基于沃尔什-哈达玛变换的线性向量符号架构
Vector Symbolic Architectures (VSAs) are one approach to developing Neuro-symbolic AI, where two vectors in are 'bound' together to produce a new vector in the same space.
背景与学术渊源
起源与学术渊源
本文所解决的问题源于向量符号架构 (Vector Symbolic Architectures, VSAs) 领域,这是一种开发神经符号人工智能的独特方法。这一学术渊源可以精确追溯到 Smolensky [38] 的工作,他通过张量积表示 (Tensor Product Representation, TPR) 开启了 VSA 的方法。在 TPR 中,概念被表示为高维向量,这些向量通过计算外积来“绑定”在一起,形成新的复合概念。这项基础性工作旨在实现连接主义框架内的符号式操作,从而能够表示逻辑语句和结构 [13]。
历史上,大多数 VSA 的发展都早于深度学习和自动微分的广泛应用。它们主要关注在手工设计的系统中的有效性,这些系统通常受到经典人工智能任务或认知科学的启发。然而,这种早期的关注点导致了在尝试将 VSA 集成到现代可微分系统中时,出现了一些根本性的限制或“痛点”:
- 计算复杂度: 早期的 VSA 方法,例如 TPR,存在不切实际的计算复杂度。例如,使用 TPR 绑定 $p$ 个项的复杂度为 O($d^p$),其中 $d$ 是向量维度。即使是更通用的线性 VSA,将绑定表示为矩阵运算,通常也需要 O($d^2$) 的复杂度,这使得它们对于实时或大规模应用来说过于缓慢。
- 数值不稳定性: 其他流行的 VSA 方法,如全息降维表示 (Holographic Reduced Representations, HRR) [32],依赖于傅里叶变换 (FT) 和循环卷积。虽然功能强大,但这些运算涉及无理数乘法和复数,这可能导致实际实现中的数值不稳定性。先前的工作 [9] 尝试通过投影步骤来缓解这一问题,但根本性问题依然存在。
- 在可微分系统中的性能不佳: 许多现有的 VSA 方法并非为了无缝集成到深度学习框架而设计。它们在使用梯度下降和自动微分时,通常缺乏有利的计算效率和数值稳定性,导致在现代神经符号人工智能任务中的性能低于预期。
本文旨在通过推导一种新的 VSA——哈达玛变换导出的线性绑定 (Hadamard-derived Linear Binding, HLB),来解决这些限制。HLB 旨在通过利用沃尔什-哈达玛变换的特性,为绑定提供 O($d$) 的复杂度,提高数值稳定性,并在可微分深度学习应用中获得更好的性能。
直观领域术语
为了使本文的概念易于理解,让我们用日常类比来解释一些专业术语:
- 向量符号架构 (VSAs): 想象你的大脑中有一组独特的“思维向量”,每个向量代表一个基本概念,如“猫”、“快乐”或“红色”。VSA 就像一种特殊的思维语言,可以让你将这些思维向量组合起来,形成新的、更复杂的想法,例如“快乐的猫”或“红色的汽车”,然后稍后“询问”你的大脑来检索这些复杂想法的组成部分。这是一种让计算机像我们用语言一样操纵概念的方式,但使用的是数字。
- 绑定 (Binding): 这是将两个或多个概念向量组合起来,创建一个表示它们之间关系或组成的新的向量的过程。把它想象成在食谱中混合两种配料,比如“面粉”和“水”,得到“面团”。“面团”是一个新的实体,包含了两种原始配料,但以一种组合的形式。在 VSA 中,绑定“猫”和“快乐”会创建一个表示“快乐的猫”的新向量。
- 解绑 (Unbinding): 这是绑定的逆过程。给定一个组合的概念向量(如“面团”)和它的一个原始组成部分(“面粉”),解绑允许你检索另一个组成部分(“水”)。这就像获取“快乐的猫”向量和“快乐”向量,然后能够检索出“猫”向量。这个操作对于查询和提取组合表示中的信息至关重要。
- 哈达玛变换 (Hadamard Transform): 想象一种特殊的数字“洗牌”或“编码”过程。与处理波浪和虚数的傅里叶变换不同,哈达玛变换要简单得多。它只涉及加法和减法,其输出值始终是 +1 或 -1。这使得它非常快速且数值稳定,就像一个超级高效、朴实无华且易于逆转的数据压缩器。
- 神经符号人工智能 (Neuro-symbolic AI): 这是一种人工智能方法,试图兼顾两全其美:神经网络的直观模式学习能力(如人类识别面孔的方式)和传统符号 AI 的逻辑、基于规则的推理能力(如计算机遵循指令的方式)。它是一种能够以结构化方式“感受”和“思考”的 AI,旨在克服每种方法单独使用时的局限性。
符号表
| 符号 | 描述 |
|---|---|
| $B(x, y)$ | 绑定操作,它将两个概念/向量 $x$ 和 $y$ 连接起来,生成一个新的向量 $z$。 |
| $B^*(x, y)$ | 解绑操作,它在给定另一个分量的情况下检索绑定向量的一个分量。 |
| $x, y, z$ | 表示 VSA 空间中的概念或数据点的通用向量。 |
| $d$ | VSA 中向量的维度,即 $x \in \mathbb{R}^d$。 |
问题定义与约束
核心问题表述与困境
本文所解决的核心问题在于现有向量符号架构 (VSAs) 应用于现代深度学习系统时的局限性。
起点(输入/当前状态):
当前的 VSA 通过绑定两个向量 $x, y \in R^d$,它们代表概念,使用绑定操作 $B(x, y) = z$ 将它们绑定成一个新的复合向量 $z \in R^d$。逆解绑操作 $B^*(x, y)$ 允许检索一个分量。虽然这些架构因其自然的符号人工智能风格的操作(交换性、结合性、逆操作)而为神经符号方法提供了有吸引力的平台,但它们大多是在深度学习和自动微分广泛应用之前开发的。因此,许多现有的 VSA 方法表现出几个关键的缺点:
1. 高计算复杂度: 许多 VSA,特别是那些被视为线性操作 $B(a,b) = a^T G b$ 和 $B^*(a,b) = a^T F b$(其中 $G$ 和 $F$ 是 $d \times d$ 矩阵)的方法,在绑定步骤中会产生 $O(d^2)$ 的计算复杂度。虽然对于对角矩阵可以降低到 $O(d)$,但对于更复杂、更具表现力的绑定,情况并非如此。例如,张量积表示 (TPR) 在绑定 $p$ 个项时具有不切实际的 $O(d^p)$ 复杂度。
2. 数值不稳定性: 像全息降维表示 (HRR) 这样依赖傅里叶变换和复数的方法,由于在实值向量上操作时涉及“无理数乘法”,容易出现数值不稳定性。
3. 在可微分系统中的性能不佳: 现有的 VSA 并非专门为基于梯度的学习而设计,这意味着如果它们的底层矩阵通过梯度下降学习而没有额外的约束,它们的属性(如交换性)可能不会得到维持。它们在深度学习应用中的性能通常低于预期。
期望终点(输出/目标状态):
本文旨在引入一种新颖的 VSA,称为哈达玛变换导出的线性绑定 (HLB),它克服了这些局限性。目标是开发一种 VSA,它具有:
1. 计算效率高: 在绑定步骤中实现 $O(d)$ 的复杂度,显著快于 $O(d^2)$ 或 $O(d \log d)$(后者通常与哈达玛变换本身相关,但这里的推导产生了线性复杂度)。
2. 数值稳定: 通过仅使用实数和简单的算术运算(加法、减法和 $\{-1, 1\}$ 值)来避免基于复数的 VSA 的不稳定性问题。
3. 高效性高: 在经典 VSA 任务和现代深度学习应用中,性能与现有 VSA 相当或更优。
4. 可微分系统兼容: 从头开始设计,以便无缝集成到可微分系统中并表现良好,支持神经符号人工智能。
5. 对称性: 绑定操作 $B(x,y)$ 应该是对称的,即 $B(x,y) = B(y,x)$,这对于许多 VSA 应用来说是一个理想的属性。
缺失环节或数学鸿沟:
确切的缺失环节是推导出一种 VSA 绑定和解绑机制,该机制利用哈达玛变换的有利特性来实现线性计算复杂度和数值稳定性,同时保留核心的符号操作能力并易于进行可微分学习。之前的尝试要么存在复杂性、不稳定性问题,要么缺乏明确为深度学习集成而设计。本文通过用哈达玛变换替换傅里叶变换(HRR 中使用),并仔细设计绑定和解绑操作以利用其独特性质(如递归结构和自逆性质),来弥合这一鸿沟。
痛苦的权衡或困境:
试图解决这个问题的研究人员一直被几个痛苦的权衡所困扰:
* 表现力与计算成本: 实现丰富的组合表示(例如,绑定多个项)通常会导致计算复杂度呈指数级增长,如 TPR 的 $O(d^p)$ 成本所示。这迫使人们在高度表现力的符号结构和实际计算之间做出选择。
* 符号保真度与可学习性: 虽然 VSA 提供了强大的符号属性,但为了在深度神经网络中进行梯度下降学习而对其进行调整,常常会冒着损害这些属性的风险。学习底层矩阵 $G$ 和 $F$ 而没有额外约束可能会破坏所需的交换性或结合性。这在保持“神经符号属性”和优化现代机器学习范式之间造成了两难。
* 数学优雅性与数值鲁棒性: 使用傅里叶变换等数学上优雅的工具进行循环卷积(如 HRR 中)会引入复数和无理数乘法,这在用实值向量进行实际系统实现时可能导致数值不稳定性。这迫使人们在理论纯粹性和鲁棒的实际性能之间做出选择。
约束与失败模式
这个问题因作者遇到的几个严峻的现实障碍而变得异常困难:
- 计算复杂度墙: 对绑定步骤实现 $O(d)$ 复杂度的需求是一个严格的约束。许多现有的 VSA 具有 $O(d^2)$ 或 $O(d \log d)$ 的复杂度,这对于高维向量 ($d$) 的可扩展性是一个重大障碍。这限制了它们在大规模深度学习模型中的应用,因为效率至关重要。
- 数值不稳定性: 像 HRR 这样的现有 VSA 的一个主要失败模式是数值不稳定性。这源于涉及复数和无理数乘法的运算,可能导致浮点误差和不可靠的结果,尤其是在处理实值向量时。提出的解决方案必须从根本上避免这一点。
- 复合表示中的噪声累积: 当多个概念被绑定到一个单一的复合向量中时(即捆绑了 $p \ge 2$ 个项),噪声不可避免地会累积。这种噪声会降低解绑操作的准确性,使得可靠地检索单个分量变得困难。如果没有机制来缓解这一点,VSA 在复杂符号结构中的效用将受到严重限制。本文表明,如果没有投影步骤,噪声分量 $\eta'$ 会显著高于有投影的 $\eta''$。
- 向量初始化挑战: 为了使绑定和解绑操作能够正确工作,向量必须具有零的期望值。然而,如果向量分量被初始化得接近零,那么在解绑过程中对这些查询向量进行后续除法可能会“破坏噪声分量并产生数值不稳定性”。这种特定的初始化约束需要仔细的设计选择,从而引入了混合正态分布 (Mixture of Normal Distribution, MiND)。
- 多次绑定的幅度稳定性: 理想的 VSA 应该保持其复合向量的幅度稳定,这意味着幅度不应“随着 $p$ 的增加而爆炸/消失”(绑定的项数)。这是其他 VSA 中近似解绑程序的常见失败模式,其中相似度分数随着 $p$ 的增加而衰减或幅度变得不稳定。
- 硬件内存限制: 实验设置使用了单个 NVIDIA TESLA P100 GPU 和 32GB 内存,这隐含地施加了一个约束,即任何提出的 VSA 都必须足够内存高效,以便在典型的深度学习硬件环境中运行。
- 多标签分类中的极端稀疏性: 在极端多标签 (Extreme Multi-label, XML) 分类等应用中,可能的类别数量 ($L \ge 100,000$) 远远超过输入维度 ($d \approx 5000$),并且对于任何给定输入,只有一小部分类别是相关的(通常少于 100)。这种极端稀疏性使得传统的线性层在计算上不可行($O(L)$ 复杂度),需要一种 VSA 来有效地表示这个庞大、稀疏的输出空间(将复杂度降低到 $O(K)$,其中 $K$ 是存在的类别数)。
为什么选择这种方法
选择的必然性
采用哈达玛变换导出的线性绑定 (HLB) 不仅仅是一种偏好,而是由现有向量符号架构 (VSAs) 应用于现代深度学习环境时的固有局限性所驱动的必然选择。作者认识到,传统的“SOTA”VSA 方法,如全息降维表示 (HRR)、向量导出变换绑定 (VTB) 和乘加置换 (MAP),在数值稳定性、计算效率和与可微分系统的无缝集成方面,根本不足以满足他们的目标。
关键的认识源于这样一个观察:虽然 VSA 为神经符号方法提供了一个有吸引力的平台,但许多现有方法是在深度学习和自动微分广泛普及之前开发的。例如,HRR 依赖于傅里叶变换 (FT) 和循环卷积,由于其依赖于复数和无理数乘法,存在数值不稳定性(第 3 页)。这使得它在需要鲁棒数值运算的系统中难以使用,尤其是在涉及梯度时。
相比之下,哈达玛变换天然地避免了这些问题。它仅在实数上运行,仅执行加法和减法,从而消除了无理数乘法和复数算术(第 3 页)。这一特性使其成为维持数值稳定性的独特可行解决方案,而数值稳定性是可微分系统中至关重要的问题,因为微小的数值误差会传播并导致学习不稳定。此外,哈达玛矩阵的自逆性质简化了解绑操作 $B^*$ 的设计,使整个系统更加优雅和鲁棒。
比较优势
HLB 在几个关键方面展示了优于先前黄金标准的定性优势,这些优势超出了单纯的性能指标。
首先,在计算复杂度方面,HLB 在其绑定步骤中实现了令人印象深刻的 $O(d)$ 复杂度(第 1 页)。与通用线性运算的 $O(d^2)$ 复杂度(许多 VSA 可以视为此类)甚至通常与沃尔什-哈达玛变换本身相关的 $O(d \log d)$ 复杂度(第 2 页)相比,这是一个显著的结构优势。这种线性复杂度是通过将绑定函数重新定义为哈达玛域中的逐元素乘积 $B'(x, y) = x \odot y$ 来实现的(第 5 页),这对于高维向量来说非常高效。
其次,数值稳定性是核心优势。如前所述,哈达玛变换仅使用 $\{-1, 1\}$ 值和实数算术,完全避开了基于傅里叶变换的方法(如 HRR)中普遍存在的数值不稳定性问题,后者涉及复数和无理数乘法(第 2、3 页)。这种固有的稳定性对于可靠运行至关重要,尤其是在对数值精度敏感的模型深度学习中。
第三,HLB 表现出优越的噪声处理能力。本文引入了一个投影步骤(定义 3.2,第 4 页),该步骤显著减小了解绑过程中累积的噪声。实证结果(图 4,第 15 页)清楚地表明,带有此投影的噪声分量 ($\eta''$) 远低于没有投影的噪声分量 ($\eta'$),从而提高了检索准确性。这种结构性增强直接解决了 VSA 中噪声随多次绑定而累积的常见挑战。
最后,HLB 展示了幅度与相似度分数的出色一致性和稳定性。图 3(第 7 页)说明,HLB 对于存在的项始终返回理想的相似度分数 1,并且无论绑定向量的数量如何,都保持恒定的幅度。这可以防止 HRR、VTB 和 MAP 中观察到的“爆炸/消失”值,这是设计稳定 VSA 解决方案和确保可靠信息检索的关键属性。这种稳定性归因于用于向量初始化的混合正态分布 (Mixture of Normal Distribution, MiND) 的性质(性质 3.1,第 5 页)。
与约束的对齐
所选的 HLB 方法完美地符合开发适用于现代神经符号人工智能的 VSA 的隐式和显式约束。
- 计算效率: VSA 的一个主要约束,尤其是在深度学习中,是低计算开销。HLB 的 $O(d)$ 绑定复杂度直接解决了这个问题,使其适用于高维数据和大规模应用(第 1、5 页)。
- 数值稳定性: 通过哈达玛变换(避免复数和无理数算术)来满足鲁棒数值运算的要求,确保了稳定性(第 2、3 页)。
- 在可微分系统中的性能: 本文明确指出目标是开发一种“在可微分系统中表现良好”的 VSA(摘要,第 1 页)。HLB 的线性运算、实值性质和数值稳定性使其与梯度下降优化(深度学习的基石)天然兼容。
- 神经符号属性: VSA 因其符号操作能力(交换性、结合性、逆操作)而受到重视。哈达玛变换“已经是结合性和分配性”(第 2 页),简化了设计以在没有额外复杂约束的情况下保留这些基本属性。
- 噪声管理: 复合表示中噪声累积的问题是一个重大挑战。HLB 的 MiND 初始化(方程 6,第 5 页)和明确的投影步骤(定义 3.2,第 4 页)旨在最小化和管理此噪声,即使有许多绑定项也能确保准确检索。
问题严峻要求与 HLB 的独特属性之间的这种“结合”在其设计选择中显而易见,从变换选择到初始化和投影步骤。
替代方案的拒绝
本文为拒绝其他流行的 VSA 方法以及普遍的深度学习方法,针对特定问题背景提供了清晰的理由。
- 现有 VSA (HRR, VTB, MAP):
- 数值不稳定性: HRR 是一个关键的基线,因其“由于复数的无理数乘法而导致的数值不稳定性”(第 3 页)而受到明确批评。这是寻求像 HLB 这样使用实值运算的替代方案的直接原因。
- 计算复杂度: 本文指出,许多 VSA 如果实现为通用线性运算,将产生 $O(d^2)$ 的复杂度,这太高了(第 1 页)。张量积表示 (TPR) 因“绑定多个项时 $O(d^p)$ 的复杂度而不切实际”(第 2 页)而被排除。HLB 的 $O(d)$ 复杂度提供了实质性的改进。
- 在可微分系统中的性能: 对“大多数 VSA”的普遍批评是,它们“是在深度学习和自动微分变得流行之前开发的,而是专注于手工设计的系统中的有效性”,并且“在数值稳定性、计算复杂度或在可微分系统上下文中的其他方面低于预期的性能”(第 1 页)。这凸显了它们不适合本文的主要应用领域。
- 噪声和稳定性问题: 图 3(第 7 页)经验性地证明,HRR、VTB 和 MAP-C/B 在绑定的向量数量增加时,存在相似度分数衰减和幅度爆炸/消失的问题。HLB 保持恒定幅度和理想相似度分数的能力直接解决了替代方案中的这些故障。
- 通用深度学习(例如,标准 CNN、基本扩散、Transformer): 虽然没有在直接比较中明确“拒绝”,但本文对“神经符号人工智能”(摘要,第 1 页)的关注暗示纯粹的连接主义模型缺乏 VSA 提供的固有符号操作能力。对于“连接主义符号伪秘密”(CSPS)或“极端多标签分类”(XML)等任务,利用 VSA 的符号属性来获得特定优势:
- CSPS: 对于安全计算卸载,同态加密 (HE) 被认为“比运行神经网络本身更昂贵”,从而使其无效(第 8 页)。VSA 提供了一种启发式替代方法,用于在减少本地计算的同时隐藏输入/输出。纯神经网络不会固有地提供这种“加密/解密”机制。
- XML: VSA 用于“规避这种成本”,即 $O(L)$ 的计算复杂度(其中 $L$ 是类别数量),通过利用符号操作将其降低到 $O(K)$(其中 $K$ 是存在的类别数量,$K \ll L$)(第 9 页)。标准的深度学习架构通常需要一个大型输出层,从而产生 VSA 旨在避免的 $O(L)$ 成本。
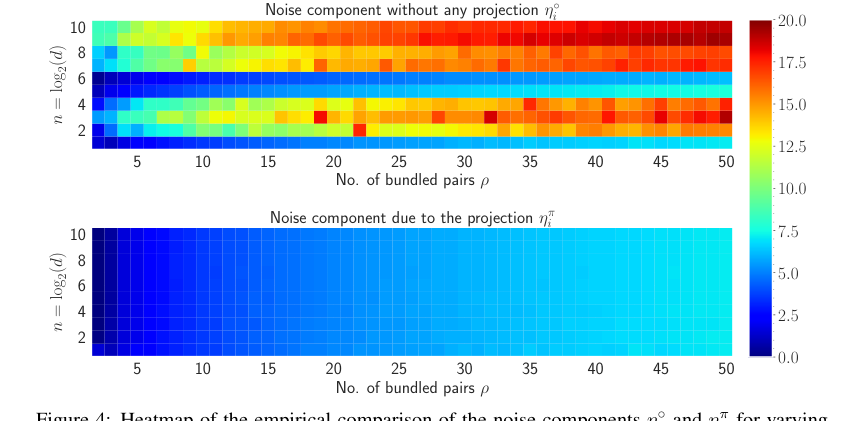 Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
Figure 4. shows the heatmap visualization of the noise for both η˝ i and ηπ i in natural log scale. The amount of noise accumulated without any projection to the inputs is much higher compared to the noise accumulation with the projection. For varying n and ρ, the maximum amount of noise accumulated when projection is applied is 7.18 and without any projection, the maximum amount of noise is 19.38. Also, most of the heatmap of ηπ i remains in the blue region whereas as n and ρ increase, the heatmap of η˝ i moves towards the red region. Therefore, it is evident that the projection to the inputs diminishes the amount of accumulated noise with the retrieved output
数学与逻辑机制
主方程
哈达玛变换导出的线性绑定 (HLB) 机制的核心在于其绑定和解绑操作的定义,这些操作利用了沃尔什-哈达玛变换。定义这种变换逻辑的绝对核心方程是绑定函数和解绑函数,特别是在应用于投影输入以增强性能和稳定性时。
两个向量 $x, y \in \mathbb{R}^d$ 的绑定操作 $B(x,y)$ 定义为:
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) \quad \text{(方程 2)} $$
当处理由多个绑定对求和形成的复合表示,并在输入向量应用投影步骤后,解绑操作 $B^*(\chi_p, \pi(y_i)^\dagger)$ 会产生一个中间结果。投影函数 $\pi(v)$ 定义为 $\pi(v) = \frac{1}{d} Hv$。复合表示 $\chi_p$ 由 $p$ 个投影绑定对的求和形成:$\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$。解绑操作应用于此复合表示,并使用投影查询向量 $\pi(y_i)$ 的逆,给出:
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) \quad \text{(方程 4)} $$
然后,本文表明,在进行额外的反向投影步骤后,这个中间结果简化为最终检索到的输出,它近似等于 $x_i$(与 $y_i$ 相关的原始向量)加上一个噪声项 $\eta''$,当 $p > 1$ 时。
逐项解剖
让我们剖析这些主方程的组成部分,以理解它们的数学定义、物理/逻辑作用以及作者的设计选择。
绑定方程(方程 2)的解剖
$$ B(x,y) = \frac{1}{d} H(Hx \odot Hy) $$
- $B(x,y)$:
- 数学定义: 输入向量 $x$ 和 $y$ 之间绑定操作产生的输出向量。
- 物理/逻辑作用: 这是将由向量 $x$ 和 $y$ 表示的两个概念关联成一个单一的新向量的核心函数。它是 VSA 中创建组合表示的基本构建块。
- 为何选择此项: 这种特定形式是通过用哈达玛变换替换循环卷积中的傅里叶变换(HRR 中使用)推导出来的,旨在提高计算效率和数值稳定性。
- $x, y$:
- 数学定义: 维度为 $d$ 的输入向量,$x, y \in \mathbb{R}^d$。
- 物理/逻辑作用: 每个向量在 VSA 框架内代表一个单独的概念、符号或信息片段。
- 为何选择此项: VSA 天然地在处理高维实值向量以编码和操作符号信息。
- $d$:
- 数学定义: 输入向量 $x$ 和 $y$ 的维度。
- 物理/逻辑作用: 作为归一化因子。
- 为何选择此项: 除以 $d$ 是 VSA 中保持结果绑定向量幅度在合理范围内的一种常见做法,可以防止值爆炸并确保近似正交性。它还抵消了两次应用哈达玛变换引入的缩放因子 ($H(Hv) = dv$)。
- $H$:
- 数学定义: $d \times d$ 的哈达玛矩阵。该矩阵仅包含 $+1$ 和 $-1$ 的条目,并以递归方式定义(例如,$H_1 = [1]$,$H_{2n} = \begin{pmatrix} H_n & H_n \\ H_n & -H_n \end{pmatrix}$)。
- 物理/逻辑作用: 对向量执行哈达玛变换。
- 为何选择此项: 选择哈达玛变换是因为其计算效率(在此推导中为线性复杂度 $O(d)$,或对于快速沃尔什-哈达玛变换为 $O(d \log d)$)、数值稳定性(仅 $\pm 1$ 值,避免复数或无理数乘法)以及其方便的性质,即其转置是其自身的逆 ($H^T = H$ 且 $H H = dI$),这简化了逆运算的设计。
- $Hx$:
- 数学定义: 向量 $x$ 的哈达玛变换。
- 物理/逻辑作用: 将输入向量 $x$ 从其原始域转换到哈达玛域。
- 为何选择此项: 此变换对于绑定操作至关重要。通过将向量转换到哈达玛域,逐元素乘法可以实现一种绑定效果,类似于原始域中的循环卷积(这通常通过 HRR 在傅里叶域中的逐元素乘法来完成)。
- $Hy$:
- 数学定义: 向量 $y$ 的哈达玛变换。
- 物理/逻辑作用: 将输入向量 $y$ 转换到哈达玛域。
- 为何选择此项: 与 $Hx$ 原因相同。
- $\odot$:
- 数学定义: 逐元素乘积(也称为哈达玛积)。
- 物理/逻辑作用: 此运算符在哈达玛域中执行变换后向量的实际绑定。
- 为何选择此项: 在哈达玛域中,逐元素乘法作为绑定机制,类似于它在傅里叶域中对于循环卷积的作用。此操作计算效率高,并保持 VSA 所需的代数性质。
- $H(\dots)$:
- 数学定义: 反哈达玛变换。由于 $H$ 是其自身的逆( up to a scaling factor $d$),再次应用 $H$ 有效地逆转了之前的变换。
- 物理/逻辑作用: 将绑定向量从哈达玛域转换回原始向量空间。
- 为何选择此项: 以确保生成的绑定向量 $B(x,y)$ 与原始输入向量位于同一向量空间中,从而允许进行一致的操作,如与其他向量求和。
解绑方程(方程 4)的解剖
$$ B^*(\chi_p, \pi(y_i)^\dagger) = \frac{1}{d} H \left( H \left( \sum_{j=1}^p \pi(x_j) \odot \pi(y_j) \right) \odot \frac{1}{H \pi(y_i)} \right) $$
- $B^*(\chi_p, \pi(y_i)^\dagger)$:
- 数学定义: 应用于复合表示 $\chi_p$ 并使用投影查询向量 $\pi(y_i)$ 的逆的解绑操作产生的输出向量。
- 物理/逻辑作用: 这是绑定的逆操作,旨在从捆绑表示中检索特定概念(理想情况下是 $\pi(x_i)$)。
- 为何选择此项: 此操作是 VSA 中知识检索的基础,允许系统“询问”与给定查询绑定的内容。
- $\chi_p$:
- 数学定义: 由 $p$ 个单独的绑定对求和形成的复合表示,其中每个输入向量都经过了投影函数 $\pi$ 的预处理。数学上,$\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$。
- 物理/逻辑作用: 一个紧凑地存储多个关联或概念的单一向量。
- 为何选择此项: VSA 允许对绑定向量进行求和以表示复合结构或关联集,利用了向量加法的线性。
- $\pi(x_j), \pi(y_j)$:
- 数学定义: 投影后的输入向量,其中 $\pi(v) = \frac{1}{d} Hv$。
- 物理/逻辑作用: 原始概念向量 $x_j, y_j$ 的预处理版本。
- 为何选择此项: 投影步骤对向量进行归一化并将它们转换到哈达玛域。这有助于减轻数值不稳定性并减少噪声累积,这在捆绑了多个项时尤其重要。
- $\sum_{j=1}^p (\dots)$:
- 数学定义: 对 $p$ 个单独项的求和,每个项都是投影输入向量的逐元素乘积。
- 物理/逻辑作用: 将聚合的单个绑定表示(在中间形式)组合成一个单一的复合向量。
- 为何选择此项: 加法的线性允许将多个绑定对捆绑到一个向量中,这是 VSA 表示复杂结构的关键特征。
- $\odot$:
- 数学定义: 逐元素乘积。
- 物理/逻辑作用: 在求和内部,它在哈达玛域中执行投影输入的绑定。在求和外部,它通过与查询的逆相乘来执行解绑。
- 为何选择此项: 由于其效率和代数性质,逐元素乘法是哈达玛域中选择的绑定/解绑机制。
- $H(\sum \dots)$:
- 数学定义: 哈达玛变换应用于投影输入向量的逐元素乘积之和。
- 物理/逻辑作用: 这是应用于复合表示的中间哈达玛变换。
- 为何选择此项: 这是解绑过程的一部分,将求和转换到适合逐元素除法(乘以查询的逆)的域。
- $\frac{1}{H \pi(y_i)}$:
- 数学定义: 投影查询向量 $\pi(y_i)$ 的哈达玛变换的逐元素逆。
- 物理/逻辑作用: 该项在哈达玛域中充当“解绑密钥”。
- 为何选择此项: 为了执行逆操作,人们有效地“除以”查询向量。在哈达玛域中,这通过与查询的哈达玛变换的逆进行逐元素乘法来实现。使用逆是源于性质 $Hx \cdot Hx^\dagger = 1$。
- $H(\dots)$:
- 数学定义: 反哈达玛变换。
- 物理/逻辑作用: 将结果从哈达玛域转换回原始向量空间。
- 为何选择此项: 以获得与原始输入向量相同的空间中的检索向量,使其可解释并可用于进一步的 VSA 操作。
- $\frac{1}{d}$:
- 数学定义: 缩放因子。
- 物理/逻辑作用: 归一化检索向量的幅度。
- 为何选择此项: 与绑定操作类似,这种缩放确保了向量幅度的恒定性,并抵消了哈达玛变换引入的缩放,从而保持了数值稳定性。
逐步流程
让我们追踪一个抽象数据点(例如 $x_1$)的生命周期,它与 $y_1$ 绑定成一个复合表示 $\chi_p$(以及 $p-1$ 个其他对),然后随后被解绑。
-
概念初始化: 我们从原始概念向量开始,例如 $x_1, y_1, \dots, x_p, y_p$,它们都位于 $\mathbb{R}^d$ 中。这些向量通常通过从混合正态分布 (MiND) $\Omega(\mu, 1/d)$ 中采样来初始化,这确保了它们的期望值为零但绝对均值非零。这种初始化是数值稳定性的基础步骤。
-
输入投影: 在进行任何绑定之前,每个单独的概念向量(例如 $x_j$ 和 $y_j$)都会经过投影步骤。对于任何向量 $v$,这包括应用哈达玛变换和缩放:$\pi(v) = \frac{1}{d} Hv$。这会将原始输入向量转换为“投影”形式 $\pi(x_j)$ 和 $\pi(y_j)$,它们是归一化且处于哈达玛域中的。这种预处理对于稍后减少噪声至关重要。
-
单个绑定(每对): 对于每对投影后的概念向量,例如 $(\pi(x_j), \pi(y_j))$,执行 HLB 绑定操作 $B(\pi(x_j), \pi(y_j))$:
- 哈达玛变换(隐式): $\pi(v)$ 的定义意味着 $H(\pi(v)) = H(\frac{1}{d} Hv) = \frac{1}{d} H(Hv) = v$。因此,当使用方程 2 计算 $B(\pi(x_j), \pi(y_j))$ 时,$H(\pi(x_j))$ 和 $H(\pi(y_j))$ 有效地变为 $x_j$ 和 $y_j$。
- 逐元素绑定: 然后通过逐元素乘积 $x_j \odot y_j$ 将向量 $x_j$ 和 $y_j$ 组合起来。这是核心的结合步骤,在类似哈达玛的域中创建了一个绑定表示。
- 反哈达玛变换与缩放: 这个逐元素乘积 $x_j \odot y_j$ 然后通过应用哈达玛矩阵 $H$ 并乘以 $1/d$ 来转换回来。结果是 $B(\pi(x_j), \pi(y_j)) = \frac{1}{d} H(x_j \odot y_j)$。
-
复合表示形成: 所有这 $p$ 个单独的绑定向量 $B(\pi(x_j), \pi(y_j))$ 被加在一起。这种线性求和创建了一个单一的高维向量 $\chi_p = \sum_{j=1}^p B(\pi(x_j), \pi(y_j))$,它现在代表了所有 $p$ 个关联的捆绑。
-
查询投影(用于解绑): 当我们想从复合表示 $\chi_p$ 中检索特定概念(例如 $x_i$)时,我们使用其关联的查询向量 $y_i$。这个查询向量 $y_i$ 也经过相同的投影步骤:$\pi(y_i) = \frac{1}{d} Hy_i$。
-
解绑操作(方程 4): 解绑过程 $B^*(\chi_p, \pi(y_i)^\dagger)$ 然后展开:
- 变换复合表示: 哈达玛变换 $H$ 应用于复合表示 $\chi_p$。由于 $H$ 的线性和 $\chi_p$ 的结构,这简化为 $H(\chi_p) = \sum_{j=1}^p (x_j \odot y_j)$。这使得整个捆绑进入一个可以清楚表示各个绑定对作为逐元素乘积的域。
- 变换查询: 哈达玛变换 $H$ 应用于投影查询向量 $\pi(y_i)$,这简化为 $H(\pi(y_i)) = y_i$。
- 逆查询: 计算此变换后查询的逐元素逆 $1/y_i$。这在哈达玛域中充当“解绑密钥”。
- 逐元素解绑: 然后将变换后的复合表示 $\sum_{j=1}^p (x_j \odot y_j)$ 与逆查询 $1/y_i$ 进行逐元素乘法。此步骤试图“除掉” $y_i$ 分量,理想情况下隔离 $x_i$。
- 反哈达玛变换与缩放: 然后通过应用哈达玛矩阵 $H$ 并乘以 $1/d$ 将此逐元素乘法的结果转换回。这产生了中间解绑结果 $B^*(\chi_p, \pi(y_i)^\dagger)$。
-
反向投影(最终输出): 本文指出,为了从这个中间结果中获得“原始数据”(即原始 $x_i$),应用了反向投影步骤。这个最终步骤有效地将中间结果简化为方程 5 中所示的形式,当只绑定一对时($p=1$),它近似等于 $x_i$,或者当绑定多对时($p>1$),它近似等于 $x_i + \eta''$(其中 $\eta''$ 是一个减小的噪声分量)。
优化动力学
如本文所述,哈达玛变换导出的线性绑定 (HLB) 机制本身并不是一种学习算法;相反,它是一套固定的、数学推导的操作,旨在实现高效率和数值稳定性。因此,它的“优化动力学”不涉及通过梯度进行迭代参数更新。相反,它的动力学是其设计固有的,以及它如何促进更大、可微分系统中的学习:
-
固定、确定性操作: HLB 的核心绑定和解绑函数是基于哈达玛矩阵和逐元素操作的确定性变换。HLB 操作本身没有可训练的权重、偏置或其他参数,这些参数会通过梯度下降或任何其他学习规则进行更新。哈达玛矩阵是一个预定义的、静态的组件。
-
固有的数值稳定性: HLB 的一个关键动力学特性是其内置的数值稳定性。哈达玛变换的设计仅涉及 $\pm 1$ 值的运算,避免了可能导致 HRR 等其他 VSA 方法不稳定的复数和无理数乘法。此外,用于向量初始化的混合正态分布 (MiND)(方程 6)确保向量的期望值为零但绝对均值非零。这种设计选择可以防止在解绑过程中出现除以接近零的值的情况,否则会导致数值爆炸。
-
降噪机制: 投影步骤($\pi(x) = \frac{1}{d} Hx$)是 HLB 内部动力学中用于提高检索准确性的关键部分。通过在绑定之前将此投影应用于输入向量,该机制会主动减小当多个项被捆绑在一起时产生的累积噪声($\eta''$)。这是一种静态的、预定义的降噪策略,而不是学习到的策略,但它显著影响了系统的性能和鲁棒性。
-
可微分性以实现系统集成: 虽然 HLB 本身不学习,但它被明确设计为与“可微分系统”兼容。这意味着构成 HLB 的数学运算(矩阵乘法、逐元素乘积、求和)都是可微分的。因此,当 HLB 被嵌入到更大的神经网络架构中时(如在连接主义符号伪秘密和极端多标签分类任务中所演示的),整个系统仍然可以使用标准的基于梯度的优化算法(例如,随机梯度下降)进行端到端训练。HLB 机制提供了一种稳定且高效的方式来表示和操作这些学习系统内部的符号信息,允许周围的网络参数根据定义的损失函数(例如,XML 分类中的方程 11 中的余弦相似度损失)进行优化。HLB 操作本身只是将梯度传递过去,而无需修改。
结果、局限性与结论
实验设计与基线
作者精心设计了实验,以在经典的向量符号架构 (VSA) 任务和现代深度学习应用中验证哈达玛变换导出的线性绑定 (HLB),并无情地将其与已建立的基线进行比较。
对于经典 VSA 任务,构建了两个主要场景:
-
基本绑定/解绑准确性: 此实验旨在证明 HLB 从复合表示中正确检索绑定向量的能力。设置包括创建一个包含 1000 个随机向量的池。从该池中,采样 $p$ 对向量(其中 $p$ 从 1 到 25 不等),使用 VSA 的绑定操作 $B(x_i, y_i)$ 将它们绑定,然后求和形成复合表示 $s = \sum_{i=1}^p B(x_i, y_i)$。目标基线模型包括全息降维表示 (HRR) [32]、向量导出变换绑定 (VTB) [12] 和乘加置换 (MAP) [10]。对于每个复合表示 $s$,实验遍历了所有作为原始捆绑一部分的左侧分量 $x_q$,并尝试使用解绑操作 $B^*(s, x_q)$ 检索其对应的 $y_q$。如果点积 $B^*(s, x_q)^T y_q$ 大于所有其他 $j \neq q$ 的 $B^*(s, x_q)^T y_j$,则认为检索成功。此过程重复了 50 次试验,最终证据以准确性与绑定项数 $p$ 之间的曲线下面积 (AUC) 的形式呈现,跨越各种向量维度 $d$(特别是,为了适应 VTB 的约束,选择了完全平方数)。
-
顺序绑定/解绑稳定性: 此任务评估了在重复绑定操作下相似度分数的质量和向量幅度稳定性。测试了两个子场景:
- 随机绑定: 初始向量 $b_0$ 通过与新随机向量 $x_t$ 绑定 $p$ 轮来顺序修改,得到 $b_{t+1} = B(b_t, x_t)$。目标是解绑每个 $x_t$ 并恢复之前的 $b_t$。
- 自动绑定: 单个随机向量 $x$ 被反复绑定到不断演变的状态:$b_{t+1} = B(b_t, x)$。
此实验的基线是 HRR、VTB 和 MAP-C。寻求的关键证据是相似度分数 $B^*(b_{t+1}, x_t)^T b_t$ 是否保持理想的 1(对于存在的项),以及向量幅度 $||B^*(b_{t+1}, x_t)||_2$ 是否保持恒定,避免了 VSA 中随着 $p$ 增加而出现的常见爆炸或消失值。
在深度学习应用方面,HLB 被集成到两个最近的神经符号任务中:
-
连接主义符号伪秘密 (CSPS) [3]: 此任务探索使用 VSA 进行启发式安全,模拟“一次性密码”来隐藏输入和输出,以便将计算卸载到不受信任的第三方。实验涉及将随机 VSA 向量 $s$(“秘密”)绑定到输入 $x$ 以创建隐藏表示 $B(s, x)$。第三方网络处理此隐藏输入,返回输出 $y$,然后本地使用秘密 $B^*(y, s)$ 解绑以获得最终答案。基线是 HRR、VTB、MAP-C 和 MAP-B。实验在单个 NVIDIA TESLA P100 GPU 和 32GB 内存上运行。
- 准确性: 主要指标是在五个标准图像数据集(MNIST、SVHN、CIFAR-10、CIFAR-100 和 Mini-ImageNet)上的 Top@1 和 Top@5 分类准确率。
- 安全性: 为了无情地证明信息隐藏的声明,计算了调整兰德指数 (Adjusted Rand Index, ARI)。窥探的第三方尝试使用各种聚类算法(K-means、高斯混合模型、Birch、HDBSCAN)对隐藏的输入 $B(x, s)$ 和输出 $y$ 进行聚类。ARI 分数接近零是信息隐藏成功的决定性证据,表明攻击者的角度是随机标签分配。
-
极端多标签 (XML) 分类 [9]: 此任务解决了单个输入需要分类到大量可能类别($C \gg d$,其中 $d$ 是输入维度)的场景,这在电子商务中很常见。VSA 用于表示稀疏输出空间。实验设置遵循 [9] 中的网络细节,用 HLB 和基线 VSA(HRR、VTB、MAP)替换了他们原来的 VSA。评估在八个不同的数据集上进行(BIBTEX、DELICIOUS、MEDIAMILL、EURLEX-4K、EURLEX-4.3K、WIKI10-31K、AMAZON-13K、DELICIOUS-200K)。关键指标是归一化折扣累积增益 (nDCG) 和倾向得分 nDCG (PSnDCG),这些是评估多标签分类性能的标准指标。
证据证明了什么
实证证据有力地支持了理论主张,并展示了 HLB 在广泛的 VSA 应用中具有优越或有竞争力的性能。
理论验证:
本文提供了令人信服的证据,表明 HLB 的核心数学机制按预期工作。原始向量 $x_i$ 和其检索版本 $\hat{x}_i$ 之间的余弦相似度 $\phi$ 近似为 $1/\sqrt{p}$ 的理论关系(定理 3.2)通过热图(图 1)和图表(图 6)得到了经验验证。这证实了所提出的相似度增强的有效性。此外,复合表示范数 $||X_p||_2 \approx \mu^2 \sqrt{p} \cdot d$ 的理论预测(定理 B.1)也与实验结果(图 5)非常吻合,尽管随着 $p$ 的增加由于近似而略有变化。至关重要的是,HLB 中引入的投影步骤被明确证明可以减小累积的噪声。与有无投影的噪声分量进行比较的热图(图 4)清楚地表明,没有投影的最大噪声(19.38)远高于有投影的噪声(7.18),证明了这一架构选择在提高检索准确性方面是有效的。
经典 VSA 任务:
在基本绑定/解绑准确性任务中,HLB 在各种维度上始终显示出与 HRR 和 VTB 相当甚至更优的性能,同时明确优于 MAP(图 2)。这些硬证据,以 AUC 分数形式呈现,证明了 HLB 的绑定和解绑操作是鲁棒且对基本 VSA 操作有效的。更令人印象深刻的是,在顺序绑定/解绑稳定性任务(图 3)中,HLB 脱颖而出,它保持了存在的项的理想相似度分数 1,并且至关重要的是,向量幅度保持恒定,与绑定向量的数量 $p$ 无关。这与 HRR、VTB 和 MAP 等基线相比是一个显著优势,后者表现出相似度分数衰减或幅度爆炸/消失。这种稳定性是 HLB 解决了其他 VSA 中普遍存在的关键数值稳定性问题的明确证据,使其成为复杂符号处理更可靠的基础。
深度学习任务:
HLB 的有效性在深度学习环境中得到了强有力的扩展。在连接主义符号伪秘密 (CSPS) 任务中,HLB 不仅在所有五个数据集(MNIST、SVHN、CIFAR-10、CIFAR-100、Mini-ImageNet)上的分类准确率方面显著优于所有先前的 VSA 方法(如表 2 所示),而且还实现了更优的信息隐藏。HLB 的调整兰德指数 (ARI) 分数(表 3)在 SVHN、CIFARs 和 Mini-ImageNet 上始终更接近于零,表明窥探的第三方在聚类输入或输出时会遇到更大的困难,从而证明了其双重好处:提高准确性和增强安全性。虽然 MNIST 的 ARI 结果显示出一些退化,但正如 CSPS 安全性已知问题所承认的,这被认为是可接受的。这种双重改进是 HLB 实际效用的有力证明。
对于极端多标签 (XML) 分类,HLB 设定了新的最先进水平 (SOTA)。表 4 展示了在八个不同数据集上的 nDCG 和 PSnDCG 分数,这些数据集的难度从“容易”到“困难”不等,涉及特征和标签。HLB 在所有数据集上都实现了两个指标的最佳分数,证明了其在高效有效地处理高维稀疏输出空间方面的卓越能力。在多个数据集和指标上的这种全面胜利提供了明确、不可否认的证据,表明 HLB 的核心机制转化为复杂、现实世界深度学习场景中的实际性能提升。
局限性与未来方向
尽管提出的哈达玛变换导出的线性绑定 (HLB) 表现出令人印象深刻的性能和理论上的合理性,但承认某些局限性并考虑未来发展方向以进一步演进这些发现也很重要。
局限性:
一个隐含的局限性,尽管没有明确说明,源于数学推导。哈达玛矩阵是 HLB 的基石,通常要求向量维度 $d$ 是 2 的幂。虽然这在许多计算环境中很常见,但对于任意维度的应用,可能需要填充或其他变通方法,这可能会引入效率低下或复杂性。本文还指出,定理 B.1 中所做的近似(忽略方程 17 中的噪声项 $\xi$)导致复合表示的范数随着捆绑对数量 $p$ 的增加而出现更大的变化(图 5)。虽然总体趋势得以维持,但这表明对于极大的 $p$,近似可能变得不那么精确,可能影响系统的可预测性或需要更复杂的噪声处理。
此外,CSPS 提供的安全性虽然得到了 HLB 的显著改善,但被描述为启发式而非密码学保证。MNIST 数据集的 ARI 结果显示出一些退化,这提醒人们此类安全性并非绝对。这意味着对于需要严格、可证明安全性的应用,HLB 在 CSPS 框架内可能不足以单独使用。最后,虽然绑定步骤本身具有高效的 $O(d)$ 复杂度,但本文并未深入探讨 HLB 集成到大规模深度学习系统中的整体计算足迹(例如,内存使用、非常大模型的训练时间或能耗),特别是当 $d$ 或 $p$ 扩展到极端值时。
未来方向:
-
推广到任意维度和替代变换:
- 讨论: 如何在不诉诸于可能效率低下的简单填充的情况下,将 HLB 的优势扩展到非 2 的幂次向量维度?能否研究用于非 2 的幂次维度的“近似”哈达玛变换,或探索提供类似计算优势和理想 VSA 性质但对维度更灵活的其他正交变换?这可以极大地拓宽 HLB 的适用范围。
- 视角: 从理论角度来看,这挑战了哈达玛基的严格数学优雅性,但为实际工程解决方案打开了大门。从应用角度来看,它消除了集成到各种现有数据集和模型中的潜在障碍。
-
迈向神经符号人工智能中的可证明安全:
- 讨论: 鉴于 CSPS 安全性是启发式的,下一步是将 HLB 与更强大的密码学原语集成是什么?能否利用 HLB 的线性特性和高效解绑来设计提供可证明安全保证的神经符号系统,也许将其与同态加密方案或安全多方计算协议相结合?这将超越启发式安全,实现真正可信的人工智能。
- 视角: 这是敏感应用的关键领域。安全研究人员可能会探索形式化验证方法,而人工智能从业者可能会寻找平衡安全与性能的实际高效实现。
-
动态 $p$ 估计和自适应相似度增强:
- 讨论: 本文强调了知道或估计 $p$(捆绑对的数量)对于相似度增强步骤的重要性。在复杂、动态的神经符号系统中,$p$ 可能并不总是明确已知的。我们能否开发自适应机制或学习估计器,能够从复合表示本身动态推断 $p$,从而实现实时、上下文感知的相似度校正?
- 视角: 这将增强基于 VSA 的系统的自主性和鲁棒性。机器学习专家可能会提出用于 $p$ 估计的神经网络架构,而认知科学家可能会将其与生物系统如何处理组合表示中的不确定性进行类比。
-
探索非对称绑定和高级组合性:
- 讨论: 虽然 HLB 是对称的,但本文提到了 VTB 的非对称性质。哪种类型的符号关系或认知任务本质上受益于非对称绑定(例如,“主体-动作-对象”关系)?能否扩展或修改基于哈达玛的框架以支持非对称绑定操作,同时保留其计算效率和数值稳定性?这可以为表示定向关系和更复杂的语义结构解锁新的功能。
- 视角: 这深入探讨了 VSA 的表现力。语言学家或认知人工智能研究人员可能会识别出需要非对称绑定的特定语法或逻辑结构,从而推动数学框架以适应更丰富的符号表示。
-
与先进深度学习架构的更深层集成:
- 讨论: HLB 在 CSPS 和 XML 中已显示出潜力。如何将其更深入、更本地地集成到最前沿的深度学习架构中?HLB 绑定的绑定和解绑操作能否替换或增强 Transformer 模型(例如,用于注意力机制或位置编码)、图神经网络或循环神经网络的组件,以赋予它们更强的符号推理能力和改进的组合泛化能力?
- 视角: 这是关于弥合符号和连接主义人工智能之间的差距。神经网络架构设计师可能会探索新颖的层设计,而理论计算机科学家可能会分析这些混合系统中的计算图和信息流。
-
对对抗性攻击和真实世界噪声的鲁棒性:
- 讨论: 尽管投影步骤可以减少噪声,但 HLB 对各种形式的对抗性攻击或真实世界传感器噪声有多鲁棒,尤其是在安全关键应用中?是否可以集成其他机制,如鲁棒初始化策略、噪声感知训练或纠错码,与 HLB 一起增强其在噪声或对抗性环境中的韧性和可靠性?
- 视角: 这对于部署至关重要。安全研究人员将专注于攻击向量和防御措施,而工程师可能会考虑实际的噪声模型和硬件级别的韧性。
-
硬件加速和能效实现:
- 讨论: 鉴于 HLB 的绑定复杂度为 $O(d)$ 及其对哈达玛变换(易于快速算法)的依赖,专门的硬件加速有哪些机会?HLB 能否在神经形态芯片、FPGA 或其他定制硬件上高效实现,以实现超低功耗和高吞吐量,用于边缘 AI 设备或大规模符号处理系统?
- 视角: 这是一个软硬件协同设计挑战。计算机架构师将研究并行化和内存访问模式,而可持续发展倡导者可能会强调能效 AI 的潜力。
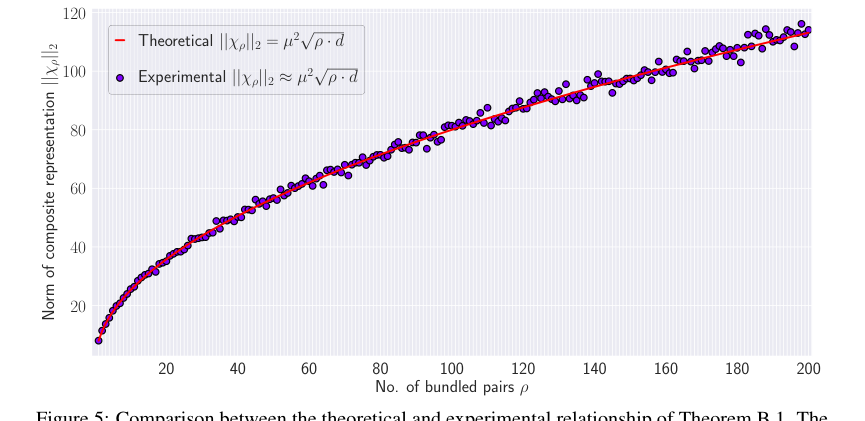 Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
Figure 5. shows the comparison between the theoretical relationship and actual experimental results where the norm of the composite representation is computed for µ “ 0.5 and ρ “ t1, 2, ¨ ¨ ¨ , 200u. The figure indicates that the theoretical relationship aligns with the experimental results. However, as the number of bundled pair increases, the variation in the norm increases. This is because of making the approximation by discarding ξ in Equation 17
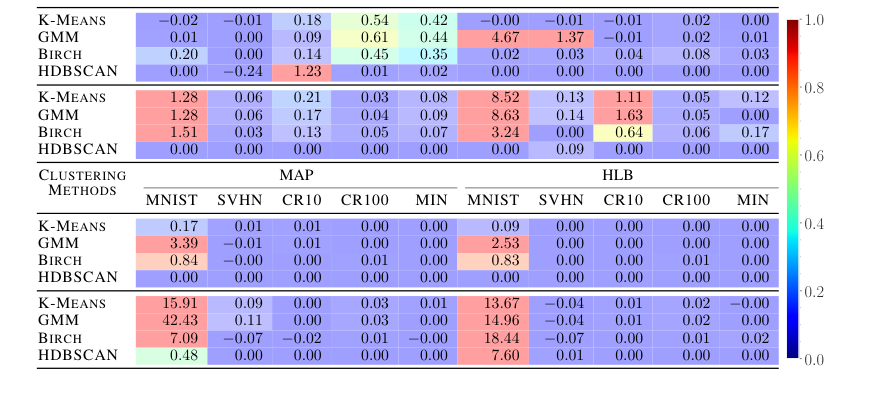 Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
Table 3. Clustering results of the main network inputs (top rows) and outputs (bottom rows) in terms of Adjusted Rand Index (ARI). Because CSPS is trying to hide information, scores near zero are better. Cell color corresponds to the cell absolute value, with blue indicating lower ARI and red indicating higher ARI. All numbers in percentages, and show HLB is better at information hiding
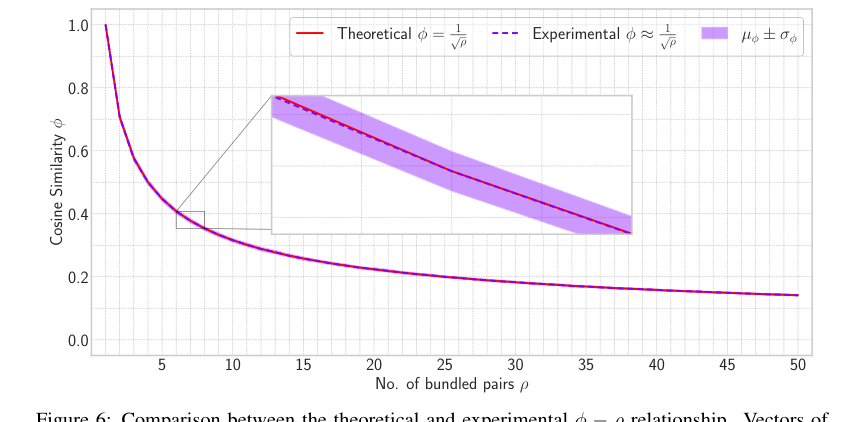 Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion
Figure 6. Comparison between the theoretical and experimental ϕ ´ ρ relationship. Vectors of dimension d “ 512 are combined and retrieved with a varied number of vectors from 1 to 50. The zoom portion shows how closely experimental results match with the theoretical conclusion