DentEval: Оценка в стоматологическом образовании без дообучения, согласованная с экспертами, с помощью LLM-агентов
Точное происхождение проблемы, рассматриваемой в данной статье, коренится в недавней революции, вызванной большими языковыми моделями (LLM) в области образования, особенно в автоматизированной оценке.
Предыстория и академическая родословная
Происхождение и академическая родословная
Точное происхождение проблемы, рассматриваемой в данной статье, коренится в недавней революции, вызванной большими языковыми моделями (LLM) в области образования, особенно в автоматизированной оценке. В то время как LLM, такие как серия GPT от OpenAI, продемонстрировали значительный потенциал в обеспечении эффективной и последовательной оценки заданий, их применение в узкоспециализированных областях, таких как стоматология, представляет собой серьезные проблемы.
Исторически системы автоматизированной оценки существовали, но появление LLM открыло новые возможности для обработки открытых вопросов. Однако при попытке использовать LLM для оценки экспертного уровня возникли две основные проблемы:
1. Интерпретация в предметной области: LLM часто испытывают трудности с нюансированной профессиональной лексикой и сложными концепциями, уникальными для специализированных областей. Они могут неправильно интерпретировать терминологию или не обладать глубоким контекстным пониманием, необходимым для точной оценки.
2. Согласование с экспертной оценкой: Обеспечение соответствия результатов LLM конкретным, часто субъективным, критериям оценки, установленным экспертами-людьми (например, профессорами стоматологии), стало серьезным препятствием.
Предыдущие подходы к преодолению этих ограничений обычно включали обширное дообучение или переобучение LLM с использованием больших, тщательно аннотированных наборов данных. Этот процесс не только трудоемок, но и требует значительных ресурсов, что делает его непрактичным для многих образовательных учреждений, особенно с ограниченными вычислительными ресурсами. "Болевая точка", которая заставила авторов разработать DentEval, заключается именно в этом: существующие методы применения LLM для специализированных задач открытой оценки требовали непомерного количества данных и вычислительных усилий, что приводило к несоответствию с оценкой человека и затрудняло практическое применение в реальном времени. Авторы искали решение без дообучения, которое могло бы эффективно обеспечить оценку, согласованную с экспертами.
Интуитивные термины предметной области
Вот несколько специализированных терминов из статьи, переведенных в повседневные аналогии для читателя с нулевой базой знаний:
- Большие языковые модели (LLM): Представьте себе суперумного цифрового помощника, который прочитал почти каждую книгу, статью и веб-страницу, когда-либо написанную. Он может понимать, что вы говорите, генерировать новый текст и отвечать на вопросы, но он не обязательно является экспертом во всем. Это как блестящий генералист, но иногда ему нужна небольшая дополнительная помощь по очень специфическим, нишевым темам.
- Генерация с дополненным поиском (RAG): Думайте об этом как об экзамене с открытой книгой для нашего суперумного цифрового помощника. Когда вы задаете ему вопрос, вместо того чтобы просто полагаться на свои общие знания, он сначала быстро ищет в конкретной, доверенной библиотеке (например, в стоматологическом справочнике) соответствующую информацию. Затем он использует эту свежеполученную информацию вместе со своим собственным "мозгом" для формирования гораздо более точного и обоснованного ответа. Это похоже на наличие личного ассистента по исследованиям перед ответом.
- Промптинг с ролевой игрой: Это похоже на то, как мы даем нашему цифровому помощнику конкретного персонажа для игры. Вместо того чтобы просто просить его "оценить это", вы говорите ему: "Хорошо, теперь ты строгий профессор стоматологии, и тебе нужно оценить ответ этого студента по этим правилам". Принимая эту роль, LLM пытается думать и отвечать точно так же, как это сделал бы профессор стоматологии, делая его оценки более соответствующими экспертным стандартам.
- Обучение на малом числе примеров (Few-shot learning): Представьте, что вы учите ребенка распознавать новый вид фруктов. Вместо того чтобы показывать ему сотни картинок, вы показываете ему всего несколько примеров (например, "Это яблоко, это еще одно яблоко, а вот так выглядит плохое яблоко"). Из этих ограниченных примеров ребенок быстро учится распознавать другие яблоки. Аналогично, обучение на малом числе примеров позволяет ИИ изучать новую задачу или адаптироваться к определенному стилю, увидев лишь небольшое количество примеров, вместо того чтобы требовать огромные наборы обучающих данных.
Таблица обозначений
| Обозначение | Описание |
|---|---|
Определение проблемы и ограничения
Формулировка основной проблемы и дилемма
Основная проблема, рассматриваемая в данной статье, заключается в точной и эффективной автоматизированной оценке ответов студентов на открытые короткие вопросы, особенно в специализированных областях, таких как стоматологическое образование.
Входное/текущее состояние для существующих систем — это ответ студента в свободной форме ($A_{student}$), вопрос ($Q$), который может включать текстовый и визуальный контент, и оценочная рубрика ($R$), определяющая критерии оценки. Дополнительно доступен корпус для поиска ($C$), такой как стоматологические справочники. Современные большие языковые модели (LLM) продемонстрировали потенциал в автоматизированной оценке, предлагая эффективность и последовательность. Однако они сталкиваются со значительными препятствиями:
1. Интерпретация в предметной области: LLM испытывают трудности с точной интерпретацией нюансированной профессиональной лексики и специфической для предметной области терминологии, присущей таким областям, как стоматология.
2. Согласование с экспертными рубриками: Существующие системы LLM часто дают результаты, несогласующиеся с оценками человеческого уровня, не соответствующие конкретным, установленным экспертами оценочным рубрикам.
3. Требования к ресурсам: Решение этих проблем обычно требует обширного дообучения и переобучения с использованием больших аннотированных наборов данных, что является трудоемким, вычислительно дорогим и непрактичным для образовательных учреждений с ограниченными ресурсами.
Желаемый конечный результат (выходное/целевое состояние) — это числовая оценка $S_{final} \in [0, 5]$, которая точно отражает успеваемость студента и тесно соответствует стандартам оценки экспертов-людей. Эта система должна быть:
1. Осведомленной о предметной области: Способной понимать и применять специализированные стоматологические знания.
2. Согласованной с экспертами: Последовательно давать оценки, которые сильно коррелируют с оценками профессоров-людей.
3. Ресурсоэффективной: Эффективно работать без необходимости обширного дообучения или переобучения, тем самым сокращая время оценки и финансовые затраты.
4. Мультимодальной: Способной обрабатывать вопросы, включающие как текстовый, так и визуальный контент (например, клинические изображения).
Отсутствующее звено или математический пробел заключается именно в том, как построить функцию $S_{final} = DentEval(A_{student}, Q, R, C)$, которая может надежно и экономически эффективно отображать эти входные данные в оценку, согласованную с экспертами. Предыдущие подходы с трудом преодолевали разрыв между общими возможностями LLM и нюансированными, специализированными требованиями экспертной оценки, особенно для открытых вопросов, где не всегда существует единственно "правильный" ответ. Основная дилемма заключается в достижении высокой точности и согласованности с оценкой экспертов-людей в специализированных открытых вопросах без высоких затрат и требований к ресурсам традиционного дообучения. Улучшение одного аспекта, такого как специфичность предметной области, обычно нарушает другой, такой как вычислительная эффективность или требования к данным.
Ограничения и режимы сбоя
Проблема автоматизированной оценки, согласованной с экспертами, в специализированных областях, таких как стоматология, делает ее чрезвычайно сложной из-за нескольких суровых, реалистичных стен:
-
Ограничения, основанные на данных:
- Разреженность аннотированных данных: Существует критическая потребность в больших, аннотированных экспертами наборах данных для дообучения или дополнительного обучения, которые редки и дороги в создании в узкоспециализированных областях, таких как стоматология. Это делает традиционные подходы к обучению с учителем непрактичными.
- Вариативность открытых вопросов: Открытые вопросы, распространенные в высшем образовании, не всегда имеют единственный, уникальный правильный ответ. Ответы студентов могут демонстрировать значительную вариативность в длине, структуре и сложности рассуждений, отражая подлинное разнообразие в выражении учащихся. Эта присущая вариативность затрудняет определение окончательного "правильного" ответа для автоматизированных систем.
- Шум в извлеченной информации: Даже при использовании генерации с дополненным поиском (RAG), сегментированные фрагменты доказательств из корпуса могут содержать контент, не относящийся напрямую к запросу или его ключевым терминам. Эта нерелевантная информация может вносить шум, негативно влияя на точность и качество генерации примеров ответов.
-
Вычислительные ограничения и ограничения ресурсов:
- Высокая вычислительная стоимость дообучения: Традиционные методы адаптации LLM к специализированным областям требуют обширных вычислительных ресурсов и значительного времени для дообучения и переобучения. Это часто непрактично для образовательных учреждений с ограниченными ресурсами.
- Финансовые затраты: Оценка человеком со стороны специалистов высшего образования является дорогостоящей (например, примерно 1,275 доллара США за ответ), что делает масштабируемую ручную оценку финансово неустойчивой для больших когорт. Любое автоматизированное решение должно предлагать существенную финансовую экономию.
-
Ограничения модели и функциональные ограничения:
- Отсутствие экспертных знаний в предметной области в общих LLM: LLM "из коробки" испытывают трудности с точной интерпретацией специфической для предметной области терминологии и нюансированной профессиональной лексики, что приводит к неточным оценкам в специализированных областях.
- Несоответствие с оценкой человека: Основной режим сбоя существующих систем — это несоответствие между результатами LLM и оценками человеческого уровня. LLM часто не соответствуют конкретным критериям оценки, установленным профессионалами, что приводит к отсутствию доверия и внедрения.
- Вариативность оценки LLM: Даже при одинаковых входных данных LLM могут демонстрировать вариативность в своих оценках, что снижает надежность и устойчивость системы оценки. Это требует механизмов для обеспечения последовательных и надежных оценок.
- Неправильная интерпретация при обучении на малом числе примеров: Для открытых вопросов, допускающих несколько допустимых точек зрения, предоставление единственного набора примеров на малом числе примеров может привести к тому, что LLM неправильно интерпретируют их как единственно правильные ответы, что приведет к ошибочным суждениям о других допустимых ответах студентов. Это болезненный компромисс, когда попытка направить модель с помощью примеров может непреднамеренно сузить ее понимание.
Почему такой подход
Неизбежность выбора
Принятие конкретного подхода DentEval, интегрирующего самосовершенствующуюся генерацию с дополненным поиском (SR-RAG) и LLM-агентов с ролевой игрой, было не просто предпочтением, а необходимостью, обусловленной присущими ограничениями традиционных методов при их применении к специализированной образовательной оценке. Авторы осознали, что стандартные "SOTA" методы, особенно те, которые полагаются на обширное дообучение больших языковых моделей (LLM), были недостаточны для этой проблемы из-за нескольких критических проблем.
Во-первых, оценка открытых коротких вопросов в специализированных областях, таких как стоматология, требует тонкого понимания профессиональной лексики и сложных концепций. Традиционные LLM, даже мощные, часто испытывают трудности с этим без существенного обучения, специфичного для предметной области. "Точный момент" этого осознания — это не единичное событие, а признание того, что существующие системы требовали "больших, аннотированных наборов данных для дообучения или дополнительного обучения", что является "трудоемким и непрактичным для учреждений с ограниченными ресурсами". Это ограничение сделало подходы, основанные на дообучении, нежизнеспособными.
Во-вторых, обеспечение тесного соответствия автоматизированных оценок экспертным оценкам человека является серьезным препятствием. Стандартные приложения LLM часто демонстрируют "несоответствия между результатами модели и оценками человеческого уровня". Это отсутствие согласованности особенно проблематично в контекстах образования с высокими ставками, где справедливость и точность имеют первостепенное значение. Необходимость соблюдения конкретных, профессионально установленных критериев оценки означала, что требовался более динамичный и контекстно-зависимый подход, чем тот, который мог предложить базовый LLM-промптинг или простое дообучение. В статье прямо указано, что решение этих проблем обычно требует "обширного дообучения и переобучения", что было признано непрактичным.
Сравнительное превосходство
DentEval демонстрирует качественное превосходство над предыдущими золотыми стандартами и базовыми методами благодаря своим структурным инновациям, которые напрямую решают основные проблемы оценки в специализированных областях. Помимо достижения превосходных метрик производительности (корреляция Спирмена до 0,9259 и корреляция Пирсона до 0,8957, превосходя SciEx и FairEval), его преимущества коренятся в его дизайне:
- Отсутствие необходимости дообучения: В отличие от многих предыдущих подходов, которые требуют обширного дообучения с использованием больших аннотированных наборов данных, DentEval эффективно работает без этого ресурсоемкого шага. Это огромное структурное преимущество, делающее его практичным для образовательных учреждений с ограниченными ресурсами и значительно снижающее накладные расходы на разработку и внедрение.
- Оптимизированный процесс RAG с самосовершенствованием: Самосовершенствующаяся генерация с дополненным поиском (SR-RAG) является ключевой инновацией. Она не просто извлекает информацию; она совершенствует ее и автономно оценивает ее достаточность. Это означает, что система может приобрести достаточные знания в предметной области без явного дообучения. Этот процесс по своей сути лучше обрабатывает высокоразмерный шум, поскольку он активно отфильтровывает нерелевантную информацию из извлеченных фрагментов, которая в противном случае могла бы негативно повлиять на точность генерации примеров ответов. Этот цикл самооценки (где $K$ динамически настраивается) гарантирует, что LLM имеет достаточную основу, что является структурным преимуществом по сравнению со стандартным RAG, который может извлекать шумный или недостаточный контекст.
- Промптинг с ролевой игрой и генерация примеров ответов (SAG): Назначая LLM-агентам роль "профессора" для генерации нескольких эталонных ответов и "оценщика" (учителя) для оценки, DentEval структурно согласовывает свой процесс оценки с человеческими педагогическими практиками. Этот многоагентный подход с ролевой игрой повышает согласованность с человеческими стандартами оценки и улучшает последовательность. Для открытых вопросов генерация разнообразных эталонных ответов (вместо единственного "правильного") позволяет системе уловить присущую сложность и вариативность допустимых ответов студентов, что делает ее подавляюще превосходящей для таких задач.
- Повышение эффективности: Система предлагает существенное "повышение эффективности" как по времени, так и по финансовым затратам. Человек-оценщик обычно тратит около 1,5 минут на ответ, при этом стоимость составляет примерно 1,275 доллара США. В отличие от этого, DentEval обрабатывает каждый вопрос примерно за 0,13 минуты при стоимости всего 0,007 доллара США. Это драматическое сокращение времени и затрат является качественным преимуществом, которое позволяет преподавателям перераспределять ресурсы на более педагогически ценные виды деятельности.
Соответствие ограничениям
Выбранный метод DentEval идеально соответствует суровым требованиям автоматизированной оценки в специализированных областях, таких как стоматологическое образование, формируя прочный "брак" между проблемой и решением.
- Ограничение: Необходимость в больших, аннотированных наборах данных для дообучения.
- Соответствие: "Отсутствие необходимости дообучения" в DentEval напрямую решает эту проблему. Его модуль SR-RAG позволяет ему приобретать знания в предметной области без необходимости в обширных, дорогостоящих и трудоемких аннотированных наборах данных для переобучения, что делает его практичным для специализированных областей, где такие данные редки.
- Ограничение: Несоответствия между результатами модели и оценками человеческого уровня.
- Соответствие: Компоненты "Промптинг с ролевой игрой" и "SR-RAG" разработаны для обеспечения тесного соответствия результатов человеческим стандартам оценки. Оценщик LLM, назначенный в роли учителя, усиливает это соответствие, а SR-RAG предоставляет фактически последовательную и релевантную для предметной области информацию. Использование большинства голосов от нескольких оценок LLM дополнительно снижает вариативность и повышает последовательность.
- Ограничение: Специализированная предметная область (стоматология), требующая точной интерпретации терминологии.
- Соответствие: SR-RAG специально разработан для приобретения достаточных знаний в предметной области путем извлечения соответствующей информации из стоматологических справочников и ее совершенствования. Кроме того, DentEval поддерживает мультимодальные входные данные (текст и клинические изображения), что крайне важно для такой области, как стоматология, которая в значительной степени полагается на визуальную информацию.
- Ограничение: Соответствие экспертным рубрикам оценки.
- Соответствие: Система явно принимает "рубрику оценки R" в качестве входных данных. Модуль генерации примеров ответов (SAG) назначает LLM роль "профессора" для генерации эталонных ответов, а оценщик LLM действует как "учитель", обеспечивая соответствие процесса оценки заранее определенным критериям и профессиональным стандартам.
- Ограничение: Ресурсоограниченные учреждения.
- Соответствие: Устраняя необходимость дообучения и значительно сокращая время оценки и финансовые затраты (с 1,275 до 0,007 доллара США за ответ), DentEval предоставляет ресурсоэффективное решение, которое является высокопрактичным для образовательных учреждений.
- Ограничение: Оценка открытых коротких вопросов.
- Соответствие: Модуль SAG генерирует несколько эталонных ответов, признавая присущую сложность и вариативность возможных правильных ответов на открытые вопросы. Это предотвращает ошибочные суждения системы о разнообразных, но допустимых ответах студентов, что является распространенной ловушкой для более простых методов.
Отклонение альтернатив
Статья неявно и явно отклоняет несколько альтернативных подходов, в частности, те, которые полагаются на базовый LLM-промптинг или обширное дообучение, из-за их присущих ограничений для конкретной проблемы оценки, согласованной с экспертами, в специализированных областях.
Основным отклонением являются традиционные методы дообучения LLM. Авторы подчеркивают, что эти методы требуют "больших, аннотированных наборов данных для дообучения или дополнительного обучения", что является "трудоемким и непрактичным для учреждений с ограниченными ресурсами". Это делает их непригодными для специализированных областей, таких как стоматология, где такие наборы данных редки, а стоимость аннотации экспертами высока. Бесплатный подход DentEval к дообучению напрямую обходит эту непрактичность.
Кроме того, в статье представлено четкое отклонение базового обучения на малом числе примеров для определенных типов вопросов. Хотя обучение на малом числе примеров в целом улучшает производительность по сравнению с обучением без примеров (Zero-shot), авторы отмечают "заметное снижение производительности оценки для Вопроса 2" (открытый вопрос, допускающий несколько точек зрения) при использовании базового метода обучения на малом числе примеров. Причина в том, что "во время обучения на малом числе примеров LLM может интерпретировать предоставленные примеры как единственно правильные ответы, что приводит к ошибочным суждениям о других ответах студентов". Это ограничение является критическим недостатком для открытых вопросов, где один окончательный ответ не всегда уместен. DentEval преодолевает это, включая модуль генерации примеров ответов (SAG), который генерирует несколько разнообразных эталонных ответов, тем самым улавливая вариативность допустимых ответов и предотвращая ошибочные суждения.
Хотя статья не углубляется в прямое сравнение с другими парадигмами глубокого обучения, такими как GAN или диффузионные модели (поскольку проблема в первую очередь связана с пониманием и оценкой языка, а не с генерацией сложной медиа, такой как изображения из шума), ее фокус на решениях на основе LLM подразумевает, что такие модели не являются напрямую применимыми или эффективными для этой конкретной задачи. Основная проблема связана с семантическим пониманием, приобретением знаний в предметной области и согласованностью с человеческими суждениями — областями, где LLM, дополненные RAG и агентными возможностями, занимают уникальное положение.
 Figure 2. Scoring Rubric and Example Content Illustration
Figure 2. Scoring Rubric and Example Content Illustration
Математический и логический механизм
Мастер-уравнение
Основная часть механизма оценки DentEval, особенно для генерации окончательной оценки, заключена в двучастном уравнении, которое сначала производит индивидуальные оценки от нескольких оценочных агентов, а затем агрегирует их. Этот процесс обеспечивает надежность и соответствует стандартам оценки человека посредством ролевой игры и обучения на малом числе примеров.
Генерация индивидуальной оценки для каждого экземпляра оценки $i$ задается как:
$$S_i = \text{LLM}_{\text{evaluator}}(Q, A_{student}, \{A_{sample},..., A_{sample}\}, R), \quad i \in \{1,..., n\}$$
И окончательная агрегированная оценка определяется как:
$$S_{final} = \text{Mode}(\{S_1, S_2, ..., S_n\})$$
Пословный разбор
Давайте разберем эти уравнения, чтобы понять роль каждого компонента:
-
$S_i$:
- Математическое определение: Это числовая оценка, присвоенная ответу студента одним экземпляром LLM-оценщика. Это скалярное значение, обычно в пределах предопределенного диапазона (например, $[0, 5]$, как указано в статье).
- Физическая/логическая роль: $S_i$ — это промежуточная, индивидуальная оценка ответа студента. Система генерирует $n$ таких оценок, чтобы учесть потенциальную вариативность результатов LLM и повысить надежность.
- Почему используется: Авторы используют несколько значений $S_i$, чтобы уменьшить влияние любого индивидуального суждения LLM, тем самым повышая последовательность и надежность общей оценки. Это распространенная стратегия для снижения шума в оценках, управляемых ИИ.
-
$\text{LLM}_{\text{evaluator}}(\cdot)$:
- Математическое определение: Это обозначает функцию, выполняемую большой языковой моделью, специально настроенной для роли "оценщика". Она принимает несколько входных данных и выдает одну числовую оценку.
- Физическая/логическая роль: Это центральный интеллектуальный агент, ответственный за оценку ответа студента. Назначая ему роль "оценщика" с помощью промптинга, система направляет LLM к принятию критической, ориентированной на оценку персоны, отражающей учителя-человека.
- Почему используется: LLM выбирается из-за его продвинутых возможностей понимания и генерации естественного языка, что позволяет ему интерпретировать сложные вопросы, ответы студентов, рубрики и эталонные ответы для принятия тонкого суждения. Промптинг с ролевой игрой помогает согласовать его выходные данные с критериями оценки экспертов.
-
$Q$:
- Математическое определение: Это входной запрос или вопрос, заданный студенту. Он может быть текстовым и может опционально включать визуальный контент (например, рисунки).
- Физическая/логическая роль: $Q$ определяет задачу или проблему, на которую студент должен ответить. Это основной контекст для оценки.
- Почему используется: Вопрос является фундаментальным для любой оценки. Он предоставляет основу, по которой оценивается ответ студента.
-
$A_{student}$:
- Математическое определение: Это ответ студента в свободной форме на вопрос $Q$.
- Физическая/логическая роль: $A_{student}$ — это оцениваемый элемент. Это необработанная точка данных, качество и правильность которой необходимо оценить.
- Почему используется: Это прямой результат от студента, который система стремится оценить.
-
$\{A_{sample},..., A_{sample}\}$:
- Математическое определение: Это обозначает набор эталонных примеров ответов. Они генерируются внутренне другим LLM-агентом, $\text{LLM}_{\text{professor}}(Q, E)$, где $E$ — это усовершенствованная информация из стоматологического справочника. В статье указано, что генерируется несколько примеров ответов для учета открытого характера вопросов.
- Физическая/логическая роль: Эти примеры ответов служат эталонными ориентирами, согласованными с экспертами, или "золотыми стандартами", по которым сравнивается ответ студента $A_{student}$. Они предоставляют LLM-оценщику примеры того, как выглядит хороший ответ, фактически действуя как примеры для обучения на малом числе примеров.
- Почему используется: Предоставление нескольких эталонных ответов помогает LLM-оценщику понять широту допустимых ответов на открытые вопросы, уменьшая предвзятость к единственному "правильному" ответу и улучшая его способность улавливать разнообразные, но допустимые выражения студентов. Это крайне важно для специализированных областей, где ответы могут иметь несколько допустимых интерпретаций.
-
$R$:
- Математическое определение: Это оценочная рубрика, набор критериев и руководств для оценки.
- Физическая/логическая роль: $R$ предоставляет явные правила и стандарты для оценки. Это обеспечивает объективность и последовательность оценки в соответствии с педагогическими требованиями.
- Почему используется: Рубрика необходима для структурированной оценки, гарантируя, что оценка LLM является прозрачной, справедливой и соответствует принципам оценки человека. Она действует как ограничение и руководство для суждения LLM.
-
$i \in \{1,..., n\}$:
- Математическое определение: Это индекс, указывающий, что процесс оценки повторяется $n$ раз, генерируя $n$ индивидуальных оценок.
- Физическая/логическая роль: Это означает множественность процесса оценки. Каждый $S_i$ является независимым запуском $\text{LLM}_{\text{evaluator}}$.
- Почему используется: Повторение оценки несколько раз с последующей агрегацией результатов (через Mode) является стратегией для повышения надежности и стабильности окончательной оценки, снижая присущую стохастичность или вариативность результатов LLM.
-
$S_{final}$:
- Математическое определение: Это окончательная числовая оценка, присвоенная ответу студента, полученная путем агрегации индивидуальных оценок.
- Физическая/логическая роль: $S_{final}$ — это окончательный результат системы DentEval, представляющий собой окончательную оценку ответа студента.
- Почему используется: Это желаемый конечный продукт системы, единая, надежная оценка, которую можно использовать для выставления оценок.
-
$\text{Mode}(\cdot)$:
- Математическое определение: Это статистическая функция, которая возвращает наиболее часто встречающееся значение в наборе данных.
- Физическая/логическая роль: Функция Mode действует как механизм консенсуса. Выбирая наиболее распространенную оценку среди $n$ индивидуальных оценок, она фактически отфильтровывает выбросы и усиливает наиболее последовательное суждение от LLM-агентов.
- Почему используется: Голосование большинством через Mode используется для снижения вариативности и повышения последовательности и надежности окончательной оценки, особенно в ситуациях, когда индивидуальные результаты LLM могут незначительно отличаться. Это простой, но эффективный способ достижения надежного консенсуса.
Пошаговый поток
Представьте, что ответ студента $A_{student}$ отправляется в путешествие через систему DentEval, подобно элементу на сложном сборочном конвейере:
-
Первоначальный прием входных данных: Процесс начинается с трех основных входных данных: ответа студента ($A_{student}$), вопроса ($Q$, потенциально с соответствующим рисунком) и оценочной рубрики ($R$). Дополнительно доступен обширный корпус для поиска ($C$) стоматологических знаний.
-
Встраивание запроса и первоначальный поиск: Вопрос $Q$ сначала преобразуется в числовое векторное представление (встраивание). Этот встраиваемый запрос затем подается в поисковую систему (например, Milvus) для поиска в корпусе стоматологических знаний $C$. Система извлекает "топ K" наиболее релевантных фрагментов информации.
-
Совершенствование информации: Эти первоначальные "топ K" фрагменты вместе с исходным вопросом $Q$ передаются специализированному LLM-агенту. Задача этого агента — обобщить и усовершенствовать эту необработанную информацию в более сжатый и релевантный набор доказательств, $E$. Этот шаг имеет решающее значение для удаления шума и обеспечения того, чтобы информация была непосредственно связана с вопросом.
-
Проверка достаточности и итеративный поиск: Усовершенствованные доказательства $E$ затем оцениваются другим LLM-агентом для определения, являются ли они "достаточными" для генерации высококачественного эталонного ответа. Если доказательства признаны недостаточными, система возвращается к этапу поиска, увеличивая значение $K$ (на "шаг") для сбора дополнительной информации. Эта итеративная самокоррекция гарантирует всестороннюю основу.
-
Генерация примеров ответов (SAG): Как только достаточное количество доказательств $E$ получено, оно объединяется с вопросом $Q$ и передается агенту $\text{LLM}_{\text{professor}}$. Этот агент, играющий роль академика-стоматолога, генерирует несколько разнообразных примеров ответов $\{A_{sample},..., A_{sample}\}$ на основе усовершенствованных доказательств и вопроса. Этот шаг имеет решающее значение для открытых вопросов, где может существовать несколько допустимых правильных ответов.
-
Генерация индивидуальной оценки: Теперь система готовится к фактической оценке. Для $n$ отдельных оценочных запусков вызывается агент $\text{LLM}_{\text{evaluator}}$. В каждом запуске $i$ этот оценщик LLM получает вопрос $Q$, ответ студента $A_{student}$, набор сгенерированных примеров ответов $\{A_{sample},..., A_{sample}\}$ и оценочную рубрику $R$. Он также включает примеры для обучения на малом числе примеров (ответы студентов из каждого уровня оценки с обратной связью по оценке), чтобы направить свое суждение. На основе всех этих входных данных $\text{LLM}_{\text{evaluator}}$ генерирует индивидуальную оценку $S_i$.
-
Агрегация окончательной оценки: После генерации $n$ индивидуальных оценок ($S_1, S_2, ..., S_n$) они собираются. Окончательная оценка, $S_{final}$, затем определяется путем применения функции Mode к этому набору оценок. Это означает, что наиболее часто встречающаяся оценка среди $n$ оценок становится окончательной оценкой. Этот механизм голосования большинством обеспечивает надежную и последовательную окончательную оценку, минимизируя влияние любой отдельной аномальной оценки.
Динамика оптимизации
DentEval работает по парадигме "без дообучения", что означает, что он не включает традиционную оптимизацию на основе градиентов для обновления параметров базовых больших языковых моделей. Вместо этого его поведение "обучения", "обновления" или "сходимости" достигается за счет комбинации интеллектуального дизайна системы, итеративных процессов и сложных стратегий промптинга:
-
Самосовершенствующаяся генерация с дополненным поиском (SR-RAG): Основной механизм "обучения" системы встроен в ее компонент SR-RAG. Когда первоначальные извлеченные доказательства $E$ признаются недостаточными LLM-агентом, система не сдается; она итеративно расширяет свой поиск, увеличивая параметр $K$ (количество наиболее релевантных фрагментов). Этот цикл самокоррекции позволяет системе "узнать", когда ее база знаний недостаточна, и активно искать более полную информацию. Эта динамическая настройка параметров поиска является формой адаптивной оптимизации самого процесса RAG, гарантируя, что контекст, предоставленный LLM, максимально полон и релевантен.
-
Промптинг с ролевой игрой: Производительность системы "оптимизируется" путем тщательного создания промптов, которые назначают конкретные роли (например, "профессор", "оценщик") LLM-агентам. Это не математическая оптимизация в традиционном смысле, а мощная форма контекстного руководства. Принимая эти персоны, LLM направляются к проявлению поведения и моделей рассуждений, которые точно имитируют экспертов-людей, тем самым согласовывая их выходные данные с желаемыми стандартами оценки. Это "инженерия промптов" является решающим рычагом для неявного формирования "ландшафта потерь" LLM, направляя его к более точным и последовательным оценкам без изменения его внутренних весов.
-
Обучение на малом числе примеров: LLM-оценщику предоставляется небольшой набор примеров (примеры для обучения на малом числе примеров), которые включают ответы студентов, рубрики и оценки, назначенные человеком, с обратной связью. Это позволяет LLM "изучить" желаемые шаблоны и критерии оценки непосредственно из примеров, а не через явные обновления параметров. Это контекстное обучение помогает LLM сходиться к последовательной политике оценки, демонстрируя ожидаемые взаимосвязи между входом и выходом.
-
Голосование большинством для надежности: Агрегация нескольких индивидуальных оценок ($S_i$) в окончательную оценку ($S_{final}$) с использованием функции Mode является статистической оптимизацией. Она действует как надежный оценщик, эффективно сглаживая индивидуальные вариации и предвзятости, которые могут возникнуть из-за одной оценки LLM. Этот механизм помогает системе сходиться к более стабильной и надежной оценке, улучшая последовательность с течением времени и для разных ответов студентов. Это форма ансамблевого обучения, применяемая к результатам LLM.
-
Постобработка с отображением CDF: Как упоминается в деталях реализации, система применяет отображение функции кумулятивного распределения (CDF) в качестве шага постобработки. Этот метод калибрует необработанные оценки LLM для снижения предвзятости и повышения справедливости, более тесно согласовывая их с распределениями оценок человека. Хотя это не является частью внутреннего обучения LLM, это внешний шаг калибровки, который "оптимизирует" окончательный результат для лучшего соответствия человеческим суждениям.
По сути, "оптимизация" DentEval — это не столько градиентный спуск по функции потерь, сколько интеллектуально разработанный многоагентный рабочий процесс, который использует присущие возможности больших языковых моделей посредством итеративного совершенствования, стратегического промптинга и надежных методов агрегации для достижения оценки, согласованной с экспертами, без необходимости обширного дообучения. Таким образом, "обучение" системы является процедурным и контекстным, а не параметрическим.
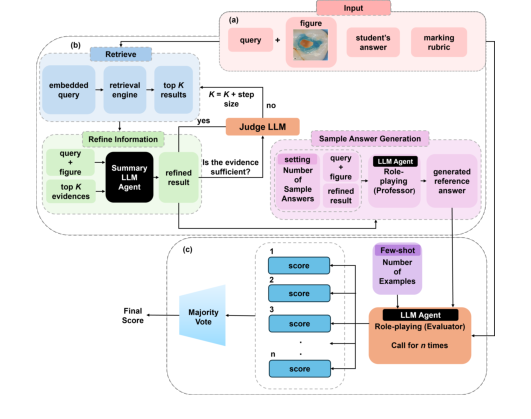 Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Результаты, ограничения и заключение
Экспериментальный дизайн и базовые линии
Для строгой проверки математических утверждений и практической эффективности DentEval исследователи разработали комплексную экспериментальную установку. Основу их оценки составил уникальный набор данных, аннотированный профессорами, специально подобранный для стоматологических учебных программ. Этот набор данных включал 28 ответов студентов на каждый вопрос, тщательно оцененных академиками-стоматологами по заранее определенной оценочной рубрике. Важно отметить, что набор данных включал два различных типа открытых вопросов: один, требующий мультимодального рассуждения (текст и изображения), и другой, чисто текстовый. Это разнообразие было преднамеренным, отражая разнообразный характер оценок в стоматологическом образовании, охватывая различные поддомены, такие как стоматологическая морфология и реставрационные материалы, и демонстрируя широкий диапазон длин и сложностей ответов.
Для оценки использовался подход обучения на малом числе примеров. Из 28 ответов на вопрос один ответ из каждого уровня оценки был выбран в качестве примера для обучения на малом числе примеров, что привело к 6 примерам на вопрос. Оставшиеся 22 ответа составили тестовый набор. Эта конструкция позволила LLM-агентам учиться на примерах, оцененных экспертами, без обширного дообучения. GPT-40 (специально gpt-40-mini) был выбран в качестве базовой LLM-агента, используя его мультимодальные возможности. Для обеспечения справедливости и последовательности в качестве шага постобработки применялось отображение функции кумулятивного распределения (CDF) для снижения потенциальной предвзятости в оценках.
Производительность DentEval сравнивалась с несколькими "жертвенными" базовыми моделями и передовыми методами:
- Zero-shot: Прямой подход, при котором LLM оценивает ответы без каких-либо модификаций или ролевой игры.
- Few-shot: Улучшение Zero-shot, включающее эталонные примеры для руководства LLM.
- SciEx [5]: Передовой метод, сочетающий обучение на малом числе примеров с промптингом с ролевой игрой.
- FairEval [22]: Другой продвинутый метод, использующий множественную калибровку доказательств (MEC) и калибровку сбалансированного положения (BPC) для снижения предвзятости в оценках LLM.
Окончательные доказательства основного механизма DentEval искались с помощью стандартных метрик оценки: точность (Acc.), коэффициент ранговой корреляции Спирмена (SROCC) [17] и коэффициент линейной корреляции Пирсона (PLCC) [16]. SROCC и PLCC были особенно важны, поскольку они напрямую измеряют последовательность и линейную корреляцию оценок DentEval с оценками экспертов-людей, предоставляя надежную меру согласованности.
Наконец, было проведено исследование с абляцией, чтобы безжалостно доказать вклад каждого инновационного компонента в DentEval (SR-RAG, генерация примеров ответов (SAG) и промптинг с ролевой игрой). Систематически удаляя или изолируя эти компоненты, исследователи могли точно определить их индивидуальное влияние на общую производительность системы, используя базовую линию Zero-shot для сравнения.
Что доказывают доказательства
Экспериментальные данные подавляющим большинством демонстрируют превосходную производительность и надежность DentEval в различных сценариях оценки в стоматологическом образовании.
Для Вопроса 1, который включал мультимодальное рассуждение (текст и изображения) и имел единственный правильный ответ, DentEval достиг наилучшей производительности по всем метрикам оценки. Он показал SROCC 0,7447, PLCC 0,7288 и точность 68,2%, все с наименьшими p-значениями, что указывает на статистически значимое соответствие оценкам человека. Хотя SciEx и FairEval превзошли базовую линию Zero-shot, они немного уступили базовому методу обучения на малом числе примеров, подчеркивая тонкие проблемы автоматизированной оценки даже для передовых методов. Способность DentEval интегрировать мультимодальные входные данные и механизмы, согласованные с экспертами, явно дала ему преимущество здесь.
Для Вопроса 2, чисто текстового, открытого вопроса, допускающего несколько допустимых ответов, производительность DentEval была еще более впечатляющей. Он достиг SROCC 0,9259 и PLCC 0,8957, оба выше, чем для Вопроса 1, и сохранил точность 68,2%. Это особенно важно, поскольку, в отличие от Вопроса 1, базовый метод обучения на малом числе примеров продемонстрировал заметное снижение производительности оценки для Вопроса 2. Авторы объясняют это природой открытых вопросов, где примеры для обучения на малом числе примеров могут непреднамеренно привести LLM к интерпретации их как единственно правильных ответов, вызывая ошибочные суждения о других допустимых ответах студентов. Надежность DentEval в обработке таких сложных открытых вопросов, где не ожидается единственного окончательного ответа, является сильным свидетельством его передового дизайна, особенно его механизмов SR-RAG и промптинга с ролевой игрой, которые генерируют разнообразные эталонные ответы.
Помимо точности и корреляции, DentEval также предоставил неоспоримые доказательства значительного повышения эффективности. Человек-оценщик обычно тратит около 1,5 минут на ответ студента, что стоит примерно 1,275 доллара США. В отличие от этого, LLM-агенты DentEval GPT-40 обрабатывали каждый вопрос примерно за 0,13 минуты, при стоимости всего 0,007 доллара США за ответ. Это представляет собой огромное сокращение как времени, так и финансовых ресурсов, освобождая преподавателей для сосредоточения на более педагогически ценных видах деятельности.
Исследование с абляцией далее укрепило вклад основных компонентов DentEval. Каждый инновационный компонент — SR-RAG, генерация примеров ответов (SAG) и промптинг с ролевой игрой — индивидуально улучшал последовательность с оценками человека и повышал точность. Например, один только SR-RAG значительно повысил точность для Вопроса 1 с 9,1% (Zero-shot) до 54,5%, а для Вопроса 2 — с 50,0% до 68,2%. Полная структура DentEval последовательно превосходила все абляционные версии, подтверждая, что синергетическая интеграция этих компонентов действительно обеспечивает его превосходную производительность и согласованность с человеческими суждениями.
Ограничения и будущие направления
Хотя DentEval представляет собой убедительный прогресс в автоматизированной оценке для специализированных областей, важно признать его текущие ограничения и рассмотреть направления для будущего развития.
Одним из явных ограничений, как неявно отмечают авторы, является размер набора данных. Хотя собранные ответы были разнообразны по структуре и содержанию, "ограниченное количество вопросов" (были оценены только два различных вопроса) может ограничить обобщаемость выводов на весь спектр стоматологических учебных программ или другие специализированные области. Расширение набора данных для включения более широкого спектра типов вопросов, уровней сложности и вариаций ответов обеспечит более надежную валидацию возможностей DentEval.
Другим моментом, который следует учитывать, является зависимость от конкретной LLM, GPT-40. Хотя и мощная, она вводит потенциальные проблемы, связанные с колебаниями стоимости, доступностью API и проприетарным характером модели. Будущая работа может изучить адаптивность структуры DentEval к LLM с открытым исходным кодом или более экономичным альтернативам, обеспечивая более широкую доступность и устойчивость.
Статья также освещает проблему, создаваемую открытыми вопросами, допускающими несколько правильных ответов, отмечая снижение производительности для базового метода обучения на малом числе примеров. Хотя DentEval хорошо справляется с этим, присущая сложность таких вопросов предполагает, что постоянное совершенствование модулей генерации примеров ответов (SAG) и самосовершенствующейся генерации с дополненным поиском (SR-RAG) будет иметь решающее значение для поддержания высокой согласованности с суждениями экспертов в еще более широком спектре субъективных оценок.
Заглядывая вперед, сами авторы предлагают захватывающие будущие направления:
- Расширение мультимодального RAG: Естественным развитием было бы включение более сложных мультимодальных входных данных, таких как клинические видео и 3D-модели. Это позволило бы DentEval оценивать практические навыки и диагностическое рассуждение более целостно и реалистично, выходя за рамки статических изображений и текста. Представьте себе LLM-агента, оценивающего технику студента в симуляции хирургической процедуры на основе видеодоказательств!
- Адаптивная калибровка: Разработка адаптивных механизмов калибровки для повышения надежности в различных типах вопросов является еще одной критически важной областью. Это подразумевает систему, которая может динамически корректировать свою рубрику оценки или стратегию оценки на основе конкретных характеристик вопроса (например, ожидает ли он единственного фактического ответа или тонкого, многоперспективного ответа). Это повысит гибкость и надежность системы в различных контекстах оценки.
Помимо этого, несколько других тем для обсуждения могли бы далее развить эти выводы:
- Объяснимость и качество обратной связи: Хотя DentEval предоставляет оценки, педагогическая ценность автоматизированной оценки значительно повышается за счет высококачественной, действенной обратной связи. Будущие исследования могли бы сосредоточиться на повышении прозрачности процесса рассуждения LLM и генерации подробной, конструктивной обратной связи, которая помогает студентам понять, почему они получили определенную оценку и как улучшиться. Это могло бы включать интеграцию промптинга "цепочки рассуждений" специально для генерации обратной связи.
- Этический ИИ в образовании: По мере того как автоматизированная оценка становится все более распространенной, крайне важно решать этические проблемы, связанные со справедливостью, предвзятостью и равенством. Как мы можем гарантировать, что оценки DentEval непредвзяты по отношению к различным демографическим группам студентов или стилям обучения? Какие механизмы могут быть внедрены для обнаружения и снижения потенциальной алгоритмической предвзятости? Исследования в области аудируемости и объяснимого ИИ для оценки были бы бесценны.
- Интеграция с системами управления обучением (LMS): Для широкого внедрения необходима бесшовная интеграция DentEval в существующие образовательные инфраструктуры, такие как Canvas или Moodle. Это включало бы разработку надежных API и удобных интерфейсов для преподавателей, чтобы легко развертывать, настраивать и контролировать автоматизированные оценки.
- Применимость в различных областях: Хотя DentEval разработан для стоматологии, лежащие в основе принципы SR-RAG, промптинга с ролевой игрой и обработки мультимодальных входных данных могут быть обобщены на другие специализированные области, требующие оценки, согласованной с экспертами, такие как медицина, инженерия или право. Изучение этих изоморфизмов могло бы открыть более широкие возможности применения и воздействия.
- Адаптивное обучение в реальном времени: Может ли DentEval быть интегрирован в среды обучения в реальном времени для предоставления немедленной, персонализированной обратной связи и адаптивных путей обучения? Представьте, что студент получает мгновенную оценку и индивидуальные ресурсы для исправления по мере выполнения практических вопросов, ускоряя процесс обучения.
Эти разнообразные точки зрения подчеркивают, что DentEval — это не просто инструмент для автоматизированной оценки, а основополагающая структура, способная коренным образом изменить образовательную оценку и опыт обучения в специализированных областях.
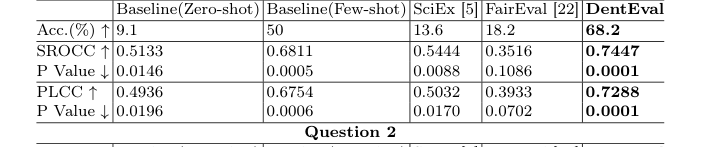 Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval
Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval