Magic Tricycles: Efficient Magic-State Generation with Finite Block-Length Quantum LDPC Codes
The preparation of high-fidelity non-Clifford (magic) states is an essential subroutine for universal quantum computation but imposes substantial space-time overhead.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the fundamental requirements for achieving universal fault-tolerant quantum computation. A seminal result by Eastin and Knill [2] established that it's impossible to implement a universal set of quantum gates purely transversally (i.e., by applying the same physical gate to each qubit independently) within a quantum error-correcting code. This limitation means that non-Clifford gates, often called "magic gates," must be implemented through other means, typically by teleporting specially prepared non-Clifford resource states into the code space.
The primary method for preparing these high-fidelity resource states is known as magic-state distillation (MSD). Historically, MSD protocols, such as the 15-to-1 distillation scheme [3], have been extremely resource-intensive, requiring multiple levels of repeated distillation and concatenation with inner codes. This process contributes significantly to the overall space-time overhead, to the point where magic-state generation has been estimated to dominate the total qubit and gate counts in state-of-the-art fault-tolerant architectures, even for algorithms like Shor's [4,5]. The core motivation for this research is to drastically reduce this overhead.
Over the past decade, researchers have made progress in designing quantum codes with transversal non-Clifford gates to reduce MSD overhead [6-9]. However, these earlier approaches faced significant limitations. Many proposed low-overhead distillation schemes relied on codes with high-weight parity checks, meaning their syndrome extraction circuits had depths that scaled with the code's block length. This made them not inherently fault-tolerant against circuit-level noise and prevented exponential subthreshold error suppression. Furthermore, these schemes often implicitly assumed noiseless Clifford operations, which is an unrealistic assumption that further inflated the practical overhead due to the need for high-distance inner codes. Clifford encoding and unencoding circuits also suffered from depths scaling linearly with the number of physical qubits, leading to substantial temporal overhead.
Quantum low-density parity-check (qLDPC) codes emerged as a promising pathway to reduce the cost of quantum error correction due to their sparse stabilizer checks and favorable scaling of rate and distance. While qLDPC codes have been explored for quantum memory [12,13], their application to magic-state generation has only recently begun to be investigated. This is largely because constructing qLDPC codes that can host transversal non-Clifford gates has proven challenging. Previous constructions of homological product codes for magic-state generation, for instance, often required thousands or even tens of thousands of physical qubits for the smallest block lengths with good parameters, due to the cubic growth of the code size relative to classical codes [Page 5, left column, paragraph 1]. This large qubit count was a major pain point.
This paper directly addresses these limitations by introducing "tricycle codes," a novel class of finite block-length quantum LDPC codes specifically designed to support efficent, fault-tolerant magic-state generation. These codes are constructed to enable transversal logical CCZ (Controlled-Controlled-Z) gate action, which is crucial for magic-state distillation, while overcoming the high overhead and fault-tolerance challenges of previous methods.
Intuitive Domain Terms
-
Magic States: Imagine you're playing a complex video game. Most of your actions are basic moves like walking, jumping, or simple attacks (Clifford gates). But to perform a powerful, game-changing special move (like a super combo or a teleport), you need a specific "power-up" item. These "power-up" items are like magic states in quantum computing. They are special quantum states that unlock capabilities beyond the basic operations, enabling universal computation.
-
Magic-State Distillation (MSD): Continuing the video game analogy, sometimes you find many weak, low-quality "power-up" items that aren't very effective on their own. Magic-state distillation is like a "refinement process" where you take many of these noisy, low-quality power-ups and combine them to produce a smaller number of much stronger, higher-quality power-ups. The goal is to get very pure, reliable special moves.
-
Quantum Low-Density Parity-Check (qLDPC) Codes: Think of a library with millions of books. To check for misplaced books (errors), a traditional system might require every librarian to check every single shelf. A qLDPC code is like a smart error-checking system where each librarian (a "check") is only responsible for verifying a small, specific, and scattered set of books. This "low-density" of connections makes the system easier to build, scale, and manage, allowing for more robust error detection with less complex hardware.
-
Transversal Gate: If you have a team of chefs, and each chef is preparing a dish, a transversal gate is like telling every chef to perform the exact same simple step on their individual dish at the same time. For example, "everyone add a pinch of salt." The key is that each chef acts independently on their own dish, so a mistake by one chef doesn't easily spread to another's dish. In quantum computing, this means applying a physical gate to each qubit in a code block, which naturally limits error propagation and makes the operation fault-tolerant.
-
CCZ Gate (Controlled-Controlled-Z): This is a specific type of magic gate involving three qubits. Imagine a secret vault with three locks. The CCZ gate is like a mechanism that only activates if all three locks are turned simultaneously. If any one of the locks isn't turned, nothing happens. This "triple-control" allows for very complex and powerful operations in quantum computation.
Notation Table
| Notation | Description |
|---|---|
| $N$ | Total number of physical qubits in a code block. |
| $K$ | Number of encoded logical qubits in a code block. |
| $D$ | Minimum distance of the quantum code, representing its error-correcting capability. $D_X$ and $D_Z$ refer to distances in the X and Z bases, respectively. |
| $H_X$ | X-type parity-check matrix, defining the X-stabilizer generators. |
| $H_Z$ | Z-type parity-check matrix, defining the Z-stabilizer generators. |
| $A, B, C$ | $n_G \times n_G$ binary permutation matrices derived from group-algebra elements, defining connectivity patterns within tricycle codes. |
| $O$ | $n_G \times n_G$ zero matrix. |
| $\mathbb{F}_2$ | The binary field $\{0,1\}$, where arithmetic is performed modulo 2. |
| $n_G$ | Linear size of each sector, equal to the order of the finite Abelian group $G$. Total physical qubits $N = 3n_G$. |
| $f_{CCZ}$ | A trilinear binary function that defines the transversal CCZ circuit. $f_{CCZ}(p^I, q^{II}, r^{III}) = 1$ means a physical CCZ gate is applied to qubits $p^I, q^{II}, r^{III}$. |
| $\cup$ | The cup product operator from algebraic topology, used to construct transversal non-Clifford gates. |
| $a_{in}, a_{out}, a_{free}$ | "In," "out," and "free" partitions (preorientations) of group-algebra elements, crucial for defining the cup product and ensuring code-space-preserving CCZ circuits. |
| $|...|_{d_{i \neq j \neq k}}$ | Denotes the Hamming weight (size of support) of the argument, with the condition that qubits must be from distinct sectors for a CCZ gate. |
| $\pmod{2}$ | Modulo 2 arithmetic, ensuring binary output for gate application. |
| $p_{2q}$ | Physical error rate for two-qubit entangling gates (e.g., CNOT). |
| $p_{3q}$ | Physical error rate for three-qubit CCZ gates. |
| $K_{CCZ}$ | Maximum number of disjoint logical CCZ gates that can be extracted from a hypergraph magic state. |
| STCP | Symmetric Triple Cup Product formalism, an analytical method for constructing CCZ circuits. |
| NLR | Numerical Leibniz Rule method, a complementary numerical method for constructing CCZ circuits. |
| MSD | Magic-State Distillation, a protocol for preparing high-fidelity non-Clifford resource states. |
| qLDPC | Quantum Low-Density Parity-Check codes. |
| CSS | Calderbank-Shor-Steane codes, a class of quantum error-correcting codes. |
| MLE | Maximum Likelihood Error decoder. |
| BP + LSD | Belief Propagation + Localized Statistics Decoding, an efficient approximate decoder. |
| BP + OSD | Belief Propagation + Ordered Statistics Decoding, another approximate decoder. |
| AOD | Acousto-Optical Deflector, used for atom movement in neutral-atom arrays. |
| SLM | Spatial Light Modulator, used to generate traps for qubits. |
| $t_{wsp}, t_{ent}$ | Time overheads for AOD movements in the workspace and entangling zone, respectively. |
| $d_{min}$ | Minimal optical resolving distance, limiting qubit density and movement speed. |
| $d_{iso}$ | Isolation distance for Rydberg interactions, ensuring intended CNOT pairs. |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem this paper addresses is the inefficient and resource-intensive generation of high-fidelity non-Clifford (magic) states, which are indispensable for universal fault-tolerant quantum computation.
Input/Current State:
Universal quantum computation relies on both Clifford and non-Clifford operations. While logical Clifford gates can often be implemented transversally in many quantum error-correcting codes, the Eastin-Knill theorem dictates that a universal gate set cannot be implemented transversally. Consequently, non-Clifford gates (magic gates) are typically implemented by teleporting specially prepared non-Clifford resource states into the code space. The current state-of-the-art for preparing these high-fidelity resource states, known as magic-state distillation (MSD), suffers from significant drawbacks:
1. Substantial Space-Time Overhead: MSD protocols, such as the 15-to-1 distillation, require multiple levels of repeated distillation and concatenation with inner codes. This leads to an estimated dominance of magic-state generation in total qubit and gate counts for large-scale quantum algorithms like Shor's algorithm.
2. Compromised Fault Tolerance in Previous "Low-Overhead" Schemes: Recent proposals for low-overhead MSD protocols, while achieving transversal non-Clifford gates, often come with high-weight parity checks. This necessitates syndrome extraction circuits whose depths grow with the code's block length, making them not obviously fault-tolerant to circuit-level noise.
3. Unrealistic Assumptions: Many existing protocols implicitly assume noiseless Clifford operations for encoding and unencoding circuits, which exaggerates their reported overheads. These Clifford circuits can also have depths scaling linearly with the number of physical qubits, leading to significant temporal overhead.
Desired Endpoint (Output/Goal State):
The paper aims to achieve efficient, fault-tolerant magic-state production that significantly reduces the space-time overhead associated with current methods. Specifically, the goal is to:
1. Generate Magic States with High Fidelity and Throughput: Produce magic states with logical error rates as low as $2 \times 10^{-8}$ to below $3 \times 10^{-11}$ for practical applications like Shor's algorithm.
2. Utilize Finite Block-Length Codes: Employ codes with block lengths of approximately 50-100 qubits to make them experimentally feasible.
3. Support Constant-Depth Circuits: Implement logical CCZ gates and syndrome extraction using physical circuits of constant depth, independent of code size.
4. Enable Single-Shot State Preparation and Error Correction: Allow for the initial logical state of a magic-state preparation circuit to be prepared in constant depth, and to correct errors without repeated rounds of syndrome extraction in one basis.
5. Circumvent Concatenation: Eliminate the need for concatenation with an inner code that supports transversal Clifford gates, simplifying the overall architecture.
Missing Link & Mathematical Gap:
The exact missing link is the construction of quantum low-density parity-check (qLDPC) codes that simultaneously possess high rates, high distances, and support constant-depth transversal non-Clifford gates (specifically CCZ gates), while also enabling single-shot error correction. Previous qLDPC code research struggled with the transversal non-Clifford gate requirement.
This paper attempts to bridge this gap by introducing "tricycle codes", a new class of finite block-length quantum LDPC codes. These codes are constructed as three-dimensional balanced products of classical binary linear codes over Abelian group algebras, generalizing the well-known bicycle codes. The mathematical gap is bridged by:
1. Developing a Modified Cup-Product Formalism: The paper extends the theoretical framework for constructing transversal non-Clifford gates in three-dimensional product codes by modifying the cup-product formalism from algebraic topology. This leads to a new set of conditions that high-rate and -distance tricycle codes must satisfy to host nontrivial CCZ action.
2. Introducing a Numerical Leibniz Rule (NLR) Method: A complementary numerical method is developed to find short-depth, code-space-preserving CCZ circuits on iterated balanced-product quantum codes, especially for cases where the analytical cup-product formalism is too restrictive.
The Dilemma:
The painful trade-off that has trapped previous researchers is the tension between achieving high-rate, high-distance codes with transversal non-Clifford gates and maintaining true fault tolerance with efficient syndrome extraction. Historically, improving one aspect (e.g., achieving transversal non-Clifford gates for low overhead) often compromised another (e.g., requiring syndrome extraction circuits with depths that grew with block length, thus breaking fault tolerance in the presence of circuit-level noise). The dilemma is how to simultaneously achieve:
* High-fidelity magic states (requiring high code distance for error suppression).
* Efficient generation (requiring high code rate for parallel distillation and low space-time overhead).
* Fault tolerance (requiring constant-depth syndrome extraction and state preparation, and robustness to circuit-level noise).
* Transversal non-Clifford gates (to avoid complex, non-fault-tolerant gate implementations).
Previous approaches either achieved some of these goals at the expense of others or relied on simplifying assumptions that are not realistic in practical quantum computing architectures. For instance, 4-4-4 tricycle codes, while offering higher rates and distances, come with the cost of higher check weights and deeper CCZ circuits, illustrating this inherent trade-off.
Constraints & Failure Modes
The problem of efficient, fault-tolerant magic-state generation is insanely difficult due to a combination of physical, computational, and data-driven constraints, as well as inherent failure modes:
Physical Constraints:
1. Qubit Error Rates and Noise Bias: Physical CCZ gates are assumed to have a specific error rate (e.g., $p_{3q} = 0.002$), which is twice that of two-qubit entangling gates ($p_{2q} = 0.001$). Furthermore, native phase-type gates (like CCZ) exhibit noise profiles strongly biased toward Z-type errors, which must be accounted for in error models.
2. Hardware Memory Limits: The need for "finite block-length" codes (e.g., 50-100 qubits) implies practical limits on the number of physical qubits available for a code block.
3. Real-Time Latency Requirements: The demand for "single-shot" state preparation and error correction is crucial to prevent errors from spreading and accumulating, especially since CCZ gates can propagate X errors into CZ errors. This imposes strict latency requirements on decoding and correction cycles.
4. Neutral-Atom Array Platform Limitations: The proposed implementation on reconfigurable neutral-atom arrays introduces specific constraints:
* Trap Spacing: Qubit pairs involved in parallel CNOTs must be separated by a sufficient distance ($d_{iso}$, e.g., 10 µm) to isolate Rydberg interactions and prevent unintended interactions within the same sector.
* Optical Resolution ($d_{min}$): The minimal optical resolving distance (e.g., 2 µm) limits the speed and density of qubit permutations.
* AOD Movement Timings: Atom-optical deflector (AOD) movements for permutations (x, y, z cycling) and fetching/put-back operations have associated time overheads ($t_{wsp}, t_{ent}$), which contribute to the overall circuit depth.
5. Eastin-Knill Theorem: This fundamental theorem prevents universal transversal gate sets, forcing the use of magic states and thus adding complexity to non-Clifford operations.
Computational Constraints:
1. NP-Hardness of Code Distance and Subrank Problems:
* Finding exact code distances for linear codes is an NP-hard problem, making it computationally challenging to precisely characterize the performance of larger tricycle codes.
* Finding the subrank of a binary tensor (which corresponds to extracting the maximum number of disjoint CCZ gates from a hypergraph magic state) is also NP-hard. This limits the ability to efficiently extract the full potential of the generated magic states.
2. Solver Timeouts: Numerical solvers used for logical circuit optimization (e.g., mixed-integer programming for $K_{CCZ}$) often time out for larger values, indicating the computational intractability of finding optimal solutions.
3. Decoding Complexity: While efficient decoders like Belief Propagation + Localized Statistics Decoding (BP + LSD) are used, they are approximations. Exact Maximum Likelihood Error (MLE) decoders are exponentially expensive, making them impractical for real-time fault-tolerant operation.
4. Numerical Search Limitations: The numerical Leibniz rule method for constructing CCZ circuits does not guarantee short depths, requiring extensive searches and hyperparameter tuning to find suitable codes.
Data-Driven Constraints & Failure Modes:
1. Circuit-Level Noise: The entire protocol must operate under realistic circuit-level noise models, including two-qubit depolarizing noise and biased three-qubit depolarizing noise for CCZ gates. This noise introduces errors that must be detected and corrected.
2. Error Propagation: A significant failure mode is that CCZ gates propagate pre-existing X errors into CZ errors on other qubits. These CZ errors then collapse into non-deterministic Z errors after syndrome measurement, which can quickly accumulate if not handled by single-shot error correction.
3. Non-Deterministic Z-Stabilizer Measurements: Initial Z-type stabilizer measurements produce non-deterministic $\pm 1$ outcomes, which must be reliably fixed to $+1$ on hardware before applying CCZ gates. This requires robust metachecks and decoders to identify and correct syndrome measurement errors.
4. Imbalanced Code Distances: Tricycle codes naturally exhibit higher distances in the X basis compared to the Z basis ($d_Z \leq d_X$). While potentially useful for noise-biased platforms, this imbalance means that the more challenging X-basis error correction often dictates overall performance.
5. Limited Postselection Success Rate: While postselection can significantly improve logical error rates, it comes at the cost of a reduced acceptance fraction (e.g., 3% to 30% for the codes studied), which impacts the overall throughput of magic-state generation.
Why This Approach
The Inevitability of the Choice
The adoption of tricycle codes was not merely a preference but a necessity driven by the inherent limitations of existing approaches to fault-tolerant magic-state generation. Universal quantum computation critically relies on non-Clifford (magic) states, but their production has historically imposed substantial space-time overheads. Traditional magic-state distillation (MSD) protocols, such as the widely used 15-to-1 distillation, demand multiple levels of repeated refinement and often require concatenation with inner codes (like two-dimensional color codes) to support transversal Clifford gates. This multi-layered approach leads to an exorbitant consumption of qubits and gate operations, frequently dominating the resource estimates for large-scale quantum algorithms like Shor's.
Furthermore, while recent proposals for low-overhead MSD protocols have introduced quantum codes with transversal non-Clifford gates and favorable asymptotic parameters, they come with significant caveats. These codes often feature high-weight parity checks, meaning their syndrome extraction circuits have depths that scale with the code block length. Such scaling undermines fault tolerance in the presence of circuit-level noise, as it prevents constant-depth syndrome extraction. Moreover, these schemes frequently assume noiseless Clifford operations for encoding and unencoding, an assumption that, in practice, exaggerates the true resource overhead. The linear scaling of Clifford circuit depths with the number of physical qubits also contributes to substantial temporal overhead.
It became evident that a fundamentally different class of codes was required to overcome these bottlenecks. The authors realized that quantum low-density parity-check (qLDPC) codes, which inherently offer sparse stabilizer checks alongside favorable rate and distance scaling, presented the most promising pathway. Specifically, the challenge was to construct qLDPC codes that could host strongly transversal non-Clifford gates (i.e., constant-depth physical circuits without the need for Clifford corrections or concatenation with an inner code) while maintaining constant-depth syndrome extraction. This realization motivated the introduction of tricycle codes: finite block-length, high-rate, and high-distance quantum LDPC codes explicitly designed to support a transversal logical CCZ circuit action, thereby enabling efficient, single-shot magic-state generation.
Comparative Superiority
Tricycle codes exhibit overwhelming qualitative superiority over previous gold standards, extending far beyond simple performance metrics. Their structural design offers distinct advantages for efficient, fault-tolerant magic-state generation.
Firstly, tricycle codes are constructed as three-dimensional balanced products of classical binary linear codes over Abelian group algebras. This innovative generalization of the well-known bicycle codes to three homological dimensions is crucial because it intrinsically allows for transversal gates from the third level of the Clifford hierarchy, specifically logical CCZ gates. This is a fundamental structural advantage, as it enables direct, constant-depth implementation of a key non-Clifford gate, which is often a bottleneck in other architectures.
Secondly, a paramount advantage is the enablement of single-shot state preparation and error correction (Sec. I.B, II.C). Unlike traditional MSD schemes that necessitate multiple, iterative rounds of distillation, tricycle codes can prepare high-fidelity hypergraph magic states in a single round. This is facilitated by two key properties: intrinsic fault tolerance in one stabilizer basis during state initialization, and the presence of "metachecks." These metachecks are redundant Z parity checks that form a classical code on the syndrome bits, allowing for robust identification and correction of syndrome measurement errors in the Z basis. This capability is a significant departure from codes like the surface code, which typically lack single-shot state preparation, and drastically reduces the temporal overhead from $O(d)$ rounds (where $d$ is the code distance) to a constant number.
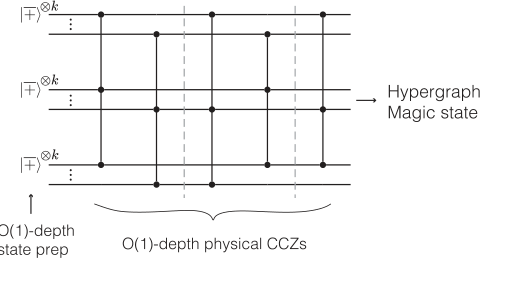 FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
Furthermore, tricycle codes achieve favorable parameters—high rates and distances—at relatively small block lengths (e.g., [[48, 6, 4]], [[108, 21, 6]] as shown in Table I). This compactness is vital for practical implementation on near-term quantum hardware. The paper also highlights that specific families, such as the 4-2-2 tricycle codes, are particularly relevant due to their lower check weights and a minimal depth-8 CCZ circuit, which directly translates to reduced circuit-level noise propagation.
Quantitatively, the superiority is evident in the space-time cost. As shown in Table II, tricycle codes achieve logical error rates (e.g., $2 \times 10^{-8}$ for [[48, 6, 4]] and $4 \times 10^{-10}$ for [[84, 6, 5]]) at comparable or significantly lower space-time costs (89 and 527 qubit rounds, respectively) compared to state-of-the-art color-code-based magic-state cultivation (e.g., 90 qubit rounds for $6 \times 10^{-7}$ error rate for [[7, 1, 3]] color code, or 3000 qubit rounds for $6 \times 10^{-10}$ error rate for [[19, 1, 5]] color code). This demonstrates a substantial improvement in resource efficiency for producing high-fidelity magic states.
Alignment with Constraints
The chosen approach of tricycle codes demonstrates a remarkable "marriage" with the stringent requirements for practical, fault-tolerant quantum computation. The design principles of tricycle codes were specifically tailored to address the core constraints identified in the problem definition.
Firstly, the overarching goal of universal fault-tolerant quantum computation is directly met by tricycle codes' ability to host transversal logical CCZ gates. The CCZ gate is a non-Clifford operation essential for universal gate sets, and its constant-depth, transversal implementation within tricycle codes is a direct solution to this requirement (Sec. I.B, II.B).
Secondly, the critical constraint of reducing space-time overhead is addressed through multiple facets of the tricycle code design. The single-shot magic-state generation protocol (Sec. I.B, II.C) eliminates the need for multiple distillation rounds, drastically cutting down the temporal resources. High-rate codes allow for the parallel distillation of multiple magic states within a single code block, boosting throughput and reducing overall time. Furthermore, both the logical CCZ operations and the syndrome extraction circuits are designed to be constant-depth (Sec. I.B, II.E), ensuring that circuit complexity does not scale unfavorably with code size, thereby preventing the linear scaling overheads seen in other methods. The use of finite block-length codes with favorable parameters (Table I) also ensures that the codes are practical and resource-efficient for implementation.
Thirdly, the demand for high-fidelity magic states is satisfied through robust error suppression. Numerical simulations confirm that tricycle codes can achieve extremely low logical error rates (e.g., $2 \times 10^{-8}$ to below $3 \times 10^{-11}$) for CCZ magic states, even at modest block lengths and under realistic circuit-level noise, particularly with postselection (Sec. I.B, Table II).
Finally, fault tolerance is intrinsically built into the tricycle code architecture. The constant-depth syndrome extraction circuits (Sec. I.A, II.E) are designed to be resilient against circuit-level noise. The transversal nature of the non-Clifford gates inherently limits the spread of errors between physical qubits (Sec. I.A). High relative distances ensure effective error suppression during distillation. Crucially, the presence of metachecks enables single-shot error correction in the Z-basis, allowing for immediate correction of X errors and preventing their propagation, which is vital for maintaining fault tolerance during magic-state preparation (Sec. II.C). The proposed implementation on reconfigurable neutral-atom platforms (Sec. I.B, II.E) also aligns with the practical hardware constraints of modern quantum computing.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches by highlighting their shortcomings or demonstrating the superior capabilities of tricycle codes.
Traditional Magic-State Distillation (MSD) Schemes: The paper's introduction (Sec. I.A) serves as a strong rejection of traditional MSD protocols, such as the 15-to-1 distillation. These methods are criticized for requiring "multiple levels of repeated distillation" and "concatenation with an inner code of sufficiently large distance," which "contribut[es] significantly to the space-time overhead." The authors explicitly state that magic-state generation "dominates the latest resource estimates of factoring RSA integers with Shor's algorithm despite significant optimizations [4,5]." Tricycle codes, by contrast, aim for single-shot distillation, drastically reducing this overhead.
Existing Non-LDPC Constant-Overhead MSD Protocols: While some prior works proposed codes with transversal non-Clifford gates and constant overhead, the paper points out their critical flaws (Sec. I.A). These codes often have "high-weight parity checks," leading to syndrome extraction circuits whose "depths that grow with the block length." This makes them "not obviously fault tolerant on their own" and unable to support a finite threshold. Additionally, they "implicitly assume that Clifford operations are noiseless," which is an unrealistic simplification that inflates their perceived efficiency. Tricycle codes, as qLDPC codes, overcome these by ensuring sparse checks and constant-depth syndrome extraction.
Bicycle Codes (Two-Dimensional Group-Algebra Codes): Tricycle codes are presented as a generalization of bicycle codes to "three homological dimensions" (Sec. I.B). This generalization is essential because it "allow[s], in principle, for transversal gates from the third level of the Clifford hierarchy [23]," specifically the logical CCZ gate. While bicycle codes are effective for lower-level Clifford hierarchy gates, they are insufficient for directly realizing the CCZ gate transversally, which is the target non-Clifford operation for this work. The paper notes that while bicycle codes might have higher rates, tricycle codes offer the necessary 3D structure for CCZ.
Specific 2-2-2 Tricycle Code Parameters: Within the family of tricycle codes, the authors empirically rejected certain parameter choices. They found that "2-2-2 codes with weight-6 X checks and weight-4 Z checks" did not offer "as favorable" rates and distances for a nontrivial transversal CCZ action (Sec. II.A). Specifically, they "could not find any such codes with K > 3 encoded logical qubits and distance D > 7," leading them to focus on 4-2-2, 4-4-2, and 4-4-4 codes which exhibited better performance.
Original Cup-Product Formalism of Ref. [27]: The paper also details a refinement of the theoretical framework for constructing transversal non-Clifford gates. The "original cup-product conditions of Ref. [27]" were found to be "too restrictive on the parameters of the code" (Sec. II.B, Appendix D). These original conditions, for instance, led to 2-2-2 codes with limited logical qubits (K=3) and distance (D=2), and similarly constrained 4-2-2 and 4-4-4 codes. The authors developed a "new symmetric triple cup product" formalism that allows for greater flexibility in parameter choices, leading to tricycle codes with "better parameters" (higher distances), thus rejecting the original, more restrictive formalism.
Mathematical & Logical Mechanism
The Master Equation
The foundational mathematical engine of this paper lies in the definition of the tricycle codes themselves, which are a class of quantum Calderbank-Shor-Steane (CSS) codes. These codes are primarily characterized by their X-type and Z-type parity-check matrices. Additionally, the paper introduces a specific trilinear function that defines the transversal controlled-controlled-Z (CCZ) gates, which are central to the magic-state generation protocol.
The parity-check matrices are given by:
$$ H_X = \begin{bmatrix} A^T & B^T & C^T \end{bmatrix} \in \mathbb{F}_2^{n_G \times 3n_G} $$
$$ H_Z = \begin{bmatrix} C & O & A \\ O & C & B \\ B & A & O \end{bmatrix} \in \mathbb{F}_2^{3n_G \times 3n_G} $$
These matrices define the stabilizers of the quantum code. Beyond the code definition, the paper's core mechanism for magic-state generation relies on a transversal CCZ circuit, whose structure is encoded in a binary function derived from a symmetric triple cup product. While the paper presents a general form (Eq. 2), the specific construction for tricycle codes is detailed in Proposition D4 (Eq. D27):
$$ f_{CCZ}(p^I, q^{II}, r^{III}) = |r^{III} \cup a_{out}^{III} \cup q^{II} \cup a_{in}^{II} \cup p^I \cup a_{in}^I \cup a_{out}^I|_{d_{i \neq j \neq k}} \pmod{2} $$
Term-by-Term Autopsy
Let's dissect these equations to understand each component's role.
For the Parity-Check Matrices ($H_X, H_Z$):
- $\mathbf{H_X}$: This is the X-type parity-check matrix.
- Mathematical Definition: A binary matrix whose rows define the generators of the X-stabilizer group.
- Physical/Logical Role: It dictates which physical qubits are involved in each X-type stabilizer measurement. These measurements are used to detect Z-type errors on the data qubits.
- Why this structure: The block structure $[A^T \ B^T \ C^T]$ indicates that X-checks are formed by combining elements from the three sectors (I, II, III) of the code block. The transpose ($^T$) is standard for defining X-checks in CSS codes when $H_Z$ is given in a certain form.
- $\mathbf{H_Z}$: This is the Z-type parity-check matrix.
- Mathematical Definition: A binary matrix whose rows define the generators of the Z-stabilizer group.
- Physical/Logical Role: It dictates which physical qubits are involved in each Z-type stabilizer measurement. These measurements are used to detect X-type errors on the data qubits.
- Why this structure: The $3n_G \times 3n_G$ block matrix structure reflects the partitioning of the $N=3n_G$ physical qubits into three equal-sized sectors (I, II, III). The off-diagonal $A, B, C$ matrices indicate connections between these sectors for Z-checks, while the diagonal $C$ matrices suggest intra-sector connections or connections that wrap around.
- $\mathbf{A, B, C}$: These are $n_G \times n_G$ binary matrices.
- Mathematical Definition: Permutation matrices derived from group-algebra elements $a, b, c \in \mathbb{F}_2[G]$. A permutation matrix has exactly one '1' in each row and column.
- Physical/Logical Role: They define the specific connectivity patterns between qubits across different sectors within a code block. Their permutation property implies a one-to-one mapping, ensuring a balanced distribution of connections. The choice of these elements is crucial for the code's distance and rate.
- Why permutation matrices: Using permutation matrices ensures that each qubit participates in a fixed number of checks, leading to low-density parity-check (LDPC) properties, which are desirable for efficient decoding.
- $\mathbf{O}$: This is the $n_G \times n_G$ zero matrix.
- Mathematical Definition: A matrix where all entries are zero.
- Physical/Logical Role: It signifies the absence of connections between certain sectors for specific Z-type stabilizer generators. For example, in the first row of $H_Z$, $O$ means no direct Z-check connections between sector II and sector I.
- $\mathbf{\mathbb{F}_2}$: The binary field $\{0,1\}$.
- Mathematical Definition: A field with two elements, where arithmetic is performed modulo 2.
- Physical/Logical Role: This is fundamental to quantum CSS codes, where Pauli operators ($X, Y, Z$) square to the identity and their products follow binary arithmetic rules (e.g., $X \cdot X = I$, $X \cdot Z = -iY$, $Z \cdot X = iY$, so $X \cdot Z \cdot X \cdot Z = I$). All matrix operations (multiplication, addition) are performed modulo 2.
- $\mathbf{n_G}$: The linear size of each block, equal to the order of the finite Abelian group $G$.
- Mathematical Definition: $n_G = |G|$.
- Physical/Logical Role: It determines the number of qubits in each of the three sectors, and thus the total number of physical qubits $N = 3n_G$.
For the CCZ Function ($f_{CCZ}$):
- $\mathbf{f_{CCZ}(p^I, q^{II}, r^{III})}$: This is a trilinear binary function.
- Mathematical Definition: A function that takes three inputs (qubits from distinct sectors/blocks) and outputs 0 or 1.
- Physical/Logical Role: If $f_{CCZ}=1$, it means a physical CCZ gate is applied to the triple of qubits $(p^I, q^{II}, r^{III})$. If $f_{CCZ}=0$, no gate is applied. This function defines the entire transversal CCZ circuit.
- $\mathbf{p^I, q^{II}, r^{III}}$: These represent specific physical qubits.
- Mathematical Definition: Variables representing individual qubits, indexed by their code block (I, II, III) and position within that block/sector.
- Physical/Logical Role: These are the target qubits for the CCZ gate. The superscripts $I, II, III$ indicate that the qubits must come from three distinct code blocks (or sectors within a block, as clarified in the paper's Fig. 1(a) and related text).
- $\mathbf{\cup}$: The cup product operator.
- Mathematical Definition: A bilinear map from algebraic topology, specifically homological algebra, that combines cochains. The paper uses a "symmetric triple cup product" (Definition 6, page 21), which implies a specific ordering of these operations.
- Physical/Logical Role: This operator is the core algebraic tool used to construct transversal non-Clifford gates. It naturally arises from the homological product structure of the codes and is related to the "triple intersection of logical operators." The specific sequence of cup products in the equation is designed to ensure the resulting CCZ circuit is code-space-preserving and coboundary invariant.
- Why cup product: It provides a systematic way to derive higher-order Clifford hierarchy gates (like CCZ) from the underlying algebraic structure of the codes, ensuring they act correctly on the logical subspace.
- $\mathbf{a_{in}^I, a_{out}^I, \dots, a_{out}^{III}}$: These are "in" and "out" partitions of the group-algebra elements $a_I, a_{II}, a_{III}$ that define the classical codes.
- Mathematical Definition: For a group-algebra element $a$, it is partitioned into $a = a_{in} + a_{out} + a_{free}$ (Eq. D20, page 22). $a_{in}$ and $a_{out}$ are themselves group-algebra elements.
- Physical/Logical Role: These partitions, called "preorientations," induce the cup product on the classical codes. The specific choice of these partitions, which must satisfy the "symmetric integrated Leibniz rule" conditions (Eqs. D15-D19, page 22), is crucial for the CCZ circuit to be code-space-preserving and coboundary invariant. The paper notes that for tricycle codes, $a_{free}$ is often set to empty.
- Why partitions: These partitions allow for a fine-grained control over how the cup product operates, enabling the construction of CCZ gates with desirable properties (e.g., non-trivial action, better code parameters).
- $\mathbf{|...|_{d_{i \neq j \neq k}}}$: This denotes the size of the support of the argument.
- Mathematical Definition: The Hamming weight of the resulting binary vector after the cup product operations. The subscript $d_{i \neq j \neq k}$ is a condition that implies $f_{CCZ}=0$ if any two or more qubits from its arguments are in the same sector (Proposition D4, page 24).
- Physical/Logical Role: The Hamming weight determines if the combined algebraic expression is non-zero, which then triggers the application of a CCZ gate. The condition $d_{i \neq j \neq k}$ is vital for ensuring the transversal nature of the CCZ circuit, meaning gates only act between qubits in different sectors/blocks, which is a key property for fault tolerance.
- $\mathbf{\pmod{2}}$: Arithmetic modulo 2.
- Mathematical Definition: The result of the entire expression is taken modulo 2.
- Physical/Logical Role: This ensures the output is binary (0 or 1), directly indicating the presence or absence of a CCZ gate. It's consistent with the binary nature of quantum information and Pauli operators.
Step-by-Step Flow
Let's trace the journey of an abstract data point, say a single qubit, through the mechanisms described.
1. Code Definition and Error Detection (via $H_X, H_Z$):
Imagine a single physical qubit, let's call it $q_j$, within one of the three sectors of a tricycle code block.
* Initialization: First, $q_j$ is initialized, typically in a computational basis state like $|0\rangle$ or $|+\rangle$. For Z-basis single-shot state preparation, all physical data qubits are initialized in $|+\rangle$.
* Stabilizer Interaction: To detect errors, $q_j$ becomes part of various stabilizer measurements.
* If we're checking for X-type errors (using Z-stabilizers), $q_j$ interacts with other qubits as defined by the rows of $H_Z$. For example, if $H_Z[i, j] = 1$, then the Pauli Z operator on $q_j$ ($Z_j$) is part of the $i$-th Z-stabilizer generator. This involves entangling $q_j$ with an ancilla qubit and then measuring the ancilla.
* Similarly, if we're checking for Z-type errors (using X-stabilizers), $q_j$ interacts with other qubits as defined by the rows of $H_X$. If $H_X[i, j] = 1$, then $X_j$ is part of the $i$-th X-stabilizer generator.
* Syndrome Generation: The measurement outcomes from these stabilizer checks form the "syndrome." If $q_j$ has experienced an error (e.g., a Pauli X error if we're measuring Z-stabilizers), this will flip the outcome of any stabilizer measurement it participates in.
* Decoding: The syndrome, a collection of binary values, is fed into a decoder. The decoder processes this information to infer the most likely error pattern that occurred on $q_j$ and other qubits.
* Correction: Based on the decoder's output, a correction operation (e.g., applying a Pauli X or Z gate) is applied to $q_j$ to restore it to its intended state within the code space. This completes one cycle of error correction.
2. Logical CCZ Gate Application (via $f_{CCZ}$):
Now, consider three distinct physical qubits, $p^I, q^{II}, r^{III}$, each residing in a different sector (I, II, III) of three separate code blocks. These qubits are part of the logical state on which a CCZ operation is desired.
* Input to Function: The identities of these three qubits ($p^I, q^{II}, r^{III}$) are fed as inputs to the $f_{CCZ}$ function.
* Algebraic Processing: Inside the $f_{CCZ}$ function, a series of abstract algebraic operations, specifically "cup products," are performed. This involves combining the qubit identifiers with the preorientation partitions ($a_{in}, a_{out}$) of the underlying group-algebra elements that define the code. This is a complex, multi-step calculation within the binary field $\mathbb{F}_2$.
* Support Calculation: The result of these cup products is an algebraic expression. Its "support" (Hamming weight) is then calculated. This essentially checks if the combined algebraic entity is non-zero.
* Transversality Check: A crucial condition, $d_{i \neq j \neq k}$, is implicitly applied. This ensures that the three input qubits indeed come from distinct sectors/blocks. If they don't, the function immediately outputs 0.
* Gate Decision: The final result, taken modulo 2, is either 0 or 1.
* If $f_{CCZ}(p^I, q^{II}, r^{III}) = 1$, then a physical CCZ gate is applied to the qubits $(p^I, q^{II}, r^{III})$. This gate acts simultaneously on all three qubits.
* If $f_{CCZ}(p^I, q^{II}, r^{III}) = 0$, no gate is applied to this specific triple.
* Circuit Execution: This process is repeated for all relevant triples of qubits across the code blocks. The entire collection of physical CCZ gates determined by $f_{CCZ}$ forms a "constant-depth" circuit, meaning all these gates can be scheduled in a fixed, small number of parallel layers, regardless of the code size. This ensures rapid execution and limits error propagation.
The physical qubits of each tricycle code block can be naturally partitioned into three sectors in accordance with block structure of the parity-check matrices in Eq. (1). The code-space-preserving CCZ circuits always act across sectors of the three code blocks, as illustrated in Fig. 1.
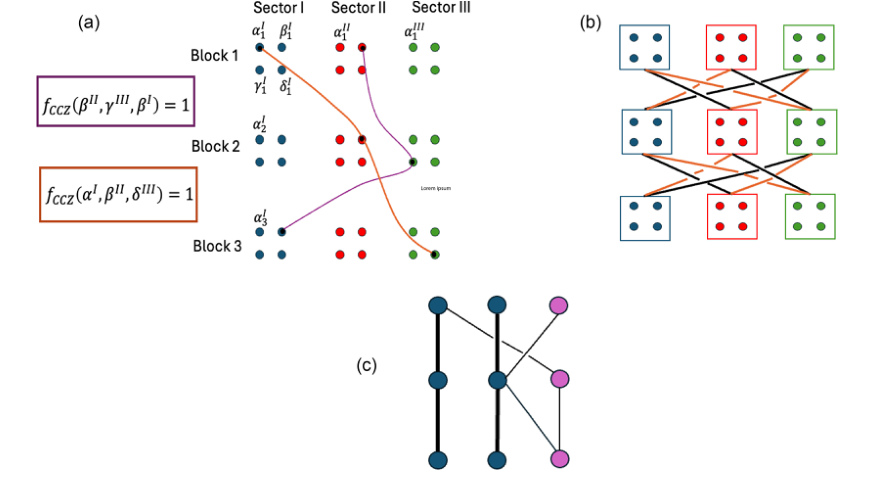 FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
Optimization Dynamics
The "learning" or "optimization" in this paper isn't about a model iteratively updating its parameters through gradients in a continuous loss landscape, as in typical machine learning. Instead, it's a multi-faceted design and search process for optimal code parameters and circuit constructions within a discrete, algebraic space.
1. Code Parameter Search:
The paper describes constructing tricycle codes by selecting specific group-algebra elements ($a, b, c$) and their weights ($w_a, w_b, w_c$) for the parity-check matrices $H_X$ and $H_Z$. This is a search problem to find codes with favorable parameters (high rate $K$ and distance $D$) for given block lengths $N$. The authors use numerical methods, including SAT solvers and mixed-integer programs (MIPs), to find the minimum distances $D_X$ and $D_Z$ for candidate codes. This is an exhaustive or heuristic search over discrete choices, not a gradient-based optimization. The "loss" here would be an undesirable code parameter (e.g., low distance), and the "update" is trying a different set of group-algebra elements.
2. CCZ Circuit Construction (Symmetric Triple Cup Product - STCP):
For the $f_{CCZ}$ function derived from the symmetric triple cup product, the "optimization" involves carefully choosing the "preorientations" ($a_{in}, a_{out}, a_{free}$) of the group-algebra elements. These choices must satisfy a set of algebraic conditions known as the "symmetric integrated Leibniz rule" (Eqs. D15-D19). The paper presents a prescription (Theorem D1) for constructing these preorientations for weight-4 elements. This is a design principle that guarantees the desired properties (code-space-preserving, coboundary invariant) rather than an iterative learning process. The "dynamics" are in the derivation of these conditions and the proof that they lead to valid circuits. The goal is to find preorientations that yield short-depth CCZ circuits.
3. CCZ Circuit Construction (Numerical Leibniz Rule - NLR):
Appendix E introduces a "numerical Leibniz rule" method. Here, the process is more akin to a search algorithm:
* Basis Construction: A basis set of group-equivariant trilinear functions $f_i^j$ is constructed. This involves finding the null space of a parity-check matrix $H_{leibniz}$, which encodes the "generalized Leibniz rule" conditions (Eq. E5). This is a linear algebra problem, not an iterative optimization.
* Heuristic Search: The actual $f_{CCZ}$ function is then constructed by randomly searching over candidates for these $f_i^j$ functions. The "optimization" objective is to find candidates that result in a low maximum degree for the $f_{CCZ}$ function, which directly translates to a short circuit depth. This is a heuristic search, potentially using techniques like Monte Carlo sampling or simulated annealing, to explore the discrete space of possible functions. The "loss landscape" is highly irregular and non-convex, with no clear gradients to follow.
4. Logical Circuit Optimization (Maximizing $K_{CCZ}$):
Appendix F describes optimizing the logical CCZ circuit to maximize the number of disjoint CCZ magic gates ($K_{CCZ}$) that can be extracted. This is framed as finding the "subrank" of a binary 3-tensor $T_{ijk}^{log}$ that represents the logical connectivity.
* Problem Formulation: This is an NP-hard problem. The authors use a Mixed-Integer Program (MIP) solver (Gurobi) to find suboptimal solutions.
* Iterative Search: The solver iteratively explores possible assignments for binary variables (representing change-of-basis matrices $M^1, M^2, M^3$) to satisfy the conditions for $r$ disjoint CCZ gates (Eq. F3). The "state" here is the set of basis matrices, and the "update" is the solver's internal mechanism for exploring the solution space. It's a discrete optimization, not a gradient-based one. The "loss" is the inability to find a solution for a given $r$, or finding a solution with a low $r$. The "convergence" is when the solver finds a feasible solution or times out.
In essence, the "optimization dynamics" are characterized by a combination of algebraic derivations, systematic constructions, and heuristic or exact searches over discrete spaces, rather than continuous gradient descent. The goal is to design codes and circuits with inherent fault-tolerance properties and efficient performance, not to learn them from data. The "loss landscape" is often discrete and non-convex, requiring specialized solvers or clever design principles to navigate.
 FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
Results, Limitations & Conclusion
Experimental Design & Baselines
The authors meticulously architected their experiments to rigorously validate the mathematical claims surrounding tricycle codes. Their core approach involved numerical simulations of these codes under realistic circuit-level noise models, directly comparing their performance against established baselines.
To prove the efficacy of tricycle codes, the experimental design focused on several key aspects:
1. Code Construction & Properties: They introduced tricycle codes as finite block-length quantum Low-Density Parity-Check (LDPC) codes, generalizing bicycle codes to three homological dimensions. These codes were designed to support constant-depth physical circuits for implementing logical CCZ gates. The construction involved developing novel analytical and numerical techniques, including a modified symmetric triple cup-product formalism (Appendix D) and a numerical Leibniz rule method (Appendix E), to find codes with favorable parameters (high rate and distance) and short-depth CCZ circuits.
2. Noise Model: A standard two-qubit depolarizing noise model was adopted, where each entangling operation is followed by one of 15 nontrivial two-qubit Pauli errors with probability $p_{2q}$. For the crucial CCZ gates, a three-qubit-biased depolarizing noise model was used, assuming a physical error rate $p_{3q} = 0.002$. This $p_{3q}$ was conservatively estimated to be twice that of two-qubit entangling gates, reflecting experimental realities. Furthermore, the model incorporated a strong bias towards Z-type errors for CCZ gates (10 times more likely), a characteristic of native phase-type gates on many quantum platforms.
3. Decoding Strategies:
* For single-shot Z-basis error correction (crucial for state preparation), a windowed decoding protocol was employed. This involved three rounds of syndrome extraction, repeated 14 times for a total of 42 rounds, using a Belief Propagation + Ordered Statistics Decoding (BP + OSD) scheme.
* For d-round X-basis error correction (for memory performance), the conventional d-round protocol was used, decoding the full record of accumulated syndrome information with a Most-Likely-Error (MLE) decoder. For postselection, they utilized a cluster-based postselection method combined with BP + LSD (Localized Statistics Decoding).
4. Implementation Protocol: A concrete protocol for efficiently implementing syndrome extraction circuits on a reconfigurable neutral-atom array platform was presented (Fig. 5, Appendix I). This included detailed atom rearrangement procedures and CNOT scheduling.
The "victims" (baseline models) against which tricycle codes were ruthlessly compared were primarily state-of-the-art magic-state cultivation schemes based on color codes, specifically the [[7, 1, 3]] and [[19, 1, 5]] color codes from Ref. [36]. These traditional schemes typically require multiple rounds of distillation and concatenation, leading to substantial space-time overheads. The authors also implicitly challenged previous cup-product constructions (Ref. [27]) that yielded codes with less favorable parameters (e.g., 2-2-2 codes with $K=3$ and $D=2$).
What the Evidence Proves
The evidence presented in the paper definitively proves that tricycle codes offer a highly efficient and robust solution for magic-state generation, outperforming existing baselines in key metrics.
- Robust Performance and High Threshold: Numerical simulations under circuit-level noise demonstrated a high circuit-noise threshold of >0.5% for the 4-2-2 family of tricycle codes (Fig. 4b). This is a strong indicator of their resilience to physical errors.
- Exceptional Logical Error Rates for Memory: With full error detection and modest postselection (e.g., 30% acceptance fraction), the smallest [[48, 6, 4]] tricycle code achieved logical memory error rates of approximately $6 \times 10^{-10}$ at a two-qubit gate error rate of $p_{2q} = 0.001$. For a larger [[84, 6, 5]] code, logical memory error rates were estimated to be < $10^{-13}$ at $p_{2q} = 0.001$ with an approximately 9% acceptance fraction. These figures represent extremely high fidelity for quantum memory.
- Superior Magic-State Production Fidelity and Cost: The tricycle codes produced hypergraph magic states with remarkably low logical error rates:
- [[48, 6, 4]] tricycle code: $2 \times 10^{-8}$
- [[84, 6, 5]] tricycle code: $4 \times 10^{-10}$
- [[108, 6, 6]] tricycle code: approximately $3 \times 10^{-11}$
Crucially, these impressive fidelities were achieved at comparable or even lower space-time costs than state-of-the-art color-code-based magic-state cultivation schemes (Table II). For instance, the [[48, 6, 4]] tricycle code had a space-time cost of 89 qubit rounds per logical qubit, significantly lower than the 90 for [[7, 1, 3]] color code cultivation, while achieving a much lower logical error rate ($2 \times 10^{-8}$ vs. $6 \times 10^{-7}$). This is undeniable evidence that the core mechanism of using high-rate, high-distance LDPC codes with transversal non-Clifford gates for single-shot magic-state generation works in reality.
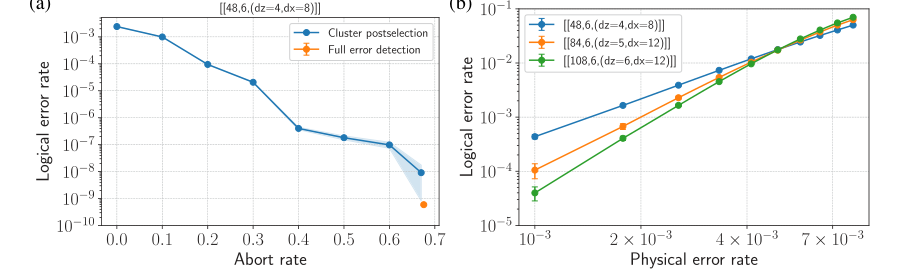 FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
- Single-Shot State Preparation: The numerical evidence (Fig. 3) clearly shows exponential suppression of logical error with increasing code distance for single-shot state preparation in the Z basis. This confirms that tricycle codes enable fault-tolerant preparation of logical $|+\rangle$ states in a constant number of rounds, a significant improvement over $O(d)$ rounds required by many other codes. This constant-depth preparation, combined with constant-depth logical CCZ operations, yields high-fidelity hypergraph magic states in constant depth.
- Constant-Depth CCZ Circuits: The construction of tricycle codes successfully yielded constant-depth physical CCZ circuits (e.g., depth-8 for 4-2-2 codes), which is essential for fault-tolerant operation and limits error propagation. The constant-depth CCZ circuit was shown to have a minimal effect on the final logical state error rate compared to the memory performance.
- High Magic State Yield: The ability to extract $K_{CCZ} \ge 2$ disjoint logical CCZ gates from the produced hypergraph magic states for all codes in Table I demonstrates the practical utility of these codes as magic-state factories.
The authors' rigorous simulations, comparison against strong baselines, and detailed analysis of logical error rates and space-time costs provide compelling evidence that tricycle codes represent a significant advancement in efficient, fault-tolerant magic-state generation.
Limitations & Future Directions
While tricycle codes present a promising pathway towards efficient, fault-tolerant quantum computation, the paper also highlights several limitations and opens up diverse avenues for future research and development.
Current Limitations:
- Optimality of $K_{CCZ}$ Extraction: The problem of finding the maximum number of disjoint CCZ gates ($K_{CCZ}$) from the hypergraph magic states is NP-hard. The current mixed-integer programming method yields suboptimal solutions and often times out for larger values of $K_{CCZ}$, meaning the reported values are lower bounds. This limits the immediate throughput of CCZ-type magic states.
- Code Family Asymptotic Goodness: Although the construction allows for defining a family of codes, it is unlikely to be asymptotically good. While larger block-length codes with larger distances are expected, this isn't a formal asymptotic guarantee.
- Deeper CCZ Circuits for Larger Codes: For larger 4-4-2 and 4-4-4 tricycle codes, the deeper physical CCZ circuits (e.g., depth-128 for some 4-4-4 codes) may lead to greater deviations of the logical fidelity from the pure memory setting. While concatenation with repetition codes can reduce depth, it comes at the cost of code rate.
- Numerical Leibniz Rule Method Guarantees: The numerical Leibniz rule (NLR) method for constructing CCZ circuits does not guarantee specific depths, and finding low-degree circuits often requires a code search in conjunction with the method.
- Selective State Initialization: Extracting disjoint CCZ gates requires selective initialization of gauge logical qubits in the $|0\rangle$ state and other logical qubits in the $|+\rangle$ state, which is nontrivial for LDPC codes in constant depth.
- Imbalanced Distances: Tricycle codes naturally exhibit higher distances in the X basis compared to the Z basis. While potentially useful for noise-biased platforms, a detailed exploration of how this bias can boost experimental performance is left for future work.
Future Directions & Discussion Topics:
-
Enhanced Decoding Strategies:
- The observed order-of-magnitude gap between standard BP+OSD/BP+LSD and exact MLE decoders suggests a critical need for new, more efficient decoders that can approach MLE performance while maintaining practical inference times. This could involve exploring machine learning-based decoders or advanced statistical methods.
- Tailored Noise Bias Exploitation: Given the asymmetry in X and Z sectors and the prevalence of noise bias in experimental platforms (e.g., Z-type errors in neutral atoms), future work should focus on integrating tailored noise bias exploitation directly into syndrome extraction circuits and decoding algorithms. How can we optimally design circuits and decoders to leverage specific hardware noise characteristics for maximum performance gains?
- Loss and Leakage Management: Many hardware architectures suffer from loss and leakage errors. Developing explicit strategies to leverage or mitigate these errors within the tricycle code framework could further improve logical error rates. This might involve new measurement protocols or error-correction techniques.
-
Optimization of Magic-State Factory Throughput:
- Improving $K_{CCZ}$ Extraction: The NP-hard problem of finding the subrank of the logical tensor $T^{log}$ is a major bottleneck. Developing tailored heuristic optimization strategies for the binary tensor subrank problem is crucial to extract larger values of $K_{CCZ}$ and significantly improve the throughput of CCZ-type magic states. Can we find approximate solutions that are good enough for practical purposes?
- Direct Compilation of Hypergraph Magic States: Instead of extracting disjoint CCZ gates, a deeper understanding of the structure of the produced hypergraph magic states might allow for direct compilation into useful quantum circuits. This could offer an alternative, potentially more efficient, route to utilizing these high-magic resource states.
-
Integration into Broader Quantum Architectures:
- Seamless Magic State Injection/Teleportation: A key open problem is the seamless injection or teleportation of distilled magic states from tricycle code factories into computational code blocks (e.g., high-performance bicycle codes). Exploring transversal teleportation based on natural isomorphisms between tricycle and bicycle codes, similar to protocols for 3D and 2D color codes, is a promising direction. What are the practical challenges and overheads associated with such code-switching protocols?
- Modular Architectures: How can tricycle codes be integrated into highly modular fault-tolerant quantum computing architectures? This involves not just magic-state generation but also efficient logical operation, communication, and memory within a larger system.
-
Advanced Code Construction and Circuit Optimization:
- Further Exploration of Numerical Leibniz Rule: A more thorough exploration of the numerical Leibniz rule method and its application to other 3D balanced-product codes could yield codes with even shorter-depth CCZ circuits. Can we develop better hyperparameters or search strategies to guarantee low-depth circuits?
- Syndrome Extraction Circuit Optimization: The paper presents optimal-depth syndrome extraction circuits. Further optimization of sector layout and atom movement schemes on reconfigurable neutral-atom platforms, potentially using mathematical programming or graph theory, could reduce space-time overhead.
- Comparison with Other LDPC Families: A detailed, direct comparison of the overhead and performance of tricycle codes with other recently proposed LDPC constructions (e.g., those based on homological products of expander codes or algebraic sheaves) would provide valuable insights into the relative merits and optimal application scenarios for each.
These discussion topics highlight the ongoing challenges and exciting opportunities in advancing fault-tolerant quantum computation, with tricycle codes serving as a significant stepping stone. The interplay between theoretical advancements, experimental capabilities, and algorithmic optimizations will be key to unlocking the full potential of these findings.
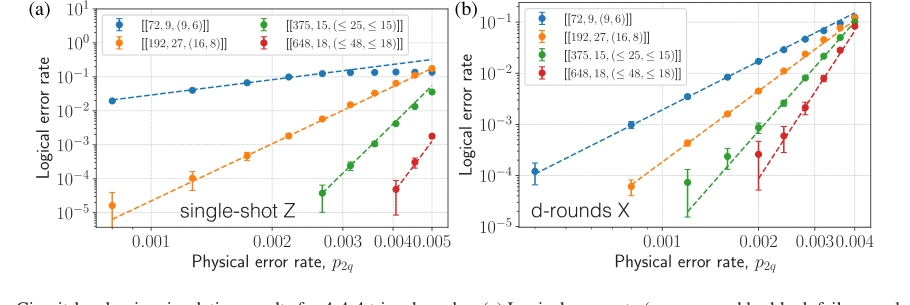 FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
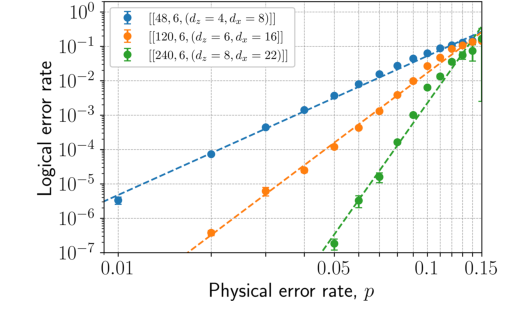 FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples
FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples