Common Corpus: LLM事前学習のための最大規模の倫理的データセット
背景と学術的系譜
起源と学術的系譜
本論文が取り組む問題、すなわち大規模言語モデル(LLM)の事前学習における倫理的に調達され、許可ライセンスが付与されたデータの希少性は、LLMの急速なスケールアップと広範な普及から生じたものである。歴史的に、この分野はGPT-3(Brown et al., 2020)のようなモデルによって大きな転換期を迎え、数兆トークンに達することもある膨大なデータセットでの学習というパラダイムを確立した。この傾向は続き、LLMの学習データサイズは2025年までに年間対数的に増加し、推定14兆から36兆トークンに達すると予測されている。
過去のアプローチにおける根本的な限界と「ペインポイント」は、ウェブスクレイピングされたデータへの依存に起因していた。これらのデータは公開されているものの、明確な許可ライセンスを欠いていることが多かった。NLPの実務家はしばしば「フェアユース」の原則に基づいて行動し、LLM学習の変革的な性質が著作権コンテンツの使用を正当化すると主張していた。しかし、このアプローチは、ニューヨーク・タイムズがOpenAIを著作権侵害で訴える(Roth, 2023; Pope, 2024)といった、法的な課題の増加につながった。さらに、Books3、LAION、GEITje、MATHといった著名なデータセットのいくつかは、著作権問題やCSAM(児童性的虐待資料)のような問題のあるコンテンツの存在により、法的措置による削除や制限に直面し、以前の研究の再現性を損ない、開発者の多大な投資損失を引き起こした。法的な問題を超えて、既存のオープンデータセットは多言語的な多様性の欠如に悩まされることが多く、主に英語中心であり、特にリソースの少ない言語では低品質または使用不可能なデータが含まれることが頻繁にあった。この集団的な圧力は、オープンサイエンスの研究とLLMの開発を促進するために、真にオープンで、法的に準拠し、高品質で、多様な事前学習データセットの緊急の必要性を浮き彫りにした。
直感的なドメイン用語
以下に、本論文からの専門的なドメイン用語を、初心者のための直感的なアナロジーで翻訳したものを示す。
- 大規模言語モデル(LLM): インターネットや書籍に書かれたほぼ全てのものを「読んだ」超知能的なデジタル脳を想像してほしい。それは、高度に教育され多才なアシスタントのように、人間のような方法で理解し、生成し、質問に答えることができる。
- トークン: LLMが理解する言語の基本的な構成要素と考えてほしい。これらは、モデルが処理する「単語」や、さらに小さな単語の断片(「un-」や「-ing」のような)に似ており、私たちが文を理解するために個々の単語に分解するのと同様である。
- 事前学習: これはLLMの初期の、大規模な学習フェーズである。特定のキャリアに特化する前に、多くの科目にわたる広範で一般的な教育を受けるために、学生が小学校、中学校、高校、大学に進むようなものである。モデルは一般的な言語パターンと知識を学習する。
- 許可ライセンス: データの「普遍的な許可証」と考えてほしい。これは、特別な許可を求めたり、著作権訴訟を心配したりすることなく、AIモデルの学習を含むほぼ全ての目的で、データを自由に利用、共有、さらには変更できることを明示的に述べている。「All rights reserved」の反対である。
- OCRエラー: 古い色あせた本をスキャンしてコンピューターに取り込む様子を想像してほしい。スキャナーが間違いを犯し、「e」を「c」に変えたり、2つの単語を結合したりすることがある。OCRエラーとは、古い文書からの画像のようなテキストを編集可能なテキストに変換する際に発生する、デジタルな「タイプミス」や歪みのことである。
表記表
率直に言って、本論文は新しい数学モデルやアルゴリズムを導入するのではなく、主に大規模データセットの作成と特性を記述している。そのため、数式における特定の数学変数やパラメータに依存するものではない。したがって、数式による後続の説明に必要な、論文の本文や図で明示的に定義または使用されている主要な数学的表記(変数、パラメータ)は存在しない。論文では、「トークン」、「ドキュメント」、「単語」といった記述的な用語を使用してデータを定量化しているが、これらは数式における単一文字の数学記号で表されるものではない。
問題定義と制約
コア問題の定式化とジレンマ
本論文が取り組む核心的な問題は、大規模言語モデル(LLM)のための、大規模、高品質、真にオープン、かつ許可ライセンスが付与された事前学習データの深刻な不足である。
入力/現状:
現在、LLMは、主にウェブからスクレイピングされた、しばしば数兆トークンからなる巨大なデータセットで事前学習されている。しかし、このデータの大部分は著作権で保護されているか、プロプライエタリであるか、あるいは明確な許可ライセンスを欠いている。これは、多数の法的課題(例:OpenAIに対する訴訟、Books3、LAION、MATHのようなデータセットのDMCA削除通知)によって証明されているように、LLM開発、特にオープンサイエンスの取り組みにとって、不安定な状況をもたらしている。既存の「オープン」データセットはしばしば限界を抱えている。それらはしばしば単一言語(主に英語)であり、ライセンスが不明確なウェブクロール(Common Crawlなど)に大きく依存しているか、あるいは低品質、使用不可能、または倫理的に問題のあるコンテンツ(例:個人識別情報(PII)、有害な言語)を含んでいる。さらに、コンテンツ所有者はAI学習のためのデータスクレイピングに対して技術的および法的な制限をますます実施しており、容易に入手可能なデータのプールはさらに縮小している。
望ましい終点(出力/目標状態):
望ましい終点は、LLM事前学習のための、堅牢で、法的に準拠し、倫理的に健全な基盤の確立である。これには、以下の条件を満たす大規模データセットの作成が含まれる。
1. 真にオープンで許可ライセンスが付与されていること: 全てのコンテンツは著作権フリーであるか、明確な許可ライセンスの下で利用可能でなければならず、法的確実性を保証し、オープンサイエンスを促進する。
2. 多言語・多ドメイン: データセットは、リソースの少ない言語を含む幅広い言語を網羅し、多様なドメイン(例:政府、文化、科学、コード、ウェブ、セマンティックデータ)をカバーし、汎化可能で強力なモデル性能を促進する。
3. 高品質でキュレーション済み: データは、PII、有害性、OCRエラーについて注意深くクリーニングおよびフィルタリングされ、透明性と再現性のために詳細な出所とメタデータが提供されなければならない。
欠落しているリンクまたは数学的ギャップ:
正確な欠落しているリンクは、LLM学習に使用されているプロプライエタリまたは曖昧なライセンスのデータセットの規模と多様性に匹敵できる、包括的で、倫理的に調達され、法的に明確なデータコモンズの欠如である。本論文は、これらの厳格な法的および倫理的基準を満たすようにゼロから設計され、同時に多言語事前学習に適した多様なトークンの実質的な量を提供するデータセットであるCommon Corpusを収集、キュレーション、リリースすることによって、このギャップを埋めようとしている。数学的なギャップは特定の数式にあるのではなく、LLM学習を構成する複雑な最適化問題のための適切に定義された、大規模で、法的にクリーンな入力空間の欠如にある。
ジレンマ:
過去の研究者を閉じ込めてきた中心的な、苦痛なトレードオフは、「スケール対合法性/倫理性/品質」のジレンマである。最先端のLLM性能に必要な大規模なスケールを達成するには、歴史的に、しばしば無差別にスクレイピングされた膨大なウェブデータを使用する必要があった。このアプローチは、スケールには効果的であるが、必然的に以下につながる。
* 法的脆弱性: 著作権またはプロプライエタリなコンテンツの包含は、訴訟やデータセットの削除につながり、再現性とオープンリサーチを損なう。
* 倫理的妥協: PII、有害または偏ったコンテンツの存在は、倫理的な懸念や規制不遵守(例:GDPR)につながる。
* 品質低下: ウェブスクレイピングされたデータは、しばしば低品質でノイズが多く、使用不可能なテキストを含んでおり、モデル性能に悪影響を与え、広範でコストのかかる事後処理を必要とする可能性がある。
ジレンマは、一方の側面(例:厳格な法的準拠の確保)を改善すると、通常は利用可能なデータスケールが劇的に減少し、キュレーションコストが指数関数的に増加し、競争力のあるLLMの学習が困難になるということである。逆に、スケールを優先すると、法的および倫理的基準が損なわれることが多い。本論文はまた、「オープンデータパラドックス」を強調している。これは、真にオープンなコンテンツが、主要な事前学習ソースでは逆説的に目立たず、その集約が本質的に困難であることを意味する。
制約と失敗モード
真にオープンで、許可ライセンスが付与され、高品質なLLM事前学習データセットを構築するという問題は、いくつかの厳しい現実的な制約により、非常に困難である。
-
法的・ライセンス制約:
- 厳格な許容性: データは著作権フリー(パブリックドメイン)であるか、明示的な許可ライセンス(例:CC-By、MIT、Apache-2.0)の下にある必要がある。これは、一般的なウェブスクレイピングと比較して、使用可能なデータのプールを大幅に制限する。なぜなら、公開されているウェブコンテンツの多くは、AI学習のための許可ライセンスが付与されていないからである。
- 著作権期間の複雑さ: 特に国際的および歴史的な作品のパブリックドメインステータスを決定するには、複雑な法的基準(例:作者の生涯+70年、米国作者の場合は出版+95年)が関わり、慎重な権利検証が必要となる。
- DMCA削除通知: 非準拠データに対する法的措置およびDMCA削除通知の絶え間ない脅威は、曖昧なソースに基づいたデータセットを長期的な研究にとって不安定で信頼性の低いものにする。
-
データ駆動型・品質制約:
- 高品質オープンデータの極端な希少性: ウェブは広大であるが、明確な許可ライセンスを持つ高品質で多言語・多ドメインのデータのサブセットは、比較的に希少で断片的である。
- 歴史的テキストにおけるOCR品質の低さ: 貴重な歴史的データ(Open Culture, Open Government)の大部分は、OCR(光学文字認識)品質の低いデジタル化されたソースから来ており、ノイズやエラーを導入してテキスト品質を低下させる。これには、高度で計算集約的なOCRエラー検出および修正ツールの必要性が生じる。
- PIIおよび有害コンテンツ: パブリックドメインやその他のオープンソースには、個人識別情報(PII)や有害/偏ったコンテンツ(例:時代遅れの規範を反映した歴史的テキスト、画像データセット内のCSAM)が含まれる可能性がある。堅牢で正確かつ効率的なPII削除および有害性検出パイプラインは必須であるが、多様な言語やドメインにわたって大規模に実装するのは困難である。
- メタデータの欠如: 多くの潜在的なデータソースは、出所、ライセンス、言語に関する十分なメタデータを欠いており、自動キュレーションを困難にし、手動介入または高度な推論を必要とする。
- 多言語多様性の課題: データ処理(セグメンテーション、品質評価)のためのツールは、既存のNLPツールがしばしば一般化しないリソースの少ない言語を含む、幅広い言語で確実に機能する必要がある。
-
計算・インフラストラクチャ制約:
- 大規模処理: 「約2兆トークン」の処理とキュレーションには、ストレージ、処理、フィルタリング、品質評価のためのかなりの計算リソースが必要である。
- キュレーションツールの計算コスト: 必須であるにもかかわらず、OCRエラー検出(例:OCRerrcr)のような高度なキュレーションツールは、より高速で精度の低い代替手段よりも効率が悪く、計算集約的である可能性がある。これは、非常に大規模なコーパスに対する精度と処理速度の間のトレードオフを提示する。
- データ出所追跡: 多様なソースにわたる各データオブジェクトの出所、ライセンス、メタデータを綿密に追跡することは、データパイプラインにかなりのオーバーヘッドを追加する。
-
失敗モード:
- 法的不遵守: 許可ライセンスが付与されていないコンテンツを正確に特定およびフィルタリングできないと、法的リスクとデータセット削除の可能性につながる。
- 倫理的違反: 不十分なPII削除または有害性フィルタリングは、プライバシー侵害や、学習済みLLMにおける有害なバイアスの永続化につながる可能性がある。
- モデル性能の低下: 低品質でノイズが多く、または十分に多様でないデータを使用すると、性能が低い、汎化性が限られている、または望ましくない動作(例:修正タスクでの「言語切り替え」、一般的な執筆スタイル)をするLLMにつながる可能性がある。
- 再現性の欠如: データセットが安定しておらず、十分に文書化されておらず、一貫して利用できない場合、それに基づいた研究は再現不可能になる。
- 非効率的なキュレーション: 手動または遅いキュレーションプロセスは、最新のLLM学習に必要な規模では実行不可能になり、効率的で自動化された、しかし正確なツールが必要となる。
- 偶発的な誤った繰り返し: OCRonosのような高度なツールを使用しても、偶発的に誤って繰り返された単語が含まれる可能性があり、事後処理が必要となる。
なぜこのアプローチか
選択の必然性
本論文が取り組む中心的な問題は、大規模言語モデル(LLM)自体のための新しい数学モデルやアルゴリズムの開発ではなく、高品質で、真にオープンで、許可ライセンスが付与され、多言語・多ドメインの事前学習データの決定的な不足である。著者らは、従来の「SOTA」のデータ収集およびキュレーション方法は、法的な問題、倫理的な問題、品質の問題の連鎖を引き起こし、オープンサイエンスの研究と堅牢なLLMの開発を著しく妨げたため、根本的に不十分であると認識した。
C4、Books3、LAION、RefinedWeb、Dolmaのような既存のデータセットは、その規模にもかかわらず、重大な欠点を示していた。
* 法的・倫理的な地雷原: 多くのデータセットには著作権またはプロプライエタリなコンテンツが含まれており、法的紛争(例:ニューヨーク・タイムズによるOpenAI訴訟、Books3のDMCA削除通知、CSAMコンテンツによるLAIONの削除)につながった。これにより、研究の再現性が損なわれ、開発者にとって多大なリスクが生じた。
* アクセス制限: コンテンツ所有者はAI学習のためのスクレイピングに対して技術的な措置や法的規定をますます実施しており、公開されているウェブデータの大部分(例:C4の45%)がアクセス不可能または制限された。
* 単一言語バイアス: ほとんどの新興「オープン」データセットは主に英語のみであった(例:C4C、Open License Corpus、KL3M、Common Pile)。これにより、多言語LLMの開発が著しく制限された。
* 低品質とバイアス: ウェブスクレイピングされたデータは、しばしば低品質、機械生成テキスト、個人識別情報(PII)、有害または偏ったコンテンツに悩まされていた。特に多言語データセットは、多くの使用不可能なデータを含んでいることが判明した。
これらの蔓延する問題に鑑み、著者らは、データ収集とキュレーションのための新しいパラダイムが唯一実行可能な解決策であると結論付けた。これには、法的に準拠し、倫理的に健全で、高品質で、言語およびドメイン全体にわたって多様であることを意図的に設計されたデータセットを組み立てるための、綿密な、ゼロからのアプローチが必要であった。Common Corpusのアプローチ—明確なライセンス、包括的な出所、高度なキュレーションツールに焦点を当てる—は、単なる改善ではなく、オープンLLM研究のための必要な基盤であった。
比較優位性
Common Corpusのアプローチは、単なるトークン数ではなく、法的準拠、データ品質、多様性への構造的なコミットメントを通じて、以前のデータ収集方法および既存のデータセットに対する質的な優位性を提供する。
- 前例のない法的・倫理的準拠: 法的紛争や削除に直面したデータセットとは異なり、Common Corpusは、著作権フリーまたは許可ライセンスが付与されたデータ(表4に詳述されているパブリックドメイン、CC-By、MIT、Apache-2.0など)のみから構築されている。この構造的な利点は、Common Corpusで学習されたモデルが、多くの商用モデルや「オープン」モデルを悩ませる法的不確実性なしにリリースおよび使用できることを保証する。この「オープン」への最も強力な意味でのコミットメントは、根本的な質的飛躍である。
- 専門的なキュレーションによるデータ品質の向上: 本論文は、「バッドデータツールボックス」(セクション5)を紹介している。これは、多言語、歴史的、デジタル化されたコンテンツに特有の課題を克服するために設計されたカスタムツールのスイートである。
- Segmentext: レイアウトベースの方法が視覚情報が失われた場合に失われる場合に、壊れたり構造化されていない入力からでも、堅牢なテキストセグメンテーションのためのトークン分類モデル。
- OCRエラー検出(OCRoscope & OCRerrcr): OCRoscopeは高速で大規模な品質推定を提供し、OCRerrcrはトークンレベルのきめ細かいエラー識別を提供する。これは歴史的およびデジタル化された文書にとって重要であり、生のOCR出力よりも高い入力品質を保証する。
- OCR補正(OCRonos): Llama-3-8Bからファインチューニングされた生成LLMで、OCRエラー、単語の分割、構造的なアーティファクトを修正するために特別にトレーニングされている。これは保守的に設計されており、言語切り替えという一般的な失敗モードに抵抗する。
- PII削除: MicrosoftのPresidioをカスタム正規表現で使用し、PIIを識別して偽の現実的な値に置き換えることで、テキスト形式とモデルの理解を維持する。これは単純な削除またはタグ付けよりも高度なアプローチである。
- 有害性検出(Celadon): 歴史的テキスト、OCRノイズ、非英語コンテンツに最適化された多言語有害性分類器(DeBERTa-v3-small)。はるかに大きなモデル(Llama 3.1-8B-Instruct)と同等の性能を達成するが、40倍以上高速であり、大規模なフィルタリングを実用的する。これにより、ウェブスクレイピングコーパスの主要な問題である有害コンテンツの存在が大幅に削減される。
- 真の多言語・多ドメイン多様性: Common Corpusは、幅広い高リソースおよび低リソース言語をカバーする、最大規模の完全にオープンなデータセット(2兆トークン)である(図2、表5)。多様なドメイン(オープンガバメント、オープンカルチャー、オープンサイエンス、オープンコード、オープンウェブ、オープンセマンティック)にわたるその構成は、図1に詳述されており、「ウェブクロール」データ(表1、図3b)を超えている。これらのコレクションの時間的および意味的な概要は、図3にさらに示されている。この構造的な多様性は、異なるタスクや言語でうまく機能する、汎化可能で強力なLLMをトレーニングするために不可欠であり、主に単一言語またはウェブテキスト中心のデータセットに対する明確な利点である。
- 再現性とオープンサイエンスインフラストラクチャ: 詳細な出所、処理手順を提供し、キュレーションツールをオープンにリリースすることにより、Common Corpusはオープンサイエンスの重要なインフラストラクチャとして機能する。この透明性とツールの共有は、データセットの突然の削除によって引き起こされる再現不可能な研究の問題に直接対処する。
本論文は、データキュレーションプロセスにおけるメモリ複雑性の$O(N^2)$から$O(N)$への削減を明示的に詳細に説明していないが、Celadon(有害性検出で40倍高速)やOCRoscope(大規模スケールで計算コストが低い)のような効率的なツールへの重点は、LLM事前学習に必要なデータ量を処理する上での構造的な利点を示している。この効率性により、このような高品質で大規模なキュレーション済みコーパスの作成が可能になる。
制約との整合性
Common Corpusのアプローチは、LLM事前学習のための法的サウンド、高品質、多様、かつオープンにアクセス可能なデータセットの必要性中心の、問題定義から導き出された暗黙的および明示的な制約と完全に整合している。
- 制約:厳格な法的・倫理的準拠: 本論文の主な動機は、「データセキュリティ規制に準拠し」、「著作権またはその他の法的制限から解放された」データを提供することである。Common Corpusは、著作権フリーまたは許可ライセンスが付与されたコンテンツ(表4)のみを調達することでこれを達成する。さらに、堅牢なPII削除(Presidioを使用)と有害性検出(Celadonを使用)を実装し、プライバシーと有害コンテンツの倫理的な懸念に直接対処する。この「結婚」により、Common Corpusで学習されたLLMは、以前のデータセットに伴う法的および評判上のリスクなしに展開できることが保証される。
- 制約:高品質で使いやすいデータ: 問題は、既存のデータセットがしばしば「低品質または完全に使い物にならないデータ」を含んでいることを強調している。特に多言語コンテキストでは。Common Corpusソリューションは、「バッドデータツールボックス」でこれを直接解決する。Segmentextは構造化されていないデジタル化されたテキストを処理し、OCRoscopeとOCRerrcrはエラーを検出し、OCRonosはそれらを修正して、劣化した入力を使用可能なテキストに変換する。このツールのスイートは、歴史的またはノイズの多いデータでさえ学習に意味のある貢献をすることを保証し、高品質な入力の要件を満たす。
- 制約:多言語・多ドメイン多様性: 以前の「オープン」データセットの主な限界は、単一言語性または限られたドメインカバレッジであった。Common Corpusは、最大規模の完全にオープンな事前学習データセットであり、「高い多言語多様性」(図2、表5)を持ち、幅広いドメイン(オープンガバメント、カルチャー、サイエンス、コード、ウェブ、セマンティック)をカバーするように明示的に設計されている。これは、異なる言語や知識領域で強力で汎化可能なLLMの必要性に対処する。
- 制約:オープンサイエンスと再現性: 本論文は、「真にオープンな事前学習データ」と「再現可能な研究成果物」の必要性を強調している。Common Corpusは、詳細な出所、処理手順を提供し、キュレーションツール(バッドデータツールボックス)をオープンにリリースすることで整合している。この透明性と方法論の共有は、このデータに基づいた研究が検証および再現可能であることを保証し、オープンサイエンスエコシステムを直接サポートする。
- 制約:大規模: LLMは「大量の学習データ」を必要とする(序論)。Common Corpusは、「約2兆トークン」でこの規模の要件を満たしている。そのキュレーションツールの効率性(例:Celadonの速度)により、このような巨大なコーパスを処理および維持することが実用的になり、この巨大な規模でさえ品質と多様性の制約が満たされることが保証される。
代替案の却下
本論文は、Common Corpusが克服しようとする根本的な欠点を強調することによって、いくつかの人気のあるアプローチや既存のデータセットを暗黙的および明示的に却下している。
- 無差別なウェブスクレイピングの却下(例:C4、Books3のCommon Crawl): 著者らは、「ほとんどのウェブデータは、許可ライセンスが付与されているかどうかを判断するための十分なメタデータを欠いている」と明確に述べており、「このデータの使用に対する法的紛争はますます増えている」としている。彼らは、NYTによるOpenAI訴訟、Books3のDMCA削除通知、およびCSAMによるLAIONデータセットの問題を、このようなアプローチの失敗の直接的な証拠として引用している。本論文は、「C4の45%がサービス利用規約の変更により現在制限されている」と指摘している。Common Corpusのアプローチは、明確な出所を持つ著作権フリーまたは許可ライセンスが付与されたコンテンツのみを含めることであり、広範なウェブスクレイピングに固有の法的および倫理的リスクを直接却下している。
- 既存の「オープン」データセットの不十分さとしての却下: 本論文は、Common CorpusをC4C、Open License Corpus、KL3M、Common Pile(表1)のような他のイニシアチブと比較している。それらの多くが「単一言語であり、実質的に言語モデルの範囲を英語圏に限定している」と指摘している。例えば、KL3Mは「英語の行政および法的文書に限定されている」。Common Corpusの、多言語、多ドメイン、ウェブクロールを超えた、完全に許可ライセンスという4つの基準すべてを同時に満たす独自の能力は、オープンで汎用的なLLM開発というより広範な目標にとって、これらの代替案の不十分さを示している。
- キュレーションされていない、または不適切にキュレーションされた多言語データセットの却下: 本論文は、「多くの多言語データセットには、低品質または完全に使い物にならないデータが多く含まれている」(Kreutzer et al., 2022)ことを強調している。これは、本論文で示されているように、厳格なキュレーションなしに様々な言語からのデータを単に集約するアプローチが、最適ではない学習データにつながることを示唆している。Common Corpusの「バッドデータツールボックス」(Segmentext、OCR補正、有害性検出)は、この問題に対する直接的な対抗策であり、多様で困難な言語ソースであっても高品質を保証する。
- PIIと有害性を無視するアプローチの却下: 本論文は、「ウェブデータは有害で偏ったコンテンツの主要な供給源」であり、「パブリックドメインデータは…歴史的な定期刊行物やモノグラフで構成されており…これらのテキストの多くは現代の倫理基準を満たしていない」と明示的に述べている。PII削除のためのPresidioや多言語有害性検出のためのCeladonのような専門ツールの開発は、これらの重要なフィルタリングステップを優先しないデータ収集戦略の明確な却下である。
本質的に、著者らは、厳格な法的および倫理的要件を満たせない、十分な多言語および多ドメインカバレッジを欠いている、またはデータ品質を損なっている、オープンLLMの持続可能な開発にとって最も重要な、これらのいずれかを満たせない代替案を却下した。
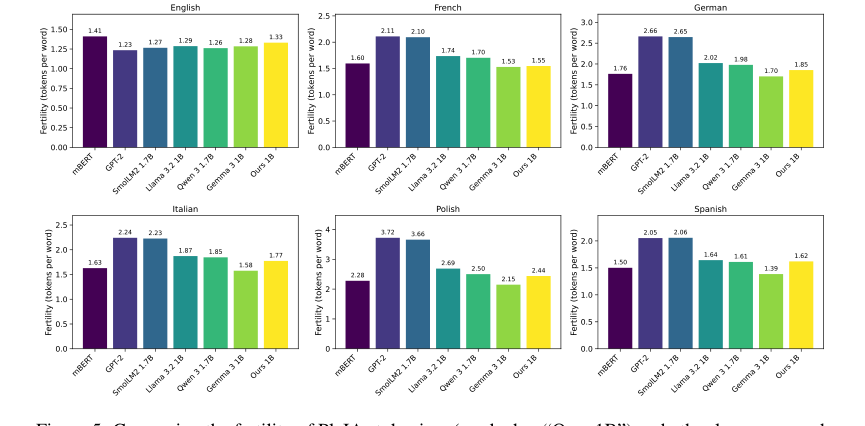 Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
数学的・論理的メカニズム
論文「Common CORPUS: LLM事前学習のための最大規模の倫理的データセット」は、主に大規模言語モデル(LLM)の学習のための、細心の注意を払って構築およびキュレーションされた、倫理的に調達された大規模データセットに焦点を当てている。このデータセットを使用したLLMの後の学習と評価を記述しているが、本論文によって導入または詳細に説明されている中心的な数学的および論理的メカニズムは、主にデータキュレーションパイプラインに関連しており、新しいLLMアーキテクチャや学習目的関数自体ではない。言及されているLLM(Llamaベース、DeBERTaバリアント)は既存のモデルであり、それらの学習のための基盤となる数学エンジンは、文献で確立されている。したがって、このセクションでは、論文の中心的な貢献であるデータキュレーションプロセスに採用されている論理的およびアルゴリズム的メカニズムに焦点を当てる。
マスター方程式
率直に言って、本論文は、新しい機械学習モデルの目的関数や新しい物理プロセスを記述する微分方程式のような、伝統的な意味での単一の「マスター方程式」を提示していない。むしろ、その「数学エンジン」は、データクリーニング、セグメンテーション、エラー検出、補正、および有害性フィルタリングのために設計されたアルゴリズムおよびモデルベースのプロセスのスイートである。これらのプロセスは、生のテキストデータに順次適用され、最終的なCommon Corpusを生成する。
「マスター方程式」に最も近いのは、データ品質の重要な側面を定量化するものではないが、OCR品質の評価である。これは、言語識別スコアを比較することに依存している。概念的には、OCR品質スコア、$Q_{OCR}$は、ドキュメントに対して次のように表すことができる。
$$ Q_{OCR} = 1 - \frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})} $$
この方程式は、簡略化されているものの、OCRoscopeのロジックの本質を捉えている。
用語ごとの解剖
OCRoscope品質スコアの概念的な構成要素を分解してみよう。
- $N$: これは、入力テキストドキュメントから抽出されたローリングnグラム(具体的には論文で言及されている7グラム)の総数である。その数学的定義は、これらのオーバーラップするテキストセグメントの数である。その物理的/論理的な役割は、ローカル言語識別が実行される粒度を定義することである。著者らは、言語識別モデルが短いシーケンスに対してノイズに敏感であるため、ドキュメントレベルの識別がノイズに対して堅牢であるのとは対照的に、OCRエラーの指標として適しているため、nグラムを使用した。
- $g_i$: これは、ドキュメントから抽出された$i$番目のローリング7グラムである。数学的には、長さ7のサブ文字列である。その論理的な役割は、OCRエラーが言語パターンを破壊しやすい、小さな局所的なテキストウィンドウを提供することである。
- $L(g_i)$: これは、7グラムの$i$番目の言語を
pycld2モデルによって識別した結果である。数学的には、カテゴリカルな出力(言語ラベルまたは「Unknown」)である。その論理的な役割は、ローカル言語の一貫性を検出することである。7グラムがOCRエラーによってひどく破損している場合、pycld2はその言語を誤って分類するか、「Unknown」とラベル付けする可能性が高い。 - $L_{doc}$: これは、ドキュメント全体に対して
pycld2によって識別された言語である。数学的には、単一のカテゴリカルな出力である。その論理的な役割は、ノイズが多少含まれていても堅牢に識別されると仮定されるドキュメントのグラウンドトゥルース言語を確立することである。ローカル$L(g_i)$とグローバル$L_{doc}$の比較は、不一致を特定する鍵となる。 - $\mathbb{I}(\cdot)$: これは指示関数であり、引数が真の場合は1、偽の場合は0を返す。数学的には、ブール値から整数へのマッピングである。その論理的な役割は、ローカル7グラムの言語識別がドキュメント全体の言語と一致しないか、または識別不能であるインスタンスをカウントすることである。著者らは、両方とも問題を示す「または」を使用して、明示的な誤識別と完全な識別失敗の両方を捉えた。
- $\mathbb{I}(g_i \text{ is valid})$: この項は、無効な入力によるゼロ除算または偏った比率を防ぐために、有効な7グラム(例:空でない、または句読点のみでない)のみを分母で考慮することを保証する。
- $\sum_{i=1}^{N} \dots$: これは問題のある7グラムの数を集計する。ここでの合計の使用は、離散イベントをシーケンス全体でカウントするために自然である。
- $\frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})}$: これは問題のある7グラムの割合を計算する。その論理的な役割は、OCRノイズの正規化された尺度を提供することである。
- $1 - \dots$: この最後の減算は、「エラー率」を「品質スコア」に変換する。1は完璧な品質を示し、低い値はデジタル化ノイズの増加を示す。これにより、スコアは「品質」メトリックとしてより直感的になる。
ステップバイステップの流れ
生のデジタル化されたドキュメント、おそらくスキャンされた歴史的な新聞が、Common Corpusキュレーションパイプラインに入力されると想像してほしい。それはテキストのための複雑な組み立てラインのようなものである。
- 初期取り込みとメタデータ抽出: ドキュメントが最初にシステムに入る。ソースURL、潜在的なライセンス情報、作成日などの基本的なメタデータが抽出または推測される。
- 言語識別(ドキュメントレベル): ドキュメント全体が言語識別モデル(
fastTextまたはcld2など)を通過し、その主要言語、$L_{doc}$を決定する。これは、後続のツールが言語に依存することが多いため、重要な最初のステップである。 - テキストセグメンテーション(Segmentext): ドキュメントの生の文字シーケンスが、
Segmentext、DeBERTa-v2スタイルのトークン分類モデルにフィードされる。このモデルはスマートパーサーのように機能し、異なる構造コンポーネントを識別およびタグ付けする:「これは[Title]です」、「これは[Text]です」、「これは[Table]です」、「これは[Paratext](ページ番号など)です」。純粋にテキスト上で動作するため、レイアウト情報の喪失に対して堅牢である。 - OCRエラー検出(OCRoscope & OCRerrcr):
- OCRoscope(粗粒度): 次にドキュメントが
OCRoscopeに渡される。このツールは7文字のウィンドウ(7グラム)をテキスト全体にスライドさせる。各7グラムについて、その言語、$L(g_i)$を識別しようとする。$L(g_i)$が$L_{doc}$と一致しないか、「Unknown」の場合、潜在的なOCRエラーとしてフラグが立てられる。OCRoscopeはこれらのフラグを集計して、ドキュメントの全体的なOCR品質スコアを生成する。これは、ドキュメントがより集中的な処理を必要とするかどうかを決定するための、高速な初期チェックである。 - OCRerrcr(微細粒度): より注意が必要と判断されたドキュメントの場合、DeBERTa-v3-smallモデルである
OCRerrcrが導入される。これはテキストをトークンごとに処理し、各トークンを正しいかエラーかのいずれかに分類する。これにより、エラーがどこにあるかの正確なマップが提供され、ターゲットを絞った補正の準備が整う。
- OCRoscope(粗粒度): 次にドキュメントが
- OCRエラー補正(OCRonos): エラーが特定されたドキュメントは、ファインチューニングされたLlama-3-8B生成モデルである
OCRonosに移動する。OCRonosは熟練したエディターのように機能し、ノイズの多いテキストを受け取り、OCRエラーを修正し、不正確な単語の分割や結合を修正し、広範な構造的整合性を回復しようとする。これは保守的に設計されており、元のテキストを可能な限り保持するが、ひどく劣化した部分を「合成的に書き直す」ことができる。 - 個人識別情報(PII)の削除: 構造的に健全で、ほぼエラーのないテキストは、PIIのスキャンを受ける。これは、カスタム正規表現で強化された
Microsoft Presidioを使用して行われる。このツールは、電話番号、メールアドレス、IPアドレスなどの機密情報を識別する。単に削除または編集するのではなく、テキストの流れとコンテキストを維持するために、偽の現実的な値に置き換える。 - 重複排除: ドキュメントは既存のデータと比較され、重複が削除される。これはしばしばPDFメタデータまたはコンテンツハッシュを使用して行われる。これにより、一意性が保証され、コーパス内の冗長性が回避される。
- 有害性検出(Celadon): 最後に、クリーニングされたドキュメントは、DeBERTa-v3-small多言語有害性分類器である
Celadonに渡される。注釈付きの有害コンテンツの多様なデータセットでトレーニングされたこのモデルは、複数の次元(例:人種差別、性差別、暴力)にわたる有害または偏った言語を識別およびフラグ付けする。特定の有害性しきい値を超えるドキュメントまたはセグメントはフィルタリングされ、コーパスの倫理的整合性が保証される。 - 最終的な組み立てとメタデータ強化: クリーンで、セグメント化され、補正され、PIIフリーで、有害性のないテキストが組み立てられる。その豊富なメタデータ(ライセンス、言語、コレクション、ドメインなど)が付加され、Common Corpusへの含める準備が整う。
このプロセス全体により、各「データポイント」(ドキュメント)が、最終的な高品質データセットの一部となる前に、厳密に処理および検証されることが保証される。
最適化ダイナミクス
この論文における「学習」または「収束」は、主にデータキュレーションパイプライン内で使用されるニューラルネットワークモデルに適用される。なぜなら、論文自体は新しいLLMトレーニング目的関数や新しいLLMアーキテクチャを提案するものではないからである。これらのモデルは、標準的な深層学習最適化技術を使用してトレーニングされる。
- Segmentext、OCRerrcr、およびCeladon(トークン分類モデル):
- 損失ランドスケープ: これらのモデルはDeBERTa-vXのバリアントであり、トランスフォーマーベースのアーキテクチャである。それらの損失ランドスケープは、典型的には高次元で非凸である。トレーニングの目標は、特定の損失関数を最小化する重みのセットを見つけることである。
- 損失関数:
SegmentextとOCRerrcrはトークン分類(例:各トークンの構造的役割またはエラー状態の分類)を実行するため、主要な損失関数はクロスエントロピー損失である。これは、各トークンのクラスに対するモデルの予測確率分布と真のクラスラベルとの差を測定する。Celadon、有害性分類器は、明示的に「クラス不均衡を処理するためのカスタム重み付きクロスエントロピー損失関数」を使用している。この重み付けメカニズムは、少数クラス(例:通常は非有害コンテンツよりも希少な有害コンテンツ)の誤分類に高いペナルティを割り当て、モデルがこれらの重要なケースをより効果的に識別することを学習するのを助ける。 - 勾配: トレーニング中、モデルはバックプロパゲーションを使用して、損失関数に対するモデルパラメータ(重みとバイアス)すべての勾配を計算する。これらの勾配は、学習率でスケーリングされた勾配の反対方向への各パラメータの調整が必要な方向と大きさを指示する。
- 最適化アルゴリズム: 明示的に述べられていないが、Adam(適応モーメント推定)またはSGD(確率的勾配降下法)とモーメンタムのような標準的なオプティマイザーが使用されるだろう。これらのアルゴリズムは、学習率でスケーリングされた勾配の反対方向へのステップを取ることによって、モデルのパラメータを反復的に更新する。
- 収束: モデルは、検証セット上の損失関数が大幅に減少しなくなったときに収束する。これは、モデルがトレーニングデータの基盤となるパターンを学習し、うまく一般化することを示している。反復的な更新は、局所的または大域的な最小値を目指して、モデルパラメータを損失ランドスケープを通じて移動させる。
- OCRonos(生成言語モデル):
- 損失ランドスケープ: Llama-3-8Bモデルをファインチューニングした結果として、
OCRonosは大規模な生成トランスフォーマーの広大で複雑な損失ランドスケープ上で動作する。 - 損失関数: 生成言語モデルの主要な損失関数は、通常、次トークン予測損失(これもクロスエントロピーの一種)である。モデルは、先行するトークンを与えられたシーケンスの次のトークンを予測するようにトレーニングされる。OCR補正の文脈では、これはノイズの多い入力シーケンスからクリーンなテキストを生成するように学習することを意味する。
- 勾配と最適化: 分類モデルと同様に、
OCRonosはバックプロパゲーションとオプティマイザー(おそらくAdamまたはそのバリアント)を使用してパラメータを更新する。モデルは、ノイズの多い入力パターンをクリーンな出力パターンにマッピングするように学習する。 - 収束: モデルは、元の意図に忠実でありながらエラーを軽減し、言語切り替えのような望ましくない動作に抵抗する高品質で補正されたテキストを確実に生成できるときに収束する。トレーニングプロセスは、劣化したテキストを首尾一貫した正確な形式に「書き直す」モデルの能力を反復的に洗練させる。
- 損失ランドスケープ: Llama-3-8Bモデルをファインチューニングした結果として、
本質的に、これらのコンポーネントの最適化ダイナミクスは、これらのニューラルネットワークの内部パラメータを反復的に調整して、それぞれの損失関数を最小化し、それによって多様でノイズの多いデータを効果的に処理およびクリーニングするパイプラインの能力を向上させることである。この反復的な洗練により、パイプラインは多様でノイズの多いデータを効果的に処理およびクリーニングする方法を「学習」できる。
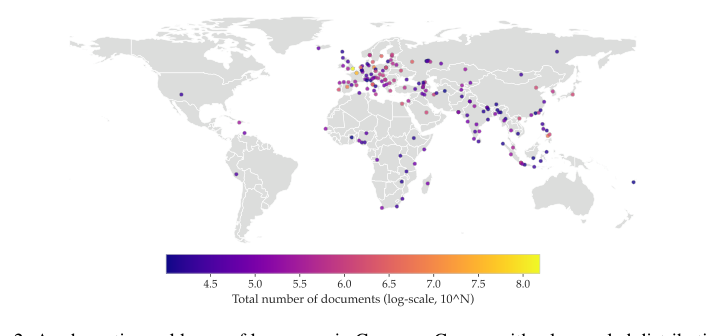 Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
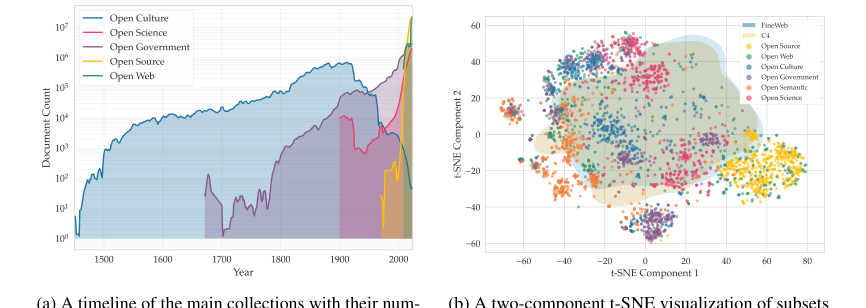 Figure 3. Temporal and semantic overview of the Common Corpus collections
Figure 3. Temporal and semantic overview of the Common Corpus collections
結果、限界、および結論
実験設計とベースライン
Common Corpusの有用性を厳密に検証するために、著者らは集中的な実験設計に着手した。彼らは、Llamaベースのアーキテクチャに基づいた2つの異なる言語モデル、PleIAs 350MとPleIAs 1.2Bをトレーニングした。65,536の語彙サイズを持つカスタムLlamaスタイルのトークナイザーが開発され、Common Corpusの代表的なサブサンプルでトレーニングされた。より小さいPleIAs 350Mモデルは、Common Corpusのフィルタリングされたサブセットから約1兆トークンでトレーニングされ、2,944 H100時間を消費した。より大きいPleIAs 1.2Bモデルは、フィルタリングされたサブセットの3エポックで完全なCommon Corpusでトレーニングされ、23,040 H100時間というかなりの時間を要した。
Common Corpusでトレーニングされたモデルが評価された「犠牲者」(ベースラインモデル)には、いくつかの著名な多言語言語モデルが含まれていた。Gemma 3(270Mおよび1Bパラメータ)、XGLM(564Mおよび1.7Bパラメータ)、BLOOM(560Mおよび1.7Bパラメータ)、およびOLMO 1Bである。これらのベースラインは、クローズドで非許可ライセンスのデータでトレーニングされたモデル、またはOLMO 1Bの場合のように、公開リリースされたデータセットでトレーニングされたモデルの組み合わせを表している。評価は、3つの確立された多言語ベンチマーク:MultiBLiMP、XStoryCloze、およびXCOPAにわたって標準的なLM評価ハーネスを使用して実施された。このセットアップは、許可ライセンスが付与され、倫理的にキュレーションされたデータのみでトレーニングされたモデルが、より広範で、しばしば法的に曖昧なデータセットでトレーニングされたモデルと比較して、その地位を維持できるかどうかを特に強調するように設計された、直接的なパフォーマンス比較を提供する。
証拠が証明すること
本論文で提示された証拠は、Common Corpusが多言語事前学習に適しており、効果的なデータセットであり、規制および倫理規範を厳密に遵守しながらLLM開発を可能にすることを断定的に証明している。中心的なメカニズム—大規模で多様な、許可ライセンスが付与されたコーパスでのトレーニング—は、PleIAsモデルのパフォーマンスを通じて、現実に機能することが示された。
具体的には、Common Corpusでトレーニングされたモデルは、ベースラインと比較して同等、場合によってはそれを上回るパフォーマンスを示した。特に言語カバレッジが広いため困難なMultiBLiMPベンチマークでは、PleIAsモデルは優れたパフォーマンスを示した。特に、より小さいPleIAs 350Mモデルは、そのサイズにもかかわらず、Gemma 3 1Bを除くほとんどの1B範囲のベースラインモデルを上回った。さらに、両方のPleIAsモデルは、公開リリースされたデータセットでも事前学習されたベースラインであるOLMO 1Bを、一貫して安定して上回った。これは、他のオープンソース代替案に対するCommon Corpusの品質と有用性を直接検証するため、重要な証拠である。
生のメトリックを超えて、本論文はデータセットの倫理的および質的な利点の確固たる証拠を提供する。詳細な出所、フィルタリング、PII削除、有害性検出、および重複排除プロセス(セクション5で説明されている)により、データが著作権フリーまたは許可ライセンスの下にあることが保証され、LLMトレーニングにおける重要な法的および倫理的ギャップに対処している。文字構成メトリック(図4)のような質的評価は、データ分布が予想範囲内であり、コードや規制テキストのような特殊コンテンツに対して妥当な偏差があることを確認した。PleIAsモデルの基盤となるコンポーネントであるカスタムトークナイザーも良好なパフォーマンスを示し、語彙サイズが4倍大きいGemma 3のトークナイザーにのみ劣った。この集団的な証拠は、Common Corpusが単なる大規模データセットではなく、競争力のある多言語LLMをトレーニングするための高品質で倫理的に健全で効果的なデータセットであることを強調している。
限界と将来の方向性
Common CorpusはLLM開発におけるオープンサイエンスにとって大きな前進を表しているが、著者らは将来の研究と進化への道を開くいくつかの限界を率直に認めている。第一に、2兆トークンという印象的なサイズにもかかわらず、Common Corpusは利用可能なオープンデータの全スペクトルを網羅するにはまだ程遠い。この「オープンデータパラドックス」、すなわちオープンコンテンツの主要なソースがオンラインでは逆説的に見えにくいという事実は、より大きなモデルが現在Common Corpusだけでは提供できないよりもはるかに多くのデータを必要とすることを意味する。
第二に、Common Corpusの現在のイテレーションは、指示チューニングや特殊タスクのために本質的に設計されているわけではない。その主な有用性は事前学習にあり、追加のタスク固有データなしに特定のアプリケーションのためにモデルをファインチューニングするのには直接適していないことを意味する。これは、その多言語、時間的、意味的な多様性を活用する倫理的なファインチューニングデータセットを開発することによって、将来の作業のための機会を提供する。
第三の限界は、特に歴史的およびデジタル化されたテキストにおけるデータキュレーションの固有の課題にある。著者らは、洗練された「バッドデータツールボックス」(Segmentext、OCRoscope、OCRerrcr、OCRonos、Celadonを含む)を使用しても、キュレーションの精度を100%達成することは困難であると認めている。特にOCRエラーは依然としてかなりの課題であり、モデルパフォーマンスに影響を与え、モデルがタイプミスをどのように処理するかさえ影響を与える可能性がある。これらのキュレーションツールの改善、おそらくより高度なAI駆動型メソッドを通じて、明確な将来の方向性である。
将来を見据えると、この論文からの発見はいくつかの議論のトピックを刺激する。
- オープンデータイニシアチブのスケールアップ: 「オープンデータパラドックス」を克服して、LLMトレーニングのために許可ライセンスが付与されたコンテンツをより多く可視化し、アクセス可能にするにはどうすればよいか?これには、文化機関、政府、研究機関からのデータ共有の奨励、またはそのようなデータを大規模に発見および集約するための新しい方法の開発が含まれる可能性がある。
- 倫理的なファインチューニングとタスク固有データセット: Common Corpusの多様で倫理的に調達された事前学習データの強みを考慮して、コミュニティは、同じ高い倫理基準を維持する指示チューニングおよびタスク固有データセットをどのように共同で構築できるか?これには、合成データ生成、人間参加型アノテーション、およびフェデレーテッド学習アプローチの方法を探求して、プライバシーやライセンスを損なうことなく特殊なデータセットを作成することが含まれるだろう。
- データキュレーションツールの進歩: 本論文は、OCRエラーやその他のデータ品質問題の継続的な課題を強調している。OCRonosやCeladonのようなツールを、おそらくより高度なマルチモーダル理解を統合したり、ノイズの多いデータでの自己教師あり学習を活用したりすることによって、大規模なデータ品質をほぼ完璧に達成するために、さらに進化させるにはどうすればよいか?LLM自体が、そのような不完全性に対してより堅牢になるように、またはそれらをより成功裏に修正するようにトレーニングできるだろうか?
- 責任あるAIにおけるメタデータの役割: Common Corpusにおける豊富なメタデータへの重点は、ユーザーがライセンス、言語、および潜在的な問題に基づいてデータをフィルタリングすることを可能にする。すべてのオープンデータセットでメタデータ慣行を標準化および拡張して、LLMの実務家にトレーニングデータに対するより大きな制御を付与し、より責任ある透明性の高いAI開発を促進するにはどうすればよいか?
- クロスリンガルおよび低リソース言語開発: Common Corpusの多言語多様性(低リソース言語を含む)は主要な強みである。このデータセットを、これらの言語でのLLMパフォーマンスの限界を押し広げるために、デジタルデバイドを削減し、より包括的なAIを促進する可能性をどのように活用できるか?これには、転移学習戦略、多言語アライメント技術、または多様な言語入力に最適化された新しいアーキテクチャ設計が含まれる可能性がある。
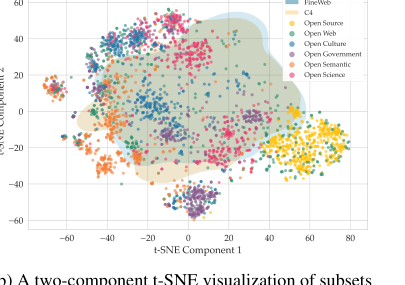 Table 1. Comparison of the contemporary datasets for LLM training
Table 1. Comparison of the contemporary datasets for LLM training
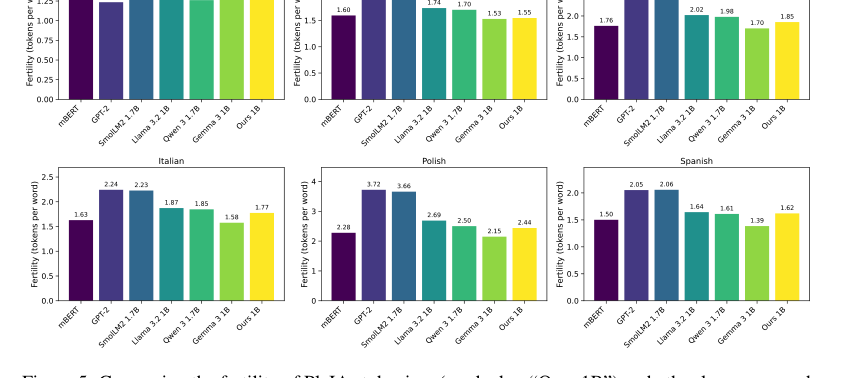 Table 6. Finance Commons sources distribution with languages
Table 6. Finance Commons sources distribution with languages
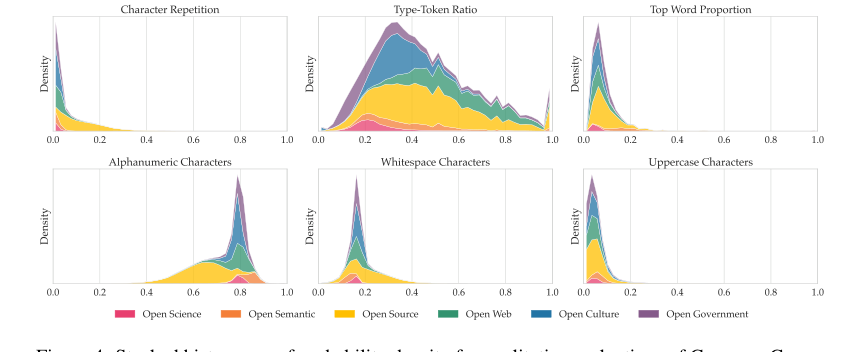 Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
他分野との同型性
構造的骨格
本論文は、厳格な倫理的および品質的制約の下で、広大で異種混在のデータを取得、クリーニング、および検証するための、堅牢な多段階パイプラインを提示している。
遠い親戚
-
対象分野: サプライチェーン管理
関連性: グローバルサプライチェーン管理の領域では、国際的なサプライヤーの無数のソースからの原材料や製造部品の真正性、品質、倫理的な出所を確保することが、永続的な課題である。これにはしばしば複雑な規制環境をナビゲートし、認証を検証し、偽造品または倫理的に調達されていない商品の流入を防ぐことが含まれる。本論文のデータ出所の綿密な追跡、多層フィルタリング(品質、PII、有害性のため)の適用、および許可ライセンスの確保という中心的なロジックは、物理的な製品のための「クリーン」、「監査可能」、「倫理的に健全」なサプライチェーンの必要性の鏡像である。本論文で説明されている「オープンデータパラドックス」、すなわち価値のあるオープンコンテンツが逆説的に見つけにくく利用しにくいという事実は、断片化されたグローバル市場で真に信頼でき透明なサプライヤーを特定することの難しさと共鳴する。 -
対象分野: ゲノミクスと個別化医療
関連性: ゲノミクスでは、研究者はDNA配列、遺伝子発現プロファイル、患者の医療記録など、さまざまな研究機関や公開リポジトリから集約された、膨大で異種混在の生物学的データセットを日常的に扱っている。重要な、長年の問題は、特に大規模分析のために統合したり、個別化治療モデルを開発したりする際に、この機密データの品質、一貫性、および倫理的な使用(例:患者のプライバシー、インフォームドコンセント)を確保することである。本論文の個人識別情報(PII)の特定および削除、データエラーの補正(テキスト用のOCRonosのような)、および多様なデータソースの適切なライセンスの強制という体系的なアプローチは、データ整合性と厳格な倫理ガイドラインが最重要である医療研究のための「クリーン」、「プライバシーを保護する」、「倫理的に準拠した」ゲノムコホートをキュレーションするというバイオインフォマティクス上の課題を直接反映している。
もしシナリオ
もしサプライチェーン管理の研究者が、この論文の正確な「数式」—つまり、その専門ツールを含む包括的なデータキュレーションと検証パイプラインを採用したとしたら—明日、どうなるだろうか?グローバル貿易の透明性と誠実さにおいて、深遠なブレークスルーが起こるだろう。Segmentextのようなモデルを適用して、元のフォーマットや言語に関係なく、さまざまな出荷明細書、通関申告書、サプライヤー契約書を自動的に解析および構造化することを想像してほしい。OCRoscopeとOCRerrcrは、製品ID、数量、または原産地宣言の異常または不整合を検出するように適応され、前例のない精度で偽造品、誤表示された商品、またはコンプライアンス違反の可能性をフラグ付けできるだろう。OCRonosは、破損または不完全なデジタル記録を「修正」し、サプライチェーン全体でデータ整合性を確保できるだろう。さらに、Celadonの原則は、サプライヤーの文書および公開記録内の「倫理違反」(例:強制労働、環境非準拠、または不公正貿易慣行の兆候)を検出するように適応できるだろう。これにより、グローバルコマースにおける前例のないレベルの透明性、監査可能性、および倫理的準拠が実現し、詐欺が大幅に削減され、製品安全性が向上し、真に「クリーン」なサプライチェーンが可能になり、おそらく「グローバル貿易データのための共通コーパス」さえも作成され、それは広大で検証可能に倫理的になるだろう。
構造の普遍的ライブラリ
本論文は、厳格なデータ出所、多層品質管理、および倫理的準拠の原則が、言語を処理するか、サプライチェーンを管理するか、生物学的データを分析するかに関わらず、信頼できるシステムを構築するための普遍的な要件であり、ドメイン固有の課題ではないことを実証することにより、構造の普遍的ライブラリを大幅に豊かにする。これは、共通の数学的パターンを通じて科学的問題の相互接続性を強化する。