Выбор данных с учетом вычислительных ограничений
Область больших языковых моделей (LLM) переживает взрывной рост, что привело к созданию моделей с миллиардами параметров, способных к выдающимся достижениям в понимании и генерации естественного языка.
Общие сведения и академическая преемственность
Область больших языковых моделей (LLM) переживает взрывной рост, что привело к созданию моделей с миллиардами параметров, способных к выдающимся достижениям в понимании и генерации естественного языка. Однако эта мощь сопряжена со значительными вычислительными затратами. Обучение таких массивных моделей или даже их адаптация для конкретных задач посредством процесса, называемого fine-tuning, требует огромных вычислительных ресурсов, часто измеряемых в часах работы графических процессоров (GPU) или FLOPs (операциях с плавающей запятой).
Точное происхождение проблемы, рассматриваемой в данной статье, проистекает из практической реальности этих ресурсных ограничений. По мере того как LLM становились все более распространенными, исследователи и практики быстро осознали, что общий вычислительный бюджет для обучения или fine-tuning часто предопределен и фиксирован заранее. Это означает, что количество ускорителей (например, GPU) и часы их использования распределяются авансом. Это осознание стимулировало исследования в области «compute-optimal LLMs», где цель состоит в достижении наилучшей возможной производительности модели (например, минимальной перплексии) в рамках заданного вычислительного бюджета. Ранние работы, такие как Hoffmann et al. (2022), исследовали, как сбалансировать архитектурный выбор и решения по обучению для достижения этой цели.
Данная статья расширяет эту линию исследований применительно к фазе fine-tuning LLM. Многообещающей стратегией снижения вычислительных требований для fine-tuning является «выбор данных» (data selection), при котором вместо обучения на всем доступном наборе данных выбирается меньшее, более значимое подмножество. Сам по себе выбор данных является фундаментальной концепцией в машинном обучении, корни которой уходят в конец 1960-х (Hart, 1968) и 1970-е годы (John, 1975), и направлен на создание минимальных наборов данных для эффективного обучения.
Однако фундаментальное ограничение или «болевая точка» предыдущих подходов, побудившая авторов написать эту статью, заключается в том, что они в значительной степени игнорировали вычислительную стоимость самого процесса выбора данных. Хотя методы выбора данных были разработаны для уменьшения размера обучающих данных (и, следовательно, вычислительных затрат на обучение), многие «мощные» или «сложные» методы выбора требуют значительных вычислительных усилий для идентификации лучших точек данных. Основная проблема заключается в том, что «даже если выбор данных эффективен, это априори не означает, что он является compute-optimal». Предыдущие модели фокусировались на максимизации производительности для заданного бюджета данных (т.е. количества точек данных), но не обязательно для заданного вычислительного бюджета, который охватывает как затраты на выбор, так и затраты на обучение. Это упущение означало, что метод, выбирающий «лучшие» данные, может быть настолько дорогим в исполнении, что общий вычислительный бюджет лучше потратить просто на обучение на большем объеме данных с использованием более дешевой или даже случайной стратегии выбора. Авторы утверждают, что для практического внедрения compute-optimal метод должен одновременно улучшать обучение и быть дешевым в вычислениях — критический фактор, который до сих пор недостаточно учитывался.
Ниже приведены 3–5 узкоспециализированных терминов из статьи, переведенных в интуитивно понятные аналогии для читателя с нулевой базой:
- LLMs (Large Language Models): Представьте себе невероятно умного цифрового помощника, который прочитал почти все, что когда-либо было написано людьми. Он может понимать ваши вопросы, писать рассказы, резюмировать статьи и даже помогать вам писать код, просто предсказывая следующее наиболее вероятное слово.
- Finetuning: Подумайте об этом так: у вас есть блестящий шеф-повар широкого профиля (LLM), который умеет готовить блюда всех кухонь мира. Теперь вы хотите, чтобы он стал экспертом в выпечке французских десертов. Вы даете ему специальную книгу рецептов французской выпечки и заставляете практиковаться только на этих рецептах. Он не забывает, как готовить другие блюда, но становится гораздо лучше в приготовлении французских десертов.
- Compute-Optimal: Это похоже на попытку получить «максимальную отдачу от вложенных средств» при создании чего-либо. У вас есть фиксированная сумма денег (вычислительный бюджет), и вы хотите достичь наилучшего результата (производительности модели). Речь идет о разумном выборе того, на что потратить деньги, чтобы получить наибольшую ценность, а не просто о тратах на самые дорогие или кажущиеся «лучшими» части.
- Perplexity: Представьте, что вы пытаетесь угадать следующее слово в предложении. Если предложение звучит как «Кот сидел на...», вы не сильно удивитесь, если следующим словом будет «коврике». Ваша «перплексия» низка. Но если бы следующим словом было «банан», вы были бы очень удивлены, и ваша «перплексия» была бы высокой. В LLM более низкая перплексия означает, что модель лучше предсказывает текст и понимает язык более бегло.
- FLOPs (Floating Point Operations): Это базовые арифметические вычисления (сложение, вычитание, умножение, деление), которые выполняет компьютер. Когда мы говорим о FLOPs, это похоже на подсчет каждого нажатия кнопки на калькуляторе. Это способ измерить, сколько «мышления» или «работы» выполняет компьютер. Более высокое количество FLOPs означает большие вычислительные усилия.
Таблица обозначений
| Обозначение | Описание |
|---|---|
| LLMs | Большие языковые модели, предварительно обученные на огромных массивах текстовых данных. |
| Finetuning | Процесс адаптации предварительно обученной LLM к конкретной целевой задаче с использованием меньшего, специализированного набора данных. |
| Вычислительный бюджет ($\mathcal{K}$) | Общие фиксированные вычислительные ресурсы (например, FLOPs, часы работы GPU), выделенные как на выбор данных, так и на обучение модели. |
| FLOPs | Операции с плавающей запятой, мера вычислительной работы. |
| $\mathcal{D}$ | Весь доступный пул потенциальных обучающих данных. |
| $\mathcal{S}$ | Подмножество данных, выбранное из $\mathcal{D}$ для fine-tuning. |
| $\mathcal{S}^*$ | Оптимальное подмножество данных, выбранное из $\mathcal{D}$, которое максимизирует производительность модели при вычислительных ограничениях. |
| $P(\cdot)$ | Функция, представляющая производительность LLM в данной задаче (например, точность, перплексия). |
| $\mathcal{T}(\mathcal{S})$ | Модель LLM, обученная (fine-tuned) на подмножестве данных $\mathcal{S}$. |
| $\mathcal{T}$ | Целевой тестовый набор данных, используемый для финальной оценки производительности модели. |
| $\mathcal{V}$ | Валидационный набор данных, используемый как прокси для $\mathcal{T}$ во время выбора данных и разработки модели. |
| $C_T(\mathcal{S})$ | Вычислительная стоимость (в FLOPs) обучения LLM на выбранном подмножестве данных $\mathcal{S}$. |
| $C_U(x)$ | Вычислительная стоимость (в FLOPs) вычисления функции полезности для одной точки данных $x$ в процессе выбора данных. |
| $\sum_{x \in \mathcal{D}} C_U(x)$ | Общая вычислительная стоимость вычисления функций полезности для всех точек данных в исходном наборе $\mathcal{D}$ для выполнения выбора данных. |
| $K$ (в традиционной задаче) | Максимальная мощность (количество точек данных), разрешенная в выбранном подмножестве $\mathcal{S}$ (бюджет данных). |
| $K$ (в задаче с вычислительными ограничениями) | Общий вычислительный бюджет (в FLOPs) как для выбора данных, так и для обучения. |
| $v(x; \mathcal{V})$ | Функция полезности, которая присваивает балл точке данных $x$ на основе ее релевантности или ценности, часто вычисляемая относительно валидационного набора $\mathcal{V}$. |
| $P_0$ | Zero-shot производительность LLM (производительность без какого-либо fine-tuning). |
| $P$ | Верхняя граница производительности, представляющая максимально достижимую производительность. |
| $\lambda$ | Параметр в параметрической модели производительности, который контролирует, насколько эффективно метод выбора данных извлекает ценность из дополнительных вычислений. |
| $C(k)$ | Общая вычислительная стоимость (выбор + обучение) для стратегии, которая приводит к обучению на $k$ точках данных. |
| $C(|\mathcal{D}|)$ | Общая вычислительная стоимость обучения на всем наборе данных $\mathcal{D}$ (без какого-либо выбора данных). |
| $\exp(\cdot)$ | Экспоненциальная функция, используемая для моделирования убывающей отдачи. |
| Levenberg-Marquardt | Алгоритм, используемый для решения нелинейных задач наименьших квадратов, применяемый здесь для подбора параметров параметрической модели производительности. |
| LoRA | Low-Rank Adaptation, метод эффективного fine-tuning по параметрам, который снижает использование памяти. |
| QLoRA | Quantized LoRA, дальнейшая оптимизация для уменьшения памяти, особенно для очень больших моделей. |
| MMLU | Massive Multitask Language Understanding, бенчмарк для оценки фактических знаний. |
| BBH | Big-Bench Hard, бенчмарк для оценки сложных рассуждений. |
| IFEval | Instruction Following Evaluation, бенчмарк для оценки способностей следования инструкциям. |
| BM25 | Лексический метод выбора данных, использующий статистические свойства текста. |
| Embed | Метод выбора данных на основе эмбеддингов, использующий плотные модели эмбеддингов. |
| PPL | Метод выбора данных на основе перплексии, использующий функцию потерь (перплексию) LLM. |
| LESS | Метод выбора данных на основе градиентов, использующий градиенты для оценки влияния. |
Определение проблемы и ограничения
Основная проблема, которую решает данная статья, вращается вокруг оптимизации fine-tuning больших языковых моделей (LLM) в рамках строгого, заранее определенного общего вычислительного бюджета.
Отправная точка (входные данные/текущее состояние) — это сценарий, в котором у нас есть:
* Обширный пул потенциальных обучающих данных, обозначенный как $\mathcal{D}$.
* Конкретная целевая задача, для которой необходимо выполнить fine-tuning базовой LLM.
* Связанные тестовые ($\mathcal{T}$) и валидационные ($\mathcal{V}$) наборы данных для оценки производительности.
* Фиксированный общий вычислительный бюджет $\mathcal{K}$, обычно измеряемый в FLOPs, который представляет собой общие ресурсы, выделенные как на выбор данных, так и на последующее обучение модели. Этот бюджет часто устанавливается заранее, например, количеством ускорителей и часами их использования.
* Разнообразие существующих методов выбора данных, каждый из которых имеет свою вычислительную стоимость и эффективность в идентификации ценных обучающих данных.
Желаемый результат (целевое состояние) — это идентификация оптимального подмножества данных $\mathcal{S}^* \subset \mathcal{D}$ такого, что при fine-tuning LLM на этом подмножестве, $\mathcal{T}(\mathcal{S}^*)$, она достигает наивысшей возможной производительности $P(\mathcal{T}; \mathcal{T}(\mathcal{S}^*))$ на целевом тестовом наборе. Крайне важно, что эта оптимальная производительность должна быть достигнута при соблюдении общего вычислительного бюджета $\mathcal{K}$, что означает, что совокупная вычислительная стоимость выбора $\mathcal{S}^*$ и обучения на нем не должна превышать $\mathcal{K}$. Конечная цель — предоставить практикам основу для принятия обоснованных решений о том, как наилучшим образом распределить свои ограниченные вычислительные ресурсы между выбором данных и обучением модели.
Точный недостающий элемент или математический пробел, который пытается преодолеть эта статья, заключается в переходе от оптимизации, ориентированной на данные, к оптимизации, ориентированной на вычисления. Традиционно задачи выбора данных формулируются как:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{T}; \mathcal{T}(\mathcal{S})) \quad \text{при условии } |\mathcal{S}| \le K $$
Здесь $K$ представляет бюджет данных (максимальное количество точек данных). Эта формулировка неявно предполагает, что стоимость выбора данных пренебрежимо мала или обрабатывается отдельно.
В данной статье представлена новая, более реалистичная формулировка, которая явно включает вычислительную стоимость выбора данных в общее бюджетное ограничение. Задача переформулирована как:
$$ \mathcal{S}^* = \arg \max_{\mathcal{S} \subset \mathcal{D}} P(\mathcal{V}; \mathcal{T}(\mathcal{S})) \quad \text{при условии } C_T(\mathcal{S}) + \sum_{x \in \mathcal{D}} C_U(x) \le \mathcal{K} $$
где:
* $P(\mathcal{V}; \mathcal{T}(\mathcal{S}))$ используется как прокси для $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$, с использованием валидационного набора $\mathcal{V}$.
* $C_T(\mathcal{S})$ — вычислительная стоимость обучения модели на выбранном подмножестве $\mathcal{S}$.
* $\sum_{x \in \mathcal{D}} C_U(x)$ — общая вычислительная стоимость вычисления функции полезности $v(x; \mathcal{V})$ для всех точек данных в исходном наборе $\mathcal{D}$ для идентификации подмножества $\mathcal{S}$.
* $\mathcal{K}$ — общий вычислительный бюджет.
Математический пробел заключается именно во включении члена $\sum_{x \in \mathcal{D}} C_U(x)$ в ограничение, что превращает оптимизацию из задачи, касающейся исключительно количества данных, в задачу, касающуюся общих вычислительных затрат.
Болезненный компромисс или дилемма, в которую попали предыдущие исследователи, — это внутренний конфликт между эффективностью метода выбора данных и его вычислительной стоимостью. Более сложные методы выбора данных, такие как методы, основанные на перплексии модели или градиентах, часто высокоэффективны в идентификации меньшего, высококачественного подмножества данных, которое может привести к лучшей производительности модели или более быстрой сходимости во время обучения. Однако эти «мощные» методы также требуют значительно больших вычислительных затрат.
Дилемма заключается в том, что, хотя эти продвинутые методы уменьшают размер обучающих данных, существенные вычисления, требуемые для самого процесса выбора, могут легко перевесить выгоды от сокращения времени обучения. В сценарии с фиксированным общим вычислительным бюджетом трата большего количества FLOPs на выбор означает, что меньше FLOPs доступно для фактического процесса fine-tuning, что потенциально приводит к худшей общей производительности, несмотря на наличие «лучшего» подмножества данных. Исследователи ранее фокусировались на максимизации производительности для заданного размера данных, а не обязательно для заданного общего вычислительного бюджета, тем самым упуская из виду этот критический компромисс.
Суровые, реалистичные стены, которые делают эту проблему невероятно сложной для решения, многогранны:
- Вычислительная неразрешимость оптимального выбора: Задача поиска абсолютно оптимального подмножества данных $\mathcal{S}^*$ является задачей комбинаторной оптимизации. Исчерпывающий поиск всех возможных подмножеств вычислительно невозможен для больших наборов данных, что делает точные решения непрактичными. Это вынуждает полагаться на жадные алгоритмы и аппроксимации.
- Высокая стоимость операций LLM: Fine-tuning LLM, даже с использованием эффективных по параметрам методов, таких как LoRA, по своей сути является вычислительно интенсивным процессом. Каждый шаг градиента, прямой или обратный проход через большую модель-трансформер потребляет огромное количество FLOPs. Это делает оба члена $C_T(\mathcal{S})$ и $C_U(x)$ существенными.
- Различная стоимость методов выбора: Разные методы выбора данных имеют радикально разные вычислительные следы. Лексические методы (например, BM25) очень дешевы (близки к 0 FLOPs), методы на основе эмбеддингов умеренно дороги (например, $4.4 \times 10^{16}$ FLOPs для Embed), в то время как методы на основе перплексии и градиентов чрезвычайно дороги (например, $1.53 \times 10^{18}$ FLOPs для PPL, $8.27 \times 10^{18}$ FLOPs для LESS, как показано в Таблице 5). Этот широкий диапазон означает, что метод, который является «лучшим» с точки зрения сокращения данных, может быть «худшим» с точки зрения общей вычислительной эффективности.
- Законы масштабирования и убывающая отдача: Эффективность выбора данных часто масштабируется с инвестированными в него вычислениями, но с убывающей отдачей. Большие вычисления могут дать немного лучшее подмножество, но прирост производительности может не оправдать дополнительные затраты. Связь между вычислениями и производительностью нелинейна и сложна, как моделируется параметрической функцией $P(k) = (P - P_0) \times (1 - \exp(-\frac{\lambda C(k)}{C(|\mathcal{D}|)})) + P_0$.
- Зависимость от прокси: Истинная цель $P(\mathcal{T}; \mathcal{T}(\mathcal{S}))$ не может быть напрямую оптимизирована, поскольку тестовый набор $\mathcal{T}$ недоступен во время выбора. Исследователи должны полагаться на валидационный набор $\mathcal{V}$ и функции полезности $v(x; \mathcal{V})$ в качестве прокси, что вносит потенциальные неточности и допущения (например, что $\mathcal{V}$ является IID с $\mathcal{T}$).
- Зависимость от модели и задачи: Оптимальное распределение вычислений и «лучший» метод выбора данных не являются универсальными. Они зависят от конкретного размера LLM (например, 7B, 13B, 70B параметров), характера целевой задачи (например, MMLU, BBH, IFEval) и доступного общего вычислительного бюджета. Это делает поиск общего решения довольно сложным.
- Ограничения памяти оборудования: Хотя это не является центральным фокусом, в статье упоминается использование QLoRA для моделей 70B для снижения требований к памяти (Приложение D.1), что указывает на то, что ограничения памяти являются практической стеной при масштабировании fine-tuning LLM, что косвенно влияет на стратегии распределения вычислений.
По сути, проблема невероятно сложна, потому что она требует навигации по сложному, нелинейному ландшафту оптимизации, где «лучший» выбор сильно зависит от контекста, а сам акт улучшения одного аспекта (качества данных) может непреднамеренно подорвать другой (общую вычислительную эффективность).
Почему именно этот подход
Основная проблема, которую решает данная статья, заключается в практической задаче fine-tuning больших языковых моделей (LLM) в рамках заранее определенного, конечного вычислительного бюджета. Традиционно методы выбора данных фокусировались на оптимизации производительности модели для заданного бюджета данных — то есть выборе лучшего подмножества фиксированного размера $K$ из большего набора данных $D$. Цель, как описано в Разделе 3, состоит в том, чтобы найти подмножество $S^*$, которое максимизирует производительность $P(T; T(S))$ на тестовом наборе $T$ при условии $|S| \le K$.
Авторы осознали, что этот традиционный подход недостаточен для реального fine-tuning LLM. «Точный момент» этого осознания четко сформулирован в Разделе 4: «Хотя структура, представленная в Разделе 3, обеспечивает общий метод выбора данных, мы утверждаем, что она недостаточна для практической задачи fine-tuning LLM. Проблема в том, что fine-tuning LLM часто ограничивается вычислительным бюджетом, а не бюджетом данных». Они заметили, что общий вычислительный бюджет часто фиксируется заранее (например, выделенные ускорители и часы использования), и этот бюджет должен покрывать как стоимость выбора данных, так и стоимость обучения модели на этих выбранных данных. Предыдущие «SOTA» методы выбора данных, хотя и эффективны в идентификации высококачественных подмножеств данных, часто сами по себе несли существенные вычислительные затраты, которые в значительной степени игнорировались при их оценке.
Подход статьи заключается не в представлении нового алгоритма выбора данных, а скорее в новой, ограниченной вычислительными ресурсами структуре для оценки и выбора методов выбора данных. Эта структура является единственным жизнеспособным решением для принятия действительно оптимальных решений в среде с ограниченными вычислениями, поскольку она явно учитывает общие вычислительные затраты. Авторы формализуют эту задачу как:
$$S^* = \arg \max_{S \subset D} P(V; T(S)) \quad \text{при условии} \quad C_T(S) + \sum_{x \in D} C_U(x) \le K$$
Здесь $K$ представляет общий вычислительный бюджет (например, максимальное количество FLOPs), $C_T(S)$ — стоимость обучения модели на выбранном подмножестве $S$, а $\sum_{x \in D} C_U(x)$ — стоимость вычисления функции полезности для выбора данных по всему набору данных $D$. Это фундаментальный сдвиг от оптимизации для фиксированного размера данных к оптимизации для фиксированных общих вычислений.
Сравнительное превосходство (логика бенчмаркинга):
Качественное превосходство этой структуры, ограниченной вычислительными ресурсами, заключается в ее целостной и практической метрике оценки. Предыдущий «золотой стандарт» неявно предполагал бесконечные или пренебрежимо малые вычисления для выбора данных, фокусируясь исключительно на производительности, достигаемой выбранными данными. Эта новая структура, однако, предоставляет границу Парето (как видно на Рисунках 2, 3, 5, 7, 8), которая сопоставляет общие вычисления (ось x) с производительностью модели (ось y). Это позволяет напрямую сравнивать методы на основе их эффективности в преобразовании вычислений в производительность, а не просто на основе их «сырой» производительности на наборе данных фиксированного размера.
Эта структура по своей сути не обрабатывает шум высокой размерности лучше и не снижает сложность памяти базовых алгоритмов выбора данных. Вместо этого ее структурное преимущество заключается в том, что она выявляет истинные compute-optimal методы при различных бюджетных сценариях. Она демонстрирует, что методы с более низкой вычислительной сложностью выбора (например, лексический BM25 или основанный на эмбеддингах) часто становятся подавляюще превосходящими более сложные, вычислительно интенсивные методы (например, основанные на перплексии PPL или основанные на градиентах LESS), когда общий вычислительный бюджет ограничен. Например, в аннотации отмечается, что «более дешевые альтернативы выбора данных доминируют как с теоретической, так и с эмпирической точки зрения». Это глубокое качественное преимущество: оно меняет то, какие методы считаются «лучшими», путем введения критического реального ограничения. Концептуальное поведение этих методов при различных вычислительных бюджетах проиллюстрировано в симуляции.
Соответствие ограничениям («Брак»):
«Брак» между суровыми требованиями задачи и уникальными свойствами решения идеален. Суровые требования задачи, как указано во введении:
1. Предопределенный общий вычислительный бюджет: Обучение LLM дорого, и ресурсы (ускорители, часы использования) выделяются заранее.
2. Оптимальное распределение ресурсов: Критически важно определить, как наилучшим образом распределить этот фиксированный бюджет.
3. Выбор данных должен быть compute-optimal: Любой метод выбора данных должен улучшать обучение пропорционально своим дополнительным затратам.
Целевая функция, ограниченная вычислительными ресурсами (Уравнение 2), напрямую отвечает этим требованиям:
* Она устанавливает строгую верхнюю границу $K$ на общие вычисления, вынуждая идти на компромисс между стоимостью выбора и стоимостью обучения.
* Она количественно определяет «дополнительные затраты» на выбор данных ($C_U(x)$) и интегрирует их со стоимостью обучения ($C_T(S)$), позволяя практикам принимать обоснованные решения о распределении ресурсов.
* Она позволяет идентифицировать методы, которые действительно являются «compute-optimal», путем рассмотрения всего конвейера, а не только изолированных частей. Это гарантирует, что выбранный метод не только эффективен, но и экономически жизнеспособен в рамках заданных вычислительных ограничений. Эта структура является прямым ответом на практическую потребность в эффективности в мире с ограниченными ресурсами.
Отказ от альтернатив:
Статья неявно «отвергает» традиционные «SOTA» методы выбора данных, такие как основанные на перплексии (PPL) и градиентах (LESS), когда вычисления ограничены. Она не обсуждает альтернативы, такие как GAN или диффузионные модели, поскольку ее область применения — именно выбор данных для fine-tuning.
Обоснование отказа от этих в остальном мощных методов заключается в их высокой вычислительной стоимости выбора, что делает их FLOP-неэффективными при общем вычислительном бюджете.
* Высокая стоимость: Раздел 4.1 и Приложение B предоставляют четкие доказательства. Лексический метод (BM25) стоит примерно $1 \times 10^8$ FLOPs, а основанный на эмбеддингах (Embed) — около $4.4 \times 10^{16}$ FLOPs. В резком контрасте, основанный на перплексии (PPL) стоит около $1.53 \times 10^{18}$ FLOPs, а основанный на градиентах (LESS) — ошеломляющие $8.27 \times 10^{18}$ FLOPs. Это на порядки дороже.
* FLOP-неэффективность: Аннотация и Раздел 7 прямо заявляют, что «многие мощные методы выбора данных почти никогда не являются compute-optimal» и что PPL и LESS являются «FLOP-неэффективными как с теоретической, так и с эмпирической точки зрения».
* Эмпирический провал: Рисунки 1 и 2 демонстрируют это. Для малых и средних вычислительных бюджетов более дешевые методы BM25 и Embed последовательно превосходят PPL и LESS на границе Парето «вычисления-производительность». Это означает, что для заданного общего вычислительного бюджета можно достичь лучшей производительности модели, используя более дешевый метод выбора и выделяя больше вычислений на фактическое обучение модели.
* Точка безубыточности: Статья обнаруживает, что PPL и LESS становятся compute-optimal только тогда, когда обучаемая модель значительно больше модели выбора (в 5 раз для PPL, в 10 раз для LESS, как подробно описано в Разделе 8 и Приложении G). Это подразумевает, что в большинстве практических сценариев, где модель выбора сопоставима по размеру или меньше относительно обучаемой модели, эти сложные методы не были бы compute-optimal. Маржинальная выгода от их превосходного качества выбора данных просто не перевешивает их непомерную вычислительную стоимость.
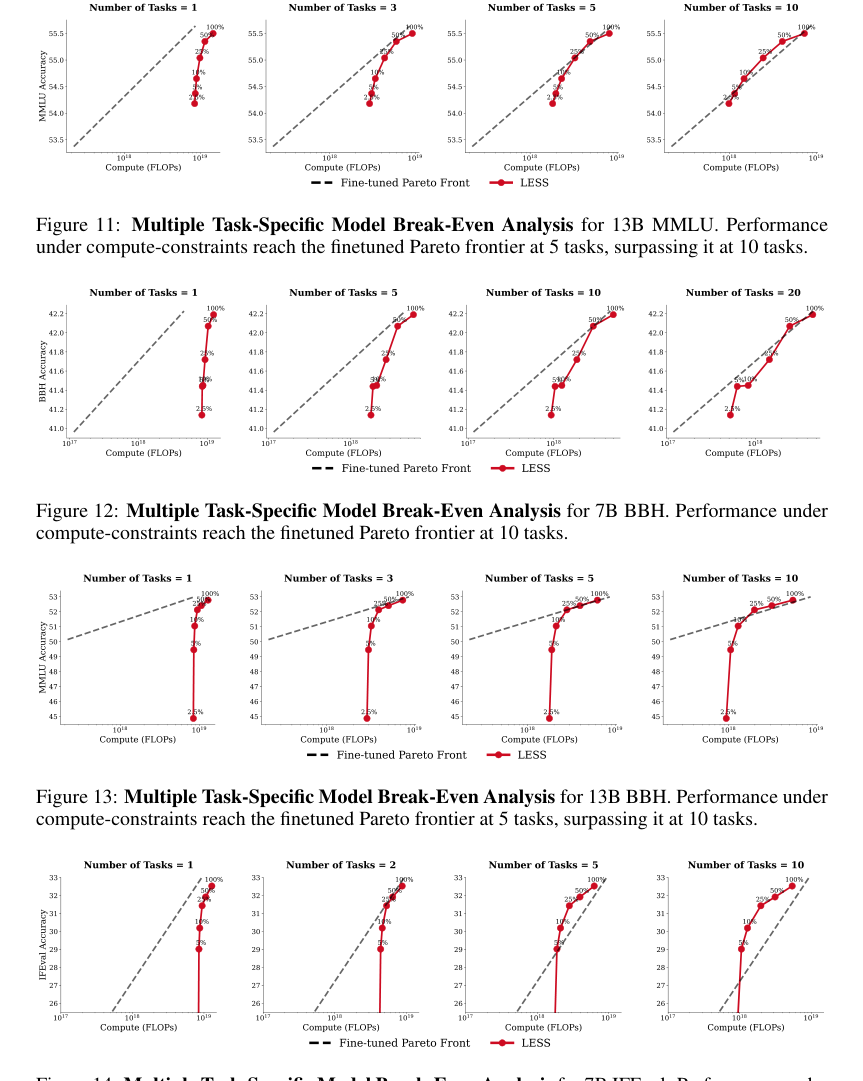 Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
Figure 16. and Figure 17 show the Jaccard similarity of data selected by different data selection meth- ods for the BBH and IFEval target tasks, respectively. Across various percentages of selected data, Embedding and BM25 exhibit the highest similarity. In contrast, LESS shares the least similarity with the other data selection methods
Математический и логический механизм
Как мета-ученый, я тщательно изучил представленную статью «COMPUTE-CONSTRAINED DATA SELECTION», которая решает важнейшую задачу в эпоху больших языковых моделей (LLM): как оптимально распределить фиксированный вычислительный бюджет между выбором обучающих данных и фактическим fine-tuning модели. Авторы представляют убедительный анализ, демонстрируя, что простой выбор наиболее «мощного» метода выбора данных не всегда является наиболее вычислительно эффективным подходом.
Базовые знания для читателя с нулевой базой
Прежде чем углубляться в специфику статьи, давайте установим некоторые фундаментальные концепции:
- Большие языковые модели (LLM): Представьте себе невероятно умного цифрового помощника, который может понимать и генерировать человекоподобный текст. Это и есть LLM. Они «большие», потому что имеют миллиарды внутренних параметров (как ручки настройки) и обучены на огромных объемах текстовых данных (как весь интернет). Этот процесс обучения невероятно дорог и требует много времени.
- Finetuning: После того как LLM предварительно обучена, она является универсалом. Чтобы сделать ее хорошей в конкретной задаче (например, отвечать на медицинские вопросы, писать код), мы «дообучаем» (fine-tune) ее. Это включает в себя дальнейшее обучение на меньшем, специализированном наборе данных. Это похоже на обучение шеф-повара широкого профиля специализации на французской кухне.
- Вычислительный бюджет: Думайте об этом как о вашем общем лимите на вычислительные ресурсы. Он измеряется в FLOPs (операциях с плавающей запятой), которые являются базовыми арифметическими вычислениями. Обучение LLM требует множества FLOPs, часто с использованием дорогостоящего оборудования, такого как GPU, работающих днями или неделями. Этот бюджет часто фиксируется заранее.
- Выбор данных: Вместо fine-tuning на всех доступных специализированных данных (которые все равно могут быть огромными), выбор данных — это процесс интеллектуального подбора меньшего, более значимого подмножества этих данных. Идея в том, что не все точки данных одинаково ценны, а некоторые могут быть даже избыточными или вредными. Выбор «лучших» данных может сделать fine-tuning быстрее и эффективнее.
- Производительность: Насколько хорошо LLM справляется со своей целевой задачей после fine-tuning. Это может измеряться точностью, связностью генерируемого текста или другими метриками.
- Убывающая отдача: Это общий экономический принцип: чем больше вы инвестируете во что-то, тем меньшую дополнительную выгоду вы получаете от каждой последующей инвестиции. Например, первые несколько часов подготовки к экзамену могут дать огромные улучшения, но 100-й час может дать лишь крошечный прирост. Это применимо к вычислениям и данным при обучении LLM.
Мотивация: Основная проблема
Центральная мотивация этой статьи проистекает из практической дилеммы:
- Fine-tuning LLM дорог: Обучение этих массивных моделей, даже для конкретных задач, потребляет значительные вычислительные ресурсы.
- Выбор данных может помочь: Выбирая меньший, высококачественный набор данных, мы можем уменьшить количество вычислительных ресурсов для обучения. Это звучит отлично!
- Но сам выбор данных стоит вычислений: Чтобы выяснить, какие точки данных «лучшие», вам часто нужно выполнить некоторые вычисления, иногда даже используя другую LLM. Этот процесс не бесплатен.
Авторы осознали, что предыдущие работы часто фокусировались на эффективности выбора данных в сокращении размера данных или улучшении производительности на шаг обучения, но не полностью учитывали вычислительную стоимость самого процесса выбора. Метод выбора данных может быть «мощным» (означает, что он выбирает отличные данные), но если он стоит огромного количества вычислений, он может не быть наиболее эффективным выбором, когда у вас есть строгий общий вычислительный бюджет.
Проблема, которую авторы намеревались решить, такова: Учитывая фиксированный общий вычислительный бюджет, как практикующему специалисту оптимально сбалансировать вычисления, потраченные на выбор данных, против вычислений, потраченных на обучение модели на этих выбранных данных, чтобы достичь наивысшей возможной производительности модели? Они хотят количественно оценить этот компромисс и идентифицировать действительно «compute-optimal» стратегии.
Ограничения, которые пришлось преодолеть
Авторы столкнулись с несколькими практическими и теоретическими ограничениями:
- Фиксированный общий вычислительный бюджет ($K$): Это всеобъемлющее ограничение. Все вычислительные усилия, от оценки точек данных для выбора до фактического обучения модели, должны укладываться в этот предопределенный лимит. Это похоже на наличие фиксированной суммы денег на проект, и вам нужно решить, сколько потратить на планирование (выбор данных) против исполнения (обучение).
- Вычислительная стоимость выбора данных ($C_U(x)$): Разные методы выбора данных имеют совершенно разные вычислительные следы. Некоторые дешевы (например, простая текстовая статистика), в то время как другие очень дороги (например, выполнение прямого/обратного прохода через LLM). Эта стоимость часто возникает для каждой точки данных в исходном, большом наборе данных, чтобы определить ее полезность, даже если в конечном итоге выбирается только небольшое подмножество. Эти «накладные расходы» могут быстро съесть весь бюджет.
- Вычислительная стоимость обучения ($C_T(S)$): Даже с выбранным подмножеством $S$ обучение все равно требует вычислений. Эта стоимость масштабируется с размером выбранных данных и размером LLM, которая проходит fine-tuning.
- Ограниченный доступ к истинному тестовому набору ($T$): В реальных сценариях окончательный тестовый набор (данные, на которых модель будет оцениваться после развертывания) обычно недоступен на этапе выбора данных. Поэтому авторам пришлось полагаться на валидационный набор ($V$) в качестве прокси для оценки производительности во время процесса выбора. Это вносит потенциальный разрыв между прокси-производительностью и истинной производительностью.
- Комбинаторная сложность: Выбор абсолютно лучшего подмножества данных из большого пула — это задача комбинаторной оптимизации, что означает, что количество возможных подмножеств астрономически велико. Прямой поиск оптимального подмножества вычислительно невозможен. Авторы решают это, используя жадные аппроксимации (оценка всех точек и выбор лучших), а затем моделируя производительность с помощью параметрической функции.
- Моделирование убывающей отдачи: Связь между вычислениями и производительностью не является линейной. Первоначальные инвестиции в вычисления дают высокую отдачу, но эта отдача уменьшается по мере добавления дополнительных вычислений. Точное моделирование этого нелинейного поведения было критически важным для их анализа.
Математическая интерпретация: Двигатель под капотом
Статья представляет две ключевые математические формулировки. Первая определяет саму проблему, а вторая — параметрическую модель, используемую для анализа и понимания связи между вычислениями и производительностью.
Основное уравнение: Формулировка проблемы
Абсолютно центральная проблема, которую решает эта статья, формализована как поиск оптимального подмножества точек данных $S^*$ из большего набора данных $D$, которое максимизирует производительность дообученной модели при условии общего вычислительного бюджета $K$.
$$S^* = \arg \max_{S \subset D} P(V; \mathcal{T}(S))$$
$$\text{при условии } C_T(S) + \sum_{x \in D} C_U(x) \le K$$
Разберем уравнение по частям:
- $S^*$:
1) Математическое определение: Это обозначает оптимальное подмножество точек данных.
2) Физическая/логическая роль: Это конечная цель всего процесса: конкретная коллекция обучающих примеров, которая при использовании даст наилучшую производительность модели при вычислительных ограничениях. Это «ответ» на задачу выбора данных.
3) Почему $\arg \max$: Нас интересует не просто само максимальное значение производительности, а какое подмножество $S$ достигает этой максимальной производительности. «Arg max» означает «аргумент (в данном случае $S$), который максимизирует выражение». - $P(V; \mathcal{T}(S))$:
1) Математическое определение: Это метрика производительности модели $\mathcal{T}(S)$, которая была обучена (fine-tuned) на подмножестве данных $S$, оцененная на валидационном наборе $V$.
2) Физическая/логическая роль: Этот член представляет качество или эффективность дообученной модели. Это цель, которую мы хотим максимизировать. Более высокое значение здесь означает лучшую модель. Валидационный набор $V$ выступает в качестве замены истинных, невидимых тестовых данных, позволяя нам оценивать производительность во время процесса выбора. - $S \subset D$:
1) Математическое определение: Это указывает на то, что $S$ должно быть подмножеством исходного, большого обучающего набора данных $D$.
2) Физическая/логическая роль: Это определяет пространство поиска. Мы выбираем точки данных из доступного пула $D$, а не создаем новые. Основная идея выбора данных — уменьшить объем данных, поэтому $S$ обычно намного меньше, чем $D$. - $C_T(S)$:
1) Математическое определение: Это вычислительная стоимость (измеряемая в FLOPs), необходимая для обучения модели $\mathcal{T}$ на выбранном подмножестве данных $S$.
2) Физическая/логическая роль: Это компонент «стоимости обучения» нашего общего вычислительного бюджета. Это вычисления, потраченные на фактическое обучение модели с использованием выбранных данных. Эта стоимость обычно увеличивается с размером $S$ и сложностью модели.
3) Почему сложение: Эта стоимость добавляется к стоимости выбора данных, потому что оба вида деятельности потребляют ресурсы из одного и того же общего вычислительного бюджета. Это две части одного расхода. - $\sum_{x \in D} C_U(x)$:
1) Математическое определение: Это сумма вычислительных стоимостей $C_U(x)$ для вычисления полезности (или «балла») каждой отдельной точки данных $x$ во всем исходном наборе данных $D$.
2) Физическая/логическая роль: Это представляет накладные расходы на «стоимость выбора данных». Для многих методов выбора данных вам сначала нужно оценить все потенциальные точки данных, чтобы решить, какие из них наиболее ценны. Эта сумма — фиксированная вычислительная инвестиция, необходимая для выполнения фазы выбора, независимо от того, сколько точек в конечном итоге выбрано для обучения. Это стоимость «похода по магазинам» за лучшими данными.
3) Почему суммирование: Стоимость полезности вычисляется для каждой отдельной точки данных, и эти индивидуальные стоимости затем суммируются, чтобы получить общую стоимость для фазы вычисления полезности. Авторы используют суммирование по $D$, потому что в своем жадном подходе они оценивают все точки в $D$, чтобы выбрать лучшие $K$. - $K$:
1) Математическое определение: Это общий максимальный вычислительный бюджет (в FLOPs), который доступен как для выбора данных, так и для обучения модели.
2) Физическая/логическая роль: Это жесткое ограничение ресурсов. Это «баланс банковского счета», который нельзя превышать. Вся проблема вращается вокруг максимизации производительности в рамках этого бюджета.
3) Почему $\le$: Общие использованные вычисления должны быть меньше или равны выделенному бюджету. Мы не можем потратить больше вычислений, чем у нас есть.
Основное уравнение: Модель производительности для анализа
Чтобы проанализировать компромисс и понять, как производительность меняется с вычислениями, статья вводит параметрическую модель ожидаемой производительности $P(k)$ после обучения на $k$ точках данных. Эта модель используется для подгонки эмпирических данных и экстраполяции выводов.
$$P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0$$
Разберем уравнение по частям (для модели производительности):
- $P(k)$:
1) Математическое определение: Ожидаемая производительность модели после обучения на $k$ выбранных точках данных.
2) Физическая/логическая роль: Это предсказанное значение производительности. Это выход нашей модели, говорящий нам, насколько хорошо LLM, как ожидается, будет работать при определенном количестве вычислений и выбранных данных. Это то, что отображается на оси y графиков производительности. - $P$:
1) Математическое определение: Верхняя граница производительности.
2) Физическая/логическая роль: Это представляет максимально возможную производительность, которую модель может достичь в задаче, даже если она обучена на всем наборе данных $D$. Это «потолок» или «идеальная» производительность, к которой модель асимптотически приближается. - $P_0$:
1) Математическое определение: Zero-shot производительность.
2) Физическая/логическая роль: Это базовая производительность модели до какого-либо fine-tuning. Это отправная точка, от которой измеряются все приросты производительности. - $(P - P_0)$:
1) Математическое определение: Общий потенциальный прирост производительности.
2) Физическая/логическая роль: Этот член масштабирует экспоненциальный рост. Он представляет максимально возможное улучшение, которое мы можем получить от fine-tuning, от базового уровня $P_0$ до потолка $P$. - $\times$:
1) Математическое определение: Умножение.
2) Физическая/логическая роль: Этот оператор масштабирует дробный прирост (из экспоненциального члена) на общий потенциальный прирост производительности.
3) Почему умножение: Экспоненциальный член вычисляет долю общего потенциального прироста, которая была достигнута. Умножение ее на $(P - P_0)$ преобразует эту долю в абсолютный прирост производительности. - $1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)$:
1) Математическое определение: Функция экспоненциального роста, которая начинается с 0 и приближается к 1.
2) Физическая/логическая роль: Это основной компонент «кривой обучения». Он моделирует убывающую отдачу. При малых вычислениях этот член растет быстро, указывая на значительные приросты производительности. По мере увеличения вычислений его рост замедляется, отражая то, что каждая дополнительная единица вычислений дает все меньше и меньше дополнительной производительности. Экспоненциальная функция — естественный выбор для моделирования такого поведения насыщения.
3) Почему экспоненциальная: Экспоненциальные функции отлично подходят для моделирования процессов, которые демонстрируют убывающую отдачу или насыщение, где скорость изменения уменьшается по мере увеличения входных данных. - $\exp(\cdot)$:
1) Математическое определение: Экспоненциальная функция $e^x$.
2) Физическая/логическая роль: Используется для создания кривой убывающей отдачи. - $-$ (внутри $1 - \exp$):
1) Математическое определение: Вычитание.
2) Физическая/логическая роль: Член $\exp(-x)$ начинается с 1 и убывает к 0. Вычитая это из 1, мы получаем функцию $1 - \exp(-x)$, которая начинается с 0 и растет к 1, что подходит для представления достигнутой доли общего потенциального прироста. - $\lambda$:
1) Математическое определение: Положительный скалярный параметр.
2) Физическая/логическая роль: Это параметр «эффективности». Он диктует, насколько эффективно конкретный метод выбора данных (и связанное с ним обучение) преобразует вычисления в прирост производительности. Более высокое $\lambda$ означает, что метод более эффективен, достигая более высокой производительности при том же количестве вычислений, делая кривую обучения более крутой.
3) Почему умножение: $\lambda$ напрямую масштабирует эффективные вычисления, делая метод более или менее чувствительным к инвестициям в вычисления. - $C(k)$:
1) Математическое определение: Общая вычислительная стоимость выбора $k$ точек данных и обучения на них. Это вычисляется как $c \times k + \sum_{x \in D} C_U(x)$, где $c$ — стоимость на точку данных для обучения.
2) Физическая/логическая роль: Это фактические вычисления, потраченные для данной стратегии. Он объединяет стоимость выбора данных и обучения. Это «вход» в функцию производительности, представляющий общую инвестицию.
3) Почему деление: Это часть отношения, нормализующая фактические потраченные вычисления относительно общих вычислений для полного обучения. - $C(|\mathcal{D}|)$:
1) Математическое определение: Общая вычислительная стоимость обучения на всем наборе данных $D$ (без какого-либо выбора данных).
2) Физическая/логическая роль: Это служит нормализующим фактором для стоимости вычислений $C(k)$. Это помещает $C(k)$ в контекст относительно стоимости «ничегонеделания» (т.е. обучения на всех доступных данных без выбора).
3) Почему деление: Нормализует $C(k)$ до безразмерного отношения, делая экспоненциальный член более общим и интерпретируемым как доля от общего возможного объема вычислений. - $+$ (вне $\exp$):
1) Математическое определение: Сложение.
2) Физическая/логическая роль: Этот оператор сдвигает всю кривую производительности вверх на величину zero-shot производительности $P_0$. Это гарантирует, что когда эффективные вычисления не используются (или $k=0$), предсказанная производительность начинается с базового уровня $P_0$.
3) Почему сложение: Экспоненциальный член вычисляет прирост сверх $P_0$. Чтобы получить абсолютную производительность, этот прирост добавляется к базовому уровню $P_0$.
Пошаговый поток: Отслеживание абстрактной точки данных (через модель производительности)
Давайте представим, что мы оцениваем конкретную стратегию выбора данных и хотим предсказать ее производительность. Это не о том, как одна точка данных течет через LLM, а скорее о том, как общие вычисления, связанные со стратегией, преобразуются в предсказание производительности с использованием параметрической модели.
- Определение стратегии: Мы начинаем с выбора конкретного метода выбора данных (например, «на основе перплексии») и решаем целевое количество точек данных ($k$), которые мы хотим выбрать для fine-tuning.
- Вычисление накладных расходов на выбор данных: Выбранный метод выбора данных сначала должен вычислить «балл полезности» для каждой отдельной точки данных в исходном, большом наборе данных $D$. Это включает фиксированную вычислительную стоимость, $\sum_{x \in D} C_U(x)$, которая похожа на первоначальный «взнос за установку» для использования этого метода.
- Определение стоимости обучения: На основе выбранных $k$ точек данных (которые были бы топ-$k$ точками после оценки всех $D$), мы вычисляем стоимость обучения LLM на этом конкретном подмножестве. Это $c \times k$, где $c$ — стоимость на точку данных.
- Агрегирование общих вычислений ($C(k)$): Мы суммируем эти две стоимости: $C(k) = (c \times k) + \sum_{x \in D} C_U(x)$. Этот $C(k)$ — общая вычислительная инвестиция для этой конкретной стратегии (использование этого метода для выбора $k$ точек, а затем обучение на них).
- Нормализация инвестиций в вычисления: Эти общие вычисления $C(k)$ затем делятся на эталонную стоимость: $C(|\mathcal{D}|)$, которая является стоимостью простого обучения на всем исходном наборе данных $D$ без какого-либо выбора. Это дает нам нормализованное отношение, указывающее, сколько вычислений мы тратим относительно «полного» прогона обучения.
- Применение эффективности метода ($\lambda$): Нормализованное отношение вычислений затем умножается на $\lambda$, параметр, уникальный для выбранного метода выбора данных. Это $\lambda$ действует как «усилитель» или «аттенюатор», отражая, насколько эффективно этот конкретный метод преобразует вычисления в прирост производительности. Метод с высоким $\lambda$ получает больше «отдачи от вложенных средств» от инвестиций в вычисления.
- Вычисление фактора прироста производительности: Результат из шага 6 подается в экспоненциальный член: $1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)$. Эта функция начинается с 0 и изгибается вверх, постепенно приближаясь к 1. Она математически захватывает идею убывающей отдачи: первоначально небольшие увеличения вычислений приводят к большим скачкам в этом факторе, но по мере роста вычислений фактор увеличивается медленнее.
- Масштабирование на потенциальное улучшение: Этот фактор прироста затем умножается на общий потенциальный прирост производительности, $(P - P_0)$. Это преобразует абстрактный фактор прироста в конкретное количество пунктов производительности, полученных сверх базового уровня.
- Добавление базовой производительности: Наконец, zero-shot производительность $P_0$ (производительность модели до fine-tuning) добавляется к вычисленному приросту. Это дает нам финальную предсказанную абсолютную производительность $P(k)$ для выбранной стратегии.
Весь этот процесс повторяется для различных методов выбора данных и различных количеств выбранных точек данных ($k$), генерируя серию кривых производительности. Сравнивая эти кривые, авторы могут идентифицировать, какой метод является «compute-optimal» для различных общих вычислительных бюджетов.
Динамика оптимизации: Как механизм учится, обновляется или сходится
Статья не описывает итеративный процесс обучения для самой LLM (как градиентный спуск для обновления весов модели). Вместо этого она фокусируется на двух уровнях «оптимизации»:
-
Изучение ландшафта производительности (подгонка параметров): Основной «механизм обучения», описанный в статье, — это процесс подгонки параметров ($P_0, P, \lambda$) параметрической модели производительности (Уравнение 3) к наблюдаемым эмпирическим данным.
- Ландшафт потерь: Для этого процесса подгонки «ландшафт потерь» определяется суммой квадратов разностей между предсказанной моделью производительностью $P(k_i; P_0, P, \lambda)$ и фактической наблюдаемой производительностью $P_{obs,i}$ из экспериментов. Цель — найти $P_0, P, \lambda$, которые минимизируют эту сумму.
- Градиенты и обновления состояния: Авторы используют алгоритм Левенберга-Марквардта для решения этой задачи нелинейных наименьших квадратов. Этот алгоритм итеративно обновляет параметры ($P_0, P, \lambda$), используя как градиентную информацию (насколько чувствительна ошибка к изменениям каждого параметра), так и аппроксимацию матрицы Гессе (которая захватывает кривизну ландшафта ошибки). Он эффективно перемещается по этому ландшафту, следуя направлению «наискорейшего спуска» (или более сложному пути), чтобы найти самую низкую точку (минимальную ошибку).
- Сходимость: Алгоритм сходится, когда найдены параметры, минимизирующие ошибку, при условии ограничений (например, $P_0 \ge 0$, $P_0 \le P$, $\lambda \ge 0$). Это дает «подобранные значения» для $P_0, P, \lambda$, которые лучше всего описывают связь между вычислениями и производительностью для каждого метода выбора данных.
-
Поиск compute-optimal стратегий (сравнительный анализ): Как только параметрические модели подобраны для каждого метода выбора данных, «оптимизация» для исходной задачи (Уравнение 2) достигается через сравнительный анализ, а не через единый итеративный алгоритм.
- Ландшафт потерь (неявный): Для заданного общего вычислительного бюджета $K$ «оптимальной» стратегией является та, которая дает наивысшую производительность $P(k)$. Подобранные параметрические кривые эффективно отображают производительность, достижимую каждым методом в диапазоне вычислительных бюджетов.
- Обновления состояния (принятие решений): Практик изучил бы эти подобранные кривые (как на Рисунке 1 или Рисунке 3). Для любого заданного вычислительного бюджета на оси x он посмотрел бы соответствующую производительность на оси y для каждого метода. Метод, чья кривая выше при этом бюджете, является compute-optimal выбором. Это процесс принятия решений, основанный на изученных моделях, а не итеративное обновление весов самой LLM.
- Граница Парето: Статья идентифицирует «границу Парето», которая представляет набор всех недоминируемых решений. Решение находится на границе Парето, если вы не можете улучшить его производительность без увеличения вычислений или уменьшить вычисления без ущерба для производительности. Цель — работать на этой границе.
По сути, статья «изучает» поведение различных методов выбора данных при вычислительных ограничениях путем подгонки математической модели к эмпирическим данным. Эта модель затем позволяет проводить анализ, экстраполяцию и принимать обоснованные решения о том, как наилучшим образом распределить вычисления, а не напрямую оптимизировать веса LLM или процесс выбора данных итеративным способом. Идеи, полученные из этого анализа, такие как требуемые соотношения размера модели обучения к модели выбора для методов перплексии и градиентов, являются ключевыми «обновлениями» нашего понимания.
Результаты, ограничения и заключение
Хорошо, давайте погрузимся в эту увлекательную статью о «Compute-Constrained Data Selection». Как мета-ученый, моя цель — разбить сложные идеи на легко усваиваемые инсайты, чтобы даже если вы совершенно новичок в этом, вы поняли основные концепции и их последствия.
Базовые знания для новичка
Представьте, что у вас есть суперумный мозг робота, называемый Большой языковой моделью (LLM), который может писать рассказы, отвечать на вопросы и даже писать код. Чтобы сделать этот мозг робота еще лучше в конкретной задаче, например, написании стихов о кошках, вам нужно показать ему много примеров стихов о кошках. Этот процесс называется fine-tuning.
Теперь, эти LLM огромны, и их обучение невероятно дорого, как с точки зрения электричества (вычисления), так и времени. Думайте об этом как о работе массивного суперкомпьютера днями или неделями. Часто у организаций есть фиксированный бюджет на это, измеряемый в FLOPs (операциях с плавающей запятой в секунду), что является причудливым способом сказать, сколько вычислений может сделать компьютер. Это похоже на наличие фиксированной суммы денег, которую можно потратить на время суперкомпьютера.
Традиционная идея выбора данных умна: вместо того чтобы показывать LLM все доступные стихи о кошках (которые могут включать много плохих или нерелевантных), почему бы не выбрать только лучшие и наиболее информативные? Таким образом, LLM учится быстрее и лучше, и вы экономите на стоимости обучения, потому что используете меньший, более качественный набор данных. Цель состоит в том, чтобы найти небольшое подмножество данных, $S$, из большей коллекции, $\mathcal{D}$, которое максимизирует производительность LLM в целевой задаче. Математически это часто выражается как:
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(T; \mathcal{T}(S)) \quad \text{при условии} \quad |S| \le K $$
Здесь $P(T; \mathcal{T}(S))$ представляет производительность модели $\mathcal{T}$ (обученной на данных $S$) на тестовом наборе $T$. Ограничение $|S| \le K$ означает, что вы можете выбрать только до $K$ точек данных. Для этого методы выбора данных обычно присваивают «балл полезности» каждой точке данных, указывая, насколько она ценна, а затем выбирают те, что имеют наивысший балл.
Мотивация проблемы
Здесь эта статья вводит решающий поворот. Хотя выбор данных уменьшает стоимость обучения, сам акт выбора данных не бесплатен! Некоторые методы выбора «лучших» стихов о кошках очень просты и дешевы, например, просто подсчет того, сколько раз появляется слово «кошка». Другие невероятно сложны, например, заставить другую, меньшую LLM прочитать каждое стихотворение и оценить его качество, или даже проанализировать сложные математические «градиенты» (как изменились бы внутренние параметры модели, если бы она училась на этом стихотворении). Эти сложные методы часто очень хороши в поиске высококачественных данных, но они приходят с существенным вычислительным ценником.
Проблема в том, что предыдущие исследования часто фокусировались на том, насколько лучше модель работает с выбранными данными, или сколько вычислительных ресурсов обучения сэкономлено, не полностью учитывая стоимость самого процесса выбора. Если метод выбора данных настолько дорог, что его стоимость перевешивает выгоды, которые он дает при обучении, то он не является по-настоящему «оптимальным» с практической, ограниченной бюджетом точки зрения.
Мотивация этой статьи — устранить это упущение. Они хотят понять общую вычислительную стоимость — как для выбора данных, так и для обучения модели на этих выбранных данных — чтобы определить, какие методы выбора данных являются наиболее эффективными при фиксированном, реальном вычислительном бюджете. Они утверждают, что это критический фактор для практического внедрения, который «недостаточно учитывался» при разработке методов.
Ограничения, которые пришлось преодолеть
Авторы столкнулись с несколькими ограничениями и проблемами при решении этой проблемы:
- Фиксированный общий вычислительный бюджет: Основное ограничение заключается в том, что общий вычислительный бюджет (например, в FLOPs) для всего процесса fine-tuning (выбор + обучение) предопределен. Это означает, что существует компромисс: тратьте больше на выбор данных, и у вас останется меньше на обучение, или наоборот.
- Различная стоимость методов выбора данных: Разные методы выбора данных имеют совершенно разные вычислительные стоимости. Простые методы (например, сопоставление ключевых слов) дешевы, в то время как сложные методы (например, выбор на основе градиентов) очень дороги, часто требуя прямого и обратного проходов через LLM.
- Убывающая отдача: Ценность добавления большего количества точек данных (или траты большего количества вычислений на выбор) обычно уменьшается. В какой-то момент модель не станет намного лучше, независимо от того, сколько еще данных или вычислений вы на нее бросите. Этот эффект «насыщения» нужно моделировать.
- Масштабируемость: LLM бывают разных размеров (от миллиардов до десятков миллиардов параметров), и оптимальная стратегия может меняться в зависимости от масштаба модели. Эксперименты должны были охватить широкий диапазон.
- Обобщаемость: Выводы должны в идеале применяться к разным задачам и архитектурам LLM, а не только к одному конкретному сценарию.
Чтобы преодолеть это, авторы:
- Переформулировали проблему: Они явно включили стоимость выбора данных в цель оптимизации, сместив ограничение с просто размера данных на общие вычисления.
- Категоризировали и количественно оценили затраты: Они систематически разделили методы выбора данных на четыре класса (лексические, основанные на эмбеддингах, основанные на перплексии, основанные на градиентах) и тщательно рассчитали их вычислительную стоимость в FLOPs (см. Таблицу 1 и Приложение B).
- Разработали параметрическую модель: Они создали математическую модель (Уравнение 3) для захвата убывающей отдачи производительности как функции общих вычислений, позволяя им подгонять эмпирические данные и экстраполировать.
- Провели масштабную экспериментальную серию: Они провели более 600 экспериментов с различными размерами LLM (от 7B до 70B параметров), 6 методами выбора данных и 3 целевыми задачами, обеспечивая широкий охват и надежные эмпирические доказательства.
Математическая интерпретация: Проблема решена и как
Авторы фундаментально переформулировали задачу выбора данных.
Проблема, которую они решили:
Вместо максимизации производительности при условии бюджета данных (количество точек данных), они стремились максимизировать производительность при условии общего вычислительного бюджета. Их новая целевая функция:
$$ S^* = \arg \max_{S \subset \mathcal{D}} P(V; \mathcal{T}(S)) \quad \text{при условии} \quad C_T(S) + \sum_{x \in \mathcal{D}} C_U(x) \le K $$
Давайте разберем это:
* $S^*$: Оптимальное подмножество данных для выбора.
* $P(V; \mathcal{T}(S))$: Производительность модели $\mathcal{T}$ (обученной на выбранном подмножестве $S$) на валидационном наборе $V$. Они используют $V$ как прокси для тестового набора $T$, обычная практика, когда $T$ недоступен во время выбора.
* $C_T(S)$: Это вычислительная стоимость обучения LLM на выбранном подмножестве данных $S$. Эта стоимость зависит от размера $S$ и архитектуры LLM.
* $\sum_{x \in \mathcal{D}} C_U(x)$: Это общая вычислительная стоимость вычисления баллов полезности для всех точек данных $x$ в исходном большом наборе данных $\mathcal{D}$. Эта стоимость возникает до выбора, так как вам нужно оценить все точки, чтобы решить, какие из них выбрать.
* $K$: Это общий вычислительный бюджет в FLOPs, охватывающий как выбор, так и обучение.
Эта формулировка подчеркивает основной компромисс: более дорогой метод выбора данных (более высокий $\sum C_U(x)$) оставляет меньше бюджета на обучение ($C_T(S)$), потенциально вынуждая вас обучать на меньшей модели или меньшее количество шагов, что может повредить финальной производительности.
Как они это решили:
-
Параметрическая модель производительности: Чтобы систематически анализировать этот компромисс, они предложили параметрическую модель ожидаемой производительности $P(k)$ как функцию общей вычислительной стоимости $C(k)$:
$$ P(k) = (P - P_0) \times \left(1 - \exp\left(-\frac{\lambda C(k)}{C(|\mathcal{D}|)}\right)\right) + P_0 $$
- $P_0$: «Zero-shot» производительность, означающая производительность модели без какого-либо fine-tuning (или обучения на нуле точек данных).
- $P$: Верхняя граница производительности, представляющая максимально возможную производительность, которую модель может достичь, даже при бесконечных вычислениях.
- $\lambda$: Решающий параметр, который контролирует, насколько эффективно метод выбора данных извлекает ценность из дополнительных вычислений. Более высокое $\lambda$ означает, что метод более эффективен.
- $C(k)$: Общая вычислительная стоимость для выбора $k$ точек данных и обучения на них.
- $C(|\mathcal{D}|)$: Общая вычислительная стоимость обучения на всем наборе данных $\mathcal{D}$ (без какого-либо выбора).
Эта модель захватывает идею о том, что производительность улучшается с вычислениями, но с убывающей отдачей, в конечном итоге плато, приближаясь к $P$.
-
Эмпирическая валидация и подгонка: Они не просто теоретизировали; они провели масштабную серию экспериментов. Для каждой комбинации размера модели, метода выбора данных и процента используемых данных они измеряли фактическую производительность и общие FLOPs, потребленные. Затем они использовали эти эмпирические данные, чтобы «подогнать» параметры ($P_0, P, \lambda$) своей параметрической модели с помощью алгоритма Левенберга-Марквардта (метод нелинейных наименьших квадратов). Это позволило им количественно оценить эффективность ($\lambda$) каждого метода выбора данных.
-
Анализ границы Парето: Построив график производительности против общих FLOPs для всех своих экспериментальных прогонов, они идентифицировали «compute-optimal границу Парето». Эта граница представляет набор стратегий (метод выбора данных + процент данных), которые достигают наивысшей возможной производительности для любого заданного общего вычислительного бюджета. Любая точка ниже этой границы является субоптимальной.
-
Экстраполяция: Используя подобранные параметрические модели, они могли затем экстраполировать, чтобы предсказать, когда более дорогие методы (такие как PPL и LESS) станут compute-optimal, особенно для очень больших обучаемых моделей, где относительная стоимость выбора становится меньше.
Архитектура экспериментов, базовые линии и окончательные доказательства
Авторы спроектировали свои эксперименты, чтобы безжалостно доказать свои математические утверждения о выборе данных с учетом вычислительных ограничений.
Архитектура экспериментов:
- Комплексная серия: Они выполнили «комплексную серию экспериментов» по нескольким измерениям:
- Размеры моделей: Модели LLAMA2 (7B, 13B, 70B параметров) и LLAMA3 8B. Это позволило им изучить эффекты масштабирования.
- Методы выбора данных:
- Random: Простая базовая линия, выбор данных случайным образом.
- BM25 (Лексический): Дешевый, статистический метод, основанный на частоте терминов.
- Embed (Основанный на эмбеддингах): Использует небольшую плотную модель эмбеддингов на базе T5 для поиска похожих данных.
- PPL (Основанный на перплексии): Использует LLM для вычисления перплексии (потерь модели) для каждой точки данных.
- LESS (Основанный на градиентах): Самый сложный, использующий градиенты для оценки влияния на потери модели.
- Бюджеты обучающих данных: Они варьировали процент используемых токенов fine-tuning от 2.5% до 100% от общего объема доступных данных.
- Целевые задачи: MMLU (фактические знания), BBH (сложные рассуждения) и IFEval (следование инструкциям). Это обеспечило обобщаемость для разных способностей LLM.
- Настройка fine-tuning: Они использовали LoRA (метод эффективного fine-tuning по параметрам) для уменьшения использования памяти, оптимизатор AdamW, точность BFloat16 и специфические скорости обучения, следуя стандартным практикам. QLoRA использовалась для модели 70B для управления памятью.
- Отслеживание FLOPs: Решающим фактором было то, что для каждого прогона они тщательно рассчитывали общие FLOPs, потребленные, которые включали как FLOPs для выбора данных, так и FLOPs для обучения. Это было ядром их анализа с учетом вычислительных ограничений.
- Идентификация границы Парето: Для каждого размера модели и задачи они строили график производительности (например, точность MMLU) против общих вычислений (FLOPs) для всех комбинаций методов выбора данных и процентов данных. Затем они идентифицировали «границу Парето» — кривую, соединяющую точки, которые предлагают лучшую производительность для заданного вычислительного бюджета.
«Жертвы» (базовые модели/методы), которые они победили:
«Жертвы» в этом контексте — не обязательно модели, которые они победили, а скорее допущения и методы, которые являются субоптимальными при общем вычислительном бюджете.
- Допущение, что «более сложное — всегда лучше»: Многие исследователи могут предположить, что более сложный метод выбора данных (например, основанный на градиентах) всегда даст лучшие результаты. Эта статья безжалостно оспаривает это допущение, когда вычисления ограничены.
- Сложные методы выбора данных (PPL и LESS) при малых/средних бюджетах: Для малых и средних вычислительных бюджетов (например, с моделями LLM 7B и 13B) статья показывает, что PPL и LESS часто являются «жертвами». Хотя они выбирают более качественные данные, их высокая вычислительная стоимость выбора означает, что они потребляют слишком много общего бюджета, оставляя меньше на обучение. Это делает их вычислительно неэффективными по сравнению с более простыми методами.
- Случайный выбор данных: Хотя случайный выбор является базовой линией, он часто превосходится даже более дешевыми методами, показывая, что некоторый выбор почти всегда лучше, чем никакой.
Окончательные, неоспоримые доказательства того, что их основной механизм действительно работал:
Самые окончательные доказательства исходят из эмпирических границ Парето, представленных на Рисунке 2, и результатов экстраполяции на Рисунках 9 и 10.
-
Рисунок 2 (Эмпирические границы Парето):
- Для моделей 7B и 13B (малые и средние вычислительные бюджеты): Панели (A, B, D, E) четко показывают, что методы BM25 (лексический) и Embed (основанный на эмбеддингах) последовательно лежат на или очень близко к compute-optimal границе Парето. Во многих случаях они превосходят PPL и LESS с точки зрения вычислительной эффективности. Это неоспоримое доказательство. Например, на Рисунке 2 (A) для MMLU 7B, BM25 и Embed достигают более высокой точности при том же бюджете FLOPs, чем PPL и LESS в широком диапазоне вычислений. Это доказывает, что даже если PPL и LESS выбирают «лучшие» данные, их высокая стоимость выбора делает их менее эффективными в целом, когда общие вычисления ограничены.
- Контраст с фиксированным бюджетом обучения (Рисунок 5a): Статья предоставляет решающий контрпример на Рисунке 5 (a). Если вы только рассматриваете бюджет обучения (игнорируя стоимость выбора), то LESS последовательно превосходит все другие методы. Этот резкий контраст между Рисунком 5(a) и Рисунком 2 — «дымящийся пистолет»: он окончательно показывает, что учет общего вычислительного бюджета (выбор + обучение) фундаментально меняет то, какая стратегия выбора данных является оптимальной. Основной механизм статьи — целевая функция, ограниченная вычислительными ресурсами — напрямую приводит к другим выводам об эффективности методов.
-
Результаты экстраполяции (Рисунки 9 и 10): Эти рисунки предоставляют количественные доказательства «точки перелома». Они показывают, что PPL и LESS действительно становятся compute-optimal, но только тогда, когда обучаемая модель значительно больше модели, используемой для выбора данных. В частности, PPL требует соотношения размера модели обучения к модели выбора 5x (около 35B параметров для обучаемой модели), а LESS требует соотношения 10x (около 70B параметров). Это математически точное открытие, полученное из их параметрической модели, подогнанной к эмпирическим данным, предоставляет неоспоримые доказательства условий, при которых эти более дорогие методы становятся жизнеспособными. Дело не в том, что они никогда не работают, а в том, что их стоимость вычислений диктует специфическое требование к масштабу для обучаемой модели.
По сути, авторы не просто заявили, что стоимость вычислений имеет значение; они тщательно измерили ее, смоделировали ее влияние и эмпирически продемонстрировали, что более дешевые методы часто выигрывают гонку вычислительной эффективности, особенно для меньших LLM. Доказательства — в кривых и количественных соотношениях.
Темы для обсуждения для будущего развития и эволюции
Эта статья открывает богатую жилу исследований. Вот несколько тем для обсуждения, представленных с разных точек зрения, чтобы стимулировать дальнейшее критическое мышление:
-
Динамические и адаптивные стратегии выбора данных:
- Текущее ограничение: Статья оценивает фиксированные методы выбора данных.
- Будущее направление: Можем ли мы разработать интеллектуального агента, который динамически выбирает или комбинирует методы выбора данных на основе текущего вычислительного бюджета, размера целевой LLM и наблюдаемой производительности? Например, начать с дешевого метода, и если бюджет позволяет, а прирост производительности плато, переключиться на более сложный метод для меньшего, критически важного подмножества данных. Это потребует мониторинга FLOPs и производительности в реальном времени, возможно, с использованием обучения с подкреплением или адаптивных систем управления.
- Критическое мышление: Как такой агент справится с неопределенностью в предсказании производительности или внезапными изменениями бюджета? Каковы вычислительные затраты самого «агента»?
-
Архитектуры LLM и методы fine-tuning с учетом стоимости:
- Текущее ограничение: Методы выбора данных часто разрабатываются независимо от архитектуры LLM или метода fine-tuning.
- Будущее направление: Можем ли мы спроектировать LLM или методы fine-tuning (например, варианты LoRA), которые по своей сути более восприимчивы к вычислительно эффективному выбору данных? Например, может ли LLM быть спроектирована с «дружественными к выбору» промежуточными представлениями, которые делают вычисления перплексии или градиентов значительно дешевле? Или могут ли быть разработаны методы fine-tuning, которые менее чувствительны к качеству данных, уменьшая потребность в дорогостоящем выборе?
- Критическое мышление: Не скомпрометируют ли такие специализированные архитектуры обобщаемость или другие метрики производительности? Каковы компромиссы между дружественностью к выбору и основными возможностями модели?
-
Амортизация за пределами многозадачных настроек:
- Текущее ограничение: Статья затрагивает многозадачную амортизацию (Рисунок 4), где затраты на выбор распределяются между несколькими прогонами fine-tuning для разных задач.
- Будущее направление: Исследуйте другие сценарии амортизации. Как насчет непрерывного обучения, где LLM периодически обновляется новыми данными? Можно ли выполнить дорогостоящий выбор данных один раз, а затем повторно использовать его для нескольких последующих циклов fine-tuning или для разных пользователей с похожими потребностями? Рассмотрите модель «выбор данных как услуга», где предварительно вычисленные баллы полезности или выбранные подмножества передаются.
- Критическое мышление: Как быстро баллы полезности устаревают в динамичной среде данных? Каковы последствия для конфиденциальности и интеллектуальной собственности при обмене выбранными наборами данных или баллами полезности?
-
За пределами FLOPs: Целостная модель стоимости вычислений:
- Текущее ограничение: Статья в основном фокусируется на FLOPs как мере стоимости вычислений.
- Будущее направление: Расширьте модель стоимости вычислений, включив другие критические ресурсы. Это может включать:
- Использование памяти: Особенно важно для больших моделей и сред с ограниченными ресурсами.
- Потребление энергии: Напрямую влияет на экологическую устойчивость и эксплуатационные расходы.
- Затраты на участие человека: Для методов, требующих маркировки или проверки человеком, эта стоимость может быть существенной.
- Задержка: Время, затраченное на выбор и обучение, может быть критическим фактором при реальном развертывании.
- Критическое мышление: Как взаимодействуют эти разные измерения стоимости? Существует ли единая, унифицированная метрика, которая может захватить все эти аспекты, или нам нужна многоцелевая оптимизация?
-
Предиктивное моделирование $\lambda$ и оптимальных соотношений:
- Текущее ограничение: Параметр эффективности $\lambda$ и оптимальные соотношения размера модели обучения к модели выбора определяются эмпирически путем подгонки параметрической модели.
- Будущее направление: Можем ли мы разработать теоретические основы или подходы мета-обучения для предсказания $\lambda$ или оптимальных соотношений для новых задач, наборов данных или архитектур моделей без проведения обширных эмпирических серий? Это потребует понимания внутренних свойств данных, задач и моделей, которые влияют на эффективность выбора.
- Критическое мышление: Какие характеристики набора данных или задачи коррелируют с более высоким $\lambda$ для данного метода выбора? Можем ли мы использовать меньшие пилотные эксперименты для информирования этих предсказаний для развертываний большего масштаба?
-
Этические последствия выбора с учетом вычислительных ограничений:
- Текущее ограничение: Статья фокусируется на эффективности и производительности.
- Будущее направление: Рассмотрите этические последствия. Если более дешевые методы предпочтительнее при вычислительных ограничениях, не вводят ли они непреднамеренно предвзятость или не снижают ли они справедливость по сравнению с более сложными методами, которые могут идентифицировать более разнообразные или репрезентативные данные? Например, если BM25 выбирает данные на основе общих ключевых слов, он может усилить существующую предвзятость в данных.
- Критическое мышление: Как мы можем гарантировать, что compute-optimal выбор данных не приведет к моделям «достаточно хорошим», которые менее надежны или справедливы, чем те, что обучены с более дорогим, но потенциально более справедливым выбором данных? Существует ли минимальный порог «качества» для выбора данных, который следует поддерживать, даже если он не является строго compute-optimal?
Эти пункты обсуждения подчеркивают, что, хотя эта статья предоставляет блестящую и практическую структуру, путь к действительно оптимальному и ответственному fine-tuning LLM в реальных условиях еще далек от завершения.
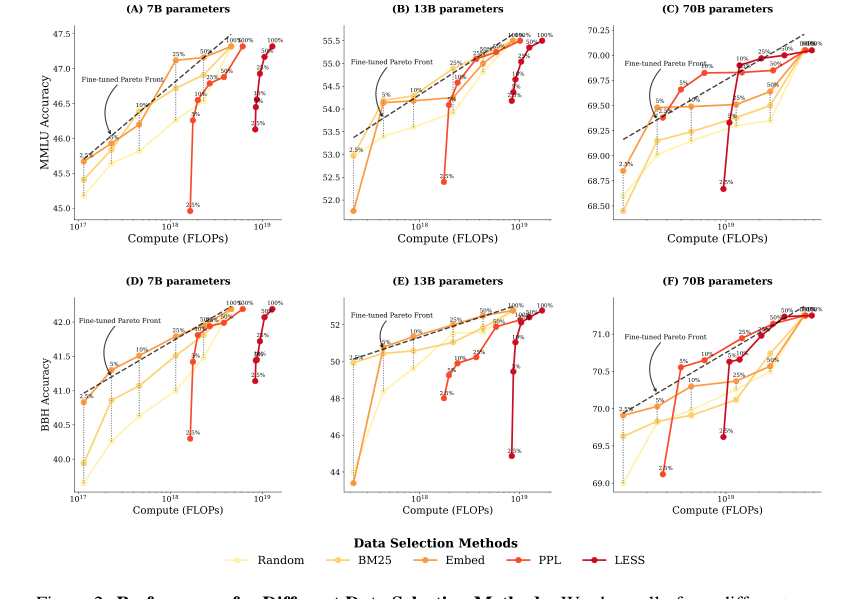 Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
Figure 2. Performance for Different Data Selection Methods. We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (A, B, C) show MMLU results across three model sizes, while (D, E, F) present BBH results across three model sizes. For each run, we determine the optimal finetuning strategy—a combination of data selection method and number of finetuning tokens—that achieves the highest performance un- der a particular FLOPs budget. We fit a pareto front in dashed line based on these optimal strategies, which is a line in the linear-log space. At small and medium compute budgets (A, B, D, E), cheaper data selection methods like BM25 and EMBED outperform PPL and LESS, which rely on model information. At larger compute budgets (C, F), however, PPL and LESS become compute-optimal after using 5% of the fine-tuning tokens
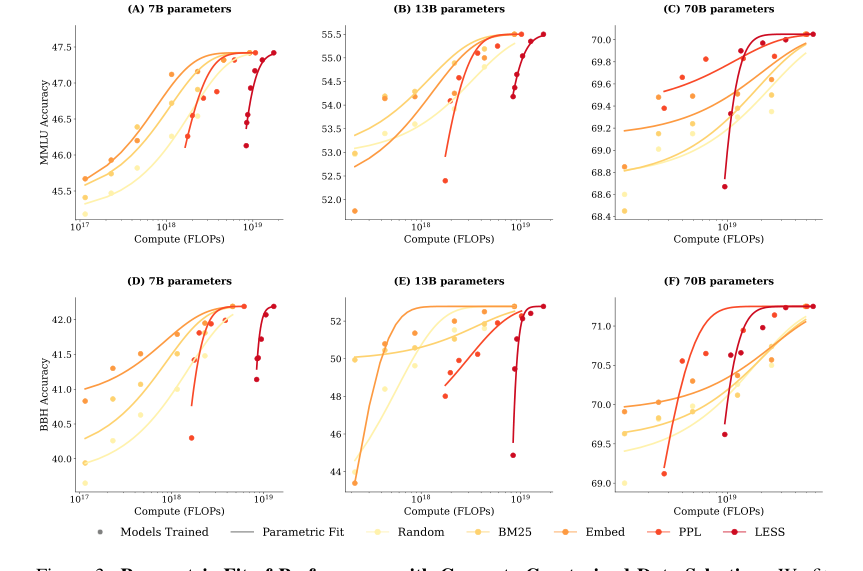 Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
Figure 3. Parametric Fit of Performance with Compute-Constrained Data Selection. We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points. (A, B, C) show MMLU results and their parametric fit across three model sizes, while (D, E, F) present BBH results and their parametric fit across three model sizes
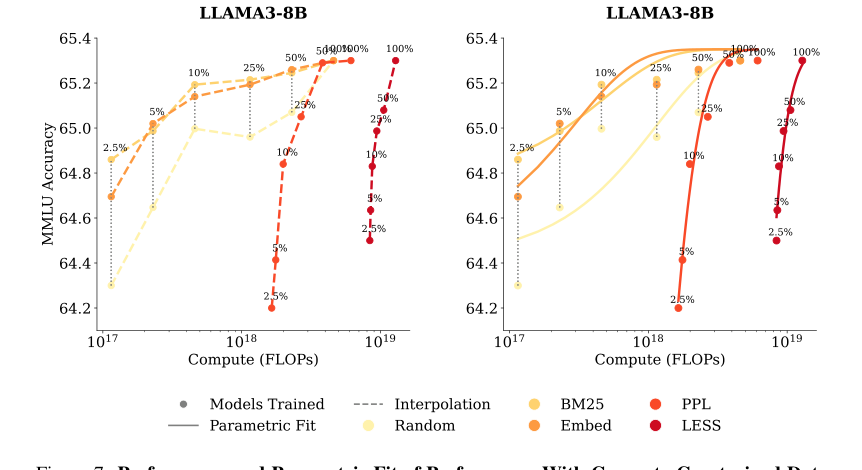 Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points
Figure 7. Performance and Parametric Fit of Performance With Compute-Constrained Data Selection. (Left) We show all of our different runs for a given model size, where each scatter point is the final target task performance of a single run. (Right) We fit a parametric model of the performance in Equation (3) and display that as curves to pair with the empirical results as scatter points