइए इसके गणितीय परिभाषा, भौतिक/तार्किक भूमिका और इसके ऑपरेटरों के पीछे के तर्क को समझने के लिए मास्टर समीकरण को पद-दर-पद विच्छेदित करें।
-
$\Delta_S$:
- गणितीय परिभाषा: यह एक स्केलर मान है जो एक विशिष्ट लक्ष्य सुपर आर्म $S$ के अपेक्षित पुरस्कार और किसी अन्य अन्य सुपर आर्म $S'$ के अधिकतम अपेक्षित पुरस्कार के बीच अंतर का प्रतिनिधित्व करता है, जब एक संशोधित माध्य पुरस्कार वेक्टर के तहत मूल्यांकन किया जाता है।
- भौतिक/तार्किक भूमिका: यह एक विशिष्ट लक्ष्य सुपर आर्म $S$ के लिए "भेद्यता संकेतक" के रूप में कार्य करता है। एक सकारात्मक $\Delta_S$ का तात्पर्य है कि लक्ष्य सुपर आर्म $S$ आंतरिक रूप से किसी भी विकल्प $S'$ से "बेहतर" है यदि उन विकल्पों का मूल्यांकन केवल उन आधार भुजाओं पर किया जाता है जिन्हें $S$ स्वयं देखता है। यह एक प्रतिकूलता के लिए डाकू एल्गोरिथम को $S$ की ओर गलत मार्गदर्शन करने के लिए एक संभावित मार्ग का सुझाव देता है। यदि $\Delta_S$ नकारात्मक है, तो यह इंगित करता है कि $S$ इस विशिष्ट मूल्यांकन के तहत भी सबसे अच्छा विकल्प नहीं है, जिससे हमला करना कठिन हो जाता है।
- घटाव और अधिकतम क्यों: घटाव का उपयोग $S$ के उसके सबसे मजबूत विकल्प पर "लाभ" को मापने के लिए किया जाता है। $\max$ ऑपरेटर $S$ के सबसे मजबूत प्रतियोगी की पहचान करता है, यह सुनिश्चित करते हुए कि गैप वास्तव में सबसे चुनौतीपूर्ण विकल्प को दूर करने को दर्शाता है।
-
$r_S(\mu)$:
- गणितीय परिभाषा: यह आधार भुजाओं के माध्य पुरस्कार वेक्टर $\mu$ के सत्य होने पर सुपर आर्म $S$ का चयन करने के अपेक्षित पुरस्कार को दर्शाता है।
- भौतिक/तार्किक भूमिका: यह सुपर आर्म $S$ का वास्तविक, अपरिवर्तित अपेक्षित प्रदर्शन है। यह वह है जो डाकू एल्गोरिथम को आदर्श रूप से प्राप्त करना चाहिए यदि कोई प्रतिकूलता नहीं होती।
- यह रूप क्यों: यह डाकू समस्याओं में एक क्रिया (सुपर आर्म) की अपेक्षित उपयोगिता का प्रतिनिधित्व करने का एक मानक तरीका है, जो अंतर्निहित वास्तविक पुरस्कार वितरण पर निर्भर करता है।
-
$\mu$:
- गणितीय परिभाषा: यह एक $m$-आयामी वेक्टर $(\mu_1, \mu_2, \ldots, \mu_m)$ है, जहाँ $\mu_i = E_{X \sim D}[X_i^{(t)}]$ आधार भुजा $i$ का वास्तविक माध्य पुरस्कार है।
- भौतिक/तार्किक भूमिका: यह वेक्टर CMAB वातावरण में सभी व्यक्तिगत आधार भुजाओं के वास्तविक, अंतर्निहित पुरस्कार वितरण का प्रतिनिधित्व करता है। यह वह सत्य है जिसे डाकू एल्गोरिथम अनुमानित करने का प्रयास करता है और जिसे प्रतिकूलता हेरफेर करने का प्रयास करती है।
-
$\max_{S' \neq S}$:
- गणितीय परिभाषा: यह ऑपरेटर उन सभी सुपर आर्म $S'$ के अपेक्षित पुरस्कारों में से अधिकतम मान पाता है जो लक्ष्य सुपर आर्म $S$ नहीं हैं।
- भौतिक/तार्किक भूमिका: यह लक्ष्य सुपर आर्म $S$ के लिए प्रतिकूलता की हेरफेर रणनीति के दृष्टिकोण से "सर्वश्रेष्ठ विकल्प" की पहचान करता है। प्रतिकूलता चाहती है कि $S$ को सभी अन्य विकल्पों से बेहतर दिखाया जाए, इसलिए उन्हें सबसे मजबूत प्रतियोगी पर विचार करना होगा।
-
$S'$:
- गणितीय परिभाषा: किसी भी सुपर आर्म को क्रिया स्थान $\mathcal{S}$ में लक्ष्य सुपर आर्म $S$ से भिन्न के रूप में दर्शाता है।
- भौतिक/तार्किक भूमिका: ये वैकल्पिक क्रियाएं हैं जिन्हें डाकू एल्गोरिथम लक्ष्य सुपर आर्म $S$ के बजाय चुन सकता है। प्रतिकूलता का लक्ष्य इन विकल्पों को कम आकर्षक दिखाना है।
-
$\mu \odot O_S$:
- गणितीय परिभाषा: यह वास्तविक माध्य पुरस्कार वेक्टर $\mu$ और एक बाइनरी वेक्टर $O_S$ के बीच एक तत्व-वार उत्पाद (हैडमार्ड उत्पाद) है। वेक्टर $O_S$ में उन आधार भुजाओं के लिए प्रविष्टियाँ $1$ होती हैं जिन्हें सुपर आर्म $S$ द्वारा ट्रिगर किया जा सकता है (अर्थात, $i \in O_S$) और अन्यथा $0$ होती हैं।
- भौतिक/तार्किक भूमिका: यह संशोधित माध्य वेक्टर एक काल्पनिक परिदृश्य का प्रतिनिधित्व करता है जहाँ लक्ष्य सुपर आर्म $S$ द्वारा अवलोकनीय नहीं होने वाली आधार भुजाओं के पुरस्कार प्रभावी ढंग से "शून्य" या अनदेखे किए जाते हैं। यह महत्वपूर्ण है क्योंकि प्रतिकूलता की हमला रणनीति (एल्गोरिथम 1) में अक्सर गैर-लक्ष्य आधार भुजाओं के देखे गए पुरस्कारों को 0 पर सेट करना शामिल होता है। $S'$ का $\mu \odot O_S$ के तहत मूल्यांकन करके, पत्र वैकल्पिक सुपर आर्म पर प्रतिकूलता के हेरफेर के प्रभाव का मॉडल करता है। यह पूछता है: "यदि हम केवल उन आधार भुजाओं पर विचार करते हैं जिन्हें $S$ 'देख' सकता है, तो अन्य सुपर आर्म $S'$ कितने अच्छे हैं?"
- तत्व-वार उत्पाद क्यों: $O_S$ के साथ तत्व-वार उत्पाद प्रभावी ढंग से $\mu$ वेक्टर को फ़िल्टर करता है, केवल $O_S$ का हिस्सा होने वाली आधार भुजाओं के लिए माध्य पुरस्कारों को बनाए रखता है। यह गणितीय रूप से $S$ सुपर आर्म से संबंधित आधार भुजाओं के उपसमूह पर ध्यान केंद्रित करने के विचार को दर्शाता है।
चरण-दर-चरण प्रवाह
आइए देखें कि गैप परिभाषा का उपयोग करके CMAB उदाहरण की हमले की क्षमता कैसे निर्धारित की जाती है, जिससे यह एक यांत्रिक असेंबली लाइन की तरह महसूस होता है:
-
उदाहरण लक्षण वर्णन इनपुट: एक विशिष्ट CMAB उदाहरण को सिस्टम में फीड किया जाता है। यह उदाहरण इसके आधार भुजाओं $[m]$, सुपर आर्म $\mathcal{S}$ के क्रिया स्थान, पर्यावरण के ट्रिगरिंग वितरण $D$, संभाव्य ट्रिगरिंग फ़ंक्शन $D_{trig}$, और पुरस्कार फ़ंक्शन $R$ द्वारा परिभाषित किया गया है। महत्वपूर्ण रूप से, सभी आधार भुजाओं के लिए वास्तविक माध्य पुरस्कार वेक्टर $\mu$ को इस प्रारंभिक मूल्यांकन के लिए ज्ञात माना जाता है।
-
लक्ष्य सेट पहचान: प्रतिकूलता $M$ लक्ष्य सुपर आर्म के एक सेट को निर्दिष्ट करती है जिसे वे चाहते हैं कि डाकू एल्गोरिथम खींचे।
-
व्यक्तिगत सुपर आर्म मूल्यांकन (प्रत्येक $S \in M$ के लिए): लक्ष्य सेट $M$ में प्रत्येक सुपर आर्म $S$ के लिए:
- वास्तविक पुरस्कार गणना: इस सुपर आर्म $S$ के लिए अपेक्षित पुरस्कार $r_S(\mu)$ की गणना वास्तविक माध्य पुरस्कार $\mu$ के आधार पर की जाती है। यह इसका आधार प्रदर्शन है।
- अवलोकनीय आधार भुजा पहचान: सेट $O_S$ निर्धारित किया जाता है। यह आधार भुजाओं का संग्रह है जिन्हें सुपर आर्म $S$ का चयन करने पर संभाव्य रूप से ट्रिगर किया जा सकता है। इसे $S$ के "दृष्टि क्षेत्र" या उन संसाधनों के रूप में सोचें जिन्हें यह सीधे प्रभावित कर सकता है।
- संशोधित पर्यावरण सिमुलेशन: एक काल्पनिक वातावरण का निर्माण किया जाता है जहाँ $O_S$ में नहीं होने वाली आधार भुजाओं के वास्तविक माध्य पुरस्कार प्रभावी ढंग से शून्य पर सेट किए जाते हैं। यह $\mu \odot O_S$ माध्य पुरस्कार वेक्टर बनाता है। यह प्रतिकूलता की रणनीति का अनुकरण करता है जो अप्रासंगिक आधार भुजाओं के पुरस्कारों को दबा देती है।
- प्रतिस्पर्धी मूल्यांकन: प्रत्येक अन्य सुपर आर्म $S' \neq S$ (अर्थात, वर्तमान में लक्ष्य के रूप में माने जा रहे सुपर आर्म को छोड़कर कोई भी सुपर आर्म) के लिए, इसके अपेक्षित पुरस्कार $r_{S'}(\mu \odot O_S)$ की गणना इस संशोधित माध्य पुरस्कार वेक्टर का उपयोग करके की जाती है। यह कदम यह आकलन करता है कि यदि प्रतिस्पर्धियों को केवल वही देखने की अनुमति दी जाती है जो $S$ देखता है, या यदि प्रतिकूलता ने अन्य भुजाओं में हेरफेर किया है, तो वे कितने अच्छे होंगे।
- सबसे मजबूत प्रतियोगी की पहचान: इन सभी मूल्यांकित प्रतिस्पर्धियों के बीच अधिकतम अपेक्षित पुरस्कार, $\max_{S' \neq S} r_{S'}(\mu \odot O_S)$, की पहचान की जाती है। यह सबसे बड़ी बाधा है जिसे $S$ को दूर करना होगा।
- गैप गणना: व्यक्तिगत गैप $\Delta_S$ की गणना सबसे मजबूत प्रतियोगी के पुरस्कार (संशोधित पर्यावरण के तहत) को $S$ के वास्तविक पुरस्कार से घटाकर की जाती है। इस मान को फिर संग्रहीत किया जाता है।
-
समग्र हमले की क्षमता निर्धारण: $M$ में सभी $S$ के लिए $\Delta_S$ की गणना करने के बाद, इन व्यक्तिगत गैप्स का अधिकतम, $\Delta_M = \max_{S \in M} \Delta_S$, पाया जाता है।
-
हमले की क्षमता आउटपुट:
- यदि $\Delta_M > 0$, तो CMAB उदाहरण को "बहुपद रूप से हमला करने योग्य" घोषित किया जाता है। इसका मतलब है कि कम से कम एक लक्ष्य सुपर आर्म $S$ है जिसमें पर्याप्त लाभ है, भले ही प्रतिस्पर्धियों का मूल्यांकन प्रतिकूलता के हेरफेर के तहत किया गया हो।
- यदि $\Delta_M < 0$, तो CMAB उदाहरण को "बहुपद रूप से अयोग्य" घोषित किया जाता है। इसका तात्पर्य है कि $M$ में कोई भी लक्ष्य सुपर आर्म $S$ का स्पष्ट लाभ नहीं है जो प्रतिकूलता के प्रस्तावित हेरफेर के तहत है, जिससे एक सफल हमला कठिन या असंभव हो जाता है।
अनुकूलन गतिकी
इस पत्र में "गणितीय और तार्किक तंत्र" में गैप के लिए पारंपरिक सीखने या अनुकूलन प्रक्रिया शामिल नहीं है, क्योंकि $\Delta_S$ CMAB उदाहरण और लक्ष्य सेट की एक स्थिर संपत्ति है। इसके बजाय, गतिकी इस बात के इर्द-गिर्द घूमती है कि प्रतिकूलता की निश्चित रणनीति (एल्गोरिथम 1) डाकू एल्गोरिथम के सीखने की गतिकी का फायदा उठाकर अपने लक्ष्य को कैसे प्राप्त करती है, और गैप $\Delta_M$ सफलता का भविष्यवक्ता कैसे कार्य करता है।
-
प्रतिकूलता का उद्देश्य: प्रतिकूलता का "अनुकूलन" डाकू एल्गोरिथम को समय क्षितिज $T$ पर $T - o(T)$ बार एक लक्ष्य सुपर आर्म $S \in M$ खींचने के लिए मजबूर करना है, जबकि एक उप-रैखिक हमले की लागत $o(T)$ का वहन करना है। यह एक लक्ष्य-संचालित हेरफेर है, न कि एक पुनरावृत्त पैरामीटर अद्यतन।
-
डाकू एल्गोरिथम का सीखना (जैसे, CUCB): पीड़ित डाकू एल्गोरिथम (जैसे, CUCB) आधार भुजाओं के अपेक्षित पुरस्कारों का अनुमान लगाकर और ऊपरी विश्वास सीमाओं (UCBs) का निर्माण करके पुनरावृत्त रूप से संचालित होता है। प्रत्येक दौर $t$ में:
- यह खींची गई सुपर आर्म $S^{(t)}$ और ट्रिगर की गई आधार भुजाओं के परिणामों $X^{(t)}$ का अवलोकन करता है।
- यह आधार भुजा माध्य पुरस्कारों ($\hat{\mu}_i^{(t)}$) और उनके विश्वास अंतरालों के अपने अनुभवजन्य अनुमानों को अद्यतन करता है।
- यह इन अनुमानों का उपयोग सभी सुपर आर्म के लिए UCB की गणना करने के लिए करता है।
- फिर यह अगले दौर के लिए उच्चतम UCB वाली सुपर आर्म का चयन करता है। यह प्रक्रिया अन्वेषण (अनिश्चित भुजाओं को आज़माना) और शोषण (उच्च अनुमानित पुरस्कारों वाली भुजाओं को खींचना) को संतुलित करके पश्चता को कम करने का लक्ष्य रखती है।
-
प्रतिकूलता का हेरफेर (एल्गोरिथम 1): प्रतिकूलता इस सीखने के लूप में हस्तक्षेप करती है। जब डाकू एल्गोरिथम एक सुपर आर्म $S^{(t)}$ खींचता है और परिणाम $X^{(t)}$ का अवलोकन करता है, तो प्रतिकूलता इन परिणामों को $\tilde{X}^{(t)}$ में संशोधित करती है। विशेष रूप से, किसी भी आधार भुजा $i$ के लिए जो ट्रिगर की गई है लेकिन लक्ष्य सुपर आर्म $S$ के अवलोकनीय सेट $O_S$ का हिस्सा नहीं है (अर्थात, $i \in \mathcal{T}^{(t)} \setminus O_S$), प्रतिकूलता इसके देखे गए पुरस्कार $\tilde{X}_i^{(t)} = 0$ पर सेट करती है। अन्य परिणाम अपरिवर्तित छोड़ दिए जाते हैं।
-
डाकू के UCB पर प्रभाव: यह हेरफेर सीधे डाकू के सीखने को प्रभावित करता है:
- $O_S$ में नहीं होने वाली आधार भुजाओं के लिए पुरस्कारों को लगातार 0 पर सेट करके, प्रतिकूलता व्यवस्थित रूप से उन आधार भुजाओं के लिए अनुभवजन्य माध्य पुरस्कार अनुमानों ($\hat{\mu}_i^{(t)}$) को दबाती है।
- यह, बदले में, किसी भी सुपर आर्म $S'$ के UCB को कम करता है जो इन "शून्य-आउट" आधार भुजाओं पर बहुत अधिक निर्भर करता है।
- लक्ष्य सुपर आर्म $S$, हालांकि, इसके वास्तविक अपेक्षित पुरस्कार $r_S(\mu)$ (या इसके UCB, जिसे प्रतिकूलता उच्च रखना चाहती है) के आधार पर मूल्यांकन किया जाता है।
-
लक्ष्य भुजा पर अभिसरण: यदि गैप $\Delta_M > 0$ है, तो यह इंगित करता है कि कम से कम एक लक्ष्य सुपर आर्म $S$ है जिसका वास्तविक अपेक्षित पुरस्कार $r_S(\mu)$ किसी भी विकल्प $S'$ की तुलना में पर्याप्त रूप से अधिक है जब उन विकल्पों का मूल्यांकन प्रतिकूलता के हेरफेर ($\mu \odot O_S$) के तहत किया जाता है। यह सकारात्मक गैप इंगित करता है कि डाकू एल्गोरिथम के लिए "हानि परिदृश्य" को प्रतिकूलता द्वारा प्रभावी ढंग से आकार दिया जा सकता है। गैर-$O_S$ भुजाओं के पुरस्कारों को दबाने की प्रतिकूलता की रणनीति गैर-लक्ष्य सुपर आर्म के UCB को लक्ष्य सुपर आर्म के UCB से नीचे गिरा देगी। समय के साथ, डाकू एल्गोरिथम के पुनरावृत्त अद्यतन लगातार $M$ से एक लक्ष्य सुपर आर्म का चयन करने के लिए अभिसरण करेंगे, क्योंकि इसका UCB हेरफेर किए गए फीडबैक के कारण बेहतर दिखाई देगा। हमला तब "सफल" होता है जब डाकू के UCB पर्याप्त रूप से तिरछे हो जाते हैं।
-
अयोग्यता ($\Delta_M < 0$): यदि $\Delta_M < 0$ है, तो इसका मतलब है कि प्रतिकूलता के सबसे अनुकूल हेरफेर (गैर-$O_S$ भुजाओं को शून्य करना) के तहत भी, कोई लक्ष्य सुपर आर्म $S \in M$ नहीं है जो सभी अन्य विकल्पों से बेहतर दिखाई देता है। इस परिदृश्य में, डाकू एल्गोरिथम के UCB लगातार एक लक्ष्य का पक्ष लेने के लिए अभिसरण नहीं करेंगे, क्योंकि कोई गैर-लक्ष्य भुजा हमेशा उच्च (या तुलनीय) UCB रखेगी, जिससे उदाहरण आंतरिक रूप से इस प्रकार के हमले के प्रति मजबूत हो जाएगा। पुरस्कारों में हेरफेर करने के लिए प्रतिकूलता के प्रयास व्यर्थ होंगे या घातीय लागत की आवश्यकता होगी, जो बहुपद हमले की क्षमता की परिभाषा का उल्लंघन करता है। डाकू एल्गोरिथम का प्राकृतिक अन्वेषण और शोषण इसे लगातार गलत मार्गदर्शन करने से रोकेगा।
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
संयोजी बहु-भुजा वाले डाकू (CMAB) उदाहरणों की बहुपद हमले की क्षमता के संबंध में सैद्धांतिक दावों का कठोरता से परीक्षण करने के लिए प्रयोगात्मक सत्यापन को सावधानीपूर्वक डिजाइन किया गया था। शोधकर्ताओं ने वास्तविक दुनिया के डेटासेट और CMAB अनुप्रयोगों की एक श्रृंखला का उपयोग करते हुए एक बहुआयामी दृष्टिकोण अपनाया, प्रत्येक में विशिष्ट लक्ष्य विन्यास और बेसलाइन एल्गोरिदम थे।
संभाव्य अधिकतम कवरेज (PMC), ऑनलाइन न्यूनतम स्पैनिंग ट्री (MST), और ऑनलाइन शॉर्टेस्ट पाथ समस्याओं के लिए, Flickr डेटासेट (McAuley & Leskovec, 2012) का उपयोग किया गया था। एक उप-ग्राफ को डाउनसैंपल किया गया था, जिसमें सबसे बड़ा कमजोर रूप से जुड़ा हुआ घटक था, जिसके परिणामस्वरूप 1,892 नोड और 7,052 निर्देशित किनारे थे, साथ ही उनके अंतर्निहित किनारे सक्रियण भार भी थे। कैस्केडिंग डाकू के लिए, MovieLens छोटा डेटासेट (Harper & Konstan, 2015), जिसमें 9,000 फिल्में शामिल थीं, का लाभ उठाया गया था, जिसमें 5,000 फिल्मों को प्रयोगों के लिए यादृच्छिक रूप से नमूना लिया गया था। उपयोगकर्ता क्लिक संभावनाओं में मूवी रेटिंग को मैप करने के लिए डी-रैंक एसवीडी सन्निकटन का उपयोग किया गया था। सांख्यिकीय मजबूती सुनिश्चित करने के लिए सभी प्रयोगों को कम से कम 10 बार दोहराया गया था, जिसमें औसत परिणाम और विचरण की रिपोर्ट की गई थी।
"पीड़ित" (बेसलाइन मॉडल) मानक CMAB सीखने वाले एल्गोरिदम थे। PMC के लिए, ग्रीडी ओरेकल के साथ CUCB एल्गोरिथम का उपयोग किया गया था। हमले के दो प्रकार के लक्ष्य माने गए: एक "निश्चित लक्ष्य" जिसमें घटते औसत आउटगोइंग एज भार वाले नोड शामिल थे, और 0.5 से अधिक औसत आउटगोइंग एज भार वाले K यादृच्छिक रूप से नमूना किए गए नोड्स का "यादृच्छिक लक्ष्य"।
ऑनलाइन MST समस्या के लिए, Flickr डेटासेट को एक अप्रत्यक्ष ग्राफ में परिवर्तित किया गया था, जिसमें औसत संभावनाओं को अपेक्षित एज लागत के रूप में उपयोग किया गया था। हमले ने एल्गोरिथम 1 के एक संशोधित संस्करण का उपयोग किया, जहाँ उद्देश्य संशोधित आधार भुजा परिणाम $X_T = 1$ निर्धारित करके लागत को कम करना था। बेसलाइन मानक CUCB एल्गोरिदम थे। लक्ष्यों में एक "निश्चित लक्ष्य" (दूसरा सबसे अच्छा न्यूनतम स्पैनिंग ट्री) और एक "यादृच्छिक लक्ष्य" (यादृच्छिक एज भार के साथ एक न्यूनतम स्पैनिंग ट्री) शामिल था।
ऑनलाइन शॉर्टेस्ट पाथ समस्या में, CUCB के खिलाफ दो अलग-अलग लक्ष्य प्रकारों का मूल्यांकन किया गया था: एक "अयोग्य लक्ष्य" (एक सावधानीपूर्वक निर्मित पथ जहां लक्ष्य पथ पर लागत स्वाभाविक रूप से इष्टतम पथ से अधिक थी, जिससे एल्गोरिथम को गलत मार्गदर्शन करना मुश्किल हो गया) और एक "यादृच्छिक लक्ष्य" (यादृच्छिक रूप से नमूना किए गए स्रोत और गंतव्य नोड्स के बीच एक सबसे छोटा पथ यादृच्छिक एज भार के साथ)। यह सेटअप उन उदाहरणों को प्रदर्शित करने के लिए महत्वपूर्ण था जो स्वाभाविक रूप से हमलों के प्रति मजबूत थे।
कैस्केडिंग डाकू के लिए, अध्ययन ने CascadeKL-UCB, CascadeUCB1, और CascadeUCB-V एल्गोरिदम के खिलाफ हमले को खड़ा किया। लक्ष्य सुपर आर्म को 0.1 से अधिक औसत क्लिक संभावना वाले आधार भुजाओं के उपसमूह से चुना गया था।
इसके अलावा, ऑनलाइन प्रभाव अधिकतमकरण (IM) पर प्रयोग, परिशिष्ट A.2 में विस्तृत, समस्या की NP-कठिन प्रकृति के कारण एक (α, β)-अनुमान ओरेकल (IMM ओरेकल) का उपयोग किया गया था। हमला रणनीति में एक ह्यूरिस्टिक शामिल था जिसने एक "विस्तारित लक्ष्य सेट" $S_{ex}$ के बाहर किनारों के लिए देखे गए किनारे की वास्तविकताओं को 0 में संशोधित किया, जिसमें लक्ष्य नोड्स और एक निश्चित दूरी $l$ के भीतर नोड्स शामिल थे। इन प्रयोगों को कम से कम 5 बार दोहराया गया था। इस व्यापक प्रयोगात्मक डिजाइन, विभिन्न CMAB अनुप्रयोगों और लक्ष्य विन्यासों में फैले हुए, हमले की क्षमता की सैद्धांतिक स्थितियों के गहन अनुभवजन्य सत्यापन की अनुमति दी।
साक्ष्य क्या साबित करता है
प्रयोगात्मक साक्ष्य CMAB हमले की क्षमता के बारे में पत्र के मुख्य गणितीय दावों के लिए सम्मोहक और निर्णायक सत्यापन प्रदान करते हैं, विशेष रूप से प्रमेय 3.6 और सहकर्मी 3.8 में उल्लिखित शर्तों के संबंध में।
संभाव्य अधिकतम कवरेज (PMC) के लिए, जैसा कि चित्र 2(a) और 2(b) में दिखाया गया है, हमले ने CUCB एल्गोरिथम को समय के साथ रैखिक रूप से लक्ष्य भुजा खींचने में सफलतापूर्वक मजबूर किया, जबकि कुल हमले की लागत उप-रैखिक रूप से बढ़ी। यह उप-रैखिक लागत, नोड्स और किनारों की बड़ी संख्या के बावजूद, आधार भुजाओं की संख्या के लिए स्पष्ट रूप से बहुपद थी, जो सीधे प्रमेय 3.9 को मान्य करती है, जो कहता है कि जब $\Delta_M > 0$ होता है तो PMC बहुपद रूप से हमला करने योग्य होता है। उप-रैखिक लागत के साथ लक्ष्य भुजा की खींचों में रैखिक वृद्धि निर्विवाद प्रमाण है कि हमला तंत्र प्रभावी ढंग से CUCB बेसलाइन को गलत मार्गदर्शन करता है। यादृच्छिक लक्ष्यों पर हमलों ने उच्च विचरण प्रदर्शित किया, जो ऐसे परिदृश्यों की अंतर्निहित अप्रत्याशितता का सुझाव देता है।
इसी तरह, ऑनलाइन न्यूनतम स्पैनिंग ट्री (MST) समस्या (चित्र 2(c) और 2(d)) के लिए, कुल हमले की लागत उप-रैखिक बनी रही, और लक्ष्य भुजा रैखिक रूप से खींची गई। यह परिणाम सहकर्मी 3.8 के साथ पूरी तरह से संरेखित होता है, जो मानता है कि ऑनलाइन MST समस्याएं हमेशा हमला करने योग्य होती हैं क्योंकि उनका गैप $\Delta_M \ge 0$ होता है। CUCB बेसलाइन के खिलाफ प्रयोगों में लगातार उप-रैखिक लागत और रैखिक लक्ष्य भुजा खींचों इस डोमेन में हमले की क्षमता के सैद्धांतिक भविष्यवाणी के लिए मजबूत अनुभवजन्य समर्थन प्रदान करते हैं।
ऑनलाइन शॉर्टेस्ट पाथ प्रयोग (चित्र 2(e) और 2(f)) हमला करने योग्य और अयोग्य दोनों उदाहरणों का एक महत्वपूर्ण प्रदर्शन प्रदान करते हैं। "यादृच्छिक लक्ष्यों" के लिए, हमले ने PMC और MST के समान उप-रैखिक लागत और रैखिक लक्ष्य भुजा खींचों को प्राप्त किया। हालांकि, "अयोग्य लक्ष्यों" (हमले के प्रति मजबूत होने के लिए सावधानीपूर्वक निर्मित पथ) के लिए, कुल लागत रैखिक रूप से बढ़ी, और, महत्वपूर्ण रूप से, लक्ष्य भुजा की खींच लगभग स्थिर बनी रही। यह स्पष्ट अंतर निश्चित रूप से आंतरिक रूप से अयोग्य CMAB उदाहरणों के अस्तित्व को साबित करता है, जो $\Delta_M$ स्थिति के आधार पर हमला करने योग्य और अयोग्य परिदृश्यों के बीच सैद्धांतिक अंतर को मान्य करता है। इस मामले में CUCB एल्गोरिथम को धोखा नहीं दिया गया था, हमले की क्षमता की सीमाओं के लिए कठोर सबूत प्रदान करता है।
कैस्केडिंग डाकू (चित्र 2(g) और 2(h)) में, हमले ने CascadeKL-UCB, CascadeUCB1, और CascadeUCB-V के खिलाफ उप-रैखिक हमले की लागत के साथ लक्ष्य भुजा के रैखिक नाटकों को सफलतापूर्वक प्रेरित किया। यह परिणाम सहकर्मी 3.8 की पुष्टि करता है, यह पुष्टि करता है कि कैस्केडिंग डाकू बहुपद रूप से हमला करने योग्य हैं। विभिन्न बेसलाइन एल्गोरिदम में न्यूनतम लागत के साथ लक्ष्य भुजा के नाटकों में लगातार रैखिक वृद्धि हमले की प्रभावशीलता के मजबूत प्रमाण प्रदान करती है।
ऑनलाइन प्रभाव अधिकतमकरण (IM) परिणाम (चित्र 4(a) और 4(b)) एक अधिक सूक्ष्म तस्वीर प्रस्तुत करते हैं। जबकि हमले की लागत कम हो गई, लक्ष्य नोड्स का प्रतिशत 0 पर स्थिर रहा, जिसमें लक्ष्य नोड चयन में वृद्धि का कोई स्पष्ट प्रवृत्ति नहीं थी। यह परिणाम, हमले की क्षमता को गलत साबित करने के बजाय, IM पर हमला करने की कठिनाई को उजागर करता है और पत्र के दावे को रेखांकित करता है कि गैर-सटीक (α-अनुमान) ओरेकल वाले CMAB उदाहरणों के लिए, हमले की क्षमता का विश्लेषण उदाहरण-दर-उदाहरण आधार पर किया जाना चाहिए। यह बताता है कि वर्तमान हमला ह्यूरिस्टिक IM के लिए अपर्याप्त है, लेकिन इसकी आंतरिक हमले की क्षमता को खारिज नहीं करता है, जिससे आगे के शोध को बढ़ावा मिलता है।
संक्षेप में, प्रयोगों ने गणितीय दावों को क्रूरतापूर्वक साबित किया, यह दिखाते हुए कि उन उदाहरणों के लिए जहां $\Delta_M > 0$ (PMC, MST, कैस्केडिंग डाकू), हमला एल्गोरिथम ने विभिन्न CUCB-आधारित बेसलाइन को उप-रैखिक लागत और रैखिक लक्ष्य भुजा खींचों के साथ सफलतापूर्वक गलत मार्गदर्शन किया। इसके विपरीत, उन उदाहरणों के लिए जहां $\Delta_M < 0$ (कुछ शॉर्टेस्ट पाथ विन्यास), हमला विफल हो जाता है, जिसके परिणामस्वरूप रैखिक लागत और स्थिर लक्ष्य भुजा खींचें होती हैं, इस प्रकार यह निश्चित, निर्विवाद प्रमाण प्रदान करता है कि हमले की क्षमता (या अयोग्यता) का मूल तंत्र वास्तविकता में काम करता है।
सीमाएँ और भविष्य की दिशाएँ
जबकि यह पत्र CMAB हमले की क्षमता के एक अभूतपूर्व लक्षण वर्णन को प्रस्तुत करता है, यह खुले तौर पर कई सीमाओं को स्वीकार करता है और भविष्य के अनुसंधान के लिए रोमांचक रास्ते प्रस्तावित करता है।
एक महत्वपूर्ण सीमा यह है कि प्रस्तावित हमला एल्गोरिथम (एल्गोरिथम 1) हमले की लागत के मामले में इष्टतम नहीं हो सकता है। वर्तमान निष्कर्ष हमले की क्षमता के लिए पर्याप्तता स्थापित करते हैं लेकिन न्यूनतम संभव लागत की गारंटी नहीं देते हैं। एक महत्वपूर्ण भविष्य की दिशा कम हमले की लागत प्राप्त करने में सक्षम अधिक परिष्कृत हमला एल्गोरिदम विकसित करना है। इसके लिए CMAB उदाहरणों में हमले की लागतों के लिए सैद्धांतिक निचली सीमाओं की स्थापना की भी आवश्यकता होगी, जो एक आकर्षक और चुनौतीपूर्ण क्षेत्र है।
चर्चा के लिए एक और प्रमुख क्षेत्र ज्ञात और अज्ञात डाकू वातावरण के बीच अंतर के इर्द-गिर्द घूमता है। पत्र एक आश्चर्यजनक तथ्य प्रकट करता है: एक ही CMAB उदाहरण के लिए बहुपद हमले की क्षमता भिन्न हो सकती है, यह इस बात पर निर्भर करता है कि प्रतिकूलता के पास पर्यावरण के मापदंडों (जैसे, पुरस्कार वितरण) का पूर्व ज्ञान है या नहीं। निर्मित "कठिन उदाहरण" (प्रमेय 4.1) एक उदाहरण प्रदर्शित करता है जो एक ज्ञात वातावरण में बहुपद रूप से हमला करने योग्य है लेकिन जब पर्यावरण अज्ञात होता है तो अयोग्य होता है। यह बताता है कि किसी भी CMAB उदाहरण के लिए ब्लैक-बॉक्स सेटिंग्स में एक सामान्य हमला रणनीति मौजूद नहीं हो सकती है। भविष्य के काम को अज्ञात वातावरण में CMAB उदाहरणों के लिए मजबूती गारंटी को चिह्नित करने पर ध्यान केंद्रित करना चाहिए, खासकर शॉर्टेस्ट पाथ जैसी समस्याओं के लिए जहां गैप $\Delta_M$ सकारात्मक या नकारात्मक हो सकता है। अयोग्य CMAB समस्याओं को इन कठिन उदाहरणों में कम करने के लिए एक सामान्य ढांचा विकसित करना अत्यधिक मूल्यवान होगा।
इसके अलावा, वर्तमान हमले की क्षमता लक्षण वर्णन पुरस्कार विषाक्तता हमलों तक सख्ती से सीमित है। लेखक स्पष्ट रूप से बताते हैं कि उनके निष्कर्षों को अन्य, संभावित रूप से अधिक शक्तिशाली, खतरे के मॉडल जैसे पर्यावरण विषाक्तता हमलों (जहां प्रतिकूलता पुरस्कार फ़ंक्शन को सीधे बदल सकती है) या क्रिया विषाक्तता हमलों में सीधे सामान्यीकृत नहीं किया जा सकता है। भविष्य के शोध को CMAB कमजोरियों की अधिक व्यापक समझ प्रदान करने के लिए इन वैकल्पिक खतरे के मॉडल में विश्लेषण का विस्तार करना चाहिए। इसमें यह जांचना शामिल होगा कि विभिन्न प्रकार के प्रतिकूल गड़बड़ी हमले की क्षमता की शर्तों और लागतों को कैसे प्रभावित करती हैं।
अंत में, पत्र का निष्कर्ष संभाव्य ट्रिगर किए गए हथियारों के हमले की क्षमता पर प्रभाव की आगे जांच की आवश्यकता पर प्रकाश डालता है। यह तंत्र, जहां आधार भुजाओं को संभाव्य रूप से ट्रिगर किया जाता है, CMAB में जटिलता की एक और परत जोड़ता है। हमले की क्षमता पर इसके प्रभाव को समझना, विशेष रूप से विभिन्न प्रसार मॉडल के साथ ऑनलाइन प्रभाव अधिकतमकरण जैसे अनुप्रयोगों में, नए अंतर्दृष्टि और अधिक मजबूत एल्गोरिदम को जन्म दे सकता है। ऑनलाइन प्रभाव अधिकतमकरण के लिए प्रारंभिक परिणाम, जहां हमला रणनीति स्पष्ट रूप से सफल नहीं थी, इस पूछताछ की विशिष्ट पंक्ति के महत्व को रेखांकित करता है, खासकर सन्निकटन ओरेकल से निपटते समय।
ये आगे की चर्चाएँ, हमले की लागतों को अनुकूलित करने से लेकर विविध खतरे के मॉडल और पर्यावरणीय ज्ञान की खोज तक, CMAB एल्गोरिदम को अधिक मजबूत बनाने और वास्तविक दुनिया के अनुप्रयोगों में उनकी सुरक्षा निहितार्थों को बेहतर ढंग से समझने का लक्ष्य रखने वाले शोधकर्ताओं के लिए एक समृद्ध एजेंडा प्रदान करती हैं।