Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed by this paper, the scarcity of ethically sourced and permissively licensed data for Large Language Model (LLM) pre-training, precisely emerged from the rapd scaling and widespread adoption of LLMs. Historically, the field saw a significant shift with models like GPT-3 (Brown et al., 2020), which established a paradigm of training on colossal datasets, often reaching trillions of tokens. This trend continued, with LLM training data sizes growing logarithmically to an estimated 14-36 trillion tokens by 2025.
The fundamental limitation and "pain point" of previous approaches stemmed from their reliance on web-scraped data, which, while publicly available, frequently lacked clear permissive licenses. NLP practitioners often operated under the assumption of "fair use," arguing that the transformative nature of LLM training justified using copyrighted content. However, this approach has led to increasing legal challenges, such as the New York Times suing OpenAI for copyright infringement (Roth, 2023; Pope, 2024). Furthermore, several prominent datasets, including Books3, LAION, GEITje, and MATH, faced legal takedowns or restrictions due to copyright issues or the presence of problematic content like CSAM (Child Sexual Abuse Material), rendering prior research unreplicable and causing substantial investment losses for developers. Beyond legal woes, existing open datasets often suffered from a lack of multilingual diversity, being predominantly English-centric, and frequently contained low-quality or unusable data, especially in low-resource languages. This collective pressure highlighted an urgent need for a truly open, legally compliant, high-quality, and diverse pre-training dataset to foster open science research and developement in LLMs.
Intuitive Domain Terms
Here are a few specialized domain terms from the paper, translated into intuitive analogies for a beginner:
- Large Language Model (LLM): Imagine a super-smart digital brain that has "read" almost everything ever writen on the internet and in books. It can then understand, generate, and answer questions in human-like ways, like a highly educated and versatile assistant.
- Tokens: Think of these as the fundamental building blocks of language that an LLM understands. They're like the "words" or even smaller pieces of words (like "un-" or "-ing") that the model processes, similar to how we break sentences into individual words to understand them.
- Pre-training: This is the initial, massive learning phase for an LLM. It's like sending a student through elementary school, high school, and college to get a broad, general education across many subjects before they specialize in a particular career. The model learns general language patterns and knowledge.
- Permissive Licenses: Consider this a "universal permission slip" for data. It explicitly states that you can freely use, share, and even change the data for almost any purpose, including training AI models, without needing to ask for special permission or worrying about copyright lawsuits. It's the opposite of "all rights reserved."
- OCR Errors: Picture scanning an old, faded book into your computer. Sometimes the scanner makes mistakes, turning an "e" into a "c" or merging two words together. OCR errors are those digital "typos" or distortions that happen when converting images of text (like from old documents) into editable text.
Notation Table
To be honest, this paper primarily describes the creation and characteristics of a large dataset rather than introducing a new mathematical model or algorithm that relies on specific mathematical variables or parameters in equations. Therefore, there are no key mathematical notations (variables, parameters) explicitly defined or used in LaTeX syntax within the paper's prose or figures that would be necessary for subsequent mathematical explanations. The paper uses descriptive terms like "tokens," "documents," and "words" to quantify data, but these are not represented by single-letter mathematical symbols in formulas.
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper is the critical shortage of large-scale, high-quality, truly open, and permissively licensed pre-training data for Large Language Models (LLMs).
Input/Current State:
Currently, LLMs are pre-trained on enormous datasets, often comprising trillions of tokens sourced from various domains, predominantly scraped from the web. However, a significant portion of this data is either copyrighted, proprietary, or lacks clear permissive licenses. This has led to a precarious situation for LLM development, particularly for open science initiatives, as evidenced by numerous legal challenges (e.g., lawsuits against OpenAI, DMCA takedowns of datasets like Books3, LAION, and MATH). Existing "open" datasets often suffer from limitations: they are frequently monolingual (primarily English), heavily reliant on web crawls (like Common Crawl) with ambiguous licensing, or contain low-quality, unusable, or ethically problematic content (e.g., Personally Identifiable Information (PII), toxic language). Furthermore, content owners are increasingly implementing technical and legal restrictions against data scraping for AI training, further shrinking the pool of readily available data.
Desired Endpoint (Output/Goal State):
The desired endpoint is the establishment of a robust, legally compliant, and ethically sound foundation for LLM pre-training. This entails creating a massive dataset that is:
1. Truly Open and Permissively Licensed: All content must be uncopyrighted or available under clear, permissive licenses, ensuring legal certainty and fostering open science.
2. Multilingual and Multi-domain: The dataset should encompass a wide array of languages, including low-resource ones, and cover diverse domains (e.g., government, culture, science, code, web, semantic data) to promote generalizable and powerful model performance.
3. High-Quality and Curated: The data must be meticulously cleaned, filtered for PII, toxicity, and OCR errors, with detailed provenance and metadata provided for transparency and reproducibility.
Missing Link or Mathematical Gap:
The exact missing link is the absence of a comprehensive, ethically sourced, and legally clear data commons that can rival the scale and diversity of proprietary or ambiguously licensed datasets currently used for LLM training. This paper attempts to bridge this gap by assembling, curating, and releasing Common Corpus, a dataset designed from the ground up to meet these stringent legal and ethical criteria while still providing a substantial volume of diverse tokens suitable for multilingual pre-training. The mathematical gap isn't in a specific equation, but rather in the lack of a well-defined, large-scale, and legally clean input space for the complex optimization problems that constitute LLM training.
The Dilemma:
The central, painfull trade-off that has trapped previous researchers is the "Scale vs. Legality/Ethics/Quality" dilemma. Achieving the massive scale required for state-of-the-art LLM performance has historically necessitated the use of vast, often indiscriminately scraped web data. This approach, while effective for scale, inevitably leads to:
* Legal Vulnerability: Inclusion of copyrighted or proprietary content, resulting in lawsuits and dataset takedowns, undermining reproducibility and open research.
* Ethical Compromises: Presence of PII, harmful, or biased content, leading to ethical concerns and regulatory non-compliance (e.g., GDPR).
* Quality Degradation: Web-scraped data often contains low-quality, noisy, or unusable text, which can negatively impact model performance and require extensive, costly post-processing.
The dilemma is that improving one aspect (e.g., ensuring strict legal compliance) usually drastically reduces the available data scale or increases curration costs exponentially, making it harder to train competitive LLMs. Conversely, prioritizing scale often compromises legal and ethical standards. The paper also highlights an "open data paradox," where genuinely open content is paradoxically less visible in leading pre-training sources, making its aggregation inherently difficult.
Constraints & Failure Modes
The problem of building a truly open, permissively licensed, and high-quality LLM pre-training dataset is insanely difficult due to several harsh, realistic constraints:
-
Legal & Licensing Constraints:
- Strict Permissibility: Data must be uncopyrighted (public domain) or under explicit permissive licenses (e.g., CC-By, MIT, Apache-2.0). This severely limits the pool of usable data compared to general web scrapes, as much publicly available web content is not permissively licensed for AI training.
- Copyright Term Complexity: Determining public domain status, especially for international and historical works, involves complex legal criteria (e.g., author life + 70 years, publication + 95 years for US authors), requiring meticulous rights verification.
- DMCA Takedowns: The constant threat of legal action and DMCA takedowns for non-compliant data makes any dataset built on ambiguous sources unstable and unreliable for long-term research.
-
Data-Driven & Quality Constraints:
- Extreme Sparsity of High-Quality Open Data: While the web is vast, the subset of high-quality, multilingual, multi-domain data with clear permissive licenses is comparatively sparse and fragmented.
- Poor OCR Quality in Historical Texts: A significant portion of valuable historical data (Open Culture, Open Government) comes from digitized sources with poor Optical Character Recognition (OCR) quality, introducing noise and errors that degrade text quality. This necessitates advanced, computationally intensive OCR error detection and correction tools.
- PII and Harmful Content: Public domain and other open sources can contain Personally Identifiable Information (PII) or harmful/biased content (e.g., historical texts reflecting outdated norms, CSAM in image datasets). Robust, accurate, and efficient PII removal and toxicity detection pipelines are mandatory but challenging to implement at scale across diverse languages and domains.
- Lack of Metadata: Many potential data sources lack sufficient metadata regarding provenance, licensing, and language, making automated curation difficult and requiring manual intervention or sophisticated inference.
- Multilingual Diversity Challenges: Tools for data processing (segmentation, quality assessment) must perform reliably across a wide range of languages, including low-resource ones, where existing NLP tools often generalize poorly.
-
Computational & Infrastructure Constraints:
- Massive Scale Processing: Handling and curating "about two trillion tokens" requires substantial computational resources for storage, processing, filtering, and quality assessment.
- Computational Cost of Curation Tools: While essential, advanced curation tools like OCR error detection (e.g., OCRerrcr) can be computationally intensive, scaling less efficiently than faster, less accurate alternatives, posing a trade-off between accuracy and processing speed for very large corpora.
- Data Provenance Tracking: Meticulously tracking the provenance, license, and metadata for each data object across diverse sources adds significant overhead to the data pipeline.
-
Failure Modes:
- Legal Non-Compliance: Failure to accurately identify and filter non-permissively licensed content leads to legal risks and potential dataset takedowns.
- Ethical Breaches: Inadequate PII removal or toxicity filtering can lead to privacy violations or the perpetuation of harmful biases in trained LLMs.
- Low Model Performance: Using low-quality, noisy, or insufficiently diverse data can result in LLMs with poor performance, limited generalizability, or undesirable behaviors (e.g., "language switching" in correction tasks, generic writing styles).
- Lack of Reproducibility: If the dataset is not stable, well-documented, and consistently available, research built upon it becomes irreproducible.
- Inefficient Curation: Manual or slow curation processes become infeasible at the scale required for modern LLM training, necessitating efficient, automated, yet accurate tools.
- Occassional Spurious Repetitions: Even with advanced tools like OCRonos, there can be an occasional inclusion of spuriously repeated words, which needs post-processing.
Why This Approach
The Inevitability of the Choice
The core problem addressed by this paper is not the development of a new mathematical model or algorithm for Large Language Models (LLMs) themselves, but rather the critical lack of high-quality, truly open, permissively licensed, multilingual, and multi-domain pre-training data. The authors realized that traditional "SOTA" data collection and curation methods were fundamentally insufficient because they led to a cascade of legal, ethical, and quality issues that severely hampered open science research and the development of robust LLMs.
Existing datasets, such as C4, Books3, LAION, RefinedWeb, and Dolma, despite their scale, presented significant drawbacks:
* Legal and Ethical Minefields: Many contained copyrighted or proprietary content, leading to legal challenges (e.g., the New York Times lawsuit against OpenAI, the DMCA takedown of Books3, and the removal of LAION due to CSAM content). This made research unreplicable and posed substantial risks for developers.
* Access Restrictions: Content owners increasingly implemented technical measures and legal provisions against scraping for AI training, rendering large portions of publicly available web data (e.g., 45% of C4) inaccessible or restricted.
* Monolingual Bias: Most emerging "open" datasets were predominantly English-only (e.g., C4C, Open License Corpus, KL3M, Common Pile), severely limiting the development of multilingual LLMs.
* Low Quality and Bias: Web-scraped data often suffered from low quality, machine-generated text, Personally Identifiable Information (PII), and harmful or biased content. Multilingual datasets, in particular, were found to contain a lot of unusable data.
Given these pervasive issues, the authors concluded that a new paradigm for data collection and curation was the only viable solution. This necessitated a meticulous, ground-up approach to assemble a dataset that was explicitly designed to be legally compliant, ethically sound, high-quality, and diverse across languages and domains. The "approach" of Common Corpus—focusing on clear licensing, comprehensive provenance, and advanced curation tools—was not just an improvement, but a necessary foundation for open LLM research.
Comparative Superiority
The Common Corpus approach offers qualitative superiority over previous data collection methods and existing datasets primarily through its structural commitment to legal compliance, data quality, and diversity, rather than just raw token count.
- Unprecedented Legal & Ethical Compliance: Unlike datasets that faced legal battles and takedowns, Common Corpus is built exclusively from uncopyrighted or permissively licensed data (Public Domain, CC-By, MIT, Apache-2.0, etc., as detailed in Table 4). This structural advantage ensures that models trained on Common Corpus can be released and used without the legal uncertainties that plague many commercial and even "open" models. This commitment to "open" in the strongest possible sense is a fundamental qualitative leap.
- Enhanced Data Quality through Specialized Curation: The paper introduces the "Bad Data Toolbox" (Section 5), a suite of custom tools designed to overcome challenges unique to multilingual, historical, and digitized content:
- Segmentext: A token classification model for robust text segmentation, even from broken or unstructured input, which is superior to layout-based methods when visual information is lost.
- OCR Error Detection (OCRoscope & OCRerrcr): OCRoscope provides fast, large-scale quality estimation, while OCRerrcr offers fine-grained, token-level error identification. This is crucial for historical and digitized documents, ensuring higher input quality than raw OCR output.
- OCR Correction (OCRonos): A generative LLM fine-tuned from Llama-3-8B, specifically trained to correct OCR errors, word splits, and structural artifacts. It's designed to be conservative and resist language switching, a common failure mode in smaller generalist LLMs when faced with noisy input.
- PII Removal: Utilizes Microsoft's Presidio with custom regular expressions to identify and replace PII with fictitious but realistic values, preserving text format and model understanding, a more sophisticated approach than simple removal or tagging.
- Toxicity Detection (Celadon): A multilingual toxicity classifier (DeBERTa-v3-small) optimized for historical text, OCR noise, and non-English content. It achieves comparable performance to much larger models (Llama 3.1-8B-Instruct) but is over 40 times faster, making large-scale filtering practical. This significantly reduces the presence of harmful content, a major issue in web-scraped corpora.
- True Multilingual and Multi-domain Diversity: Common Corpus is the largest fully open dataset (2 trillion tokens) with high multilingual diversity, covering a wide range of high- and low-resource languages (Figure 2, Table 5). Its composition across diverse domains (Open Government, Open Culture, Open Science, Open Code, Open Web, Open Semantic) is detailed in Figure 1, going "beyond web crawl" data (Table 1, Figure 3b). The temporal and semantic overview of these collections is further illustrated in Figure 3. This structural diversity is essential for training generalizable and powerful LLMs that perform well across different tasks and languages, a clear advantage over predominantly monolingual or web-text-focused datasets.
- Reproducibility and Open Science Infrastructure: By providing detailed provenance, processing steps, and openly releasing the curation tools, Common Corpus acts as a critical infrastructure for open science. This transparency and tool sharing directly address the problem of unreplicable research caused by the sudden removal of datasets.
While the paper doesn't explicitly detail memory complexity reductions from $O(N^2)$ to $O(N)$ for the data curation process, the emphasis on efficient tools like Celadon (40x faster for toxicity detection) and OCRoscope (less computationally expensive for large scales) demonstrates a structural advantage in handling the sheer volume of data required for LLM pre-training. This efficiency makes the creation of such a high-quality, large-scale, curated corpus feasible.
Alignment with Constraints
The Common Corpus approach perfectly aligns with the implicit and explicit constraints derived from the problem definition, which centers on the need for legally sound, high-quality, diverse, and openly accessible data for LLM pre-training.
- Constraint: Strict Legal and Ethical Compliance: The paper's primary motivation is to provide data "that complies with data security regulations" and is "free from copyright or other legal limitations." Common Corpus achieves this by exclusively sourcing uncopyrighted or permissively licensed content (Table 4). Furthermore, it implements robust PII removal (using Presidio) and toxicity detection (using Celadon), directly addressing the ethical concerns of privacy and harmful content. This "marriage" ensures that LLMs trained on Common Corpus can be deployed without the legal and reputational risks associated with previous datasets.
- Constraint: High Data Quality and Usability: The problem highlights that existing datasets often contain "low-quality or entirely unusable data," especially in multilingual contexts. The Common Corpus solution directly tackles this with its "Bad Data Toolbox." Segmentext handles unstructured and digitized texts, OCRoscope and OCRerrcr detect errors, and OCRonos corrects them, transforming degraded inputs into usable text. This suite of tools ensures that even historical or noisy data contributes meaningfully to training, fulfilling the requirement for high-quality input.
- Constraint: Multilingual and Multi-domain Diversity: A key limitation of prior "open" datasets was their monolingual nature or limited domain coverage. Common Corpus is explicitly designed to be "the largest fully open pre-training dataset... having high multilingual diversity" (Figure 2, Table 5) and covering a wide array of domains (Open Government, Culture, Science, Code, Web, Semantic). This directly addresses the need for LLMs that are powerful and generalizable across different languages and knowledge areas.
- Constraint: Open Science and Reproducibility: The paper emphasizes the need for "truly open pre-training data" and "reproducible research artifacts." Common Corpus aligns by providing detailed provenance, processing steps, and openly releasing its curation tools (the Bad Data Toolbox). This transparency and sharing of methodology directly support the open science ecosystem, ensuring that research built upon this data can be verified and replicated.
- Constraint: Large Scale: LLMs demand "large amounts of training data" (Introduction). Common Corpus, at "about 2 trillion tokens," meets this scale requirement. The efficiency of its curation tools (e.g., Celadon's speed) makes it practical to process and maintain such a massive corpus, ensuring that the quality and diversity constraints are met even at this enormous scale.
Rejection of Alternatives
The paper implicitly and explicitly rejects several popular approaches and existing datasets by highlighting their fundamental shortcomings that Common Corpus aims to overcome.
- Rejection of Indiscriminate Web Scraping (e.g., Common Crawl for C4, Books3): The authors clearly state that "Most web data does not have sufficient metadata to determine whether it is permissively licensed" and that "There are increasingly more legal challenges to the use of this data." They cite the NYT lawsuit against OpenAI, the DMCA takedown of Books3, and the LAION dataset's issues with CSAM as direct evidence of the failure of such approaches. The paper notes that "a full 45% of C4 is now restricted" due to Terms of Service changes. Common Corpus's approach of only including uncopyrighted or permissively licensed data with clear provenance is a direct rejection of the legal and ethical risks inherent in broad web scraping.
- Rejection of Existing "Open" Datasets as Sufficient: The paper compares Common Corpus to other initiatives like C4C, Open License Corpus, KL3M, and Common Pile (Table 1). It points out that many of these are "monolingual, restricting in effect the reach of language models to the English-speaking audience." KL3M, for instance, is "limited to administrative and legal documents in English." Common Corpus's unique ability to satisfy all four criteria simultaneously—multilingual, multi-domain, beyond web crawl, and fully permissive licensing—demonstrates the inadequacy of these alternatives for the broader goal of open, general-purpose LLM development.
- Rejection of Uncurated or Poorly Curated Multilingual Datasets: The paper highlights that "many multilingual datasets contain a lot of low-quality or entirely unusable data" (Kreutzer et al., 2022). This implies that simply aggregating data from various languages without rigorous curation, as might be done in some alternative approaches, leads to suboptimal training data. Common Corpus's "Bad Data Toolbox" (Segmentext, OCR correction, toxicity detection) is a direct counter to this problem, ensuring high quality even for diverse and challenging linguistic sources.
- Rejection of Approaches that Neglect PII and Toxicity: The paper explicitly states that "web data is a major source of harmful and biased content" and that "Public Domain data... comprise historical periodicals and monographs... many of these texts do not meet modern ethical standards." The development of specialized tools like Presidio for PII removal and Celadon for multilingual toxicity detection is a clear rejection of any data collection strategy that does not prioritize these critical filtering steps.
In essence, the authors rejected alternatives that either failed to meet the stringent legal and ethical requirements, lacked sufficient multilingual and multi-domain coverage, or compromised on data quality, all of which are paramount for the sustainable development of open LLMs.
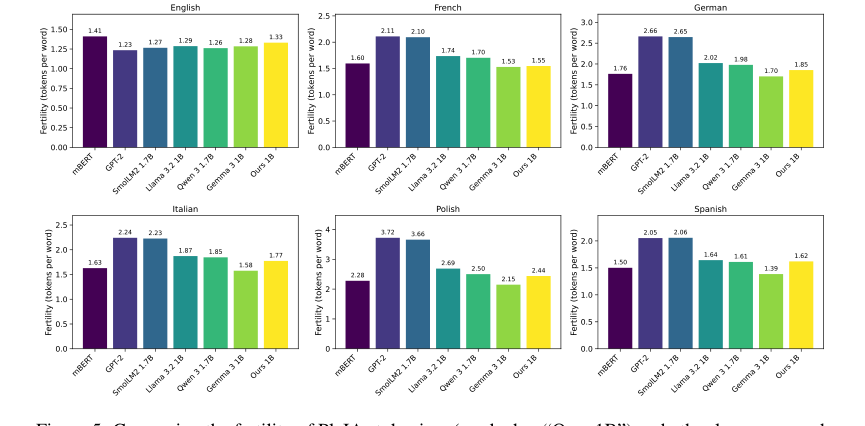 Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Mathematical & Logical Mechanism
The paper "Common CORPUS: THE LARGEST COLLECTION OF ETHICAL DATA FOR LLM PRE-TRAINING" primarily focuses on the meticulous construction and curation of a large-scale, ethically sourced dataset for training Large Language Models (LLMs). While it describes the subsequent training and evaluation of LLMs using this dataset, the core mathematical and logical mechanisms introduced or detailed by this paper are predominantly related to the data curation pipeline rather than a novel LLM architecture or training objective function itself. The LLMs mentioned (Llama-style, DeBERTa variants) are existing models, and their underlying mathematical engines for learning are well-established in the literature. Therefore, this section will focus on the logical and algorithmic mechanisms employed in the data curation process, which is the paper's central contribution.
The Master Equation
To be honest, this paper does not present a single "master equation" in the traditional sense, like an objective function for a novel machine learning model or a differential equation describing a new physical process. Instead, its "mathematical engine" is a suite of algorithmic and model-based processes designed for data cleaning, segmentation, error detection, correction, and toxicity filtering. These processes are applied sequentially to raw text data to produce the final Common Corpus.
The closest we get to a "core mechanism" is the evaluation of OCR quality by OCRoscope, which relies on comparing language identification scores. While not an objective function for learning, it quantifies a critical aspect of data quality. The OCR quality score, $Q_{OCR}$, for a document can be conceptually represented as:
$$ Q_{OCR} = 1 - \frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})} $$
This equation, though simplified, captures the essence of OCRoscope's logic.
Term-by-Term Autopsy
Let's break down the conceptual components of the OCRoscope quality score:
- $N$: This represents the total number of rolling n-grams (specifically 7-grams, as mentioned in the paper) extracted from the input text document. Its mathematical definition is a count of these overlapping text segments. Its physical/logical role is to define the granularity at which local language identification is performed. The author used n-grams because language identification models are more sensitive to noise on short sequences, making them good indicators of OCR errors, unlike document-level identification which is robust to noise.
- $g_i$: This denotes the $i$-th rolling 7-gram extracted from the document. Mathematically, it's a substring of length 7. Its logical role is to provide a small, localized window of text for language identification, where OCR errors are more likely to disrupt the linguistic pattern.
- $L(g_i)$: This is the language identified by the
pycld2model for the $i$-th 7-gram. Mathematically, it's a categorical output (a language label or 'Unknown'). Its logical role is to detect the local linguistic coherence. If a 7-gram is heavily corrupted by OCR errors,pycld2is likely to misclassify its language or label it as 'Unknown'. - $L_{doc}$: This is the language identified by
pycld2for the entire document. Mathematically, it's a single categorical output. Its logical role is to establish the ground truth language of the document, which is assumed to be robustly identified even with some noise. The comparison between local $L(g_i)$ and global $L_{doc}$ is key to identifying discrepancies. - $\mathbb{I}(\cdot)$: This is the indicator function, which returns 1 if its argument is true and 0 otherwise. Mathematically, it's a boolean-to-integer mapping. Its logical role is to count instances where a local 7-gram's language identification deviates from the document's overall language or is unidentifiable.
- $\mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})$: This term counts the number of "mismatched" or "unknown" 7-grams. Mathematically, it's a sum of indicator functions. Its logical role is to quantify the presence of local linguistic inconsistencies, which are proxies for OCR errors. The author used "or" to capture both explicit misidentification and complete failure to identify, both indicating issues.
- $\mathbb{I}(g_i \text{ is valid})$: This term ensures that only valid 7-grams (e.g., not empty or purely punctuation) are considered in the denominator, preventing division by zero or skewed ratios from malformed inputs.
- The summation $\sum_{i=1}^{N} \dots$: This aggregates the counts of problematic 7-grams. The use of summation here is natural for counting discrete events across a sequence.
- The fraction $\frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})}$: This calculates the proportion of problematic 7-grams. Its logical role is to provide a normalized measure of OCR noise.
- $1 - \dots$: This final subtraction transforms the "error rate" into a "quality score," where 1 signifies perfect quality and lower values indicate increasing digitisation noise. This makes the score more intuitive as a "quality" metric.
Step-by-Step Flow
Imagine a raw, digitized document, perhaps a scanned historical newspaper, entering the Common Corpus curation pipeline. It's like a complex assembly line for text:
- Initial Ingestion & Metadata Extraction: The document first enters the system. Basic metadata like its source URL, potential license information, and creation date are extracted or inferred.
- Language Identification (Document-Level): The entire document is passed through a language identification model (like
fastTextorcld2) to determine its primary language, $L_{doc}$. This is a crucial first step, as subsequent tools are often language-dependent. - Text Segmentation (Segmentext): The raw character sequence of the document is fed into
Segmentext, a DeBERTa-v2-style token classification model. This model acts like a smart parser, identifying and tagging different structural components: "This is a[Title]," "This is[Text]," "This is a[Table]," "This is[Paratext](like a page number)." It works purely on text, making it robust to lost layout information. - OCR Error Detection (OCRoscope & OCRerrcr):
- OCRoscope (Coarse-Grained): The document is then passed to
OCRoscope. This tool slides a window of 7 characters (a 7-gram) across the text. For each 7-gram, it attempts to identify its language, $L(g_i)$. If $L(g_i)$ doesn't match $L_{doc}$ or is "Unknown," it's flagged as a potential OCR error.OCRoscopeaggregates these flags to produce an overall OCR quality score for the document. This is a fast, initial check to decide if a document needs more intensive processing. - OCRerrcr (Fine-Grained): For documents identified as needing more attention,
OCRerrcr, a DeBERTa-v3-small model, steps in. It processes the text token by token, classifying each token as either correct or erroneous. This provides a precise map of where errors are located, preparing the document for targeted correction.
- OCRoscope (Coarse-Grained): The document is then passed to
- OCR Error Correction (OCRonos): The document, now with identified errors, moves to
OCRonos, a fine-tuned Llama-3-8B generative model.OCRonosacts as a skilled editor, taking the noisy text and attempting to correct OCR errors, fix incorrect word splits or merges, and restore broader structural integrity. It's designed to be conservative, preserving original text where possible, but can "synthetically rewrite" heavily degraded parts to make them usable. - Personally Identifiable Information (PII) Removal: The text, now structurally sound and largely error-free, is scanned for PII using
Microsoft Presidio, augmented with custom regex patterns. This tool identifies sensitive information like phone numbers, email addresses, and IP addresses. Instead of simply removing or redacting, it replaces PII with fictitious but realistic values to maintain text flow and context. - Deduplication: The document is checked against existing data to remove duplicates, often using PDF metadata or content hashes. This ensures uniqueness and avoids redundancy in the corpus.
- Toxicity Detection (Celadon): Finally, the cleaned document is passed to
Celadon, a DeBERTa-v3-small multilingual toxicity classifier. This model, trained on a diverse dataset of annotated toxic content, identifies and flags harmful or biased language across multiple dimensions (e.g., racism, sexism, violence). Documents or segments exceeding a certain toxicity threshold are filtered out, ensuring the ethical integrity of the corpus. - Final Assembly & Metadata Enrichment: The now clean, segmented, corrected, PII-free, and non-toxic text is assembled. Its rich metadata (license, language, collection, domain, etc.) is attached, making it ready for inclusion in the Common Corpus.
This entire process ensures that each "data point" (document) is rigorously processed and vetted before becoming part of the final, high-quality dataset.
Optimization Dynamics
The "learning" or "convergence" in this paper primarily applies to the neural network models used within the data curation pipeline, as the paper itself doesn't propose a novel LLM training optimization. These models are trained using standard deep learning optimization techniques.
- Segmentext, OCRerrcr, and Celadon (Token Classification Models):
- Loss Landscape: These models are variants of DeBERTa-vX, which are transformer-based architectures. Their loss landscapes are typically high-dimensional and non-convex. The goal of training is to find a set of weights that minimizes a specific loss function.
- Loss Function: For
SegmentextandOCRerrcr, which perform token classification (e.g., classifying each token's structural role or error status), the primary loss function would be cross-entropy loss. This measures the difference between the model's predicted probability distribution over classes for each token and the true class label.Celadon, the toxicity classifier, explicitly uses a "custom weighted cross-entropy loss function to handle class imbalance." This weighting mechanism assigns higher penalties to misclassifications of minority classes (e.g., toxic content, which is typically rarer than non-toxic content), helping the model learn to identify these crucial cases more effectively. - Gradients: During training, the models use backpropagation to compute gradients of the loss function with respect to all model parameters (weights and biases). These gradients indicate the direction and magnitude by which each parameter should be adjusted to reduce the loss.
- Optimization Algorithm: While not explicitly stated, standard optimizers like Adam (Adaptive Moment Estimation) or SGD (Stochastic Gradient Descent) with momentum would be used. These algorithms iteratively update the model's parameters by taking steps in the direction opposite to the gradient, scaled by a learning rate.
- Convergence: The models converge when the loss function on a validation set stops significantly decreasing, indicating that the model has learned the underlying patterns in the training data and generalizes well. The iterative updates move the model's parameters through the loss landscape, aiming for a local or global minimum.
- OCRonos (Generative Language Model):
- Loss Landscape: As a fine-tuned Llama-3-8B model,
OCRonosoperates on a vast, complex loss landscape characteristic of large generative transformers. - Loss Function: The primary loss function for generative language models is typically next-token prediction loss (also a form of cross-entropy). The model is trained to predict the next token in a sequence given the preceding ones. In the context of OCR correction, this means learning to generate the correct, clean text from a noisy input sequence.
- Gradients & Optimization: Similar to the classification models,
OCRonosrelies on backpropagation and an optimizer (likely Adam or a variant) to update its parameters. The model learns to map noisy input patterns to clean output patterns. - Convergence: The model converges when it can reliably generate high-quality, corrected text that is faithful to the original intent while mitigating errors and resisting undesirable behaviors like language switching. The training process iteratively refines the model's ability to "rewrite" degraded text into a coherent and accurate form.
- Loss Landscape: As a fine-tuned Llama-3-8B model,
In essence, the optimization dynamics for these components are about iteratively adjusting the internal parameters of these neural networks to minimize their respective loss functions, thereby improving their performance on their specific data curation tasks. This iterative refinement allows the pipeline to "learn" how to process and clean diverse, noisy data effectively.
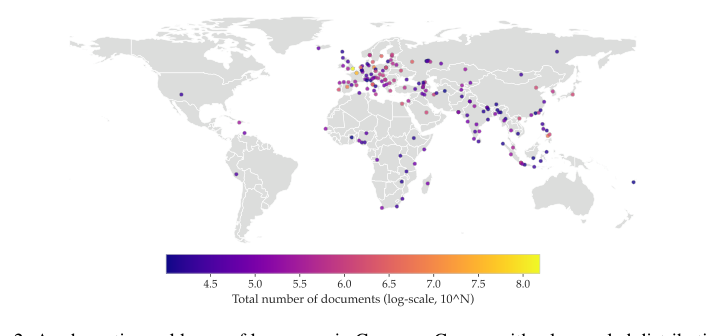 Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
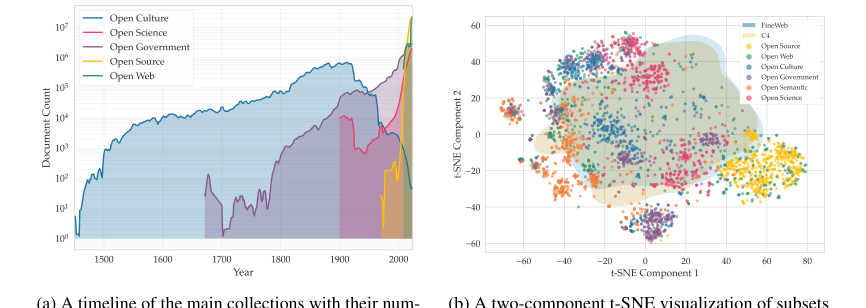 Figure 3. Temporal and semantic overview of the Common Corpus collections
Figure 3. Temporal and semantic overview of the Common Corpus collections
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate the utility of Common Corpus, the authors embarked on a focused experimental design. They trained two distinct language models, PleIAs 350M and PleIAs 1.2B, both built upon a Llama-based architecture. A custom Llama-style tokenizer, featuring a vocabulary size of 65,536, was developed and trained on a representative subsample of the Common Corpus itself. The smaller PleIAs 350M model was trained on approximately 1 trillion tokens from a filtered subset of Common Corpus, consuming 2,944 H100 hours. The larger PleIAs 1.2B model was trained on the full Common Corpus for three epochs of the filtered subset, requiring a substantial 23,040 H100 hours.
The "victims" (baseline models) against which Common Corpus-trained models were evaluated included several prominent multilingual language models: Gemma 3 (270M and 1B parameters), XGLM (564M and 1.7B parameters), BLOOM (560M and 1.7B parameters), and OLMO 1B. These baselines represent a mix of models trained on either closed, non-permissively licensed data, or, in the case of OLMO 1B, on a publicly released dataset. The evaluation was conducted using the standard LM Evaluation Harness across three established multilingual benchmarks: MultiBLiMP, XStoryCloze, and XCOPA. This setup was designed to provide a direct comparison of performance, specifically highlighting whether models trained exclusively on permissively licensed, ethically curated data could hold their own against those trained on broader, often legally ambiguous, datasets.
What the Evidence Proves
The evidence presented in the paper definitively proves that Common Corpus is a suitable and effective dataset for multilingual pre-training, enabling LLM development while strictly adhering to regulatory and ethical norms. The core mechanism—training on a massive, diverse, and permissively licensed corpus—was shown to work in reality through the performance of the PleIAs models.
Specifically, the models trained on Common Corpus demonstrated performance comparble to, and in some cases exceeding, their baselines. On the MultiBLiMP benchmark, which is particularly challenging due to its extensive language coverage, the PleIAs models showed outstandng performance. Notably, the smaller PleIAs 350M model, despite its size, managed to outperform most 1B-range baseline models, with the exception of Gemma 3 1B. Furthermore, both PleIAs models consistently and stably outperformed OLMO 1B, a baseline also pre-trained on a publicly released dataset. This is a crucial piece of evidence, as it directly validates the quality and utility of Common Corpus against another open-source alternative.
Beyond raw metrics, the paper provides hard evidence of the dataset's ethical and qualitative advantages. The detailed provenance, filtering, PII removal, toxicity detection, and deduplication processes (as described in Section 5) ensure that the data is uncopyrighted or under permissive licenses, addressing a critical legal and ethical gap in LLM training. Qualitative evaluations, such as the character composition metrics (Figure 4), confirmed that the data distributions were largely within expected ranges, with sensible deviations for specialized content like code or regulatory texts. The custom tokenizer, a foundational component of the PleIAs models, also performed well, being outperformed only by Gemma 3's tokenizer, which boasts a vocabulary four times larger. This collective evidence underscores that Common Corpus is not just a large dataset, but a high-quality, ethically sound, and effective one for training competitive multilingual LLMs.
Limitations & Future Directions
While Common Corpus represents a significant step forward for open science in LLM development, the authors candidly acknowledge several limitations that pave the way for future research and evolution. Firstly, despite its impressive size of 2 trillion tokens, Common Corpus is still far from encompassing the entire spectrum of available open data. This "open data paradox," where major sources of open content are often less visible online, means that larger models currently require significantly more data than Common Corpus alone can provide.
Secondly, the current iteration of Common Corpus is not inherently designed for instruction-tuning or specialized tasks. Its primary utility lies in pre-training, meaning it's not directly suitable for fine-tuning models for specific applications without additional, task-specific datasets. This presents an opportunity for future work to build upon Common Corpus by developing ethical fine-tuning datasets that leverage its multilingual, temporal, and semantic diversity.
A third limitation lies in the inherent challenges of data curation, particularly with historical and digitized texts. The authors admit that even with their sophisticated "Bad Data Toolbox" (including Segmentext, OCRoscope, OCRerrcr, OCRonos, and Celadon), achieving 100% accuracy in curation is difficult. OCR errors, in particular, remain a considerable challenge, potentially impacting model performance and even influencing how models handle typos. Improving these curation tools, perhaps through more advanced AI-driven methods, is a clear future direction.
Looking ahead, the findings from this paper stimulate several discussion topics:
- Scaling Open Data Initiatives: How can we overcome the "open data paradox" to make more permissively licensed content visible and accessible for LLM training? This could involve incentivizing data sharing from cultural institutions, governments, and research bodies, or developing new methods for discovering and aggregating such data at scale.
- Ethical Fine-tuning and Task-Specific Datasets: Given Common Corpus's strength in diverse, ethically sourced pre-training data, how can the community collaboratively build instruction-tuning and task-specific datasets that maintain the same high ethical standards? This would involve exploring methods for synthetic data generation, human-in-the-loop annotation, and federated learning approaches to create specialized datasets without compromising privacy or licensing.
- Advancements in Data Curation Tools: The paper highlights the ongoing challenge of OCR errors and other data quality issues. How can we further evolve tools like OCRonos and Celadon, perhaps integrating more sophisticated multimodal understanding or leveraging self-supervised learning on noisy data, to achieve near-perfect data quality at scale? Could LLMs themselves be trained to be more robust to, or even to correct, such imperfections more succesfully?
- The Role of Metadata in Responsible AI: The emphasis on rich metadata in Common Corpus allows users to filter data based on licenses, language, and potential issues. How can we standardize and expand metadata practices across all open datasets to empower LLM practitioners with greater control over their training data, fostering more responsible and transparent AI development?
- Cross-Lingual and Low-Resource Language Development: Common Corpus's multilingual diversity, including low-resource languages, is a key strength. How can this dataset be leveraged to push the boundaries of LLM performance in these languages, potentially reducing the digital divide and fostering more inclusive AI? This could involve transfer learning strategies, multilingual alignment techniques, or even novel architectural designs optimized for diverse linguistic inputs.
 Table 1. Comparison of the contemporary datasets for LLM training
Table 1. Comparison of the contemporary datasets for LLM training
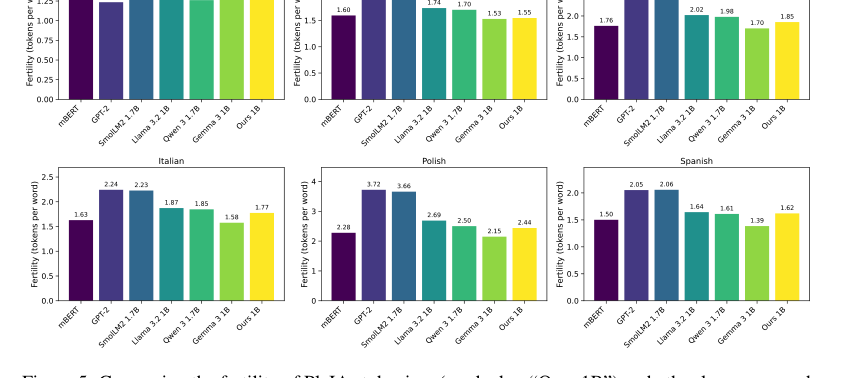 Table 6. Finance Commons sources distribution with languages
Table 6. Finance Commons sources distribution with languages
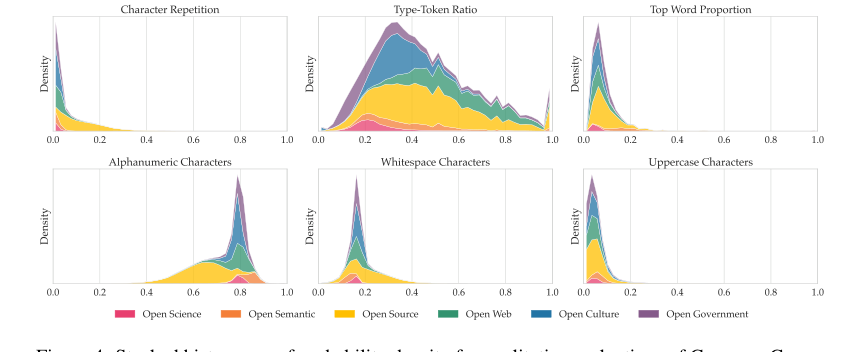 Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Isomorphisms with other fields
Structural Skeleton
This paper presents a robust, multi-stage pipeline for acquiring, cleaning, and validating vast, heterogeneous data under strict ethical and quality constraints.
Distant Cousins
-
Target Field: Supply Chain Management
The Connection: In the realm of global supply chain management, a persistent challenge is ensuring the authenticity, quality, and ethical provenance of raw materials and manufactured components from a myriad of international suppliers. This often involves navigating complex regulatory landscapes, verifying certifications, and preventing the infiltration of counterfeit or unethically sourced goods. The paper's core logic of meticulously tracing data provenance, applying multi-layered filtering (for quality, PII, and toxicity), and ensuring permissive licensing is a mirror image of the need for a "clean," "auditable," and "ethically sound" supply chain for physical products. The "open data paradox" described in the paper, where valuable open content is paradoxically hard to find and utilize, resonates with the difficulty of identifying truly reliable and transparent suppliers in a fragmented global market. -
Target Field: Genomics and Personalized Medicine
The Connection: In genomics, researchers routinely work with immense, heterogeneous biological datasets, including DNA sequences, gene expression profiles, and patient medical records, often aggregated from various research institutions and public repositories. A critical, long-standing problem is ensuring the quality, consistency, and ethical use (e.g., patient privacy, informed consent) of this sensitive data, especially when integrating it for large-scale analyses or developing personalized treatment models. The paper's systematic approach to identifying and removing Personally Identifiable Information (PII), correcting data errors (like OCRonos for text), and enforcing proper licensing for diverse data sources directly mirrors the bioinformatics challenge of curating "clean," "privacy-preserving," and "ethically compliant" genomic cohorts for medical research, where data integrity and stringent ethical guidelines are paramount.
What If Scenario
What if a researcher in Supply Chain Management "stole" this paper's exact equation—meaning, they adopted its comprehensive data curation and validation pipeline, including its specialized tools—tomorrow? A profound breakthrough would occur in global trade transparency and integrity. Imagine applying Segmentext-like models to automatically parse and structure diverse shipping manifests, customs declarations, and supplier contracts, even from scanned, historical documents, regardless of their original format or language. OCRoscope and OCRerrcr could then be adapted to detect anomalies or inconsistencies in product IDs, quantities, or origin declarations, flagging potential counterfeits, mislabeled goods, or compliance breaches with unprecedented precision. OCRonos could "correct" corrupted or incomplete digital records, ensuring data integrity across the entire supply chain. Furthermore, Celadon's principles could be adapted to detect "ethical violations" (e.g., indicators of forced labor, environmental non-compliance, or unfair trade practices) within supplier documentation and public records. This would lead to an unprecedented level of transparency, auditability, and ethical compliance in global commerce, drastically reducing fraud, improving product safety, and enabling truly "clean" supply chains, potentially even creating a "Common Corpus for Global Trade Data" that is both vast and verifiably ethical.
Universal Library of Structures
This paper significantly enriches the Universal Library of Structures by demonstrating that the principles of rigorous data provenance, multi-layered quality control, and ethical compliance are not domain-specific challenges but universal requirements for building reliable systems, whether they process language, manage supply chains, or analyze biological data, reinforcing the interconnectedness of scientific problems through shared mathematical patterns.