Magic Tricycles: 使用有限块长量子LDPC码实现高效魔态生成
The preparation of high-fidelity non-Clifford (magic) states is an essential subroutine for universal quantum computation but imposes substantial space-time overhead.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于实现通用容错量子计算的基本需求。Eastin 和 Knill [2] 的开创性工作证明,在量子纠错码中,无法仅通过横向(即对每个量子比特独立应用相同的物理门)的方式实现一套通用的量子门。这一限制意味着,通常被称为“魔术门”的非Clifford门必须通过其他方式实现,通常是通过将经过特殊制备的高保真度非Clifford资源态“传送”到码空间中。
制备这些高保真度资源态的主要方法是魔态蒸馏(Magic-State Distillation, MSD)。历史上,MSD协议,例如15选1蒸馏方案 [3],资源消耗极其巨大,需要多层重复蒸馏并与内码进行级联。这一过程显著增加了整体时空开销,以至于在最先进的容错架构中,魔态生成已被估计为占据总量子比特和门数量的主导地位,即使对于Shor算法 [4,5] 等算法也是如此。本研究的核心动机正是为了大幅降低这一开销。
在过去的十年里,研究人员在设计具有横向非Clifford门以降低MSD开销的量子码方面取得了进展 [6-9]。然而,这些早期方法面临着显著的局限性。许多提出的低开销蒸馏方案依赖于高权重奇偶校验的码,这意味着它们的综合提取电路深度会随着码的块长而扩展。这使得它们本身无法容错电路级噪声,也无法实现指数级的亚阈值错误抑制。此外,这些方案通常隐式地假设Clifford操作是无噪声的,这是一个不切实际的假设,由于需要高距离的内码,这进一步夸大了实际开销。Clifford编码和解码电路的深度也随着物理量子比特数量的线性增长而增长,导致了巨大的时间开销。
量子低密度奇偶校验(qLDPC)码因其稀疏的稳定子检查和有利的速率与距离缩放特性,成为降低量子纠错成本的有希望的途径。尽管qLDPC码已被用于量子存储器 [12,13],但其在魔态生成中的应用才刚刚开始被探索。这主要是因为构建能够支持横向非Clifford门的qLDPC码已被证明具有挑战性。例如,先前为魔态生成构建的同调乘积码,由于码的大小相对于经典码呈立方增长 [第5页,左栏,段落1],通常需要数千甚至数万个物理量子比特才能获得参数良好的最小块长。如此庞大的量子比特数量是一个主要的痛点。
本文直接解决了这些局限性,引入了“三轮车码”(tricycle codes),这是一类新颖的有限块长量子LDPC码,专门设计用于支持高效、容错的魔态生成。这些码的构建旨在实现横向逻辑CCZ(受控-受控-Z)门操作,这对于魔态蒸馏至关重要,同时克服了先前方法的高开销和容错挑战。
直观的领域术语
-
魔态(Magic States): 想象你在玩一个复杂的多人电子游戏。你大部分的动作都是基础操作,比如行走、跳跃或简单的攻击(Clifford门)。但是,要执行一个强大的、改变游戏进程的特殊招式(比如超级连击或传送),你需要一个特定的“能量提升”道具。这些“能量提升”道具就像量子计算中的魔态。它们是特殊的量子态,能够解锁超越基础操作的能力,从而实现通用计算。
-
魔态蒸馏(Magic-State Distillation, MSD): 继续游戏类比,有时你会发现很多弱的、质量差的“能量提升”道具,它们单独使用效果不佳。魔态蒸馏就像一个“精炼过程”,你将许多这些有噪声的、低质量的能量提升道具组合起来,以产生数量更少但质量高得多的能量提升道具。目标是获得非常纯净、可靠的特殊招式。
-
量子低密度奇偶校验(Quantum Low-Density Parity-Check, qLDPC)码: 想象一个拥有数百万本书的图书馆。为了检查是否有放错位置的书(错误),一个传统的系统可能需要每个图书管理员检查每一个书架。qLDPC码就像一个智能错误检查系统,其中每个图书管理员(一个“检查”)只负责验证一小部分、特定且分散的书籍。这种“低密度”的连接使得系统更容易构建、扩展和管理,从而用更少的复杂硬件实现更强大的错误检测。
-
横向门(Transversal Gate): 如果你有一队厨师,每个厨师都在准备一道菜,那么横向门就像是告诉每个厨师同时对他们各自的菜肴执行完全相同的简单步骤。例如,“大家加一撮盐”。关键在于每个厨师独立地处理自己的菜肴,所以一个厨师的错误不会轻易传播到另一个厨师的菜肴上。在量子计算中,这意味着对码块中的每个量子比特应用一个物理门,这自然地限制了错误传播,并使得操作具有容错性。
-
CCZ门(Controlled-Controlled-Z Gate): 这是一种涉及三个量子比特的特定类型的魔术门。想象一个有三个锁的秘密保险库。CCZ门就像一个只有当所有三个锁同时转动时才会激活的机制。如果其中任何一个锁没有转动,什么都不会发生。这种“三重控制”使得量子计算中的复杂而强大的操作成为可能。
符号表
| 符号 | 描述 |
|---|---|
| $N$ | 码块中物理量子比特的总数。 |
| $K$ | 码块中编码的逻辑量子比特的数量。 |
| $D$ | 量子码的最小距离,代表其纠错能力。$D_X$ 和 $D_Z$ 分别指X和Z基下的距离。 |
| $H_X$ | X型奇偶校验矩阵,定义X稳定子生成元。 |
| $H_Z$ | Z型奇偶校验矩阵,定义Z稳定子生成元。 |
| $A, B, C$ | 从有限阿贝尔群$G$的群代数元素派生出的$n_G \times n_G$二元置换矩阵,定义了三轮车码内的连接模式。 |
| $O$ | $n_G \times n_G$零矩阵。 |
| $\mathbb{F}_2$ | 二元域$\{0,1\}$,其中算术模2进行。 |
| $n_G$ | 每个扇区的线性尺寸,等于有限阿贝尔群$G$的阶。总物理量子比特数 $N = 3n_G$。 |
| $f_{CCZ}$ | 定义横向CCZ电路的三线性二元函数。$f_{CCZ}(p^I, q^{II}, r^{III}) = 1$表示对量子比特$p^I, q^{II}, r^{III}$应用了物理CCZ门。 |
| $\cup$ | 代数拓扑中的cup积算子,用于构造横向非Clifford门。 |
| $a_{in}, a_{out}, a_{free}$ | 群代数元素的“内”、“外”和“自由”分区(预定向),对于定义cup积并确保码空间保持的CCZ电路至关重要。 |
| $|...|_{d_{i \neq j \neq k}}$ | 表示参数的Hamming权重(支撑集的大小),条件是CCZ门必须作用于来自不同扇区的量子比特。 |
| $\pmod{2}$ | 模2算术,确保门应用的二元输出。 |
| $p_{2q}$ | 双量子比特纠缠门(例如CNOT)的物理错误率。 |
| $p_{3q}$ | 三量子比特CCZ门的物理错误率。 |
| $K_{CCZ}$ | 从超图魔态中提取的离散逻辑CCZ门的最大数量。 |
| STCP | 对称三元cup积形式主义,一种用于构造CCZ电路的分析方法。 |
| NLR | 数值Leibniz规则方法,一种用于构造CCZ电路的互补数值方法。 |
| MSD | 魔态蒸馏,一种制备高保真度非Clifford资源态的协议。 |
| qLDPC | 量子低密度奇偶校验码。 |
| CSS | Calderbank-Shor-Steane码,一类量子纠错码。 |
| MLE | 最大似然错误解码器。 |
| BP + LSD | 置信传播+局部统计解码,一种高效的近似解码器。 |
| BP + OSD | 置信传播+有序统计解码,另一种近似解码器。 |
| AOD | 声光偏转器,用于中性原子阵列中的原子移动。 |
| SLM | 空间光调制器,用于生成量子比特的陷阱。 |
| $t_{wsp}, t_{ent}$ | AOD在工作空间和纠缠区域移动的时间开销。 |
| $d_{min}$ | 最小光学分辨距离,限制了量子比特密度和移动速度。 |
| $d_{iso}$ | 里德堡相互作用的隔离距离,确保预期的CNOT对。 |
问题定义与约束
核心问题表述与困境
本文所解决的核心问题是低效且资源消耗巨大的高保真度非Clifford(魔态)状态生成,这对于通用容错量子计算是不可或缺的。
输入/当前状态:
通用量子计算依赖于Clifford和非Clifford操作。虽然逻辑Clifford门通常可以在许多量子纠错码中横向实现,但Eastin-Knill定理规定,一个通用的门集无法横向实现。因此,非Clifford门(魔术门)通常通过传送专门制备的非Clifford资源态到码空间中来实现。当前制备这些高保真度资源态(称为魔态蒸馏,MSD)的最先进方法存在显著缺点:
1. 巨大的时空开销: MSD协议,如15选1蒸馏,需要多层重复蒸馏并与内码级联。这导致魔态生成在Shor算法等大规模量子算法的总量子比特和门计数中占据主导地位。
2. 先前“低开销”方案的容错性受损: 最近提出的低开销MSD方案,虽然实现了横向非Clifford门,但通常伴随着高权重的奇偶校验。这需要综合提取电路的深度随着码的块长而增长,使其本身无法容错电路级噪声。
3. 不切实际的假设: 许多现有协议隐式地假设编码和解码电路的Clifford操作是无噪声的,这夸大了其报告的开销。这些Clifford电路的深度也可能随着物理量子比特数量的线性增长而增长,导致巨大的时间开销。
期望终点(输出/目标状态):
本文旨在实现高效、容错的魔态生产,从而显著降低当前方法的时空开销。具体而言,目标是:
1. 高保真度和高吞吐量生成魔态: 为Shor算法等实际应用生成逻辑错误率低至$2 \times 10^{-8}$至低于$3 \times 10^{-11}$的魔态。
2. 使用有限块长码: 采用块长约为50-100个量子比特的码,使其在实验上可行。
3. 支持恒定深度的电路: 使用恒定深度的物理电路实现逻辑CCZ门和综合提取,独立于码的大小。
4. 实现单次状态制备和错误校正: 允许魔态制备电路的初始逻辑状态以恒定深度制备,并在一个基中无需重复综合提取即可纠正错误。
5. 规避级联: 消除与支持横向Clifford门的内码进行级联的需要,简化整体架构。
缺失环节与数学鸿沟:
确切的缺失环节是构建能够同时具备高速率、高距离,并支持恒定深度横向非Clifford门(特别是CCZ门)的量子低密度奇偶校验(qLDPC)码,同时还能实现单次错误校正。先前的qLDPC码研究在横向非Clifford门要求方面遇到了困难。
本文试图通过引入“三轮车码”来弥合这一鸿沟,这是一类新的有限块长量子LDPC码。这些码被构建为阿贝尔群代数上的经典二元线性码的三维平衡乘积,泛化了众所周知的双轮车码。数学鸿沟通过以下方式弥合:
1. 开发改进的Cup积形式主义: 本文扩展了在三维乘积码中构造横向非Clifford门的理论框架,通过修改代数拓扑的cup积形式主义。这导致了一组新的条件,高速率和高距离的三轮车码必须满足这些条件才能支持非平凡的CCZ作用。
2. 引入数值Leibniz规则(NLR)方法: 开发了一种互补的数值方法,用于在迭代平衡乘积量子码上寻找短深度、保持码空间的CCZ电路,尤其是在解析cup积形式主义过于受限的情况下。
困境:
困扰先前研究人员的痛苦权衡是高速率、高距离码与横向非Clifford门之间的张力,以及保持高效综合提取的真正容错性。历史上,改进一个方面(例如,实现低开销的横向非Clifford门)常常会损害另一个方面(例如,需要深度随块长增长的综合提取电路,从而在电路级噪声存在的情况下破坏容错性)。困境是如何同时实现:
* 高保真度魔态(需要高码距离以抑制错误)。
* 高效生成(需要高码速率以进行并行蒸馏和低时空开销)。
* 容错性(需要恒定深度的综合提取和状态制备,以及对电路级噪声的鲁棒性)。
* 横向非Clifford门(以避免复杂、非容错的门实现)。
先前的方法要么牺牲了其他目标来实现某些目标,要么依赖于不适用于实际量子计算架构的简化假设。例如,4-4-4三轮车码虽然提供了更高的速率和距离,但其代价是更高的校验权重和更深的CCZ电路,这说明了这种固有的权衡。
约束与失效模式
高效、容错的魔态生成问题由于物理、计算和数据驱动的约束以及固有的失效模式的结合,变得极其困难:
物理约束:
1. 量子比特错误率和噪声偏差: 假设物理CCZ门的错误率为特定值(例如,$p_{3q} = 0.002$),是双量子比特纠缠门($p_{2q} = 0.001$)的两倍。此外,本地相位类门(如CCZ)表现出强烈偏向Z型错误的噪声特性,必须在错误模型中加以考虑。
2. 硬件内存限制: “有限块长”码(例如,50-100个量子比特)的需求意味着码块可用的物理量子比特数量存在实际限制。
3. 实时延迟要求: “单次”状态制备和错误校正的需求对于防止错误传播和累积至关重要,尤其因为CCZ门可以将X错误传播为CZ错误。这对解码和校正周期施加了严格的延迟要求。
4. 中性原子阵列平台限制: 在可重构中性原子阵列上提出的实现引入了特定的约束:
* 陷阱间距: 并行CNOT操作涉及的量子比特对必须保持足够的距离($d_{iso}$,例如10 µm),以隔离里德堡相互作用并防止同一扇区内发生意外相互作用。
* 光学分辨率($d_{min}$): 最小光学分辨距离(例如2 µm)限制了量子比特排列的速度和密度。
* AOD移动时序: 用于排列(x、y、z循环)和取放操作的原子光偏转器(AOD)移动具有相关的时间开销($t_{wsp}, t_{ent}$),这会增加整体电路深度。
5. Eastin-Knill定理: 这个基本定理阻止了通用横向门集,迫使使用魔态,从而增加了非Clifford操作的复杂性。
计算约束:
1. 码距离和子秩问题的NP难性:
* 寻找线性码的精确码距离是一个NP难问题,使得精确表征更大三轮车码的性能在计算上具有挑战性。
* 寻找二元张量的子秩(对应于从超图魔态中提取最大数量的离散CCZ门)也是NP难的。这限制了有效提取生成魔态的全部潜力的能力。
2. 求解器超时: 用于逻辑电路优化的数值求解器(例如,用于$K_{CCZ}$的混合整数规划)对于较大的值经常超时,表明找到最优解的计算不可行性。
3. 解码复杂度: 虽然使用了像置信传播+局部统计解码(BP + LSD)这样的高效解码器,但它们是近似的。精确的最大似然错误(MLE)解码器是指数级昂贵的,使其不适用于实时容错操作。
4. 数值搜索限制: 用于构造CCZ电路的数值Leibniz规则方法不能保证短深度,需要广泛的搜索和超参数调整来找到合适的码。
数据驱动约束与失效模式:
1. 电路级噪声: 整个协议必须在实际的电路级噪声模型下运行,包括双量子比特的退相干噪声和CCZ门的偏置三量子比特退相干噪声。这种噪声引入了必须检测和纠正的错误。
2. 错误传播: 一个显著的失效模式是CCZ门会将预先存在的X错误传播为其他量子比特上的CZ错误。这些CZ错误在综合测量后会迅速累积为非确定性的Z错误,如果不是通过单次错误校正来处理,则会迅速累积。
3. 非确定性的Z稳定子测量: 初始的Z型稳定子测量会产生非确定性的$\pm 1$结果,在应用CCZ门之前必须可靠地将其固定为硬件上的$+1$。这需要鲁棒的元检查和解码器来识别和纠正综合测量错误。
4. 不平衡的码距离: 三轮车码自然地表现出X基下的距离高于Z基下的距离($d_Z \leq d_X$)。虽然可能对噪声偏置平台有用,但这种不平衡意味着更具挑战性的X基错误校正通常决定了整体性能。
5. 后选成功率有限: 虽然后选可以显著提高逻辑错误率,但其代价是接受率降低(例如,对于所研究的码,从3%到30%),这会影响魔态生成的整体吞吐量。
为什么选择此方法
选择的必然性
选择三轮车码并非仅仅是偏好,而是由现有容错魔态生成方法固有的局限性所驱动的必然选择。通用量子计算关键依赖于非Clifford(魔态)状态,但其生产历来带来了巨大的时空开销。传统的魔态蒸馏(MSD)协议,例如广泛使用的15选1蒸馏,需要多层重复精炼,并且通常需要与内码(如二维彩色码)级联以支持横向Clifford门。这种多层方法导致了对量子比特和门操作的过高消耗,常常主导了Shor算法等大规模量子算法的资源估计。
此外,尽管最近提出的低开销MSD方案引入了具有横向非Clifford门和有利渐近参数的量子码,但它们也附带了重要的注意事项。这些码通常具有高权重的奇偶校验,这意味着它们的综合提取电路深度会随着码块长度而增长。这种增长破坏了容错性,因为电路级噪声的存在使得恒定深度的综合提取成为不可能。此外,这些方案通常假设编码和解码的Clifford操作是无噪声的,这一假设在实践中夸大了真实的资源开销。Clifford电路深度与物理量子比特数量的线性增长也导致了巨大的时间开销。
显然,需要一种根本不同的码类来克服这些瓶颈。作者意识到,量子低密度奇偶校验(qLDPC)码,其本身就提供了稀疏的稳定子检查以及有利的速率和距离缩放特性,是最有希望的途径。具体而言,挑战在于构建能够支持强横向非Clifford门(即,无需Clifford校正或与内码级联的恒定深度物理电路)同时保持恒定深度综合提取的qLDPC码。这一认识促使引入三轮车码:有限块长、高速率、高距离的量子LDPC码,专门设计用于支持横向逻辑CCZ电路作用,从而实现高效、单次的魔态生成。
相对优越性
三轮车码在定性上远超先前黄金标准,其优势远远超出了简单的性能指标。其结构设计为高效、容错的魔态生成提供了独特的优势。
首先,三轮车码被构建为阿贝尔群代数上的经典二元线性码的三维平衡乘积。这种对众所周知的双轮车码的三同调维度的创新泛化至关重要,因为它内在地允许来自Clifford层次结构第三层的横向门,特别是逻辑CCZ门。这是一个根本性的结构优势,因为它允许直接、恒定深度的实现一个关键的非Clifford门,这通常是其他架构中的瓶颈。
其次,一个至关重要的优势是实现了单次状态制备和错误校正(第I.B节,II.C节)。与需要多次迭代蒸馏的传统MSD方案不同,三轮车码可以在单次蒸馏中制备高保真度的超图魔态。这得益于两个关键特性:状态初始化期间在一个稳定子基中的内禀容错性,以及“元检查”的存在。这些元检查是冗余的Z奇偶校验,在综合比特上形成一个经典码,允许可靠地识别和纠正Z基中的综合测量错误。这一能力与表面码等通常缺乏单次状态制备的码相比,是一个显著的进步,并极大地减少了从$O(d)$轮(其中$d$是码距离)到恒定数量的时间开销。
此外,三轮车码在相对较小的块长(例如,表I中的[[48, 6, 4]],[[108, 21, 6]])下实现了有利的参数——高速率和高距离。这种紧凑性对于在近期的量子硬件上实现至关重要。本文还强调,特定的家族,如4-2-2三轮车码,由于其较低的校验权重和最小深度为8的CCZ电路,直接转化为减少的电路级噪声传播,因此特别相关。
从数量上看,其优越性在时空成本上显而易见。如表II所示,三轮车码在可比或显著更低的时空成本(分别为89和527量子比特轮)下,实现了与最先进的基于彩色码的魔态培养(例如,[[7, 1, 3]]彩色码的$6 \times 10^{-7}$错误率需要90量子比特轮,[[19, 1, 5]]彩色码的$6 \times 10^{-10}$错误率需要3000量子比特轮)相当或更低的逻辑错误率(例如,[[48, 6, 4]]为$2 \times 10^{-8}$,[[84, 6, 5]]为$4 \times 10^{-10}$)。这表明在制备高保真度魔态的资源效率方面取得了显著的改进。
与约束的契合
所选的三轮车码方法展示了与实际、容错量子计算的严格要求之间的绝佳“结合”。三轮车码的设计原则是专门为了解决问题定义中确定的核心约束而量身定制的。
首先,通用容错量子计算的总体目标通过三轮车码支持横向逻辑CCZ门的能力直接实现。CCZ门是实现通用门集所必需的非Clifford操作,其在三轮车码内的恒定深度、横向实现是这一要求的直接解决方案(第I.B节,II.B节)。
其次,减少时空开销的关键约束通过三轮车码设计的多个方面得到解决。单次魔态生成协议(第I.B节,II.C节)消除了多次蒸馏的需求,极大地削减了时间资源。高速率码允许在单个码块内并行蒸馏多个魔态,提高了吞吐量并降低了总时间。此外,逻辑CCZ操作和综合提取电路都被设计为恒定深度(第I.B节,II.E节),确保电路复杂度不会随着码大小而不利地扩展,从而避免了其他方法中出现的线性扩展开销。使用具有有利参数的有限块长码(表I)也确保了这些码在实现上是实用且资源高效的。
第三,通过强大的错误抑制满足了高保真度魔态的需求。数值模拟证实,即使在适度的块长和实际的电路级噪声下,三轮车码也能实现极低的逻辑错误率(例如,$2 \times 10^{-8}$至低于$3 \times 10^{-11}$),尤其是在进行后选时(第I.B节,表II)。
最后,容错性内在地构建在三轮车码架构中。恒定深度的综合提取电路(第I.A节,II.E节)被设计为对电路级噪声具有鲁棒性。非Clifford门的横向性质本质上限制了错误在物理量子比特之间的传播(第I.A节)。高相对距离确保了蒸馏过程中有效的错误抑制。至关重要的是,元检查的存在使得在Z基中进行单次错误校正成为可能,允许立即纠正X错误并防止其传播,这对于在魔态制备过程中维持容错性至关重要(第II.C节)。在中性原子平台上的拟议实现(第I.B节,II.E节)也与现代量子计算的实际硬件约束相符。
替代方案的拒绝
本文通过强调其缺点或展示三轮车码的优越能力,隐式和显式地拒绝了几种替代方法。
传统魔态蒸馏(MSD)方案: 本文的引言(第I.A节)强烈否定了传统的MSD协议,如15选1蒸馏。这些方法因需要“多层重复蒸馏”和“与足够大距离的内码级联”而受到批评,这“显著增加了时空开销”。作者明确指出,魔态生成“尽管进行了大量优化 [4,5],但仍占据了Shor算法因子分解资源估计的主导地位”。相比之下,三轮车码旨在实现单次蒸馏,从而极大地降低了这一开销。
现有的非LDPC恒定开销MSD协议: 虽然一些先前的工作提出了具有横向非Clifford门和恒定开销的码,但本文指出了它们的关键缺陷(第I.A节)。这些码通常具有“高权重奇偶校验”,导致综合提取电路的“深度随块长增长”。这使得它们“本身并非显然容错”,并且无法支持有限阈值。此外,它们“隐式地假设Clifford操作是无噪声的”,这是一个不切实际的简化,夸大了其感知效率。三轮车码作为qLDPC码,通过确保稀疏校验和恒定深度综合提取来克服这些问题。
双轮车码(二维群代数码): 三轮车码被呈现为将众所周知的双轮车码泛化到“三同调维度”(第I.B节)。这种泛化至关重要,因为它“原则上允许来自Clifford层次结构第三层的横向门 [23]”,特别是逻辑CCZ门。虽然双轮车码对于较低层次的Clifford层次门是有效的,但它们不足以直接横向实现CCZ门,这是本工作目标中的非Clifford操作。本文指出,虽然双轮车码可能具有更高的速率,但三轮车码提供了CCZ横向实现的必要3D结构。
特定的2-2-2三轮车码参数: 在三轮车码家族中,作者通过经验拒绝了某些参数选择。他们发现“具有权重6的X校验和权重4的Z校验的2-2-2码”对于非平凡的横向CCZ作用,并未提供“同样有利”的速率和距离(第II.A节)。具体来说,他们“未能找到任何具有K > 3个编码逻辑量子比特和距离D > 7的此类码”,这促使他们专注于4-2-2、4-4-2和4-4-4码,这些码表现出更好的性能。
原始参考文献[27]的Cup积形式主义: 本文还详细介绍了构造横向非Clifford门的理论框架的改进。发现“参考文献[27]的原始cup积条件”对“码的参数过于严格”(第II.B节,附录D)。这些原始条件,例如,导致了具有有限逻辑量子比特(K=3)和距离(D=2)的2-2-2码,以及类似限制的4-2-2和4-4-4码。作者开发了一种“新的对称三元cup积”形式主义,它允许在参数选择上具有更大的灵活性,从而产生了具有“更好参数”(更高距离)的三轮车码,从而拒绝了原始的、更严格的形式主义。
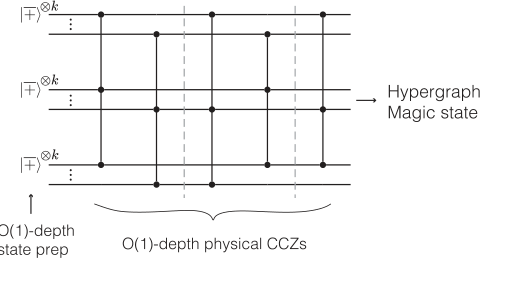 FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
FIG. 2. Single-shot distillation with tricycle codes. The logical jþi⊗K state of the tricycle code can be prepared fault tolerantly in constant depth by harnessing the code’s intrinsic resilience in one basis—namely, by preparing the physical qubits such that the associated stabilizer checks are deterministic—together with single-shot error correction in the complementary, nondetermin- istic, basis. The logical non-Clifford operation is implemented via a constant-depth circuit composed of physical CCZ gates. The output is a logical hypergraph magic state which embeds KCCZ ≤K disjoint logical jCCZi resource states
数学与逻辑机制
主方程
本文的基础数学引擎在于三轮车码本身的定义,它们是一类量子Calderbank-Shor-Steane(CSS)码。这些码主要由它们的X型和Z型奇偶校验矩阵表征。此外,本文引入了一个特定的三线性函数,该函数定义了横向受控-受控-Z(CCZ)门,这是魔态生成协议的核心。
奇偶校验矩阵给出为:
$$ H_X = \begin{bmatrix} A^T & B^T & C^T \end{bmatrix} \in \mathbb{F}_2^{n_G \times 3n_G} $$
$$ H_Z = \begin{bmatrix} C & O & A \\ O & C & B \\ B & A & O \end{bmatrix} \in \mathbb{F}_2^{3n_G \times 3n_G} $$
这些矩阵定义了量子码的稳定子。除了码的定义之外,本文魔态生成的核心机制依赖于一个横向CCZ电路,其结构编码在一个由对称三元cup积导出的二元函数中。虽然本文给出了一个通用形式(方程2),但三轮车码的具体构造在命题D4(方程D27)中详细说明:
$$ f_{CCZ}(p^I, q^{II}, r^{III}) = |r^{III} \cup a_{out}^{III} \cup q^{II} \cup a_{in}^{II} \cup p^I \cup a_{in}^I \cup a_{out}^I|_{d_{i \neq j \neq k}} \pmod{2} $$
按项解剖
让我们剖析这些方程,以理解每个组成部分的作用。
对于奇偶校验矩阵($H_X, H_Z$):
- $H_X$: 这是X型奇偶校验矩阵。
- 数学定义: 一个二元矩阵,其行定义了X稳定子群的生成元。
- 物理/逻辑作用: 它决定了哪些物理量子比特参与每个X型稳定子测量。这些测量用于检测数据量子比特上的Z型错误。
- 为何采用此结构: 块结构$[A^T \ B^T \ C^T]$表明X校验是由来自码块三个扇区(I、II、III)的元素组合而成的。转置($^T$)是在给定$H_Z$的特定形式时,在CSS码中定义X校验的标准方法。
- $H_Z$: 这是Z型奇偶校验矩阵。
- 数学定义: 一个二元矩阵,其行定义了Z稳定子群的生成元。
- 物理/逻辑作用: 它决定了哪些物理量子比特参与每个Z型稳定子测量。这些测量用于检测数据量子比特上的X型错误。
- 为何采用此结构: $3n_G \times 3n_G$块矩阵结构反映了$N=3n_G$个物理量子比特被划分为三个相等大小的扇区(I、II、III)。非对角线矩阵$A, B, C$表示Z校验在扇区之间的连接,而对角线矩阵$C$则暗示了扇区内部连接或环绕连接。
- $A, B, C$: 这些是$n_G \times n_G$的二元矩阵。
- 数学定义: 从群代数元素$a, b, c \in \mathbb{F}_2[G]$派生的置换矩阵。置换矩阵在每一行和每一列中恰好有一个'1'。
- 物理/逻辑作用: 它们定义了码块中跨越不同扇区的量子比特之间的特定连接模式。它们的置换性质意味着一对一映射,确保了连接的平衡分布。这些元素的选择对于码的距离和速率至关重要。
- 为何采用置换矩阵: 使用置换矩阵确保每个量子比特参与固定数量的校验,从而实现低密度奇偶校验(LDPC)特性,这对于高效解码是有益的。
- $O$: 这是$n_G \times n_G$的零矩阵。
- 数学定义: 所有条目均为零的矩阵。
- 物理/逻辑作用: 它表示在某些Z型稳定子生成元之间缺乏连接。例如,在$H_Z$的第一行中,$O$表示扇区II和扇区I之间没有直接的Z校验连接。
- $\mathbb{F}_2$: 二元域$\{0,1\}$。
- 数学定义: 一个有两个元素的域,其中算术模2进行。
- 物理/逻辑作用: 这是量子CSS码的基础,其中泡利算符($X, Y, Z$)的平方是单位算符,它们的乘积遵循二元算术规则(例如,$X \cdot X = I$, $X \cdot Z = -iY$, $Z \cdot X = iY$,因此$X \cdot Z \cdot X \cdot Z = I$)。所有矩阵运算(乘法、加法)均按模2进行。
- $n_G$: 每个扇区的线性尺寸,等于有限阿贝尔群$G$的阶。
- 数学定义: $n_G = |G|$。
- 物理/逻辑作用: 它决定了三个扇区中每个扇区的量子比特数量,从而决定了总物理量子比特数 $N = 3n_G$。
对于CCZ函数($f_{CCZ}$):
- $f_{CCZ}(p^I, q^{II}, r^{III})$: 这是一个三线性二元函数。
- 数学定义: 一个接受三个输入(来自不同扇区/码块的量子比特)并输出0或1的函数。
- 物理/逻辑作用: 如果$f_{CCZ}=1$,则表示对量子比特三元组$(p^I, q^{II}, r^{III})$应用了物理CCZ门。如果$f_{CCZ}=0$,则不应用门。此函数定义了整个横向CCZ电路。
- $p^I, q^{II}, r^{III}$: 这些代表特定的物理量子比特。
- 数学定义: 代表单个量子比特的变量,按其码块(I、II、III)和在该块/扇区中的位置索引。
- 物理/逻辑作用: 这些是CCZ门的目标量子比特。上标$I, II, III$表示量子比特必须来自三个不同的码块(或块内的扇区,如论文图1(a)及相关文本所澄清)。
- $\cup$: cup积算子。
- 数学定义: 来自代数拓扑的双线性映射,特别是同调代数,它组合上链。本文使用“对称三元cup积”(定义6,第21页),这意味着特定顺序的操作。
- 物理/逻辑作用: 这个算子是用于构造横向非Clifford门的中心代数工具。它自然地源于码的同调乘积结构,并与“逻辑算符的三重交集”相关。方程中cup积的特定序列旨在确保生成的CCZ电路保持码空间并保持上链不变。
- 为何采用cup积: 它提供了一种系统的方法来从码的底层代数结构中推导出高阶Clifford层次门(如CCZ),确保它们在逻辑子空间上正确作用。
- $a_{in}^I, a_{out}^I, \dots, a_{out}^{III}$: 这些是定义经典码的群代数元素$a_I, a_{II}, a_{III}$的“内”和“外”分区。
- 数学定义: 对于群代数元素$a$,它被划分为$a = a_{in} + a_{out} + a_{free}$(方程D20,第22页)。$a_{in}$和$a_{out}$本身也是群代数元素。
- 物理/逻辑作用: 这些分区,称为“预定向”,诱导了经典码上的cup积。这些分区的特定选择,必须满足“对称积分Leibniz规则”条件(方程D15-D19,第22页),对于CCZ电路保持码空间和上链不变至关重要。本文指出,对于三轮车码,$a_{free}$通常设为空。
- 为何采用分区: 这些分区允许对cup积的操作进行精细控制,从而能够构造具有期望属性(例如,非平凡作用,更好的码参数)的CCZ门。
- $|...|_{d_{i \neq j \neq k}}$: 这表示参数的支撑集大小。
- 数学定义: cup积运算后生成的二元向量的Hamming权重。下标$d_{i \neq j \neq k}$是一个条件,它意味着如果其参数中的任何两个或多个量子比特来自同一扇区,则$f_{CCZ}=0$(命题D4,第24页)。
- 物理/逻辑作用: Hamming权重决定了组合代数表达式是否非零,进而触发CCZ门的应用。条件$d_{i \neq j \neq k}$对于确保CCZ电路的横向性质至关重要,这意味着门只作用于来自不同扇区/码块的量子比特之间,这是容错性的关键特性。
- $\pmod{2}$: 模2算术。
- 数学定义: 整个表达式的结果按模2取值。
- 物理/逻辑作用: 这确保了输出是二元的(0或1),直接指示CCZ门的存在或不存在。它与量子信息和泡利算符的二元性质一致。
分步流程
让我们追踪一个抽象数据点,例如一个量子比特,通过所描述的机制的历程。
1. 码定义与错误检测(通过$H_X, H_Z$):
想象一个物理量子比特,$q_j$,位于三轮车码块的三个扇区之一内。
* 初始化: 首先,通常将$q_j$初始化在计算基态,如$|0\rangle$或$|+\rangle$。对于Z基单次状态制备,所有物理数据量子比特都初始化在$|+\rangle$。
* 稳定子相互作用: 为了检测错误,$q_j$会参与各种稳定子测量。
* 如果我们正在检查X型错误(使用Z稳定子),$q_j$将根据$H_Z$的行定义与其他量子比特相互作用。例如,如果$H_Z[i, j] = 1$,则$q_j$上的泡利Z算符($Z_j$)是第$i$个Z稳定子生成元的一部分。这涉及到将$q_j$与一个辅助量子比特纠缠,然后测量辅助量子比特。
* 类似地,如果我们正在检查Z型错误(使用X稳定子),$q_j$将根据$H_X$的行定义与其他量子比特相互作用。如果$H_X[i, j] = 1$,则$X_j$是第$i$个X稳定子生成元的一部分。
* 综合生成: 这些稳定子检查的测量结果构成了“综合”。如果$q_j$发生了错误(例如,如果我们正在测量Z稳定子,则发生了泡利X错误),这将翻转它参与的任何稳定子测量的结果。
* 解码: 综合信息,即一组二元值,被输入到解码器中。解码器处理这些信息以推断最有可能发生在$q_j$和其他量子比特上的错误模式。
* 校正: 基于解码器的输出,将校正操作(例如,应用泡利X或Z门)应用于$q_j$,以将其恢复到其在码空间中的预期状态。这完成了一个错误校正周期。
2. 逻辑CCZ门应用(通过$f_{CCZ}$):
现在,考虑三个不同的物理量子比特,$p^I, q^{II}, r^{III}$,它们分别位于三个独立码块的三个不同扇区(I、II、III)中。这些量子比特是期望执行CCZ操作的逻辑状态的一部分。
* 函数输入: 这三个量子比特的身份($p^I, q^{II}, r^{III}$)被作为输入馈送到$f_{CCZ}$函数。
* 代数处理: 在$f_{CCZ}$函数内部,执行一系列抽象的代数运算,特别是“cup积”。这涉及到将量子比特标识符与定义码的群代数元素的预定向分区($a_{in}, a_{out}$)相结合。这是在二元域$\mathbb{F}_2$内的一个复杂的多步计算。
* 支撑集计算: 这些cup积的结果是一个代数表达式。然后计算其“支撑集”(Hamming权重)。这基本上检查组合代数实体是否非零。
* 横向性检查: 一个关键条件$d_{i \neq j \neq k}$被隐式应用。这确保了三个输入量子比特确实来自不同的扇区/码块。如果不是,函数立即输出0。
* 门决策: 最终结果按模2取值,是0或1。
* 如果$f_{CCZ}(p^I, q^{II}, r^{III}) = 1$,则对量子比特$(p^I, q^{II}, r^{III})$应用物理CCZ门。该门同时作用于所有三个量子比特。
* 如果$f_{CCZ}(p^I, q^{II}, r^{III}) = 0$,则不对该特定三元组应用门。
* 电路执行: 此过程对所有相关的码块量子比特三元组重复进行。由$f_{CCZ}$确定的整个物理CCZ门集合构成一个“恒定深度”电路,这意味着所有这些门都可以安排在固定的、少数的并行层中,而与码的大小无关。这确保了快速执行并限制了错误传播。
每个三轮车码块的物理量子比特可以根据方程(1)中奇偶校验矩阵的块结构自然地划分为三个扇区。保持码空间的CCZ电路始终作用于三个码块的扇区之间,如图1所示。
优化动力学
这里的“学习”或“优化”并非像典型机器学习那样通过梯度在连续损失景观中迭代更新参数。相反,它是在离散的代数空间中进行最佳码参数和电路构造的多方面设计和搜索过程。
1. 码参数搜索:
本文描述了通过选择奇偶校验矩阵$H_X$和$H_Z$的特定群代数元素($a, b, c$)及其权重($w_a, w_b, w_c$)来构造三轮车码。这是一个搜索问题,旨在为给定的块长$N$找到具有有利参数(高速率$K$和距离$D$)的码。作者使用数值方法,包括SAT求解器和混合整数规划(MIP),来寻找候选码的最小距离$D_X$和$D_Z$。这是对离散选择的穷举或启发式搜索,而不是基于梯度的优化。这里的“损失”将是期望的码参数(例如,低距离),而“更新”是尝试另一组群代数元素。
2. CCZ电路构造(对称三元cup积 - STCP):
对于由对称三元cup积导出的$f_{CCZ}$函数,其“优化”涉及仔细选择群代数元素的“预定向”($a_{in}, a_{out}, a_{free}$)。这些选择必须满足一组称为“对称积分Leibniz规则”(方程D15-D19)的代数条件。本文提出了一种构造方法(定理D1)来构造权重为4的元素的这些预定向。这是一个设计原则,保证了期望的属性(保持码空间、保持上链不变),而不是一个迭代学习过程。其“动力学”在于这些条件的推导以及证明它们能导致有效的电路。目标是找到产生短深度CCZ电路的预定向。
3. CCZ电路构造(数值Leibniz规则 - NLR):
附录E引入了一种“数值Leibniz规则”方法。在这里,过程更类似于搜索算法:
* 基构造: 构建了一组群等变的双线性函数$f_i^j$的基。这涉及到寻找编码“广义Leibniz规则”条件(方程E5)的奇偶校验矩阵$H_{leibniz}$的零空间。这是一个线性代数问题,而不是迭代优化。
* 启发式搜索: 然后通过随机搜索这些$f_i^j$函数的候选者来构造实际的$f_{CCZ}$函数。“优化”目标是找到导致$f_{CCZ}$函数低最大次数的候选者,这直接转化为短电路深度。这是一个启发式搜索,可能使用蒙特卡洛采样或模拟退火等技术来探索可能的函数离散空间。“损失景观”高度不规则且非凸,没有明确的梯度可循。
4. 逻辑电路优化(最大化$K_{CCZ}$):
附录F描述了优化逻辑CCZ电路以最大化($K_{CCZ}$)可以从超图魔态中提取的离散CCZ魔态数量。这被表述为寻找代表逻辑连通性的二元3张量$T_{ijk}^{log}$的“子秩”。
* 问题表述: 这是一个NP难问题。作者使用混合整数规划(MIP)求解器(Gurobi)来寻找次优解。
* 迭代搜索: 求解器迭代地探索二元变量(代表基变换矩阵$M^1, M^2, M^3$)的可能赋值,以满足$r$个离散CCZ门的条件(方程F3)。这里的“状态”是基矩阵的集合,而“更新”是求解器探索解空间的内部机制。这是一个离散优化,而不是基于梯度的优化。“损失”是找不到给定$r$的解,或者找到$r$较低的解。“收敛”是指求解器找到可行解或超时。
本质上,“优化动力学”的特点是代数推导、系统构造以及离散空间上的启发式或精确搜索的结合,而不是连续梯度下降。目标是设计具有内禀容错特性和高效性能的码和电路,而不是从数据中学习它们。“损失景观”通常是离散且非凸的,需要专门的求解器或巧妙的设计原则来导航。
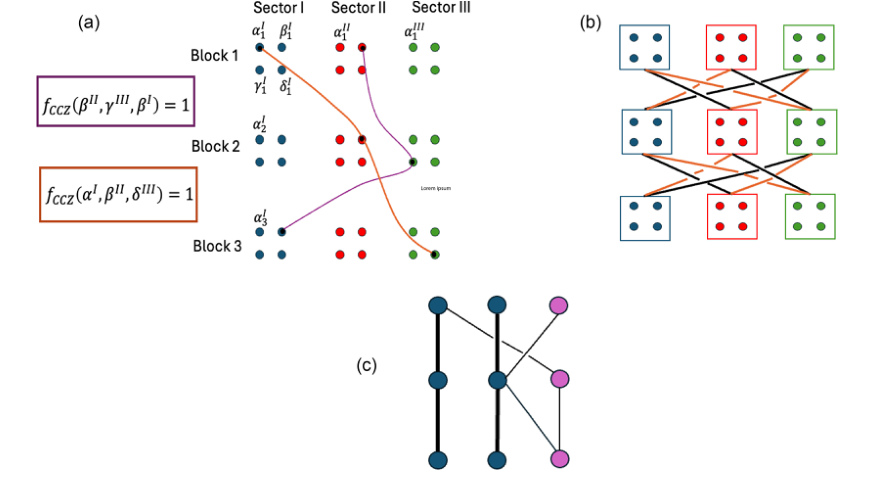 FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
FIG. 1. Structure of transversal CCZ gates of tricycle codes. (a) Schematic of a transversal CCZ circuit on a 12-qubit code. Each code block is partitioned into three sectors of four qubits, labeled α, β, γ, and δ with subscripts and superscripts indicating the code block and sector. Colored curves denote CCZ gates between triples of qubits where fCCZ is nonzero. (b) Structure of transversal CCZ circuits: all sectors participate via two disjoint sets of circuit layers denoted by orange and black edges that can individually be parallelized across qubits. Each qubit undergoes a maximum of l black and a maximum of m orange CCZ gates, leading to a maximum degree of l þ m. (c) Logical CCZ connectivity after basis optimization for a K ¼ 3 code. Circles denote logical qubits; rows correspond to separate code blocks. Thick black lines indicate usable CCZ gates for magic-state distillation (KCCZ ¼ 2 shown), while thin lines involve gauge qubits (pink), initialized in j0i. Blue circles represent logical qubits in disjoint triples connected only to other qubits in the triple or to gauge qubits
 FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
FIG. 9. Reference neutral-atom array architecture. Rydberg interactions are enabled only within the entangling zone. We slice the zones to regions Ei and Si; each one can store a sector. Each region contains two trap arrays (dots=−and circles=þ) to facilitate sector permutation or parallel CNOTs. In the work space, traps are spaced by twice the minimal distance permitted by optical resolution, dmin, allowing qubits to move between traps along dashed paths. In the entangling zone, traps are spaced so that qubit pairs involved in parallel CNOTs are separated by a distance to sufficiently isolate the Rydberg interaction, diso
结果、局限性与结论
实验设计与基线
作者精心设计了他们的实验,以严格验证围绕三轮车码的数学主张。他们的核心方法是在实际的电路级噪声模型下对这些码进行数值模拟,并将其性能与已建立的基线进行直接比较。
为了证明三轮车码的有效性,实验设计侧重于几个关键方面:
1. 码构造与性质: 他们引入了三轮车码作为有限块长量子低密度奇偶校验(LDPC)码,将双轮车码泛化到三个同调维度。这些码被设计用于支持实现逻辑CCZ门的恒定深度物理电路。构造过程涉及开发新颖的分析和数值技术,包括改进的对称三元cup积形式主义(附录D)和数值Leibniz规则方法(附录E),以找到具有有利参数(高速率和距离)和短深度CCZ电路的码。
2. 噪声模型: 采用标准的双量子比特退相干噪声模型,其中每个纠缠操作后都跟着一个概率为$p_{2q}$的15种非平凡双量子比特泡利错误之一。对于关键的CCZ门,使用了三量子比特偏置的退相干噪声模型,假设物理错误率为$p_{3q} = 0.002$。这个$p_{3q}$保守估计是双量子比特纠缠门的双倍,反映了实验现实。此外,该模型包含了CCZ门Z型错误的强偏置(可能性高10倍),这是许多量子平台上的本地相位类门的特征。
3. 解码策略:
* 对于单次Z基错误校正(对状态制备至关重要),采用了窗口解码协议。这包括三轮综合提取,重复14次,共42轮,使用置信传播+有序统计解码(BP + OSD)方案。
* 对于d轮X基错误校正(用于内存性能),使用了传统的d轮协议,使用最大似然错误(MLE)解码器对累积的综合信息进行完整解码。对于后选,他们使用了基于簇的后选方法结合BP + LSD(局部统计解码)。
4. 实现协议: 在可重构的中性原子阵列平台上,提出了一种高效实现综合提取电路的协议(图5,附录I)。这包括详细的原子重排程序和CNOT调度。
三轮车码所“攻击”的(基线模型)主要是基于彩色码的最先进魔态培养方案,特别是参考文献[36]中的[[7, 1, 3]]和[[19, 1, 5]]彩色码。这些传统方案通常需要多次蒸馏和级联,导致巨大的时空开销。作者还隐式地挑战了先前产生参数不那么有利的码(例如,K=3和D=2的2-2-2码)的cup积构造(参考文献[27])。
证据证明了什么
本文提出的证据明确证明了三轮车码为魔态生成提供了一种高效且鲁棒的解决方案,在关键指标上优于现有基线。
- 鲁棒的性能和高阈值: 在电路级噪声下的数值模拟表明,4-2-2系列三轮车码具有高达>0.5%的电路噪声阈值(图4b)。这是其对物理错误抵抗力的有力指标。
- 卓越的内存逻辑错误率: 通过完整的错误检测和适度的后选(例如,30%的接受率),最小的[[48, 6, 4]]三轮车码在$p_{2q} = 0.001$的双量子比特门错误率下,实现了约$6 \times 10^{-10}$的逻辑内存错误率。对于更大的[[84, 6, 5]]码,在$p_{2q} = 0.001$且接受率约为9%的情况下,逻辑内存错误率估计为< $10^{-13}$。这些数值代表了极高的量子内存保真度。
-
卓越的魔态生产保真度和成本: 三轮车码产生的超图魔态具有极低的逻辑错误率:
- [[48, 6, 4]]三轮车码:$2 \times 10^{-8}$
- [[84, 6, 5]]三轮车码:$4 \times 10^{-10}$
- [[108, 6, 6]]三轮车码:约$3 \times 10^{-11}$
至关重要的是,这些令人印象深刻的保真度是在与基于彩色码的魔态培养方案相当甚至更低的时空成本下实现的(表II)。例如,[[48, 6, 4]]三轮车码的每逻辑量子比特时空成本为89量子比特轮,远低于[[7, 1, 3]]彩色码培养的90量子比特轮,同时实现了低得多的逻辑错误率($2 \times 10^{-8}$ vs. $6 \times 10^{-7}$)。这无可辩驳地证明了使用高速率、高距离LDPC码和横向非Clifford门进行单次魔态生成的核心机制在现实中是有效的。
-
单次状态制备: 数值证据(图3)清楚地显示了在Z基中单次状态制备的逻辑错误随码距离呈指数级抑制。这证实了三轮车码能够在恒定数量的轮次中容错地制备逻辑$|+\rangle$态,与许多其他码所需的$O(d)$轮相比,这是一个显著的改进。这种恒定深度的制备,结合恒定深度的逻辑CCZ操作,在恒定深度下产生了高保真度的超图魔态。
- 恒定深度的CCZ电路: 三轮车码的构造成功地产生了恒定深度的物理CCZ电路(例如,4-2-2码的深度为8),这对于容错操作至关重要,并限制了错误传播。事实证明,恒定深度的CCZ电路对最终逻辑状态保真度的影响比纯内存设置要小。
- 高魔态产率: 对于表I中的所有码,能够从产生的超图魔态中提取$K_{CCZ} \ge 2$个离散逻辑CCZ门,证明了这些码作为魔态工厂的实际效用。
作者严谨的模拟、与强基线的比较以及对逻辑错误率和时空成本的详细分析,提供了令人信服的证据,表明三轮车码代表了高效、容错魔态生成方面的重大进步。
局限性与未来方向
尽管三轮车码为实现高效、容错的量子计算提供了一条有希望的途径,但本文也强调了若干局限性,并为未来的研究和开发开辟了多样化的途径。
当前局限性:
- $K_{CCZ}$提取的最优性: 从超图魔态中提取最大数量的离散CCZ门($K_{CCZ}$)的问题是NP难的。当前的混合整数规划方法产生次优解,并且对于较大的$K_{CCZ}$值经常超时,这意味着报告的值是下界。这限制了CCZ型魔态的即时吞吐量。
- 码族渐近优良性: 尽管构造允许定义一个码族,但它不太可能渐近优良。虽然预期更大的块长码具有更大的距离,但这并非正式的渐近保证。
- 更大码的更深CCZ电路: 对于更大的4-4-2和4-4-4三轮车码,更深的物理CCZ电路(例如,某些4-4-4码的深度为128)可能导致逻辑保真度与纯内存设置的偏差更大。虽然与重复码级联可以减小深度,但会以牺牲码速率为代价。
- 数值Leibniz规则方法的保证: 用于构造CCZ电路的数值Leibniz规则(NLR)方法不能保证特定的深度,并且找到低次数电路通常需要与该方法结合进行码搜索。
- 选择性状态初始化: 提取离散CCZ门需要将某些逻辑量子比特初始化在$|0\rangle$态,而其他逻辑量子比特初始化在$|+\rangle$态,这对于LDPC码在恒定深度下来说并不简单。
- 不平衡距离: 三轮车码自然地表现出X基下的距离高于Z基下的距离。虽然可能对噪声偏置平台有用,但详细探讨这种偏置如何提升实验性能的工作留待未来。
未来方向与讨论主题:
-
增强的解码策略:
- 观察到的标准BP+OSD/BP+LSD与精确MLE解码器之间数量级上的差距,表明迫切需要新的、更高效的解码器,它们能在保持实际推理时间的同时接近MLE性能。这可能涉及探索基于机器学习的解码器或先进的统计方法。
- 利用噪声偏置: 考虑到X和Z扇区的不对称性以及实验平台中噪声偏置的普遍性(例如,中性原子中的Z型错误),未来的工作应侧重于将定制的噪声偏置利用直接整合到综合提取电路和解码算法中。如何最优地设计电路和解码器以利用特定硬件噪声特性来获得最大性能提升?
- 损耗和泄漏管理: 许多硬件架构遭受损耗和泄漏错误。开发利用或缓解三轮车码框架内这些错误的显式策略可以进一步提高逻辑错误率。这可能涉及新的测量协议或错误校正技术。
-
优化魔态工厂吞吐量:
- 改进$K_{CCZ}$提取: 寻找逻辑张量$T^{log}$子秩的NP难问题是主要瓶颈。开发针对二元张量子秩问题的定制启发式优化策略对于提取更大的$K_{CCZ}$值和显著提高CCZ型魔态的吞吐量至关重要。我们能否找到足够用于实际目的的近似解?
- 超图魔态的直接编译: 与其提取离散CCZ门,不如深入理解产生的超图魔态的结构,可能允许直接编译成有用的量子电路。这可能提供一种替代的、可能更有效的方式来利用这些高魔态资源。
-
整合到更广泛的量子架构中:
- 无缝魔态注入/传送: 一个关键的开放问题是将蒸馏出的魔态从三轮车码工厂无缝注入或传送到计算码块中(例如,高性能双轮车码)。探索基于三轮车码和双轮车码之间自然同构的横向传送,类似于3D和2D彩色码的协议,是一个有希望的方向。这种码切换协议的实际挑战和开销是什么?
- 模块化架构: 如何将三轮车码整合到高度模块化的容错量子计算架构中?这不仅包括魔态生成,还包括在更大系统内的高效逻辑操作、通信和内存。
-
先进的码构造和电路优化:
- 进一步探索数值Leibniz规则: 对数值Leibniz规则方法及其在其他3D平衡乘积码中的应用进行更彻底的探索,可能会产生具有更短深度CCZ电路的码。我们能否开发更好的超参数或搜索策略来保证低深度电路?
- 综合提取电路优化: 本文提出了最优深度综合提取电路。在可重构中性原子平台上,通过数学规划或图论进行扇区布局和原子移动方案的进一步优化,可以减少时空开销。
- 与其他LDPC族的比较: 与其他最近提出的LDPC构造(例如,基于扩张码或代数层析的同调乘积)的开销和性能进行详细的直接比较,将为每种方法的相对优点和最佳应用场景提供宝贵的见解。
这些讨论主题突显了在推进容错量子计算方面持续的挑战和令人兴奋的机会,而三轮车码作为重要的垫脚石。理论进步、实验能力和算法优化之间的相互作用将是释放这些发现全部潜力的关键。
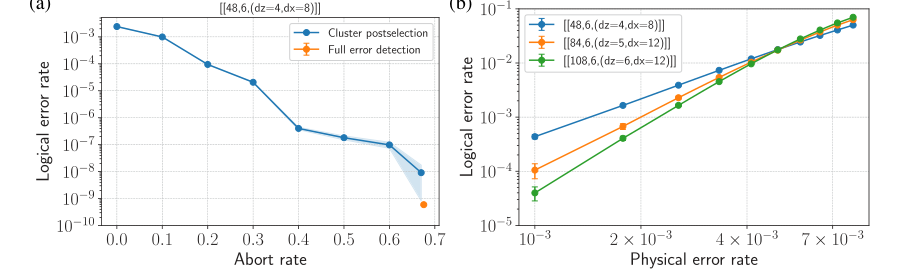 FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 4. Circuit-level noise simulation results for tricycle codes. (a) Logical error rate for the ½½48; 6; ðdz ¼ 4; dx ¼ 8Þ code as a function of abort rate under cluster postselection (blue) and full error detection (orange). The cluster postselection data show the trade- off between logical error rate and postselection (abort) probability using a BP þ LSD decoder, while full error detection corresponds to strictly accepting only trials with no detected stabilizer flips. (b) Logical error rate versus two-qubit physical gate error rate p2q for d-round, fault-tolerant error correction in the X basis, for tricycle codes of increasing size and distance using a MLE decoder. In both panels, errors are sampled according to a standard two-qubit depolarizing circuit-level noise model, and the logical error rate corresponds to the total logical error rate normalized by the number of QEC rounds and by the number of logical qubits. Logical error rates are determined via Monte Carlo simulations, with each data point corresponding to M samples; error bars indicate the standard error as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
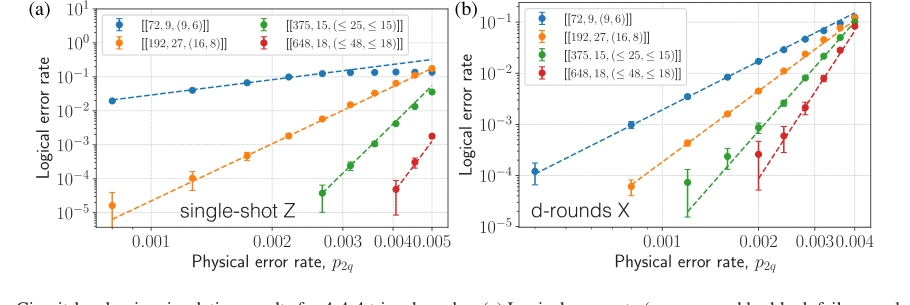 FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
FIG. 6. Circuit-level noise simulation results for 4-4-4 tricycle codes. (a) Logical error rate (as measured by block failure probability) versus two-qubit physical gate error rate (p2q) for single-shot error correction in the Z basis. Single-shot performance is evaluated using a windowed decoding protocol: three rounds of syndrome extraction followed by decoding and correction, with the window repeated 14 times (for 42 total rounds) to probe sustainable suppression of logical errors. (b) Logical error rate versus p2q for fault-tolerant, d-round error correction in the X basis. In both panels, errors are sampled under a standard two-qubit depolarizing circuit-level noise model, and results are shown for various tricycle codes. Logical error rates are determined via Monte Carlo simulations using a BP þ OSD decoder, with each data point corresponding to M samples; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p
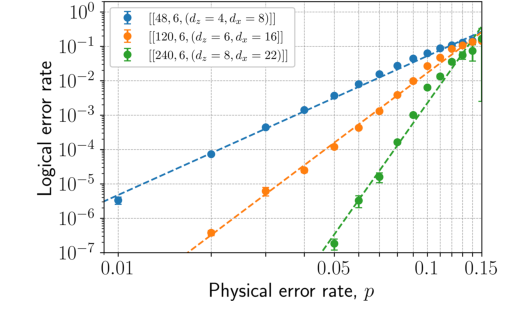 FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples
FIG. 3. Phenomenological noise simulation of single-shot state preparation in the Z basis for 4-2-2 tricycle codes. Our method follows Ref. [57] and assumes that the initial Z syndrome is trivial. For each code, we simulate one round of syndrome measurement in which measurement errors occur with probability p, though we expect performance to improve with a larger decoding window (see Sec. II D). A most-likely-error (MLE) decoder applies a minimum weight correction to both the data and measurement qubits. Then, we simulate a noisy transversal Z basis measurement of the data qubits, decode the reconstructed syndrome with the MLE decoder, and apply the corresponding correction. A logical failure is said to occur if the residual X operator is a logical operator of the tricycle code, and the logical error rate is normalized per logical qubit. The observed phe- nomenological threshold is ≳13%. Logical error rates are determined via Monte Carlo simulations; error bars indicate standard errors, computed as ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi pLð1 −pLÞ=M p , where M is the number of samples