Few-Shot臓器セグメンテーションのための正則化低ランク適応(Regularized Low-Rank Adaptation)
New method auto-adjusts rank for better segmentation, outperforming others in few-shot learning.
背景と学術的系譜
限られたデータで大規模な事前学習済みモデルを特定の医療タスクに適応させる「Few-Shotセグメンテーション」という課題は、深層ニューラルネットワークをゼロから学習させる際に伴う膨大な計算コストと手作業によるアノテーションコストを削減するという実用的な要請から生じた。アノテーション済みのボリュームデータが希少かつ高コストである臨床環境において、研究者は、過学習を招きやすくメモリ消費も激しい全パラメータの更新を避けつつ、巨大な基盤モデル(Foundation Models)を「ファインチューニング(Fine-tuning)」する手法を必要としていた。
既存のアプローチ、特に標準的なLow-Rank Adaptation (LoRA) における根本的な「ペインポイント」は、固定された事前定義済みのランク $r$ への依存にある。実際には、異なる解剖学的構造のニュアンスを捉えるために必要な最適ランクは大きく変動する。このランクを手動で選択することは困難であり、多くの場合バリデーションデータが必要となるが、厳密なFew-Shotシナリオではそのようなデータは利用できない。そのため、従来モデルは柔軟性に欠けるか、あるいは不適切なランク初期化によって最適以下の性能に陥る傾向があった。
直感的なドメイン用語
- 基盤モデル (Foundation Models): 膨大な医療画像ライブラリで学習された「ジェネラリストの医師」と見なすことができる。解剖学に関する広範な理解を有しているが、特定の希少な臓器の専門家となるためには、短期間の専門的なトレーニング(ファインチューニング)を必要とする。
- Few-Shot適応 (Few-Shot Adaptation): 5〜10個のサンプルのみを見て、新しい複雑なスキルを習得しようとすることに等しい。これは、「教科書」的なデータがほとんどない状態で、モデルにタスクを実行させるための挑戦である。
- 特異値分解 (SVD): 本質的には数学的な「データ圧縮機」である。複雑な重み行列をより小さく本質的な成分に分解し、特定のタスクにとって真に重要なモデルの部位を特定することを可能にする。
- 近接最適化手法 (Proximal Optimizer): 学習中の「スマートフィルター」と考えることができる。標準的な最適化手法では複雑な数学的ペナルティ(スパース性を強制するために使用されるものなど)の扱いに苦慮する場合があるが、このツールはランクに対して設定したルールを厳格に適用しながら、最適化のランドスケープをモデルが探索するのを支援する。
表記法一覧
| 表記 | 説明 |
|---|---|
| $W_0$ | 基盤モデルの固定された事前学習済み重み行列。 |
| $\Delta W$ | 適応中に重みに適用される増分更新。 |
| $r$ | 適応部分空間の次元性を表す内在的ランク。 |
| $A, B$ | 重み更新を近似するために使用される低ランク行列。 |
| $v$ | 特異値を含む $r$ 次元のベクトル。 |
| $\lambda$ | $l_1$ スパース性ペナルティの強度を制御するハイパーパラメータ。 |
| $\xi(x, \tau)$ | $v$ 内の小さな値を剪定(pruning)するために使用されるソフト閾値関数。 |
| $\mathcal{L}$ | 学習中に最小化される損失関数(例:Dice loss)。 |
数学的解釈
著者らは、LoRAの更新を特異値分解として再パラメータ化することで、固定ランクの制限という問題を解決している。
$$W = W_0 + B \text{Diag}(v) A$$
ベクトル $v$ に対して $l_1$ スパース性正則化を導入することで、著者らはランク選択問題を最適化問題へと変換した。目的関数は以下の通りとなる。
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
これを解くために、ブロック座標降下法(block-coordinate descent strategy)を採用している。行列 $A$ および $B$ に対しては標準的な勾配降下法を、ベクトル $v$ に対しては近接更新(proximal update)を交互に実行する。近接更新では、以下のように定義されるソフト閾値関数 $\xi(x, \tau)$ を用いる。
$$\xi(x, \tau) := \begin{cases} x - \tau, & x > \tau \\ 0, & -\tau \leq x \leq \tau \\ x + \tau, & x < -\tau \end{cases}$$
このメカニズムは、学習中に適応部分空間内の不要な次元を効果的に「ゼロ化」する。その結果、モデルは手動調整やバリデーションセットを必要とすることなく、各臓器に最適なランクを自動的に発見する。このアプローチは、初期のランク選択が理想から遠い場合でも、セグメンテーション精度に寄与しない冗長な成分を単に剪定できるため、不適切な初期化に対して極めて高い堅牢性を発揮する。本手法は、パラメータ効率とタスク固有の性能との間のギャップを埋めることに成功しており、初期ランクの選択が理想的でなくとも高品質な結果が得られることを証明している。
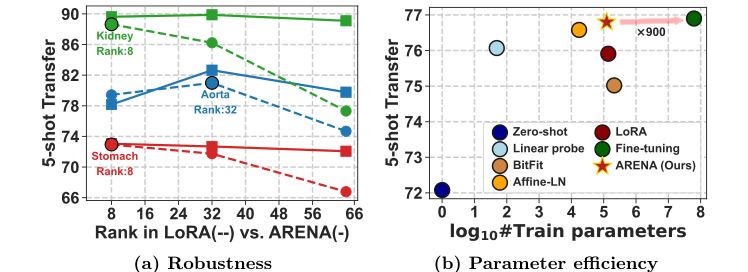 Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
Figure 1. Adaptive-LoRA. We introduce a novel few-shot PEFT technique for Adaptive Rank Segmentation (ARENA) that is (a) robust to rank initializa- tion and (b) enhances the parameter efficiency vs. performance trade-off
問題定義と制約
中核となる問題設定とジレンマ
出発点と目標:
出発点は、大規模な医療データセットから一般的な特徴を学習した事前学習済み基盤モデル(3D-SwinUNETRなど)である。目標は、ラベル付きボリュームの非常に小さな「サポートセット」のみを使用して、このモデルを新しい特定の医療セグメンテーションタスク(特定の臓器のセグメンテーションなど)に適応させることである。これはFew-Shot学習として知られるシナリオである。欠けているリンクは、壊滅的忘却(catastrophic forgetting)や過学習を引き起こすことなく、かつタスクごとに手作業による試行錯誤的なハイパーパラメータ調整を必要とせずに、モデルの内部表現を効率的に更新する方法である。
ジレンマ:
研究者は、モデルの表現力とパラメータ効率という古典的なトレードオフに直面している。フルファインチューニング(FFT)は新しいデータに完璧に適応できるが、膨大な計算リソースを必要とし、データが希少な場合には過学習を非常に起こしやすい。逆に、Low-Rank Adaptation (LoRA) のような既存のパラメータ効率的なファインチューニング(PEFT)手法は、重みの更新が低次元部分空間で発生すると仮定することで、学習可能なパラメータ数を劇的に削減する。しかし、LoRAはユーザーに対して、これらの更新のために固定された「ランク」 ($r$) を選択することを強いる。ランクが低すぎればモデルはタスクを学習する能力を欠き、高すぎれば過学習する。すべての固有の臓器に対して「ちょうど良い(Goldilocks)」ランクを見つけることは、バリデーションデータが限られている臨床現場では手作業でコストがかかり、多くの場合不可能である。
厳しい制約:
著者らは、この問題を困難にするいくつかの「壁」に突き当たっている。
1. バリデーションフリーの要件: 現実の臨床展開において、ランク $r$ を調整するための独立したバリデーションセットが存在しないことは珍しくない。モデルは初回で良好な性能を発揮しなければならない。
2. 非滑らかな最適化: 行列のランクは、本質的に非ゼロの特異値の数と結びついている。ランクに直接制約を課すことは、微分不可能な離散問題であり、標準的な勾配ベースの深層学習フレームワークで解くことは極めて困難である。
3. リソースの希少性: 医療機関には計算予算の制限がある。このソリューションは、高いセグメンテーション精度を維持しつつ、標準的なハードウェアで動作するほど軽量でなければならない。
ソリューションの数学的解釈
このギャップを埋めるため、著者らはLoRAの重み更新を再定式化している。標準的なLoRAは更新を $\Delta W = BA$ と定義する(ここで $B \in \mathbb{R}^{m \times r}$、$A \in \mathbb{R}^{r \times n}$)。著者らは、特異値ベクトル $v$ を分解に組み込むことでこれを拡張した。
$$W = W_0 + B \text{Diag}(v) A$$
ここで $v$ は特異値の $r$ 次元ベクトルである。適応のランクは、実質的に $v$ 内の非ゼロ要素の数($\|v\|_0$ と表記)によって決定される。
この「ランク」を学習可能にするため、損失関数 $\mathcal{L}$ に $l_1$ スパース性正則化を導入した。
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
この正則化はランクに対するペナルティとして機能する。これを最小化することで、モデルは重要でない特異値をゼロに押しやるよう促され、学習中にランクを自動的に「剪定」する。
$l_1$ ノルムは非滑らか(ゼロ地点で鋭い「キンク」を持つ)であるため、標準的な勾配降下法は失敗する。著者らはこれを 近接最適化手法(proximal optimizer) を用いて解決した。以下の2段階を交互に実行する。
1. タスク固有の損失を最小化するための $A$ および $B$ に対する勾配ステップ。
2. ソフト閾値関数 $\xi(x, \tau)$ を用いた $v$ に対する近接更新:
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
この関数は動的フィルターとして機能し、小さな値をゼロに設定し、大きな値を縮小する。これにより、モデルは人間の介入なしに、タスク固有の最適なランクを自動的に発見できる。
なぜこのアプローチなのか
本論文の著者らは、医療画像セグメンテーションへの標準的なLow-Rank Adaptation (LoRA) の適用における決定的なボトルネック、すなわち「固定ランク」制約を特定した。従来のLoRAでは、分解行列のランク $r$ は学習前に設定しなければならないハイパーパラメータである。著者らは、セグメンテーション対象となる特定の解剖学的構造に応じて、最適なランクが大きく変動することを観察した。医療機関はデータが希少なFew-Shot環境で運用されることが多いため、新しい臓器ごとに「完璧な」ランクを見つけるためにグリッドサーチや交差検証を行うことは、計算コストが高く、実用的ではない。
選択の必然性
著者らは、標準的なLoRAが、本質的に多様なタスクに対して静的で画一的な複雑さを強いるため不十分であると認識した。ランクが低すぎれば、モデルは複雑な臓器のニュアンスを捉える能力を欠き、高すぎれば、限られたサポートデータに対して過学習してしまう。
比較優位性(ベンチマークの論理):
ランクを固定的な構造制約として扱う標準的なLoRAとは異なり、提案された ARENA (Adaptive Rank Segmentation) 手法は、ランクを動的な変数として扱う。重み更新を $W = W_0 + B \text{Diag}(v) A$ に分解することで、著者らは問題を「ランクを選択する」ことから「特異値ベクトル $v$ を学習する」ことへとシフトさせた。
* 構造的利点: ベクトル $v$ に $l_1$ スパース性正則化を適用することで、モデルは学習中に不要な次元を自動的に剪定する。これは実質的に「自動ランク選択」を実行する。
* 数学的エレガンス: 近接最適化手法(具体的にはソフト閾値関数 $\xi(x, \tau)$)の使用により、モデルは小さな特異値を正確にゼロに追い込むことができる。これは、手動介入なしに特定のタスクに必要な内在的次元をモデルが「発見」できるため、標準的なLoRAよりも質的に優れている。
制約との整合性:
問題と解決策の「融合」は、近接更新ルールに見出される。
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
この式はFew-Shotの制約に完璧に対応している。モデルは標準的な学習プロセスの中でランクを学習するため、ハイパーパラメータを調整するためのバリデーションセットが不要となる。これは、スパース性を強制することでデータの希少性に対応する「自己調整」メカニズムであり、過学習に対する自然な正則化として機能する。
数学的・論理的メカニズム
数学的エンジン
本論文の核心的な革新は、標準的なLow-Rank Adaptation (LoRA) の重み更新を、動的でスパースな特異値分解(SVD)フレームワークへと変換したことにある。このメカニズムを支配するマスター方程式は以下の通りである。
$$W = W_0 + B \text{Diag}(v) A$$
方程式の分解
- $W$: モデルの最終的な適応済み重み行列。
- $W_0$: 元の事前学習済み重み行列。これはプロセス全体を通じて凍結されたままであり、安定した基盤として機能する。
- $B \in \mathbb{R}^{m \times r}$ および $A \in \mathbb{R}^{r \times n}$: これらは、新しいタスクに必要な「デルタ」または増分変化を捉える低ランク行列である。
- $\text{Diag}(v)$: これは $v$ を対角成分とする対角行列であり、$v$ は特異値の $r$ 次元ベクトルである。この項はモデルの「スロットル」である。$v$ 内の値を調整することで、モデルは適応の特定の次元を効果的にオフにし、それによって更新の内在的ランクを変更できる。
- 単純な加算ではなく $B \text{Diag}(v) A$ という乗算が使用されているのは、これが低ランク分解を表しているためである。これにより、モデルは入力を低次元空間に投影し($A$ を介して)、それらの次元の重要度をスケーリングし($\text{Diag}(v)$ を介して)、出力空間に再投影する($B$ を介して)ことが可能になる。
最適化のダイナミクス
モデルは、ブロック座標降下法として知られる2つの異なる最適化フェーズを交互に行うことで学習する。
- $A$ および $B$ に対する勾配降下法: モデルは標準的な勾配ステップを使用して行列 $A$ および $B$ を更新し、Dice損失を最小化する。これはモデルが適応のための最適な方向を発見する「学習」フェーズである。
- $v$ に対する近接更新: $l_1$ 正則化を扱うため、モデルは近接演算子を使用する。更新ルールは以下の通りである。
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
ここで $\xi$ はソフト閾値関数である。これはフィルターのように機能する。もし特異値が小さければ(閾値 $\eta_t \lambda$ 未満)、正確にゼロに設定される。これがモデルが不要な次元を「剪定」し、特定の医療タスクに最適なランクを自動的に見つける仕組みである。
結果、限界、および結論
ARENA: Adaptive Rank Segmentation の分析
医療画像分野において、我々はしばしば「データの希少性」のパラドックスに直面する。数千のスキャンで事前学習された巨大な基盤モデルが存在する一方で、それらを特定の病院の固有のニーズ(特定の臓器のセグメンテーションなど)に適応させることは、ラベル付きのサンプルがわずかしかないために困難である。これが Few-Shotセグメンテーション の問題である。
核心的な問題:「固定ランク」の罠
標準的な Low-Rank Adaptation (LoRA) は、すべてのパラメータを更新することなく大規模モデルをファインチューニングするための一般的な手法である。これは、重み更新を近似するために、学習可能な小さな行列をモデルに注入することで機能する。しかし、LoRAはユーザーに対して、適応中にモデルがどれだけの情報を学習できるかを決定するハイパーパラメータである「ランク」 ($r$) を選択することを強いる。
ランクを低く設定しすぎれば、モデルは新しいタスクを学習するには単純すぎる。高すぎれば、利用可能なわずかなデータに対して過学習してしまう。臨床現場において、臓器ごとに「完璧な」ランクを見つけることは、試行錯誤を繰り返す退屈なプロセスであり、到底実行不可能である。
ソリューション:ARENA
著者らは ARENA (Adaptive Rank Segmentation) を導入した。固定ランクを強制する代わりに、低ランク更新を 特異値分解 (SVD) として扱う。更新を次のように表現する。
$$W = W_0 + B \text{Diag}(v) A$$
ここで $v$ は特異値のベクトルである。重要な革新は、損失関数に $l_1$ スパース性正則化を追加したことである。
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
これを最小化することで、モデルは数学的に $v$ 内の不要な値をゼロに押しやるよう動機付けられる。これにより、学習中にランクが自動的に「剪定」される。彼らは $l_1$ ペナルティの非滑らかな性質を扱うために 近接最適化手法(具体的にはソフト閾値関数)を使用し、人間の介入なしに各臓器に最適なランクを発見できるようにした。
実証方法
著者らは成功を主張するだけでなく、いくつかのベースラインに対して「容赦のない」評価を設定した。
* 比較対象: Few-Shot設定で過学習しやすい フルファインチューニング (FFT)、単純すぎる 線形プロービング (Linear Probing)、そしてランク選択に苦慮する標準的な LoRA および AdaLoRA を打ち破った。
* 証拠: LoRAの性能が初期ランクの選択によって大きく変動する一方で、ARENAは安定していることを示した。TotalSegmentator データセットでの実験において、ARENAは標準的なLoRAと比較して、5-shotおよび10-shot設定でそれぞれDiceスコアで +8.9 および +11.2 という大幅な性能向上を達成した。彼らは、本手法が単なる理論的な改善ではなく、計算フットプリントを小さく保ちながらフルファインチューニングに近い性能レベルに達する実用的なツールであることを証明した。
他分野との同型性(Isomorphisms)
Few-Shot臓器セグメンテーションのための正則化低ランク適応の分析
背景と動機
現代の医療画像処理では、膨大で多様なデータセットで事前学習された「基盤モデル」が頻繁に使用される。これらのモデルは強力だが、特定の臨床タスク(特定の臓器のセグメンテーションなど)ごとに完全に再学習するには大きすぎる。研究者は、パラメータのほんの一部のみを更新することでこれらのモデルを適応させる パラメータ効率的ファインチューニング (PEFT) を使用する。
一般的な手法である Low-Rank Adaptation (LoRA) は、モデルの重みに必要な変更は低次元部分空間で捉えられると仮定する。LoRAは重み更新を2つの小さな行列 $A$ と $B$ の積として表現し、その部分空間のサイズを「ランク」 $r$ が定義する。問題は、LoRAがユーザーに対して事前に固定ランク $r$ を選択することを要求することである。ランクが低すぎればモデルは学習能力を欠き、高すぎればFew-Shotシナリオで利用可能な限られたデータに対して過学習する。著者らは、最適なランクが臓器間で大きく異なるため、手動選択が非現実的であることを特定した。
数学的解釈
著者らは、ランク選択をハイパーパラメータの選択ではなく最適化問題として扱うことでこれを解決した。彼らは重み更新 $\Delta W$ を特異値分解 (SVD) 構造を用いて分解する。
$$W = W_0 + B \text{Diag}(v) A$$
ここで $v$ は特異値のベクトルである。適応のランクは実質的に $v$ 内の非ゼロ要素の数($\|v\|_0$)である。これを適応的にするため、損失関数に $l_1$ スパース性正則化を導入した。
$$\mathcal{L}(A, B, v) + \lambda \|v\|_1$$
これを最小化することで、モデルは重要でない特異値を自然にゼロに押しやる。彼らは非滑らかな $l_1$ 項を扱うために 近接最適化手法 を使用し、学習中に $v$ を更新するためにソフト閾値関数 $\xi(x, \tau)$ を採用した。
$$v^{(t+1)} = \xi(v^{(t)} - \rho \nabla_v \mathcal{L}(A, B, v), \eta_t \lambda)$$
これにより、モデルは学習中に自身のランクを「剪定」し、セグメンテーション対象の特定の臓器に最適な複雑さを自動的に見つけることができる。
構造的骨格
勾配降下法中に特異値に対してスパース性ペナルティを適用することで、変換行列の次元を動的に剪定するメカニズム。