A Walsh Hadamard Derived Linear Vector Symbolic Architecture
Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in are 'bound' together to produce a new vector in the same space.
Background & Academic Lineage
The Origin & Academic Lineage
The problem addressed in this paper originates from the field of Vector Symbolic Architectures (VSAs), a unique approach to developing Neuro-symbolic AI. This academic lineage can be precisely traced back to Smolensky [38], who initiated the VSA approach with the Tensor Product Representation (TPR). In the TPR, concepts are represented as high-dimensional vectors, and these vectors are "bound" together by computing an outer product to form new, composite concepts. This foundational work emerged as a way to enable symbolic-style manipulations within a connectionist framework, allowing for the representation of logical statements and structures [13].
Historically, most VSAs were developed before the widespread adoption of deep learning and automatic differentiation. Their primary focus was on efficacy in hand-designed systems, often inspired by classical AI tasks or cognitive science. However, this early focus led to several fundamental limitations, or "pain points," when attempting to integrate VSAs into modern differentiable systems:
- Computational Complexity: Early VSA methods, such as the TPR, suffered from impractical computational complexity. For instance, binding $p$ items together using TPR resulted in an O($d^p$) complexity, where $d$ is the vector dimension. Even more general linear VSAs, which represent binding as a matrix operation, typically incurred O($d^2$) complexity, making them too slow for real-time or large-scale applications.
- Numerical Instability: Other popular VSA methods, like Holographic Reduced Representations (HRR) [32], rely on the Fourier Transform (FT) and circular convolution. While powerful, these operations involve irrational multiplications and complex numbers, which can lead to numerical instability in practical implementations. Prior work [9] attempted projection steps to mitigate this, but the underlying issue remained.
- Suboptimal Performance in Differentiable Systems: Many existing VSA methods were not designed with the properties required for seamless integration into deep learning frameworks. They often lacked favorable computational efficiency and numerical stability when used with gradient descent and automatic differentiation, leading to lower-than-desired performance in modern neuro-symbolic AI tasks.
This paper addresses these limitations by deriving a new VSA, the Hadamard-derived Linear Binding (HLB), which aims to provide O($d$) complexity for binding, improved numerical stability, and better performance in differentiable deep learning applications, by leveraging the properties of the Walsh Hadamard transform.
Intuitive Domain Terms
To make the concepts in this paper accessible, let's break down some specialized terms with everyday analogies:
- Vector Symbolic Architectures (VSAs): Imagine you have a set of unique "thought-vectors" in your brain, where each vector represents a basic concept like "cat," "happy," or "red." VSAs are like a special mental language that lets you combine these thought-vectors to form new, more complex ideas, such as "happy cat" or "red car," and then later "ask" your brain to retrieve parts of those complex ideas. It's a way for computers to manipulate concepts like we do with words, but using numbers.
- Binding: This is the process of combining two or more concept-vectors to create a new vector that represents their relationship or composition. Think of it like mixing two ingredients in a recipe, say "flour" and "water," to get "dough." The "dough" is a new entity that contains both original ingredients, but in a combined form. In VSAs, binding "cat" and "happy" creates a new vector for "happy cat."
- Unbinding: This is the reverse of binding. Given a combined concept-vector (like "dough") and one of its original components ("flour"), unbinding allows you to retrieve the other component ("water"). It's like taking the "happy cat" vector and the "happy" vector, and then being able to retrieve the "cat" vector. This operation is crucial for querying and extracting information from composite representations.
- Hadamard Transform: Picture a special kind of digital "shuffling" or "encoding" process. Unlike the more complex Fourier Transform, which deals with waves and imaginary numbers, the Hadamard Transform is much simpler. It only uses additions and subtractions, and its output values are always either +1 or -1. This makes it very fast and numerically stable, like a super-efficient, no-frills data compressor that's easy to reverse.
- Neuro-symbolic AI: This is an approach to Artificial Intelligence that tries to get the best of both worlds: the intuitive, pattern-learning abilities of neural networks (like how humans recognize faces) and the logical, rule-based reasoning of traditional symbolic AI (like how computers follow instructions). It's an AI that can both "feel" and "think" in a structured way, aiming to overcome the limitations of each approach when used alone.
Notation Table
| Notation | Description |
|---|---|
| $B(x, y)$ | The binding operation, which connects two concepts/vectors $x$ and $y$ to produce a new vector $z$. |
| $B^*(x, y)$ | The unbinding operation, which retrieves one component of a bound vector given the other component. |
| $x, y, z$ | Generic vectors representing concepts or data points in the VSA space. |
| $d$ | The dimension of the vectors in the VSA, i.e., $x \in \mathbb{R}^d$. |
Problem Definition & Constraints
Core Problem Formulation & The Dilemma
The core problem addressed by this paper lies in the limitations of existing Vector Symbolic Architectures (VSAs) when applied to modern deep learning systems.
Starting Point (Input/Current State):
Current VSAs operate by binding two vectors, $x, y \in R^d$, representing concepts, into a new composite vector $z \in R^d$ using a binding operation $B(x, y) = z$. An inverse unbinding operation, $B^*(x, y)$, allows for the retrieval of a component. While these architectures offer attractive platforms for neuro-symbolic methods due to their natural symbolic AI-style manipulations (commutativity, associativity, inverse operation), they were largely developed before the widespread adoption of deep learning and automatic differentiation. Consequently, many existing VSA methods exhibit several critical drawbacks:
1. High Computational Complexity: Many VSAs, particularly those viewed as linear operations $B(a,b) = a^T G b$ and $B^*(a,b) = a^T F b$ (where $G$ and $F$ are $d \times d$ matrices), incur a computational complexity of $O(d^2)$ for the binding step. While this can be reduced to $O(d)$ for diagonal matrices, it's often not the case for more complex, expressive bindings. The Tensor Product Representation (TPR), for instance, has an impractical $O(d^p)$ complexity for binding $p$ items.
2. Numerical Instability: Methods like Holographic Reduced Representations (HRR), which rely on the Fourier Transform and complex numbers, are prone to numerical instability due to "irrational multiplications" when operating on real-valued vectors.
3. Suboptimal Performance in Differentiable Systems: Existing VSAs were not explicitly designed for gradient-based learning, meaning their properties (like commutativity) might not be maintained if their underlying matrices were learned via gradient descent without additional constraints. Their performance in deep learning applications is often lower than desired.
Desired Endpoint (Output/Goal State):
The paper aims to introduce a novel VSA, termed Hadamard-derived Linear Binding (HLB), that overcomes these limitations. The goal is to develop a VSA that is:
1. Computationally Efficient: Achieves $O(d)$ complexity for the binding step, significantly faster than $O(d^2)$ or $O(d \log d)$ (which is typically associated with the Hadamard transform itself, but the derivation here yields linear complexity).
2. Numerically Stable: Avoids the instability issues of complex-number-based VSAs by operating solely with real numbers and simple arithmetic (addition, subtraction, and $\{-1, 1\}$ values).
3. Highly Efficacious: Performs comparably to or better than existing VSAs in both classical VSA tasks and modern deep learning applications.
4. Differentiable System Compatible: Designed from the ground up to integrate seamlessly and perform well within differentiable systems, supporting neuro-symbolic AI.
5. Symmetric: The binding operation $B(x,y)$ should be symmetric, i.e., $B(x,y) = B(y,x)$, which is a desirable property for many VSA applications.
Missing Link or Mathematical Gap:
The exact missing link is the derivation of a VSA binding and unbinding mechanism that leverages the favorable properties of the Hadamard transform to achieve linear computational complexity and numerical stability, while preserving the core symbolic manipulation capabilities and being amenable to differentiable learning. Previous attempts either suffered from complexity, instability, or lacked explicit design for deep learning integration. The paper bridges this by replacing the Fourier Transform (used in HRR) with the Hadamard transform, and carefully designing the binding and unbinding operations to exploit its unique characteristics, such as its recursive structure and self-inverse property.
Painful Trade-off or Dilemma:
Previous researchers attempting to solve this problem have been trapped by several painful trade-offs:
* Expressiveness vs. Computational Cost: Achieving rich, compositional representations (e.g., binding many items) often leads to exponentially increasing computational complexity, as seen with TPR's $O(d^p)$ cost. This forces a choice between highly expressive symbolic structures and practical computation.
* Symbolic Fidelity vs. Learnability: While VSAs offer powerful symbolic properties, adapting them for gradient-based learning in deep neural networks often risks compromising these very properties. Learning the underlying matrices $G$ and $F$ without additional constraints might break the desired commutativity or associativity. This creates a dilemma between maintaining the "neuro-symbolic properties" and optimizing for modern machine learning paradigms.
* Mathematical Elegance vs. Numerical Robustness: Using mathematically elegant tools like the Fourier Transform for circular convolution (as in HRR) introduces complex numbers and irrational multiplications, which can lead to numerical instability when implemented with real-valued vectors in practical systems. This forces a choice between theoretical purity and robust, real-world performance.
Constraints & Failure Modes
The problem is made insanely difficult by several harsh, realistic walls the authors hit:
- Computational Complexity Wall: The need for $O(d)$ complexity for the binding step is a strict constraint. Many existing VSAs have $O(d^2)$ or $O(d \log d)$ complexity, which is a significant barrier to scalability for high-dimensional vectors ($d$). This limits their applicability in large-scale deep learning models where efficiency is paramount.
- Numerical Instability: A major failure mode for existing VSAs like HRR is numerical instability. This arises from operations involving complex numbers and irrational multiplications, which can lead to floating-point errors and unreliable results, especially when dealing with real-valued vectors. The proposed solution must inherently avoid this.
- Noise Accumulation in Composite Representations: When multiple concepts are bound together into a single composite vector (i.e., $p \ge 2$ items are bundled), noise inevitably accumulates. This noise degrades the accuracy of the unbinding operation, making it difficult to reliably retrieve individual components. Without a mechanism to mitigate this, the utility of VSAs for complex symbolic structures is severely limited. The paper shows that without a projection step, the noise component $\eta'$ is significantly higher than $\eta''$ with projection.
- Vector Initialization Challenges: For the binding and unbinding operations to function correctly, vectors must have an expected value of zero. However, if vector components are initialized such that values are close to zero, subsequent division by these query vectors during unbinding can "destabilize the noise component and create numerical instability." This specific initialization constraint requires a careful design choice, leading to the introduction of a Mixture of Normal Distribution (MiND).
- Magnitude Stability Over Multiple Bindings: An ideal VSA should maintain a stable magnitude for its composite vectors, meaning the magnitude should not "explode/vanish as $p$ increases" (the number of bound items). This is a common failure mode for approximate unbinding procedures in other VSAs, where similarity scores decay or magnitudes become unstable with increasing $p$.
- Hardware Memory Limits: The experimental setup, using a single NVIDIA TESLA P100 GPU with 32GB memory, implicitly imposes a constraint that any proposed VSA must be memory-efficient enough to operate within such typical deep learning hardware environments.
- Extreme Sparsity in Multi-Label Classification: In applications like Extreme Multi-label (XML) classification, the number of possible classes ($L \ge 100,000$) vastly exceeds the input dimension ($d \approx 5000$), and only a small fraction of classes are relevant for any given input (often less than 100). This extreme sparsity makes traditional linear layers computationally prohibitive ($O(L)$ complexity), demanding a VSA that can represent this vast, sparse output space efficiently (reducing complexity to $O(K)$ where $K$ is the number of present classes).
Why This Approach
The Inevitability of the Choice
The adoption of the Hadamard-derived linear Binding (HLB) was not merely a preference but a necessity driven by the inherent limitations of existing Vector Symbolic Architectures (VSAs) when applied to modern deep learning contexts. The authors recognized that traditional "SOTA" VSA methods, such as Holographic Reduced Representations (HRR), Vector-Derived Transformation Binding (VTB), and Multiply Add Permute (MAP), were fundamentally insufficient for their goals, particularly concerning numerical stability, computaional efficiency, and seamless integration with differentiable systems.
The critical realization stemmed from the observation that while VSAs offer an attractive platform for neuro-symbolic methods, many existing approaches were developed before the widespread adoption of deep learning and automatic differentiation. For instance, HRR, which relies on the Fourier Transform (FT) and circular convolution, suffers from numerical instability due to its reliance on complex numbers and irrational multiplications (page 3). This makes it challenging to use in systems that require robust numerical operations, especially when gradients are involved.
The Hadamard Transform, in contrast, inherently avoids these issues. It operates exclusively on real numbers, performing only additions and subtractions, thereby eliminating irrational multiplications and complex number arithmetic (page 3). This property makes it a uniquely viable solution for maintaining numerical stability, a paramount concern in differentiable systems where small numerical errors can propagate and destabilize learning. Furthermore, the Hadamard matrix's property of being its own inverse simplifies the design of the unbinding operation $B^*$, making the overall system more elegant and robust.
Comparative Superiority
HLB demonstrates qualitative superiority over previous gold standards in several key aspects, extending beyond mere performance metrics.
Firstly, in terms of computational complexity, HLB achieves an impressive $O(d)$ complexity for its binding step (page 1). This is a significant structural advantage compared to the $O(d^2)$ complexity of general linear operations (which many VSAs can be viewed as) or even the $O(d \log d)$ complexity typically associated with the Walsh-Hadamard Transform itself (page 2). This linear complexity is achieved by redefining the binding function as an element-wise product in the Hadamard domain, $B'(x, y) = x \odot y$ (page 5), making it exceptionally efficient for high-dimensional vectors.
Secondly, numerical stability is a core advantage. As mentioned, the Hadamard Transform exclusively uses $\{-1, 1\}$ values and real arithmetic, completely sidestepping the numerical instability issues prevalent in Fourier Transform-based methods like HRR, which involve complex numbers and irrational multiplications (page 2, 3). This intrinsic stability is crucial for reliable operation, especially in deep learning where models are sensitive to numerical precision.
Thirdly, HLB exhibits superior noise handling. The paper introduces a projection step (Definition 3.2, page 4) that significantly diminishes accumulated noise during unbinding. Empirical results (Figure 4, page 15) clearly show that the noise component with this projection ($\eta''$) is substantially lower than without it ($\eta'$), leading to improved retrieval accuracy. This structural enhancement directly addresses a common challenge in VSAs where noise accumulates with multiple bindings.
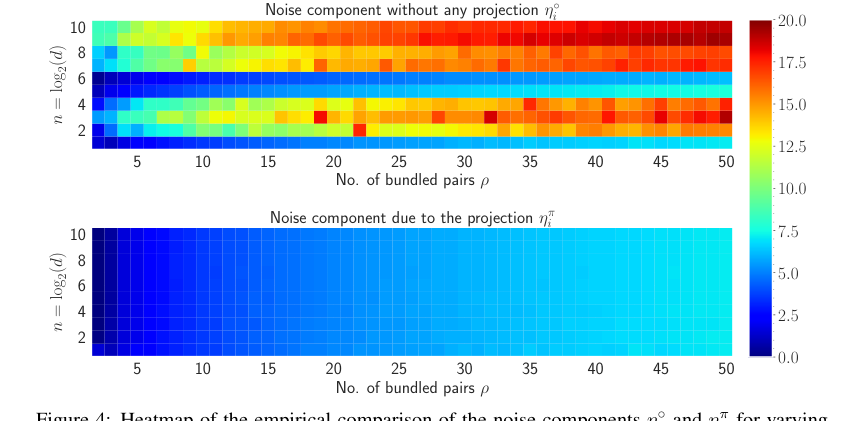 Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
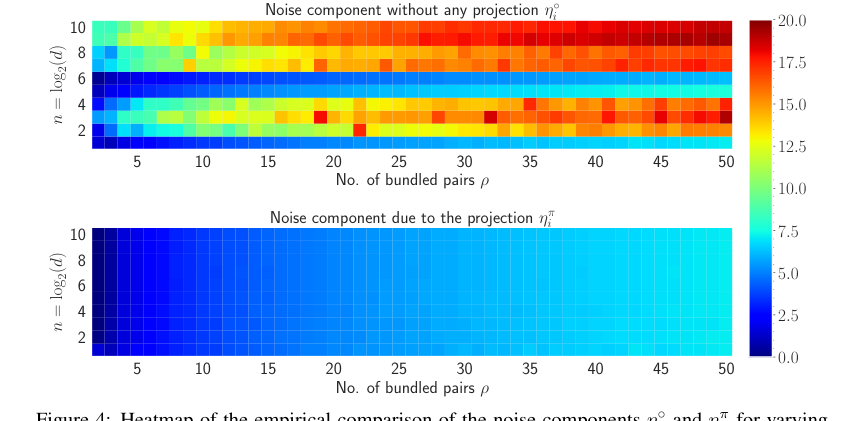 Figure 4. Heatmap of the empirical comparison of the noise components η˝ i and ηπ i for varying n and ρ shown in natural logarithm scale. The dimension, i.e., d “ 2n is varied from 2 to 1024 pn P t1, 2, ¨ ¨ ¨ , 10uq and the number of vector pairs bundled is varied from 2 to 50
Figure 4. Heatmap of the empirical comparison of the noise components η˝ i and ηπ i for varying n and ρ shown in natural logarithm scale. The dimension, i.e., d “ 2n is varied from 2 to 1024 pn P t1, 2, ¨ ¨ ¨ , 10uq and the number of vector pairs bundled is varied from 2 to 50
Finally, HLB demonstrates remarkable consistency and stability of magnitude and similarity scores. Figure 3 (page 7) illustrates that HLB consistently returns an ideal similarity score of 1 for present items and maintains a constant magnitude regardless of the number of bound vectors. This prevents the "exploding/vanishing" values observed in HRR, VTB, and MAP, which is a critical property for designing stable VSA solutions and ensuring reliable information retrieval. This stability is attributed to the properties of the Mixture of Normal Distribution (MiND) used for vector initialization (Properties 3.1, page 5).
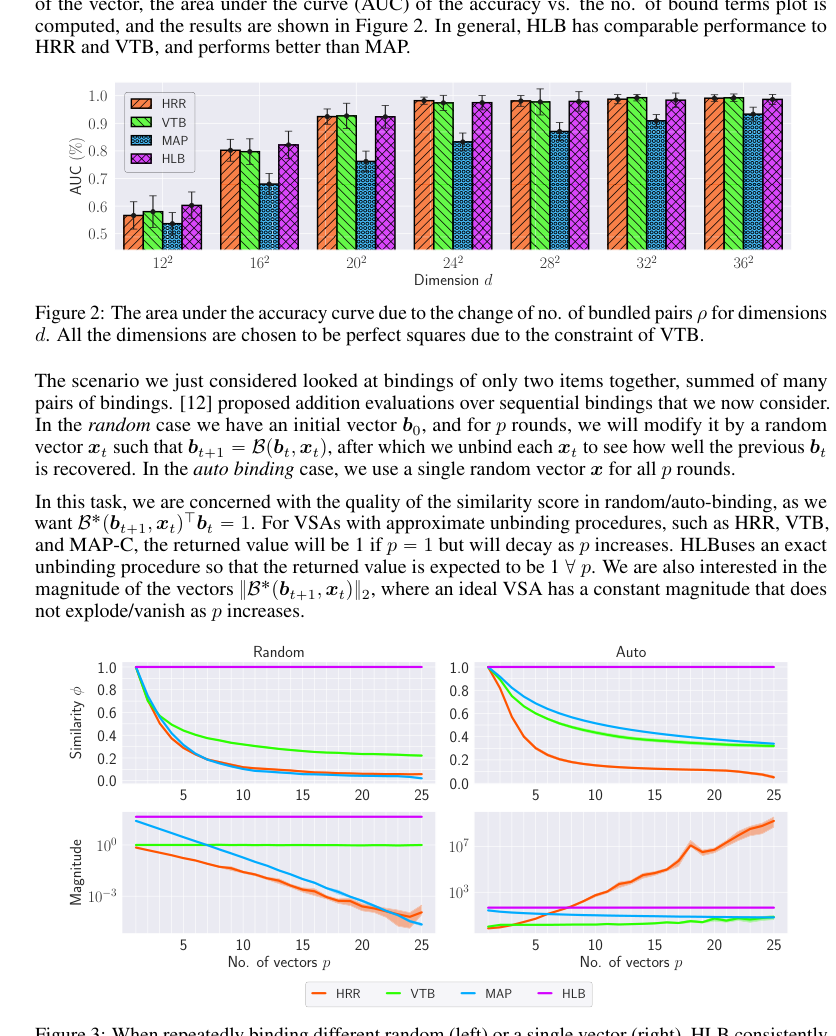 Figure 3. When repeatedly binding different random (left) or a single vector (right), HLB consistently returns the ideal similarity score of 1 for a present item (top row) and has a constant magnitude (bottom row), avoiding exploding/vanishing values
Figure 3. When repeatedly binding different random (left) or a single vector (right), HLB consistently returns the ideal similarity score of 1 for a present item (top row) and has a constant magnitude (bottom row), avoiding exploding/vanishing values
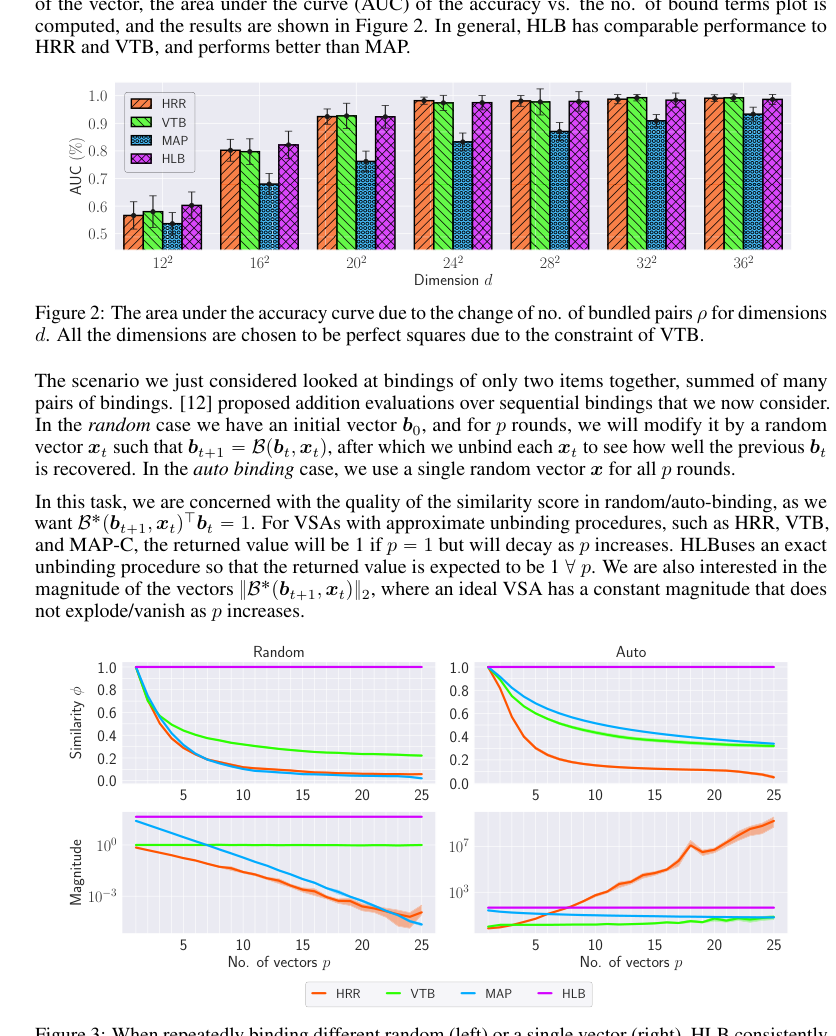 Figure 3. shows that HLB maintains a stable magnitude regardless of the number of bound vectors in both cases. This property arises due to the properties of the distribution shown in Properties 3.1. As all components have an expected absolute value of 1, the product of all components also has an expected absolute value of 1. Thus, the norm of the binding is simply ?
Figure 3. shows that HLB maintains a stable magnitude regardless of the number of bound vectors in both cases. This property arises due to the properties of the distribution shown in Properties 3.1. As all components have an expected absolute value of 1, the product of all components also has an expected absolute value of 1. Thus, the norm of the binding is simply ?
Alignment with Constraints
The chosen HLB method perfectly aligns with the implicit and explicit constraints of developing a VSA suitable for modern neuro-symbolic AI.
- Computational Efficiency: A primary constraint for VSAs, especially in deep learning, is low computational overhead. HLB's $O(d)$ binding complexity directly addresses this, making it feasible for high-dimensional data and large-scale applications (page 1, 5).
- Numerical Stability: The requirement for robust numerical operations is met by HLB's foundation in the Hadamard Transform, which avoids complex numbers and irrational arithmetic, ensuring stability (page 2, 3).
- Performance in Differentiable Systems: The paper explicitly states the goal of a VSA that "perform[s] well in differentiable systems" (Abstract, page 1). HLB's linear operations, real-valued nature, and numerical stability make it inherently compatible with gradient-based optimization, a cornerstone of deep learning.
- Neuro-symbolic Properties: VSAs are valued for their symbolic manipulation capabilities (commutativity, associativity, inverse operation). The Hadamard Transform is "already associative and distributive" (page 2), simplifying the design to preserve these essential properties without additional complex constraints.
- Noise Management: The problem of noise accumulation in composite representations is a significant challenge. HLB's MiND initialization (Equation 6, page 5) and the explicit projection step (Definition 3.2, page 4) are tailored to minimize and manage this noise, ensuring accurate retrieval even with many bound items.
This "marriage" between the problem's harsh requirements and HLB's unique properies is evident in its design choices, from the transform selection to the initialization and projection steps.
Rejection of Alternatives
The paper provides clear reasoning for rejecting other popular VSA approaches and implicitly, general deep learning methods, for the specific problem context.
- Existing VSAs (HRR, VTB, MAP):
- Numerical Instability: HRR, a key baseline, is explicitly criticized for its "numerical instability due to irrational multiplications of complex numbers" (page 3). This is a direct reason for seeking an alternative like HLB that uses real-valued operations.
- Computational Complexity: The paper notes that many VSAs, if implemented as general linear operations, would incur $O(d^2)$ complexity, which is too high (page 1). Tensor Product Representation (TPR) is dismissed as "impractical due to the $O(d^p)$ complexity" for binding multiple items (page 2). HLB's $O(d)$ complexity offers a substantial improvement.
- Performance in Differentiable Systems: A general critique of "most VSAs" is that they "were developed before deep learning and automatic differentiation became popular and instead focused on efficacy in hand-designed systems" and "have shown issues in numerical stability, computational complexity, or otherwise lower-than-desired perfomance in the context of a differentiable system" (page 1). This highlights their unsuitability for the paper's primary application domain.
- Noise and Stability Issues: Figure 3 (page 7) empirically demonstrates that HRR, VTB, and MAP-C/B suffer from decaying similarity scores and exploding/vanishing magnitudes as the number of bound vectors increases. HLB's ability to maintain constant magnitude and ideal similarity scores directly addresses these failures in alternatives.
- General Deep Learning (e.g., standard CNNs, basic Diffusion, Transformers): While not explicitly "rejected" in a direct comparison, the paper's focus on "Neuro-symbolic AI" (Abstract, page 1) implies that purely connectionist models lack the inherent symbolic manipulation capabilities that VSAs provide. For tasks like "Connectionist Symbolic Pseudo Secrets" (CSPS) or "Xtreme Multi-Label Classification" (XML), the symbolic properties of VSAs are leveraged for specific advantages:
- CSPS: For secure computation offloading, homomorphic encryption (HE) is deemed "more expensive to perform than running a neural network itself," defeating its utility (page 8). VSAs offer a heuristic alternative for obscuring input/output while reducing local compute. Pure neural networks wouldn't inherently provide this "encryption/decryption" mechanism.
- XML: VSAs are used to "side-step this cost" of $O(L)$ computational complexity (where $L$ is the number of classes) by leveraging symbolic manipulation to reduce it to $O(K)$ (where $K$ is the number of present classes, $K \ll L$) (page 9). Standard deep learning architectures would typically require a large output layer, incurring the $O(L)$ cost that VSAs are designed to avoid.
Mathematical & Logical Mechanism
The Master Equation
The core of the Hadamard-derived Linear Binding (HLB) mechanism lies in its definition of binding and unbinding operations, which leverage the Walsh-Hadamard transform. The absolute core equations that define this transformation logic are the binding function and the unbinding function, particularly when applied to projected inputs to enhance performance and stability.
The binding operation $B(x,y)$ for two vectors $x, y \in \mathbb{R}^d$ is defined as:
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) \quad \text{(Equation 2)} $$
When dealing with a composite representation formed by summing multiple bound pairs, and after applying a projection step to the input vectors, the unbinding operation $B^*(\chi_p, \pi(y_i)^\dagger)$ yields an intermediate result. The projection function $\pi(v)$ is defined as $\pi(v) = \frac{1}{d} Hv$. The composite representation $\chi_p$ is formed by summing $p$ projected bound pairs: $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$. The unbinding operation, applied to this composite representation with a projected query vector $\pi(y_i)$, is given by:
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) \quad \text{(Equation 4)} $$
The paper then shows that after an additional reverse projection step, this intermediate result simplifies to the final retrieved output, which is approximately $x_i$ (the original vector associated with $y_i$) plus a noise term $\eta''$ when $p > 1$.
Term-by-Term Autopsy
Let's dissect the components of these master equations to understand their mathematical definitions, physical/logical roles, and the author's design choices.
Autopsy of the Binding Equation (Equation 2)
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) $$
- $B(x,y)$:
- Mathematical Definition: The output vector resulting from the binding operation between input vectors $x$ and $y$.
- Physical/Logical Role: This is the core function that associates two concepts, represented by vectors $x$ and $y$, into a single, new vector. It's the fundamental building block for creating compositional representations in VSAs.
- Why this choice: This specific form is derived from replacing the Fourier Transform in circular convolution (used in Holographic Reduced Representations, HRR) with the Hadamard Transform, aiming for better computational efficiency and numerical stability.
- $x, y$:
- Mathematical Definition: Input vectors of dimension $d$, $x, y \in \mathbb{R}^d$.
- Physical/Logical Role: Each vector represents an individual concept, symbol, or piece of information within the VSA framework.
- Why this choice: VSAs inherently operate on high-dimensional real-valued vectors to encode and manipulate symbolic information.
- $d$:
- Mathematical Definition: The dimensionality of the input vectors $x$ and $y$.
- Physical/Logical Role: Acts as a normalization factor.
- Why this choice: Division by $d$ is a common practice in VSAs to maintain the magnitude of the resulting bound vector within a reasonable range, preventing values from exploding and ensuring approximate orthogonality properties. It also counteracts the scaling factor introduced by applying the Hadamard transform twice ($H(Hv) = dv$).
- $H$:
- Mathematical Definition: The Hadamard matrix of size $d \times d$. This matrix consists only of $+1$ and $-1$ entries and is recursively defined (e.g., $H_1 = [1]$, $H_{2n} = \begin{pmatrix} H_n & H_n \\ H_n & -H_n \end{pmatrix}$).
- Physical/Logical Role: Performs the Hadamard Transform on a vector.
- Why this choice: The Hadamard Transform is chosen for its computational efficiency (linear complexity $O(d)$ in this derivation, or $O(d \log d)$ for the general Fast Walsh-Hadamard Transform), numerical stability (only $\pm 1$ values, avoiding complex numbers or irrational multiplications), and its convenient property that its transpose is its own inverse ($H^T = H$ and $H H = dI$), which simplifies the design of inverse operations.
- $Hx$:
- Mathematical Definition: The Hadamard transform of vector $x$.
- Physical/Logical Role: Transforms the input vector $x$ from its original domain into the Hadamard domain.
- Why this choice: This transformation is cruical for the binding operation. By transforming vectors into the Hadamard domain, element-wise multiplication can achieve a binding effect analogous to circular convolution in the original domain (which is typically done via element-wise multiplication in the Fourier domain for HRR).
- $Hy$:
- Mathematical Definition: The Hadamard transform of vector $y$.
- Physical/Logical Role: Transforms the input vector $y$ into the Hadamard domain.
- Why this choice: Same reasoning as for $Hx$.
- $\odot$:
- Mathematical Definition: The element-wise product (also known as the Hadamard product).
- Physical/Logical Role: This operator performs the actual binding of the transformed vectors in the Hadamard domain.
- Why this choice: In the Hadamard domain, element-wise multiplication serves as the binding mechanism, similar to how it works in the Fourier domain for circular convolution. This operation is computationally efficient and maintains the desired algebraic propeties for VSAs.
- $H(\dots)$:
- Mathematical Definition: The inverse Hadamard transform. Since $H$ is its own inverse (up to a scaling factor $d$), applying $H$ again effectively inverts the previous transform.
- Physical/Logical Role: Transforms the bound vector back from the Hadamard domain to the original vector space.
- Why this choice: To ensure that the resulting bound vector $B(x,y)$ resides in the same vector space as the original inputs, allowing for consistent operations like summation with other vectors.
Autopsy of the Unbinding Equation (Equation 4)
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) $$
- $B^*(\chi_p, \pi(y_i)^\dagger)$:
- Mathematical Definition: The output vector resulting from the unbinding operation, applied to a composite representation $\chi_p$ using the inverse of a projected query vector $\pi(y_i)$.
- Physical/Logical Role: This is the inverse operation to binding, designed to retrieve a specific concept (ideally $\pi(x_i)$) from a bundled representation.
- Why this choice: This operation is fundamental for knowledge retrieval in VSAs, allowing the system to "ask" what was bound with a given query.
- $\chi_p$:
- Mathematical Definition: A composite representation formed by summing $p$ individual bound pairs, where each input vector has been pre-processed by the projection function $\pi$. Mathematically, $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$.
- Physical/Logical Role: A single vector that compactly stores multiple associations or concepts.
- Why this choice: VSAs allow for the summation of bound vectors to represent composite structures or sets of associations, leveraging the linearity of vector addition.
- $\pi(x_j), \pi(y_j)$:
- Mathematical Definition: Projected input vectors, where $\pi(v) = \frac{1}{d} Hv$.
- Physical/Logical Role: Pre-processed versions of the original concept vectors $x_j, y_j$.
- Why this choice: The projection step normalizes the vectors and transforms them into the Hadamard domain. This helps mitagate numerical instability and reduces noise accumulation, which is particularly important when multiple items are bundled together.
- $\sum_{j=1}^p (\dots)$:
- Mathematical Definition: Summation over $p$ individual terms, each being an element-wise product of projected input vectors.
- Physical/Logical Role: Aggregates the individual bound representations (in an intermediate form) into a single composite vector.
- Why this choice: The linearity of addition allows for bundling multiple bound pairs into a single vector, which is a key feature of VSAs for representing complex structures.
- $\odot$:
- Mathematical Definition: The element-wise product.
- Physical/Logical Role: Within the sum, this performs the binding of the projected inputs in the Hadamard domain. Outside the sum, it performs the unbinding by multiplying with the inverse of the query.
- Why this choice: Element-wise multiplication is the chosen binding/unbinding mechanism in the Hadamard domain due to its efficiency and algebraic propeties.
- $H(\sum \dots)$:
- Mathematical Definition: The Hadamard transform applied to the sum of element-wise products of projected inputs.
- Physical/Logical Role: This is an intermediate Hadamard transform applied to the composite representation.
- Why this choice: This step is part of the unbinding process, transforming the sum into a domain suitable for the element-wise division (multiplication by inverse).
- $\frac{1}{H \pi(y_i)}$:
- Mathematical Definition: The element-wise inverse of the Hadamard transform of the projected query vector $\pi(y_i)$.
- Physical/Logical Role: This term acts as the "unbinding key" in the Hadamard domain.
- Why this choice: To perform the inverse operation, one effectively "divides" by the query vector. In the Hadamard domain, this is achieved by element-wise multiplication with the inverse of the Hadamard-transformed query. The use of the inverse is derived from the property $Hx \cdot Hx^\dagger = 1$.
- $H(\dots)$:
- Mathematical Definition: The inverse Hadamard transform.
- Physical/Logical Role: Transforms the result back from the Hadamard domain to the original vector space.
- Why this choice: To obtain the retrieved vector in the same space as the original input vectors, making it interpretable and usable for further VSA operations.
- $\frac{1}{d}$:
- Mathematical Definition: A scaling factor.
- Physical/Logical Role: Normalizes the magnitude of the retrieved vector.
- Why this choice: Similar to the binding operation, this scaling ensures consistent vector magnitudes and counteracts the scaling introduced by the Hadamard transform, maintaining numerical stability.
Step-by-Step Flow
Let's trace the lifecycle of an abstract data point, say $x_1$, as it is bound with $y_1$ into a composite representation $\chi_p$ (along with $p-1$ other pairs) and then subsequently unbound.
-
Concept Initialization: We begin with raw concept vectors, for instance, $x_1, y_1, \dots, x_p, y_p$, all residing in $\mathbb{R}^d$. These vectors are typically initialized by sampling from a Mixture of Normal Distribution (MiND) $\Omega(\mu, 1/d)$, which ensures they have an expected value of zero but a non-zero absolute mean. This initialization is a foundational step for numerical stability.
-
Input Projection: Before any binding occurs, each individual concept vector (e.g., $x_j$ and $y_j$) undergoes a projection step. For any vector $v$, this involves applying the Hadamard transform and scaling: $\pi(v) = \frac{1}{d} Hv$. This transforms the raw input vectors into a "projected" form, $\pi(x_j)$ and $\pi(y_j)$, which are normalized and in the Hadamard domain. This pre-processing is crucial for reducing noise later.
-
Individual Binding (per pair): For each pair of projected concept vectors, say $(\pi(x_j), \pi(y_j))$, the HLB binding operation $B(\pi(x_j), \pi(y_j))$ is performed:
- Hadamard Transform (Implicit): The definition of $\pi(v)$ means $H(\pi(v)) = H(\frac{1}{d} Hv) = \frac{1}{d} H(Hv) = v$. So, when $B(\pi(x_j), \pi(y_j))$ is computed using Equation 2, the terms $H(\pi(x_j))$ and $H(\pi(y_j))$ effectively become $x_j$ and $y_j$.
- Element-wise Binding: The vectors $x_j$ and $y_j$ are then combined via an element-wise product: $x_j \odot y_j$. This is the core associative step, creating a bound representation in a Hadamard-like domain.
- Inverse Hadamard Transform & Scaling: This element-wise product $x_j \odot y_j$ is then transformed back by applying the Hadamard matrix $H$ and scaled by $1/d$. The result is $B(\pi(x_j), \pi(y_j)) = \frac{1}{d} H(x_j \odot y_j)$.
-
Composite Representation Formation: All $p$ of these individually bound vectors $B(\pi(x_j), \pi(y_j))$ are summed together. This linear summation creates a single, high-dimensional vector $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$, which now represents the bundle of all $p$ associations.
-
Query Projection (for unbinding): When we want to retrieve a specific concept, say $x_i$, from the composite $\chi_p$, we use its associated query vector $y_i$. This query vector $y_i$ also undergoes the same projection step: $\pi(y_i) = \frac{1}{d} Hy_i$.
-
Unbinding Operation (Equation 4): The unbinding process $B^*(\chi_p, \pi(y_i)^\dagger)$ then unfolds:
- Transform Composite: The Hadamard transform $H$ is applied to the composite representation $\chi_p$. Due to the linearity of $H$ and the structure of $\chi_p$, this simplifies to $H(\chi_p) = \sum_{j=1}^p (x_j \odot y_j)$. This brings the entire bundle into a domain where the individual bound pairs are clearly represented as element-wise products.
- Transform Query: The Hadamard transform $H$ is applied to the projected query vector $\pi(y_i)$, which simplifies to $H(\pi(y_i)) = y_i$.
- Inverse Query: The element-wise inverse of this transformed query, $1/y_i$, is computed. This acts as the "unbinding key" in the Hadamard domain.
- Element-wise Unbinding: The transformed composite representation $\sum_{j=1}^p (x_j \odot y_j)$ is then element-wise multiplied by the inverse query $1/y_i$. This step attempts to "divide out" the $y_i$ component, ideally isolating $x_i$.
- Inverse Hadamard Transform & Scaling: The result of this element-wise multiplication is then transformed back by applying the Hadamard matrix $H$ and scaled by $1/d$. This yields the intermediate unbinding result $B^*(\chi_p, \pi(y_i)^\dagger)$.
-
Reverse Projection (Final Output): The paper states that to obtain the "original data" (i.e., the original $x_i$) from this intermediate result, a reverse projection step is applied. This final step effectively simplifies the intermediate result to the form shown in Equation 5, which is approximately $x_i$ if only one pair was bound ($p=1$), or $x_i + \eta''$ (where $\eta''$ is a reduced noise component) if multiple pairs were bound ($p>1$).
Optimization Dynamics
The Hadamard-derived Linear Binding (HLB) mechanism, as described in the paper, is not a learning algorithm in itself; rather, it is a fixed, mathematically derived set of operations designed to be highly efficient and numerically stable. Therefore, its "optimization dynamics" do not involve iterative updates of internal parameters via gradients. Instead, its dynamics are inherent to its design and how it facilitates learning in larger, differentiable systems:
-
Fixed, Deterministic Operations: The core binding and unbinding functions of HLB are deterministic transformations based on the Hadamard matrix and element-wise operations. There are no trainable weights, biases, or other parameters within the HLB operations themselves that are updated through gradient descent or any other learning rule. The Hadamard matrix is a predefined, static component.
-
Inherent Numerical Stability: A key dynamic property of HLB is its built-in numerical stability. The Hadamard transform, by design, only involves operations with $\pm 1$ values, avoiding the complex numbers and irrational multiplications that can lead to instability in other VSA methods like HRR. Furthermore, the Mixture of Normal Distribution (MiND) used for vector initialization (Equation 6) ensures that vectors have an expected value of zero but a non-zero absolute mean. This design choice prevents division by near-zero values during the unbinding process, which would otherwise cause numerical explosions.
-
Noise Reduction Mechanism: The projection step ($\pi(x) = \frac{1}{d} Hx$) is a crucial part of HLB's internal dynamics for improving retrieval accuracy. By applying this projection to the input vectors before binding, the mechanism actively diminishes the accumulated noise ($\eta''$) that arises when multiple items are bundled together. This is a static, pre-defined noise reduction strategy, not a learned one, but it significantly impacts the system's performance and robustness.
-
Differentiability for System Integration: While HLB itself does not learn, it is explicitly designed to be compatible with "differentiable systems." This means that the mathematical operations comprising HLB (matrix multiplications, element-wise products, sums) are all differentiable. Consequently, when HLB is embedded within a larger neural network architecture (as demonstrated in the Connectionist Symbolic Pseudo Secrets and Xtreme Multi-Label Classification tasks), the entire system can still be trained end-to-end using standard gradient-based optimization algorithms (e.g., stochastic gradient descent). The HLB mechanism provides a stable and efficient way to represent and manipulate symbolic information within these learning systems, allowing the surrounding network parameters to be optimized based on a defined loss landscape (e.g., the cosine similarity loss in Equation 11 for XML classification). The HLB operations themselves simply pass gradients through without modification.
Results, Limitations & Conclusion
Experimental Design & Baselines
The authors meticulously designed experiments to validate the Hadamard-derived Linear Binding (HLB) across both classical Vector Symbolic Architecture (VSA) tasks and modern deep learning applications, ruthlessly pitting it against established baselines.
For classical VSA tasks, two primary scenarios were constructed:
-
Basic Binding/Unbinding Accuracy: This experiment aimed to prove HLB's ability to correctly retrieve a bound vector from a composite representation. The setup involved creating a pool of 1000 random vectors. From this pool, $p$ pairs of vectors (where $p$ ranged from 1 to 25) were sampled, bound together using the VSA's binding operation $B(x_i, y_i)$, and then summed to form a composite representation $s = \sum_{i=1}^p B(x_i, y_i)$. The "victim" baseline models included Holographic Reduced Representations (HRR) [32], Vector-Derived Transformation Binding (VTB) [12], and Multiply Add Permute (MAP) [10]. For each composite $s$, the experiment iterated through all left-hand components $x_q$ that were part of the original bundle and attempted to retrieve their corresponding $y_q$ using the unbinding operation $B^*(s, x_q)$. A retrieval was deemed correct if the dot product $B^*(s, x_q)^T y_q$ was greater than $B^*(s, x_q)^T y_j$ for all other $j \neq q$. This process was repeated for 50 trials, and the definitive evidence was presented as the Area Under the Curve (AUC) of accuracy versus the number of bound terms $p$, across various vector dimensions $d$ (specifically, perfect squares to accommodate VTB's constraints).
-
Sequential Binding/Unbinding Stability: This task evaluated the quality of the similarity score and the magnitude stability of the vectors under repeated binding operations. Two sub-scenarios were tested:
- Random Binding: An initial vector $b_0$ was sequentially modified by binding it with a new random vector $x_t$ for $p$ rounds, resulting in $b_{t+1} = B(b_t, x_t)$. The goal was to unbind each $x_t$ and recover the previous $b_t$.
- Auto Binding: A single random vector $x$ was repeatedly bound with the evolving state: $b_{t+1} = B(b_t, x)$.
The baselines for this experiment were HRR, VTB, and MAP-C. The crucial evidence sought was whether the similarity score $B^*(b_{t+1}, x_t)^T b_t$ remained ideally at 1 (for a present item) and if the magnitude of the vectors $||B^*(b_{t+1}, x_t)||_2$ remained constant, avoiding the common VSA pitfalls of exploding or vanishing values as $p$ increased.
For deep learning applications, HLB was integrated into two recent neuro-symbolic tasks:
-
Connectionist Symbolic Pseudo Secrets (CSPS) [3]: This task explored using VSAs for heuristic security, mimicking a "one-time-pad" to obscure inputs and outputs when offloading computation to untrusted third parties. The experiment involved binding a random VSA vector $s$ (the "secret") to the input $x$ to create an obscured representation $B(s, x)$. A third-party network processed this obscured input, returning an output $y$, which was then locally unbound with the secret $B^*(y, s)$ to get the final answer. The baselines were HRR, VTB, MAP-C, and MAP-B. The experiments were run on a single NVIDIA TESLA P100 GPU with 32GB memory.
- Accuracy: The primary metric was Top@1 and Top@5 classification accuracy on five standard image datasets: MNIST, SVHN, CIFAR-10, CIFAR-100, and Mini-ImageNet.
- Security: To ruthlessly prove the information-hiding claim, the Adjusted Rand Index (ARI) was calculated. A snooping third-party attempted to cluster the obscured inputs $B(x, s)$ and outputs $y$ using various clustering algorithms (K-means, Gaussian Mixture Model, Birch, HDBSCAN). An ARI score near zero was the definitive evidence of successful information hiding, indicating random label assignment from the attacker's perspective.
-
Xtreme Multi-Label (XML) Classification [9]: This task addressed scenarios where a single input needs to be classified into a vast number of possible classes ($C \gg d$, where $d$ is the input dimension), common in e-commerce. The VSA was used to represent the sparse output space. The experimental setup followed the network details from [9], replacing their original VSA with HLB and the baseline VSAs (HRR, VTB, MAP). The evaluation was performed on eight diverse datasets (BIBTEX, DELICIOUS, MEDIAMILL, EURLEX-4K, EURLEX-4.3K, WIKI10-31K, AMAZON-13K, DELICIOUS-200K). The key metrics were normalized discounted cumulative gain (nDCG) and propensity-scored nDCG (PSnDCG), which are standard for evaluating multi-label classification performance.
What the Evidence Proves
The empirical evidence strongly supports the theoretical claims and demonstrates HLB's superior or competitive performance across a broad spectrum of VSA applications.
Theoretical Validation:
The paper provides compelling evidence that HLB's core mathematical mechanisms work as intended. The theoretical relationship that the cosine similarity $\phi$ between an original vector $x_i$ and its retrieved version $\hat{x}_i$ is approximately $1/\sqrt{p}$ (Theorem 3.2) is empirically validated by heatmaps (Figure 1) and plots (Figure 6). This confirms the effectiveness of the proposed similarity augmentation.
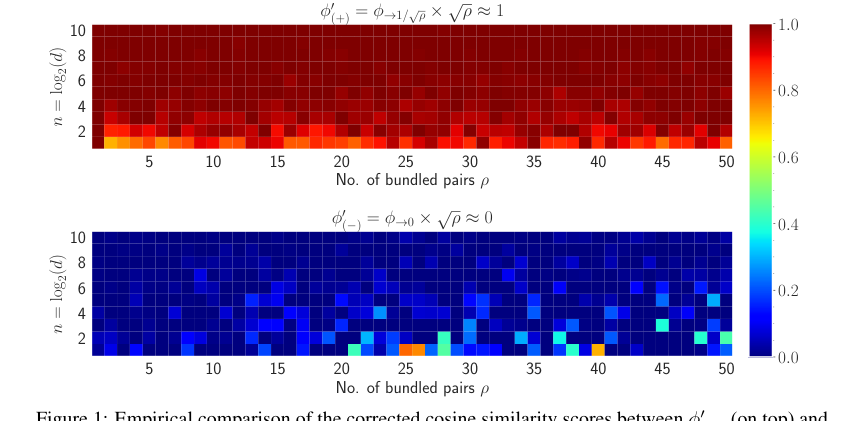 Figure 1. Empirical comparison of the corrected cosine similarity scores between ϕ1 p`q (on top) and ϕ1 p´q (on bottom) for varying n and ρ shown in heatmap. The dimension, i.e., d “ 2n is varied from 2 to 1024 pn P t1, 2, ¨ ¨ ¨ , 10uq and the number of vector pairs bundled is varied from 1 to 50. This shows that we can accurately identify when a vector x has been bound to a VSA or not when we keep track of how many pairs of terms ρ are included
Figure 1. Empirical comparison of the corrected cosine similarity scores between ϕ1 p`q (on top) and ϕ1 p´q (on bottom) for varying n and ρ shown in heatmap. The dimension, i.e., d “ 2n is varied from 2 to 1024 pn P t1, 2, ¨ ¨ ¨ , 10uq and the number of vector pairs bundled is varied from 1 to 50. This shows that we can accurately identify when a vector x has been bound to a VSA or not when we keep track of how many pairs of terms ρ are included
Furthermore, the theoretical prediction for the norm of the composite representation, $||X_p||_2 \approx \mu^2 \sqrt{p} \cdot d$ (Theorem B.1), is also closely matched by experimental results (Figure 5), albeit with some variation as $p$ increases due to approximations. Crucially, the projection step introduced in HLB is definitively shown to diminish accumulated noise. Heatmaps comparing noise components with and without projection (Figure 4) clearly illustrate that the maximum noise without projection is significantly higher (19.38) compared to with projection (7.18), proving that this architectural choice is effective in improving retrieval accuracy.
Classical VSA Tasks:
In the basic binding/unbinding accuracy task, HLB consistently shows performance comparable to, or even exceeding, HRR and VTB, while definitively outperforming MAP across various dimensions (Figure 2). This hard evidence, presented as AUC scores, proves that HLB's binding and unbinding operations are robust and effective for fundamental VSA operations. More impressively, in the sequential binding/unbinding stability task (Figure 3), HLB stands out by maintaining an ideal similarity score of 1 for present items and, critically, a constant vector magnitude regardless of the number of bound vectors $p$. This is a significant advantage over baselines like HRR, VTB, and MAP, which exhibit decaying similarity scores or exploding/vanishing magnitudes. This stability is undeniable evidence that HLB addresses a key numerical stability issue prevalent in other VSAs, making it a more reliable foundation for complex symbolic processing.
Deep Learning Tasks:
HLB's efficacy extends robustly to deep learning contexts. In the Connectionist Symbolic Pseudo Secrets (CSPS) task, HLB not only significantly outperforms all prior VSA methods in classification accuracy across all five datasets (MNIST, SVHN, CIFAR-10, CIFAR-100, Mini-ImageNet) as shown in Table 2, but it also achieves superior information hiding. The Adjusted Rand Index (ARI) scores (Table 3) for HLB are consistently closer to zero for SVHN, CIFARs, and Mini-ImageNet, indicating that a snooping third-party would find it much harder to cluster inputs or outputs, thus proving its dual benefit of improved accuracy and enhanced security. While MNIST showed some degeneracy in ARI for all methods, this is acknowledged as a known issue for CSPS security. This dual improvement is a strong testament to HLB's practical utility.
For Xtreme Multi-Label (XML) Classification, HLB sets a new state-of-the-art (SOTA). Table 4 presents the nDCG and PSnDCG scores across eight diverse datasets, ranging from "easy" to "hard" in terms of features and labels. HLB achieves the best scores on all datasets for both metrics, demonstrating its superior ability to handle high-dimensional, sparse output spaces efficiently and effectively. This comprehensive victory across multiple datasets and metrics provides definitive, undeniable evidence that HLB's core mechanism translates into tangible performance gains in complex, real-world deep learning scenarios.
Limitations & Future Directions
While the proposed Hadamard-derived Linear Binding (HLB) demonstrates impressive performance and theoretical soundness, it's important to acknowledge certain limitations and consider avenues for future development to further evolve these findings.
Limitations:
One implicit limitation, though not explicitly stated as such, arises from the mathematical derivation. The Hadamard matrix, a cornerstone of HLB, typically requires vector dimensions $d$ to be powers of 2. While this is common in many computational contexts, it might necessitate padding or other workarounds for applications with arbitrary dimensions, potentially introducing inefficiencies or complexities. The paper also notes that the approximation made in Theorem B.1 (discarding the noise term $\xi$ in Equation 17) leads to increased variation in the norm of the composite representation as the number of bundled pairs $p$ grows (Figure 5). While the overall trend is maintained, this suggests that for extremely large $p$, the approximation might become less precise, potentially impacting the system's predictability or requiring more sophisticated noise handling.
Furthermore, the security offered by CSPS, while significantly improved by HLB, is described as heuristic rather than cryptographically guaranteed. The MNIST dataset's ARI results, showing some degeneracy, serve as a reminder that such security is not absolute. This implies that for applications demanding stringent, provable security, HLB within the CSPS framework might not be sufficient on its own. Finally, while the binding step itself boasts an efficient $O(d)$ complexity, the paper doesn't delve deeply into the overall computational footprint (e.g., memory usage, training time for very large models, or energy consumption) of HLB when integrated into large-scale deep learning systems, particularly as $d$ or $p$ scale to extreme values.
Future Directions:
-
Generalization to Arbitrary Dimensions and Alternative Transforms:
- Discussion: How can HLB's benefits be extended to vector dimensions that are not powers of 2 without resorting to simple padding, which can be inefficient? Could research explore "approximate" Hadamard transforms for non-power-of-2 dimensions, or investigate other orthogonal transforms that offer similar computational advantages and desirable VSA properties but are more flexible with dimensionality? This could broaden HLB's applicability significantly.
- Perspective: From a theoretical standpoint, this challenges the strict mathematical elegance of the Hadamard basis but opens doors to practical engineering solutions. From an application perspective, it removes a potential barrier for integration into diverse existing datasets and models.
-
Towards Provable Security in Neuro-Symbolic AI:
- Discussion: Given that CSPS security is heuristic, what are the next steps to integrate HLB with more robust cryptographic primitives? Can HLB's linear properties and efficient unbinding be leveraged to design neuro-symbolic systems that offer provable security guarantees, perhaps by combining it with homomorphic encryption schemes or secure multi-party computation protocols? This would move beyond heuristic security to truly trustworthy AI.
- Perspective: This is a critical area for sensitive applications. A security-focused researcher might explore formal verification methods, while an AI practitioner might look for practical, efficient implementations that balance security with performance.
-
Dynamic $p$ Estimation and Adaptive Similarity Augmentation:
- Discussion: The paper highlights the importance of knowing or estimating $p$ (the number of bundled pairs) for the similarity augmentation step. In complex, dynamic neuro-symbolic systems, $p$ might not always be explicitly known. How can we develop adaptive mechanisms or learned estimators that can dynamically infer $p$ from the composite representation itself, allowing for real-time, context-aware similarity correction?
- Perspective: This would enhance the autonomy and robustness of VSA-based systems. A machine learning expert might propose neural network architectures for $p$ estimation, while a cognitive scientist might draw parallels to how biological systems handle uncertainty in compositional representations.
-
Exploration of Non-Symmetric Binding and Advanced Compositionality:
- Discussion: While HLB is symmetric, the paper mentions VTB's non-symmetric nature. What specific types of symbolic relationships or cognitive tasks inherently benefit from non-symmetric binding (e.g., "agent-action-object" relationships)? Can the Hadamard-derived framework be extended or modified to support non-symmetric binding operations while retaining its computational efficiency and numerical stability? This could unlock new capabilities for representing directed relationships and more complex semantic structures.
- Perspective: This delves into the expressiveness of VSAs. A linguist or cognitive AI researcher might identify specific grammatical or logical structures that demand non-symmetric binding, pushing the mathematical framework to accommodate richer symbolic representations.
-
Deeper Integration with Advanced Deep Learning Architectures:
- Discussion: HLB has shown promise in CSPS and XML. How can it be more deeply and natively integrated into cutting-edge deep learning architectures? Could HLB-based binding and unbinding operations replace or augment components in transformer models (e.g., for attention mechanisms or positional encodings), graph neural networks, or recurrent neural networks to imbue them with stronger symbolic reasoning capabilities and improved compositional generalization?
- Perspective: This is about bridging the gap between symbolic and connectionist AI. A neural architecture designer might explore novel layer designs, while a theoretical computer scientist might analyze the computational graphs and information flow in such hybrid systems.
-
Robustness to Adversarial Attacks and Real-World Noise:
- Discussion: While the projection step reduces noise, how robust is HLB to various forms of adversarial attacks or real-world sensor noise, especially in safety-critical applications? What further mechanisms, such as robust initialization strategies, noise-aware training, or error-correction codes, could be integrated with HLB to enhance its resilience and reliability in noisy or adversarial environments?
- Perspective: This is crucial for deployment. A security researcher would focus on attack vectors and defenses, while an engineer might consider practical noise models and hardware-level resilience.
-
Hardware Acceleration and Energy-Efficient Implementations:
- Discussion: Given HLB's $O(d)$ complexity for binding and its reliance on Hadamard transforms (which are amenable to fast algorithms), what are the opportunities for specialized hardware acceleration? Could HLB be efficiently implemented on neuromorphic chips, FPGAs, or other custom hardware to achieve ultra-low power consumption and high throughput for edge AI devices or large-scale symbolic processing systems?
- Perspective: This is a hardware-software co-design challenge. A computer architect would investigate parallelization and memory access patterns, while a sustainability advocate might highlight the potential for energy-efficient AI.
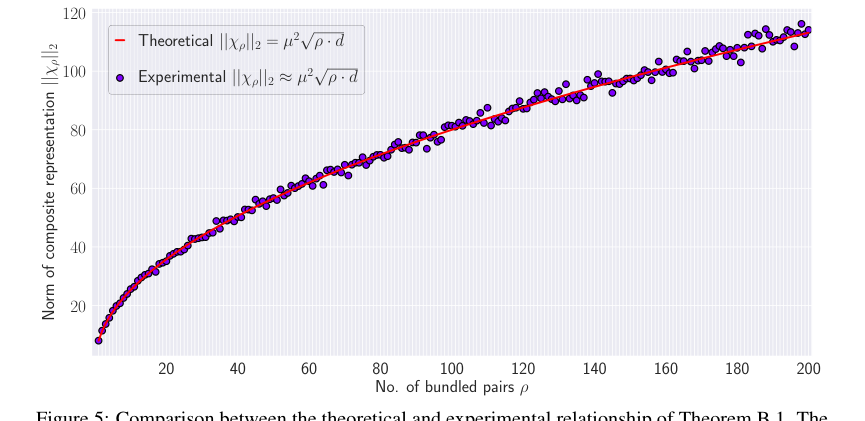 Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
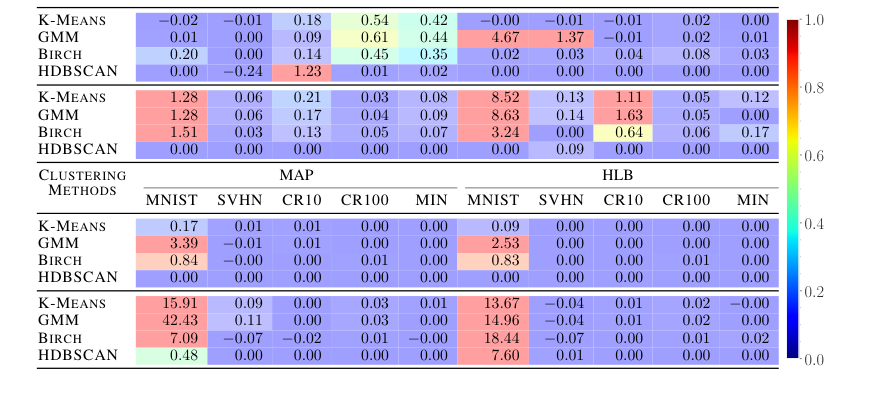 Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding