Magic Tricycles: Finite Block-Length Quantum LDPC Codesによる効率的なマジック状態生成
The preparation of high-fidelity non-Clifford (magic) states is an essential subroutine for universal quantum computation but imposes substantial space-time overhead.
背景と学術的系譜
起源と学術的系譜
本論文で取り組む問題は、普遍的な耐故障性量子計算達成のための根本的な要件に由来する。EastinとKnillによる画期的な結果[2]は、量子誤り訂正符号内で、普遍的な量子ゲートセットを純粋に横断的(すなわち、各量子ビットに独立して同じ物理ゲートを適用すること)に実装することは不可能であることを確立した。この限界は、しばしば「マジックゲート」と呼ばれる非クリフォードゲートが、特別に準備された非クリフォードリソース状態をコード空間にテレポートすることによって、他の手段で実装されなければならないことを意味する。
これらの高忠実度リソース状態を準備する主要な方法は、マジック状態蒸留(MSD)として知られている。歴史的に、15対1蒸留スキーム[3]のようなMSDプロトコルは、非常にリソース集約的であり、複数レベルの繰り返し蒸留と内部コードとの連結を必要とした。このプロセスは全体的な時空間オーバーヘッドに大きく寄与し、マジック状態生成は、Shorのアルゴリズム[4,5]のようなアルゴリズムでさえ、最先端の耐故障性アーキテクチャにおける総量子ビット数とゲート数の大部分を占めると推定されている。この研究の根本的な動機は、このオーバーヘッドを劇的に削減することである。
過去10年間、研究者たちはMSDオーバーヘッドを削減するために、横断的な非クリフォードゲートを持つ量子コードの設計において進歩を遂げてきた[6-9]。しかし、これらの初期のアプローチは重大な限界に直面していた。提案された低オーバーヘッド蒸留スキームの多くは、高重みパリティチェックを持つコードに依存していた。これは、それらのシンドローム抽出回路の深さがコードのブロック長に比例してスケーリングすることを意味する。これにより、回路レベルのノイズに対して本質的に耐故障性を持たず、指数関数的な閾値以下の誤り抑制を妨げた。さらに、これらのスキームはしばしばクリフォード演算のノイズレス性を暗黙のうちに仮定していたが、これは非現実的な仮定であり、高距離の内部コードの必要性により実質的なオーバーヘッドをさらに増加させた。クリフォード符号化および復号化回路も、物理量子ビット数に線形にスケーリングする深さを持ち、かなりの時間的オーバーヘッドにつながった。
量子低密度パリティチェック(qLDPC)コードは、そのスパースなスタビライザーチェックと、レートおよび距離の良好なスケーリングにより、量子誤り訂正のコストを削減する有望な経路として登場した。qLDPCコードは量子メモリ[12,13]のために探求されてきたが、マジック状態生成への応用は最近になってようやく調査され始めた。これは主に、マジック状態生成のために横断的な非クリフォードゲートをホストできるqLDPCコードを構築することが困難であることが証明されているためである。例えば、マジック状態生成のためのホモロジカル積コードの以前の構築では、古典コードに対するコードサイズの立方体的成長により、良好なパラメータを持つ最小ブロック長に対して、数千、あるいは数万の物理量子ビットが必要となることが多かった[Page 5, left column, paragraph 1]。この大規模な量子ビット数は大きな問題点であった。
本論文は、「トリサイクルコード」という、効率的で耐故障性のあるマジック状態生成をサポートするために特別に設計された、有限ブロック長量子LDPCコードの新しいクラスを導入することにより、これらの限界に直接対処する。これらのコードは、マジック状態蒸留に不可欠な論理CCZ(Controlled-Controlled-Z)ゲート作用を横断的に可能にするように構築されており、以前の方法の高オーバーヘッドと耐故障性の課題を克服している。
直感的なドメイン用語
-
マジック状態 (Magic States): 複雑なビデオゲームをプレイしていると想像してください。ほとんどのアクションは、歩く、ジャンプする、簡単な攻撃(クリフォードゲート)のような基本的な動きです。しかし、強力でゲームを変えるような特別な動き(スーパーコンボやテレポートなど)を実行するには、特定の「パワーアップ」アイテムが必要です。これらの「パワーアップ」アイテムは、量子コンピューティングにおけるマジック状態のようなものです。これらは、基本的な操作を超えた能力をアンロックし、普遍的な計算を可能にする特別な量子状態です。
-
マジック状態蒸留 (Magic-State Distillation, MSD): ビデオゲームのアナロジーを続けると、時には弱くて低品質の「パワーアップ」アイテムがたくさん見つかることがありますが、それらは単独ではあまり効果がありません。マジック状態蒸留は、「精製プロセス」のようなもので、これらのノイズが多く低品質のパワーアップを多数集めて、より少なく、はるかに強力で高品質のパワーアップを生成します。目標は、非常に純粋で信頼性の高い特別な動きを得ることです。
-
量子低密度パリティチェック(qLDPC)コード (Quantum Low-Density Parity-Check (qLDPC) Codes): 数百万冊の本がある図書館を考えてみてください。本の紛失(エラー)をチェックするために、従来のシステムではすべての図書館員がすべての棚をチェックする必要があるかもしれません。qLDPCコードは、各図書館員(「チェック」)が、小さく、特定され、散在した本のセットのみを担当するスマートなエラーチェックシステムのようなものです。この「低密度」の接続により、システムは構築、スケーリング、管理が容易になり、より複雑なハードウェアなしでより堅牢なエラー検出が可能になります。
-
横断的ゲート (Transversal Gate): シェフのチームがいて、各シェフが料理を準備しているとします。横断的ゲートは、すべてのシェフに、それぞれの料理にまったく同じ簡単なステップを同時に実行するように指示するようなものです。例えば、「全員、ひとつまみの塩を加える」です。重要なのは、各シェフが自分の料理に独立して作用するため、一人のシェフの間違いが他のシェフの料理に簡単に広がることはないということです。量子コンピューティングでは、これはコードブロック内の各量子ビットに物理ゲートを適用することを意味し、エラーの伝播を自然に制限し、操作を耐故障性にします。
-
CCZゲート (Controlled-Controlled-Z Gate): これは3つの量子ビットが関与する特定のタイプのマジックゲートです。3つのロックがある秘密の金庫を想像してください。CCZゲートは、3つのロックすべてが同時に回された場合にのみアクティブになるメカニズムのようなものです。ロックのいずれかが回されなかった場合、何も起こりません。この「トリプルコントロール」により、量子計算で非常に複雑で強力な操作が可能になります。
記法表
| 記法 | 説明 |
|---|---|
| $N$ | コードブロック内の物理量子ビットの総数。 |
| $K$ | コードブロック内のエンコードされた論理量子ビットの数。 |
| $D$ | 量子コードの最小距離。その誤り訂正能力を表す。$D_X$ および $D_Z$ はそれぞれX基およびZ基における距離を指す。 |
| $H_X$ | X型パリティチェック行列。Xスタビライザー生成子を定義する。 |
| $H_Z$ | Z型パリティチェック行列。Zスタビライザー生成子を定義する。 |
| $A, B, C$ | $n_G \times n_G$ の二値置換行列。群代数要素から導出され、トリサイクルコード内の接続パターンを定義する。 |
| $O$ | $n_G \times n_G$ のゼロ行列。 |
| $\mathbb{F}_2$ | 二値体 $\{0,1\}$。算術は2を法として実行される。 |
| $n_G$ | 各セクターの線形サイズ。有限アーベル群 $G$ の位数に等しい。総物理量子ビット数 $N = 3n_G$。 |
| $f_{CCZ}$ | 横断的CCZ回路を定義する3重線形二値関数。$f_{CCZ}(p^I, q^{II}, r^{III}) = 1$ は、物理CCZゲートが量子ビット $p^I, q^{II}, r^{III}$ に適用されることを意味する。 |
| $\cup$ | 代数的トポロジーからのカップ積演算子。横断的な非クリフォードゲートの構築に使用される。 |
| $a_{in}, a_{out}, a_{free}$ | 群代数要素の「入力」、「出力」、「自由」分割(事前配向)。カップ積の定義とコード空間を保存するCCZ回路の確保に不可欠。 |
| $|...|_{d_{i \neq j \neq k}}$ | ハミング重み(サポートのサイズ)を示す。ただし、CCZゲートの場合、量子ビットは異なるセクターから来る必要があるという条件付き。 |
| $\pmod{2}$ | 2を法とする算術。ゲート適用における二値出力を保証する。 |
| $p_{2q}$ | 2量子ビットエンタングルメントゲート(例:CNOT)の物理エラー率。 |
| $p_{3q}$ | 3量子ビットCCZゲートの物理エラー率。 |
| $K_{CCZ}$ | ハイパーグラフマジック状態から抽出できる、互いに素な論理CCZゲートの最大数。 |
| STCP | 対称トリプルカップ積形式。CCZ回路構築のための解析的手法。 |
| NLR | 数値ライプニッツ則法。CCZ回路構築のための補完的な数値的手法。 |
| MSD | マジック状態蒸留。高忠実度の非クリフォードリソース状態を準備するためのプロトコル。 |
| qLDPC | 量子低密度パリティチェックコード。 |
| CSS | Calderbank-Shor-Steaneコード。量子誤り訂正コードの一種。 |
| MLE | 最大尤度誤りデコーダー。 |
| BP + LSD | Belief Propagation + Localized Statistics Decoding。効率的な近似デコーダー。 |
| BP + OSD | Belief Propagation + Ordered Statistics Decoding。別の近似デコーダー。 |
| AOD | Acousto-Optical Deflector。中性原子アレイにおける原子移動に使用される。 |
| SLM | Spatial Light Modulator。量子ビットのトラップを生成するために使用される。 |
| $t_{wsp}, t_{ent}$ | 作業空間およびエンタングルメント領域におけるAOD移動の時間オーバーヘッド。 |
| $d_{min}$ | 最小光学分解距離。量子ビット密度と移動速度を制限する。 |
| $d_{iso}$ | ライデンベルグ相互作用のアイソレーション距離。意図したCNOTペアを保証する。 |
問題定義と制約
コア問題の定式化とジレンマ
本論文が取り組む中心的な問題は、普遍的な耐故障性量子計算に不可欠な、高忠実度の非クリフォード(マジック)状態の非効率的かつリソース集約的な生成である。
入力/現在の状態:
普遍的な量子計算は、クリフォード演算と非クリフォード演算の両方に依存する。論理クリフォードゲートは多くの量子誤り訂正コードで横断的に実装できることが多いが、Eastin-Knill定理は、普遍的なゲートセットを横断的に実装することは不可能であると規定している。その結果、非クリフォードゲート(マジックゲート)は通常、特別に準備された非クリフォードリソース状態をコード空間にテレポートすることによって実装される。これらの高忠実度リソース状態を準備するための現在の最先端技術であるマジック状態蒸留(MSD)は、重大な欠点に悩まされている。
1. 実質的な時空間オーバーヘッド: 15対1蒸留のようなMSDプロトコルは、複数レベルの繰り返し蒸留と内部コードとの連結を必要とする。これにより、Shorのアルゴリズムのような大規模な量子アルゴリズムの総量子ビット数とゲート数の大部分をマジック状態生成が占めると推定されている。
2. 以前の「低オーバーヘッド」スキームにおける耐故障性の妥協: 低オーバーヘッドMSDプロトコルの最近の提案は、横断的な非クリフォードゲートを達成したものの、しばしば高重みパリティチェックを伴っていた。これは、それらのシンドローム抽出回路の深さがコードブロック長に比例して増加することを必要とし、回路レベルのノイズに対して本質的に耐故障性を持たず、指数関数的な閾値以下の誤り抑制を不可能にした。
3. 非現実的な仮定: 多くの既存プロトコルは、符号化および復号化回路のクリフォード演算のノイズレス性を暗黙のうちに仮定しているが、これは報告されたオーバーヘッドを誇張している。これらのクリフォード回路は、物理量子ビット数に線形にスケーリングする深さを持つこともあり、かなりの時間的オーバーヘッドにつながる。
望ましい終点(出力/目標状態):
本論文は、現在の方法に関連する時空間オーバーヘッドを大幅に削減する、効率的で耐故障性のあるマジック状態生成を達成することを目標としている。具体的には、目標は以下の通りである。
1. 高忠実度と高スループットでのマジック状態生成: Shorのアルゴリズムのような実用的なアプリケーションのために、論理誤り率を $2 \times 10^{-8}$ から $3 \times 10^{-11}$ 未満でマジック状態を生成する。
2. 有限ブロック長コードの使用: 実験的に実現可能なコードとして、約50〜100量子ビットのブロック長を持つコードを使用する。
3. 定深回路のサポート: コードサイズに依存しない物理回路を使用して、論理CCZゲートとシンドローム抽出を実装する。
4. 単発状態準備と誤り訂正の実現: マジック状態準備回路の初期論理状態を定深で準備できるようにし、一方の基底で繰り返しシンドローム抽出を行うことなく誤りを訂正できるようにする。
5. 連結の回避: 横断的なクリフォードゲートをサポートする内部コードとの連結の必要性を排除し、全体的なアーキテクチャを簡素化する。
欠けているリンクと数学的ギャップ:
正確に欠けているリンクは、高いレート、高い距離、および定深横断非クリフォードゲート(特にCCZゲート)を同時にサポートし、さらに単発誤り訂正を可能にする量子低密度パリティチェック(qLDPC)コードの構築である。以前のqLDPCコードの研究は、横断的な非クリフォードゲートの要件で苦労していた。
本論文は、「トリサイクルコード」という、有限ブロック長量子LDPCコードの新しいクラスを導入することにより、このギャップを埋めようとしている。これらのコードは、古典二値線形コードのアーベル群代数上の3次元平衡積として構築されており、よく知られたバイサイクルコードを一般化している。数学的ギャップは、以下の方法で埋められている。
1. 修正カップ積形式の開発: 本論文は、3次元積コードにおける横断的な非クリフォードゲートを構築するための理論的枠組みを、代数的トポロジーからのカップ積形式を修正することによって拡張している。これにより、高レートおよび高距離のトリサイクルコードが非自明なCCZ作用をホストするために満たさなければならない新しい条件セットが得られる。
2. 数値ライプニッツ則(NLR)法の導入: 解析的なカップ積形式が制約的すぎる場合のために、反復平衡積量子コード上で短深さでコード空間を保存するCCZ回路を見つけるための補完的な数値的手法が開発されている。
ジレンマ:
以前の研究者を閉じ込めてきた痛みを伴うトレードオフは、高レート、高距離のコードと横断非クリフォードゲートの達成と、効率的なシンドローム抽出による真の耐故障性の維持との間の緊張である。歴史的に、一方の側面を改善すること(例:低オーバーヘッドのための横断非クリフォードゲートの達成)は、しばしばもう一方を妥協させた(例:ブロック長とともに増加する深さを持つシンドローム抽出回路の必要性、したがって回路レベルノイズの存在下での耐故障性を破る)。ジレンマは、以下のすべてを同時に達成する方法である。
* 高忠実度のマジック状態(誤り抑制のための高コード距離が必要)。
* 効率的な生成(蒸留の並列化と低時空間オーバーヘッドのための高コードレートが必要)。
* 耐故障性(定深シンドローム抽出と状態準備、および回路レベルノイズへの耐性が必要)。
* 横断非クリフォードゲート(複雑で耐故障性のないゲート実装を回避するため)。
以前のアプローチは、これらの目標の一部を他の目標を犠牲にして達成したか、または実用的な量子コンピューティングアーキテクチャでは現実的ではない単純化の仮定に依存していた。例えば、4-4-4トリサイクルコードは、より高いレートと距離を提供するものの、より高いチェック重みとより深いCCZ回路のコストを伴い、この固有のトレードオフを示している。
制約と失敗モード
効率的で耐故障性のあるマジック状態生成の問題は、物理的、計算的、データ駆動型の制約の組み合わせ、および固有の失敗モードにより、非常に困難である。
物理的制約:
1. 量子ビットエラー率とノイズバイアス: 物理CCZゲートは特定の誤り率(例:$p_{3q} = 0.002$)を持つと仮定されており、これは2量子ビットエンタングルメントゲート($p_{2q} = 0.001$)の2倍である。さらに、ネイティブな位相型ゲート(CCZなど)は、Z型エラーに強くバイアスされたノイズプロファイルを示すため、誤りモデルで考慮する必要がある。
2. ハードウェアメモリ制限: 「有限ブロック長」コード(例:50〜100量子ビット)の必要性は、コードブロックで利用可能な物理量子ビット数に実用的な制限があることを意味する。
3. リアルタイム遅延要件: 「単発」状態準備と誤り訂正の要求は、特にCCZゲートがXエラーをCZエラーに伝播させる可能性があるため、エラーの拡散と蓄積を防ぐために重要である。これは、デコーディングおよび訂正サイクルに厳格な遅延要件を課す。
4. 中性原子アレイプラットフォームの制限: 再構成可能な中性原子アレイでの提案された実装は、特定の制約を導入する。
* トラップ間隔: 並列CNOTに関与する量子ビットペアは、同じセクター内での意図しない相互作用を防ぐために、十分な距離($d_{iso}$、例:10 µm)で分離する必要がある。
* 光学分解能 ($d_{min}$): 最小光学分解距離(例:2 µm)は、量子ビットの置換の速度と密度を制限する。
* AOD移動タイミング: 置換(x、y、zサイクリング)および取得/返却操作のための原子光学デフレクター(AOD)移動には、関連する時間オーバーヘッド($t_{wsp}, t_{ent}$)があり、全体の回路深さに寄与する。
5. Eastin-Knill定理: この基本的な定理は、普遍的な横断的ゲートセットを妨げるため、マジック状態の使用を強制し、それによって非クリフォード操作の複雑さを増す。
計算的制約:
1. コード距離とサブランク問題のNP困難性:
* 線形コードの正確なコード距離の発見はNP困難な問題であり、より大きなトリサイクルコードの性能を正確に特徴付けることが計算上困難である。
* 二値テンソルのサブランクの発見(ハイパーグラフマジック状態から抽出できる互いに素なCCZゲートの最大数を抽出することに対応する)もNP困難である。これは、生成されたマジック状態の可能性を効率的に抽出する能力を制限する。
2. ソルバータイムアウト: 論理回路最適化(例:$K_{CCZ}$ の混合整数プログラミング)に使用される数値ソルバーは、より大きな値に対してタイムアウトすることが多く、最適なソリューションを見つけることの計算上の非現実性を示している。
3. デコーディング複雑性: Belief Propagation + Localized Statistics Decoding (BP + LSD) のような効率的なデコーダーが使用されているが、これらは近似である。正確な最大尤度誤り(MLE)デコーダーは指数関数的に高コストであり、リアルタイムの耐故障性操作には非現実的である。
4. 数値探索の制限: CCZ回路を構築するための数値ライプニッツ則法は、短い深さを保証しないため、適切なコードを見つけるために広範な探索とハイパーパラメータチューニングが必要となる。
データ駆動型制約と失敗モード:
1. 回路レベルノイズ: プロトコル全体は、2量子ビットのデポリライジングノイズとCCZゲートのバイアス付き3量子ビットデポリライジングノイズを含む、現実的な回路レベルノイズモデルの下で動作する必要がある。このノイズは、検出および訂正されなければならないエラーを導入する。
2. エラー伝播: 重大な失敗モードは、CCZゲートが既存のXエラーを他の量子ビットのCZエラーに伝播させることである。これらのCZエラーは、単発誤り訂正によって処理されない場合、シンドローム測定後に非決定的なZエラーに崩壊し、急速に蓄積する可能性がある。
3. 非決定的なZスタビライザー測定: 初期Z型スタビライザー測定は非決定的な $\pm 1$ の結果を生成し、CCZゲートを適用する前にハードウェア上で信頼性高く $+1$ に修正する必要がある。これには、シンドローム測定エラーを特定および訂正するための堅牢なメタチェックとデコーダーが必要である。
4. 不均衡なコード距離: トリサイクルコードは、Z基よりもX基で自然に高い距離を示す($d_Z \leq d_X$)。ノイズバイアスのあるプラットフォームに有用である可能性があるが、この不均衡は、より困難なX基誤り訂正がしばしば全体的な性能を決定することを意味する。
5. ポストセレクション成功率の制限: ポストセレクションは論理誤り率を大幅に改善できるが、受け入れ率の低下(研究されたコードで3%から30%)というコストがかかり、マジック状態生成の全体的なスループットに影響を与える。
なぜこのアプローチなのか
選択の必然性
トリサイクルコードの採用は、単なる好みではなく、耐故障性マジック状態生成に対する既存のアプローチの固有の限界によって駆動された必然性であった。普遍的な量子計算は非クリフォード(マジック)状態に決定的に依存するが、その生成は歴史的に実質的な時空間オーバーヘッドを課してきた。15対1蒸留のような従来のマジック状態蒸留(MSD)プロトコルは、複数レベルの繰り返し精製を必要とし、しばしば横断的クリフォードゲートをサポートするために内部コード(2次元カラーコードなど)との連結を必要とした。この多層アプローチは、量子ビットとゲート操作の法外な消費につながり、Shorのアルゴリズムのような大規模量子アルゴリズムのリソース推定の大部分を頻繁に占めた。
さらに、低オーバーヘッドMSDプロトコルの最近の提案は、横断的な非クリフォードゲートと有利な漸近的パラメータを持つ量子コードを導入したが、それらは重大な注意点とともに来た。これらのコードはしばしば高重みパリティチェックを特徴とし、そのシンドローム抽出回路の深さがコードブロック長に比例してスケーリングすることを意味する。このようなスケーリングは、回路レベルノイズの存在下で耐故障性を損なう。なぜなら、定深シンドローム抽出を不可能にするからである。さらに、これらのスキームは、符号化および復号化のためのクリフォード演算のノイズレス性を暗黙のうちに仮定することが多いが、これは実際には真のリソースオーバーヘッドを誇張する仮定である。物理量子ビット数に対するクリフォード回路深さの線形スケーリングも、かなりの時間的オーバーヘッドに寄与する。
これらのボトルネックを克服するには、根本的に異なるクラスのコードが必要であることが明らかになった。著者らは、固有のスパーススタビライザーチェックと有利なレートおよび距離スケーリングを組み合わせたqLDPCコードが、最も有望な経路を提供すると認識した。具体的には、課題は、「強く横断的な非クリフォードゲート」(クリフォード補正や内部コードとの連結なしの定深物理回路)をホストできるqLDPCコードを構築し、同時に定深シンドローム抽出を維持することであった。この認識が、トリサイクルコードの導入を動機づけた。有限ブロック長、高レート、高距離の量子LDPCコードであり、横断論理CCZ回路作用をサポートするように明示的に設計されており、それによって効率的で単発のマジック状態生成を可能にする。
比較優位性
トリサイクルコードは、単純な性能指標を超えて、以前のゴールドスタンダードに対して圧倒的な質的優位性を示す。それらの構造設計は、効率的で耐故障性のあるマジック状態生成に明確な利点を提供する。
第一に、トリサイクルコードは、アーベル群代数上の古典二値線形コードの3次元平衡積として構築される。アーベル群代数上の古典二値線形コードの3次元平衡積として構築される。これは、よく知られたバイサイクルコードを3つのホモロジカル次元に一般化したものであり、クリフォード階層の第3レベル、特に論理CCZゲートからの横断的ゲートを本質的に可能にするため、重要である。これは基本的な構造的利点であり、他のアーキテクチャではしばしばボトルネックとなる鍵となる非クリフォードゲートの直接的で定深実装を可能にする。
第二に、最も重要な利点は、単発状態準備と誤り訂正(Sec. I.B, II.C)の実現である。従来のMSDスキームは複数回の反復蒸留を必要とするが、トリサイクルコードは単一ラウンドで高忠実度のハイパーグラフマジック状態を準備できる。これは、2つの主要な特性によって促進される。状態初期化中の一方のスタビライザー基底における固有の耐故障性、および「メタチェック」の存在である。これらのメタチェックは冗長なZパリティチェックであり、シンドロームビット上に古典コードを形成し、Z基におけるシンドローム測定エラーの堅牢な識別と訂正を可能にする。この機能は、通常単発状態準備を欠くサーフェスコードのようなコードとは大きく異なり、時間的オーバーヘッドを $O(d)$ ラウンド($d$ はコード距離)から定数に劇的に削減する。
さらに、トリサイクルコードは、比較的短いブロック長(例:[[48, 6, 4]]、[[108, 21, 6]]、表Iに示す)で有利なパラメータ—高レートと高距離—を達成する。このコンパクトさは、近接量子ハードウェアでの実用的な実装に不可欠である。論文はまた、4-2-2トリサイクルコードのような特定のファミリが、それらの低いチェック重みと最小深さ8のCCZ回路により、特に重要であると強調している。これは直接、回路レベルのノイズ伝播の削減につながる。
定量的に、優位性は時空間コストに明らかである。表IIに示すように、トリサイクルコードは、最先端のカラーコードベースのマジック状態育成([[7, 1, 3]]カラーコードで $6 \times 10^{-7}$ の誤り率で90量子ビットラウンド、または[[19, 1, 5]]カラーコードで $6 \times 10^{-10}$ の誤り率で3000量子ビットラウンド)と比較して、同等または大幅に低い時空間コスト(それぞれ89および527量子ビットラウンド)で論理誤り率([[48, 6, 4]]で $2 \times 10^{-8}$、[[84, 6, 5]]で $4 \times 10^{-10}$)を達成する。これは、高忠実度のマジック状態を生成するためのリソース効率における大幅な改善を示している。
制約との整合性
トリサイクルコードという選択されたアプローチは、実用的で耐故障性のある量子計算の厳格な要件との顕著な「結婚」を示している。トリサイクルコードの設計原則は、問題定義で特定されたコア制約に対処するために特別に調整された。
第一に、普遍的な耐故障性量子計算という包括的な目標は、トリサイクルコードが横断的な論理CCZゲートをホストできる能力によって直接満たされる。CCZゲートは普遍的なゲートセットに不可欠な非クリフォード操作であり、トリサイクルコード内でのその定深、横断的な実装は、この要件に対する直接的な解決策である(Sec. I.B, II.B)。
第二に、時空間オーバーヘッドの削減という重要な制約は、トリサイクルコード設計の複数の側面によって対処されている。単発マジック状態生成プロトコル(Sec. I.B, II.C)は、複数回の蒸留ラウンドの必要性を排除し、時間的リソースを劇的に削減する。高レートコードは、単一コードブロック内で複数のマジック状態の並列蒸留を可能にし、スループットを向上させ、全体的な時間を削減する。さらに、論理CCZ操作とシンドローム抽出回路の両方が定深になるように設計されており(Sec. I.B, II.E)、回路複雑性がコードサイズに対して不利にスケーリングしないことを保証し、他の方法で見られる線形スケーリングオーバーヘッドを防ぐ。有限ブロック長コードと有利なパラメータ(表I)の使用も、コードが実用的でリソース効率的であることを保証する。
第三に、高忠実度のマジック状態という要求は、堅牢な誤り抑制を通じて満たされる。数値シミュレーションは、トリサイクルコードが、特にポストセレクション(Sec. I.B, Table II)を使用して、中程度のブロック長と現実的な回路レベルノイズの下でも、CCZマジック状態に対して非常に低い論理誤り率(例:$2 \times 10^{-8}$ から $3 \times 10^{-11}$ 未満)を達成できることを確認している。
最後に、耐故障性はトリサイクルコードアーキテクチャに固有に組み込まれている。定深シンドローム抽出回路(Sec. I.A, II.E)は、回路レベルノイズに対して耐性があるように設計されている。非クリフォードゲートの横断的な性質は、物理量子ビット間のエラーの広がりを本質的に制限する(Sec. I.A)。高い相対距離は、蒸留中の効果的な誤り抑制を保証する。特に、メタチェックの存在は、Z基における単発誤り訂正を可能にし、即時のXエラー訂正を可能にし、マジック状態準備中の耐故障性を維持するために不可欠な、その伝播を防ぐ(Sec. II.C)。再構成可能な中性原子プラットフォーム(Sec. I.B, II.E)での提案された実装も、現代の量子コンピューティングの実用的なハードウェア制約と一致している。
代替案の却下
本論文は、それらの欠点を強調したり、トリサイクルコードの優れた能力を実証したりすることによって、暗黙的かつ明示的にいくつかの代替アプローチを却下している。
従来のマジック状態蒸留(MSD)スキーム: 本論文の導入部(Sec. I.A)は、従来のMSDプロトコル、例えば15対1蒸留に対する強力な却下として機能する。これらの方法は、「複数レベルの繰り返し蒸留」と「十分な距離を持つ内部コードとの連結」を必要とし、「時空間オーバーヘッドに大きく寄与する」と批判されている。著者らは、マジック状態生成が「最適化[4,5]にもかかわらず、Shorのアルゴリズムを用いたRSA整数因数分解の最新のリソース推定を支配する」と明確に述べている。対照的に、トリサイクルコードは単発蒸留を目指し、このオーバーヘッドを劇的に削減する。
既存の非LDPC定数オーバーヘッドMSDプロトコル: いくつかの先行研究は、横断的な非クリフォードゲートと定数オーバーヘッドを持つコードを提案したが、本論文はそれらの重大な欠点を指摘している(Sec. I.A)。これらのコードはしばしば「高重みパリティチェック」を持ち、そのシンドローム抽出回路の深さがブロック長に比例して増加する結果となる。これは、それらを「それ自体では耐故障性があるとは言えない」ものにし、有限閾値をサポートできないようにする。さらに、それらは「クリフォード演算がノイズレスであると暗黙のうちに仮定している」が、これはその認識された効率を誇張する非現実的な単純化である。トリサイクルコードは、LDPCコードとして、スパースチェックと定深シンドローム抽出を保証することによって、これらを克服する。
バイサイクルコード(2次元群代数コード): トリサイクルコードは、バイサイクルコードを「3つのホモロジカル次元」に一般化したものとして提示されている(Sec. I.B)。この一般化は、「クリフォード階層の第3レベル、特に論理CCZゲートからの横断的ゲートを原理的に可能にする」ため、不可欠である[23]。バイサイクルコードはクリフォード階層の低レベルゲートには効果的であるが、この作業のターゲット非クリフォード操作であるCCZゲートを横断的に直接実現するには不十分である。論文は、バイサイクルコードが高いレートを持つ可能性がある一方で、トリサイクルコードはCCZに必要な3D構造を提供すると指摘している。
特定の2-2-2トリサイクルコードパラメータ: トリサイクルコードのファミリ内では、著者らは経験的に特定のパラメータ選択を却下した。彼らは、「重み6のXチェックと重み4のZチェックを持つ2-2-2コード」が、非自明な横断CCZ作用に対して「それほど有利な」レートと距離を提供しないことを見出した(Sec. II.A)。具体的には、「K > 3のエンコードされた論理量子ビットと距離D > 7を持つそのようなコードを見つけることができなかった」ため、より良い性能を示した4-2-2、4-4-2、および4-4-4コードに焦点を当てることになった。
Ref. [27]の元のカップ積形式: 本論文はまた、横断的な非クリフォードゲートを構築するための理論的枠組みの洗練を詳述している。「Ref. [27]の元のカップ積条件」は、「コードのパラメータに対して制約が厳しすぎる」ことが判明した(Sec. II.B, Appendix D)。これらの元の条件は、例えば、2-2-2コードに限定された論理量子ビット(K=3)と距離(D=2)をもたらし、同様に4-2-2および4-4-4コードを制約した。著者らは、パラメータ選択に greater flexibility を可能にする新しい「対称トリプルカップ積」形式を開発し、「より良いパラメータ」(より高い距離)を持つトリサイクルコードにつながり、それによって元の、より制約的な形式を却下した。
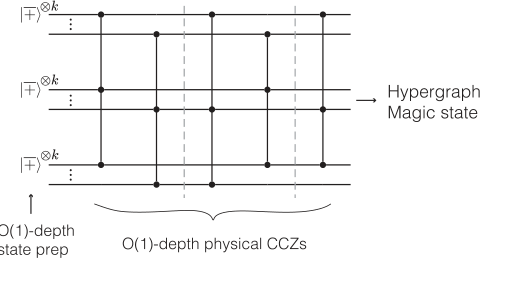 FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
数学的・論理的メカニズム
マスター方程式
本論文の基礎となる数学的エンジンは、トリサイクルコード自体の定義にあり、これは量子カルダーバンク・ショーア・ステーン(CSS)コードの一種である。これらのコードは主に、それらのX型およびZ型パリティチェック行列によって特徴付けられる。さらに、本論文は、マジック状態生成プロトコルに中心的な、横断的な制御-制御-Z(CCZ)ゲートを定義する特定の3重線形関数を導入する。
パリティチェック行列は以下のように与えられる。
$$ H_X = \begin{bmatrix} A^T & B^T & C^T \end{bmatrix} \in \mathbb{F}_2^{n_G \times 3n_G} $$
$$ H_Z = \begin{bmatrix} C & O & A \\ O & C & B \\ B & A & O \end{bmatrix} \in \mathbb{F}_2^{3n_G \times 3n_G} $$
これらの行列は、量子コードのスタビライザーを定義する。コード定義を超えて、マジック状態生成のための論文のコアメカニズムは、対称トリプルカップ積から派生した二値関数にエンコードされた横断CCZ回路に依存する。論文は一般的な形式(Eq. 2)を提示しているが、トリサイクルコードの特定の構築は命題D4(Eq. D27)で詳述されている。
$$ f_{CCZ}(p^I, q^{II}, r^{III}) = |r^{III} \cup a_{out}^{III} \cup q^{II} \cup a_{in}^{II} \cup p^I \cup a_{in}^I \cup a_{out}^I|_{d_{i \neq j \neq k}} \pmod{2} $$
項ごとの解剖
これらの等式を分解して、各コンポーネントの役割を理解しよう。
パリティチェック行列 ($H_X, H_Z$) について:
- $H_X$: これはX型パリティチェック行列である。
- 数学的定義: 行がXスタビライザー群の生成子を定義する二値行列。
- 物理的/論理的役割: どの物理量子ビットが各X型スタビライザー測定に関与するかを決定する。これらの測定は、データ量子ビット上のZ型エラーを検出するために使用される。
- この構造である理由: ブロック構造 $[A^T \ B^T \ C^T]$ は、Xチェックがコードブロックの3つのセクター(I、II、III)からの要素を組み合わせることによって形成されることを示している。転置($^T$)は、$H_Z$ が特定の形式で与えられた場合にCSSコードでXチェックを定義するために標準的である。
- $H_Z$: これはZ型パリティチェック行列である。
- 数学的定義: 行がZスタビライザー群の生成子を定義する二値行列。
- 物理的/論理的役割: どの物理量子ビットが各Z型スタビライザー測定に関与するかを決定する。これらの測定は、データ量子ビット上のX型エラーを検出するために使用される。
- この構造である理由: $3n_G \times 3n_G$ のブロック行列構造は、$N=3n_G$ の物理量子ビットが3つの等しいサイズのセクター(I、II、III)に分割されていることを反映している。対角外の $A, B, C$ 行列は、Zチェックのためのセクター間の接続を示し、対角の $C$ 行列はセクター内の接続またはラップアラウンド接続を示唆している。
- $A, B, C$: これらは $n_G \times n_G$ の二値行列である。
- 数学的定義: アーベル群 $G$ 上の群代数要素 $a, b, c \in \mathbb{F}_2[G]$ から派生した置換行列。置換行列は、各行と各列に正確に1つの「1」を持つ。
- 物理的/論理的役割: コードブロック内の異なるセクター間で量子ビット間の特定の接続パターンを定義する。それらの置換特性は、接続のバランスの取れた分布を保証する1対1のマッピングを意味する。これらの要素の選択は、コードの距離とレートにとって重要である。
- 置換行列である理由: 置換行列を使用することで、各量子ビットが固定数のチェックに関与することが保証され、低密度パリティチェック(LDPC)特性につながり、効率的なデコーディングに望ましい。
- $O$: これは $n_G \times n_G$ のゼロ行列である。
- 数学的定義: すべてのエントリがゼロの行列。
- 物理的/論理的役割: 特定のZ型スタビライザー生成子に対するセクター間の接続の不在を示す。例えば、$H_Z$ の最初の行では、$O$ はセクターIIとセクターIの間に直接的なZチェック接続がないことを意味する。
- $\mathbb{F}_2$: 二値体 $\{0,1\}$。
- 数学的定義: 2つの要素を持つ体。算術は2を法として実行される。
- 物理的/論理的役割: これは量子CSSコードの基本であり、パウリ演算子($X, Y, Z$)は恒等式に二乗し、それらの積は二値算術規則(例:$X \cdot X = I$、$X \cdot Z = -iY$、$Z \cdot X = iY$、したがって $X \cdot Z \cdot X \cdot Z = I$)に従う。すべての行列演算(乗算、加算)は2を法として実行される。
- $n_G$: 各ブロックの線形サイズ。有限アーベル群 $G$ の位数に等しい。
- 数学的定義: $n_G = |G|$。
- 物理的/論理的役割: 3つのセクターのそれぞれに含まれる量子ビットの数を決定し、したがって物理量子ビットの総数 $N = 3n_G$ を決定する。
CCZ関数 ($f_{CCZ}$) について:
- $f_{CCZ}(p^I, q^{II}, r^{III})$: これは3重線形二値関数である。
- 数学的定義: 3つの入力(異なるセクター/ブロックからの量子ビット)を取り、0または1を出力する関数。
- 物理的/論理的役割: $f_{CCZ}=1$ の場合、物理CCZゲートが量子ビットのトリプル $(p^I, q^{II}, r^{III})$ に適用されることを意味する。$f_{CCZ}=0$ の場合、ゲートは適用されない。この関数は、横断CCZ回路全体を定義する。
- $p^I, q^{II}, r^{III}$: これらは特定の物理量子ビットを表す。
- 数学的定義: コードブロック(I、II、III)とそのブロック/セクター内の位置によってインデックス付けされた、個々の量子ビットを表す変数。
- 物理的/論理的役割: これらはCCZゲートのターゲット量子ビットである。上付き文字 $I, II, III$ は、量子ビットが3つの異なるコードブロック(またはブロック内のセクター、論文の図1(a)および関連テキストで明確化されている)から来る必要があることを示している。
- $\cup$: カップ積演算子。
- 数学的定義: 代数的トポロジー、特にホモロジー代数からの双線形写像。コチェインを結合する。論文は「対称トリプルカップ積」(定義6、p. 21)を使用しており、これはこれらの演算の特定の順序を意味する。
- 物理的/論理的役割: この演算子は、横断的な非クリフォードゲートを構築するために使用されるコア代数ツールである。それはコードの基盤となる代数構造のホモロジカル積構造から自然に生じ、「論理演算子のトリプル交差」に関連している。方程式内のカップ積の特定のシーケンスは、結果のCCZ回路がコード空間を保存し、コバウンダリー不変であることを保証するように設計されている。
- カップ積である理由: コードの基盤となる代数構造から、CCZのような高次のクリフォード階層ゲートを導出する体系的な方法を提供し、それらが論理部分空間上で正しく作用することを保証する。
- $a_{in}^I, a_{out}^I, \dots, a_{out}^{III}$: これらは、コードを定義する群代数要素 $a_I, a_{II}, a_{III}$ の「入力」および「出力」分割である。
- 数学的定義: 群代数要素 $a$ に対して、$a = a_{in} + a_{out} + a_{free}$(Eq. D20, p. 22)に分割される。$a_{in}$ および $a_{out}$ はそれ自体群代数要素である。
- 物理的/論理的役割: 「事前配向」と呼ばれるこれらの分割は、古典コード上のカップ積を誘発する。これらの分割の特定の選択(「対称統合ライプニッツ則」条件(Eqs. D15-D19, p. 22)を満たす必要がある)は、CCZ回路がコード空間を保存し、コバウンダリー不変であるために不可欠である。論文は、トリサイクルコードの場合、$a_{free}$ はしばしば空に設定されると指摘している。
- 分割である理由: これらの分割により、カップ積の操作方法を細かく制御でき、望ましい特性(例:非自明な作用、より良いコードパラメータ)を持つCCZゲートの構築が可能になる。
- $|...|_{d_{i \neq j \neq k}}$: これは引数のサポートのサイズを示す。
- 数学的定義: カップ積演算後の結果の二値ベクトルのハミング重み。添え字 $d_{i \neq j \neq k}$ は、$f_{CCZ}=0$ が引数のうち2つ以上の量子ビットが同じセクターにある場合に発生するという条件を意味する(命題D4, p. 24)。
- 物理的/論理的役割: ハミング重みは、結合された代数式がゼロでないかどうかを決定し、それがCCZゲートの適用をトリガーする。条件 $d_{i \neq j \neq k}$ は、CCZ回路の横断性を保証するために不可欠であり、ゲートは量子ビット間で異なるセクター/ブロック間でしか作用しないことを意味し、これは耐故障性のための主要な特性である。
- $\pmod{2}$: 2を法とする算術。
- 数学的定義: 全体の式の結果を2を法として取る。
- 物理的/論理的役割: 出力が二値(0または1)であることを保証し、CCZゲートの存在または不在を直接示す。これは、量子情報とパウリ演算子の二値性質と一致する。
ステップバイステップの流れ
抽象的なデータポイント、例えば単一の量子ビットが、記述されたメカニズムを通過する旅を追ってみよう。
1. コード定義とエラー検出($H_X, H_Z$ を介して):
トリサイクルコードブロックの3つのセクターのいずれかに存在する物理量子ビット $q_j$ を想像してください。
* 初期化: まず、$q_j$ は通常、計算基底状態 $|0\rangle$ または $|+\rangle$ で初期化される。Z基単発状態準備の場合、すべての物理データ量子ビットは $|+\rangle$ で初期化される。
* スタビライザー相互作用: エラーを検出するために、$q_j$ は様々なスタビライザー測定に関与する。
* X型エラー(Zスタビライザーを使用して)をチェックしている場合、$q_j$ は $H_Z$ の行で定義された他の量子ビットと相互作用する。例えば、$H_Z[i, j] = 1$ の場合、 $q_j$ 上のパウリZ演算子($Z_j$)は $i$ 番目のZスタビライザー生成子の一部である。これには、$q_j$ をアンシラ量子ビットとエンタングルし、その後アンシラを測定することが含まれる。
* 同様に、Z型エラー(Xスタビライザーを使用して)をチェックしている場合、$q_j$ は $H_X$ の行で定義された他の量子ビットと相互作用する。$H_X[i, j] = 1$ の場合、$X_j$ は $i$ 番目のXスタビライザー生成子の一部である。
* シンドローム生成: これらのスタビライザーチェックからの測定結果は「シンドローム」を形成する。$q_j$ がエラー(例えば、Zスタビライザーを測定している場合にパウリXエラー)を経験した場合、それは関与するスタビライザー測定の結果を反転させる。
* デコーディング: シンドローム(二値値のコレクション)はデコーダーに供給される。デコーダーはこの情報を使用して、$q_j$ および他の量子ビットで発生した最も可能性の高いエラーパターンを推測する。
* 訂正: デコーダーの出力に基づいて、訂正操作(例えば、パウリXまたはZゲートの適用)が $q_j$ に適用され、コード空間内の意図された状態に復元される。これにより、誤り訂正の1サイクルが完了する。
2. 論理CCZゲート適用($f_{CCZ}$ を介して):
次に、3つの異なるセクター(I、II、III)のそれぞれに存在する3つの異なる物理量子ビット、$p^I, q^{II}, r^{III}$ を考える。これらの量子ビットは、CCZ操作が望まれる論理状態の一部である。
* 関数への入力: これらの3つの量子ビットの識別子($p^I, q^{II}, r^{III}$)が $f_{CCZ}$ 関数への入力として供給される。
* 代数処理: $f_{CCZ}$ 関数内部で、一連の抽象的な代数演算、特に「カップ積」が実行される。これには、量子ビット識別子を、コードを定義する群代数要素の事前配向分割($a_{in}, a_{out}$)と組み合わせることが含まれる。これは、$\mathbb{F}_2$ 内の複雑な多段階計算である。
* サポート計算: これらのカップ積の結果は代数式である。その「サポート」(ハミング重み)が計算される。これは基本的に、結合された代数エンティティがゼロでないかどうかをチェックする。
* 横断性チェック: 重要な条件 $d_{i \neq j \neq k}$ が暗黙のうちに適用される。これは、3つの入力量子ビットが実際に異なるセクター/ブロックから来ることを保証する。そうでない場合、関数は即座に0を出力する。
* ゲート決定: 最終結果(2を法として取られる)は0または1のいずれかである。
* $f_{CCZ}(p^I, q^{II}, r^{III}) = 1$ の場合、物理CCZゲートが量子ビット $(p^I, q^{II}, r^{III})$ に適用される。このゲートは3つの量子ビットすべてに同時に作用する。
* $f_{CCZ}(p^I, q^{II}, r^{III}) = 0$ の場合、この特定のトリプルにはゲートは適用されない。
* 回路実行: このプロセスは、コードブロック全体にわたる関連する量子ビットのトリプルのすべてに対して繰り返される。$f_{CCZ}$ によって決定される物理CCZゲートの全体のコレクションは、「定深」回路を形成する。これは、コードサイズに関係なく、これらのすべてのゲートを固定された少数の並列レイヤーでスケジュールできることを意味する。これにより、高速な実行が保証され、エラー伝播が制限される。
各トリサイクルコードブロックの物理量子ビットは、式(1)のパリティチェック行列のブロック構造に従って、3つのセクターに自然に分割できる。コード空間を保存するCCZ回路は、図1に示すように、常に3つのコードブロックのセクター間で作用する。
最適化ダイナミクス
この論文における「学習」または「最適化」は、勾配を介して連続的な損失ランドスケープを反復的にパラメータを更新する、典型的な機械学習とは異なり、離散的で代数的な空間内での最適なコードパラメータと回路構築の多面的な設計と探索プロセスである。
1. コードパラメータ探索:
論文は、パリティチェック行列 $H_X$ および $H_Z$ のために特定の群代数要素($a, b, c$)とその重み($w_a, w_b, w_c$)を選択することによって、トリサイクルコードを構築することを説明している。これは、与えられたブロック長 $N$ に対して有利なパラメータ(高レート $K$ と距離 $D$)を持つコードを見つけるための探索問題である。著者らは、SATソルバーや混合整数プログラム(MIP)を含む数値的手法を使用して、候補コードの最小距離 $D_X$ と $D_Z$ を見つける。これは、離散的な選択肢に対する網羅的またはヒューリスティックな探索であり、勾配ベースの最適化ではない。ここでの「損失」は望ましくないコードパラメータ(例:低い距離)であり、「更新」は異なる群代数要素のセットを試すことである。
2. CCZ回路構築(対称トリプルカップ積 - STCP):
対称トリプルカップ積から派生した $f_{CCZ}$ 関数については、「最適化」には群代数要素の「事前配向」($a_{in}, a_{out}, a_{free}$)を慎重に選択することが含まれる。これらの選択は、「対称統合ライプニッツ則」(Eqs. D15-D19)として知られる一連の代数条件を満たす必要がある。論文は、重み4要素のためのこれらの事前配向を構築するための処方箋(定理D1)を提示している。これは、望ましい特性(コード空間を保存し、コバウンダリー不変)を持つ回路につながることを保証する設計原則であり、反復学習プロセスではない。 「ダイナミクス」は、これらの条件の導出と、それらが有効な回路につながるという証明にある。目標は、短い深さのCCZ回路をもたらす事前配向を見つけることである。
3. CCZ回路構築(数値ライプニッツ則 - NLR):
付録Eは、「数値ライプニッツ則」法を導入している。ここでは、プロセスは探索アルゴリズムにさらに近い。
* 基底構築: 群同変3重線形関数 $f_i^j$ の基底セットが構築される。これには、「一般化ライプニッツ則」(Eq. E5)の条件をエンコードするパリティチェック行列 $H_{leibniz}$ のヌル空間を見つけることが含まれる。これは線形代数問題であり、反復最適化ではない。
* ヒューリスティック探索: 実際の $f_{CCZ}$ 関数は、これらの $f_i^j$ 関数の候補をランダムに探索することによって構築される。「最適化」目標は、$f_{CCZ}$ 関数の最大次数が低くなる候補を見つけることであり、これは直接回路深さの短縮につながる。これはヒューリスティック探索であり、モンテカルロサンプリングや焼きなまし法などの技術を使用して、可能な関数の離散空間を探索する可能性がある。「損失ランドスケープ」は非常に不規則で非凸であり、従うべき明確な勾配はない。
4. 論理回路最適化($K_{CCZ}$ の最大化):
付録Fは、ハイパーグラフマジック状態から抽出できる互いに素なCCZマジックゲートの数($K_{CCZ}$)を最大化するために、論理的CCZ回路を最適化することを説明している。これは、論理接続を表す二値3テンソル $T_{ijk}^{log}$ の「サブランク」を見つける問題として定式化されている。
* 問題定式化: これはNP困難な問題である。著者らは、二値変数(基底変換行列 $M^1, M^2, M^3$ の代入を表す)の可能な割り当てを探索して、$r$ 個の互いに素なCCZゲート(Eq. F3)の条件を満たすために、混合整数プログラム(MIP)ソルバー(Gurobi)を使用している。ここでの「状態」は基底行列のセットであり、「更新」はソルバーの内部メカニズムが解空間を探索することである。これは離散最適化であり、勾配ベースのものではない。「損失」は、与えられた $r$ に対して解を見つけられないこと、または低い $r$ の解を見つけることである。「収束」は、ソルバーが実行可能な解を見つけるか、タイムアウトすることである。
本質的に、「最適化ダイナミクス」は、代数導出、体系的な構築、および離散空間でのヒューリスティックまたは正確な探索の組み合わせによって特徴付けられる。目標は、勾配降下ではなく、固有の耐故障性特性と効率的な性能を持つコードと回路を設計することである。「損失ランドスケープ」はしばしば離散的で非凸であり、ナビゲートするために特殊なソルバーまたは巧妙な設計原則を必要とする。
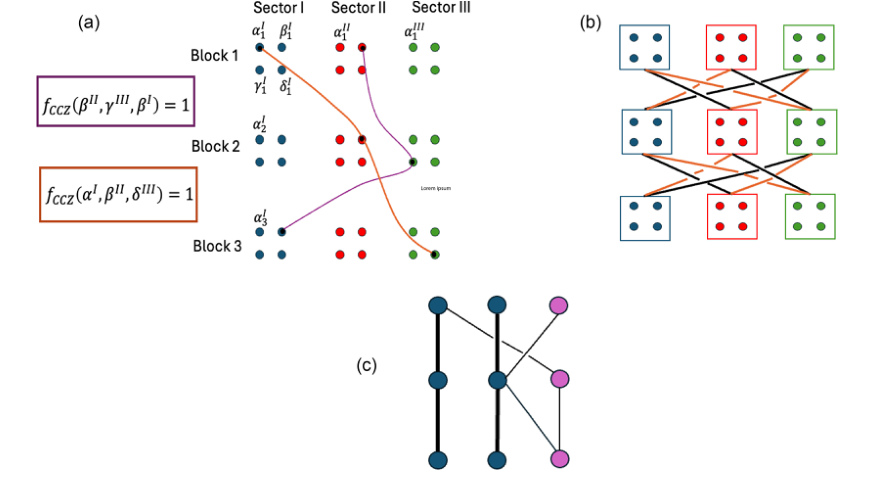 FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
 FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
結果、限界、結論
実験設計とベースライン
著者らは、トリサイクルコードに関する数学的主張を厳密に検証するために、その実験を細心の注意を払って設計した。彼らのコアアプローチは、現実的な回路レベルノイズモデルの下でのこれらのコードの数値シミュレーションに焦点を当て、確立されたベースラインと比較した。
トリサイクルコードの有効性を証明するために、実験設計はいくつかの重要な側面に焦点を当てた。
1. コード構築とプロパティ: 彼らは、トリサイクルコードを、バイサイクルコードを3つのホモロジカル次元に一般化した、有限ブロック長量子低密度パリティチェック(LDPC)コードとして導入した。これらのコードは、論理CCZゲートを実装するための定深物理回路をサポートするように設計された。構築には、修正された対称トリプルカップ積形式(付録D)および数値ライプニッツ則法(付録E)を含む新しい解析的および数値的手法が含まれ、有利なパラメータ(高レートと距離)と短深さのCCZ回路を持つコードを見つけることができた。
2. ノイズモデル: 標準的な2量子ビットデポリライジングノイズモデルが採用され、各エンタングルメント操作の後に、確率 $p_{2q}$ で15の非自明な2量子ビットパウリエラーのいずれかが続く。重要なCCZゲートについては、3量子ビットバイアス付きデポリライジングノイズモデルが使用され、物理エラー率 $p_{3q} = 0.002$ が仮定された。この $p_{3q}$ は、多くの量子プラットフォームにおけるネイティブ位相型ゲートの特性を反映して、2量子ビットエンタングルメントゲートの2倍であると保守的に推定された。さらに、モデルはCCZゲートのZ型エラーへの強いバイアス(10倍可能性が高い)を組み込んだ。
3. デコーディング戦略:
* 単発Z基誤り訂正(状態準備に不可欠)については、ウィンドウデコーディングプロトコルが採用された。これには、Belief Propagation + Ordered Statistics Decoding (BP + OSD) スキームを使用した合計42ラウンドのシンドローム抽出の3ラウンドが含まれた。
* dラウンドX基誤り訂正(メモリ性能のため)については、従来のdラウンドプロトコルが使用され、累積シンドローム情報の完全な記録が最大尤度誤り(MLE)デコーダーでデコードされた。ポストセレクションについては、BP + LSD(Localized Statistics Decoding)と組み合わせたクラスターベースのポストセレクション方法が使用された。
4. 実装プロトコル: 再構成可能な中性原子アレイプラットフォームでのシンドローム抽出回路を効率的に実装するための具体的なプロトコルが提示された(図5、付録I)。これには、詳細な原子再配置手順とCNOTスケジューリングが含まれた。
トリサイクルコードと ruthlessly 比較された「犠牲者」(ベースラインモデル)は、主にカラーコードに基づいた最先端のマジック状態育成スキーム(Ref. [36]からの [[7, 1, 3]] および [[19, 1, 5]] カラーコード)であった。これらの従来のスキームは通常、複数回の蒸留と連結を必要とし、実質的な時空間オーバーヘッドにつながった。著者らはまた、パラメータが不利なコード(例:$K=3$ および $D=2$ の2-2-2コード)をもたらした以前のカップ積構築(Ref. [27])を暗黙のうちに挑戦した。
証拠が証明すること
本論文で提示された証拠は、トリサイクルコードがマジック状態生成のための非常に効率的で堅牢なソリューションを提供し、主要な指標において既存のベースラインを上回ることを断定的に証明している。
- 堅牢な性能と高い閾値: 回路レベルノイズ下での数値シミュレーションは、4-2-2ファミリのトリサイクルコードに対して >0.5% の高い回路ノイズ閾値を示した(図4b)。これは、物理エラーに対するそれらの耐性の強力な指標である。
- メモリに対する卓越した論理誤り率: 完全な誤り検出と適度なポストセレクション(例:30%の受け入れ率)により、最小の [[48, 6, 4]] トリサイクルコードは、 $p_{2q} = 0.001$ の2量子ビットゲートエラー率で、約 $6 \times 10^{-10}$ の論理メモリ誤り率を達成した。より大きな [[84, 6, 5]] コードでは、論理メモリ誤り率は、約9%の受け入れ率で $p_{2q} = 0.001$ で < $10^{-13}$ と推定された。これらの数値は、量子メモリに対して非常に高い忠実度を表している。
-
優れたマジック状態生成忠実度とコスト: トリサイクルコードは、驚くほど低い論理誤り率でハイパーグラフマジック状態を生成した。
- [[48, 6, 4]] トリサイクルコード: $2 \times 10^{-8}$
- [[84, 6, 5]] トリサイクルコード: $4 \times 10^{-10}$
- [[108, 6, 6]] トリサイクルコード: 約 $3 \times 10^{-11}$
決定的に、これらの印象的な忠実度は、最先端のカラーコードベースのマジック状態育成スキーム(表II)と比較して、同等またはそれ以下の時空間コストで達成された。例えば、[[48, 6, 4]] トリサイクルコードは、論理量子ビットあたり89量子ビットラウンドの時空間コストを持ち、[[7, 1, 3]] カラーコード育成の90量子ビットラウンドよりも大幅に低く、はるかに低い論理誤り率($2 \times 10^{-8}$ 対 $6 \times 10^{-7}$)を達成した。これは、単発マジック状態生成のために高レート、高距離のLDPCコードと横断非クリフォードゲートを使用するというコアメカニズムが実際に機能することの否定できない証拠である。
-
単発状態準備: 数値証拠(図3)は、Z基における単発状態準備の論理誤り率がコード距離の増加とともに指数関数的に抑制されることを明確に示している。これは、トリサイクルコードが定数ラウンドで耐故障性のある論理 $|+\rangle$ 状態の準備を可能にすることを確認しており、多くの他のコードで必要とされる $O(d)$ ラウンドよりも大幅な改善である。この定深準備は、定深論理CCZ操作と組み合わされて、定深で高忠実度のハイパーグラフマジック状態をもたらす。
- 定深CCZ回路: トリサイクルコードの構築は、定深物理CCZ回路(例:4-2-2コードの場合は深さ8)の生成に成功し、これは耐故障性操作に不可欠であり、エラー伝播を制限する。定深CCZ回路は、純粋なメモリ設定からの論理忠実度の最終的なずれに対して最小限の影響しか与えないことが示された。
- 高マジック状態収量: 表Iのすべてのコードについて、生成されたハイパーグラフマジック状態から $K_{CCZ} \ge 2$ の互いに素な論理CCZゲートを抽出できる能力は、これらのコードがマジック状態工場として実用的であることの実証である。
著者らの厳密なシミュレーション、強力なベースラインとの比較、および論理誤り率と時空間コストの詳細な分析は、トリサイクルコードが効率的で耐故障性のあるマジック状態生成における大幅な進歩を表すという説得力のある証拠を提供している。
限界と将来の方向性
トリサイクルコードは効率的で耐故障性のある量子計算への有望な経路を提供する一方で、本論文はいくつかの限界を強調し、多様な将来の研究および開発の方向性を開いている。
現在の限界:
- $K_{CCZ}$ 抽出の最適性: ハイパーグラフマジック状態から互いに素なCCZゲートの最大数($K_{CCZ}$)を見つける問題はNP困難である。現在の混合整数プログラミング法は劣最適解をもたらし、しばしばより大きな $K_{CCZ}$ 値に対してタイムアウトするため、報告された値は下限である。これはCCZ型マジック状態のマジック状態生成の即時スループットを制限する。
- コードファミリの漸近的優秀性: コードのファミリーを定義することを可能にする構築にもかかわらず、それは漸近的に優秀である可能性は低い。より大きなブロック長を持つより大きな距離を持つコードが期待されるが、これは正式な漸近的保証ではない。
- より大きなコードのためのより深いCCZ回路: より大きな4-4-2および4-4-4トリサイクルコードの場合、より深い物理CCZ回路(例:一部の4-4-4コードでは深さ128)は、論理忠実度がメモリ設定からより大きなずれをもたらす可能性がある。繰り返しコードとの連結は深さを減らすことができるが、コードレートのコストがかかる。
- 数値ライプニッツ則法の保証: CCZ回路を構築するための数値ライプニッツ則法のより徹底的な探索は、コードの探索と方法の組み合わせを必要とする低次回路を保証しない。
- 選択的状態初期化: 互いに素なCCZゲートを抽出するには、ゲージ論理量子ビットを $|0\rangle$ 状態に、他の論理量子ビットを $|+\rangle$ 状態に選択的に初期化する必要があるが、これはLDPCコードでは定深で単純ではない。
- 不均衡な距離: トリサイクルコードは、Z基よりもX基で自然に高い距離を示す。ノイズバイアスのあるプラットフォームに有用である可能性があるが、このバイアスを実験性能を向上させるためにどのように活用できるかの詳細な探求は、将来の研究に残されている。
将来の方向性と議論トピック:
-
強化されたデコーディング戦略:
- 標準的なBP+OSD/BP+LSDと正確なMLEデコーダーとの間のオーダーの大きさのギャップの観測は、新しい、より効率的なデコーダーの重大な必要性を示唆しており、これらは実用的な推論時間を維持しながらMLE性能に近づくことができる。これには、機械学習ベースのデコーダーや高度な統計的手法の探求が含まれる可能性がある。
- ノイズバイアスを狙った活用: 中性原子などの実験プラットフォームにおけるノイズバイアスの普及(例:Z型エラー)と、XおよびZセクターの非対称性を考慮すると、将来の研究は、ノイズバイアスを直接デコーディングアルゴリズムとシンドローム抽出回路に統合することに焦点を当てるべきである。最大性能向上を得るために、特定のハードウェアノイズ特性を活用するように回路とデコーダーを最適に設計するにはどうすればよいか?
- 損失と漏洩管理: 多くのハードウェアアーキテクチャは、損失と漏洩エラーに悩まされている。トリサイクルコードフレームワーク内でこれらのエラーを活用または軽減するための明示的な戦略を開発することは、論理誤り率をさらに改善する可能性がある。これには、新しい測定プロトコルや誤り訂正技術が含まれる可能性がある。
-
マジック状態工場のスループット最適化:
- $K_{CCZ}$ 抽出の改善: 論理テンソル $T^{log}$ のサブランクを見つけるNP困難な問題は、主要なボトルネックである。CCZ型マジック状態の抽出効率を大幅に向上させるために、二値テンソルサブランク問題のための的を絞ったヒューリスティック最適化戦略を開発することが不可欠である。実用的な目的で十分な近似解を見つけることができるか?
- ハイパーグラフマジック状態の直接コンパイル: 互いに素なCCZゲートを抽出する代わりに、生成されたハイパーグラフマジック状態の構造をより深く理解することで、これらの高マジックリソース状態を利用するための代替的で潜在的に効率的なルートである、有用な量子回路への直接コンパイルが可能になる可能性がある。
-
広範な量子アーキテクチャへの統合:
- シームレスなマジック状態注入/テレポート: 主要な未解決問題は、トリサイクルコード工場から計算コードブロック(例:高性能バイサイクルコード)への蒸留されたマジック状態のシームレスな注入またはテレポートである。トリサイクルコードとバイサイクルコード間の自然な同型性に基づく横断テレポートの探求は、3Dおよび2Dカラーコードのプロトコルと同様に、有望な方向性である。そのようなコードスイッチングプロトコルに伴う実用的な課題とオーバーヘッドは何であるか?
- モジュラーアーキテクチャ: トリサイクルコードは、高度にモジュラーな耐故障性量子コンピューティングアーキテクチャにどのように統合できるか?これには、マジック状態生成だけでなく、より大きなシステム内での効率的な論理操作、通信、およびメモリも含まれる。
-
高度なコード構築と回路最適化:
- 数値ライプニッツ則のさらなる探求: 数値ライプニッツ則法のより徹底的な探求と、他の3D平衡積コードへの適用は、さらに短い深さのCCZ回路を持つコードをもたらす可能性がある。低次回路を保証するために、より良いハイパーパラメータまたは探索戦略を開発できるか?
- シンドローム抽出回路最適化: 本論文は最適深さのシンドローム抽出回路を提示している。再構成可能な中性原子プラットフォームでのセクターレイアウトと原子移動スキームのさらなる最適化は、数学的プログラミングまたはグラフ理論を使用して、時空間オーバーヘッドを削減する可能性がある。
- 他のLDPCファミリとの比較: トリサイクルコードと他の最近提案されたLDPC構築(例:エクスペンダーコードまたは代数層のホモロジカル積に基づくもの)のオーバーヘッドと性能の直接的な詳細な比較は、各コードの相対的なメリットと最適な適用シナリオに関する貴重な洞察を提供するだろう。
これらの議論トピックは、耐故障性量子コンピューティングを進歩させる上での継続的な課題とエキサイティングな機会を強調しており、トリサイクルコードは重要なステップストーンとして機能している。理論的進歩、実験的能力、およびアルゴリズム最適化の相互作用が、これらの発見の可能性を最大限に引き出す鍵となるだろう。
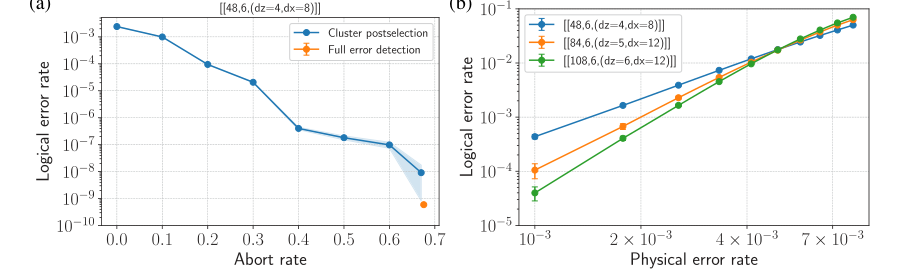 FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
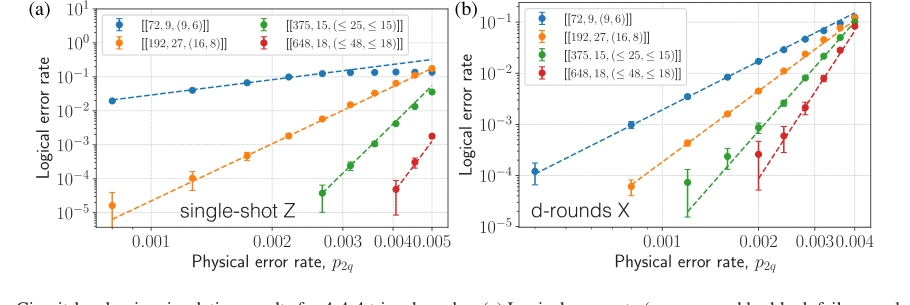 FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
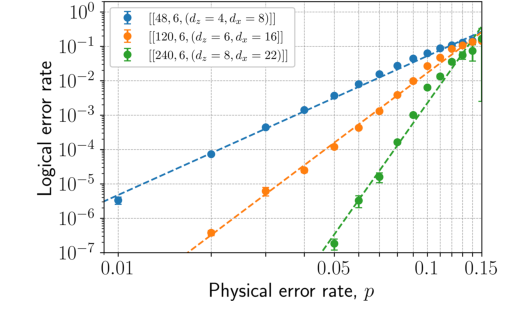 FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples
FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples