用于少样本器官分割的正则化低秩自适应(Regularized Low-Rank Adaptation)
New method auto-adjusts rank for better segmentation, outperforming others in few-shot learning.
背景与学术渊源
将大型预训练模型适配至特定医学任务(即少样本分割,Few-Shot Segmentation)的问题,源于降低从零开始训练深度神经网络所带来的高昂计算成本与人工标注成本的现实需求。在临床环境中,标注的体积数据(volumetric data)稀缺且昂贵,研究人员亟需一种能够“微调(fine-tune)”海量基础模型(foundation models)的方法,且无需更新所有参数,因为全参数更新往往会导致过拟合(overfitting)并消耗过多的内存。
既有方法(特别是标准低秩自适应,LoRA)的核心“痛点”在于其对预定义固定秩 $r$ 的依赖。在实践中,捕获不同解剖结构细微差别所需的最佳秩差异显著。由于手动选择该秩不仅困难,且通常需要验证集(而在严格的少样本场景下验证集往往不可用),导致以往的模型要么过于僵化,要么因秩初始化不当而导致性能欠佳。
直观领域术语
- 基础模型(Foundation Models): 可将其视为在海量医学图像库上训练过的“全科医生”。它们对解剖结构有广泛的理解,但需要通过简短的专业训练(微调)才能成为特定罕见器官的专家。
- 少样本自适应(Few-Shot Adaptation): 想象一下仅通过 5 到 10 个示例来学习一项复杂的新技能。这是在几乎没有“教科书”数据的情况下,教会模型执行任务的挑战。
- 奇异值分解(SVD): 本质上是一种数学上的“数据压缩器”。它将复杂的权重矩阵分解为较小的核心分量,从而识别出模型中哪些部分对于特定任务真正重要。
- 近端优化器(Proximal Optimizer): 可将其视为训练过程中的“智能过滤器”。当标准优化器难以处理复杂的数学惩罚项(如用于强制稀疏性的惩罚项)时,该工具能帮助模型在优化地形中导航,同时严格执行我们设定的秩约束规则。
符号表
| 符号 | 描述 |
|---|---|
| $W_0$ | 基础模型的固定预训练权重矩阵。 |
| $\Delta W$ | 自适应过程中应用于权重的增量更新。 |
| $r$ | 本征秩(intrinsic rank),代表自适应子空间的维度。 |
| $A, B$ | 用于近似权重更新的低秩矩阵。 |
| $v$ | 包含奇异值的 $r$ 维向量。 |
| $\lambda$ | 控制 $l_1$ 稀疏性惩罚强度的超参数。 |
| $\xi(x, \tau)$ | 用于剪枝 $v$ 中较小值的软阈值函数(soft thresholding function)。 |
| $\mathcal{L}$ | 训练过程中最小化的损失函数(如 Dice loss)。 |
数学解释
作者通过将 LoRA 更新重参数化为奇异值分解来解决固定秩限制问题:
$$W = W_0 + B \text{Diag}(v) A$$
通过在向量 $v$ 上引入 $l_1$ 稀疏正则化,作者将秩选择问题转化为一个优化问题。目标函数变为:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
为了求解该问题,他们采用了块坐标下降(block-coordinate descent)策略。在针对矩阵 $A$ 和 $B$ 的标准梯度下降与针对向量 $v$ 的近端更新之间交替进行。近端更新使用了定义如下的软阈值函数 $\xi(x, \tau)$:
$$\xi(x, \tau) := \begin{cases} x - \tau, & x > \tau \\ 0, & -\tau \leq x \leq \tau \\ x + \tau, & x < -\tau \end{cases}$$
该机制在训练过程中有效地将自适应子空间中不必要的维度“置零”。因此,模型无需手动调参或验证集即可自动发现每个特定器官的最佳秩。这种方法使系统对错误的初始化具有极强的鲁棒性,因为模型可以简单地剪除对分割精度无贡献的冗余分量。该方法成功弥合了参数效率与任务特定性能之间的鸿沟,证明了即使初始秩的选择远非理想,也能获得高质量的结果。
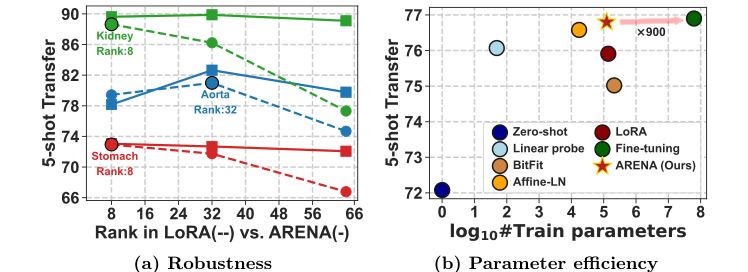 Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
问题定义与约束
核心问题表述与困境
起点与目标:
起点是一个已从大规模医学数据集中学习到通用特征的预训练基础模型(如 3D-SwinUNETR)。目标是仅使用极少量的标注体积“支持集(support set)”,将该模型适配到新的特定医学分割任务(例如分割特定器官)——即所谓的少样本学习场景。缺失的环节在于:如何高效更新模型的内部表示,而不引发灾难性遗忘(catastrophic forgetting)或过拟合,同时避免为每个新任务进行繁琐的试错式超参数调优。
困境:
研究人员面临着模型表达能力(model expressiveness)与参数效率(parameter efficiency)之间的经典权衡。全参数微调(FFT)允许模型完美适配新数据,但需要巨大的计算资源,且在数据稀缺时极易过拟合。相反,现有的参数高效微调(PEFT)方法(如 LoRA)通过假设权重更新发生在低维子空间中,大幅减少了可训练参数的数量。然而,LoRA 强制用户为这些更新选择一个固定的“秩” ($r$)。如果秩太低,模型缺乏学习新任务的能力;如果秩太高,模型则会过拟合。在验证数据有限的临床环境中,为每个独特的器官寻找“黄金秩”是一项昂贵且往往无法实现的手动任务。
严苛约束:
作者面临着几个使该问题变得困难的“壁垒”:
1. 无需验证集要求: 在实际临床部署中,通常没有独立的验证集来调整秩 $r$。模型必须在第一次尝试时就表现良好。
2. 非平滑优化: 矩阵的秩从根本上与非零奇异值的数量相关。直接对秩施加约束是一个不可微的离散问题,这在标准的基于梯度的深度学习框架中极难求解。
3. 资源稀缺: 医疗机构的计算预算有限。该解决方案必须足够轻量,以便在标准硬件上运行,同时保持高分割精度。
解决方案的数学解释
为了弥合这一差距,作者重新表述了 LoRA 权重更新。标准 LoRA 将更新定义为 $\Delta W = BA$,其中 $B \in \mathbb{R}^{m \times r}$ 且 $A \in \mathbb{R}^{r \times n}$。作者通过将奇异值向量 $v$ 纳入分解中对其进行了扩展:
$$W = W_0 + B \text{Diag}(v) A$$
此处,$v$ 是一个 $r$ 维的奇异值向量。自适应的秩实际上由 $v$ 中非零元素的数量决定,记为 $\|v\|_0$。
为了使该“秩”可学习,他们在损失函数 $\mathcal{L}$ 中引入了 $l_1$ 稀疏正则化项:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
该正则化项充当了秩的惩罚项。通过最小化该函数,模型被鼓励将不重要的奇异值推向零,从而在训练过程中自动“剪枝”秩。
由于 $l_1$ 范数是非平滑的(在零点处有一个尖锐的“折点”),标准梯度下降法失效。作者使用近端优化器解决了这一问题。他们交替执行:
1. 针对 $A$ 和 $B$ 的梯度步骤,以最小化任务特定损失。
2. 使用软阈值函数 $\xi(x, \tau)$ 对 $v$ 进行近端更新:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
该函数充当动态过滤器,将小值置零并缩小较大值。这使得模型无需人工干预即可自动发现特定任务的最佳秩。
为何选择此方法
本文作者识别出将标准低秩自适应(LoRA)应用于医学图像分割时的关键瓶颈:即“固定秩”约束。在传统 LoRA 中,分解矩阵的秩 $r$ 是一个必须在训练前设定的超参数。作者观察到,最佳秩会根据所分割的具体解剖结构而显著变化。由于医疗机构通常在数据稀缺的少样本环境下运行,通过网格搜索或交叉验证来为每个新器官寻找“完美秩”在计算上是昂贵的,在实践中也是不可行的。
选择的必然性
作者意识到标准 LoRA 是不足的,因为它对本质上多样化的任务强加了一种静态的、一刀切的复杂性。如果秩太低,模型缺乏捕获复杂器官细微差别的能力;如果秩太高,模型则会过拟合有限的支持数据。
比较优势(基准逻辑):
与将秩视为固定结构约束的标准 LoRA 不同,所提出的 ARENA(自适应秩分割,Adaptive Rank Segmentation)方法将秩视为动态变量。通过将权重更新分解为 $W = W_0 + B \text{Diag}(v) A$,作者将问题从“选择一个秩”转变为“学习一个奇异值向量 $v$”。
* 结构优势: 通过对向量 $v$ 应用 $l_1$ 稀疏正则化,模型在训练过程中自动剪除不必要的维度。这有效地实现了“自动秩选择”。
* 数学优雅性: 使用近端优化器(特别是软阈值函数 $\xi(x, \tau)$)允许模型将小的奇异值精确地驱动至零。这在定性上优于标准 LoRA,因为它允许模型在无需人工干预的情况下“发现”特定任务所需的本征维度。
与约束的对齐:
问题与解决方案之间的“结合点”在于近端更新规则:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
该方程完美解决了少样本约束问题。由于模型在标准训练过程中学习秩,它消除了对验证集调参的需求。这是一种“自调优”机制,通过强制稀疏性来适应数据的稀缺性,而稀疏性本身就是一种对抗过拟合的天然正则化手段。
数学与逻辑机制
数学引擎
本文的核心创新在于将标准低秩自适应(LoRA)权重更新转化为动态、稀疏的奇异值分解(SVD)框架。控制该机制的主方程为:
$$W = W_0 + B \text{Diag}(v) A$$
方程拆解
- $W$:模型最终的自适应权重矩阵。
- $W_0$:原始的预训练权重矩阵。它在整个过程中保持冻结,作为稳定的基础。
- $B \in \mathbb{R}^{m \times r}$ 和 $A \in \mathbb{R}^{r \times n}$:这些是捕获新任务所需“增量(delta)”或增量变化的低秩矩阵。
- $\text{Diag}(v)$:这是一个对角矩阵,其中 $v$ 是 $r$ 维的奇异值向量。该项是模型的“节流阀”。通过调整 $v$ 中的值,模型可以有效地关闭自适应的特定维度,从而改变更新的本征秩。
- 乘法 $B \text{Diag}(v) A$ 之所以被使用,是因为它代表了一种低秩分解。它允许模型将输入投影到低维空间(通过 $A$),缩放这些维度的重要性(通过 $\text{Diag}(v)$),并投影回输出空间(通过 $B$)。
优化动力学
模型通过在两个不同的优化阶段之间交替进行学习,这一过程称为块坐标下降。
- 针对 $A$ 和 $B$ 的梯度下降:模型使用标准梯度步骤更新矩阵 $A$ 和 $B$,以最小化 Dice 损失。这是模型发现自适应最佳方向的“学习”阶段。
- 针对 $v$ 的近端更新:为了处理 $l_1$ 正则化,模型使用了近端算子。更新规则为:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
此处,$\xi$ 是软阈值函数。它像过滤器一样工作:如果奇异值较小(低于阈值 $\eta_t \lambda$),它会被精确地设为零。这就是模型在训练过程中“剪枝”不必要维度、自动为特定医学任务找到最佳秩的方式。
结果、局限性与结论
ARENA:自适应秩分割分析
在医学影像领域,我们经常面临“数据稀缺”悖论:虽然我们拥有在数千次扫描上预训练的海量基础模型,但将它们适配到特定医院的独特需求(例如分割特定器官)却很困难,因为我们只有少量的标注示例。这就是少样本分割问题。
核心问题:“固定秩”陷阱
标准低秩自适应(LoRA)是一种在不更新所有参数的情况下微调大型模型的流行技术。它通过向模型注入小的、可训练的矩阵来近似权重更新。然而,LoRA 强制用户选择一个“秩” ($r$)——这是一个决定模型在自适应过程中能学习多少信息的超参数。
如果选择的秩太低,模型过于简单,无法学习新任务。如果秩太高,模型则会过拟合有限的数据。在临床实践中,为每个不同的器官寻找“完美秩”是一个繁琐的试错过程,这在实践中是不可行的。
解决方案:ARENA
作者引入了 ARENA(自适应秩分割)。他们不再强制固定秩,而是将低秩更新视为奇异值分解(SVD)。他们将更新表示为:
$$W = W_0 + B \text{Diag}(v) A$$
此处,$v$ 是奇异值向量。关键创新在于向损失函数中添加了 $l_1$ 稀疏正则化项:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
通过最小化该函数,模型在数学上受到激励,将 $v$ 中的不必要值推向零。这有效地在训练过程中自动“剪枝”了秩。他们使用近端优化器(特别是软阈值函数)来处理 $l_1$ 惩罚项的非平滑性,从而允许模型在无需人工干预的情况下发现每个特定器官的最佳秩。
验证方法
作者不仅宣称成功,还针对多个基线进行了“严苛”的评估:
* 对比对象: 他们击败了在少样本设置中经常过拟合的全参数微调(FFT);过于简单的线性探测(Linear Probing);以及在秩选择上表现挣扎的标准 LoRA 和 AdaLoRA。
* 证据: 他们证明了虽然 LoRA 的性能会根据初始秩的选择而剧烈波动,但 ARENA 始终保持稳定。在 TotalSegmentator 数据集上的实验中,ARENA 取得了显著的性能提升——在 5-shot 和 10-shot 设置下,Dice 分数分别比标准 LoRA 高出 +8.9 和 +11.2。他们证明了该方法不仅是理论上的改进,更是一种实用的工具,在保持极小计算足迹的同时,达到了接近全参数微调的性能水平。
与其他领域的同构性
正则化低秩自适应在少样本器官分割中的分析
背景与动机
在现代医学影像中,我们经常使用“基础模型”——在庞大且多样化的数据集上预训练的海量神经网络。虽然这些模型功能强大,但通常太大,无法为每个特定的临床任务(如分割特定器官)进行完全重训练。研究人员使用参数高效微调(PEFT),通过仅更新极小一部分参数来适配这些模型。
一种流行的方法是低秩自适应(LoRA),它假设模型权重所需的必要变化可以被捕获在低维子空间中。LoRA 将权重更新表示为两个较小矩阵 $A$ 和 $B$ 的乘积,其中“秩” $r$ 定义了该子空间的大小。问题在于 LoRA 要求用户预先选择一个固定秩 $r$。如果秩太低,模型缺乏学习能力;如果秩太高,它会在少样本场景下过拟合有限的数据。作者发现最佳秩在不同器官之间差异显著,使得手动选择变得不切实际。
数学解释
作者通过将秩选择视为优化问题而非超参数选择来解决这一问题。他们使用奇异值分解(SVD)结构分解权重更新 $\Delta W$:
$$W = W_0 + B \text{Diag}(v) A$$
此处,$v$ 是奇异值向量。自适应的秩实际上是 $v$ 中非零元素的数量,记为 $\|v\|_0$。为了使其具有自适应性,他们在损失函数中引入了 $l_1$ 稀疏正则化项:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
通过最小化该函数,模型自然地将不重要的奇异值推向零。他们使用近端优化器处理非平滑的 $l_1$ 项,在训练过程中使用软阈值函数 $\xi(x, \tau)$ 更新 $v$:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
这允许模型在训练过程中“剪枝”其自身的秩,自动为所分割的特定器官找到最佳复杂度。
结构骨架
一种通过在梯度下降过程中对变换矩阵的奇异值施加稀疏惩罚,从而动态剪枝其维度的机制。