D3M: 뇌종양 조영 증강 MRI 합성을 위한 변형(Deformation)-구동 확산 모델
Contrast-enhanced magnetic resonance images (CEMRIs) provide valuable information for brain tumor diagnosis and treatment planning.
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 핵심 문제는 뇌종양 진단에 특화된, 비조영 증강 자기공명영상(NCMRI)으로부터 조영 증강 자기공명영상(CEMRI)을 합성하는 것이다. 이 특정 과제는 임상 현장에서의 중요한 요구로부터 발생하였다. CEMRI는 뇌종양의 식별 및 치료 계획 수립에 귀중한 정보를 제공하지만, 획득을 위해서는 조영제 주입이 필수적이다. 이 절차는 잠재적인 환자 건강 위험 [15, 25], 상당한 고비용 [27], 그리고 이러한 조영제 폐기와 관련된 환경 문제의 증가 [2, 8]를 포함한 여러 가지 중대한 단점을 수반한다.
역사적으로 연구자들은 표준 NCMRIs로부터 계산적으로 CEMRIs를 생성하는 방법을 개발함으로써 이러한 문제들을 우회하고자 하였으며, 이를 통해 조영제 주입의 필요성을 제거하면서도 진단 영상의 품질을 유지하였다. 이 분야의 초기 노력은 Pix2Pix [17, 6]와 같은 모델에서 영감을 받은 3D Convolutional Neural Networks (CNNs) 기반의 U-Net과 조건부 Generative Adversarial Networks (GANs)와 같은 딥러닝 아키텍처를 활용하였다. 최근에는 학술적 계보에서 확산 모델(diffusion models)로의 상당한 전환이 이루어졌으며, 이는 사실적인 의료 영상 생성에 있어 놀라운 성공을 입증하였다 [16, 24, 26, 29]. 이러한 최신 확산 모델들은 CEMRI 합성에 적용되었으며, 일부 접근 방식은 간과 같은 특정 장기에 초점을 맞추기도 하였다 [26].
기존 확산 모델을 포함한 이전 접근 방식들의 근본적인 한계점, 즉 "고충점(pain point)"은 NCMRIs로부터의 CEMRI 합성이 여전히 매우 ill-posed 문제라는 것이다. NCMRIs는 종종 증강된 영역에 대해 모호한 증거만을 제공하여, 모델이 조영 증강이 어디에서 발생해야 하는지를 정확하게 예측하기 어렵게 만든다. 결과적으로, 이전 방법들은 빈번하게 눈에 띄는 거짓 양성(false positive) 및 거짓 음성(false negative) 증강 결과를 생성하였다. 이는 증강되지 않은 영역에서 잘못된 증강을 표시하거나(거짓 양성), 증강되어야 할 영역에서 증강을 표시하지 못하는 경우(거짓 음성)를 의미한다. 이 문제는 특히 종양 영역에서 두드러지는데, 종양 하위 구성 요소의 복잡하고 종종 복잡한 형태가 정확하게 포착되지 않기 때문이다. 본 논문의 저자들은 이 문제를 문제 재정의를 통해 해결한다. 즉, 증강 오류를 단순히 강도 불일치(종종 크고 수정하기 어려운)로 취급하는 대신, 종양 하위 구성 요소의 잘못된 기하학적 해석으로 개념화한다. 이는 필요한 기하학적 조정이 일반적으로 작기 때문에 공간 변형을 통한 수정이 가능한 작업이 된다.
직관적인 도메인 용어
제로베이스 독자가 개념을 이해하도록 돕기 위해, 몇 가지 전문 용어를 일상적인 비유로 번역하였다.
- 조영 증강 자기공명영상 (CEMRIs): 도시 지도를 보고 있는데, 중요한 건물(병원이나 랜드마크 등)이 구별하기 어렵다고 상상해보라. CEMRI는 이러한 중요한 건물들을 밝게 빛나게 하는 특별한 형광펜을 사용하는 것과 같아서, 즉시 눈에 띄고 식별하기 쉽게 만든다.
- 비조영 증강 자기공명영상 (NCMRIs): 지도 비유를 이어가면, NCMRI는 특별한 하이라이팅이 없는 일반 지도이다. 모든 건물이 있지만, 중요한 건물은 스스로 눈에 띄지 않는다.
- 확산 모델 (Diffusion Model): 흐릿하고 픽셀화된 사진이 마치 예술가가 세심하게 세부 사항을 다시 추가하는 것처럼 점차 선명하고 상세해지는 것을 생각해보라. 확산 모델은 이 과정을 반대로 학습하는 AI이다. 순수한 노이즈(신호 없는 TV와 같은)로 시작하여 점진적으로 "흐림을 제거"하거나 "노이즈를 제거"하여 완전하고 사실적인 이미지를 드러낸다.
- Ill-posed 문제: 여러 가지 가능한 답이 있거나, 초기 추측의 작은 변화가 완전히 다른 결과로 이어지는 수수께끼를 푸는 것과 같다. CEMRI 합성의 경우, 조영제 없이는 입력(NCMRI)이 완벽한 CEMRI를 안정적으로 생성할 만큼 명확한 단서를 제공하지 않아 오류가 발생하기 쉽다는 것을 의미한다.
- 공간 변형 (Spatial Deformation): 풍선에 얼굴을 그리는 것을 상상해보라. 공간 변형은 눈이나 입의 위치를 미묘하게 이동시키기 위해 풍선을 부드럽게 짜거나 늘리는 것과 같으며, 지우고 다시 그리는 것이 아니다. 이미지의 일부를 기하학적으로 이동시켜 위치를 수정하는 것이다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 비조영 증강 자기공명영상(NCMRIs), 특히 T1-weighted, T2-weighted, FLAIR 영상으로부터 조영 증강 자기공명영상(CEMRIs)을 합성하는 것이다.
모델의 시작점(입력)은 NCMRIs 세트이다. 학습 중에는 학습 과정을 안내하기 위해 조영 증강된 종양의 주석이 달린 마스크 형태의 보조 정보도 활용된다. 원하는 종점(출력)은 실제 조영제 주입 없이 뇌종양과 그 증강 패턴을 정확하게 묘사하는 고품질의 합성 CEMRI이다.
정확히 누락된 연결고리 또는 수학적 격차는 NCMRIs로부터 CEMRIs를 합성하는 본질적인 "ill-posed" 특성에 있다. NCMRIs는 "증강된 영역에 대한 모호한 증거"만을 제공하여, 조영 증강이 어디에서 어떻게 나타나야 하는지를 정확하게 예측하는 것을 극도로 어렵게 만든다. 확산 모델 기반 방법을 포함한 이전 연구들은 이 문제로 어려움을 겪었으며, 빈번하게 "거짓 양성 및 거짓 음성 증강 결과"를 생성하였다. 이는 비증강 영역이 높은 강도로 잘못 묘사되거나(거짓 양성), 증강되어야 하는 영역이 낮은 강도로 표시되는(거짓 음성) 것을 의미한다. 결정적인 격차는 이러한 모델들이 "종양 하위 구성 요소의 복잡한 형태"와 그 특정 증강 특성을 정확하게 포착하지 못한다는 것이다.
이전 연구자들이 갇혀 있던 고통스러운 절충 또는 딜레마는 이러한 오류를 수정하는 접근 방식에서 비롯된다. 그들은 일반적으로 증강 불일치를 강도 오류로 모델링한다. 그러나 이러한 강도 오류를 수정하는 것은 "일반적으로 크고 수정하기 어렵다." 이는 어려운 균형 잡기를 만든다. 증강의 충실도를 개선하려면 종종 급격하고 관리하기 어려운 강도 조정이 필요하며, 이는 인공물(artifacts)이나 전반적으로 덜 사실적인 이미지로 이어질 수 있다. 본 논문은 새로운 재정의를 제안한다. 이를 강도 오류로 보는 대신, "종양 하위 구성 요소의 잘못된 해석"으로 프레임화한다. 이는 공간 변형을 통한 기하학적 수정을 가능하게 하며, 이는 큰 강도 수정에 비해 "상대적으로 작고 관리하기 쉬운" 것으로 제시된다.
제약 조건 및 실패 모드
NCMRIs로부터 CEMRIs를 합성하는 문제는 몇 가지 혹독하고 현실적인 제약 조건으로 인해 극도로 어렵게 만들어진다.
- 물리적 제약 조건:
- 조영제의 건강 위험 및 비용: 이 연구의 주요 동기는 "건강 위험, 높은 비용 및 환경 문제"를 수반하는 가돌리늄 기반 조영제의 필요성을 우회하는 것이다. 이 제약 조건은 정확한 합성의 필요성을 추진한다.
- 모호한 입력 정보: NCMRIs는 본질적으로 "증강된 영역에 대한 모호한 증거"를 제공한다. 이는 입력 데이터 자체가 조영 증강을 직접 추론하는 데 필요한 명시적인 정보를 부족하게 하여, 합성 작업을 근본적으로 어렵게 만든다.
- 계산적 제약 조건:
- Ill-posed 문제: NCMRIs로부터 CEMRIs를 합성하는 것은 "매우 ill-posed" 문제이다. 이는 단일 NCMRI 입력에 대해 여러 개의 가능한 CEMRI가 존재할 수 있음을 의미하며, 모델이 추가적인 안내 없이 올바른 증강 이미지를 고유하게 결정하기 어렵게 만든다.
- 복잡한 형태: 기존 모델은 "종양 하위 구성 요소의 복잡한 형태"를 포착하지 못한다. 이는 단순한 픽셀 단위 또는 강도 기반 매핑이 증강된 종양 영역의 복잡한 모양과 경계를 나타내기에 불충분함을 시사한다.
- 단계적 노이즈 제거 과정: 확산 모델은 "단계적" 노이즈 제거 과정을 통해 작동한다. 이러한 다단계 과정 내에서 오류를 축적하거나 확산 과정을 방해하지 않고 기하학적 수정을 효과적으로 통합하는 것은 상당한 계산 및 아키텍처 과제이다.
- 데이터 기반 제약 조건:
- 고품질 주석의 필요성 (학습용): 추론 시 조영제를 피하는 것이 목표이지만, 모델은 학습 중에 "증강된 종양의 주석 보조 정보"에 의존한다. 이러한 마스크는 "고품질 레이블을 보장하기 위해 임상 전문가가 수동으로 주석을 달고 검토"해야 하며, 이는 노동 집약적이고 비용이 많이 드는 과정이다. 이러한 정확한 Ground Truth 데이터의 품질과 가용성은 성공적인 모델 학습에 매우 중요하다.
- 일반화의 어려움: 뇌종양의 복잡하고 다양한 특성은 모델이 다양한 종양 유형과 환자 해부학적 구조 전반에 걸쳐 정확한 증강을 합성할 수 있을 만큼 강력해야 함을 의미하며, 이는 상당한 일반화 과제이다.
왜 이 접근 방식인가
선택의 불가피성
저자들은 특히 뇌종양의 경우, 비조영 증강 MRI(NCMRI)로부터 조영 증강 MRI(CEMRI)를 합성하는 데 있어 상당한 장애물에 직면했다. 그들은 NCMRIs가 증강된 영역에 대해 모호한 증거만을 제공하기 때문에 이 작업이 "매우 ill-posed"라고 명시적으로 언급한다. 기존의 최신(SOTA) 방법들, 즉 표준 CNN, Palette와 같은 기본 확산 모델, 그리고 I2SB와 같은 더 발전된 확산 모델을 포함한 방법들은 "눈에 띄는 거짓 양성 및 거짓 음성 증강 결과"를 생성하는 것으로 밝혀졌다. 이는 특히 종양 영역에서 문제가 되었는데, 이러한 모델들은 종양 하위 구성 요소의 복잡한 형태를 포착하지 못했다.
D³M 접근 방식으로 이어진 결정적인 깨달음은 이러한 증강 오류에 대한 근본적인 재해석이었다. 이를 수정하기 어렵고 큰 강도 오류로 보는 대신, 저자들은 이를 "종양 하위 구성 요소의 잘못된 해석"으로 인식했으며, 증강된 영역이 비증강으로 잘못 해석되거나 그 반대의 경우였다. 이러한 관점의 전환은 공간 변형을 통한 기하학적 수정을 통해 문제가 더 효과적으로 해결될 수 있음을 분명히 했다. 저자들은 강도 오류는 일반적으로 크고 어렵지만, 필요한 기하학적 수정(작은 변위)은 "상대적으로 작고 관리하기 쉽다"는 것을 이해했다. 이러한 통찰력은 변형 구동 접근 방식을 단순한 개선이 아닌, 내재된 ill-posed 문제와 복잡한 종양 구조를 처리하는 기존 방법의 특정 실패 모드를 극복하기 위한 유일하게 실행 가능한 해결책으로 만들었다.
비교 우위
D³M 방법은 단순한 성능 지표를 넘어서는 여러 구조적 이점을 통해 질적인 우수성을 달성한다. 핵심 혁신은 강도 오류가 아닌 기하학적 오류로 증강 오류를 해결하는 능력에 있다. 이는 큰 공간적 오정렬을 수정하는 것이 잘못된 큰 강도 값을 수정하려고 시도하는 것보다 본질적으로 더 안정적이고 효과적이기 때문에 심오한 구조적 이점이다.
구체적으로, 다단계 공간 변형 모듈(Multi-step Spatial Deformation Module, MSSDM)은 핵심 차별점이다. 기존의 후처리 변형과 달리, MSSDM은 확산 모델의 단계적 노이즈 제거 과정 내부에 긴밀하게 통합되어 있다. 이 통합은 두 가지 이유로 중요하다. 첫째, 나중에 수정하기 어려운 심각한 오류의 축적을 방지한다. 둘째, 영상 생성과 기하학적 수정의 공동 최적화를 촉진한다. 이는 모델이 각 단계에서 기하학적 정확도를 동시에 수정하면서 영상을 합성하는 것을 학습한다는 것을 의미하며, 이는 더 강력하고 정확한 출력을 가져온다.
또한, 이중 스트림 영상-마스크 디코더(Dual-stream Image-Mask Decoder, DSIMD)는 증강된 종양을 분할하는 보조 작업을 제공한다. 이것은 단순한 추가 기능이 아니라, 모델의 근본적인 "조영 증강 이해"를 향상시키는 구조적 개선이다. 중간 증강 영상과 마스크를 공동으로 생성함으로써, DSIMD는 공간 변형을 위한 MSSDM에 명시적인 고수준 안내를 제공한다. 이 이중 스트림 처리는 기하학적 수정이 종양의 경계와 증강된 영역에 대한 명확한 의미론적 이해에 의해 정보화되도록 보장하여, 특히 종양의 복잡한 형태를 보존하는 데 있어 전반적인 합성을 질적으로 우수하게 만든다. 무결성 연구(ablation studies)는 MSSDM과 DSIMD 모두 성능 향상, 특히 종양 영역에서 상당한 기여를 확인하며, 이는 그들의 구조적 중요성을 강조한다.
제약 조건과의 정렬
D³M 접근 방식은 문제의 혹독한 요구 사항과 고유한 해결책 속성 간의 "결혼"을 놀랍게 보여준다. 문제 정의에서 확인된 주요 제약 조건은 NCMRIs로부터의 CEMRI 합성의 "매우 ill-posed" 특성이며, 이는 "거짓 양성 및 거짓 음성 증강"과 "종양 하위 구성 요소의 복잡한 형태"를 포착하지 못하는 결과로 이어진다.
D³M은 다음을 통해 이러한 제약 조건과 완벽하게 정렬된다.
1. 오류 재해석: 증강 오류를 기하학적 오해로 재구성하는 해결책의 핵심 아이디어는 ill-posed 문제를 직접적으로 해결한다. 크고 관리하기 어려운 강도 오류로 어려움을 겪는 대신, D³M은 더 작고 관리하기 쉬운 기하학적 수정에 초점을 맞춘다. 이 속성은 NCMRIs의 모호한 증거를 처리하는 데 고유하게 적합하다.
2. 다단계 기하학적 수정 (MSSDM): 확산 과정 내에 MSSDM을 통합함으로써 점진적이고 단계적인 기하학적 조정을 가능하게 한다. 이는 "증강된 영역을 이동시켜 제거"함으로써 이러한 오류를 수정하는 것을 통해 거짓 양성 및 거짓 음성 증강 문제를 직접적으로 해결한다. 노이즈 제거 과정 전반에 걸쳐 오류를 지속적으로 수정하는 능력은 종양의 복잡하고 종종 미묘한 세부 사항을 개선하는 데 완벽하게 적합하며, 이는 이전 방법들이 어려움을 겪었던 부분이다.
3. 향상된 이해 (DSIMD): DSIMD를 통한 종양 분할의 보조 작업은 모델에 증강된 종양이 무엇인지에 대한 더 깊고 의미론적인 이해를 제공한다. 이 명시적인 안내는 "종양 하위 구성 요소의 복잡한 형태"를 정확하게 합성하는 데 중요하며, 기하학적 수정이 생물학적으로 타당하고 임상적으로 관련성이 있도록 보장한다. 이 이중 스트림 접근 방식은 모델이 단순히 이미지를 생성하는 것이 아니라, 의료 영상에 중요한 해부학적 및 병리학적 구조를 존중하는 이미지를 생성하도록 보장한다.
대안의 거부
본 논문은 본질적으로, 그러나 강력하게, 특정 과제에 대한 기존 방법들의 근본적인 한계를 강조함으로써 대안적 접근 방식을 거부한다. 저자들이 각 대안에 대한 직접적인 "거부 진술"을 제공하지는 않지만, GANs 및 기본 확산 모델을 포함한 인기 있는 방법들을 포함한 기존 방법들이 왜 불충분한지에 대한 명확한 근거를 확립한다.
대안을 거부하는 핵심 이유는 "매우 ill-posed" 문제와 그 결과인 "눈에 띄는 거짓 양성 및 거짓 음성 증강 결과", 특히 "종양 하위 구성 요소의 복잡한 형태"를 효과적으로 처리하지 못하기 때문이다. Pix2Pix (GAN 기반) 및 Palette (기본 확산 모델)와 같은 방법들은 근본적으로 강도 분포에 기반한 매핑을 학습하거나 이미지를 생성하도록 설계되었다. 저자들이 설명하듯이, 이들의 주요 한계는 증강 오류를 주로 강도 오류로 취급한다는 것이다. 이러한 강도 오류는 "일반적으로 크고 수정하기 어렵다."
본 논문의 비교 분석 (표 1)은 이러한 거부를 더욱 강화한다. D³M은 Pix2Pix, ResViT (적대적 학습과 트랜스포머 및 CNN을 결합한 다중 모달 모델), Palette, 그리고 I2SB (슈뢰딩거 다리 확산 모델)를 일관되게 능가하며, 특히 중요한 종양 영역 내에서 그렇다. 이러한 경험적 증거는, 기존 방법들이 강도 기반 오류 처리를 인해 복잡한 종양 형태를 포착하지 못한다는 이론적 주장과 결합되어, 이러한 대안들에 대한 설득력 있는 거부를 제공한다. D³M의 기하학적 수정 패러다임은 이 어려운 의료 영상 합성 작업에 내재된 특정 유형의 오해 오류를 해결하기에 적합하지 않았던 이러한 이전 접근 방식에서 벗어나야 할 필수적인 단계로 제시된다.
수학적 및 논리적 메커니즘
마스터 방정식
D³M 모델의 핵심, 특히 조영 증강 자기공명영상(CEMRI)이 합성되는 추론 단계에서는, 기하학적 변형을 통한 반복적인 노이즈 제거 및 수정 단계가 포함된다. 이 과정은 다음 방정식으로 요약되며, 이는 시간 $t$에서의 노이즈 상태를 시간 $t-1$에서의 노이즈가 적고 기하학적으로 수정된 상태로 업데이트한다.
$$x_{t-1} = \phi_{\hat{u}_t} \left( \sqrt{\bar{\alpha}_{t-1}} \hat{x}_0^{(t)} + \sqrt{1-\bar{\alpha}_{t-1}} \hat{\epsilon}_{i,t} \right)$$
이 방정식은 Denoising Diffusion Implicit Model (DDIM)의 수정된 결정론적 역방향 단계를 나타내며, 여기서 예측된 원본 이미지 $\hat{x}_0^{(t)}$와 예측된 노이즈 $\hat{\epsilon}_{i,t}$는 현재 노이즈 이미지 $x_t$와 모델의 속도 예측으로부터 먼저 추정된 후, 다음의 노이즈가 적은 이미지 $x_{t-1}$을 형성하기 위해 결합되기 전에 $\phi_{\hat{u}_t}$에 의해 공간적으로 변형된다.
항별 분석
마스터 방정식과 그 기본 구성 요소를 자세히 살펴보자.
- $x_{t-1}$: 이는 시간 단계 $t-1$에서의 추정된 CEMRI 영상이다. 이는 현재 역확산 단계의 출력으로, 노이즈 제거 및 기하학적 수정 모두를 거쳤다. 물리적 역할은 노이즈로부터 원하는 CEMRI를 점진적으로 재구성하는 것이다.
- $\phi_{\hat{u}_t}(\cdot)$: 이는 공간 변형 연산자이다. 이는 입력에 기하학적 변환을 적용하여, 변형 필드 $\hat{u}_t$에 따라 영상 내용을 왜곡한다. 저자는 이 연산자를 단순한 산술 연산 대신 사용했는데, 이는 문제가 종양 하위 구성 요소의 기하학적 오해로 프레임화되어 강도 수정뿐만 아니라 공간적 조정이 필요하기 때문이다.
- $\hat{u}_t$: 이는 시간 단계 $t$에서의 예측된 변형 필드이다. 이는 각 픽셀이 어떻게 변위되어야 하는지를 지정하는 2D 벡터 필드(2D 슬라이스의 경우)이다. 물리적 역할은 합성 영상에서 거짓 양성 및 거짓 음성 증강을 기하학적으로 수정하는 것이다. 이는 중간 마스크 추정치 $\hat{m}_0^{(t)}$를 입력으로 받는 다단계 공간 변형 모듈(MSSDM) 내의 변형 추정 모듈 $U(\cdot)$에 의해 추정된다.
- $\hat{m}_0^{(t)}$: 이는 시간 $t$에서의 원본(Ground Truth) 증강 종양 마스크의 중간 추정치이다. 이는 노이즈가 있는 마스크 $m_t$와 예측된 마스크 속도 $\hat{v}_{m,t}$를 사용하여 다음 공식으로 계산된다.
$$\hat{m}_0^{(t)} = \sqrt{\bar{\alpha}_t} m_t - \sqrt{1-\bar{\alpha}_t} \cdot \hat{v}_{m,t}$$
논리적 역할은 변형 필드 추정을 안내하는 데 중요한, 깨끗하고 손상되지 않은 종양의 증강된 영역의 표현을 제공하는 것이다. 여기서의 빼기는 순방향 확산 과정을 역으로 수행하는 부분으로, 마스크를 효과적으로 "노이즈 제거"한다.
- $\sqrt{\bar{\alpha}_{t-1}}$: 이는 예측된 원본 이미지 구성 요소에 대한 스케일링 인수이다. 이는 노이즈 스케줄 매개변수에서 파생되며, 재구성에서 "신호"(예측된 원본 이미지)의 가중치를 결정한다. 제곱근은 분산을 처리하기 위해 확산 모델에서 표준적으로 사용된다.
- $\hat{x}_0^{(t)}$: 이는 시간 단계 $t$에서 현재 노이즈 이미지 $x_t$로부터 추정된 원본(노이즈 없는) CEMRI 영상에 대한 모델의 예측이다. 물리적 역할은 확산 과정이 복구하려고 하는 기본 깨끗한 이미지를 나타내는 것이다. 이는 다음과 같이 파생된다.
$$\hat{x}_0^{(t)} = \frac{\sqrt{\alpha_t} x_t - \sqrt{1-\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
덧셈/뺄셈 및 스케일링 인수의 조합은 확산 과정의 역변환과 예측된 속도를 예측된 원본 이미지로 연결하는 직접적인 결과이다. - $\sqrt{1-\bar{\alpha}_{t-1}}$: 이는 예측된 노이즈 구성 요소에 적용되는 또 다른 스케일링 인수이다. 이는 재구성에서 "노이즈"의 가중치를 나타낸다. $\sqrt{\bar{\alpha}_{t-1}}$와 마찬가지로, 그 형태는 분산 스케줄에서 파생된다.
- $\hat{\epsilon}_{i,t}$: 이는 $x_t$를 생성하기 위해 원본 이미지에 추가된 가우시안 노이즈 구성 요소에 대한 모델의 예측이다. 물리적 역할은 제거해야 하는 무작위 변동을 나타내는 것이다. 이는 $x_t$와 예측된 이미지 속도 $\hat{v}_{i,t}$로부터 다음과 같이 파생된다.
$$\hat{\epsilon}_{i,t} = \frac{\sqrt{1-\bar{\alpha}_t} x_t + \sqrt{\bar{\alpha}_t} \hat{v}_{i,t}}{\sqrt{\alpha_t \bar{\alpha}_t} + 1-\bar{\alpha}_t}$$
다시 말하지만, 산술 연산은 확산 과정의 수학적 역변환의 일부이다. - $x_t$: 이는 현재 시간 단계 $t$에서의 노이즈가 있는 CEMRI 영상으로, 현재 노이즈 제거 단계의 입력으로 사용된다.
- $\hat{v}_{i,t}$: 이는 시간 단계 $t$에서의 예측된 이미지 속도 항이다. 이는 이중 스트림 영상-마스크 디코더(DSIMD) $D(\cdot)$의 주요 출력으로, 노이즈가 있는 영상 $x_t$, 노이즈가 있는 마스크 $m_t$, 조건부 NCMRIs $c$, 그리고 시간 단계 $t$를 입력으로 받는다.
$$(\hat{v}_{i,t}, \hat{v}_{m,t}) = D(E(x_t, m_t, c, t), t)$$
논리적 역할은 모델이 직접 노이즈 또는 노이즈 제거된 이미지를 예측하는 대신 학습할 더 안정적이고 효율적인 대상(target)을 제공하는 것이다. - $m_t$: 이는 현재 시간 단계 $t$에서의 노이즈가 있는 증강 종양 마스크이다. 이는 마스크 속도 예측을 안내하기 위해 $x_t$와 함께 처리된다.
- $c$: 이는 조건부 영상, 특히 비조영 증강 자기공명영상(NCMRIs)이다. 이는 모델에 중요한 해부학적 맥락을 제공하여 CEMRI 합성을 안내한다. 이는 노이즈가 있는 입력과 연결되어 디코더에 공급된다.
- $t$: 이는 확산 과정에서 현재 시간 단계를 나타내며, $T$(순수한 노이즈)에서 $0$(깨끗한 이미지)까지 범위를 갖는다. 이는 현재 노이즈 수준에 대한 정보를 모델에 제공하기 위해 네트워크에 공급된다.
- $E(\cdot)$: 이는 PixelCNN++ 기반의 Wide ResNet 백본을 사용하는 인코더 네트워크이다. 이는 노이즈가 있는 영상, 마스크, 그리고 조건부 NCMRIs로부터 관련 특징을 추출하는 역할을 한다.
- $D(\cdot)$: 이는 이중 스트림 영상-마스크 디코더(DSIMD)로, 인코딩된 특징과 시간 단계 $t$를 받아 예측된 이미지 속도 $\hat{v}_{i,t}$와 마스크 속도 $\hat{v}_{m,t}$를 공동으로 생성한다. 이중 스트림 설계는 영상 및 마스크 정보를 별도로 처리할 수 있게 하여, 모델의 조영 증강 이해도를 향상시킨다.
- $\bar{\alpha}_t = \prod_{s=1}^t \alpha_s$: 이는 시간 $t$까지의 노이즈 스케줄 매개변수 $\alpha_s$의 누적 곱이다. 이는 순방향 확산 과정에서 원본 이미지 구성 요소의 전반적인 스케일링을 결정한다. 독립적인 가우시안 노이즈 추가에서 분산이 합산되기 때문에 곱셈이 사용된다.
- $\alpha_t$: 이는 시간 단계 $t$에서의 노이즈 스케줄의 매개변수로, 각 단계에서 추가되거나 제거되는 노이즈의 양을 결정한다.
단계별 흐름
추론(합성) 과정 동안 변환되는 뇌의 복셀을 나타내는 단일 추상 데이터 포인트를 상상해보라. 목표는 순수한 노이즈($x_T$)의 초기 상태로부터 깨끗하고 조영 증강된 MRI($x_0$)를 생성하는 것이다.
- 초기화: 프로세스는 가장 큰 시간 단계인 $t=T$에서 시작한다. 우리는 완전히 노이즈가 있는 영상 $x_T$와 노이즈가 있는 마스크 $m_T$로 시작하며, 둘 다 본질적으로 무작위 가우시안 노이즈이다.
- 특징 추출 (인코더): 각 단계 $t$(T부터 1까지)에서, 현재 노이즈가 있는 영상 $x_t$, 노이즈가 있는 마스크 $m_t$, 조건부 비조영 증강 MRI $c$, 그리고 현재 시간 단계 $t$가 인코더 $E(\cdot)$에 공급된다. 이 인코더는 정교한 필터처럼 작동하여, 노이즈 속에서도 기본 구조 및 증강 패턴을 나타내는 의미 있는 특징을 추출한다.
- 속도 예측 (DSIMD): 인코더에 의해 추출된 특징은 이중 스트림 영상-마스크 디코더 $D(\cdot)$에 전달된다. 두 개의 병렬 스트림으로 설계된 이 디코더는 이러한 특징을 처리하여 영상에 대한 $\hat{v}_{i,t}$와 마스크에 대한 $\hat{v}_{m,t}$라는 두 가지 중요한 "속도" 항을 예측한다. 이러한 속도는 노이즈 상태에서 깨끗한 원본 영상 및 마스크로 이동하는 데 필요한 변화의 방향과 크기를 나타낸다.
- 중간 영상 및 마스크 추정:
- 예측된 이미지 속도 $\hat{v}_{i,t}$와 현재 노이즈가 있는 영상 $x_t$를 사용하여, 모델은 순방향 확산 과정을 수학적으로 역으로 수행하여 원본, 깨끗한 CEMRI 영상($\hat{x}_0^{(t)}$)이 어떻게 보일지, 그리고 노이즈 구성 요소($\hat{\epsilon}_{i,t}$)가 무엇이었을지를 추정한다. 이는 $\hat{x}_0^{(t)}$ 및 $\hat{\epsilon}_{i,t}$에 대한 파생 공식들을 사용하여 수행된다.
- 마찬가지로, 예측된 마스크 속도 $\hat{v}_{m,t}$와 현재 노이즈가 있는 마스크 $m_t$를 사용하여, 원본, 깨끗한 증강 종양 마스크($\hat{m}_0^{(t)}$)의 중간 추정치가 계산된다 (Eq 4에 따름). 이 마스크는 종양 하위 구성 요소를 이해하는 데 중요하다.
- 변형 필드 추정 (MSSDM): 중간 마스크 추정치 $\hat{m}_0^{(t)}$는 다단계 공간 변형 모듈(MSSDM)의 일부인 변형 추정 모듈 $U(\cdot)$에 공급된다. 이 모듈은 추정된 마스크를 분석하여 거짓 양성 또는 거짓 음성 증강 영역을 식별하고 변형 필드 $\hat{u}_t$를 계산한다. 이 필드는 이러한 증강 오류를 기하학적으로 수정하기 위해 픽셀을 어떻게 이동시켜야 하는지를 지정한다.
- 기하학적 수정 (공간 변형): 추정된 원본 영상 $\hat{x}_0^{(t)}$와 노이즈 추정치 $\hat{\epsilon}_{i,t}$는 공간 변형 연산자 $\phi_{\hat{u}_t}$를 통해 전달된다. 이 연산자는 $\hat{u}_t$ 변형 필드에 따라 이러한 영상을 왜곡하여, 증강된 영역을 올바른 위치로 효과적으로 "이동"시키거나 잘못된 영역을 제거한다. 이는 D³M을 차별화하는 중요한 단계로, 강도 조정만으로는 아닌 기하학적으로 오류를 수정한다.
- 역확산 단계: 마지막으로, 변형된 $\hat{x}_0^{(t)}$와 $\hat{\epsilon}_{i,t}$는 DDIM 역방향 단계(마스터 방정식)를 사용하여 결합된다. 이 단계는 영상에서 소량의 노이즈를 효과적으로 제거하여, 새롭고 노이즈가 적으며 기하학적으로 수정된 영상 $x_{t-1}$을 생성한다.
- 반복: 이 전체 과정은 $x_{t-1}$이 다음 단계의 새로운 $x_t$가 되면서 $t$가 0에 도달할 때까지 반복된다. $t=0$에서, 최종 합성 CEMRI 영상 $x_0$가 얻어지며, 이는 정확한 종양 형태를 가진 조영 증강 영상에 대한 모델의 최상의 추정치를 나타낸다.
이 순차적이고 반복적인 과정은 모델이 기하학적 왜곡을 동시에 수정하면서 영상을 점진적으로 개선하고 노이즈를 제거할 수 있도록 한다.
최적화 역학
D³M 메커니즘은 신중하게 구성된 손실 함수를 기반으로 내부 매개변수(신경망의 가중치)를 반복적으로 조정함으로써 학습하고 수렴한다. 이 과정은 두 가지 주요 구성 요소의 상호 작용에 의해 주도된다.
-
손실 함수: 모델은 두 부분으로 구성된 결합된 손실을 최소화하도록 학습된다.
- 가중 평균 제곱 오차 손실 ($\mathcal{L}_{wmse}$): 이는 일반적으로 모델의 예측(예: 예측된 노이즈 $\hat{\epsilon}_{i,t}$ 또는 예측된 속도 $\hat{v}_{i,t}$)과 실제 값 간의 불일치를 측정하는 확산 모델의 표준 손실이다. 논문에서는 "각 단계에서의 합성 결과"에 적용된다고 명시되어 있으며, 이는 손실이 모델이 정확한 CEMRI 영상을 생성하도록 안내함을 의미한다. "가중"이라는 측면은 영상의 다른 부분이나 다른 시간 단계가 전체 손실에 다르게 기여할 수 있음을 의미하며, 잠재적으로 종양과 같은 중요한 영역에 더 집중할 수 있다. 이 손실은 모델의 예측이 Ground Truth와 밀접하게 일치하는 "계곡"을 생성함으로써 손실 지형을 형성하여 정확한 영상 합성을 장려한다.
- 변형 평활도 정규화 ($\mathcal{L}_{sreg}$): 이 항은 각 단계에서 변형 필드 $\hat{u}_t$에 적용된다. 이는 일반적으로 공간 기울기의 L2 노름을 계산함으로써 변형 필드의 크거나 급격한 변화를 페널티화한다. 목적은 기하학적 수정이 부드럽고 물리적으로 타당하도록 보장하여, 모델이 비현실적이거나 들쭉날쭉한 변형을 생성하는 것을 방지하는 것이다. 이 정규화 항은 변형과 관련된 손실 지형에서 지나치게 복잡하거나 노이즈가 많은 영역을 평탄화하는 "페널티" 역할을 하여, 모델을 더 안정적이고 해석 가능한 변환으로 안내한다. 저자는 이를 모델이 노이즈에 과적합하거나 변형에서 인공물을 생성하는 것을 방지하기 위해 사용했다.
-
기울기 기반 최적화: 학습 중에 결합된 손실이 계산되고, 그런 다음 인코더 $E(\cdot)$, 이중 스트림 영상-마스크 디코더 $D(\cdot)$, 그리고 변형 추정 모듈 $U(\cdot)$의 모든 학습 가능한 매개변수에 대한 이 손실의 기울기가 역전파를 사용하여 계산된다. 이러한 기울기는 각 매개변수가 손실을 줄이기 위해 조정되어야 하는 방향과 크기를 나타낸다.
-
최적화기: Adam 최적화기 [12]가 모델의 매개변수를 업데이트하는 데 사용된다. Adam은 기울기의 첫 번째 및 두 번째 모멘트 추정치를 기반으로 각 매개변수에 대한 학습률을 효율적으로 조정하는 적응형 학습률 최적화 알고리즘이다. 이는 모델이 더 복잡한 손실 지형을 더 효과적으로 탐색하고 더 빠르게 수렴하도록 돕는다. 학습률은 $8 \times 10^{-5}$로 설정되었으며, 배치 크기는 16으로 사용되어, 매개변수는 16개의 영상-마스크 쌍을 처리한 후에 업데이트된다.
-
반복적 상태 업데이트 및 수렴: 모델은 200,000번의 학습 반복을 거친다. 각 반복에서 데이터 배치 하나가 처리되고, 손실이 계산되며, 매개변수가 업데이트된다. 이 반복적인 과정은 모델이 노이즈가 있는 입력, 조건부 정보, 그리고 원하는 깨끗하고 기하학적으로 수정된 CEMRI 및 마스크 간의 복잡한 관계를 점진적으로 학습할 수 있도록 한다. $\mathcal{L}_{wmse}$와 $\mathcal{L}_{sreg}$ 모두에 의해 형성된 손실 지형은 모델을 정확한 속도와 변형 필드를 예측할 수 있는 최소값으로 안내한다. 영상 생성과 기하학적 수정의 공동 최적화는 MSSDM을 노이즈 제거 과정에 긴밀하게 통합함으로써 가능해지며, 오류 축적을 방지하고 더 강력한 수렴을 촉진한다.
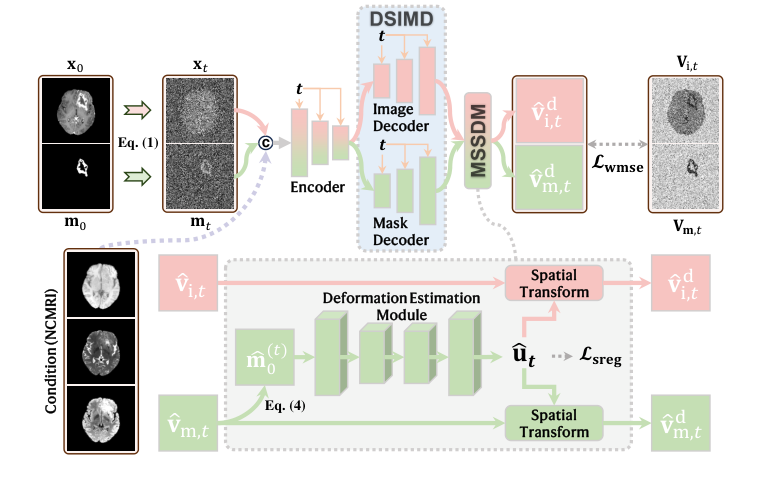 Figure 1. An overview of the network architecture of D3M
Figure 1. An overview of the network architecture of D3M
결과, 한계 및 결론
실험 설계 및 기준선
변형 구동 확산 모델(D³M)을 엄격하게 검증하기 위해, 저자들은 두 개의 공개적으로 사용 가능한 데이터셋인 BraSyn [13] 및 BraTS-PEDs [11]에 대해 광범위한 실험을 수행했다. 이 데이터셋들은 각각 1,470명과 307명의 뇌종양 환자의 뇌 자기공명영상으로 풍부하며, 정렬된 T1-weighted, T2-weighted, FLAIR, 그리고 목표 조영 증강 T1-weighted (CEMRI) 영상을 포함한다. 학습을 위해, 모델은 1,251명의 BraSyn 환자와 216명의 BraTS-PEDs 환자로부터 얻은 수동으로 주석이 달리고 임상적으로 검토된 증강 종양 마스크 형태의 보조 정보를 활용했다. 데이터셋은 편향되지 않은 평가를 보장하기 위해 학습, 검증 및 테스트 세트로 분할되었으며, 각각 BraSyn의 경우 1,001/250/219명, BraTS-PEDs의 경우 173/43/91명의 환자를 포함했다.
D³M이 철저하게 테스트된 "희생양"(기준선 모델)은 다양한 최신 영상 합성 방법들을 포함했다. 이들은 다음과 같다.
- Pix2Pix [10]: CNN 아키텍처를 활용하는 기초적인 GAN 기반 영상-영상 변환 모델.
- ResViT [4]: 비전 트랜스포머와 컨볼루션 연산자 및 적대적 학습을 독창적으로 결합한 최신 다중 모달 의료 영상 합성 모델.
- Palette [18]: 영상 합성을 위한 대표적인 기본 확산 모델.
- I2SB [14]: 기존 확산 모델을 개선하는 고급 변형인 슈뢰딩거 다리 확산 모델.
공정한 경쟁을 보장하기 위해, 모든 경쟁 방법은 D³M과 정확히 동일한 데이터 분할을 사용하여 학습, 검증 및 테스트되었다. 또한, 저자들은 D³M의 접근 방식을 반영하여 기준선 방법들의 학습 중에도 보조 작업으로 증강 종양 마스크를 제공함으로써 경쟁의 장을 평준화하기 위해 한 걸음 더 나아갔다. 이 세심한 실험 설계는 D³M의 핵심 아키텍처 혁신의 영향을 분리하는 것을 목표로 했다.
성능은 영상 품질 평가에서 널리 사용되는 두 가지 지표인 Peak Signal-to-Noise Ratio (PSNR) 및 Structural Similarity Index Measure (SSIM)을 사용하여 정량적으로 평가되었으며, 이는 합성된 CEMRI와 실제 CEMRI 간에 계산되었다. 종양 영역의 중요성을 인식하여, 이러한 지표는 이 영역 내에서도 특별히 계산되었다. 테스트 영상의 종양 영역을 구분하기 위해, nnU-Net 분할 모델 [9]이 학습 데이터의 종양 주석에 대해 학습되었다. 개선의 통계적 유의성은 $p < 0.001$의 엄격한 임계값을 사용하여 Wilcoxon 부호 순위 검정을 사용하여 결정되었다. 영상은 0.5번째 및 99.5번째 백분위수 사이의 강도 값을 클리핑하고 [0,1]로 재스케일링하여 정규화되었으며, 입력 크기는 256 × 256, 200,000번의 반복으로 학습되었으며, Adam 최적화기 [12]를 배치 크기 16, 학습률 $8 \times 10^{-5}$로 사용했다.
증거가 증명하는 것
증거는 D³M의 CEMRI 합성 접근 방식의 효과, 특히 공간 변형을 통한 기하학적 증강 오류 수정의 핵심 메커니즘을 명백하게 증명한다. 증강 오류를 단순한 강도 오류가 아닌 종양 하위 구성 요소의 잘못된 해석으로 재구성한다는 저자들의 가설은 질적 및 양적 결과 모두에 의해 강력하게 뒷받침된다.
-
시각적 우수성 (그림 2): 그림 2에 제시된 질적 결과는 설득력 있는 시각적 증거를 제공한다. D³M의 합성 CEMRI는 모든 기준선 방법과 비교하여 "실제 영상과 훨씬 더 일관적"이다. 결정적으로, 복잡한 종양 및 혈관 영역(빨간색 화살표로 강조 표시됨) 내에서 D³M은 Ground Truth와 매우 유사한 증강 패턴을 정확하게 재현한다. 대조적으로, 경쟁 방법들은 "눈에 띄는 거짓 양성 및/또는 거짓 음성 증강"을 자주 나타내며, 잘못된 증강 영역을 생성하거나 증강되어야 할 영역을 증강하지 못한다. 특히 복잡한 병리학적 구조에서의 이러한 시각적 충실도는 미묘한 기하학적 불일치를 포착하고 수정하는 D³M의 능력을 직접적으로 증명한다.
-
정량적 지배 (표 1): 정량적 지표는 확실하고 통계적인 증거를 제공한다. D³M은 BraSyn 및 BraTS-PEDs 데이터셋 모두에서 "전체 영상"뿐만 아니라, 더 중요하게는 "종양 영역"에 대해서도 일관되게 가장 높은 PSNR 및 SSIM 값을 달성했다. 예를 들어, BraSyn에서 D³M은 전체 영상에 대해 PSNR $25.11 \pm 3.33$ 및 SSIM $90.95 \pm 3.86$을 기록했으며, 종양 영역에 대해서는 PSNR $17.33 \pm 4.56$ 및 SSIM $73.21 \pm 16.22$를 기록했다. 이러한 수치는 모든 기준선에 대한 명확한 개선을 나타낸다. Wilcoxon 부호 순위 검정을 사용한 통계 분석은 이러한 개선이 "매우 통계적으로 유의미하다($p < 0.001$)"고 확인하여, D³M의 우수한 성능에 대한 의심의 여지를 남기지 않았다. 특히 진단적으로 중요한 종양 영역 내에서의 이러한 정량적 이점은 D³M의 메커니즘이 CEMRI 합성의 "ill-posed" 특성을 효과적으로 완화한다는 것을 강조한다.
-
무결성 연구 검증 (표 2): BraSyn 데이터셋에 대한 무결성 연구는 D³M의 아키텍처 혁신에 대한 직접적이고 구성 요소 수준의 증거를 제공한다.
- MSSDM의 이점: 다단계 공간 변형 모듈(MSSDM)이 제거되고 DSIMD의 출력이 직접 속도 항에 사용되었을 때, PSNR과 SSIM 모두 크게 감소했으며, "특히 종양 영역에서" 그렇다. 이는 증강을 조정하기 위해 합성화된 영상을 변형시키는 MSSDM의 기하학적 수정이 정확한 종양 표현에 중요한 구성 요소임을 직접적으로 검증한다. 이는 강도 조정만으로는 아닌 공간 변형을 통한 증강 수정이 실제로 유익하다는 것을 확인한다.
- DSIMD의 이점: 이중 스트림 영상-마스크 디코더(DSIMD)를 제거하고 단일 디코더로 대체했을 때 PSNR과 SSIM이 더욱 크게 감소했다. 이는 중간 증강 영상과 마스크를 공동으로 생성하는 데 있어 DSIMD의 필수적인 역할을 보여준다. 이 이중 스트림 접근 방식은 명백히 MSSDM에 필요한 안내를 제공하여, 모델의 조영 증강 이해도를 향상시키고 더 정확한 기하학적 수정을 가능하게 한다.
요약하자면, 실험 설계, 강력한 기준선 모델의 패배, 그리고 세심한 무결성 연구는 D³M의 핵심 메커니즘—이중 스트림 영상-마스크 디코더에 의해 안내되는 공간 변형을 통한 기하학적 증강 오류 수정—이 고품질 CEMRI, 특히 뇌종양에 대한 합성에서 매우 효과적이고 통계적으로 유의미한 발전이라는 확실하고 부인할 수 없는 증거를 제공한다.
한계 및 향후 방향
D³M은 특히 뇌종양에 대한 CEMRI 합성에서 상당한 발전을 이루었지만, 어떤 과학적 노력도 그 경계와 미래 탐색의 기회 없이 이루어지지 않는다는 점을 인식하는 것이 중요하다. 논문 자체는 명시적으로 "한계" 섹션을 포함하지 않지만, CEMRI 합성에서 NCMRIs로의 합성이 "매우 ill-posed"이며 기존 방법들이 "종양 하위 구성 요소의 복잡한 형태"로 어려움을 겪는다는 점을 언급하며 문제의 내재된 복잡성을 암묵적으로 지적한다. D³M이 이러한 과제를 효과적으로 해결하지만, 최상의 성능을 보이는 모델조차도 합성 영상과 실제 영상 간의 격차가 있음을 시사하는 절대적인 PSNR 및 SSIM 값은 추가적인 개선의 여지가 있음을 나타낸다. 기하학적 수정은 강력하지만, "상대적으로 작다"고 설명되어 있으며, 이는 합성 과정의 완전한 재정비보다는 표적 개선임을 시사한다.
앞으로 D³M의 발견은 미래 개발을 위한 몇 가지 흥미롭고 중요한 논의 주제를 열어준다.
-
병리학 및 해부학 전반의 일반화 가능성: 현재의 성공은 뇌종양에 대해 입증되었다. 중요한 다음 단계는 D³M의 성능과 다른 병리학(예: 염증, 전이) 및 다른 해부학적 영역(예: 간, 전립선, 유방)으로의 적응성을 조사하는 것이다. 각 장기와 질병은 조영 증강 패턴과 해부학적 변동성 측면에서 고유한 과제를 제시한다. 이러한 다양한 맥락에서 성능을 유지하거나 심지어 향상시키기 위해 어떤 아키텍처 수정 또는 학습 전략이 필요할까?
-
임상 통합 및 규제 경로: 이러한 연구의 궁극적인 목표는 임상적 유용성이다. 합성 CEMRI는 실제 임상 환경에서 진단 정확도 및 치료 계획을 위해 어떻게 엄격하게 검증될 수 있을까? 실제 CEMRI와의 동의 수준은 어느 정도가 임상의 및 규제 기관에서 수용 가능한 것으로 간주되는가? 이는 영상 품질 지표뿐만 아니라 임상 결과 연구를 포함한다. 또한, 환자 치료를 위해 AI 생성 영상을 사용하는 윤리적 함의, 책임 및 환자 신뢰 문제 포함, 신중한 고려와 강력한 규제 프레임워크가 필요하다.
-
불확실성 정량화 및 설명 가능성: 의료 영상에서 진단에 대한 신뢰는 가장 중요하다. D³M은 고품질 영상을 생성하지만, 특히 중요한 종양 경계에서의 합성 증강과 관련된 불확실성을 정량화하는 것은 매우 가치 있을 것이다. 불확실성 추정 기법은 임상의에게 합성 영상의 신뢰도 측정치를 제공할 수 있다. 또한, 변형 필드의 설명 가능성을 개선하는 것—모델이 특정 기하학적 수정을 적용하는 이유를 이해하는 것—은 의료 전문가들에게 더 큰 신뢰와 해석 가능성을 높일 수 있다.
-
계산 효율성 및 실시간 응용: 확산 모델은 강력하지만, 특히 3D 볼륨 및 다단계 프로세스의 경우 계산 집약적일 수 있다. 임상 채택, 특히 시간 민감 시나리오 또는 대규모 데이터 처리를 위해, D³M을 더 빠른 추론을 위해 최적화하는 것이 필수적이다. 고급 샘플링 기법, 모델 증류 또는 하드웨어 가속을 탐색하면 품질을 손상시키지 않으면서 합성 시간을 크게 줄일 수 있다. 이는 임상 워크플로우에 더 실용적인 통합을 가능하게 할 것이다.
-
종단 모니터링 및 질병 진행: CEMRI는 종양 치료 반응의 종단 모니터링을 위해 자주 사용된다. D³M은 여러 시간 지점에서 크기, 형태 및 증강의 미묘한 변화를 정확하게 반영하는 CEMRI를 일관되게 합성할 수 있을까? 여러 시간 지점에 걸쳐 진행 또는 퇴행에 대한 일관성과 민감성을 유지하는 것은 D³M의 기하학적 수정 기능을 크게 활용할 수 있는 복잡한 과제이다.
-
다중 모달 및 다중 시퀀스 융합: 현재 NCMRIs는 T1, T2, FLAIR를 포함한다. 미래 연구는 조직 특성에 대한 모델의 이해를 더욱 향상시키고 더 정확하고 강력한 CEMRI 합성을 이끌 수 있는 확산 가중 영상(DWI) 또는 관류 영상과 같은 추가적인 비조영 증강 시퀀스를 통합하는 것을 탐색할 수 있을까?
이러한 논의점들은 D³M이 상당한 발전을 이루었지만, 합성 의료 영상의 잠재력을 완전히 실현하기 위한 여정은 계속되고 있으며, 학제 간 협력과 지속적인 혁신을 요구한다는 것을 강조한다.
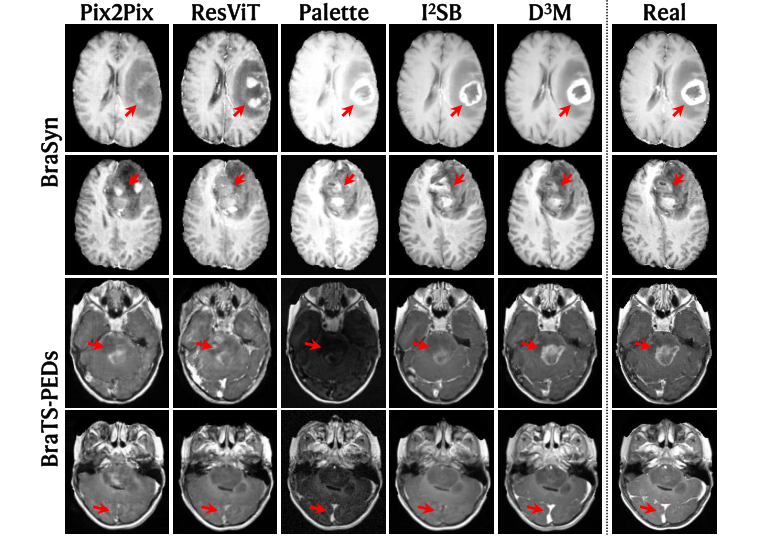 Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison
Figure 2. Examples of synthesis results, shown together with the real CEMRI for refer- ence. Note the tumor and vessel regions highlighted by arrows for comparison