컴퓨팅 제약 조건 하에서의 데이터 선택
The field of large language models (LLMs) has seen explosive growth, leading to models with billions of parameters capable of remarkable feats in natural language understanding and generation.
배경 및 학문적 계보
대규모 언어 모델(LLM) 분야는 폭발적인 성장을 거듭하며 수십억 개의 매개변수를 가진 모델들이 자연어 이해 및 생성에서 놀라운 능력을 발휘하게 되었다. 그러나 이러한 강력한 성능은 상당한 계산 비용을 수반한다. 이러한 거대 모델을 훈련시키거나, finetuning이라는 과정을 통해 특정 작업에 맞게 조정하는 데에도 막대한 계산 자원이 필요하며, 이는 종종 그래픽 처리 장치(GPU) 시간 또는 FLOPs(Floating Point Operations)로 측정된다.
본 논문에서 다루는 문제의 정확한 기원은 이러한 자원 제약이라는 현실적인 문제에서 비롯된다. LLM이 보편화되면서 연구자들과 실무자들은 훈련 또는 finetuning을 위한 총 계산 예산이 종종 사전에 결정되고 고정되어 있다는 사실을 빠르게 인지하게 되었다. 이는 GPU와 같은 가속기의 수와 사용 시간이 미리 할당된다는 것을 의미한다. 이러한 인식은 "계산 최적화 LLM(compute-optimal LLMs)"에 대한 연구를 촉발시켰으며, 이는 주어진 계산 예산 내에서 가능한 최고의 모델 성능(예: 가장 낮은 perplexity)을 달성하는 것을 목표로 한다. Hoffmann et al. (2022)과 같은 초기 연구는 이를 달성하기 위해 아키텍처 선택과 훈련 결정을 어떻게 균형 있게 조절할 수 있는지 탐구했다.
본 논문은 이러한 연구 흐름을 LLM의 finetuning 단계에 구체적으로 확장한다. finetuning을 위한 계산 요구 사항을 줄이는 유망한 전략은 "데이터 선택(data selection)"으로, 전체 사용 가능한 데이터셋으로 훈련하는 대신 더 작지만 영향력 있는 하위 집합을 선택하는 것이다. 데이터 선택 자체는 머신러닝의 근본적인 개념으로, 1960년대 후반(Hart, 1968)과 1970년대(John, 1975)로 거슬러 올라가는 뿌리를 가지고 있으며, 효과적인 훈련을 위한 최소한의 데이터셋을 생성하는 것을 목표로 한다.
그러나 저자들이 본 논문을 작성하게 된 근본적인 한계 또는 "고충점(pain point)"은 데이터 선택 과정 자체의 계산 비용을 거의 무시했다는 점이다. 데이터 선택 방법은 훈련 데이터 크기(따라서 훈련 계산량)를 줄이도록 설계되었지만, 많은 "강력한" 또는 "정교한" 선택 방법은 최적의 데이터 포인트를 식별하는 데 상당한 계산 노력을 요구한다. 핵심 문제는 "데이터 선택이 효과적이더라도, 그것이 사전에 계산 최적화(compute-optimal)임을 의미하지는 않는다"는 것이다. 이전 모델들은 주어진 데이터 예산(즉, 데이터 포인트 수)에 대한 성능을 최대화하는 데 초점을 맞추었지만, 선택 및 훈련 비용을 모두 포함하는 주어진 계산 예산에 대해서는 그렇지 않았다. 이러한 간과로 인해 "최고의" 데이터를 선택하는 방법이 실행하는 데 너무 비싸서, 전체 계산 예산을 단순히 더 저렴하거나 심지어 무작위 선택 전략을 사용하여 더 많은 데이터로 훈련하는 데 사용하는 것이 더 나을 수 있다는 결론에 이르게 되었다. 저자들은 실질적인 채택을 위해서는 계산 최적화 방법이 훈련을 개선하고 계산 비용이 저렴해야 한다는 두 가지 조건을 모두 충족해야 한다고 주장하며, 이는 간과되어 온 중요한 요소이다.
다음은 본 논문에서 사용된 3~5개의 고도로 전문화된 도메인 용어를 제로베이스 독자를 위한 직관적인 일상 비유로 번역한 것이다.
- LLMs (Large Language Models): 거의 모든 인간이 쓴 글을 읽은 매우 똑똑한 디지털 비서라고 상상해보라. 이 비서는 당신의 질문을 이해하고, 이야기를 쓰고, 기사를 요약하며, 심지어 코딩까지 도와줄 수 있다. 이 모든 것은 다음에 올 가장 가능성 있는 단어를 예측함으로써 이루어진다.
- Finetuning: 이렇게 생각하면 된다. 당신은 모든 종류의 요리를 할 줄 아는 훌륭하고 다재다능한 요리사(LLM)를 가지고 있다. 이제 당신은 그 요리사가 프랑스 페이스트리 제빵 전문가가 되기를 원한다. 당신은 그에게 프랑스 페이스트리에 관한 특정 요리책을 주고 그 레시피만 연습하게 한다. 그는 다른 요리를 하는 법을 잊지 않지만, 프랑스 페이스트리에는 훨씬 더 능숙해진다.
- Compute-Optimal: 이것은 무언가를 만들 때 "가성비"를 최대한 얻으려고 노력하는 것과 같다. 당신은 고정된 양의 돈(계산 예산)을 가지고 있고 최고 품질의 결과(모델 성능)를 달성하고 싶다. 이것은 가장 비싸거나 겉보기에 "최고인" 부분에 돈을 쓰는 것뿐만 아니라, 가장 많은 가치를 얻기 위해 어디에 돈을 쓸지 현명하게 선택하는 것이다.
- Perplexity: 문장에서 다음에 올 단어를 추측하려고 한다고 상상해보라. 문장이 "The cat sat on the..."라면, 다음에 올 단어가 "mat" 또는 "rug"일 때 그다지 놀라지 않을 것이다. 당신의 "perplexity"는 낮다. 하지만 다음에 올 단어가 "banana"라면 매우 놀랄 것이고, 당신의 "perplexity"는 높아질 것이다. LLM에서 낮은 perplexity는 모델이 텍스트를 예측하는 데 더 뛰어나고 언어를 더 유창하게 이해한다는 것을 의미한다.
- FLOPs (Floating Point Operations): 이것은 컴퓨터가 수행하는 기본적인 산술 계산(덧셈, 뺄셈, 곱셈, 나눗셈 등)이다. FLOPs에 대해 이야기할 때, 그것은 계산기 버튼을 누르는 모든 횟수를 세는 것과 같다. 이것은 컴퓨터가 얼마나 많은 "사고" 또는 "작업"을 하는지 측정하는 방법이다. 높은 FLOPs 수는 더 많은 계산 노력을 의미한다.
Notation Table
| Notation | Description |
|---|---|
| LLMs | 대규모 언어 모델, 방대한 텍스트 데이터로 사전 훈련됨. |
| Finetuning | 소규모의 작업별 데이터셋을 사용하여 사전 훈련된 LLM을 특정 다운스트림 작업에 맞게 조정하는 과정. |
| Compute Budget ($\mathcal{K}$) | 데이터 선택 및 모델 훈련 모두에 할당된 총 고정 계산 리소스(예: FLOPs, GPU 시간). |
| FLOPs | 부동 소수점 연산, 계산 작업의 측정 단위. |
| $\mathcal{D}$ | 사용 가능한 전체 잠재적 훈련 데이터 풀. |
| $\mathcal{S}$ | finetuning을 위해 $\mathcal{D}$에서 선택된 데이터의 하위 집합. |
| $\mathcal{S}^*$ | 계산 제약 조건 하에서 모델 성능을 최대화하는 $\mathcal{D}$에서 선택된 최적의 데이터 하위 집합. |
| $P(\cdot)$ | 주어진 작업에 대한 LLM의 성능을 나타내는 함수(예: 정확도, perplexity). |
| $\mathcal{T}(\mathcal{S})$ | 데이터 하위 집합 $\mathcal{S}$에서 훈련(finetuning)된 LLM 모델. |
| $\mathcal{T}$ | 모델 성능의 최종 평가에 사용되는 대상 테스트 데이터셋. |
| $\mathcal{V}$ | 데이터 선택 및 모델 개발 중에 $\mathcal{T}$의 대리 역할을 하는 검증 데이터셋. |
| $C_T(\mathcal{S})$ | 선택된 데이터 하위 집합 $\mathcal{S}$에서 LLM을 훈련하는 데 드는 계산 비용(FLOPs 단위). |
| $C_U(x)$ | 데이터 선택 과정에서 단일 데이터 포인트 $x$에 대한 유틸리티 함수를 계산하는 데 드는 계산 비용(FLOPs 단위). |
| $\sum_{x \in \mathcal{D}} C_U(x)$ | 데이터 선택을 수행하기 위해 원본 데이터셋 $\mathcal{D}$의 모든 데이터 포인트에 대한 유틸리티 함수를 계산하는 총 계산 비용. |
| $K$ (전통적인 문제에서) | 선택된 하위 집합 $\mathcal{S}$에서 허용되는 최대 카디널리티(데이터 포인트 수) (데이터 예산). |
| $K$ (계산 제약 문제에서) | 데이터 선택 및 훈련을 위한 총 계산 예산(FLOPs 단위). |
| $v(x; \mathcal{V})$ | 검증 세트 $\mathcal{V}$에 대해 종종 계산되는 관련성 또는 가치를 기준으로 데이터 포인트 $x$에 점수를 할당하는 유틸리티 함수. |
| $P_0$ | LLM의 제로샷 성능(finetuning 없이 얻는 성능). |
| $P$ | 달성 가능한 최대 성능을 나타내는 성능의 상한선. |
| $\lambda$ | 매개변수화된 성능 모델에서 데이터 선택 방법이 추가 계산에서 얼마나 효율적으로 가치를 추출하는지를 제어하는 매개변수. |
| $C(k)$ | $k$개의 데이터 포인트로 훈련하는 결과를 낳는 전략에 대한 총 계산 비용(선택 + 훈련). |
| $C(|\mathcal{D}|)$ | 전체 데이터셋 $\mathcal{D}$로 훈련하는 총 계산 비용(데이터 선택 없음). |
| $\exp(\cdot)$ | 지수 함수, 감소하는 수익을 모델링하는 데 사용됨. |
| Levenberg-Marquardt | 비선형 최소 제곱 문제를 해결하는 데 사용되는 알고리즘으로, 여기서는 매개변수화된 성능 모델의 매개변수를 맞추는 데 사용됨. |
| LoRA | Low-Rank Adaptation, 메모리 사용량을 줄이는 매개변수 효율적인 finetuning 방법. |
| QLoRA | Quantized LoRA, 특히 매우 큰 모델의 메모리 감소를 위한 추가 최적화. |
| MMLU | Massive Multitask Language Understanding, 사실적 지식을 위한 벤치마크. |
| BBH | Big-Bench Hard, 복잡한 추론을 위한 벤치마크. |
| IFEval | Instruction Following Evaluation, 지시 사항 이행 능력을 위한 벤치마크. |
| BM25 | 텍스트의 통계적 속성을 사용하는 사전 기반 데이터 선택 방법. |
| Embed | 임베딩 기반 데이터 선택 방법, 밀집 임베딩 모델 사용. |
| PPL | LLM 손실(perplexity)을 사용하는 Perplexity 기반 데이터 선택 방법. |
| LESS | 영향력을 추정하기 위해 그래디언트를 사용하는 그래디언트 기반 데이터 선택 방법. |
문제 정의 및 제약 조건
본 논문이 다루는 핵심 문제는 엄격하게 사전 결정된 총 컴퓨팅 예산 하에서 대규모 언어 모델(LLM)의 파인튜닝을 최적화하는 데 있다.
시작점 (입력/현재 상태)은 다음과 같은 시나리오이다:
* $\mathcal{D}$로 표시되는 방대한 잠재적 훈련 데이터 풀.
* 기반 LLM을 파인튜닝해야 하는 특정 다운스트림 태스크.
* 성능 평가를 위한 관련 테스트($\mathcal{T}$) 및 검증($\mathcal{V}$) 데이터셋.
* 데이터 선택 및 후속 모델 훈련 모두에 할당된 총 리소스를 나타내는 FLOPs(부동소수점 연산)로 측정되는 고정된 전체 계산 예산 $\mathcal{K}$. 이 예산은 종종 가속기의 수와 사용 시간 등으로 사전에 설정된다.
* 각각 고유의 계산 비용과 가치 있는 훈련 데이터를 식별하는 효과를 가진 다양한 기존 데이터 선택 방법.
원하는 종착점 (출력/목표 상태)은 LLM이 이 부분집합에 파인튜닝될 때 대상 테스트 세트에서 가능한 최고 성능 $P(\mathcal{T}; \mathcal{T}(\mathcal{S}^*))$를 달성하도록 하는 최적의 데이터 부분집합 $\mathcal{S}^* \subset \mathcal{D}$를 식별하는 것이다. 결정적으로, 이 최적 성능은 총 컴퓨팅 예산 $\mathcal{K}$를 준수하면서 달성되어야 하며, 이는 $\mathcal{S}^*$ 선택과 이에 대한 훈련의 결합된 계산 비용이 $\mathcal{K}$를 초과하지 않음을 의미한다. 궁극적인 목표는 실무자들에게 유한한 컴퓨팅 리소스를 데이터 선택과 모델 훈련 간에 어떻게 최적으로 할당할지에 대한 정보에 입각한 결정을 내릴 수 있는 프레임워크를 제공하는 것이다.
본 논문이 연결하고자 하는 정확한 누락된 연결 또는 수학적 간극은 데이터 중심 최적화에서 컴퓨팅 중심 최적화로의 전환에 있다. 전통적으로 데이터 선택 문제는 다음과 같이 공식화된다:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{T}; \mathcal{T}(\mathcal{S})) \quad \text{subject to } |\mathcal{S}| \le K $$
여기서 $K$는 데이터 예산(최대 데이터 포인트 수)을 나타낸다. 이 공식은 데이터 선택 비용이 무시할 수 있거나 별도로 처리된다고 암묵적으로 가정한다.
본 논문은 데이터 선택의 계산 비용을 전체 예산 제약에 명시적으로 통합하는 새롭고 더 현실적인 공식을 도입한다. 문제는 다음과 같이 재구성된다:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{V}; \mathcal{T}(\mathcal{S})) \quad \text{subject to } C_T(\mathcal{S}) + \sum_{x \in \mathcal{D}} C_U(x) \le \mathcal{K} $$
여기서:
* $P(\mathcal{V}; \mathcal{T}(\mathcal{S}))$는 $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$의 대리 지표로 사용되며, 검증 세트 $\mathcal{V}$를 활용한다.
* $C_T(\mathcal{S})$는 선택된 부분집합 $\mathcal{S}$에 대한 모델 훈련의 계산 비용이다.
* $\sum_{x \in \mathcal{D}} C_U(x)$는 부분집합 $\mathcal{S}$를 식별하기 위해 원본 데이터셋 $\mathcal{D}$의 모든 데이터 포인트에 대한 유틸리티 함수 $v(x; \mathcal{V})$를 계산하는 총 계산 비용이다.
* $\mathcal{K}$는 총 컴퓨팅 예산이다.
수학적 간극은 정확히 제약 조건에 $\sum_{x \in \mathcal{D}} C_U(x)$ 항을 포함시켜, 최적화가 단순히 데이터 양에 관한 것이 아니라 총 컴퓨팅 지출에 관한 것이 되도록 변환하는 것이다.
이전 연구자들이 갇혀 있던 고통스러운 절충 또는 딜레마는 데이터 선택 방법의 효과성과 계산 비용 사이의 내재된 충돌이다. 모델 복잡도 또는 기울기와 같은 모델 기반의 더 정교한 데이터 선택 방법은 종종 더 작고 고품질의 데이터 부분집합을 식별하는 데 매우 효과적이어서 더 나은 모델 성능이나 훈련 중 더 빠른 수렴을 가져올 수 있다. 그러나 이러한 "강력한" 방법은 실행하는 데 계산 집약적이다.
딜레마는 이러한 고급 방법이 훈련 데이터 크기를 줄이지만, 선택 과정 자체에 필요한 상당한 컴퓨팅이 훈련 시간 감소로 인한 이익을 쉽게 상쇄할 수 있다는 것이다. 고정된 총 컴퓨팅 예산 시나리오에서 선택에 더 많은 FLOPs를 소비하는 것은 실제 파인튜닝 프로세스에 사용할 수 있는 FLOPs가 줄어든다는 것을 의미하며, "더 나은" 데이터 부분집합을 가졌음에도 불구하고 전반적인 성능이 저하될 수 있다. 연구자들은 이전에는 주어진 데이터 크기에 대한 성능 극대화에 집중했으며, 반드시 주어진 총 컴퓨팅 예산에 대해서는 그렇지 않았기 때문에 이 중요한 절충을 간과했다.
이 문제를 해결하기 어렵게 만드는 가혹하고 현실적인 장벽은 다면적이다:
- 최적 선택의 계산적 난해성: 절대적인 최적 데이터 부분집합 $\mathcal{S}^*$를 찾는 문제는 조합 최적화 문제이다. 모든 가능한 부분집합을 철저히 탐색하는 것은 대규모 데이터셋의 경우 계산적으로 불가능하여 정확한 해법을 비현실적으로 만든다. 이는 탐욕 알고리즘과 근사에 의존하게 만든다.
- LLM 연산의 높은 비용: 파라미터 효율적인 방법(예: LoRA)을 사용하더라도 LLM의 파인튜닝은 본질적으로 계산 집약적이다. 대규모 트랜스포머 모델을 통한 각 기울기 단계, 순방향 패스 또는 역방향 패스는 방대한 양의 FLOPs를 소비한다. 이는 $C_T(\mathcal{S})$와 $C_U(x)$ 항 모두를 상당하게 만든다.
- 선택 방법의 다양한 비용: 서로 다른 데이터 선택 방법은 계산 발자국이 크게 다르다. 사전 기반 방법(예: BM25)은 매우 저렴하며(0 FLOPs에 가까움), 임베딩 기반 방법은 중간 정도의 비용이 들며(예: Embed의 경우 $4.4 \times 10^{16}$ FLOPs), 복잡도 기반 및 기울기 기반 방법은 매우 비용이 많이 든다(예: PPL의 경우 $1.53 \times 10^{18}$ FLOPs, LESS의 경우 $8.27 \times 10^{18}$ FLOPs, 표 5 참조). 이 광범위한 범위는 데이터 감소 측면에서 "최고"인 방법이 총 컴퓨팅 효율성 측면에서 "최악"일 수 있음을 의미한다.
- 스케일링 법칙 및 수확 체감: 데이터 선택의 효능은 종종 이에 투자된 컴퓨팅과 함께 스케일링되지만, 수확 체감 현상이 나타난다. 더 많은 컴퓨팅은 약간 더 나은 부분집합을 제공할 수 있지만, 성능 향상이 추가 비용을 정당화하지 못할 수 있다. 컴퓨팅과 성능 간의 관계는 비선형적이고 복잡하며, 매개변수 함수 $P(k) = (P - P_0) \times (1 - \exp(-\frac{\lambda C(k)}{C(|\mathcal{D}|)})) + P_0$로 모델링된다.
- 대리 지표 의존성: 실제 목표 $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$는 테스트 세트 $\mathcal{T}$가 선택 중에 사용할 수 없기 때문에 직접 최적화할 수 없다. 연구자들은 대리 지표로 검증 세트 $\mathcal{V}$와 유틸리티 함수 $v(x; \mathcal{V})$에 의존해야 하며, 이는 잠재적인 부정확성과 가정(예: $\mathcal{V}$가 $\mathcal{T}$와 IID라는 가정)을 도입한다.
- 모델 및 태스크 종속성: 최적의 컴퓨팅 할당과 "최고의" 데이터 선택 방법은 보편적이지 않다. 이는 특정 LLM 크기(예: 7B, 13B, 70B 파라미터), 다운스트림 태스크의 성격(예: MMLU, BBH, IFEval), 그리고 사용 가능한 총 컴퓨팅 예산에 따라 달라진다. 이는 일반적인 솔루션을 찾는 것을 매우 어렵게 만든다.
- 하드웨어 메모리 제한: 중심적인 초점은 아니지만, 본 논문은 70B 모델에 대한 QLoRA를 사용하여 메모리 요구 사항을 줄인다고 언급하며(부록 D.1), 메모리 제약이 LLM 파인튜닝 스케일링에서 실질적인 장벽임을 나타내며, 이는 간접적으로 컴퓨팅 할당 전략에 영향을 미친다.
본질적으로, 이 문제는 "최고의" 선택이 매우 맥락에 따라 달라지고, 한 측면(데이터 품질)을 개선하려는 시도 자체가 다른 측면(총 컴퓨팅 효율성)을 약화시킬 수 있는 복잡하고 비선형적인 최적화 환경을 탐색해야 하기 때문에 매우 어렵다.
이 접근 방식은 왜
본 논문이 다루는 핵심 문제는 미리 정해진 유한한 계산 예산 하에서 Large Language Model (LLM)의 finetuning에 대한 실질적인 도전 과제이다. 전통적으로 데이터 선택 방법은 주어진 데이터 예산에 대한 모델 성능 최적화에 초점을 맞춰왔다. 이는 전체 데이터셋 $D$에서 고정된 크기 $K$의 최적 부분집합을 선택하는 것을 의미한다. 섹션 3에서 설명된 목표는 테스트셋 $T$에 대한 성능 $P(T; T(S))$을 최대화하는 부분집합 $S^*$를 찾는 것이며, 이는 $|S| \le K$를 제약 조건으로 한다.
저자들은 이러한 전통적인 접근 방식이 실제 LLM finetuning에는 불충분하다는 것을 인지했다. 이러한 인식이 명확하게 드러나는 시점은 섹션 4에 기술되어 있다: "섹션 3에서 제시된 프레임워크는 데이터 선택에 대한 일반적인 방법을 제공하지만, 우리는 이것이 LLM finetuning의 실질적인 도전 과제에는 불충분하다고 주장한다. 문제는 LLM finetuning이 종종 데이터 예산이 아닌 계산 예산에 의해 병목 현상을 겪는다는 것이다." 그들은 총 계산 예산이 종종 사전에 고정되며 (예: 할당된 가속기 및 사용 시간), 이 예산은 데이터 선택 비용과 선택된 데이터로 모델을 훈련하는 비용 모두를 충당해야 한다는 점을 관찰했다. 데이터 선택을 위한 이전의 "SOTA" 방법들은 고품질 데이터 부분집합을 식별하는 데 효과적이었지만, 그 자체로 상당한 계산 비용을 수반했으며, 이는 평가에서 대부분 무시되었다.
본 논문의 접근 방식은 새로운 데이터 선택 알고리즘을 도입하는 것이 아니라, 데이터 선택 방법을 평가하고 선택하기 위한 새롭고 계산 제약이 있는 프레임워크를 제시하는 것이다. 이 프레임워크는 총 계산 지출을 명시적으로 고려하기 때문에 계산이 제한된 환경에서 진정으로 최적의 결정을 내릴 수 있는 유일하게 실행 가능한 해결책이다. 저자들은 이 문제를 다음과 같이 공식화한다:
$$S^* = \arg \max_{S \subset D} P(V; T(S)) \quad \text{subject to} \quad C_T(S) + \sum_{x \in D} C_U(x) \le K$$
여기서 $K$는 총 계산 예산 (예: 최대 FLOPs)을 나타내고, $C_T(S)$는 선택된 부분집합 $S$로 모델을 훈련하는 비용이며, $\sum_{x \in D} C_U(x)$는 전체 데이터셋 $D$에 걸쳐 데이터 선택을 위한 유틸리티 함수를 계산하는 비용이다. 이는 고정된 데이터 크기를 최적화하는 것에서 고정된 총 계산량을 최적화하는 것으로의 근본적인 전환이다.
비교 우위 (벤치마킹 논리):
이 계산 제약 프레임워크의 질적 우수성은 전체적이고 실질적인 평가 지표에 있다. 이전의 "골드 스탠다드"는 데이터 선택을 위한 계산량을 무한하거나 무시할 수 있다고 암묵적으로 가정하고, 선택된 데이터에 의해 달성된 성능에만 초점을 맞췄다. 그러나 이 새로운 프레임워크는 총 계산량 (x축)과 모델 성능 (y축)을 매핑하는 Pareto frontier (그림 2, 3, 5, 7, 8 참조)를 제공한다. 이를 통해 단순히 고정 크기 데이터셋에서의 순수 성능이 아닌, 계산량을 성능으로 전환하는 효율성을 기준으로 방법들을 직접 비교할 수 있다.
이 프레임워크는 본질적으로 고차원 노이즈를 더 잘 처리하거나 기본 데이터 선택 알고리즘의 메모리 복잡성을 줄이지는 않는다. 대신, 그 구조적 이점은 다양한 예산 시나리오 하에서 진정한 계산량 최적의 방법들을 드러낸다는 것이다. 이는 선택을 위한 계산 복잡성이 낮은 방법들 (예: Lexicon-Based BM25 또는 Embedding-Based)이 총 계산 예산이 제한될 때, 계산 집약적인 더 정교한 방법들 (예: Perplexity-Based PPL 또는 Gradient-Based LESS)보다 압도적으로 우수해진다는 것을 보여준다. 예를 들어, 초록에서는 "더 저렴한 데이터 선택 대안이 이론적 및 경험적 관점에서 모두 지배적이다"라고 언급한다. 이는 중요한 질적 이점이다: 중요한 실제 제약을 도입함으로써 "최고"로 간주되는 방법들을 변화시킨다. 다양한 계산 예산 하에서의 이러한 방법들의 개념적 행동은 시뮬레이션으로 설명된다.
제약과의 정렬 ("결혼"):
문제의 엄격한 요구 사항과 해결책의 고유한 속성 간의 "결혼"은 완벽하다. 서론에서 언급된 문제의 엄격한 요구 사항은 다음과 같다:
1. 미리 정해진 총 계산 예산: LLM 훈련은 비용이 많이 들며, 리소스 (가속기, 사용 시간)는 사전에 할당된다.
2. 최적의 리소스 할당: 이 고정 예산을 어떻게 가장 잘 할당할지 결정하는 것이 중요하다.
3. 데이터 선택은 계산량 최적이어야 함: 어떤 데이터 선택 방법이든 추가 비용에 비례하여 훈련을 개선해야 한다.
계산 제약 목표 (식 2)는 이러한 요구 사항을 직접적으로 해결한다:
* 이는 총 계산량에 대한 엄격한 상한선 $K$를 설정하여, 선택 비용과 훈련 비용 간의 절충을 강제한다.
* 이는 데이터 선택의 "추가 비용"($C_U(x)$)을 정량화하고 훈련 비용($C_T(S)$)과 통합하여, 실무자가 리소스 할당에 대해 정보에 입각한 결정을 내릴 수 있도록 한다.
* 이는 전체 파이프라인을 고려함으로써 진정으로 "계산량 최적"인 방법을 식별할 수 있게 하며, 단순히 분리된 부분을 고려하는 것이 아니다. 이는 선택된 방법이 효과적일 뿐만 아니라 주어진 계산량 제한 내에서 경제적으로 실행 가능하도록 보장한다. 이 프레임워크는 리소스가 제한된 세상에서 효율성에 대한 실질적인 요구에 대한 직접적인 대응이다.
대안의 거부:
본 논문은 계산량이 제한될 때, 전통적인 "SOTA" 데이터 선택 방법들, 예를 들어 Perplexity-Based (PPL) 및 Gradient-Based (LESS)를 암묵적으로 "거부"한다. GANs 또는 Diffusion 모델과 같은 대안은 다루지 않는데, 이는 본 논문의 범위가 finetuning을 위한 데이터 선택에 국한되기 때문이다.
이러한 강력한 방법들을 거부하는 이유는 선택을 위한 높은 계산 비용이며, 이는 총 계산 예산 하에서 FLOPs 비효율성을 야기한다.
* 높은 비용: 섹션 4.1과 부록 B는 명확한 증거를 제공한다. Lexicon-Based (BM25)는 약 $1 \times 10^8$ FLOPs의 비용이 들고, Embedding-Based (Embed)는 약 $4.4 \times 10^{16}$ FLOPs의 비용이 든다. 이와 극명하게 대조적으로, Perplexity-Based (PPL)는 약 $1.53 \times 10^{18}$ FLOPs, Gradient-Based (LESS)는 무려 $8.27 \times 10^{18}$ FLOPs의 비용이 든다. 이는 수십억 배 더 비싼 수치이다.
* FLOP 비효율성: 초록과 섹션 7은 명시적으로 "많은 강력한 데이터 선택 방법은 거의 계산량 최적이 아니며", PPL과 LESS는 "이론적 및 경험적 관점에서 FLOP 비효율적"이라고 명시한다.
* 경험적 실패: 그림 1과 2는 이를 보여준다. 작거나 중간 규모의 계산 예산의 경우, 더 저렴한 BM25 및 Embed 방법들이 계산-성능 Pareto frontier에서 PPL 및 LESS보다 일관되게 더 나은 성능을 보인다. 이는 주어진 총 계산 예산에 대해, 더 저렴한 선택 방법을 사용하고 실제 모델 훈련에 더 많은 계산량을 할당함으로써 더 나은 모델 성능을 달성할 수 있다는 것을 의미한다.
* 손익분기점: 본 논문은 PPL과 LESS가 훈련 모델이 선택 모델보다 훨씬 클 때 (PPL의 경우 5배, LESS의 경우 10배, 섹션 8 및 부록 G에 상세히 설명됨) 계산량 최적이 된다는 것을 발견했다. 이는 선택 모델이 훈련 모델에 비해 비슷한 크기이거나 더 작은 대부분의 실질적인 시나리오에서 이러한 정교한 방법들이 계산량 최적이 되지 못했을 것임을 시사한다. 그들의 우수한 데이터 선택 품질의 한계적 이점은 단순히 과도한 계산 비용을 상쇄하지 못한다.
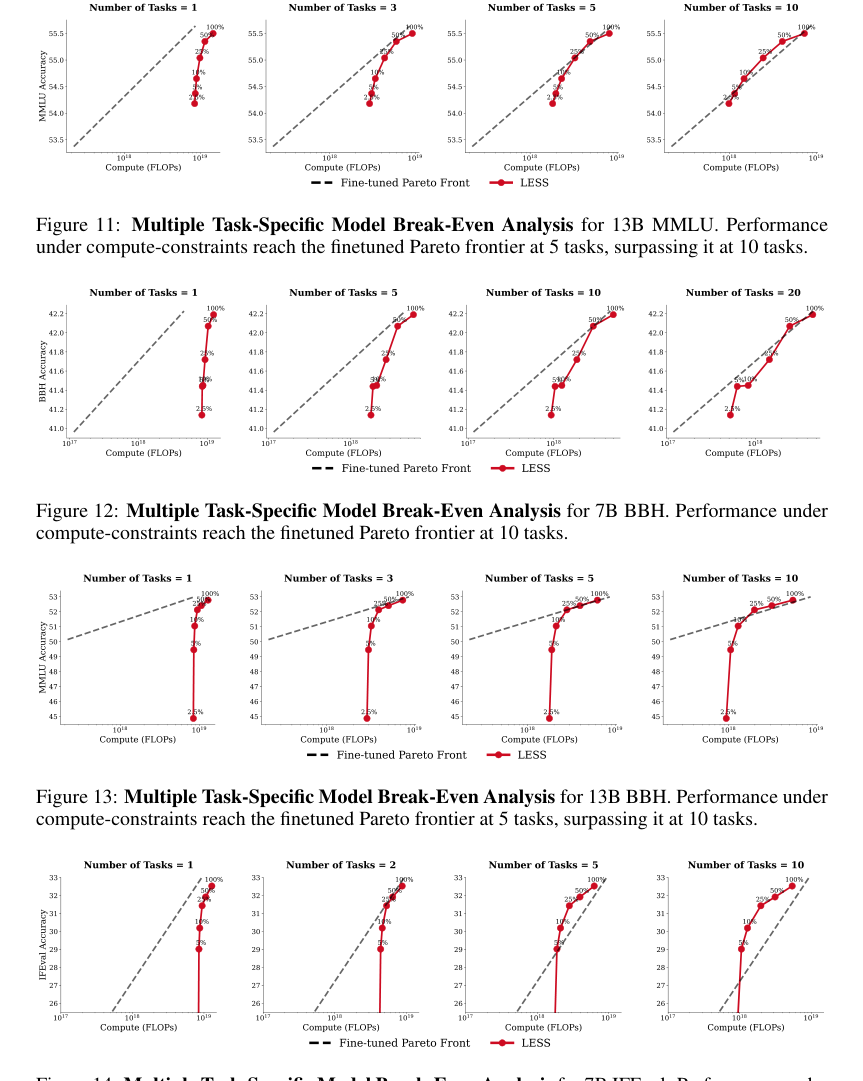 Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
수학적 및 논리적 메커니즘
메타과학자로서, 저는 대규모 언어 모델(LLM) 시대의 중요한 과제, 즉 훈련 데이터 선택과 모델 파인튜닝 사이에 고정된 계산 예산을 어떻게 최적으로 할당할 것인가를 다루는 "계산 제약 데이터 선택(COMPUTE-CONSTRAINED DATA SELECTION)"이라는 논문을 철저히 검토했습니다. 저자들은 가장 "강력한" 데이터 선택 방법이 항상 가장 계산 효율적인 접근 방식은 아니라는 설득력 있는 분석을 제시합니다.
제로베이스 독자를 위한 배경 지식
논문의 세부 사항으로 들어가기 전에 몇 가지 기초 개념을 확립해 보겠습니다.
- 대규모 언어 모델(LLM): 인간과 유사한 텍스트를 이해하고 생성할 수 있는 매우 똑똑한 디지털 비서를 상상해 보세요. 이것이 LLM입니다. LLM은 수십억 개의 내부 매개변수(손잡이와 같음)를 가지고 방대한 양의 텍스트 데이터(전체 인터넷과 같음)로 훈련되기 때문에 "대규모"입니다. 이 훈련 과정은 엄청나게 비용이 많이 들고 시간이 오래 걸립니다.
- 파인튜닝: LLM이 사전 훈련되면 일반적인 능력을 갖게 됩니다. 특정 작업(예: 의료 질문 답변, 코드 작성)을 잘 수행하도록 하려면 "파인튜닝"합니다. 이는 더 작고 작업별 데이터셋으로 추가 훈련하는 것을 포함합니다. 일반적인 셰프에게 프랑스 요리 전문성을 가르치는 것과 같습니다.
- 계산 예산: 이를 계산 리소스에 대한 총 허용량으로 생각하세요. FLOPs(Floating Point Operations)로 측정되며, 이는 기본적인 산술 계산입니다. LLM 훈련에는 많은 FLOPs가 필요하며, 종종 GPU와 같은 고가의 하드웨어를 며칠 또는 몇 주 동안 실행해야 합니다. 이 예산은 종종 사전에 고정됩니다.
- 데이터 선택: 사용 가능한 모든 작업별 데이터로 파인튜닝하는 대신(여전히 방대할 수 있음), 데이터 선택은 해당 데이터의 더 작고 영향력 있는 하위 집합을 지능적으로 선택하는 프로세스입니다. 모든 데이터 포인트가 동일하게 가치 있는 것은 아니며 일부는 중복되거나 해로울 수 있다는 아이디어입니다. "최고의" 데이터를 선택하면 파인튜닝이 더 빠르고 효과적일 수 있습니다.
- 성능: 파인튜닝 후 LLM이 대상 작업에서 얼마나 잘 수행하는지를 나타냅니다. 이는 정확도, 생성된 텍스트의 일관성 또는 기타 지표로 측정될 수 있습니다.
- 수확 체감: 이것은 일반적인 경제 원칙입니다. 어떤 것에 더 많이 투자할수록 각 후속 투자에서 얻는 추가 이익이 줄어듭니다. 예를 들어, 시험 공부의 처음 몇 시간은 큰 개선을 가져올 수 있지만, 100번째 시간은 약간의 향상만 가져올 수 있습니다. 이는 LLM 훈련의 계산 및 데이터에도 적용됩니다.
동기: 핵심 문제
이 논문의 중심 동기는 실질적인 딜레마에서 비롯됩니다.
- LLM 파인튜닝은 비용이 많이 듭니다: 이러한 대규모 모델을 훈련하는 것은 특정 작업에 대해서도 상당한 계산 리소스를 소비합니다.
- 데이터 선택이 도움이 될 수 있습니다: 더 작고 고품질의 데이터셋을 선택하면 필요한 훈련 계산량을 줄일 수 있습니다. 이것은 훌륭하게 들립니다!
- 하지만 데이터 선택 자체도 계산 비용이 듭니다: 어떤 데이터 포인트가 "최고"인지 알아내려면 종종 일부 계산을 실행해야 하며, 때로는 다른 LLM을 사용해야 할 수도 있습니다. 이 프로세스는 무료가 아닙니다.
저자들은 이전 연구가 종종 데이터 크기 감소 또는 훈련 단계당 성능 향상 측면에서 데이터 선택의 효과에 초점을 맞추었지만, 선택 프로세스 자체의 계산 비용을 완전히 고려하지 않았다는 것을 깨달았습니다. 데이터 선택 방법은 "강력할" 수 있지만(훌륭한 데이터를 선택한다는 의미), 실행하는 데 막대한 계산 비용이 든다면 엄격한 총 계산 예산이 있는 경우 가장 효율적인 선택이 아닐 수 있습니다.
저자들이 해결하고자 하는 문제는 다음과 같습니다: 고정된 총 계산 예산이 주어졌을 때, 실무자는 모델 성능을 최대한 높이기 위해 데이터 선택에 사용되는 계산과 선택된 데이터로 모델을 훈련하는 데 사용되는 계산을 어떻게 최적으로 균형 잡아야 할까요? 그들은 이 절충점을 정량화하고 진정한 "계산 최적" 전략을 식별하고자 합니다.
극복해야 했던 제약 사항
저자들은 여러 실질적 및 이론적 제약에 직면했습니다.
- 고정된 총 계산 예산 ($K$): 이것이 포괄적인 제약입니다. 데이터 포인트 평가부터 실제 모델 훈련까지 모든 계산 노력은 이 사전 결정된 한계 내에 있어야 합니다. 프로젝트에 고정된 금액이 있고 계획(데이터 선택)과 실행(훈련)에 얼마를 지출할지 결정해야 하는 것과 같습니다.
- 데이터 선택의 계산 비용 ($C_U(x)$): 데이터 선택 방법마다 계산량이 크게 다릅니다. 일부는 저렴하고(예: 간단한 텍스트 통계), 다른 일부는 매우 비쌉니다(예: LLM에서 순방향/역방향 패스 실행). 이 비용은 최종적으로 소수의 하위 집합만 선택되더라도 유용성을 결정하기 위해 원래의 대규모 데이터셋의 모든 데이터 포인트에 대해 발생하는 경우가 많습니다. 이 "오버헤드"는 총 예산을 빠르게 소모할 수 있습니다.
- 훈련의 계산 비용 ($C_T(S)$): 선택된 하위 집합 $S$가 있더라도 훈련에는 여전히 계산이 필요합니다. 이 비용은 선택된 데이터의 크기와 파인튜닝되는 LLM의 크기에 따라 달라집니다.
- 실제 테스트 세트($T$)에 대한 제한된 액세스: 실제 시나리오에서는 모델이 배포 후 평가될 최종 테스트 세트가 데이터 선택 단계에서 일반적으로 사용 가능하지 않습니다. 따라서 저자들은 데이터 선택 프로세스 중에 성능을 평가하기 위한 대리자로 검증 세트($V$)에 의존해야 했습니다. 이는 대리 성능과 실제 성능 사이에 잠재적인 격차를 도입합니다.
- 조합 복잡성: 대규모 풀에서 데이터의 절대적으로 최상의 하위 집합을 선택하는 것은 조합 최적화 문제입니다. 즉, 가능한 하위 집합의 수가 천문학적으로 많다는 것을 의미합니다. 최적의 하위 집합을 직접 검색하는 것은 계산적으로 불가능합니다. 저자들은 탐욕적 근사(모든 포인트의 점수를 매기고 최고를 선택)를 사용한 다음 매개변수 함수로 성능을 모델링하여 이를 해결합니다.
- 수확 체감 모델링: 계산과 성능 간의 관계는 선형적이지 않습니다. 초기 계산 투자는 높은 수익을 가져오지만, 더 많은 계산이 추가됨에 따라 이러한 수익은 감소합니다. 이 비선형 동작을 정확하게 모델링하는 것이 분석에 중요했습니다.
수학적 해석: 엔진의 내부
이 논문은 두 가지 주요 수학적 공식을 제시합니다. 첫 번째는 문제 자체를 정의하고, 두 번째는 계산-성능 관계를 분석하고 이해하는 데 사용되는 매개변수 모델입니다.
마스터 방정식: 문제 공식화
이 논문이 다루는 핵심 문제는 총 계산 예산 $K$에 대한 제약 조건 하에서 파인튜닝된 모델의 성능을 최대화하는 대규모 데이터셋 $D$에서 최적의 데이터 포인트 하위 집합 $S^*$을 찾는 것으로 공식화됩니다.
$$S^* = \arg \max_{S \subset D} P(V; \mathcal{T}(S))$$
$$\text{subject to } C_T(S) + \sum_{x \in D} C_U(x) \le K$$
방정식을 분해해 봅시다:
- $S^*$:
1) 수학적 정의: 최적의 데이터 포인트 하위 집합을 나타냅니다.
2) 물리적/논리적 역할: 이는 전체 프로세스의 궁극적인 목표입니다. 즉, 계산 제약 조건 하에서 최상의 모델 성능을 산출할 때 사용될 훈련 예제의 특정 컬렉션입니다. 이것은 데이터 선택 문제에 대한 "답"입니다.
3) 왜 $\arg \max$인가: 우리는 단순히 최대 성능 값 자체에 관심이 있는 것이 아니라, 해당 최대 성능을 달성하는 어떤 하위 집합 $S$에 관심이 있습니다. "Arg max"는 "표현식을 최대화하는 인수(이 경우 $S$)"를 의미합니다. - $P(V; \mathcal{T}(S))$:
1) 수학적 정의: 이는 하위 집합 $S$의 데이터로 훈련(파인튜닝)된 모델 $\mathcal{T}(S)$의 성능 지표이며, 검증 세트 $V$에서 평가됩니다.
2) 물리적/논리적 역할: 이 항은 파인튜닝된 모델의 품질 또는 효과성을 나타냅니다. 이는 우리가 최대화하고자 하는 목표입니다. 값이 높을수록 더 나은 모델을 의미합니다. 검증 세트 $V$는 선택 프로세스 중에 성능을 추정할 수 있도록 실제 보이지 않는 테스트 데이터의 대리자 역할을 합니다. - $S \subset D$:
1) 수학적 정의: $S$가 원래의 대규모 훈련 데이터셋 $D$의 하위 집합이어야 함을 나타냅니다.
2) 물리적/논리적 역할: 검색 공간을 정의합니다. 우리는 새로운 데이터를 만드는 것이 아니라 사용 가능한 풀 $D$에서 데이터 포인트를 선택합니다. 데이터 선택의 핵심 아이디어는 데이터 양을 줄이는 것이므로 $S$는 일반적으로 $D$보다 훨씬 작습니다. - $C_T(S)$:
1) 수학적 정의: 선택된 데이터 하위 집합 $S$로 모델 $\mathcal{T}$를 훈련하는 데 필요한 계산 비용(FLOPs 단위)입니다.
2) 물리적/논리적 역할: 이는 총 계산 예산의 "훈련 비용" 구성 요소입니다. 선택한 데이터를 사용하여 모델을 실제로 가르치는 데 소비되는 계산입니다. 이 비용은 일반적으로 $S$의 크기와 모델의 복잡성에 따라 증가합니다.
3) 왜 덧셈인가: 두 활동 모두 동일한 전체 계산 예산에서 리소스를 소비하기 때문에 이 비용은 데이터 선택 비용에 추가됩니다. 둘 다 단일 지출의 두 부분입니다. - $\sum_{x \in D} C_U(x)$:
1) 수학적 정의: 전체 원본 데이터셋 $D$의 모든 데이터 포인트 $x$의 유용성(또는 "점수")을 계산하는 계산 비용 $C_U(x)$의 합입니다.
2) 물리적/논리적 역할: 이는 "데이터 선택 비용" 오버헤드를 나타냅니다. 많은 데이터 선택 방법의 경우, 어떤 데이터 포인트가 가장 가치 있는지 결정하기 위해 먼저 모든 잠재적 데이터 포인트를 평가해야 합니다. 이 합계는 실제로 선택되는 포인트 수에 관계없이 선택을 수행하는 데 필요한 고정 계산 투자입니다. 이것은 최고의 데이터를 "쇼핑"하는 비용입니다.
3) 왜 합계인가: 유용성 비용은 각 개별 데이터 포인트에 대해 계산되며, 이러한 개별 비용은 유틸리티 계산 단계에 대한 총 비용을 얻기 위해 합산됩니다. 저자들은 $D$의 모든 포인트를 점수 매겨 최고의 $K$를 선택하는 탐욕적 접근 방식에서 합계를 사용합니다. - $K$:
1) 수학적 정의: 데이터 선택과 모델 훈련 모두에 사용할 수 있는 총 최대 계산 예산(FLOPs 단위)입니다.
2) 물리적/논리적 역할: 이것은 엄격한 리소스 제약입니다. 초과할 수 없는 "은행 계좌 잔고"입니다. 전체 문제는 이 예산 내에서 성능을 최대화하는 데 중점을 둡니다.
3) 왜 $\le$인가: 사용된 총 계산량은 할당된 예산보다 작거나 같아야 합니다. 우리가 가진 것보다 더 많은 계산을 소비할 수 없습니다.
마스터 방정식: 분석을 위한 성능 모델
계산과 성능 간의 절충점을 분석하고 이해하기 위해 이 논문은 $k$개의 데이터 포인트로 훈련한 후의 예상 성능 $P(k)$에 대한 매개변수 모델을 도입합니다. 이 모델은 경험적 데이터를 맞추고 결과를 외삽하는 데 사용됩니다.
$$P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0$$
방정식을 분해해 봅시다 (성능 모델의 경우):
- $P(k)$:
1) 수학적 정의: $k$개의 선택된 데이터 포인트로 훈련한 후 모델의 예상 성능입니다.
2) 물리적/논리적 역할: 이것은 예측된 성능 값입니다. 우리의 모델 출력이며, 특정 양의 계산과 선택된 데이터가 주어졌을 때 LLM이 얼마나 잘 수행될 것으로 예상되는지를 알려줍니다. 이것이 성능 그래프의 y축에 플롯되는 것입니다. - $P$:
1) 수학적 정의: 성능의 상한입니다.
2) 물리적/논리적 역할: 전체 데이터셋 $D$로 훈련하더라도 모델이 달성할 수 있는 최대 성능을 나타냅니다. 이것은 모델이 점근적으로 접근하는 "천장" 또는 "이상적인" 성능입니다. - $P_0$:
1) 수학적 정의: 제로샷 성능입니다.
2) 물리적/논리적 역할: 이것은 파인튜닝 전 모델의 기준 성능입니다. 모든 성능 향상이 측정되는 시작점입니다. - $(P - P_0)$:
1) 수학적 정의: 총 잠재적 성능 향상입니다.
2) 물리적/논리적 역할: 이 항은 지수 성장을 조정합니다. 기준 $P_0$에서 천장 $P$까지 얻을 수 있는 최대 가능한 개선을 나타냅니다. - $\times$:
1) 수학적 정의: 곱셈입니다.
2) 물리적/논리적 역할: 이 연산자는 지수 항의 분수 이득을 총 잠재적 성능 개선으로 스케일링합니다.
3) 왜 곱셈인가: 지수 항은 달성된 총 잠재적 이득의 분수를 계산합니다. 이를 $(P - P_0)$로 곱하면 이 분수가 절대 성능 이득으로 변환됩니다. - $1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)$:
1) 수학적 정의: 0에서 시작하여 1에 접근하는 지수 성장 함수입니다.
2) 물리적/논리적 역할: 이것은 핵심 "학습 곡선" 구성 요소입니다. 수확 체감을 모델링합니다. 적은 계산량으로 이 항은 빠르게 증가하여 상당한 성능 향상을 나타냅니다. 계산량이 증가함에 따라 성장이 느려져 각 추가 계산 단위가 얻는 추가 성능이 점점 줄어드는 것을 반영합니다. 지수 함수는 이러한 포화 동작을 모델링하는 데 자연스러운 선택입니다.
3) 왜 지수 함수인가: 지수 함수는 입력이 증가함에 따라 변화율이 감소하는 수확 체감을 보이거나 포화되는 프로세스를 모델링하는 데 탁월합니다. - $\exp(\cdot)$:
1) 수학적 정의: 지수 함수 $e^x$입니다.
2) 물리적/논리적 역할: 수확 체감 곡선을 만드는 데 사용됩니다. - $-$ ( $1 - \exp$ 안에서):
1) 수학적 정의: 뺄셈입니다.
2) 물리적/논리적 역할: $\exp(-x)$ 항은 1에서 시작하여 0으로 감소합니다. 이를 1에서 빼면 0에서 시작하여 1에 접근하는 함수 $1 - \exp(-x)$가 생성되며, 이는 달성된 이득의 분수를 나타내는 데 적합합니다. - $\lambda$:
1) 수학적 정의: 양수 스칼라 매개변수입니다.
2) 물리적/논리적 역할: 이것은 "효율성" 매개변수입니다. 특정 데이터 선택 방법(및 관련 훈련)이 계산을 성능 향상으로 얼마나 효과적으로 전환하는지를 결정합니다. $\lambda$가 클수록 해당 방법은 더 효율적이어서 동일한 양의 계산으로 더 높은 성능을 달성하며, 학습 곡선을 더 가파르게 만듭니다.
3) 왜 곱셈인가: $\lambda$는 효과적인 계산량을 직접 스케일링하여 해당 방법이 계산 투자에 대해 더 민감하거나 덜 민감하게 만듭니다. - $C(k)$:
1) 수학적 정의: $k$개의 데이터 포인트를 선택하고 훈련하는 총 계산 비용입니다. 이는 $c \times k + \sum_{x \in D} C_U(x)$로 계산되며, 여기서 $c$는 훈련당 데이터 포인트 비용입니다.
2) 물리적/논리적 역할: 이것은 특정 전략에 대한 총 계산 투자입니다. 데이터 선택 비용과 훈련 비용을 결합합니다. 이는 전략에 대한 "입력"이며 총 투자량을 나타냅니다.
3) 왜 나누기인가: 이는 전체 훈련 비용에 대한 비율로 $C(k)$를 정규화하는 데 사용됩니다. - $C(|\mathcal{D}|)$:
1) 수학적 정의: 데이터 선택 없이 전체 데이터셋 $D$로 훈련하는 총 계산 비용입니다.
2) 물리적/논리적 역할: 이것은 $C(k)$에 대한 정규화 계수 역할을 합니다. $C(k)$를 "아무것도 하지 않는 것"(즉, 선택 없이 모든 사용 가능한 데이터로 훈련하는 것)의 비용과 비교하여 맥락에 맞게 배치합니다.
3) 왜 나누기인가: $C(k)$를 무차원 비율로 정규화하여 지수 항을 더 일반적이고 전체 가능한 계산의 분수로 해석 가능하게 만듭니다. - $+$ ( $\exp$ 외부):
1) 수학적 정의: 덧셈입니다.
2) 물리적/논리적 역할: 이 연산자는 전체 성능 곡선을 제로샷 성능 $P_0$만큼 위로 이동시킵니다. 이를 통해 효과적인 계산이 사용되지 않거나 ($k=0$) 예측된 성능이 기준 $P_0$에서 시작하도록 보장합니다.
3) 왜 덧셈인가: 지수 항은 $P_0$ 이상의 이득을 계산합니다. 절대 성능을 얻으려면 이 이득을 기준 $P_0$에 더합니다.
단계별 흐름: 추상적인 데이터 포인트 추적 (성능 모델을 통해)
특정 데이터 선택 전략을 평가하고 성능을 예측한다고 가정해 보겠습니다. 이것은 LLM을 통과하는 단일 데이터 포인트에 관한 것이 아니라, 전략과 관련된 총 계산량이 매개변수 모델을 사용하여 성능 예측으로 어떻게 변환되는지에 관한 것입니다.
- 전략 정의: 특정 데이터 선택 방법(예: "Perplexity-Based")을 선택하고 파인튜닝을 위해 선택하려는 목표 데이터 포인트 수($k$)를 결정하는 것으로 시작합니다.
- 데이터 선택 오버헤드 계산: 선택한 데이터 선택 방법은 먼저 원래의 대규모 데이터셋 $D$의 모든 데이터 포인트에 대한 "유용성 점수"를 계산해야 합니다. 여기에는 고정된 계산 비용 $\sum_{x \in D} C_U(x)$가 포함되며, 이는 이 방법을 사용하는 초기 "설정 수수료"와 같습니다.
- 훈련 비용 결정: $D$의 모든 포인트를 점수 매긴 후 상위 $k$개의 포인트로 선택된 $k$개의 데이터 포인트에 따라 LLM을 훈련하는 비용을 계산합니다. 이는 데이터 포인트당 비용 $c$에 $k$를 곱한 값입니다.
- 총 계산량 집계 ($C(k)$): 이 두 가지 비용을 합산합니다: $C(k) = (c \times k) + \sum_{x \in D} C_U(x)$. 이 $C(k)$는 이 특정 전략(이 방법을 사용하여 $k$개의 포인트를 선택하고 훈련하는 것)에 대한 총 계산 투자입니다.
- 계산 투자 정규화: 이 총 계산량 $C(k)$는 참조 비용 $C(|\mathcal{D}|)$로 나뉩니다. $C(|\mathcal{D}|)$는 선택 없이 전체 원본 데이터셋 $D$로 훈련하는 비용입니다. 이렇게 하면 계산량의 상대적인 비율이 제공되며, 이는 "전체" 훈련 실행과 비교하여 얼마나 많은 계산을 지출하는지를 나타냅니다.
- 방법 효율성 적용 ($\lambda$): 정규화된 계산 비율은 선택한 데이터 선택 방법에 고유한 매개변수인 $\lambda$를 곱합니다. 이 $\lambda$는 이 특정 방법이 계산에서 성능 향상으로 얼마나 효율적으로 전환되는지를 반영하는 "부스터" 또는 "감쇠기" 역할을 합니다. 높은 $\lambda$를 가진 방법은 계산에서 더 많은 "가성비"를 얻습니다.
- 성능 향상 계수 계산: 단계 6의 결과는 지수 항에 적용됩니다: $1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)$. 이 함수는 0에서 시작하여 위로 곡선을 그리며 점차 1에 접근합니다. 이는 수확 체감의 아이디어를 수학적으로 포착합니다. 초기에는 계산량의 작은 증가가 이 계수의 큰 점프를 유발하지만, 계산량이 증가함에 따라 계수의 증가가 느려집니다.
- 잠재적 개선으로 스케일링: 이 이득 계수는 총 잠재적 성능 개선 $(P - P_0)$을 곱합니다. 이렇게 하면 추상적인 이득 계수가 기준선 이상의 구체적인 성능 포인트 양으로 변환됩니다.
- 기준 성능 추가: 마지막으로 제로샷 성능 $P_0$(파인튜닝 전 모델의 성능)를 계산된 이득에 더합니다. 이렇게 하면 선택한 전략에 대한 최종 예측 절대 성능 $P(k)$가 얻어집니다.
이 전체 프로세스는 다양한 데이터 선택 방법과 다양한 수의 선택된 데이터 포인트($k$)에 대해 반복되어 일련의 성능 곡선을 생성합니다. 이러한 곡선을 비교함으로써 저자들은 다양한 총 계산 예산에 대해 어떤 방법이 "계산 최적"인지 식별할 수 있습니다.
최적화 동역학: 메커니즘이 학습, 업데이트 또는 수렴하는 방법
이 논문은 LLM 자체의 반복적인 학습 프로세스(가중치를 업데이트하기 위한 경사 하강법과 같은)를 설명하지 않습니다. 대신, 두 가지 수준의 "최적화"에 초점을 맞춥니다.
-
성능 지형 학습 (매개변수 피팅): 논문에서 설명하는 주요 "학습" 메커니즘은 경험적 데이터에 매개변수 성능 모델(방정식 3)의 매개변수($P_0, P, \lambda$)를 피팅하는 프로세스입니다.
- 손실 지형: 이 피팅 프로세스의 경우, "손실 지형"은 모델이 예측한 성능 $P(k_i; P_0, P, \lambda)$과 실험에서 관찰된 실제 성능 $P_{obs,i}$ 간의 제곱 오차 합으로 정의됩니다. 목표는 이 합을 최소화하는 $P_0, P, \lambda$를 찾는 것입니다.
- 기울기 및 상태 업데이트: 저자들은 이 비선형 최소 제곱 문제를 해결하기 위해 Levenberg-Marquardt 알고리즘을 사용합니다. 이 알고리즘은 기울기 정보(각 매개변수 변경에 대한 오류의 민감도)와 헤세 행렬의 근사치(오류 지형의 곡률을 포착함)를 모두 사용하여 매개변수($P_0, P, \lambda$)를 반복적으로 업데이트합니다. 이는 효과적으로 이 지형을 탐색하며 "가장 가파른 하강" 방향(또는 더 정교한 경로)을 따라 최저점(최소 오류)을 찾습니다.
- 수렴: 알고리즘은 제약 조건(예: $P_0 \ge 0$, $P_0 \le P$, $\lambda \ge 0$) 하에서 오류를 최소화하는 매개변수를 찾으면 수렴합니다. 이렇게 하면 각 데이터 선택 방법에 대한 계산-성능 관계를 가장 잘 설명하는 $P_0, P, \lambda$의 "피팅된 값"이 얻어집니다.
-
계산 최적 전략 찾기 (비교 분석): 각 데이터 선택 방법에 대한 매개변수 모델이 피팅되면, 원래 문제(방정식 2)에 대한 "최적화"는 단일 반복 알고리즘이 아니라 비교 분석을 통해 달성됩니다.
- 손실 지형 (암시적): 주어진 총 계산 예산 $K$에 대해 "최적" 전략은 가장 높은 성능 $P(k)$를 산출하는 전략입니다. 피팅된 매개변수 곡선은 다양한 계산 예산 범위에 걸쳐 각 방법으로 달성 가능한 성능을 효과적으로 매핑합니다.
- 상태 업데이트 (의사 결정): 실무자는 이러한 피팅된 곡선(그림 1 또는 그림 3과 같은)을 검토합니다. x축의 특정 계산 예산에 대해 각 방법에 대한 해당 성능을 조회합니다. 해당 예산에서 곡선이 가장 높은 방법이 계산 최적 선택입니다. 이것은 LLM 자체를 반복적으로 업데이트하는 것이 아니라 학습된 모델을 기반으로 한 의사 결정 프로세스입니다.
- 파레토 최전선: 논문은 "파레토 최전선"을 식별합니다. 이는 비지배적인 모든 솔리션 집합을 나타냅니다. 솔루션은 성능을 향상시키지 않고 계산량을 늘릴 수 없거나 성능을 희생하지 않고 계산량을 줄일 수 없는 경우 파레토 최전선에 있습니다. 목표는 이 최전선에서 작동하는 것입니다.
본질적으로 이 논문은 경험적 데이터에 수학적 모델을 피팅함으로써 계산 제약 조건 하에서 다양한 데이터 선택 방법의 동작을 "학습"합니다. 이 모델은 반복적인 방식으로 LLM의 가중치나 데이터 선택 프로세스 자체를 직접 최적화하는 대신 분석, 외삽 및 정보에 입각한 의사 결정을 가능하게 합니다. 이 분석에서 얻은 통찰력, 예를 들어 퍼플렉시티 및 기울기 방법에 필요한 훈련 대 선택 모델 크기 비율은 우리의 이해에 대한 주요 "업데이트"입니다.
결과, 한계점 및 결론
컴퓨팅 제약 조건 하에서의 데이터 선택: 효율성 극대화
이 흥미로운 "컴퓨팅 제약 조건 하에서의 데이터 선택" 논문에 대해 자세히 살펴보겠습니다. 메타 과학자로서 저의 목표는 복잡한 아이디어를 쉽게 이해할 수 있는 통찰력으로 분해하여, 이 분야에 완전히 처음 접하는 사람이라도 핵심 개념과 그 함의를 파악할 수 있도록 하는 것입니다.
초심자를 위한 배경 지식
대규모 언어 모델(LLM)이라 불리는 매우 똑똑한 로봇 두뇌가 있다고 상상해 보세요. 이 두뇌는 이야기를 쓰고, 질문에 답하고, 심지어 코딩까지 할 수 있습니다. 이 로봇 두뇌를 고양이 시 쓰기와 같은 특정 작업에 더욱 뛰어나게 만들려면, 많은 고양이 시 예시를 보여주어야 합니다. 이 과정을 파인튜닝(finetuning)이라고 합니다.
이제 이러한 LLM은 매우 거대하며 이를 훈련하는 것은 전기(컴퓨팅)와 시간 모두에서 엄청나게 비용이 많이 듭니다. 며칠 또는 몇 주 동안 거대한 슈퍼컴퓨터를 실행하는 것과 같다고 생각하면 됩니다. 종종 조직은 FLOPs(초당 부동 소수점 연산)로 측정되는 고정된 예산을 가지고 있습니다. 이는 컴퓨터가 수행할 수 있는 계산 횟수를 나타내는 멋진 표현입니다. 슈퍼컴퓨터 시간에 사용할 수 있는 고정된 금액을 가지고 있는 것과 같습니다.
데이터 선택의 전통적인 아이디어는 현명합니다. LLM에게 가능한 모든 고양이 시를 보여주는 대신(나쁘거나 관련 없는 시가 많이 포함될 수 있음), 최고의 그리고 가장 유익한 시만 선택하는 것은 어떨까요? 이렇게 하면 LLM은 더 빠르고 더 잘 학습할 수 있으며, 더 작고 고품질의 데이터셋을 사용하므로 훈련 비용을 절약할 수 있습니다. 목표는 더 큰 컬렉션 $\mathcal{D}$에서 LLM의 목표 작업 성능을 최대화하는 작은 데이터 하위 집합 $S$를 찾는 것입니다. 수학적으로 이는 종종 다음과 같이 표현됩니다.
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(T; \mathcal{T}(S)) \quad \text{subject to} \quad |S| \le K $$
여기서 $P(T; \mathcal{T}(S))$는 데이터 $S$로 훈련된 모델 $\mathcal{T}$의 테스트 세트 $T$에서의 성능을 나타냅니다. 제약 조건 $|S| \le K$는 최대 $K$개의 데이터 포인트를 선택할 수 있음을 의미합니다. 이를 위해 데이터 선택 방법은 일반적으로 각 데이터 포인트에 "유용성 점수"를 할당하여 얼마나 가치 있는지 나타낸 다음, 최고 점수를 받은 항목을 선택합니다.
문제의 동기
여기서 이 논문은 중요한 전환점을 제시합니다. 데이터 선택은 훈련 비용을 줄이지만, 데이터를 선택하는 행위 자체는 무료가 아닙니다! "최고의" 고양이 시를 선택하는 일부 방법은 "cat"이라는 단어가 나타나는 횟수를 세는 것과 같이 매우 간단하고 저렴합니다. 다른 방법들은 매우 정교합니다. 예를 들어, 또 다른 더 작은 LLM이 모든 시를 읽고 품질을 평가하거나, 해당 시로부터 학습할 경우 모델의 내부 매개변수가 어떻게 변경될지를 분석하는 복잡한 수학적 "기울기(gradients)"를 분석하는 것입니다. 이러한 정교한 방법은 종종 고품질 데이터를 찾는 데 매우 뛰어나지만, 상당한 컴퓨팅 비용이 발생합니다.
문제는 이전 연구들이 종종 선택된 데이터로 모델이 얼마나 더 잘 수행되는지, 또는 훈련 컴퓨팅이 얼마나 절약되는지에 초점을 맞추었지만, 선택 과정 자체의 비용을 완전히 고려하지 않았다는 것입니다. 데이터 선택 방법이 너무 비싸서 훈련에서 제공하는 이점보다 비용이 더 크다면, 고정된 예산 제약 관점에서 실제로 "최적"이라고 할 수 없습니다.
이 논문의 동기는 이러한 간과를 해결하는 것입니다. 그들은 데이터 선택 비용과 선택된 데이터로 모델을 훈련하는 비용, 즉 총 컴퓨팅 비용을 이해하여 고정된 실제 컴퓨팅 예산 하에서 어떤 데이터 선택 방법이 진정으로 가장 효율적인지 결정하고자 합니다. 그들은 이것이 방법 개발에서 "과소평가"된 실질적인 채택을 위한 중요한 요소라고 주장합니다.
극복해야 했던 제약 조건
저자들은 이 문제를 해결하는 데 있어 여러 제약 조건과 과제에 직면했습니다.
- 고정된 총 컴퓨팅 예산: 주요 제약 조건은 전체 파인튜닝 프로세스(선택 + 훈련)에 대한 총 계산 예산(예: FLOPs)이 미리 결정되어 있다는 것입니다. 이는 절충이 있음을 의미합니다. 데이터 선택에 더 많이 지출하면 훈련에 사용할 예산이 줄어들거나 그 반대가 될 수 있습니다.
- 다양한 데이터 선택 방법의 비용: 서로 다른 데이터 선택 방법은 계산 비용이 매우 다릅니다. 간단한 방법(예: 키워드 일치)은 저렴하지만, 복잡한 방법(예: 기울기 기반 선택)은 매우 비싸며 종종 LLM을 통한 순방향 및 역방향 통과가 필요합니다.
- 수확 체감: 더 많은 데이터 포인트를 추가하거나(또는 선택에 더 많은 컴퓨팅을 지출하는) 가치는 일반적으로 감소합니다. 어떤 시점에서는 모델이 더 많은 데이터나 컴퓨팅을 투입하더라도 크게 개선되지 않을 것입니다. 이러한 "포화" 효과는 모델링되어야 합니다.
- 확장성: LLM은 다양한 크기(수십억에서 수백억 개의 매개변수)로 제공되며, 최적의 전략은 모델의 규모에 따라 달라질 수 있습니다. 실험은 광범위한 범위를 포함해야 했습니다.
- 일반화 가능성: 결과는 이상적으로 단일 특정 시나리오가 아닌 다양한 작업과 LLM 아키텍처에 적용되어야 합니다.
이를 극복하기 위해 저자들은 다음과 같은 조치를 취했습니다.
- 문제 재정의: 데이터 선택 비용을 최적화 목표에 명시적으로 통합하여, 제약 조건을 단순히 데이터 크기가 아닌 총 컴퓨팅으로 전환했습니다.
- 비용 분류 및 정량화: 데이터 선택 방법을 네 가지 범주(어휘 기반, 임베딩 기반, 복잡도 기반, 기울기 기반)로 체계적으로 분류하고 FLOPs 단위의 계산 비용을 세심하게 계산했습니다(표 1 및 부록 B 참조).
- 매개변수 모델 개발: 성능의 수확 체감 효과를 총 컴퓨팅의 함수로 포착하는 수학적 모델(방정식 3)을 개발하여 경험적 데이터를 맞추고 외삽할 수 있도록 했습니다.
- 대규모 실험 수행: 600개 이상의 실험을 다양한 LLM 크기(7B ~ 70B 매개변수), 6가지 데이터 선택 방법, 3가지 다운스트림 작업에 걸쳐 수행하여 광범위한 적용 범위와 강력한 경험적 증거를 확보했습니다.
수학적 해석: 문제 해결 및 방법
저자들은 데이터 선택 문제를 근본적으로 재구성했습니다.
그들이 해결한 문제:
데이터 예산(데이터 포인트 수)에 대한 성능을 최대화하는 대신, 총 컴퓨팅 예산에 대한 성능을 최대화하는 것을 목표로 했습니다. 그들의 새로운 목표 함수는 다음과 같습니다.
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(V; \mathcal{T}(S)) \quad \text{subject to} \quad C_T(S) + \sum_{x \in \mathcal{D}} C_U(x) \le K $$
이를 자세히 살펴보겠습니다.
* $S^*$: 선택할 최적의 데이터 하위 집합입니다.
* $P(V; \mathcal{T}(S))$: 선택된 하위 집합 $S$로 훈련된 모델 $\mathcal{T}$의 검증 세트 $V$에서의 성능입니다. 그들은 $T$가 선택 중에 사용 가능하지 않을 때 일반적인 관행인 $V$를 테스트 세트 $T$의 대리자로 사용합니다.
* $C_T(S)$: 선택된 데이터 하위 집합 $S$로 LLM을 훈련하는 계산 비용입니다. 이 비용은 $S$의 크기와 LLM의 아키텍처에 따라 달라집니다.
* $\sum_{x \in \mathcal{D}} C_U(x)$: 원래의 대규모 데이터셋 $\mathcal{D}$의 모든 데이터 포인트 $x$에 대한 유용성 점수 계산의 총 계산 비용입니다. 이 비용은 선택하기 전에 발생합니다. 어떤 것을 선택할지 결정하기 위해 모든 점수를 평가해야 하기 때문입니다.
* $K$: 선택 및 훈련을 모두 포함하는 FLOPs 단위의 총 컴퓨팅 예산입니다.
이 공식은 핵심적인 절충점을 강조합니다. 더 비싼 데이터 선택 방법(높은 $\sum C_U(x)$)은 훈련을 위한 예산을 더 적게 남겨두고($C_T(S)$), 이는 더 작은 모델로 훈련하거나 더 적은 단계로 훈련하도록 강제하여 최종 성능을 저하시킬 수 있습니다.
해결 방법:
-
매개변수 성능 모델: 이 절충점을 체계적으로 분석하기 위해 총 컴퓨팅 비용 $C(k)$의 함수로서 예상 성능 $P(k)$에 대한 매개변수 모델을 제안했습니다.
$$ P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0 $$
- $P_0$: "제로샷" 성능, 즉 파인튜닝 없이(또는 0개의 데이터 포인트로 훈련) 모델의 성능입니다.
- $P$: 무한한 컴퓨팅을 사용하더라도 모델이 달성할 수 있는 최대 성능을 나타내는 성능의 상한선입니다.
- $\lambda$: 데이터 선택 방법이 추가 컴퓨팅에서 가치를 얼마나 효율적으로 추출하는지를 제어하는 중요한 매개변수입니다. $\lambda$가 높을수록 해당 방법은 더 효율적입니다.
- $C(k)$: $k$개의 데이터 포인트를 선택하고 훈련하는 데 드는 총 컴퓨팅 비용입니다.
- $C(|\mathcal{D}|)$: 전체 데이터셋 $\mathcal{D}$로 훈련하는 데 드는 총 컴퓨팅 비용입니다(선택 없음).
이 모델은 성능이 컴퓨팅과 함께 개선되지만 수확 체감하며 결국 $P$ 근처에서 평탄화된다는 아이디어를 포착합니다.
-
경험적 검증 및 적합: 그들은 이론만 세운 것이 아니라 대규모 실험을 수행했습니다. 모델 크기, 데이터 선택 방법, 사용된 데이터 비율의 각 조합에 대해 실제 성능과 소비된 총 FLOPs를 측정했습니다. 그런 다음 이 경험적 데이터를 사용하여 Levenberg-Marquardt 알고리즘(비선형 최소 제곱법)을 사용하여 매개변수($P_0, P, \lambda$)를 "맞추었습니다". 이를 통해 각 데이터 선택 방법의 효율성($\lambda$)을 정량화할 수 있었습니다.
-
파레토 최적 전선 분석: 모든 실험 실행에 대해 성능을 총 FLOPs에 대해 플로팅함으로써, 그들은 "컴퓨팅 최적 파레토 최적 전선"을 식별했습니다. 이 최적 전선은 주어진 총 컴퓨팅 예산에 대해 가능한 가장 높은 성능을 달성하는 전략(데이터 선택 방법 + 데이터 비율)의 집합을 나타냅니다. 이 최적 전선 아래의 모든 지점은 최적이 아닙니다.
-
외삽: 맞춤형 매개변수 모델을 사용하여, 특히 훈련 모델에 대한 선택의 상대적 비용이 작아지는 매우 큰 훈련 모델의 경우, 더 비싼 방법(예: PPL 및 LESS)이 언제 컴퓨팅 최적이 될지 예측할 수 있었습니다.
실험 아키텍처, 기준선 및 결정적 증거
저자들은 컴퓨팅 제약 조건 하에서의 데이터 선택에 대한 수학적 주장을 무자비하게 증명하기 위해 실험을 설계했습니다.
실험 아키텍처:
- 포괄적인 스윕: 여러 차원에 걸쳐 "포괄적인 실험 스윕"을 수행했습니다.
- 모델 크기: LLAMA2 모델(7B, 13B, 70B 매개변수) 및 LLAMA3 8B. 이를 통해 확장 효과를 연구할 수 있었습니다.
- 데이터 선택 방법:
- 무작위(Random): 간단한 기준선으로 데이터를 무작위로 선택합니다.
- BM25 (어휘 기반): 용어 빈도에 기반한 저렴한 통계 방법입니다.
- Embed (임베딩 기반): 작은 T5 기반 밀집 임베딩 모델을 사용하여 유사한 데이터를 찾습니다.
- PPL (복잡도 기반): LLM을 사용하여 각 데이터 포인트의 복잡도(모델 손실)를 계산합니다.
- LESS (기울기 기반): 가장 정교하며, 기울기를 사용하여 모델 손실에 대한 영향력을 추정합니다.
- 훈련 데이터 예산: 총 데이터의 2.5%에서 100%까지 파인튜닝 토큰 비율을 변경했습니다.
- 대상 작업: MMLU(사실 지식), BBH(복잡한 추론), IF Eval(지시 따르기). 이는 다양한 LLM 기능에 걸쳐 일반화 가능성을 보장했습니다.
- 파인튜닝 설정: 메모리 사용량을 줄이기 위해 LoRA(매개변수 효율적인 파인튜닝 방법)를 사용했으며, AdamW 옵티마이저, BFloat16 정밀도, 특정 학습률을 표준 관행에 따라 사용했습니다. 70B 모델에는 메모리 관리를 위해 QLoRA를 사용했습니다.
- FLOPs 추적: 결정적으로, 모든 개별 실행에 대해 데이터 선택 FLOPs와 훈련 FLOPs를 모두 포함하는 총 FLOPs를 세심하게 계산했습니다. 이것이 컴퓨팅 제약 조건 분석의 핵심이었습니다.
- 파레토 최적 전선 식별: 각 모델 크기와 작업에 대해 데이터 선택 방법과 데이터 비율의 모든 조합에 대한 성능(예: MMLU 정확도)을 총 컴퓨팅(FLOPs)에 대해 플로팅했습니다. 그런 다음 "파레토 최적 전선"을 식별했습니다. 이는 주어진 컴퓨팅 예산에 대해 최상의 성능을 제공하는 지점들을 연결하는 곡선입니다.
그들이 이긴 "희생자들"(기준선 모델/방법):
여기서 "희생자들"은 반드시 그들이 이긴 모델을 의미하는 것이 아니라, 총 컴퓨팅 예산 하에서 최적이 아닌 가정과 방법을 의미합니다.
- "더 정교한 것이 항상 더 낫다"는 가정: 많은 연구자들은 기울기 기반과 같은 더 복잡한 데이터 선택 방법이 항상 더 나은 결과를 낳을 것이라고 가정할 수 있습니다. 이 논문은 컴퓨팅이 제약될 때 이러한 가정을 무자비하게 도전합니다.
- 작은/중간 예산 하에서의 정교한 데이터 선택 방법(PPL 및 LESS): 작고 중간 규모의 컴퓨팅 예산(예: 7B 및 13B LLM 사용)의 경우, 이 논문은 PPL과 LESS가 종종 "희생자들"이라고 보여줍니다. 그들은 더 높은 품질의 데이터를 선택하지만, 선택에 대한 높은 계산 비용은 총 예산의 너무 많은 부분을 소비하여 훈련에 사용할 예산이 줄어듭니다. 이로 인해 단순한 방법보다 컴퓨팅 효율성이 떨어집니다.
- 무작위 데이터 선택: 무작위 선택은 기준선이지만, 종종 더 저렴한 방법보다 성능이 떨어지므로 어떤 형태의 선택이든 전혀 선택하지 않는 것보다 거의 항상 낫다는 것을 보여줍니다.
핵심 메커니즘이 실제로 작동했다는 결정적이고 부인할 수 없는 증거:
가장 결정적인 증거는 그림 2의 경험적 파레토 최적 전선과 그림 9 및 10의 외삽 결과에서 나옵니다.
-
그림 2 (경험적 파레토 최적 전선):
- 7B 및 13B 모델(작고 중간 규모의 컴퓨팅 예산)의 경우: 패널(A, B, D, E)은 BM25(어휘 기반) 및 Embed(임베딩 기반) 방법이 일관되게 컴퓨팅 최적 파레토 최적 전선에 있거나 매우 가깝다는 것을 명확하게 보여줍니다. 많은 경우, 그들은 단순한 방법보다 PPL 및 LESS보다 더 나은 성능을 보입니다. 이것은 부인할 수 없는 증거입니다. 예를 들어, 7B MMLU에 대한 그림 2(A)에서 BM25와 Embed는 PPL 및 LESS보다 넓은 범위의 컴퓨팅에서 동일한 FLOPs 예산으로 더 높은 정확도를 달성합니다. 이는 PPL과 LESS가 "더 나은" 데이터를 선택하더라도, 선택 비용이 높기 때문에 총 컴퓨팅이 제한될 때 전반적으로 덜 효율적임을 증명합니다.
- 고정 훈련 예산과의 대조 (그림 5a): 이 논문은 그림 5(a)에서 중요한 반례를 제공합니다. 훈련 예산만 고려하고(선택 비용 무시) PPL 및 LESS를 포함한 모든 다른 방법보다 일관되게 더 나은 성능을 보입니다. 그림 5(a)와 그림 2의 이러한 극명한 대조는 결정적인 증거입니다. 총 컴퓨팅 예산(선택 + 훈련)을 고려하는 것이 데이터 선택 전략의 최적성에 대한 결론을 근본적으로 바꾼다는 것을 명확히 보여줍니다. 논문의 핵심 메커니즘인 컴퓨팅 제약 조건 목표는 방법 효율성에 대한 다른 결론으로 직접 이어집니다.
-
외삽 결과 (그림 9 및 10): 이 그림들은 "티핑 포인트"에 대한 정량적 증거를 제공합니다. PPL과 LESS가 컴퓨팅 최적이 되지만, 훈련 모델이 데이터 선택에 사용된 모델보다 훨씬 클 때만 된다는 것을 보여줍니다. 구체적으로, PPL은 훈련 모델이 선택 모델보다 5배 클 때(약 35B 매개변수), LESS는 10배 클 때(약 70B 매개변수) 필요합니다. 경험적 데이터에 맞춰진 매개변수 모델에서 파생된 이 수학적으로 정확한 결과는 이러한 더 비싼 방법이 언제 실행 가능한지에 대한 조건에 대한 부인할 수 없는 증거를 제공합니다. 그것들은 결코 작동하지 않는다는 것이 아니라, 훈련 모델의 특정 규모 요구 사항을 결정하는 컴퓨팅 비용이 있다는 것입니다.
본질적으로 저자들은 컴퓨팅 비용이 중요하다는 주장만 한 것이 아니라, 그것을 세심하게 측정하고, 그 영향을 모델링했으며, 특히 더 작은 LLM의 경우 더 저렴한 방법이 컴퓨팅 효율성 경쟁에서 종종 승리한다는 것을 경험적으로 입증했습니다. 증거는 곡선과 정량화된 비율에 있습니다.
향후 개발 및 진화를 위한 토론 주제
이 논문은 풍부한 연구의 장을 열었습니다. 다음은 추가적인 비판적 사고를 자극하기 위한 다양한 관점에서 제시된 토론 주제입니다.
-
동적 및 적응형 데이터 선택 전략:
- 현재 한계: 논문은 고정된 데이터 선택 방법을 평가합니다.
- 향후 방향: 현재 컴퓨팅 예산, 대상 LLM 크기 및 관찰된 성능에 따라 데이터 선택 방법을 동적으로 선택하거나 결합할 수 있는 지능형 에이전트를 개발할 수 있을까요? 예를 들어, 저렴한 방법으로 시작하고, 예산이 허용되고 성능 향상이 정체되면, 매우 중요하고 작은 데이터 하위 집합에 대해 더 정교한 방법으로 전환하는 것입니다. 이는 FLOPs 및 성능의 실시간 모니터링을 포함할 수 있으며, 강화 학습 또는 적응형 제어 시스템을 사용할 수 있습니다.
- 비판적 사고: 이러한 에이전트는 성능 예측의 불확실성이나 예산의 갑작스러운 변화를 어떻게 처리할까요? "에이전트" 자체의 계산 비용은 얼마일까요?
-
비용 인식 LLM 아키텍처 및 파인튜닝 방법:
- 현재 한계: 데이터 선택 방법은 종종 LLM 아키텍처 또는 파인튜닝 기술과 독립적으로 개발됩니다.
- 향후 방향: 컴퓨팅 효율적인 데이터 선택에 본질적으로 더 적합한 LLM 또는 파인튜닝 방법(예: LoRA 변형)을 설계할 수 있을까요? 예를 들어, LLM이 "선택 친화적인" 중간 표현을 가지고 있어 복잡도 또는 기울기 계산이 훨씬 저렴해질 수 있을까요? 또는 데이터 품질에 덜 민감하여 비싼 선택의 필요성을 줄이는 파인튜닝 방법이 개발될 수 있을까요?
- 비판적 사고: 이러한 특수 아키텍처는 일반화 가능성이나 다른 성능 지표를 손상시킬까요? 선택 용이성과 핵심 모델 기능 간의 절충점은 무엇일까요?
-
다중 작업 설정을 넘어선 상각:
- 현재 한계: 논문은 다중 작업 상각(그림 4)에 대해 언급합니다. 여기서 선택 비용은 여러 작업에 대한 여러 파인튜닝 실행에 걸쳐 분산됩니다.
- 향후 방향: 다른 상각 시나리오를 탐색합니다. LLM이 주기적으로 새 데이터로 업데이트되는 연속 학습은 어떨까요? 비싼 데이터 선택을 한 번 수행한 다음 여러 후속 파인튜닝 주기 또는 유사한 요구 사항을 가진 다른 사용자를 위해 재사용할 수 있을까요? 사전 계산된 유용성 점수 또는 선택된 하위 집합이 공유되는 "데이터 선택 서비스" 모델을 고려합니다.
- 비판적 사고: 동적 데이터 환경에서 유용성 점수는 얼마나 빨리 오래될까요? 선택된 데이터셋 또는 유용성 점수를 공유하는 것의 개인 정보 보호 및 지적 재산권 문제는 무엇일까요?
-
FLOPs를 넘어서는 전체론적 컴퓨팅 비용 모델:
- 현재 한계: 논문은 주로 FLOPs를 컴퓨팅 비용의 척도로 사용합니다.
- 향후 방향: 다른 중요한 리소스를 포함하도록 컴퓨팅 비용 모델을 확장합니다. 여기에는 다음이 포함될 수 있습니다.
- 메모리 사용량: 특히 대규모 모델 및 리소스 제약 환경에서 중요합니다.
- 에너지 소비: 환경 지속 가능성 및 운영 비용에 직접적인 영향을 미칩니다.
- 인간 참여 비용: 인간의 레이블링 또는 검증이 필요한 방법의 경우 이 비용이 상당할 수 있습니다.
- 지연 시간: 선택 및 훈련에 걸리는 시간은 실제 배포에서 중요한 요소일 수 있습니다.
- 비판적 사고: 이러한 다양한 비용 차원은 어떻게 상호 작용할까요? 이러한 모든 측면을 포착할 수 있는 단일 통합 지표가 있을까요, 아니면 다중 목표 최적화가 필요할까요?
-
$\lambda$ 및 최적 비율의 예측 모델링:
- 현재 한계: 효율성 매개변수 $\lambda$ 및 최적 훈련 대 선택 모델 크기 비율은 매개변수 모델을 맞추기 위한 경험적 조사를 통해 결정됩니다.
- 향후 방향: 광범위한 경험적 조사를 실행하지 않고도 새로운 작업, 데이터셋 또는 모델 아키텍처에 대한 $\lambda$ 또는 최적 비율을 예측하기 위한 이론적 프레임워크 또는 메타 학습 접근 방식을 개발할 수 있을까요? 여기에는 선택 효율성에 영향을 미치는 데이터, 작업 및 모델의 고유한 속성을 이해하는 것이 포함될 것입니다.
- 비판적 사고: 데이터셋 또는 작업의 어떤 특징이 특정 선택 방법에 대한 더 높은 $\lambda$와 상관 관계가 있을까요? 더 큰 규모의 배포에 대한 이러한 예측을 알리기 위해 더 작은 파일럿 실험을 사용할 수 있을까요?
-
컴퓨팅 제약 조건 하에서의 선택의 윤리적 함의:
- 현재 한계: 논문은 효율성과 성능에 초점을 맞춥니다.
- 향후 방향: 윤리적 함의를 고려합니다. 컴퓨팅 제약 조건 하에서 더 저렴한 방법이 선호된다면, 더 정교한 방법이 더 다양하거나 대표적인 데이터를 식별할 수 있는 것에 비해 의도치 않게 편향을 도입하거나 공정성을 감소시킬까요? 예를 들어, BM25가 일반적인 키워드를 기반으로 데이터를 선택하면 데이터의 기존 편향을 강화할 수 있습니다.
- 비판적 사고: 컴퓨팅 최적 데이터 선택이 "충분히 좋은" 모델로 이어지지 않도록 어떻게 보장할 수 있을까요? 이러한 모델은 더 비싸지만 잠재적으로 더 공정한 데이터 선택으로 훈련된 모델보다 덜 견고하거나 공정할까요? 엄격하게 컴퓨팅 최적이 아니더라도 유지해야 하는 최소한의 "품질" 임계값이 있을까요?
이러한 토론 주제는 이 논문이 훌륭하고 실용적인 프레임워크를 제공하지만, 실제 제약 조건 하에서 LLM 파인튜닝을 진정으로 최적화하고 책임감 있게 수행하기 위한 여정은 아직 끝나지 않았음을 강조합니다.
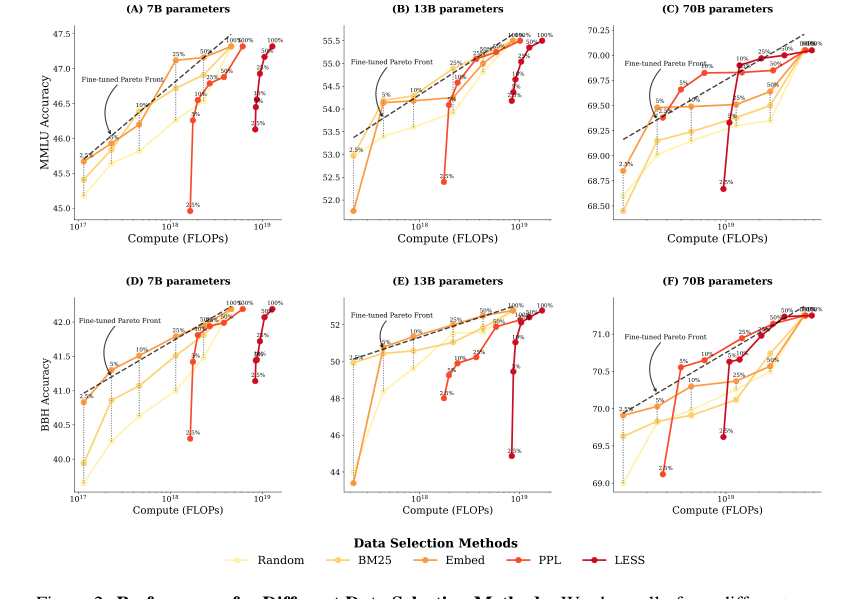 Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
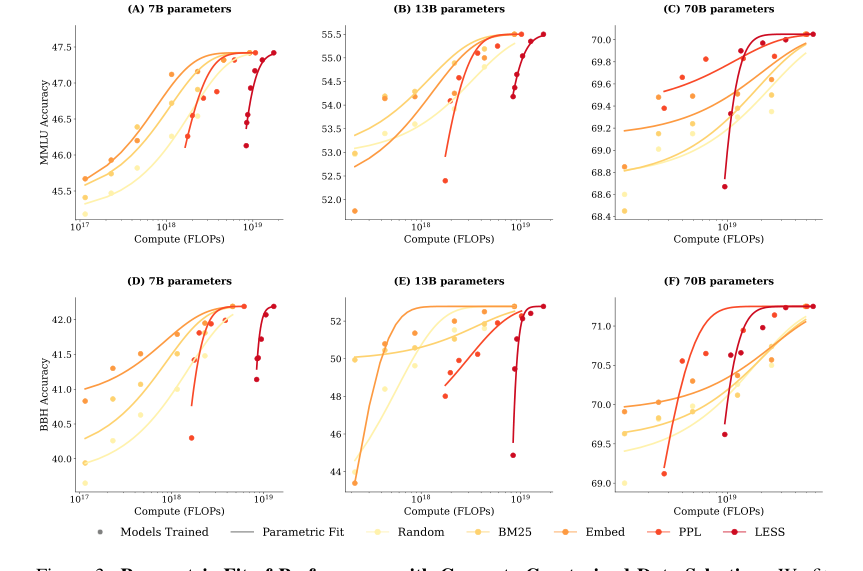 Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
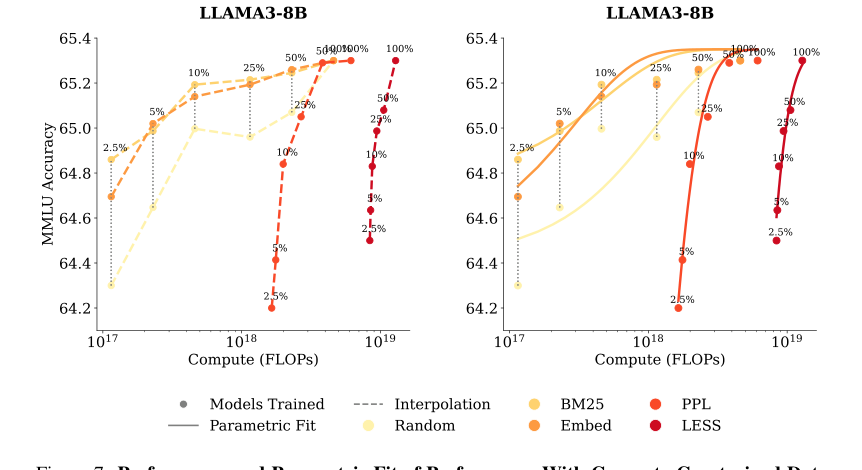 Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points
Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points
다른 분야와의 동형 사상
본 논문의 "구조적 골격"은 고정된 총 계산 예산을 자원 집약적인 '선택' 단계와 '처리' 단계 사이에 최적으로 할당하여 성능 결과를 극대화하는 메커니즘이다.