Prompt-DAS: Эффективное обучение с подсказками (Prompt Learning) для доменно-адаптивной семантической сегментации изображений электронной микроскопии
Область семантической сегментации, предполагающая точное оконтуривание и классификацию каждого пикселя на изображении, достигла значительных успехов благодаря глубоким нейронным сетям, таким как сверточные нейронные...
Общие сведения и академическая преемственность
Область семантической сегментации, предполагающая точное оконтуривание и классификацию каждого пикселя на изображении, достигла значительных успехов благодаря глубоким нейронным сетям, таким как сверточные нейронные сети (CNN) и трансформеры зрения (ViT). Этот прогресс оказался особенно значимым при анализе изображений электронной микроскопии (ЭМ), которые критически важны для изучения субклеточных органелл, таких как митохондрии, в исследованиях рака и биологии.
Тем не менее, данная технология столкнулась с двумя серьезными препятствиями. Во-первых, обучение таких сложных моделей требует колоссального объема попиксельной разметки. Представьте необходимость кропотливого нанесения точных границ вокруг каждой отдельной митохондрии на тысячах сверхдетализированных ЭМ-изображений — это невероятно трудоемкая, дорогостоящая и времязатратная задача, часто требующая участия узкопрофильных экспертов. Столь высокая нагрузка по аннотированию делает применение таких методов в широких масштабах непрактичным.
Во-вторых, модели, обученные на одном наборе ЭМ-изображений («исходный домен» / source domain), часто демонстрируют низкую эффективность при работе с новыми ЭМ-изображениями («целевой домен» / target domain), полученными с других микроскопов или на других типах тканей. Это явление, известное как «сдвиг домена» (domain shift), означает, что модель, обученная на изображениях мозга крысы, может испытывать трудности с изображениями печени человека, даже если в обоих случаях присутствуют митохондрии.
Для решения проблем нагрузки по аннотированию и сдвига домена исследователи обратились к «адаптации домена» (Domain Adaptation, DA). Ранние попытки включали неконтролируемую адаптацию домена (Unsupervised Domain Adaptation, UDA), которая предполагает отсутствие аннотаций в целевом домене. Несмотря на привлекательность, методы UDA часто приводили к относительно низкой производительности в сложных задачах сегментации, что ограничивало их практическую ценность. Слабоконтролируемая адаптация домена (Weakly Supervised Domain Adaptation, WDA) стала более практичной альтернативой, использующей «разреженные точки» (sparse points) — несколько меток, указывающих на расположение объекта — в качестве дешевых слабых меток в целевом домене для повышения производительности при минимальных затратах на аннотирование. Хотя этот подход эффективнее, WDA все еще требовала ручного ввода и не всегда была достаточно гибкой для различных сценариев разметки.
Совсем недавно появление «prompt-driven» фундаментальных моделей, таких как Segment Anything Model (SAM), произвело революцию в сегментации естественных изображений. SAM, предварительно обученная на миллиардах изображений, способна сегментировать объекты на основе простых «подсказок» (prompts), таких как один клик (точка), ограничивающая рамка или грубый набросок. Это открыло путь к интерактивной сегментации, где пользователи могут направлять работу модели.
Однако сама SAM имела критические ограничения при применении к области медицинской и ЭМ-визуализации. Она испытывала трудности со сдвигом домена на медицинских изображениях и часто демонстрировала низкую производительность, особенно при использовании точечных подсказок, из-за отсутствия специфических медицинских знаний, неоднозначности биологических границ и сложной формы органелл. Важно отметить, что SAM требует подсказку для каждого отдельного экземпляра объекта. Для ЭМ-изображений, изобилующих сотнями или тысячами крошечных органелл, предоставление подсказки для каждой из них столь же непрактично, как и попиксельная разметка. Более того, производительность SAM при использовании точечных подсказок в медицинском контексте зачастую была субоптимальной.
Эти ограничения — непомерная стоимость попиксельной разметки, слабая обобщающая способность на различных наборах ЭМ-данных, а также недостатки существующих методов DA и даже мощных фундаментальных моделей вроде SAM в медицинской сфере — в совокупности побудили авторов разработать Prompt-DAS. Их мотивация заключалась в создании гибкой, эффективной с точки зрения аннотирования и поддерживающей подсказки модели-трансформера, специально предназначенной для доменно-адаптивной семантической сегментации ЭМ-изображений, которая могла бы преодолеть эти вызовы за счет эффективного использования разреженных точечных подсказок как при обучении, так и при тестировании, демонстрируя высокую эффективность в сценариях UDA, WDA и интерактивной сегментации.
Аналогии доменных терминов
- Семантическая сегментация: Представьте раскраску с изображением сада. Семантическая сегментация — это как раскрашивание всех «цветов» в красный, всех «листьев» в зеленый, а всей «почвы» в коричневый цвет. Вы не просто рисуете рамку вокруг каждого цветка; вы закрашиваете каждый пиксель, принадлежащий цветку, листу или почве, основываясь на их категории.
- Адаптация домена (DA): Представьте студента, который учится распознавать различные типы автомобилей в солнечной Калифорнии («исходный домен»). Теперь этот студент переезжает в заснеженную Аляску («целевой домен») и должен распознавать автомобили там. Вместо того чтобы забыть все и начинать сначала, адаптация домена — это использование студентом своих существующих знаний об автомобилях, но с корректировкой их с учетом снега, льда и других условий освещения. Он адаптирует свое обучение к новой среде.
- Изображения электронной микроскопии (ЭМ): Представьте, что вы рассматриваете крошечные, сложные шестеренки внутри часов. Обычная камера использует свет для создания снимка. Электронный микроскоп, однако, использует пучок электронов вместо света, чтобы «видеть» объекты, которые невероятно малы (например, внутренние структуры клетки), с гораздо большим увеличением и детализацией, чем обычный микроскоп. Таким образом, ЭМ-изображения — это сверхдетализированные, высококонтрастные черно-белые фотографии микроскопического мира.
- Обучение с подсказками (Promptable Learning): Представьте, что у вас есть очень талантливый художник, который может нарисовать что угодно. Вместо того чтобы просто сказать «нарисуй дом», что звучит расплывчато, вы даете ему «подсказку» — например, указываете на конкретное место на бумаге и говорите «нарисуй дом здесь», или рисуете грубый контур и говорите «заполни эту форму домом». «Подсказка» — это небольшая, конкретная подсказка (например, точка или рамка), которая направляет художника (модель ИИ) для выполнения сложной задачи (рисования/сегментации) именно там и так, как вы хотите.
- Псевдоразметка (Pseudo-labeling): Представьте, что учитель дает вам тест. На некоторые вопросы даны ответы (размеченные данные), но на большинство — нет. Вы пытаетесь ответить на вопросы без ответов, и те, в которых вы очень уверены, помечаете как правильные. Затем вы используете эти «самостоятельно оцененные» ответы (псевдометки) для дальнейшего обучения, как если бы они были настоящими ответами. В ИИ «модель-учитель» генерирует такие уверенные «самостоятельно оцененные» ответы для «модели-ученика», помогая ей обучаться на неразмеченных данных.
Таблица обозначений
| Обозначение | Тип | Описание |
|---|---|---|
| $D_s$ | Переменная | Набор данных исходного домена, состоящий из изображений и их полных попиксельных меток. |
| $D_t$ | Переменная | Набор данных целевого домена, состоящий из изображений и разреженных точечных меток. |
| $x^s, x^t$ | Переменная | Входные изображения из исходного и целевого доменов соответственно. |
| $y^s$ | Переменная | Полные попиксельные ground truth метки для исходных изображений. |
| $c^t$ | Переменная | Ground truth точечные метки для нескольких экземпляров объектов на целевых изображениях. |
| $\hat{c}^t$ | Переменная | Бинарная карта точечных меток, где 1 указывает на аннотированную разреженную точку. |
| $d$ | Переменная | Карта плотности, полученная из точечных меток путем свертки с ядром Гаусса. |
| $k_\sigma$ | Параметр | Ядро Гаусса, используемое для генерации карты плотности. |
| $f_e$ | Компонент модели | Энкодер изображений, извлекает признаки из входных изображений. |
| $f_p$ | Компонент модели | Энкодер точечных подсказок, обрабатывает входные точечные подсказки. |
| $f_D$ | Компонент модели | Многозадачный декодер, интегрирует признаки изображения и подсказки. |
| $f_s$ | Компонент модели | Голова семантической сегментации, выдает предсказания сегментации. |
| $f_r$ | Компонент модели | Регрессионная голова обнаружения центральных точек, выдает детекции точек. |
| $M$ | Параметр | Количество точек, подаваемых на вход энкодера подсказок. |
| $L_{det}$ | Переменная | Функция потерь детекции, измеряет точность обнаружения центральных точек. |
| $L_{seg}$ | Переменная | Функция потерь сегментации, измеряет точность семантической сегментации. |
| $L_{pcl}$ | Переменная | Контрастивная функция потерь с учетом подсказок, повышает различимость признаков. |
| $F_R$ | Компонент модели | Полная сеть детекции, составленная как $f_r \circ f_D \circ f_e$. |
| $F_S$ | Компонент модели | Полная сеть сегментации, составленная как $f_s \circ f_D \circ f_e$. |
| $MSE$ | Переменная | Функция потерь среднеквадратичной ошибки (Mean Square Error). |
| $CE$ | Переменная | Функция потерь перекрестной энтропии (Cross-Entropy). |
| $\hat{d}^t$ | Переменная | Предсказанная карта плотности для целевого домена, используемая для псевдоразметки. |
| $\hat{y}^t$ | Переменная | Псевдометки, сгенерированные моделью-учителем для целевой сегментации. |
| $n_s$ | Параметр | Количество случайно выбранных центральных точек, используемых как обучающие подсказки для исходных данных. |
| $z^t$ | Переменная | Эмбеддинг признаков, полученный из точки $p^t$ целевого домена. |
| $\phi$ | Компонент модели | Слой MLP (многослойный перцептрон), используемый перед контрастивным обучением. |
| $N_q$ | Переменная | Количество эмбеддингов подсказок переднего плана. |
| $N_n$ | Переменная | Количество эмбеддингов подсказок фона. |
| $\mu^s$ | Переменная | Средний эмбеддинг разреженных точечных подсказок. |
| $\tau$ | Параметр | Параметр температуры для контрастивной функции потерь, контролирующий резкость разделения признаков. |
| $\delta_f$ | Параметр | Порог уверенности для выбора точек переднего плана для псевдоразметки. |
| $\delta_b$ | Параметр | Порог уверенности для выбора точек фона для псевдоразметки. |
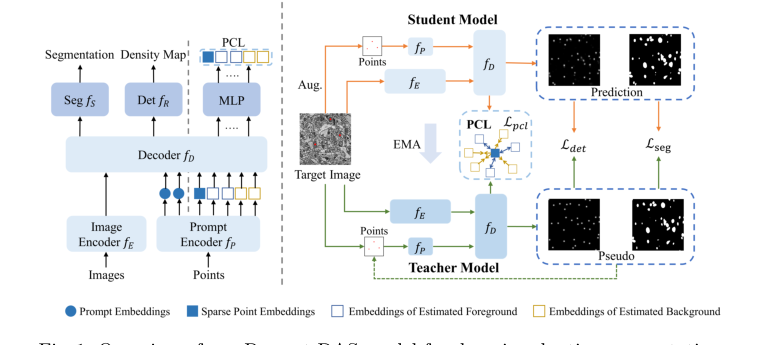 Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
Постановка задачи и ограничения
Формулировка основной проблемы и дилемма
Отправная точка (входные данные/текущее состояние):
Авторы начинают с исходного домена $\mathcal{D}^s = \{(x^s, y^s)\}$, содержащего изображения электронной микроскопии (ЭМ) с полными попиксельными ground-truth метками. У них также есть целевой домен $\mathcal{D}^t = \{(x^t, \bar{c}^t)\}$, состоящий из изображений из другого распределения (например, другие типы тканей или методы микроскопии), где доступны только разреженные точечные метки $\bar{c}^t$ для небольшой подвыборки экземпляров органелл.
Желаемый результат (целевое состояние):
Цель состоит в разработке надежного фреймворка сегментации с поддержкой подсказок, способного точно сегментировать все экземпляры органелл в целевом домене. Модель должна быть достаточно гибкой, чтобы функционировать в трех различных сценариях:
1. Неконтролируемая адаптация домена (UDA): где на обучающих данных целевого домена предоставлено $M=0$ точек.
2. Слабоконтролируемая адаптация домена (WDA): где в качестве обучающих подсказок предоставлено $M > 0$ разреженных точек.
3. Интерактивная сегментация: где модель может принимать предоставленные пользователем точечные подсказки на этапе тестирования для уточнения или исправления результатов сегментации.
Дилемма и ограничения:
Основная дилемма заключается в «компромиссе между аннотированием и производительностью». Хотя глубокие нейронные сети (такие как U-Net или Vision Transformers) достигают высокой точности, они печально известны своей «прожорливостью» к данным и требуют дорогостоящей попиксельной разметки экспертного уровня. Когда эти модели обучаются на одном домене и применяются к другому, они страдают от значительного снижения производительности из-за сдвига домена.
Авторы сталкиваются с несколькими «жесткими барьерами», которые затрудняют решение этой задачи:
* Сдвиг домена: ЭМ-изображения сильно различаются по внешнему виду в зависимости от используемого метода микроскопии, что делает стандартные предобученные модели (например, оригинальную SAM) неэффективными без значительной адаптации.
* Дефицит меток: Получение масок попиксельного уровня для каждой органеллы в новом наборе ЭМ-данных является трудоемким и часто невыполнимым для крупномасштабных исследований.
* Сложность экземпляров: В отличие от естественных изображений, ЭМ-изображения содержат многочисленные, плотно упакованные и часто неоднозначные экземпляры органелл. Стандартные фундаментальные модели, такие как SAM, испытывают трудности с ними, поскольку им не хватает специфических медицинских знаний, и они часто требуют подсказку для каждого отдельного экземпляра, что является непрактичным бременем для крупномасштабных биологических наборов данных.
* Вычислительные ограничения: Авторы должны сбалансировать потребность в извлечении признаков высокого разрешения с ограничениями памяти современных GPU (например, 24 ГБ VRAM), обеспечивая при этом достаточную эффективность модели для обучения с нуля, а не полагаясь на масштабное предобучение на миллиардах данных.
Чтобы преодолеть этот разрыв, авторы представляют многозадачный фреймворк, который рассматривает сегментацию как задачу с поддержкой подсказок, используя вспомогательную голову обнаружения центральных точек для генерации псевдометок и управления процессом сегментации. Это эффективно превращает ограничение «разреженных точек» в структурное преимущество, позволяя модели изучать дискриминативные признаки даже при отсутствии полных ground-truth масок.
Почему именно этот подход
Авторы данной статьи выявили критическое «узкое место» в анализе изображений электронной микроскопии (ЭМ): хотя фундаментальные модели, такие как SAM (Segment Anything Model), произвели революцию в общем компьютерном зрении, они терпят значительную неудачу при применении к ЭМ-изображениям. Этот провал обусловлен отсутствием доменно-специфических знаний, наличием сложных, неоднозначных границ у субклеточных органелл и неспособностью SAM сегментировать многочисленные экземпляры одновременно без индивидуальных подсказок.
Почему этот подход был единственным жизнеспособным решением
Авторы осознали, что традиционные методы «SOTA» — включая стандартную UDA (Unsupervised Domain Adaptation) и даже дообученные фундаментальные модели — были недостаточны, поскольку они либо требовали масштабной попиксельной разметки экспертного уровня, либо испытывали трудности со «сдвигом домена», присущим ЭМ-визуализации. Момент «эврики» наступил, когда они поняли, что задачу сегментации можно упростить, рассматривая ее как многозадачную проблему. Соединив задачу плотной сегментации с более простой задачей обнаружения центральных точек на основе регрессии, они смогли генерировать собственные псевдоподсказки. Это эффективно устранило необходимость в дорогостоящей ручной разметке при сохранении высокой точности.
Сравнительное превосходство (логика бенчмаркинга)
Превосходство Prompt-DAS заключается не только в метриках точности, но и в структурной эффективности:
- Эффективность аннотирования: В отличие от моделей, требующих полных попиксельных масок, Prompt-DAS достигает результатов уровня state-of-the-art, используя лишь 15% разреженных точечных аннотаций. Это значительно сокращает объем экспертного труда.
- Гибкость: В то время как SAM требует подсказку для каждого отдельного экземпляра объекта, Prompt-DAS спроектирована для обработки любого количества подсказок — от нуля (UDA) до разреженных точек (WDA) — и даже может выполнять интерактивную сегментацию во время тестирования.
- Дискриминативное обучение: Внедрение контрастивного обучения с учетом подсказок (PCL) обеспечивает структурное преимущество. Приближая эмбеддинги переднего плана к ground-truth точкам и отдаляя эмбеддинги фона, модель изучает более надежное представление признаков, чем это могла бы обеспечить стандартная функция потерь перекрестной энтропии.
«Союз» ограничений и решения
Статья решает «жесткие требования» ЭМ-визуализации — в частности, дефицит меток и высокую вариативность форм органелл — через фреймворк «учитель-ученик». Используя модель-учитель для генерации псевдометок и применяя подавление немаксимумов (Non-Maxima Suppression) для идентификации локальных максимумов, модель создает самосовершенствующийся цикл. Это идеально согласуется с ограничением по ограниченности данных: модель использует «более простую» задачу детекции для контроля «более сложной» задачи сегментации.
Математический и логический механизм
Математический движок
Ядром Prompt-DAS является фреймворк многозадачного обучения, который одновременно выполняет обнаружение центральных точек и семантическую сегментацию. «Мастер-уравнение» системы представляет собой комбинированную функцию потерь, которая балансирует эти две задачи между исходным и целевым доменами:
$$\mathcal{L}_{total} = \mathcal{L}_{det} + \mathcal{L}_{seg} + \lambda \mathcal{L}_{pcl}$$
Где $\mathcal{L}_{det}$ и $\mathcal{L}_{seg}$ определяются как:
$$\mathcal{L}_{det} = \frac{1}{|D^s|} \sum_{x^s} MSE(F_R(x^s), d^s) + \frac{1}{|D^t|} \sum_{x^t} MSE(F_R(x^t), \hat{d}^t)$$
$$\mathcal{L}_{seg} = \frac{1}{|D^s|} \sum_{x^s} CE(F_S(x^s), y^s) + \frac{1}{|D^t|} \sum_{x^t} CE(F_S(x^t), \hat{y}^t)$$
Разбор уравнений
- $MSE(F_R(x), d)$: Это среднеквадратичная ошибка. Она измеряет попиксельную разницу между предсказанной картой плотности и картой плотности ground truth (или псевдометки). Она действует как штраф регрессии, заставляя модель размещать «пики» высокой интенсивности точно там, где расположен центр органеллы.
- $CE(F_S(x), y)$: Это функция потерь перекрестной энтропии. Это стандартная функция потерь классификации для сегментации, штрафующая модель, когда предсказанная вероятность класса для пикселя отклоняется от ground truth метки.
- $F_R$ и $F_S$: Они представляют композицию энкодера изображений $f_E$, декодера $f_D$ и соответствующих голов ($f_R$ для детекции, $f_S$ для сегментации). Автор использует композицию функций ($\circ$) для обозначения потока данных через общий бэкбон в специализированные ветви для конкретных задач.
- $\hat{d}^t$ и $\hat{y}^t$: Это псевдометки, сгенерированные моделью-учителем. Они критически важны, поскольку обеспечивают контроль в целевом домене, где ground truth дефицитен.
Пошаговый поток
Представьте, что одно ЭМ-изображение попадает на сборочную линию:
1. Извлечение признаков: Изображение $x$ проходит через энкодер $f_E$, который преобразует необработанные пиксели в карту признаков высокой размерности.
2. Внедрение подсказок: Если доступны точечные подсказки, энкодер подсказок $f_P$ преобразует эти координаты в эмбеддинги, которые затем внедряются в декодер $f_D$ через механизм cross-attention.
3. Многозадачное ветвление: Декодер $f_D$ разделяет поток. Одна ветвь ($f_R$) предсказывает карту плотности (где находятся органеллы), а другая ($f_S$) предсказывает финальную маску сегментации.
4. Псевдоразметка: Модель-учитель (EMA-версия ученика) анализирует выходные данные. Если учитель уверен, он генерирует «псевдометку», которая выступает в роли учителя для ученика, эффективно направляя его через неразмеченный целевой домен.
5. Контрастивное уточнение: Модуль PCL берет эмбеддинги переднего плана и фона и использует контрастивную функцию потерь, чтобы «притянуть» похожие признаки друг к другу и «оттолкнуть» фоновый шум, гарантируя, что модель не запутается в сложных текстурах ЭМ-изображений.
Динамика оптимизации
Модель обучается через фреймворк Mean-Teacher. Модель-ученик обновляет свои веса посредством обратного распространения ошибки, используя функции потерь, приведенные выше. Одновременно модель-учитель обновляется с использованием экспоненциального скользящего среднего (EMA) весов ученика. Это создает «стабильного» учителя, который предоставляет последовательные, высококачественные псевдометки, предотвращая «погоню» ученика за шумными, нестабильными предсказаниями на ранних этапах обучения.
Результаты, ограничения и заключение
Анализ Prompt-DAS: преодоление доменного разрыва в электронной микроскопии
Экспериментальные доказательства
Авторы провели жесткое тестирование своей модели против множества «жертв», включая стандартные методы UDA (такие как DAMT-Net) и подходы на основе SAM (такие как WeSAM).
* Доказательства: В Таблице 1 результаты очевидны. В то время как SAM и ее медицинские варианты (SAM-Med2D) демонстрируют значительно сниженную производительность на ЭМ-изображениях, Prompt-DAS последовательно достигает более высоких оценок Dice.
* Подтверждение: Абляционное исследование (Таблица 2) является наиболее убедительным доказательством. Оно показывает, что добавление псевдоразметки детекции, затем псевдоразметки сегментации, затем обучающих подсказок и, наконец, PCL, обеспечивает кумулятивный, измеримый прирост производительности. Каждый компонент не просто «добавлялся»; он был математически обоснован для решения конкретного режима отказа предыдущего шага. Модель достигает производительности, близкой к контролируемому обучению, при затратах на аннотирование всего в 15%, что является огромным достижением в плане эффективности.
Обсуждение и будущая эволюция
Эта статья — блестящий пример того, как сделать фундаментальные модели действительно полезными для специализированных научных областей. Однако есть несколько областей, в которых мы могли бы продвинуться дальше:
- Адаптация без исходных данных (Source-Free Adaptation): Авторы признают, что их модель требует доступа к исходным данным. В реальных клинических условиях исходные данные часто являются проприетарными или ограничены законами о конфиденциальности. Будущие исследования могли бы изучить адаптацию «без исходных данных», где модель адаптируется к новому домену, используя только целевые данные и предобученные веса, никогда не видя оригинальных исходных изображений.
- Обработка 3D-объемной непрерывности: ЭМ-данные часто являются 3D, но эта модель в основном рассматривает их как серию 2D-изображений. Интеграция временной или пространственной согласованности между срезами могла бы еще больше снизить потребность в разреженных точках, поскольку модель могла бы «отслеживать» органеллу через весь объем.
- Количественная оценка неопределенности: В медицинской диагностике знание того, когда модель делает предположение, так же важно, как и само предположение. Интеграция байесовской неопределенности или конформного прогнозирования в механизм PCL могла бы помочь клиницистам определить, какие сегментации требуют ручной проверки, делая инструмент более надежным в лабораторных условиях.
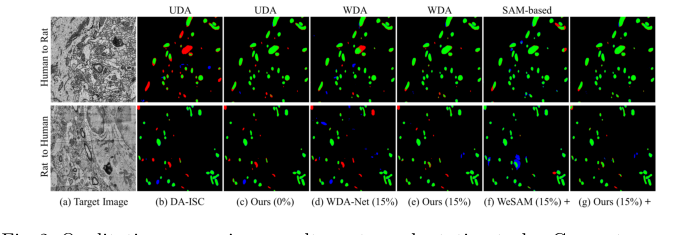 Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives
Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives