Prompt-DAS: 面向电子显微镜图像域自适应语义分割的标注高效型提示学习
Prompt-DAS adapts AI to segment tiny cell parts in electron microscope images, offering flexible, efficient, and interactive annotation.
背景与学术脉络
语义分割(Semantic Segmentation)旨在精确勾勒并分类图像中的每一个像素,得益于卷积神经网络(CNN)和视觉变换器(ViT)等深度神经网络的发展,该领域已取得显著进展。这一进步在电子显微镜(EM)图像分析中尤为关键,对于癌症研究及生物学中线粒体等亚细胞器的研究具有重要意义。
然而,该技术在应用中面临两大严峻挑战。首先,训练此类复杂模型需要海量的像素级标注。设想在数千张超高分辨率的 EM 图像中,为每一个线粒体精确绘制边界——这是一项极其耗时、昂贵且劳动密集型的任务,且通常需要高度专业的人员参与。这种沉重的标注负担使得大规模应用难以实现。
其次,在特定 EM 图像集(“源域”)上训练的模型,在应用于来自不同显微镜或组织类型的 EM 图像(“目标域”)时,往往表现不佳。这种现象被称为“域偏移”(Domain Shift),意味着即便大鼠脑部图像与人类肝脏图像中都包含线粒体,在前者上训练的模型也难以直接迁移至后者。
为解决标注负担与域偏移问题,研究人员转向了“域自适应”(Domain Adaptation, DA)。早期尝试包括无监督域自适应(UDA),即假设目标域完全无标注。尽管 UDA 具有吸引力,但其在复杂分割任务中往往表现出相对较低的性能,限制了其实际应用价值。弱监督域自适应(WDA)作为一种更具实践意义的替代方案应运而生,它利用“稀疏点”(仅标注对象位置的少量点)作为目标域的廉价弱标签,以极小的标注成本提升性能。尽管有所改善,但 WDA 仍需人工输入,且在多变的标注场景下灵活性不足。
近期,以 Segment Anything Model (SAM) 为代表的“提示驱动”(Prompt-driven)基础模型的出现,彻底改变了自然图像的分割范式。SAM 在数十亿张图像上进行预训练,能够根据单点点击、边界框或粗略涂鸦等简单“提示”对对象进行分割。这为交互式分割开启了大门,允许用户引导模型进行操作。
然而,SAM 在应用于医学及 EM 图像领域时存在显著局限。由于缺乏特定的医学知识、生物边界模糊以及细胞器形状复杂,SAM 在医学图像中难以应对域偏移,且在点提示下往往表现出较低的性能。至关重要的是,SAM 要求为每一个对象实例提供提示。对于充斥着成百上千个微小细胞器的 EM 图像而言,为每一个实例提供提示与像素级标注一样不切实际。此外,SAM 在医学场景下对点提示的响应往往次优。
这些局限性——像素级标注的高昂成本、跨 EM 数据集的泛化能力不足、现有 DA 方法的缺陷,以及 SAM 等基础模型在医学领域的表现不佳——共同促使作者开发了 Prompt-DAS。其核心动机在于构建一个灵活、标注高效且可提示的 Transformer 模型,专门用于 EM 图像的域自适应语义分割,通过在训练和测试阶段有效利用稀疏点提示,克服上述挑战,并在 UDA、WDA 及交互式分割场景中均表现出色。
领域术语类比
- 语义分割 (Semantic Segmentation): 想象一本填色书。语义分割就像将所有“花朵”涂成红色,所有“叶子”涂成绿色,所有“土壤”涂成棕色。你不仅是在花朵周围画个框,而是根据类别,为属于花朵、叶子或土壤的每一个像素进行着色。
- 域自适应 (Domain Adaptation, DA): 想象一名学生在阳光明媚的加州(“源域”)学习识别各种汽车。现在,这名学生搬到了白雪皑皑的阿拉斯加(“目标域),需要识别那里的汽车。域自适应就像是学生利用已有的汽车知识,并根据雪地、冰面和不同的光照条件进行调整,从而适应新环境。
- 电子显微镜 (EM) 图像: 想象观察手表内部精密的齿轮。普通相机利用光线成像,而电子显微镜利用电子束观察极微小的物体(如细胞内部结构),其放大倍率和细节远超普通显微镜。因此,EM 图像就像是微观世界中高对比度、超高细节的黑白照片。
- 提示学习 (Promptable Learning): 想象你有一位才华横溢的艺术家。与其模糊地说“画个房子”,不如给出一个“提示”——比如指着纸上的特定位置说“在这里画个房子”,或者画一个粗略的轮廓说“把这个形状填成房子”。“提示”是一个微小而具体的线索(如点或框),引导艺术家(AI 模型)在指定位置以特定方式执行复杂任务(绘图/分割)。
- 伪标签 (Pseudo-labeling): 想象老师给你测验。有些题目提供了答案(标注数据),但大多数没有。你尝试在没有答案的情况下作答,对于那些非常有把握的题目,你将其标记为正确。然后,你利用这些“自评分”答案(伪标签)进行进一步学习,就像它们是真实答案一样。在 AI 中,由“教师模型”为“学生模型”生成这些高置信度的“自评分”答案,帮助其从无标签数据中学习。
符号表
| 符号 | 类型 | 描述 |
|---|---|---|
| $D_s$ | 变量 | 源域数据集,包含图像及其完整的像素级标签。 |
| $D_t$ | 变量 | 目标域数据集,包含图像及稀疏点标签。 |
| $x^s, x^t$ | 变量 | 分别来自源域和目标域的输入图像。 |
| $y^s$ | 变量 | 源域图像的完整像素级 Ground Truth 标签。 |
| $c^t$ | 变量 | 目标域图像中少量对象实例的 Ground Truth 点标签。 |
| $\hat{c}^t$ | 变量 | 二值点标签图,1 表示已标注的稀疏点。 |
| $d$ | 变量 | 密度图,由点标签通过高斯核卷积导出。 |
| $k_\sigma$ | 参数 | 用于生成密度图的高斯核。 |
| $f_e$ | 模型组件 | 图像编码器,提取输入图像特征。 |
| $f_p$ | 模型组件 | 点提示编码器,处理输入点提示。 |
| $f_D$ | 模型组件 | 多任务解码器,整合图像与提示特征。 |
| $f_s$ | 模型组件 | 语义分割头,输出分割预测。 |
| $f_r$ | 模型组件 | 基于回归的中心点检测头,输出点检测结果。 |
| $M$ | 参数 | 输入到提示编码器的点数量。 |
| $L_{det}$ | 变量 | 检测损失,衡量中心点检测的准确性。 |
| $L_{seg}$ | 变量 | 分割损失,衡量语义分割的准确性。 |
| $L_{pcl}$ | 变量 | 提示引导的对比损失,增强特征判别力。 |
| $F_R$ | 模型组件 | 完整检测网络,表示为 $f_r \circ f_D \circ f_e$。 |
| $F_S$ | 模型组件 | 完整分割网络,表示为 $f_s \circ f_D \circ f_e$。 |
| $MSE$ | 变量 | 均方误差损失函数。 |
| $CE$ | 变量 | 交叉熵损失函数。 |
| $\hat{d}^t$ | 变量 | 目标域预测密度图,用于伪标签生成。 |
| $\hat{y}^t$ | 变量 | 由教师模型生成的用于目标域分割的伪标签。 |
| $n_s$ | 参数 | 用于源域数据训练提示的随机采样中心点数量。 |
| $z^t$ | 变量 | 从目标域点 $p^t$ 导出的特征嵌入。 |
| $\phi$ | 模型组件 | 对比学习前使用的 MLP 层。 |
| $N_q$ | 变量 | 前景提示嵌入数量。 |
| $N_n$ | 变量 | 背景提示嵌入数量。 |
| $\mu^s$ | 变量 | 稀疏点提示的平均嵌入。 |
| $\tau$ | 参数 | 对比损失的温度参数,控制特征分离的锐度。 |
| $\delta_f$ | 参数 | 用于选择伪标签前景点的置信度阈值。 |
| $\delta_b$ | 参数 | 用于选择伪标签背景点的置信度阈值。 |
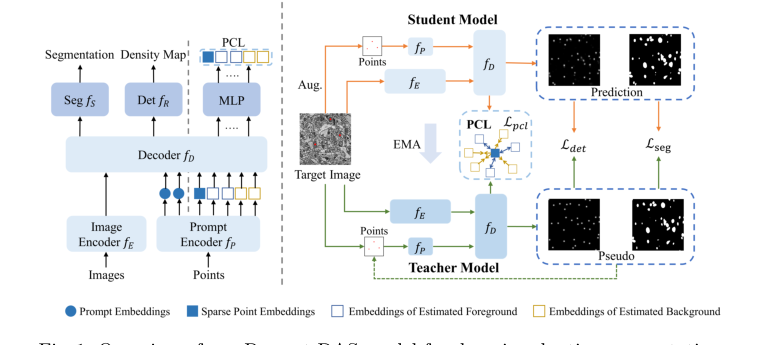 Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
Figure 1. Overview of our Prompt-DAS model for domain adaptive segmentation
问题定义与约束
核心问题表述与困境
起点(输入/当前状态):
作者从源域 $\mathcal{D}^s = \{(x^s, y^s)\}$ 开始,其中包含具有完整像素级 Ground Truth 标签的 EM 图像。同时拥有目标域 $\mathcal{D}^t = \{(x^t, \bar{c}^t)\}$,该域由来自不同分布(如不同组织类型或显微技术)的图像组成,且仅对一小部分细胞器实例提供稀疏的点标签 $\bar{c}^t$。
终点(输出/目标状态):
目标是开发一个稳健的“可提示”分割框架,能够准确分割目标域中的所有细胞器实例。该模型必须足够灵活,以在三种不同场景下运行:
1. 无监督域自适应 (UDA): 目标域训练数据中 $M=0$。
2. 弱监督域自适应 (WDA): 提供 $M > 0$ 的稀疏点作为训练提示。
3. 交互式分割: 模型在测试阶段可接受用户提供的点提示,以优化或修正分割结果。
困境与约束:
主要困境在于“标注与性能的权衡”。尽管深度神经网络(如 U-Net 或 Vision Transformers)能达到高精度,但它们极其依赖数据,且需要昂贵的专家级像素级标注。当这些模型在某一域训练并应用于另一域时,由于域偏移,性能会显著下降。
作者面临几道“硬墙”,使得问题极具挑战性:
* 域偏移: EM 图像的外观因所用显微技术而异,导致标准预训练模型(如原始 SAM)在没有显著自适应的情况下失效。
* 标签稀缺: 为新 EM 数据集中的每个细胞器获取像素级掩码是劳动密集型的,在大规模研究中往往不可行。
* 实例复杂性: 与自然图像不同,EM 图像包含大量、密集堆叠且边界模糊的细胞器实例。SAM 等标准基础模型因缺乏领域特定的医学知识,且通常要求为每一个实例提供提示,难以应对此类场景。
* 计算约束: 作者必须在高分辨率特征提取需求与现代 GPU(如 24GB VRAM)的内存限制之间取得平衡,同时确保模型足够高效,能够从头训练,而非依赖于数十亿规模的预训练。
为弥合这一差距,作者引入了一个多任务框架,将分割视为可提示任务,利用辅助中心点检测头生成伪标签并引导分割过程。这有效地将“稀疏点”限制转化为结构性优势,使模型即便在缺乏完整 Ground Truth 掩码的情况下也能学习判别性特征。
方案选择依据
作者识别出 EM 图像分析中的关键瓶颈:尽管 SAM 等基础模型彻底改变了通用计算机视觉,但在应用于 EM 图像时却表现不佳。这种失败源于领域知识的匮乏、亚细胞器复杂模糊的边界,以及 SAM 无法在不提供独立提示的情况下同时分割大量实例。
为何该方案是唯一可行的解决路径
作者意识到,传统的“SOTA”方法——包括标准 UDA 和微调后的基础模型——均不足以应对,因为它们要么需要海量的专家级像素级标注,要么难以克服 EM 成像中固有的“域偏移”。当他们意识到可以通过将分割任务简化为多任务问题来解决时,灵感迸发。通过将密集分割任务与更简单的基于回归的中心点检测任务相结合,他们能够生成自己的伪提示。这有效地绕过了昂贵的人工标注需求,同时保持了高精度。
比较优势(基准逻辑)
Prompt-DAS 的优越性不仅体现在准确性指标上,更在于其结构效率:
- 标注效率: 与需要完整像素级掩码的模型不同,Prompt-DAS 仅使用 15% 的稀疏点标注即可达到 SOTA 水平。这大幅降低了专家劳动需求。
- 灵活性: SAM 要求为每个对象实例提供提示,而 Prompt-DAS 设计为可处理任意数量的提示——从零(UDA)到稀疏点(WDA),甚至支持测试阶段的交互式分割。
- 判别性学习: 提示引导对比学习 (PCL) 的引入提供了结构性优势。通过拉近前景嵌入与 Ground Truth 点的距离,并推开背景嵌入,模型学习到了比单纯使用交叉熵损失更稳健的特征表示。
约束与方案的“结合”
该论文通过教师-学生框架解决了 EM 成像的“严苛要求”——特别是标签稀缺和细胞器形状的高变异性。通过利用教师模型生成伪标签,并采用非极大值抑制(NMS)来识别局部极大值,模型创建了一个自我改进的循环。这与数据受限的约束完美契合:模型利用“较简单”的检测任务来监督“较困难”的分割任务。
数学与逻辑机制
数学引擎
Prompt-DAS 的核心是一个同时执行中心点检测和语义分割的多任务学习框架。系统的“主方程”是组合损失函数,它平衡了源域和目标域上的这两个任务:
$$\mathcal{L}_{total} = \mathcal{L}_{det} + \mathcal{L}_{seg} + \lambda \mathcal{L}_{pcl}$$
其中 $\mathcal{L}_{det}$ 和 $\mathcal{L}_{seg}$ 定义如下:
$$\mathcal{L}_{det} = \frac{1}{|D^s|} \sum_{x^s} MSE(F_R(x^s), d^s) + \frac{1}{|D^t|} \sum_{x^t} MSE(F_R(x^t), \hat{d}^t)$$
$$\mathcal{L}_{seg} = \frac{1}{|D^s|} \sum_{x^s} CE(F_S(x^s), y^s) + \frac{1}{|D^t|} \sum_{x^t} CE(F_S(x^t), \hat{y}^t)$$
方程解析
- $MSE(F_R(x), d)$: 这是均方误差。它衡量预测密度图与 Ground Truth(或伪标签)密度图之间的像素级差异。它作为回归惩罚,强制模型在细胞器中心位置精确放置高强度“峰值”。
- $CE(F_S(x), y)$: 这是交叉熵损失。它是分割的标准分类损失,当像素的预测类别概率偏离 Ground Truth 标签时对模型进行惩罚。
- $F_R$ 和 $F_S$: 这些代表图像编码器 $f_E$、解码器 $f_D$ 以及各自任务头($f_R$ 用于检测,$f_S$ 用于分割)的组合。作者使用函数组合($\circ$)来表示数据流经共享骨干网络进入特定任务分支的过程。
- $\hat{d}^t$ 和 $\hat{y}^t$: 这些是由教师模型生成的伪标签。它们至关重要,因为它们为 Ground Truth 稀缺的目标域提供了监督。
流程步骤
设想一张 EM 图像进入流水线:
1. 特征提取: 图像 $x$ 通过编码器 $f_E$,将原始像素转换为高维特征图。
2. 提示注入: 若有点提示可用,提示编码器 $f_P$ 将坐标转换为嵌入,并通过交叉注意力注入解码器 $f_D$。
3. 多任务分支: 解码器 $f_D$ 分流。一个分支 ($f_R$) 预测密度图(细胞器位置),另一个 ($f_S$) 预测最终分割掩码。
4. 伪标签生成: 教师模型(学生模型的 EMA 版本)观察输出。若教师置信度高,则生成“伪标签”,作为学生的导师,有效引导其在无标签目标域中学习。
5. 对比细化: PCL 模块获取前景和背景嵌入,并利用对比损失将相似特征“拉近”,将背景噪声“推开”,确保模型不会被 EM 图像复杂的纹理所干扰。
优化动力学
模型通过 Mean-Teacher 框架进行学习。学生模型通过上述损失函数进行反向传播更新权重。同时,教师模型使用学生权重的指数移动平均 (EMA) 进行更新。这创建了一个“稳定”的教师,提供一致、高质量的伪标签,防止学生在训练初期追逐噪声大、不稳定的预测。
结果、局限性与结论
Prompt-DAS 分析:弥合电子显微镜中的域鸿沟
实验证据
作者针对多种“对手”严格测试了模型,包括标准 UDA 方法(如 DAMT-Net)和基于 SAM 的方法(如 WeSAM)。
* 证据: 表 1 显示结果清晰。虽然 SAM 及其医学变体(SAM-Med2D)在 EM 图像上表现出严重的性能退化,但 Prompt-DAS 始终保持更高的 Dice 分数。
* 证明: 消融实验(表 2)是最具说服力的证据。它表明,添加检测伪标签、分割伪标签、训练提示,最后是 PCL,带来了累积且可衡量的性能提升。每个组件不仅是“添加”的,而且在数学上被证明是为了解决前一步骤的特定失效模式。该模型仅用 15% 的标注工作量就实现了接近监督学习的性能,这是效率上的巨大胜利。
讨论与未来演进
本文是使基础模型真正服务于专业科学领域的杰出范例。然而,仍有几个方向值得进一步探索:
- 无源域自适应 (Source-Free Adaptation): 作者承认模型需要访问源数据。在现实临床环境中,源数据通常是专有的或受隐私法限制。未来研究可探索“无源域”自适应,即模型仅利用目标数据和预训练权重适应新域,而无需接触原始源图像。
- 处理 3D 体积连续性: EM 数据通常是 3D 的,但该模型主要将其视为一系列 2D 图像。整合切片间的时空一致性可进一步减少对稀疏点的需求,因为模型可以“追踪”体积内的细胞器。
- 不确定性量化: 在医学诊断中,知道模型“何时在猜测”与猜测本身同样重要。将贝叶斯不确定性或共形预测整合到 PCL 机制中,可以帮助临床医生识别哪些分割需要人工复核,从而使该工具在实验室环境中更具可信度。
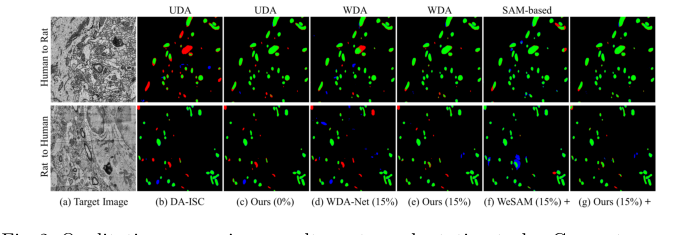 Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives
Figure 2. Qualitative comparison results on two adaptation tasks. Green: true pos- itives; Red: false negatives; Blue: false positives
与其他领域的同构性
结构骨架
一种利用稀疏、高置信度锚点,通过多任务对比正则化在不同数据分布间对齐潜在特征表示的机制。