Regularized Low-Rank Adaptation for Few-Shot Organ Segmentation
Few shot segmentation, the task of adapting large pre trained models to specific medical applications with limited data, emerged from the practical necessity of mitigating the substantial computational and manual...
Background & Academic Lineage
Few-shot segmentation, the task of adapting large pre-trained models to specific medical applications with limited data, emerged from the practical necessity of mitigating the substantial computational and manual annotation costs associated with training deep neural networks from scratch. In clinical environments, where annotated volumetric data is scarce and costly, researchers required a methodology to "fine-tune" massive foundation models without updating the entire parameter space, which frequently induces overfitting and necessitates excessive memory.
The fundamental limitation of previous approaches, specifically standard Low-Rank Adaptation (LoRA), lies in its reliance on a fixed, pre-defined rank $r$. In practice, the optimal rank required to capture the nuances of distinct anatomical structures varies significantly. Since selecting this rank manually is challenging and often requires validation data—which is unavailable in strict few-shot scenarios—previous models were either overly rigid or prone to suboptimal performance due to inadequate rank initialization.
Intuitive Domain Terms
- Foundation Models: 대규모 의료 영상 라이브러리로 사전 학습된 "범용 전문의"와 같다. 해부학적 구조에 대한 광범위한 이해를 갖추고 있으나, 특정 희귀 장기에 대한 전문가가 되기 위해서는 짧고 전문화된 훈련(fine-tuning) 과정이 필요하다.
- Few-Shot Adaptation: 5~10개의 예시만을 사용하여 복잡한 새로운 기술을 습득하는 과정과 같다. "교과서" 데이터가 거의 없는 상태에서 모델이 특정 작업을 수행하도록 학습시키는 도전적인 과제이다.
- Singular Value Decomposition (SVD): 수학적인 "데이터 압축기"이다. 복잡한 가중치 행렬을 더 작고 필수적인 구성 요소로 분해하여, 특정 작업에 있어 모델의 어떤 부분이 진정으로 중요한지 식별할 수 있게 한다.
- Proximal Optimizer: 훈련 과정에서의 "지능형 필터"와 같다. 일반적인 최적화 도구는 복잡한 수학적 페널티(예: 희소성(sparsity)을 강제하기 위해 사용되는 페널티)를 처리하는 데 어려움을 겪을 수 있으나, 이 도구는 우리가 설정한 랭크 규칙을 엄격히 준수하면서 모델이 최적화 경로를 탐색하도록 돕는다.
Notation Table
| Notation | Description |
|---|---|
| $W_0$ | 파운데이션 모델의 고정된 사전 학습 가중치 행렬. |
| $\Delta W$ | 적응(adaptation) 과정에서 가중치에 적용되는 증분 업데이트. |
| $r$ | 적응 부분 공간(subspace)의 차원을 나타내는 내재적 랭크. |
| $A, B$ | 가중치 업데이트를 근사하는 데 사용되는 저랭크(low-rank) 행렬. |
| $v$ | 특잇값(singular values)을 포함하는 $r$ 차원 벡터. |
| $\lambda$ | $l_1$ 희소성 페널티의 강도를 제어하는 하이퍼파라미터. |
| $\xi(x, \tau)$ | $v$ 내의 작은 값을 가지치기(pruning)하는 데 사용되는 soft thresholding 함수. |
| $\mathcal{L}$ | 훈련 중 최소화되는 손실 함수(예: Dice loss). |
Mathematical Interpretation
저자들은 특잇값 분해(Singular Value Decomposition)를 통해 LoRA 업데이트를 재매개변수화함으로써 고정 랭크의 한계를 극복한다:
$$W = W_0 + B \text{Diag}(v) A$$
벡터 $v$에 $l_1$ 희소성 정규화(sparsity regularizer)를 도입함으로써, 저자들은 랭크 선택 문제를 최적화 문제로 변환한다. 목적 함수는 다음과 같다:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
이를 해결하기 위해 블록 좌표 하강법(block-coordinate descent) 전략을 채택한다. 행렬 $A$와 $B$에 대해서는 표준 경사 하강법(gradient descent)을, 벡터 $v$에 대해서는 근사 업데이트(proximal update)를 교대로 수행한다. 근사 업데이트는 다음과 같이 정의된 soft thresholding 함수 $\xi(x, \tau)$를 사용한다:
$$\xi(x, \tau) := \begin{cases} x - \tau, & x > \tau \\ 0, & -\tau \leq x \leq \tau \\ x + \tau, & x < -\tau \end{cases}$$
이 메커니즘은 훈련 과정에서 적응 부분 공간 내의 불필요한 차원을 효과적으로 "0으로 처리(zeroes out)"한다. 결과적으로, 모델은 수동 튜닝이나 검증 세트 없이도 각 특정 장기에 대한 최적의 랭크를 자동으로 발견한다. 이러한 방식은 모델이 세분화 정확도에 기여하지 않는 중복 구성 요소를 단순히 제거할 수 있게 함으로써, 초기화 오류에 대해 매우 강력한 견고성을 제공한다. 본 접근 방식은 매개변수 효율성과 작업별 성능 사이의 간극을 성공적으로 메우며, 초기 랭크 선택이 이상적이지 않더라도 고품질의 결과를 도출할 수 있음을 입증한다.
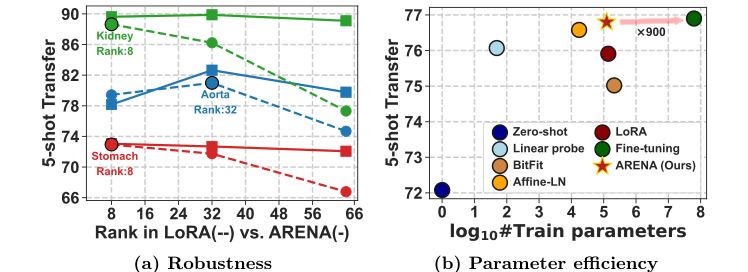 Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
시작점과 목표:
시작점은 대규모 의료 데이터셋으로부터 일반적인 특징을 학습한 사전 학습 파운데이션 모델(예: 3D-SwinUNETR)이다. 목표는 라벨링된 볼륨의 매우 작은 "서포트 세트(support set)"만을 사용하여 이 모델을 새로운 특정 의료 세분화 작업(예: 특정 장기 세분화)에 적응시키는 것으로, 이를 few-shot learning이라 한다. 여기서 누락된 연결 고리는 파괴적 망각(catastrophic forgetting)이나 과적합(overfitting)을 유발하지 않으면서 모델의 내부 표현을 효율적으로 업데이트하고, 동시에 새로운 작업마다 수동적인 시행착오를 통한 하이퍼파라미터 튜닝을 피하는 방법이다.
딜레마:
연구자들은 모델 표현력(model expressiveness)과 매개변수 효율성(parameter efficiency) 사이의 고전적인 상충 관계에 직면한다. 전체 미세 조정(Full fine-tuning, FFT)은 모델이 새로운 데이터에 완벽하게 적응하도록 하지만 막대한 계산 자원을 요구하며 데이터가 부족할 경우 과적합에 매우 취약하다. 반면, LoRA와 같은 기존의 매개변수 효율적 미세 조정(PEFT) 방법은 가중치 업데이트가 저차원 부분 공간에서 발생한다고 가정하여 학습 가능한 매개변수 수를 획기적으로 줄인다. 그러나 LoRA는 사용자가 이러한 업데이트를 위해 고정된 "랭크($r$)"를 선택하도록 강제한다. 랭크가 너무 낮으면 모델은 새로운 작업을 학습할 능력이 부족해지고, 너무 높으면 과적합이 발생한다. 모든 고유한 장기에 대해 "최적의(Goldilocks)" 랭크를 찾는 것은 임상 환경에서 검증 데이터가 제한적인 경우 수동적이고 비용이 많이 들며, 종종 불가능한 작업이다.
엄격한 제약 조건:
저자들은 이 문제를 어렵게 만드는 몇 가지 "장벽"에 직면한다:
1. 검증 데이터 부재(Validation-Free Requirement): 실제 임상 배치 환경에서는 랭크 $r$을 튜닝하기 위한 별도의 검증 세트가 없는 경우가 많다. 모델은 첫 시도에서 우수한 성능을 발휘해야 한다.
2. 비매끄러운 최적화(Non-Smooth Optimization): 행렬의 랭크는 근본적으로 0이 아닌 특잇값의 개수와 연결되어 있다. 랭크에 직접 제약을 가하는 것은 비미분 가능하고 이산적인 문제이며, 이는 표준 경사 기반 딥러닝 프레임워크를 사용하여 해결하기 매우 어렵기로 악명이 높다.
3. 자원 부족(Resource Scarcity): 의료 기관은 계산 예산이 제한적이다. 따라서 솔루션은 높은 세분화 정확도를 유지하면서도 표준 하드웨어에서 실행될 수 있을 만큼 경량화되어야 한다.
Mathematical Interpretation of the Solution
이 간극을 메우기 위해 저자들은 LoRA 가중치 업데이트를 재구성한다. 표준 LoRA는 업데이트를 $\Delta W = BA$로 정의하며, 여기서 $B \in \mathbb{R}^{m \times r}$, $A \in \mathbb{R}^{r \times n}$이다. 저자들은 분해 과정에 특잇값 벡터 $v$를 통합하여 이를 확장한다:
$$W = W_0 + B \text{Diag}(v) A$$
여기서 $v$는 특잇값으로 구성된 $r$ 차원 벡터이다. 적응의 랭크는 효과적으로 $\|v\|_0$로 표기되는 $v$ 내 0이 아닌 요소의 개수에 의해 결정된다.
이 "랭크"를 학습 가능하게 만들기 위해, 그들은 손실 함수 $\mathcal{L}$에 $l_1$ 희소성 정규화 항을 도입한다:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
이 정규화 항은 랭크에 대한 페널티 역할을 한다. 이를 최소화함으로써 모델은 중요하지 않은 특잇값을 0으로 밀어내도록 유도되며, 훈련 과정에서 랭크를 자동으로 "가지치기(pruning)"하게 된다.
$l_1$ 노름은 비매끄럽기 때문에(0에서 급격한 "꺾임"이 존재), 표준 경사 하강법은 실패한다. 저자들은 이를 근사 최적화 도구(proximal optimizer)를 사용하여 해결한다. 그들은 다음 두 단계를 교대로 수행한다:
1. 작업별 손실을 최소화하기 위한 $A$와 $B$에 대한 경사 단계(Gradient steps).
2. soft-thresholding 함수 $\xi(x, \tau)$를 사용하는 $v$에 대한 근사 업데이트(Proximal updates):
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
이 함수는 동적 필터 역할을 하여 작은 값을 0으로 설정하고 큰 값을 축소한다. 이를 통해 모델은 인간의 개입 없이도 작업별 최적 랭크를 자동으로 발견할 수 있다.
Why This Approach
본 논문의 저자들은 의료 영상 세분화에 표준 LoRA를 적용하는 데 있어 결정적인 병목 현상인 "고정 랭크" 제약을 식별했다. 전통적인 LoRA에서 분해 행렬의 랭크 $r$은 훈련 전에 설정해야 하는 하이퍼파라미터이다. 저자들은 세분화 대상인 해부학적 구조에 따라 최적의 랭크가 크게 달라진다는 점을 관찰했다. 의료 기관은 종종 데이터가 부족한 few-shot 환경에서 운영되므로, 새로운 장기마다 최적의 랭크를 찾기 위해 그리드 서치나 교차 검증을 수행하는 것은 계산적으로 불가능하며 실제 적용도 어렵다.
선택의 필연성
저자들은 표준 LoRA가 본질적으로 다양한 작업에 대해 정적이고 일률적인 복잡성을 강요하기 때문에 불충분하다는 것을 깨달았다. 랭크가 너무 낮으면 모델은 복잡한 장기의 뉘앙스를 포착할 능력이 부족하고, 너무 높으면 제한된 서포트 데이터에 과적합된다.
비교 우위 (벤치마킹 논리):
랭크를 고정된 구조적 제약으로 취급하는 표준 LoRA와 달리, 제안된 ARENA (Adaptive Rank Segmentation) 방법은 랭크를 동적 변수로 취급한다. 가중치 업데이트를 $W = W_0 + B \text{Diag}(v) A$로 분해함으로써, 저자들은 문제를 "랭크 선택"에서 "특잇값 벡터 $v$ 학습"으로 전환한다.
* 구조적 이점: 벡터 $v$에 $l_1$ 희소성 정규화 항을 적용함으로써, 모델은 훈련 중 불필요한 차원을 자동으로 가지치기한다. 이는 효과적으로 "자동 랭크 선택"을 수행한다.
* 수학적 우아함: 근사 최적화 도구(특히 soft-thresholding 함수 $\xi(x, \tau)$)의 사용은 모델이 작은 특잇값을 정확히 0으로 유도할 수 있게 한다. 이는 모델이 수동 개입 없이 특정 작업에 필요한 내재적 차원을 "발견"할 수 있게 하므로 표준 LoRA보다 질적으로 우월하다.
제약 조건과의 정렬:
문제와 해결책 사이의 "결합"은 근사 업데이트 규칙에서 발견된다:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
이 방정식은 few-shot 제약 조건을 완벽하게 해결한다. 모델이 표준 훈련 과정에서 랭크를 학습하기 때문에 하이퍼파라미터 튜닝을 위한 검증 세트가 필요 없다. 이는 희소성을 강제함으로써 데이터 부족에 적응하는 "자기 튜닝(self-tuning)" 메커니즘이며, 과적합에 대한 자연스러운 정규화 역할을 한다.
Mathematical & Logical Mechanism
The Mathematical Engine
본 논문의 핵심 혁신은 표준 LoRA 가중치 업데이트를 동적이고 희소한 SVD 프레임워크로 변환한 것이다. 이 메커니즘을 지배하는 마스터 방정식은 다음과 같다:
$$W = W_0 + B \text{Diag}(v) A$$
방정식의 분해
- $W$: 모델의 최종 적응 가중치 행렬.
- $W_0$: 원래의 사전 학습 가중치 행렬. 이는 전체 과정 동안 고정된 상태로 유지되어 안정적인 기반 역할을 한다.
- $B \in \mathbb{R}^{m \times r}$ 및 $A \in \mathbb{R}^{r \times n}$: 새로운 작업을 위해 필요한 "델타" 또는 증분 변화를 포착하는 저랭크 행렬.
- $\text{Diag}(v)$: $v$가 특잇값의 $r$ 차원 벡터인 대각 행렬. 이 항은 모델의 "스로틀(throttle)"이다. $v$의 값을 조정함으로써 모델은 적응의 특정 차원을 효과적으로 끄고, 결과적으로 업데이트의 내재적 랭크를 변경할 수 있다.
- 곱셈 $B \text{Diag}(v) A$는 단순 덧셈 대신 저랭크 분해를 나타내기 때문에 사용된다. 이는 모델이 입력을 저차원 공간으로 투영하고($A$를 통해), 해당 차원의 중요도를 조정하며($\text{Diag}(v)$를 통해), 출력 공간으로 다시 투영($B$를 통해)할 수 있게 한다.
Optimization Dynamics
모델은 블록 좌표 하강법(block-coordinate descent)으로 알려진 두 가지 별개의 최적화 단계를 교대로 수행하며 학습한다.
- $A$와 $B$에 대한 경사 하강법: 모델은 표준 경사 단계를 사용하여 $A$와 $B$ 행렬을 업데이트하고 Dice 손실을 최소화한다. 이는 모델이 적응을 위한 최적의 방향을 발견하는 "학습" 단계이다.
- $v$에 대한 근사 업데이트: $l_1$ 정규화를 처리하기 위해 모델은 근사 연산자(proximal operator)를 사용한다. 업데이트 규칙은 다음과 같다:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
여기서 $\xi$는 soft-thresholding 함수이다. 이는 필터처럼 작동한다. 만약 특잇값이 작으면(임계값 $\eta_t \lambda$ 미만), 정확히 0으로 설정된다. 이것이 모델이 불필요한 차원을 "가지치기"하여 특정 의료 작업에 대한 최적의 랭크를 자동으로 찾는 방식이다.
Results, Limitations & Conclusion
Analysis of ARENA: Adaptive Rank Segmentation
의료 영상 분야에서 우리는 종종 "데이터 부족"의 역설에 직면한다. 수천 개의 스캔으로 사전 학습된 거대한 파운데이션 모델을 보유하고 있음에도 불구하고, 이를 특정 병원의 고유한 요구 사항(예: 특정 장기 세분화)에 적응시키는 것은 라벨링된 예시가 소수에 불과하기 때문에 어렵다. 이것이 바로 few-shot segmentation 문제이다.
핵심 문제: "고정 랭크"의 함정
표준 LoRA는 모든 매개변수를 업데이트하지 않고도 대형 모델을 미세 조정하는 인기 있는 기술이다. 이는 모델에 작고 학습 가능한 행렬을 주입하여 가중치 업데이트를 근사하는 방식으로 작동한다. 그러나 LoRA는 사용자가 적응 과정에서 모델이 얼마나 많은 정보를 학습할 수 있는지를 결정하는 하이퍼파라미터인 "랭크($r$)"를 선택하도록 강제한다.
랭크를 너무 낮게 선택하면 모델이 새로운 작업을 학습하기에 너무 단순해진다. 너무 높게 선택하면 가용한 소량의 데이터에 과적합된다. 임상 실무에서 모든 서로 다른 장기에 대해 "완벽한" 랭크를 찾는 것은 시행착오가 따르는 지루한 과정이며, 현실적으로 불가능하다.
솔루션: ARENA
저자들은 ARENA (Adaptive Rank Segmentation)를 도입한다. 고정 랭크를 강제하는 대신, 저랭크 업데이트를 SVD로 취급한다. 그들은 업데이트를 다음과 같이 표현한다:
$$W = W_0 + B \text{Diag}(v) A$$
여기서 $v$는 특잇값 벡터이다. 핵심 혁신은 손실 함수에 $l_1$ 희소성 정규화 항을 추가하는 것이다:
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
이를 최소화함으로써 모델은 수학적으로 $v$ 내의 불필요한 값을 0으로 밀어내도록 유도된다. 이는 훈련 과정에서 랭크를 자동으로 "가지치기"한다. 그들은 $l_1$ 페널티의 비매끄러운 특성을 처리하기 위해 근사 최적화 도구(구체적으로 soft-thresholding 함수)를 사용하여, 인간의 개입 없이 각 특정 장기에 대한 최적 랭크를 발견할 수 있게 한다.
입증 방법
저자들은 성공을 주장하는 데 그치지 않고, 여러 베이스라인에 대해 "가혹한" 평가를 설정했다:
* 비교 대상: few-shot 설정에서 종종 과적합되는 FFT, 너무 단순한 Linear Probing, 그리고 랭크 선택에 어려움을 겪는 표준 LoRA 및 AdaLoRA를 능가했다.
* 증거: LoRA의 성능은 초기 랭크 선택에 따라 크게 변동하는 반면, ARENA는 안정적으로 유지됨을 입증했다. TotalSegmentator 데이터셋에 대한 실험에서 ARENA는 5-shot 및 10-shot 설정에서 표준 LoRA 대비 각각 +8.9 및 +11.2의 Dice 점수 향상을 기록하며 상당한 성능 개선을 달성했다. 그들은 본 방법이 단순한 이론적 개선이 아니라, 계산 비용을 최소화하면서도 전체 미세 조정에 근접한 성능 수준에 도달하는 실용적인 도구임을 증명했다.