D3M: Модель диффузии, управляемая деформацией, для синтеза МРТ с контрастным усилением при опухолях головного мозга
Основная проблема, рассматриваемая в данной статье, заключается в синтезе МРТ с контрастным усилением (CEMRI) из МРТ без контрастного усиления (NCMRI), особенно для диагностики опухолей головного мозга.
Предыстория и академическая родословная
Происхождение и академическая родословная
Основная проблема, рассматриваемая в данной статье, заключается в синтезе МРТ с контрастным усилением (CEMRI) из МРТ без контрастного усиления (NCMRI), особенно для диагностики опухолей головного мозга. Эта специфическая задача возникла из критической потребности в клинической практике: хотя CEMRI предоставляют бесценную информацию для выявления и планирования лечения опухолей головного мозга, их получение требует введения контрастных агентов. Эта процедура несет в себе несколько существенных недостатков, включая потенциальные риски для здоровья пациентов [15, 25], значительные высокие затраты [27] и растущие экологические проблемы, связанные с утилизацией этих агентов [2, 8].
Исторически исследователи стремились обойти эти проблемы, разрабатывая методы для вычислительного создания CEMRI из стандартных NCMRI, тем самым устраняя необходимость в инъекциях контрастных агентов при сохранении диагностического качества изображения. Ранние усилия в этой области использовали архитектуры глубокого обучения, такие как 3D сверточные нейронные сети (CNN) на основе U-Net и условные генеративно-состязательные сети (GAN), вдохновленные моделями типа Pix2Pix [17, 6]. В последнее время академическая родословная претерпела значительный сдвиг в сторону диффузионных моделей, которые продемонстрировали замечательный успех в генерации реалистичных медицинских изображений [16, 24, 26, 29]. Эти передовые диффузионные модели были адаптированы для синтеза CEMRI, причем некоторые подходы фокусировались на конкретных органах, таких как печень [26].
Фундаментальное ограничение или "болевая точка" этих предыдущих подходов, включая существующие диффузионные модели, заключается в том, что синтез CEMRI из NCMRI остается крайне некорректно поставленной задачей. NCMRI часто предоставляют лишь неоднозначные свидетельства относительно усиленных областей, что затрудняет точное предсказание моделями того, где должно произойти контрастное усиление. Следовательно, предыдущие методы часто дают заметные ложноположительные и ложноотрицательные результаты усиления. Это означает, что они могут ошибочно показывать усиление в не усиленных областях (ложноположительные) или не показывать усиление в областях, которые должны быть усилены (ложноотрицательные). Эта проблема особенно выражена в опухолевых областях, где сложная и часто комплексная морфология субкомпонентов опухоли не улавливается точно. Авторы данной статьи решают эту проблему, переформулируя задачу: вместо того, чтобы рассматривать ошибки усиления исключительно как расхождения в интенсивности (которые часто велики и трудно поддаются коррекции), они концептуализируют их как некорректные геометрические интерпретации субкомпонентов опухоли. Это позволяет осуществлять коррекцию посредством пространственной деформации, что является более управляемой задачей, поскольку требуемые геометрические корректировки обычно меньше.
Интуитивные термины предметной области
Чтобы помочь читателю с нулевым уровнем знаний понять концепции, здесь приведены некоторые специализированные термины, переведенные в повседневные аналогии:
- МРТ с контрастным усилением (CEMRI): Представьте, что вы смотрите на карту города, но некоторые важные здания (например, больницы или достопримечательности) трудно различить. CEMRI — это как использование специального маркера, чтобы эти важные здания ярко светились, так что они сразу выделяются и их легко идентифицировать.
- МРТ без контрастного усиления (NCMRI): Продолжая аналогию с картой, NCMRI — это просто обычная карта без специального выделения. Все здания на месте, но важные не выделяются сами по себе.
- Диффузионная модель: Подумайте о размытой, пикселизированной фотографии, которая медленно становится четкой и детализированной, как будто художник тщательно восстанавливает детали. Диффузионная модель — это ИИ, который учится делать это в обратном порядке: он начинается с чистого шума (как телевизор без сигнала) и постепенно "размывает" или "очищает от шума" его шаг за шагом, пока не раскроет полное, реалистичное изображение.
- Некорректно поставленная задача: Это похоже на попытку решить загадку, где есть много возможных ответов, или где крошечное изменение вашей первоначальной догадки приводит к совершенно другому результату. Для синтеза CEMRI это означает, что без контрастного агента входные данные (NCMRI) не дают достаточно четких подсказок для надежного получения идеального CEMRI, что делает его склонным к ошибкам.
- Пространственная деформация: Представьте, что вы рисуете лицо на воздушном шаре. Пространственная деформация — это как осторожное сжатие или растяжение шара, чтобы тонко изменить положение глаз или рта, вместо того чтобы стирать и перерисовывать их. Это перемещение частей изображения геометрически для коррекции их положения.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в синтезе МРТ с контрастным усилением (CEMRI) из МРТ без контрастного усиления (NCMRI), в частности, изображений T1-взвешенных, T2-взвешенных и FLAIR.
Отправная точка (входные данные) для модели — это набор NCMRI. Во время обучения также используется вспомогательная информация в виде аннотированных масок усиленных опухолей для управления процессом обучения. Желаемая конечная точка (выходные данные) — это высококачественный синтетический CEMRI, который точно отображает опухоли головного мозга и их паттерны усиления, без необходимости фактического введения контрастного агента.
Точное недостающее звено или математический разрыв заключается в присущей "некорректности" синтеза CEMRI из NCMRI. NCMRI предоставляют лишь "неоднозначные свидетельства относительно усиленных областей", что делает чрезвычайно сложным точное предсказание того, где и как должно появиться контрастное усиление. Предыдущие исследования, включая методы на основе диффузионных моделей, сталкивались с этой проблемой, часто давая "ложноположительные и ложноотрицательные результаты усиления". Это означает, что не усиленные области могут быть ошибочно изображены с высокой интенсивностью (ложноположительные), в то время как области, которые должны быть усилены, показаны с низкой интенсивностью (ложноотрицательные). Критический разрыв заключается в неспособности этих моделей точно уловить "сложную морфологию субкомпонентов опухоли" и их специфические характеристики усиления.
Болезненный компромисс или дилемма, которая поставила в тупик предыдущих исследователей, проистекает из их подхода к исправлению этих ошибок. Они обычно моделируют расхождения в усилении как ошибки интенсивности. Однако исправление этих ошибок интенсивности "обычно велико и трудно поддается коррекции". Это создает трудный баланс: улучшение точности усиления часто требует радикальных и трудноуправляемых корректировок интенсивности, которые могут привести к артефактам или общему менее реалистичному изображению. Данная статья предлагает новую переформулировку: вместо того, чтобы рассматривать их как ошибки интенсивности, они представлены как "некорректная интерпретация субкомпонентов опухоли". Это позволяет осуществлять геометрическую коррекцию посредством пространственной деформации, которая представлена как "относительно небольшая и более управляемая" по сравнению с большими корректировками интенсивности.
Ограничения и режимы сбоя
Проблема синтеза CEMRI из NCMRI делает ее чрезвычайно сложной из-за нескольких жестких, реалистичных ограничений:
- Физические ограничения:
- Риски для здоровья и стоимость контрастных агентов: Основная мотивация этой работы — обойти необходимость в гадолиний-содержащих контрастных агентах, которые несут "риски для здоровья, высокую стоимость и экологические проблемы". Это ограничение обуславливает необходимость точного синтеза.
- Неоднозначная входная информация: NCMRI по своей сути предоставляют "неоднозначные свидетельства относительно усиленных областей". Это означает, что входные данные сами по себе не содержат явной информации, необходимой для прямого вывода контрастного усиления, что делает задачу синтеза фундаментально сложной.
- Вычислительные ограничения:
- Некорректно поставленная задача: Синтез CEMRI из NCMRI является "крайне некорректно поставленной" задачей. Это подразумевает, что одному входному сигналу NCMRI может соответствовать несколько возможных CEMRI, что затрудняет для модели однозначное определение правильного усиленного изображения без дополнительного руководства.
- Сложная морфология: Существующие модели не могут уловить "сложную морфологию субкомпонентов опухоли". Это предполагает, что простые попиксельные или основанные на интенсивности отображения недостаточны для представления сложных форм и границ усиленных опухолевых областей.
- Пошаговый процесс шумоподавления: Диффузионные модели работают посредством "пошагового" процесса шумоподавления. Эффективная интеграция геометрической коррекции в эти множественные шаги без накопления ошибок или нарушения диффузионного процесса является значительной вычислительной и архитектурной проблемой.
- Ограничения, связанные с данными:
- Необходимость высококачественных аннотаций (для обучения): Хотя цель состоит в том, чтобы избежать контрастных агентов при выводе, модель полагается на "вспомогательную информацию аннотаций усиленных опухолей" во время обучения. Эти маски должны быть "вручную аннотированы и проверены клиническими экспертами для обеспечения высококачественных меток", что является трудоемким и дорогостоящим процессом. Качество и доступность таких точных истинных данных имеют решающее значение для успешного обучения модели.
- Трудность обобщения: Сложный и разнообразный характер опухолей головного мозга означает, что модели должны быть достаточно надежными, чтобы синтезировать точные усиления для различных типов опухолей и анатомий пациентов, что является значительной проблемой обобщения.
Почему такой подход
Неизбежность выбора
Авторы столкнулись со значительным препятствием при синтезе контрастно-усиленного МРТ (CEMRI) из неконтрастного МРТ (NCMRI), особенно для опухолей головного мозга. Они явно заявляют, что эта задача "крайне некорректно поставлена", поскольку NCMRI предоставляют лишь неоднозначные свидетельства для усиленных областей. Традиционные передовые (SOTA) методы, включая стандартные CNN, базовые диффузионные модели, такие как Palette, и даже более продвинутые диффузионные модели, такие как I2SB, показали "заметные ложноположительные и ложноотрицательные результаты усиления". Это было особенно проблематично для опухолевых областей, где эти модели не смогли уловить сложную морфологию субкомпонентов опухоли.
Критическое осознание, которое привело к подходу D³M, заключалось в фундаментальном переосмыслении этих ошибок усиления. Вместо того, чтобы рассматривать их как большие, трудно поддающиеся коррекции ошибки интенсивности, авторы признали их как "некорректную интерпретацию субкомпонентов опухоли", где усиленные области были неправильно интерпретированы как не усиленные, и наоборот. Этот сдвиг в перспективе сделал очевидным, что задача может быть более эффективно решена посредством геометрической коррекции путем пространственной деформации. Авторы поняли, что, хотя ошибки интенсивности обычно велики и сложны, необходимые геометрические корректировки (небольшие смещения) "относительно невелики и более управляемы". Это понимание сделало деформационно-управляемый подход не просто улучшением, а единственным жизнеспособным решением для преодоления присущей некорректности и специфических режимов сбоя существующих методов в обработке сложных опухолевых структур.
Сравнительное превосходство
Метод D³M достигает качественного превосходства благодаря нескольким структурным преимуществам, выходящим за рамки простых метрик производительности. Основное новшество заключается в его способности решать ошибки усиления геометрически, а не как ошибки интенсивности. Это глубокое структурное преимущество, поскольку исправление небольших пространственных несоответствий по своей сути более стабильно и эффективно, чем попытка исправить большие ошибочные значения интенсивности.
В частности, Модуль многошаговой пространственной деформации (MSSDM) является ключевым отличием. В отличие от традиционной пост-обработки деформации, MSSDM тесно интегрирован внутри пошагового процесса шумоподавления диффузионной модели. Эта интеграция имеет решающее значение по двум причинам: во-первых, она предотвращает накопление серьезных ошибок, которые было бы трудно исправить позже; во-вторых, она способствует совместной оптимизации как генерации изображений, так и геометрической коррекции. Это означает, что модель учится синтезировать изображение, одновременно корректируя его геометрическую точность на каждом шаге, что приводит к более надежному и точному результату.
Кроме того, Двухпоточный декодер изображений и масок (DSIMD) предоставляет вспомогательную задачу сегментации усиленной опухоли. Это не просто дополнение; это структурное улучшение, которое повышает фундаментальное "понимание моделью контрастного усиления". Совместно генерируя промежуточные усиленные изображения и маски, DSIMD предоставляет явное, высокоуровневое руководство для MSSDM по пространственной деформации. Эта двухпоточная обработка гарантирует, что геометрические корректировки основаны на четком семантическом понимании границ опухоли и усиленных областей, что делает общий синтез качественно превосходящим, особенно в сохранении сложной морфологии опухолей. Эксперименты по абляции подтверждают, что как MSSDM, так и DSIMD вносят значительный вклад в улучшение производительности, особенно в опухолевых областях, подчеркивая их структурную важность.
Соответствие ограничениям
Подход D³M демонстрирует замечательное "сочетание" жестких требований проблемы и ее уникальных свойств решения. Основное ограничение, как определено в постановке проблемы, заключается в "крайне некорректной" природе синтеза CEMRI из NCMRI, которая приводит к "ложноположительному и ложноотрицательному усилению" и неспособности уловить "сложную морфологию субкомпонентов опухоли".
D³M идеально соответствует этим ограничениям, путем:
1. Переосмысления ошибок: Основная идея решения — переформулировка ошибок усиления как геометрических неверных интерпретаций — напрямую решает проблему некорректности. Вместо того, чтобы бороться с большими, неуправляемыми ошибками интенсивности, D³M фокусируется на меньших, более управляемых геометрических корректировках. Это свойство уникально подходит для задачи неоднозначных свидетельств от NCMRI.
2. Многошаговая геометрическая коррекция (MSSDM): Интеграция MSSDM в диффузионный процесс позволяет осуществлять инкрементальные, пошаговые геометрические корректировки. Это напрямую решает проблему ложноположительного и ложноотрицательного усиления путем "смещения усиленных областей для устранения" этих ошибок. Способность непрерывно корректировать ошибки на протяжении всего процесса шумоподавления идеально подходит для уточнения сложной и часто тонкой детализации морфологии опухоли, с которой сталкивались предыдущие методы.
3. Улучшенное понимание (DSIMD): Вспомогательная задача сегментации опухоли с помощью DSIMD предоставляет модели более глубокое, семантическое понимание того, что представляет собой усиленная опухоль. Это явное руководство имеет решающее значение для точного синтеза "сложной морфологии субкомпонентов опухоли", гарантируя, что геометрические корректировки являются биологически правдоподобными и клинически значимыми. Этот двухпоточный подход гарантирует, что модель не просто генерирует изображение, а такое, которое уважает лежащие в основе анатомические и патологические структуры, что является критическим требованием для медицинской визуализации.
Отклонение альтернатив
Статья неявно, но убедительно отвергает альтернативные подходы, подчеркивая их фундаментальные ограничения в решении специфических задач синтеза CEMRI из NCMRI. Хотя авторы не предоставляют прямого "заявления об отказе" для каждой альтернативы, они устанавливают четкое обоснование того, почему существующие методы, включая популярные, такие как GAN и базовые диффузионные модели, недостаточны.
Основное обоснование отказа от альтернатив проистекает из их неспособности эффективно справляться с "крайне некорректной" природой проблемы и результирующими "заметными ложноположительными и ложноотрицательными результатами усиления", особенно в отношении "сложной морфологии субкомпонентов опухоли". Методы, такие как Pix2Pix (на основе GAN) и Palette (базовая диффузионная модель), по своей сути предназначены для изучения отображений или генерации изображений на основе распределений интенсивности. Их основное ограничение, как подразумевается в статье, заключается в том, что они рассматривают ошибки усиления преимущественно как ошибки интенсивности. Как объясняют авторы, эти ошибки интенсивности "обычно велики и трудно поддаются коррекции".
Сравнительный анализ статьи (Таблица 1) далее подкрепляет этот отказ. D³M последовательно превосходит Pix2Pix, ResViT (мультимодальную модель, объединяющую трансформеры и CNN с состязательным обучением), Palette и I2SB (диффузионную модель Шрёдингера), особенно в критических опухолевых областях. Эти эмпирические данные, в сочетании с теоретическим аргументом о том, что существующие методы не могут уловить сложную морфологию опухоли из-за их обработки ошибок на основе интенсивности, служат убедительным отказом от этих альтернатив. Парадигма геометрической коррекции D³M представлена как необходимое отступление от этих предыдущих подходов, которые просто не были оснащены для разрешения специфического типа ошибок интерпретации, присущих этой сложной задаче синтеза медицинских изображений.
Математический и логический механизм
Основное уравнение
Ядром модели D³M, особенно на этапе вывода, где синтезируется МРТ с контрастным усилением (CEMRI), является итеративный шаг шумоподавления и геометрической коррекции. Этот процесс инкапсулируется следующим уравнением, которое обновляет изображение из зашумленного состояния во времени $t$ в менее зашумленное, геометрически скорректированное состояние во времени $t-1$:
$$x_{t-1} = \phi_{\hat{u}_t} \left( \sqrt{\bar{\alpha}_{t-1}} \hat{x}_0^{(t)} + \sqrt{1-\bar{\alpha}_{t-1}} \hat{\epsilon}_{i,t} \right)$$
Это уравнение представляет собой модифицированный детерминированный обратный шаг неявной диффузионной модели шумоподавления (DDIM), где предсказанное исходное изображение $\hat{x}_0^{(t)}$ и предсказанный шум $\hat{\epsilon}_{i,t}$ сначала оцениваются из текущего зашумленного изображения $x_t$ и предсказанных скоростей модели $\phi_{\hat{u}_t}$, а затем пространственно деформируются $\phi_{\hat{u}_t}$ перед объединением для формирования следующего, менее зашумленного изображения $x_{t-1}$.
Пословный разбор
Давайте разберем основное уравнение и его лежащие в основе компоненты:
- $x_{t-1}$: Это представляет собой оценку CEMRI изображения на предыдущем временном шаге $t-1$. Это выход текущего шага обратной диффузии, прошедший как шумоподавление, так и геометрическую коррекцию. Его физическая роль заключается в постепенной реконструкции желаемого CEMRI из шума.
- $\phi_{\hat{u}_t}(\cdot)$: Это оператор пространственной деформации. Он применяет геометрическое преобразование к своему входу, искажая содержимое изображения в соответствии с полем деформации $\hat{u}_t$. Авторы использовали этот оператор вместо простых арифметических операций, потому что задача сформулирована как геометрическая неверная интерпретация субкомпонентов опухоли, требующая пространственной корректировки, а не просто коррекции интенсивности.
- $\hat{u}_t$: Это предсказанное поле деформации на временном шаге $t$. Это 2D векторное поле (для 2D срезов), которое указывает, как каждый пиксель должен быть смещен. Его физическая роль заключается в геометрической коррекции ложноположительного и ложноотрицательного усиления в синтезированном изображении. Оно оценивается модулем оценки деформации $U(\cdot)$ в модуле многошаговой пространственной деформации (MSSDM), принимая в качестве входных данных промежуточную оценку маски $\hat{m}_0^{(t)}$.
- $\hat{m}_0^{(t)}$: Это промежуточная оценка исходной (истинной) маски усиленной опухоли на шаге $t$. Она вычисляется из зашумленной маски $m_t$ и предсказанной скорости маски $\hat{v}_{m,t}$ по формуле:
$$\hat{m}_0^{(t)} = \sqrt{\bar{\alpha}_t} m_t - \sqrt{1-\bar{\alpha}_t} \cdot \hat{v}_{m,t}$$
Его логическая роль заключается в предоставлении чистого, неискаженного представления усиленных областей опухоли, что имеет решающее значение для оценки поля деформации. Вычитание здесь является частью обращения прямого диффузионного процесса, эффективно "очищая" маску от шума.
- $\sqrt{\bar{\alpha}_{t-1}}$: Это масштабный коэффициент для компонента предсказанного исходного изображения. Он выводится из параметров расписания шума и определяет вес "сигнала" (предсказанного исходного изображения) в реконструкции. Квадратный корень является стандартным в диффузионных моделях для обработки дисперсий.
- $\hat{x}_0^{(t)}$: Это предсказание моделью исходного (не зашумленного) изображения CEMRI, оцененное из текущего зашумленного изображения $x_t$ и предсказанной скорости изображения $\hat{v}_{i,t}$ на временном шаге $t$. Его физическая роль заключается в представлении лежащего в основе чистого изображения, которое диффузионный процесс пытается восстановить. Оно выводится как:
$$\hat{x}_0^{(t)} = \frac{\sqrt{\alpha_t} x_t - \sqrt{1-\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
Комбинация сложения/вычитания и масштабных коэффициентов является прямым следствием инверсии прямого диффузионного процесса и связи предсказанной скорости с предсказанным исходным изображением. - $\sqrt{1-\bar{\alpha}_{t-1}}$: Это еще один масштабный коэффициент, применяемый к компоненту предсказанного шума. Он представляет вес "шума" в реконструкции. Как и $\sqrt{\bar{\alpha}_{t-1}}$, его форма выводится из расписания дисперсии.
- $\hat{\epsilon}_{i,t}$: Это предсказание моделью компонента Гауссова шума, который был добавлен к исходному изображению для получения $x_t$. Его физическая роль заключается в представлении случайных флуктуаций, которые необходимо удалить. Оно выводится из $x_t$ и предсказанной скорости изображения $\hat{v}_{i,t}$ как:
$$\hat{\epsilon}_{i,t} = \frac{\sqrt{1-\bar{\alpha}_t} x_t + \sqrt{\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
Опять же, арифметические операции являются частью математической инверсии диффузионного процесса. - $x_t$: Это зашумленное изображение CEMRI на текущем временном шаге $t$, служащее входными данными для текущего шага шумоподавления.
- $\hat{v}_{i,t}$: Это предсказанный член скорости изображения на временном шаге $t$. Это основной выход двухпоточного декодера изображений и масок (DSIMD) $D(\cdot)$, который принимает зашумленное изображение $x_t$, зашумленную маску $m_t$, условные NCMRI $c$ и временной шаг $t$ в качестве входных данных:
$$(\hat{v}_{i,t}, \hat{v}_{m,t}) = D(E(x_t, m_t, c, t), t)$$
Его логическая роль заключается в предоставлении более стабильной и эффективной цели для обучения модели, в отличие от прямого предсказания шума или шумоподавленного изображения. - $m_t$: Это зашумленная маска усиленной опухоли на текущем временном шаге $t$. Она обрабатывается вместе с $x_t$ для управления предсказанием скорости маски.
- $c$: Это условные изображения, в частности, неконтрастные МРТ (NCMRI). Они предоставляют критически важный анатомический контекст для модели, направляя синтез CEMRI. Они конкатенируются с зашумленными входными данными перед подачей в энкодер.
- $t$: Это представляет текущий временной шаг в диффузионном процессе, варьирующийся от $T$ (чистый шум) до $0$ (чистое изображение). Он подается в сеть, чтобы информировать модель об текущем уровне шума.
- $E(\cdot)$: Это энкодерная сеть, основанная на PixelCNN++ с бэкбоном Wide ResNet. Ее роль заключается в извлечении релевантных признаков из зашумленного изображения, маски и условных NCMRI.
- $D(\cdot)$: Это двухпоточный декодер изображений и масок (DSIMD), который принимает закодированные признаки и временной шаг $t$ для совместного получения предсказанной скорости изображения $\hat{v}_{i,t}$ и скорости маски $\hat{v}_{m,t}$. Двухпоточная конструкция позволяет раздельно обрабатывать информацию об изображении и маске, улучшая понимание моделью контрастного усиления.
- $\bar{\alpha}_t = \prod_{s=1}^t \alpha_s$: Это кумулятивное произведение параметров расписания шума $\alpha_s$ до времени $t$. Оно определяет общее масштабирование компонента исходного изображения в прямом диффузионном процессе. Произведение используется, потому что дисперсии складываются при независимом добавлении Гауссова шума.
- $\alpha_t$: Это параметр из расписания шума на временном шаге $t$, определяющий количество добавляемого или удаляемого шума на каждом шаге.
Пошаговый поток
Представьте себе один абстрактный элемент данных, представляющий воксель в мозге, по мере его трансформации в процессе вывода (синтеза). Цель — создать чистое, контрастно-усиленное МРТ ($x_0$) из начального состояния чистого шума ($x_T$).
- Инициализация: Процесс начинается с наибольшего временного шага, $t=T$. Мы начинаем с полностью зашумленного изображения $x_T$ и зашумленной маски $m_T$, оба из которых являются, по сути, случайным Гауссовым шумом.
- Извлечение признаков (Энкодер): На каждом шаге $t$ (начиная с $T$ и двигаясь вниз до $1$) текущее зашумленное изображение $x_t$, зашумленная маска $m_t$, условные неконтрастные МРТ $c$ и текущий временной шаг $t$ подаются в Энкодер $E(\cdot)$. Этот энкодер действует как сложный фильтр, извлекая релевантные признаки, представляющие лежащую в основе структуру и паттерны усиления, даже среди шума.
- Предсказание скорости (DSIMD): Признаки, извлеченные энкодером, затем передаются в двухпоточный декодер изображений и масок $D(\cdot)$. Этот декодер, разработанный с двумя параллельными потоками, обрабатывает эти признаки для предсказания двух критически важных членов "скорости": $\hat{v}_{i,t}$ для изображения и $\hat{v}_{m,t}$ для маски. Эти скорости указывают направление и величину изменения, необходимого для перехода от зашумленного состояния к чистому исходному изображению и маске.
- Оценка промежуточного изображения и маски:
- Используя предсказанную скорость изображения $\hat{v}_{i,t}$ и текущее зашумленное изображение $x_t$, модель математически инвертирует прямой диффузионный процесс для оценки того, как будет выглядеть исходное, чистое изображение CEMRI ($\hat{x}_0^{(t)}$), и каким был компонент шума ($\hat{\epsilon}_{i,t}$). Это делается с использованием выведенных формул для $\hat{x}_0^{(t)}$ и $\hat{\epsilon}_{i,t}$.
- Аналогично, используя предсказанную скорость маски $\hat{v}_{m,t}$ и текущую зашумленную маску $m_t$, вычисляется промежуточная оценка исходной, чистой усиленной маски опухоли ($\hat{m}_0^{(t)}$) (согласно Уравнению 4). Эта маска имеет решающее значение для понимания субкомпонентов опухоли.
- Оценка поля деформации (MSSDM): Промежуточная оценка маски $\hat{m}_0^{(t)}$ затем подается в модуль оценки деформации $U(\cdot)$, который является частью модуля многошаговой пространственной деформации (MSSDM). Этот модуль анализирует оцененную маску для выявления областей ложноположительного или ложноотрицательного усиления и вычисляет поле деформации $\hat{u}_t$. Это поле указывает, как пиксели должны быть смещены для геометрической коррекции этих ошибок усиления.
- Геометрическая коррекция (Пространственная деформация): Оцененное изображение $\hat{x}_0^{(t)}$ и оценка шума $\hat{\epsilon}_{i,t}$ затем пропускаются через оператор пространственной деформации $\phi_{\hat{u}_t}$. Этот оператор искажает эти изображения в соответствии с полем деформации $\hat{u}_t$, эффективно "перемещая" усиленные области в их правильные положения или удаляя ложные. Это критический шаг, который отличает D³M, поскольку он корректирует ошибки геометрически, а не просто по интенсивности.
- Шаг обратной диффузии: Наконец, деформированные $\hat{x}_0^{(t)}$ и $\hat{\epsilon}_{i,t}$ объединяются с использованием шага обратной DDIM (основное уравнение). Этот шаг эффективно удаляет небольшое количество шума из изображения, производя новое, менее зашумленное и геометрически скорректированное изображение $x_{t-1}$.
- Итерация: Этот весь процесс повторяется, причем $x_{t-1}$ становится новым $x_t$ для следующего шага, пока $t$ не достигнет $0$. При $t=0$ получается окончательное синтезированное изображение CEMRI $x_0$, представляющее наилучшую оценку моделью контрастно-усиленного изображения с точной морфологией опухоли.
Этот последовательный, итеративный процесс позволяет модели постепенно уточнять изображение, очищая его от шума и одновременно корректируя геометрические искажения, связанные с усилением опухоли.
Динамика оптимизации
Механизм D³M обучается и сходится путем итеративной корректировки своих внутренних параметров (весов нейронных сетей) на основе тщательно сконструированной функции потерь. Этот процесс управляется взаимодействием двух основных компонентов:
-
Функция потерь: Модель обучается минимизировать комбинированную потерю, которая состоит из двух частей:
- Взвешенная потеря среднеквадратичной ошибки ($\mathcal{L}_{wmse}$): Это стандартная потеря в диффузионных моделях, обычно измеряющая расхождение между предсказаниями модели (например, предсказанный шум $\hat{\epsilon}_{i,t}$ или предсказанная скорость $\hat{v}_{i,t}$) и истинными значениями. В статье указано, что она применяется к "результату синтеза на каждом шаге", подразумевая, что она направляет модель на получение точных изображений CEMRI. "Взвешенный" аспект означает, что разные части изображения или разные временные шаги могут вносить разный вклад в общую потерю, потенциально фокусируясь больше на критических областях, таких как опухоли. Эта потеря формирует ландшафт, создавая "долины", где предсказания модели точно соответствуют истинным данным, способствуя точному синтезу изображений.
- Регуляризация гладкости деформации ($\mathcal{L}_{sreg}$): Этот член применяется к полю деформации $\hat{u}_t$ на каждом шаге. Он обычно штрафует большие или резкие изменения в поле деформации, часто путем вычисления L2-нормы его пространственных градиентов. Его цель — обеспечить, чтобы геометрические корректировки были гладкими и физически правдоподобными, предотвращая генерацию моделью нереалистичных или ступенчатых деформаций. Этот член регуляризации действует как "штраф", который сглаживает чрезмерно сложные или зашумленные области в ландшафте потерь, связанных с деформацией, направляя модель к более стабильным и интерпретируемым преобразованиям. Авторы использовали это, чтобы предотвратить переобучение модели на шуме или создание артефактов в деформации.
-
Оптимизация на основе градиентов: Во время обучения вычисляется комбинированная потеря, а затем вычисляются градиенты этой потери по отношению ко всем обучаемым параметрам в Энкодере $E(\cdot)$, Двухпоточном декодере изображений и масок $D(\cdot)$ и Модуле оценки деформации $U(\cdot)$ с помощью обратного распространения ошибки. Эти градиенты указывают направление и величину, с которой каждый параметр должен быть скорректирован для уменьшения потерь.
-
Оптимизатор: Используется оптимизатор Adam [12] для обновления параметров модели. Adam — это алгоритм оптимизации с адаптивной скоростью обучения, который эффективно корректирует скорость обучения для каждого параметра на основе оценок первых и вторых моментов градиентов. Это помогает модели более эффективно перемещаться по сложному ландшафту потерь и быстрее сходиться. Скорость обучения установлена на уровне $8 \times 10^{-5}$, а размер пакета — 16, что означает, что параметры обновляются после обработки 16 пар изображений-масок.
-
Итеративные обновления состояния и сходимость: Модель проходит 200 000 итераций обучения. В каждой итерации обрабатывается пакет данных, вычисляется потеря, и параметры обновляются. Этот итеративный процесс позволяет модели постепенно изучать сложные взаимосвязи между зашумленными входными данными, условной информацией и желаемым чистым, геометрически скорректированным CEMRI и маской. Ландшафт потерь, сформированный как $\mathcal{L}_{wmse}$, так и $\mathcal{L}_{sreg}$, направляет модель к минимуму, где она может точно предсказывать скорости и поля деформации. Сходимость достигается, когда производительность модели на валидационных данных больше не улучшается значительно, что указывает на то, что она изучила стабильное отображение для синтеза высококачественных CEMRI с точной геометрической коррекцией, что подтверждается превосходными показателями PSNR и SSIM. Совместная оптимизация генерации изображений и геометрической коррекции, обеспечиваемая тесной интеграцией MSSDM в процесс шумоподавления, помогает предотвратить накопление ошибок и способствует более надежной сходимости.
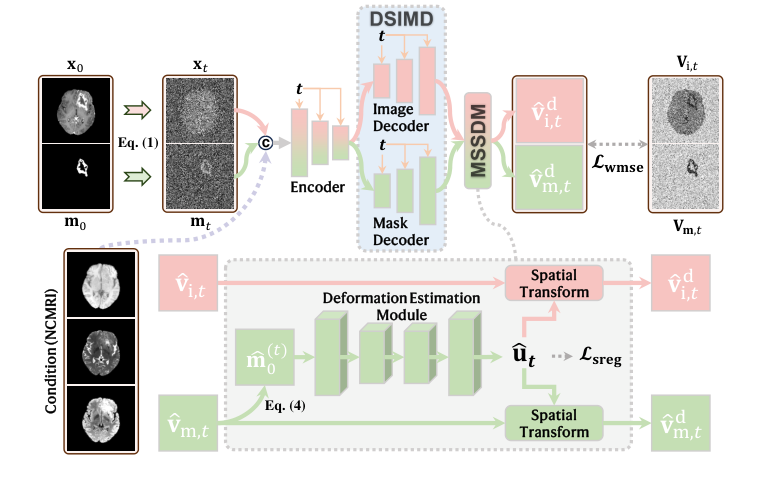 Figure 1. An overview of the network architecture of D3M
Figure 1. An overview of the network architecture of D3M
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Для строгой проверки своей деформационно-управляемой диффузионной модели (D³M) авторы провели обширные эксперименты на двух общедоступных наборах данных: BraSyn [13] и BraTS-PEDs [11]. Эти наборы данных богаты, содержат МРТ головного мозга от 1470 и 307 пациентов соответственно, у всех диагностированы опухоли головного мозга. Важно отметить, что они включают выровненные изображения T1-взвешенные, T2-взвешенные, FLAIR и целевые МРТ с контрастным усилением T1-взвешенные (CEMRI). Для обучения модель использовала вспомогательную информацию в виде вручную аннотированных и клинически проверенных масок усиленных опухолей, доступных для 1251 пациента в BraSyn и 216 в BraTS-PEDs. Наборы данных были разделены на обучающую, валидационную и тестовую выборки для обеспечения беспристрастной оценки, с 1001/250/219 пациентами для BraSyn и 173/43/91 для BraTS-PEDs соответственно.
"Жертвы" (базовые модели), против которых D³M была безжалостно протестирована, включали разнообразный набор передовых методов синтеза изображений. К ним относились:
- Pix2Pix [10]: Фундаментальная модель перевода изображений на основе GAN, использующая архитектуру CNN.
- ResViT [4]: Более новая мультимодальная модель синтеза медицинских изображений, которая гениально объединяет трансформеры зрения с сверточными операторами и состязательным обучением.
- Palette [18]: Представительная базовая диффузионная модель для синтеза изображений.
- I2SB [14]: Диффузионная модель Шрёдингера, которая является продвинутым вариантом, улучшающим традиционные диффузионные модели.
Чтобы обеспечить справедливое сравнение, все конкурирующие методы были обучены, валидированы и протестированы с использованием тех же разделений данных, что и D³M. Кроме того, авторы пошли дальше, чтобы выровнять игровое поле, также предоставляя маски усиленных опухолей в качестве вспомогательной задачи во время обучения для базовых методов, отражая подход D³M. Этот тщательный экспериментальный дизайн был направлен на изоляцию влияния основных архитектурных инноваций D³M.
Производительность количественно оценивалась с использованием двух общепринятых метрик оценки качества изображения: пикового отношения сигнал/шум (PSNR) и показателя структурного сходства (SSIM), рассчитанных между синтезированными и реальными CEMRI. Признавая критическую важность опухолевых областей, эти метрики также были специально рассчитаны в этих областях. Для разграничения опухолевых областей на тестовых изображениях была обучена модель сегментации nnU-Net [9] на аннотациях опухолей из обучающих данных. Статистическая значимость улучшений определялась с помощью критерия знаковых рангов Уилкоксона с строгим порогом $p < 0,001$. Изображения нормализовались путем обрезки значений интенсивности между 0,5-м и 99,5-м перцентилями и масштабирования до [0,1], с входным размером 256 × 256, обучением в течение 200 000 итераций с использованием оптимизатора Adam [12] с размером пакета 16 и скоростью обучения $8 \times 10^{-5}$.
Что доказывают доказательства
Доказательства недвусмысленно подтверждают эффективность нового подхода D³M к синтезу CEMRI, особенно его основного механизма геометрической коррекции ошибок усиления посредством пространственной деформации. Гипотеза авторов о том, что переформулировка ошибок усиления как некорректных интерпретаций субкомпонентов опухоли, а не просто ошибок интенсивности, позволяет осуществлять более управляемую геометрическую коррекцию, находит сильную поддержку как в качественных, так и в количественных результатах.
-
Визуальное превосходство (Рис. 2): Качественные результаты, представленные на Рисунке 2, предлагают убедительные визуальные доказательства. Синтезированные CEMRI D³M поразительно "более согласуются с реальным изображением" по сравнению со всеми базовыми методами. Важно отметить, что в пределах сложных областей опухоли и сосудов (выделенных красными стрелками) D³M точно воспроизводит паттерны усиления, которые тесно соответствуют истинным данным. В отличие от этого, конкурирующие методы часто демонстрируют "заметное ложноположительное и/или ложноотрицательное усиление", генерируя либо ложные усиленные области, либо не усиливая области, которые должны быть. Эта визуальная точность, особенно в сложных патологических структурах, является прямым свидетельством способности D³M улавливать и корректировать тонкие геометрические несоответствия.
-
Количественное доминирование (Таблица 1): Количественные метрики предоставляют жесткие, статистические доказательства. D³M последовательно достигал самых высоких значений PSNR и SSIM по обоим наборам данных BraSyn и BraTS-PEDs, не только для "Всего изображения", но, что более важно, для "Области опухоли". Например, на BraSyn D³M показал PSNR $25,11 \pm 3,33$ и SSIM $90,95 \pm 3,86$ для всего изображения, и PSNR $17,33 \pm 4,56$ и SSIM $73,21 \pm 16,22$ для области опухоли. Эти цифры представляют собой явное улучшение по сравнению со всеми базовыми моделями. Статистический анализ с использованием критерия знаковых рангов Уилкоксона подтвердил, что эти улучшения "высоко статистически значимы ($p < 0,001$)", не оставляя сомнений в превосходной производительности D³M. Это количественное преимущество, особенно в диагностически критических опухолевых областях, подчеркивает, что механизм D³M эффективно смягчает "некорректную" природу синтеза CEMRI.
-
Валидация экспериментов по абляции (Таблица 2): Эксперименты по абляции на наборе данных BraSyn предоставляют прямые, компонентные доказательства архитектурных инноваций D³M.
- Преимущество MSSDM: При удалении модуля многошаговой пространственной деформации (MSSDM), что привело к прямому использованию выхода DSIMD для членов скорости, как PSNR, так и SSIM значительно снизились, "особенно в области опухоли". Это напрямую подтверждает, что геометрическая коррекция MSSDM, которая деформирует синтезированное изображение для корректировки усиления, является критическим компонентом для точного представления опухоли. Это подтверждает, что коррекция усиления посредством пространственной деформации, а не просто корректировки интенсивности, действительно полезна.
- Преимущество DSIMD: Дальнейшее удаление двухпоточного декодера изображений и масок (DSIMD) и замена его одним декодером привело к еще более выраженному снижению PSNR и SSIM. Это демонстрирует незаменимую роль DSIMD в совместном создании промежуточных усиленных изображений и масок. Этот двухпоточный подход явно предоставляет необходимое руководство для MSSDM, улучшая понимание моделью контрастного усиления и позволяя осуществлять более точные геометрические корректировки.
В совокупности экспериментальная архитектура, победа над сильными базовыми моделями и тщательные эксперименты по абляции предоставляют окончательные и неоспоримые доказательства того, что основной механизм D³M — геометрическая коррекция ошибок усиления посредством пространственной деформации, управляемой двухпоточным декодером изображений и масок — является высокоэффективным и статистически значимым достижением в синтезе высококачественных CEMRI, особенно для опухолей головного мозга.
Ограничения и будущие направления
Хотя D³M представляет собой значительный шаг вперед в синтезе CEMRI, особенно для опухолей головного мозга, важно признать, что ни одно научное начинание не обходится без своих границ и направлений для будущих исследований. Сама статья, хотя и не содержит явно раздела "Ограничения", неявно указывает на присущую сложность проблемы, отмечая, что синтез CEMRI из NCMRI является "крайне некорректной" задачей, и что существующие методы сталкиваются с "сложной морфологией субкомпонентов опухоли". Хотя D³M эффективно решает эти проблемы, абсолютные значения PSNR и SSIM, даже для лучшей модели, предполагают, что все еще существует разрыв между синтетическими и реальными изображениями, указывая на пространство для дальнейшего уточнения. Геометрическая коррекция, хотя и мощная, описывается как "относительно небольшая", что подразумевает, что это целенаправленное уточнение, а не полное переосмысление процесса синтеза.
Заглядывая вперед, выводы D³M открывают несколько захватывающих и критически важных тем для обсуждения в будущем:
-
Обобщаемость для различных патологий и анатомий: Текущий успех демонстрируется на опухолях головного мозга. Критически важным следующим шагом является исследование производительности и адаптивности D³M к другим патологиям (например, воспалениям, метастазам) и различным анатомическим областям (например, печени, простаты, молочной железы). Каждый орган и заболевание представляют уникальные проблемы с точки зрения паттернов контрастного усиления и анатомической вариабельности. Какие архитектурные модификации или стратегии обучения потребуются для поддержания или даже улучшения производительности в этих разнообразных контекстах?
-
Клиническая интеграция и регуляторные пути: Конечная цель таких исследований — клиническая полезность. Как синтетические CEMRI могут быть строго валидированы для диагностической точности и планирования лечения в реальных клинических условиях? Какой уровень согласия с фактическими CEMRI считается приемлемым для клиницистов и регулирующих органов? Это включает не только метрики качества изображения, но и исследования клинических исходов. Кроме того, необходимо тщательно рассмотреть этические последствия использования изображений, сгенерированных ИИ, для ухода за пациентами, включая вопросы ответственности и доверия пациентов, а также разработать надежные регуляторные рамки.
-
Квантификация неопределенности и объяснимость: В медицинской визуализации уверенность в диагнозе имеет первостепенное значение. Хотя D³M генерирует высококачественные изображения, количественная оценка неопределенности, связанной с синтезированным усилением, особенно на критических границах опухоли, была бы бесценной. Методы оценки неопределенности могли бы предоставить клиницистам меру надежности синтетических изображений. Кроме того, улучшение объяснимости полей деформации — понимание почему модель применяет определенные геометрические корректировки — могло бы способствовать большему доверию и интерпретируемости для медицинских работников.
-
Вычислительная эффективность и приложения в реальном времени: Диффузионные модели, хотя и мощные, могут быть вычислительно затратными, особенно для 3D-объемов и многошаговых процессов. Для клинического внедрения, особенно в сценариях, требующих срочности, или для крупномасштабной обработки данных, оптимизация D³M для более быстрого вывода имеет важное значение. Исследование продвинутых методов выборки, дистилляции моделей или аппаратного ускорения может значительно сократить время синтеза без ущерба для качества. Это позволило бы более практичную интеграцию в клинические рабочие процессы.
-
Лонгитюдный мониторинг и прогрессирование заболевания: CEMRI часто используются для лонгитюдного мониторинга реакции опухоли на лечение. Может ли D³M последовательно синтезировать CEMRI, которые точно отражают тонкие изменения в размере, морфологии и усилении опухоли с течением времени? Поддержание согласованности и чувствительности к прогрессированию или регрессии в течение нескольких временных точек является сложной задачей, которая может значительно выиграть от возможностей геометрической коррекции D³M.
-
Мультимодальное и многопоследовательное слияние: Текущие NCMRI включают T1, T2 и FLAIR. Будущие работы могут исследовать включение дополнительных неконтрастных последовательностей, таких как диффузионно-взвешенная визуализация (DWI) или перфузионная визуализация, которые предоставляют дополнительную физиологическую информацию. Может ли более богатый входной набор данных улучшить понимание моделью свойств тканей и привести к еще более точному и надежному синтезу CEMRI?
Эти пункты обсуждения подчеркивают, что, хотя D³M добилась значительных успехов, путь к полному раскрытию потенциала синтетической медицинской визуализации продолжается, требуя междисциплинарного сотрудничества и постоянных инноваций.
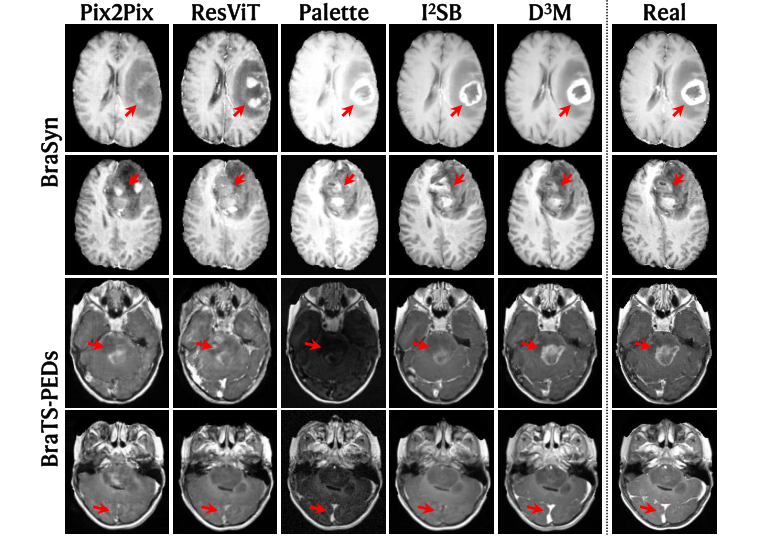 Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison
Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison