Regularized Low-Rank Adaptation for Few-Shot Organ Segmentation
New method auto-adjusts rank for better segmentation, outperforming others in few-shot learning.
Background & Academic Lineage
The problem of adapting large pre-trained models to specific medical tasks with limited data—known as few-shot segmentation—emerged from the practical necessity of reducing the heavy computational and manual annotation costs associated with training deep neural networks from scratch. In clinical environments, where annotated volumetric data is scarce and expensive, researchers needed a way to "fine-tune" massive foundation models without updating every single parameter, which often leads to overfitting and requires excessive memory.
The fundamental "pain point" of previous approaches, specifically standard Low-Rank Adaptation (LoRA), is its reliance on a fixed, pre-defined rank $r$. In practice, the optimal rank required to capture the nuances of different anatomical structures varies significantly. Because selecting this rank manually is difficult and often requires validation data—which is unavailable in strict few-shot scenarios—previous models were either too rigid or prone to suboptimal performance due to poor rank initialization.
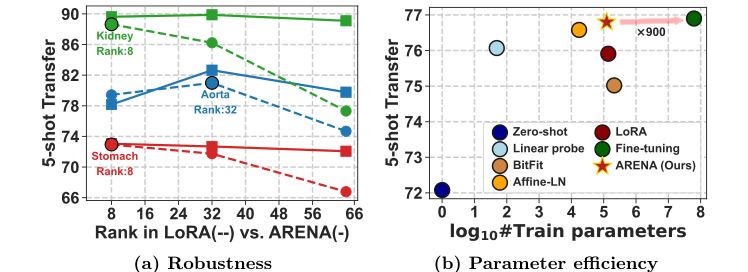 Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Intuitive Domain Terms
- Foundation Models: Think of these as "generalist doctors" who have been trained on a massive library of medical images. They have a broad understanding of anatomy but need a short, specialized training session (fine-tuning) to become experts in a specific, rare organ.
- Few-Shot Adaptation: Imagine trying to learn a new, complex skill by looking at only 5 to 10 examples. It is the challenge of teaching a model to perform a task with almost no "textbook" data.
- Singular Value Decomposition (SVD): This is essentially a mathematical "data compressor." It breaks down a complex weight matrix into smaller, essential components, allowing us to identify which parts of the model are truly important for a specific task.
- Proximal Optimizer: Think of this as a "smart filter" during training. While standard optimizers might struggle with complex mathematical penalties (like the one used to force sparsity), this tool helps the model navigate the optimization landscape while strictly enforcing the rules we set for the rank.
Notation Table
| Notation | Description |
|---|---|
| $W_0$ | The fixed, pre-trained weight matrix of the foundation model. |
| $\Delta W$ | The incremental update applied to the weights during adaptation. |
| $r$ | The intrinsic rank, representing the dimensionality of the adaptation subspace. |
| $A, B$ | Low-rank matrices used to approximate the weight updates. |
| $v$ | An $r$-dimensional vector containing singular values. |
| $\lambda$ | A hyperparameter controlling the strength of the $l_1$ sparsity penalty. |
| $\xi(x, \tau)$ | The soft thresholding function used to prune small values in $v$. |
| $\mathcal{L}$ | The loss function (e.g., Dice loss) being minimized during training. |
The authors solve the problem of fixed-rank limitation by re-parameterizing the LoRA update as a Singular Value Decomposition:
$$W = W_0 + B \text{Diag}(v) A$$
By introducing an $l_1$ sparsity regularizer on the vector $v$, the authors transform the rank selection problem into an optimization problem. The objective function becomes:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
To solve this, they employ a block-coordinate descent strategy. They alternate between standard gradient descent for the matrices $A$ and $B$, and a proximal update for the vector $v$. The proximal update uses the soft thresholding function $\xi(x, \tau)$ defined as:
$$\xi(x, \tau) := \begin{cases} x - \tau, & x > \tau \\ 0, & -\tau \leq x \leq \tau \\ x + \tau, & x < -\tau \end{cases}$$
This mechanism effectively "zeroes out" unnecessary dimensions in the adaptation subspace during training. Consequently, the model automatically discovers the optimal rank for each specific organ without requiring manual tuning or validation sets. This makes the system highly robust to bad initializations, as the model can simply prune away redundant components that do not contribute to the segmentation accuracy. The approach successfully bridges the gap between parameter efficiency and task-specific performance, proving that we can achieve high-quality results even when the initial rank choice is far from ideal.
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The Starting Point and Goal:
The starting point is a pre-trained foundation model (like 3D-SwinUNETR) that has learned general features from large-scale medical datasets. The goal is to adapt this model to a new, specific medical segmentation task (e.g., segmenting a specific organ) using only a very small "support set" of labeled volumes—a scenario known as few-shot learning. The missing link is an efficient way to update the model's internal representations without triggering catastrophic forgetting or overfitting, while simultaneously avoiding the need for manual, trial-and-error hyperparameter tuning for each new task.
The Dilemma:
Researchers face a classic trade-off between model expressiveness and parameter efficiency. Full fine-tuning (FFT) allows the model to adapt perfectly to new data but requires massive computational resources and is highly prone to overfitting when data is scarce. Conversely, existing parameter-efficient fine-tuning (PEFT) methods like Low-Rank Adaptation (LoRA) drastically reduce the number of trainable parameters by assuming that weight updates occur in a low-dimensional subspace. However, LoRA forces the user to choose a fixed "rank" ($r$) for these updates. If the rank is too low, the model lacks the capacity to learn the new task; if it is too high, the model overfits. Finding the "Goldilocks" rank for every unique organ is a manual, expensive, and often impossible task in clinical settings where validation data is limited.
The Harsh Constraints:
The authors hit several "walls" that make this problem difficult:
1. Validation-Free Requirement: In real-world clinical deployment, there is often no separate validation set to tune the rank $r$. The model must perform well on the first try.
2. Non-Smooth Optimization: The rank of a matrix is fundamentally tied to the number of non-zero singular values. Imposing a constraint on the rank directly is a non-differentiable, discrete problem, which is notoriously hard to solve using standard gradient-based deep learning frameworks.
3. Resource Scarcity: Medical institutions have limited computational budgets. The solution must be lightweight enough to run on standard hardware while maintaining high segmentation accuracy.
To bridge this gap, the authors reformulate the LoRA weight update. Standard LoRA defines the update as $\Delta W = BA$, where $B \in \mathbb{R}^{m \times r}$ and $A \in \mathbb{R}^{r \times n}$. The authors extend this by incorporating a singular value vector $v$ into the decomposition:
$$W = W_0 + B \text{Diag}(v) A$$
Here, $v$ is an $r$-dimensional vector of singular values. The rank of the adaptation is effectively determined by the number of non-zero elements in $v$, denoted as $\|v\|_0$.
To make this "rank" learnable, they introduce an $l_1$ sparsity regularizer to the loss function $\mathcal{L}$:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
This regularizer acts as a penalty on the rank. By minimizing this, the model is encouraged to push unimportant singular values to zero, effectively "pruning" the rank automatically during training.
Because the $l_1$ norm is non-smooth (it has a sharp "kink" at zero), standard gradient descent fails. The authors solve this using a proximal optimizer. They alternate between:
1. Gradient steps for $A$ and $B$ to minimize the task-specific loss.
2. Proximal updates for $v$ using the soft-thresholding function $\xi(x, \tau)$:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
This function acts as a dynamic filter, setting small values to zero and scaling down larger ones. This allows the model to discover the optimal, task-specific rank automatically without human intervention.
Why This Approach
The authors of this paper identified a critical bottleneck in applying standard Low-Rank Adaptation (LoRA) to medical image segmentation: the "fixed-rank" constraint. In traditional LoRA, the rank $r$ of the decomposition matrices is a hyperparameter that must be set before training. The authors observed that the optimal rank varies significantly depending on the specific anatomical structure being segmented. Because medical institutions often operate in data-scarce, few-shot environments, performing a grid search or cross-validation to find the "perfect" rank for every new organ is computationally prohibitive and practically infeasible.
The Inevitability of the Choice
The authors realized that standard LoRA was insufficient because it forces a static, one-size-fits-all complexity on tasks that are inherently diverse. If the rank is too low, the model lacks the capacity to capture the nuances of a complex organ; if it is too high, the model overfits the limited support data.
Comparative Superiority (The Benchmarking Logic):
Unlike standard LoRA, which treats the rank as a fixed structural constraint, the proposed ARENA (Adaptive Rank Segmentation) method treats the rank as a dynamic variable. By decomposing the weight update into $W = W_0 + B \text{Diag}(v) A$, the authors shift the problem from "choosing a rank" to "learning a vector of singular values $v$."
* Structural Advantage: By applying an $l_1$ sparsity regularizer to the vector $v$, the model automatically prunes unnecessary dimensions during training. This effectively performs "automatic rank selection."
* Mathematical Elegance: The use of a proximal optimizer (specifically the soft-thresholding function $\xi(x, \tau)$) allows the model to drive small singular values to exactly zero. This is qualitatively superior to standard LoRA because it allows the model to "discover" the intrinsic dimensionality required for a specific task without manual intervention.
Alignment with Constraints:
The "marriage" between the problem and the solution is found in the proximal update rule:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
This equation perfectly addresses the few-shot constraint. Because the model learns the rank during the standard training process, it eliminates the need for a validation set to tune hyperparameters. It is a "self-tuning" mechanism that adapts to the scarcity of data by enforcing sparsity, which acts as a natural regularizer against overfitting.
Mathematical & Logical Mechanism
The Mathematical Engine
The core innovation of this paper is the transformation of the standard Low-Rank Adaptation (LoRA) weight update into a dynamic, sparse Singular Value Decomposition (SVD) framework. The master equation governing this mechanism is:
$$W = W_0 + B \text{Diag}(v) A$$
Tearing Down the Equation
- $W$: The final adapted weight matrix of the model.
- $W_0$: The original, pre-trained weight matrix. This remains frozen throughout the entire process, acting as the stable foundation.
- $B \in \mathbb{R}^{m \times r}$ and $A \in \mathbb{R}^{r \times n}$: These are the low-rank matrices that capture the "delta" or the incremental change needed for the new task.
- $\text{Diag}(v)$: This is a diagonal matrix where $v$ is an $r$-dimensional vector of singular values. This term is the "throttle" of the model. By adjusting the values in $v$, the model can effectively turn off specific dimensions of the adaptation, thereby changing the intrinsic rank of the update.
- The multiplication $B \text{Diag}(v) A$ is used instead of simple addition because it represents a low-rank factorization. It allows the model to project the input into a lower-dimensional space (via $A$), scale the importance of those dimensions (via $\text{Diag}(v)$), and project back to the output space (via $B$).
Optimization Dynamics
The model learns by alternating between two distinct optimization phases, a process known as block-coordinate descent.
- Gradient Descent for $A$ and $B$: The model uses standard gradient steps to update the matrices $A$ and $B$, minimizing the Dice loss. This is the "learning" phase where the model discovers the optimal directions for adaptation.
- Proximal Update for $v$: To handle the $l_1$ regularization, the model uses a proximal operator. The update rule is:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
Here, $\xi$ is the soft-thresholding function. It acts like a filter: if a singular value is small (below the threshold $\eta_t \lambda$), it is set to exactly zero. This is how the model "prunes" unnecessary dimensions, automatically finding the optimal rank for the specific medical task.
Results, Limitations & Conclusion
In the field of medical imaging, we often face a "data scarcity" paradox: while we have massive foundation models pre-trained on thousands of scans, adapting them to a specific hospital's unique needs (e.g., segmenting a specific organ) is difficult because we only have a handful of labeled examples. This is the few-shot segmentation problem.
The Core Problem: The "Fixed Rank" Trap
Standard Low-Rank Adaptation (LoRA) is a popular technique to fine-tune large models without updating all their parameters. It works by injecting small, trainable matrices into the model to approximate the weight updates. However, LoRA forces the user to choose a "rank" ($r$)—a hyperparameter that dictates how much information the model can learn during adaptation.
If you pick a rank that is too low, the model is too simple to learn the new task. If it is too high, the model overfits the tiny amount of data available. In clinical practice, finding the "perfect" rank for every different organ is a tedious, trial-and-error process that is simply not feasible.
The Solution: ARENA
The authors introduce ARENA (Adaptive Rank Segmentation). Instead of forcing a fixed rank, they treat the low-rank update as a Singular Value Decomposition (SVD). They represent the update as:
$$W = W_0 + B \text{Diag}(v) A$$
Here, $v$ is a vector of singular values. The key innovation is adding an $l_1$ sparsity regularizer to the loss function:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
By minimizing this, the model is mathematically incentivized to push unnecessary values in $v$ to zero. This effectively "prunes" the rank automatically during training. They use a proximal optimizer (specifically, a soft-thresholding function) to handle the non-smooth nature of the $l_1$ penalty, allowing the model to discover the optimal rank for each specific organ without human intervention.
How They Proved It
The authors didn't just claim success; they set up a "ruthless" evaluation against several baselines:
* The Victims: They defeated Full Fine-Tuning (FFT), which often overfits in few-shot settings; Linear Probing, which is too simplistic; and standard LoRA and AdaLoRA, which struggle with rank selection.
* The Evidence: They demonstrated that while LoRA's performance fluctuates wildly depending on the initial rank choice, ARENA remains stable. In their experiments on the TotalSegmentator dataset, ARENA achieved significant performance gains—specifically +8.9 and +11.2 in Dice score over standard LoRA for 5-shot and 10-shot settings, respectively. They proved that their method is not just a theoretical improvement but a practical tool that reaches performance levels near full fine-tuning while keeping the computational footprint tiny.