Prompt-DAS: 電子顕微鏡画像におけるドメイン適応型セマンティックセグメンテーションのためのアノテーション効率的なプロンプト学習
Prompt-DAS adapts AI to segment tiny cell parts in electron microscope images, offering flexible, efficient, and interactive annotation.
背景と学術的系譜
画像内の全画素を精密に輪郭抽出し分類するセマンティックセグメンテーションの分野は、Convolutional Neural Networks (CNN) や Vision Transformers (ViT) といった深層学習モデルの台頭により、目覚ましい進歩を遂げた。この進展は、がん研究や生物学におけるミトコンドリアなどの細胞内小器官の解析に不可欠な電子顕微鏡(EM)画像の解析において、特に大きな影響を与えている。
しかし、この強力な技術は2つの大きな障壁に直面している。第一に、これらの洗練されたモデルの学習には、膨大な量の画素単位のアノテーションが必要となる点である。数千枚もの超高精細なEM画像において、すべてのミトコンドリアの正確な境界を緻密に描画することを想像してほしい。これは極めて時間的・経済的コストが高く、労働集約的な作業であり、多くの場合、高度な専門知識を持つ専門家を必要とする。この高いアノテーション負荷が、大規模な実用化を阻む要因となっていた。
第二に、特定のEM画像群(ソースドメイン)で学習されたモデルは、異なる顕微鏡や組織標本から得られた新しいEM画像(ターゲットドメイン)に対して、性能が著しく低下するという問題がある。これは「ドメインシフト」として知られる現象であり、ラットの脳画像で学習したモデルが、同じミトコンドリアを含んでいてもヒトの肝臓画像に対しては苦戦を強いられることを意味する。
アノテーション負荷とドメインシフトという課題に対処するため、研究者は「ドメイン適応(Domain Adaptation: DA)」に注目した。初期の試みである教師なしドメイン適応(Unsupervised Domain Adaptation: UDA)は、ターゲットドメインにアノテーションが存在しないことを前提とする。魅力的なアプローチではあるが、UDA手法は複雑なセグメンテーションタスクにおいて比較的低い性能にとどまることが多く、実用上の有用性が制限されていた。これに対し、弱教師ありドメイン適応(Weakly Supervised Domain Adaptation: WDA)は、ターゲットドメインにおいて「スパースポイント(物体の位置を示す数個の点)」を安価な弱ラベルとして活用することで、最小限のアノテーション努力で性能を向上させる実用的な代替案として浮上した。しかし、WDAであっても依然として手動入力が必要であり、多様なアノテーションシナリオに対して必ずしも十分な柔軟性を備えているわけではなかった。
近年、Segment Anything Model (SAM) のような「プロンプト駆動型」の基盤モデルの出現が、自然画像のセグメンテーションに革命をもたらした。数十億枚の画像で事前学習されたSAMは、シングルクリック(点)、バウンディングボックス、あるいは大まかな落書きといった単純な「プロンプト」に基づいて物体をセグメント化できる。これにより、ユーザーがモデルを誘導するインタラクティブ・セグメンテーションへの道が開かれた。
しかし、SAM自体にも医療・EM画像ドメインへの適用において重大な限界があった。医療画像におけるドメインシフトに弱く、特に点プロンプトを用いた場合に性能が低下する傾向があった。これは、医療特有の知識の欠如、生物学的な境界の曖昧さ、そして小器官の複雑な形状に起因する。決定的な問題として、SAMは個々の物体インスタンスごとにプロンプトを必要とする。数百から数千もの微細な小器官が密集するEM画像において、すべてに対してプロンプトを提供することは、画素単位のアノテーションと同様に非現実的である。さらに、医療コンテキストにおける点プロンプトを用いたSAMの性能は、多くの場合最適とは言えなかった。
これらの限界――画素単位アノテーションの法外なコスト、異なるEM画像データセット間での汎化性能の低さ、既存のDA手法やSAMのような強力な基盤モデルが医療ドメインで抱える欠点――が、著者らにPrompt-DASの開発を促した。その動機は、学習時および推論時の双方でスパースな点プロンプトを効果的に活用し、UDA、WDA、およびインタラクティブ・セグメンテーションの各シナリオにおいて高い性能を発揮する、柔軟かつアノテーション効率の高いプロンプト対応型Transformerモデルを構築することにあった。
ドメイン用語の類推
- セマンティックセグメンテーション: 庭の絵が描かれた塗り絵を想像してほしい。セマンティックセグメンテーションとは、「花」をすべて赤、「葉」をすべて緑、「土」をすべて茶色に塗るような作業である。単に花を囲む箱を描くのではなく、そのカテゴリに属するすべての画素を塗り分けるのである。
- ドメイン適応 (DA): 晴天のカリフォルニア(ソースドメイン)で様々な種類の車を識別することを学んだ学生を想像してほしい。今、この学生は雪の降るアラスカ(ターゲットドメイン)に移動し、そこで車を識別する必要がある。すべてを忘れて一からやり直すのではなく、ドメイン適応とは、学生が既存の車の知識を維持しつつ、雪、氷、異なる照明条件を考慮して知識を調整することである。彼らは新しい環境に合わせて学習を適応させる。
- 電子顕微鏡 (EM) 画像: 時計内部の微細で複雑な歯車を覗き込む様子を想像してほしい。通常のカメラは光を使って撮影するが、電子顕微鏡は光の代わりに電子ビームを使用して、通常の顕微鏡よりもはるかに高い倍率と詳細さで、細胞の内部構造のような極めて小さな対象を「見る」。つまり、EM画像は、微細な世界を写し出した超高精細かつ高コントラストなモノクロ写真のようなものである。
- プロンプト学習 (Promptable Learning): 何でも描ける非常に才能のあるアーティストがいると想像してほしい。単に「家を描いて」と言うだけでは曖昧だが、「プロンプト」を与えることで――例えば紙の特定の場所を指差して「ここに家を描いて」と言ったり、大まかな輪郭を描いて「この形を家で埋めて」と言ったりする。この「プロンプト」は、アーティスト(AIモデル)が複雑なタスク(描画/セグメンテーション)を、望む場所と方法で正確に実行するように導く、小さく具体的なヒント(点やボックスなど)である。
- 疑似ラベリング (Pseudo-labeling): 教師がクイズを出す場面を考える。一部の問題には回答が提供されている(ラベル付きデータ)が、ほとんどにはない。回答のない問題に解答を試み、非常に自信があるものについては正解としてマークする。その後、これらの「自己採点」した回答(疑似ラベル)を、あたかも正解であるかのように学習に利用する。AIにおいて、「教師モデル」は「生徒モデル」が学習するための自信のある「自己採点」回答を生成し、ラベルのないデータから学習することを支援する。
表記一覧
| 表記 | 型 | 説明 |
|---|---|---|
| $D_s$ | 変数 | ソースドメインデータセット。画像と完全な画素単位ラベルで構成される。 |
| $D_t$ | 変数 | ターゲットドメインデータセット。画像とスパースな点ラベルで構成される。 |
| $x^s, x^t$ | 変数 | それぞれソースおよびターゲットドメインからの入力画像。 |
| $y^s$ | 変数 | ソース画像の完全な画素単位Ground Truthラベル。 |
| $c^t$ | 変数 | ターゲット画像内の少数の物体インスタンスに対するGround Truth点ラベル。 |
| $\hat{c}^t$ | 変数 | 二値点ラベルマップ。1はアノテーションされたスパース点を示す。 |
| $d$ | 変数 | 点ラベルからGaussianカーネルとの畳み込みにより導出された密度マップ。 |
| $k_\sigma$ | パラメータ | 密度マップ生成に使用されるGaussianカーネル。 |
| $f_e$ | モデル構成要素 | 画像エンコーダ。入力画像から特徴量を抽出する。 |
| $f_p$ | モデル構成要素 | 点プロンプトエンコーダ。入力点プロンプトを処理する。 |
| $f_D$ | モデル構成要素 | マルチタスクデコーダ。画像特徴量とプロンプト特徴量を統合する。 |
| $f_s$ | モデル構成要素 | セマンティックセグメンテーションヘッド。セグメンテーション予測を出力する。 |
| $f_r$ | モデル構成要素 | 回帰ベースの中心点検出ヘッド。点検出結果を出力する。 |
| $M$ | パラメータ | プロンプトエンコーダへの入力として提供される点の数。 |
| $L_{det}$ | 変数 | 検出損失。中心点検出の精度を測定する。 |
| $L_{seg}$ | 変数 | セグメンテーション損失。セマンティックセグメンテーションの精度を測定する。 |
| $L_{pcl}$ | 変数 | プロンプト誘導型対照学習損失(Prompt-guided contrastive loss)。特徴量の識別性を高める。 |
| $F_R$ | モデル構成要素 | 全体検出ネットワーク。$f_r \circ f_D \circ f_e$ として構成される。 |
| $F_S$ | モデル構成要素 | 全体セグメンテーションネットワーク。$f_s \circ f_D \circ f_e$ として構成される。 |
| $MSE$ | 変数 | 平均二乗誤差(Mean Square Error)損失関数。 |
| $CE$ | 変数 | 交差エントロピー(Cross-Entropy)損失関数。 |
| $\hat{d}^t$ | 変数 | ターゲットドメインの予測密度マップ。疑似ラベリングに使用される。 |
| $\hat{y}^t$ | 変数 | ターゲットセグメンテーションのために教師モデルが生成した疑似ラベル。 |
| $n_s$ | パラメータ | ソースデータの学習プロンプトとして使用されるランダムサンプリングされた中心点の数。 |
| $z^t$ | 変数 | ターゲットドメインの点 $p^t$ から導出された特徴埋め込み。 |
| $\phi$ | モデル構成要素 | 対照学習の前に使用されるMLP(多層パーセプトロン)層。 |
| $N_q$ | 変数 | 前景プロンプト埋め込みの数。 |
| $N_n$ | 変数 | 背景プロンプト埋め込みの数。 |
| $\mu^s$ | 変数 | スパース点プロンプトの平均埋め込み。 |
| $\tau$ | パラメータ | 対照学習の温度パラメータ。特徴分離の鋭さを制御する。 |
| $\delta_f$ | パラメータ | 疑似ラベリングのための前景点選択の信頼度閾値。 |
| $\delta_b$ | パラメータ | 疑似ラベリングのための背景点選択の信頼度閾値。 |
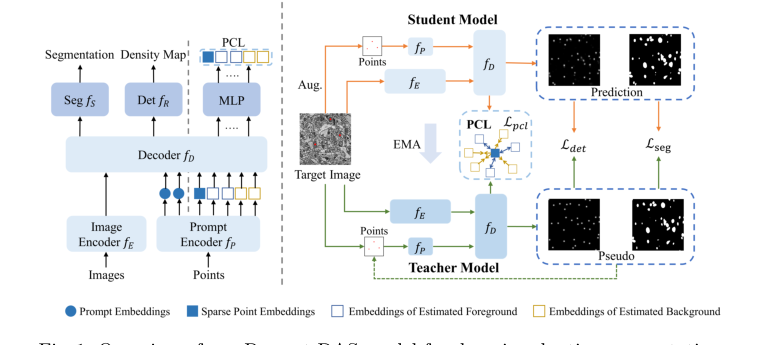 Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
問題定義と制約
中核となる問題設定とジレンマ
出発点(入力/現在の状態):
著者らは、完全な画素単位のGround Truthラベルを持つ電子顕微鏡(EM)画像を含むソースドメイン $\mathcal{D}^s = \{(x^s, y^s)\}$ から開始する。また、異なる分布(例:異なる組織タイプや顕微鏡技術)に由来し、少数の小器官インスタンスに対してのみスパースな点ベースのラベル $\bar{c}^t$ が利用可能なターゲットドメイン $\mathcal{D}^t = \{(x^t, \bar{c}^t)\}$ を有する。
目指すべき終着点(出力/目標状態):
目標は、ターゲットドメイン内のすべての小器官インスタンスを正確にセグメント化できる、堅牢な「プロンプト対応型」セグメンテーションフレームワークを開発することである。モデルは以下の3つの異なるシナリオ下で機能する柔軟性を備える必要がある。
1. 教師なしドメイン適応 (UDA): ターゲット学習データに対して $M=0$ 点が提供される場合。
2. 弱教師ありドメイン適応 (WDA): 学習プロンプトとして $M > 0$ 個のスパース点が提供される場合。
3. インタラクティブ・セグメンテーション: テストフェーズ中にユーザーが提供した点プロンプトを受け入れ、セグメンテーション結果を洗練または修正できる場合。
ジレンマと制約:
主要なジレンマは「アノテーションと性能のトレードオフ」である。深層ニューラルネットワーク(U-NetやVision Transformersなど)は高い精度を達成する一方で、データ飢餓的であり、高価で専門家レベルの画素単位アノテーションを必要とすることが知られている。これらのモデルをあるドメインで学習し別のドメインに適用すると、ドメインシフトにより性能が著しく低下する。
著者らは、この問題を困難にするいくつかの「厳しい壁」に直面している。
* ドメインシフト: EM画像は使用される特定の顕微鏡技術に基づいて外観が大きく異なるため、標準的な事前学習済みモデル(オリジナルのSAMなど)は大幅な適応なしには効果を発揮しない。
* ラベルの希少性: 新しいEMデータセットのすべての小器官に対して画素レベルのマスクを取得することは労働集約的であり、大規模な研究ではしばしば実行不可能である。
* インスタンスの複雑性: 自然画像とは異なり、EM画像には多数の、高密度に詰め込まれた、しばしば曖昧な小器官インスタンスが含まれる。SAMのような標準的な基盤モデルは、ドメイン特有の医療知識を欠いており、またすべての個々のインスタンスに対してプロンプトを必要とするため、大規模な生物学的データセットにとっては非現実的な負担となる。
* 計算上の制約: 著者らは、高解像度の特徴抽出の必要性と現代のGPU(例:24 GB VRAM)のメモリ制限とのバランスを取る必要がある。同時に、巨大な数億規模の事前学習に頼るのではなく、ゼロから学習可能な効率性を維持しなければならない。
このギャップを埋めるため、著者らはセグメンテーションをプロンプト対応タスクとして扱うマルチタスクフレームワークを導入し、補助的な中心点検出ヘッドを使用して疑似ラベルを生成し、セグメンテーションプロセスを誘導する。これにより、「スパース点」という制約を構造的な利点へと効果的に転換し、完全なGround Truthマスクが欠如している場合でも、モデルが識別的な特徴量を学習できるようにしている。
本アプローチの妥当性
著者らは、電子顕微鏡(EM)画像解析における決定的なボトルネックを特定した。SAM(Segment Anything Model)のような基盤モデルは汎用コンピュータビジョンに革命をもたらしたが、EM画像に適用した場合には著しく失敗する。この失敗は、ドメイン特有の知識の欠如、細胞内小器官における複雑で曖昧な境界の存在、そして個別のプロンプトなしに多数のインスタンスを同時にセグメント化できないSAMの能力不足に起因する。
なぜこのアプローチが唯一の実行可能な解決策であったか
著者らは、標準的なUDAや微調整された基盤モデルを含む従来の「SOTA」手法では不十分であることを認識した。それらは、膨大な専門家レベルの画素単位アノテーションを必要とするか、EM画像に固有の「ドメインシフト」に苦戦したためである。彼らの「アハ体験」は、セグメンテーションタスクをマルチタスク問題として扱うことで簡略化できると認識した時に訪れた。高密度なセグメンテーションタスクと、より単純な回帰ベースの中心点検出タスクを組み合わせることで、独自の疑似プロンプトを生成できるようになった。これにより、高価な手動ラベリングの必要性を効果的に回避しつつ、高い精度を維持することが可能となった。
比較優位性(ベンチマークの論理)
Prompt-DASの優位性は、単なる精度指標ではなく、その構造的な効率性にある。
- アノテーション効率: 完全な画素単位マスクを必要とするモデルとは異なり、Prompt-DASはわずか15%のスパース点アノテーションを使用して最先端の結果を達成する。これにより、必要な専門家の労力が大幅に削減される。
- 柔軟性: SAMはすべての物体インスタンスに対してプロンプトを必要とするが、Prompt-DASはゼロ(UDA)からスパース点(WDA)まで、任意の数のプロンプトを処理できるように設計されており、テスト中にインタラクティブ・セグメンテーションを実行することさえ可能である。
- 識別的学習: プロンプト誘導型対照学習 (PCL) の導入は構造的な利点をもたらす。前景の埋め込みをGround Truth点に近づけ、背景の埋め込みを遠ざけることで、標準的な交差エントロピー損失単体よりも堅牢な特徴表現を学習する。
制約と解決策の「融合」
本論文は、EM画像が抱える「厳しい要件」――具体的にはラベルの希少性と小器官形状の高い変動性――に対して、教師・生徒フレームワークを通じて対処している。教師モデルを使用して疑似ラベルを生成し、Non-Maxima Suppression(非最大値抑制)を用いて局所最大値を特定することで、モデルは自己改善ループを構築する。これはデータが限られているという制約と完全に合致しており、モデルは「より容易な」検出タスクを使用して「より困難な」セグメンテーションタスクを監督する。
数学的・論理的メカニズム
数学的エンジン
Prompt-DASの中核は、中心点検出とセマンティックセグメンテーションを同時に実行するマルチタスク学習フレームワークである。システムの「マスター方程式」は、ソースドメインとターゲットドメインの両方でこれら2つのタスクのバランスを取る結合損失関数である。
$$\mathcal{L}_{total} = \mathcal{L}_{det} + \mathcal{L}_{seg} + \lambda \mathcal{L}_{pcl}$$
ここで、$\mathcal{L}_{det}$ および $\mathcal{L}_{seg}$ は以下のように定義される。
$$\mathcal{L}_{det} = \frac{1}{|D^s|} \sum_{x^s} MSE(F_R(x^s), d^s) + \frac{1}{|D^t|} \sum_{x^t} MSE(F_R(x^t), \hat{d}^t)$$
$$\mathcal{L}_{seg} = \frac{1}{|D^s|} \sum_{x^s} CE(F_S(x^s), y^s) + \frac{1}{|D^t|} \sum_{x^t} CE(F_S(x^t), \hat{y}^t)$$
方程式の分解
- $MSE(F_R(x), d)$: これは平均二乗誤差である。予測密度マップとGround Truth(または疑似ラベル)密度マップとの間の画素単位の差を測定する。これは回帰ペナルティとして機能し、モデルに対して小器官の中心が位置する場所に正確に高強度の「ピーク」を配置するよう強制する。
- $CE(F_S(x), y)$: これは交差エントロピー損失である。セグメンテーションのための標準的な分類損失であり、画素に対する予測クラス確率がGround Truthラベルから逸脱した場合にモデルにペナルティを課す。
- $F_R$ および $F_S$: これらは画像エンコーダ $f_E$、デコーダ $f_D$、およびそれぞれのヘッド(検出用の $f_R$、セグメンテーション用の $f_S$)の合成を表す。著者らは、共有バックボーンからタスク特化型のブランチへのデータの流れを示すために、関数合成($\circ$)を使用している。
- $\hat{d}^t$ および $\hat{y}^t$: これらは教師モデルによって生成された疑似ラベルである。これらはGround Truthが希少なターゲットドメインにおいて監督を提供するため、極めて重要である。
ステップ・バイ・ステップの流れ
単一のEM画像がアセンブリラインに入る様子を想像してほしい。
1. 特徴抽出: 画像 $x$ はエンコーダ $f_E$ を通過し、生の画素を高次元の特徴マップへと変換する。
2. プロンプト注入: 点プロンプトが利用可能な場合、プロンプトエンコーダ $f_P$ がこれらの座標を埋め込みに変換し、クロスアテンションを介してデコーダ $f_D$ に注入される。
3. マルチタスク分岐: デコーダ $f_D$ は流れを分岐させる。一方のブランチ($f_R$)は密度マップ(小器官の場所)を予測し、もう一方($f_S$)は最終的なセグメンテーションマスクを予測する。
4. 疑似ラベリング: 教師モデル(生徒モデルのEMAバージョン)が出力を確認する。教師が確信を持っている場合、疑似ラベルを生成し、これが生徒の教師として機能することで、ラベルのないターゲットドメインを通じて効果的に誘導する。
5. 対照的洗練: PCLモジュールは前景および背景の埋め込みを取り込み、対照損失を使用して類似の特徴量を「引き寄せ」、背景ノイズを「遠ざける」ことで、EM画像の複雑なテクスチャによってモデルが混乱しないようにする。
最適化のダイナミクス
モデルはMean-Teacherフレームワークを通じて学習する。生徒モデルは上記の損失関数を用いてバックプロパゲーションにより重みを更新する。同時に、教師モデルは生徒の重みの指数移動平均 (EMA) を用いて更新される。これにより、一貫した高品質の疑似ラベルを提供する「安定した」教師が作成され、学習初期段階において生徒がノイズの多い不安定な予測を追うことを防ぐ。
結果、限界、および結論
Prompt-DASの分析:電子顕微鏡におけるドメインギャップの解消
実験的証拠
著者らは、標準的なUDA手法(DAMT-Netなど)やSAMベースのアプローチ(WeSAMなど)を含む様々な「犠牲者」に対して、モデルを容赦なくテストした。
* 証拠: 表1の結果は明白である。SAMおよびその医療用バリアント(SAM-Med2D)はEM画像において性能が著しく低下するが、Prompt-DASは一貫して高いDiceスコアを達成している。
* 証明: アブレーション研究(表2)が最も説得力のある証拠である。検出疑似ラベリング、セグメンテーション疑似ラベリング、学習プロンプト、そして最後にPCLを追加することで、累積的かつ測定可能な性能向上が得られることが示されている。各コンポーネントは単に「追加」されたのではなく、前のステップの特定の失敗モードを解決するために数学的に正当化されている。モデルはわずか15%のアノテーション努力でほぼ教師あり学習と同等の性能を達成しており、これは効率性において大きな勝利である。
考察と将来の進化
本論文は、基盤モデルを専門的な科学ドメインに対して実際に有用なものにする方法を示す素晴らしい例である。しかし、さらに推し進めることができる領域がいくつか存在する。
- ソースフリー適応: 著者らは、モデルがソースデータへのアクセスを必要とすることを認めている。実際の臨床現場では、ソースデータは多くの場合、専有物であるか、プライバシー法によって制限されている。将来の研究では、元のソース画像を見ることなく、ターゲットデータと事前学習済み重みのみを使用して新しいドメインに適応する「ソースフリー」適応を探求できる可能性がある。
- 3Dボリューム連続性の処理: EMデータは多くの場合3Dであるが、本モデルは主に一連の2D画像として扱う。スライス間での時間的または空間的な一貫性を統合することで、モデルがボリューム全体で小器官を「追跡」できるようになり、スパース点の必要性をさらに低減できる可能性がある。
- 不確実性の定量化: 医療診断において、モデルが「いつ」推測しているかを知ることは、推測そのものと同じくらい重要である。ベイズ的な不確実性やコンフォーマル予測をPCLメカニズムに統合することで、臨床医がどのセグメンテーションに手動レビューが必要かを特定する助けとなり、ラボ環境においてツールをより信頼性の高いものにできるだろう。
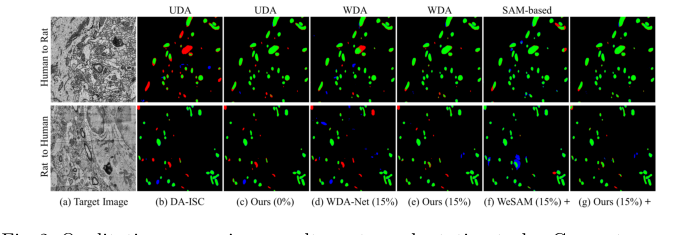 Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives
Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives
他分野との同型性(Isomorphisms)
構造的骨格
マルチタスク対照正則化を通じて、分散したデータ分布間で潜在的な特徴表現を整列させるために、スパースで信頼性の高いアンカーポイントを使用するメカニズム。