DentEval: LLM 에이전트를 활용한 치의학 교육에서의 Fine-tuning-Free 전문가 정렬 평가
Large language models (LLMs) have demonstrated considerable potential in automating assignment scoring within higher education, providing efficient and consistent evaluations.
배경 및 학문적 계보
기원 및 학문적 계보
본 논문에서 다루는 문제의 정확한 기원은 교육, 특히 자동화된 평가 분야에서 대규모 언어 모델(LLM)이 가져온 최근의 혁명에서 비롯된다. OpenAI의 GPT 시리즈와 같은 LLM은 과제에 대한 효율적이고 일관된 평가를 제공하는 데 상당한 가능성을 보여주었지만, 치의학과 같이 고도로 전문화된 분야에 적용하는 것은 상당한 어려움을 제시한다.
역사적으로 자동화된 평가 시스템은 존재해 왔지만, LLM의 등장은 개방형 질문을 처리하는 새로운 가능성을 열었다. 그러나 전문가 수준의 평가에 LLM을 활용하려 할 때 두 가지 핵심 문제가 발생했다.
1. 분야별 해석: LLM은 종종 전문 분야 고유의 미묘한 전문 용어와 복잡한 개념을 다루는 데 어려움을 겪는다. 용어를 잘못 해석하거나 정확한 평가에 필요한 깊은 맥락적 이해가 부족할 수 있다.
2. 전문가 채점과의 정렬: 인간 전문가(예: 치과 교수)가 설정한 특정, 종종 주관적인 평가 기준을 LLM 출력이 준수하도록 보장하는 것이 주요 장애물이었다.
이러한 한계를 극복하기 위한 이전 접근 방식은 일반적으로 LLM을 대규모의 세심하게 주석이 달린 데이터셋을 사용하여 광범위하게 fine-tuning하거나 재훈련하는 것을 포함했다. 이 과정은 시간이 많이 소요될 뿐만 아니라 리소스 집약적이어서, 특히 계산 리소스가 제한된 많은 교육 환경에서는 비현실적이다. 저자들이 DentEval를 개발하도록 강요한 "고충점"은 바로 이것이다. 전문화된 개방형 평가 작업에 LLM을 적용하는 기존 방법은 막대한 양의 데이터와 계산 노력을 필요로 하여 인간 채점과의 불일치를 초래하고 실시간 실용적인 적용을 어렵게 만들었다. 저자들은 전문가 정렬 평가를 효율적으로 달성할 수 있는 fine-tuning-free 솔루션을 모색했다.
직관적인 분야 용어
다음은 논문의 몇 가지 전문 용어를 제로베이스 독자를 위한 일상적인 비유로 번역한 것이다.
- 대규모 언어 모델(LLM): 거의 모든 책, 기사, 웹페이지를 읽은 매우 똑똑한 디지털 비서라고 상상해 보라. 당신의 말을 이해하고, 새로운 텍스트를 생성하며, 질문에 답할 수 있지만, 모든 것에 대한 전문가가 아닐 수도 있다. 뛰어난 제너럴리스트와 같지만, 때로는 매우 구체적이고 틈새 주제에 대해 약간의 추가 도움이 필요하다.
- 검색 증강 생성(RAG): 이것을 우리 매우 똑똑한 디지털 비서를 위한 오픈북 시험이라고 생각하라. 질문을 할 때, 단순히 일반 지식에 의존하는 대신, 먼저 관련 정보를 찾기 위해 특정 신뢰할 수 있는 라이브러리(치과 핸드북과 같은)를 빠르게 검색한다. 그런 다음, 그 새로 검색된 정보와 자신의 두뇌를 사용하여 훨씬 더 정확하고 정보에 입각한 답변을 공식화한다. 답변하기 전에 개인 연구 조수가 있는 것과 같다.
- 역할극 프롬프팅: 이것은 우리 디지털 비서에게 특정 캐릭터를 연기하도록 하는 것과 유사하다. 단순히 "이것을 채점해"라고 요청하는 대신, "자, 이제 당신은 엄격한 치과 교수이며, 이 규칙에 따라 이 학생의 답변을 채점해야 합니다."라고 말한다. 이 페르소나를 채택함으로써 LLM은 인간 치과 교수가 생각하고 응답하는 방식과 정확히 동일하게 생각하고 응답하려고 시도하여 평가가 전문가 표준과 더 일관되도록 한다.
- 소수샷 학습(Few-shot learning): 아이에게 새로운 종류의 과일을 식별하는 방법을 가르치는 것을 상상해 보라. 수백 장의 사진을 보여주는 대신, 몇 개의 예시만 보여준다(예: "이것은 사과이고, 이것은 또 다른 사과이며, 이것은 나쁜 사과입니다."). 이러한 제한된 예시로부터 아이는 다른 사과를 빠르게 인식하는 법을 배운다. 마찬가지로, 소수샷 학습은 AI가 대규모 훈련 데이터셋이 아닌 소수의 예시만 보고 새로운 작업을 학습하거나 특정 스타일에 적응할 수 있도록 한다.
표기법 표
| 표기법 | 설명 |
|---|---|
문제 정의 및 제약 조건
핵심 문제 공식화 및 딜레마
본 논문에서 다루는 핵심 문제는 치의학 교육과 같은 전문 분야에서 개방형 단답형 질문에 대한 학생 응답의 정확하고 효율적인 자동화된 평가이다.
기존 시스템의 입력/현재 상태는 학생의 자유 텍스트 답변($A_{student}$), 텍스트 및 시각적 콘텐츠를 포함할 수 있는 질문($Q$), 그리고 채점 기준을 정의하는 채점 루브릭($R$)이다. 또한, 치과 핸드북과 같은 검색 코퍼스($C$)를 사용할 수 있다. 현재의 대규모 언어 모델(LLM)은 자동 채점에서 가능성을 보여주며 효율성과 일관성을 제공한다. 그러나 그들은 상당한 장애물에 직면해 있다.
1. 분야별 해석: LLM은 치의학과 같은 분야에 내재된 미묘한 전문 용어와 분야별 용어의 정확한 해석에 어려움을 겪는다.
2. 전문가 루브릭과의 정렬: 기존 LLM 시스템은 종종 인간 수준의 평가와 일관되지 않은 출력을 생성하여 전문가가 설정한 특정 채점 루브릭과 일치하지 못한다.
3. 리소스 요구 사항: 이러한 문제를 해결하려면 일반적으로 대규모 주석이 달린 데이터셋을 사용한 광범위한 fine-tuning 및 재훈련이 필요하며, 이는 시간이 많이 소요되고 계산 비용이 많이 들며 리소스가 제한된 교육 환경에서는 비현실적이다.
원하는 최종 상태(출력/목표 상태)는 학생의 성과를 정확하게 반영하고 인간 전문가 채점 기준과 밀접하게 일치하는 숫자 점수 $S_{final} \in [0, 5]$이다. 이 시스템은 다음과 같아야 한다.
1. 분야 인식: 전문 치과 지식을 이해하고 적용할 수 있어야 한다.
2. 전문가 정렬: 인간 교수 평가와 강하게 상관되는 점수를 일관되게 생성해야 한다.
3. 리소스 효율성: 광범위한 fine-tuning 또는 재훈련 없이 효과적으로 작동하여 평가 시간과 재정 비용을 줄여야 한다.
4. 다중 모달: 텍스트 및 시각적 콘텐츠(예: 임상 이미지)를 포함하는 질문을 처리할 수 있어야 한다.
누락된 연결 또는 수학적 격차는 정확히 이러한 입력들을 전문가 정렬 점수로 안정적이고 비용 효율적으로 매핑할 수 있는 함수 $S_{final} = DentEval(A_{student}, Q, R, C)$를 구성하는 방법이다. 이전 접근 방식은 일반 LLM 기능과 전문가 평가의 미묘하고 전문화된 요구 사항 간의 격차를 해소하는 데 어려움을 겪었으며, 특히 단일 "정답"이 항상 가능한 것은 아닌 개방형 질문의 경우 더욱 그러했다. 핵심 딜레마는 전통적인 fine-tuning의 높은 비용과 리소스 요구 사항을 발생시키지 않고 전문적인 개방형 질문에서 높은 정확도와 인간 전문가 채점과의 정렬을 달성하는 것이다. 한 측면(예: 분야 특이성)을 개선하면 일반적으로 다른 측면(계산 효율성 또는 데이터 요구 사항)이 깨진다.
제약 조건 및 실패 모드
치의학과 같은 전문 분야에서 자동화된 전문가 정렬 평가의 문제는 다음과 같은 몇 가지 가혹하고 현실적인 벽으로 인해 엄청나게 어려워진다.
-
데이터 기반 제약 조건:
- 주석 데이터의 희소성: fine-tuning 또는 추가 훈련을 위한 대규모 전문가 주석 데이터셋에 대한 심각한 요구가 있지만, 치의학과 같은 고도로 전문화된 분야에서는 부족하고 생성 비용이 많이 든다. 이는 전통적인 지도 학습 접근 방식을 비현실적으로 만든다.
- 개방형 질문의 다양성: 고등 교육에서 흔히 사용되는 개방형 질문은 항상 단일하고 고유한 정답을 갖는 것은 아니다. 학생 응답은 길이, 구조 및 추론 복잡성에서 상당한 변동성을 나타낼 수 있으며, 이는 학습자 표현의 진정한 다양성을 반영한다. 이러한 고유한 다양성은 자동화된 시스템에 대한 명확한 "정답"을 정의하는 것을 어렵게 만든다.
- 검색 정보의 노이즈: 검색 증강 생성(RAG)을 사용하더라도 코퍼스에서 분할된 증거 청크에는 쿼리 또는 해당 핵심 용어와 직접 관련이 없는 콘텐츠가 포함될 수 있다. 이 관련 없는 정보는 노이즈를 도입하여 샘플 답변 생성의 정확성과 품질에 부정적인 영향을 미칠 수 있다.
-
계산 및 리소스 제약 조건:
- fine-tuning의 높은 계산 비용: LLM을 전문 분야에 맞게 조정하는 전통적인 방법은 fine-tuning 및 재훈련을 위해 광범위한 컴퓨팅 리소스와 상당한 시간이 필요하다. 이는 리소스가 제한된 교육 환경에서는 종종 비현실적이다.
- 재정적 비용: 고등 교육 전문가의 인간 평가는 비용이 많이 든다(예: 응답당 약 1.275 USD). 이는 대규모 코호트에 대한 확장 가능한 수동 평가를 재정적으로 지속 불가능하게 만든다. 모든 자동화된 솔루션은 상당한 재정적 절감을 제공해야 한다.
-
모델 및 기능 제약 조건:
- 일반 LLM의 분야 전문성 부족: 즉시 사용 가능한 LLM은 분야별 용어와 미묘한 전문 용어의 정확한 해석에 어려움을 겪어 전문 분야에서 부정확한 평가를 초래한다.
- 인간 채점과의 불일치: 기존 시스템의 주요 실패 모드는 LLM 출력과 인간 수준 평가 간의 불일치이다. LLM은 종종 전문가가 설정한 특정 평가 기준을 준수하지 못하여 신뢰와 채택 부족을 초래한다.
- LLM 채점의 변동성: 동일한 입력으로도 LLM은 채점에서 변동성을 나타낼 수 있으며, 이는 평가 시스템의 신뢰성과 견고성을 감소시킨다. 이는 일관되고 신뢰할 수 있는 평가를 보장하기 위한 메커니즘을 요구한다.
- 소수샷 학습에서의 오해: 여러 유효한 관점을 허용하는 개방형 질문의 경우, 단일 소수샷 예시 세트를 제공하면 LLM이 이를 유일한 정답으로 오해하여 다른 유효한 학생 응답을 잘못 판단하게 될 수 있다. 이는 모델을 예시로 안내하려고 시도할 때 의도치 않게 이해를 좁힐 수 있는 고통스러운 절충점이다.
왜 이 접근 방식인가
선택의 불가피성
DentEval의 특정 접근 방식, 즉 자체 정제 검색 증강 생성(SR-RAG)과 역할극 LLM 에이전트의 통합 채택은 단순히 선호가 아니라 전문 분야 교육 평가에 전통적인 방법의 고유한 한계를 적용할 때 내재된 제약 조건에 의해 주도된 필요성이었다. 저자들은 특히 대규모 언어 모델(LLM)의 광범위한 fine-tuning에 의존하는 표준 "SOTA" 방법이 여러 가지 중요한 과제로 인해 이 문제에 불충분하다는 것을 깨달았다.
첫째, 치의학과 같은 전문 분야에서 개방형 단답형 질문을 평가하려면 전문 용어와 복잡한 개념에 대한 미묘한 이해가 필요하다. 전통적인 LLM은 상당한 분야별 훈련 없이는 종종 이에 어려움을 겪는다. 이러한 깨달음의 "정확한 순간"은 단일 사건이 아니라 기존 시스템이 "fine-tuning 또는 추가 훈련을 위한 대규모 주석 데이터셋"을 필요로 한다는 인식이며, 이는 "시간이 많이 소요되고 리소스가 제한된 환경에서는 비현실적"이다. 이 제약 조건은 fine-tuning 중심의 접근 방식을 실행 불가능하게 만들었다.
둘째, 자동화된 평가가 전문가 인간 채점 루브릭과 밀접하게 일치하도록 보장하는 것은 중요한 장애물이다. 표준 LLM 응용 프로그램은 종종 "모델 출력과 인간 수준 평가 간의 불일치"를 나타낸다. 이러한 정렬 부족은 공정성과 정확성이 가장 중요한 고위험 교육 맥락에서 특히 문제가 된다. 특정 전문적으로 확립된 평가 기준을 준수해야 할 필요성은 기본 LLM 프롬프팅 또는 단순 fine-tuning이 제공할 수 있는 것보다 더 동적이고 맥락 인식적인 접근 방식이 필요함을 의미했다. 논문은 명시적으로 이러한 문제를 해결하려면 "광범위한 fine-tuning 및 재훈련"이 필요하다고 명시했으며, 이는 비현실적인 것으로 간주되었다.
비교 우위
DentEval는 전문 분야 평가의 핵심 과제를 직접 해결하는 구조적 혁신을 통해 이전의 황금 표준 및 기준선 방법보다 질적으로 우수함을 입증한다. 우수한 성능 지표(Spearman 상관 계수 최대 0.9259 및 Pearson 상관 계수 최대 0.8957, SciEx 및 FairEval 능가)를 달성하는 것 외에도 그 장점은 설계에 뿌리를 두고 있다.
- fine-tuning 불필요: 많은 이전 접근 방식이 대규모 주석 데이터셋을 사용한 광범위한 fine-tuning을 요구하는 것과 달리, DentEval는 이 리소스 집약적인 단계 없이 효과적으로 작동한다. 이는 리소스가 제한된 교육 환경에 실용적이며 개발 및 배포 오버헤드를 크게 줄이는 거대한 구조적 이점이다.
- 최적화된 RAG 프로세스와 자체 정제: 자체 정제 검색 증강 생성(SR-RAG)은 핵심 혁신이다. 단순히 정보를 검색하는 것이 아니라 정보를 정제하고 그 적절성을 자율적으로 평가한다. 이는 시스템이 명시적인 fine-tuning 없이도 충분한 분야별 지식을 습득할 수 있음을 의미한다. 이 프로세스는 검색된 청크에서 관련 없는 정보를 적극적으로 필터링하여 샘플 답변 생성의 정확성에 부정적인 영향을 미칠 수 있으므로 고차원 노이즈를 본질적으로 더 잘 처리한다. 이 자체 평가 루프($K$가 동적으로 조정됨)는 LLM이 충분한 기반을 갖도록 보장하며, 노이즈가 많거나 불충분한 컨텍스트를 검색할 수 있는 표준 RAG보다 구조적 이점이다.
- 역할극 프롬프팅 및 샘플 답변 생성(SAG): LLM 에이전트를 "교수"로 지정하여 여러 참조 답변을 생성하고 "평가자"(교사)를 채점하도록 함으로써 DentEval는 구조적으로 평가 프로세스를 인간 교육 관행과 일치시킨다. 이 다중 에이전트, 역할극 접근 방식은 인간 채점 기준과의 정렬을 향상시키고 일관성을 개선한다. 개방형 질문의 경우, 다양한 참조 답변을 생성하는 것(단일 "정답"이 아닌)은 시스템이 허용 가능한 학생 응답의 고유한 복잡성과 다양성을 포착할 수 있도록 하여 이러한 작업에 압도적으로 우수하다.
- 효율성 향상: 이 시스템은 시간과 재정 비용 모두에서 상당한 "효율성 향상"을 제공한다. 인간 평가자는 일반적으로 응답당 약 1.5분을 소비하며 비용은 약 1.275 USD이다. 대조적으로, DentEval는 각 질문을 약 0.13분 만에 처리하며 비용은 응답당 0.007 USD에 불과하다. 시간과 비용의 이러한 극적인 감소는 교육자가 교육적으로 더 가치 있는 활동에 리소스를 재할당할 수 있도록 하는 질적 이점이다.
제약 조건과의 정렬
DentEval의 선택된 방법은 치의학 교육과 같은 전문 분야의 자동화된 평가의 가혹한 요구 사항과 완벽하게 일치하여 문제와 해결책 간의 강력한 "결합"을 형성한다.
- 제약 조건: fine-tuning을 위한 대규모 주석 데이터셋의 필요성.
- 정렬: DentEval의 "fine-tuning 불필요"는 이를 직접적으로 해결한다. SR-RAG 모듈은 재훈련을 위한 광범위하고 비용이 많이 들며 시간이 많이 소요되는 주석 데이터셋이 필요 없이 분야별 지식을 습득할 수 있도록 하여, 이러한 데이터가 부족한 전문 분야에 실용적이다.
- 제약 조건: 모델 출력과 인간 수준 평가 간의 불일치.
- 정렬: "역할극 프롬프팅" 및 "SR-RAG" 구성 요소는 출력이 인간 채점 기준과 밀접하게 일치하도록 설계되었다. 평가자 LLM은 교사 역할을 할당받아 이러한 정렬을 향상시키고, SR-RAG는 사실적으로 일관되고 분야 관련 정보를 제공한다. 여러 LLM 점수에서 다수결 투표를 사용하는 것은 변동성을 더욱 줄이고 일관성을 개선한다.
- 제약 조건: 전문 지식 분야(치의학)는 용어의 정확한 해석을 요구한다.
- 정렬: SR-RAG는 치과 핸드북에서 관련 정보를 검색하고 이를 정제하여 충분한 분야별 지식을 습득하도록 맞춤화되었다. 또한 DentEval는 치의학과 같이 시각 정보에 크게 의존하는 분야에 중요한 다중 모달 입력(텍스트 및 임상 이미지)을 지원한다.
- 제약 조건: 전문가 채점 루브릭과의 정렬.
- 정렬: 이 시스템은 명시적으로 "채점 루브릭 R"을 입력으로 받는다. 샘플 답변 생성(SAG) 모듈은 LLM을 "교수"로 지정하여 참조 답변을 생성하고, 평가자 LLM은 "교사" 역할을 하여 평가 프로세스가 사전 정의된 기준과 전문 표준을 준수하도록 한다.
- 제약 조건: 리소스 제한 환경.
- 정렬: fine-tuning의 필요성을 제거하고 평가 시간과 재정 비용(응답당 1.275 USD에서 0.007 USD로)을 크게 줄임으로써 DentEval는 교육 기관에 매우 실용적인 리소스 효율적인 솔루션을 제공한다.
- 제약 조건: 개방형 단답형 질문 평가.
- 정렬: SAG 모듈은 개방형 질문에 대한 가능한 정답의 고유한 복잡성과 다양성을 인정하여 여러 참조 답변을 생성한다. 이는 간단한 방법의 일반적인 함정인 다양한 그러나 유효한 학생 응답을 잘못 판단하는 것을 시스템이 방지한다.
대안의 거부
이 논문은 특히 전문 분야에서 전문가 정렬 평가의 특정 문제에 대해 기본 LLM 프롬프팅 또는 광범위한 fine-tuning에 의존하는 여러 대안 접근 방식을 암묵적으로 그리고 명시적으로 거부한다.
주요 거부는 전통적인 LLM fine-tuning 방법이다. 저자들은 이러한 방법이 "fine-tuning 또는 추가 훈련을 위한 대규모 주석 데이터셋"을 필요로 하며, 이는 "시간이 많이 소요되고 리소스가 제한된 환경에서는 비현실적"이라고 강조한다. 이는 이러한 데이터가 부족하고 전문가에 의한 주석 비용이 높은 치의학과 같은 전문 분야에 부적합하다. DentEval의 fine-tuning-free 접근 방식은 이러한 비현실성을 직접적으로 우회한다.
또한, 이 논문은 특정 유형의 질문에 대한 기본 소수샷 학습을 명확하게 거부한다. 소수샷 학습은 일반적으로 제로샷보다 성능을 향상시키지만, 저자들은 기준 소수샷 방법을 사용할 때 "질문 2"(여러 관점을 허용하는 개방형 질문)에 대한 "채점 성능의 눈에 띄는 감소"를 관찰한다. 이유는 "소수샷 학습 중에 LLM이 제공된 예시를 유일한 정답으로 해석하여 다른 학생의 응답을 잘못 판단할 수 있다"는 것이다. 이러한 한계는 단일 명확한 정답이 항상 적절하지 않은 개방형 질문에 대한 치명적인 결함이다. DentEval는 샘플 답변 생성(SAG) 모듈을 통합하여 이러한 문제를 극복하며, 이 모듈은 다양한 참조 답변을 생성하여 허용 가능한 응답의 다양성을 포착하고 잘못된 판단을 방지한다.
이 논문은 GAN 또는 확산 모델과 같은 다른 딥러닝 패러다임과의 직접적인 비교를 다루지 않지만(이 문제의 본질은 복잡한 미디어 생성보다는 언어 이해 및 평가에 관한 것이기 때문에), LLM 기반 솔루션에 대한 초점은 이러한 모델이 이 특정 작업에 직접 적용 가능하거나 효율적이지 않음을 시사한다. 핵심 문제는 의미론적 이해, 분야 지식 습득 및 인간 판단과의 정렬에 관한 것이며, RAG 및 에이전트 기능으로 증강된 LLM이 독특하게 위치하는 영역이다.
 Figure 2. Scoring Rubric and Example Content Illustration
Figure 2. Scoring Rubric and Example Content Illustration
수학적 및 논리적 메커니즘
마스터 방정식
DentEval의 평가 메커니즘의 핵심, 특히 최종 점수 생성에 있어서는 여러 평가 에이전트로부터 개별 점수를 먼저 생성한 다음 이를 집계하는 두 부분으로 구성된 방정식으로 요약된다. 이 프로세스는 역할극 및 소수샷 학습을 통해 견고성을 보장하고 인간 채점 기준과 일치시킨다.
각 평가 인스턴스 $i$에 대한 개별 점수 생성은 다음과 같이 주어진다.
$$S_i = \text{LLM}_{\text{evaluator}}(Q, A_{student}, \{A_{sample},..., A_{sample}\}, R), \quad i \in \{1,..., n\}$$
그리고 최종 집계 점수는 다음과 같이 결정된다.
$$S_{final} = \text{Mode}(\{S_1, S_2, ..., S_n\})$$
용어별 분석
이 방정식들을 해부하여 각 구성 요소의 역할을 이해해 보자.
-
$S_i$:
- 수학적 정의: 이것은 단일 LLM 평가자 인스턴스가 학생 답변에 할당한 숫자 점수를 나타낸다. 일반적으로 미리 정의된 범위(예: 논문에서 언급된 $[0, 5]$) 내의 스칼라 값이다.
- 물리적/논리적 역할: $S_i$는 중간적인 개별 학생 응답 평가이다. 시스템은 잠재적인 LLM 출력 변동성을 설명하고 신뢰성을 높이기 위해 이러한 $n$개의 점수를 생성한다.
- 사용 이유: 저자들은 단일 LLM의 고유한 판단의 영향을 줄이기 위해 여러 $S_i$ 값을 사용하여 전반적인 평가의 일관성과 견고성을 높인다. 이는 AI 기반 평가의 노이즈를 완화하기 위한 일반적인 전략이다.
-
$\text{LLM}_{\text{evaluator}}(\cdot)$:
- 수학적 정의: 이것은 "평가자" 역할을 하도록 특별히 구성된 대규모 언어 모델이 수행하는 함수를 나타낸다. 여러 입력을 받아 단일 숫자 점수를 생성한다.
- 물리적/논리적 역할: 이것은 학생 답변을 판단하는 책임이 있는 핵심 지능형 에이전트이다. 프롬프팅을 통해 평가자 역할을 할당함으로써 시스템은 LLM을 비판적이고 평가 중심적인 페르소나를 채택하도록 안내하여 인간 교사를 모방한다.
- 사용 이유: LLM은 고급 자연어 이해 및 생성 기능을 위해 선택되며, 복잡한 질문, 학생 응답, 루브릭 및 참조 답변을 해석하여 미묘한 판단을 내릴 수 있다. 역할극 프롬프트는 그 출력을 전문가 인간 채점 기준과 일치시키는 데 도움이 된다.
-
$Q$:
- 수학적 정의: 이것은 학생에게 제시된 입력 쿼리 또는 질문이다. 텍스트일 수 있으며 선택적으로 시각적 콘텐츠(예: 그림)를 포함할 수 있다.
- 물리적/논리적 역할: $Q$는 학생이 답해야 하는 작업 또는 문제를 정의한다. 이것은 평가의 기본 맥락이다.
- 사용 이유: 질문은 모든 평가의 기본이다. 학생의 응답이 측정되는 기준을 제공한다.
-
$A_{student}$:
- 수학적 정의: 이것은 학생이 질문 $Q$에 대한 자유 텍스트 응답이다.
- 물리적/논리적 역할: $A_{student}$는 평가 대상 항목이다. 이것은 품질과 정확성을 평가해야 하는 원시 데이터 포인트이다.
- 사용 이유: 이것은 시스템이 점수를 매기려고 하는 학생의 직접적인 출력이다.
-
$\{A_{sample},..., A_{sample}\}$:
- 수학적 정의: 이것은 샘플 참조 답변 세트를 나타낸다. 이들은 다른 LLM 에이전트, $\text{LLM}_{\text{professor}}(Q, E)$에 의해 내부적으로 생성되며, 여기서 $E$는 치과 핸드북에서 정제된 정보이다. 논문에서는 질문의 개방형 특성을 설명하기 위해 여러 샘플 답변이 생성된다고 명시한다.
- 물리적/논리적 역할: 이러한 샘플 답변은 학생의 응답 $A_{student}$가 비교되는 전문가 정렬 벤치마크 또는 "황금 표준" 역할을 한다. LLM 평가자에게 좋은 답변이 어떻게 보이는지에 대한 예시를 제공하여 소수샷 학습 예시 역할을 효과적으로 수행한다.
- 사용 이유: 여러 참조 답변을 제공하면 LLM 평가자가 개방형 질문에 대한 허용 가능한 응답의 범위를 이해하는 데 도움이 되며, 단일 "정답"에 대한 편향을 줄이고 다양한 그러나 유효한 학생 표현을 포착하는 능력을 향상시킨다. 이는 답변에 여러 유효한 해석이 있을 수 있는 전문 분야에 매우 중요하다.
-
$R$:
- 수학적 정의: 이것은 채점 기준, 즉 채점 지침 및 기준 세트이다.
- 물리적/논리적 역할: $R$은 구조화된 평가를 보장하는 명시적인 규칙과 표준을 제공한다. 채점이 객관적이고 교육적 요구 사항과 일치하도록 보장한다.
- 사용 이유: 루브릭은 구조화된 평가에 필수적이며, LLM의 평가가 투명하고 공정하며 인간 채점 원칙과 일치하도록 보장한다. 이는 LLM의 판단에 대한 제약 조건 및 지침 역할을 한다.
-
$i \in \{1,..., n\}$:
- 수학적 정의: 이것은 평가 프로세스가 $n$번 반복되어 $n$개의 개별 점수를 생성함을 나타내는 인덱스이다.
- 물리적/논리적 역할: 이것은 평가 프로세스의 다중성을 나타낸다. 각 $S_i$는 $\text{LLM}_{\text{evaluator}}$의 독립적인 실행이다.
- 사용 이유: 평가를 여러 번 반복하고 결과를 집계하는 것(모드를 통해)은 최종 점수의 안정성과 안정성을 향상시키고 LLM 출력의 고유한 확률성 또는 변동성을 완화하기 위한 전략이다.
-
$S_{final}$:
- 수학적 정의: 이것은 개별 점수의 집계에서 파생된 학생 답변에 할당된 궁극적인 숫자 점수이다.
- 물리적/논리적 역할: $S_{final}$은 DentEval 시스템의 최종 출력이며, 학생 응답의 최종 평가를 나타낸다.
- 사용 이유: 이것은 시스템의 원하는 최종 결과이며, 등급에 사용할 수 있는 단일의 견고한 점수이다.
-
$\text{Mode}(\cdot)$:
- 수학적 정의: 이것은 데이터 세트에서 가장 자주 발생하는 값을 반환하는 통계 함수이다.
- 물리적/논리적 역할: 모드 함수는 합의 메커니즘 역할을 한다. $n$개의 개별 평가 중에서 가장 일반적인 점수를 선택함으로써, 이는 개별 LLM 평가의 이상치를 효과적으로 필터링하고 가장 일관된 판단을 강화한다.
- 사용 이유: 다수결 투표는 최종 점수의 변동성을 줄이고 일관성과 신뢰성을 향상시키기 위해 사용되며, 특히 개별 LLM 출력이 약간 다를 수 있는 상황에서 그러하다. 이는 LLM 출력에 적용된 앙상블 학습의 간단하지만 효과적인 방법이다.
단계별 흐름
학생의 답변 $A_{student}$가 정교한 조립 라인의 항목처럼 DentEval 시스템을 통과하는 여정을 상상해 보라.
-
초기 입력 수신: 프로세스는 학생의 답변($A_{student}$), 질문($Q$, 잠재적으로 관련 그림 포함), 채점 루브릭($R$)의 세 가지 주요 입력으로 시작된다. 또한, 치과 지식의 방대한 검색 코퍼스($C$)를 사용할 수 있다.
-
쿼리 임베딩 및 초기 검색: 질문 $Q$는 먼저 숫자 벡터 표현(임베딩)으로 변환된다. 이 임베딩된 쿼리는 검색 엔진(Milvus와 같은)에 공급되어 치과 지식 코퍼스 $C$를 검색한다. 엔진은 가장 관련성이 높은 "상위 K" 정보 청크를 가져온다.
-
정보 정제: 이러한 초기 "상위 K" 청크는 원래 질문 $Q$와 함께 특수 LLM 에이전트에 전달된다. 이 에이전트의 작업은 이 원시 정보를 요약하고 정제하여 보다 간결하고 관련성 있는 증거 세트 $E$로 만드는 것이다. 이 단계는 노이즈를 제거하고 정보가 질문에 직접 관련되도록 하는 데 중요하다.
-
충분성 확인 및 반복 검색: 정제된 증거 $E$는 다른 LLM 에이전트에 의해 평가되어 고품질 참조 답변을 생성하기에 "충분한지" 여부를 결정한다. 증거가 불충분하다고 판단되면 시스템은 검색 단계로 다시 루프하고 $K$ 값을 증가시켜( "단계 크기"만큼) 더 많은 정보를 수집한다. 이 반복적인 자체 수정은 LLM에 제공되는 컨텍스트가 가능한 한 완전하고 관련성이 있도록 보장한다.
-
샘플 답변 생성(SAG): 충분한 증거 $E$가 확보되면 질문 $Q$와 결합되어 $LLM_{professor}$ 에이전트에 전달된다. 치과 학자 역할을 하는 이 에이전트는 정제된 증거와 질문을 기반으로 여러 다양한 샘플 답변 $\{A_{sample},..., A_{sample}\}$을 생성한다. 이 단계는 여러 개의 올바른 응답이 존재할 수 있는 개방형 질문에 매우 중요하다.
-
개별 점수 생성: 이제 시스템은 실제 채점을 준비한다. $n$개의 별도 평가 실행을 위해 $LLM_{evaluator}$ 에이전트가 호출된다. 각 실행 $i$에서 이 평가자 LLM은 질문 $Q$, 학생의 답변 $A_{student}$, 생성된 샘플 답변 세트 $\{A_{sample},..., A_{sample}\}$, 채점 루브릭 $R$을 받는다. 또한, 소수샷 학습 예시(각 점수 계층의 학생 응답과 평가 피드백)를 통합하여 판단을 안내한다. 이러한 모든 입력에 기반하여 $LLM_{evaluator}$는 개별 점수 $S_i$를 생성한다.
-
최종 점수 집계: $n$개의 개별 점수($S_1, S_2, ..., S_n$)가 생성된 후 수집된다. 그런 다음 최종 점수 $S_{final}$은 이 점수 세트에 모드 함수를 적용하여 결정된다. 이는 $n$번의 평가 중에서 가장 자주 발생하는 점수가 최종 등급이 된다는 것을 의미한다. 이 다수결 투표 메커니즘은 견고하고 일관된 최종 평가를 보장하여 단일 이상치 평가의 영향을 최소화한다.
최적화 역학
DentEval는 "fine-tuning-free" 패러다임에서 작동하므로 대규모 언어 모델의 매개변수를 업데이트하기 위해 전통적인 그래디언트 기반 최적화를 포함하지 않는다. 대신, 그 "학습", "업데이트" 또는 "수렴" 동작은 지능형 시스템 설계, 반복 프로세스 및 정교한 프롬프팅 전략의 조합을 통해 달성된다.
-
자체 정제 검색 증강 생성(SR-RAG): 시스템의 주요 "학습" 메커니즘은 SR-RAG 구성 요소에 내장되어 있다. 초기 검색 증거 $E$가 LLM 에이전트에 의해 불충분하다고 판단되면 시스템은 포기하지 않고 검색을 반복적으로 확장하여 매개변수 $K$(가장 관련성 높은 청크 수)를 증가시킨다. 이 자체 수정 루프는 시스템이 지식 기반이 부적절할 때 "학습"하고 더 포괄적인 정보를 적극적으로 검색할 수 있도록 한다. 검색 매개변수의 이러한 동적 조정은 RAG 프로세스 자체에 대한 적응형 최적화의 한 형태이며, LLM에 제공되는 컨텍스트가 가능한 한 완전하고 관련성이 있도록 보장한다.
-
역할극 프롬프팅: 시스템의 성능은 LLM 에이전트에 특정 역할(예: "교수", "평가자")을 할당하는 프롬프트를 신중하게 작성하여 "최적화"된다. 이것은 전통적인 의미의 수학적 최적화가 아니라 강력한 형태의 인컨텍스트 안내이다. 이러한 페르소나를 채택함으로써 LLM은 인간 전문가의 행동 및 추론 패턴을 모방하도록 유도되어 출력을 원하는 채점 기준과 일치시킨다. 이 "프롬프트 엔지니어링"은 내부 가중치를 변경하지 않고 LLM의 "손실 지형"을 암묵적으로 형성하여 보다 정확하고 일관된 평가를 향해 안내하는 중요한 레버이다.
-
소수샷 학습: 평가 LLM에는 학생 응답, 루브릭 및 인간 할당 점수와 피드백을 포함하는 소수의 예시(소수샷 예시)가 제공된다. 이를 통해 LLM은 명시적인 매개변수 업데이트를 통해가 아니라 예시에서 직접 원하는 채점 패턴과 기준을 "학습"할 수 있다. 이 인컨텍스트 학습은 LLM이 예상되는 입력-출력 관계를 시연함으로써 일관된 채점 정책으로 수렴하도록 돕는다.
-
견고성을 위한 다수결 투표: 모드 함수를 사용하여 여러 개별 점수($S_i$)를 최종 점수($S_{final}$)로 집계하는 것은 통계적 최적화이다. 이는 단일 LLM 평가에서 발생할 수 있는 개별 변동 및 편향을 효과적으로 평활화하는 견고한 추정기 역할을 한다. 이 메커니즘은 시스템이 시간이 지남에 따라 그리고 다른 학생 응답에 걸쳐 더 안정적이고 신뢰할 수 있는 점수로 수렴하도록 돕는다. 이는 LLM 출력에 적용된 앙상블 학습의 한 형태이다.
-
CDF 매핑을 통한 후처리: 구현 세부 정보에서 언급했듯이, 시스템은 후처리 단계로 누적 분포 함수(CDF) 매핑을 적용한다. 이 방법은 LLM의 원시 점수를 보정하여 편향을 완화하고 공정성을 향상시켜 인간 점수 분포와 더 가깝게 일치시킨다. LLM의 내부 학습의 일부는 아니지만, 최종 출력을 인간 판단과의 더 나은 정렬을 위해 "최적화"하는 외부 보정 단계이다.
본질적으로 DentEval의 "최적화"는 손실 함수에 대한 그래디언트 하강보다는 반복 정제, 전략적 프롬프팅 및 견고한 집계 기술을 통해 대규모 언어 모델의 고유한 기능을 활용하는 지능적으로 설계된 다중 에이전트 워크플로에 관한 것이며, 광범위한 fine-tuning 없이 전문가 정렬 평가를 달성한다. 따라서 시스템의 "학습"은 매개변수적이 아닌 절차적이고 맥락적이다.
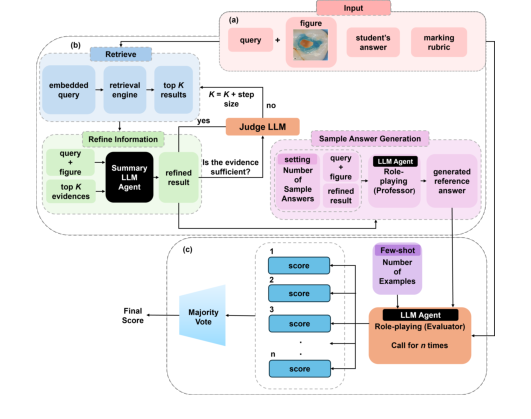 Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
결과, 한계 및 결론
실험 설계 및 기준선
DentEval의 수학적 주장과 실용적인 효능을 엄격하게 검증하기 위해 연구자들은 포괄적인 실험 설계를 구성했다. 그들의 평가의 핵심은 치과 커리큘럼을 위해 특별히 큐레이션된 고유한 교수 주석 데이터셋을 중심으로 이루어졌다. 이 데이터셋은 사전 정의된 채점 루브릭에 대해 치의학 학자들이 신중하게 채점한 28개의 학생 응답으로 구성되었다. 중요하게도, 이 데이터셋에는 두 가지 다른 유형의 개방형 질문이 포함되었다. 하나는 다중 모달 추론(텍스트 및 이미지)을 요구하고 다른 하나는 순전히 텍스트 기반이었다. 이러한 다양성은 치과 교육에서 평가의 다양한 특성을 반영하고, 치과 형태학 및 수복 재료와 같은 별도의 하위 분야를 다루며, 광범위한 응답 길이와 복잡성을 나타내는 의도적인 것이었다.
평가를 위해 소수샷 학습 접근 방식이 채택되었다. 질문당 28개의 응답에서 각 점수 계층에서 하나의 응답이 선택되어 소수샷 예시 역할을 했으며, 질문당 6개의 예시가 생성되었다. 나머지 22개의 응답이 테스트 세트를 구성했다. 이 설계는 LLM 에이전트가 광범위한 fine-tuning 없이 전문가 채점 예시로부터 학습할 수 있도록 했다. GPT-40(특히 gpt-40-mini)이 기본 LLM 에이전트로 선택되었으며, 그 다중 모달 기능을 활용했다. 공정성과 일관성을 보장하기 위해 누적 분포 함수(CDF) 매핑이 채점의 잠재적 편향을 완화하기 위한 후처리 단계로 적용되었다.
DentEval의 성능은 여러 "피해자" 기준선 모델 및 고급 기술과 비교되었다.
- 제로샷: LLM이 수정이나 역할극 없이 응답을 채점하는 간단한 접근 방식.
- 소수샷: LLM을 안내하기 위해 참조 예시를 통합한 제로샷의 향상.
- SciEx [5]: 소수샷 학습과 역할극 프롬프팅을 결합한 최첨단 방법.
- FairEval [22]: LLM 평가의 편향을 줄이기 위해 다중 증거 보정(MEC) 및 균형 위치 보정(BPC)을 사용하는 또 다른 고급 기술.
DentEval의 핵심 메커니즘에 대한 확실한 증거는 표준 평가 지표인 정확도(Acc.), 스피어만 순위 상관 계수(SROCC) [17] 및 피어슨 선형 상관 계수(PLCC) [16]를 통해 추구되었다. SROCC와 PLCC는 특히 중요했는데, 이는 DentEval의 점수와 인간 전문가 평가 간의 일관성과 선형 상관 관계를 직접 측정하여 정렬의 견고한 척도를 제공했기 때문이다.
마지막으로, DentEval 내의 각 혁신적인 구성 요소(SR-RAG, 샘플 답변 생성(SAG) 및 역할극 프롬프팅)의 기여를 무자비하게 증명하기 위해 축소 연구가 수행되었다. 이러한 구성 요소를 체계적으로 제거하거나 분리함으로써 연구자들은 제로샷 기준선을 사용하여 시스템의 전반적인 성능에 대한 개별 영향을 파악할 수 있었다.
증거가 증명하는 것
실험 증거는 치과 교육의 다양한 평가 시나리오에서 DentEval의 우수한 성능과 신뢰성을 압도적으로 입증한다.
질문 1의 경우, 다중 모달 추론(텍스트 및 이미지)을 포함하고 단일 정답이 있는 경우, DentEval는 모든 평가 지표에서 최고의 성능을 달성했다. SROCC 0.7447, PLCC 0.7288, 정확도 68.2%를 기록했으며, 모두 가장 낮은 p-값과 함께 통계적으로 유의미한 인간 채점과의 정렬을 나타냈다. SciEx와 FairEval는 기본 제로샷 기준선을 능가했지만, 기준 소수샷 방법을 약간 밑돌았으며, 이는 고급 기술에서도 자동화된 평가의 미묘한 어려움을 강조한다. 다중 모달 입력과 전문가 정렬 메커니즘을 통합하는 DentEval의 능력은 여기서 분명히 우위를 점했다.
질문 2의 경우, 순전히 텍스트 기반의 개방형 질문으로 여러 유효한 응답을 허용하는 경우, DentEval의 성능은 더욱 인상적이었다. SROCC 0.9259 및 PLCC 0.8957을 달성했으며, 둘 다 질문 1보다 높았고 정확도 68.2%를 유지했다. 이는 질문 1과 달리 기준 소수샷 방법이 질문 2에 대한 채점 성능의 눈에 띄는 감소를 보였다는 점에서 특히 중요하다. 저자들은 이를 개방형 질문의 특성으로 설명하며, 소수샷 예시가 의도치 않게 LLM이 이를 유일한 정답으로 해석하게 하여 다른 유효한 학생 응답을 잘못 판단하게 할 수 있다고 설명한다. 단일 명확한 정답이 예상되지 않는 이러한 복잡한 개방형 질문을 처리하는 DentEval의 견고성은 특히 SR-RAG 및 다양한 참조 답변을 생성하는 역할극 프롬프팅 메커니즘을 고려할 때 그 고급 설계에 대한 강력한 증거이다.
정확성과 상관 관계 외에도 DentEval는 상당한 효율성 향상에 대한 부인할 수 없는 증거를 제공했다. 인간 평가자는 일반적으로 학생 응답당 약 1.5분을 소비하며 비용은 약 1.275 USD이다. 대조적으로, DentEval의 GPT-40 LLM 에이전트는 각 질문을 약 0.13분 만에 처리했으며, 응답당 비용은 0.007 USD에 불과했다. 이는 시간과 재정 자원 모두에서 엄청난 감소를 나타내며, 교육자가 교육적으로 더 가치 있는 활동에 집중할 수 있도록 한다.
축소 연구는 DentEval의 핵심 구성 요소의 기여를 더욱 공고히 했다. 각 혁신(SR-RAG, 샘플 답변 생성(SAG) 및 역할극 프롬프팅)은 개별적으로 인간 평가와의 일관성을 개선하고 정확도를 높이는 것으로 나타났다. 예를 들어, SR-RAG만으로도 질문 1의 정확도를 9.1%(제로샷)에서 54.5%로, 질문 2의 정확도를 50.0%에서 68.2%로 크게 향상시켰다. 전체 DentEval 프레임워크는 모든 축소된 버전보다 일관되게 우수했으며, 이러한 구성 요소의 시너지 통합이 실제로 우수한 성능과 인간 판단과의 정렬을 주도한다는 것을 확인했다.
한계 및 향후 방향
DentEval는 전문 분야의 자동화된 평가에서 설득력 있는 발전을 제시하지만, 현재의 한계를 인정하고 향후 개발을 위한 길을 고려하는 것이 중요하다.
한 가지 명확한 한계는 저자들이 암묵적으로 언급했듯이 데이터셋 크기이다. 수집된 응답은 구조와 내용 면에서 다양했지만, "제한된 수의 질문"(평가된 질문은 단 두 개뿐)은 치과 커리큘럼 전체 또는 다른 전문 분야에 대한 결과의 일반화 가능성을 제한할 수 있다. 더 넓은 범위의 질문 유형, 난이도 및 응답 변형을 포함하도록 데이터셋을 확장하면 DentEval의 기능에 대한 보다 강력한 검증을 제공할 것이다.
또 다른 고려 사항은 특정 LLM인 GPT-40에 대한 의존성이다. 강력하지만, 이는 비용 변동, API 가용성 및 모델의 독점적 특성과 관련된 잠재적 문제를 야기한다. 향후 작업에서는 오픈 소스 LLM 또는 보다 비용 효율적인 대안에 대한 DentEval 프레임워크의 적응성을 탐색하여 더 넓은 접근성과 지속 가능성을 보장할 수 있다.
이 논문은 또한 개방형 질문이 여러 정답을 허용하는 경우의 어려움을 강조하며, 기준 소수샷 방법의 성능 저하를 언급한다. DentEval는 이를 잘 처리하지만, 이러한 질문의 고유한 복잡성은 샘플 답변 생성(SAG) 및 자체 정제 검색 증강 생성(SR-RAG) 모듈의 지속적인 개선이 주관적인 평가의 훨씬 더 넓은 스펙트럼에 걸쳐 전문가 정렬을 높은 수준으로 유지하기 위해 중요할 것임을 시사한다.
앞으로 저자들 스스로 흥미로운 향후 방향을 제안한다.
- 다중 모달 RAG 확장: 자연스러운 발전은 임상 비디오 및 3D 모델과 같은 보다 복잡한 다중 모달 입력을 통합하는 것이다. 이를 통해 DentEval는 보다 전체적이고 현실적인 방식으로 실무 기술 및 진단 추론을 평가할 수 있으며, 정적 이미지 및 텍스트를 넘어선다. 시뮬레이션된 수술 절차에서 비디오 증거를 기반으로 학생의 기술을 평가하는 LLM 에이전트를 상상해 보라!
- 적응형 보정: 다양한 질문 유형에 걸쳐 견고성을 개선하기 위한 적응형 보정 메커니즘 개발은 또 다른 중요한 영역이다. 이는 질문의 특정 특성(예: 단일 사실적 답변을 기대하는지 또는 미묘한 다중 관점 응답을 기대하는지)에 따라 채점 루브릭 또는 평가 전략을 동적으로 조정할 수 있는 시스템을 의미한다. 이는 다양한 평가 맥락에서 시스템의 유연성과 신뢰성을 향상시킬 것이다.
이러한 것 외에도 몇 가지 다른 논의 주제는 이러한 발견을 더욱 발전시킬 수 있다.
- 설명 가능성 및 피드백 품질: DentEval는 점수를 제공하지만, 자동화된 평가의 교육적 가치는 고품질의 실행 가능한 피드백으로 크게 향상된다. 향후 연구는 LLM의 추론 프로세스를 보다 투명하게 만들고 학생들이 특정 점수를 받은 이유를 이해하고 개선 방법을 배우는 데 도움이 되는 상세하고 건설적인 피드백을 생성하는 데 중점을 둘 수 있다. 이는 피드백 생성을 위해 연쇄 사고 프롬프팅을 통합하는 것을 포함할 수 있다.
- 교육에서의 윤리적 AI: 자동화된 평가가 보편화됨에 따라 공정성, 편향 및 형평성에 대한 윤리적 우려를 해결하는 것이 가장 중요하다. DentEval의 평가가 다양한 학생 인구 또는 학습 스타일에 걸쳐 편향되지 않도록 어떻게 보장할 수 있는가? 잠재적인 알고리즘 편향을 감지하고 완화하기 위해 어떤 메커니즘을 마련할 수 있는가? 채점을 위한 감사 가능성 및 설명 가능한 AI에 대한 연구는 매우 귀중할 것이다.
- 학습 관리 시스템(LMS)과의 통합: 광범위한 채택을 위해 기존 교육 인프라(예: Canvas 또는 Moodle)에 DentEval를 원활하게 통합하는 것이 필수적이다. 여기에는 교육자가 자동화된 평가를 쉽게 배포, 사용자 정의 및 모니터링할 수 있도록 강력한 API 및 사용자 친화적인 인터페이스 개발이 포함될 것이다.
- 교차 도메인 적용 가능성: 치의학을 위해 맞춤화되었지만, SR-RAG, 역할극 프롬프팅 및 다중 모달 입력 처리의 기본 원칙은 전문가 정렬 평가를 요구하는 다른 전문 분야(예: 의학, 공학 또는 법률)로 일반화될 수 있다. 이러한 동형성을 탐색하면 더 넓은 응용 및 영향을 열 수 있다.
- 실시간 적응형 학습: DentEval를 실시간 학습 환경에 통합하여 즉각적이고 개인화된 피드백과 적응형 학습 경로를 제공할 수 있는가? 학생이 연습 문제를 완료하면서 즉각적인 평가와 맞춤형 보충 자료를 받는 것을 상상해 보라. 학습 과정을 가속화할 것이다.
이러한 다양한 관점은 DentEval가 자동화된 채점 도구일 뿐만 아니라 전문 분야의 교육 평가 및 학습 경험을 근본적으로 변화시킬 잠재력을 가진 기본 프레임워크임을 강조한다.
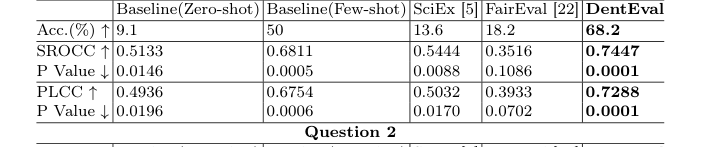 Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval
Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval