DentEval: एलएलएम एजेंटों के माध्यम से दंत शिक्षा में फाइन-ट्यूनिंग-मुक्त विशेषज्ञ-संरेखित मूल्यांकन
इस पत्र में संबोधित समस्या की सटीक उत्पत्ति शिक्षा के क्षेत्र में, विशेष रूप से स्वचालित मूल्यांकन में, बड़े भाषा मॉडल (एलएलएम) द्वारा लाई गई हालिया क्रांति से उपजी है। जबकि ओपनएआई के जीपीटी श्रृंखला जैसे एलएलएम...
पृष्ठभूमि और अकादमिक वंश
उत्पत्ति और अकादमिक वंश
इस पत्र में संबोधित समस्या की सटीक उत्पत्ति शिक्षा के क्षेत्र में, विशेष रूप से स्वचालित मूल्यांकन में, बड़े भाषा मॉडल (एलएलएम) द्वारा लाई गई हालिया क्रांति से उपजी है। जबकि ओपनएआई के जीपीटी श्रृंखला जैसे एलएलएम असाइनमेंट के लिए कुशल और सुसंगत मूल्यांकन प्रदान करने में काफी संभावनाएं दिखाते हैं, दंत चिकित्सा जैसे अत्यधिक विशिष्ट डोमेन में उनका अनुप्रयोग महत्वपूर्ण चुनौतियां प्रस्तुत करता है।
ऐतिहासिक रूप से, स्वचालित मूल्यांकन प्रणालियां मौजूद रही हैं, लेकिन एलएलएम के आगमन ने खुले-अंत वाले प्रश्नों को संभालने के लिए नई संभावनाएं खोलीं। हालांकि, विशेषज्ञ-स्तर के मूल्यांकन के लिए एलएलएम का लाभ उठाने की कोशिश करते समय दो मुख्य मुद्दे उभरे:
1. डोमेन-विशिष्ट व्याख्या: एलएलएम अक्सर विशिष्ट क्षेत्रों के लिए अद्वितीय सूक्ष्म पेशेवर शब्दावली और जटिल अवधारणाओं के साथ संघर्ष करते हैं। वे शब्दावली की गलत व्याख्या कर सकते हैं या सटीक मूल्यांकन के लिए आवश्यक गहन प्रासंगिक समझ की कमी हो सकती है।
2. विशेषज्ञ ग्रेडिंग के साथ संरेखण: यह सुनिश्चित करना कि एलएलएम आउटपुट मानव पेशेवरों (जैसे, दंत प्रोफेसरों) द्वारा स्थापित विशिष्ट, अक्सर व्यक्तिपरक, मूल्यांकन मानदंडों का पालन करते हैं, एक बड़ी बाधा रही है।
इन सीमाओं को दूर करने के पिछले दृष्टिकोणों में आम तौर पर बड़े, सावधानीपूर्वक एनोटेट किए गए डेटासेट का उपयोग करके एलएलएम के व्यापक फाइन-ट्यूनिंग या पुनः प्रशिक्षण शामिल था। यह प्रक्रिया न केवल समय लेने वाली है बल्कि संसाधन-गहन भी है, जो इसे कई शैक्षिक सेटिंग्स के लिए अव्यावहारिक बनाती है, विशेष रूप से सीमित कम्प्यूटेशनल संसाधनों वाले। "दर्द बिंदु" जिसने लेखकों को डेंटईवेल विकसित करने के लिए मजबूर किया, वह यही है: विशेष, खुले-अंत वाले मूल्यांकन कार्यों के लिए एलएलएम लागू करने की मौजूदा विधियों के लिए अत्यधिक डेटा और कम्प्यूटेशनल प्रयास की आवश्यकता होती है, जिससे मानव ग्रेडिंग के साथ असंगति होती है और वास्तविक समय, व्यावहारिक अनुप्रयोग मुश्किल हो जाता है। लेखकों ने एक फाइन-ट्यूनिंग-मुक्त समाधान की मांग की जो कुशलतापूर्वक विशेषज्ञ-संरेखित मूल्यांकन प्राप्त कर सके।
सहज डोमेन शब्द
यहां पेपर से कुछ विशेष शब्द दिए गए हैं, जिन्हें शून्य-आधार पाठक के लिए रोजमर्रा की सादृश्यताओं में अनुवादित किया गया है:
- बड़े भाषा मॉडल (एलएलएम): एक सुपर-स्मार्ट डिजिटल सहायक की कल्पना करें जिसने लगभग हर किताब, लेख और वेबपेज पढ़ा है जो कभी लिखा गया है। यह समझ सकता है कि आप क्या कहते हैं, नया टेक्स्ट उत्पन्न कर सकता है, और सवालों के जवाब दे सकता है, लेकिन यह सब कुछ में विशेषज्ञ नहीं हो सकता है। यह एक प्रतिभाशाली सामान्यवादी की तरह है, लेकिन कभी-कभी बहुत विशिष्ट, आला विषयों के लिए थोड़ी अतिरिक्त मदद की आवश्यकता होती है।
- पुनर्प्राप्ति-संवर्धित पीढ़ी (आरएजी): इसे हमारे सुपर-स्मार्ट डिजिटल सहायक के लिए एक खुली-पुस्तक परीक्षा के रूप में सोचें। जब आप इससे कोई प्रश्न पूछते हैं, तो केवल अपने सामान्य ज्ञान पर भरोसा करने के बजाय, यह पहले एक विशिष्ट, विश्वसनीय पुस्तकालय (जैसे दंत हैंडबुक) में प्रासंगिक जानकारी के लिए जल्दी से खोज करता है। फिर, यह उस ताज़ा प्राप्त जानकारी का उपयोग करता है, अपने स्वयं के मस्तिष्क के साथ, एक बहुत अधिक सटीक और सूचित उत्तर तैयार करने के लिए। यह उत्तर देने से पहले एक व्यक्तिगत अनुसंधान सहायक होने जैसा है।
- भूमिका-निर्वहन संकेत (Role-playing Prompting): यह हमारे डिजिटल सहायक को एक विशिष्ट चरित्र निभाने के लिए कहने जैसा है। इसे केवल "इसे ग्रेड करें" कहने के बजाय, आप इसे बताते हैं, "ठीक है, आप अब एक सख्त दंत प्रोफेसर हैं, और आपको इन नियमों के अनुसार इस छात्र के उत्तर को ग्रेड करना होगा।" इस व्यक्तित्व को अपनाकर, एलएलएम एक मानव दंत प्रोफेसर की तरह सोचने और प्रतिक्रिया करने की कोशिश करता है, जिससे इसके मूल्यांकन विशेषज्ञ मानकों के अनुरूप होते हैं।
- कुछ-शॉट सीखना (Few-shot learning): एक बच्चे को एक नए प्रकार का फल पहचानना सिखाने की कल्पना करें। उन्हें सैकड़ों चित्र दिखाने के बजाय, आप उन्हें केवल कुछ उदाहरण दिखाते हैं (जैसे, "यह एक सेब है, यह एक और सेब है, और यह एक खराब सेब कैसा दिखता है")। इन सीमित उदाहरणों से, बच्चा जल्दी से अन्य सेबों को पहचानना सीखता है। इसी तरह, कुछ-शॉट सीखना एआई को केवल कुछ उदाहरणों को देखकर एक नया कार्य सीखने या एक विशिष्ट शैली के अनुकूल होने की अनुमति देता है, बजाय इसके कि बड़े प्रशिक्षण डेटासेट की आवश्यकता हो।
संकेतन तालिका
| संकेतन | विवरण |
|---|---|
समस्या परिभाषा और बाधाएं
मुख्य समस्या सूत्रीकरण और दुविधा
इस पत्र द्वारा संबोधित केंद्रीय समस्या दंत शिक्षा जैसे विशेष डोमेन के भीतर, खुले-अंत वाले लघु-उत्तर प्रश्नों के छात्र प्रतिक्रियाओं का सटीक और कुशल स्वचालित मूल्यांकन है।
मौजूदा प्रणालियों के लिए इनपुट/वर्तमान स्थिति एक छात्र का मुक्त-पाठ उत्तर ($A_{student}$), एक प्रश्न ($Q$) है जिसमें पाठ्य और दृश्य सामग्री शामिल हो सकती है, और एक अंकन रूब्रिक ($R$) है जो स्कोरिंग मानदंड को परिभाषित करता है। इसके अतिरिक्त, एक पुनर्प्राप्ति कॉर्पस ($C$) जैसे दंत हैंडबुक उपलब्ध है। वर्तमान बड़े भाषा मॉडल (एलएलएम) स्वचालित स्कोरिंग में वादा दिखाते हुए, दक्षता और स्थिरता प्रदान करते हैं। हालांकि, वे महत्वपूर्ण बाधाओं का सामना करते हैं:
1. डोमेन-विशिष्ट व्याख्या: एलएलएम दंत चिकित्सा जैसे क्षेत्रों में अंतर्निहित सूक्ष्म पेशेवर शब्दावली और डोमेन-विशिष्ट शब्दावली की सटीक व्याख्या के साथ संघर्ष करते हैं।
2. विशेषज्ञ रूब्रिक्स के साथ संरेखण: मौजूदा एलएलएम सिस्टम अक्सर मानव-स्तरीय मूल्यांकन के साथ असंगत आउटपुट उत्पन्न करते हैं, जो विशिष्ट, विशेषज्ञ-स्थापित ग्रेडिंग रूब्रिक्स के साथ संरेखित होने में विफल रहते हैं।
3. संसाधन मांगें: इन मुद्दों को संबोधित करने के लिए आम तौर पर बड़े, एनोटेट किए गए डेटासेट के साथ व्यापक फाइन-ट्यूनिंग और पुनः प्रशिक्षण की आवश्यकता होती है, जो समय लेने वाला, कम्प्यूटेशनल रूप से महंगा और संसाधन-बाधित शैक्षिक सेटिंग्स के लिए अव्यावहारिक है।
वांछित अंतिम बिंदु (आउटपुट/लक्ष्य स्थिति) एक संख्यात्मक स्कोर $S_{final} \in [0, 5]$ है जो छात्र के प्रदर्शन को सटीक रूप से दर्शाता है, मानव विशेषज्ञ ग्रेडिंग मानकों के साथ निकटता से संरेखित होता है। यह प्रणाली होनी चाहिए:
1. डोमेन-जागरूक: विशेष दंत ज्ञान को समझने और लागू करने में सक्षम।
2. विशेषज्ञ-संरेखित: लगातार स्कोर उत्पन्न करना जो मानव प्रोफेसर मूल्यांकन के साथ दृढ़ता से सहसंबंधित हों।
3. संसाधन-कुशल: व्यापक फाइन-ट्यूनिंग या पुनः प्रशिक्षण की आवश्यकता के बिना प्रभावी ढंग से संचालन, इस प्रकार मूल्यांकन समय और वित्तीय लागत को कम करना।
4. मल्टीमॉडल: पाठ्य और दृश्य सामग्री (जैसे, नैदानिक छवियां) दोनों को शामिल करने वाले प्रश्नों को संसाधित करने में सक्षम।
लुप्त कड़ी या गणितीय अंतर ठीक यही है कि एक फ़ंक्शन, $S_{final} = DentEval(A_{student}, Q, R, C)$, का निर्माण कैसे किया जाए जो इन इनपुट को मज़बूती से और लागत-प्रभावी ढंग से विशेषज्ञ-संरेखित स्कोर पर मैप कर सके। पिछले दृष्टिकोणों ने सामान्य एलएलएम क्षमताओं और विशेषज्ञ मूल्यांकन की सूक्ष्म, विशेष आवश्यकताओं के बीच की खाई को पाटने के लिए संघर्ष किया है, खासकर खुले-अंत वाले प्रश्नों के लिए जहां एक एकल "सही" उत्तर हमेशा उपलब्ध नहीं होता है। मुख्य दुविधा उच्च सटीकता और मानव विशेषज्ञ ग्रेडिंग के साथ संरेखण प्राप्त करना है, विशेष, खुले-अंत वाले प्रश्नों में बिना पारंपरिक फाइन-ट्यूनिंग की उच्च लागत और संसाधन मांगों को वहन किए। एक पहलू में सुधार, जैसे डोमेन विशिष्टता, आमतौर पर दूसरे को तोड़ता है, जैसे कम्प्यूटेशनल दक्षता या डेटा आवश्यकताएं।
बाधाएं और विफलता मोड
दंत चिकित्सा जैसे विशेष डोमेन में स्वचालित विशेषज्ञ-संरेखित मूल्यांकन की समस्या कई कठोर, यथार्थवादी दीवारों से बेहद मुश्किल हो जाती है:
-
डेटा-संचालित बाधाएं:
- एनोटेट किए गए डेटा की विरलता: फाइन-ट्यूनिंग या अतिरिक्त प्रशिक्षण के लिए बड़े, विशेषज्ञ-एनोटेट किए गए डेटासेट की एक महत्वपूर्ण आवश्यकता है, जो दंत चिकित्सा जैसे अत्यधिक विशेष क्षेत्रों में दुर्लभ और बनाने में महंगे हैं। यह पारंपरिक पर्यवेक्षित शिक्षण दृष्टिकोणों को अव्यावहारिक बनाता है।
- खुले-अंत वाले प्रश्न की परिवर्तनशीलता: उच्च शिक्षा में आम खुले-अंत वाले प्रश्नों का हमेशा एक एकल, अद्वितीय सही उत्तर नहीं होता है। छात्र प्रतिक्रियाएं लंबाई, संरचना और तर्क जटिलता में काफी भिन्नता प्रदर्शित कर सकती हैं, जो शिक्षार्थी अभिव्यक्ति में प्रामाणिक विविधता को दर्शाती है। यह अंतर्निहित परिवर्तनशीलता स्वचालित प्रणालियों के लिए एक निश्चित "सही" उत्तर को परिभाषित करना चुनौतीपूर्ण बनाती है।
- पुनर्प्राप्त जानकारी में शोर: पुनर्प्राप्ति-संवर्धित पीढ़ी (आरएजी) के साथ भी, एक कॉर्पस से खंडित साक्ष्य खंडों में ऐसी सामग्री हो सकती है जो क्वेरी या उसके प्रमुख शब्दों से सीधे संबंधित नहीं है। यह अप्रासंगिक जानकारी शोर पेश कर सकती है, जिससे नमूना उत्तर पीढ़ी की सटीकता और गुणवत्ता पर नकारात्मक प्रभाव पड़ सकता है।
-
कम्प्यूटेशनल और संसाधन बाधाएं:
- फाइन-ट्यूनिंग की उच्च कम्प्यूटेशनल लागत: विशेष डोमेन के लिए एलएलएम को अनुकूलित करने की पारंपरिक विधियों के लिए व्यापक कंप्यूटिंग संसाधनों और फाइन-ट्यूनिंग और पुनः प्रशिक्षण के लिए महत्वपूर्ण समय की आवश्यकता होती है। यह अक्सर संसाधन-बाधित शैक्षिक सेटिंग्स के लिए अव्यावहारिक होता है।
- वित्तीय लागत: उच्च शिक्षा पेशेवरों द्वारा मानव मूल्यांकन महंगा है (उदाहरण के लिए, प्रति प्रतिक्रिया लगभग USD 1.275), बड़े समूहों के लिए स्केलेबल मैनुअल मूल्यांकन को वित्तीय रूप से अस्थिर बनाता है। किसी भी स्वचालित समाधान को महत्वपूर्ण वित्तीय बचत प्रदान करनी चाहिए।
-
मॉडल और कार्यात्मक बाधाएं:
- जेनेरिक एलएलएम में डोमेन विशेषज्ञता की कमी: आउट-ऑफ-द-बॉक्स एलएलएम डोमेन-विशिष्ट शब्दावली और सूक्ष्म पेशेवर शब्दावली की सटीक व्याख्या के साथ संघर्ष करते हैं, जिससे विशेष क्षेत्रों में गलत मूल्यांकन होता है।
- मानव ग्रेडिंग के साथ असंगति: मौजूदा प्रणालियों का एक प्रमुख विफलता मोड एलएलएम आउटपुट और मानव-स्तरीय मूल्यांकन के बीच असंगति है। एलएलएम अक्सर पेशेवरों द्वारा स्थापित विशिष्ट मूल्यांकन मानदंडों का पालन करने में विफल रहते हैं, जिससे विश्वास और अपनाने की कमी होती है।
- एलएलएम स्कोरिंग में परिवर्तनशीलता: समान इनपुट के साथ भी, एलएलएम अपने स्कोरिंग में परिवर्तनशीलता प्रदर्शित कर सकते हैं, जो मूल्यांकन प्रणाली की विश्वसनीयता और मजबूती को कम करता है। इसके लिए सुसंगत और भरोसेमंद मूल्यांकन सुनिश्चित करने के लिए तंत्र की आवश्यकता होती है।
- कुछ-शॉट सीखने में गलत व्याख्या: खुले-अंत वाले प्रश्नों के लिए जो कई मान्य दृष्टिकोणों की अनुमति देते हैं, कुछ-शॉट उदाहरणों का एक सेट प्रदान करने से एलएलएम इन उदाहरणों को केवल सही उत्तरों के रूप में गलत व्याख्या कर सकते हैं, जिसके परिणामस्वरूप अन्य मान्य छात्र प्रतिक्रियाओं का गलत निर्णय होता है। यह एक दर्दनाक ट्रेड-ऑफ है जहां उदाहरणों के साथ मॉडल को निर्देशित करने का प्रयास अनजाने में उसकी समझ को सीमित कर सकता है।
यह दृष्टिकोण क्यों
पसंद की अनिवार्यता
डेंटईवेल के विशिष्ट दृष्टिकोण को अपनाने, सेल्फ-रिफाइनिंग रिट्रीवल-ऑगमेंटेड जनरेशन (एसआर-आरएजी) और रोल-प्लेइंग एलएलएम एजेंटों को एकीकृत करने, केवल एक वरीयता नहीं बल्कि विशेष शैक्षिक मूल्यांकन के लिए पारंपरिक तरीकों की अंतर्निहित सीमाओं द्वारा संचालित एक आवश्यकता थी। लेखकों ने महसूस किया कि मानक "एसओटीए" विधियां, विशेष रूप से बड़े भाषा मॉडल (एलएलएम) के व्यापक फाइन-ट्यूनिंग पर निर्भर रहने वाली, कई महत्वपूर्ण चुनौतियों के कारण इस समस्या के लिए अपर्याप्त थीं।
सबसे पहले, दंत चिकित्सा जैसे विशेष डोमेन में खुले-अंत वाले लघु-उत्तर प्रश्नों का मूल्यांकन करने के लिए पेशेवर शब्दावली और जटिल अवधारणाओं की सूक्ष्म समझ की आवश्यकता होती है। पारंपरिक एलएलएम, यहां तक कि शक्तिशाली वाले भी, अक्सर पर्याप्त डोमेन-विशिष्ट प्रशिक्षण के बिना इससे संघर्ष करते हैं। इस अहसास का "सही क्षण" एक एकल घटना नहीं है, बल्कि यह पहचान है कि मौजूदा प्रणालियों के लिए "फाइन-ट्यूनिंग या अतिरिक्त प्रशिक्षण के लिए बड़े, एनोटेट किए गए डेटासेट" की आवश्यकता होती है, जो "समय लेने वाला और संसाधन-बाधित सेटिंग्स के लिए अव्यावहारिक" है। इस बाधा ने फाइन-ट्यूनिंग-भारी दृष्टिकोणों को अव्यवहारिक बना दिया।
दूसरे, यह सुनिश्चित करना कि स्वचालित मूल्यांकन विशेषज्ञ मानव ग्रेडिंग रूब्रिक्स के साथ निकटता से संरेखित हों, एक महत्वपूर्ण बाधा है। मानक एलएलएम अनुप्रयोग अक्सर "मॉडल आउटपुट और मानव-स्तरीय मूल्यांकन के बीच असंगति" प्रदर्शित करते हैं। उच्च-दांव वाले शैक्षिक संदर्भों में जहां निष्पक्षता और सटीकता सर्वोपरि है, संरेखण की यह कमी विशेष रूप से समस्याग्रस्त है। विशिष्ट, पेशेवर रूप से स्थापित मूल्यांकन मानदंडों का पालन करने की आवश्यकता का मतलब था कि एक अधिक गतिशील और संदर्भ-जागरूक दृष्टिकोण की आवश्यकता थी, जो कि बुनियादी एलएलएम संकेत या सरल फाइन-ट्यूनिंग प्रदान कर सके। पत्र स्पष्ट रूप से कहता है कि इन मुद्दों को संबोधित करने के लिए आम तौर पर "व्यापक फाइन-ट्यूनिंग और पुनः प्रशिक्षण" की आवश्यकता होती है, जिसे अव्यावहारिक माना गया था।
तुलनात्मक श्रेष्ठता
डेंटईवेल अपनी संरचनात्मक नवाचारों के माध्यम से पिछले स्वर्ण मानकों और बेसलाइन विधियों पर गुणात्मक श्रेष्ठता प्रदर्शित करता है, जो विशेष डोमेन मूल्यांकन की मुख्य चुनौतियों का सीधे समाधान करते हैं। बेहतर प्रदर्शन मेट्रिक्स (स्पीयरमैन के सहसंबंध 0.9259 तक और पियर्सन के सहसंबंध 0.8957 तक, SciEx और FairEval को बेहतर प्रदर्शन करते हुए) से परे, इसके फायदे इसके डिजाइन में निहित हैं:
- कोई फाइन-ट्यूनिंग आवश्यकता नहीं: कई पूर्ववर्ती दृष्टिकोणों के विपरीत, जिन्हें बड़े, एनोटेट किए गए डेटासेट के साथ व्यापक फाइन-ट्यूनिंग की आवश्यकता होती है, डेंटईवेल इस संसाधन-गहन कदम के बिना प्रभावी ढंग से संचालित होता है। यह एक विशाल संरचनात्मक लाभ है, जो इसे संसाधन-बाधित शैक्षिक सेटिंग्स के लिए व्यावहारिक बनाता है और विकास और परिनियोजन ओवरहेड को काफी कम करता है।
- अनुकूलित आरएजी प्रक्रिया स्व-सुधार के साथ: सेल्फ-रिफाइनिंग रिट्रीवल-ऑगमेंटेड जनरेशन (एसआर-आरएजी) एक प्रमुख नवाचार है। यह केवल जानकारी प्राप्त नहीं करता है; यह इसे परिष्कृत करता है और स्वायत्त रूप से इसकी पर्याप्तता का मूल्यांकन करता है। इसका मतलब है कि सिस्टम स्पष्ट फाइन-ट्यूनिंग की आवश्यकता के बिना पर्याप्त डोमेन-विशिष्ट ज्ञान प्राप्त कर सकता है। यह प्रक्रिया स्वाभाविक रूप से उच्च-आयामी शोर को बेहतर ढंग से संभालती है क्योंकि यह सक्रिय रूप से पुनर्प्राप्त खंडों से अप्रासंगिक जानकारी को फ़िल्टर करती है, जो अन्यथा नमूना उत्तर पीढ़ी की सटीकता को नकारात्मक रूप से प्रभावित कर सकती है। यह स्व-मूल्यांकन लूप (जहां $K$ गतिशील रूप से समायोजित किया जाता है) सुनिश्चित करता है कि एलएलएम के पास पर्याप्त ग्राउंडिंग है, जो मानक आरएजी पर एक संरचनात्मक लाभ है जो शोर या अपर्याप्त संदर्भ प्राप्त कर सकता है।
- भूमिका-निर्वहन संकेत और नमूना उत्तर पीढ़ी (एसएजी): एलएलएम एजेंटों को कई संदर्भ उत्तर उत्पन्न करने के लिए एक "प्रोफेसर" के रूप में और स्कोरिंग के लिए एक "मूल्यांकक" (शिक्षक) के रूप में नामित करके, डेंटईवेल संरचनात्मक रूप से अपनी मूल्यांकन प्रक्रिया को मानव शैक्षणिक प्रथाओं के साथ संरेखित करता है। यह बहु-एजेंट, भूमिका-निर्वहन दृष्टिकोण मानव ग्रेडिंग मानकों के साथ संरेखण को बढ़ाता है और स्थिरता में सुधार करता है। खुले-अंत वाले प्रश्नों के लिए, विविध संदर्भ उत्तर उत्पन्न करना (एकल "सही" उत्तर के बजाय) सिस्टम को स्वीकार्य छात्र प्रतिक्रियाओं की अंतर्निहित जटिलता और परिवर्तनशीलता को पकड़ने की अनुमति देता है, जिससे ऐसे कार्यों के लिए यह अत्यधिक श्रेष्ठ हो जाता है।
- दक्षता लाभ: सिस्टम समय और वित्तीय लागत दोनों में महत्वपूर्ण "दक्षता लाभ" प्रदान करता है। एक मानव मूल्यांकनकर्ता आम तौर पर प्रति प्रतिक्रिया लगभग 1.5 मिनट खर्च करता है, जिसकी लागत लगभग USD 1.275 होती है। इसके विपरीत, डेंटईवेल प्रति प्रश्न लगभग 0.13 मिनट में प्रत्येक प्रश्न को संसाधित करता है, जिसकी लागत केवल USD 0.007 होती है। समय और लागत में यह नाटकीय कमी एक गुणात्मक लाभ है जो शिक्षकों को अधिक शैक्षणिक रूप से मूल्यवान गतिविधियों के लिए संसाधनों को पुन: आवंटित करने में सक्षम बनाता है।
बाधाओं के साथ संरेखण
डेंटईवेल की चुनी हुई विधि दंत शिक्षा जैसे विशेष डोमेन में स्वचालित मूल्यांकन की कठोर आवश्यकताओं के साथ पूरी तरह से संरेखित होती है, जो समस्या और समाधान के बीच एक मजबूत "विवाह" बनाती है।
- बाधा: फाइन-ट्यूनिंग के लिए बड़े, एनोटेट किए गए डेटासेट की आवश्यकता।
- संरेखण: डेंटईवेल की "कोई फाइन-ट्यूनिंग आवश्यकता नहीं" सीधे इस समस्या का समाधान करती है। इसका एसआर-आरएजी मॉड्यूल इसे पुनः प्रशिक्षण के लिए व्यापक, महंगे और समय लेने वाले एनोटेट किए गए डेटासेट की आवश्यकता के बिना डोमेन-विशिष्ट ज्ञान प्राप्त करने की अनुमति देता है, जिससे यह विशेष क्षेत्रों के लिए व्यावहारिक हो जाता है जहां ऐसा डेटा दुर्लभ है।
- बाधा: मॉडल आउटपुट और मानव-स्तरीय मूल्यांकन के बीच असंगति।
- संरेखण: "भूमिका-निर्वहन संकेत" और "एसआर-आरएजी" घटक यह सुनिश्चित करने के लिए डिज़ाइन किए गए हैं कि आउटपुट मानव ग्रेडिंग मानकों के साथ निकटता से संरेखित हों। मूल्यांकनकर्ता एलएलएम, एक शिक्षक की भूमिका सौंपी गई, इस संरेखण को बढ़ाता है, जबकि एसआर-आरएजी तथ्यात्मक रूप से सुसंगत और डोमेन-प्रासंगिक जानकारी प्रदान करता है। कई एलएलएम स्कोर से बहुमत वोट का उपयोग परिवर्तनशीलता को कम करता है और स्थिरता में सुधार करता है।
- बाधा: विशेष ज्ञान डोमेन (दंत चिकित्सा) जिसके लिए शब्दावली की सटीक व्याख्या की आवश्यकता होती है।
- संरेखण: एसआर-आरएजी दंत हैंडबुक से प्रासंगिक जानकारी प्राप्त करके और इसे परिष्कृत करके पर्याप्त डोमेन-विशिष्ट ज्ञान प्राप्त करने के लिए तैयार किया गया है। इसके अलावा, डेंटईवेल मल्टीमॉडल इनपुट (पाठ और नैदानिक छवियां) का समर्थन करता है, जो दंत चिकित्सा जैसे क्षेत्र के लिए महत्वपूर्ण है जो दृश्य जानकारी पर बहुत अधिक निर्भर करता है।
- बाधा: विशेषज्ञ ग्रेडिंग रूब्रिक्स के साथ संरेखण।
- संरेखण: सिस्टम स्पष्ट रूप से एक "अंकन रूब्रिक R" को इनपुट के रूप में लेता है। नमूना उत्तर पीढ़ी (एसएजी) मॉड्यूल एलएलएम को संदर्भ उत्तर उत्पन्न करने के लिए एक "प्रोफेसर" के रूप में नामित करता है, और मूल्यांकनकर्ता एलएलएम एक "शिक्षक" के रूप में कार्य करता है, यह सुनिश्चित करता है कि मूल्यांकन प्रक्रिया पूर्वनिर्धारित मानदंडों और पेशेवर मानकों का पालन करती है।
- बाधा: संसाधन-बाधित सेटिंग्स।
- संरेखण: फाइन-ट्यूनिंग की आवश्यकता को समाप्त करके और मूल्यांकन समय और वित्तीय लागतों (USD 1.275 से USD 0.007 प्रति प्रतिक्रिया तक) को काफी कम करके, डेंटईवेल एक संसाधन-कुशल समाधान प्रदान करता है जो शैक्षिक संस्थानों के लिए अत्यधिक व्यावहारिक है।
- बाधा: खुले-अंत वाले लघु-उत्तर प्रश्नों का मूल्यांकन।
- संरेखण: एसएजी मॉड्यूल कई संदर्भ उत्तर उत्पन्न करता है, जो खुले-अंत वाले प्रश्नों के लिए स्वीकार्य प्रतिक्रियाओं की अंतर्निहित जटिलता और परिवर्तनशीलता को स्वीकार करता है। यह सिस्टम को विविध लेकिन मान्य छात्र उत्तरों के गलत निर्णय लेने से रोकता है, जो सरल विधियों के लिए एक सामान्य नुकसान है।
विकल्पों का अस्वीकरण
यह पत्र स्पष्ट रूप से और अंतर्निहित रूप से कई वैकल्पिक दृष्टिकोणों को अस्वीकार करता है, विशेष रूप से वे जो बुनियादी एलएलएम संकेत या व्यापक फाइन-ट्यूनिंग पर निर्भर करते हैं, विशेष डोमेन में विशेषज्ञ-संरेखित मूल्यांकन की विशिष्ट समस्या के लिए उनकी अंतर्निहित सीमाओं के कारण।
प्राथमिक अस्वीकरण पारंपरिक एलएलएम फाइन-ट्यूनिंग विधियों का है। लेखकों ने इस बात पर प्रकाश डाला है कि इन विधियों के लिए "फाइन-ट्यूनिंग या अतिरिक्त प्रशिक्षण के लिए बड़े, एनोटेट किए गए डेटासेट" की आवश्यकता होती है, जो "समय लेने वाला और संसाधन-बाधित सेटिंग्स के लिए अव्यावहारिक" है। यह उन्हें दंत चिकित्सा जैसे विशेष क्षेत्रों के लिए अनुपयुक्त बनाता है जहां ऐसे डेटासेट दुर्लभ हैं और विशेषज्ञों द्वारा एनोटेशन की लागत अधिक है। डेंटईवेल का फाइन-ट्यूनिंग-मुक्त दृष्टिकोण सीधे इस अव्यवहारिकता को दूर करता है।
इसके अलावा, पत्र बुनियादी कुछ-शॉट सीखने को कुछ प्रकार के प्रश्नों के लिए एक स्पष्ट अस्वीकरण प्रदान करता है। जबकि कुछ-शॉट सीखना आम तौर पर ज़ीरो-शॉट की तुलना में प्रदर्शन में सुधार करता है, लेखकों ने "प्रश्न 2" (एक खुले-अंत वाला प्रश्न जो कई दृष्टिकोणों की अनुमति देता है) के लिए स्कोरिंग प्रदर्शन में "उल्लेखनीय गिरावट" देखी है जब बेसलाइन कुछ-शॉट विधि का उपयोग किया जाता है। इसका कारण यह है कि "कुछ-शॉट सीखने के दौरान, एलएलएम प्रदान किए गए उदाहरणों को केवल सही उत्तरों के रूप में व्याख्या कर सकता है, जिससे अन्य छात्रों की प्रतिक्रियाओं का गलत निर्णय होता है।" खुले-अंत वाले प्रश्नों के लिए यह एक महत्वपूर्ण दोष है जहां एक एकल निश्चित उत्तर हमेशा उपयुक्त नहीं होता है। डेंटईवेल अपने नमूना उत्तर पीढ़ी (एसएजी) मॉड्यूल को शामिल करके इसे दूर करता है, जो कई विविध संदर्भ उत्तर उत्पन्न करता है, इस प्रकार सही प्रतिक्रियाओं की परिवर्तनशीलता को कैप्चर करता है और गलत निर्णयों को रोकता है।
हालांकि पत्र सीधे तौर पर जीएएन या डिफ्यूजन मॉडल जैसे अन्य डीप लर्निंग प्रतिमानों के साथ तुलना में गहराई से नहीं जाता है (क्योंकि समस्या मौलिक रूप से भाषा समझ और मूल्यांकन की है, न कि शोर से जटिल मीडिया जैसे छवियों की पीढ़ी की), एलएलएम-आधारित समाधानों पर इसका ध्यान यह दर्शाता है कि ऐसे मॉडल इस विशिष्ट कार्य के लिए सीधे लागू या कुशल नहीं हैं। मुख्य समस्या सिमेंटिक समझ, डोमेन ज्ञान अधिग्रहण और मानव निर्णय के साथ संरेखण से संबंधित है, ऐसे क्षेत्र जहां एलएलएम, आरएजी और एजेंटिक क्षमताओं के साथ संवर्धित, अद्वितीय रूप से स्थित हैं।
 Figure 2. Scoring Rubric and Example Content Illustration
Figure 2. Scoring Rubric and Example Content Illustration
गणितीय और तार्किक तंत्र
मास्टर समीकरण
डेंटईवेल के मूल्यांकन तंत्र का मूल, विशेष रूप से अंतिम स्कोर उत्पन्न करने के लिए, एक दो-भाग समीकरण में समाहित है जो पहले कई मूल्यांकन एजेंटों से व्यक्तिगत स्कोर उत्पन्न करता है और फिर उन्हें एकत्रित करता है। यह प्रक्रिया भूमिका-निर्वहन और कुछ-शॉट सीखने के माध्यम से मजबूती सुनिश्चित करती है और मानव ग्रेडिंग मानकों के साथ संरेखित होती है।
प्रत्येक मूल्यांकन उदाहरण $i$ के लिए व्यक्तिगत स्कोर पीढ़ी इस प्रकार दी गई है:
$$S_i = \text{LLM}_{\text{evaluator}}(Q, A_{student}, \{A_{sample},..., A_{sample}\}, R), \quad i \in \{1,..., n\}$$
और अंतिम एकत्रित स्कोर द्वारा निर्धारित किया जाता है:
$$S_{final} = \text{Mode}(\{S_1, S_2, ..., S_n\})$$
पद-दर-पद विच्छेदन
आइए इन समीकरणों को प्रत्येक घटक की भूमिका को समझने के लिए विच्छेदित करें:
-
$S_i$:
- गणितीय परिभाषा: यह एलएलएम मूल्यांकनकर्ता के एक एकल उदाहरण द्वारा छात्र के उत्तर को सौंपा गया संख्यात्मक स्कोर दर्शाता है। यह एक स्केलर मान है, जो आम तौर पर एक पूर्वनिर्धारित सीमा (जैसे, $[0, 5]$ जैसा कि पत्र में उल्लेख किया गया है) के भीतर होता है।
- भौतिक/तार्किक भूमिका: $S_i$ छात्र की प्रतिक्रिया का एक मध्यवर्ती, व्यक्तिगत मूल्यांकन है। सिस्टम संभावित एलएलएम आउटपुट परिवर्तनशीलता को ध्यान में रखने और विश्वसनीयता बढ़ाने के लिए ऐसे $n$ स्कोर उत्पन्न करता है।
- क्यों उपयोग किया जाता है: लेखक किसी भी एकल एलएलएम के विशिष्ट निर्णय के प्रभाव को कम करने के लिए कई $S_i$ मानों का उपयोग करते हैं, जिससे समग्र मूल्यांकन की स्थिरता और मजबूती में वृद्धि होती है। यह एआई-संचालित मूल्यांकन में शोर को कम करने के लिए एक सामान्य रणनीति है।
-
$\text{LLM}_{\text{evaluator}}(\cdot)$:
- गणितीय परिभाषा: यह एक बड़े भाषा मॉडल द्वारा किए गए फ़ंक्शन को दर्शाता है जिसे विशेष रूप से "मूल्यांकनकर्ता" के रूप में कार्य करने के लिए कॉन्फ़िगर किया गया है। यह कई इनपुट लेता है और एक एकल संख्यात्मक स्कोर उत्पन्न करता है।
- भौतिक/तार्किक भूमिका: यह केंद्रीय बुद्धिमान एजेंट है जो छात्र के उत्तर का मूल्यांकन करने के लिए जिम्मेदार है। इसे संकेत के माध्यम से "मूल्यांकनकर्ता" भूमिका सौंपकर, सिस्टम एलएलएम को एक महत्वपूर्ण, मूल्यांकन-केंद्रित व्यक्तित्व अपनाने के लिए निर्देशित करता है, जो एक मानव शिक्षक को दर्शाता है।
- क्यों उपयोग किया जाता है: एलएलएम को इसकी उन्नत प्राकृतिक भाषा समझ और पीढ़ी क्षमताओं के लिए चुना जाता है, जिससे यह जटिल प्रश्नों, छात्र प्रतिक्रियाओं, रूब्रिक्स और संदर्भ उत्तरों की व्याख्या करके एक सूक्ष्म निर्णय ले सकता है। भूमिका-निर्वहन संकेत इसके आउटपुट को विशेषज्ञ मानव ग्रेडिंग मानदंडों के साथ संरेखित करने में मदद करता है।
-
$Q$:
- गणितीय परिभाषा: यह छात्र को प्रस्तुत की गई इनपुट क्वेरी या प्रश्न है। यह पाठ्य हो सकता है और इसमें वैकल्पिक रूप से दृश्य सामग्री (जैसे, आंकड़े) शामिल हो सकती है।
- भौतिक/तार्किक भूमिका: $Q$ उस कार्य या समस्या को परिभाषित करता है जिसका उत्तर छात्र से अपेक्षित है। यह मूल्यांकन का प्राथमिक संदर्भ है।
- क्यों उपयोग किया जाता है: प्रश्न किसी भी मूल्यांकन के लिए मौलिक है। यह वह आधार प्रदान करता है जिसके विरुद्ध छात्र की प्रतिक्रिया को मापा जाता है।
-
$A_{student}$:
- गणितीय परिभाषा: यह प्रश्न $Q$ के छात्र की मुक्त-पाठ प्रतिक्रिया है।
- भौतिक/तार्किक भूमिका: $A_{student}$ वह आइटम है जिसका मूल्यांकन किया जा रहा है। यह कच्चा डेटा बिंदु है जिसकी गुणवत्ता और शुद्धता का मूल्यांकन करने की आवश्यकता है।
- क्यों उपयोग किया जाता है: यह छात्र से प्रत्यक्ष आउटपुट है जिसे सिस्टम स्कोर करने का लक्ष्य रखता है।
-
$\{A_{sample},..., A_{sample}\}$:
- गणितीय परिभाषा: यह नमूना संदर्भ उत्तरों का एक सेट दर्शाता है। ये आंतरिक रूप से एक अन्य एलएलएम एजेंट, $\text{LLM}_{\text{professor}}(Q, E)$ द्वारा उत्पन्न किए जाते हैं, जहां $E$ एक दंत हैंडबुक से परिष्कृत जानकारी है। पत्र कहता है कि प्रश्नों की खुले-अंत प्रकृति को ध्यान में रखते हुए कई नमूना उत्तर उत्पन्न किए जाते हैं।
- भौतिक/तार्किक भूमिका: ये नमूना उत्तर छात्र की प्रतिक्रिया $A_{student}$ की तुलना में विशेषज्ञ-संरेखित बेंचमार्क या "स्वर्ण मानक" के रूप में काम करते हैं। वे एलएलएम मूल्यांकनकर्ता को अच्छे उत्तर के उदाहरण प्रदान करते हैं, प्रभावी ढंग से कुछ-शॉट सीखने के उदाहरणों के रूप में कार्य करते हैं।
- क्यों उपयोग किया जाता है: कई संदर्भ उत्तर प्रदान करने से एलएलएम मूल्यांकनकर्ता को खुले-अंत वाले प्रश्नों के लिए स्वीकार्य प्रतिक्रियाओं की चौड़ाई को समझने में मदद मिलती है, एक "सही" उत्तर के प्रति पूर्वाग्रह को कम किया जाता है और विविध, फिर भी मान्य, छात्र अभिव्यक्तियों को पकड़ने की इसकी क्षमता में सुधार होता है। यह विशेष डोमेन के लिए महत्वपूर्ण है जहां उत्तरों की कई मान्य व्याख्याएं हो सकती हैं।
-
$R$:
- गणितीय परिभाषा: यह अंकन रूब्रिक है, जो स्कोरिंग के लिए मानदंडों और दिशानिर्देशों का एक सेट है।
- भौतिक/तार्किक भूमिका: $R$ मूल्यांकन के लिए स्पष्ट नियम और मानक प्रदान करता है। यह सुनिश्चित करता है कि स्कोरिंग वस्तुनिष्ठ और शैक्षणिक आवश्यकताओं के अनुरूप हो।
- क्यों उपयोग किया जाता है: एक रूब्रिक संरचित मूल्यांकन के लिए आवश्यक है, यह सुनिश्चित करता है कि एलएलएम का मूल्यांकन पारदर्शी, निष्पक्ष और मानव ग्रेडिंग सिद्धांतों के साथ संरेखित हो। यह एलएलएम के निर्णय के लिए एक बाधा और मार्गदर्शक के रूप में कार्य करता है।
-
$i \in \{1,..., n\}$:
- गणितीय परिभाषा: यह एक सूचकांक है जो इंगित करता है कि मूल्यांकन प्रक्रिया को $n$ बार दोहराया जाता है, जिससे $n$ व्यक्तिगत स्कोर उत्पन्न होते हैं।
- भौतिक/तार्किक भूमिका: यह मूल्यांकन प्रक्रिया की बहुलता को दर्शाता है। प्रत्येक $S_i$ $\text{LLM}_{\text{evaluator}}$ का एक स्वतंत्र रन है।
- क्यों उपयोग किया जाता है: व्यक्तिगत एलएलएम आउटपुट में भिन्नता और स्टोकेस्टिकिटी के प्रभाव को कम करने के लिए कई बार मूल्यांकन दोहराना और फिर परिणामों को एकत्रित करना (मोड के माध्यम से) स्थिरता और अंतिम स्कोर की विश्वसनीयता को बढ़ाने की एक रणनीति है।
-
$S_{final}$:
- गणितीय परिभाषा: यह छात्र के उत्तर को सौंपा गया अंतिम संख्यात्मक स्कोर है, जो व्यक्तिगत स्कोर के एकत्रीकरण से प्राप्त होता है।
- भौतिक/तार्किक भूमिका: $S_{final}$ डेंटईवेल प्रणाली का निश्चित आउटपुट है, जो छात्र की प्रतिक्रिया का अंतिम मूल्यांकन दर्शाता है।
- क्यों उपयोग किया जाता है: यह प्रणाली का वांछित अंतिम उत्पाद है, एक एकल, मजबूत स्कोर जिसका उपयोग ग्रेडिंग के लिए किया जा सकता है।
-
$\text{Mode}(\cdot)$:
- गणितीय परिभाषा: यह एक सांख्यिकीय फ़ंक्शन है जो डेटा के एक सेट में सबसे अधिक बार आने वाला मान लौटाता है।
- भौतिक/तार्किक भूमिका: मोड फ़ंक्शन एक सर्वसम्मति तंत्र के रूप में कार्य करता है। $n$ व्यक्तिगत मूल्यांकन में से सबसे आम स्कोर का चयन करके, यह आउटलायर्स को प्रभावी ढंग से फ़िल्टर करता है और एलएलएम एजेंटों से सबसे सुसंगत निर्णय को मजबूत करता है।
- क्यों उपयोग किया जाता है: अंतिम स्कोर की मजबूती और स्थिरता में सुधार, विशेष रूप से उन स्थितियों में जहां व्यक्तिगत एलएलएम आउटपुट थोड़ा भिन्न हो सकते हैं, को कम करने के लिए बहुमत वोटिंग का उपयोग किया जाता है। यह एक मजबूत सर्वसम्मति प्राप्त करने का एक सरल लेकिन प्रभावी तरीका है।
चरण-दर-चरण प्रवाह
कल्पना कीजिए कि एक छात्र का उत्तर $A_{student}$ डेंटईवेल प्रणाली के माध्यम से एक यात्रा पर निकलता है, जो एक परिष्कृत असेंबली लाइन पर एक आइटम की तरह है:
-
प्रारंभिक इनपुट रिसेप्शन: प्रक्रिया तीन प्राथमिक इनपुट के साथ शुरू होती है: छात्र का उत्तर ($A_{student}$), प्रश्न ($Q$, संभावित रूप से एक संबद्ध चित्र के साथ), और अंकन रूब्रिक ($R$)। इसके अतिरिक्त, दंत ज्ञान का एक विशाल पुनर्प्राप्ति कॉर्पस ($C$) उपलब्ध है।
-
क्वेरी एम्बेडिंग और प्रारंभिक पुनर्प्राप्ति: प्रश्न $Q$ को पहले एक संख्यात्मक वेक्टर प्रतिनिधित्व (एक एम्बेडिंग) में परिवर्तित किया जाता है। इस एम्बेडेड क्वेरी को फिर दंत ज्ञान कॉर्पस $C$ में खोजने के लिए एक पुनर्प्राप्ति इंजन (जैसे मिलवस) में फीड किया जाता है। इंजन "शीर्ष K" सबसे प्रासंगिक सूचना खंडों को खींचता है।
-
सूचना शोधन: ये प्रारंभिक "शीर्ष K" खंड, मूल प्रश्न $Q$ के साथ, एक विशेष एलएलएम एजेंट को पारित किए जाते हैं। इस एजेंट का कार्य इस कच्चे माल को एक अधिक संक्षिप्त और प्रासंगिक साक्ष्य सेट, $E$ में सारांशित और परिष्कृत करना है। यह कदम शोर को दूर करने और यह सुनिश्चित करने के लिए महत्वपूर्ण है कि जानकारी सीधे प्रश्न से संबंधित है।
-
पर्याप्तता जांच और पुनरावृत्ति पुनर्प्राप्ति: परिष्कृत साक्ष्य $E$ का मूल्यांकन एक अन्य एलएलएम एजेंट द्वारा यह निर्धारित करने के लिए किया जाता है कि क्या यह उच्च-गुणवत्ता वाला संदर्भ उत्तर उत्पन्न करने के लिए "पर्याप्त" है। यदि साक्ष्य अपर्याप्त माना जाता है, तो सिस्टम पुनर्प्राप्ति चरण में वापस चला जाता है, अधिक जानकारी एकत्र करने के लिए $K$ के मान को (एक "चरण आकार" द्वारा) बढ़ाता है। यह पुनरावृत्ति स्व-सुधार सुनिश्चित करता है कि एलएलएम को व्यापक ग्राउंडिंग मिले।
-
नमूना उत्तर पीढ़ी (एसएजी): एक बार पर्याप्त साक्ष्य $E$ प्राप्त हो जाने के बाद, इसे प्रश्न $Q$ के साथ जोड़ा जाता है और एक $\text{LLM}_{\text{professor}}$ एजेंट को फीड किया जाता है। यह एजेंट, एक दंत शिक्षाविद की भूमिका निभाते हुए, परिष्कृत साक्ष्य और प्रश्न के आधार पर कई विविध नमूना उत्तर, $\{A_{sample},..., A_{sample}\}$ उत्पन्न करता है। खुले-अंत वाले प्रश्नों के लिए यह कदम महत्वपूर्ण है जहां कई सही उत्तर मौजूद हो सकते हैं।
-
व्यक्तिगत स्कोर पीढ़ी: अब, सिस्टम वास्तविक स्कोरिंग के लिए तैयारी करता है। $n$ अलग-अलग मूल्यांकन रनों के लिए, एक $\text{LLM}_{\text{evaluator}}$ एजेंट को बुलाया जाता है। प्रत्येक रन $i$ में, यह मूल्यांकनकर्ता एलएलएम प्रश्न $Q$, छात्र के उत्तर $A_{student}$, उत्पन्न नमूना उत्तरों के सेट $\{A_{sample},..., A_{sample}\}$, और अंकन रूब्रिक $R$ प्राप्त करता है। यह अपने निर्णय को निर्देशित करने के लिए कुछ-शॉट सीखने के उदाहरणों (मूल्यांकन प्रतिक्रिया के साथ प्रत्येक स्कोर टियर से छात्र प्रतिक्रियाएं) को भी शामिल करता है। इन सभी इनपुट के आधार पर, $\text{LLM}_{\text{evaluator}}$ एक व्यक्तिगत स्कोर $S_i$ उत्पन्न करता है।
-
अंतिम स्कोर एकत्रीकरण: $n$ व्यक्तिगत स्कोर ($S_1, S_2, ..., S_n$) उत्पन्न होने के बाद, उन्हें एकत्र किया जाता है। अंतिम स्कोर, $S_{final}$, फिर इन स्कोर के सेट पर मोड फ़ंक्शन लागू करके निर्धारित किया जाता है। इसका मतलब है कि $n$ मूल्यांकन में से सबसे अधिक बार आने वाला स्कोर निश्चित ग्रेड बन जाता है। यह बहुमत वोटिंग तंत्र एक मजबूत और सुसंगत अंतिम मूल्यांकन सुनिश्चित करता है, जो किसी भी एकल विषम मूल्यांकन के प्रभाव को कम करता है।
अनुकूलन गतिशीलता
डेंटईवेल "फाइन-ट्यूनिंग-मुक्त" प्रतिमान पर संचालित होता है, जिसका अर्थ है कि यह बड़े भाषा मॉडल के अंतर्निहित मापदंडों को अद्यतन करने के लिए पारंपरिक ग्रेडिएंट-आधारित अनुकूलन को शामिल नहीं करता है। इसके बजाय, इसके "सीखने," "अद्यतन करने," या "अभिसरण" व्यवहार को बुद्धिमान प्रणाली डिजाइन, पुनरावृत्ति प्रक्रियाओं और परिष्कृत संकेत रणनीतियों के संयोजन के माध्यम से प्राप्त किया जाता है:
-
सेल्फ-रिफाइनिंग रिट्रीवल-ऑगमेंटेड जनरेशन (एसआर-आरएजी): सिस्टम का प्राथमिक "सीखने" तंत्र इसके एसआर-आरएजी घटक के भीतर एम्बेडेड है। जब प्रारंभिक पुनर्प्राप्त साक्ष्य $E$ को एक एलएलएम एजेंट द्वारा अपर्याप्त माना जाता है, तो सिस्टम सिर्फ हार नहीं मानता; यह पुनरावृत्ति रूप से अपनी खोज का विस्तार करता है पैरामीटर $K$ (शीर्ष प्रासंगिक खंडों की संख्या) को बढ़ाकर। यह स्व-सुधार लूप सिस्टम को "सीखने" की अनुमति देता है जब इसका ज्ञान आधार अपर्याप्त होता है और सक्रिय रूप से अधिक व्यापक जानकारी की तलाश करता है। पुनर्प्राप्ति मापदंडों का यह गतिशील समायोजन आरएजी प्रक्रिया के लिए अनुकूलन का एक रूप है, यह सुनिश्चित करता है कि एलएलएम को प्रदान किया गया संदर्भ यथासंभव पूर्ण और प्रासंगिक हो।
-
भूमिका-निर्वहन संकेत: सिस्टम के प्रदर्शन को विशिष्ट भूमिकाएं (जैसे, "प्रोफेसर," "मूल्यांकनकर्ता") सौंपने वाले संकेतों को सावधानीपूर्वक तैयार करके "अनुकूलित" किया जाता है। यह पारंपरिक अर्थों में गणितीय अनुकूलन नहीं है, बल्कि इन-कॉन्टेक्स्ट मार्गदर्शन का एक शक्तिशाली रूप है। इन व्यक्तित्वों को अपनाकर, एलएलएम को ऐसे व्यवहार और तर्क पैटर्न प्रदर्शित करने के लिए निर्देशित किया जाता है जो मानव विशेषज्ञों की बारीकी से नकल करते हैं, इस प्रकार उनके आउटपुट को वांछित ग्रेडिंग मानकों के साथ संरेखित करते हैं। यह "संकेत इंजीनियरिंग" एलएलएम के "हानि परिदृश्य" को निहित रूप से आकार देने के लिए एक महत्वपूर्ण लीवर है, जो इसे आंतरिक भार को बदले बिना अधिक सटीक और सुसंगत मूल्यांकन की ओर निर्देशित करता है।
-
कुछ-शॉट सीखना: मूल्यांकन एलएलएम को उदाहरणों का एक छोटा सेट (कुछ-शॉट उदाहरण) प्रदान किया जाता है जिसमें छात्र प्रतिक्रियाएं, रूब्रिक्स और मानव-निर्धारित स्कोर प्रतिक्रिया के साथ शामिल होते हैं। यह एलएलएम को स्पष्ट पैरामीटर अपडेट के माध्यम से नहीं, बल्कि सीधे उदाहरणों से वांछित स्कोरिंग पैटर्न और मानदंडों को "सीखने" की अनुमति देता है। यह इन-कॉन्टेक्स्ट सीखना एलएलएम को अपेक्षित इनपुट-आउटपुट संबंधों को प्रदर्शित करके एक सुसंगत स्कोरिंग नीति पर अभिसरण करने में मदद करता है।
-
मजबूती के लिए बहुमत वोटिंग: अंतिम स्कोर ($S_{final}$) में कई व्यक्तिगत स्कोर ($S_i$) के एकत्रीकरण को मोड फ़ंक्शन का उपयोग करके एक सांख्यिकीय अनुकूलन के रूप में लागू किया जाता है। यह एक मजबूत अनुमानक के रूप में कार्य करता है, जो एक एकल एलएलएम मूल्यांकन से उत्पन्न व्यक्तिगत भिन्नताओं और पूर्वाग्रहों को प्रभावी ढंग से सुचारू करता है। यह तंत्र समय के साथ और विभिन्न छात्र प्रतिक्रियाओं में स्थिरता में सुधार करते हुए, अधिक स्थिर और विश्वसनीय स्कोर पर अभिसरण करने में मदद करता है। यह एलएलएम आउटपुट पर लागू एक एन्सेम्बल लर्निंग का एक रूप है।
-
सीडीएफ मैपिंग के साथ पोस्ट-प्रोसेसिंग: जैसा कि कार्यान्वयन विवरण में उल्लेख किया गया है, सिस्टम संभावित पूर्वाग्रहों को कम करने और निष्पक्षता बढ़ाने के लिए एलएलएम के कच्चे स्कोर को कैलिब्रेट करने के लिए एक पोस्ट-प्रोसेसिंग चरण के रूप में संचयी वितरण फ़ंक्शन (सीडीएफ) मैपिंग लागू करता है, उन्हें मानव स्कोर वितरण के साथ अधिक निकटता से संरेखित करता है। जबकि एलएलएम के आंतरिक सीखने का हिस्सा नहीं है, यह एक बाहरी अंशांकन कदम है जो मानव निर्णय के साथ बेहतर संरेखण के लिए अंतिम आउटपुट को "अनुकूलित" करता है।
संक्षेप में, डेंटईवेल का "अनुकूलन" हानि फ़ंक्शन पर ग्रेडिएंट डिसेंट की तुलना में पुनरावृत्ति शोधन, रणनीतिक संकेत और मजबूत एकत्रीकरण तकनीकों के माध्यम से बड़े भाषा मॉडल की अंतर्निहित क्षमताओं का लाभ उठाने वाले बुद्धिमानी से डिज़ाइन किए गए, बहु-एजेंट वर्कफ़्लो का अधिक है, ताकि व्यापक फाइन-ट्यूनिंग की आवश्यकता के बिना विशेषज्ञ-संरेखित मूल्यांकन प्राप्त किया जा सके। सिस्टम का "सीखना" इसलिए पैरामीट्रिक के बजाय प्रक्रियात्मक और प्रासंगिक है।
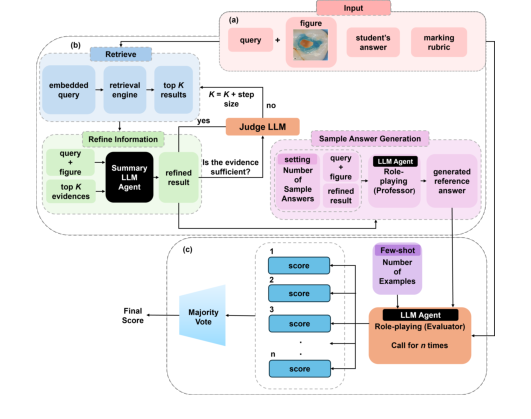 Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
Figure 1. DentEval Workflow Diagram consists of three main steps: (a) The system requires three types of input: the query (question), with an associated figure provided optionally, the student’s answer, and the marking rubric; (b) Retrieving the most rel- evant knowledge from the dental handbook and generating reference answers to aid in assessment; (c) Grading the student’s response with the assistance of reference an- swers and few-shot learning, and returning the final score through majority voting. Role-playing prompts are employed in LLM agents to simulate human-like reasoning
परिणाम, सीमाएं और निष्कर्ष
प्रयोगात्मक डिजाइन और बेसलाइन
डेंटईवेल के गणितीय दावों और व्यावहारिक प्रभावकारिता को कठोरता से मान्य करने के लिए, शोधकर्ताओं ने एक व्यापक प्रयोगात्मक सेटअप तैयार किया। उनके मूल्यांकन का मूल दंत चिकित्सा पाठ्यक्रम के लिए विशेष रूप से तैयार किए गए एक अद्वितीय, प्रोफेसर-एनोटेट किए गए डेटासेट के आसपास केंद्रित था। इस डेटासेट में प्रत्येक प्रश्न के लिए 28 छात्र प्रतिक्रियाएं शामिल थीं, जिन्हें एक पूर्वनिर्धारित अंकन रूब्रिक के विरुद्ध दंत शिक्षाविदों द्वारा सावधानीपूर्वक स्कोर किया गया था। महत्वपूर्ण रूप से, डेटासेट में दो अलग-अलग प्रकार के खुले-अंत वाले प्रश्न शामिल थे: एक को मल्टीमॉडल तर्क (पाठ और चित्र) की आवश्यकता थी और दूसरा विशुद्ध रूप से पाठ्य था। यह विविधता जानबूझकर थी, जो दंत शिक्षा में मूल्यांकन की विविध प्रकृति को दर्शाती है, जो दंत आकारिकी और पुनर्स्थापनात्मक सामग्री जैसे विभिन्न उप-डोमेन को कवर करती है, और प्रतिक्रिया की लंबाई और जटिलताओं की एक विस्तृत श्रृंखला प्रदर्शित करती है।
मूल्यांकन के लिए, कुछ-शॉट सीखने के दृष्टिकोण को अपनाया गया था। प्रति प्रश्न 28 प्रतिक्रियाओं में से, प्रत्येक स्कोर टियर से एक प्रतिक्रिया को कुछ-शॉट उदाहरण के रूप में चुना गया था, जिसके परिणामस्वरूप प्रति प्रश्न 6 उदाहरण थे। शेष 22 प्रतिक्रियाओं ने परीक्षण सेट का गठन किया। इस डिजाइन ने एलएलएम एजेंटों को व्यापक फाइन-ट्यूनिंग की आवश्यकता के बिना विशेषज्ञ-ग्रेड उदाहरणों से सीखने की अनुमति दी। जीपीटी-40 (विशेष रूप से gpt-40-mini) को अंतर्निहित एलएलएम एजेंट के रूप में चुना गया था, जो इसकी मल्टीमॉडल क्षमताओं का लाभ उठा रहा था। निष्पक्षता और स्थिरता सुनिश्चित करने के लिए, स्कोरिंग में संभावित पूर्वाग्रहों को कम करने के लिए संचयी वितरण फ़ंक्शन (सीडीएफ) मैपिंग को एक पोस्ट-प्रोसेसिंग चरण के रूप में लागू किया गया था।
डेंटईवेल के प्रदर्शन को कई "पीड़ित" बेसलाइन मॉडल और उन्नत तकनीकों के मुकाबले बेंचमार्क किया गया था:
- ज़ीरो-शॉट: एक सीधा दृष्टिकोण जहां एलएलएम बिना किसी संशोधन या भूमिका-निर्वहन के प्रतिक्रियाओं को स्कोर करता है।
- कुछ-शॉट: एलएलएम को निर्देशित करने के लिए संदर्भ उदाहरणों को शामिल करते हुए, ज़ीरो-शॉट का एक संवर्द्धन।
- SciEx [5]: एक अत्याधुनिक विधि जो कुछ-शॉट सीखने को भूमिका-निर्वहन संकेतों के साथ जोड़ती है।
- FairEval [22]: एक और उन्नत तकनीक जो एलएलएम मूल्यांकन में पूर्वाग्रह को कम करने के लिए मल्टीपल एविडेंस कैलिब्रेशन (एमईसी) और बैलेंस्ड पोजीशन कैलिब्रेशन (बीपीसी) का उपयोग करती है।
डेंटईवेल के मुख्य तंत्र के निश्चित प्रमाण के लिए मानक मूल्यांकन मेट्रिक्स की मांग की गई थी: सटीकता (Acc.), स्पीयरमैन का रैंक-ऑर्डर सहसंबंध गुणांक (SROCC) [17], और पियर्सन रैखिक सहसंबंध गुणांक (PLCC) [16]। SROCC और PLCC विशेष रूप से महत्वपूर्ण थे क्योंकि वे सीधे डेंटईवेल के स्कोर की मानव विशेषज्ञ मूल्यांकन के साथ स्थिरता और रैखिक सहसंबंध को मापते हैं, जो संरेखण का एक मजबूत माप प्रदान करते हैं।
अंत में, डेंटईवेल के भीतर प्रत्येक अभिनव घटक (एसआर-आरएजी, नमूना उत्तर पीढ़ी (एसएजी), और भूमिका-निर्वहन संकेत) के योगदान को क्रूरता से साबित करने के लिए एक एब्लेशन अध्ययन आयोजित किया गया था। इन घटकों को व्यवस्थित रूप से हटाकर या अलग करके, शोधकर्ता सिस्टम के समग्र प्रदर्शन पर उनके व्यक्तिगत प्रभाव को इंगित कर सकते थे, तुलना के लिए ज़ीरो-शॉट बेसलाइन का उपयोग करते हुए।
साक्ष्य क्या साबित करते हैं
प्रायोगिक साक्ष्य दंत शिक्षा में विविध मूल्यांकन परिदृश्यों में डेंटईवेल के बेहतर प्रदर्शन और विश्वसनीयता को भारी रूप से प्रदर्शित करते हैं।
प्रश्न 1 के लिए, जिसमें मल्टीमॉडल तर्क (पाठ और चित्र) शामिल था और एक एकल सही उत्तर था, डेंटईवेल ने सभी मूल्यांकन मेट्रिक्स में सर्वश्रेष्ठ प्रदर्शन हासिल किया। इसने 0.7447 का SROCC, 0.7288 का PLCC, और 68.2% की सटीकता दर्ज की, सभी सबसे कम पी-मानों के साथ, जो मानव ग्रेडिंग के साथ सांख्यिकीय रूप से महत्वपूर्ण संरेखण का संकेत देते हैं। जबकि SciEx और FairEval ने बुनियादी ज़ीरो-शॉट बेसलाइन को बेहतर प्रदर्शन किया, उन्होंने बेसलाइन कुछ-शॉट विधि की तुलना में थोड़ा कम प्रदर्शन किया, जो उन्नत तकनीकों के साथ भी स्वचालित मूल्यांकन की सूक्ष्म चुनौतियों को उजागर करता है। मल्टीमॉडल इनपुट और विशेषज्ञ-संरेखित तंत्रों को एकीकृत करने की डेंटईवेल की क्षमता ने स्पष्ट रूप से इसे यहां बढ़त दी।
प्रश्न 2 के लिए, एक विशुद्ध रूप से पाठ्य, खुले-अंत वाला प्रश्न जो कई मान्य प्रतिक्रियाओं की अनुमति देता है, डेंटईवेल का प्रदर्शन और भी अधिक प्रभावशाली था। इसने प्रश्न 1 की तुलना में उच्च SROCC 0.9259 और PLCC 0.8957 हासिल किया, और 68.2% की सटीकता बनाए रखी। यह विशेष रूप से महत्वपूर्ण है क्योंकि, प्रश्न 1 के विपरीत, बेसलाइन कुछ-शॉट विधि ने प्रश्न 2 के लिए स्कोरिंग प्रदर्शन में उल्लेखनीय गिरावट प्रदर्शित की। लेखकों ने इसे खुले-अंत वाले प्रश्नों की प्रकृति के लिए जिम्मेदार ठहराया, जहां कुछ-शॉट उदाहरण अनजाने में एलएलएम को उन्हें केवल सही उत्तरों के रूप में व्याख्या करने के लिए प्रेरित कर सकते हैं, जिससे अन्य मान्य छात्र प्रतिक्रियाओं का गलत निर्णय होता है। ऐसे जटिल, खुले-अंत वाले प्रश्नों को संभालने में डेंटईवेल की मजबूती, जहां एक एकल निश्चित उत्तर की अपेक्षा नहीं की जाती है, इसकी उन्नत डिजाइन का एक मजबूत प्रमाण है, विशेष रूप से इसके एसआर-आरएजी और भूमिका-निर्वहन संकेत तंत्र जो विविध संदर्भ उत्तर उत्पन्न करते हैं।
सटीकता और सहसंबंध से परे, डेंटईवेल ने महत्वपूर्ण दक्षता लाभ का भी निर्विवाद प्रमाण प्रदान किया। एक मानव मूल्यांकनकर्ता को आम तौर पर प्रति छात्र प्रतिक्रिया लगभग 1.5 मिनट लगते हैं, जिसकी लागत लगभग USD 1.275 होती है। इसके विपरीत, डेंटईवेल के GPT-40 एलएलएम एजेंटों ने प्रति प्रश्न लगभग 0.13 मिनट में प्रत्येक प्रश्न को संसाधित किया, जिसकी लागत केवल USD 0.007 प्रति प्रतिक्रिया थी। यह समय और वित्तीय संसाधनों दोनों में एक भारी कमी का प्रतिनिधित्व करता है, जिससे शिक्षकों को अधिक शैक्षणिक रूप से मूल्यवान गतिविधियों पर ध्यान केंद्रित करने के लिए मुक्त किया जा सकता है।
एब्लेशन अध्ययन ने डेंटईवेल के मुख्य घटकों के योगदान को और मजबूत किया। प्रत्येक नवाचार—एसआर-आरएजी, नमूना उत्तर पीढ़ी (एसएजी), और भूमिका-निर्वहन संकेत—ने व्यक्तिगत रूप से मानव मूल्यांकन के साथ स्थिरता में सुधार और सटीकता में वृद्धि दिखाई। उदाहरण के लिए, एसआर-आरएजी ने अकेले प्रश्न 1 के लिए सटीकता को 9.1% (ज़ीरो-शॉट) से 54.5% तक, और प्रश्न 2 के लिए 50.0% से 68.2% तक काफी बढ़ाया। पूर्ण डेंटईवेल फ्रेमवर्क लगातार सभी एब्लेटेड संस्करणों से बेहतर प्रदर्शन करता है, यह पुष्टि करता है कि इन घटकों का सहक्रियात्मक एकीकरण ही वास्तव में इसके बेहतर प्रदर्शन और मानव निर्णय के साथ संरेखण को संचालित करता है।
सीमाएं और भविष्य की दिशाएं
जबकि डेंटईवेल विशेष डोमेन में स्वचालित मूल्यांकन में एक सम्मोहक प्रगति प्रस्तुत करता है, इसकी वर्तमान सीमाओं को स्वीकार करना और भविष्य के विकास के लिए रास्ते पर विचार करना महत्वपूर्ण है।
एक स्पष्ट सीमा, जैसा कि लेखकों द्वारा अंतर्निहित रूप से नोट किया गया है, डेटासेट का आकार है। हालांकि एकत्र की गई प्रतिक्रियाएं संरचना और सार में विविध थीं, "सीमित संख्या में प्रश्न" (केवल दो अलग-अलग प्रश्नों का मूल्यांकन किया गया था) निष्कर्षों की सामान्यता को दंत चिकित्सा पाठ्यक्रम की पूरी चौड़ाई या अन्य विशेष क्षेत्रों तक सीमित कर सकता है। प्रश्न प्रकारों, कठिनाई स्तरों और प्रतिक्रिया भिन्नताओं की एक विस्तृत श्रृंखला को शामिल करने के लिए डेटासेट का विस्तार डेंटईवेल की क्षमताओं का अधिक मजबूत सत्यापन प्रदान करेगा।
एक और बिंदु पर विचार करना एक विशिष्ट एलएलएम, जीपीटी-40 पर निर्भरता है। शक्तिशाली होने के बावजूद, यह लागत में उतार-चढ़ाव, एपीआई उपलब्धता और मॉडल की मालिकाना प्रकृति से संबंधित संभावित मुद्दे प्रस्तुत करता है। भविष्य के काम में डेंटईवेल के ढांचे को ओपन-सोर्स एलएलएम या अधिक लागत प्रभावी विकल्पों के अनुकूलता का पता लगाया जा सकता है, जिससे व्यापक पहुंच और स्थिरता सुनिश्चित हो सके।
पत्र खुले-अंत वाले प्रश्नों द्वारा प्रस्तुत चुनौती को भी उजागर करता है जहां कई सही उत्तर संभव हैं, बेसलाइन कुछ-शॉट विधि के लिए प्रदर्शन में गिरावट को नोट करता है। जबकि डेंटईवेल इसे अच्छी तरह से संभालता है, ऐसे प्रश्नों की अंतर्निहित जटिलता बताती है कि नमूना उत्तर पीढ़ी (एसएजी) और सेल्फ-रिफाइनिंग रिट्रीवल-ऑगमेंटेड जनरेशन (एसआर-आरएजी) मॉड्यूल का निरंतर शोधन व्यक्तिपरक मूल्यांकन की एक व्यापक स्पेक्ट्रम में विशेषज्ञ निर्णय के साथ उच्च संरेखण बनाए रखने के लिए महत्वपूर्ण होगा।
आगे देखते हुए, लेखक स्वयं रोमांचक भविष्य की दिशाओं का प्रस्ताव करते हैं:
- मल्टीमॉडल आरएजी का विस्तार: एक प्राकृतिक विकास में अधिक जटिल मल्टीमॉडल इनपुट को शामिल करना शामिल होगा, जैसे नैदानिक वीडियो और 3डी मॉडल। यह डेंटईवेल को अधिक समग्र और यथार्थवादी तरीके से व्यावहारिक कौशल और नैदानिक तर्क का मूल्यांकन करने की अनुमति देगा, जो स्थिर छवियों और पाठ से परे है। कल्पना कीजिए कि एक एलएलएम एजेंट वीडियो साक्ष्य के आधार पर एक सिम्युलेटेड सर्जिकल प्रक्रिया में छात्र की तकनीक का मूल्यांकन कर रहा है!
- अनुकूली अंशांकन: विभिन्न प्रश्न प्रकारों में मजबूती में सुधार के लिए अनुकूली अंशांकन तंत्र विकसित करना एक और महत्वपूर्ण क्षेत्र है। इसका तात्पर्य एक ऐसी प्रणाली से है जो प्रश्न की विशिष्ट विशेषताओं (जैसे, क्या यह एक एकल तथ्यात्मक उत्तर की अपेक्षा करता है या एक सूक्ष्म, बहु-परिप्रेक्ष्य प्रतिक्रिया) के आधार पर अपनी स्कोरिंग रूब्रिक या मूल्यांकन रणनीति को गतिशील रूप से समायोजित कर सकती है। यह विविध मूल्यांकन संदर्भों में सिस्टम के लचीलेपन और विश्वसनीयता को बढ़ाएगा।
इनके अलावा, कई अन्य चर्चा विषय इन निष्कर्षों को और विकसित कर सकते हैं:
- स्पष्टता और प्रतिक्रिया की गुणवत्ता: जबकि डेंटईवेल स्कोर प्रदान करता है, स्वचालित मूल्यांकन का शैक्षणिक मूल्य उच्च-गुणवत्ता, कार्रवाई योग्य प्रतिक्रिया से काफी बढ़ जाता है। भविष्य के शोध एलएलएम की तर्क प्रक्रिया को अधिक पारदर्शी बनाने और विस्तृत, रचनात्मक प्रतिक्रिया उत्पन्न करने पर ध्यान केंद्रित कर सकते हैं जो छात्रों को यह समझने में मदद करती है कि उन्हें एक निश्चित स्कोर क्यों मिला और कैसे सुधार किया जाए। इसमें प्रतिक्रिया पीढ़ी के लिए विशेष रूप से चेन-ऑफ-थॉट संकेत को एकीकृत करना शामिल हो सकता है।
- शिक्षा में नैतिक एआई: जैसे-जैसे स्वचालित मूल्यांकन अधिक प्रचलित होता जाता है, निष्पक्षता, पूर्वाग्रह और इक्विटी के आसपास नैतिक चिंताओं को संबोधित करना सर्वोपरि है। हम यह कैसे सुनिश्चित कर सकते हैं कि डेंटईवेल का मूल्यांकन विभिन्न छात्र जनसांख्यिकी या सीखने की शैलियों में निष्पक्ष हो? संभावित एल्गोरिथम पूर्वाग्रह का पता लगाने और उसे कम करने के लिए क्या तंत्र स्थापित किए जा सकते हैं? ग्रेडिंग के लिए ऑडिटेबिलिटी और व्याख्या योग्य एआई में अनुसंधान अमूल्य होगा।
- लर्निंग मैनेजमेंट सिस्टम (एलएमएस) के साथ एकीकरण: व्यापक अपनाने के लिए, मौजूदा शैक्षिक बुनियादी ढांचे, जैसे कैनवास या मूडल में डेंटईवेल का निर्बाध एकीकरण आवश्यक है। इसमें शिक्षकों के लिए स्वचालित मूल्यांकन को आसानी से तैनात करने, अनुकूलित करने और निगरानी करने के लिए मजबूत एपीआई और उपयोगकर्ता-अनुकूल इंटरफेस विकसित करना शामिल होगा।
- क्रॉस-डोमेन प्रयोज्यता: हालांकि दंत चिकित्सा के लिए तैयार किया गया है, एसआर-आरएजी, भूमिका-निर्वहन संकेत और मल्टीमॉडल इनपुट हैंडलिंग के अंतर्निहित सिद्धांत विशेषज्ञ-संरेखित मूल्यांकन की आवश्यकता वाले अन्य विशेष डोमेन में सामान्यीकृत किए जा सकते हैं, जैसे चिकित्सा, इंजीनियरिंग, या कानून। इन समरूपताओं की खोज व्यापक अनुप्रयोगों और प्रभाव को खोल सकती है।
- वास्तविक समय अनुकूली शिक्षण: क्या डेंटईवेल को तत्काल, व्यक्तिगत प्रतिक्रिया और अनुकूली सीखने के पथ प्रदान करने के लिए वास्तविक समय सीखने के वातावरण में एकीकृत किया जा सकता है? कल्पना कीजिए कि एक छात्र अभ्यास प्रश्नों को पूरा करते ही तत्काल मूल्यांकन और अनुरूप उपचारात्मक संसाधन प्राप्त करता है, जिससे उनकी सीखने की प्रक्रिया तेज हो जाती है।
ये विविध दृष्टिकोण इस बात पर प्रकाश डालते हैं कि डेंटईवेल केवल स्वचालित ग्रेडिंग के लिए एक उपकरण नहीं है, बल्कि एक मूलभूत ढांचा है जिसमें विशेष क्षेत्रों में शैक्षिक मूल्यांकन और सीखने के अनुभवों को गहराई से बदलने की क्षमता है।
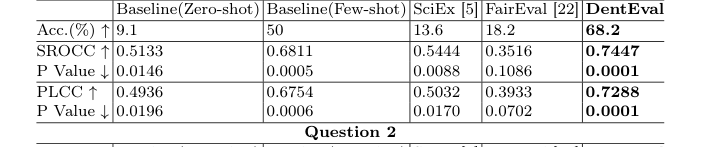 Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval
Table 1. Performance Comparison of DentEval on Question 1 & 2 with Baselines, SciEx, and FairEval