कंप्यूट-बाधित डेटा चयन
Large Language Models (LLMs) के क्षेत्र में अभूतपूर्व वृद्धि देखी गई है, जिसके परिणामस्वरूप अरबों पैरामीटर्स वाले ऐसे मॉडल्स विकसित हुए हैं जो प्राकृतिक भाषा की समझ (natural language understanding) और सृजन...
पृष्ठभूमि और शैक्षणिक वंशावली
Large Language Models (LLMs) के क्षेत्र में अभूतपूर्व वृद्धि देखी गई है, जिसके परिणामस्वरूप अरबों पैरामीटर्स वाले ऐसे मॉडल्स विकसित हुए हैं जो प्राकृतिक भाषा की समझ (natural language understanding) और सृजन (generation) में उल्लेखनीय क्षमताएं प्रदर्शित करते हैं। हालाँकि, यह क्षमता महत्वपूर्ण कंप्यूटेशनल लागत के साथ आती है। इन विशाल मॉडल्स को प्रशिक्षित करना, या 'finetuning' नामक प्रक्रिया के माध्यम से विशिष्ट कार्यों के लिए उन्हें अनुकूलित करना, अत्यधिक कंप्यूटेशनल संसाधनों की मांग करता है, जिन्हें अक्सर Graphics Processing Unit (GPU) घंटों या FLOPs (Floating Point Operations) के संदर्भ में मापा जाता है।
इस शोध पत्र में संबोधित समस्या की सटीक उत्पत्ति इन संसाधन बाधाओं की व्यावहारिक वास्तविकता से उत्पन्न होती है। जैसे-जैसे LLMs का प्रचलन बढ़ा, शोधकर्ताओं और विशेषज्ञों ने शीघ्र ही यह महसूस किया कि प्रशिक्षण या finetuning के लिए कुल कंप्यूट बजट अक्सर पहले से निर्धारित और निश्चित होता है। इसका अर्थ यह है कि एक्सेलेरेटर्स (जैसे GPUs) की संख्या और उनके उपयोग के घंटे पहले ही आवंटित कर दिए जाते हैं। इस बोध ने "compute-optimal LLMs" के क्षेत्र में अनुसंधान को प्रेरित किया, जहाँ लक्ष्य एक निश्चित कंप्यूटेशनल बजट के भीतर सर्वोत्तम संभव मॉडल प्रदर्शन (जैसे, न्यूनतम perplexity) प्राप्त करना है। Hoffmann et al. (2022) जैसे प्रारंभिक कार्यों ने इसे प्राप्त करने के लिए आर्किटेक्चरल विकल्पों और प्रशिक्षण निर्णयों को संतुलित करने के तरीकों का अन्वेषण किया।
यह शोध पत्र इस जांच को विशेष रूप से LLMs के finetuning चरण तक विस्तारित करता है। finetuning के लिए कंप्यूट आवश्यकताओं को कम करने की एक आशाजनक रणनीति "data selection" है, जहाँ संपूर्ण उपलब्ध डेटासेट पर प्रशिक्षण के बजाय, एक छोटा और अधिक प्रभावशाली सबसेट (subset) चुना जाता है। Data selection स्वयं मशीन लर्निंग में एक मूलभूत अवधारणा है, जिसकी जड़ें 1960 के दशक के अंत (Hart, 1968) और 1970 के दशक (John, 1975) में निहित हैं, जिनका उद्देश्य प्रभावी प्रशिक्षण के लिए न्यूनतम डेटासेट तैयार करना था।
हालाँकि, पिछली पद्धतियों की मूलभूत सीमा या "pain point", जिसने लेखकों को यह शोध पत्र लिखने के लिए प्रेरित किया, यह है कि उन्होंने डेटा चयन प्रक्रिया की स्वयं की कंप्यूटेशनल लागत को काफी हद तक नजरअंदाज कर दिया। यद्यपि डेटा चयन विधियों को प्रशिक्षण डेटा के आकार (और इस प्रकार प्रशिक्षण कंप्यूट) को कम करने के लिए डिज़ाइन किया गया था, लेकिन कई "शक्तिशाली" या "परिष्कृत" चयन विधियों को सर्वोत्तम डेटा बिंदुओं की पहचान करने के लिए महत्वपूर्ण कंप्यूटेशनल प्रयास की आवश्यकता होती है। मुख्य समस्या यह है कि "भले ही डेटा चयन प्रभावी हो, यह a priori यह संकेत नहीं देता कि यह compute-optimal है।" पिछले मॉडल्स ने एक निश्चित डेटा बजट (अर्थात, डेटा बिंदुओं की संख्या) के लिए प्रदर्शन को अधिकतम करने पर ध्यान केंद्रित किया, लेकिन जरूरी नहीं कि उस कंप्यूट बजट के लिए जो चयन और प्रशिक्षण दोनों लागतों को समाहित करता हो। इस चूक का अर्थ यह था कि जो विधि "सर्वोत्तम" डेटा का चयन करती है, उसे चलाने की लागत इतनी अधिक हो सकती है कि कुल कंप्यूट बजट को एक सस्ती, या यादृच्छिक (random) चयन रणनीति के साथ अधिक डेटा पर प्रशिक्षित करने में खर्च करना बेहतर होता। लेखकों का तर्क है कि व्यावहारिक अपनाने के लिए, एक compute-optimal विधि को प्रशिक्षण में सुधार करने के साथ-साथ कंप्यूट करने में भी सस्ता होना चाहिए, जो कि एक महत्वपूर्ण कारक है जिसे अब तक कम आंका गया है।
डोमेन शब्दावली (सरल सादृश्य)
- LLMs (Large Language Models): एक अत्यंत बुद्धिमान डिजिटल सहायक की कल्पना करें जिसने मनुष्यों द्वारा लिखित लगभग सब कुछ पढ़ लिया है। यह आपके प्रश्नों को समझ सकता है, कहानियां लिख सकता है, लेखों का सारांश दे सकता है, और कोडिंग में भी सहायता कर सकता है, यह सब अगले सबसे संभावित शब्द की भविष्यवाणी करके करता है।
- Finetuning: इसे इस तरह सोचें: आपके पास एक प्रतिभाशाली, सामान्य-उद्देश्य वाला रसोइया (LLM) है जो सभी प्रकार के व्यंजन बनाना जानता है। अब, आप चाहते हैं कि वह फ्रेंच पेस्ट्री बनाने में विशेषज्ञ बन जाए। आप उन्हें फ्रेंच पेस्ट्री की एक विशिष्ट कुकबुक देते हैं और उनसे केवल उन व्यंजनों का अभ्यास करवाते हैं। वे अन्य चीजें बनाना नहीं भूलते, लेकिन वे फ्रेंच पेस्ट्री में कहीं अधिक बेहतर हो जाते हैं।
- Compute-Optimal: यह कुछ निर्माण करते समय "कम लागत में सर्वोत्तम परिणाम" प्राप्त करने जैसा है। आपके पास पैसे (कंप्यूट बजट) की एक निश्चित राशि है और आप उच्चतम गुणवत्ता वाला परिणाम (मॉडल प्रदर्शन) प्राप्त करना चाहते हैं। यह इस बारे में है कि सबसे अधिक मूल्य प्राप्त करने के लिए अपना पैसा कहाँ खर्च किया जाए, न कि केवल सबसे महंगे या दिखने में "सर्वोत्तम" हिस्सों पर खर्च करना।
- Perplexity: कल्पना करें कि आप एक वाक्य में अगले शब्द का अनुमान लगाने की कोशिश कर रहे हैं। यदि वाक्य "The cat sat on the..." है, तो आप बहुत आश्चर्यचकित नहीं होंगे यदि अगला शब्द "mat" या "rug" है। आपकी "perplexity" कम है। लेकिन अगर अगला शब्द "banana" होता, तो आप बहुत आश्चर्यचकित होते, और आपकी "perplexity" अधिक होती। LLMs में, कम perplexity का अर्थ है कि मॉडल टेक्स्ट की भविष्यवाणी करने में बेहतर है और भाषा को अधिक धाराप्रवाह समझता है।
- FLOPs (Floating Point Operations): ये बुनियादी अंकगणितीय गणनाएं (जैसे जोड़, घटाव, गुणा, भाग) हैं जो एक कंप्यूटर करता है। जब हम FLOPs की बात करते हैं, तो यह हर बार कैलकुलेटर बटन दबाने की गिनती करने जैसा है। यह मापने का एक तरीका है कि कंप्यूटर कितना "सोच" या "काम" करता है। उच्च FLOP गणना का अर्थ है अधिक कंप्यूटेशनल प्रयास।
नोटेशन तालिका
| नोटेशन | विवरण |
|---|---|
| LLMs | Large Language Models, जो विशाल टेक्स्ट डेटा पर पूर्व-प्रशिक्षित हैं। |
| Finetuning | एक पूर्व-प्रशिक्षित LLM को छोटे, कार्य-विशिष्ट डेटासेट का उपयोग करके किसी विशिष्ट डाउनस्ट्रीम कार्य के लिए अनुकूलित करने की प्रक्रिया। |
| Compute Budget ($\mathcal{K}$) | डेटा चयन और मॉडल प्रशिक्षण दोनों के लिए आवंटित कुल, निश्चित कंप्यूटेशनल संसाधन (जैसे, FLOPs, GPU घंटे)। |
| FLOPs | Floating Point Operations, कंप्यूटेशनल कार्य का एक माप। |
| $\mathcal{D}$ | संभावित प्रशिक्षण डेटा का संपूर्ण उपलब्ध पूल। |
| $\mathcal{S}$ | finetuning के लिए $\mathcal{D}$ से चुना गया डेटा का एक सबसेट। |
| $\mathcal{S}^*$ | $\mathcal{D}$ से चुना गया डेटा का इष्टतम सबसेट जो कंप्यूट बाधाओं के तहत मॉडल प्रदर्शन को अधिकतम करता है। |
| $P(\cdot)$ | किसी दिए गए कार्य पर LLM के प्रदर्शन का प्रतिनिधित्व करने वाला एक फंक्शन (जैसे, सटीकता, perplexity)। |
| $\mathcal{T}(\mathcal{S})$ | डेटा सबसेट $\mathcal{S}$ पर प्रशिक्षित (finetuned) LLM मॉडल। |
| $\mathcal{T}$ | मॉडल प्रदर्शन के अंतिम मूल्यांकन के लिए उपयोग किया जाने वाला लक्ष्य परीक्षण डेटासेट। |
| $\mathcal{V}$ | सत्यापन डेटासेट, जिसका उपयोग डेटा चयन और मॉडल विकास के दौरान $\mathcal{T}$ के प्रॉक्सी के रूप में किया जाता है। |
| $C_T(\mathcal{S})$ | चयनित डेटा सबसेट $\mathcal{S}$ पर LLM को प्रशिक्षित करने की कंप्यूटेशनल लागत (FLOPs में)। |
| $C_U(x)$ | डेटा चयन प्रक्रिया के दौरान एक एकल डेटा बिंदु $x$ के लिए उपयोगिता फंक्शन की गणना करने की कंप्यूटेशनल लागत (FLOPs में)। |
| $\sum_{x \in \mathcal{D}} C_U(x)$ | डेटा चयन करने के लिए मूल डेटासेट $\mathcal{D}$ में सभी डेटा बिंदुओं के लिए उपयोगिता फंक्शन की गणना करने की कुल कंप्यूटेशनल लागत। |
| $K$ (पारंपरिक समस्या में) | चयनित सबसेट $\mathcal{S}$ में अनुमत अधिकतम कार्डिनैलिटी (डेटा बिंदुओं की संख्या) (एक डेटा बजट)। |
| $K$ (कंप्यूट-बाधित समस्या में) | डेटा चयन और प्रशिक्षण दोनों के लिए कुल कंप्यूट बजट (FLOPs में)। |
| $v(x; \mathcal{V})$ | एक उपयोगिता फंक्शन जो सत्यापन सेट $\mathcal{V}$ के संबंध में डेटा बिंदु $x$ को उसकी प्रासंगिकता या मूल्य के आधार पर स्कोर प्रदान करता है। |
| $P_0$ | LLM का zero-shot प्रदर्शन (बिना किसी finetuning के प्रदर्शन)। |
| $P$ | प्रदर्शन पर ऊपरी सीमा, जो अधिकतम प्राप्त करने योग्य प्रदर्शन का प्रतिनिधित्व करती है। |
| $\lambda$ | पैरामीट्रिक प्रदर्शन मॉडल में एक पैरामीटर जो नियंत्रित करता है कि डेटा चयन विधि अतिरिक्त कंप्यूट से कितनी कुशलतापूर्वक मूल्य निकालती है। |
| $C(k)$ | उस रणनीति के लिए कुल कंप्यूटेशनल लागत (चयन + प्रशिक्षण) जो $k$ डेटा बिंदुओं पर प्रशिक्षण में परिणामित होती है। |
| $C(|\mathcal{D}|)$ | संपूर्ण डेटासेट $\mathcal{D}$ पर प्रशिक्षण की कुल कंप्यूटेशनल लागत (बिना किसी डेटा चयन के)। |
| $\exp(\cdot)$ | घातीय फंक्शन, जिसका उपयोग घटते रिटर्न (diminishing returns) को मॉडल करने के लिए किया जाता है। |
| Levenberg-Marquardt | गैर-रेखीय न्यूनतम वर्ग समस्याओं को हल करने के लिए उपयोग किया जाने वाला एक एल्गोरिदम, जिसका उपयोग यहाँ पैरामीट्रिक प्रदर्शन मॉडल के पैरामीटर्स को फिट करने के लिए किया गया है। |
| LoRA | Low-Rank Adaptation, एक पैरामीटर-कुशल finetuning विधि जो मेमोरी उपयोग को कम करती है। |
| QLoRA | Quantized LoRA, मेमोरी में कमी के लिए एक और अनुकूलन, विशेष रूप से बहुत बड़े मॉडल्स के लिए। |
| MMLU | Massive Multitask Language Understanding, तथ्यात्मक ज्ञान के लिए एक बेंचमार्क। |
| BBH | Big-Bench Hard, जटिल तर्क के लिए एक बेंचमार्क। |
| IFEval | Instruction Following Evaluation, निर्देश पालन क्षमताओं के लिए एक बेंचमार्क। |
| BM25 | एक लेक्सिकॉन-आधारित डेटा चयन विधि, जो टेक्स्ट के सांख्यिकीय गुणों का उपयोग करती है। |
| Embed | एक एम्बेडिंग-आधारित डेटा चयन विधि, जो सघन एम्बेडिंग मॉडल्स का उपयोग करती है। |
| PPL | एक Perplexity-आधारित डेटा चयन विधि, जो LLM लॉस (perplexity) का उपयोग करती है। |
| LESS | एक ग्रेडिएंट-आधारित डेटा चयन विधि, जो प्रभाव का अनुमान लगाने के लिए ग्रेडिएंट्स का उपयोग करती है। |
समस्या की परिभाषा और बाधाएं
यह शोध-पत्र मुख्य रूप से एक कठोर और पूर्व-निर्धारित कुल कंप्यूट बजट (total compute budget) के अंतर्गत Large Language Models (LLMs) की fine-tuning को अनुकूलित (optimize) करने की समस्या पर केंद्रित है।
प्रारंभिक स्थिति (Input/Current State):
इस परिदृश्य में हमारे पास निम्नलिखित घटक विद्यमान हैं:
* संभावित प्रशिक्षण डेटा का एक विशाल संग्रह, जिसे $\mathcal{D}$ के रूप में निरूपित किया गया है।
* एक विशिष्ट डाउनस्ट्रीम कार्य, जिसके लिए एक बेस LLM को fine-tune किया जाना आवश्यक है।
* प्रदर्शन के मूल्यांकन हेतु संबंधित टेस्ट ($\mathcal{T}$) और वैलिडेशन ($\mathcal{V}$) डेटासेट।
* एक निश्चित, समग्र कंप्यूटेशनल बजट, $\mathcal{K}$, जिसे सामान्यतः FLOPs (Floating Point Operations) में मापा जाता है। यह बजट डेटा चयन और उसके बाद के मॉडल प्रशिक्षण, दोनों के लिए आवंटित कुल संसाधनों का प्रतिनिधित्व करता है। यह बजट अक्सर पहले से निर्धारित होता है, उदाहरण के लिए, एक्सेलेरेटर की संख्या और उनके उपयोग के घंटों के आधार पर।
* विभिन्न मौजूदा डेटा चयन विधियाँ, जिनमें से प्रत्येक की अपनी कंप्यूटेशनल लागत और मूल्यवान प्रशिक्षण डेटा की पहचान करने की प्रभावशीलता होती है।
वांछित लक्ष्य (Output/Goal State):
लक्ष्य डेटा का एक इष्टतम सबसेट (optimal subset), $\mathcal{S}^* \subset \mathcal{D}$ की पहचान करना है, ताकि जब किसी LLM को इस सबसेट $\mathcal{T}(\mathcal{S}^*)$ पर fine-tune किया जाए, तो वह लक्षित टेस्ट सेट पर उच्चतम संभव प्रदर्शन $P(\mathcal{T}; \mathcal{T}(\mathcal{S}^*))$ प्राप्त कर सके। महत्वपूर्ण बात यह है कि यह इष्टतम प्रदर्शन कुल कंप्यूट बजट $\mathcal{K}$ का पालन करते हुए प्राप्त किया जाना चाहिए; अर्थात, $\mathcal{S}^*$ के चयन और उस पर प्रशिक्षण की संयुक्त कंप्यूटेशनल लागत $\mathcal{K}$ से अधिक नहीं होनी चाहिए। अंतिम उद्देश्य शोधकर्ताओं को एक ऐसा फ्रेमवर्क प्रदान करना है जिससे वे अपने सीमित कंप्यूट संसाधनों को डेटा चयन और मॉडल प्रशिक्षण के बीच सर्वोत्तम तरीके से आवंटित करने हेतु सूचित निर्णय ले सकें।
गणितीय अंतराल (Mathematical Gap):
यह शोध-पत्र डेटा-केंद्रित अनुकूलन से कंप्यूट-केंद्रित अनुकूलन की ओर बढ़ने के माध्यम से उस अंतराल को भरने का प्रयास करता है। पारंपरिक रूप से, डेटा चयन समस्याओं को इस प्रकार तैयार किया जाता है:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{T}; \mathcal{T}(\mathcal{S})) \quad \text{subject to } |\mathcal{S}| \le K $$
यहाँ, $K$ एक डेटा बजट (डेटा बिंदुओं की अधिकतम संख्या) का प्रतिनिधित्व करता है। यह सूत्रीकरण अंतर्निहित रूप से यह मान लेता है कि डेटा चयन की लागत नगण्य है या उसे अलग से प्रबंधित किया जाता है।
यह शोध-पत्र एक नया, अधिक यथार्थवादी सूत्रीकरण प्रस्तुत करता है जो डेटा चयन की कंप्यूटेशनल लागत को समग्र बजट बाधा में स्पष्ट रूप से शामिल करता है। समस्या को इस प्रकार पुनर्गठित किया गया है:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{V}; \mathcal{T}(\mathcal{S})) \quad \text{subject to } C_T(\mathcal{S}) + \sum_{x \in \mathcal{D}} C_U(x) \le \mathcal{K} $$
जहाँ:
* $P(\mathcal{V}; \mathcal{T}(\mathcal{S}))$ का उपयोग $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$ के प्रॉक्सी के रूप में किया जाता है, जो वैलिडेशन सेट $\mathcal{V}$ का लाभ उठाता है।
* $C_T(\mathcal{S})$ चयनित सबसेट $\mathcal{S}$ पर मॉडल को प्रशिक्षित करने की कंप्यूटेशनल लागत है।
* $\sum_{x \in \mathcal{D}} C_U(x)$ मूल डेटासेट $\mathcal{D}$ में सभी डेटा बिंदुओं के लिए यूटिलिटी फंक्शन $v(x; \mathcal{V})$ की गणना करने की कुल कंप्यूटेशनल लागत है, ताकि सबसेट $\mathcal{S}$ की पहचान की जा सके।
* $\mathcal{K}$ कुल कंप्यूट बजट है।
गणितीय अंतराल वास्तव में बाधा में $\sum_{x \in \mathcal{D}} C_U(x)$ पद का समावेश है, जो अनुकूलन को केवल डेटा की मात्रा से बदलकर कुल कंप्यूट व्यय पर केंद्रित कर देता है।
दुविधा (The Dilemma):
पूर्व शोधकर्ताओं को जिस कठिन व्यापार-बंद (trade-off) का सामना करना पड़ा है, वह डेटा चयन विधि की प्रभावशीलता और उसकी कंप्यूटेशनल लागत के बीच का अंतर्निहित संघर्ष है। अधिक परिष्कृत डेटा चयन विधियाँ, जैसे कि मॉडल परप्लेक्सिटी (perplexity) या ग्रेडिएंट्स पर आधारित विधियाँ, अक्सर डेटा के एक छोटे, उच्च-गुणवत्ता वाले सबसेट की पहचान करने में अत्यधिक प्रभावी होती हैं, जो बेहतर मॉडल प्रदर्शन या प्रशिक्षण के दौरान तीव्र कन्वर्जेंस (convergence) की ओर ले जा सकती हैं। हालाँकि, ये "शक्तिशाली" विधियाँ निष्पादन हेतु काफी अधिक कंप्यूट-गहन (compute-intensive) भी होती हैं।
दुविधा यह है कि यद्यपि ये उन्नत विधियाँ प्रशिक्षण डेटा के आकार को कम करती हैं, लेकिन स्वयं चयन प्रक्रिया के लिए आवश्यक पर्याप्त कंप्यूट, प्रशिक्षण समय में कमी से प्राप्त लाभों को आसानी से समाप्त कर सकता है। एक निश्चित कुल कंप्यूट बजट परिदृश्य में, चयन पर अधिक FLOPs खर्च करने का अर्थ है कि वास्तविक fine-tuning प्रक्रिया के लिए कम FLOPs उपलब्ध हैं, जो संभवतः "बेहतर" डेटा सबसेट होने के बावजूद समग्र प्रदर्शन को खराब कर सकता है। शोधकर्ताओं ने पहले एक दिए गए डेटा आकार के लिए प्रदर्शन को अधिकतम करने पर ध्यान केंद्रित किया था, न कि किसी दिए गए कुल कंप्यूट बजट के लिए, जिससे यह महत्वपूर्ण व्यापार-बंद अनदेखा रह गया।
चुनौतियां (The Realistic Walls):
इस समस्या को हल करना निम्नलिखित कारणों से अत्यंत कठिन है:
- इष्टतम चयन की कंप्यूटेशनल जटिलता: इष्टतम डेटा सबसेट $\mathcal{S}^*$ को खोजना एक कॉम्बिनेटरियल ऑप्टिमाइज़ेशन समस्या है। बड़े डेटासेट के लिए सभी संभावित सबसेट की व्यापक खोज कंप्यूटेशनल रूप से असंभव है, जिससे सटीक समाधान अव्यावहारिक हो जाते हैं। यह ग्रीडी एल्गोरिदम और अनुमानों पर निर्भरता को अनिवार्य बनाता है।
- LLM ऑपरेशंस की उच्च लागत: LoRA जैसी पैरामीटर-कुशल विधियों के साथ भी, LLMs की fine-tuning स्वाभाविक रूप से कंप्यूट-गहन है। एक बड़े ट्रांसफॉर्मर मॉडल के माध्यम से प्रत्येक ग्रेडिएंट स्टेप, फॉरवर्ड पास या बैकवर्ड पास भारी संख्या में FLOPs की खपत करता है। यह $C_T(\mathcal{S})$ और $C_U(x)$ दोनों पदों को पर्याप्त रूप से बड़ा बनाता है।
- चयन विधियों की भिन्न लागत: विभिन्न डेटा चयन विधियों के कंप्यूटेशनल फुटप्रिंट काफी भिन्न होते हैं। लेक्सिकॉन-आधारित विधियाँ (जैसे BM25) बहुत सस्ती हैं, एम्बेडिंग-आधारित विधियाँ मध्यम रूप से महंगी हैं, जबकि परप्लेक्सिटी-आधारित और ग्रेडिएंट-आधारित विधियाँ अत्यधिक महंगी हैं (जैसा कि तालिका 5 में दिखाया गया है)। इस व्यापक रेंज का अर्थ है कि जो विधि डेटा कटौती के मामले में "सर्वश्रेष्ठ" है, वह कुल कंप्यूट दक्षता के मामले में "सबसे खराब" हो सकती है।
- स्केलिंग लॉ और घटते प्रतिफल (Diminishing Returns): डेटा चयन की प्रभावकारिता अक्सर उस पर निवेश किए गए कंप्यूट के साथ बढ़ती है, लेकिन घटते प्रतिफल के साथ। अधिक कंप्यूट से थोड़ा बेहतर सबसेट मिल सकता है, लेकिन प्रदर्शन में लाभ अतिरिक्त लागत को उचित नहीं ठहरा सकता है। कंप्यूट और प्रदर्शन के बीच का संबंध गैर-रेखीय और जटिल है, जिसे पैरामीट्रिक फंक्शन $P(k) = (P - P_0) \times (1 - \exp(-\frac{\lambda C(k)}{C(|\mathcal{D}|)})) + P_0$ द्वारा मॉडल किया गया है।
- प्रॉक्सी पर निर्भरता: वास्तविक उद्देश्य $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$ को सीधे अनुकूलित नहीं किया जा सकता है क्योंकि चयन के दौरान टेस्ट सेट $\mathcal{T}$ उपलब्ध नहीं होता है। शोधकर्ताओं को वैलिडेशन सेट $\mathcal{V}$ और यूटिलिटी फंक्शन $v(x; \mathcal{V})$ पर प्रॉक्सी के रूप में निर्भर रहना पड़ता है, जो संभावित अशुद्धियों और मान्यताओं को जन्म देता है।
- मॉडल और कार्य निर्भरता: इष्टतम कंप्यूट आवंटन और "सर्वश्रेष्ठ" डेटा चयन विधि सार्वभौमिक नहीं हैं। वे विशिष्ट LLM आकार, डाउनस्ट्रीम कार्य की प्रकृति और उपलब्ध कुल कंप्यूट बजट पर निर्भर करते हैं। यह एक सामान्य समाधान खोजना कठिन बनाता है।
- हार्डवेयर मेमोरी सीमाएँ: यद्यपि यह मुख्य केंद्र नहीं है, लेकिन 70B मॉडल के लिए QLoRA का उपयोग मेमोरी आवश्यकताओं को कम करने के लिए किया जाता है, जो यह दर्शाता है कि मेमोरी बाधाएं LLM fine-tuning को स्केल करने में एक व्यावहारिक दीवार हैं, जो अप्रत्यक्ष रूप से कंप्यूट आवंटन रणनीतियों को प्रभावित करती हैं।
संक्षेप में, यह समस्या इसलिए अत्यंत कठिन है क्योंकि इसके लिए एक जटिल, गैर-रेखीय अनुकूलन परिदृश्य को नेविगेट करने की आवश्यकता होती है, जहाँ "सर्वश्रेष्ठ" विकल्प अत्यधिक संदर्भ-निर्भर होता है, और एक पहलू (डेटा गुणवत्ता) को सुधारने का कार्य अनजाने में दूसरे (कुल कंप्यूट दक्षता) को बाधित कर सकता है।
यह दृष्टिकोण क्यों
यह शोध-पत्र मुख्य रूप से एक पूर्व-निर्धारित और सीमित कंप्यूटेशनल बजट के अंतर्गत Large Language Models (LLMs) की फाइन-ट्यूनिंग (finetuning) की व्यावहारिक चुनौती को संबोधित करता है। पारंपरिक रूप से, डेटा चयन विधियाँ एक निश्चित data budget के लिए मॉडल के प्रदर्शन को अनुकूलित करने पर केंद्रित रही हैं—अर्थात, एक बड़े डेटासेट $D$ से $K$ आकार के सर्वोत्तम सबसेट (subset) का चयन करना। जैसा कि अनुभाग 3 में वर्णित है, इसका उद्देश्य एक ऐसा सबसेट $S^*$ खोजना है जो $|S| \le K$ की शर्त के अधीन, टेस्ट सेट $T$ पर प्रदर्शन $P(T; T(S))$ को अधिकतम करे।
लेखकों ने पाया कि यह पारंपरिक दृष्टिकोण वास्तविक दुनिया की LLM फाइन-ट्यूनिंग के लिए अपर्याप्त है। इस अहसास का "सटीक क्षण" अनुभाग 4 में स्पष्ट रूप से व्यक्त किया गया है: "यद्यपि अनुभाग 3 में प्रस्तुत ढांचा डेटा चयन के लिए एक सामान्य विधि प्रदान करता है, हमारा तर्क है कि यह LLMs की फाइन-ट्यूनिंग की व्यावहारिक चुनौती के लिए अपर्याप्त है। समस्या यह है कि LLM फाइन-ट्यूनिंग अक्सर डेटा बजट के बजाय कंप्यूटेशनल बजट द्वारा बाधित (bottlenecked) होती है।" उन्होंने देखा कि कुल कंप्यूट बजट अक्सर पहले से ही निर्धारित होता है (जैसे, आवंटित एक्सेलेरेटर और उपयोग के घंटे), और इस बजट को डेटा चयन की लागत तथा चयनित डेटा पर मॉडल को प्रशिक्षित करने की लागत, दोनों को कवर करना चाहिए। डेटा चयन के लिए पिछली "SOTA" विधियाँ, हालांकि उच्च-गुणवत्ता वाले डेटा सबसेट की पहचान करने में प्रभावी थीं, अक्सर स्वयं पर्याप्त कंप्यूटेशनल लागत वहन करती थीं, जिसे उनके मूल्यांकन में काफी हद तक अनदेखा कर दिया गया था।
इस शोध-पत्र का दृष्टिकोण कोई नया डेटा चयन एल्गोरिदम पेश करना नहीं है, बल्कि डेटा चयन विधियों के मूल्यांकन और चयन के लिए एक नया, कंप्यूट-constrained ढांचा प्रस्तुत करना है। यह ढांचा कंप्यूट-सीमित वातावरण में वास्तव में इष्टतम निर्णय लेने के लिए एकमात्र व्यवहार्य समाधान है, क्योंकि यह कुल कंप्यूटेशनल व्यय को स्पष्ट रूप से ध्यान में रखता है। लेखक इस समस्या को इस प्रकार औपचारिक रूप देते हैं:
$$S^* = \arg \max_{S \subset D} P(V; T(S)) \quad \text{subject to} \quad C_T(S) + \sum_{x \in D} C_U(x) \le K$$
यहाँ, $K$ कुल कंप्यूट बजट (जैसे, अधिकतम FLOPs) का प्रतिनिधित्व करता है, $C_T(S)$ चयनित सबसेट $S$ पर मॉडल को प्रशिक्षित करने की लागत है, और $\sum_{x \in D} C_U(x)$ संपूर्ण डेटासेट $D$ पर डेटा चयन के लिए यूटिलिटी फंक्शन की गणना करने की लागत है। यह एक निश्चित डेटा आकार के लिए अनुकूलन से हटकर एक निश्चित कुल कंप्यूट के लिए अनुकूलन की ओर एक मौलिक बदलाव है।
तुलनात्मक श्रेष्ठता (बेंचमार्किंग तर्क):
इस कंप्यूट-constrained ढांचे की गुणात्मक श्रेष्ठता इसके समग्र और व्यावहारिक मूल्यांकन मेट्रिक में निहित है। पिछला "गोल्ड स्टैंडर्ड" डेटा चयन के लिए अनंत या नगण्य कंप्यूट मान लेता था, जो केवल चयनित डेटा द्वारा प्राप्त प्रदर्शन पर ध्यान केंद्रित करता था। हालाँकि, यह नया ढांचा एक Pareto frontier (जैसा कि चित्र 2, 3, 5, 7, 8 में देखा गया है) प्रदान करता है जो कुल कंप्यूट (x-अक्ष) को मॉडल प्रदर्शन (y-अक्ष) से मैप करता है। यह केवल एक निश्चित आकार के डेटासेट पर कच्चे प्रदर्शन के बजाय, कंप्यूट को प्रदर्शन में बदलने की उनकी दक्षता (efficiency) के आधार पर विधियों की सीधी तुलना करने की अनुमति देता है।
यह ढांचा स्वाभाविक रूप से उच्च-आयामी शोर (high-dimensional noise) को बेहतर ढंग से नहीं संभालता है और न ही अंतर्निहित डेटा चयन एल्गोरिदम की मेमोरी जटिलता को कम करता है। इसके बजाय, इसका संरचनात्मक लाभ यह है कि यह विभिन्न बजट परिदृश्यों के तहत सच्ची कंप्यूट-इष्टतम विधियों को उजागर करता है। यह प्रदर्शित करता है कि जब कुल कंप्यूट बजट सीमित होता है, तो चयन के लिए कम कंप्यूटेशनल जटिलता वाली विधियाँ (जैसे Lexicon-Based BM25 या Embedding-Based) अक्सर अधिक परिष्कृत, कंप्यूट-गहन विधियों (जैसे Perplexity-Based PPL या Gradient-Based LESS) की तुलना में अत्यधिक श्रेष्ठ हो जाती हैं। उदाहरण के लिए, सार में उल्लेख किया गया है कि "सस्ते डेटा चयन विकल्प सैद्धांतिक और अनुभवजन्य दोनों दृष्टिकोणों से प्रभावी हैं।" यह एक गहरा गुणात्मक लाभ है: यह एक महत्वपूर्ण वास्तविक दुनिया की बाधा को पेश करके यह बदल देता है कि किन विधियों को "सर्वोत्तम" माना जाता है। विभिन्न कंप्यूट बजटों के तहत इन विधियों का वैचारिक व्यवहार एक सिमुलेशन में दर्शाया गया है।
बाधाओं के साथ संरेखण ("Marriage"):
समस्या की कठोर आवश्यकताओं और समाधान के अद्वितीय गुणों के बीच का "मेल" सटीक है। परिचय में बताए अनुसार समस्या की कठोर आवश्यकताएं हैं:
1. पूर्व-निर्धारित कुल कंप्यूट बजट: LLM प्रशिक्षण महंगा है, और संसाधन (एक्सेलेरेटर, उपयोग के घंटे) पहले से आवंटित किए जाते हैं।
2. इष्टतम संसाधन आवंटन: यह निर्धारित करना महत्वपूर्ण है कि इस निश्चित बजट को सर्वोत्तम तरीके से कैसे आवंटित किया जाए।
3. डेटा चयन कंप्यूट-इष्टतम होना चाहिए: किसी भी डेटा चयन विधि को अपनी अतिरिक्त लागत के अनुपात में प्रशिक्षण में सुधार करना चाहिए।
कंप्यूट-constrained उद्देश्य (समीकरण 2) सीधे इन आवश्यकताओं को संबोधित करता है:
* यह कुल कंप्यूट पर एक सख्त ऊपरी सीमा $K$ निर्धारित करता है, जो चयन लागत और प्रशिक्षण लागत के बीच ट्रेड-ऑफ को मजबूर करता है।
* यह डेटा चयन की "अतिरिक्त लागत" ($C_U(x)$) को मापता है और इसे प्रशिक्षण लागत ($C_T(S)$) के साथ एकीकृत करता है, जिससे अभ्यासकर्ताओं को संसाधन आवंटन के बारे में सूचित निर्णय लेने में मदद मिलती है।
* यह केवल अलग-थलग हिस्सों के बजाय पूरी पाइपलाइन पर विचार करके उन विधियों की पहचान करने की अनुमति देता है जो वास्तव में "कंप्यूट-इष्टतम" हैं। यह सुनिश्चित करता है कि चुनी गई विधि न केवल प्रभावी है, बल्कि दी गई कंप्यूटेशनल सीमाओं के भीतर आर्थिक रूप से भी व्यवहार्य है। यह ढांचा संसाधन-सीमित दुनिया में दक्षता की व्यावहारिक आवश्यकता के लिए एक सीधा उत्तर है।
विकल्पों का अस्वीकरण:
यह शोध-पत्र पारंपरिक "SOTA" डेटा चयन विधियों, जैसे Perplexity-Based (PPL) और Gradient-Based (LESS) को स्पष्ट रूप से "अस्वीकार" करता है, जब कंप्यूट सीमित हो। यह GANs या Diffusion मॉडल्स जैसे विकल्पों पर चर्चा नहीं करता है, क्योंकि इसका दायरा विशेष रूप से फाइन-ट्यूनिंग के लिए डेटा चयन तक सीमित है।
इन अन्यथा शक्तिशाली विधियों को अस्वीकार करने का तर्क चयन के लिए उनकी उच्च कंप्यूटेशनल लागत है, जो उन्हें कुल कंप्यूट बजट के तहत FLOP-अक्षम (FLOP-inefficient) बनाती है।
* उच्च लागत: अनुभाग 4.1 और परिशिष्ट B स्पष्ट प्रमाण प्रदान करते हैं। Lexicon-Based (BM25) की लागत लगभग $1 \times 10^8$ FLOPs है, और Embedding-Based (Embed) की लागत लगभग $4.4 \times 10^{16}$ FLOPs है। इसके विपरीत, Perplexity-Based (PPL) की लागत लगभग $1.53 \times 10^{18}$ FLOPs है, और Gradient-Based (LESS) की लागत $8.27 \times 10^{18}$ FLOPs है। ये लागत परिमाण के कई क्रम (orders of magnitude) अधिक महंगी हैं।
* FLOP अक्षमता: सार और अनुभाग 7 स्पष्ट रूप से बताते हैं कि "कई शक्तिशाली डेटा चयन विधियाँ लगभग कभी भी कंप्यूट-इष्टतम नहीं होती हैं" और PPL तथा LESS "सैद्धांतिक और अनुभवजन्य दोनों दृष्टिकोणों से FLOP अक्षम हैं।"
* अनुभवजन्य विफलता: चित्र 1 और 2 इसे प्रदर्शित करते हैं। छोटे और मध्यम कंप्यूट बजट के लिए, सस्ते BM25 और Embed तरीके कंप्यूट-प्रदर्शन Pareto frontier पर लगातार PPL और LESS से बेहतर प्रदर्शन करते हैं। इसका मतलब है कि एक निश्चित कुल कंप्यूट बजट के लिए, कोई सस्ती चयन विधि का उपयोग करके और वास्तविक मॉडल प्रशिक्षण के लिए अधिक कंप्यूट आवंटित करके बेहतर मॉडल प्रदर्शन प्राप्त कर सकता है।
* ब्रेक-ईवन पॉइंट: शोध-पत्र में पाया गया है कि PPL और LESS केवल तभी कंप्यूट-इष्टतम होते हैं जब प्रशिक्षण मॉडल, चयन मॉडल की तुलना में काफी बड़ा हो (PPL के लिए 5 गुना, LESS के लिए 10 गुना, जैसा कि अनुभाग 8 और परिशिष्ट G में विस्तृत है)। इसका तात्पर्य यह है कि अधिकांश व्यावहारिक परिदृश्यों में जहाँ चयन मॉडल, प्रशिक्षण मॉडल के सापेक्ष तुलनीय आकार का या छोटा होता है, ये परिष्कृत विधियाँ कंप्यूट-इष्टतम होने में विफल रहती हैं। उनकी बेहतर डेटा चयन गुणवत्ता का सीमांत लाभ उनकी अत्यधिक कंप्यूटेशनल लागत से अधिक नहीं होता है।
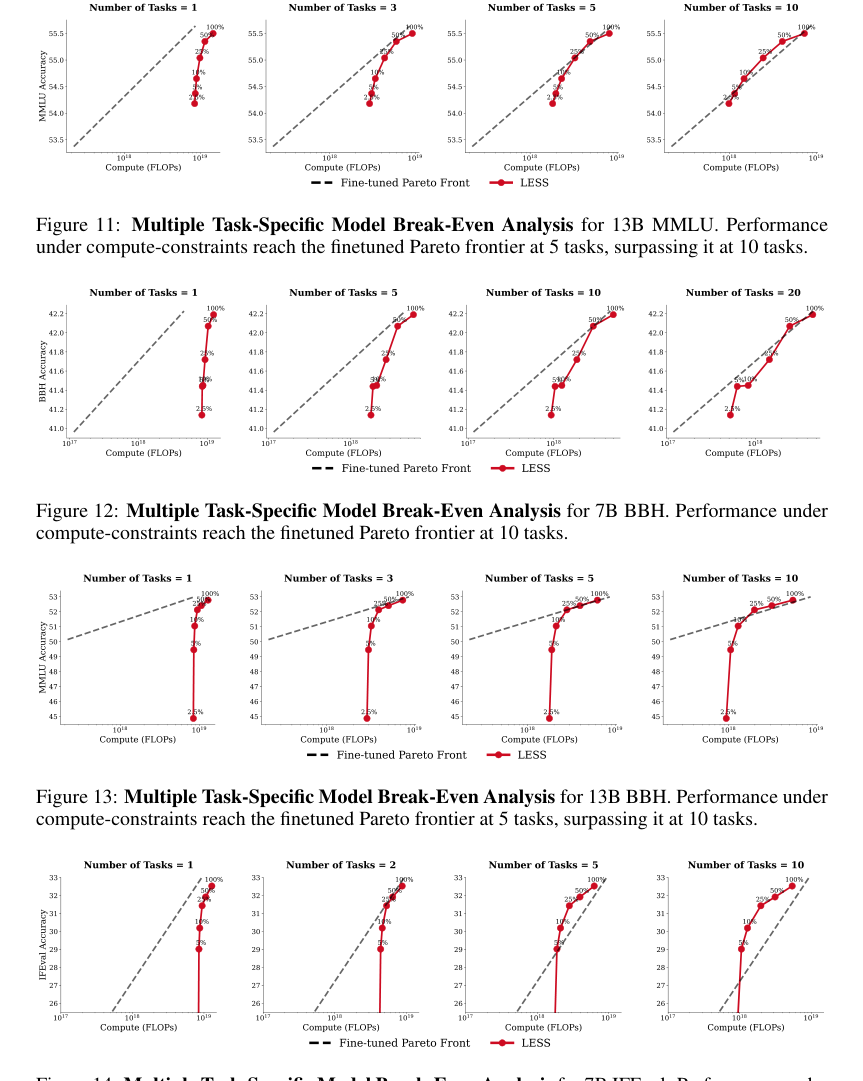 Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
गणितीय और तार्किक तंत्र
एक मेटा-साइंटिस्ट (Meta-scientist) के रूप में, मैंने "COMPUTE-CONSTRAINED DATA SELECTION" नामक शोध-पत्र का गहन विश्लेषण किया है। यह शोध लार्ज लैंग्वेज मॉडल्स (LLMs) के युग में एक महत्वपूर्ण चुनौती का समाधान करता है: प्रशिक्षण डेटा के चयन और मॉडल की फाइन-ट्यूनिंग (Fine-tuning) के बीच एक निश्चित कंप्यूटेशनल बजट (Computational budget) को इष्टतम (optimally) रूप से कैसे आवंटित किया जाए। लेखकों ने एक प्रभावशाली विश्लेषण प्रस्तुत किया है, जिसमें यह दर्शाया गया है कि केवल सबसे "शक्तिशाली" डेटा चयन विधि को चुनना हमेशा कंप्यूट-कुशल (compute-efficient) दृष्टिकोण नहीं होता है।
शून्य-आधारित पाठक के लिए पृष्ठभूमि ज्ञान
शोध-पत्र की बारीकियों में जाने से पहले, आइए कुछ मूलभूत अवधारणाओं को स्थापित करें:
- लार्ज लैंग्वेज मॉडल्स (LLMs): कल्पना कीजिए कि एक अत्यंत बुद्धिमान डिजिटल सहायक है जो मानवीय भाषा को समझ और उत्पन्न कर सकता है। ये LLMs हैं। इन्हें "लार्ज" इसलिए कहा जाता है क्योंकि इनमें अरबों आंतरिक पैरामीटर्स होते हैं और इन्हें विशाल मात्रा में टेक्स्ट डेटा पर प्रशिक्षित किया जाता है। यह प्रशिक्षण प्रक्रिया अत्यंत महंगी और समय लेने वाली होती है।
- फाइन-ट्यूनिंग (Fine-tuning): एक बार जब LLM प्री-ट्रेन हो जाता है, तो वह एक सामान्य विशेषज्ञ होता है। इसे किसी विशिष्ट कार्य (जैसे चिकित्सा संबंधी प्रश्नों के उत्तर देना, कोड लिखना) में कुशल बनाने के लिए हम इसे "फाइन-ट्यून" करते हैं। यह एक सामान्य रसोइए को फ्रेंच व्यंजनों में विशेषज्ञ बनाने जैसा है।
- कंप्यूट बजट (Compute Budget): इसे कंप्यूटेशनल संसाधनों के लिए आपके कुल भत्ते के रूप में सोचें। इसे FLOPs (Floating Point Operations) में मापा जाता है, जो बुनियादी अंकगणितीय गणनाएं हैं। LLMs के प्रशिक्षण के लिए बहुत सारे FLOPs की आवश्यकता होती है, जिसमें अक्सर महंगे GPUs का उपयोग दिनों या हफ्तों तक करना पड़ता है। यह बजट अक्सर पहले से निर्धारित होता है।
- डेटा चयन (Data Selection): उपलब्ध सभी कार्य-विशिष्ट डेटा पर फाइन-ट्यूनिंग करने के बजाय (जो बहुत विशाल हो सकता है), डेटा चयन उस डेटा का एक छोटा, अधिक प्रभावशाली उपसमुच्चय (subset) बुद्धिमानी से चुनने की प्रक्रिया है। विचार यह है कि सभी डेटा बिंदु समान रूप से मूल्यवान नहीं होते, और कुछ अनावश्यक या हानिकारक भी हो सकते हैं। "सर्वश्रेष्ठ" डेटा का चयन फाइन-ट्यूनिंग को तेज और अधिक प्रभावी बना सकता है।
- प्रदर्शन (Performance): फाइन-ट्यूनिंग के बाद LLM अपने लक्षित कार्य पर कैसा प्रदर्शन करता है। इसे सटीकता (accuracy), उत्पन्न टेक्स्ट की सुसंगतता, या अन्य मेट्रिक्स द्वारा मापा जा सकता है।
- घटते प्रतिफल (Diminishing Returns): यह एक सामान्य आर्थिक सिद्धांत है: आप किसी चीज़ में जितना अधिक निवेश करते हैं, प्रत्येक बाद के निवेश से आपको उतना ही कम अतिरिक्त लाभ मिलता है। यह LLM प्रशिक्षण में कंप्यूट और डेटा पर लागू होता है।
प्रेरणा: मूल समस्या
इस शोध-पत्र की केंद्रीय प्रेरणा एक व्यावहारिक दुविधा से उत्पन्न होती है:
- LLM फाइन-ट्यूनिंग महंगी है: इन विशाल मॉडलों को प्रशिक्षित करना, विशिष्ट कार्यों के लिए भी, महत्वपूर्ण कंप्यूटेशनल संसाधनों की खपत करता है।
- डेटा चयन सहायक हो सकता है: एक छोटे, उच्च-गुणवत्ता वाले डेटासेट को चुनकर, हम प्रशिक्षण कंप्यूट की मात्रा को कम कर सकते हैं। यह सुनने में बहुत अच्छा लगता है!
- लेकिन डेटा चयन स्वयं कंप्यूट की खपत करता है: यह पता लगाने के लिए कि कौन से डेटा बिंदु "सर्वश्रेष्ठ" हैं, आपको अक्सर कुछ गणनाएं करनी पड़ती हैं, कभी-कभी किसी अन्य LLM का उपयोग करके। यह प्रक्रिया मुफ्त नहीं है।
लेखकों ने महसूस किया कि पिछला शोध अक्सर डेटा आकार को कम करने या प्रति प्रशिक्षण चरण प्रदर्शन में सुधार करने में डेटा चयन की प्रभावशीलता पर केंद्रित था, लेकिन इसने स्वयं चयन प्रक्रिया की कंप्यूटेशनल लागत का पूर्ण लेखा-जोखा नहीं लिया। एक डेटा चयन विधि "शक्तिशाली" हो सकती है (अर्थात वह बेहतरीन डेटा चुनती है), लेकिन यदि इसे चलाने में बहुत अधिक कंप्यूट खर्च होता है, तो सख्त कुल कंप्यूट बजट होने पर यह सबसे कुशल विकल्प नहीं हो सकती है।
लेखकों द्वारा हल की जाने वाली समस्या यह है: एक निश्चित कुल कंप्यूट बजट को देखते हुए, एक अभ्यासकर्ता को डेटा चुनने पर खर्च किए गए कंप्यूट और उस चयनित डेटा पर मॉडल को प्रशिक्षित करने पर खर्च किए गए कंप्यूट के बीच इष्टतम संतुलन कैसे बनाना चाहिए, ताकि उच्चतम संभव मॉडल प्रदर्शन प्राप्त हो सके? वे इस ट्रेड-ऑफ को परिमाणित (quantify) करना चाहते हैं और वास्तव में "कंप्यूट-ऑप्टिमल" रणनीतियों की पहचान करना चाहते हैं।
वे बाधाएं जिन्हें पार करना आवश्यक था
लेखकों ने कई व्यावहारिक और सैद्धांतिक बाधाओं का सामना किया:
- निश्चित कुल कंप्यूट बजट ($K$): यह सर्वोपरि बाधा है। डेटा चयन के लिए डेटा बिंदुओं के मूल्यांकन से लेकर वास्तविक मॉडल प्रशिक्षण तक, सभी कंप्यूटेशनल प्रयासों को इस पूर्व निर्धारित सीमा के भीतर फिट होना चाहिए।
- डेटा चयन की कंप्यूटेशनल लागत ($C_U(x)$): विभिन्न डेटा चयन विधियों के कंप्यूटेशनल पदचिह्न (footprints) बहुत अलग होते हैं। कुछ सस्ते होते हैं (जैसे सरल टेक्स्ट सांख्यिकी), जबकि अन्य बहुत महंगे होते हैं (जैसे LLM पर फॉरवर्ड/बैकवर्ड पास चलाना)। यह लागत अक्सर मूल, बड़े डेटासेट के प्रत्येक डेटा बिंदु के लिए उठानी पड़ती है।
- प्रशिक्षण की कंप्यूटेशनल लागत ($C_T(S)$): एक चयनित उपसमुच्चय $S$ के साथ भी, प्रशिक्षण के लिए कंप्यूट की आवश्यकता होती है। यह लागत चयनित डेटा के आकार और फाइन-ट्यून किए जा रहे LLM के आकार के साथ बढ़ती है।
- सत्य परीक्षण सेट ($T$) तक सीमित पहुंच: वास्तविक दुनिया के परिदृश्यों में, अंतिम परीक्षण सेट डेटा चयन चरण के दौरान उपलब्ध नहीं होता है। इसलिए, लेखकों को चयन प्रक्रिया के दौरान प्रदर्शन का मूल्यांकन करने के लिए एक वैलिडेशन सेट ($V$) पर निर्भर रहना पड़ा।
- संयोजन जटिलता (Combinatorial Complexity): एक बड़े पूल से डेटा का पूर्णतः सर्वश्रेष्ठ उपसमुच्चय चुनना एक संयोजन अनुकूलन समस्या है। लेखकों ने इसे ग्रीडी एप्रोक्सिमेशन (सभी बिंदुओं को स्कोर करना और सर्वश्रेष्ठ को चुनना) का उपयोग करके और फिर एक पैरामीट्रिक फ़ंक्शन के साथ प्रदर्शन को मॉडल करके संबोधित किया है।
- घटते प्रतिफल का मॉडलिंग: कंप्यूट और प्रदर्शन के बीच का संबंध रैखिक (linear) नहीं है। प्रारंभिक कंप्यूट निवेश उच्च प्रतिफल देते हैं, लेकिन जैसे-जैसे अधिक कंप्यूट जोड़ा जाता है, ये प्रतिफल कम होते जाते हैं।
गणितीय व्याख्या: हुड के नीचे का इंजन
यह शोध-पत्र दो प्रमुख गणितीय सूत्रीकरण प्रस्तुत करता है। पहला समस्या को परिभाषित करता है, और दूसरा कंप्यूट-प्रदर्शन संबंध का विश्लेषण करने के लिए एक पैरामीट्रिक मॉडल है।
मास्टर समीकरण: समस्या सूत्रीकरण
यह शोध जिस मूल समस्या का समाधान करता है, उसे एक बड़े डेटासेट $D$ से डेटा बिंदुओं के इष्टतम उपसमुच्चय $S^*$ को खोजने के रूप में औपचारिक रूप दिया गया है, जो कुल कंप्यूटेशनल बजट $K$ के अधीन एक फाइन-ट्यून किए गए मॉडल के प्रदर्शन को अधिकतम करता है।
$$S^* = \arg \max_{S \subset D} P(V; \mathcal{T}(S))$$
$$\text{subject to } C_T(S) + \sum_{x \in D} C_U(x) \le K$$
समीकरण का विश्लेषण:
- $S^*$: यह इष्टतम उपसमुच्चय है। "Arg max" का अर्थ है वह तर्क (इस मामले में, $S$) जो अभिव्यक्ति को अधिकतम करता है।
- $P(V; \mathcal{T}(S))$: यह उपसमुच्चय $S$ पर प्रशिक्षित मॉडल $\mathcal{T}(S)$ का प्रदर्शन मेट्रिक है, जिसका मूल्यांकन वैलिडेशन सेट $V$ पर किया गया है।
- $S \subset D$: यह दर्शाता है कि $S$ मूल प्रशिक्षण डेटासेट $D$ का एक उपसमुच्चय होना चाहिए।
- $C_T(S)$: चयनित डेटा उपसमुच्चय $S$ पर मॉडल $\mathcal{T}$ को प्रशिक्षित करने के लिए आवश्यक कंप्यूटेशनल लागत (FLOPs में)।
- $\sum_{x \in D} C_U(x)$: मूल डेटासेट $D$ के प्रत्येक डेटा बिंदु $x$ की उपयोगिता (utility) की गणना करने के लिए कंप्यूटेशनल लागतों का योग। यह डेटा चयन का "ओवरहेड" है।
- $K$: डेटा चयन और मॉडल प्रशिक्षण दोनों के लिए उपलब्ध कुल अधिकतम कंप्यूटेशनल बजट।
मास्टर समीकरण: विश्लेषण के लिए प्रदर्शन मॉडल
कंप्यूट के साथ प्रदर्शन कैसे बदलता है, इसका विश्लेषण करने के लिए, शोध-पत्र $k$ डेटा बिंदुओं पर प्रशिक्षण के बाद अपेक्षित प्रदर्शन $P(k)$ के लिए एक पैरामीट्रिक मॉडल पेश करता है:
$$P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0$$
- $P(k)$: $k$ चयनित डेटा बिंदुओं पर प्रशिक्षण के बाद मॉडल का अपेक्षित प्रदर्शन।
- $P$: प्रदर्शन की ऊपरी सीमा (ceiling)।
- $P_0$: ज़ीरो-शॉट प्रदर्शन (फाइन-ट्यूनिंग से पहले का आधारभूत प्रदर्शन)।
- $\lambda$: "दक्षता" पैरामीटर। यह निर्धारित करता है कि कोई विशेष डेटा चयन विधि कितनी प्रभावी ढंग से कंप्यूट को प्रदर्शन लाभ में परिवर्तित करती है।
- $C(k)$: $k$ डेटा बिंदुओं को चुनने और उन पर प्रशिक्षण लेने की कुल कंप्यूटेशनल लागत।
- $C(|\mathcal{D}|)$: संपूर्ण डेटासेट $D$ पर प्रशिक्षण की कुल कंप्यूटेशनल लागत।
अनुकूलन गतिशीलता (Optimization Dynamics)
यह शोध-पत्र LLM के लिए एक पुनरावृत्ति सीखने की प्रक्रिया (जैसे ग्रेडिएंट डिसेंट) का वर्णन नहीं करता है। इसके बजाय, यह दो स्तरों पर "अनुकूलन" पर केंद्रित है:
- प्रदर्शन परिदृश्य को सीखना (पैरामीटर फिटिंग): प्राथमिक "सीखने" की प्रक्रिया पैरामीट्रिक प्रदर्शन मॉडल (समीकरण 3) के मापदंडों ($P_0, P, \lambda$) को देखे गए अनुभवजन्य डेटा के साथ फिट करना है। इसके लिए लेखक लेवेनबर्ग-मार्क्वार्ड एल्गोरिदम (Levenberg-Marquardt algorithm) का उपयोग करते हैं, जो गैर-रैखिक न्यूनतम वर्गों (non-linear least squares) की समस्या को हल करता है।
- कंप्यूट-ऑप्टिमल रणनीतियों को खोजना (तुलनात्मक विश्लेषण): एक बार जब प्रत्येक डेटा चयन विधि के लिए पैरामीट्रिक मॉडल फिट हो जाते हैं, तो मूल समस्या के लिए "अनुकूलन" तुलनात्मक विश्लेषण के माध्यम से प्राप्त किया जाता है। अभ्यासकर्ता इन फिट किए गए वक्रों (curves) की जांच करते हैं; किसी भी दिए गए कंप्यूट बजट के लिए, जिस विधि का वक्र सबसे ऊंचा होता है, वह कंप्यूट-ऑप्टिमल विकल्प होता है।
संक्षेप में, यह शोध-पत्र अनुभवजन्य डेटा के लिए एक गणितीय मॉडल फिट करके कंप्यूट बाधाओं के तहत विभिन्न डेटा चयन विधियों के व्यवहार को "सीखता" है। यह मॉडल विश्लेषण, एक्सट्रपलेशन और इस बारे में सूचित निर्णय लेने की अनुमति देता है कि कंप्यूट को सर्वोत्तम तरीके से कैसे आवंटित किया जाए।
परिणाम, सीमाएँ और निष्कर्ष
"Compute-Constrained Data Selection" पर आधारित इस शोध पत्र का विश्लेषण प्रस्तुत है। एक मेटा-साइंटिस्ट के रूप में, मेरा उद्देश्य जटिल वैज्ञानिक अवधारणाओं को सुलभ बनाना है ताकि शोधकर्ता और विद्यार्थी इसके मूल सिद्धांतों और निहितार्थों को समझ सकें।
शुरुआती शोधकर्ताओं के लिए पृष्ठभूमि
कल्पना कीजिए कि आपके पास एक अत्यंत बुद्धिमान रोबोट मस्तिष्क है, जिसे Large Language Model (LLM) कहा जाता है, जो कहानियाँ लिख सकता है, प्रश्नों के उत्तर दे सकता है और कोडिंग भी कर सकता है। इस रोबोट मस्तिष्क को किसी विशिष्ट कार्य (जैसे बिल्लियों पर कविताएँ लिखना) में बेहतर बनाने के लिए, आपको इसे उस विषय के कई उदाहरण दिखाने होते हैं। इस प्रक्रिया को fine-tuning कहा जाता है।
ये LLMs आकार में अत्यंत विशाल होते हैं और इन्हें प्रशिक्षित (train) करना बिजली (compute) और समय दोनों के मामले में बेहद खर्चीला होता है। इसे एक विशाल सुपरकंप्यूटर को हफ्तों तक चलाने जैसा समझें। अक्सर, संगठनों के पास इसके लिए एक निश्चित बजट होता है, जिसे FLOPs (Floating Point Operations Per Second) में मापा जाता है। यह कंप्यूटर की गणना क्षमता की एक इकाई है।
Data selection का पारंपरिक विचार यह है कि LLM को उपलब्ध सभी डेटा (जिसमें कई खराब या अप्रासंगिक उदाहरण हो सकते हैं) दिखाने के बजाय, केवल सर्वश्रेष्ठ और सबसे अधिक जानकारीपूर्ण डेटा का चयन क्यों न किया जाए? इससे LLM तेजी से और बेहतर सीखता है, और आप छोटे, उच्च-गुणवत्ता वाले डेटासेट का उपयोग करके प्रशिक्षण लागत बचाते हैं। लक्ष्य एक बड़े संग्रह $\mathcal{D}$ से डेटा का एक छोटा उपसमुच्चय $S$ खोजना है, जो किसी लक्ष्य कार्य पर LLM के प्रदर्शन को अधिकतम करे। गणितीय रूप से, इसे अक्सर इस प्रकार व्यक्त किया जाता है:
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(T; \mathcal{T}(S)) \quad \text{subject to} \quad |S| \le K $$
यहाँ, $P(T; \mathcal{T}(S))$ परीक्षण सेट $T$ पर मॉडल $\mathcal{T}$ (जो डेटा $S$ पर प्रशिक्षित है) के प्रदर्शन को दर्शाता है। $|S| \le K$ बाधा का अर्थ है कि आप केवल $K$ डेटा बिंदुओं का चयन कर सकते हैं। इसके लिए, डेटा चयन विधियाँ आमतौर पर प्रत्येक डेटा बिंदु को एक "उपयोगिता स्कोर" (utility score) प्रदान करती हैं और फिर उच्चतम स्कोर वाले बिंदुओं को चुनती हैं।
समस्या के पीछे की प्रेरणा
यहीं पर यह शोध पत्र एक महत्वपूर्ण मोड़ लाता है। हालाँकि डेटा चयन प्रशिक्षण की लागत को कम करता है, लेकिन डेटा चयन की प्रक्रिया स्वयं मुफ्त नहीं है! "सर्वश्रेष्ठ" डेटा चुनने की कुछ विधियाँ सरल और सस्ती हैं, जैसे कि यह गिनना कि "बिल्ली" शब्द कितनी बार आया है। अन्य विधियाँ अविश्वसनीय रूप से परिष्कृत हैं, जैसे कि किसी अन्य छोटे LLM से प्रत्येक कविता को पढ़वाना और उसकी गुणवत्ता को रेट करना, या जटिल गणितीय "gradients" का विश्लेषण करना। ये परिष्कृत विधियाँ उच्च-गुणवत्ता वाला डेटा खोजने में बहुत प्रभावी हैं, लेकिन इनकी एक महत्वपूर्ण कम्प्यूटेशनल कीमत होती है।
समस्या यह है कि पिछला शोध अक्सर इस बात पर केंद्रित रहा है कि चयनित डेटा के साथ मॉडल कितना बेहतर प्रदर्शन करता है, या कितनी प्रशिक्षण गणना (training compute) की बचत होती है, बिना इस बात का हिसाब रखे कि चयन प्रक्रिया की स्वयं की लागत क्या है। यदि कोई डेटा चयन विधि इतनी महंगी है कि उसकी लागत प्रशिक्षण से मिलने वाले लाभों से अधिक है, तो व्यावहारिक और बजट-सीमित दृष्टिकोण से वह वास्तव में "इष्टतम" (optimal) नहीं है।
इस शोध पत्र का उद्देश्य इस कमी को दूर करना है। लेखक कुल कम्प्यूटेशनल लागत — डेटा चयन और उस चयनित डेटा पर मॉडल के प्रशिक्षण, दोनों के लिए — को समझना चाहते हैं ताकि यह निर्धारित किया जा सके कि एक निश्चित, वास्तविक दुनिया के बजट के तहत कौन सी डेटा चयन विधियाँ वास्तव में सबसे कुशल हैं।
जिन बाधाओं को पार किया गया
लेखकों ने इस समस्या से निपटने में कई चुनौतियों का सामना किया:
- निश्चित कुल कम्प्यूट बजट: मुख्य बाधा यह है कि पूरी fine-tuning प्रक्रिया (चयन + प्रशिक्षण) के लिए कुल कम्प्यूटेशनल बजट (जैसे FLOPs में) पहले से निर्धारित होता है।
- डेटा चयन विधियों की बदलती लागत: सरल विधियाँ (जैसे कीवर्ड मिलान) सस्ती हैं, जबकि जटिल विधियाँ (जैसे ग्रेडिएंट-आधारित चयन) बहुत महंगी हैं।
- घटता प्रतिफल (Diminishing Returns): अधिक डेटा बिंदु जोड़ने या चयन पर अधिक गणना खर्च करने का मूल्य आमतौर पर कम होता जाता है। एक बिंदु के बाद, मॉडल में सुधार रुक जाता है।
- स्केलेबिलिटी: LLMs विभिन्न आकारों में आते हैं, और इष्टतम रणनीति मॉडल के पैमाने के आधार पर बदल सकती है।
- सामान्यीकरण (Generalizability): निष्कर्षों को विभिन्न कार्यों और LLM आर्किटेक्चर पर लागू होना चाहिए।
इन बाधाओं को दूर करने के लिए, लेखकों ने:
* समस्या को पुनर्गठित किया: उन्होंने डेटा चयन की लागत को अनुकूलन उद्देश्य (optimization objective) में स्पष्ट रूप से शामिल किया।
* लागतों का वर्गीकरण और मात्रा निर्धारण किया: उन्होंने डेटा चयन विधियों को चार वर्गों (Lexicon-Based, Embedding-Based, Perplexity-Based, Gradient-Based) में वर्गीकृत किया और उनकी कम्प्यूटेशनल लागत की गणना की।
* पैरामीट्रिक मॉडल विकसित किया: उन्होंने कुल गणना के फलन के रूप में प्रदर्शन के घटते प्रतिफल को पकड़ने के लिए एक गणितीय मॉडल (समीकरण 3) बनाया।
* व्यापक प्रयोगात्मक परीक्षण किया: उन्होंने विभिन्न LLM आकारों (7B से 70B पैरामीटर्स) पर 600 से अधिक प्रयोग किए।
गणितीय व्याख्या: समस्या का समाधान
लेखकों द्वारा हल की गई समस्या:
उन्होंने प्रदर्शन को डेटा बजट के बजाय कुल कम्प्यूट बजट के अधीन अधिकतम करने का लक्ष्य रखा। उनका नया उद्देश्य फलन है:
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(V; \mathcal{T}(S)) \quad \text{subject to} \quad C_T(S) + \sum_{x \in \mathcal{D}} C_U(x) \le K $$
- $C_T(S)$: चयनित डेटा उपसमुच्चय $S$ पर LLM को प्रशिक्षित करने की कम्प्यूटेशनल लागत।
- $\sum_{x \in \mathcal{D}} C_U(x)$: मूल बड़े डेटासेट $\mathcal{D}$ में सभी डेटा बिंदुओं के लिए उपयोगिता स्कोर की गणना करने की कुल लागत।
समाधान की विधि:
1. पैरामीट्रिक प्रदर्शन मॉडल: उन्होंने अपेक्षित प्रदर्शन $P(k)$ के लिए एक मॉडल प्रस्तावित किया:
$$ P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0 $$
यहाँ $\lambda$ एक महत्वपूर्ण पैरामीटर है जो यह नियंत्रित करता है कि एक डेटा चयन विधि अतिरिक्त गणना से कितनी कुशलता से मूल्य निकालती है।
2. Pareto Frontier विश्लेषण: उन्होंने प्रदर्शन बनाम कुल FLOPs को प्लॉट करके "compute-optimal Pareto frontier" की पहचान की, जो किसी भी बजट के लिए उच्चतम प्रदर्शन प्रदान करने वाली रणनीतियों का समूह है।
निष्कर्ष और भविष्य की दिशाएँ
यह शोध पत्र स्पष्ट रूप से सिद्ध करता है कि डेटा चयन विधियों की प्रभावशीलता केवल उनके द्वारा चुने गए डेटा की गुणवत्ता पर निर्भर नहीं करती, बल्कि उनकी अपनी कम्प्यूटेशनल लागत पर भी निर्भर करती है। छोटे और मध्यम बजट के लिए, सरल विधियाँ (जैसे BM25 और Embed) अक्सर अधिक परिष्कृत विधियों (जैसे PPL और LESS) को पीछे छोड़ देती हैं।
भविष्य के शोध के लिए विषय:
1. गतिशील और अनुकूली चयन रणनीतियाँ: क्या कोई ऐसा एजेंट विकसित किया जा सकता है जो बजट के आधार पर चयन विधियों को गतिशील रूप से बदल सके?
2. लागत-जागरूक LLM आर्किटेक्चर: क्या ऐसे LLMs डिज़ाइन किए जा सकते हैं जो चयन-अनुकूल (selection-friendly) हों?
3. FLOPs से परे: क्या ऊर्जा खपत और मानवीय लागत जैसे अन्य कारकों को भी कम्प्यूटेशनल मॉडल में शामिल किया जा सकता है?
4. नैतिक निहितार्थ: क्या कम्प्यूट-इष्टतम चयन अनजाने में पूर्वाग्रहों को बढ़ावा देता है?
यह शोध पत्र LLM fine-tuning के क्षेत्र में एक व्यावहारिक और गणितीय रूप से कठोर ढांचा प्रदान करता है, जो यह रेखांकित करता है कि वास्तविक दुनिया की बाधाओं के तहत "दक्षता" ही सफलता की कुंजी है।
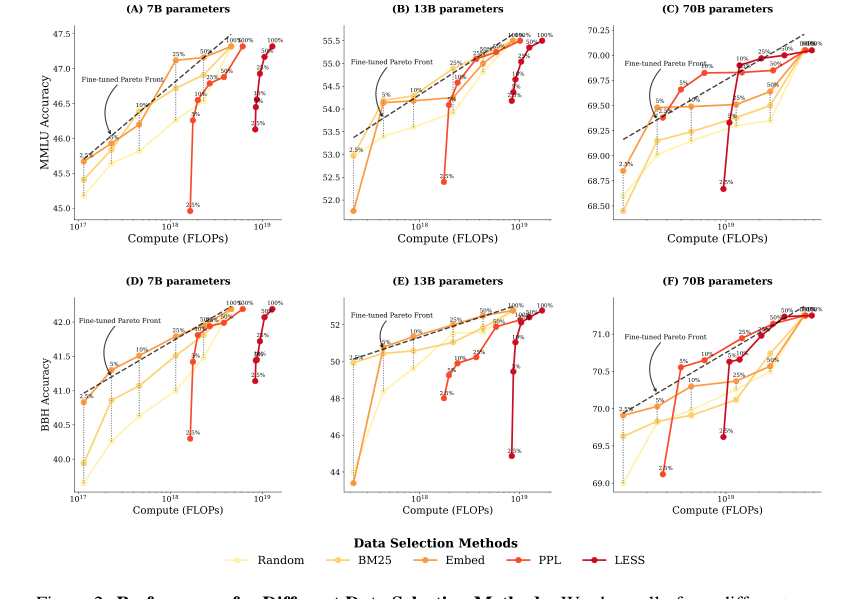 Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
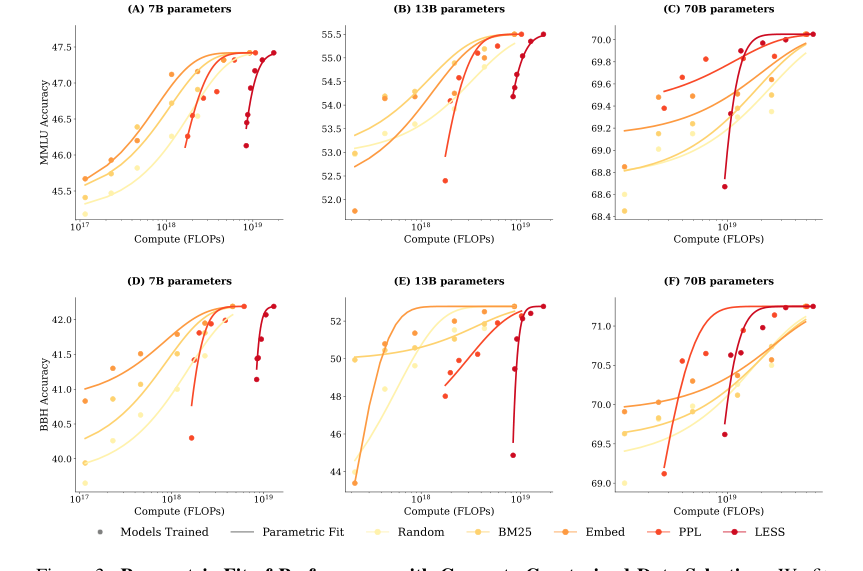 Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
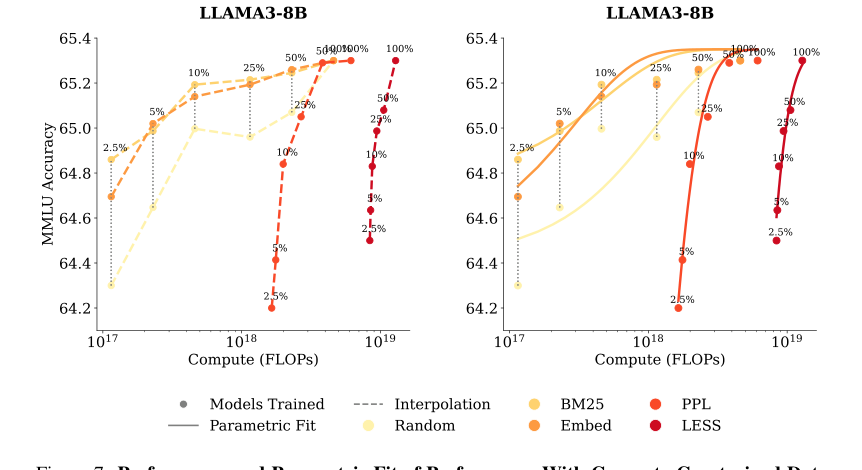 Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points
Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points