Common Corpus: LLM 사전 훈련을 위한 최대 규모의 윤리적 데이터 컬렉션
배경 및 학술적 계보
기원 및 학술적 계보
본 논문에서 다루는 문제, 즉 대규모 언어 모델(LLM) 사전 훈련을 위한 윤리적으로 소싱되고 허가된 라이선스의 데이터 부족은 LLM의 급격한 확장과 광범위한 채택에서 비롯되었다. 역사적으로, GPT-3(Brown et al., 2020)와 같은 모델은 수조 개의 토큰에 달하는 방대한 데이터셋으로 훈련하는 패러다임을 확립하며 해당 분야에 중대한 변화를 가져왔다. 이러한 추세는 계속되어, LLM 훈련 데이터의 크기는 2025년까지 로그적으로 증가하여 약 14~36조 개의 토큰에 이를 것으로 추정된다.
이전 접근 방식의 근본적인 한계와 "고충점"은 웹 스크랩 데이터에 의존했다는 점에서 비롯되었다. 이 데이터는 공개적으로 이용 가능했지만, 명확한 허가 라이선스가 부족한 경우가 많았다. 자연어 처리(NLP) 실무자들은 종종 "공정 이용(fair use)"을 주장하며 LLM 훈련의 변형적 특성이 저작권 콘텐츠 사용을 정당화한다고 논했다. 그러나 이러한 접근 방식은 뉴욕 타임스가 OpenAI를 상고한 저작권 침해 소송(Roth, 2023; Pope, 2024)과 같은 법적 분쟁을 야기했다. 더욱이, Books3, LAION, GEITje, MATH를 포함한 여러 유명 데이터셋은 저작권 문제나 CSAM(아동 성적 학대 자료)과 같은 문제성 콘텐츠의 존재로 인해 법적 삭제 또는 제한에 직면했으며, 이는 이전 연구의 재현을 불가능하게 만들고 개발자들에게 상당한 투자 손실을 초래했다. 법적 문제 외에도, 기존의 공개 데이터셋은 다국어 다양성이 부족하고 주로 영어 중심이었으며, 특히 저자원 언어의 경우 저품질이거나 사용할 수 없는 데이터를 포함하는 경우가 빈번했다. 이러한 집단적 압력은 오픈 과학 연구 및 LLM 개발을 촉진하기 위한 진정으로 개방적이고 법적으로 준수되며 고품질이며 다양한 사전 훈련 데이터셋에 대한 시급한 필요성을 강조했다.
직관적인 도메인 용어
다음은 논문의 몇 가지 전문 용어를 초보자를 위한 직관적인 비유로 번역한 것이다.
- 대규모 언어 모델 (Large Language Model, LLM): 인터넷과 책에 쓰인 거의 모든 것을 "읽은" 매우 똑똑한 디지털 두뇌라고 상상해 보라. 그런 다음, 고도로 교육받고 다재다능한 비서처럼 인간과 유사한 방식으로 이해하고 생성하며 질문에 답할 수 있다.
- 토큰 (Tokens): LLM이 이해하는 언어의 기본 구성 요소라고 생각하면 된다. 모델이 처리하는 "단어" 또는 단어의 더 작은 조각(예: "un-" 또는 "-ing")과 같으며, 우리가 문장을 이해하기 위해 개별 단어로 분해하는 방식과 유사하다.
- 사전 훈련 (Pre-training): LLM의 초기 대규모 학습 단계이다. 특정 직업에 전문화되기 전에 다양한 주제에 걸쳐 광범위하고 일반적인 교육을 받기 위해 학생을 초등학교, 중학교, 대학교에 보내는 것과 같다. 모델은 일반적인 언어 패턴과 지식을 학습한다.
- 허가 라이선스 (Permissive Licenses): 데이터에 대한 "보편적인 허가증"으로 생각하면 된다. AI 모델 훈련을 포함하여 거의 모든 목적으로 데이터를 자유롭게 사용, 공유, 변경할 수 있음을 명시적으로 명시하며, 특별한 허가를 구하거나 저작권 소송을 걱정할 필요가 없다. "모든 권리 보유"와 반대되는 개념이다.
- OCR 오류 (OCR Errors): 오래되고 희미한 책을 컴퓨터로 스캔하는 것을 상상해 보라. 때때로 스캐너가 실수를 하여 "e"를 "c"로 바꾸거나 두 단어를 합쳐버린다. OCR 오류는 오래된 문서의 이미지와 같은 텍스트 이미지를 편집 가능한 텍스트로 변환할 때 발생하는 디지털 "오타" 또는 왜곡이다.
표기법 표
솔직히 말해서, 이 논문은 주로 새로운 수학적 모델이나 방정식의 특정 수학적 변수 또는 매개변수에 의존하는 알고리즘을 소개하기보다는 대규모 데이터셋의 생성 및 특성을 설명한다. 따라서 후속 수학적 설명을 위해 필요한 방정식이나 그림의 명시적인 수학적 표기법(변수, 매개변수)은 없다. 논문은 데이터 양을 측정하기 위해 "토큰", "문서", "단어"와 같은 서술적 용어를 사용하지만, 이는 공식에서 단일 문자 수학 기호로 표현되지 않는다.
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 대규모 언어 모델(LLM)을 위한 대규모, 고품질, 진정으로 개방적이며 허가된 라이선스의 사전 훈련 데이터의 심각한 부족이다.
입력/현재 상태:
현재 LLM은 주로 웹에서 스크랩된 다양한 도메인에서 수조 개의 토큰으로 구성된 방대한 데이터셋으로 사전 훈련된다. 그러나 이 데이터의 상당 부분은 저작권이 있거나, 독점적이거나, 명확한 허가 라이선스가 부족하다. 이는 LLM 개발, 특히 오픈 과학 이니셔티브에 있어 불안정한 상황을 초래했으며, 수많은 법적 분쟁(예: OpenAI에 대한 소송, Books3, LAION, MATH와 같은 데이터셋의 DMCA 삭제)으로 입증되었다. 기존의 "개방형" 데이터셋은 종종 다음과 같은 한계를 가진다. 종종 단일 언어(주로 영어)이고, 라이선스가 불분명한 웹 크롤(예: Common Crawl)에 크게 의존하거나, 저품질, 사용 불가능, 또는 윤리적으로 문제가 있는 콘텐츠(예: 개인 식별 정보(PII), 유해 언어)를 포함한다. 또한, 콘텐츠 소유자는 AI 훈련을 위한 데이터 스크래핑에 대해 기술적 및 법적 제한을 점점 더 많이 시행하고 있어 즉시 사용 가능한 데이터 풀이 더욱 줄어들고 있다.
원하는 최종 상태 (출력/목표 상태):
원하는 최종 상태는 LLM 사전 훈련을 위한 강력하고 법적으로 준수되며 윤리적으로 건전한 기반을 구축하는 것이다. 이는 다음을 포함하는 대규모 데이터셋을 생성하는 것을 의미한다.
1. 진정으로 개방적이며 허가된 라이선스: 모든 콘텐츠는 저작권이 없거나 명확하고 허가된 라이선스 하에 있어야 하며, 법적 확실성을 보장하고 오픈 과학을 촉진한다.
2. 다국어 및 다중 도메인: 데이터셋은 저자원 언어를 포함한 광범위한 언어와 다양한 도메인(예: 정부, 문화, 과학, 코드, 웹, 의미론적 데이터)을 포괄하여 일반화 가능하고 강력한 모델 성능을 촉진해야 한다.
3. 고품질 및 큐레이션: 데이터는 투명성과 재현성을 위해 신중하게 정리되고, PII, 유해성, OCR 오류에 대해 필터링되며, 상세한 출처 및 메타데이터가 제공되어야 한다.
누락된 연결 또는 수학적 격차:
정확한 누락된 연결은 LLM 훈련에 사용되는 독점적이거나 모호하게 라이선스된 데이터셋의 규모와 다양성에 필적할 수 있는 포괄적이고 윤리적으로 소싱되었으며 법적으로 명확한 데이터 커먼즈의 부재이다. 본 논문은 이러한 엄격한 법적 및 윤리적 기준을 충족하도록 처음부터 설계된 데이터셋인 Common Corpus를 조립, 큐레이션 및 공개함으로써 이 격차를 해소하고자 한다. 수학적 격차는 특정 방정식에 있는 것이 아니라, LLM 훈련을 구성하는 복잡한 최적화 문제에 대한 잘 정의되고 대규모이며 법적으로 깨끗한 입력 공간의 부족에 있다.
딜레마:
이전 연구자들을 가두었던 중심적이고 고통스러운 상충 관계는 "규모 대 법규/윤리/품질" 딜레마이다. 최첨단 LLM 성능에 필요한 막대한 규모를 달성하기 위해서는 역사적으로 방대하고 종종 무차별적으로 스크랩된 웹 데이터를 사용하는 것이 필수적이었다. 이러한 접근 방식은 규모에는 효과적이지만 필연적으로 다음과 같은 결과를 초래한다.
* 법적 취약성: 저작권이 있거나 독점적인 콘텐츠 포함으로 인한 소송 및 데이터셋 삭제는 재현성과 개방형 연구를 약화시킨다.
* 윤리적 타협: PII, 유해하거나 편향된 콘텐츠의 존재는 윤리적 우려와 규정 미준수(예: GDPR)를 야기한다.
* 품질 저하: 웹 스크랩 데이터는 종종 저품질, 노이즈가 많거나 사용할 수 없는 텍스트를 포함하며, 이는 모델 성능에 부정적인 영향을 미치고 광범위하고 비용이 많이 드는 후처리 작업이 필요할 수 있다.
딜레마는 한 측면을 개선하는 것(예: 엄격한 법적 준수 보장)이 일반적으로 사용 가능한 데이터 규모를 크게 줄이거나 큐레이션 비용을 기하급수적으로 증가시켜 경쟁력 있는 LLM을 훈련하기 어렵게 만든다는 것이다. 반대로, 규모를 우선시하면 법적 및 윤리적 기준이 희생되는 경우가 많다. 본 논문은 또한 "개방형 데이터 역설"을 강조하는데, 진정으로 개방적인 콘텐츠는 역설적으로 주요 사전 훈련 소스에서 덜 눈에 띄어 집계가 본질적으로 어렵다.
제약 조건 및 실패 모드
진정으로 개방적이고 허가된 라이선스의 고품질 LLM 사전 훈련 데이터셋을 구축하는 문제는 다음과 같은 여러 가지 가혹하고 현실적인 제약 조건으로 인해 매우 어렵다.
-
법률 및 라이선스 제약:
- 엄격한 허가성: 데이터는 저작권이 없거나(공공 도메인) 명시적인 허가 라이선스(예: CC-By, MIT, Apache-2.0) 하에 있어야 한다. 이는 일반 웹 스크랩에 비해 사용 가능한 데이터 풀을 심각하게 제한한다. 공개적으로 이용 가능한 웹 콘텐츠의 상당 부분이 AI 훈련을 위해 허가된 라이선스가 아니기 때문이다.
- 저작권 기간 복잡성: 특히 국제 및 역사적 저작물의 경우 공공 도메인 상태를 결정하는 것은 복잡한 법적 기준(예: 저자 생존 기간 + 70년, 미국 저자의 경우 출판 + 95년)을 포함하며, 세심한 권리 검증이 필요하다.
- DMCA 삭제: 비준수 데이터에 대한 법적 조치 및 DMCA 삭제의 지속적인 위협은 모호한 소스를 기반으로 구축된 모든 데이터셋을 장기 연구에 불안정하고 신뢰할 수 없게 만든다.
-
데이터 기반 및 품질 제약:
- 고품질 개방형 데이터의 극심한 희소성: 웹은 방대하지만, 명확한 허가 라이선스를 가진 고품질, 다국어, 다중 도메인 데이터의 하위 집합은 비교적 희소하고 파편화되어 있다.
- 역사적 텍스트의 낮은 OCR 품질: 귀중한 역사적 데이터(Open Culture, Open Government)의 상당 부분은 낮은 광학 문자 인식(OCR) 품질을 가진 디지털화된 소스에서 나오며, 이는 텍스트 품질을 저하시키는 노이즈와 오류를 도입한다. 이는 고급의 계산 집약적인 OCR 오류 감지 및 수정 도구를 필요로 한다.
- PII 및 유해 콘텐츠: 공공 도메인 및 기타 개방형 소스에는 개인 식별 정보(PII) 또는 유해/편향된 콘텐츠(예: 시대에 뒤떨어진 규범을 반영하는 역사적 텍스트, 이미지 데이터셋의 CSAM)가 포함될 수 있다. 강력하고 정확하며 효율적인 PII 제거 및 유해성 감지 파이프라인은 필수적이지만, 다양한 언어와 도메인에 걸쳐 대규모로 구현하기는 어렵다.
- 메타데이터 부족: 많은 잠재적 데이터 소스는 출처, 라이선스 및 언어에 대한 충분한 메타데이터가 부족하여 자동 큐레이션이 어렵고 수동 개입 또는 정교한 추론이 필요하다.
- 다국어 다양성 문제: 데이터 처리(분할, 품질 평가)를 위한 도구는 기존 NLP 도구가 종종 일반화 성능이 떨어지는 저자원 언어를 포함한 광범위한 언어에 대해 안정적으로 작동해야 한다.
-
계산 및 인프라 제약:
- 대규모 처리: "약 2조 개의 토큰"을 처리하고 큐레이션하려면 저장, 처리, 필터링 및 품질 평가에 상당한 계산 리소스가 필요하다.
- 큐레이션 도구의 계산 비용: 필수적이지만, OCR 오류 감지(예: OCRerrcr)와 같은 고급 큐레이션 도구는 더 빠르고 덜 정확한 대안보다 효율성이 떨어지는 계산 집약적일 수 있으며, 매우 큰 코퍼스의 정확성과 처리 속도 간의 절충점을 제시한다.
- 데이터 출처 추적: 다양한 소스에 걸쳐 각 데이터 객체의 출처, 라이선스 및 메타데이터를 꼼꼼하게 추적하는 것은 데이터 파이프라인에 상당한 오버헤드를 추가한다.
-
실패 모드:
- 법규 미준수: 허가 라이선스가 없는 콘텐츠를 정확하게 식별하고 필터링하지 못하면 법적 위험과 잠재적인 데이터셋 삭제로 이어진다.
- 윤리적 위반: 불충분한 PII 제거 또는 유해성 필터링은 개인 정보 침해 또는 훈련된 LLM에 유해한 편견을 영속시키는 결과를 초래할 수 있다.
- 낮은 모델 성능: 저품질, 노이즈가 많거나 불충분하게 다양한 데이터를 사용하면 성능이 낮은 LLM, 일반화 능력이 제한되거나 바람직하지 않은 동작(예: 교정 작업에서의 "언어 전환", 일반적인 글쓰기 스타일)이 발생할 수 있다.
- 재현성 부족: 데이터셋이 안정적이고 잘 문서화되어 있으며 일관되게 사용 가능하지 않으면 이를 기반으로 한 연구는 재현 불가능하게 된다.
- 비효율적인 큐레이션: 수동 또는 느린 큐레이션 프로세스는 현대 LLM 훈련에 필요한 규모에서는 비현실적이므로 효율적이고 자동화되었지만 정확한 도구가 필요하다.
- 간헐적인 잘못된 반복: OCRonos와 같은 고급 도구를 사용하더라도, 사후 처리가 필요한 간헐적인 잘못된 반복 단어가 포함될 수 있다.
왜 이 접근 방식인가
선택의 불가피성
본 논문에서 다루는 핵심 문제는 대규모 언어 모델(LLM) 자체를 위한 새로운 수학적 모델이나 알고리즘 개발이 아니라, 고품질의 진정으로 개방적이며 허가된 라이선스의 다국어 및 다중 도메인 사전 훈련 데이터의 심각한 부족이다. 저자들은 전통적인 "SOTA" 데이터 수집 및 큐레이션 방법이 법적, 윤리적, 품질 문제를 연쇄적으로 야기하여 오픈 과학 연구와 강력한 LLM 개발을 심각하게 방해했기 때문에 근본적으로 불충분하다고 결론지었다.
C4, Books3, LAION, RefinedWeb, Dolma와 같은 기존 데이터셋은 규모에도 불구하고 상당한 단점을 제시했다.
* 법적 및 윤리적 지뢰밭: 많은 데이터셋이 저작권이 있거나 독점적인 콘텐츠를 포함하여 법적 분쟁(예: 뉴욕 타임스의 OpenAI 소송, Books3의 DMCA 삭제, CSAM 콘텐츠로 인한 LAION 삭제)을 야기했다. 이는 연구의 재현을 불가능하게 만들고 개발자들에게 상당한 위험을 초래했다.
* 접근 제한: 콘텐츠 소유자는 AI 훈련을 위한 스크래핑에 대해 기술적 조치와 법적 조항을 점점 더 많이 시행하여 공개적으로 이용 가능한 웹 데이터의 상당 부분(예: C4의 45%)에 대한 접근을 차단하거나 제한했다.
* 단일 언어 편향: 대부분의 신흥 "개방형" 데이터셋은 주로 영어 전용(예: C4C, Open License Corpus, KL3M, Common Pile)으로, 다국어 LLM 개발을 심각하게 제한했다.
* 저품질 및 편향: 웹 스크랩 데이터는 종종 저품질, 기계 생성 텍스트, 개인 식별 정보(PII), 유해하거나 편향된 콘텐츠를 포함했다. 특히 다국어 데이터셋은 사용 불가능한 데이터가 많이 포함된 것으로 나타났다.
이러한 만연한 문제들을 고려할 때, 저자들은 데이터 수집 및 큐레이션을 위한 새로운 패러다임이 유일하게 실행 가능한 해결책이라고 결론지었다. 이는 법적으로 준수되고, 윤리적으로 건전하며, 고품질이고, 언어 및 도메인 전반에 걸쳐 다양한 데이터셋을 명시적으로 설계하여 조립하는 세심한, 처음부터 접근 방식을 필요로 했다. Common Corpus의 "접근 방식"—명확한 라이선스, 포괄적인 출처, 고급 큐레이션 도구에 중점—은 오픈 LLM 연구를 위한 개선뿐만 아니라 필수적인 기반이었다.
비교 우위
Common Corpus 접근 방식은 단순히 원시 토큰 수보다는 법적 준수, 데이터 품질 및 다양성에 대한 구조적 약속을 통해 이전 데이터 수집 방법 및 기존 데이터셋에 비해 질적인 우수성을 제공한다.
- 전례 없는 법적 및 윤리적 준수: 법적 분쟁 및 삭제에 직면한 데이터셋과 달리, Common Corpus는 저작권이 없거나 허가된 라이선스 데이터(표 4에 자세히 설명된 공공 도메인, CC-By, MIT, Apache-2.0 등)로만 구축된다. 이러한 구조적 이점은 Common Corpus로 훈련된 모델이 많은 상업용 및 심지어 "개방형" 모델을 괴롭히는 법적 불확실성 없이 출시되고 사용될 수 있도록 보장한다. "개방형"이라는 가장 강력한 의미에 대한 이러한 약속은 근본적인 질적 도약이다.
- 특수 큐레이션을 통한 향상된 데이터 품질: 본 논문은 다국어, 역사적, 디지털화된 콘텐츠에 고유한 문제를 극복하기 위해 설계된 맞춤형 도구 모음인 "Bad Data Toolbox"(섹션 5)를 소개한다.
- Segmentext: 시각적 정보가 손실되었을 때 레이아웃 기반 방법보다 우수한, 깨지거나 구조화되지 않은 입력에서도 강력한 텍스트 분할을 위한 토큰 분류 모델이다.
- OCR 오류 감지 (OCRoscope & OCRerrcr): OCRoscope는 빠르고 대규모 품질 추정을 제공하는 반면, OCRerrcr은 세분화된 토큰 수준 오류 식별을 제공한다. 이는 역사적 및 디지털화된 문서에 중요하며 원시 OCR 출력보다 높은 입력 품질을 보장한다.
- OCR 수정 (OCRonos): Llama-3-8B에서 미세 조정된 생성 LLM으로, OCR 오류, 단어 분할 및 구조적 아티팩트를 수정하도록 특별히 훈련되었다. 이는 보수적으로 설계되어 언어 전환 실패 모드에 저항하며, 노이즈가 많은 입력에 직면했을 때 작은 범용 LLM에서 흔히 발생하는 실패 모드이다.
- PII 제거: Microsoft의 Presidio를 사용자 정의 정규 표현식과 함께 사용하여 PII를 식별하고 가상의 현실적인 값으로 대체하여 텍스트 형식과 모델 이해를 유지한다. 이는 단순한 제거 또는 태그 지정보다 더 정교한 접근 방식이다.
- 유해성 감지 (Celadon): 역사적 텍스트, OCR 노이즈 및 비영어 콘텐츠에 최적화된 다국어 유해성 분류기(DeBERTa-v3-small)이다. 훨씬 더 큰 모델(Llama 3.1-8B-Instruct)과 유사한 성능을 달성하지만 40배 이상 빠르므로 대규모 필터링이 실용적이다. 이는 웹 스크랩 코퍼스의 주요 문제인 유해 콘텐츠의 존재를 크게 줄인다.
- 진정한 다국어 및 다중 도메인 다양성: Common Corpus는 고 다국어 다양성을 가진 최대 규모의 완전 개방형 데이터셋(2조 토큰)이며, 광범위한 고자원 및 저자원 언어(그림 2, 표 5)를 포괄한다. 다양한 도메인(개방형 정부, 문화, 과학, 코드, 웹, 의미론적 데이터)에 걸친 구성은 그림 1에 자세히 설명되어 있으며, "웹 크롤" 데이터(표 1, 그림 3b)를 넘어선다. 이러한 컬렉션의 시간적 및 의미론적 개요는 그림 3에 더 자세히 설명되어 있다. 이러한 구조적 다양성은 다양한 작업 및 언어에서 잘 수행되는 일반화 가능하고 강력한 LLM을 훈련하는 데 필수적이며, 주로 단일 언어 또는 웹 텍스트 중심 데이터셋에 비해 명확한 이점이다.
- 재현성 및 오픈 과학 인프라: Common Corpus는 상세한 출처, 처리 단계, 큐레이션 도구의 공개 릴리스를 제공함으로써 오픈 과학을 위한 중요한 인프라 역할을 한다. 이러한 투명성과 도구 공유는 데이터셋의 갑작스러운 제거로 인한 재현 불가능한 연구 문제를 직접적으로 해결한다.
본 논문이 데이터 큐레이션 프로세스의 $O(N^2)$에서 $O(N)$으로의 메모리 복잡성 감소를 명시적으로 자세히 설명하지는 않지만, Celadon(유해성 감지 40배 빠름) 및 OCRoscope(대규모 처리에 덜 계산 집약적)와 같은 효율적인 도구에 대한 강조는 LLM 사전 훈련에 필요한 데이터의 엄청난 양을 처리하는 데 있어 구조적 이점을 보여준다. 이러한 효율성은 이러한 고품질, 대규모, 큐레이션된 코퍼스의 생성을 실현 가능하게 한다.
제약 조건과의 일치
Common Corpus 접근 방식은 LLM 사전 훈련을 위한 법적으로 건전하고, 고품질이며, 다양하고, 공개적으로 접근 가능한 데이터의 필요성에 초점을 맞춘 문제 정의에서 파생된 암묵적 및 명시적 제약 조건과 완벽하게 일치한다.
- 제약 조건: 엄격한 법률 및 윤리적 준수: 본 논문의 주요 동기는 "데이터 보안 규정을 준수"하고 "저작권 또는 기타 법적 제한이 없는" 데이터를 제공하는 것이다. Common Corpus는 저작권이 없거나 허가된 라이선스 콘텐츠(표 4)만 독점적으로 소싱함으로써 이를 달성한다. 또한, 강력한 PII 제거(Presidio 사용) 및 유해성 감지(Celadon 사용)를 구현하여 개인 정보 보호 및 유해 콘텐츠에 대한 윤리적 우려를 직접적으로 해결한다. 이러한 "결합"은 Common Corpus로 훈련된 LLM이 이전 데이터셋과 관련된 법적 및 평판 위험 없이 배포되고 사용될 수 있도록 보장한다.
- 제약 조건: 높은 데이터 품질 및 사용성: 본 논문은 기존 데이터셋에 "저품질이거나 완전히 사용할 수 없는 데이터"가 포함되어 있다고 강조하며, 특히 다국어 맥락에서 그렇다. Common Corpus 솔루션은 "Bad Data Toolbox"로 이를 직접 해결한다. Segmentext는 구조화되지 않고 디지털화된 텍스트를 처리하고, OCRoscope 및 OCRerrcr은 오류를 감지하며, OCRonos는 이를 수정하여 저하된 입력을 사용 가능한 텍스트로 변환한다. 이 도구 모음은 역사적이거나 노이즈가 많은 데이터조차도 훈련에 의미 있게 기여하도록 보장하여 고품질 입력에 대한 요구 사항을 충족한다.
- 제약 조건: 다국어 및 다중 도메인 다양성: 이전 "개방형" 데이터셋의 주요 한계는 단일 언어이거나 제한된 도메인 범위를 가졌다는 것이다. Common Corpus는 명시적으로 "가장 큰 완전 개방형 사전 훈련 데이터셋... 높은 다국어 다양성을 가짐"(그림 2, 표 5)으로 설계되었으며 광범위한 도메인(개방형 정부, 문화, 과학, 코드, 웹, 의미론적)을 포괄한다. 이는 다양한 언어 및 지식 영역에서 강력한 LLM 개발에 필요한 것을 직접적으로 해결한다.
- 제약 조건: 오픈 과학 및 재현성: 본 논문은 "진정한 개방형 사전 훈련 데이터" 및 "재현 가능한 연구 아티팩트"의 필요성을 강조한다. Common Corpus는 상세한 출처, 처리 단계, 큐레이션 도구(Bad Data Toolbox)의 공개 릴리스를 제공함으로써 이를 준수한다. 이러한 투명성과 방법론 공유는 오픈 과학 생태계를 직접적으로 지원하며, 이 데이터를 기반으로 한 연구가 검증되고 재현될 수 있도록 보장한다.
- 제약 조건: 대규모: LLM은 "대량의 훈련 데이터"를 요구한다(서론). Common Corpus는 "약 2조 개의 토큰"으로 이 규모 요구 사항을 충족한다. 큐레이션 도구(예: Celadon의 속도)의 효율성은 이러한 막대한 규모에서도 품질 및 다양성 제약이 충족되도록 보장하면서 이러한 방대한 코퍼스를 처리하고 유지하는 것을 실현 가능하게 만든다.
대안의 거부
본 논문은 Common Corpus가 극복하고자 하는 근본적인 단점을 강조함으로써 여러 인기 있는 접근 방식과 기존 데이터셋을 암묵적으로 그리고 명시적으로 거부한다.
- 무차별 웹 스크래핑 거부 (예: C4, Books3의 Common Crawl): 저자들은 "대부분의 웹 데이터는 허가된 라이선스인지 여부를 결정하기에 충분한 메타데이터를 가지고 있지 않다"고 명확히 밝히며, "이 데이터 사용에 대한 법적 분쟁이 점점 더 많아지고 있다"고 말한다. 그들은 NYT의 OpenAI 소송, Books3의 DMCA 삭제, LAION 데이터셋의 CSAM 문제 등을 이러한 접근 방식의 실패에 대한 직접적인 증거로 인용한다. 본 논문은 "C4의 45%가 이제 서비스 약관 변경으로 인해 제한되었다"고 언급한다. 명확한 출처와 허가된 라이선스만 포함하는 Common Corpus의 접근 방식은 광범위한 웹 스크래핑에 내재된 법적 및 윤리적 위험을 직접적으로 거부하는 것이다.
- 기존 "개방형" 데이터셋의 불충분성 거부: 본 논문은 C4C, Open License Corpus, KL3M, Common Pile(표 1)과 같은 다른 이니셔티브와 Common Corpus를 비교한다. 그들은 이러한 데이터셋 중 다수가 "단일 언어이며, 사실상 언어 모델의 범위를 영어 사용자에게 제한한다"고 지적한다. 예를 들어 KL3M은 "영어 관리 및 법률 문서로 제한된다." Common Corpus의 모든 네 가지 기준(다국어, 다중 도메인, 웹 크롤을 넘어, 완전 허가 라이선스)을 동시에 충족하는 고유한 능력은 개방형, 범용 LLM 개발이라는 더 넓은 목표에 대한 이러한 대안의 부적절함을 보여준다.
- 큐레이션되지 않거나 잘못 큐레이션된 다국어 데이터셋 거부: 본 논문은 "많은 다국어 데이터셋에 저품질이거나 완전히 사용할 수 없는 데이터가 포함되어 있다"(Kreutzer et al., 2022)고 강조한다. 이는 엄격한 큐레이션 없이 다양한 언어의 데이터를 단순히 집계하는 것(일부 대안 접근 방식에서 수행될 수 있음)이 최적이 아닌 훈련 데이터로 이어진다는 것을 시사한다. Common Corpus의 "Bad Data Toolbox"(Segmentext, OCR 수정, 유해성 감지)는 이러한 문제에 대한 직접적인 대응으로, 다양하고 어려운 언어 소스에 대해서도 높은 품질을 보장한다.
- PII 및 유해성 무시 접근 방식 거부: 본 논문은 "웹 데이터는 유해하고 편향된 콘텐츠의 주요 출처"이며 "공공 도메인 데이터... 역사적 정기간행물 및 단행본을 포함하며... 이러한 텍스트 중 다수는 현대 윤리 기준을 충족하지 못한다"고 명시적으로 밝힌다. PII 제거를 위한 Presidio 및 다국어 유해성 감지를 위한 Celadon과 같은 특수 도구의 개발은 이러한 중요한 필터링 단계를 우선시하지 않는 모든 데이터 수집 전략을 명확히 거부하는 것이다.
본질적으로 저자들은 법적 및 윤리적 요구 사항을 충족하지 못하거나, 다국어 및 다중 도메인 범위를 충분히 확보하지 못하거나, 데이터 품질을 희생하는 대안을 거부했으며, 이 모든 것이 개방형 LLM의 지속 가능한 개발에 매우 중요하다.
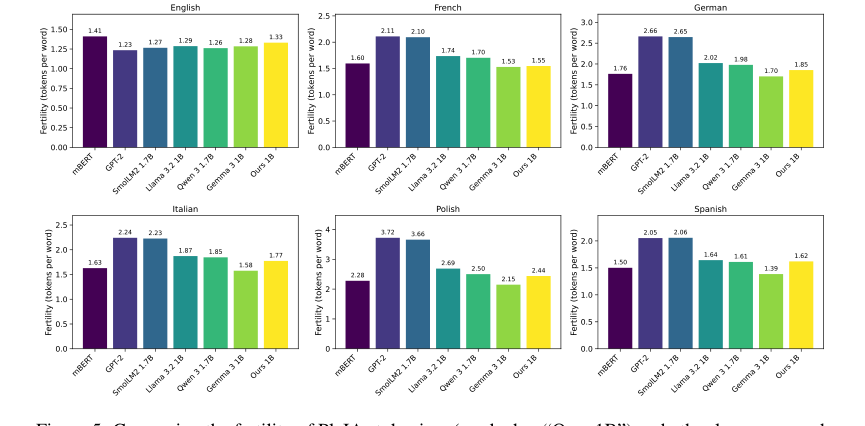 Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
수학적 및 논리적 메커니즘
"Common CORPUS: LLM 사전 훈련을 위한 최대 규모의 윤리적 데이터 컬렉션" 논문은 주로 대규모 언어 모델(LLM) 훈련을 위한 대규모, 윤리적으로 소싱된 데이터셋의 세심한 구축 및 큐레이션에 초점을 맞춘다. 이 데이터셋을 사용하여 LLM을 훈련하고 평가하는 것을 설명하지만, 이 논문에서 소개하거나 자세히 설명하는 핵심 수학적 및 논리적 메커니즘은 주로 데이터 큐레이션 파이프라인과 관련이 있으며, 새로운 LLM 아키텍처 또는 훈련 목표 함수 자체와는 관련이 없다. 언급된 LLM(Llama-style, DeBERTa 변형)은 기존 모델이며, 학습을 위한 기본 수학적 엔진은 문헌에서 잘 확립되어 있다. 따라서 이 섹션은 논문의 핵심 기여인 데이터 큐레이션 프로세스에 사용된 논리적 및 알고리즘적 메커니즘에 초점을 맞출 것이다.
마스터 방정식
솔직히 말해서, 이 논문은 새로운 기계 학습 모델의 목표 함수나 새로운 물리적 프로세스를 설명하는 미분 방정식과 같은 전통적인 의미의 단일 "마스터 방정식"을 제시하지 않는다. 대신, 그 "수학적 엔진"은 LLM 사전 훈련을 위한 대규모, 윤리적으로 소싱된 데이터셋의 세심한 구축 및 큐레이션에 초점을 맞춘다. 이 논문은 데이터 큐레이션 파이프라인과 관련된 논리적 및 알고리즘적 메커니즘에 초점을 맞출 것이다. LLM을 훈련하고 평가하는 것을 설명하지만, 이 논문에서 소개하거나 자세히 설명하는 핵심 수학적 및 논리적 메커니즘은 새로운 LLM 아키텍처 또는 훈련 목표 함수 자체와는 관련이 없다. 언급된 LLM(Llama-style, DeBERTa 변형)은 기존 모델이며, 학습을 위한 기본 수학적 엔진은 문헌에서 잘 확립되어 있다. 따라서 이 섹션은 논문의 핵심 기여인 데이터 큐레이션 프로세스에 사용된 논리적 및 알고리즘적 메커니즘에 초점을 맞출 것이다.
용어별 분석
OCRoscope 품질 점수의 개념적 구성 요소를 분석해 보자.
- $N$: 이는 입력 텍스트 문서에서 추출된 총 7-그램(논문에서 언급된 대로)의 수를 나타낸다. 수학적 정의는 이러한 중첩 텍스트 세그먼트의 개수이다. 물리적/논리적 역할은 지역 언어 식별이 수행되는 세분성을 정의하는 것이다. 저자는 언어 식별 모델이 짧은 시퀀스에 대해 노이즈에 더 민감하기 때문에 문서 수준 식별과 달리 언어 식별에 좋은 지표이기 때문에 n-그램을 사용했다.
- $g_i$: 이는 문서에서 추출된 $i$-번째 7-그램을 나타낸다. 수학적으로는 길이가 7인 부분 문자열이다. 논리적 역할은 언어 식별을 위한 작고 국지적인 텍스트 창을 제공하는 것이며, OCR 오류가 언어 패턴을 방해할 가능성이 더 높다.
- $L(g_i)$: 이는 $i$-번째 7-그램에 대해
pycld2모델이 식별한 언어이다. 수학적으로는 범주형 출력(언어 레이블 또는 '알 수 없음')이다. 논리적 역할은 지역 언어 일관성을 감지하는 것이다. 7-그램이 OCR 오류로 심하게 손상되면pycld2는 언어를 잘못 분류하거나 '알 수 없음'으로 레이블을 지정할 가능성이 높다. - $L_{doc}$: 이는 전체 문서에 대해
pycld2가 식별한 언어이다. 수학적으로는 단일 범주형 출력이다. 논리적 역할은 문서의 기본 진실 언어를 설정하는 것이며, 이는 일부 노이즈에도 불구하고 강력하게 식별된다고 가정된다. 지역 $L(g_i)$와 전역 $L_{doc}$ 간의 비교는 불일치를 식별하는 데 핵심이다. - $\mathbb{I}(\cdot)$: 이는 인디케이터 함수로, 인수가 참이면 1을 반환하고 거짓이면 0을 반환한다. 수학적으로는 불리언-투-정수 매핑이다. 논리적 역할은 지역 7-그램의 언어 식별이 문서의 전반적인 언어와 다르거나 식별할 수 없는 경우의 수를 세는 것이다. 저자는 명시적인 오분류와 완전한 식별 실패 모두 문제를 나타내므로 "또는"을 사용하여 두 경우를 모두 포착했다.
- $\mathbb{I}(g_i \text{ is valid})$: 이 항은 잘못된 입력으로 인한 0으로 나누거나 왜곡된 비율을 방지하기 위해 유효한 7-그램(예: 비어 있지 않거나 순수하게 구두점만 있는 경우)만 분모에 고려하도록 보장한다.
- $\sum_{i=1}^{N} \dots$: 이는 문제의 7-그램 수를 집계한다. 여기서 합계의 사용은 시퀀스에 걸쳐 이산 이벤트를 세는 데 자연스럽다.
- $\frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})}$: 이는 문제의 7-그램 비율을 계산한다. 논리적 역할은 OCR 노이즈의 정규화된 척도를 제공하는 것이다.
- $1 - \dots$: 이 최종 빼기는 "오류율"을 "품질 점수"로 변환하며, 여기서 1은 완벽한 품질을 나타내고 낮은 값은 증가하는 디지털화 노이즈를 나타낸다. 이는 점수를 "품질" 지표로 더 직관적으로 만든다.
단계별 흐름
원시 디지털 문서, 아마도 스캔된 역사적 신문이 Common Corpus 큐레이션 파이프라인에 들어온다고 상상해 보라. 마치 텍스트를 위한 복잡한 조립 라인과 같다.
- 초기 수집 및 메타데이터 추출: 문서는 먼저 시스템에 들어온다. 소스 URL, 잠재적 라이선스 정보, 생성 날짜와 같은 기본 메타데이터가 추출되거나 추론된다.
- 언어 식별 (문서 수준): 전체 문서는 언어 식별 모델(예:
fastText또는cld2)을 통과하여 기본 언어 $L_{doc}$를 결정한다. 이는 후속 도구가 종종 언어에 따라 달라지기 때문에 중요한 첫 번째 단계이다. - 텍스트 분할 (Segmentext): 문서의 원시 문자 시퀀스는 DeBERTa-v2 스타일 토큰 분류 모델인
Segmentext에 공급된다. 이 모델은 스마트 파서처럼 작동하여 "이것은[제목]이다", "이것은[텍스트]이다", "이것은[표]이다", "이것은[부제목](페이지 번호와 같은)이다"와 같은 다양한 구조적 구성 요소를 식별하고 태그를 지정한다. 순전히 텍스트에 기반하여 작동하므로 레이아웃 정보 손실에 강건하다. - OCR 오류 감지 (OCRoscope & OCRerrcr):
- OCRoscope (거친 수준): 문서는
OCRoscope에 전달된다. 이 도구는 7자(7-그램) 창을 텍스트 전체에 슬라이드한다. 각 7-그램에 대해 언어 $L(g_i)$를 식별하려고 시도한다. $L(g_i)$가 $L_{doc}$와 일치하지 않거나 "알 수 없음"이면 잠재적인 OCR 오류로 플래그가 지정된다.OCRoscope는 이러한 플래그를 집계하여 문서에 대한 전반적인 OCR 품질 점수를 생성한다. 이는 문서에 더 집중적인 처리가 필요한지 여부를 결정하는 빠른 초기 확인이다. - OCRerrcr (세분화된 수준): 더 많은 주의가 필요한 문서로 식별된 경우, DeBERTa-v3-small 모델인
OCRerrcr이 개입한다. 각 토큰을 올바르거나 오류가 있는 것으로 분류하여 텍스트를 토큰별로 처리한다. 이는 오류가 있는 위치를 정확하게 파악하여 대상 수정을 준비한다.
- OCRoscope (거친 수준): 문서는
- OCR 오류 수정 (OCRonos): 이제 오류가 식별된 문서는 Llama-3-8B 생성 모델을 미세 조정한
OCRonos로 이동한다.OCRonos는 숙련된 편집자처럼 작동하여 노이즈가 많은 텍스트를 받아 OCR 오류를 수정하고, 잘못된 단어 분할 또는 병합을 수정하며, 전반적인 구조적 무결성을 복원하려고 시도한다. 이는 원본 텍스트를 가능한 한 보존하도록 보수적으로 설계되었지만, 손상된 부분을 사용 가능하게 만들기 위해 "합성적으로 다시 작성"할 수 있다. - 개인 식별 정보 (PII) 제거: 이제 구조적으로 건전하고 대부분 오류가 없는 텍스트는 사용자 정의 정규 표현식 패턴으로 보강된
Microsoft Presidio를 사용하여 PII를 검색한다. 이 도구는 전화 번호, 이메일 주소, IP 주소와 같은 민감한 정보를 식별한다. 단순히 제거하거나 편집하는 대신, 텍스트 흐름과 맥락을 유지하기 위해 가상의 현실적인 값으로 PII를 대체한다. - 중복 제거: 문서는 기존 데이터와 비교하여 중복을 제거하며, 종종 PDF 메타데이터 또는 콘텐츠 해시를 사용한다. 이는 고유성을 보장하고 코퍼스의 중복을 방지한다.
- 유해성 감지 (Celadon): 마지막으로, 정리된 문서는
Celadon에 전달되며, 이는 DeBERTa-v3-small 다국어 유해성 분류기이다. 다양한 주석이 달린 유해 콘텐츠 데이터셋으로 훈련된 이 모델은 여러 차원(예: 인종 차별, 성 차별, 폭력)에 걸쳐 유해하거나 편향된 언어를 식별하고 플래그를 지정한다. 특정 유해성 임계값을 초과하는 문서 또는 세그먼트는 필터링되어 코퍼스의 윤리적 무결성을 보장한다. - 최종 조립 및 메타데이터 강화: 이제 깨끗하고, 분할되고, 수정되고, PII가 없고, 유해성이 없는 텍스트가 조립된다. 풍부한 메타데이터(라이선스, 언어, 컬렉션, 도메인 등)가 첨부되어 Common Corpus에 포함될 준비가 된다.
이 전체 프로세스는 각 "데이터 포인트"(문서)가 최종 고품질 데이터셋의 일부가 되기 전에 엄격하게 처리되고 검증되도록 보장한다.
최적화 역학
이 논문에서 "학습" 또는 "수렴"은 주로 데이터 큐레이션 파이프라인 내에서 사용되는 신경망 모델에 적용되며, 논문 자체는 새로운 LLM 훈련 최적화 방법을 제안하지 않는다. 이러한 모델은 표준 딥러닝 최적화 기술을 사용하여 훈련된다.
- Segmentext, OCRerrcr, Celadon (토큰 분류 모델):
- 손실 지형: 이러한 모델은 트랜스포머 기반 아키텍처인 DeBERTa-vX의 변형이다. 손실 지형은 일반적으로 고차원이고 비볼록하다. 훈련의 목표는 특정 손실 함수를 최소화하는 가중치 집합을 찾는 것이다.
- 손실 함수:
Segmentext및OCRerrcr의 경우 토큰 분류(예: 각 토큰의 구조적 역할 또는 오류 상태 분류)를 수행하므로 주요 손실 함수는 교차 엔트로피 손실이다. 이는 각 토큰에 대한 모델의 예측 확률 분포와 실제 클래스 레이블 간의 차이를 측정한다.Celadon, 유해성 분류기는 "클래스 불균형을 처리하기 위해 사용자 정의 가중 교차 엔트로피 손실 함수를 사용한다." 이 가중치 메커니즘은 소수 클래스(예: 일반적으로 비유해성 콘텐츠보다 드문 유해 콘텐츠)의 잘못된 분류에 더 높은 페널티를 할당하여 모델이 이러한 중요한 사례를 더 효과적으로 식별하도록 학습하는 데 도움이 된다. - 기울기: 훈련 중에 모델은 역전파를 사용하여 손실 함수를 모든 모델 매개변수(가중치 및 편향)에 대해 계산한다. 이러한 기울기는 각 매개변수가 손실을 줄이기 위해 조정되어야 하는 방향과 크기를 나타낸다.
- 최적화 알고리즘: 명시적으로 명시되지는 않았지만, Adam (적응 모멘트 추정) 또는 모멘텀이 있는 SGD (확률적 경사 하강법)와 같은 표준 최적화 프로그램이 사용될 것이다. 이러한 알고리즘은 기울기의 반대 방향으로 학습률에 의해 스케일링된 단계를 밟아 모델 매개변수를 반복적으로 업데이트한다.
- 수렴: 모델은 검증 세트의 손실 함수가 더 이상 크게 감소하지 않을 때 수렴하며, 이는 모델이 훈련 데이터의 기본 패턴을 학습하고 잘 일반화됨을 나타낸다. 반복 업데이트는 모델 매개변수를 손실 지형을 통해 이동시켜 지역 또는 전역 최소값을 목표로 한다.
- OCRonos (생성 언어 모델):
- 손실 지형: Llama-3-8B 모델을 미세 조정한 것으로서,
OCRonos는 대규모 생성 트랜스포머의 광범위하고 복잡한 손실 지형에서 작동한다. - 손실 함수: 생성 언어 모델의 주요 손실 함수는 일반적으로 다음 토큰 예측 손실(또한 교차 엔트로피의 한 형태)이다. 모델은 이전 토큰을 주어진 시퀀스의 다음 토큰을 예측하도록 훈련된다. OCR 수정의 맥락에서 이는 노이즈가 많은 입력 시퀀스에서 깨끗한 출력 시퀀스를 생성하도록 학습하는 것을 의미한다.
- 기울기 및 최적화: 분류 모델과 유사하게,
OCRonos는 역전파 및 최적화 프로그램(아마도 Adam 또는 변형)을 사용하여 매개변수를 업데이트한다. 모델은 노이즈가 많은 입력 패턴을 깨끗한 출력 패턴에 매핑하도록 학습한다. - 수렴: 모델은 오류를 완화하고 바람직하지 않은 동작(예: 언어 전환)에 저항하면서 원본 의도에 충실한 고품질의 수정된 텍스트를 안정적으로 생성할 수 있을 때 수렴한다. 훈련 프로세스는 모델의 퇴화된 텍스트를 일관되고 정확한 형태로 "다시 작성"하는 능력을 반복적으로 개선한다.
- 손실 지형: Llama-3-8B 모델을 미세 조정한 것으로서,
본질적으로 이러한 구성 요소의 최적화 역학은 이러한 신경망의 내부 매개변수를 반복적으로 조정하여 해당 손실 함수를 최소화함으로써 특정 데이터 큐레이션 작업에 대한 성능을 향상시키는 것이다. 이러한 반복적인 개선을 통해 파이프라인은 다양하고 노이즈가 많은 데이터를 효과적으로 처리하고 정리하는 방법을 "학습"할 수 있다.
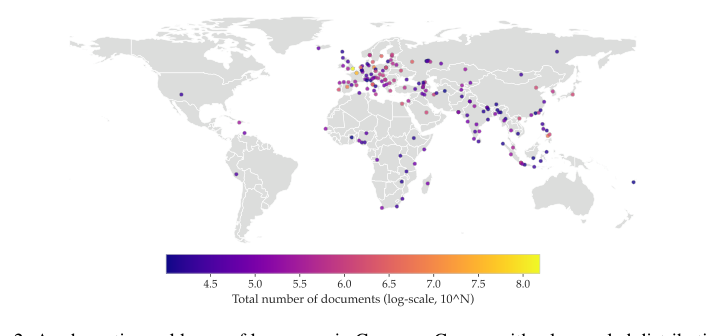 Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
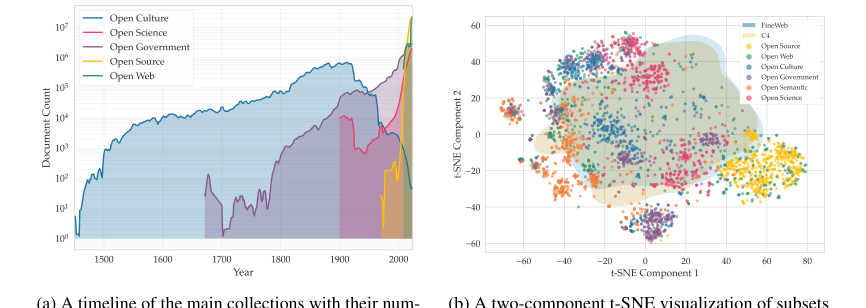 Figure 3. Temporal and semantic overview of the Common Corpus collections
Figure 3. Temporal and semantic overview of the Common Corpus collections
결과, 한계 및 결론
실험 설계 및 기준선
Common Corpus의 유용성을 엄격하게 검증하기 위해 저자들은 집중적인 실험 설계를 시작했다. 그들은 Llama 기반 아키텍처를 기반으로 하는 두 가지 별개의 언어 모델, PleIAs 350M 및 PleIAs 1.2B를 훈련했다. 65,536개의 어휘 크기를 특징으로 하는 사용자 정의 Llama 스타일 토크나이저가 개발되었으며, Common Corpus의 대표적인 하위 집합으로 훈련되었다. 더 작은 PleIAs 350M 모델은 Common Corpus의 필터링된 하위 집합에서 약 1조 개의 토큰으로 훈련되었으며, 2,944개의 H100 시간을 소비했다. 더 큰 PleIAs 1.2B 모델은 필터링된 하위 집합의 3개 에포크 동안 전체 Common Corpus로 훈련되었으며, 상당한 23,040개의 H100 시간을 필요로 했다.
Common Corpus로 훈련된 모델을 평가하기 위해 "피해자"(기준선 모델)에는 여러 유명 다국어 언어 모델이 포함되었다. Gemma 3 (270M 및 1B 매개변수), XGLM (564M 및 1.7B 매개변수), BLOOM (560M 및 1.7B 매개변수), OLMO 1B이다. 이러한 기준선은 폐쇄된, 비허가 라이선스 데이터로 훈련된 모델 또는 OLMO 1B의 경우 공개 릴리스 데이터셋으로 훈련된 모델의 조합을 나타낸다. 평가는 세 가지 확립된 다국어 벤치마크인 MultiBLiMP, XStoryCloze, XCOPA에 걸쳐 표준 LM 평가 하네스를 사용하여 수행되었다. 이 설정은 성능을 직접 비교하도록 설계되었으며, 특히 허가된 라이선스의 윤리적으로 큐레이션된 데이터로만 훈련된 모델이 더 광범위하고 종종 법적으로 모호한 데이터셋으로 훈련된 모델과 경쟁할 수 있는지 여부를 강조했다.
증거가 증명하는 것
본 논문에서 제시된 증거는 Common Corpus가 규제 및 윤리적 규범을 엄격히 준수하면서 LLM 개발을 가능하게 하는 다국어 사전 훈련에 적합하고 효과적인 데이터셋임을 명확하게 증명한다. 핵심 메커니즘—방대하고 다양하며 허가된 라이선스의 코퍼스로 훈련하는 것—은 PleIAs 모델의 성능을 통해 실제로 작동하는 것으로 입증되었다.
구체적으로, Common Corpus로 훈련된 모델은 기준선과 비교할 때 유사하거나 일부 경우 더 뛰어난 성능을 보였다. 특히 광범위한 언어 범위를 포함하는 MultiBLiMP 벤치마크에서 PleIAs 모델은 뛰어난 성능을 보였다. 특히 더 작은 PleIAs 350M 모델은 크기에도 불구하고 Gemma 3 1B를 제외한 대부분의 1B 범위 기준선 모델을 능가했다. 또한, 두 PleIAs 모델은 공개 릴리스 데이터셋으로 사전 훈련된 또 다른 기준선인 OLMO 1B를 일관되게 안정적으로 능가했다. 이는 Common Corpus의 품질과 유용성을 다른 오픈 소스 대안과 직접적으로 검증하는 중요한 증거이다.
원시 메트릭을 넘어, 본 논문은 데이터셋의 윤리적 및 질적 이점에 대한 확실한 증거를 제공한다. 상세한 출처, 필터링, PII 제거, 유해성 감지 및 중복 제거 프로세스(섹션 5에 설명됨)는 데이터가 저작권이 없거나 허가된 라이선스 하에 있음을 보장하여 LLM 훈련에서 중요한 법적 및 윤리적 격차를 해결한다. 문자 구성 메트릭(그림 4)과 같은 질적 평가에서는 데이터 분포가 대부분 예상 범위 내에 있으며 코드 또는 규제 텍스트와 같은 특수 콘텐츠에 대해 합리적인 편차가 있음을 확인했다. PleIAs 모델의 기본 구성 요소인 사용자 정의 토크나이저도 잘 수행되었으며, 어휘 크기가 4배 더 큰 Gemma 3의 토크나이저에 의해서만 능가했다. 이러한 집단적 증거는 Common Corpus가 단순히 큰 데이터셋이 아니라 경쟁력 있는 다국어 LLM을 훈련하기 위한 고품질의 윤리적으로 건전하고 효과적인 데이터셋임을 강조한다.
한계 및 향후 방향
Common Corpus는 LLM 개발에서 오픈 과학을 위한 중요한 발걸음을 나타내지만, 저자들은 미래 연구 및 발전을 위한 길을 열어주는 몇 가지 한계를 솔직하게 인정한다. 첫째, 2조 토큰이라는 인상적인 규모에도 불구하고 Common Corpus는 사용 가능한 모든 개방형 데이터의 스펙트럼을 포괄하기에는 아직 멀었다. 이러한 "개방형 데이터 역설"은 귀중한 개방형 콘텐츠의 주요 소스가 역설적으로 찾고 활용하기 어렵다는 것을 의미하며, 현재 더 큰 모델은 Common Corpus만으로는 제공할 수 있는 것보다 훨씬 더 많은 데이터가 필요하다.
둘째, Common Corpus의 현재 반복은 본질적으로 지시 튜닝 또는 특수 작업용으로 설계되지 않았다. 주요 유용성은 사전 훈련에 있으며, 이는 추가적인 작업별 데이터셋 없이는 특정 응용 프로그램에 대한 모델 미세 조정을 위해 직접적으로 적합하지 않음을 의미한다. 이는 Common Corpus를 기반으로 Common Corpus의 다국어, 시간적, 의미론적 다양성을 활용하는 윤리적 미세 조정 데이터셋을 개발하는 미래 작업을 위한 기회를 제공한다.
세 번째 한계는 특히 역사적 및 디지털화된 텍스트의 데이터 큐레이션의 고유한 어려움에 있다. 저자들은 정교한 "Bad Data Toolbox"(Segmentext, OCRoscope, OCRerrcr, OCRonos, Celadon 포함)를 사용하더라도 큐레이션에서 100% 정확도를 달성하는 것이 어렵다고 인정한다. 특히 OCR 오류는 상당한 과제로 남아 있으며, 모델 성능에 영향을 미치고 모델이 오타를 처리하는 방식에 영향을 미칠 수 있다. 이러한 큐레이션 도구를 개선하는 것, 아마도 더 고급 AI 기반 방법을 통해, 명확한 미래 방향이다.
앞으로 이 논문의 결과는 여러 논의 주제를 자극한다.
- 개방형 데이터 이니셔티브 확장: "개방형 데이터 역설"을 극복하여 LLM 훈련을 위해 더 많은 허가된 라이선스 콘텐츠를 가시화하고 접근 가능하게 만들려면 어떻게 해야 하는가? 이는 문화 기관, 정부 및 연구 기관의 데이터 공유를 장려하거나, 이러한 데이터를 대규모로 발견하고 집계하는 새로운 방법을 개발하는 것을 포함할 수 있다.
- 윤리적 미세 조정 및 작업별 데이터셋: Common Corpus의 다양한 윤리적으로 소싱된 사전 훈련 데이터의 강점을 고려할 때, 커뮤니티는 개인 정보 보호 또는 라이선스를 희생하지 않고 특수 데이터셋을 생성하기 위해 합성 데이터 생성, 인간-루프 주석, 연합 학습 접근 방식을 탐색하는 것을 포함하여 동일한 높은 윤리적 기준을 유지하는 지시 튜닝 및 작업별 데이터셋을 어떻게 협력적으로 구축할 수 있는가?
- 데이터 큐레이션 도구의 발전: 본 논문은 OCR 오류 및 기타 데이터 품질 문제의 지속적인 과제를 강조한다. OCRonos 및 Celadon과 같은 도구를 더욱 발전시켜, 아마도 더 정교한 다중 모드 이해를 통합하거나 노이즈가 많은 데이터에 대한 자체 지도 학습을 활용하여 대규모에서 거의 완벽한 데이터 품질을 달성하려면 어떻게 해야 하는가? LLM 자체가 이러한 불완전성에 더 강건하거나 심지어 수정하도록 훈련될 수 있는가?
- 책임감 있는 AI에서 메타데이터의 역할: Common Corpus의 풍부한 메타데이터에 대한 강조는 사용자가 라이선스, 언어 및 잠재적 문제를 기반으로 데이터를 필터링할 수 있도록 한다. 모든 개방형 데이터셋에서 메타데이터 관행을 표준화하고 확장하여 LLM 실무자에게 훈련 데이터에 대한 더 큰 제어권을 부여하고 더 책임감 있고 투명한 AI 개발을 촉진하려면 어떻게 해야 하는가?
- 교차 언어 및 저자원 언어 개발: Common Corpus의 다국어 다양성(저자원 언어 포함)은 주요 강점이다. 이 데이터셋을 활용하여 이러한 언어에서 LLM 성능의 경계를 넓히고, 잠재적으로 디지털 격차를 줄이고 더 포괄적인 AI를 육성하려면 어떻게 해야 하는가? 이는 전이 학습 전략, 다국어 정렬 기술 또는 다양한 언어 입력에 최적화된 새로운 아키텍처 설계를 포함할 수 있다.
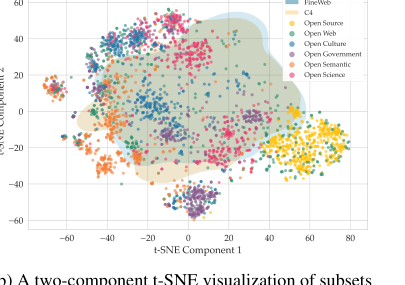 Table 1. Comparison of the contemporary datasets for LLM training
Table 1. Comparison of the contemporary datasets for LLM training
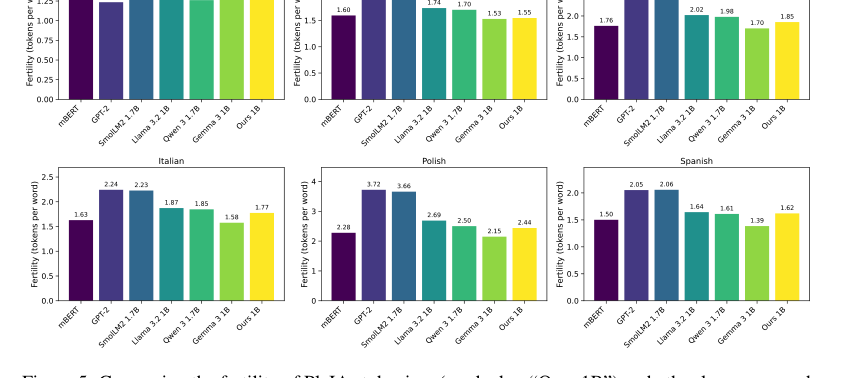 Table 6. Finance Commons sources distribution with languages
Table 6. Finance Commons sources distribution with languages
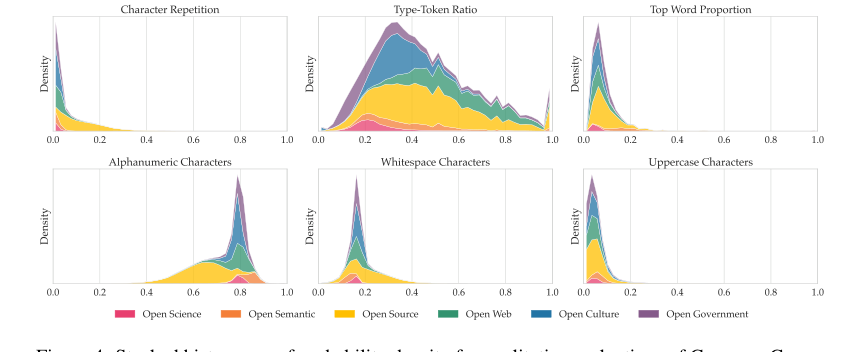 Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
다른 분야와의 동형성
구조적 골격
본 논문은 엄격한 윤리 및 품질 제약 조건 하에서 방대하고 이질적인 데이터를 획득, 정리 및 검증하기 위한 강력한 다단계 파이프라인을 제시한다.
먼 친척
-
대상 분야: 공급망 관리
연결점: 글로벌 공급망 관리 영역에서, 수많은 국제 공급업체로부터 원자재 및 제조 부품의 진위성, 품질 및 윤리적 출처를 보장하는 것은 지속적인 과제이다. 이는 종종 복잡한 규제 환경을 탐색하고, 인증을 확인하고, 위조품 또는 비윤리적으로 소싱된 상품의 침투를 방지하는 것을 포함한다. 본 논문의 데이터 출처 추적, 다층 필터링(품질, PII 및 유해성) 적용, 허가 라이선스 보장이라는 핵심 논리는 물리적 제품에 대한 "깨끗하고", "감사 가능하며", "윤리적으로 건전한" 공급망의 필요성과 거울 이미지이다. 논문에서 설명하는 "개방형 데이터 역설", 즉 귀중한 개방형 콘텐츠가 역설적으로 찾고 활용하기 어렵다는 것은 파편화된 글로벌 시장에서 진정으로 신뢰할 수 있고 투명한 공급업체를 식별하는 어려움과 공명한다. -
대상 분야: 유전체학 및 개인 맞춤 의학
연결점: 유전체학에서 연구자들은 다양한 연구 기관 및 공개 저장소에서 집계된 DNA 서열, 유전자 발현 프로파일 및 환자 의료 기록을 포함한 방대한 이질적인 생물학적 데이터를 일상적으로 다룬다. 중요한 오랜 문제는 이러한 민감한 데이터를 통합하여 대규모 분석을 수행하거나 개인 맞춤 치료 모델을 개발할 때 품질, 일관성 및 윤리적 사용(예: 환자 개인 정보 보호, 사전 동의)을 보장하는 것이다. 개인 식별 정보(PII) 제거, 데이터 오류 수정(텍스트의 OCRonos와 같은), 다양한 데이터 소스에 대한 적절한 라이선스 시행에 대한 논문의 체계적인 접근 방식은 데이터 무결성과 엄격한 윤리 지침이 가장 중요한 의료 연구를 위한 "깨끗하고", "개인 정보 보호를 유지하며", "윤리적으로 준수하는" 유전체 코호트를 큐레이션하는 생물정보학적 과제와 직접적으로 유사하다.
만약 시나리오
만약 공급망 관리 분야의 연구자가 오늘 이 논문의 정확한 방정식을 "훔쳤다"면, 즉 포괄적인 데이터 큐레이션 및 검증 파이프라인과 전문 도구를 채택했다면 어떻게 될까? 글로벌 무역 투명성 및 무결성에 심오한 돌파구가 생길 것이다. Segmentext와 유사한 모델을 적용하여 원래 형식이나 언어에 관계없이 다양한 운송 명세서, 세관 신고서 및 공급업체 계약서를 자동으로 구문 분석하고 구조화한다고 상상해 보라. OCRoscope 및 OCRerrcr은 제품 ID, 수량 또는 원산지 신고서의 이상 또는 불일치를 감지하도록 조정되어 위조품, 잘못 라벨링된 상품 또는 규정 위반을 전례 없는 정밀도로 플래그 지정할 수 있다. OCRonos는 손상되거나 불완전한 디지털 기록을 "수정"하여 전체 공급망에 걸쳐 데이터 무결성을 보장할 수 있다. 또한 Celadon의 원칙은 공급업체 문서 및 공개 기록 내에서 "윤리적 위반"(예: 강제 노동, 환경 비준수 또는 불공정 무역 관행의 징후)을 감지하도록 조정될 수 있다. 이는 글로벌 상거래에서 전례 없는 수준의 투명성, 감사 가능성 및 윤리적 준수를 가져와 사기를 크게 줄이고 제품 안전을 개선하며, 방대하고 검증 가능하게 윤리적인 "글로벌 무역 데이터 공동체"를 창출할 수 있는 잠재력을 가진 진정한 "깨끗한" 공급망을 가능하게 할 것이다.
구조의 보편적 라이브러리
본 논문은 언어, 공급망 관리 또는 생물학적 데이터를 처리하든, 신뢰할 수 있는 시스템을 구축하는 데 있어 엄격한 데이터 출처, 다층 품질 관리 및 윤리적 준수 원칙이 도메인별 과제가 아니라 보편적인 요구 사항임을 입증함으로써 구조의 보편적 라이브러리를 크게 풍부하게 한다. 이는 공유 수학적 패턴을 통해 과학적 문제의 상호 연결성을 강화한다.