DentEval: LLMエージェントによる歯科教育におけるファインチューニングフリーな専門家整合型評価
Large language models (LLMs) have demonstrated considerable potential in automating assignment scoring within higher education, providing efficient and consistent evaluations.
背景と学術的系譜
起源と学術的系譜
本稿で取り上げる問題の正確な起源は、教育分野、特に自動評価における大規模言語モデル(LLM)によってもたらされた最近の革命に端を発する。OpenAIのGPTシリーズのようなLLMは、課題に対する効率的かつ一貫した評価を提供する上で大きな可能性を示しているが、歯科のような高度に専門化された領域への応用は、重大な課題を提示している。
歴史的に自動評価システムは存在したが、LLMの登場は、自由記述式の質問を扱う新たな可能性を開いた。しかし、専門家レベルの評価にLLMを活用しようとする際に、2つの中心的な問題が生じた。
1. 専門分野固有の解釈: LLMは、専門分野に固有の微妙な専門用語や複雑な概念を理解するのに苦労することが多い。専門用語を誤解したり、正確な評価に必要な深い文脈理解を欠いたりする可能性がある。
2. 専門家による採点との整合性: 人間の専門家(例:歯科教授)によって確立された特定の、しばしば主観的な評価基準にLLMの出力が準拠することを保証することは、大きな障害となってきた。
これらの限界を克服するためのこれまでのアプローチは、通常、大規模で綿密に注釈付けされたデータセットを使用したLLMの広範なファインチューニングまたは再トレーニングを伴っていた。このプロセスは時間のかかるだけでなく、リソース集約的であり、特に計算リソースが限られている多くの教育現場では非現実的である。著者らがDentEvalを開発するに至った「ペインポイント」はまさにこれである。専門的な自由記述式評価タスクにLLMを適用するための既存の方法は、法外な量のデータと計算労力を必要とし、人間の採点との不整合につながり、リアルタイムでの実用的な応用を困難にしていた。著者らは、専門家整合型評価を効率的に達成できるファインチューニングフリーなソリューションを求めた。
直感的な専門用語の例え
以下に、本稿で用いられる専門用語を、ゼロベースの読者向けに日常的なアナロジーで翻訳したものを示す。
- 大規模言語モデル(LLM): これまでに書かれたほぼ全ての書籍、記事、ウェブページを読んだ超知能デジタルアシスタントを想像してほしい。それはあなたの言うことを理解し、新しいテキストを生成し、質問に答えることができるが、全ての分野の専門家であるとは限らない。それは優秀なジェネラリストのようなものだが、非常に特定のニッチなトピックについては、しばしば追加の助けが必要となる。
- 検索拡張生成(RAG): これは、私たちの超知能デジタルアシスタントのための持ち込み試験のようなものだ。アシスタントに質問をすると、単に一般的な知識に頼るのではなく、まず歯科ハンドブックのような特定の信頼できるライブラリを素早く検索して関連情報を取得する。そして、その新しく取得した情報と自身の知識を組み合わせて、より正確で情報に基づいた回答を生成する。これは、回答する前にパーソナルリサーチアシスタントがいるようなものだ。
- ロールプレイングプロンプティング: これは、デジタルアシスタントに特定のキャラクターを演じさせるようなものだ。「これを採点して」と単に尋ねるのではなく、「さて、あなたは今から厳格な歯科教授であり、これらの規則に従ってこの学生の回答を採点する必要がある」と指示する。このペルソナを採用することで、LLMは人間の歯科教授が考えるように、あるいは応答するように努め、その評価を専門家基準により一致させる。
- 少数ショット学習(Few-shot learning): 子供に新しい種類の果物を識別するように教えることを想像してほしい。何百枚もの写真を見せる代わりに、ほんの数枚の例(例:「これはリンゴです、これもリンゴです、そしてこれは悪いリンゴの見た目です」)を見せる。これらの限られた例から、子供はすぐに他のリンゴを認識することを学ぶ。同様に、少数ショット学習は、AIが大量のトレーニングデータセットを必要とせずに、ほんの一握りの例を見るだけで、新しいタスクを学習したり、特定のスタイルに適応したりすることを可能にする。
記法表
| 記法 | 説明 |
|---|---|
問題定義と制約
中心的な問題定式化とジレンマ
本稿で取り上げる中心的な問題は、特に歯科教育のような専門分野における、自由記述式の短答問題に対する学生の回答の正確かつ効率的な自動評価である。
既存システムの入力/現在の状態は、学生の自由記述回答 ($A_{student}$)、テキストおよび視覚コンテンツを含む可能性のある質問 ($Q$)、および採点基準を定義する採点ルーブリック ($R$) である。さらに、歯科ハンドブックのような検索コーパス ($C$) も利用可能である。現在のLLMは自動採点において有望であり、効率性と一貫性を提供している。しかし、それらは重大な障害に直面している。
1. 専門分野固有の解釈: LLMは、歯科のような分野に固有の、微妙な専門用語や専門分野固有の用語の正確な解釈に苦労する。
2. 専門家ルーブリックとの整合性: 既存のLLMシステムは、人間の評価と一貫性のない出力を生成することが多く、専門家によって確立された特定の採点ルーブリックに整合しない。
3. リソース要求: これらの問題に対処するには、通常、大規模で注釈付けされたデータセットを使用した広範なファインチューニングと再トレーニングが必要であり、これは時間のかかる、計算コストの高い、リソースが制約された教育現場では非現実的である。
望ましい終点(出力/目標状態)は、学生のパフォーマンスを正確に反映し、人間の専門家による採点基準に密接に整合する数値スコア $S_{final} \in [0, 5]$ である。このシステムは以下であるべきである。
1. 専門分野認識: 専門的な歯科知識を理解し、適用できること。
2. 専門家整合: 人間の教授による評価と強く相関するスコアを一貫して生成すること。
3. リソース効率: 広範なファインチューニングや再トレーニングの必要なく効果的に動作し、評価時間と財務コストを削減すること。
4. マルチモーダル: テキストと視覚コンテンツ(例:臨床画像)の両方を含む質問を処理できること。
欠けているリンクまたは数学的なギャップは、まさにこれらの入力を専門家整合型スコアに確実に、かつ費用対効果の高い方法でマッピングできる関数 $S_{final} = DentEval(A_{student}, Q, R, C)$ をどのように構築するかである。これまでのアプローチは、一般的なLLMの機能と、特に単一の「正解」が常に利用可能ではない自由記述式の質問に対する専門家評価の微妙で専門的な要件との間のギャップを埋めるのに苦労してきた。中心的なジレンマは、従来のファインチューニングの高コストとリソース要求を発生させることなく、専門的な自由記述式の質問で高い精度と人間の専門家による採点との整合性を達成することである。1つの側面(例:専門分野の特異性)を改善すると、通常は別の側面(例:計算効率やデータ要件)が損なわれる。
制約と失敗モード
歯科のような専門分野における自動専門家整合型評価の問題は、いくつかの厳しい現実的な壁によって非常に困難になっている。
-
データ駆動型制約:
- 注釈付きデータの希少性: ファインチューニングや追加トレーニングのために、大規模で専門家によって注釈付けされたデータセットに対する重大なニーズがあるが、歯科のような高度に専門化された分野では希少で作成コストが高い。これにより、従来の教師あり学習アプローチは非現実的になる。
- 自由記述式質問の多様性: 高等教育で一般的な自由記述式質問には、常に単一のユニークな正解があるとは限らない。学生の回答は、学習者の表現の真の多様性を反映して、長さ、構造、推論の複雑さにおいてかなりのばらつきを示す可能性がある。この固有のばらつきは、自動システムに対して決定的な「正解」を定義することを困難にする。
- 取得情報におけるノイズ: 検索拡張生成(RAG)を使用しても、コーパスからのセグメント化された証拠チャンクには、クエリまたはその主要な用語に直接関連しないコンテンツが含まれる場合がある。この無関係な情報はノイズを導入し、サンプル回答生成の精度と品質に悪影響を与える可能性がある。
-
計算およびリソース制約:
- ファインチューニングの高計算コスト: 専門分野にLLMを適応させるための従来のメソッドは、広範なコンピューティングリソースと、ファインチューニングおよび再トレーニングのためのかなりの時間を必要とする。これは、リソースが制約された教育現場ではしばしば非現実的である。
- 財務コスト: 高等教育の専門家による人間の評価は高価である(例:応答あたり約1.275米ドル)。そのため、大規模なコホートに対してスケーラブルな手動評価は財務的に持続不可能である。自動ソリューションは、大幅な財務的節約を提供する必要がある。
-
モデルおよび機能制約:
- 汎用LLMにおける専門知識の欠如: 標準的なLLMは、専門分野固有の用語や微妙な専門用語の正確な解釈に苦労し、専門分野での不正確な評価につながる。
- 人間の採点との不整合: 既存システムの主要な失敗モードは、LLMの出力と人間の評価との間の不整合である。LLMは、専門家によって確立された特定の評価基準に準拠できないことが多く、信頼と採用の欠如につながる。
- LLM採点のばらつき: 同じ入力であっても、LLMは採点においてばらつきを示す可能性があり、評価システムの信頼性と堅牢性を低下させる。これには、一貫した信頼性の高い評価を保証するためのメカニズムが必要である。
- 少数ショット学習における誤解: 複数の有効な視点を許容する自由記述式質問の場合、単一の少数ショット例のセットを提供すると、LLMがそれらを唯一の正解と誤解する可能性があり、他の有効な学生の回答の誤った判断につながる。これは、モデルを例で導こうとすることが意図せず理解を狭める可能性があるという痛みを伴うトレードオフである。
なぜこのアプローチなのか
選択の必然性
DentEvalの特定のアプローチ、すなわち自己洗練検索拡張生成(SR-RAG)とロールプレイングLLMエージェントの統合の採用は、単なる好みではなく、専門分野の教育評価に従来のメソッドを適用する際の固有の限界によって駆動された必然であった。著者らは、特に大規模言語モデル(LLM)の広範なファインチューニングに依存する標準的な「SOTA」メソッドが、いくつかの重要な課題のためにこの問題には不十分であることを認識した。
第一に、歯科教育のような専門分野における自由記述式の短答問題の評価は、専門用語や複雑な概念の微妙な理解を必要とする。従来のLLMでさえ、大幅な専門分野固有のトレーニングなしでは、これに苦労することが多い。「この認識の正確な瞬間」は単一のイベントではなく、既存のシステムが「ファインチューニングまたは追加トレーニングのための大規模で注釈付けされたデータセット」を必要とし、それが「時間のかかる、リソースが制約された設定では非現実的」であるという認識である。この制約により、ファインチューニングを多用するアプローチは実行不可能となった。
第二に、自動評価が専門家の人間による採点ルーブリックに密接に整合することを保証することは、重大な障害である。標準的なLLMアプリケーションは、「モデルの出力と人間の評価との間の不整合」を示すことが多い。この整合性の欠如は、特に公平性と正確性が最優先される高リスクの教育コンテキストにおいて問題となる。専門家によって確立された特定の評価基準に準拠する必要性は、基本的なLLMプロンプティングや単純なファインチューニングでは提供できない、より動的で文脈を意識したアプローチが必要であることを意味した。本稿では、これらの問題に対処するために通常「広範なファインチューニングと再トレーニング」が必要であると明記されており、これは非現実的と見なされた。
比較優位性
DentEvalは、専門分野の評価のコアチャレンジに直接対処する構造的イノベーションを通じて、以前のゴールドスタンダードおよびベースラインメソッドに対する質的な優位性を示している。優れたパフォーマンスメトリクス(Spearman相関係数0.9259、Pearson相関係数0.8957まで、SciExおよびFairEvalを上回る)を達成するだけでなく、その利点は設計に根ざしている。
- ファインチューニング不要: 多くの以前のアプローチが大規模で注釈付けされたデータセットを使用した広範なファインチューニングを要求するのに対し、DentEvalはこのようなリソース集約的なステップなしで効果的に動作する。これは、リソースが制約された教育現場で実用的であり、開発および展開のオーバーヘッドを大幅に削減する、巨大な構造的利点である。
- 自己洗練による最適化されたRAGプロセス: 自己洗練検索拡張生成(SR-RAG)は、主要なイノベーションである。単に情報を取得するだけでなく、それを洗練し、その十分性を自律的に評価する。これは、システムが明示的なファインチューニングなしで十分な専門分野固有の知識を取得できることを意味する。このプロセスは、取得されたチャンクから無関係な情報を積極的にフィルタリングするため、サンプル回答生成の精度に悪影響を与える可能性のある高次元ノイズを本質的に処理する。この自己評価ループ($K$が動的に調整される)は、LLMが十分な根拠を持っていることを保証し、ノイズが多い、または不十分なコンテキストを取得する可能性のある標準RAGに対する構造的利点となる。
- ロールプレイングプロンプティングとサンプル回答生成(SAG): LLMエージェントを「教授」として指定して複数の参照回答を生成させ、「評価者」(教師)として採点させることで、DentEvalは評価プロセスを人間の教育実践と構造的に整合させる。このマルチエージェント、ロールプレイングアプローチは、人間の採点基準との整合性を高め、一貫性を向上させる。自由記述式質問の場合、(単一の「正解」ではなく)多様な参照回答を生成することは、許容可能な学生の回答の固有の複雑さと多様性を捉えることをシステムに可能にし、そのようなタスクに対して圧倒的に優れている。
- 効率の向上: システムは、時間と財務コストの両方で大幅な「効率の向上」を提供する。人間の評価者は通常、応答あたり約1.5分を費やし、約1.275米ドルのコストがかかる。対照的に、DentEvalは各質問を約0.13分で処理し、コストはわずか0.007米ドルである。時間とコストのこの劇的な削減は、教育者がより教育的に価値のある活動にリソースを再割り当てすることを可能にする質的な利点である。
制約との整合性
DentEvalの選択された方法は、歯科教育のような専門分野における自動評価の厳しい要件に完全に整合し、問題と解決策の堅牢な「結婚」を形成する。
- 制約:ファインチューニングのための大規模な注釈付きデータセットの必要性。
- 整合性: DentEvalの「ファインチューニング不要」は、これを直接解決する。そのSR-RAGモジュールは、再トレーニングのための広範で高価で時間のかかる注釈付きデータセットを必要とせずに、専門分野固有の知識を取得することを可能にし、そのようなデータが希少な専門分野で実用的になる。
- 制約:モデルの出力と人間の評価との間の不整合。
- 整合性: 「ロールプレイングプロンプティング」と「SR-RAG」コンポーネントは、出力が人間の採点基準に密接に整合するように設計されている。評価者LLMは、教師の役割を割り当てられ、この整合性を高め、SR-RAGは事実上一貫した専門分野関連の情報を提供する。複数のLLMスコアからの多数決の使用は、ばらつきをさらに減らし、一貫性を向上させる。
- 制約:専門知識の専門分野(歯科)は、用語の正確な解釈を必要とする。
- 整合性: SR-RAGは、歯科ハンドブックから関連情報を取得して洗練することにより、十分な専門分野固有の知識を取得するように調整されている。さらに、DentEvalは、歯科のような視覚情報に大きく依存する分野にとって重要な、マルチモーダル入力(テキストと臨床画像)をサポートする。
- 制約:専門家の採点ルーブリックとの整合性。
- 整合性: システムは明示的に「採点ルーブリックR」を入力として受け取る。サンプル回答生成(SAG)モジュールは、LLMを「教授」として指定して参照回答を生成し、評価者LLMは「教師」として機能し、評価プロセスが定義済みの基準と専門家基準に準拠することを保証する。
- 制約:リソースが制約された設定。
- 整合性: ファインチューニングの必要性を排除し、評価時間と財務コスト(応答あたり1.275米ドルから0.007米ドルへ)を大幅に削減することにより、DentEvalは教育機関にとって非常に実用的なリソース効率の高いソリューションを提供する。
- 制約:自由記述式の短答問題の評価。
- 整合性: SAGモジュールは複数の参照回答を生成し、自由記述式質問に対する可能な正解の固有の複雑さと多様性を認識する。これにより、システムは単純な方法で一般的な落とし穴である多様だが有効な学生の回答を誤って判断することを防ぐ。
代替案の却下
本稿は、特に専門分野における専門家整合型評価の特定の問題に対して、それらの固有の限界のために、基本的なLLMプロンプティングや広範なファインチューニングに依存するいくつかの代替アプローチを、暗黙的かつ明示的に却下している。
主な却下は、従来のLLMファインチューニングメソッドである。著者らは、これらのメソッドが「ファインチューニングまたは追加トレーニングのための大規模で注釈付けされたデータセット」を必要とし、それが「時間のかかる、リソースが制約された設定では非現実的」であると強調している。これは、そのようなデータが希少で、専門家による注釈のコストが高い歯科のような専門分野には不向きである。DentEvalのファインチューニングフリーアプローチは、この非現実性を直接回避する。
さらに、本稿は、特定の種類の質問に対する基本的な少数ショット学習を明確に却下している。少数ショット学習は一般的にゼロショットよりもパフォーマンスを向上させるが、著者らは、ベースラインの少数ショット法を使用したときに、「質問2」(複数の視点を許容する自由記述式質問)の採点パフォーマンスの「顕著な低下」を観察している。その理由は、「少数ショット学習中、LLMは提供された例を唯一の正解と解釈する可能性があり、他の学生の回答の誤った判断につながる」ことである。この限界は、単一の決定的な答えが常に適切であるとは限らない自由記述式質問にとって重大な欠陥である。DentEvalは、サンプル回答生成(SAG)モジュールを組み込むことでこれを克服しており、これは複数の多様な参照回答を生成し、それによって正解の多様性を捉え、誤った判断を防ぐ。
本稿では、GANや拡散モデルのような他の深層学習パラダイムとの直接的な比較(問題が本質的に言語理解と評価に関するものであり、ノイズからの画像のような複雑なメディアの生成ではないため)には触れていないが、LLMベースのソリューションに焦点を当てていることは、そのようなモデルがこの特定のタスクに直接適用可能または効率的ではないことを示唆している。コア問題は、意味理解、専門分野知識の取得、および人間の判断との整合性に関わるものであり、RAGとエージェント機能を備えたLLMがユニークな位置を占める分野である。
 Figure 2. Scoring Rubric and Example Content Illustration
Figure 2. Scoring Rubric and Example Content Illustration
数学的および論理的メカニズム
マスター方程式
DentEvalの評価メカニズムのコア、特に最終スコアの生成に関しては、複数の評価エージェントから個々のスコアを生成し、それらを集約する2部構成の方程式にカプセル化されている。このプロセスは、ロールプレイングと少数ショット学習を通じて、堅牢性を保証し、人間の採点基準に整合する。
各評価インスタンス $i$ からの個々のスコア生成は、次のように与えられる。
$$S_i = \text{LLM}_{\text{evaluator}}(Q, A_{student}, \{A_{sample},..., A_{sample}\}, R), \quad i \in \{1,..., n\}$$
そして最終的な集約スコアは、次のように決定される。
$$S_{final} = \text{Mode}(\{S_1, S_2, ..., S_n\})$$
用語ごとの解剖
これらの数式を分解して、各コンポーネントの役割を理解しよう。
-
$S_i$:
- 数学的定義: これは、LLM評価者の単一インスタンスによって学生の回答に割り当てられた数値スコアを表す。これはスカラー値であり、通常は定義済みの範囲(例:論文で言及されているように $[0, 5]$)内にある。
- 物理的/論理的役割: $S_i$ は、中間的な、個々の回答の評価である。システムは、LLM出力の潜在的なばらつきを考慮し、信頼性を高めるために、このようなスコアを $n$ 個生成する。
- なぜ使用されるか: 著者らは、個々のLLMの特異な判断の影響を減らすために、複数の $S_i$ 値を使用しており、全体的な評価の一貫性と堅牢性を高めている。これは、AI駆動型評価におけるノイズを軽減するための一般的な戦略である。
-
$\text{LLM}_{\text{evaluator}}(\cdot)$:
- 数学的定義: これは、「評価者」として機能するように特別に構成された大規模言語モデルによって実行される関数を表す。複数の入力を受け取り、単一の数値スコアを生成する。
- 物理的/論理的役割: これは、学生の回答を判断する責任を負う中心的なインテリジェントエージェントである。プロンプティングを通じてこのエージェントに「評価者」の役割を割り当てることで、システムはLLMを批判的で評価に焦点を当てたペルソナを採用するように導き、人間の教師を模倣する。
- なぜ使用されるか: LLMは、高度な自然言語理解および生成能力のために選択されており、複雑な質問、学生の回答、ルーブリック、および参照回答を解釈して、微妙な判断を下すことができる。ロールプレイングプロンプトは、その出力を専門家の採点基準に整合させるのに役立つ。
-
$Q$:
- 数学的定義: これは、学生に提示される入力クエリまたは質問である。テキストベースであり、オプションで視覚コンテンツ(例:図)を含む場合がある。
- 物理的/論理的役割: $Q$ は、学生が回答することを期待されるタスクまたは問題を定義する。これは評価の主要なコンテキストである。
- なぜ使用されるか: 質問は、あらゆる評価の基本である。それは、学生の回答が測定される基盤を提供する。
-
$A_{student}$:
- 数学的定義: これは、学生が質問 $Q$ に対して行った自由記述回答である。
- 物理的/論理的役割: $A_{student}$ は評価される項目である。これは、その品質と正確性を評価する必要がある学生からの生のデータポイントである。
- なぜ使用されるか: これは、システムがスコアリングを目指す学生からの直接の出力である。
-
$\{A_{sample},..., A_{sample}\}$:
- 数学的定義: これは、サンプル参照回答のセットを表す。これらは、歯科ハンドブックからの洗練された情報 $E$ を用いた別のLLMエージェント、$\text{LLM}_{\text{professor}}(Q, E)$ によって内部的に生成される。論文では、質問の自由記述的な性質を考慮して、複数のサンプル回答が生成されると述べている。
- 物理的/論理的役割: これらのサンプル回答は、学生の回答 $A_{student}$ が比較される専門家整合型ベンチマークまたは「ゴールドスタンダード」として機能する。それらは、LLM評価者に良い回答がどのように見えるかの例を提供し、事実上少数ショット学習の例として機能する。
- なぜ使用されるか: 複数の参照回答を提供することで、LLM評価者は自由記述式質問に対する許容可能な回答の範囲を理解できるようになり、単一の「正解」へのバイアスを減らし、多様だが有効な学生の表現を捉える能力を向上させる。これは、複数の有効な解釈を持つ可能性のある回答において、専門分野にとって非常に重要である。
-
$R$:
- 数学的定義: これは、採点基準とガイドラインのセットである採点ルーブリックである。
- 物理的/論理的役割: $R$ は、評価のための明示的なルールと基準を提供する。採点が客観的で、教育的要件に整合していることを保証する。
- なぜ使用されるか: ルーブリックは構造化された評価に不可欠であり、LLMの評価が透明で、公平で、人間の採点原則に整合していることを保証する。それはLLMの判断に対する制約とガイドとして機能する。
-
$i \in \{1,..., n\}$:
- 数学的定義: これは、評価プロセスが $n$ 回繰り返され、 $n$ 個の個々のスコアが生成されることを示すインデックスである。
- 物理的/論理的役割: これは、評価プロセスの複数性を示す。各 $S_i$ は、$\text{LLM}_{\text{evaluator}}$ の独立した実行である。
- なぜ使用されるか: 評価を複数回繰り返し、その後結果を集約する(モードを介して)ことは、個々のLLMの判断のいずれかの影響を軽減し、最終スコアの信頼性と安定性を高めるための戦略である。これは、AI駆動型評価におけるノイズを軽減するための一般的な戦略である。
-
$S_{final}$:
- 数学的定義: これは、個々のスコアの集約から派生した、学生の回答に割り当てられた最終的な数値スコアである。
- 物理的/論理的役割: $S_{final}$ は、DentEvalシステムの最終的な出力であり、学生の回答の最終的な評価を表す。
- なぜ使用されるか: これは、 gradingに使用できる単一の堅牢なスコアである、システムの望ましい最終製品である。
-
$\text{Mode}(\cdot)$:
- 数学的定義: これは、データセット内で最も頻繁に出現する値を返す統計関数である。
- 物理的/論理的役割: モード関数は、コンセンサスメカニズムとして機能する。 $n$ 個の個々の評価の中で最も一般的なスコアを選択することにより、それは事実上外れ値をフィルタリングし、LLMエージェントからの最も一貫した判断を強化する。
- なぜ使用されるか: 多数決(モードを介して)は、ばらつきを減らし、最終スコアの一貫性と信頼性を向上させるために使用される。特に個々のLLM出力がわずかに異なる可能性がある状況では。これは、LLM出力に適用されるアンサンブル学習のシンプルでありながら効果的な方法である。
ステップバイステップフロー
学生の回答 $A_{student}$ が、洗練された組み立てラインのアイテムのように、DentEvalシステムを旅する様子を想像してください。
-
初期入力受付: プロセスは、学生の回答 ($A_{student}$)、質問 ($Q$、関連する図を含む場合がある)、および採点ルーブリック ($R$) という3つの主要な入力で開始される。さらに、歯科知識の広範な検索コーパス ($C$) が利用可能である。
-
クエリ埋め込みと初期検索: 質問 $Q$ は、まず数値ベクトル表現(埋め込み)に変換される。この埋め込みクエリは、検索エンジン(Milvusなど)にフィードされ、歯科知識コーパス $C$ を検索する。エンジンは、「トップK」の最も関連性の高い情報チャンクをプルする。
-
情報洗練: これらの初期の「トップK」チャンクは、元の質問 $Q$ とともに、専門的なLLMエージェントに渡される。このエージェントのタスクは、この生の情報を要約および洗練して、より簡潔で関連性の高い証拠セット $E$ を作成することである。このステップは、ノイズを除去し、情報が質問に直接関連していることを保証するために重要である。
-
十分性チェックと反復検索: 洗練された証拠 $E$ は、次に別のLLMエージェントによって評価され、高品質な参照回答を生成するのに「十分」かどうかを判断する。証拠が不十分と判断された場合、システムは検索ステージに戻り、$K$ の値を(「ステップサイズ」で)増やして、より多くの情報を収集する。この反復的な自己修正により、LLMに提供されるコンテキストが可能な限り完全で関連性の高いものになるように、知識ベースが不十分な場合にシステムが「学習」できるようになる。
-
サンプル回答生成(SAG): 十分な証拠 $E$ が取得されると、それは質問 $Q$ と組み合わされ、歯科アカデミックのロールを演じる $\text{LLM}_{\text{professor}}$ エージェントにフィードされる。このエージェントは、洗練された証拠と質問に基づいて、複数の多様なサンプル回答 $\{A_{sample},..., A_{sample}\}$ を生成する。このステップは、複数の正解が存在する可能性のある自由記述式質問にとって不可欠である。
-
個々のスコア生成: 次に、システムは実際の採点の準備をする。 $n$ 回の個別の評価実行のために、$\text{LLM}_{\text{evaluator}}$ エージェントが呼び出される。各実行 $i$ では、この評価者LLMは、質問 $Q$、学生の回答 $A_{student}$、生成されたサンプル回答のセット $\{A_{sample},..., A_{sample}\}$、および採点ルーブリック $R$ を受け取る。また、少数ショット学習の例(各スコア階層からの学生の回答と評価フィードバック)を組み込んで、判断を導く。これらすべての入力に基づいて、$\text{LLM}_{\text{evaluator}}$ は個々のスコア $S_i$ を生成する。
-
最終スコア集約: $n$ 個の個々のスコア ($S_1, S_2, ..., S_n$) が生成された後、それらは収集される。最終スコア $S_{final}$ は、このスコアセットにモード関数を適用することによって決定される。これは、 $n$ 回の評価の中で最も頻繁に出現するスコアが、最終的な成績となることを意味する。この多数決メカニズムは、堅牢で一貫した最終評価を保証し、単一の異常な評価から生じる可能性のある影響を最小限に抑える。
最適化ダイナミクス
DentEvalは「ファインチューニングフリー」パラダイムで動作する。つまり、大規模言語モデルの基盤となるモデルのパラメータを更新するために、従来の勾配降下法を伴わない。代わりに、その「学習」、「更新」、または「収束」の動作は、インテリジェントなシステム設計、反復プロセス、および洗練されたプロンプティング戦略の組み合わせを通じて達成される。
-
自己洗練検索拡張生成(SR-RAG): システムの主要な「学習」メカニズムは、SR-RAGコンポーネント内に埋め込まれている。初期に取得された証拠 $E$ がLLMエージェントによって不十分と判断された場合、システムは単に諦めるのではなく、反復的に検索範囲を拡大する。パラメータ $K$(最も関連性の高いチャンクの数)を増やすことによって。この自己修正ループにより、システムは知識ベースが不十分な場合に「学習」し、より包括的な情報を積極的に求めることができる。検索パラメータのこの動的な調整は、RAGプロセス自体の適応的最適化の一形態であり、LLMに提供されるコンテキストが可能な限り完全で関連性の高いものになることを保証する。
-
ロールプレイングプロンプティング: システムのパフォーマンスは、LLMエージェントに特定の役割(例:「教授」、「評価者」)を割り当てるプロンプトを慎重に作成することによって「最適化」される。これは伝統的な意味での数学的最適化ではないが、強力なコンテキスト内ガイダンスの形態である。これらのペルソナを採用することで、LLMは人間の専門家の行動や推論パターンを密接に模倣するように誘導され、それによってその出力を望ましい採点基準に整合させる。この「プロンプトエンジニアリング」は、LLMの内部重みを変更することなく、LLMの「損失ランドスケープ」を暗黙的に形成して、より正確で一貫した評価に向けて導くための重要なレバーである。
-
少数ショット学習: 評価LLMには、学生の回答、ルーブリック、および人間が割り当てたスコアとフィードバックを含む少数の例(少数ショット例)が提供される。これにより、LLMは明示的なパラメータ更新を介してではなく、例から直接、望ましい採点パターンと基準を「学習」できるようになる。このコンテキスト内学習は、LLMが期待される入力-出力関係を示すことによって、一貫した採点ポリシーに収束するのに役立つ。
-
堅牢性のための多数決: モード関数を使用して複数の個々のスコア ($S_i$) を最終スコア ($S_{final}$) に集約することは、統計的最適化である。それは堅牢な推定器として機能し、単一のLLM評価から生じる可能性のある個々の変動とバイアスを効果的に平滑化する。このメカニズムは、システムがより安定した信頼性の高いスコアに収束するのを助け、時間と異なる学生の回答全体で一貫性を向上させる。それはLLM出力に適用されるアンサンブル学習の一形態である。
-
CDFマッピングによる後処理: 実装の詳細で述べられているように、システムは後処理ステップとして累積分布関数(CDF)マッピングを適用する。この方法は、LLMの生のスコアをキャリブレーションしてバイアスを軽減し、公平性を向上させ、人間のスコア分布との整合性を高める。LLMの内部学習の一部ではないが、人間の判断との整合性を向上させるために最終出力を「最適化」する外部キャリブレーションステップである。
本質的に、DentEvalの「最適化」は、勾配降下法よりも、反復的な洗練、戦略的なプロンプティング、および堅牢な集約技術を通じて大規模言語モデルの固有の能力を活用するインテリジェントに設計されたマルチエージェントワークフローであり、広範なファインチューニングを必要とせずに専門家整合型評価を達成する。したがって、システムの「学習」は、パラメトリックなものではなく、手続き的かつ文脈的なものである。
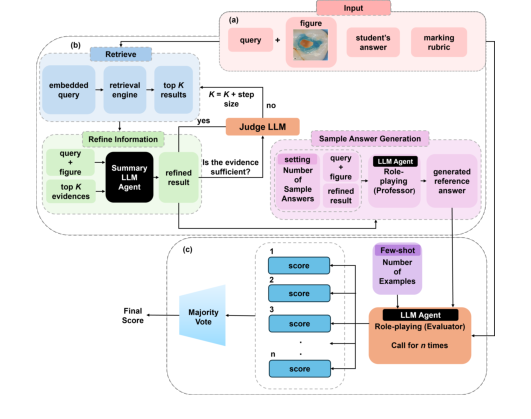 Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
結果、限界、および結論
実験デザインとベースライン
DentEvalの数学的主張と実用的な有効性を厳密に検証するために、研究者たちは包括的な実験セットアップを設計した。彼らの評価の中核は、歯科カリキュラムのために特別にキュレーションされた、ユニークな教授注釈付きデータセットを中心に展開された。このデータセットは、定義済みの採点ルーブリックに対して、歯科医によって慎重に採点された28の学生回答で構成されていた。重要なことに、データセットには2種類の自由記述式質問が含まれていた。1つはマルチモーダル推論(テキストと画像)を必要とし、もう1つは純粋にテキストベースであった。この多様性は意図的なものであり、歯科教育における評価の多様な性質を反映し、歯科形態学や修復材料のような異なるサブドメインをカバーし、幅広い回答の長さと複雑さを示していた。
評価のために、少数ショット学習アプローチが採用された。質問あたり28の回答から、各スコア階層から1つの回答が少数ショットの例として選択され、質問あたり6つの例が生成された。残りの22の回答がテストセットを形成した。この設計により、LLMエージェントは広範なファインチューニングなしで専門家採点済みの例から学習することができた。GPT-40(特にgpt-40-mini)が基盤となるLLMエージェントとして選択され、そのマルチモーダル機能が活用された。公平性と一貫性を確保するために、累積分布関数(CDF)マッピングが後処理ステップとして適用され、採点における潜在的なバイアスを軽減した。
DentEvalのパフォーマンスは、いくつかの「犠牲」ベースラインモデルおよび高度な技術と比較してベンチマークされた。
- ゼロショット: LLMが変更やロールプレイングなしで回答を採点する、単純なアプローチ。
- 少数ショット: LLMを導くために参照例を組み込んだ、ゼロショットの強化。
- SciEx [5]: 少数ショット学習とロールプレイングプロンプトを組み合わせた最先端の方法。
- FairEval [22]: LLM評価におけるバイアスを軽減するために、複数の証拠キャリブレーション(MEC)とバランスポジションキャリブレーション(BPC)を採用した別の高度な技術。
DentEvalのコアメカニズムの決定的な証拠は、標準的な評価メトリクスによって求められた。精度(Acc.)、Spearman順位順相関係数(SROCC)[17]、およびPearson線形相関係数(PLCC)[16]。SROCCとPLCCは特に重要であった。なぜなら、それらはDentEvalのスコアと人間の専門家による評価との一貫性と線形相関を直接測定し、整合性の堅牢な尺度を提供したからである。
最後に、アブレーションスタディが実施され、DentEval内の各革新的なコンポーネント(SR-RAG、サンプル回答生成(SAG)、およびロールプレイングプロンプティング)の貢献を徹底的に証明した。これらのコンポーネントを体系的に削除または分離することにより、研究者はシステムの全体的なパフォーマンスに対する個々の影響を特定でき、ゼロショットベースラインを比較に使用した。
証拠が証明すること
実験的証拠は、歯科教育における多様な評価シナリオ全体で、DentEvalの優れたパフォーマンスと信頼性を圧倒的に示している。
質問1(テキストと画像を含むマルチモーダル推論を必要とし、単一の正解があった)については、DentEvalはすべての評価メトリクスで最高のパフォーマンスを達成した。SROCC 0.7447、PLCC 0.7288、精度68.2%を記録し、すべて最低のp値が伴い、人間の採点との統計的に有意な整合性を示した。SciExとFairEvalは基本的なゼロショットベースラインを上回ったが、ベースラインの少数ショット法と比較してわずかにパフォーマンスが低下した。これは、高度な技術でさえ自動評価の微妙な課題を浮き彫りにした。マルチモーダル入力と専門家整合型メカニズムを統合するDentEvalの能力は、明らかにここで優位性を与えた。
質問2(複数の有効な回答を許可する純粋なテキストベースの自由記述式質問)については、DentEvalのパフォーマンスはさらに顕著であった。SROCC 0.9259、PLCC 0.8957を達成し、どちらも質問1よりも高く、精度68.2%を維持した。これは特に重要である。なぜなら、質問1とは異なり、ベースラインの少数ショット法は質問2のパフォーマンスの「顕著な低下」を示したからである。著者らはこれを自由記述式質問の性質に起因するとし、少数ショットの例がLLMにそれらを唯一の正解と解釈するように誤って導き、他の有効な学生の回答の誤った判断を引き起こす可能性があると指摘している。このような複雑な自由記述式質問(単一の決定的な答えが期待されない)を処理するDentEvalの堅牢性は、多様な参照回答を生成するそのSR-RAGおよびロールプレイングプロンプティングメカニズム、特に、その高度な設計の強力な証である。
精度と相関を超えて、DentEvalはまた、顕著な効率の向上をもたらした。人間の評価者は通常、学生の回答あたり約1.5分を費やし、約1.275米ドルのコストがかかる。対照的に、DentEvalのGPT-40 LLMエージェントは、各質問を約0.13分で処理し、応答あたりわずか0.007米ドルのコストで済んだ。これは、時間と財務リソースの両方で大幅な削減を表し、教育者はより教育的に価値のある活動に集中できるようになった。
アブレーションスタディは、DentEvalのコアコンポーネントの貢献をさらに強化した。各イノベーション—SR-RAG、サンプル回答生成(SAG)、およびロールプレイングプロンプティング—は、個別に人間の評価との一貫性を向上させ、精度を高めることが示された。例えば、SR-RAG単独で、質問1の精度を9.1%(ゼロショット)から54.5%に、質問2では50.0%から68.2%に大幅に向上させた。完全なDentEvalフレームワークは、すべてのアブレーションバージョンを常に上回り、これらのコンポーネントの相乗的な統合が、その優れたパフォーマンスと人間の判断との整合性を真に推進していることを確認した。
限界と将来の方向性
DentEvalは専門分野における自動評価の説得力のある進歩を示しているが、現在の限界を認識し、将来の開発の方向性を検討することが重要である。
1つの明確な限界は、著者らが暗黙的に指摘しているように、データセットのサイズである。収集された回答は構造と実質において多様であったが、「質問数が限られている」(評価されたのはわずか2つの異なる質問)ことは、歯科カリキュラム全体や他の専門分野への調査結果の一般化可能性を制限する可能性がある。より幅広い質問タイプ、難易度レベル、および回答の多様性を含むデータセットを拡張することは、DentEvalの機能のより堅牢な検証を提供するだろう。
もう1つの考慮事項は、特定のLLM、GPT-40への依存である。強力ではあるが、これはコスト変動、API可用性、およびモデルの専有性質に関する潜在的な問題をもたらす。将来の研究では、オープンソースLLMまたはより費用対効果の高い代替案に対するDentEvalのフレームワークの適応性を探求し、より広範なアクセス可能性と持続可能性を確保することができる。
本稿はまた、複数の正解が存在する可能性のある自由記述式質問によってもたらされる課題を強調しており、ベースラインの少数ショット法のパフォーマンスの低下を指摘している。DentEvalはこれをうまく処理するが、そのような質問の固有の複雑さは、サンプル回答生成(SAG)および自己洗練検索拡張生成(SR-RAG)モジュールの継続的な洗練が、主観的評価のさらに広いスペクトル全体で高い専門家判断との整合性を維持するために不可欠であることを示唆している。
将来に向けて、著者自身がエキサイティングな将来の方向性を提案している。
- マルチモーダルRAGの拡張: 自然な進化は、臨床ビデオや3Dモデルのような、より複雑なマルチモーダル入力を組み込むことだろう。これにより、DentEvalは、静的な画像やテキストを超えて、より包括的で現実的な方法で実践的なスキルや診断推論を評価できるようになる。LLMエージェントがビデオ証拠に基づいてシミュレートされた外科処置における学生の技術を評価することを想像してほしい!
- 適応型キャリブレーション: さまざまな質問タイプ全体での堅牢性を向上させるための適応型キャリブレーションメカニズムの開発は、もう1つの重要な領域である。これは、システムが質問の特定の特性(例:単一の事実回答を期待するか、微妙な多視点回答を期待するか)に基づいて、採点ルーブリックまたは評価戦略を動的に調整できるシステムを意味する。これにより、多様な評価コンテキストでのシステムの柔軟性と信頼性が向上する。
これらに加えて、いくつかの他の議論トピックは、これらの発見をさらに進化させる可能性がある。
- 説明可能性とフィードバックの質: DentEvalはスコアを提供するが、自動評価の教育的価値は、高品質で実行可能なフィードバックによって大幅に向上する。将来の研究は、LLMの推論プロセスをより透明にし、学生が特定のスコアを受け取った理由と改善方法を理解するのに役立つ、詳細で建設的なフィードバックを生成することに焦点を当てるべきである。これには、フィードバック生成に特化した思考連鎖プロンプティングの統合が含まれる可能性がある。
- 教育における倫理的AI: 自動評価がますます普及するにつれて、公平性、バイアス、および平等性に関する倫理的懸念に対処することが最優先事項である。DentEvalの評価が、さまざまな学生の人口統計や学習スタイル全体で偏りがないことをどのように保証できるか?潜在的なアルゴリズムバイアスを検出および軽減するためにどのようなメカニズムを導入できるか?採点のための監査可能性と説明可能なAIに関する研究は非常に価値があるだろう。
- 学習管理システム(LMS)との統合: 広範な採用のために、既存の教育インフラストラクチャ(CanvasやMoodleなど)へのDentEvalのシームレスな統合が不可欠である。これには、教育者が自動評価を簡単に展開、カスタマイズ、および監視できるように、堅牢なAPIとユーザーフレンドリーなインターフェースの開発が含まれるだろう。
- クロスドメイン適用可能性: 歯科向けに調整されているが、SR-RAG、ロールプレイングプロンプティング、およびマルチモーダル入力処理の基盤となる原則は、専門家整合型評価を必要とする他の専門分野(医学、工学、法律など)に一般化できる可能性がある。これらの同型性を探求することは、より広範なアプリケーションと影響を解き放く可能性がある。
- リアルタイム適応学習: DentEvalをリアルタイム学習環境に統合して、即時的でパーソナライズされたフィードバックと適応学習パスを提供できるか?学生が練習問題を完了すると同時に、即時の評価と調整された補習リソースを受け取り、学習プロセスを加速することを想像してほしい。
これらの多様な視点は、DentEvalが単なる自動採点ツールではなく、専門分野における教育評価と学習体験を根本的に変革する可能性のある基盤フレームワークであることを強調している。
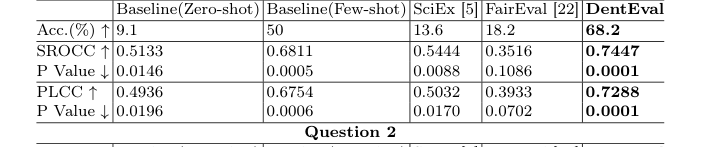 Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval
Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval