Magic Tricycles: 유한 블록 길이 양자 LDPC 코드를 이용한 효율적인 매직 상태 생성
The preparation of high-fidelity non-Clifford (magic) states is an essential subroutine for universal quantum computation but imposes substantial space-time overhead.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제는 보편적인 내결함성 양자 계산을 달성하기 위한 근본적인 요구사항에서 비롯된다. Eastin과 Knill의 기념비적인 결과 [2]는 양자 오류 정정 코드 내에서 보편적인 양자 게이트 집합을 순수하게 횡단적으로(즉, 각 큐비트에 독립적으로 동일한 물리적 게이트를 적용하여) 구현하는 것이 불가능함을 확립했다. 이 제한은 "매직 게이트"라고도 불리는 비-클리포드 게이트가 특별히 준비된 비-클리포드 자원 상태를 코드 공간으로 텔레포트하는 등의 다른 수단을 통해 구현되어야 함을 의미한다.
이러한 고충실도 자원 상태를 준비하는 주요 방법은 매직-상태 증류(Magic-State Distillation, MSD)로 알려져 있다. 역사적으로 MSD 프로토콜, 예를 들어 15-대-1 증류 방식 [3]은 매우 많은 자원을 요구했으며, 반복적인 증류와 내부 코드와의 연결을 여러 단계에 걸쳐 수행해야 했다. 이 과정은 전체 시공간 오버헤드에 크게 기여하며, 심지어 쇼어 알고리즘 [4,5]과 같은 알고리즘에서도 매직-상태 생성은 최첨단 내결함성 아키텍처의 총 큐비트 및 게이트 수에서 지배적인 부분을 차지하는 것으로 추정된다. 본 연구의 핵심 동기는 이러한 오버헤드를 대폭 줄이는 것이다.
지난 10년간 연구자들은 MSD 오버헤드를 줄이기 위해 횡단적인 비-클리포드 게이트를 갖는 양자 코드를 설계하는 데 진전을 이루었다 [6-9]. 그러나 이러한 초기 접근 방식은 상당한 한계에 직면했다. 제안된 저오버헤드 증류 방식 중 다수는 높은 가중치의 패리티 검사에 의존했는데, 이는 신드롬 추출 회로의 깊이가 코드의 블록 길이에 따라 증가함을 의미했다. 이로 인해 회로 수준의 노이즈에 대해 본질적으로 내결함성이 없었으며 지수적인 임계값 이하의 오류 억제를 방해했다. 또한, 이러한 방식은 종종 암묵적으로 노이즈 없는 클리포드 연산을 가정했는데, 이는 내부 코드의 높은 거리를 필요로 함으로써 실제 오버헤드를 더욱 부풀리는 비현실적인 가정이었다. 클리포드 인코딩 및 디코딩 회로 역시 물리적 큐비트 수에 선형적으로 비례하는 깊이를 가졌으며, 이는 상당한 시간적 오버헤드를 초래했다.
양자 저밀도 패리티 검사(Quantum Low-Density Parity-Check, qLDPC) 코드는 희소한 안정자 검사와 비율 및 거리의 유리한 스케일링으로 인해 양자 오류 정정 비용을 줄이는 유망한 경로로 부상했다. qLDPC 코드는 양자 메모리에 대해 탐구되었지만 [12,13], 매직-상태 생성에 대한 적용은 최근에야 시작되었다. 이는 횡단적인 비-클리포드 게이트를 호스팅할 수 있는 qLDPC 코드를 구성하는 것이 어렵다는 것이 입증되었기 때문이다. 예를 들어, 매직-상태 생성을 위한 호몰로지 곱 코드의 이전 구성은 고전적 코드에 비해 코드 크기가 세제곱으로 증가하기 때문에 [5페이지, 왼쪽 열, 첫 번째 문단] 좋은 매개변수를 가진 가장 작은 블록 길이에 대해 수천 또는 수만 개의 물리적 큐비트를 요구하는 경우가 많았다. 이 많은 큐비트 수는 주요 문제점이었다.
본 논문은 효율적이고 내결함성 있는 매직-상태 생성을 지원하도록 특별히 설계된 유한 블록 길이 양자 LDPC 코드의 새로운 클래스인 "트라이사이클 코드"를 도입함으로써 이러한 한계를 직접적으로 해결한다. 이 코드들은 이전 방법들의 높은 오버헤드와 내결함성 문제를 극복하면서 매직-상태 증류에 필수적인 횡단적인 논리적 CCZ(Controlled-Controlled-Z) 게이트 동작을 가능하게 하도록 구성된다.
직관적인 도메인 용어
-
매직 상태 (Magic States): 복잡한 비디오 게임을 하고 있다고 상상해 보세요. 대부분의 행동은 걷기, 점프, 간단한 공격(클리포드 게이트)과 같은 기본 동작입니다. 하지만 강력하고 게임을 바꿀 수 있는 특수 동작(슈퍼 콤보나 순간이동과 같은)을 수행하려면 특정 "파워업" 아이템이 필요합니다. 이러한 "파워업" 아이템은 양자 컴퓨팅의 매직 상태와 같습니다. 이는 기본 연산을 넘어서는 기능을 잠금 해제하여 보편적인 계산을 가능하게 하는 특별한 양자 상태입니다.
-
매직-상태 증류 (Magic-State Distillation, MSD): 비디오 게임 비유를 계속하자면, 때로는 혼자서는 그다지 효과적이지 않은 약하고 품질이 낮은 "파워업" 아이템을 많이 찾을 수 있습니다. 매직-상태 증류는 이러한 많은 노이즈가 많고 품질이 낮은 파워업을 가져와 결합하여 훨씬 더 강력하고 고품질의 파워업을 적은 수로 생산하는 "정제 과정"과 같습니다. 목표는 매우 순수하고 신뢰할 수 있는 특수 동작을 얻는 것입니다.
-
양자 저밀도 패리티 검사 (Quantum Low-Density Parity-Check, qLDPC) 코드: 수백만 권의 책이 있는 도서관을 생각해 보세요. 잘못 놓인 책(오류)을 확인하기 위해 기존 시스템은 모든 사서가 모든 선반을 확인해야 할 수 있습니다. qLDPC 코드는 각 사서("검사")가 책의 작고 특정하며 흩어진 세트에 대한 검증만 책임지는 스마트 오류 검사 시스템과 같습니다. 이러한 연결의 "저밀도"는 시스템을 구축, 확장 및 관리하기 쉽게 만들어 덜 복잡한 하드웨어로 더 강력한 오류 감지를 가능하게 합니다.
-
횡단적 게이트 (Transversal Gate): 요리사 팀이 있고 각 요리사가 요리를 준비하고 있다면, 횡단적 게이트는 각 요리사에게 동시에 자신의 개별 요리에 정확히 동일한 간단한 단계를 수행하도록 지시하는 것과 같습니다. 예를 들어, "모두 소금을 약간 넣으세요." 핵심은 각 요리사가 자신의 요리에 독립적으로 행동하므로 한 요리사의 실수가 다른 요리사의 실수로 쉽게 퍼지지 않는다는 것입니다. 양자 컴퓨팅에서는 코드 블록의 각 큐비트에 물리적 게이트를 적용하는 것을 의미하며, 이는 자연스럽게 오류 전파를 제한하고 연산을 내결함성으로 만듭니다.
-
CCZ 게이트 (Controlled-Controlled-Z): 세 개의 큐비트를 포함하는 특정 유형의 매직 게이트입니다. 세 개의 잠금 장치가 있는 비밀 금고를 상상해 보세요. CCZ 게이트는 세 개의 잠금 장치 모두가 동시에 잠겨야만 활성화되는 메커니즘과 같습니다. 잠금 장치 중 하나라도 잠겨 있지 않으면 아무 일도 일어나지 않습니다. 이 "삼중 제어"는 양자 계산에서 매우 복잡하고 강력한 연산을 가능하게 합니다.
표기법 표
| 표기법 | 설명 |
|---|---|
| $N$ | 코드 블록의 총 물리적 큐비트 수. |
| $K$ | 코드 블록에 인코딩된 논리적 큐비트 수. |
| $D$ | 양자 코드의 최소 거리, 오류 정정 능력을 나타냄. $D_X$ 및 $D_Z$는 각각 X 및 Z 기저에서의 거리를 나타냄. |
| $H_X$ | X 안정자 생성기를 정의하는 X 유형 패리티 검사 행렬. |
| $H_Z$ | Z 안정자 생성기를 정의하는 Z 유형 패리티 검사 행렬. |
| $A, B, C$ | 그룹 대수 요소에서 파생된 $n_G \times n_G$ 이진 순열 행렬, 트라이사이클 코드 내의 연결 패턴을 정의함. |
| $O$ | $n_G \times n_G$ 영행렬. |
| $\mathbb{F}_2$ | 이진 필드 $\{0,1\}$, 여기서 산술은 모듈로 2로 수행됨. |
| $n_G$ | 각 섹터의 선형 크기, 유한 아벨 군 $G$의 위수와 같음. 총 물리적 큐비트 $N = 3n_G$. |
| $f_{CCZ}$ | 횡단적 CCZ 회로를 정의하는 삼선형 이진 함수. $f_{CCZ}(p^I, q^{II}, r^{III}) = 1$은 물리적 CCZ 게이트가 큐비트 $p^I, q^{II}, r^{III}$에 적용됨을 의미함. |
| $\cup$ | 대수적 위상학에서 오는 컵 곱 연산자, 횡단적 비-클리포드 게이트 구성을 위해 사용됨. |
| $a_{in}, a_{out}, a_{free}$ | 그룹 대수 요소의 "입력", "출력", "자유" 분할(사전 방향), 컵 곱 정의 및 코드 공간 보존 CCZ 회로 보장에 필수적임. |
| $|...|_{d_{i \neq j \neq k}}$ | 인수의 해밍 가중치(지원 크기)를 나타내며, CCZ 게이트의 경우 큐비트가 서로 다른 섹터에서 와야 한다는 조건이 있음. |
| $\pmod{2}$ | 모듈로 2 산술, 게이트 적용에 대한 이진 출력을 보장함. |
| $p_{2q}$ | 두 큐비트 얽힘 게이트(예: CNOT)의 물리적 오류율. |
| $p_{3q}$ | 세 큐비트 CCZ 게이트의 물리적 오류율. |
| $K_{CCZ}$ | 하이퍼그래프 매직 상태에서 추출할 수 있는 독립적인 논리적 CCZ 게이트의 최대 수. |
| STCP | 대칭 삼중 컵 곱 형식론, CCZ 회로 구성을 위한 분석 방법. |
| NLR | 수치적 라이프니츠 규칙 방법, CCZ 회로 구성을 위한 보완적인 수치적 방법. |
| MSD | 매직-상태 증류, 고충실도 비-클리포드 자원 상태 준비를 위한 프로토콜. |
| qLDPC | 양자 저밀도 패리티 검사 코드. |
| CSS | Calderbank-Shor-Steane 코드, 양자 오류 정정 코드의 한 종류. |
| MLE | 최대 가능도 오류 디코더. |
| BP + LSD | Belief Propagation + Localized Statistics Decoding, 효율적인 근사 디코더. |
| BP + OSD | Belief Propagation + Ordered Statistics Decoding, 또 다른 근사 디코더. |
| AOD | Acousto-Optical Deflector, 중성 원자 배열에서 원자 이동에 사용됨. |
| SLM | Spatial Light Modulator, 큐비트 트랩 생성에 사용됨. |
| $t_{wsp}, t_{ent}$ | 작업 공간 및 얽힘 영역에서의 AOD 이동에 대한 시간 오버헤드. |
| $d_{min}$ | 최소 광학 분해 거리, 큐비트 밀도 및 이동 속도를 제한함. |
| $d_{iso}$ | 라이버그 상호작용의 격리 거리, 의도된 CNOT 쌍을 보장함. |
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문이 다루는 핵심 문제는 보편적인 내결함성 양자 계산에 필수적인 고충실도 비-클리포드(매직) 상태의 비효율적이고 자원 집약적인 생성입니다.
입력/현재 상태:
보편적인 양자 계산은 클리포드 및 비-클리포드 연산 모두에 의존합니다. 논리적 클리포드 게이트는 종종 많은 양자 오류 정정 코드에서 횡단적으로 구현될 수 있지만, Eastin-Knill 정리는 보편적인 게이트 집합이 횡단적으로 구현될 수 없다고 규정합니다. 결과적으로 비-클리포드 게이트(매직 게이트)는 일반적으로 특별히 준비된 비-클리포드 자원 상태를 코드 공간으로 텔레포트함으로써 구현됩니다. 이러한 고충실도 자원 상태를 준비하는 최첨단 방법인 매직-상태 증류(MSD)는 다음과 같은 상당한 단점을 가지고 있습니다.
1. 상당한 시공간 오버헤드: MSD 프로토콜, 예를 들어 15-대-1 증류는 반복적인 증류와 내부 코드와의 연결을 여러 단계에 걸쳐 수행해야 합니다. 이는 쇼어 알고리즘과 같은 대규모 양자 알고리즘의 총 큐비트 및 게이트 수에서 매직-상태 생성이 지배적일 것으로 추정됩니다.
2. 이전 "저오버헤드" 방식의 내결함성 손상: 저오버헤드 MSD 프로토콜에 대한 최근 제안은 횡단적인 비-클리포드 게이트를 달성했지만, 종종 높은 가중치의 패리티 검사를 동반합니다. 이는 코드 블록 길이에 따라 깊이가 증가하는 신드롬 추출 회로를 필요로 하며, 회로 수준 노이즈에 대해 본질적으로 내결함성이 없게 만듭니다.
3. 비현실적인 가정: 많은 기존 프로토콜은 인코딩 및 디코딩 회로에 대한 노이즈 없는 클리포드 연산을 암묵적으로 가정하는데, 이는 보고된 오버헤드를 과장합니다. 이러한 클리포드 회로는 물리적 큐비트 수에 선형적으로 비례하는 깊이를 가질 수도 있으며, 이는 상당한 시간적 오버헤드를 초래합니다.
원하는 최종 상태 (출력/목표 상태):
본 논문은 현재 방법과 관련된 시공간 오버헤드를 크게 줄이는 효율적이고 내결함성 있는 매직-상태 생산을 달성하는 것을 목표로 합니다. 구체적으로 목표는 다음과 같습니다.
1. 고충실도 및 처리량으로 매직 상태 생성: 쇼어 알고리즘과 같은 실제 응용을 위해 $2 \times 10^{-8}$에서 $3 \times 10^{-11}$ 미만의 논리적 오류율로 매직 상태를 생성합니다.
2. 유한 블록 길이 코드 사용: 실험적으로 실현 가능하도록 약 50-100 큐비트의 블록 길이를 가진 코드를 사용합니다.
3. 상수 깊이 회로 지원: 코드 크기에 독립적인 상수 깊이의 물리적 회로를 사용하여 논리적 CCZ 게이트 및 신드롬 추출을 구현합니다.
4. 단일 샷 상태 준비 및 오류 수정 활성화: 매직-상태 준비 회로의 초기 논리적 상태를 상수 깊이로 준비할 수 있도록 하고, 한 기저에서 반복적인 신드롬 추출 없이 오류를 수정할 수 있도록 합니다.
5. 연결 회피: 클리포드 게이트를 횡단적으로 지원하는 내부 코드와의 연결의 필요성을 제거하여 전체 아키텍처를 단순화합니다.
누락된 연결 및 수학적 격차:
정확한 누락된 연결은 높은 비율, 높은 거리, 그리고 상수 깊이 횡단적 비-클리포드 게이트(특히 CCZ 게이트)를 지원하면서도 단일 샷 오류 수정을 가능하게 하는 양자 저밀도 패리티 검사(qLDPC) 코드를 구성하는 것입니다. 이전 qLDPC 코드 연구는 횡단적 비-클리포드 게이트 요구 사항으로 어려움을 겪었습니다.
본 논문은 "트라이사이클 코드"를 소개함으로써 이 격차를 해소하려고 합니다. 이는 유한 블록 길이, 고율, 고거리 양자 LDPC 코드의 새로운 클래스로, 효율적이고 내결함성 있는 매직-상태 생성을 지원하도록 특별히 설계되었습니다. 이 코드들은 횡단적인 논리적 CCZ 게이트 동작을 가능하게 하도록 구성되어 있으며, 이는 매직-상태 증류에 필수적이며 이전 방법들의 높은 오버헤드 및 내결함성 문제를 극복합니다.
제약 조건 및 실패 모드
효율적이고 내결함성 있는 매직-상태 생성 문제는 물리적, 계산적, 데이터 기반 제약 조건의 조합과 내재된 실패 모드로 인해 매우 어렵습니다.
물리적 제약 조건:
1. 큐비트 오류율 및 노이즈 편향: 물리적 CCZ 게이트는 특정 오류율(예: $p_{3q} = 0.002$)을 가지며, 이는 두 큐비트 얽힘 게이트($p_{2q} = 0.001$)의 두 배입니다. 또한, 기본 위상 유형 게이트(CCZ와 같은)는 Z 유형 오류에 강하게 편향된 노이즈 프로파일을 나타내며, 이는 오류 모델에서 고려되어야 합니다.
2. 하드웨어 메모리 한계: "유한 블록 길이" 코드(예: 50-100 큐비트)의 필요성은 코드 블록에 사용 가능한 물리적 큐비트 수에 대한 실질적인 한계를 의미합니다.
3. 실시간 지연 요구 사항: "단일 샷" 상태 준비 및 오류 수정에 대한 요구는 특히 CCZ 게이트가 X 오류를 CZ 오류로 전파할 수 있기 때문에 오류가 확산되고 축적되는 것을 방지하는 데 중요합니다. 이는 디코딩 및 수정 주기에 엄격한 지연 요구 사항을 부과합니다.
4. 중성 원자 배열 플랫폼 한계: 재구성 가능한 중성 원자 배열에 대한 제안된 구현은 특정 제약 조건을 도입합니다.
* 트랩 간격: 병렬 CNOT에 관여하는 큐비트 쌍은 동일한 섹터 내의 의도하지 않은 상호작용을 방지하기 위해 충분한 거리($d_{iso}$, 예: 10 µm)로 분리되어야 합니다.
* 광학 해상도($d_{min}$): 최소 광학 분해 거리(예: 2 µm)는 큐비트 순열의 속도와 밀도를 제한합니다.
* AOD 이동 타이밍: 순열(x, y, z 순환) 및 가져오기/넣기 작업에 대한 원자 광학 편향기(AOD) 이동에는 관련 시간 오버헤드($t_{wsp}, t_{ent}$)가 있으며, 이는 전체 회로 깊이에 기여합니다.
5. Eastin-Knill 정리: 이 기본 정리는 보편적인 횡단적 게이트 집합을 방지하여 매직 상태 사용을 강제하며, 따라서 비-클리포드 연산에 복잡성을 더합니다.
계산 제약 조건:
1. 코드 거리 및 부분 순위 문제의 NP-난해성:
* 정확한 코드 거리 찾기는 선형 코드에 대해 NP-난해 문제이며, 더 큰 트라이사이클 코드의 성능을 정확하게 특성화하는 것을 계산적으로 어렵게 만듭니다.
* 이진 텐서의 부분 순위 찾기(하이퍼그래프 매직 상태에서 독립적인 CCZ 게이트의 최대 수를 추출하는 것에 해당)도 NP-난해입니다. 이는 생성된 매직 상태의 전체 잠재력을 효율적으로 추출하는 능력을 제한합니다.
2. 솔버 시간 초과: 논리적 회로 최적화(예: $K_{CCZ}$에 대한 혼합 정수 프로그래밍)에 사용되는 수치 솔버는 종종 더 큰 값에 대해 시간 초과되며, 이는 최적의 솔루션을 찾는 것의 계산적 비실용성을 나타냅니다.
3. 디코딩 복잡성: Belief Propagation + Localized Statistics Decoding (BP + LSD)과 같은 효율적인 디코더가 사용되지만, 이는 근사치입니다. 정확한 최대 가능도 오류(MLE) 디코더는 지수적으로 비용이 많이 들어 실시간 내결함성 작동에 비실용적입니다.
4. 수치 검색 한계: CCZ 회로 구성을 위한 수치적 라이프니츠 규칙 방법은 짧은 깊이를 보장하지 않으므로 적합한 코드를 찾기 위해 광범위한 검색 및 하이퍼파라미터 조정이 필요합니다.
데이터 기반 제약 조건 및 실패 모드:
1. 회로 수준 노이즈: 전체 프로토콜은 두 큐비트의 분해 노이즈 및 CCZ 게이트에 대한 편향된 세 큐비트 분해 노이즈를 포함한 현실적인 회로 수준 노이즈 모델 하에서 작동해야 합니다. 이 노이즈는 감지 및 수정되어야 하는 오류를 도입합니다.
2. 오류 전파: 중요한 실패 모드는 CCZ 게이트가 기존 X 오류를 다른 큐비트의 CZ 오류로 전파한다는 것입니다. 이러한 CZ 오류는 단일 샷 오류 수정으로 처리되지 않으면 빠르게 축적될 수 있는 비결정적 Z 오류로 붕괴됩니다.
3. 비결정적 Z-안정자 측정: 초기 Z 유형 안정자 측정은 비결정적인 $\pm 1$ 결과를 생성하며, CCZ 게이트를 적용하기 전에 하드웨어에서 $+1$로 안정적으로 수정해야 합니다. 이를 위해서는 신드롬 측정 오류를 식별하고 수정하기 위한 강력한 메타 검사 및 디코더가 필요합니다.
4. 불균형 코드 거리: 트라이사이클 코드는 자연스럽게 Z 기저보다 X 기저에서 더 높은 거리를 나타냅니다 ($d_Z \leq d_X$). 노이즈 편향 플랫폼에 유용할 수 있지만, 이 불균형은 더 어려운 X 기저 오류 수정이 종종 전체 성능을 결정한다는 것을 의미합니다.
5. 제한된 후선택 성공률: 후선택은 논리적 오류율을 크게 개선할 수 있지만, 수용 분율 감소(연구된 코드의 경우 3%에서 30%)라는 비용이 발생하며, 이는 매직-상태 생성의 전체 처리량에 영향을 미칩니다.
왜 이 접근 방식인가
선택의 불가피성
트라이사이클 코드의 채택은 내결함성 매직-상태 생성에 대한 기존 접근 방식의 내재된 한계에 의해 주도된 단순한 선호가 아니라 필수였습니다. 보편적인 양자 계산은 비-클리포드(매직) 상태에 결정적으로 의존하지만, 그 생산은 역사적으로 상당한 시공간 오버헤드를 부과했습니다. 널리 사용되는 15-대-1 증류와 같은 전통적인 매직-상태 증류(MSD) 프로토콜은 여러 단계의 반복적인 정제와 횡단적 클리포드 게이트를 지원하기 위해 내부 코드(예: 2차원 컬러 코드)와의 연결을 필요로 합니다. 이 다층 접근 방식은 과도한 큐비트 및 게이트 연산 소비로 이어져, 쇼어 알고리즘과 같은 대규모 양자 알고리즘의 자원 추정치를 자주 지배합니다.
또한, 저오버헤드 MSD 프로토콜에 대한 최근 제안이 횡단적인 비-클리포드 게이트와 유리한 점근적 매개변수를 가진 양자 코드를 도입했지만, 상당한 주의 사항이 따릅니다. 이러한 코드는 종종 높은 가중치의 패리티 검사를 특징으로 하며, 이는 신드롬 추출 회로의 깊이가 코드 블록 길이에 따라 증가함을 의미합니다. 이러한 스케일링은 회로 수준 노이즈의 존재 하에서 내결함성을 약화시키며, 상수 깊이 신드롬 추출을 방해합니다. 더욱이, 이러한 방식은 종종 인코딩 및 디코딩을 위한 노이즈 없는 클리포드 연산을 가정하는데, 이는 실제 자원 효율성을 과장하는 비현실적인 가정입니다. 물리적 큐비트 수에 대한 클리포드 회로 깊이의 선형 스케일링 또한 상당한 시간적 오버헤드에 기여합니다.
이러한 병목 현상을 극복하기 위해서는 근본적으로 다른 종류의 코드가 필요하다는 것이 분명해졌습니다. 저자들은 본질적으로 희소한 안정자 검사와 유리한 비율 및 거리 스케일링을 제공하는 qLDPC 코드가 가장 유망한 경로를 제시한다고 인식했습니다. 특히, 과제는 강력하게 횡단적인 비-클리포드 게이트(클리포드 수정이나 내부 코드와의 연결 없이 상수 깊이 물리적 회로)를 호스팅하면서도 상수 깊이 신드롬 추출을 유지할 수 있는 qLDPC 코드를 구성하는 것이었습니다. 이러한 인식은 트라이사이클 코드의 도입을 동기 부여했습니다. 즉, 횡단적인 논리적 CCZ 회로 동작을 지원하도록 명시적으로 설계된 유한 블록 길이, 고율, 고거리 양자 LDPC 코드로, 효율적이고 단일 샷 매직-상태 생성을 가능하게 합니다.
비교 우위
트라이사이클 코드는 단순한 성능 지표를 넘어 압도적인 질적 우위를 보여줍니다. 그 구조적 설계는 효율적이고 내결함성 있는 매직-상태 생성에 대한 뚜렷한 이점을 제공합니다.
첫째, 트라이사이클 코드는 아벨 군 대수 위에서 고전적인 이진 선형 코드의 3차원 균형 곱으로 구성됩니다. 잘 알려진 바이사이클 코드의 3차원 호몰로지 차원으로의 혁신적인 일반화는 클리포드 계층의 세 번째 수준, 특히 논리적 CCZ 게이트에서 횡단적인 게이트를 본질적으로 허용하기 때문에 중요합니다. 이는 다른 아키텍처에서 종종 병목 현상이 되는 핵심 비-클리포드 게이트의 직접적이고 상수 깊이 구현을 가능하게 하므로 기본적인 구조적 이점입니다.
둘째, 가장 중요한 이점은 단일 샷 상태 준비 및 오류 수정(Sec. I.B, II.C)의 활성화입니다. 전통적인 MSD 방식과 달리 여러 번의 반복적인 증류가 필요한 트라이사이클 코드는 단일 라운드에서 고충실도 하이퍼그래프 매직 상태를 준비할 수 있습니다. 이는 두 가지 주요 속성에 의해 촉진됩니다. 상태 초기화 중 한 안정자 기저에서의 본질적인 내결함성, 그리고 "메타 검사"의 존재입니다. 이러한 메타 검사는 신드롬 비트에 대한 고전적인 코드를 형성하는 중복 Z 패리티 검사로, Z 기저에서 신드롬 측정 오류를 안정적으로 식별하고 수정할 수 있습니다. 이 기능은 표면 코드와 같은 코드와는 크게 다르며, 일반적으로 단일 샷 상태 준비가 부족하며, 시간적 오버헤드를 $O(d)$ 라운드(여기서 $d$는 코드 거리)에서 상수 수로 크게 줄입니다.
또한, 트라이사이클 코드는 비교적 작은 블록 길이(예: [[48, 6, 4]], [[108, 21, 6]] 표 I 참조)에서 유리한 매개변수(높은 비율 및 거리)를 달성합니다. 이 컴팩트함은 근거리 양자 하드웨어에서의 실질적인 구현에 중요합니다. 본 논문은 특히 4-2-2 트라이사이클 코드와 같은 특정 제품군이 낮은 검사 가중치와 최소 깊이-8 CCZ 회로로 인해 특히 관련성이 높다고 강조하는데, 이는 회로 수준 노이즈 전파를 직접적으로 줄입니다.
정량적으로, 우수성은 시공간 비용에서 분명합니다. 표 II에서 볼 수 있듯이, 트라이사이클 코드는 유사하거나 훨씬 낮은 시공간 비용(각각 89 및 527 큐비트 라운드)으로 논리적 오류율(예: [[48, 6, 4]]의 경우 $2 \times 10^{-8}$, [[84, 6, 5]]의 경우 $4 \times 10^{-10}$)을 달성합니다. 이는 최첨단 컬러 코드 기반 매직-상태 재배양(예: [[7, 1, 3]] 컬러 코드의 경우 $6 \times 10^{-7}$ 오류율에 대해 90 큐비트 라운드, [[19, 1, 5]] 컬러 코드의 경우 $6 \times 10^{-10}$ 오류율에 대해 3000 큐비트 라운드)과 비교됩니다. 이는 고충실도 매직 상태를 생성하기 위한 자원 효율성에서 상당한 개선을 보여줍니다.
제약 조건과의 일치
트라이사이클 코드의 선택된 접근 방식은 실용적이고 내결함성 있는 양자 계산에 대한 엄격한 요구 사항과 놀라운 "결합"을 보여줍니다. 트라이사이클 코드의 설계 원칙은 문제 정의에서 식별된 핵심 제약 조건을 해결하기 위해 특별히 맞춤화되었습니다.
첫째, 보편적인 내결함성 양자 계산이라는 포괄적인 목표는 트라이사이클 코드가 횡단적인 논리적 CCZ 게이트를 호스팅하는 능력에 의해 직접적으로 충족됩니다. CCZ 게이트는 보편적인 게이트 집합에 필수적인 비-클리포드 연산이며, 트라이사이클 코드 내에서의 상수 깊이, 횡단적 구현은 이 요구 사항에 대한 직접적인 해결책입니다(Sec. I.B, II.B).
둘째, 시공간 오버헤드 감소라는 중요한 제약 조건은 트라이사이클 코드 설계의 여러 측면을 통해 해결됩니다. 단일 샷 매직-상태 생성 프로토콜(Sec. I.B, II.C)은 여러 증류 라운드의 필요성을 제거하여 시간 자원을 대폭 줄입니다. 고율 코드는 단일 코드 블록 내에서 여러 매직 상태의 병렬 증류를 허용하여 처리량을 높이고 전체 시간을 단축합니다. 또한, 논리적 CCZ 연산과 신드롬 추출 회로 모두 상수 깊이로 설계되어(Sec. I.B, II.E) 회로 복잡성이 코드 크기에 따라 불리하게 확장되지 않도록 하여 다른 방법에서 볼 수 있는 선형 스케일링 오버헤드를 방지합니다. 유한 블록 길이 코드와 유리한 매개변수(표 I)의 사용은 코드가 구현에 실용적이고 자원 효율적임을 보장합니다.
셋째, 고충실도 매직 상태에 대한 요구는 강력한 오류 억제를 통해 충족됩니다. 수치 시뮬레이션은 트라이사이클 코드가 적당한 블록 길이와 현실적인 회로 수준 노이즈 하에서도, 특히 후선택을 통해(Sec. I.B, 표 II) CCZ 매직 상태에 대해 매우 낮은 논리적 오류율(예: $2 \times 10^{-8}$에서 $3 \times 10^{-11}$ 미만)을 달성할 수 있음을 확인합니다.
마지막으로, 내결함성은 트라이사이클 코드 아키텍처에 본질적으로 내장되어 있습니다. 상수 깊이 신드롬 추출 회로(Sec. I.A, II.E)는 회로 수준 노이즈에 대해 복원력이 있도록 설계되었습니다. 비-클리포드 게이트의 횡단적 특성은 물리적 큐비트 간의 오류 확산을 본질적으로 제한합니다(Sec. I.A). 높은 상대 거리는 증류 중 효과적인 오류 억제를 보장합니다. 결정적으로, 메타 검사의 존재는 Z 기저에서 단일 샷 오류 수정을 가능하게 하여 X 오류의 즉각적인 수정을 허용하고 매직-상태 준비 중 내결함성을 유지하는 데 필수적인 전파를 방지합니다(Sec. II.C). 재구성 가능한 중성 원자 플랫폼(Sec. I.B, II.E)에 대한 제안된 구현도 현대 양자 컴퓨팅의 실질적인 하드웨어 제약 조건과 일치합니다.
대안의 거부
본 논문은 명시적으로 또는 암묵적으로 대안적인 접근 방식을 거부하며, 그 단점을 강조하거나 트라이사이클 코드의 우월한 기능을 입증합니다.
전통적인 매직-상태 증류(MSD) 방식: 본 논문의 서론(Sec. I.A)은 15-대-1 증류와 같은 전통적인 MSD 프로토콜에 대한 강력한 거부 역할을 합니다. 이러한 방법은 "반복적인 증류의 여러 단계"와 "충분히 큰 거리의 내부 코드와의 연결"을 요구하며, 이는 "시공간 오버헤드에 크게 기여한다"고 비판받습니다. 저자들은 매직-상태 생성이 "최근 쇼어 알고리즘을 이용한 RSA 정수 인수분해의 최신 자원 추정치를 지배한다"고 명시적으로 언급합니다 [4,5]. 반대로 트라이사이클 코드는 단일 샷 증류를 목표로 하여 이 오버헤드를 대폭 줄입니다.
기존의 비-LDPC 상수 오버헤드 MSD 프로토콜: 일부 이전 연구에서는 횡단적인 비-클리포드 게이트와 유리한 상수 오버헤드를 가진 코드를 제안했지만, 본 논문은 그 결정적인 결함을 지적합니다(Sec. I.A). 이러한 코드는 종종 "높은 가중치의 패리티 검사"를 특징으로 하며, 이는 신드롬 추출 회로의 깊이가 코드 블록 길이에 따라 증가하게 만듭니다. 이는 "그 자체로는 내결함성이 명확하지 않다"고 만들고 유한 임계값을 지원할 수 없게 합니다. 또한, 그들은 "클리포드 연산이 노이즈가 없다고 암묵적으로 가정하는데", 이는 그들의 인식된 효율성을 과장하는 비현실적인 단순화입니다. qLDPC 코드로서의 트라이사이클 코드는 희소 검사와 상수 깊이 신드롬 추출을 보장함으로써 이러한 문제를 극복합니다.
바이사이클 코드 (2차원 군 대수 코드): 트라이사이클 코드는 "3차원 호몰로지 차원"으로의 일반화로 제시됩니다(Sec. I.B). 이 일반화는 "원칙적으로 클리포드 계층의 세 번째 수준 [23]에서 횡단적인 게이트, 특히 논리적 CCZ 게이트를 허용하기 때문에" 필수적입니다. 바이사이클 코드는 낮은 수준의 클리포드 계층 게이트에 효과적이지만, 이 작업의 대상 비-클리포드 연산인 CCZ 게이트를 횡단적으로 직접 실현하는 데는 불충분합니다. 본 논문은 바이사이클 코드가 더 높은 비율을 가질 수 있지만, 트라이사이클 코드는 CCZ에 필요한 3D 구조를 제공한다고 언급합니다.
특정 2-2-2 트라이사이클 코드 매개변수: 트라이사이클 코드 계열 내에서 저자들은 경험적으로 특정 매개변수 선택을 거부했습니다. 그들은 "무게-6 X 검사와 무게-4 Z 검사를 가진 2-2-2 코드가" 비-자명한 횡단적 CCZ 작용에 대해 "그렇게 유리한" 비율과 거리를 제공하지 않는다는 것을 발견했습니다(Sec. II.A). 구체적으로, 그들은 "K > 3개의 인코딩된 논리적 큐비트와 거리 D > 7을 가진 그러한 코드를 찾을 수 없었다"고 말하며, 더 나은 성능을 보인 4-2-2, 4-4-2 및 4-4-4 코드에 집중하게 되었습니다.
참고문헌 [27]의 원래 컵 곱 형식론: 본 논문은 또한 횡단적 비-클리포드 게이트 구성을 위한 이론적 프레임워크의 개선을 자세히 설명합니다. "참고문헌 [27]의 원래 컵 곱 조건"은 "코드 매개변수에 너무 제한적"인 것으로 밝혀졌습니다(Sec. II.B, 부록 D). 예를 들어, 이러한 원래 조건은 제한된 논리적 큐비트(K=3)와 거리(D=2)를 가진 2-2-2 코드를 생성했으며, 4-2-2 및 4-4-4 코드도 유사하게 제한되었습니다. 저자들은 "더 나은 매개변수"(더 높은 거리)를 가진 트라이사이클 코드를 생성할 수 있는 더 큰 유연성을 허용하는 새로운 "대칭 삼중 컵 곱" 형식론을 개발했으며, 따라서 원래의 더 제한적인 형식론을 거부했습니다.
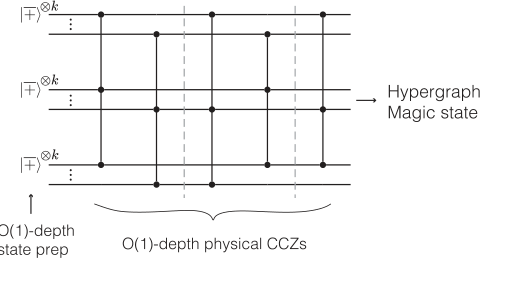 FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
수학적 및 논리적 메커니즘
마스터 방정식
본 논문의 기초적인 수학적 엔진은 트라이사이클 코드 자체의 정의에 있으며, 이는 양자 Calderbank-Shor-Steane (CSS) 코드의 한 종류입니다. 이 코드들은 주로 X 유형 및 Z 유형 패리티 검사 행렬로 특징지어집니다. 또한, 본 논문은 매직-상태 생성 프로토콜의 핵심인 횡단적 제어-제어-Z (CCZ) 게이트를 정의하는 특정 삼선형 함수를 도입합니다.
패리티 검사 행렬은 다음과 같이 주어집니다.
$$ H_X = \begin{bmatrix} A^T & B^T & C^T \end{bmatrix} \in \mathbb{F}_2^{n_G \times 3n_G} $$
$$ H_Z = \begin{bmatrix} C & O & A \\ O & C & B \\ B & A & O \end{bmatrix} \in \mathbb{F}_2^{3n_G \times 3n_G} $$
이 행렬들은 양자 코드의 안정자를 정의합니다. 코드 정의를 넘어, 매직-상태 생성을 위한 본 논문의 핵심 메커니즘은 대칭 삼중 컵 곱에서 파생된 이진 함수에 의해 인코딩된 횡단적 CCZ 회로에 의존합니다. 본 논문은 일반적인 형태(Eq. 2)를 제시하지만, 트라이사이클 코드에 대한 특정 구성은 명제 D4(Eq. D27)에 자세히 설명되어 있습니다.
$$ f_{CCZ}(p^I, q^{II}, r^{III}) = |r^{III} \cup a_{out}^{III} \cup q^{II} \cup a_{in}^{II} \cup p^I \cup a_{in}^I \cup a_{out}^I|_{d_{i \neq j \neq k}} \pmod{2} $$
항별 분석
이 방정식들을 해부하여 각 구성 요소의 역할을 이해해 봅시다.
패리티 검사 행렬 ($H_X, H_Z$)의 경우:
- $\mathbf{H_X}$: 이것은 X 유형 패리티 검사 행렬입니다.
- 수학적 정의: X-안정자 그룹의 생성기를 정의하는 행을 가진 이진 행렬입니다.
- 물리적/논리적 역할: 데이터 큐비트의 Z 유형 오류를 감지하는 데 사용되는 각 X 유형 안정자 측정에 어떤 물리적 큐비트가 관여하는지를 결정합니다.
- 이 구조인 이유: 블록 구조 $[A^T \ B^T \ C^T]$는 X 검사가 코드 블록의 세 섹터(I, II, III)의 요소들을 결합하여 형성됨을 나타냅니다. 전치($^T$)는 $H_Z$가 특정 형태로 주어졌을 때 CSS 코드에서 X 검사를 정의하는 표준입니다.
- $\mathbf{H_Z}$: 이것은 Z 유형 패리티 검사 행렬입니다.
- 수학적 정의: Z-안정자 그룹의 생성기를 정의하는 행을 가진 이진 행렬입니다.
- 물리적/논리적 역할: X 유형 오류를 감지하는 데 사용되는 각 Z 유형 안정자 측정에 어떤 물리적 큐비트가 관여하는지를 결정합니다.
- 이 구조인 이유: $3n_G \times 3n_G$ 블록 행렬 구조는 $N=3n_G$ 물리적 큐비트가 세 개의 동일한 크기의 섹터(I, II, III)로 분할된 것을 반영합니다. 비대각 $A, B, C$ 행렬은 Z 검사에 대해 이러한 섹터 간의 연결을 나타내며, 대각 $C$ 행렬은 섹터 내 연결 또는 순환 연결을 시사합니다.
- $\mathbf{A, B, C}$: 이들은 $n_G \times n_G$ 이진 행렬입니다.
- 수학적 정의: 그룹 대수 요소 $a, b, c \in \mathbb{F}_2[G]$에서 파생된 순열 행렬입니다. 순열 행렬은 각 행과 열에 정확히 하나의 '1'을 가집니다.
- 물리적/논리적 역할: 코드 블록 내에서 다른 섹터 간의 큐비트 연결에 대한 특정 패턴을 정의합니다. 순열 속성은 일대일 매핑을 보장하여 연결의 균형 잡힌 분포를 보장합니다. 이러한 요소의 선택은 코드의 거리와 비율에 중요합니다.
- 순열 행렬인 이유: 순열 행렬을 사용하면 각 큐비트가 고정된 수의 검사에 참여하게 되어, 효율적인 디코딩에 바람직한 저밀도 패리티 검사(LDPC) 속성을 갖게 됩니다.
- $\mathbf{O}$: 이것은 $n_G \times n_G$ 영행렬입니다.
- 수학적 정의: 모든 항목이 0인 행렬입니다.
- 물리적/논리적 역할: 특정 Z 유형 안정자 생성기에 대한 특정 섹터 간의 연결 부재를 나타냅니다. 예를 들어, $H_Z$의 첫 번째 행에서 $O$는 섹터 II와 섹터 I 간의 직접적인 Z 검사 연결이 없음을 의미합니다.
- $\mathbf{\mathbb{F}_2}$: 이진 필드 $\{0,1\}$.
- 수학적 정의: 두 개의 요소를 가진 필드로, 산술은 모듈로 2로 수행됩니다.
- 물리적/논리적 역할: 이는 양자 CSS 코드의 기본이며, 여기서 파울리 연산자($X, Y, Z$)는 자신을 제곱하여 항등원이 되고 그 곱은 이진 산술 규칙을 따릅니다(예: $X \cdot X = I$, $X \cdot Z = -iY$, $Z \cdot X = iY$, 따라서 $X \cdot Z \cdot X \cdot Z = I$). 모든 행렬 연산(곱셈, 덧셈)은 모듈로 2로 수행됩니다.
- $\mathbf{n_G}$: 각 블록의 선형 크기, 유한 아벨 군 $G$의 위수와 같음.
- 수학적 정의: $n_G = |G|$.
- 물리적/논리적 역할: 세 개의 섹터 각각의 큐비트 수를 결정하며, 따라서 총 물리적 큐비트 수 $N = 3n_G$를 결정합니다.
CCZ 함수 ($f_{CCZ}$)의 경우:
- $\mathbf{f_{CCZ}(p^I, q^{II}, r^{III})}$: 이것은 삼선형 이진 함수입니다.
- 수학적 정의: 세 개의 입력(다른 섹터/블록의 큐비트)을 받아 0 또는 1을 출력하는 함수입니다.
- 물리적/논리적 역할: $f_{CCZ}=1$이면 물리적 CCZ 게이트가 큐비트 삼중항 $(p^I, q^{II}, r^{III})$에 적용됨을 의미합니다. $f_{CCZ}=0$이면 게이트가 적용되지 않습니다. 이 함수는 전체 횡단적 CCZ 회로를 정의합니다.
- $\mathbf{p^I, q^{II}, r^{III}}$: 이들은 특정 물리적 큐비트를 나타냅니다.
- 수학적 정의: 코드 블록(I, II, III) 및 해당 블록/섹터 내의 위치로 인덱싱된 개별 큐비트를 나타내는 변수입니다.
- 물리적/논리적 역할: 이들은 CCZ 게이트의 대상 큐비트입니다. 위첨자 $I, II, III$는 큐비트가 세 개의 서로 다른 코드 블록(또는 블록 내 섹터, 논문의 그림 1(a) 및 관련 텍스트에서 명확해짐)에서 와야 함을 나타냅니다.
- $\mathbf{\cup}$: 컵 곱 연산자입니다.
- 수학적 정의: 대수적 위상학, 특히 호몰로지 대수학에서 코체인을 결합하는 쌍선형 맵입니다. 본 논문은 "대칭 삼중 컵 곱"(정의 6, 22페이지)을 사용하며, 이는 이러한 연산의 특정 순서를 의미합니다.
- 물리적/논리적 역할: 이 연산자는 횡단적 비-클리포드 게이트를 구성하는 핵심 대수적 도구입니다. 이는 코드의 기본 대수 구조에서 자연스럽게 발생하며 "논리적 연산자의 삼중 교차"와 관련이 있습니다. 방정식의 컵 곱의 특정 순서는 결과 CCZ 회로가 코드 공간을 보존하고 코바운더리 불변임을 보장하도록 설계되었습니다.
- 컵 곱인 이유: 이는 코드의 기본 대수 구조에서 파생된 고차 클리포드 계층 게이트(CCZ와 같은)를 체계적으로 도출하는 방법을 제공하여 논리적 부분 공간에 올바르게 작용하도록 보장합니다.
- $\mathbf{a_{in}^I, a_{out}^I, \dots, a_{out}^{III}}$: 이들은 코드의 기본이 되는 그룹 대수 요소 $a_I, a_{II}, a_{III}$의 "입력" 및 "출력" 분할입니다.
- 수학적 정의: 그룹 대수 요소 $a$에 대해 $a = a_{in} + a_{out} + a_{free}$로 분할됩니다(Eq. D20, 22페이지). $a_{in}$ 및 $a_{out}$는 자체적으로 그룹 대수 요소입니다.
- 물리적/논리적 역할: "사전 방향"이라고 불리는 이러한 분할은 고전적 코드에 대한 컵 곱을 유도합니다. 이러한 분할의 특정 선택은 "대칭 통합 라이프니츠 규칙"(Eqs. D15-D19, 22페이지) 조건을 만족해야 하며, CCZ 회로가 코드 공간을 보존하고 코바운더리 불변이 되도록 보장하는 데 중요합니다. 본 논문은 트라이사이클 코드의 경우 $a_{free}$가 종종 비어 있다고 언급합니다.
- 분할인 이유: 이러한 분할은 컵 곱이 작동하는 방식을 세밀하게 제어할 수 있게 하여 바람직한 속성(예: 비자명한 작용, 더 나은 코드 매개변수)을 가진 CCZ 게이트를 구성할 수 있게 합니다.
- $\mathbf{|...|_{d_{i \neq j \neq k}}}$: 이것은 인수의 크기(지원의 해밍 가중치)를 나타냅니다.
- 수학적 정의: 컵 곱 연산 후 결과 이진 벡터의 해밍 가중치입니다. 아래첨자 $d_{i \neq j \neq k}$는 인수의 큐비트 중 두 개 이상이 동일한 섹터에 있는 경우 $f_{CCZ}=0$임을 의미하는 조건입니다(명제 D4, 24페이지).
- 물리적/논리적 역할: 해밍 가중치는 결합된 대수적 표현식이 0이 아닌지 여부를 결정하며, 이는 CCZ 게이트의 적용을 트리거합니다. $d_{i \neq j \neq k}$ 조건은 CCZ 회로의 횡단적 특성을 보장하는 데 중요합니다. 즉, 게이트는 다른 섹터/블록의 큐비트 간에만 작용하며, 이는 내결함성의 핵심 속성입니다.
- $\mathbf{\pmod{2}}$: 모듈로 2 산술.
- 수학적 정의: 전체 표현식의 결과는 모듈로 2로 취해집니다.
- 물리적/논리적 역할: 이는 출력이 이진(0 또는 1)임을 보장하며, CCZ 게이트의 존재 또는 부재를 직접 나타냅니다. 이는 양자 정보 및 파울리 연산자의 이진 특성과 일치합니다.
단계별 흐름
추상적인 데이터 포인트, 예를 들어 단일 큐비트를 설명된 메커니즘을 통해 추적해 봅시다.
1. 코드 정의 및 오류 감지 ($H_X, H_Z$ 사용):
트라이사이클 코드 블록의 세 섹터 중 하나에 있는 물리적 큐비트 $q_j$를 상상해 보세요.
* 초기화: 먼저 $q_j$는 일반적으로 $|0\rangle$ 또는 $|+\rangle$와 같은 계산 기저 상태로 초기화됩니다. Z 기저 단일 샷 상태 준비의 경우, 모든 물리적 데이터 큐비트는 $|+\rangle$로 초기화됩니다.
* 안정자 상호작용: 오류를 감지하기 위해 $q_j$는 다양한 안정자 측정에 참여합니다.
* X 유형 오류를 검사하는 경우(Z-안정자 사용), $q_j$는 $H_Z$의 행에 의해 정의된 대로 다른 큐비트와 상호작용합니다. 예를 들어, $H_Z[i, j] = 1$이면 $q_j$의 파울리 Z 연산자($Z_j$)가 $i$-번째 Z-안정자 생성기의 일부입니다. 이는 $q_j$를 보조 큐비트와 얽히게 한 다음 보조 큐비트를 측정하는 것을 포함합니다.
* 마찬가지로, Z 유형 오류를 검사하는 경우(X-안정자 사용), $q_j$는 $H_X$의 행에 의해 정의된 대로 다른 큐비트와 상호작용합니다. $H_X[i, j] = 1$이면 $X_j$가 $i$-번째 X-안정자 생성기의 일부입니다.
* 신드롬 생성: 이러한 안정자 검사에서 나온 측정 결과는 "신드롬"을 형성합니다. $q_j$가 오류를 경험했다면(예: Z-안정자를 측정할 때 X 오류), 이는 $q_j$가 참여하는 모든 안정자 측정 결과에 영향을 미칩니다.
* 디코딩: 신드롬, 즉 이진 값들의 모음은 디코더에 공급됩니다. 디코더는 이 정보를 처리하여 $q_j$ 및 다른 큐비트에서 발생했을 가능성이 가장 높은 오류 패턴을 추론합니다.
* 수정: 디코더의 출력에 따라, 수정 연산(예: 파울리 X 또는 Z 게이트 적용)이 $q_j$에 적용되어 코드 공간 내의 의도된 상태로 복원됩니다. 이것으로 오류 수정의 한 사이클이 완료됩니다.
2. 논리적 CCZ 게이트 적용 ($f_{CCZ}$ 사용):
이제 세 개의 서로 다른 물리적 큐비트, $p^I, q^{II}, r^{III}$를 고려해 봅시다. 각 큐비트는 세 개의 별도 코드 블록의 다른 섹터(I, II, III)에 있습니다. 이 큐비트들은 CCZ 연산이 원하는 논리적 상태의 일부입니다.
* 함수 입력: 이 세 큐비트의 식별자($p^I, q^{II}, r^{III}$)가 $f_{CCZ}$ 함수에 입력으로 공급됩니다.
* 대수적 처리: $f_{CCZ}$ 함수 내부에서, "컵 곱"이라고 하는 일련의 추상 대수 연산이 수행됩니다. 여기에는 코드의 기본이 되는 그룹 대수 요소의 사전 방향 분할($a_{in}, a_{out}$)과 큐비트 식별자를 결합하는 것이 포함됩니다. 이것은 $\mathbb{F}_2$ 내에서 복잡한 다단계 계산입니다.
* 지원 계산: 이러한 컵 곱의 결과는 대수적 표현식입니다. 그 "지원"(해밍 가중치)이 계산됩니다. 이것은 본질적으로 결합된 대수적 개체가 0이 아닌지 여부를 확인합니다.
* 횡단성 확인: 중요한 조건인 $d_{i \neq j \neq k}$가 암묵적으로 적용됩니다. 이는 세 입력 큐비트가 실제로 서로 다른 섹터/블록에서 왔음을 보장합니다. 그렇지 않으면 함수는 즉시 0을 출력합니다.
* 게이트 결정: 모듈로 2로 취해진 최종 결과는 0 또는 1입니다.
* $f_{CCZ}(p^I, q^{II}, r^{III}) = 1$이면, 물리적 CCZ 게이트가 큐비트 $(p^I, q^{II}, r^{III})$에 적용됩니다. 이 게이트는 세 큐비트 모두에 동시에 작용합니다.
* $f_{CCZ}(p^I, q^{II}, r^{III}) = 0$이면, 이 특정 삼중항에 게이트가 적용되지 않습니다.
* 회로 실행: 이 과정은 코드 블록 전반에 걸쳐 모든 관련 큐비트 삼중항에 대해 반복됩니다. $f_{CCZ}$에 의해 결정된 물리적 CCZ 게이트의 전체 컬렉션은 코드 크기에 관계없이 고정된 소수의 병렬 레이어에서 예약할 수 있음을 보장하는 "상수 깊이" 회로를 형성합니다. 이는 빠른 실행을 보장하고 오류 전파를 제한합니다. 각 트라이사이클 코드 블록의 물리적 큐비트는 패리티 검사 행렬의 블록 구조에 따라 세 섹터로 자연스럽게 분할될 수 있습니다(Eq. 1). 코드 공간을 보존하는 CCZ 회로는 항상 세 코드 블록의 섹터 간에 작용하며, 그림 1에 설명되어 있습니다.
최적화 역학
이 논문에서의 "학습" 또는 "최적화"는 일반적인 기계 학습에서와 같이 기울기를 통해 연속적인 손실 지형을 반복적으로 업데이트하는 모델이 아니라, 이산적이고 대수적인 공간 내에서 최적의 코드 매개변수 및 회로 구성을 위한 다면적인 설계 및 검색 프로세스입니다.
1. 코드 매개변수 검색:
본 논문은 패리티 검사 행렬 $H_X$ 및 $H_Z$에 대해 특정 그룹 대수 요소($a, b, c$)와 그 가중치($w_a, w_b, w_c$)를 선택하여 트라이사이클 코드를 구성한다고 설명합니다. 이것은 주어진 블록 길이에 대해 유리한 매개변수(높은 비율 $K$ 및 거리 $D$)를 가진 코드를 찾기 위한 검색 문제입니다. 저자들은 SAT 솔버 및 혼합 정수 프로그램(MIP)을 포함한 수치적 방법을 사용하여 후보 코드의 최소 거리 $D_X$ 및 $D_Z$를 찾습니다. 이것은 이산적인 선택에 대한 철저하거나 휴리스틱한 검색이며, 기울기 기반 최적화가 아닙니다. 여기서 "손실"은 바람직하지 않은 코드 매개변수(예: 낮은 거리)이며, "업데이트"는 다른 그룹 대수 요소 집합을 시도하는 것입니다.
2. CCZ 회로 구성 (대칭 삼중 컵 곱 - STCP):
대칭 삼중 컵 곱에서 파생된 $f_{CCZ}$ 함수에 대해, "최적화"는 그룹 대수 요소의 "사전 방향"($a_{in}, a_{out}, a_{free}$)을 신중하게 선택하는 것을 포함합니다. 이러한 선택은 "대칭 통합 라이프니츠 규칙"(Eqs. D15-D19)으로 알려진 일련의 대수적 조건을 만족해야 합니다. 본 논문은 이러한 사전 방향을 구성하기 위한 처방(정리 D1)을 제시합니다. 이것은 원하는 속성(코드 공간 보존, 코바운더리 불변)을 가진 유효한 회로를 생성함을 보장하는 설계 원칙이며, 반복적인 학습 프로세스가 아닙니다. "역학"은 이러한 조건의 유도와 그것들이 유효한 회로를 생성한다는 증명에 있습니다. 목표는 짧은 깊이의 CCZ 회로를 생성하는 사전 방향을 찾는 것입니다.
3. CCZ 회로 구성 (수치적 라이프니츠 규칙 - NLR):
부록 E는 "수치적 라이프니츠 규칙" 방법을 소개합니다. 여기서 프로세스는 검색 알고리즘과 더 유사합니다.
* 기저 구성: 그룹 동형 삼선형 함수 $f_i^j$의 기저 집합이 구성됩니다. 여기에는 "일반화된 라이프니츠 규칙" 조건을 인코딩하는 패리티 검사 행렬 $H_{leibniz}$의 영 공간을 찾는 것이 포함됩니다(Eq. E5). 이것은 기울기 기반 최적화가 아닌 선형 대수 문제입니다.
* 휴리스틱 검색: 실제 $f_{CCZ}$ 함수는 이러한 $f_i^j$ 함수에 대한 후보를 무작위로 검색하여 구성됩니다. "최적화" 목표는 $f_{CCZ}$ 함수의 최대 차수를 낮추는 후보를 찾는 것이며, 이는 직접적으로 짧은 회로 깊이로 이어집니다. 이것은 가능한 함수의 이산 공간을 탐색하기 위한 기술(예: 몬테카를로 샘플링 또는 시뮬레이티드 어닐링)을 사용하는 휴리스틱 검색입니다. "손실 지형"은 매우 불규칙하고 비볼록하며, 따를 명확한 기울기가 없습니다.
4. 논리적 회로 최적화 ($K_{CCZ}$ 최대화):
부록 F는 하이퍼그래프 매직 상태에서 추출할 수 있는 독립적인 CCZ 게이트의 최대 수($K_{CCZ}$)를 최대화하기 위해 논리적 CCZ 회로를 최적화하는 것을 설명합니다. 이 문제는 논리적 연결을 나타내는 이진 3-텐서 $T_{ijk}^{log}$의 "부분 순위"를 찾는 것으로 프레임화됩니다.
* 문제 공식화: 이것은 NP-난해 문제입니다. 저자들은 부분적인 최적해를 찾기 위해 혼합 정수 프로그램(MIP) 솔버(Gurobi)를 사용합니다.
* 반복 검색: 솔버는 $r$개의 독립적인 CCZ 게이트(Eq. F3)에 대한 조건을 만족시키기 위해 이진 변수(기저 변경 행렬 $M^1, M^2, M^3$를 나타냄)에 대한 가능한 할당을 반복적으로 탐색합니다. 여기서 "상태"는 기저 행렬 집합이며, "업데이트"는 솔버의 내부 메커니즘으로 솔루션 공간을 탐색합니다. 이것은 기울기 기반이 아닌 이산 최적화입니다. "손실"은 주어진 $r$에 대한 솔루션을 찾지 못하거나 낮은 $r$을 가진 솔루션을 찾는 것입니다. "수렴"은 솔버가 실행 가능한 솔루션을 찾거나 시간 초과될 때입니다.
본질적으로 "최적화 역학"은 연속적인 기울기 하강이 아닌, 이산 공간에 대한 대수적 유도, 체계적인 구성 및 휴리스틱 또는 정확한 검색의 조합으로 특징지어집니다. 목표는 내결함성 속성과 효율적인 성능을 가진 코드를 설계하는 것이지, 데이터에서 학습하는 것이 아닙니다. "손실 지형"은 종종 이산적이고 비볼록하여 탐색하기 위해 특수 솔버 또는 영리한 설계 원칙이 필요합니다.
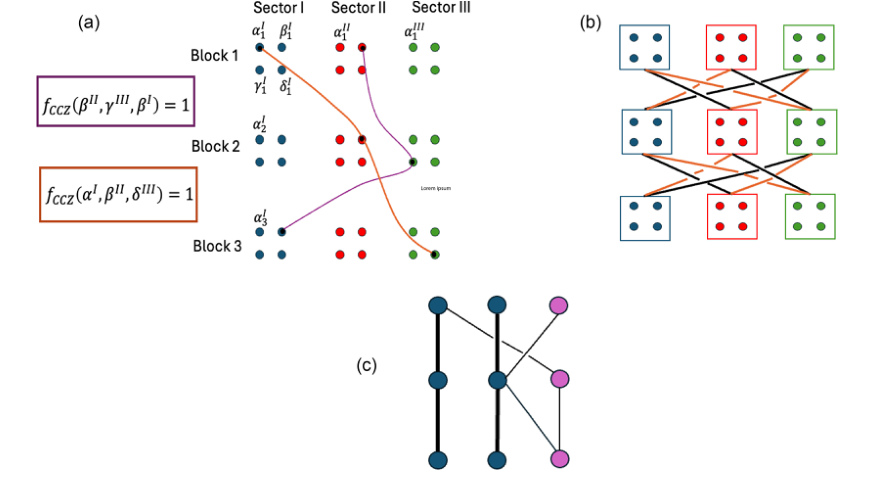 FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
 FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
결과, 한계 및 결론
실험 설계 및 기준선
저자들은 트라이사이클 코드에 대한 수학적 주장을 엄격하게 검증하기 위해 실험을 세심하게 설계했습니다. 그들의 핵심 접근 방식은 현실적인 회로 수준 노이즈 모델 하에서 이러한 코드의 수치 시뮬레이션에 중점을 두었으며, 성능을 기존 기준선과 직접 비교했습니다.
트라이사이클 코드의 효능을 입증하기 위해 실험 설계는 몇 가지 핵심 측면에 중점을 두었습니다.
1. 코드 구성 및 속성: 그들은 트라이사이클 코드를 유한 블록 길이 양자 저밀도 패리티 검사(LDPC) 코드로 소개했으며, 이는 아벨 군 대수 위에서 고전적 코드를 3차원 호몰로지 차원으로 일반화합니다. 이 코드들은 논리적 CCZ 게이트를 구현하기 위한 상수 깊이 물리적 회로를 지원하도록 설계되었습니다. 구성에는 유리한 매개변수(높은 비율 및 거리)와 짧은 깊이의 CCZ 회로를 찾기 위해 수정된 대칭 삼중 컵 곱 형식론(부록 D) 및 수치적 라이프니츠 규칙 방법(부록 E)을 포함한 새로운 분석 및 수치 기법 개발이 포함되었습니다.
2. 노이즈 모델: 표준 두 큐비트 분해 노이즈 모델이 채택되었으며, 각 얽힘 연산은 $p_{2q}$ 확률로 15개의 비자명한 두 큐비트 파울리 오류 중 하나를 따릅니다. 중요한 CCZ 게이트의 경우, 세 큐비트 편향 분해 노이즈 모델이 사용되었으며, 물리적 오류율 $p_{3q} = 0.002$를 가정했습니다. 이 $p_{3q}$는 두 큐비트 얽힘 게이트의 두 배로 보수적으로 추정되었으며, 실험 현실을 반영합니다. 또한, 모델은 CCZ 게이트에 대한 Z 유형 오류에 대한 강한 편향(10배 더 가능성 높음)을 통합했는데, 이는 많은 양자 플랫폼의 기본 위상 유형 게이트의 특징입니다.
3. 디코딩 전략:
* 단일 샷 Z-기저 오류 수정(상태 준비에 중요)의 경우, 창 디코딩 프로토콜이 사용되었습니다. 여기에는 14번의 반복을 통해 총 42번의 신드롬 추출 라운드가 포함되었으며, Belief Propagation + Ordered Statistics Decoding (BP + OSD) 방식이 사용되었습니다.
* d-라운드 X-기저 오류 수정(메모리 성능용)의 경우, 전통적인 d-라운드 프로토콜이 사용되었으며, 누적된 신드롬 정보의 전체 기록을 최대 가능도 오류(MLE) 디코더로 디코딩했습니다. 후선택의 경우, BP + LSD(Localized Statistics Decoding)와 결합된 클러스터 기반 후선택 방법이 사용되었습니다.
4. 구현 프로토콜: 재구성 가능한 중성 원자 배열 플랫폼에서 신드롬 추출 회로를 효율적으로 구현하기 위한 구체적인 프로토콜이 제시되었습니다(그림 5, 부록 I). 여기에는 상세한 원자 재배열 절차 및 CNOT 스케줄링이 포함되었습니다.
트라이사이클 코드와 무차별적으로 비교된 "희생자"(기준선 모델)는 주로 컬러 코드 기반의 최첨단 매직-상태 재배양 방식 [36]이었습니다. 이러한 전통적인 방식은 일반적으로 여러 라운드의 증류 및 연결을 필요로 하여 상당한 시공간 오버헤드를 초래합니다. 저자들은 또한 더 불리한 매개변수(예: $K=3$ 및 $D=2$를 가진 2-2-2 코드)를 생성한 이전 컵 곱 구성(참고문헌 [27])에 암묵적으로 도전했습니다.
증거가 증명하는 것
본 논문에서 제시된 증거는 트라이사이클 코드가 매직-상태 생성에 대해 매우 효율적이고 강력한 솔루션을 제공하며, 주요 지표에서 기존 기준선을 능가함을 확실하게 증명합니다.
- 강력한 성능 및 높은 임계값: 회로 수준 노이즈 하에서의 수치 시뮬레이션은 4-2-2 트라이사이클 코드 계열에 대해 >0.5%의 높은 회로 노이즈 임계값을 보여주었습니다(그림 4b). 이는 물리적 오류에 대한 복원력의 강력한 지표입니다.
- 메모리에 대한 탁월한 논리적 오류율: 완전한 오류 감지 및 적당한 후선택(예: 30% 수용 분율)을 통해 가장 작은 [[48, 6, 4]] 트라이사이클 코드는 $p_{2q} = 0.001$의 두 큐비트 게이트 오류율에서 약 $6 \times 10^{-10}$의 논리적 메모리 오류율을 달성했습니다. 더 큰 [[84, 6, 5]] 코드의 경우, 논리적 메모리 오류율은 약 9% 수용 분율에서 $p_{2q} = 0.001$에서 < $10^{-13}$으로 추정되었습니다. 이러한 수치는 양자 메모리에 대해 매우 높은 충실도를 나타냅니다.
-
우수한 매직 상태 생산 충실도 및 비용: 트라이사이클 코드는 놀랍도록 낮은 논리적 오류율로 하이퍼그래프 매직 상태를 생산했습니다.
- [[48, 6, 4]] 트라이사이클 코드: $2 \times 10^{-8}$
- [[84, 6, 5]] 트라이사이클 코드: $4 \times 10^{-10}$
- [[108, 6, 6]] 트라이사이클 코드: 약 $3 \times 10^{-11}$
결정적으로, 이러한 인상적인 충실도는 최첨단 컬러 코드 기반 매직-상태 재배양 방식보다 비교되거나 심지어 낮은 시공간 비용으로 달성되었습니다(표 II). 예를 들어, [[48, 6, 4]] 트라이사이클 코드는 큐비트 라운드당 89의 시공간 비용을 가졌으며, 이는 [[7, 1, 3]] 컬러 코드 재배양의 90보다 훨씬 낮았고, 훨씬 낮은 논리적 오류율($2 \times 10^{-8}$ 대 $6 \times 10^{-7}$)을 달성했습니다. 이는 횡단적 비-클리포드 게이트를 가진 고율, 고거리 LDPC 코드를 단일 샷 매직-상태 생성에 사용하는 핵심 메커니즘이 실제로 작동한다는 부인할 수 없는 증거입니다.
-
단일 샷 상태 준비: 수치 증거(그림 3)는 Z 기저에서 단일 샷 상태 준비에 대해 논리적 오류가 코드 거리가 증가함에 따라 지수적으로 억제됨을 명확하게 보여줍니다. 이는 트라이사이클 코드가 많은 다른 코드에 필요한 $O(d)$ 라운드보다 상수 수의 라운드에서 내결함성 있는 논리적 $|+\rangle$ 상태 준비를 가능하게 함을 확인합니다. 상수 깊이 CCZ 연산과 결합된 이 상수 깊이 준비는 상수 깊이에서 고충실도 하이퍼그래프 매직 상태를 생성합니다.
-
상수 깊이 CCZ 회로: 트라이사이클 코드의 구성은 상수 깊이 물리적 CCZ 회로(예: 4-2-2 코드의 경우 깊이-8)를 성공적으로 생성했으며, 이는 내결함성 작동에 필수적이며 오류 전파를 제한합니다. 상수 깊이 CCZ 회로는 순수 메모리 설정의 논리적 충실도에서 최종 편차에 최소한의 영향을 미치는 것으로 나타났습니다.
-
높은 매직 상태 수율: 표 I의 모든 코드에 대해 생성된 하이퍼그래프 매직 상태에서 $K_{CCZ} \ge 2$개의 독립적인 논리적 CCZ 게이트를 추출할 수 있는 능력은 이러한 매직 자원 상태의 실용적인 유용성을 입증합니다.
저자들의 엄격한 시뮬레이션, 강력한 기준선과의 비교, 논리적 오류율 및 시공간 비용에 대한 상세한 분석은 트라이사이클 코드가 효율적이고 내결함성 있는 매직-상태 생성에서 상당한 발전을 나타낸다는 설득력 있는 증거를 제공합니다.
한계 및 미래 방향
트라이사이클 코드는 효율적이고 내결함성 있는 양자 계산으로 가는 유망한 경로를 제시하지만, 본 논문은 또한 몇 가지 한계를 강조하고 다양한 미래 연구 및 개발 방향을 열어줍니다.
현재 한계:
- $K_{CCZ}$ 추출의 최적성: 하이퍼그래프 매직 상태에서 독립적인 CCZ 게이트의 최대 수($K_{CCZ}$)를 찾는 문제는 NP-난해입니다. 현재 혼합 정수 프로그래밍 방법은 부분적인 최적해를 생성하며 종종 더 큰 $K_{CCZ}$ 값에 대해 시간 초과되므로 보고된 값은 하한입니다. 이는 CCZ 유형 매직 상태의 즉각적인 처리량을 제한합니다.
- 코드 계열 점근적 우수성: 코드 구성은 코드 계열을 정의할 수 있게 하지만, 점근적으로 우수할 가능성은 낮습니다. 더 큰 블록 길이의 더 큰 거리를 가진 코드가 예상되지만, 이는 공식적인 점근적 보장이 아닙니다.
- 더 큰 코드에 대한 더 깊은 CCZ 회로: 더 큰 4-4-2 및 4-4-4 트라이사이클 코드의 경우, 더 깊은 물리적 CCZ 회로(예: 일부 4-4-4 코드의 경우 깊이-128)는 논리적 충실도가 순수 메모리 설정에서 더 큰 편차를 초래할 수 있습니다. 반복 코드로의 연결은 깊이를 줄일 수 있지만, 코드 비율이라는 비용이 발생합니다.
- 수치적 라이프니츠 규칙 방법 보장: CCZ 회로 구성을 위한 수치적 라이프니츠 규칙 방법은 특정 깊이를 보장하지 않으며, 낮은 차수 회로를 찾는 것은 종종 방법과 함께 코드 검색이 필요합니다.
- 선택적 상태 초기화: 독립적인 CCZ 게이트를 추출하려면 게이지 논리적 큐비트를 $|0\rangle$ 상태로, 다른 논리적 큐비트를 $|+\rangle$ 상태로 선택적으로 초기화해야 하며, 이는 LDPC 코드의 경우 상수 깊이에서 간단하지 않습니다.
- 불균형 거리: 트라이사이클 코드는 자연스럽게 Z 기저보다 X 기저에서 더 높은 거리를 나타냅니다. 노이즈 편향 플랫폼에 유용할 수 있지만, 이 편향이 실험 성능을 어떻게 향상시킬 수 있는지에 대한 상세한 탐구는 향후 작업으로 남겨져 있습니다.
미래 방향 및 토론 주제:
-
향상된 디코딩 전략:
- 표준 BP+OSD/BP+LSD와 정확한 MLE 디코더 간의 규모 차이에서 관찰된 격차는 실용적인 추론 시간을 유지하면서 MLE 성능에 근접할 수 있는 새롭고 더 효율적인 디코더에 대한 중요한 필요성을 시사합니다. 여기에는 기계 학습 기반 디코더 또는 고급 통계 방법 탐색이 포함될 수 있습니다.
- 맞춤형 노이즈 편향 활용: 중성 원자와 같은 실험 플랫폼에서 X 및 Z 섹터의 비대칭성과 Z 유형 오류의 만연과 같은 노이즈 편향을 고려할 때, 미래 작업은 맞춤형 노이즈 편향 활용을 신드롬 추출 회로 및 디코딩 알고리즘에 직접 통합하는 데 초점을 맞춰야 합니다. 최대 성능 향상을 위해 특정 하드웨어 노이즈 특성을 활용하기 위해 회로와 디코더를 최적으로 설계하는 방법은 무엇입니까?
- 손실 및 누수 관리: 많은 하드웨어 아키텍처는 손실 및 누수 오류로 어려움을 겪습니다. 이러한 오류를 활용하거나 완화하기 위한 명시적인 전략을 트라이사이클 코드 프레임워크 내에서 개발하면 논리적 오류율을 더욱 개선할 수 있습니다. 여기에는 새로운 측정 프로토콜 또는 오류 수정 기술이 포함될 수 있습니다.
-
매직 상태 공장 처리량 최적화:
- $K_{CCZ}$ 추출 개선: 논리적 텐서 $T^{log}$의 부분 순위를 찾는 NP-난해 문제는 주요 병목 현상입니다. 이진 텐서 부분 순위 문제에 대한 맞춤형 휴리스틱 최적화 전략을 개발하는 것은 $K_{CCZ}$의 더 큰 값을 추출하고 CCZ 유형 매직 상태의 처리량을 크게 개선하는 데 중요합니다. 실용적인 목적에 충분히 좋은 근사 솔루션을 찾을 수 있습니까?
- 하이퍼그래프 매직 상태의 직접 컴파일: 독립적인 CCZ 게이트를 추출하는 대신, 생성된 하이퍼그래프 매직 상태의 구조에 대한 더 깊은 이해는 유용한 양자 회로로의 직접 컴파일을 가능하게 할 수 있습니다. 이는 이러한 매직 자원 상태를 활용하는 대체적이고 잠재적으로 더 효율적인 경로를 제공할 수 있습니다.
-
광범위한 양자 아키텍처로의 통합:
- 원활한 매직 상태 주입/텔레포테이션: 주요 미해결 문제는 트라이사이클 코드 공장에서 계산 코드 블록(예: 고성능 바이사이클 코드)으로 증류된 매직 상태를 원활하게 주입하거나 텔레포트하는 것입니다. 트라이사이클 코드와 바이사이클 코드 간의 자연스러운 동형성을 기반으로 하는 횡단적 텔레포테이션을 탐색하는 것(3D 및 2D 컬러 코드에 대한 프로토콜과 유사)은 유망한 방향입니다. 이러한 코드 전환 프로토콜과 관련된 실제 과제와 오버헤드는 무엇입니까?
- 모듈식 아키텍처: 트라이사이클 코드는 고도로 모듈화된 내결함성 양자 컴퓨팅 아키텍처에 어떻게 통합될 수 있습니까? 여기에는 매직 상태 생성뿐만 아니라 더 큰 시스템 내에서의 효율적인 논리적 연산, 통신 및 메모리가 포함됩니다.
-
고급 코드 구성 및 회로 최적화:
- 수치적 라이프니츠 규칙 추가 탐색: 수치적 라이프니츠 규칙 방법과 다른 3D 균형 곱 코드에 대한 적용을 더 철저히 탐색하면 더 짧은 깊이의 CCZ 회로를 가진 코드를 얻을 수 있습니다. 더 나은 하이퍼파라미터 또는 검색 전략을 개발하여 저깊이 회로를 보장할 수 있습니까?
- 신드롬 추출 회로 최적화: 본 논문은 최적 깊이 신드롬 추출 회로를 제시합니다. 재구성 가능한 중성 원자 플랫폼에서 섹터 레이아웃 및 원자 이동 계획을 추가로 최적화하면(수학적 프로그래밍 또는 그래프 이론을 사용하여) 시공간 오버헤드를 줄일 수 있습니다.
- 다른 LDPC 계열과의 비교: 트라이사이클 코드와 다른 최근 제안된 LDPC 구성(예: 팽창 코드 또는 대수적 층의 호몰로지 곱 기반)의 오버헤드 및 성능에 대한 상세한 직접 비교는 각 구성의 상대적 장점과 최적의 적용 시나리오에 대한 귀중한 통찰력을 제공할 것입니다.
이러한 토론 주제는 내결함성 양자 계산을 발전시키는 데 있어 지속적인 과제와 흥미로운 기회를 강조하며, 트라이사이클 코드는 중요한 발판 역할을 합니다. 이론적 발전, 실험적 능력 및 알고리즘 최적화 간의 상호 작용은 이러한 발견의 전체 잠재력을 발휘하는 데 중요할 것입니다.
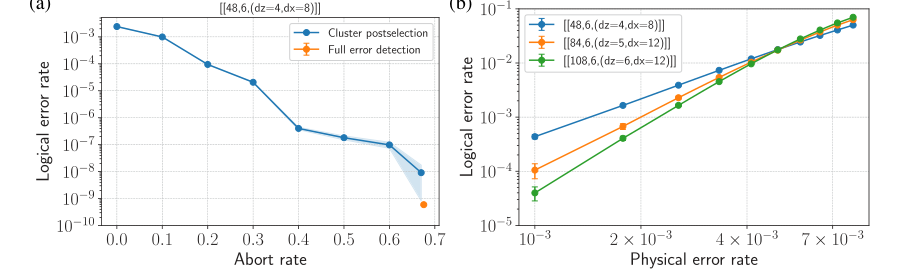 FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
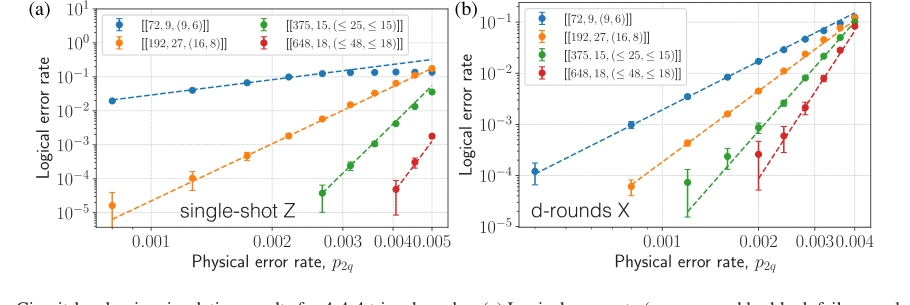 FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
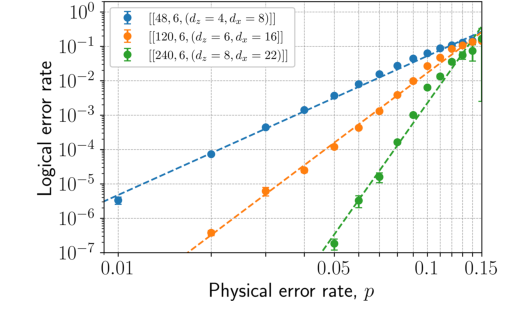 FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples
FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples