DentEval: Fine-tuning-Free Expert-Aligned Assessment in Dental Education via LLM Agents
Large language models (LLMs) have demonstrated considerable potential in automating assignment scoring within higher education, providing efficient and consistent evaluations.
Background & Academic Lineage
The Origin & Academic Lineage
The precise origin of the problem addressed in this paper stems from the recent revolution brought about by Large Language Models (LLMs) in the field of education, particularly in automated assessment. While LLMs like OpenAI's GPT series have shown considerable promise in providing efficient and consistent evaluations for assignments, their application to highly specialized domains, such as dentistry, presents significant challenges.
Historically, automated assessment systems have existed, but the advent of LLMs opened new possibilities for handling open-ended questions. However, two core issues emerged when trying to leverage LLMs for expert-level evaluation:
1. Domain-specific interpretation: LLMs often struggle with the nuanced professional vocabulary and intricate concepts unique to specialized fields. They might misinterpret terminology or lack the deep contextual understanding required for accurate assessment.
2. Alignment with expert grading: Ensuring that LLM outputs adhere to the specific, often subjective, evaluation criteria established by human professionals (e.g., dental professors) has been a major hurdle.
Previous approaches to overcome these limitations typically involved extensive fine-tuning or retraining of LLMs using large, meticulously annotated datasets. This process is not only time-consuming but also resource-intensive, making it impractical for many educational settings, especially those with limited computational resources. The "pain point" that forced the authors to develop DentEval is precisely this: the existing methods for applying LLMs to specialized, open-ended assessment tasks required prohibitive amounts of data and computational effort, leading to inconsistencies with human grading and making real-time, practical application difficult. The authors sought a fine-tuning-free solution that could achieve expert-aligned assessment efficiently.
Intuitive Domain Terms
Here are a few specialized terms from the paper, translated into everyday analogies for a zero-base reader:
- Large Language Models (LLMs): Imagine a super-smart digital assistant that has read almost every book, article, and webpage ever written. It can understand what you say, generate new text, and answer questions, but it might not be an expert in everything. It's like a brilliant generalist, but sometimes needs a little extra help for very specific, niche topics.
- Retrieval-Augmented Generation (RAG): Think of this as an open-book exam for our super-smart digital assistant. When you ask it a question, instead of just relying on its general knowledge, it first quickly searches a specific, trusted library (like a dental handbook) for relevant information. Then, it uses that freshly retrieved information, along with its own brain, to formulate a much more accurate and informed answer. It's like having a personal research assistant before answering.
- Role-playing Prompting: This is akin to giving our digital assistant a specific character to play. Instead of just asking it to "grade this," you tell it, "Okay, you are now a strict dental professor, and you need to grade this student's answer according to these rules." By adopting this persona, the LLM tries to think and respond exactly as a human dental professor would, making its evaluations more consistent with expert standards.
- Few-shot learning: Imagine teaching a child to identify a new type of fruit. Instead of showing them hundreds of pictures, you show them just a few examples (e.g., "This is an apple, this is another apple, and this is what a bad apple looks like"). From these limited examples, the child quickly learns to recognize other apples. Similarly, few-shot learning allows an AI to learn a new task or adapt to a specific style by seeing only a small handful of examples, rather than needing massive training datasets.
Notation Table
| Notation | Description |
|---|---|
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The central problem addressed by this paper is the accurate and efficient automated assessment of student responses to open-ended short-answer questions, particularly within specialized domains like dental education.
The Input/Current State for existing systems is a student's free-text answer ($A_{student}$), a question ($Q$) which may include textual and visual content, and a marking rubric ($R$) defining scoring criteria. Additionally, a retrieval corpus ($C$) like dental handbooks is available. Current large language models (LLMs) have shown promise in automated scoring, offering efficiency and consistency. However, they face significant hurdles:
1. Domain-Specific Interpretation: LLMs struggle with the precise interpretation of nuanced professional vocabulary and domain-specific terminology inherent in fields like dentistry.
2. Alignment with Expert Rubrics: Existing LLM systems often produce outputs inconsistent with human-level evaluations, failing to align with the specific, expert-established grading rubrics.
3. Resource Demands: Addressing these issues typically necessitates extensive fine-tuning and retraining with large, annotated datasets, which is time-consuming, computationally expensive, and impractical for resource-constrained educational settings.
The Desired Endpoint (Output/Goal State) is a numerical score $S_{final} \in [0, 5]$ that accurately reflects a student's performance, closely aligning with human expert grading standards. This system should be:
1. Domain-Aware: Capable of understanding and applying specialized dental knowledge.
2. Expert-Aligned: Consistently producing scores that correlate strongly with human professor evaluations.
3. Resource-Efficient: Operating effectively without the need for extensive fine-tuning or retraining, thereby reducing evaluation time and financial costs.
4. Multimodal: Able to process questions that include both textual and visual content (e.g., clinical images).
The missing link or mathematical gap is precisely how to construct a function, $S_{final} = DentEval(A_{student}, Q, R, C)$, that can reliably and cost-effectively map these inputs to an expert-aligned score. Previous approaches have struggled to bridge the gap between generic LLM capabilities and the nuanced, specialized requirements of expert assessment, especially for open-ended questions where a single "correct" answer is not always available. The core dilemma is achieving high accuracy and alignment with human expert grading in specialized, open-ended questions without incurring the high costs and resource demands of traditional fine-tuning. Improving one aspect, such as domain specificity, usually breaks another, like computational efficiency or data requirements.
Constraints & Failure Modes
The problem of automated expert-aligned assessment in specialized domains like dentistry is made insanely difficult by several harsh, realistic walls:
-
Data-Driven Constraints:
- Sparsity of Annotated Data: There is a critical need for large, expert-annotated datasets for fine-tuning or additional training, which are scarce and expensive to create in highly specialized fields such as dentistry. This makes traditional supervised learning approaches impractical.
- Open-Ended Question Variability: Open-ended questions, common in higher education, do not always have a single, unique correct answer. Student responses can exhibit considerable variation in length, structure, and reasoning complexity, reflecting authentic diversity in learner expression. This inherent variability makes it challenging to define a definitive "correct" answer for automated systems.
- Noise in Retrieved Information: Even with retrieval-augmented generation (RAG), segmented evidence chunks from a corpus may contain content not directly relevant to the query or its key terms. This irrelevant information can introduce noise, negatively impacting the accuracy and quality of sample answer generation.
-
Computational & Resource Constraints:
- High Computational Cost of Fine-tuning: Traditional methods for adapting LLMs to specialized domains require extensive computing resources and significant time for fine-tuning and retraining. This is often impractical for resource-constrained educational settings.
- Financial Costs: Human evaluation by higher education professionals is expensive (e.g., approximately USD 1.275 per response), making scalable manual assessment financially unsustainable for large cohorts. Any automated solution must offer substantial financial savings.
-
Model & Functional Constraints:
- Lack of Domain Expertise in Generic LLMs: Out-of-the-box LLMs struggle with the precise interpretation of domain-specific terminology and nuanced professional vocabulary, leading to inaccurate assessments in specialized fields.
- Inconsistency with Human Grading: A major failure mode of existing systems is the inconsistency between LLM outputs and human-level evaluations. LLMs often fail to adhere to the specific evaluation criteria established by professionals, leading to a lack of trust and adoption.
- Variability in LLM Scoring: Even with the same input, LLMs can exhibit variability in their scoring, which reduces the reliability and robustness of the assessment system. This requires mechanisms to ensure consistent and dependable evaluations.
- Misinterpretation in Few-shot Learning: For open-ended questions that allow multiple valid perspectives, providing a single set of few-shot examples can lead LLMs to misinterpret these as the only correct answers, resulting in misjudgments of other valid student responses. This is a painful trade-off where trying to guide the model with examples can inadvertently narrow its understanding.
Why This Approach
The Inevitability of the Choice
The adoption of DentEval's specific approach, integrating Self-refining Retrieval-Augmented Generation (SR-RAG) and role-playing LLM agents, wasn't merely a preference but a necessity driven by the inherent limitations of traditional methods when applied to specialized educational assessment. The authors realized that standard "SOTA" methods, particularly those relying on extensive fine-tuning of Large Language Models (LLMs), were insufficient for this problem due to several critical challenges.
Firstly, assessing open-ended short-answer questions in specialized domains like dentistry demands a nuanced understanding of professional vocabulary and complex concepts. Traditional LLMs, even powerful ones, often struggle with this without substantial domain-specific training. The "exact moment" of this realization isn't a single event but a recognition that existing systems required "large, annotated datasets for fine-tuning or additional training," which is "time-consuming and impractical for resource-constrained settings." This constraint made fine-tuning-heavy approaches non-viable.
Secondly, ensuring that automated assessments align closely with expert human grading rubrics is a significant hurdle. Standard LLM applications often exhibit "inconsistencies between model outputs and human-level evaluations." This lack of alignment is particularly problematic in high-stakes educational contexts where fairness and accuracy are paramount. The need to adhere to specific, professionally established evaluation criteria meant that a more dynamic and context-aware approach was required than what basic LLM prompting or simple fine-tuning could offer. The paper explicitly states that addressing these issues typically requires "extensive fine-tuning and retraining," which was deemed impractical.
Comparative Superiority
DentEval demonstrates qualitative superiority over previous gold standards and baseline methods through its structural innovations, which directly address the core challenges of specialized domain assessment. Beyond achieving superior performance metrics (Spearman's correlation up to 0.9259 and Pearson's correlation up to 0.8957, outperforming SciEx and FairEval), its advantages are rooted in its design:
- No Fine-tuning Requirement: Unlike many prior approaches that demand extensive fine-tuning with large, annotated datasets, DentEval operates effectively without this resource-intensive step. This is a massive structural advantage, making it practical for resource-constrained educational settings and significantly reducing development and deployment overhead.
- Optimized RAG Process with Self-Refinement: The Self-refining Retrieval-Augmented Generation (SR-RAG) is a key innovation. It doesn't just retrieve information; it refines it and autonomously evaluates its adequacy. This means the system can acquire sufficient domain-specific knowledge without explicit fine-tuning. This process inherently handles high-dimensional noise better becuase it actively filters out irrelevant information from retrieved chunks, which could otherwise negatively impact the accuracy of sample answer generation. This self-evaluation loop (where $K$ is dynamically adjusted) ensures that the LLM has sufficient grounding, a structural advantage over standard RAG that might retrieve noisy or insufficient context.
- Role-playing Prompting and Sample Answer Generation (SAG): By designating LLM agents as a "professor" to generate multiple reference answers and an "evaluator" (teacher) for scoring, DentEval structurally aligns its assessment process with human pedagogical practices. This multi-agent, role-playing approach enhances alignment with human grading standards and improves consistency. For open-ended questions, generating diverse reference answers (rather than a single "correct" one) allows the system to capture the inherent complexity and variability of acceptable student responses, making it overwhelmingly superior for such tasks.
- Efficiency Gains: The system offers substantial "efficency gains" in both time and financial cost. A human evaluator typically spends about 1.5 minutes per response at a cost of roughly USD 1.275. In contrast, DentEval processes each question in approximately 0.13 minutes at a cost of only USD 0.007. This dramatic reduction in time and cost is a qualitative advantage that enables educators to reallocate resources to more pedagogically valuable activities.
Alignment with Constraints
DentEval's chosen method perfectly aligns with the harsh requirements of automated assessment in specialized domains like dental education, forming a robust "marriage" between problem and solution.
- Constraint: Need for large, annotated datasets for fine-tuning.
- Alignment: DentEval's "No Fine-tuning Requirement" directly addresses this. Its SR-RAG module allows it to acquire domain-specific knowledge without needing extensive, costly, and time-consuming annotated datasets for retraining, making it practical for specialized fields where such data is scarce.
- Constraint: Inconsistencies between model outputs and human-level evaluations.
- Alignment: The "Role-playing Prompting" and "SR-RAG" components are designed to ensure outputs closely align with human grading standards. The Evaluator LLM, assigned a teacher role, enhances this alignment, while SR-RAG provides factually consistent and domain-relevant information. The use of majority voting from multiple LLM scores further reduces variability and improves consistency.
- Constraint: Specialized knowledge domain (dentistry) requiring precise interpretation of terminology.
- Alignment: SR-RAG is tailored to acquire sufficient domain-specific knowledge by retrieving relevant information from dental handbooks and refining it. Furthermore, DentEval supports multimodal inputs (text and clinical images), which is crucial for a field like dentistry that relies heavily on visual information.
- Constraint: Aligning with expert grading rubrics.
- Alignment: The system explicitly takes a "marking rubric R" as an input. The Sample Answer Generation (SAG) module designates the LLM as a "professor" to generate reference answers, and the Evaluator LLM acts as a "teacher," ensuring that the assessment process adheres to predefined criteria and professional standards.
- Constraint: Resource-constrained settings.
- Alignment: By eliminating the need for fine-tuning and significantly reducing evaluation time and financial costs (from USD 1.275 to USD 0.007 per response), DentEval provides a resource-efficient solution that is highly practical for educational institutions.
- Constraint: Assessing open-ended short-answer questions.
- Alignment: The SAG module generates multiple reference answers, acknowledging the inherent complexity and variability of possible correct responses for open-ended questions. This prevents the system from misjudging diverse but valid student answers, a common pitfall for simpler methods.
Rejection of Alternatives
The paper implicitly and explicitly rejects several alternative approaches, particularly those that rely on basic LLM prompting or extensive fine-tuning, due to their inherent limitations for the specific problem of expert-aligned assessment in specialized domains.
The primary rejection is of traditional LLM fine-tuning methods. The authors highlight that these methods require "large, annotated datasets for fine-tuning or additional training," which is "time-consuming and impractical for resource-constrained settings." This makes them unsuitable for specialized fields like dentistry where such datasets are scarce and the cost of annotation by experts is high. DentEval's fine-tuning-free approach directly circumvents this impracticality.
Furthermore, the paper provides a clear rejection of basic Few-shot learning for certain types of questions. While Few-shot learning generally improves performance over Zero-shot, the authors observe a "noticeable decline in scoring performance for Question 2" (an open-ended question allowing multiple perspectives) when using the baseline Few-shot method. The reasoning is that "during Few-shot learning, the LLM may interpret the provided examples as the only correct answers, leading to misjudgments of other students' responses." This limitation is a critial flaw for open-ended questions where a single definitive answer is not always appropriate. DentEval overcomes this by incorporating its Sample Answer Generation (SAG) module, which generates multiple diverse reference answers, thereby capturing the variability of correct responses and preventing misjudgments.
While the paper doesn't delve into a direct comparison with other deep learning paradigms like GANs or Diffusion models (as the problem is fundamentally about language understanding and assessment, not generation of complex media like images from noise), its focus on LLM-based solutions implies that such models are not directly applicable or efficient for this specific task. The core problem revolves around semantic understanding, domain knowledge acquisition, and alignment with human judgment, areas where LLMs, augmented with RAG and agentic capabilities, are uniquely positioned.
Mathematical & Logical Mechanism
The Master Equation
The core of DentEval's assessment mechanism, particularly for generating the final score, is encapsulated in a two-part equation that first produces individual scores from multiple evaluation agents and then aggregates them. This process ensures robustness and aligns with human grading standards through role-playing and few-shot learning.
The individual score generation for each evaluation instance $i$ is given by:
$$S_i = \text{LLM}_{\text{evaluator}}(Q, A_{student}, \{A_{sample},..., A_{sample}\}, R), \quad i \in \{1,..., n\}$$
And the final aggregated score is determined by:
$$S_{final} = \text{Mode}(\{S_1, S_2, ..., S_n\})$$
Term-by-Term Autopsy
Let's dissect these equations to understand the role of each component:
-
$S_i$:
- Mathematical Definition: This represents the numerical score assigned to a student's answer by a single instance of the LLM evaluator. It's a scalar value, typically within a predefined range (e.g., $[0, 5]$ as mentioned in the paper).
- Physical/Logical Role: $S_i$ is an intermediate, individual assessment of the student's response. The system generates $n$ such scores to account for potential variability in LLM outputs and to enhance reliability.
- Why used: The authors use multiple $S_i$ values to reduce the impact of any single LLM's idiosyncratic judgment, thereby increasing the consistency and robustness of the overall assessment. This is a common strategy to mitigate noise in AI-driven evaluations.
-
$\text{LLM}_{\text{evaluator}}(\cdot)$:
- Mathematical Definition: This denotes the function performed by a Large Language Model specifically configured to act as an "evaluator." It takes several inputs and produces a single numerical score.
- Physical/Logical Role: This is the central intelligent agent responsible for judging the student's answer. By assigning it the "evaluator" role through prompting, the system guides the LLM to adopt a critical, assessment-focused persona, mirroring a human teacher.
- Why used: An LLM is chosen for its advanced natural language understanding and generation capabilities, allowing it to interpret complex questions, student responses, rubrics, and reference answers to make a nuanced judgment. The role-playing prompt helps align its output with expert human grading criteria.
-
$Q$:
- Mathematical Definition: This is the input query or question posed to the student. It can be textual and may optionally include visual content (e.g., figures).
- Physical/Logical Role: $Q$ defines the task or problem the student is expected to answer. It's the primary context for the evaluation.
- Why used: The question is fundamental to any assessment. It provides the basis against which the student's response is measured.
-
$A_{student}$:
- Mathematical Definition: This is the student's free-text response to the question $Q$.
- Physical/Logical Role: $A_{student}$ is the item being evaluated. It's the raw data point whose quality and correctness need to be assessed.
- Why used: This is the direct output from the student that the system aims to score.
-
$\{A_{sample},..., A_{sample}\}$:
- Mathematical Definition: This represents a set of sample reference answers. These are generated internally by another LLM agent, $\text{LLM}_{\text{professor}}(Q, E)$, where $E$ is refined information from a dental handbook. The paper states that multiple sample answers are generated to account for the open-ended nature of questions.
- Physical/Logical Role: These sample answers serve as expert-aligned benchmarks or "gold standards" against which the student's response $A_{student}$ is compared. They provide the LLM evaluator with examples of what a good answer looks like, effectively acting as few-shot learning examples.
- Why used: Providing multiple reference answers helps the LLM evaluator understand the breadth of acceptable responses for open-ended questions, reducing bias towards a single "correct" answer and improving its ability to capture diverse, yet valid, student expressions. This is crucial for specialized domains where answers might have multiple valid interpretations.
-
$R$:
- Mathematical Definition: This is the marking rubric, a set of criteria and guidelines for scoring.
- Physical/Logical Role: $R$ provides the explicit rules and standards for evaluation. It ensures that the scoring is objective and consistent with pedagogical requirements.
- Why used: A rubric is essential for structured assessment, ensuring that the LLM's evaluation is transparent, fair, and aligned with human grading principles. It acts as a constraint and guide for the LLM's judgment.
-
$i \in \{1,..., n\}$:
- Mathematical Definition: This is an index indicating that the evaluation process is repeated $n$ times, generating $n$ individual scores.
- Physical/Logical Role: This signifies the multiplicity of the evaluation process. Each $S_i$ is an independent run of the $\text{LLM}_{\text{evaluator}}$.
- Why used: Repeating the evaluation multiple times and then aggregating the results (via the Mode) is a strategy to enhance the reliability and stability of the final score, mitigating the inherent stochasticity or variability of LLM outputs.
-
$S_{final}$:
- Mathematical Definition: This is the ultimate numerical score assigned to the student's answer, derived from the aggregation of individual scores.
- Physical/Logical Role: $S_{final}$ is the definitive output of the DentEval system, representing the final assessment of the student's response.
- Why used: This is the desired end product of the system, a single, robust score that can be used for grading.
-
$\text{Mode}(\cdot)$:
- Mathematical Definition: This is a statistical function that returns the most frequently occurring value in a set of data.
- Physical/Logical Role: The Mode function acts as a consensus mechanism. By selecting the most common score among the $n$ individual evaluations, it effectively filters out outliers and reinforces the most consistent judgment from the LLM agents.
- Why used: Majority voting via the Mode is employed to reduce variability and improve the consistency and reliability of the final score, especially in situations where individual LLM outputs might differ slightly. It's a simple yet effective way to achieve a robust consensus.
Step-by-Step Flow
Imagine a student's answer $A_{student}$ embarking on a journey through the DentEval system, much like an item on a sophisticated assembly line:
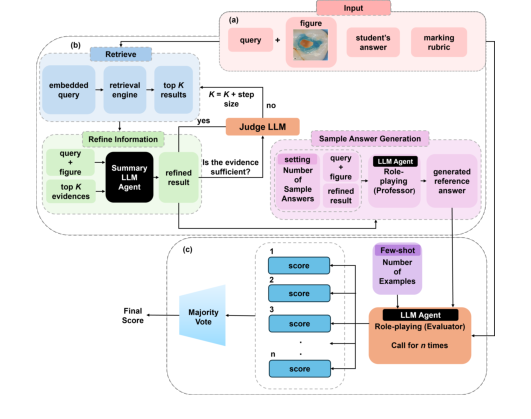 Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
-
Initial Input Reception: The process begins with three primary inputs: the student's answer ($A_{student}$), the question ($Q$, potentially with an associated figure), and the marking rubric ($R$). Additionally, a vast retrieval corpus ($C$) of dental knowledge is available.
-
Query Embedding & Initial Retrieval: The question $Q$ is first transformed into a numerical vector representation (an embedding). This embedded query is then fed into a retrieval engine (like Milvus) to search the dental knowledge corpus $C$. The engine pulls out the "top K" most relevant information chunks.
-
Information Refinement: These initial "top K" chunks, along with the original question $Q$, are passed to a specialized LLM agent. This agent's task is to summarize and refine this raw information into a more concise and relevant evidence set, $E$. This step is crucial to remove noise and ensure the information is directly pertinent to the question.
-
Sufficiency Check & Iterative Retrieval: The refined evidence $E$ is then evaluated by another LLM agent to determine if it's "sufficient" for generating a high-quality reference answer. If the evidence is deemed insufficient, the system loops back to the retrieval stage, increasing the value of $K$ (by a "step size") to gather more information. This iterative self-correction ensures comprehensive grounding.
-
Sample Answer Generation (SAG): Once sufficient evidence $E$ is acquired, it's combined with the question $Q$ and fed into an $\text{LLM}_{\text{professor}}$ agent. This agent, role-playing a dental academic, generates multiple diverse sample answers, $\{A_{sample},..., A_{sample}\}$, based on the refined evidence and the question. This step is vital for open-ended questions where multiple correct responses may exist.
-
Individual Score Generation: Now, the system prepares for the actual scoring. For $n$ separate evaluation runs, an $\text{LLM}_{\text{evaluator}}$ agent is invoked. In each run $i$, this evaluator LLM receives the question $Q$, the student's answer $A_{student}$, the set of generated sample answers $\{A_{sample},..., A_{sample}\}$, and the marking rubric $R$. It also incorporates few-shot learning examples (student responses from each score tier with evaluation feedback) to guide its judgment. Based on all these inputs, the $\text{LLM}_{\text{evaluator}}$ produces an individual score $S_i$.
-
Final Score Aggregation: After $n$ individual scores ($S_1, S_2, ..., S_n$) have been generated, they are collected. The final score, $S_{final}$, is then determined by applying the Mode function to this set of scores. This means the most frequently occurring score among the $n$ evaluations becomes the definitive grade. This majority voting mechanism ensures a robust and consistent final assessment, minimizing the impact of any single anomalous evaluation.
Optimization Dynamics
DentEval operates on a "fine-tuning-free" paradigm, meaning it does not involve traditional gradient-based optimization to update the parameters of the underlying Large Language Models. Instead, its "learning," "updating," or "converging" behavior is achieved through a combination of intelligent system design, iterative processes, and sophisticated prompting strategies:
-
Self-Refining Retrieval-Augmented Generation (SR-RAG): The system's primary "learning" mechanism is embedded within its SR-RAG component. When the initial retrieved evidence $E$ is deemed insufficient by an LLM agent, the system doesn't just give up; it iteratively expands its search by increasing the parameter $K$ (the number of top relevant chunks). This self-correction loop allows the system to "learn" when its knowledge base is inadequate and actively seek more comprehensive information. This dynamic adjustment of retrieval parameters is a form of adaptive optimization for the RAG process itself, ensuring the context provided to the LLM is as complete and relevant as possible.
-
Role-Playing Prompting: The system's performance is "optimized" by carefully crafting prompts that assign specific roles (e.g., "professor," "evaluator") to the LLM agents. This isn't a mathematical optimization in the traditional sense, but a powerful form of in-context guidance. By adopting these personas, the LLMs are steered to exhibit behaviors and reasoning patterns that closely mimic human experts, thereby aligning their outputs with desired grading standards. This "prompt engineering" is a crucial lever for shaping the LLM's "loss landscape" implicitly, guiding it towards more accurate and consistent evaluations without altering its internal weights.
-
Few-Shot Learning: The evaluation LLM is provided with a small set of examples (few-shot examples) that include student responses, rubrics, and human-assigned scores with feedback. This allows the LLM to "learn" the desired scoring patterns and criteria directly from examples, rather than through explicit parameter updates. This in-context learning helps the LLM converge on a consistent scoring policy by demonstrating the expected input-output relationships.
-
Majority Voting for Robustness: The aggregation of multiple individual scores ($S_i$) into a final score ($S_{final}$) using the Mode function is a statistical optimization. It acts as a robust estimator, effectively smoothing out individual variations and biases that might arise from a single LLM evaluation. This mechanism helps the system converge on a more stable and reliable score, improving consistency over time and across different student responses. It's a form of ensemble learning applied to the LLM outputs.
-
Post-Processing with CDF Mapping: As mentioned in the implementation details, the system applies Cumulative Distribution Function (CDF) mapping as a post-processing step. This method calibrates the LLM's raw scores to mitigate biases and enhance fairness, aligning them more closely with human score distributions. While not part of the LLM's internal learning, it's an external calibration step that "optimizes" the final output for better alignment with human judgment.
In essence, DentEval's "optimization" is less about gradient descent on a loss function and more about an intelligently designed, multi-agent workflow that leverages the inherent capabilities of large language models through iterative refinement, strategic prompting, and robust aggregation techniques to achieve expert-aligned assessment without the need for extensive fine-tuning. The system's "learning" is therefore procedural and contextual, rather than parametric.
Results, Limitations & Conclusion
Experimental Design & Baselines
To rigorously validate DentEval's mathematical claims and practical efficacy, the researchers architected a comprehensive experimental setup. The core of their evaluation revolved around a unique, professor-annotated dataset specifically curated for dental curricula. This dataset comprised 28 student responses for each question, carefully scored by dentistry academics against a predefined marking rubric. Crucially, the dataset included two distinct types of open-ended questions: one requiring multimodal reasoning (text and images) and another purely textual. This diversity was intentional, reflecting the varied nature of assessments in dental education, covering distinct subdomains like dental morphology and restorative materials, and exhibiting a wide range of response lengths and complexities.
For the evaluation, a few-shot learning approach was adopted. From the 28 responses per question, one response from each score tier was selected to serve as a few-shot example, resulting in 6 examples per question. The remaining 22 responses formed the testing set. This design allowed the LLM agents to learn from expert-graded examples without extensive fine-tuning. GPT-40 (specifically gpt-40-mini) was chosen as the underlying LLM agent, leveraging its multimodal capabilities. To ensure fairness and consistency, Cumulative Distribution Function (CDF) mapping was applied as a post-processing step to mitigate potential biases in scoring.
 Figure 2. Scoring Rubric and Example Content Illustration
Figure 2. Scoring Rubric and Example Content Illustration
DentEval's performance was benchmarked against several "victim" baseline models and advanced techniques:
- Zero-shot: A straightforward approach where the LLM scores responses without any modifications or role-playing.
- Few-shot: An enhancement of Zero-shot, incorporating reference examples to guide the LLM.
- SciEx [5]: A state-of-the-art method that combines few-shot learning with role-playing prompts.
- FairEval [22]: Another advanced technique employing Multiple Evidence Calibration (MEC) and Balanced Position Calibration (BPC) to reduce bias in LLM evaluations.
The definitive evidence of DentEval's core mechanism was sought through standard evaluation metrics: Accuracy (Acc.), Spearman's Rank-Order Correlation Coefficient (SROCC) [17], and Pearson Linear Correlation Coefficient (PLCC) [16]. SROCC and PLCC were particularly important as they directly measure the consistency and linear correlation of DentEval's scores with human expert evaluations, providing a robust measure of alignment.
Finally, an ablation study was conducted to ruthlessly prove the contribution of each innovative component within DentEval (SR-RAG, Sample Answer Generation (SAG), and Role-playing Prompting). By systematically removing or isolating these components, the researchers could pinpoint their individual impact on the system's overall performance, using the Zero-shot baseline for comparison.
What the Evidence Proves
The experimental evidence overwhelmingly demonstraits the superior performance and reliability of DentEval across diverse assessment scenarios in dental education.
For Question 1, which involved multimodal reasoning (text and images) and had a single correct answer, DentEval achieved the best performance across all evaluation metrics. It recorded an SROCC of 0.7447, a PLCC of 0.7288, and an accuracy of 68.2%, all accompanied by the lowest p-values, indicating a statistically significant alignment with human grading. While SciEx and FairEval outperformed the basic Zero-shot baseline, they slightly underperformed compared to the baseline Few-shot method, highlighting the nuanced challenges of automated assessment even for advanced techniques. DentEval's ability to integrate multimodal inputs and expert-aligned mechanisms clearly gave it an edge here.
For Question 2, a purely textual, open-ended question allowing for multiple valid responses, DentEval's performance was even more striking. It achieved an SROCC of 0.9259 and a PLCC of 0.8957, both higher than for Question 1, and maintained an accuracy of 68.2%. This is particularly significant because, unlike Question 1, the baseline Few-shot method exhibited a noticeable decline in scoring performance for Question 2. The authors attribute this to the nature of open-ended questions, where Few-shot examples might inadvertently lead the LLM to interpret them as the only correct answers, causing misjudgments of other valid student responses. DentEval's robustness in handling such complex, open-ended questions, where a single definitive answer is not expected, is a strong testament to its advanced design, particularly its SR-RAG and role-playing prompting mechanisms that generate diverse reference answers.
Beyond accuracy and correlation, DentEval also delivered undeniable evidence of significant efficiency gains. A human evaluator typically spends about 1.5 minutes per student response, costing approximately USD 1.275. In stark contrast, DentEval's GPT-40 LLM agents processed each question in approximately 0.13 minutes, at a cost of only USD 0.007 per response. This represents a massive reduction in both time and financial resouces, freeing up educators to focus on more pedagogically valuable activities.
The ablation study further solidified the contributions of DentEval's core components. Each innovation—SR-RAG, Sample Answer Generation (SAG), and Role-playing Prompting—was shown to individually improve consistency with human evaluations and increase accuracy. For instance, SR-RAG alone significantly boosted accuracy for Question 1 from 9.1% (Zero-shot) to 54.5%, and for Question 2 from 50.0% to 68.2%. The full DentEval framework consistently outperformed all ablated versions, confirming that the synergistic integration of these components is what truly drives its superior performance and alignment with human judgment.
Limitations & Future Directions
While DentEval presents a compelling advancement in automated assessment for specialized domains, it's important to acknowledge its current limitations and consider avenues for future development.
One clear limitation, as implicitly noted by the authors, is the dataset size. Although the collected responses were diverse in structure and substantivey, the "limited number of questions" (only two distinct questions were evaluated) might restrict the generalizability of the findings to the full breadth of dental curricula or other specialized fields. Expanding the dataset to include a wider array of question types, difficulty levels, and response variations would provide a more robust validation of DentEval's capabilities.
Another point to consider is the dependency on a specific LLM, GPT-40. While powerful, this introduces potential issues regarding cost fluctuations, API availability, and the proprietary nature of the model. Future work could explore the adaptability of DentEval's framework to open-source LLMs or more cost-effective alternatives, ensuring broader accessibility and sustainability.
The paper also highlights the challenge posed by open-ended questions where multiple correct answers are possible, noting the decline in performance for the baseline Few-shot method. While DentEval handles this well, the inherent complexity of such questions suggests that continuous refinement of the Sample Answer Generation (SAG) and Self-refining Retrieval-Augmented Generation (SR-RAG) modules will be crucial to maintain high alignment with expert judgment across an even wider spectrum of subjective assessments.
Looking ahead, the authors themselves propose exciting future directions:
- Extending Multimodal RAG: A natural evolution would be to incorporate more complex multimodal inputs, such as clinical videos and 3D models. This would allow DentEval to assess practical skills and diagnostic reasoning in a more holistic and realistic manner, moving beyond static images and text. Imagine an LLM agent evaluating a student's technique in a simulated surgical procedure based on video evidence!
- Adaptive Calibration: Developing adaptive calibration mechanisms to improve robustness across varied question types is another critical area. This implies a system that can dynamically adjust its scoring rubric or evaluation strategy based on the specific characteristics of a question (e.g., whether it expects a single factual answer or a nuanced, multi-perspective response). This would enhance the system's flexibility and reliability in diverse assessment contexts.
Beyond these, several other discussion topics could further evolve these findings:
- Explainability and Feedback Quality: While DentEval provides scores, the pedagogical value of automated assessment is significantly enhanced by high-quality, actionable feedback. Future research could focus on making the LLM's reasoning process more transparent and generating detailed, constructive feedback that helps students understand why they received a certain score and how to improve. This could involve integrating chain-of-thought prompting specifically for feedback generation.
- Ethical AI in Education: As automated assessment becomes more prevalent, addressing ethical concerns around fairness, bias, and equity is paramount. How can we ensure DentEval's assessments are unbiased across different student demographics or learning styles? What mechanisms can be put in place to detect and mitigate potential algorithmic bias? Research into auditability and explainable AI for grading would be invaluable.
- Integration with Learning Management Systems (LMS): For widespread adoption, seamless integration of DentEval into existing educational infrastructures, such as Canvas or Moodle, is essential. This would involve developing robust APIs and user-friendly interfaces for educators to easily deploy, customize, and monitor automated assessments.
- Cross-Domain Applicability: While tailored for dentistry, the underlying principles of SR-RAG, role-playing prompting, and multimodal input handling could be generalized to other specialized domains requiring expert-aligned assessment, such as medicine, engineering, or law. Exploring these isomorphisms could unlock broader applications and impact.
- Real-time Adaptive Learning: Could DentEval be integrated into real-time learning environments to provide immediate, personalized feedback and adaptive learning paths? Imagine a student receiving instant assessment and tailored remedial resources as they complete practice questions, accelerating their learning process.
These diverse perspectives highlight that DentEval is not just a tool for automated grading but a foundational framework with the potential to profoundly reshape educational assessment and learning experiences in specialized fields.
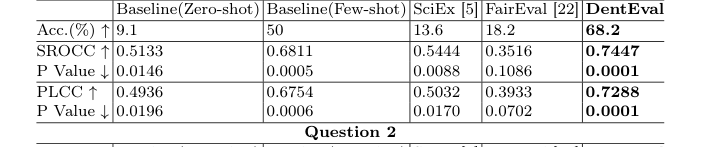 Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval
Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval