Common Corpus: Крупнейшая коллекция этичных данных для предварительного обучения LLM
Предыстория и академическая родословная
Происхождение и академическая родословная
Проблема, рассматриваемая в данной статье, — дефицит этически полученных и разрешительно лицензированных данных для предварительного обучения больших языковых моделей (LLM), — возникла именно в связи с быстрым масштабированием и широким распространением LLM. Исторически в этой области произошел значительный сдвиг с появлением таких моделей, как GPT-3 (Brown et al., 2020), которые установили парадигму обучения на колоссальных наборах данных, часто достигающих триллионов токенов. Эта тенденция продолжилась: объемы данных для обучения LLM росли логарифмически и, по оценкам, к 2025 году достигнут 14–36 триллионов токенов.
Фундаментальное ограничение и "болевая точка" предыдущих подходов заключались в их опоре на данные, собранные из Интернета, которые, хотя и были общедоступными, часто не имели четких разрешительных лицензий. Специалисты по обработке естественного языка (NLP) часто действовали исходя из предположения о "добросовестном использовании" (fair use), утверждая, что трансформирующий характер обучения LLM оправдывает использование контента, защищенного авторским правом. Однако такой подход привел к растущим юридическим проблемам, таким как иск газеты New York Times против OpenAI за нарушение авторских прав (Roth, 2023; Pope, 2024). Кроме того, несколько известных наборов данных, включая Books3, LAION, GEITje и MATH, столкнулись с юридическими ограничениями или были удалены из-за проблем с авторским правом или наличия проблемного контента, такого как CSAM (материалы сексуального насилия над детьми), что сделало предыдущие исследования невоспроизводимыми и привело к значительным инвестиционным потерям для разработчиков. Помимо юридических проблем, существующие открытые наборы данных часто страдали от недостатка многоязычного разнообразия, будучи преимущественно англоцентричными, и часто содержали низкокачественные или непригодные данные, особенно для языков с ограниченными ресурсами. Это коллективное давление подчеркнуло острую необходимость в действительно открытом, юридически соответствующем требованиям, высококачественном и разнообразном наборе данных для предварительного обучения, чтобы способствовать исследованиям в области открытой науки и разработке LLM.
Интуитивные термины предметной области
Вот несколько специализированных терминов предметной области из статьи, переведенных в интуитивные аналогии для начинающих:
- Большая языковая модель (LLM): Представьте себе сверхразумный цифровой мозг, который "прочитал" почти всё, что когда-либо было написано в Интернете и в книгах. Затем он может понимать, генерировать и отвечать на вопросы так, как это делает человек, подобно высокообразованному и универсальному помощнику.
- Токены: Думайте о них как об основных строительных блоках языка, которые понимает LLM. Это похоже на "слова" или даже более мелкие части слов (например, "не-" или "-ing"), которые обрабатывает модель, подобно тому, как мы разбиваем предложения на отдельные слова, чтобы понять их.
- Предварительное обучение (Pre-training): Это начальный, массивный этап обучения для LLM. Это похоже на отправку студента в начальную, среднюю и высшую школу для получения широкого общего образования по многим предметам, прежде чем он специализируется в определенной карьере. Модель изучает общие языковые закономерности и знания.
- Разрешительные лицензии (Permissive Licenses): Рассматривайте это как "универсальное разрешение" на использование данных. Оно явно указывает, что вы можете свободно использовать, распространять и даже изменять данные практически для любых целей, включая обучение моделей ИИ, без необходимости запрашивать специальное разрешение или беспокоиться о судебных исках по поводу авторских прав. Это противоположность "все права защищены".
- Ошибки OCR: Представьте, что вы сканируете старую, выцветшую книгу на свой компьютер. Иногда сканер делает ошибки, превращая "е" в "с" или объединяя два слова. Ошибки OCR — это те цифровые "опечатки" или искажения, которые возникают при преобразовании изображений текста (например, из старых документов) в редактируемый текст.
Таблица обозначений
Честно говоря, данная статья в первую очередь описывает создание и характеристики большого набора данных, а не вводит новую математическую модель или алгоритм, который опирается на конкретные математические переменные или параметры в уравнениях. Следовательно, в тексте или на рисунках статьи нет ключевых математических обозначений (переменных, параметров), явно определенных или используемых в синтаксисе LaTeX, которые были бы необходимы для последующих математических объяснений. В статье используются описательные термины, такие как "токены", "документы" и "слова", для количественной оценки данных, но они не представлены однобуквенными математическими символами в формулах.
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, — это критическая нехватка крупномасштабных, высококачественных, по-настоящему открытых и разрешительно лицензированных данных для предварительного обучения больших языковых моделей (LLM).
Входные данные / Текущее состояние:
В настоящее время LLM предварительно обучаются на огромных наборах данных, часто состоящих из триллионов токенов, полученных из различных доменов, преимущественно собранных из Интернета. Однако значительная часть этих данных либо защищена авторским правом, либо является проприетарной, либо не имеет четких разрешительных лицензий. Это привело к шаткой ситуации для разработки LLM, особенно для инициатив в области открытой науки, о чем свидетельствуют многочисленные юридические проблемы (например, иски против OpenAI, удаление наборов данных, таких как Books3, LAION и MATH, по DMCA). Существующие "открытые" наборы данных часто страдают от ограничений: они, как правило, моноязычны (преимущественно на английском), сильно зависят от веб-сканирования (например, Common Crawl) с неоднозначным лицензированием, или содержат низкокачественный, непригодный или этически проблематичный контент (например, персональные данные (PII), токсичный язык). Кроме того, владельцы контента все чаще внедряют технические и юридические ограничения на сбор данных для обучения ИИ, что еще больше сокращает пул легкодоступных данных.
Желаемый конечный результат (целевое состояние):
Желаемый конечный результат — создание надежной, юридически соответствующей требованиям и этически обоснованной основы для предварительного обучения LLM. Это предполагает создание массивного набора данных, который является:
1. По-настоящему открытым и разрешительно лицензированным: Весь контент должен быть не защищен авторским правом или доступен по четким, разрешительным лицензиям, обеспечивая юридическую определенность и способствуя открытой науке.
2. Многоязычным и многодоменным: Набор данных должен охватывать широкий спектр языков, включая языки с ограниченными ресурсами, и разнообразные домены (например, правительство, культура, наука, код, веб, семантические данные) для обеспечения обобщаемости и высокой производительности моделей.
3. Высококачественным и курированным: Данные должны быть тщательно очищены, отфильтрованы от PII, токсичности и ошибок OCR, с предоставлением подробного происхождения и метаданных для прозрачности и воспроизводимости.
Отсутствующее звено или математический пробел:
Точное отсутствующее звено — это отсутствие комплексного, этически полученного и юридически чистого общего репозитория данных (data commons), который мог бы конкурировать по масштабу и разнообразию с проприетарными или неоднозначно лицензированными наборами данных, используемыми в настоящее время для обучения LLM. Данная статья пытается устранить этот пробел путем сборки, курирования и выпуска Common Corpus, набора данных, разработанного с нуля для соответствия этим строгим юридическим и этическим критериям, одновременно предоставляя значительный объем разнообразных токенов, подходящих для многоязычного предварительного обучения. Математический пробел заключается не в конкретном уравнении, а скорее в отсутствии четко определенного, крупномасштабного и юридически чистого входного пространства для сложных задач оптимизации, которые составляют обучение LLM.
Дилемма:
Центральный, болезненный компромисс, который поставил в тупик предыдущих исследователей, — это дилемма "Масштаб против законности/этики/качества". Достижение огромного масштаба, необходимого для передовой производительности LLM, исторически требовало использования обширных, часто без разбора собранных веб-данных. Такой подход, хотя и эффективен для масштаба, неизбежно приводит к:
* Юридической уязвимости: Включение контента, защищенного авторским правом или проприетарного, что приводит к судебным искам и удалению наборов данных, подрывая воспроизводимость и открытые исследования.
* Этическим компромиссам: Присутствие PII, вредоносного или предвзятого контента, что вызывает этические проблемы и несоблюдение нормативных требований (например, GDPR).
* Снижению качества: Веб-данные часто содержат низкокачественный, зашумленный или непригодный для использования текст, что может негативно сказаться на производительности модели и потребовать обширной и дорогостоящей постобработки.
Дилемма заключается в том, что улучшение одного аспекта (например, обеспечение строгого соблюдения законодательства) обычно резко сокращает доступный масштаб данных или экспоненциально увеличивает затраты на курирование, затрудняя обучение конкурентоспособных LLM. И наоборот, приоритет масштаба часто нарушает юридические и этические стандарты. Статья также подчеркивает "парадокс открытых данных", когда подлинно открытый контент парадоксальным образом менее заметен в ведущих источниках предварительного обучения, что делает его агрегирование inherently трудным.
Ограничения и режимы отказа
Проблема создания по-настоящему открытого, разрешительно лицензированного и высококачественного набора данных для предварительного обучения LLM чрезвычайно сложна из-за нескольких суровых, реалистичных ограничений:
-
Юридические ограничения и ограничения лицензирования:
- Строгая разрешимость: Данные должны быть не защищены авторским правом (общественное достояние) или находиться под явными разрешительными лицензиями (например, CC-By, MIT, Apache-2.0). Это значительно ограничивает пул используемых данных по сравнению с общим веб-сканированием, поскольку большая часть общедоступного веб-контента не имеет разрешительных лицензий для обучения ИИ.
- Сложность срока действия авторских прав: Определение статуса общественного достояния, особенно для международных и исторических работ, включает сложные юридические критерии (например, жизнь автора + 70 лет, публикация + 95 лет для американских авторов), требуя тщательной проверки прав.
- Удаление по DMCA: Постоянная угроза юридических действий и удаления по DMCA для несоблюдающих требования данных делает любой набор данных, построенный на неоднозначных источниках, нестабильным и ненадежным для долгосрочных исследований.
-
Ограничения, связанные с данными и качеством:
- Крайняя разреженность высококачественных открытых данных: Хотя Интернет огромен, подмножество высококачественных, многоязычных, многодоменных данных с четкими разрешительными лицензиями является относительно разреженным и фрагментированным.
- Низкое качество OCR в исторических текстах: Значительная часть ценных исторических данных (Open Culture, Open Government) поступает из оцифрованных источников с низким качеством оптического распознавания символов (OCR), что вносит шум и ошибки, снижающие качество текста. Это требует передовых, вычислительно интенсивных инструментов для обнаружения и исправления ошибок OCR.
- PII и вредоносный контент: Общественное достояние и другие открытые источники могут содержать персональные данные (PII) или вредоносный/предвзятый контент (например, исторические тексты, отражающие устаревшие нормы, CSAM в наборах данных изображений). Надежные, точные и эффективные конвейеры удаления PII и обнаружения токсичности являются обязательными, но их сложно реализовать в масштабе для различных языков и доменов.
- Отсутствие метаданных: Многие потенциальные источники данных не имеют достаточных метаданных относительно происхождения, лицензирования и языка, что затрудняет автоматизированное курирование и требует ручного вмешательства или сложного вывода.
- Проблемы многоязычного разнообразия: Инструменты для обработки данных (сегментация, оценка качества) должны надежно работать для широкого спектра языков, включая языки с ограниченными ресурсами, где существующие инструменты NLP часто плохо обобщаются.
-
Вычислительные ограничения и ограничения инфраструктуры:
- Обработка огромного масштаба: Обработка и курирование "около двух триллионов токенов" требует значительных вычислительных ресурсов для хранения, обработки, фильтрации и оценки качества.
- Вычислительная стоимость инструментов курирования: Хотя и являются необходимыми, передовые инструменты курирования, такие как обнаружение ошибок OCR (например, OCRerrcr), могут быть вычислительно интенсивными и масштабироваться менее эффективно, чем более быстрые, но менее точные альтернативы, что создает компромисс между точностью и скоростью обработки для очень больших корпусов.
- Отслеживание происхождения данных: Тщательное отслеживание происхождения, лицензии и метаданных для каждого объекта данных из различных источников добавляет значительные накладные расходы к конвейеру данных.
-
Режимы отказа:
- Несоблюдение законодательства: Неспособность точно идентифицировать и отфильтровать контент, не имеющий разрешительных лицензий, приводит к юридическим рискам и потенциальному удалению наборов данных.
- Нарушения этических норм: Неадекватное удаление PII или фильтрация токсичности может привести к нарушениям конфиденциальности или закреплению вредоносных предубеждений в обученных LLM.
- Низкая производительность модели: Использование низкокачественных, зашумленных или недостаточно разнообразных данных может привести к LLM с низкой производительностью, ограниченной обобщаемостью или нежелательным поведением (например, "переключение языков" в задачах коррекции, общие стили письма).
- Отсутствие воспроизводимости: Если набор данных нестабилен, хорошо документирован и постоянно доступен, исследования, основанные на нем, становятся невоспроизводимыми.
- Неэффективное курирование: Ручные или медленные процессы курирования становятся невозможными в масштабе, необходимом для современного обучения LLM, что требует эффективных, автоматизированных, но точных инструментов.
- Случайные ложные повторения: Даже с передовыми инструментами, такими как OCRonos, может иногда включаться ложно повторяющееся слово, что требует постобработки.
Почему такой подход
Неизбежность выбора
Основная проблема, рассматриваемая в данной статье, заключается не в разработке новой математической модели или алгоритма для самих больших языковых моделей (LLM), а в критическом отсутствии высококачественных, по-настоящему открытых, разрешительно лицензированных, многоязычных и многодоменных данных для предварительного обучения. Авторы пришли к выводу, что традиционные методы сбора и курирования данных SOTA были принципиально недостаточными, поскольку они приводили к каскаду юридических, этических проблем и проблем с качеством, которые серьезно препятствовали исследованиям в области открытой науки и разработке надежных LLM.
Существующие наборы данных, такие как C4, Books3, LAION, RefinedWeb и Dolma, несмотря на их масштаб, имели существенные недостатки:
* Юридические и этические мина: Многие содержали контент, защищенный авторским правом или проприетарный, что приводило к юридическим спорам (например, иск New York Times против OpenAI, удаление Books3 по DMCA и удаление LAION из-за контента CSAM). Это делало исследования невоспроизводимыми и создавало значительные риски для разработчиков.
* Ограничения доступа: Владельцы контента все чаще внедряли технические меры и юридические положения против сбора данных для обучения ИИ, делая большие части общедоступных веб-данных (например, 45% C4) недоступными или ограниченными.
* Моноязычный уклон: Большинство появляющихся "открытых" наборов данных были преимущественно только на английском языке (например, C4C, Open License Corpus, KL3M, Common Pile), что серьезно ограничивало разработку многоязычных LLM.
* Низкое качество и предвзятость: Веб-данные часто страдали от низкого качества, сгенерированного машиной текста, персональных данных (PII) и вредоносного или предвзятого контента. Многоязычные наборы данных, в частности, содержали много непригодных данных.
Учитывая эти повсеместные проблемы, авторы пришли к выводу, что новая парадигма сбора и курирования данных была единственным жизнеспособным решением. Это потребовало тщательного, поэтапного подхода к сборке набора данных, который был явно разработан как юридически соответствующий требованиям, этически обоснованный, высококачественный и разнообразный по языкам и доменам. "Подход" Common Corpus — сосредоточение на четком лицензировании, всестороннем происхождении и передовых инструментах курирования — был не просто улучшением, а необходимой основой для открытых исследований LLM.
Сравнительное превосходство
Подход Common Corpus обеспечивает качественное превосходство над предыдущими методами сбора данных и существующими наборами данных, в первую очередь благодаря своей структурной приверженности соблюдению законодательства, качеству данных и разнообразию, а не просто количеству токенов.
- Беспрецедентное соблюдение законодательства и этических норм: В отличие от наборов данных, которые сталкивались с судебными разбирательствами и удалениями, Common Corpus построен исключительно из не защищенных авторским правом или разрешительно лицензированных данных (общественное достояние, CC-By, MIT, Apache-2.0 и т. д., как подробно описано в Таблице 4). Это структурное преимущество гарантирует, что модели, обученные на Common Corpus, могут быть выпущены и использованы без юридических неопределенностей, которые преследуют многие коммерческие и даже "открытые" модели. Эта приверженность "открытости" в самом сильном возможном смысле является фундаментальным качественным скачком.
- Улучшенное качество данных за счет специализированного курирования: В статье представлена "Панель инструментов для плохих данных" (Раздел 5) — набор пользовательских инструментов, предназначенных для решения проблем, уникальных для многоязычного, исторического и оцифрованного контента:
- Segmentext: Модель классификации токенов для надежной сегментации текста, даже из поврежденного или неструктурированного ввода, которая превосходит методы, основанные на макете, когда визуальная информация потеряна.
- Обнаружение ошибок OCR (OCRoscope & OCRerrcr): OCRoscope обеспечивает быструю, крупномасштабную оценку качества, а OCRerrcr — детальное обнаружение ошибок на уровне токенов. Это имеет решающее значение для исторических и оцифрованных документов, обеспечивая более высокое качество ввода, чем необработанный вывод OCR.
- Коррекция OCR (OCRonos): Генеративная LLM, дообученная на Llama-3-8B, специально обученная для исправления ошибок OCR, разделения слов и структурных артефактов. Она разработана так, чтобы быть консервативной и сопротивляться переключению языков, что является распространенным режимом отказа у меньших универсальных LLM при столкновении с зашумленным вводом.
- Удаление PII: Использует Presidio от Microsoft с пользовательскими регулярными выражениями для идентификации и замены PII фиктивными, но реалистичными значениями, сохраняя формат текста и понимание модели, что является более сложным подходом, чем простое удаление или тегирование.
- Обнаружение токсичности (Celadon): Многоязычный классификатор токсичности (DeBERTa-v3-small), оптимизированный для исторических текстов, шума OCR и неанглийского контента. Он достигает сопоставимой производительности с гораздо более крупными моделями (Llama 3.1-8B-Instruct), но более чем в 40 раз быстрее, что делает крупномасштабную фильтрацию практичной. Это значительно снижает присутствие вредоносного контента, что является серьезной проблемой в корпусах, собранных из Интернета.
- Истинное многоязычное и многодоменное разнообразие: Common Corpus является крупнейшим полностью открытым набором данных (2 триллиона токенов) с высоким многоязычным разнообразием, охватывающим широкий спектр языков с высоким и низким уровнем ресурсов (Рисунок 2, Таблица 5). Его состав по различным доменам (Открытое правительство, Открытая культура, Открытая наука, Открытый код, Открытый веб, Открытые семантические данные) подробно описан на Рисунке 1, выходя за рамки данных "веб-сканирования" (Таблица 1, Рисунок 3b). Временной и семантический обзор этих коллекций далее иллюстрируется на Рисунке 3. Это структурное разнообразие необходимо для обучения обобщаемых и мощных LLM, которые хорошо работают в различных задачах и языках, что является явным преимуществом по сравнению с преимущественно моноязычными или текстово-ориентированными наборами данных.
- Воспроизводимость и инфраструктура открытой науки: Предоставляя подробное происхождение, шаги обработки и открыто выпуская инструменты курирования, Common Corpus действует как критически важная инфраструктура для открытой науки. Эта прозрачность и обмен инструментами напрямую решают проблему невоспроизводимых исследований, вызванную внезапным удалением наборов данных.
Хотя в статье явно не детализируется сокращение сложности памяти с $O(N^2)$ до $O(N)$ для процесса курирования данных, акцент на эффективных инструментах, таких как Celadon (в 40 раз быстрее для обнаружения токсичности) и OCRoscope (менее вычислительно затратный для больших масштабов), демонстрирует структурное преимущество в обработке огромного объема данных, необходимого для предварительного обучения LLM. Эта эффективность делает создание такого высококачественного, крупномасштабного, курированного корпуса осуществимым.
Соответствие ограничениям
Подход Common Corpus идеально соответствует неявным и явным ограничениям, вытекающим из определения проблемы, которое сосредоточено на необходимости юридически обоснованных, высококачественных, разнообразных и открыто доступных данных для предварительного обучения LLM.
- Ограничение: Строгое соблюдение законодательства и этических норм: Основная мотивация статьи — предоставить данные, "которые соответствуют нормам безопасности данных" и "свободны от авторских прав или других юридических ограничений". Common Corpus достигает этого, исключительно используя не защищенный авторским правом или разрешительно лицензированный контент (Таблица 4). Кроме того, он реализует надежное удаление PII (с использованием Presidio) и обнаружение токсичности (с использованием Celadon), напрямую решая этические проблемы конфиденциальности и вредоносного контента. Этот "союз" гарантирует, что LLM, обученные на Common Corpus, могут быть развернуты без юридических и репутационных рисков, связанных с предыдущими наборами данных.
- Ограничение: Высокое качество и удобство использования данных: Проблема подчеркивает, что существующие наборы данных часто содержат "низкокачественные или совершенно непригодные данные", особенно в многоязычных контекстах. Решение Common Corpus напрямую решает эту проблему с помощью своей "Панели инструментов для плохих данных". Segmentext обрабатывает неструктурированные и оцифрованные тексты, OCRoscope и OCRerrcr обнаруживают ошибки, а OCRonos их исправляет, превращая деградировавшие входные данные в пригодный для использования текст. Этот набор инструментов гарантирует, что даже исторические или зашумленные данные вносят значимый вклад в обучение, выполняя требование к высококачественному вводу.
- Ограничение: Многоязычное и многодоменное разнообразие: Ключевым ограничением предыдущих "открытых" наборов данных была их моноязычность или ограниченный охват доменов. Common Corpus явно разработан как "крупнейший полностью открытый набор данных для предварительного обучения... обладающий высоким многоязычным разнообразием" (Рисунок 2, Таблица 5) и охватывающий широкий спектр доменов (Открытое правительство, Культура, Наука, Код, Веб, Семантические данные). Это напрямую решает потребность в LLM, которые являются мощными и обобщаемыми в различных языках и областях знаний.
- Ограничение: Открытая наука и воспроизводимость: Статья подчеркивает необходимость "по-настоящему открытых данных для предварительного обучения" и "воспроизводимых артефактов исследований". Common Corpus соответствует этому, предоставляя подробное происхождение, шаги обработки и открыто выпуская свои инструменты курирования (Панель инструментов для плохих данных). Эта прозрачность и обмен методологией напрямую поддерживают экосистему открытой науки, гарантируя, что исследования, основанные на этих данных, могут быть проверены и воспроизведены.
- Ограничение: Большой масштаб: LLM требуют "больших объемов обучающих данных" (Введение). Common Corpus, объемом "около 2 триллионов токенов", соответствует этому требованию к масштабу. Эффективность его инструментов курирования (например, скорость Celadon) делает практичным обработку и поддержание такого массивного корпуса, гарантируя, что ограничения качества и разнообразия соблюдаются даже в таком огромном масштабе.
Отклонение альтернатив
Авторы статьи неявно и явно отвергают несколько популярных подходов и существующих наборов данных, подчеркивая их фундаментальные недостатки, которые Common Corpus стремится устранить.
- Отказ от неразборчивого веб-сканирования (например, Common Crawl для C4, Books3): Авторы четко заявляют, что "большинство веб-данных не имеют достаточных метаданных для определения того, лицензированы ли они разрешительно" и что "существует все больше юридических споров относительно использования этих данных". Они приводят иск NYT против OpenAI, удаление Books3 по DMCA и проблемы набора данных LAION с CSAM в качестве прямого доказательства провала таких подходов. Статья отмечает, что "полные 45% C4 теперь ограничены" из-за изменений в Условиях обслуживания. Подход Common Corpus, заключающийся в исключительном включении не защищенного авторским правом или разрешительно лицензированного контента с четким происхождением, является прямым отказом от юридических и этических рисков, присущих широкому веб-сканированию.
- Отказ от существующих "открытых" наборов данных как достаточных: Статья сравнивает Common Corpus с другими инициативами, такими как C4C, Open License Corpus, KL3M и Common Pile (Таблица 1). Она указывает, что многие из них являются "моноязычными, что фактически ограничивает охват языковых моделей англоязычной аудиторией". KL3M, например, "ограничен административными и юридическими документами на английском языке". Уникальная способность Common Corpus удовлетворять всем четырем критериям одновременно — многоязычность, многодоменность, выход за рамки веб-сканирования и полное разрешительное лицензирование — демонстрирует неадекватность этих альтернатив для более широкой цели разработки открытых LLM общего назначения.
- Отказ от некурированных или плохо курированных многоязычных наборов данных: Статья подчеркивает, что "многие многоязычные наборы данных содержат много низкокачественных или совершенно непригодных данных" (Kreutzer et al., 2022). Это подразумевает, что простое агрегирование данных из различных языков без тщательного курирования, как это может быть сделано в некоторых альтернативных подходах, приводит к субоптимальным обучающим данным. "Панель инструментов для плохих данных" Common Corpus (Segmentext, коррекция OCR, обнаружение токсичности) является прямым противодействием этой проблеме, обеспечивая высокое качество даже для разнообразных и сложных лингвистических источников.
- Отказ от подходов, игнорирующих PII и токсичность: Статья прямо заявляет, что "веб-данные являются основным источником вредоносного и предвзятого контента" и что "данные общественного достояния... включают исторические периодические издания и монографии... многие из этих текстов не соответствуют современным этическим стандартам". Разработка специализированных инструментов, таких как Presidio для удаления PII и Celadon для многоязычного обнаружения токсичности, является явным отказом от любой стратегии сбора данных, которая не ставит в приоритет эти критические этапы фильтрации.
По сути, авторы отвергли альтернативы, которые либо не соответствовали строгим юридическим и этическим требованиям, либо не имели достаточного многоязычного и многодоменного охвата, либо компрометировали качество данных, что является первостепенным для устойчивого развития открытых LLM.
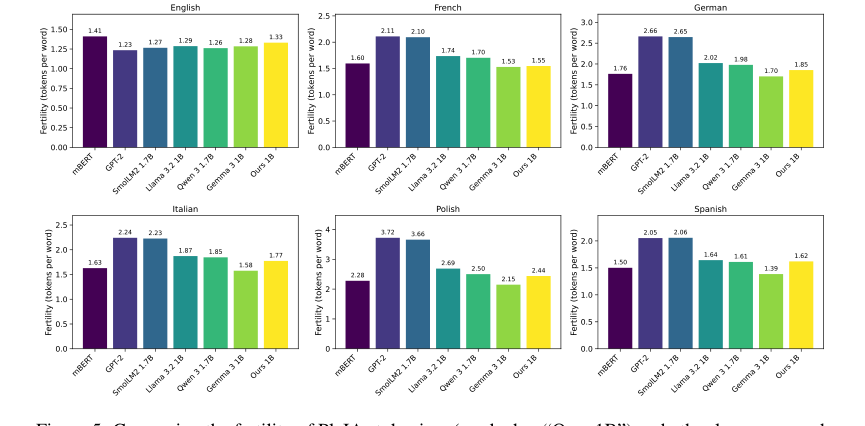 Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Математический и логический механизм
Статья "Common CORPUS: КРУПНЕЙШАЯ КОЛЛЕКЦИЯ ЭТИЧНЫХ ДАННЫХ ДЛЯ ПРЕДВАРИТЕЛЬНОГО ОБУЧЕНИЯ LLM" в основном посвящена тщательному созданию и курированию крупномасштабного, этически полученного набора данных для обучения больших языковых моделей (LLM). Хотя в ней описывается последующее обучение и оценка LLM с использованием этого набора данных, основные математические и логические механизмы, представленные или детализированные в данной статье, в основном связаны с конвейером курирования данных, а не с новой архитектурой LLM или самой целевой функцией обучения. Упомянутые LLM (на основе Llama, варианты DeBERTa) являются существующими моделями, и их базовые математические механизмы обучения хорошо установлены в литературе. Следовательно, этот раздел будет посвящен логическим и алгоритмическим механизмам, используемым в процессе курирования данных, который является центральным вкладом статьи.
Главное уравнение
Честно говоря, данная статья не представляет собой единого "главного уравнения" в традиционном смысле, такого как целевая функция для новой модели машинного обучения или дифференциальное уравнение, описывающее новый физический процесс. Вместо этого ее "математический движок" представляет собой набор алгоритмических и модельно-ориентированных процессов, предназначенных для очистки данных, сегментации, обнаружения ошибок, исправления и фильтрации токсичности. Эти процессы последовательно применяются к необработанным текстовым данным для получения окончательного Common Corpus.
Наиболее близким к "основному механизму" является оценка качества OCR с помощью OCRoscope, которая основана на сравнении показателей идентификации языка. Хотя это и не целевая функция для обучения, она количественно определяет критический аспект качества данных. Оценка качества OCR, $Q_{OCR}$, для документа может быть концептуально представлена как:
$$ Q_{OCR} = 1 - \frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})} $$
Это уравнение, хотя и упрощенное, отражает суть логики OCRoscope.
Поэтапный анализ терминов
Давайте разберем концептуальные компоненты оценки качества OCRoscope:
- $N$: Это общее количество скользящих n-грамм (в частности, 7-грамм, как указано в статье), извлеченных из текстового документа. Его математическое определение — подсчет этих перекрывающихся текстовых сегментов. Его физическая/логическая роль заключается в определении гранулярности, на которой выполняется локальная идентификация языка. Авторы использовали n-граммы, потому что модели идентификации языка более чувствительны к шуму на коротких последовательностях, что делает их хорошими индикаторами ошибок OCR, в отличие от идентификации на уровне документа, которая устойчива к шуму.
- $g_i$: Это $i$-я скользящая 7-грамма, извлеченная из документа. Математически это подстрока длиной 7. Ее логическая роль заключается в предоставлении небольшого, локализованного окна текста для идентификации языка, где ошибки OCR с большей вероятностью нарушат лингвистический шаблон.
- $L(g_i)$: Это язык, идентифицированный моделью
pycld2для $i$-й 7-граммы. Математически это категориальный вывод (метка языка или "Unknown"). Ее логическая роль заключается в обнаружении локальной лингвистической согласованности. Если 7-грамма сильно искажена ошибками OCR,pycld2, вероятно, неправильно классифицирует ее язык или пометит как "Unknown". - $L_{doc}$: Это язык, идентифицированный
pycld2для всего документа. Математически это один категориальный вывод. Ее логическая роль заключается в установлении истинного языка документа, который предполагается надежно идентифицированным даже при некотором шуме. Сравнение локального $L(g_i)$ с глобальным $L_{doc}$ является ключом к выявлению расхождений. - $\mathbb{I}(\cdot)$: Это индикаторная функция, которая возвращает 1, если ее аргумент истинен, и 0, если ложен. Математически это отображение булевых значений в целые числа. Ее логическая роль заключается в подсчете случаев, когда идентификация языка локальной 7-граммы отличается от общего языка документа или не может быть идентифицирована.
- $\mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})$: Этот член подсчитывает количество "несоответствующих" или "неизвестных" 7-грамм. Математически это сумма индикаторных функций. Ее логическая роль заключается в количественной оценке наличия локальных лингвистических несоответствий, которые являются прокси-показателями ошибок OCR. Авторы использовали "или" для охвата как явной неправильной идентификации, так и полного отказа от идентификации, оба из которых указывают на проблемы.
- $\mathbb{I}(g_i \text{ is valid})$: Этот член гарантирует, что учитываются только допустимые 7-граммы (например, не пустые или состоящие только из знаков препинания), чтобы предотвратить деление на ноль или искаженные соотношения из-за некорректных входных данных.
- Суммирование $\sum_{i=1}^{N} \dots$: Это агрегирует количество проблемных 7-грамм. Использование суммирования здесь естественно для подсчета дискретных событий в последовательности.
- Дробь $\frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})}$: Это вычисляет долю проблемных 7-грамм. Ее логическая роль заключается в предоставлении нормализованной меры шума OCR.
- $1 - \dots$: Это окончательное вычитание преобразует "уровень ошибок" в "оценку качества", где 1 означает идеальное качество, а более низкие значения указывают на возрастающий шум при оцифровке. Это делает оценку более интуитивной как метрику "качества".
Пошаговый поток
Представьте, что необработанный, оцифрованный документ, возможно, отсканированная историческая газета, поступает в конвейер курирования Common Corpus. Это похоже на сложную сборочную линию для текста:
- Первоначальное получение и извлечение метаданных: Документ сначала поступает в систему. Извлекаются или выводятся основные метаданные, такие как исходный URL, потенциальная информация о лицензии и дата создания.
- Идентификация языка (на уровне документа): Весь документ пропускается через модель идентификации языка (например,
fastTextилиcld2) для определения его основного языка, $L_{doc}$. Это важный первый шаг, поскольку последующие инструменты часто зависят от языка. - Сегментация текста (Segmentext): Необработанная последовательность символов документа подается в
Segmentext, модель классификации токенов в стиле DeBERTa-v2. Эта модель действует как умный парсер, идентифицируя и помечая различные структурные компоненты: "Это[Заголовок]", "Это[Текст]", "Это[Таблица]", "Это[Паратекст](например, номер страницы)". Она работает исключительно с текстом, что делает ее устойчивой к потере информации о макете. - Обнаружение ошибок OCR (OCRoscope & OCRerrcr):
- OCRoscope (грубая оценка): Затем документ передается в
OCRoscope. Этот инструмент скользит окном из 7 символов (7-граммы) по тексту. Для каждой 7-граммы он пытается определить ее язык, $L(g_i)$. Если $L(g_i)$ не совпадает с $L_{doc}$ или является "Unknown", он помечается как потенциальная ошибка OCR.OCRoscopeагрегирует эти флаги для получения общей оценки качества OCR для документа. Это быстрая, первоначальная проверка для принятия решения о том, нуждается ли документ в более интенсивной обработке. - OCRerrcr (точная оценка): Для документов, требующих большего внимания, вступает в работу
OCRerrcr, модель DeBERTa-v3-small. Она обрабатывает текст токен за токеном, классифицируя каждый токен как правильный или ошибочный. Это обеспечивает точную карту расположения ошибок, подготавливая документ к целенаправленному исправлению.
- OCRoscope (грубая оценка): Затем документ передается в
- Исправление ошибок OCR (OCRonos): Документ, теперь с выявленными ошибками, переходит к
OCRonos, генеративной модели Llama-3-8B с дообучением.OCRonosдействует как опытный редактор, принимая зашумленный текст и пытаясь исправить ошибки OCR, неправильные разделения или слияния слов и восстановить общую структурную целостность. Она разработана так, чтобы быть консервативной, сохраняя исходный текст, где это возможно, но может "синтетически переписывать" сильно деградировавшие части, чтобы сделать их пригодными для использования. - Удаление персональных данных (PII): Текст, теперь структурно целостный и в основном без ошибок, сканируется на наличие PII с помощью
Microsoft Presidio, дополненного пользовательскими регулярными выражениями. Этот инструмент идентифицирует конфиденциальную информацию, такую как номера телефонов, адреса электронной почты и IP-адреса. Вместо простого удаления или редактирования он заменяет PII фиктивными, но реалистичными значениями, чтобы сохранить поток и контекст текста. - Дедупликация: Документ проверяется на наличие дубликатов по сравнению с существующими данными, часто с использованием метаданных PDF или хешей содержимого. Это обеспечивает уникальность и избегает избыточности в корпусе.
- Обнаружение токсичности (Celadon): Наконец, очищенный документ передается в
Celadon, многоязычный классификатор токсичности DeBERTa-v3-small. Эта модель, обученная на разнообразном наборе аннотированного токсичного контента, идентифицирует и помечает вредоносный или предвзятый язык по нескольким измерениям (например, расизм, сексизм, насилие). Документы или сегменты, превышающие определенный порог токсичности, отфильтровываются, обеспечивая этическую целостность корпуса. - Окончательная сборка и обогащение метаданными: Теперь чистый, сегментированный, исправленный, свободный от PII и нетоксичный текст собирается. Прикрепляются его богатые метаданные (лицензия, язык, источник, домен и т. д.), что делает его готовым для включения в Common Corpus.
Весь этот процесс гарантирует, что каждая "точка данных" (документ) тщательно обрабатывается и проверяется, прежде чем стать частью окончательного, высококачественного набора данных.
Динамика оптимизации
"Обучение" или "сходимость" в данной статье в основном применяется к моделям нейронных сетей, используемым в конвейере курирования данных, поскольку сама статья не предлагает нового алгоритма оптимизации обучения LLM. Эти модели обучаются с использованием стандартных методов оптимизации глубокого обучения.
- Segmentext, OCRerrcr и Celadon (модели классификации токенов):
- Ландшафт потерь: Эти модели являются вариантами DeBERTa-vX, которые представляют собой архитектуры на основе трансформеров. Их ландшафты потерь обычно многомерны и невыпуклы. Цель обучения — найти набор весов, который минимизирует определенную функцию потерь.
- Функция потерь: Для
SegmentextиOCRerrcr, которые выполняют классификацию токенов (например, классификация структурной роли каждого токена или его статуса ошибки), основной функцией потерь будет перекрестная энтропия. Она измеряет разницу между предсказанным моделью распределением вероятностей по классам для каждого токена и истинной меткой класса.Celadon, классификатор токсичности, явно использует "пользовательскую взвешенную функцию перекрестной энтропии для обработки дисбаланса классов". Этот механизм взвешивания назначает более высокие штрафы за неправильную классификацию миноритарных классов (например, токсичного контента, который обычно реже, чем нетоксичный контент), помогая модели научиться более эффективно идентифицировать эти критически важные случаи. - Градиенты: Во время обучения модели используют обратное распространение ошибки для вычисления градиентов функции потерь по отношению ко всем параметрам модели (весам и смещениям). Эти градиенты указывают направление и величину, в которых каждый параметр должен быть скорректирован для уменьшения потерь.
- Алгоритм оптимизации: Хотя это явно не указано, будут использоваться стандартные оптимизаторы, такие как Adam (Adaptive Moment Estimation) или SGD (Stochastic Gradient Descent) с моментумом. Эти алгоритмы итеративно обновляют параметры модели, делая шаги в направлении, противоположном градиенту, масштабированные скоростью обучения.
- Сходимость: Модели сходятся, когда функция потерь на валидационном наборе перестает значительно уменьшаться, что указывает на то, что модель изучила лежащие в основе закономерности в обучающих данных и хорошо обобщается. Итеративные обновления перемещают параметры модели по ландшафту потерь, стремясь к локальному или глобальному минимуму.
- OCRonos (генеративная языковая модель):
- Ландшафт потерь: Как модель Llama-3-8B с дообучением,
OCRonosработает на огромном, сложном ландшафте потерь, характерном для больших генеративных трансформеров. - Функция потерь: Основной функцией потерь для генеративных языковых моделей является обычно потеря предсказания следующего токена (также форма перекрестной энтропии). Модель обучается предсказывать следующий токен в последовательности, учитывая предыдущие. В контексте исправления OCR это означает обучение генерации правильного, чистого текста из зашумленной входной последовательности.
- Градиенты и оптимизация: Аналогично моделям классификации,
OCRonosиспользует обратное распространение ошибки и оптимизатор (вероятно, Adam или его вариант) для обновления своих параметров. Модель учится отображать зашумленные входные закономерности в чистые выходные закономерности. - Сходимость: Модель сходится, когда она может надежно генерировать высококачественный, исправленный текст, который соответствует исходному замыслу, одновременно смягчая ошибки и сопротивляясь нежелательному поведению, такому как переключение языков. Процесс обучения итеративно уточняет способность модели "переписывать" деградировавший текст в связную и точную форму.
- Ландшафт потерь: Как модель Llama-3-8B с дообучением,
По сути, динамика оптимизации для этих компонентов заключается в итеративной корректировке внутренних параметров этих нейронных сетей для минимизации их соответствующих функций потерь, тем самым улучшая их производительность в конкретных задачах курирования данных. Это итеративное уточнение позволяет конвейеру "научиться" эффективно обрабатывать и очищать разнообразные, зашумленные данные.
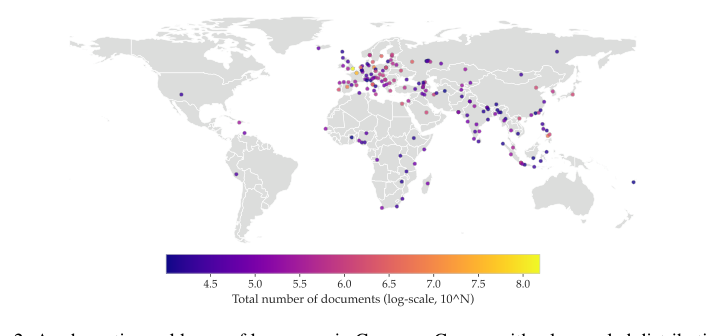 Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
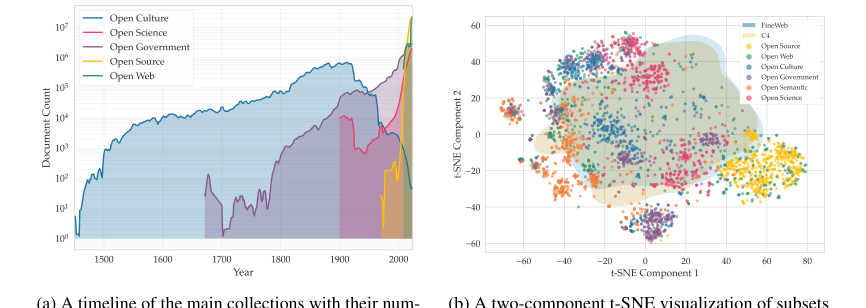 Figure 3. Temporal and semantic overview of the Common Corpus collections
Figure 3. Temporal and semantic overview of the Common Corpus collections
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые модели
Чтобы строго подтвердить полезность Common Corpus, авторы приступили к целенаправленному экспериментальному дизайну. Они обучили две различные языковые модели, PleIAs 350M и PleIAs 1.2B, обе на основе архитектуры Llama. Пользовательский токенизатор в стиле Llama с размером словаря 65 536 был разработан и обучен на репрезентативной подвыборке самого Common Corpus. Меньшая модель PleIAs 350M обучалась примерно на 1 триллионе токенов из отфильтрованного подмножества Common Corpus, что потребовало 2944 часов на H100. Большая модель PleIAs 1.2B обучалась на полном Common Corpus в течение трех эпох отфильтрованного подмножества, что потребовало значительных 23 040 часов на H100.
"Жертвы" (базовые модели), против которых оценивались модели, обученные на Common Corpus, включали несколько известных многоязычных языковых моделей: Gemma 3 (270M и 1B параметров), XGLM (564M и 1.7B параметров), BLOOM (560M и 1.7B параметров) и OLMO 1B. Эти базовые модели представляют собой смесь моделей, обученных либо на закрытых, неразрешительно лицензированных данных, либо, в случае OLMO 1B, на общедоступном наборе данных. Оценка проводилась с использованием стандартного инструмента LM Evaluation Harness на трех установленных многоязычных бенчмарках: MultiBLiMP, XStoryCloze и XCOPA. Эта настройка была разработана для обеспечения прямого сравнения производительности, особо подчеркивая, могут ли модели, обученные исключительно на разрешительно лицензированных, этически курированных данных, конкурировать с моделями, обученными на более широких, часто юридически неоднозначных наборах данных.
Что доказывают доказательства
Представленные в статье доказательства однозначно подтверждают, что Common Corpus является подходящим и эффективным набором данных для многоязычного предварительного обучения, позволяющим разрабатывать LLM при строгом соблюдении нормативных и этических норм. Основной механизм — обучение на массивном, разнообразном и разрешительно лицензированном корпусе — был продемонстрирован в реальности через производительность моделей PleIAs.
В частности, модели, обученные на Common Corpus, продемонстрировали сравнимую, а в некоторых случаях и превосходящую производительность по сравнению с их базовыми моделями. На бенчмарке MultiBLiMP, который особенно сложен из-за его обширного языкового охвата, модели PleIAs показали выдающуюся производительность. Примечательно, что меньшая модель PleIAs 350M, несмотря на свой размер, превзошла большинство базовых моделей диапазона 1B, за исключением Gemma 3 1B. Кроме того, обе модели PleIAs последовательно и стабильно превосходили OLMO 1B, базовую модель, также предварительно обученную на общедоступном наборе данных. Это важный набор доказательств, поскольку он напрямую подтверждает качество и полезность Common Corpus по сравнению с другой альтернативой с открытым исходным кодом.
Помимо сырых метрик, статья предоставляет убедительные доказательства этических и качественных преимуществ набора данных. Подробное происхождение, фильтрация, удаление PII, обнаружение токсичности и процессы дедупликации (как описано в Разделе 5) гарантируют, что данные не защищены авторским правом или находятся под разрешительными лицензиями, решая критический юридический и этический пробел в обучении LLM. Качественные оценки, такие как метрики композиции символов (Рисунок 4), подтвердили, что распределения данных в основном находились в ожидаемых пределах, с разумными отклонениями для специализированного контента, такого как код или нормативные тексты. Пользовательский токенизатор, являющийся основополагающим компонентом моделей PleIAs, также показал хорошие результаты, уступив только токенизатору Gemma 3, который имеет словарь в четыре раза больше. Эти совокупные доказательства подчеркивают, что Common Corpus — это не просто большой набор данных, а высококачественный, этически обоснованный и эффективный набор данных для обучения конкурентоспособных многоязычных LLM.
Ограничения и будущие направления
Хотя Common Corpus представляет собой значительный шаг вперед для открытой науки в разработке LLM, авторы откровенно признают несколько ограничений, которые открывают путь для будущих исследований и эволюции. Во-первых, несмотря на впечатляющий размер в 2 триллиона токенов, Common Corpus все еще далек от охвата всего спектра доступных открытых данных. Этот "парадокс открытых данных", когда основные источники открытого контента парадоксальным образом менее заметны, означает, что более крупным моделям в настоящее время требуется значительно больше данных, чем может предоставить один Common Corpus.
Во-вторых, текущая итерация Common Corpus не предназначена для инструктивного обучения или специализированных задач. Его основная полезность заключается в предварительном обучении, что означает, что он не подходит напрямую для дообучения моделей для конкретных приложений без дополнительных, специфичных для задачи наборов данных. Это представляет собой возможность для будущей работы по расширению Common Corpus путем разработки этических наборов данных для инструктивного обучения, которые используют его многоязычное, временное и семантическое разнообразие.
Третье ограничение заключается в присущих проблемах курирования данных, особенно с историческими и оцифрованными текстами. Авторы признают, что даже с их сложной "Панелью инструментов для плохих данных" (включая Segmentext, OCRoscope, OCRerrcr, OCRonos и Celadon) достижение 100% точности в курировании затруднительно. Ошибки OCR, в частности, остаются значительной проблемой, потенциально влияющей на производительность модели и даже на то, как модели обрабатывают опечатки. Улучшение этих инструментов курирования, возможно, с помощью более передовых методов на основе ИИ, является явным будущим направлением.
Заглядывая вперед, выводы из данной статьи стимулируют несколько тем для обсуждения:
- Масштабирование инициатив по открытым данным: Как мы можем преодолеть "парадокс открытых данных", чтобы сделать больше разрешительно лицензированного контента видимым и доступным для обучения LLM? Это может включать стимулирование обмена данными от культурных учреждений, правительств и исследовательских организаций, или разработку новых методов обнаружения и агрегирования таких данных в масштабе.
- Этическое инструктивное обучение и наборы данных для конкретных задач: Учитывая сильные стороны Common Corpus в разнообразных, этически полученных данных для предварительного обучения, как сообщество может совместно создавать наборы данных для инструктивного обучения и конкретных задач, которые поддерживают те же высокие этические стандарты? Это потребует изучения методов генерации синтетических данных, аннотирования с участием человека и подходов к федеративному обучению для создания специализированных наборов данных без ущерба для конфиденциальности или лицензирования.
- Достижения в инструментах курирования данных: Статья подчеркивает постоянную проблему ошибок OCR и других проблем качества данных. Как мы можем дальше развивать такие инструменты, как OCRonos и Celadon, возможно, интегрируя более сложное мультимодальное понимание или используя самообучение на зашумленных данных, для достижения почти идеального качества данных в масштабе? Могут ли сами LLM быть обучены быть более устойчивыми к таким несовершенствам или даже исправлять их более успешно?
- Роль метаданных в ответственном ИИ: Акцент на богатых метаданных в Common Corpus позволяет пользователям фильтровать данные на основе лицензий, языка и потенциальных проблем. Как мы можем стандартизировать и расширить практики метаданных во всех открытых наборах данных, чтобы предоставить специалистам по LLM больший контроль над их обучающими данными, способствуя более ответственному и прозрачному развитию ИИ?
- Кросс-языковое развитие и развитие языков с ограниченными ресурсами: Многоязычное разнообразие Common Corpus, включая языки с ограниченными ресурсами, является ключевым преимуществом. Как этот набор данных может быть использован для расширения границ производительности LLM на этих языках, потенциально сокращая цифровой разрыв и способствуя более инклюзивному ИИ? Это может включать стратегии трансферного обучения, методы многоязычного выравнивания или даже новые архитектурные решения, оптимизированные для разнообразных лингвистических вводов.
 Table 1. Comparison of the contemporary datasets for LLM training
Table 1. Comparison of the contemporary datasets for LLM training
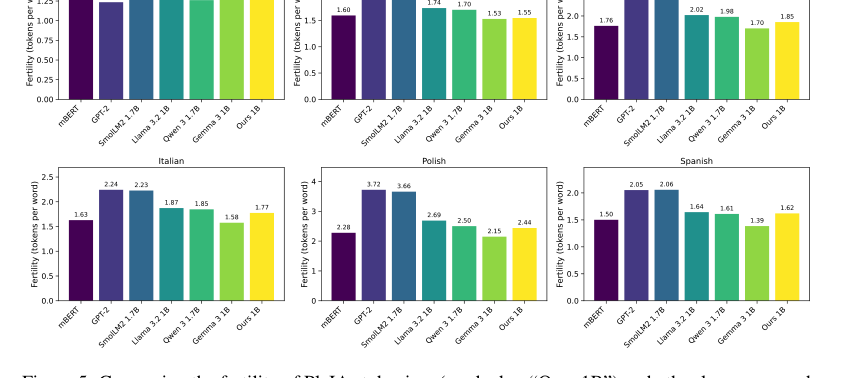 Table 6. Finance Commons sources distribution with languages
Table 6. Finance Commons sources distribution with languages
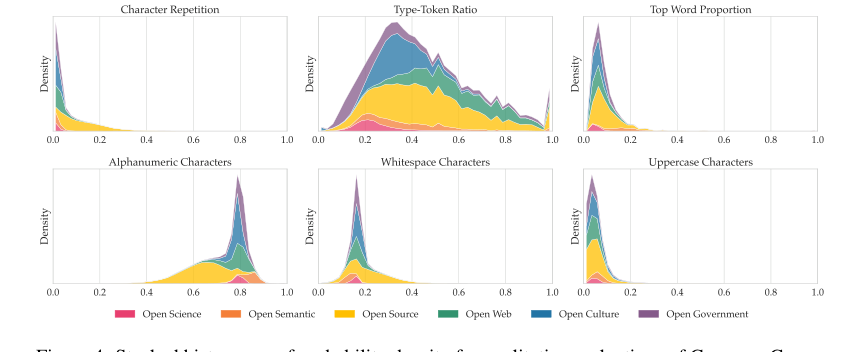 Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Изоморфизмы с другими областями
Структурный каркас
Данная статья представляет собой надежный многоэтапный конвейер для приобретения, очистки и проверки огромных, гетерогенных данных при строгих этических и качественных ограничениях.
Дальние родственники
-
Целевая область: Управление цепочками поставок
Связь: В сфере управления глобальными цепочками поставок постоянной проблемой является обеспечение подлинности, качества и этического происхождения сырья и произведенных компонентов от множества международных поставщиков. Это часто включает навигацию по сложным нормативным базам, проверку сертификатов и предотвращение проникновения контрафактных или неэтично полученных товаров. Основная логика статьи по тщательному отслеживанию происхождения данных, применению многоуровневой фильтрации (по качеству, PII и токсичности) и обеспечению разрешительного лицензирования является зеркальным отражением необходимости "чистой", "аудируемой" и "этически обоснованной" цепочки поставок для физических продуктов. "Парадокс открытых данных", описанный в статье, когда ценный открытый контент парадоксальным образом трудно найти и использовать, перекликается с трудностью выявления действительно надежных и прозрачных поставщиков на фрагментированном мировом рынке. -
Целевая область: Геномика и персонализированная медицина
Связь: В геномике исследователи постоянно работают с огромными, гетерогенными биологическими наборами данных, включая последовательности ДНК, профили экспрессии генов и медицинские записи пациентов, часто агрегированные из различных исследовательских институтов и публичных репозиториев. Критической, давней проблемой является обеспечение качества, согласованности и этического использования (например, конфиденциальность пациентов, информированное согласие) этих конфиденциальных данных, особенно при их интеграции для крупномасштабного анализа или разработки моделей персонализированного лечения. Систематический подход статьи к идентификации и удалению персональных данных (PII), исправлению ошибок данных (как OCRonos для текста) и обеспечению надлежащего лицензирования для разнообразных источников данных напрямую отражает биоинформатическую задачу курирования "чистых", "обеспечивающих конфиденциальность" и "этически соответствующих требованиям" когорт геномных данных для медицинских исследований, где целостность данных и строгие этические руководящие принципы имеют первостепенное значение.
Сценарий "Что если"
Что если бы исследователь в области управления цепочками поставок "украл" точное уравнение этой статьи — то есть, если бы он принял ее комплексный конвейер курирования и проверки данных, включая ее специализированные инструменты — завтра? Произошел бы глубокий прорыв в прозрачности и целостности мировой торговли. Представьте себе применение моделей, подобных Segmentext, для автоматического разбора и структурирования разнообразных коносаментов, таможенных деклараций и контрактов поставщиков, даже из отсканированных исторических документов, независимо от их исходного формата или языка. Затем OCRoscope и OCRerrcr могли бы быть адаптированы для обнаружения аномалий или несоответствий в идентификаторах продуктов, количествах или декларациях происхождения, выявляя потенциальные подделки, неправильно маркированные товары или нарушения соответствия с беспрецедентной точностью. OCRonos мог бы "исправлять" поврежденные или неполные цифровые записи, обеспечивая целостность данных во всей цепочке поставок. Кроме того, принципы Celadon могли бы быть адаптированы для обнаружения "нарушений этических норм" (например, признаков принудительного труда, экологической несоблюдения или несправедливой торговой практики) в документации поставщиков и общедоступных записях. Это привело бы к беспрецедентному уровню прозрачности, аудируемости и соблюдения этических норм в мировой торговле, значительно сократив мошенничество, улучшив безопасность продукции и создав действительно "чистые" цепочки поставок, потенциально даже создав "Общий корпус данных мировой торговли", который был бы как обширным, так и проверяемо этичным.
Универсальная библиотека структур
Данная статья значительно обогащает Универсальную библиотеку структур, демонстрируя, что принципы строгого происхождения данных, многоуровневого контроля качества и соблюдения этических норм являются не специфичными для конкретной области проблемами, а универсальными требованиями для создания надежных систем, будь то обработка языка, управление цепочками поставок или анализ биологических данных, тем самым укрепляя взаимосвязь научных проблем через общие математические закономерности.