कॉमन कॉर्पस: एलएलएम प्री-ट्रेनिंग के लिए नैतिक डेटा का सबसे बड़ा संग्रह
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र द्वारा संबोधित की गई समस्या, लार्ज लैंग्वेज मॉडल (एलएलएम) प्री-ट्रेनिंग के लिए नैतिक रूप से प्राप्त और अनुमत लाइसेंस वाले डेटा की कमी, विशेष रूप से एलएलएम के तेजी से पैमाने और व्यापक रूप से अपनाने से उत्पन्न हुई है। ऐतिहासिक रूप से, जीपीटी-3 (ब्राउन एट अल., 2020) जैसे मॉडलों के साथ इस क्षेत्र में एक महत्वपूर्ण बदलाव देखा गया, जिसने विशाल डेटासेट पर प्रशिक्षण का एक प्रतिमान स्थापित किया, जो अक्सर खरबों टोकन तक पहुँच जाता था। यह प्रवृत्ति जारी रही, जिसमें एलएलएम प्रशिक्षण डेटा का आकार 2025 तक अनुमानित 14-36 ट्रिलियन टोकन तक लघुगणकीय रूप से बढ़ रहा था।
पिछले दृष्टिकोणों की मौलिक सीमा और "दर्द बिंदु" वेब-स्क्रैप किए गए डेटा पर उनकी निर्भरता से उत्पन्न हुए, जो, हालांकि सार्वजनिक रूप से उपलब्ध थे, अक्सर स्पष्ट अनुमत लाइसेंस की कमी रखते थे। एनएलपी प्रैक्टिशनर्स अक्सर "उचित उपयोग" की धारणा के तहत काम करते थे, यह तर्क देते हुए कि एलएलएम प्रशिक्षण की परिवर्तनकारी प्रकृति कॉपीराइट सामग्री के उपयोग को उचित ठहराती है। हालांकि, इस दृष्टिकोण ने बढ़ते कानूनी चुनौतियों को जन्म दिया है, जैसे कि न्यूयॉर्क टाइम्स द्वारा ओपनएआई पर कॉपीराइट उल्लंघन का मुकदमा (रॉथ, 2023; पोप, 2024)। इसके अलावा, बुक्स3, LAION, GEITje, और MATH सहित कई प्रमुख डेटासेट को कॉपीराइट मुद्दों या CSAM (बाल यौन शोषण सामग्री) जैसी समस्याग्रस्त सामग्री की उपस्थिति के कारण कानूनी रूप से हटा दिया गया या प्रतिबंधित कर दिया गया, जिससे पिछले शोध अप्राप्य हो गए और डेवलपर्स के लिए पर्याप्त निवेश हानि हुई। कानूनी समस्याओं से परे, मौजूदा खुले डेटासेट में अक्सर बहुभाषी विविधता की कमी होती थी, जो मुख्य रूप से अंग्रेजी-केंद्रित थे, और अक्सर कम-संसाधन वाली भाषाओं में निम्न-गुणवत्ता या अनुपयोगी डेटा शामिल होता था। इस सामूहिक दबाव ने खुले विज्ञान अनुसंधान और एलएलएम में विकास को बढ़ावा देने के लिए एक वास्तव में खुले, कानूनी रूप से अनुपालन करने वाले, उच्च-गुणवत्ता वाले और विविध प्री-ट्रेनिंग डेटासेट की तत्काल आवश्यकता को उजागर किया।
सहज डोमेन शब्द
यहां कागज से कुछ विशेष डोमेन शब्द दिए गए हैं, जिन्हें एक नौसिखिया के लिए सहज उपमाओं में अनुवादित किया गया है:
- लार्ज लैंग्वेज मॉडल (LLM): एक सुपर-स्मार्ट डिजिटल मस्तिष्क की कल्पना करें जिसने इंटरनेट और किताबों पर लगभग सब कुछ "पढ़ा" है। यह फिर मानव-जैसी तरीकों से समझ सकता है, उत्पन्न कर सकता है और सवालों के जवाब दे सकता है, जैसे एक अत्यधिक शिक्षित और बहुमुखी सहायक।
- टोकन: इन्हें भाषा के मौलिक निर्माण खंडों के रूप में सोचें जिन्हें एक एलएलएम समझता है। वे मॉडल द्वारा संसाधित "शब्दों" या शब्दों के छोटे टुकड़ों (जैसे "अन-" या "-िंग") की तरह हैं, जैसे हम वाक्यों को समझने के लिए उन्हें अलग-अलग शब्दों में तोड़ते हैं।
- प्री-ट्रेनिंग: यह एक एलएलएम के लिए प्रारंभिक, बड़े पैमाने पर सीखने का चरण है। यह एक छात्र को प्राथमिक विद्यालय, हाई स्कूल और कॉलेज भेजने जैसा है ताकि वे किसी विशेष करियर में विशेषज्ञता हासिल करने से पहले कई विषयों में एक व्यापक, सामान्य शिक्षा प्राप्त कर सकें। मॉडल सामान्य भाषा पैटर्न और ज्ञान सीखता है।
- अनुमत लाइसेंस: इसे डेटा के लिए "सार्वभौमिक अनुमति पर्ची" मानें। यह स्पष्ट रूप से बताता है कि आप विशेष अनुमति मांगे बिना या कॉपीराइट मुकदमों की चिंता किए बिना, एआई मॉडल को प्रशिक्षित करने सहित लगभग किसी भी उद्देश्य के लिए डेटा का स्वतंत्र रूप से उपयोग, साझा और यहां तक कि बदल भी सकते हैं। यह "सभी अधिकार आरक्षित" के विपरीत है।
- ओसीआर त्रुटियाँ: अपनी कंप्यूटर में एक पुरानी, धुंधली किताब को स्कैन करने की कल्पना करें। कभी-कभी स्कैनर गलतियाँ करता है, एक "ई" को "सी" में बदल देता है या दो शब्दों को एक साथ जोड़ देता है। ओसीआर त्रुटियाँ वे डिजिटल "टाइपो" या विकृतियाँ हैं जो पाठ की छवियों (जैसे पुरानी दस्तावेजों से) को संपादन योग्य पाठ में परिवर्तित करते समय होती हैं।
संकेतन तालिका
ईमानदारी से कहूं तो, यह पत्र मुख्य रूप से एक नए गणितीय मॉडल या एल्गोरिथम को पेश करने के बजाय एक बड़े डेटासेट के निर्माण और विशेषताओं का वर्णन करता है जो समीकरणों में विशिष्ट गणितीय चर या मापदंडों पर निर्भर करता है। इसलिए, कागज के गद्य या आंकड़ों में कोई प्रमुख गणितीय संकेतन (चर, पैरामीटर) स्पष्ट रूप से परिभाषित या LaTeX सिंटैक्स में उपयोग नहीं किए गए हैं जो बाद के गणितीय स्पष्टीकरणों के लिए आवश्यक होंगे। पत्र डेटा को मापने के लिए "टोकन," "दस्तावेज," और "शब्द" जैसे वर्णनात्मक शब्दों का उपयोग करता है, लेकिन ये सूत्रों में एकल-अक्षर गणितीय प्रतीकों द्वारा दर्शाए नहीं जाते हैं।
समस्या परिभाषा और बाधाएँ
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित मुख्य समस्या लार्ज लैंग्वेज मॉडल (एलएलएम) के लिए बड़े पैमाने पर, उच्च-गुणवत्ता वाले, वास्तव में खुले, और अनुमत लाइसेंस वाले प्री-ट्रेनिंग डेटा की महत्वपूर्ण कमी है।
इनपुट/वर्तमान स्थिति:
वर्तमान में, एलएलएम को विशाल डेटासेट पर प्री-ट्रेन किया जाता है, जिसमें अक्सर विभिन्न डोमेन से प्राप्त खरबों टोकन शामिल होते हैं, जो मुख्य रूप से वेब से स्क्रैप किए जाते हैं। हालांकि, इस डेटा का एक महत्वपूर्ण हिस्सा या तो कॉपीराइटेड, मालिकाना है, या स्पष्ट अनुमत लाइसेंस की कमी है। इसने एलएलएम विकास के लिए एक अनिश्चित स्थिति पैदा कर दी है, विशेष रूप से खुले विज्ञान पहलों के लिए, जैसा कि कई कानूनी चुनौतियों (जैसे, ओपनएआई के खिलाफ मुकदमे, बुक्स3, LAION, और MATH जैसे डेटासेट के डीएमसीए टेकडाउन) से स्पष्ट है। मौजूदा "खुले" डेटासेट में अक्सर सीमाएँ होती हैं: वे अक्सर एकभाषी (मुख्य रूप से अंग्रेजी) होते हैं, वेब क्रॉल (जैसे कॉमन क्रॉल) पर भारी निर्भर करते हैं जिनके लाइसेंस अस्पष्ट होते हैं, या निम्न-गुणवत्ता, अनुपयोगी, या नैतिक रूप से समस्याग्रस्त सामग्री (जैसे, व्यक्तिगत पहचान योग्य जानकारी (पीआईआई), विषाक्त भाषा) शामिल होती है। इसके अलावा, सामग्री के मालिक एआई प्रशिक्षण के लिए डेटा स्क्रैपिंग के खिलाफ तकनीकी और कानूनी प्रतिबंधों को तेजी से लागू कर रहे हैं, जिससे आसानी से उपलब्ध डेटा का पूल और सिकुड़ रहा है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति):
वांछित अंतिम बिंदु एलएलएम प्री-ट्रेनिंग के लिए एक मजबूत, कानूनी रूप से अनुपालन करने वाले, और नैतिक रूप से ध्वनि आधार की स्थापना है। इसमें एक विशाल डेटासेट बनाना शामिल है जो है:
1. वास्तव में खुला और अनुमत लाइसेंस वाला: सभी सामग्री कॉपीराइट-मुक्त या स्पष्ट, अनुमत लाइसेंस (खुले विज्ञान को बढ़ावा देने के लिए कानूनी निश्चितता और सुनिश्चित करने) के तहत उपलब्ध होनी चाहिए।
2. बहुभाषी और बहु-डोमेन: सामान्यीकृत और शक्तिशाली मॉडल प्रदर्शन को बढ़ावा देने के लिए डेटासेट में भाषाओं की एक विस्तृत श्रृंखला, जिसमें कम-संसाधन वाली भाषाएं शामिल हैं, और विविध डोमेन (जैसे, सरकार, संस्कृति, विज्ञान, कोड, वेब, सिमेंटिक डेटा) को शामिल किया जाना चाहिए।
3. उच्च-गुणवत्ता और क्यूरेटेड: पारदर्शिता और पुनरुत्पादकता के लिए विस्तृत उत्पत्ति और मेटाडेटा के साथ डेटा को सावधानीपूर्वक साफ, पीआईआई, विषाक्तता और ओसीआर त्रुटियों के लिए फ़िल्टर किया जाना चाहिए।
लुप्त कड़ी या गणितीय अंतर:
सटीक लुप्त कड़ी एक व्यापक, नैतिक रूप से प्राप्त, और कानूनी रूप से स्पष्ट डेटा कॉमन्स की अनुपस्थिति है जो एलएलएम प्रशिक्षण के लिए वर्तमान में उपयोग किए जाने वाले मालिकाना या अस्पष्ट रूप से लाइसेंस प्राप्त डेटासेट के पैमाने और विविधता का मुकाबला कर सके। यह पत्र कॉमन कॉर्पस को इकट्ठा करके, क्यूरेट करके और जारी करके इस अंतर को पाटने का प्रयास करता है, एक डेटासेट जिसे इन कड़े कानूनी और नैतिक मानदंडों को पूरा करने के लिए जमीन से ऊपर डिजाइन किया गया है, जबकि अभी भी बहुभाषी प्री-ट्रेनिंग के लिए उपयुक्त विविध टोकन की एक पर्याप्त मात्रा प्रदान करता है। गणितीय अंतर किसी विशिष्ट समीकरण में नहीं है, बल्कि एलएलएम प्रशिक्षण के जटिल अनुकूलन समस्याओं के लिए एक अच्छी तरह से परिभाषित, बड़े पैमाने पर, और कानूनी रूप से स्वच्छ इनपुट स्थान की कमी में है।
दुविधा:
केंद्रीय, दर्दनाक ट्रेड-ऑफ जिसने पिछले शोधकर्ताओं को फंसाया है, वह है "स्केल बनाम। कानूनीता/नैतिकता/गुणवत्ता" दुविधा। अत्याधुनिक एलएलएम प्रदर्शन के लिए आवश्यक विशाल पैमाने को प्राप्त करने के लिए ऐतिहासिक रूप से विशाल, अक्सर अंधाधुंध रूप से स्क्रैप किए गए वेब डेटा के उपयोग की आवश्यकता होती है। यह दृष्टिकोण, हालांकि पैमाने के लिए प्रभावी है, अनिवार्य रूप से की ओर ले जाता है:
* कानूनी भेद्यता: कॉपीराइट या मालिकाना सामग्री का समावेश, जिसके परिणामस्वरूप मुकदमे और डेटासेट टेकडाउन होते हैं, पुनरुत्पादकता और खुले अनुसंधान को कमजोर करते हैं।
* नैतिक समझौते: पीआईआई, हानिकारक, या पक्षपाती सामग्री की उपस्थिति, जिसके परिणामस्वरूप नैतिक चिंताएं और नियामक गैर-अनुपालन (जैसे, जीडीपीआर) होते हैं।
* गुणवत्ता में गिरावट: वेब-स्क्रैप किए गए डेटा में अक्सर निम्न-गुणवत्ता, शोरगुल वाला, या अनुपयोगी पाठ होता है, जो मॉडल के प्रदर्शन को नकारात्मक रूप से प्रभावित कर सकता है और व्यापक, महंगा पोस्ट-प्रोसेसिंग की आवश्यकता होती है।
दुविधा यह है कि एक पहलू में सुधार (जैसे, सख्त कानूनी अनुपालन सुनिश्चित करना) आमतौर पर उपलब्ध डेटा पैमाने को काफी कम कर देता है या क्यूरेशन लागत को घातीय रूप से बढ़ाता है, जिससे प्रतिस्पर्धी एलएलएम को प्रशिक्षित करना कठिन हो जाता है। इसके विपरीत, पैमाने को प्राथमिकता देने से अक्सर कानूनी और नैतिक मानकों से समझौता होता है। पत्र एक "खुला डेटा विरोधाभास" भी उजागर करता है, जहां वास्तव में खुला सामग्री विरोधाभासी रूप से प्रमुख प्री-ट्रेनिंग स्रोतों में कम दिखाई देती है, जिससे इसका एकत्रीकरण स्वाभाविक रूप से कठिन हो जाता है।
बाधाएँ और विफलता मोड
एक वास्तव में खुले, अनुमत लाइसेंस वाले, और उच्च-गुणवत्ता वाले एलएलएम प्री-ट्रेनिंग डेटासेट के निर्माण की समस्या कई कठोर, यथार्थवादी बाधाओं के कारण अविश्वसनीय रूप से कठिन है:
-
कानूनी और लाइसेंसिंग बाधाएँ:
- सख्त अनुमतता: डेटा कॉपीराइट-मुक्त (सार्वजनिक डोमेन) या स्पष्ट अनुमत लाइसेंस (जैसे, सीसी-बाय, एमआईटी, अपाचे-2.0) के तहत होना चाहिए। यह सामान्य वेब स्क्रैप की तुलना में प्रयोग करने योग्य डेटा के पूल को गंभीर रूप से सीमित करता है, क्योंकि बहुत सारी सार्वजनिक रूप से उपलब्ध वेब सामग्री एआई प्रशिक्षण के लिए अनुमत रूप से लाइसेंस प्राप्त नहीं है।
- कॉपीराइट अवधि जटिलता: सार्वजनिक डोमेन स्थिति का निर्धारण, विशेष रूप से अंतरराष्ट्रीय और ऐतिहासिक कार्यों के लिए, जटिल कानूनी मानदंडों (जैसे, लेखक जीवन + 70 वर्ष, प्रकाशन + 95 वर्ष अमेरिकी लेखकों के लिए) को शामिल करता है, जिसके लिए सावधानीपूर्वक अधिकार सत्यापन की आवश्यकता होती है।
- डीएमसीए टेकडाउन: गैर-अनुपालन डेटा के लिए कानूनी कार्रवाई और डीएमसीए टेकडाउन का निरंतर खतरा किसी भी डेटासेट को अस्पष्ट स्रोतों पर निर्मित करता है, जो दीर्घकालिक अनुसंधान के लिए अस्थिर और अविश्वसनीय बनाता है।
-
डेटा-संचालित और गुणवत्ता बाधाएँ:
- उच्च-गुणवत्ता वाले खुले डेटा की अत्यधिक विरलता: जबकि वेब विशाल है, स्पष्ट अनुमत लाइसेंस के साथ उच्च-गुणवत्ता वाले, बहुभाषी, बहु-डोमेन डेटा का उपसमूह तुलनात्मक रूप से विरल और खंडित है।
- ऐतिहासिक ग्रंथों में खराब ओसीआर गुणवत्ता: मूल्यवान ऐतिहासिक डेटा (ओपन कल्चर, ओपन गवर्नमेंट) का एक महत्वपूर्ण हिस्सा डिजिटलीकृत स्रोतों से आता है जिसमें खराब ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर) गुणवत्ता होती है, जिससे शोर और त्रुटियां होती हैं जो पाठ की गुणवत्ता को खराब करती हैं। इसके लिए उन्नत, कम्प्यूटेशनल रूप से गहन ओसीआर त्रुटि पहचान और सुधार उपकरणों की आवश्यकता होती है।
- पीआईआई और हानिकारक सामग्री: सार्वजनिक डोमेन और अन्य खुले स्रोतों में व्यक्तिगत पहचान योग्य जानकारी (पीआईआई) या हानिकारक/पक्षपाती सामग्री (जैसे, पुरानी मानदंडों को दर्शाने वाले ऐतिहासिक ग्रंथ, छवि डेटासेट में सीएसएएम) हो सकती है। मजबूत, सटीक, और कुशल पीआईआई हटाने और विषाक्तता का पता लगाने वाले पाइपलाइन अनिवार्य हैं लेकिन विविध भाषाओं और डोमेन में बड़े पैमाने पर लागू करना चुनौतीपूर्ण है।
- मेटाडेटा की कमी: कई संभावित डेटा स्रोतों में उत्पत्ति, लाइसेंसिंग और भाषा के संबंध में पर्याप्त मेटाडेटा की कमी होती है, जिससे स्वचालित क्यूरेशन मुश्किल हो जाता है और मैन्युअल हस्तक्षेप या परिष्कृत अनुमान की आवश्यकता होती है।
- बहुभाषी विविधता चुनौतियाँ: डेटा प्रसंस्करण (विभाजन, गुणवत्ता मूल्यांकन) के लिए उपकरणों को भाषाओं की एक विस्तृत श्रृंखला में, जिसमें कम-संसाधन वाली भाषाएं शामिल हैं, जहां मौजूदा एनएलपी उपकरण अक्सर खराब सामान्यीकरण करते हैं, मज़बूती से प्रदर्शन करना चाहिए।
-
कम्प्यूटेशनल और अवसंरचना बाधाएँ:
- बड़े पैमाने पर प्रसंस्करण: "लगभग दो ट्रिलियन टोकन" को संभालना और क्यूरेट करना भंडारण, प्रसंस्करण, फ़िल्टरिंग और गुणवत्ता मूल्यांकन के लिए पर्याप्त कम्प्यूटेशनल संसाधनों की आवश्यकता होती है।
- क्यूरेशन टूल की कम्प्यूटेशनल लागत: आवश्यक होने पर भी, ओसीआर त्रुटि का पता लगाने (जैसे, OCRerrcr) जैसे उन्नत क्यूरेशन टूल कम्प्यूटेशनल रूप से गहन हो सकते हैं, जो तेज, कम सटीक विकल्पों की तुलना में कम कुशलता से स्केल करते हैं, बहुत बड़े कॉर्पोरा के लिए सटीकता और प्रसंस्करण गति के बीच एक ट्रेड-ऑफ प्रस्तुत करते हैं।
- डेटा उत्पत्ति ट्रैकिंग: विविध स्रोतों में प्रत्येक डेटा ऑब्जेक्ट के लिए उत्पत्ति, लाइसेंस और मेटाडेटा को सावधानीपूर्वक ट्रैक करने से डेटा पाइपलाइन में महत्वपूर्ण ओवरहेड जुड़ जाता है।
-
विफलता मोड:
- कानूनी गैर-अनुपालन: गैर-अनुमत रूप से लाइसेंस प्राप्त सामग्री की सटीक पहचान और फ़िल्टर करने में विफलता से कानूनी जोखिम और संभावित डेटासेट टेकडाउन होते हैं।
- नैतिक उल्लंघन: अपर्याप्त पीआईआई हटाने या विषाक्तता फ़िल्टरिंग से गोपनीयता उल्लंघन या प्रशिक्षित एलएलएम में हानिकारक पूर्वाग्रहों का प्रसार हो सकता है।
- कम मॉडल प्रदर्शन: निम्न-गुणवत्ता, शोरगुल वाले, या अपर्याप्त रूप से विविध डेटा का उपयोग करने से खराब प्रदर्शन, सीमित सामान्यीकरण, या अवांछनीय व्यवहार (जैसे, सुधार कार्यों में "भाषा स्विचिंग", सामान्य लेखन शैलियाँ) वाले एलएलएम हो सकते हैं।
- पुनरुत्पादकता की कमी: यदि डेटासेट स्थिर, अच्छी तरह से प्रलेखित, और लगातार उपलब्ध नहीं है, तो उस पर निर्मित अनुसंधान अप्राप्य हो जाता है।
- अक्षम क्यूरेशन: मैन्युअल या धीमी क्यूरेशन प्रक्रियाएं आधुनिक एलएलएम प्रशिक्षण के लिए आवश्यक पैमाने पर अव्यवहारिक हो जाती हैं, जिसके लिए कुशल, स्वचालित, फिर भी सटीक उपकरणों की आवश्यकता होती है।
- कभी-कभी नकली दोहराव: उन्नत उपकरणों जैसे OCRonos के साथ भी, कभी-कभी नकली दोहराए गए शब्दों का समावेश हो सकता है, जिसके लिए पोस्ट-प्रोसेसिंग की आवश्यकता होती है।
यह दृष्टिकोण क्यों
विकल्प की अनिवार्यता
इस पत्र द्वारा संबोधित मुख्य समस्या लार्ज लैंग्वेज मॉडल (एलएलएम) के लिए स्वयं एक नए गणितीय मॉडल या एल्गोरिथम का विकास नहीं है, बल्कि उच्च-गुणवत्ता, वास्तव में खुले, अनुमत लाइसेंस वाले, बहुभाषी, और बहु-डोमेन प्री-ट्रेनिंग डेटा की महत्वपूर्ण कमी है। लेखकों ने महसूस किया कि पारंपरिक "SOTA" डेटा संग्रह और क्यूरेशन विधियाँ मौलिक रूप से अपर्याप्त थीं क्योंकि वे कानूनी, नैतिक और गुणवत्ता संबंधी समस्याओं की एक श्रृंखला की ओर ले जाती थीं जो खुले विज्ञान अनुसंधान और मजबूत एलएलएम के विकास को गंभीर रूप से बाधित करती थीं।
मौजूदा डेटासेट, जैसे C4, Books3, LAION, RefinedWeb, और Dolma, उनके पैमाने के बावजूद, महत्वपूर्ण कमियां प्रस्तुत करते हैं:
* कानूनी और नैतिक खदानें: कई में कॉपीराइट या मालिकाना सामग्री शामिल थी, जिससे कानूनी चुनौतियाँ हुईं (जैसे, ओपनएआई के खिलाफ न्यूयॉर्क टाइम्स मुकदमा, बुक्स3 का डीएमसीए टेकडाउन, और सीएसएएम सामग्री के कारण LAION को हटाना)। इसने अनुसंधान को अप्राप्य बना दिया और डेवलपर्स के लिए महत्वपूर्ण जोखिम पैदा किए।
* पहुँच प्रतिबंध: सामग्री के मालिक एआई प्रशिक्षण के लिए स्क्रैपिंग के खिलाफ तकनीकी उपायों और कानूनी प्रावधानों को तेजी से लागू कर रहे थे, जिससे सार्वजनिक रूप से उपलब्ध वेब डेटा (जैसे, C4 का 45%) का बड़ा हिस्सा दुर्गम या प्रतिबंधित हो गया।
* एकभाषी पूर्वाग्रह: अधिकांश उभरते "खुले" डेटासेट मुख्य रूप से केवल अंग्रेजी (जैसे, C4C, ओपन लाइसेंस कॉर्पस, KL3M, कॉमन पाइल) थे, जिससे बहुभाषी एलएलएम के विकास में गंभीर रूप से बाधा उत्पन्न हुई।
* निम्न गुणवत्ता और पूर्वाग्रह: वेब-स्क्रैप किए गए डेटा में अक्सर निम्न गुणवत्ता, मशीन-जनित पाठ, व्यक्तिगत पहचान योग्य जानकारी (पीआईआई), और हानिकारक या पक्षपाती सामग्री होती थी। विशेष रूप से बहुभाषी डेटासेट में बहुत सारी अनुपयोगी सामग्री पाई गई।
इन व्यापक मुद्दों को देखते हुए, लेखकों ने निष्कर्ष निकाला कि डेटा संग्रह और क्यूरेशन के लिए एक नया प्रतिमान एकमात्र व्यवहार्य समाधान था। इसके लिए एक डेटासेट को इकट्ठा करने के लिए एक सावधानीपूर्वक, जमीन से ऊपर का दृष्टिकोण आवश्यक था जिसे स्पष्ट रूप से कानूनी रूप से अनुपालन करने वाले, नैतिक रूप से ध्वनि, उच्च-गुणवत्ता वाले, और भाषाओं और डोमेन में विविध होने के लिए डिज़ाइन किया गया था। कॉमन कॉर्पस का "दृष्टिकोण"—स्पष्ट लाइसेंसिंग, व्यापक उत्पत्ति, और उन्नत क्यूरेशन टूल पर ध्यान केंद्रित करना—सिर्फ एक सुधार नहीं था, बल्कि खुले एलएलएम अनुसंधान के लिए एक आवश्यक आधार था।
तुलनात्मक श्रेष्ठता
कॉमन कॉर्पस दृष्टिकोण पिछले डेटा संग्रह विधियों और मौजूदा डेटासेट पर गुणात्मक श्रेष्ठता प्रदान करता है, मुख्य रूप से केवल कच्चे टोकन गणना के बजाय कानूनी अनुपालन, डेटा गुणवत्ता और विविधता के लिए अपनी संरचनात्मक प्रतिबद्धता के माध्यम से।
- अभूतपूर्व कानूनी और नैतिक अनुपालन: कानूनी लड़ाई और टेकडाउन का सामना करने वाले डेटासेट के विपरीत, कॉमन कॉर्पस विशेष रूप से कॉपीराइट-मुक्त या अनुमत लाइसेंस वाले डेटा (सार्वजनिक डोमेन, सीसी-बाय, एमआईटी, अपाचे-2.0, आदि, जैसा कि तालिका 4 में विस्तृत है) से बनाया गया है। यह संरचनात्मक लाभ सुनिश्चित करता है कि कॉमन कॉर्पस पर प्रशिक्षित मॉडल कई वाणिज्यिक और यहां तक कि "खुले" मॉडल को त्रस्त करने वाली कानूनी अनिश्चितताओं के बिना जारी और उपयोग किए जा सकते हैं। "खुले" के इस मजबूत अर्थ के प्रति यह प्रतिबद्धता एक मौलिक गुणात्मक छलांग है।
- विशेष क्यूरेशन के माध्यम से बेहतर डेटा गुणवत्ता: पत्र "बैड डेटा टूलबॉक्स" (धारा 5) प्रस्तुत करता है, जो बहुभाषी, ऐतिहासिक और डिजिटलीकृत सामग्री के लिए अद्वितीय चुनौतियों को दूर करने के लिए डिज़ाइन किए गए कस्टम टूल का एक सूट है:
- सेगमेंटटेक्स्ट: मजबूत पाठ विभाजन के लिए एक टोकन वर्गीकरण मॉडल, यहां तक कि टूटे हुए या असंरचित इनपुट से भी, जो लेआउट-आधारित विधियों की तुलना में बेहतर है जब दृश्य जानकारी खो जाती है।
- ओसीआर त्रुटि का पता लगाना (OCRoscope & OCRerrcr): OCRoscope तेज, बड़े पैमाने पर गुणवत्ता अनुमान प्रदान करता है, जबकि OCRerrcr टोकन-स्तरीय त्रुटि पहचान प्रदान करता है। यह ऐतिहासिक और डिजिटलीकृत दस्तावेजों के लिए महत्वपूर्ण है, जो कच्चे ओसीआर आउटपुट की तुलना में उच्च इनपुट गुणवत्ता सुनिश्चित करता है।
- ओसीआर सुधार (OCRonos): Llama-3-8B से फाइन-ट्यून किया गया एक जनरेटिव एलएलएम, विशेष रूप से ओसीआर त्रुटियों, शब्द विभाजनों और संरचनात्मक कलाकृतियों को ठीक करने के लिए प्रशिक्षित किया गया है। इसे रूढ़िवादी होने और भाषा स्विचिंग का विरोध करने के लिए डिज़ाइन किया गया है, जो छोटे सामान्यवादी एलएलएम में एक सामान्य विफलता मोड है जब शोरगुल वाले इनपुट का सामना करना पड़ता है।
- पीआईआई हटाना: पाठ प्रारूप और मॉडल समझ को बनाए रखते हुए, पीआईआई की पहचान करने और उन्हें काल्पनिक लेकिन यथार्थवादी मानों से बदलने के लिए कस्टम नियमित अभिव्यक्तियों के साथ माइक्रोसॉफ्ट के प्रेसिडियो का उपयोग करता है, जो साधारण हटाने या टैगिंग की तुलना में अधिक परिष्कृत दृष्टिकोण है।
- विषाक्तता का पता लगाना (सेलाडॉन): एक बहुभाषी विषाक्तता क्लासिफायर (DeBERTa-v3-small) ऐतिहासिक पाठ, ओसीआर शोर और गैर-अंग्रेजी सामग्री के लिए अनुकूलित है। यह बहुत बड़े मॉडल (Llama 3.1-8B-Instruct) के तुलनीय प्रदर्शन प्राप्त करता है लेकिन 40 गुना तेज है, जिससे बड़े पैमाने पर फ़िल्टरिंग व्यावहारिक हो जाती है। यह हानिकारक सामग्री की उपस्थिति को काफी कम करता है, जो वेब-स्क्रैप किए गए कॉर्पोरा में एक प्रमुख मुद्दा है।
- वास्तविक बहुभाषी और बहु-डोमेन विविधता: कॉमन कॉर्पस पूरी तरह से खुला डेटासेट (2 ट्रिलियन टोकन) है जिसमें उच्च बहुभाषी विविधता है, जो भाषाओं की एक विस्तृत श्रृंखला (उच्च और निम्न-संसाधन दोनों) को कवर करता है (चित्र 2, तालिका 5)। विविध डोमेन (ओपन गवर्नमेंट, ओपन कल्चर, ओपन साइंस, ओपन कोड, ओपन वेब, ओपन सिमेंटिक) में इसकी संरचना को चित्र 1 में विस्तृत किया गया है, जो "वेब क्रॉल" डेटा (तालिका 1, चित्र 3b) से परे है। इन संग्रहों का लौकिक और सिमेंटिक अवलोकन चित्र 3 में और स्पष्ट किया गया है। यह संरचनात्मक विविधता सामान्यीकृत और शक्तिशाली एलएलएम को प्रशिक्षित करने के लिए आवश्यक है जो विभिन्न कार्यों और भाषाओं में अच्छा प्रदर्शन करते हैं, जो मुख्य रूप से एकभाषी या वेब-पाठ-केंद्रित डेटासेट पर एक स्पष्ट लाभ है।
- पुनरुत्पादकता और खुला विज्ञान अवसंरचना: विस्तृत उत्पत्ति, प्रसंस्करण चरणों को प्रदान करके, और क्यूरेशन टूल को खुले तौर पर जारी करके, कॉमन कॉर्पस खुले विज्ञान के लिए एक महत्वपूर्ण अवसंरचना के रूप में कार्य करता है। यह पारदर्शिता और उपकरण साझाकरण सीधे डेटासेट के अचानक हटाने के कारण अप्राप्य अनुसंधान की समस्या को संबोधित करता है।
जबकि पत्र स्पष्ट रूप से डेटा क्यूरेशन प्रक्रिया के लिए $O(N^2)$ से $O(N)$ तक मेमोरी जटिलता में कमी का विवरण नहीं देता है, सेलाडॉन (विषाक्तता का पता लगाने के लिए 40x तेज) और OCRoscope (बड़े पैमाने पर कम कम्प्यूटेशनल रूप से महंगा) जैसे कुशल उपकरणों पर जोर इस विशाल मात्रा में डेटा को संभालने में एक संरचनात्मक लाभ प्रदर्शित करता है जो एलएलएम प्री-ट्रेनिंग के लिए आवश्यक है। यह दक्षता ऐसे उच्च-गुणवत्ता वाले, बड़े पैमाने पर, क्यूरेटेड कॉर्पस का निर्माण संभव बनाती है।
बाधाओं के साथ संरेखण
कॉमन कॉर्पस दृष्टिकोण समस्या परिभाषा से प्राप्त अंतर्निहित और स्पष्ट बाधाओं के साथ पूरी तरह से संरेखित होता है, जो एलएलएम प्री-ट्रेनिंग के लिए कानूनी रूप से ध्वनि, उच्च-गुणवत्ता, विविध और खुले तौर पर सुलभ डेटा की आवश्यकता पर केंद्रित है।
- बाधा: सख्त कानूनी और नैतिक अनुपालन: पत्र का प्राथमिक उद्देश्य "डेटा सुरक्षा नियमों का अनुपालन करने वाले" और "कॉपीराइट या अन्य कानूनी सीमाओं से मुक्त" डेटा प्रदान करना है। कॉमन कॉर्पस विशेष रूप से कॉपीराइट-मुक्त या अनुमत लाइसेंस वाली सामग्री (तालिका 4) से प्राप्त करके इसे प्राप्त करता है। इसके अलावा, यह पीआईआई हटाने (प्रेसीडियो का उपयोग करके) और विषाक्तता का पता लगाने (सेलाडॉन का उपयोग करके) के लिए मजबूत कार्यान्वयन करता है, जो गोपनीयता और हानिकारक सामग्री की नैतिक चिंताओं को सीधे संबोधित करता है। यह "विवाह" सुनिश्चित करता है कि कॉमन कॉर्पस पर प्रशिक्षित एलएलएम को पिछले डेटासेट से जुड़े कानूनी और प्रतिष्ठा जोखिमों के बिना तैनात किया जा सके।
- बाधा: उच्च डेटा गुणवत्ता और प्रयोज्यता: समस्या इस बात पर प्रकाश डालती है कि मौजूदा डेटासेट में अक्सर "निम्न-गुणवत्ता या पूरी तरह से अनुपयोगी डेटा" शामिल होता है, खासकर बहुभाषी संदर्भों में। कॉमन कॉर्पस समाधान सीधे अपने "बैड डेटा टूलबॉक्स" के साथ इसे संबोधित करता है। सेगमेंटटेक्स्ट असंरचित और डिजिटलीकृत ग्रंथों को संभालता है, OCRoscope और OCRerrcr त्रुटियों का पता लगाते हैं, और OCRonos उन्हें ठीक करता है, जिससे खराब इनपुट प्रयोग करने योग्य पाठ में बदल जाते हैं। यह टूल सूट सुनिश्चित करता है कि ऐतिहासिक या शोरगुल वाले डेटा से भी सार्थक रूप से प्रशिक्षण में योगदान होता है, जिससे उच्च-गुणवत्ता वाले इनपुट की आवश्यकता पूरी होती है।
- बाधा: बहुभाषी और बहु-डोमेन विविधता: पिछले "खुले" डेटासेट की एक प्रमुख सीमा उनकी एकभाषी प्रकृति या सीमित डोमेन कवरेज थी। कॉमन कॉर्पस को स्पष्ट रूप से "सबसे बड़ा पूरी तरह से खुला प्री-ट्रेनिंग डेटासेट... जिसमें उच्च बहुभाषी विविधता है" (चित्र 2, तालिका 5) और विविध डोमेन (ओपन गवर्नमेंट, कल्चर, साइंस, कोड, वेब, सिमेंटिक) की एक विस्तृत श्रृंखला को कवर करने के लिए डिज़ाइन किया गया है। यह एलएलएम की आवश्यकता को सीधे संबोधित करता है जो विभिन्न भाषाओं और ज्ञान क्षेत्रों में शक्तिशाली और सामान्यीकृत होते हैं।
- बाधा: खुला विज्ञान और पुनरुत्पादकता: पत्र "वास्तव में खुले प्री-ट्रेनिंग डेटा" और "पुनरुत्पादक अनुसंधान कलाकृतियों" की आवश्यकता पर जोर देता है। कॉमन कॉर्पस विस्तृत उत्पत्ति, प्रसंस्करण चरणों को प्रदान करके और अपने क्यूरेशन टूल (बैड डेटा टूलबॉक्स) को खुले तौर पर जारी करके संरेखित होता है। यह पारदर्शिता और पद्धति साझाकरण सीधे खुले विज्ञान पारिस्थितिकी तंत्र का समर्थन करता है, यह सुनिश्चित करता है कि इस डेटा पर निर्मित अनुसंधान को सत्यापित और दोहराया जा सके।
- बाधा: बड़ा पैमाना: एलएलएम को "प्रशिक्षण डेटा की बड़ी मात्रा" (परिचय) की आवश्यकता होती है। कॉमन कॉर्पस, "लगभग 2 ट्रिलियन टोकन" पर, इस पैमाने की आवश्यकता को पूरा करता है। इसके क्यूरेशन टूल (जैसे, सेलाडॉन की दक्षता) की दक्षता इसे इतने बड़े कॉर्पस को संसाधित और बनाए रखना व्यावहारिक बनाती है, यह सुनिश्चित करती है कि गुणवत्ता और विविधता की बाधाएं इस विशाल पैमाने पर भी पूरी हों।
विकल्पों का अस्वीकरण
पत्र स्पष्ट रूप से और अंतर्निहित रूप से कई लोकप्रिय दृष्टिकोणों और मौजूदा डेटासेट को अस्वीकार करता है, उनकी मौलिक कमियों को उजागर करता है जिन्हें कॉमन कॉर्पस दूर करने का लक्ष्य रखता है।
- अंधाधुंध वेब स्क्रैपिंग का अस्वीकरण (जैसे, C4, Books3 के लिए कॉमन क्रॉल): लेखकों ने स्पष्ट रूप से कहा है कि "अधिकांश वेब डेटा में यह निर्धारित करने के लिए पर्याप्त मेटाडेटा नहीं है कि क्या यह अनुमत रूप से लाइसेंस प्राप्त है" और यह कि "इस डेटा के उपयोग के लिए तेजी से अधिक कानूनी चुनौतियाँ हैं।" उन्होंने ओपनएआई के खिलाफ एनवाईटी मुकदमे, बुक्स3 के डीएमसीए टेकडाउन, और सीएसएएम के साथ LAION डेटासेट के मुद्दों को ऐसे दृष्टिकोणों की विफलता के प्रत्यक्ष प्रमाण के रूप में उद्धृत किया है। पत्र नोट करता है कि "सेवा की शर्तों में बदलाव के कारण C4 का पूरा 45% अब प्रतिबंधित है।" कॉमन कॉर्पस का दृष्टिकोण जिसमें केवल कॉपीराइट-मुक्त या अनुमत लाइसेंस वाले डेटा को स्पष्ट उत्पत्ति के साथ शामिल किया गया है, व्यापक वेब स्क्रैपिंग के अंतर्निहित कानूनी और नैतिक जोखिमों का एक सीधा अस्वीकरण है।
- मौजूदा "खुले" डेटासेट को पर्याप्त मानने से इनकार: पत्र C4C, ओपन लाइसेंस कॉर्पस, KL3M, और कॉमन पाइल (तालिका 1) जैसी अन्य पहलों की तुलना करता है। यह बताता है कि इनमें से कई "एकभाषी हैं, जो प्रभावी रूप से भाषा मॉडल की पहुंच को अंग्रेजी बोलने वाले दर्शकों तक सीमित करते हैं।" उदाहरण के लिए, KL3M "अंग्रेजी में प्रशासनिक और कानूनी दस्तावेजों तक सीमित है।" कॉमन कॉर्पस की एक साथ सभी चार मानदंडों को पूरा करने की अनूठी क्षमता—बहुभाषी, बहु-डोमेन, वेब क्रॉल से परे, और पूरी तरह से अनुमत लाइसेंसिंग—खुले, सामान्य-उद्देश्य वाले एलएलएम विकास के व्यापक लक्ष्य के लिए इन विकल्पों की अपर्याप्तता को प्रदर्शित करती है।
- अनक्यूरेटेड या खराब क्यूरेटेड बहुभाषी डेटासेट का अस्वीकरण: पत्र इस बात पर प्रकाश डालता है कि "कई बहुभाषी डेटासेट में बहुत सारी निम्न-गुणवत्ता या पूरी तरह से अनुपयोगी सामग्री होती है" (क्रेत्ज़र एट अल., 2022)। इसका तात्पर्य है कि कठोर क्यूरेशन के बिना विभिन्न भाषाओं से डेटा को केवल एकत्रित करने से, जैसा कि कुछ वैकल्पिक दृष्टिकोणों में किया जा सकता है, उप-इष्टतम प्रशिक्षण डेटा होता है। कॉमन कॉर्पस का "बैड डेटा टूलबॉक्स" (सेगमेंटटेक्स्ट, ओसीआर सुधार, विषाक्तता का पता लगाना) इस समस्या का सीधा मुकाबला है, जो विविध और चुनौतीपूर्ण भाषाई स्रोतों के लिए भी उच्च गुणवत्ता सुनिश्चित करता है।
- पीआईआई और विषाक्तता की उपेक्षा करने वाले दृष्टिकोणों का अस्वीकरण: पत्र स्पष्ट रूप से कहता है कि "वेब डेटा हानिकारक और पक्षपाती सामग्री का एक प्रमुख स्रोत है" और यह कि "सार्वजनिक डोमेन डेटा... ऐतिहासिक आवधिक और मोनोग्राफ का गठन करता है... इनमें से कई ग्रंथ आधुनिक नैतिक मानकों को पूरा नहीं करते हैं।" पीआईआई हटाने के लिए प्रेसीडियो और बहुभाषी विषाक्तता का पता लगाने के लिए सेलाडॉन जैसे विशेष उपकरणों का विकास किसी भी डेटा संग्रह रणनीति का एक स्पष्ट अस्वीकरण है जो इन महत्वपूर्ण फ़िल्टरिंग चरणों को प्राथमिकता नहीं देता है।
संक्षेप में, लेखकों ने उन विकल्पों को अस्वीकार कर दिया जो या तो कड़े कानूनी और नैतिक आवश्यकताओं को पूरा करने में विफल रहे, पर्याप्त बहुभाषी और बहु-डोमेन कवरेज की कमी थी, या डेटा गुणवत्ता पर समझौता किया, जो सभी खुले एलएलएम के स्थायी विकास के लिए सर्वोपरि हैं।
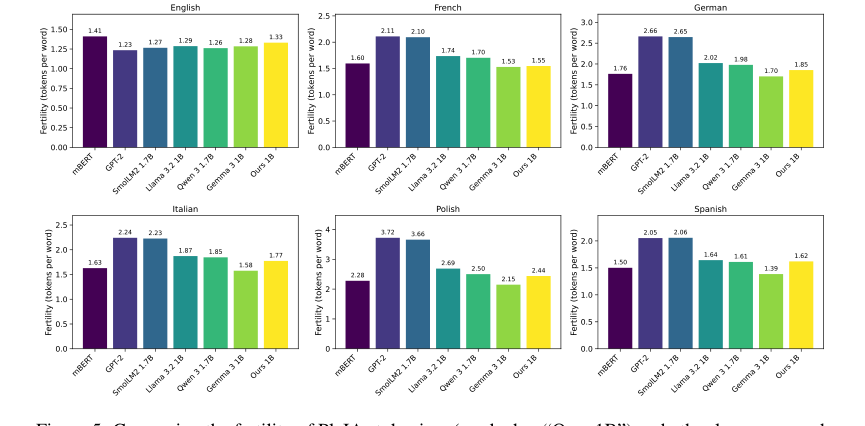 Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
Figure 5. Comparing the fertility of PleIAs tokenizer (marked as “Ours 1B”) and other language mod- els for six languages. The data source for all languages is the devtest set of FLORES200 (Costa- juss`a et al., 2022)
गणितीय और तार्किक तंत्र
"कॉमन कॉर्पस: एलएलएम प्री-ट्रेनिंग के लिए नैतिक डेटा का सबसे बड़ा संग्रह" पत्र मुख्य रूप से लार्ज लैंग्वेज मॉडल (एलएलएम) को प्रशिक्षित करने के लिए एक बड़े पैमाने पर, नैतिक रूप से प्राप्त डेटासेट के सावधानीपूर्वक निर्माण और क्यूरेशन पर केंद्रित है। जबकि यह इस डेटासेट का उपयोग करके एलएलएम के बाद के प्रशिक्षण और मूल्यांकन का वर्णन करता है, इस पत्र द्वारा पेश किए गए या विस्तृत किए गए मुख्य गणितीय और तार्किक तंत्र मुख्य रूप से डेटा क्यूरेशन पाइपलाइन से संबंधित हैं, न कि एक उपन्यास एलएलएम वास्तुकला या प्रशिक्षण उद्देश्य फ़ंक्शन से। उल्लिखित एलएलएम (लामा-शैली, डीबरटा वेरिएंट) मौजूदा मॉडल हैं, और सीखने के लिए उनके अंतर्निहित गणितीय इंजन साहित्य में अच्छी तरह से स्थापित हैं। इसलिए, यह अनुभाग डेटा क्यूरेशन प्रक्रिया में नियोजित तार्किक और एल्गोरिथम तंत्र पर ध्यान केंद्रित करेगा, जो पत्र का केंद्रीय योगदान है।
मास्टर समीकरण
ईमानदारी से कहूं तो, यह पत्र पारंपरिक अर्थों में एक एकल "मास्टर समीकरण" प्रस्तुत नहीं करता है, जैसे कि एक उपन्यास मशीन लर्निंग मॉडल के लिए एक उद्देश्य फ़ंक्शन या एक नई भौतिक प्रक्रिया का वर्णन करने वाला एक विभेदक समीकरण। इसके बजाय, इसका "गणितीय इंजन" डेटा सफाई, विभाजन, त्रुटि का पता लगाने, सुधार और विषाक्तता फ़िल्टरिंग के लिए डिज़ाइन किए गए एल्गोरिथम और मॉडल-आधारित प्रक्रियाओं का एक सूट है। इन प्रक्रियाओं को अंतिम कॉमन कॉर्पस का उत्पादन करने के लिए कच्चे पाठ डेटा पर क्रमिक रूप से लागू किया जाता है।
"मास्टर समीकरण" के सबसे करीब हम आते हैं, वह है डेटा गुणवत्ता के एक महत्वपूर्ण पहलू को मापने वाले OCRoscope द्वारा ओसीआर गुणवत्ता का मूल्यांकन। हालांकि सीखने के लिए एक उद्देश्य फ़ंक्शन नहीं है, यह डेटा गुणवत्ता के एक महत्वपूर्ण पहलू को मापता है। ओसीआर गुणवत्ता स्कोर, $Q_{OCR}$, एक दस्तावेज़ के लिए वैचारिक रूप से दर्शाया जा सकता है:
$$ Q_{OCR} = 1 - \frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})} $$
यह समीकरण, हालांकि सरलीकृत है, OCRoscope के तर्क के सार को पकड़ता है।
पद-दर-पद ऑटोप्सी
आइए OCRoscope गुणवत्ता स्कोर के वैचारिक घटकों को तोड़ें:
- $N$: यह इनपुट पाठ दस्तावेज़ से निकाले गए कुल रोलिंग एन-ग्राम (विशेष रूप से 7-ग्राम, जैसा कि पत्र में उल्लेख किया गया है) का प्रतिनिधित्व करता है। इसकी गणितीय परिभाषा इन ओवरलैपिंग टेक्स्ट सेगमेंट की गिनती है। इसकी भौतिक/तार्किक भूमिका उस ग्रैन्युलैरिटी को परिभाषित करना है जिस पर स्थानीय भाषा पहचान की जाती है। लेखक ने एन-ग्राम का उपयोग किया क्योंकि भाषा पहचान मॉडल छोटी अनुक्रमों पर शोर के प्रति अधिक संवेदनशील होते हैं, जिससे वे ओसीआर त्रुटियों के अच्छे संकेतक बन जाते हैं, न कि दस्तावेज़-स्तरीय पहचान के विपरीत जो शोर के प्रति मजबूत होती है।
- $g_i$: यह दस्तावेज़ से निकाला गया $i$-वां रोलिंग 7-ग्राम है। गणितीय रूप से, यह 7 की लंबाई का एक सबस्ट्रिंग है। इसकी तार्किक भूमिका पाठ की एक छोटी, स्थानीयकृत विंडो प्रदान करना है, जहां ओसीआर त्रुटियों से भाषाई पैटर्न बाधित होने की अधिक संभावना है।
- $L(g_i)$: यह $i$-वें 7-ग्राम के लिए
pycld2मॉडल द्वारा पहचानी गई भाषा है। गणितीय रूप से, यह एक श्रेणीबद्ध आउटपुट (एक भाषा लेबल या 'अज्ञात') है। इसकी तार्किक भूमिका स्थानीय भाषाई सुसंगतता का पता लगाना है। यदि कोई 7-ग्राम ओसीआर त्रुटियों से भारी रूप से दूषित है, तोpycld2संभवतः इसकी भाषा को गलत वर्गीकृत करेगा या इसे 'अज्ञात' के रूप में लेबल करेगा। - $L_{doc}$: यह पूरे दस्तावेज़ के लिए
pycld2द्वारा पहचानी गई भाषा है। गणितीय रूप से, यह एक एकल श्रेणीबद्ध आउटपुट है। इसकी तार्किक भूमिका दस्तावेज़ की ग्राउंड ट्रुथ भाषा स्थापित करना है, जिसे कुछ शोर के साथ भी मज़बूती से पहचाना जाता है। स्थानीय $L(g_i)$ और वैश्विक $L_{doc}$ के बीच तुलना विसंगतियों की पहचान करने की कुंजी है। - $\mathbb{I}(\cdot)$: यह संकेतक फ़ंक्शन है, जो यदि इसका तर्क सत्य है तो 1 और अन्यथा 0 लौटाता है। गणितीय रूप से, यह एक बूलियन-टू-इंटीजर मैपिंग है। इसकी तार्किक भूमिका उन उदाहरणों की गिनती करना है जहां स्थानीय 7-ग्राम की भाषा पहचान दस्तावेज़ की समग्र भाषा से विचलित होती है या अपरिचित होती है। लेखक ने स्पष्ट गलत पहचान और पहचान की पूर्ण विफलता दोनों को पकड़ने के लिए "या" का उपयोग किया, दोनों मुद्दों का संकेत देते हैं।
- $\mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})$: यह पद "बेमेल" या "अज्ञात" 7-ग्राम की संख्या की गणना करता है। गणितीय रूप से, यह संकेतक कार्यों का योग है। इसकी तार्किक भूमिका स्थानीय भाषाई विसंगतियों की उपस्थिति को मापना है, जो ओसीआर त्रुटियों के प्रॉक्सी हैं। लेखक ने त्रुटियों के "दर" को "गुणवत्ता स्कोर" में बदलने के लिए "या" का उपयोग किया, जहां 1 पूर्ण गुणवत्ता का प्रतीक है और कम मान बढ़ते डिजिटलीकरण शोर को दर्शाते हैं। यह स्कोर को "गुणवत्ता" मीट्रिक के रूप में अधिक सहज बनाता है।
- $\mathbb{I}(g_i \text{ is valid})$: यह पद सुनिश्चित करता है कि केवल मान्य 7-ग्राम (जैसे, खाली या पूरी तरह से विराम चिह्न नहीं) को भाजक में माना जाता है, जिससे शून्य से विभाजन या विकृत इनपुट से तिरछे अनुपात को रोका जा सके।
- योग $\sum_{i=1}^{N} \dots$: यह समस्याग्रस्त 7-ग्राम की गिनती को एकत्रित करता है। योग का उपयोग यहां असतत घटनाओं को एक अनुक्रम में गिनने के लिए स्वाभाविक है।
- भिन्न $\frac{\sum_{i=1}^{N} \mathbb{I}(L(g_i) \neq L_{doc} \text{ or } L(g_i) = \text{Unknown})}{\sum_{i=1}^{N} \mathbb{I}(g_i \text{ is valid})}$: यह समस्याग्रस्त 7-ग्राम के अनुपात की गणना करता है। इसकी तार्किक भूमिका ओसीआर शोर का एक सामान्यीकृत माप प्रदान करना है।
- अंतिम घटाव $1 - \dots$: यह अंतिम घटाव "त्रुटि दर" को "गुणवत्ता स्कोर" में बदल देता है, जहां 1 पूर्ण गुणवत्ता का प्रतीक है और कम मान बढ़ते डिजिटलीकरण शोर को दर्शाते हैं। यह स्कोर को "गुणवत्ता" मीट्रिक के रूप में अधिक सहज बनाता है।
चरण-दर-चरण प्रवाह
एक कच्चे, डिजिटलीकृत दस्तावेज़ की कल्पना करें, शायद एक स्कैन किया हुआ ऐतिहासिक समाचार पत्र, कॉमन कॉर्पस क्यूरेशन पाइपलाइन में प्रवेश कर रहा है। यह पाठ के लिए एक जटिल असेंबली लाइन की तरह है:
- प्रारंभिक अंतर्ग्रहण और मेटाडेटा निष्कर्षण: दस्तावेज़ पहले सिस्टम में प्रवेश करता है। इसका स्रोत यूआरएल, संभावित लाइसेंस जानकारी और निर्माण तिथि जैसे मूल मेटाडेटा निकाले या अनुमानित किए जाते हैं।
- भाषा पहचान (दस्तावेज़-स्तरीय): पूरे दस्तावेज़ को इसकी प्राथमिक भाषा, $L_{doc}$ निर्धारित करने के लिए एक भाषा पहचान मॉडल (जैसे
fastTextयाcld2) के माध्यम से पारित किया जाता है। यह एक महत्वपूर्ण पहला कदम है, क्योंकि बाद के उपकरण भाषा पर निर्भर होते हैं। - पाठ विभाजन (सेगमेंटटेक्स्ट): दस्तावेज़ के कच्चे वर्ण अनुक्रम को
Segmentextमें फीड किया जाता है, जो एक DeBERTa-v2-शैली टोकन वर्गीकरण मॉडल है। यह मॉडल एक स्मार्ट पार्सर की तरह काम करता है, विभिन्न संरचनात्मक घटकों को टैग करता है: "यह एक[शीर्षक]है," "यह[पाठ]है," "यह एक[तालिका]है," "यह[पैराटेक्स्ट]है (जैसे पृष्ठ संख्या)।" यह पूरी तरह से पाठ पर काम करता है, जिससे यह खोई हुई लेआउट जानकारी के प्रति मजबूत होता है। - ओसीआर त्रुटि का पता लगाना (OCRoscope & OCRerrcr):
- OCRoscope (मोटे-दानेदार): दस्तावेज़ को फिर
OCRoscopeमें पारित किया जाता है। यह टूल पाठ पर 7 वर्णों (एक 7-ग्राम) की एक विंडो स्लाइड करता है। प्रत्येक 7-ग्राम के लिए, यह अपनी भाषा, $L(g_i)$ की पहचान करने का प्रयास करता है। यदि $L(g_i)$ $L_{doc}$ से मेल नहीं खाता है या "अज्ञात" है, तो इसे संभावित ओसीआर त्रुटि के रूप में फ़्लैग किया जाता है।OCRoscopeदस्तावेज़ के लिए समग्र ओसीआर गुणवत्ता स्कोर का उत्पादन करने के लिए इन झंडों को एकत्रित करता है। यह तय करने के लिए एक तेज, प्रारंभिक जांच है कि क्या किसी दस्तावेज़ को अधिक गहन प्रसंस्करण की आवश्यकता है। - OCRerrcr (बारीक-दानेदार): जिन दस्तावेजों को अधिक ध्यान देने की आवश्यकता के रूप में पहचाना गया है, उनके लिए, DeBERTa-v3-small मॉडल
OCRerrcrकदम उठाता है। यह पाठ को टोकन दर टोकन संसाधित करता है, प्रत्येक टोकन को सही या त्रुटिपूर्ण के रूप में वर्गीकृत करता है। यह त्रुटियों के स्थान का एक सटीक नक्शा प्रदान करता है, जो लक्षित सुधार के लिए दस्तावेज़ तैयार करता है।
- OCRoscope (मोटे-दानेदार): दस्तावेज़ को फिर
- ओसीआर त्रुटि सुधार (OCRonos): दस्तावेज़, अब पहचानी गई त्रुटियों के साथ,
OCRonosपर चला जाता है, जो एक फाइन-ट्यून किया गया लामा-3-8B जनरेटिव मॉडल है।OCRonosएक कुशल संपादक के रूप में कार्य करता है, शोरगुल वाले पाठ को लेता है और ओसीआर त्रुटियों को ठीक करने, गलत शब्द विभाजनों या विलय को ठीक करने और व्यापक संरचनात्मक अखंडता को बहाल करने का प्रयास करता है। इसे रूढ़िवादी होने के लिए डिज़ाइन किया गया है, मूल पाठ को जहां संभव हो संरक्षित करता है, लेकिन प्रयोग करने योग्य बनाने के लिए भारी खराब इनपुट को "कृत्रिम रूप से फिर से लिख" सकता है। - व्यक्तिगत पहचान योग्य जानकारी (पीआईआई) हटाना: पाठ, अब संरचनात्मक रूप से ध्वनि और काफी हद तक त्रुटि-मुक्त, कस्टम रेगुलर एक्सप्रेशन पैटर्न के साथ संवर्धित
Microsoft Presidioका उपयोग करके पीआईआई के लिए स्कैन किया जाता है। यह टूल फोन नंबर, ईमेल पते और आईपी पते जैसी संवेदनशील जानकारी की पहचान करता है। केवल हटाने या रेडैक्ट करने के बजाय, यह पाठ प्रवाह और संदर्भ को बनाए रखने के लिए पीआईआई को काल्पनिक लेकिन यथार्थवादी मानों से बदल देता है। - डी-डुप्लीकेशन: दस्तावेज़ को डुप्लिकेट हटाने के लिए मौजूदा डेटा के विरुद्ध जांचा जाता है, अक्सर पीडीएफ मेटाडेटा या सामग्री हैश का उपयोग करके। यह विशिष्टता सुनिश्चित करता है और कॉर्पस में अतिरेक से बचता है।
- विषाक्तता का पता लगाना (सेलाडॉन): अंत में, साफ किए गए दस्तावेज़ को
सेलाडॉनमें पारित किया जाता है, जो एक DeBERTa-v3-small बहुभाषी विषाक्तता क्लासिफायर है। यह मॉडल, विभिन्न प्रकार की विषाक्त सामग्री के एनोटेट किए गए डेटा पर प्रशिक्षित, कई आयामों (जैसे, नस्लवाद, लिंगवाद, हिंसा) में हानिकारक या पक्षपाती भाषा की पहचान करता है और फ़्लैग करता है। एक निश्चित विषाक्तता सीमा से अधिक वाले दस्तावेज़ या खंडों को फ़िल्टर किया जाता है, जिससे कॉर्पस की नैतिक अखंडता सुनिश्चित होती है। - अंतिम असेंबली और मेटाडेटा संवर्धन: अब साफ, खंडित, सही, पीआईआई-मुक्त, और गैर-विषाक्त पाठ को इकट्ठा किया जाता है। इसका समृद्ध मेटाडेटा (लाइसेंस, भाषा, संग्रह, डोमेन, आदि) संलग्न किया जाता है, जिससे यह कॉमन कॉर्पस में शामिल होने के लिए तैयार हो जाता है।
यह पूरी प्रक्रिया सुनिश्चित करती है कि प्रत्येक "डेटा बिंदु" (दस्तावेज़) अंतिम, उच्च-गुणवत्ता वाले डेटासेट का हिस्सा बनने से पहले कठोरता से संसाधित और सत्यापित किया जाता है।
अनुकूलन गतिशीलता
इस पत्र में "सीखना" या "अभिसरण" मुख्य रूप से डेटा क्यूरेशन पाइपलाइन के भीतर उपयोग किए जाने वाले तंत्रिका नेटवर्क मॉडल पर लागू होता है, क्योंकि पत्र स्वयं एक उपन्यास एलएलएम प्रशिक्षण अनुकूलन का प्रस्ताव नहीं करता है। इन मॉडलों को मानक डीप लर्निंग अनुकूलन तकनीकों का उपयोग करके प्रशिक्षित किया जाता है।
- सेगमेंटटेक्स्ट, OCRerrcr, और सेलाडॉन (टोकन वर्गीकरण मॉडल):
- हानि परिदृश्य: ये मॉडल DeBERTa-vX के वेरिएंट हैं, जो ट्रांसफार्मर-आधारित आर्किटेक्चर हैं। उनके हानि परिदृश्य आम तौर पर उच्च-आयामी और गैर-उत्तल होते हैं। प्रशिक्षण का लक्ष्य एक विशिष्ट हानि फ़ंक्शन को कम करने वाले भार का एक सेट खोजना है।
- हानि फ़ंक्शन:
SegmentextऔरOCRerrcrके लिए, जो टोकन वर्गीकरण करते हैं (जैसे, प्रत्येक टोकन की संरचनात्मक भूमिका या त्रुटि स्थिति को वर्गीकृत करना), प्राथमिक हानि फ़ंक्शन क्रॉस-एंट्रॉपी हानि होगी। यह प्रत्येक टोकन के लिए वर्गों पर मॉडल की अनुमानित संभाव्यता वितरण और वास्तविक वर्ग लेबल के बीच अंतर को मापता है।Celadon, विषाक्तता क्लासिफायर, स्पष्ट रूप से "वर्ग असंतुलन को संभालने के लिए एक कस्टम भारित क्रॉस-एंट्रॉपी हानि फ़ंक्शन का उपयोग करता है।" यह भारण तंत्र अल्पसंख्यक वर्गों (जैसे, विषाक्त सामग्री, जो आम तौर पर गैर-विषाक्त सामग्री की तुलना में दुर्लभ होती है) के गलत वर्गीकरणों के लिए उच्च दंड निर्दिष्ट करता है, जिससे मॉडल को इन महत्वपूर्ण मामलों की अधिक प्रभावी ढंग से पहचान करने में मदद मिलती है। - ग्रेडिएंट्स: प्रशिक्षण के दौरान, मॉडल सभी मॉडल मापदंडों (भार और पूर्वाग्रह) के संबंध में हानि फ़ंक्शन के ग्रेडिएंट की गणना करने के लिए बैकप्रॉपैगेशन का उपयोग करते हैं। ये ग्रेडिएंट इंगित करते हैं कि हानि को कम करने के लिए प्रत्येक पैरामीटर को किस दिशा और परिमाण में समायोजित किया जाना चाहिए।
- अनुकूलन एल्गोरिथम: हालांकि स्पष्ट रूप से नहीं कहा गया है, एडम (अनुकूली क्षण अनुमान) या एसजीडी (स्टोकेस्टिक ग्रेडिएंट डिसेंट) मोमेंटम के साथ जैसे मानक अनुकूलक का उपयोग किया जाएगा। ये एल्गोरिदम पुनरावृत्त रूप से मॉडल के मापदंडों को ग्रेडिएंट के विपरीत दिशा में एक सीखने की दर से स्केल किए गए कदम उठाकर अपडेट करते हैं।
- अभिसरण: मॉडल तब अभिसरण करते हैं जब एक सत्यापन सेट पर हानि फ़ंक्शन काफी कम होना बंद हो जाता है, यह दर्शाता है कि मॉडल ने प्रशिक्षण डेटा में अंतर्निहित पैटर्न सीख लिए हैं और अच्छी तरह से सामान्यीकृत होता है। पुनरावृत्त अपडेट मॉडल के मापदंडों को हानि परिदृश्य के माध्यम से ले जाते हैं, जिसका लक्ष्य स्थानीय या वैश्विक न्यूनतम होता है।
- OCRonos (जनरेटिव भाषा मॉडल):
- हानि परिदृश्य: लामा-3-8B मॉडल के फाइन-ट्यून किए गए संस्करण के रूप में,
OCRonosबड़े जनरेटिव ट्रांसफार्मर की एक विशाल, जटिल हानि परिदृश्य पर काम करता है। - हानि फ़ंक्शन: जनरेटिव भाषा मॉडल के लिए प्राथमिक हानि फ़ंक्शन आम तौर पर अगले-टोकन भविष्यवाणी हानि (क्रॉस-एंट्रॉपी का एक रूप) है। मॉडल को पिछले वाले को देखते हुए अनुक्रम में अगले टोकन की भविष्यवाणी करने के लिए प्रशिक्षित किया जाता है। ओसीआर सुधार के संदर्भ में, इसका मतलब है कि शोरगुल वाले इनपुट अनुक्रम से सही, साफ पाठ उत्पन्न करने की क्षमता सीखना।
- ग्रेडिएंट्स और अनुकूलन: वर्गीकरण मॉडल के समान,
OCRonosअपने मापदंडों को अपडेट करने के लिए बैकप्रॉपैगेशन और एक अनुकूलक (संभवतः एडम या एक वेरिएंट) पर निर्भर करता है। मॉडल शोर इनपुट पैटर्न को साफ आउटपुट पैटर्न पर मैप करना सीखता है। - अभिसरण: मॉडल तब अभिसरण करता है जब वह मज़बूती से उच्च-गुणवत्ता, सही पाठ उत्पन्न कर सकता है जो मूल इरादे के प्रति वफादार है, जबकि त्रुटियों को कम करता है और अवांछनीय व्यवहारों जैसे भाषा स्विचिंग का विरोध करता है। प्रशिक्षण प्रक्रिया पुनरावृत्त रूप से मॉडल की खराब पाठ को सुसंगत और सटीक रूप में "फिर से लिखने" की क्षमता को परिष्कृत करती है।
- हानि परिदृश्य: लामा-3-8B मॉडल के फाइन-ट्यून किए गए संस्करण के रूप में,
संक्षेप में, इन घटकों के लिए अनुकूलन गतिशीलता इन तंत्रिका नेटवर्क के आंतरिक मापदंडों को पुनरावृत्त रूप से समायोजित करने के बारे में है ताकि उनके संबंधित हानि कार्यों को कम किया जा सके, जिससे उनके विशिष्ट डेटा क्यूरेशन कार्यों पर उनके प्रदर्शन में सुधार हो सके। यह पुनरावृत्त शोधन पाइपलाइन को विविध, शोरगुल वाले डेटा को प्रभावी ढंग से संसाधित और साफ करना "सीखने" की अनुमति देता है।
 Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
Figure 2. A schematic world map of languages in Common Corpus with a log-scaled distribution of document counts. For each language, we chose a city that is located in the region where this language is most specific to. To avoid outliers, we show only languages with 10,000+ documents
 Figure 3. Temporal and semantic overview of the Common Corpus collections
Figure 3. Temporal and semantic overview of the Common Corpus collections
परिणाम, सीमाएँ और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
कॉमन कॉर्पस की उपयोगिता को कठोरता से मान्य करने के लिए, लेखकों ने एक केंद्रित प्रयोगात्मक डिजाइन शुरू किया। उन्होंने दो अलग-अलग भाषा मॉडल, PleIAs 350M और PleIAs 1.2B को प्रशिक्षित किया, दोनों लामा-आधारित वास्तुकला पर निर्मित हैं। 65,536 की शब्दावली आकार की विशेषता वाला एक कस्टम लामा-शैली टोकनाइज़र विकसित किया गया और कॉमन कॉर्पस के एक प्रतिनिधि उप-नमूने पर प्रशिक्षित किया गया। छोटे PleIAs 350M मॉडल को कॉमन कॉर्पस के एक फ़िल्टर किए गए उपसमूह के लगभग 1 ट्रिलियन टोकन पर प्रशिक्षित किया गया था, जिसमें 2,944 H100 घंटे लगे। बड़े PleIAs 1.2B मॉडल को फ़िल्टर किए गए उपसमूह के तीन युगों के लिए पूर्ण कॉमन कॉर्पस पर प्रशिक्षित किया गया था, जिसमें 23,040 H100 घंटे लगे।
जिन "पीड़ितों" (बेसलाइन मॉडल) के खिलाफ कॉमन कॉर्पस-प्रशिक्षित मॉडल का मूल्यांकन किया गया था, उनमें कई प्रमुख बहुभाषी भाषा मॉडल शामिल थे: जेम्मा 3 (270M और 1B पैरामीटर), XGLM (564M और 1.7B पैरामीटर), BLOOM (560M और 1.7B पैरामीटर), और OLMO 1B। ये बेसलाइन बंद, गैर-अनुमत लाइसेंस वाले डेटा पर प्रशिक्षित मॉडल का मिश्रण दर्शाते हैं, या, OLMO 1B के मामले में, सार्वजनिक रूप से जारी डेटासेट पर। मूल्यांकन तीन स्थापित बहुभाषी बेंचमार्क: MultiBLiMP, XStoryCloze, और XCOPA पर मानक LM मूल्यांकन हार्नेस का उपयोग करके किया गया था। यह सेटअप प्रदर्शन की सीधी तुलना प्रदान करने के लिए डिज़ाइन किया गया था, विशेष रूप से यह उजागर करते हुए कि क्या अनुमत लाइसेंस वाले, नैतिक रूप से क्यूरेटेड डेटा पर विशेष रूप से प्रशिक्षित मॉडल व्यापक, अक्सर कानूनी रूप से अस्पष्ट, डेटासेट पर प्रशिक्षित लोगों के खिलाफ अपना स्थान बनाए रख सकते हैं।
साक्ष्य क्या साबित करते हैं
पत्र में प्रस्तुत साक्ष्य निश्चित रूप से साबित करते हैं कि कॉमन कॉर्पस बहुभाषी प्री-ट्रेनिंग के लिए एक उपयुक्त और प्रभावी डेटासेट है, जो नियामक और नैतिक मानदंडों का सख्ती से पालन करते हुए एलएलएम विकास को सक्षम बनाता है। मुख्य तंत्र—एक विशाल, विविध, और अनुमत लाइसेंस वाले कॉर्पस पर प्रशिक्षण—PleIAs मॉडल के प्रदर्शन के माध्यम से वास्तविकता में काम करने के लिए दिखाया गया था।
विशेष रूप से, कॉमन कॉर्पस पर प्रशिक्षित मॉडल ने अपने बेसलाइन की तुलना में तुलनीय, और कुछ मामलों में बेहतर प्रदर्शन प्रदर्शित किया। MultiBLiMP बेंचमार्क पर, जो अपने व्यापक भाषा कवरेज के कारण विशेष रूप से चुनौतीपूर्ण है, PleIAs मॉडल ने उत्कृष्ट प्रदर्शन दिखाया। विशेष रूप से, छोटे PleIAs 350M मॉडल, अपने आकार के बावजूद, अधिकांश 1B-रेंज बेसलाइन मॉडल को बेहतर बनाने में कामयाब रहे, जेम्मा 3 1B को छोड़कर। इसके अलावा, दोनों PleIAs मॉडल ने लगातार और स्थिर रूप से OLMO 1B को बेहतर प्रदर्शन किया, एक बेसलाइन जिसे सार्वजनिक रूप से जारी डेटासेट पर भी प्री-ट्रेन किया गया था। यह एक महत्वपूर्ण साक्ष्य है, क्योंकि यह सीधे कॉमन कॉर्पस की गुणवत्ता और उपयोगिता को एक और ओपन-सोर्स विकल्प के मुकाबले मान्य करता है।
कच्चे मेट्रिक्स से परे, पत्र डेटा के नैतिक और गुणात्मक लाभों का ठोस प्रमाण प्रदान करता है। विस्तृत उत्पत्ति, फ़िल्टरिंग, पीआईआई हटाना, विषाक्तता का पता लगाना, और डी-डुप्लीकेशन प्रक्रियाएं (धारा 5 में वर्णित) सुनिश्चित करती हैं कि डेटा कॉपीराइट-मुक्त या अनुमत लाइसेंस के तहत है, जो एलएलएम प्रशिक्षण में एक महत्वपूर्ण कानूनी और नैतिक अंतर को संबोधित करता है। गुणात्मक मूल्यांकन, जैसे कि चरित्र संरचना मेट्रिक्स (चित्र 4), ने पुष्टि की कि डेटा वितरण काफी हद तक अपेक्षित श्रेणियों के भीतर थे, जिसमें कोड या नियामक ग्रंथों जैसे विशेष सामग्री के लिए समझदार विचलन थे। कस्टम टोकनाइज़र, PleIAs मॉडल का एक मूलभूत घटक, ने भी अच्छा प्रदर्शन किया, केवल जेम्मा 3 के टोकनाइज़र से बेहतर प्रदर्शन किया, जिसमें चार गुना बड़ी शब्दावली है। यह सामूहिक साक्ष्य इस बात पर प्रकाश डालता है कि कॉमन कॉर्पस सिर्फ एक बड़ा डेटासेट नहीं है, बल्कि प्रतिस्पर्धी बहुभाषी एलएलएम को प्रशिक्षित करने के लिए एक उच्च-गुणवत्ता वाला, नैतिक रूप से ध्वनि, और प्रभावी डेटासेट है।
सीमाएँ और भविष्य की दिशाएँ
जबकि कॉमन कॉर्पस एलएलएम विकास में खुले विज्ञान के लिए एक महत्वपूर्ण कदम का प्रतिनिधित्व करता है, लेखकों ने ईमानदारी से कई सीमाओं को स्वीकार किया है जो भविष्य के अनुसंधान और विकास के लिए मार्ग प्रशस्त करती हैं। सबसे पहले, 2 ट्रिलियन टोकन के अपने प्रभावशाली आकार के बावजूद, कॉमन कॉर्पस अभी भी उपलब्ध खुले डेटा के पूरे स्पेक्ट्रम को शामिल करने से बहुत दूर है। यह "खुला डेटा विरोधाभास," जहां खुले सामग्री के प्रमुख स्रोत विरोधाभासी रूप से कम दिखाई देते हैं, का मतलब है कि बड़े मॉडल को वर्तमान में कॉमन कॉर्पस अकेले प्रदान कर सकने वाले डेटा की तुलना में काफी अधिक डेटा की आवश्यकता होती है।
दूसरे, कॉमन कॉर्पस का वर्तमान पुनरावृत्ति स्वाभाविक रूप से निर्देश-ट्यूनिंग या विशेष कार्यों के लिए डिज़ाइन नहीं किया गया है। इसकी प्राथमिक उपयोगिता प्री-ट्रेनिंग में निहित है, जिसका अर्थ है कि यह अतिरिक्त, कार्य-विशिष्ट डेटासेट के बिना, विशिष्ट अनुप्रयोगों के लिए मॉडल को फाइन-ट्यून करने के लिए सीधे उपयुक्त नहीं है। यह भविष्य के काम के लिए एक अवसर प्रस्तुत करता है जो कॉमन कॉर्पस पर निर्माण करके नैतिक फाइन-ट्यूनिंग डेटासेट विकसित करता है जो इसकी बहुभाषी, लौकिक और सिमेंटिक विविधता का लाभ उठाता है।
तीसरी सीमा डेटा क्यूरेशन की अंतर्निहित चुनौतियाँ हैं, विशेष रूप से ऐतिहासिक और डिजिटलीकृत ग्रंथों के साथ। लेखक स्वीकार करते हैं कि उनके परिष्कृत "बैड डेटा टूलबॉक्स" (सेगमेंटटेक्स्ट, OCRoscope, OCRerrcr, OCRonos, और Celadon सहित) के साथ भी, क्यूरेशन में 100% सटीकता प्राप्त करना मुश्किल है। विशेष रूप से ओसीआर त्रुटियां एक बड़ी चुनौती बनी हुई हैं, जो मॉडल के प्रदर्शन को प्रभावित कर सकती हैं और यहां तक कि मॉडल टाइपो को कैसे संभालते हैं, इसे भी प्रभावित कर सकती हैं। इन क्यूरेशन टूल में सुधार, शायद अधिक उन्नत एआई-संचालित विधियों के माध्यम से, एक स्पष्ट भविष्य की दिशा है।
आगे देखते हुए, इस पत्र के निष्कर्ष कई चर्चा विषयों को प्रेरित करते हैं:
- खुले डेटा पहलों को बढ़ाना: एलएलएम प्रशिक्षण के लिए अधिक अनुमत लाइसेंस वाली सामग्री को दृश्यमान और सुलभ बनाने के लिए "खुला डेटा विरोधाभास" को कैसे दूर किया जा सकता है? इसमें सांस्कृतिक संस्थानों, सरकारों और अनुसंधान निकायों से डेटा साझा करने को प्रोत्साहित करना, या ऐसे डेटा की खोज और एकत्रीकरण के लिए नए तरीके विकसित करना शामिल हो सकता है।
- नैतिक फाइन-ट्यूनिंग और कार्य-विशिष्ट डेटासेट: कॉमन कॉर्पस की विविध, नैतिक रूप से प्राप्त प्री-ट्रेनिंग डेटा में ताकत को देखते हुए, समुदाय समान उच्च नैतिक मानकों को बनाए रखने वाले निर्देश-ट्यूनिंग और कार्य-विशिष्ट डेटासेट को सहयोगात्मक रूप से कैसे बना सकता है? इसमें सिंथेटिक डेटा जनरेशन, मानव-इन-द-लूप एनोटेशन, और गोपनीयता या लाइसेंसिंग से समझौता किए बिना विशेष डेटासेट बनाने के लिए संघीकृत शिक्षण दृष्टिकोणों की विधियों का पता लगाना शामिल होगा।
- डेटा क्यूरेशन टूल में प्रगति: पत्र ओसीआर त्रुटियों और अन्य डेटा गुणवत्ता मुद्दों की चल रही चुनौती को उजागर करता है। हम OCRonos और Celadon जैसे टूल को कैसे और विकसित कर सकते हैं, शायद अधिक परिष्कृत मल्टीमॉडल समझ को एकीकृत करके या शोरगुल वाले डेटा पर स्व-पर्यवेक्षित सीखने का लाभ उठाकर, बड़े पैमाने पर लगभग पूर्ण डेटा गुणवत्ता प्राप्त करने के लिए? क्या एलएलएम स्वयं ऐसे अपूर्णताओं के प्रति अधिक मजबूत होने या यहां तक कि उन्हें ठीक करने के लिए प्रशिक्षित किए जा सकते हैं?
- जिम्मेदार एआई में मेटाडेटा की भूमिका: कॉमन कॉर्पस में समृद्ध मेटाडेटा पर जोर उपयोगकर्ताओं को लाइसेंस, भाषा और संभावित मुद्दों के आधार पर डेटा को फ़िल्टर करने की अनुमति देता है। हम सभी खुले डेटासेट में मेटाडेटा प्रथाओं को कैसे मानकीकृत और विस्तारित कर सकते हैं ताकि एलएलएम प्रैक्टिशनर्स को अपने प्रशिक्षण डेटा पर अधिक नियंत्रण के साथ सशक्त बनाया जा सके, अधिक जिम्मेदार और पारदर्शी एआई विकास को बढ़ावा दिया जा सके?
- क्रॉस-लिंगुअल और निम्न-संसाधन भाषा विकास: कॉमन कॉर्पस की बहुभाषी विविधता, जिसमें निम्न-संसाधन भाषाएं शामिल हैं, एक प्रमुख ताकत है। इन भाषाओं में एलएलएम प्रदर्शन की सीमाओं को आगे बढ़ाने के लिए इस डेटासेट का लाभ कैसे उठाया जा सकता है, संभावित रूप से डिजिटल विभाजन को कम किया जा सकता है और अधिक समावेशी एआई को बढ़ावा दिया जा सकता है? इसमें ट्रांसफर लर्निंग रणनीतियाँ, बहुभाषी संरेखण तकनीकें, या विविध भाषाई इनपुट के लिए अनुकूलित उपन्यास वास्तुशिल्प डिजाइन शामिल हो सकते हैं।
 Table 1. Comparison of the contemporary datasets for LLM training
Table 1. Comparison of the contemporary datasets for LLM training
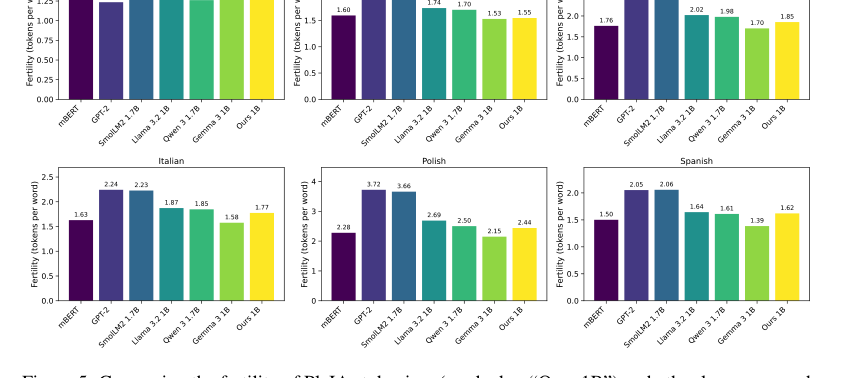 Table 6. Finance Commons sources distribution with languages
Table 6. Finance Commons sources distribution with languages
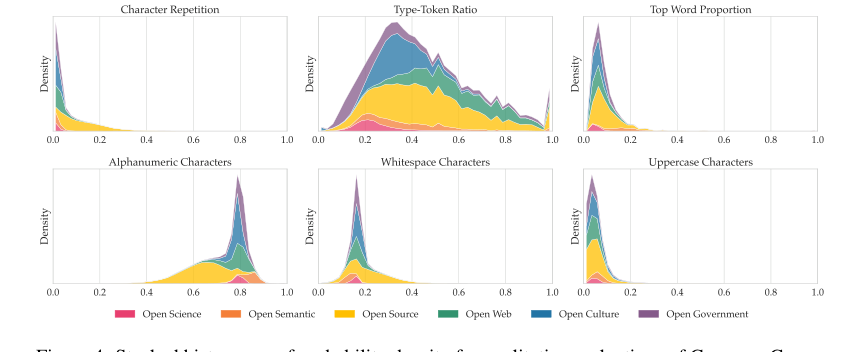 Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
Figure 4. Stacked histograms of probability density for qualitative evaluations of Common Corpus on a sample of 300,000 documents. Metric descriptions can be found in Appendix G
अन्य क्षेत्रों के साथ समरूपता
संरचनात्मक कंकाल
यह पत्र सख्त नैतिक और गुणवत्ता बाधाओं के तहत विशाल, विषम डेटा प्राप्त करने, साफ करने और मान्य करने के लिए एक मजबूत, बहु-चरणीय पाइपलाइन प्रस्तुत करता है।
दूर के चचेरे भाई
-
लक्ष्य क्षेत्र: आपूर्ति श्रृंखला प्रबंधन
संबंध: वैश्विक आपूर्ति श्रृंखला प्रबंधन के क्षेत्र में, अंतरराष्ट्रीय आपूर्तिकर्ताओं की एक भीड़ से कच्चे माल और निर्मित घटकों की प्रामाणिकता, गुणवत्ता और नैतिक उत्पत्ति सुनिश्चित करना एक लगातार चुनौती है। इसमें अक्सर जटिल नियामक परिदृश्यों को नेविगेट करना, प्रमाणपत्रों को सत्यापित करना और नकली या अनैतिक रूप से प्राप्त माल के घुसपैठ को रोकना शामिल होता है। डेटा उत्पत्ति का पता लगाने, बहु-स्तरीय फ़िल्टरिंग (गुणवत्ता, पीआईआई, और विषाक्तता के लिए) लागू करने, और अनुमत लाइसेंसिंग सुनिश्चित करने के पत्र के मूल तर्क, भौतिक उत्पादों के लिए "स्वच्छ," "ऑडिटेबल," और "नैतिक रूप से ध्वनि" आपूर्ति श्रृंखला की आवश्यकता का एक दर्पण छवि है। पत्र में वर्णित "खुला डेटा विरोधाभास," जहां मूल्यवान खुला सामग्री विरोधाभासी रूप से खोजना और उपयोग करना मुश्किल है, एक खंडित वैश्विक बाजार में वास्तव में विश्वसनीय और पारदर्शी आपूर्तिकर्ताओं की पहचान करने की कठिनाई के साथ प्रतिध्वनित होता है। -
लक्ष्य क्षेत्र: जीनोमिक्स और व्यक्तिगत चिकित्सा
संबंध: जीनोमिक्स में, शोधकर्ता नियमित रूप से डीएनए अनुक्रमों, जीन अभिव्यक्ति प्रोफाइल और रोगी चिकित्सा रिकॉर्ड सहित विशाल, विषम जैविक डेटासेट के साथ काम करते हैं, जिन्हें अक्सर विभिन्न अनुसंधान संस्थानों और सार्वजनिक रिपॉजिटरी से एकत्र किया जाता है। एक महत्वपूर्ण, लंबे समय से चली आ रही समस्या इस संवेदनशील डेटा की गुणवत्ता, स्थिरता और नैतिक उपयोग (जैसे, रोगी गोपनीयता, सूचित सहमति) सुनिश्चित करना है, खासकर जब इसे बड़े पैमाने पर विश्लेषण के लिए एकीकृत किया जाता है या व्यक्तिगत उपचार मॉडल विकसित किया जाता है। व्यक्तिगत पहचान योग्य जानकारी (पीआईआई) को हटाने, डेटा त्रुटियों को ठीक करने (जैसे पाठ के लिए OCRonos), और विभिन्न डेटा स्रोतों के लिए उचित लाइसेंस लागू करने में पत्र के व्यवस्थित दृष्टिकोण सीधे चिकित्सा अनुसंधान के लिए "स्वच्छ," "गोपनीयता-संरक्षण," और "नैतिक रूप से अनुपालन" जीनोमिक कोहोर्ट्स को क्यूरेट करने की बायोइनफॉरमैटिक्स चुनौती को दर्शाते हैं, जहां डेटा अखंडता और कड़े नैतिक दिशानिर्देश सर्वोपरि हैं।
क्या होगा यदि परिदृश्य
क्या होगा यदि आपूर्ति श्रृंखला प्रबंधन में एक शोधकर्ता ने कल इस पत्र का सटीक समीकरण—मतलब, उन्होंने अपने विशेष उपकरणों सहित इसके व्यापक डेटा क्यूरेशन और सत्यापन पाइपलाइन को अपनाया—"चोरी" कर लिया? वैश्विक व्यापार पारदर्शिता और अखंडता में एक गहरा सफल होगा। कल्पना करें कि शिपिंग मैनिफेस्ट, सीमा शुल्क घोषणाओं और आपूर्तिकर्ता अनुबंधों की विविध श्रृंखला को स्वचालित रूप से पार्स और संरचित करने के लिए सेगमेंटटेक्स्ट-जैसे मॉडल लागू किए जा रहे हैं, भले ही वे स्कैन किए गए, ऐतिहासिक दस्तावेजों से हों, उनके मूल प्रारूप या भाषा की परवाह किए बिना। OCRoscope और OCRerrcr तब उत्पाद आईडी, मात्रा, या मूल घोषणाओं में विसंगतियों या विसंगतियों का पता लगाने के लिए अनुकूलित किए जा सकते हैं, जो अभूतपूर्व सटीकता के साथ संभावित नकली, गलत लेबल वाले सामान, या अनुपालन उल्लंघनों को फ़्लैग करते हैं। OCRonos दूषित या अधूरे डिजिटल रिकॉर्ड को "सही" कर सकता है, जिससे पूरी आपूर्ति श्रृंखला में डेटा अखंडता सुनिश्चित होती है। इसके अलावा, सेलाडॉन के सिद्धांतों को आपूर्तिकर्ता दस्तावेजों और सार्वजनिक रिकॉर्ड के भीतर "नैतिक उल्लंघनों" (जैसे, जबरन श्रम, पर्यावरणीय गैर-अनुपालन, या अनुचित व्यापार प्रथाओं के संकेतक) का पता लगाने के लिए अनुकूलित किया जा सकता है। इससे वैश्विक वाणिज्य में अभूतपूर्व पारदर्शिता, ऑडिटेबिलिटी और नैतिक अनुपालन होगा, जिससे धोखाधड़ी में काफी कमी आएगी, उत्पाद सुरक्षा में सुधार होगा, और वास्तव में "स्वच्छ" आपूर्ति श्रृंखला सक्षम होगी, संभावित रूप से "वैश्विक व्यापार डेटा के लिए कॉमन कॉर्पस" भी बनाया जा सकेगा जो विशाल और सत्यापन योग्य रूप से नैतिक दोनों है।
संरचनाओं की सार्वभौमिक पुस्तकालय
यह पत्र सार्वभौमिक संरचनाओं के पुस्तकालय को महत्वपूर्ण रूप से समृद्ध करता है यह प्रदर्शित करके कि कठोर डेटा उत्पत्ति, बहु-स्तरीय गुणवत्ता नियंत्रण, और नैतिक अनुपालन के सिद्धांत डोमेन-विशिष्ट चुनौतियाँ नहीं हैं, बल्कि विश्वसनीय सिस्टम बनाने के लिए सार्वभौमिक आवश्यकताएं हैं, चाहे वे भाषा को संसाधित करें, आपूर्ति श्रृंखलाओं का प्रबंधन करें, या जैविक डेटा का विश्लेषण करें, साझा गणितीय पैटर्न के माध्यम से वैज्ञानिक समस्याओं की परस्पर संबद्धता को सुदृढ़ करते हैं।