D3M: Deformation-Driven Diffusion Model for Synthesis of Contrast-Enhanced MRI with Brain Tumors
Contrast-enhanced magnetic resonance images (CEMRIs) provide valuable information for brain tumor diagnosis and treatment planning.
Background & Academic Lineage
The Origin & Academic Lineage
本論文で取り組む中心的な問題は、特に脳腫瘍診断において、非造影MRI画像(NCMRI)から造影MRI画像(CEMRI)を合成することである。この特定の課題は、臨床現場における重要なニーズから生じた。CEMRIは脳腫瘍の特定と治療計画に不可欠な情報を提供する一方で、その取得には造影剤の注射が必要となる。この処置には、患者の健康リスク[15, 25]、相当な高コスト[27]、および造影剤の廃棄に関連する環境問題の増大[2, 8]など、いくつかの重大な欠点が伴う。
歴史的に、研究者たちは造影剤注射の必要性を排除しつつ、診断画像品質を維持するために、標準的なNCMRIから計算的にCEMRIを生成する方法を開発することで、これらの問題を回避しようとしてきた。この分野の初期の取り組みは、Pix2Pix[17, 6]のようなモデルに触発されたU-Netベースの3D畳み込みニューラルネットワーク(CNN)や条件付き敵対的生成ネットワーク(GAN)などの深層学習アーキテクチャを活用していた。より最近では、学術的な系譜は、リアルな医用画像を生成する上で顕著な成功を示している拡散モデルへと大きくシフトしている[16, 24, 26, 29]。これらの最先端の拡散モデルはCEMRI合成に適応されており、一部のアプローチは肝臓[26]のような特定の臓器に焦点を当てている。
これらの先行アプローチ、既存の拡散モデルを含む、の根本的な限界、すなわち「ペインポイント」は、NCMRIからのCEMRI合成が依然として非常に不良設定問題(ill-posed problem)であることである。NCMRIは造影領域に関する曖昧な証拠しか提供しないことが多く、モデルが造影がどこで発生すべきかを正確に予測することを困難にしている。その結果、先行手法はしばしば顕著な偽陽性および偽陰性の造影結果を生み出す。これは、非造影領域に誤って造影を示す(偽陽性)か、造影されるべき領域に造影を示さない(偽陰性)ことを意味する。この問題は、腫瘍領域において特に顕著であり、腫瘍のサブコンポーネントの複雑でしばしば複雑な形態が正確に捉えられていない。本論文の著者らは、この問題を再定式化することで対処している。すなわち、造影エラーを単なる強度差(しばしば大きく修正が困難)として扱うのではなく、腫瘍サブコンポーネントの誤った幾何学的解釈として概念化している。これにより、空間変形による修正が可能になる。必要な幾何学的調整は通常小さいため、これはより管理しやすいタスクとなる。
Intuitive Domain Terms
ゼロベースの読者が概念を理解できるように、専門用語を日常的なアナロジーに翻訳したものを以下に示す。
- 造影MRI画像(CEMRIs): 都市の地図を見ていると想像してください。しかし、重要な建物(病院やランドマークなど)が区別しにくいとします。CEMRIは、それらの重要な建物を明るく光らせる特別なハイライターを使用するようなもので、すぐに目立ち、識別しやすくなります。
- 非造影MRI画像(NCMRIs): 地図のアナロジーに従って、NCMRIは特別なハイライトのない通常の地図です。すべての建物がありますが、重要な建物はそれ自体では目立ちません。
- 拡散モデル(Diffusion Model): ぼやけたピクセル化された写真が、まるでアーティストが細部を丹念に追加していくように、ゆっくりと鮮明で詳細になる様子を想像してください。拡散モデルは、これを逆に行うAIです。純粋なノイズ(信号のないテレビのようなもの)から始まり、段階的に「ぼかしを解除」または「ノイズを除去」して、完全でリアルな画像が現れるまで続きます。
- 不良設定問題(Ill-posed problem): これは、多くの可能な答えがあるなぞなぞを解こうとするようなものです。あるいは、最初の推測のわずかな変化が完全に異なる結果につながるようなものです。CEMRI合成の場合、造影剤がないと、入力(NCMRI)は、完璧なCEMRIを確実に生成するのに十分な明確な手がかりを与えず、エラーが発生しやすくなることを意味します。
- 空間変形(Spatial Deformation): 風船に顔を描くことを想像してください。空間変形は、目を描いたり消したりするのではなく、風船をそっと押しつぶしたり伸ばしたりして、目や口の位置を微妙にシフトさせるようなものです。これは、配置を修正するために画像のパーツを幾何学的に移動することです。
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
本論文で取り組む中心的な問題は、特にT1強調、T2強調、およびFLAIR画像における、非造影MRI画像(NCMRI)からの造影MRI画像(CEMRI)の合成である。
モデルの出発点(入力)は、NCMRIのセットである。訓練中、腫瘍の造影されたアノテーションマスクの形式の補助情報も、学習プロセスをガイドするために利用される。望ましい終点(出力)は、実際の造影剤注射を必要とせずに、脳腫瘍とその造影パターンを正確に描写する高品質な合成CEMRIである。
数学的なギャップ、すなわち欠けているリンクは、NCMRIからCEMRIを合成するという固有の「不良設定」の性質にある。NCMRIは「造影領域に関する曖昧な証拠」しか提供しないため、造影がいつどのように現れるかを正確に予測することは極めて困難である。拡散モデルに基づく手法を含む以前の研究は、この点で苦労しており、しばしば「偽陽性および偽陰性の造影結果」を生み出している。これは、造影されない領域が誤って高強度で描写される(偽陽性)、または造影されるべき領域が低強度で描写される(偽陰性)ことを意味する。重要なギャップは、これらのモデルが「腫瘍サブコンポーネントの複雑な形態」とその特定の造影特性を正確に捉えられないことである。
以前の研究者を閉じ込めてきた痛みを伴うトレードオフまたはジレンマは、これらのエラーを修正するアプローチから生じる。彼らは通常、造影の不一致を強度エラーとしてモデル化する。しかし、これらの強度エラーの修正は「通常大きく、修正が困難」である。これは困難なバランスをとることを生み出す。造影の忠実度を向上させるには、しばしば抜本的で管理が難しい強度調整が必要となり、アーティファクトや全体的にリアルでない画像につながる可能性がある。本論文は、新しい再定式化を提案している。これを強度エラーとしてではなく、「腫瘍サブコンポーネントの誤った解釈」としてフレーム化している。これにより、空間変形による幾何学的修正が可能になり、大規模な強度修正と比較して「比較的小さく、より管理しやすい」と提示されている。
Constraints & Failure Modes
NCMRIからCEMRIを合成するという問題は、いくつかの厳しい現実的な制約によって非常に困難になっている。
- 物理的制約:
- 造影剤の健康リスクとコスト: この研究の主な動機は、ガドリニウムベースの造影剤の必要性を回避することである。これは「健康リスク、高コスト、環境問題」を伴う。この制約は、正確な合成の必要性を推進する。
- 曖昧な入力情報: NCMRIは本質的に「造影領域に関する曖昧な証拠」を提供する。これは、入力データ自体が造影を直接推論するために必要な明示的な情報を持たず、合成タスクを根本的に困難にすることを意味する。
- 計算的制約:
- 不良設定問題: NCMRIからCEMRIを合成することは、「非常に不良設定問題」である。これは、単一のNCMRI入力に対して複数の可能なCEMRIが存在する可能性があり、追加のガイダンスなしにモデルが正しい造影画像を一意に決定することを困難にすることを示唆している。
- 複雑な形態: 既存のモデルは、「腫瘍サブコンポーネントの複雑な形態」を捉えられない。これは、単純なピクセル単位または強度ベースのマッピングでは、造影腫瘍領域の複雑な形状と境界を表現するには不十分であることを示唆している。
- 段階的なノイズ除去プロセス: 拡散モデルは「段階的な」ノイズ除去プロセスを通じて動作する。これらの複数のステップ内で、エラーの蓄積や拡散プロセスの中断なしに幾何学的修正を効果的に統合することは、重大な計算上およびアーキテクチャ上の課題である。
- データ駆動型制約:
- 高品質なアノテーションの必要性(訓練用): 推論時に造影剤を回避することが目標であるが、モデルは訓練中に「造影腫瘍のアノテーションの補助情報」に依存する。これらのマスクは「高品質なラベルを保証するために臨床専門家によって手動でアノテーションされ、レビューされる」必要があり、これは労働集約的でコストのかかるプロセスである。このような正確なグラウンドトゥルースデータの品質と可用性は、モデル訓練の成功にとって重要である。
- 一般化の困難さ: 脳腫瘍の複雑で多様な性質は、モデルが多様な腫瘍タイプと患者の解剖学的構造全体で正確な造影を合成するのに十分な堅牢性を持つ必要があることを意味する。これは重大な一般化の課題である。
Why This Approach
The Inevitability of the Choice
著者らは、特に脳腫瘍のCEMRIからNCMRIへの合成において、重大な障害に直面した。彼らは、NCMRIが造影領域に関する曖昧な証拠しか提供しないため、このタスクが「非常に不良設定問題」であると明示している。従来の最先端(SOTA)手法、標準的なCNN、Paletteのような基本的な拡散モデル、さらにはI2SBのようなより高度な拡散モデルでさえ、「顕著な偽陽性および偽陰性の造影結果」を生み出すことが見出された。これは特に腫瘍領域で問題となり、これらのモデルは腫瘍サブコンポーネントの複雑な形態を捉えられなかった。
D³Mアプローチにつながった重要な認識は、これらの造影エラーの根本的な再解釈であった。それらを修正が困難な強度エラーとしてではなく、著者らはそれらを「腫瘍サブコンポーネントの誤った解釈」として認識した。すなわち、造影領域が非造影として誤解され、その逆も然りであった。この視点の変化により、この問題は空間変形による幾何学的修正を通じてより効果的に対処できることが明らかになった。著者らは、強度エラーは通常大きく修正が困難であるのに対し、必要な幾何学的修正(小さな変位)は「比較的小さく、より管理しやすい」と理解していた。この洞察により、変形駆動型アプローチは単なる改善ではなく、固有の不良設定と複雑な腫瘍構造の処理における既存手法の特定の失敗モードを克服するための唯一実行可能な解決策となった。
Comparative Superiority
D³Mメソッドは、単なるパフォーマンス指標を超えたいくつかの構造的利点を通じて、質的な優位性を達成している。中核的なイノベーションは、強度エラーとしてではなく幾何学的に造影エラーに対処する能力にある。これは、小さな空間的なずれを修正することは、大きな誤った強度値を修正しようとするよりも、本質的に安定して効果的であるため、深遠な構造的利点である。
具体的には、Multi-step Spatial Deformation Module (MSSDM) は重要な差別化要因である。従来の事後処理変形とは異なり、MSSDMは拡散モデルの段階的なノイズ除去プロセス内に緊密に統合されている。この統合は2つの理由で重要である。第一に、後で修正が困難になる深刻なエラーの蓄積を防ぐ。第二に、画像生成と幾何学的修正の両方の共同最適化を促進する。これは、モデルが各ステップで幾何学的な精度を同時に修正しながら画像を合成することを学習することを意味し、より堅牢で正確な出力を生み出す。
さらに、Dual-stream Image-Mask Decoder (DSIMD) は、造影腫瘍をセグメント化するという補助タスクを提供する。これは単なる追加機能ではなく、モデルの造影の基本的な「理解」を改善する構造的強化である。中間的な造影画像とマスクを共同で生成することにより、DSIMDは空間変形のためのMSSDMに明示的で高レベルのガイダンスを提供する。このデュアルストリーム処理により、幾何学的な修正は、腫瘍の境界と造影領域の明確な意味論的理解に基づいていることが保証され、特に腫瘍の複雑な形態を維持する上で、全体的な合成が質的に優れている。アブレーションスタディは、MSSDMとDSIMDの両方が、特に腫瘍領域でのパフォーマンス向上に大きく貢献していることを確認しており、それらの構造的重要性を示唆している。
Alignment with Constraints
D³Mアプローチは、問題の厳しい要件と独自のソリューションプロパティとの「結婚」を驚くほど示している。問題定義で特定された主な制約は、NCMRIからのCEMRI合成の「非常に不良設定」の性質であり、これは「偽陽性および偽陰性の造影」と「腫瘍サブコンポーネントの複雑な形態」の捉え損ないにつながる。
D³Mは、以下のことによりこれらの制約に完全に適合している。
1. エラーの再解釈: エラーを幾何学的な誤解釈として再定式化するというソリューションの中核的なアイデアは、不良設定に直接対処する。D³Mは、大きくて管理不能な強度エラーで苦労するのではなく、より小さく、より管理しやすい幾何学的修正に焦点を当てている。この特性は、NCMRIからの曖昧な証拠を扱う課題に固有に適合している。
2. 多段階幾何学的修正(MSSDM): 拡散プロセス内にMSSDMを統合することで、段階的な幾何学的調整が可能になる。これは、「造影領域を移動させて」これらのエラーを除去することにより、偽陽性および偽陰性造影のエラーを修正するという問題に直接対処する。ノイズ除去プロセス全体で継続的にエラーを修正する能力は、腫瘍形態の複雑でしばしば微妙な詳細を洗練するのに最適であり、先行手法は苦労していた。
3. 強化された理解(DSIMD): 腫瘍セグメンテーションの補助タスク(DSIMD経由)は、モデルに造影腫瘍が何であるかについてのより深く、意味論的な理解を提供する。この明示的なガイダンスは、「腫瘍サブコンポーネントの複雑な形態」を正確に合成するために不可欠であり、幾何学的な修正が生物学的に妥当で臨床的に関連性があることを保証する。このデュアルストリームアプローチは、モデルが単に画像を生成するだけでなく、解剖学的および病理学的構造を尊重する画像を生成することを保証する。これは、医用画像にとって重要な要件である。
Rejection of Alternatives
本論文は、NCMRIからのCEMRI合成の特定の課題に対処する上での既存手法の根本的な限界を強調することにより、代替アプローチを暗黙的かつ強力に拒否している。著者らは各代替案の直接的な「拒否声明」を提供していないが、GANや基本的な拡散モデルを含む一般的な手法を含む既存の手法が不十分である理由を明確な根拠で確立している。
代替案を拒否する主な理由は、問題の「非常に不良設定」の性質と、特に「腫瘍サブコンポーネントの複雑な形態」に関して生じる「顕著な偽陽性および偽陰性の造影結果」を効果的に処理できないことである。Pix2Pix(GANベース)やPalette(基本的な拡散モデル)のような手法は、基本的に強度分布に基づいたマッピングを学習したり画像を生成したりするように設計されている。それらの主な限界は、本論文が示唆するように、造影エラーを主に強度エラーとして扱っていることである。著者らが説明するように、これらの強度エラーは「通常大きく、修正が困難」である。
表1の比較分析は、この拒否をさらに強化している。D³Mは、特に腫瘍領域内において、Pix2Pix、ResViT(敵対的学習と組み合わせたトランスフォーマーとCNNを組み合わせたマルチモーダルモデル)、Palette、およびI2SB(シュレディンガーブリッジ拡散モデル)よりも一貫して優れたパフォーマンスを示している。この経験的証拠は、既存の手法が強度ベースのエラー処理のために複雑な腫瘍形態を捉えられないという理論的議論と相まって、これらの代替案を説得力のある拒否として機能する。D³Mの幾何学的修正パラダイムは、この挑戦的な医用画像合成タスクに固有の特定の種類の誤解釈エラーを解決する準備ができていなかったこれらの先行アプローチからの必要な出発点として提示されている。
Mathematical & Logical Mechanism
The Master Equation
D³Mモデルの中核、特に造影MRI(CEMRI)が合成される推論フェーズでは、反復的なノイズ除去と幾何学的修正ステップが行われる。このプロセスは、ノイズが多い状態 $x_t$ から時間 $t-1$ のノイズが少ない状態へと画像を更新する以下の式にカプセル化されている。
$$x_{t-1} = \phi_{\hat{u}_t} \left( \sqrt{\bar{\alpha}_{t-1}} \hat{x}_0^{(t)} + \sqrt{1-\bar{\alpha}_{t-1}} \hat{\epsilon}_{i,t} \right)$$
この式は、Denoising Diffusion Implicit Model(DDIM)の修正された決定論的逆ステップを表す。ここで、予測された元の画像 $\hat{x}_0^{(t)}$ と予測されたノイズ $\hat{\epsilon}_{i,t}$ は、現在のノイズが多い画像 $x_t$ とモデルの速度予測から最初に推定され、次に $\phi_{\hat{u}_t}$ によって空間的に変形されてから、次の、ノイズが少ない画像 $x_{t-1}$ を形成するために結合される。
Term-by-Term Autopsy
マスター方程式とその基盤となるコンポーネントを分解してみよう。
- $x_{t-1}$: これは、前のタイムステップ $t-1$ における推定CEMRI画像を表す。これは、ノイズ除去と幾何学的修正の両方を受けた、現在の逆拡散ステップの出力である。その物理的な役割は、ノイズから望ましいCEMRIを段階的に再構築することである。
- $\phi_{\hat{u}_t}(\cdot)$: これは空間変形演算子である。入力に幾何学的変換を適用し、変形フィールド $\hat{u}_t$ に従って画像の内容を歪ませる。著者は、腫瘍サブコンポーネントの幾何学的な誤解釈として問題がフレーム化され、強度修正だけでなく空間調整が必要であるため、単純な算術演算の代わりにこの演算子を使用した。
- $\hat{u}_t$: これはタイムステップ $t$ における予測変形フィールドである。これは、各ピクセルがどのように変位されるべきかを指定する2Dベクトルフィールド(2Dスライスの場合)である。その物理的な役割は、合成画像における偽陽性および偽陰性の造影を幾何学的に修正することである。これは、中間マスク推定値 $\hat{m}_0^{(t)}$ を入力として受け取る、Multi-Step Spatial Deformation Module(MSSDM)内のDeformation Estimation Module $U(\cdot)$ によって推定される。
- $\hat{m}_0^{(t)}$: これはタイムステップ $t$ における元の(グラウンドトゥルース)造影腫瘍マスクの中間推定値である。これは、ノイズの多いマスク $m_t$ と予測されたマスク速度 $\hat{v}_{m,t}$ から、以下の式を使用して計算される。
$$\hat{m}_0^{(t)} = \sqrt{\bar{\alpha}_t} m_t - \sqrt{1-\bar{\alpha}_t} \cdot \hat{v}_{m,t}$$
その論理的な役割は、変形フィールド推定のガイドに不可欠な、腫瘍の造影領域のクリーンで破損のない表現を提供することである。ここでの減算は、フォワード拡散プロセスを逆転させる一部であり、マスクの「ノイズ除去」を効果的に行う。
- $\sqrt{\bar{\alpha}_{t-1}}$: これは予測された元の画像コンポーネントのスケーリング係数である。ノイズスケジュールパラメータから派生し、信号(予測された元の画像)の重みを再構築に決定する。平方根は、分散を処理するために拡散モデルで標準的に使用される。
- $\hat{x}_0^{(t)}$: これは、現在のノイズの多い画像 $x_t$ から推定された、元の(ノイズのない)CEMRI画像のモデル予測であり、タイムステップ $t$ における予測画像速度 $\hat{v}_{i,t}$ である。その物理的な役割は、拡散プロセスが回復しようとしている基盤となるクリーンな画像を表すことである。これは次のように導出される。
$$\hat{x}_0^{(t)} = \frac{\sqrt{\alpha_t} x_t - \sqrt{1-\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
加算/減算とスケーリング係数の組み合わせは、拡散プロセスの逆転から直接生じるものであり、予測された速度を予測された元の画像に関連付ける。 - $\sqrt{1-\bar{\alpha}_{t-1}}$: これは予測されたノイズコンポーネントに適用される別のスケーリング係数である。再構築における「ノイズ」の重みを表す。$\sqrt{\bar{\alpha}_{t-1}}$ と同様に、その形式は分散スケジュールから派生している。
- $\hat{\epsilon}_{i,t}$: これは、元の画像に加えて $x_t$ を生成するために追加されたガウスノイズコンポーネントのモデル予測である。その物理的な役割は、除去する必要があるランダムな変動を表すことである。これは $x_t$ と予測された画像速度 $\hat{v}_{i,t}$ から次のように導出される。
$$\hat{\epsilon}_{i,t} = \frac{\sqrt{1-\bar{\alpha}_t} x_t + \sqrt{\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
ここでも、算術演算は拡散プロセスの数学的逆転の一部である。 - $x_t$: これは現在のタイムステップ $t$ におけるノイズの多いCEMRI画像であり、現在のノイズ除去ステップの入力として機能する。
- $\hat{v}_{i,t}$: これはタイムステップ $t$ における予測画像速度項である。これは、ノイズの多い画像 $x_t$、ノイズの多いマスク $m_t$、条件付きNCMRI $c$、およびタイムステップ $t$ を入力として受け取るDual-Stream Image-Mask Decoder(DSIMD) $D(\cdot)$ の主な出力である。
$$(\hat{v}_{i,t}, \hat{v}_{m,t}) = D(E(x_t, m_t, c, t), t)$$
その論理的な役割は、ノイズやノイズ除去された画像を直接予測するのではなく、モデルが学習するためのより安定した効率的なターゲットを提供することである。 - $m_t$: これは現在のタイムステップ $t$ におけるノイズの多い造影腫瘍マスクである。マスク速度予測をガイドするために $x_t$ と共に処理される。
- $c$: これらは条件付き画像、特に非造影MRI(NCMRI)である。これらはモデルに重要な解剖学的コンテキストを提供し、CEMRIの合成をガイドする。これらはノイズの多い入力と共にエンコーダに供給される。
- $t$: これは拡散プロセスにおける現在のタイムステップを表し、$T$(純粋なノイズ)から $0$(クリーンな画像)まで変化する。モデルに現在のノイズレベルを知らせるためにネットワークに供給される。
- $E(\cdot)$: これはPixelCNN++をベースとし、Wide ResNetバックボーンを持つエンコーダネットワークである。その役割は、ノイズの多い画像、マスク、および条件付きNCMRIから関連する特徴を抽出することである。
- $D(\cdot)$: これはDual-Stream Image-Mask Decoder(DSIMD)であり、エンコードされた特徴とタイムステップ $t$ を受け取り、予測画像速度 $\hat{v}_{i,t}$ とマスク速度 $\hat{v}_{m,t}$ を共同で生成する。デュアルストリーム設計により、画像とマスク情報を別々に処理でき、モデルの造影の理解を向上させる。
- $\bar{\alpha}_t = \prod_{s=1}^t \alpha_s$: これはタイムステップ $t$ までのノイズスケジュールパラメータ $\alpha_s$ の累積積である。フォワード拡散プロセスにおける元の画像コンポーネントの全体的なスケーリングを決定する。積は、独立したガウスノイズ加算において分散が加算されるため使用される。
- $\alpha_t$: これはタイムステップ $t$ におけるノイズスケジュールのパラメータであり、各ステップで追加または除去されるノイズの量を示す。
Step-by-Step Flow
単一の抽象的なデータポイント、すなわち脳のボクセルが、推論(合成)プロセス中に変換を受けると想像してください。目標は、純粋なノイズの初期状態($x_T$)からクリーンな造影MRI($x_0$)を生成することです。
- 初期化: プロセスは最大のタイムステップ $t=T$ で始まります。完全にノイズの多い画像 $x_T$ とノイズの多いマスク $m_T$ から開始します。どちらも基本的にランダムなガウスノイズです。
- 特徴抽出(エンコーダ): 各ステップ $t$($T$ から始まり $1$ まで減少)で、現在のノイズの多い画像 $x_t$、ノイズの多いマスク $m_t$、条件付き非造影MRI $c$、および現在のタイムステップ $t$ がエンコーダ $E(\cdot)$ に供給されます。このエンコーダは洗練されたフィルターのように機能し、ノイズの中でも基盤となる構造と造影パターンを表す意味のある特徴を抽出します。
- 速度予測(DSIMD): エンコーダによって抽出された特徴は、次にDual-Stream Image-Mask Decoder $D(\cdot)$ に渡されます。2つの並列ストリームで設計されたこのデコーダは、これらの特徴を処理して、画像用の $\hat{v}_{i,t}$ とマスク用の $\hat{v}_{m,t}$ という2つの重要な「速度」項を予測します。これらの速度は、ノイズの多い状態からクリーンな元の画像とマスクに向かって移動するために必要な変化の方向と大きさを指示します。
- 中間画像とマスクの推定:
- 予測された画像速度 $\hat{v}_{i,t}$ と現在のノイズの多い画像 $x_t$ を使用して、モデルはフォワード拡散プロセスを数学的に逆転させ、元のクリーンなCEMRI画像($\hat{x}_0^{(t)}$)がどのように見えるか、およびノイズコンポーネント($\hat{\epsilon}_{i,t}$)が何であったかを推定します。これは、$\hat{x}_0^{(t)}$ と $\hat{\epsilon}_{i,t}$ の導出された式を使用して行われます。
- 同様に、予測されたマスク速度 $\hat{v}_{m,t}$ と現在のノイズの多いマスク $m_t$ を使用して、元のクリーンな造影腫瘍マスク($\hat{m}_0^{(t)}$)の中間推定値が計算されます(式4による)。このマスクは、腫瘍サブコンポーネントを理解するために不可欠です。
- 変形フィールド推定(MSSDM): 中間マスク推定値 $\hat{m}_0^{(t)}$ は、次にMulti-Step Spatial Deformation Module(MSSDM)の一部であるDeformation Estimation Module $U(\cdot)$ に供給されます。このモジュールは推定されたマスクを分析して、偽陽性または偽陰性の造影領域を特定し、これらの造影エラーを幾何学的に修正するためにピクセルをシフトする必要がある変形フィールド $\hat{u}_t$ を計算します。
- 幾何学的修正(空間変形): 推定された元の画像 $\hat{x}_0^{(t)}$ とノイズ推定値 $\hat{\epsilon}_{i,t}$ は、次に空間変形演算子 $\phi_{\hat{u}_t}$ を通されます。この演算子はこれらの画像を $\hat{u}_t$ に従って歪ませ、事実上、造影領域を正しい場所に「移動」させたり、偽の領域を削除したりします。これは、D³Mを区別する重要なステップであり、強度調整だけでなく幾何学的にエラーを修正します。
- 逆拡散ステップ: 最後に、変形された $\hat{x}_0^{(t)}$ と $\hat{\epsilon}_{i,t}$ は、DDIM逆ステップ(マスター方程式)を使用して結合されます。このステップは、画像から少量のノイズを効果的に除去し、新しい、ノイズが少なく、幾何学的に修正された画像 $x_{t-1}$ を生成します。
- 反復: このプロセス全体が繰り返され、$x_{t-1}$ が新しい $x_t$ となり、次のステップに進みます。$t=0$ に達すると、最終的な合成CEMRI画像 $x_0$ が取得され、モデルの造影画像に対する最良の推定値であり、正確な腫瘍形態を持つものが表されます。
この逐次的、反復的なプロセスにより、モデルは画像を段階的に洗練させ、ノイズを除去しながら、腫瘍造影に関連する幾何学的な歪みを同時に修正できます。
Optimization Dynamics
D³Mメカニズムは、慎重に構築された損失関数に基づいて、内部パラメータ(ニューラルネットワークの重み)を反復的に調整することにより学習および収束します。このプロセスは、2つの主要なコンポーネントの相互作用によって駆動されます。
-
損失関数: モデルは、2つの部分からなる複合損失を最小化するように訓練されます。
- 重み付き平均二乗誤差損失($\mathcal{L}_{wmse}$): これは拡散モデルにおける標準的な損失であり、通常、モデルの予測(例:予測ノイズ $\hat{\epsilon}_{i,t}$ または予測速度 $\hat{v}_{i,t}$)と真の値との間の不一致を測定します。論文では、「各ステップでの合成結果」に適用されると述べられており、これは損失が正確なCEMRI画像を生成するようにモデルを導くことを意味します。 「重み付き」という側面は、画像の一部または異なるタイムステップが全体的な損失に異なる貢献をする可能性があることを意味し、腫瘍のような重要な領域に焦点を当てる可能性があります。この損失は、モデルの予測がグラウンドトゥルースに密接に一致する「谷」を作成することにより、ランドスケープを形成し、正確な画像合成を促進します。
- 変形スムーズネス正則化($\mathcal{L}_{sreg}$): この項は、各ステップでの変形フィールド $\hat{u}_t$ に適用されます。通常、空間勾配のL2ノルムを計算することにより、変形フィールドの大きすぎるまたは急激な変化をペナルティします。その目的は、幾何学的な修正がスムーズで物理的に妥当であることを保証し、モデルが非現実的またはギザギザした変形を生成するのを防ぐことです。この正則化項は、変形に関連する損失ランドスケープで過度に複雑またはノイズの多い領域を平坦化する「ペナルティ」として機能し、モデルをより安定した解釈可能な変換に導きます。著者は、モデルがノイズに過学習したり、変形にアーティファクトを作成したりするのを防ぐためにこれを使用しました。
-
勾配ベース最適化: 訓練中、複合損失が計算され、次にバックプロパゲーションを使用して、エンコーダ $E(\cdot)$、デュアルストリーム画像マスクデコーダ $D(\cdot)$、および変形推定モジュール $U(\cdot)$ のすべての訓練可能なパラメータに対するこの損失の勾配が計算されます。これらの勾配は、損失を削減するために各パラメータが調整されるべき方向と大きさを指示します。
-
オプティマイザ: Adamオプティマイザ[12]がモデルのパラメータを更新するために使用されます。Adamは適応学習率最適化アルゴリズムであり、勾配の一次モーメントと二次モーメントの推定値に基づいて各パラメータの学習率を効率的に調整します。これにより、モデルはより複雑な損失ランドスケープをより効果的にナビゲートし、より速く収束できます。学習率は $8 \times 10^{-5}$ に設定され、バッチサイズは16が使用されます。これは、パラメータが16の画像マスクペアの処理後に更新されることを意味します。
-
反復的な状態更新と収束: モデルは200,000回の訓練イテレーションを経ます。各イテレーションで、データバッチが処理され、損失が計算され、パラメータが更新されます。この反復プロセスにより、モデルはノイズの多い入力、条件付き情報、および望ましいクリーンで幾何学的に修正されたCEMRIとマスクとの間の複雑な関係を徐々に学習できます。損失ランドスケープは、$\mathcal{L}_{wmse}$ と $\mathcal{L}_{sreg}$ の両方によって形成され、モデルを、高品質なCEMRIを正確に合成し、正確な幾何学的修正を行うための最小値に導きます。MSSDMをノイズ除去プロセス内に緊密に統合することによって促進される画像生成と幾何学的修正の共同最適化は、エラーの蓄積を防ぎ、より堅牢な収束を促進します。
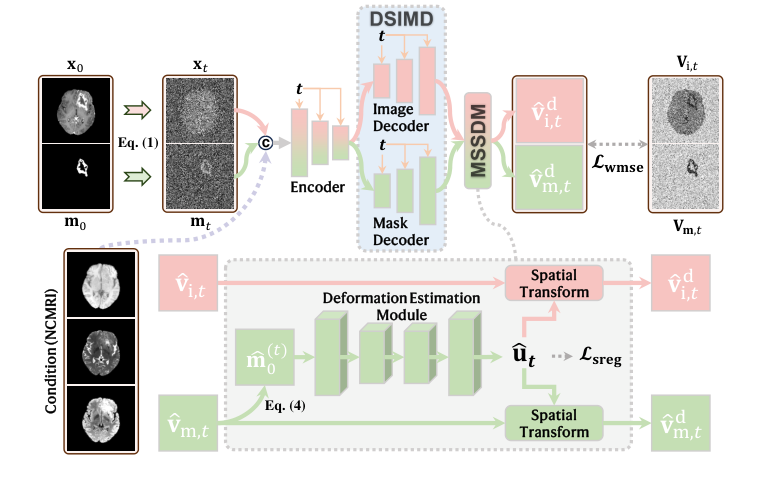 Figure 1. An overview of the network architecture of D3M
Figure 1. An overview of the network architecture of D3M
Results, Limitations & Conclusion
Experimental Design & Baselines
変形駆動型拡散モデル(D³M)を厳密に検証するために、著者らは2つの公開されているデータセット、BraSyn[13]およびBraTS-PEDs[11]で広範な実験を実施した。これらのデータセットは、それぞれ1,470および307人の脳腫瘍患者からの脳MRI画像を含み、豊富である。特に、これらは整列されたT1強調、T2強調、FLAIR、およびターゲットの造影T1強調(CEMRI)画像を含んでいる。訓練のために、モデルは、BraSynの1,251人の患者とBraTS-PEDsの216人の患者で利用可能な、手動でアノテーションされ臨床的にレビューされた造影腫瘍マスクの形式の補助情報を活用した。データセットは、無作為な評価を保証するために訓練、検証、およびテストセットに分割され、それぞれBraSynで1,001/250/219人、BraTS-PEDsで173/43/91人の患者が使用された。
D³Mが徹底的にテストされた「犠牲者」(ベースラインモデル)には、多様な最先端画像合成手法が含まれていた。これらは以下を含む。
- Pix2Pix [10]: CNNアーキテクチャを利用した基本的なGANベースの画像間翻訳モデル。
- ResViT [4]: ビジョントランスフォーマーと畳み込み演算子および敵対的学習を巧みに組み合わせた、より最近のマルチモーダル医用画像合成モデル。
- Palette [18]: 画像合成のための代表的な基本的な拡散モデル。
- I2SB [14]: 標準的な拡散モデルを改善する高度なバリアントであるシュレディンガーブリッジ拡散モデル。
公平な比較を確実にするために、すべての競合手法はD³Mと同じデータ分割を使用して訓練、検証、およびテストされた。さらに、著者らは、ベースライン手法の訓練中に、D³Mのアプローチを反映して、造影腫瘍の補助タスクとして造影腫瘍マスクを提供することによって、競争の場を平準化するためにさらに一歩進んだ。この細心の注意を払った実験設計は、D³Mのコアアーキテクチャのイノベーションの影響を分離することを目的としていた。
パフォーマンスは、画像品質評価で広く受け入れられている2つのメトリック、すなわち合成CEMRIと実際のCEMRI間のピーク信号対雑音比(PSNR)および構造的類似性指数測定(SSIM)を使用して定量的に評価された。腫瘍領域の重要な重要性を認識して、これらのメトリックはこれらの領域内でも特別に計算された。テスト画像の腫瘍領域を区切るために、nnU-Netセグメンテーションモデル[9]が訓練データからの腫瘍アノテーションで訓練された。改善の統計的有意性は、Wilcoxon符号順位検定を使用して決定され、厳格な閾値 $p < 0.001$ が適用された。画像は、強度値を0.5パーセンタイルと99.5パーセンタイルの間でクリッピングし、[0,1]に再スケーリングして正規化され、入力サイズは256×256、Adamオプティマイザ[12]を使用してバッチサイズ16、学習率 $8 \times 10^{-5}$ で200,000イテレーション訓練された。
What the Evidence Proves
証拠は、CEMRI合成、特に脳腫瘍におけるD³Mの新しいアプローチの有効性を明確に証明している。造影エラーを単なる強度エラーではなく、腫瘍サブコンポーネントの誤解釈として再定式化するという著者らの仮説は、管理しやすい幾何学的修正を可能にするという仮説は、質的および量的な結果の両方によって強く支持されている。
-
視覚的な優位性(図2): 図2に示された質的な結果は、説得力のある視覚的な証拠を提供している。D³Mの合成CEMRIは、すべてのベースライン手法と比較して、「実際の画像とより一貫性がある」。特に、腫瘍と血管の複雑な領域(赤い矢印で強調されている)内では、D³Mはグラウンドトゥルースと密接に一致する造影パターンを正確に再現している。対照的に、競合手法はしばしば「顕著な偽陽性および/または偽陰性の造影」を示し、偽の造影領域を生成したり、造影されるべき領域を造影しなかったりする。特に病理学的な複雑な構造におけるこの視覚的な忠実度は、D³Mが微妙な幾何学的な不一致を捉え、修正する能力の直接的な証である。
-
定量的優位性(表1): 定量的なメトリックは、確固たる統計的証拠を提供する。D³Mは、BraSynおよびBraTS-PEDsデータセット全体で、"Whole Image"だけでなく、より重要な"Tumor Region"でも、一貫して最高のPSNRおよびSSIM値を得た。例えば、BraSynでは、D³Mは全画像でPSNR $25.11 \pm 3.33$ およびSSIM $90.95 \pm 3.86$ を記録し、腫瘍領域ではPSNR $17.33 \pm 4.56$ およびSSIM $73.21 \pm 16.22$ を記録した。これらの数値は、すべてのベースラインを明確に上回る改善を表している。Wilcoxon符号順位検定を使用した統計分析は、これらの改善が「統計的に非常に有意($p < 0.001$)」であることを確認し、D³Mの優れたパフォーマンスについての疑いの余地を残さない。特に診断上重要な腫瘍領域におけるこの定量的な優位性は、D³MのメカニズムがCEMRI合成の「不良設定」の性質を効果的に軽減していることを示唆している。
-
アブレーションスタディ検証(表2): BraSynデータセットでのアブレーションスタディは、D³Mのアーキテクチャのイノベーションのコンポーネントレベルでの直接的な証拠を提供する。
- MSSDMの利点: Multi-Step Spatial Deformation Module(MSSDM)が削除され、DSIMDの出力を直接速度項に使用すると、PSNRとSSIMの両方が大幅に低下し、「特に腫瘍領域で」顕著であった。これは、造影を調整するために画像を歪ませるMSSDMの幾何学的修正が、正確な腫瘍表現のための重要なコンポーネントであることを直接検証している。これは、強度調整だけでなく空間変形による造影の修正が、確かに有益であることを確認している。
- DSIMDの利点: さらに、Dual-Stream Image-Mask Decoder(DSIMD)を削除し、単一のデコーダに置き換えると、PSNRとSSIMの低下がさらに顕著になった。これは、中間造影画像とマスクを共同で生成する上でDSIMDの不可欠な役割を示している。このデュアルストリームアプローチは、明らかにMSSDMにガイダンスを提供し、モデルの造影の理解を強化し、より正確な幾何学的修正を可能にする。
要するに、実験設計、強力なベースラインモデルの敗北、および細心の注意を払ったアブレーションスタディは、D³Mの中核メカニズム—デュアルストリーム画像マスクデコーダによってガイドされる空間変形による造影エラーの幾何学的修正—が、特に脳腫瘍のための高品質CEMRI合成において、非常に効果的で統計的に有意な進歩であるという決定的な、そして否定できない証拠を提供する。
Limitations & Future Directions
D³MはCEMRI合成、特に脳腫瘍において大きな進歩を示しているが、科学的探求には限界と将来の探求の道があることを認識することが重要である。論文自体は、明示的に「限界」セクションをリストアップしていないが、CEMRI合成が「非常に不良設定」であり、既存の手法が「腫瘍サブコンポーネントの複雑な形態」に苦労していることを指摘し、問題の固有の複雑さを暗黙的に示唆している。D³Mはこれらの課題を効果的に対処しているが、最高のパフォーマンスを示すモデルでさえ、合成画像と実際の画像との間にはまだギャップがあり、さらなる洗練の余地があることを示唆している。幾何学的修正は強力であるが、「比較的小さい」と説明されており、合成プロセスの完全なオーバーホールではなく、ターゲットを絞った改良であることを示唆している。
将来に向けて、D³Mの発見は、将来の開発のためのいくつかのエキサイティングで重要な議論のトピックを開いている。
-
病理学および解剖学的構造全体での一般化可能性: 現在の成功は脳腫瘍で実証されている。重要な次のステップは、D³Mのパフォーマンスと他の病理学(例:炎症、転移)および異なる解剖学的領域(例:肝臓、前立腺、乳房)への適応性を調査することである。各臓器と疾患は、造影パターンと解剖学的変動において独自の課題を提示する。これらの多様なコンテキストでパフォーマンスを維持またはさらに向上させるには、どのようなアーキテクチャ変更またはトレーニング戦略が必要になるだろうか?
-
臨床統合と規制経路: このような研究の究極の目標は、臨床的有用性である。合成CEMRIは、実際の臨床設定で診断精度と治療計画のためにどのように厳密に検証できるか?実際のCEMRIとの同意のどのレベルが、臨床医および規制当局によって許容されると見なされるか?これには、画像品質メトリックだけでなく、臨床結果研究も含まれる。さらに、患者ケアのためのAI生成画像の使用に関する倫理的影響、責任および患者の信頼の問題を含む、慎重な検討と堅牢な規制フレームワークが必要である。
-
不確実性定量化と説明可能性: 医用画像では、診断の信頼性が最重要である。D³Mは高品質な画像を生成するが、特に重要な腫瘍境界における合成造影に関連する不確実性を定量化することは非常に価値があるだろう。不確実性推定のための技術は、合成画像の信頼性の尺度を臨床医に提供できる。さらに、変形フィールドの説明可能性の向上—モデルが特定の幾何学的修正を適用する理由を理解すること—は、医療専門家にとってより大きな信頼と解釈可能性を育むことができる。
-
計算効率とリアルタイムアプリケーション: 拡散モデルは強力であるが、特に3Dボリュームや多段階プロセスでは、計算集約的になる可能性がある。臨床導入、特に時間的制約のあるシナリオや大規模データ処理の場合、品質を損なうことなくD³Mの推論速度を最適化することが不可欠である。高度なサンプリング技術、モデル蒸留、またはハードウェアアクセラレーションの探索は、品質を損なうことなく合成時間を大幅に短縮できる。これにより、臨床ワークフローへのより実用的な統合が可能になる。
-
縦断的モニタリングと疾患進行: CEMRIは、腫瘍の治療反応の縦断的モニタリングに頻繁に使用される。D³Mは、時間とともに腫瘍のサイズ、形態、および造影の微妙な変化を正確に反映するCEMRIを合成できるか?複数の時点にわたる進行または退縮に対する一貫性と感度を維持することは、D³Mの幾何学的修正能力から大きな利益を得られる複雑な課題である。
-
マルチモーダルおよびマルチシーケンス融合: 現在のNCMRIにはT1、T2、およびFLAIRが含まれる。将来の研究では、組織特性に関するモデルの理解をさらに強化し、さらに正確で堅牢なCEMRI合成につながる可能性のある、拡散強調画像(DWI)や灌流画像のような追加の非造影シーケンスの組み込みを検討できるか?
これらの議論のポイントは、D³Mが大きな進歩を遂げた一方で、合成医用画像の可能性を完全に実現するまでの道のりはまだ続いており、学際的な協力と継続的なイノベーションが必要であることを示している。
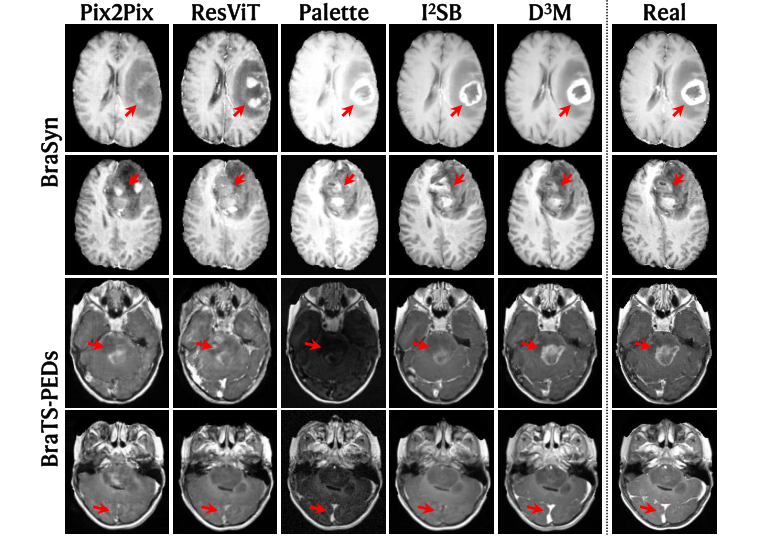 Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison
Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison